
Abstract
We introduce a framework for the reconstruction and representation of functions in a setting where these objects cannot be directly observed, but only indirect and noisy measurements are available, namely an inverse problem setting. The proposed methodology can be applied either to the analysis of indirectly observed functional images or to the associated covariance operators, representing second-order information, and thus lying on a non-Euclidean space. To deal with the ill-posedness of the inverse problem, we exploit the spatial structure of the sample data by introducing a flexible regularizing term embedded in the model. Thanks to its efficiency, the proposed model is applied to MEG data, leading to a novel approach to the investigation of functional connectivity.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
An inverse problem is the process of recovering missing information from indirect and noisy observations. Not surprisingly, inverse problems play a central role in numerous fields such as, to name a few, geophysics (Zhdanov 2002), computer vision (Hartley and Zisserman 2004), medical imaging (Arridge 1999, Lustig et al 2008) and machine learning (De Vito et al 2005).
Solving a linear inverse problem means finding an unknown x, for instance a function or a surface, from a noisy observation y, which is a solution to the model

where y and ɛ belong to an either finite or infinite dimensional Banach space. The map  is called a forward operator and is generally assumed to be known, although its uncertainty has also been taken into account in the literature (Arridge et al 2006, Golub and van Loan 1980, Gutta et al 2019, Kluth and Maass 2017, Lehikoinen et al 2007, Nissinen et al 2009, Zhu et al 2011). The term ɛ represents observational error.
is called a forward operator and is generally assumed to be known, although its uncertainty has also been taken into account in the literature (Arridge et al 2006, Golub and van Loan 1980, Gutta et al 2019, Kluth and Maass 2017, Lehikoinen et al 2007, Nissinen et al 2009, Zhu et al 2011). The term ɛ represents observational error.
Problem 1 is a well-studied problem within applied mathematics (for early works in the field, see Adorf 1995, Calderón 1980, Geman 1990). Its main difficulties arise from the fact that, in practical situations, an inverse of the forward operator does not exist, or if it does, it amplifies the noise term. For this reason such a problem is called ill-posed. Consequently, the estimation of the function x in (1) is generally tackled by minimizing a functional which is the sum of a data (fidelity) term and a regularizing term encoding prior information on the function to be recovered (see, among others, Cavalier 2008, Hu and Jacob 2012, Lefkimmiatis et al 2012, Mathé and Pereverzev 2006, Tenorio 2001). For convex optimization functionals, modern efficient optimization methods can be applied (Beck and Teboulle 2009, Boyd et al 2010, Burger et al 2016, Chambolle and Pock 2011, Chambolle and Pock 2016). Alternatively, when it is important to assess the uncertainty associated with the estimates, a Bayesian approach could be adopted (Calvetti and Somersalo 2007, Kaipio and Somersalo 2005, Repetti et al 2019, Stuart 2010). The deep convolutional neural network approach has also been applied to this setting (Jin et al 2017, McCann et al 2017).
In imaging sciences, it is sometimes of interest to find an optimal representation and perform statistics on the second order information associated with the functional samples, i.e. the covariance operators describing the variability of the underlying functional images. This is, for instance, the case in a number of areas of neuroimaging, particularly those investigating functional connectivity. In this work, we establish a framework for reconstructing and optimally representing indirectly observed samples  , that are covariance operators, expressing the second order properties of the underlying unobserved functions. The indirect observations are covariance operators generated by the model
, that are covariance operators, expressing the second order properties of the underlying unobserved functions. The indirect observations are covariance operators generated by the model

where  denotes the adjoint operator and the term
denotes the adjoint operator and the term  models observational error. The term
models observational error. The term  represents the covariance operator of
represents the covariance operator of  , with X(i) an underlying random function whose covariance operator is
, with X(i) an underlying random function whose covariance operator is  .
.
As opposed to more classical linear inverse problems formulations, problem 2 introduces the following additional difficulties:
- We are in a setting where each sample is a high-dimensional object that is a covariance operator; it is important to take advantage of the information from all the samples to reconstruct and represent each of them.
- The elements
 and live on non-Euclidean spaces, as they belong to the positive semidefinite cone, and it is important to account for this manifold structure in the formulation of the associated estimators.
and live on non-Euclidean spaces, as they belong to the positive semidefinite cone, and it is important to account for this manifold structure in the formulation of the associated estimators. - In an inverse problem setting it is fundamental to be able to introduce spatial regularization, however it is not obvious how to feasibly construct a regularizing term for covariance operators reflecting, for instance, smoothness assumptions on the underlying functional images.


More general non-Euclidean settings could also be accommodated. Specifically, the error term could be defined on a tangent space and mapped to the original space through the exponential mapping. Another setting of interest is the case of error terms that push the observables out of the original space. In our applications this is not an issue, as the contaminated observations are themselves empirical covariance matrices, which belong to the non-Euclidean space of positive semidefinite matrices.
We tackle problem 2 by generalizing the concept of principal component analysis (PCA) to optimally represent and understand the variation associated with samples that are indirectly observed covariance operators. The proposed model is also able to deal with the simpler case of samples that are indirectly observed functional images belonging to a linear functional space.
1.1. Motivating application—functional connectivity
In recent years, statistical analysis of covariance matrices has gained a predominant role in medical imaging and in particular in functional neuroimaging. In fact, covariance matrices are the natural objects to represent the brain's functional connectivity, which can be defined as a measure of covariation, in time, of the cerebral activity among brain regions. While many techniques have been proposed to describe functional connectivity, almost all can be described in terms of a function of a covariance or related matrix.
Covariance matrices representing functional connectivity can be computed from the signals arising from functional imaging modalities. The choice of a specific functional imaging modality is generally driven by the preference to have high spatial resolution signals, and thus high spatial resolution covariance matrices, versus high temporal resolution, and thus the possibility to study the temporal dynamic of the covariance matrices. Functional magnetic resonance falls in the first category, while electroencephalogram (EEG) and magnetoencephalography (MEG) in the second. However, high temporal resolution does generally come at the price of indirect measurements and, as shown in figure 1 in the case of MEG data, the signals are in practice detected on the sensors space. It is however of interest to produce results on the associated signals on the cerebral cortex, which we will refer to as brain space. The signals on the brain space are functional images whose domain is the geometric representation of the brain and are associated with the neuronal activity on the cerebral cortex. We borrow here the notion of brain space and sensors space from Johnstone and Silverman (1990) and we use it throughout the paper for convenience, however it is important to highlight that the formulation of the problem is much more general than the setting of this specific application.

Figure 1. On the top left, head model of a subject and superimposition of the 248 MEG sensors positioned around the head, called 'sensors space'. On the top right, brain model of the same subject represented by a triangular mesh of 8k nodes, which represents the 'brain space'. On the bottom left, an example of a synthetic signal detected by the MEG sensors. The dots represent the sensors, the color map represents the signal detected by the sensors. On the bottom right, intensity of the reconstructed signal on the triangular mesh of the cerebral cortex.
Download figure:
Standard image High-resolution image
Figure 2. Covariance matrices of the signal detected by the MEG sensors from three different subjects of the human connectome project. The size of the matrices is 248 × 248. The dark blue bands represent missing data, which are due to the exclusion of some channels after a quality check of the signal.
Download figure:
Standard image High-resolution imageThe signals on the brain space are related to the signals on the sensors space by a forward operator, derived from the physical modeling of the electrical/magnetic propagation, from the cerebral cortex to the sensors. This is generally referred to as the forward problem. For soft-field methods like EEG, MEG and functional near-infrared spectroscopy (Eggebrecht et al 2014, Ferrari and Quaresima 2012, Mosher et al 1999, Singh et al 2014, Ye et al 2009), the forward operator is defined through the solution to a partial differential equation of diffusion type. Such a mapping induces a strong degree of smoothing and consequently the corresponding inverse problem, i.e. the reconstruction of a signal on the brain space from observations in the sensors space, is strongly ill-posed. In fact, signals with fairly different intensities on the brain space, due to the diffusion effect, result in signals with similar intensities in the sensors space. In figure 1, we show an example of a signal on the brain space and the associated signal on the sensors space.
From a practical perspective, it is crucial to understand how the different parts of the brain interact, which is sometimes known as functional connectivity. A possible way to understand these interactions is by analyzing the covariance function associated with the signals describing the cerebral activity of an individual on the brain space (Fransson et al 2011, Lee et al 2013, Li et al 2009). More recently, the interest has shifted from this static approach to a dynamic approach. In particular, for a single individual, it is of interest to understand how these covariance functions vary in time. This is a particularly active field, known as dynamic functional connectivity (Hutchison et al 2013). Another element of interest is understanding how these covariance functions vary among individuals. In figure 2, we show the covariance matrices, on the sensors space, computed from the MEG signals of three different subjects.
The remainder of this paper is organized as follows. In section 2 we give a formal description of the problem. We then introduce a model for indirectly observed smooth functional images in section 3 and present the more general model associated with problem 2 in section 4. In section 5, we perform simulations to assess the validity of the estimation framework. In section 6 we apply the proposed models to MEG data and we finally give some concluding remarks in section 7.
2. Mathematical description of the problem
We now introduce the problem using our driving application as an example. To this purpose, let  a be a closed smooth two-dimensional manifold embedded in
a be a closed smooth two-dimensional manifold embedded in  , which in our application represents the geometry of the cerebral cortex. An example of such a surface is shown on the top right of figure 1. We denote with
, which in our application represents the geometry of the cerebral cortex. An example of such a surface is shown on the top right of figure 1. We denote with  the space of square integrable functions on
the space of square integrable functions on  . Define X to be a random function with values in a Hilbert functional space
. Define X to be a random function with values in a Hilbert functional space  with mean
with mean ![$\mu =\mathbb{E}\left[X\right]$](https://content.cld.iop.org/journals/0266-5611/36/8/085002/revision2/ipab8713ieqn15.gif) , finite second moment, and assume the continuity and square integrability of its covariance function
, finite second moment, and assume the continuity and square integrability of its covariance function ![${C}_{X}\left(v,{v}^{\prime }\right)=\mathbb{E}\left[\left(X\left(v\right)-\mu \left(v\right)\right)\left(X\left({v}^{\prime }\right)-\mu \left({v}^{\prime }\right)\right)\right]$](https://content.cld.iop.org/journals/0266-5611/36/8/085002/revision2/ipab8713ieqn16.gif) . The associated covariance operator
. The associated covariance operator  is defined as
is defined as  , for all
, for all  . Mercer's lemma (Riesz and Szokefalvi-Nagy 1955) guarantees the existence of a non-increasing sequence {γr} of eigenvalues of
. Mercer's lemma (Riesz and Szokefalvi-Nagy 1955) guarantees the existence of a non-increasing sequence {γr} of eigenvalues of  and an orthonormal sequence of corresponding eigenfunctions {ψr}, such that
and an orthonormal sequence of corresponding eigenfunctions {ψr}, such that

As a direct consequence, X can be expanded5 as  , where the random variables {ζr} are uncorrelated and are given by
, where the random variables {ζr} are uncorrelated and are given by  . The collection {ψr} defines the modes of variation of the random function X, in descending order of strength, and these are called principal component (PC) functions. The associated random variables {ζr} are called PC scores. Moreover, the defined PC functions are the best finite basis approximation in the L2-sense, therefore for any fixed
. The collection {ψr} defines the modes of variation of the random function X, in descending order of strength, and these are called principal component (PC) functions. The associated random variables {ζr} are called PC scores. Moreover, the defined PC functions are the best finite basis approximation in the L2-sense, therefore for any fixed  , the first R PC functions of X minimize the reconstruction error, i.e.
, the first R PC functions of X minimize the reconstruction error, i.e.

where ⟨⋅, ⋅⟩ denotes the  inner product and δrr' is the Kronecker delta; i.e. δrr' = 1 for r = r' and 0 otherwise.
inner product and δrr' is the Kronecker delta; i.e. δrr' = 1 for r = r' and 0 otherwise.
2.1. The case of indirectly observed functions
In the case of indirect observations, the signal is detectable only through s sensors on the sensors space. Let {Kl : l = 1, ..., m} be a collection of s × p real matrices, representing the potentially sample-specific forward operators relating the signal at p pre-defined points {vj : j = 1, ..., p} on the cortical surface  with the signal captured by the s sensors. The matrices {Kl} are discrete versions of the forward operator
with the signal captured by the s sensors. The matrices {Kl} are discrete versions of the forward operator  introduced in section 1. Moreover, define the evaluation operator
introduced in section 1. Moreover, define the evaluation operator  to be a vector-valued functional that evaluates a function
to be a vector-valued functional that evaluates a function  at the p pre-specified points
at the p pre-specified points  , returning the p dimensional vector
, returning the p dimensional vector  . The operators Ψ and {Kl} are known. However, in the described problem the random function X can be observed only through indirect measurements
. The operators Ψ and {Kl} are known. However, in the described problem the random function X can be observed only through indirect measurements  generated from the model
generated from the model

where {xl} are m independent realizations of X, and thus expandible in terms of the PC functions {ψr} and the coefficients {ζl,r} given by  . The terms {ɛl} represent observational errors and are independent realizations of an s-dimensional normal random vector, with mean the zero vector and variance σ2Ip, where Ip denotes the p-dimensional identity matrix.
. The terms {ɛl} represent observational errors and are independent realizations of an s-dimensional normal random vector, with mean the zero vector and variance σ2Ip, where Ip denotes the p-dimensional identity matrix.
We consider the problem of estimating the PC functions {ψr} in (5), and associated scores {ζl,r}, from the observations {yl}. In figure 3 we give an illustration of the introduced setting. Note that it would not be necessary to define the evaluation operator if the forward operators were defined to be functionals  , relating directly the functional objects on the brain space to the real vectors on the sensors space. It is however the case that the operators {Kl} are computed in a matrix form by third party software (see section 6 for details) for a pre-specified set of points
, relating directly the functional objects on the brain space to the real vectors on the sensors space. It is however the case that the operators {Kl} are computed in a matrix form by third party software (see section 6 for details) for a pre-specified set of points  and it is thus convenient to take this into account in the model through the introduction of an evaluation operator Ψ.
and it is thus convenient to take this into account in the model through the introduction of an evaluation operator Ψ.

Figure 3. Illustration of the setting introduced with model (5).
Download figure:
Standard image High-resolution imageIn the case of single subject studies, the surface  is the subject's reconstructed cortical surface, an example of which is shown on the right panel of figure 1. In this case, it is natural to assume that there is one common forward operator K for all the detected signals. In the more general case of multi-subject studies,
is the subject's reconstructed cortical surface, an example of which is shown on the right panel of figure 1. In this case, it is natural to assume that there is one common forward operator K for all the detected signals. In the more general case of multi-subject studies,  is assumed to be a template cortical surface. We are thus assuming that the individual cortical surfaces have been registered to the template
is assumed to be a template cortical surface. We are thus assuming that the individual cortical surfaces have been registered to the template  , which means that there is a smooth and one-to-one correspondence between the points on each individual brain surface and the template surface
, which means that there is a smooth and one-to-one correspondence between the points on each individual brain surface and the template surface  , where the PC functions are defined.
, where the PC functions are defined.
However, notice that when it comes to the computation of the forward operators, we are not assuming the brain geometries of the single subjects to be all equal to a geometric template, as in fact the model in (5) allows for sample-specific forward operators {Kl}. The individual cortical surfaces could also have different number of mesh points, in that case the subject-specific 'resampling' operator could be absorbed into the definition of sample-specific evaluation operators {Ψl}.
The estimation of the PC functions in (5) has been classically dealt with by reconstructing each observation xl independently and subsequently performing PCA. However, such an approach can be sub-optimal in particular in a low signal-to-noise setting, as when estimating one signal, the information from all the other sampled signals is systematically ignored. The statistical analysis of data samples that are random functions or surfaces, i.e. functional data, has also been explored in the functional data analysis (FDA) literature (Ramsay and Silverman 2005), however, most of those works focus on the setting of fully observed functions. An exception to this is the sparse FDA literature (see e.g. Yao et al 2005), where instead the functional samples are assumed to be observable only through irregular and noisy evaluations.
In the case of direct but noisy observations of a signal, previous works on statistical estimation of the covariance function, and associated eigenfunctions, have been made, for instance, in Bunea and Xiao (2015) for regularly sampled functions and in Huang et al (2008), Yao et al (2005) for sparsely sampled functions. A generalization to functions whose domain is a manifold is proposed in Lila et al (2016) and appropriate spatial coherence is introduced by penalizing directly the eigenfunctions of the covariance operator to be estimated, i.e. the PC functions. In the indirect observations setting, Tian et al (2012) propose a separable model in time and space for source localization. The estimation of PC functions of functional data in a linear space and on linear domains, from indirect and noisy samples, has been previously covered in Amini and Wainwright (2012). They propose a regularized M-estimator in a reproducing kernel Hilbert space (RKHS) framework. Due to the fact that in practice the introduction of an RKHS relies on the definition of a kernel, i.e. a covariance function on the domain, this approach cannot be easily extended to non-linear domains. In Katsevich et al (2015), driven by an application to cryo-electron microscopy, the authors propose an unregularized estimator for the covariance matrix of indirectly observed functions. However, a regularized approach is crucial in our setting, due to the strong ill-posedness of the inverse problem considered. In the discrete setting, also other forms of regularization have been adopted, e.g. sparsity on the inverse covariance matrix (Friedman et al 2008, Liu and Zhang 2019).
2.2. The case of indirectly observed covariance operators
A natural generalization of the setting introduced in the previous section is considering observations that have group specific covariance operators. In detail, suppose now we are given a set of n covariance functions {Ci : i = 1, ..., n}, representing the underlying covariance operators  on the brain space. In our driving application, each covariance function
on the brain space. In our driving application, each covariance function  describes the functional connectivity of the ith individual or the functional connectivity of the same individual at the ith time-point.
describes the functional connectivity of the ith individual or the functional connectivity of the same individual at the ith time-point.
We consider the problem of defining and estimating a set of covariance functions, that we call PC covariance functions, which enable the description of {Ci} through the 'linear combinations' of few components. Such a reduced order description is of interest, for example, in understanding how functional connectivity varies among individuals or over time.
We define a model for the PC covariance functions of {Ci} from the set of indirectly observed covariance matrices, computed from the signals on the sensors space, and thus given by  with
with

where  , and {vj : j = 1, ..., p} are the sampling points associated with the operator Ψ. The forward operators {Ki} act on both sides of the covariance functions {Ci}, due to the linear transformation KiΨ applied to the signals on the brain space before being detected on the sensors space. The term
, and {vj : j = 1, ..., p} are the sampling points associated with the operator Ψ. The forward operators {Ki} act on both sides of the covariance functions {Ci}, due to the linear transformation KiΨ applied to the signals on the brain space before being detected on the sensors space. The term  is an error term, where Ei is an s × s matrix such that each entry is an independent sample of a Gaussian distribution with mean zero and standard deviation σ. Model (6) could be regarded as an implementation of the idealized problem 2, where the covariance operators are represented by the associated covariance functions. An illustration of the setting introduced can be found in figure 4.
is an error term, where Ei is an s × s matrix such that each entry is an independent sample of a Gaussian distribution with mean zero and standard deviation σ. Model (6) could be regarded as an implementation of the idealized problem 2, where the covariance operators are represented by the associated covariance functions. An illustration of the setting introduced can be found in figure 4.

Figure 4. Illustration of the setting introduced with model (6).
Download figure:
Standard image High-resolution imageThe problem introduced in this section has not been extensively covered in the literature. In the discrete case, Dryden et al (2009) introduce a tangent PCA model for directly observed covariance matrices. An extension to directly observed covariance operators has been proposed in Pigoli et al (2014). Also related to our work is the setting considered in Petersen and Müller (2019), where the authors propose a regression framework for responses that are random objects (e.g. covariance matrices) with Euclidean predictors. The proposed regression model is applied to study associations between age and low-dimensional correlation matrices, representing functional connectivity, which have been computed from a parcellation of the brain. In section 4, we propose a novel PCA approach for indirectly observed high-dimensional covariance matrices.
3. Principal components of indirectly observed functions
The aim of this section is to define a model for the estimation of the PC functions {ψr} from the observations {yl}, defined in (5). Although the model proposed in this section is not the main contribution of this work, it allows us to introduce some of the concepts necessary to the definition of the more general model for indirectly observed covariance functions in section 4.
3.1. Model
Now let  be an m-dimensional real column vector and
be an m-dimensional real column vector and  be the Sobolev space of functions in
be the Sobolev space of functions in  with first and second distributional derivatives in
with first and second distributional derivatives in  . From now on
. From now on  is instantiated with
is instantiated with  . We propose to estimate
. We propose to estimate  , the first PC function of X, and the associated PC scores vector z, by solving the equation
, the first PC function of X, and the associated PC scores vector z, by solving the equation

where ||⋅|| is the Euclidean norm and Δ is the Laplace–Beltrami operator, which enables a smoothing regularizing effect on the PC function  . The data fit term encourages KlΨf to capture the strongest mode of variation of {yl}. The parameter λ controls the trade-off between the data fit term of the objective function and the regularizing term. The second PC function can be estimated by classical deflation methods, i.e. by applying model (7) on the residuals
. The data fit term encourages KlΨf to capture the strongest mode of variation of {yl}. The parameter λ controls the trade-off between the data fit term of the objective function and the regularizing term. The second PC function can be estimated by classical deflation methods, i.e. by applying model (7) on the residuals  , and so on for the subsequent PCs. The proposed model can be interpreted as a regularized least square estimation of the first PC function ψ1 in (5), with the terms {zl} playing the role of estimates of the variables {ζl,1}.
, and so on for the subsequent PCs. The proposed model can be interpreted as a regularized least square estimation of the first PC function ψ1 in (5), with the terms {zl} playing the role of estimates of the variables {ζl,1}.
In the simplified case of a single forward operator K := K1 =⋯= Km, the minimization problem (7) can be reformulated in a more classical form. In fact, fixing f in (7) and minimizing over z gives

which can then be used to show that the minimization problem (7) is equivalent to maximizing

with  an m × s real matrix, where the lth row of
an m × s real matrix, where the lth row of  is the observation
is the observation  . This reformulation gives further insights on the interpretation of
. This reformulation gives further insights on the interpretation of  in (7). In fact,
in (7). In fact,  is such that
is such that  maximizes
maximizes  subject to a norm constraint. The term
subject to a norm constraint. The term  is the empirical covariance matrix in the sensors space. The term zTz in (7) places the regularization term
is the empirical covariance matrix in the sensors space. The term zTz in (7) places the regularization term  in the denominator of the equivalent formulation (9). Thus,
in the denominator of the equivalent formulation (9). Thus,  is regularized by the choice of norm in the denominator of (9), in a similar fashion to the classic functional principal component formulation of Silverman (1996). Ignoring the spatial regularization, the point-wise evaluation of the PC function Ψf in (9) can be interpreted as the first PC vector computed from the dataset of backprojected data
is regularized by the choice of norm in the denominator of (9), in a similar fashion to the classic functional principal component formulation of Silverman (1996). Ignoring the spatial regularization, the point-wise evaluation of the PC function Ψf in (9) can be interpreted as the first PC vector computed from the dataset of backprojected data ![${\left[{K}_{1}^{T}{\mathbf{y}}_{1},\dots ,\;{K}_{m}^{T}{\mathbf{y}}_{m}\right]}^{T}$](https://content.cld.iop.org/journals/0266-5611/36/8/085002/revision2/ipab8713ieqn64.gif) , similarly to what is proposed in Dobriban et al (2017) in the context of optimal prediction.
, similarly to what is proposed in Dobriban et al (2017) in the context of optimal prediction.
3.2. Algorithm
Here we propose a minimization approach for the objective function in (7), which we approach by alternating the minimization of z and f in an iterative algorithm. In (7), a normalization constraint must be considered to make the representation unique, as in fact multiplying z by a constant and dividing f by the same constant does not change the objective function. We optimize in z under the constraint ||z|| = 1, which leads to a normalized version of the estimator (8):

For a given z, solving (7) with respect to f will turn out to be equivalent to solving an inverse problem, which we discretize adopting a mixed finite elements approach (Azzimonti et al 2014). Specifically, consider now a triangulated surface  , union of the finite set of triangles
, union of the finite set of triangles  , giving an approximated representation of the manifold
, giving an approximated representation of the manifold  . We then consider the linear finite element space V consisting of a set of globally continuous functions over
. We then consider the linear finite element space V consisting of a set of globally continuous functions over  that are affine where restricted to any triangle τ in
that are affine where restricted to any triangle τ in  , i.e.
, i.e.

This space is spanned by the nodal basis ϕ1, ..., ϕκ associated with the nodes ξ1, ..., ξκ, corresponding to the vertices of the triangulation  . Such basis functions are Lagrangian, meaning that ϕi(ξj) = 1 if i = j and ϕi(ξj) = 0 otherwise. Setting
. Such basis functions are Lagrangian, meaning that ϕi(ξj) = 1 if i = j and ϕi(ξj) = 0 otherwise. Setting  and
and  , every function f ∈ V has the form
, every function f ∈ V has the form

for all  . To ease the notation, we assume that the p points {vj} associated with the evaluation operator Ψ coincide with the nodes of the triangular mesh ξ1, ..., ξκ, and thus we have that the coefficients c are such that c = Ψf for any f ∈ V. Consequently, we are assuming the forward operators {Kl} to be s × κ matrices, relating the κ points on the cortical surface of the ith sample, in one-to-one correspondence to ξ1, ..., ξκ, to the s-dimensional signal detected on the sensors for the ith sample.
. To ease the notation, we assume that the p points {vj} associated with the evaluation operator Ψ coincide with the nodes of the triangular mesh ξ1, ..., ξκ, and thus we have that the coefficients c are such that c = Ψf for any f ∈ V. Consequently, we are assuming the forward operators {Kl} to be s × κ matrices, relating the κ points on the cortical surface of the ith sample, in one-to-one correspondence to ξ1, ..., ξκ, to the s-dimensional signal detected on the sensors for the ith sample.
Let now M and A be the mass and stiffness κ × κ matrices defined as  and
and  , where
, where  is the gradient operator on the manifold
is the gradient operator on the manifold  . Practically,
. Practically,  is a constant function on each triangle of
is a constant function on each triangle of  , and can take an arbitrary value on the edges6.
, and can take an arbitrary value on the edges6.
Let  denote the maximum diameter of the triangles forming
denote the maximum diameter of the triangles forming  , then the solution
, then the solution  of (7), in the discrete space V, is given by the following proposition.
of (7), in the discrete space V, is given by the following proposition.
Proposition 1. The surface finite element solution  of model (7), for a given unitary norm vector z, is
of model (7), for a given unitary norm vector z, is  where
where  is the solution of
is the solution of

Equation (12) has the form of a penalized regression, where the discretized version of the penalty term is AM−1A.
The sparsity of the linear system (12), namely the number of zeros, depends on the sparsity of its components. The matrices M and A are very sparse, however M−1 is not, in general. To overcome this problem, in the numerical analysis of partial differential equations literature, the matrix M−1 is generally replaced with the sparse matrix  , where
, where  is the diagonal matrix such that
is the diagonal matrix such that  (Fried and Malkus 1975, Zienkiewicz et al 2013). The penalty operator
(Fried and Malkus 1975, Zienkiewicz et al 2013). The penalty operator  approximates very well the behavior of AM−1A.
approximates very well the behavior of AM−1A.
Moreover, in the case of longitudinal studies that involve only one subject, we have a single forward operator K := K1 =⋯= Km common to all the observed signals, and consequently equation (12) can be rewritten as the sparse overdetermined system

to be interpreted in a least-square sense. A sparse QR solver can be finally applied to efficiently solve the linear system (13).
In algorithm 1 we summarize the main algorithmic steps to compute the PC functions and associated PC scores for indirectly observed functions. The initializing scores z can be chosen either at random or, when there is a correspondence between the detectors of different samples (e.g. K1 =⋯= Km), with the scores obtained by performing PCA on the observations in the sensors space.
Algorithm 1. Inverse problems—PCA algorithm
| 1: Initialization: |
| (a) Computation of M and A |
| (b) Initialize z, the scores vector associated with the first PC function |
| 2: PC function's estimation: compute c such that |
 |
 |
| 3: Scores estimation: |
 |
| 4: Repeat steps 2 and 3 until convergence |
3.3. Eigenfunctions of indirectly observed covariance operators
Suppose now we are in the case of a single forward operator K. Combining steps 2 and 3 of algorithm 1, and moving the normalization step from (zl) to fh, we obtain the iterations

The obtained algorithm depends on the data only through  that up to a constant is the covariance matrix computed on the sensors space. The proposed algorithm can thus be applied to situations where the observations {yl} are not available, but we are given only the associated s × s covariance matrix on the sensors space, computed from {yl}. This could be of interest in situations where the temporal resolution is very high and the spatial resolution is low, therefore it is convenient to store the covariance matrix rather than the entire set of observations.
that up to a constant is the covariance matrix computed on the sensors space. The proposed algorithm can thus be applied to situations where the observations {yl} are not available, but we are given only the associated s × s covariance matrix on the sensors space, computed from {yl}. This could be of interest in situations where the temporal resolution is very high and the spatial resolution is low, therefore it is convenient to store the covariance matrix rather than the entire set of observations.
4. Reconstruction and representation of indirectly observed covariance operators
Consider now n sample covariance matrices S1, ..., Sn, each of size s × s, representing n different connectivity maps on the sensors space. Three of such covariance matrices, associated with three different individuals, are shown in figure 2. Recall moreover that we denote with  the brain surface template and with
the brain surface template and with  the set of subject-specific forward operators, relating the signal at the p pre-specified points {vj} on the cortical surface
the set of subject-specific forward operators, relating the signal at the p pre-specified points {vj} on the cortical surface  with the signal detected on the s sensors.
with the signal detected on the s sensors.
The aim of this section is to introduce a model for the reconstruction and representation of the covariance functions {Ci}, on the brain space, associated with the actually observed covariance matrices {Si}, on the sensors space. The matrices {Si} are related to the covariance functions {Ci} through formula (6) that we recall here being

with  , and {vj} the sampling points associated with the operator Ψ.
, and {vj} the sampling points associated with the operator Ψ.
First, in section 4.1, we see how the PC model introduced in section 3 could be applied to individually reconstruct the covariance functions {Ci}. In section 4.2, we introduce a population model that achieves both reconstruction and joint representation of the underlying covariance functions {Ci}.
4.1. A subject-specific model
Let  be a square-root decomposition of Si, which is a decomposition such that
be a square-root decomposition of Si, which is a decomposition such that  , for all i = 1, ..., n. This could be given, for instance, by
, for all i = 1, ..., n. This could be given, for instance, by  where
where  is the spectral decomposition of Si and
is the spectral decomposition of Si and  denotes the diagonal matrix whose entries are the square-root of the (non-negative) entries of Di. Each square-root decomposition
denotes the diagonal matrix whose entries are the square-root of the (non-negative) entries of Di. Each square-root decomposition  can be interpreted as a data-matrix whose empirical covariance is Si. Another possible choice for the square-root decompositions is
can be interpreted as a data-matrix whose empirical covariance is Si. Another possible choice for the square-root decompositions is  . The output of the proposed algorithms will not depend on the specific choice of the square-root decompositions.
. The output of the proposed algorithms will not depend on the specific choice of the square-root decompositions.
In the most general setting, each covariance matrix Si is an indirect observation of an underlying covariance function Ci, which can be expressed in terms of its spectral decomposition as

where, for each i, γi1 ⩾ γi2 ⩾⋯⩾ 0 is a sequence of non-increasing variances and  a set of orthonormal eigenfunctions. Introduce now
a set of orthonormal eigenfunctions. Introduce now  and
and  , obtained by applying model (7) to each sample independently, i.e.
, obtained by applying model (7) to each sample independently, i.e.

with ||⋅||F denoting the Frobenius matrix norm. Each estimate  , from model (14), can be interpreted as a regularized estimate of the leading PC function of
, from model (14), can be interpreted as a regularized estimate of the leading PC function of  and thus of the eigenfunction ψi1. The subsequent eigenfunctions can be estimated by deflation methods, i.e. by removing the estimated components
and thus of the eigenfunction ψi1. The subsequent eigenfunctions can be estimated by deflation methods, i.e. by removing the estimated components  from
from  and reapplying model (14). This leads to a set of estimates
and reapplying model (14). This leads to a set of estimates  and
and  .
.
The unregularized version of model (14) is equivalent to a singular value decomposition applied to each matrix  independently, which would lead to a set of orthogonal estimates
independently, which would lead to a set of orthogonal estimates  , for each i = 1, ..., n. In the regularized model orthogonality is not enforced, however the estimated PC components can be orthogonalized post-estimation by means of a QR decomposition.
, for each i = 1, ..., n. In the regularized model orthogonality is not enforced, however the estimated PC components can be orthogonalized post-estimation by means of a QR decomposition.
Define now the empirical variances to be  and consider the
and consider the  -normalized version of
-normalized version of  . An approximate representation of
. An approximate representation of  is thus given by
is thus given by

and the associated approximate representation of Ci, in terms of  and
and  , is
, is

where  is an estimate of the variance γir and
is an estimate of the variance γir and  is an estimate of ψir. The tensor product
is an estimate of ψir. The tensor product  is such that
is such that  for all
for all  . The regularizing terms in (14) introduce spatial coherence on the estimated
. The regularizing terms in (14) introduce spatial coherence on the estimated  and thus on the estimated eigenfunctions of {Ci}, fundamental in an inverse problems setting.
and thus on the estimated eigenfunctions of {Ci}, fundamental in an inverse problems setting.
The reconstructed covariance functions {Ci} could be discretized on a dense grid, leading to a collection of covariance matrices  . Following the approach in Dryden et al (2009), a Riemannian metric could be defined on the space of covariance matrices, followed by projection of
. Following the approach in Dryden et al (2009), a Riemannian metric could be defined on the space of covariance matrices, followed by projection of  on the tangent space centered at the sample Fréchet mean. PCA could then be carried out on vectorizations of the tangent space representations. A related approach, for covariance functions, has been adopted in Pigoli et al (2014).
on the tangent space centered at the sample Fréchet mean. PCA could then be carried out on vectorizations of the tangent space representations. A related approach, for covariance functions, has been adopted in Pigoli et al (2014).
However, the aforementioned approaches could be prohibitive in our setting. In fact, performing PCA on tangent space projections produces modes of variation that are geodesics passing through the mean, and whose interpretation in a high-dimensional setting is often challenging. Therefore, in the next section, we propose an alternative model that enables joint reconstruction, and representation on a 'common basis', of indirectly observed covariance functions.
4.2. A population model
Let  and
and  be given by the following model:
be given by the following model:

The newly defined model, as opposed to model (14), has now a subject-specific s-dimensional vector zi and a term f that is common to all samples. As in the previous model, the subsequent components can be estimated by deflation methods, leading to a set of estimates  and
and  .
.
Define now the empirical variances to be  and consider the
and consider the  -normalized version of
-normalized version of  . The empirical term in model (16) suggests an approximate representation of Si, that is
. The empirical term in model (16) suggests an approximate representation of Si, that is

where each underlying covariance function Ci is approximated by the sum of the product between a subject-specific constant  and a component
and a component  common to all the observations. The regularizing term in (16) introduces spatial coherence on the estimated functions
common to all the observations. The regularizing term in (16) introduces spatial coherence on the estimated functions  .
.
The covariance operators  are said to be commuting if
are said to be commuting if  for all i, i' = 1, ..., n. This property can be equivalently characterized as
for all i, i' = 1, ..., n. This property can be equivalently characterized as

with  subject-specific variances and {ψr} a set of common orthonormal functions. Thus, a collection of commuting covariance operators is such that its covariance operators can be simultaneously diagonalized by a basis {ψr}. In this case, the functions
subject-specific variances and {ψr} a set of common orthonormal functions. Thus, a collection of commuting covariance operators is such that its covariance operators can be simultaneously diagonalized by a basis {ψr}. In this case, the functions  can be regarded as estimates of {ψr} and
can be regarded as estimates of {ψr} and  estimates of {γir}.
estimates of {γir}.
On the one hand, model (16) constrains the estimated covariances to be of the form  and not of the more general form
and not of the more general form  . On the other hand, such a model takes advantage of all the n samples to estimate the components
. On the other hand, such a model takes advantage of all the n samples to estimate the components  . Moreover, the associated variables
. Moreover, the associated variables  give a convenient approximate description of the ith covariance, as they are comparable across samples, as opposed to the one computed from model (14). In fact, the ith covariance function can be represented by the variance vector
give a convenient approximate description of the ith covariance, as they are comparable across samples, as opposed to the one computed from model (14). In fact, the ith covariance function can be represented by the variance vector  , for a suitable truncation level R, where each entry is associated with the rank-one component
, for a suitable truncation level R, where each entry is associated with the rank-one component  . For each r, a scatter plot of the variances
. For each r, a scatter plot of the variances  , as the one in figure 14, helps understand what the average contribution of the rth components is and what its variability across samples is. Model (17) could also be interpreted as a common PCA model (Benko et al 2009, Flury 1984), as
, as the one in figure 14, helps understand what the average contribution of the rth components is and what its variability across samples is. Model (17) could also be interpreted as a common PCA model (Benko et al 2009, Flury 1984), as  are the estimated regularized eigenfunctions of the pooled covariance
are the estimated regularized eigenfunctions of the pooled covariance  .
.
Potentially, PCA could be performed on the descriptors  to find rank-R components that maximize the variance of linear combinations of
to find rank-R components that maximize the variance of linear combinations of  (i.e. the variance of the variances). However, results would be more difficult to interpret, as they would involve variations that are rank-R covariance functions around the rank-R mean covariance function.
(i.e. the variance of the variances). However, results would be more difficult to interpret, as they would involve variations that are rank-R covariance functions around the rank-R mean covariance function.
4.3. Algorithm
The minimization in (14), for each fixed i, is a particular case of the one in (7) (see section 3.2), so we focus on the minimization problem in (16) which is also approached in an iterative fashion. We set  in the estimation procedure. This leads to the estimates of {zi}, given f, that are
in the estimation procedure. This leads to the estimates of {zi}, given f, that are

with

The estimate of f given {zi}, in the discrete space V introduced in section 3.2, is given by the following proposition.
Proposition 2. The surface finite element solution  of model (16), given the vectors {zi}, is
of model (16), given the vectors {zi}, is  where
where  is the solution of
is the solution of

Algorithm 2 contains a summary of the estimation procedure. From a practical point of view, the choice to define the representation basis to be a collection of rank one (i.e. separable) covariance functions, of the type  , is mainly driven by the following reasons. Firstly, rank-one covariance functions are easier to interpret due to their limited degrees of freedom. Secondly, on a rank one covariance function
, is mainly driven by the following reasons. Firstly, rank-one covariance functions are easier to interpret due to their limited degrees of freedom. Secondly, on a rank one covariance function  spatial coherence can be imposed by regularizing
spatial coherence can be imposed by regularizing  , as in fact done for model (14), and this is fundamental in the setting of indirectly observed covariance functions. Finally, due to their size, it might not be possible to store the full reconstructions of the covariance functions {Ci} on the brain space, instead, the representation model in (17) allows for an efficient joint representation of such covariance functions in terms of rank-one components.
, as in fact done for model (14), and this is fundamental in the setting of indirectly observed covariance functions. Finally, due to their size, it might not be possible to store the full reconstructions of the covariance functions {Ci} on the brain space, instead, the representation model in (17) allows for an efficient joint representation of such covariance functions in terms of rank-one components.
Algorithm 2. Inverse problems—covariance PCA algorithm.
| 1: Square-root decompositions |
(a) Compute the representations  from S1, ..., Sn as from S1, ..., Sn as |
 |
with  the spectral decomposition of Si. the spectral decomposition of Si. |
| 2: Initialization: |
| (a) Computation of M and A |
(b) Initialize  , the scores of the first PC , the scores of the first PC |
| 3: PC function's estimation from model (14): compute c such that |
 |
 |
| 4: Scores estimation from model (14): |
 |
 |
| 5: Repeat step 3 and 4 until convergence |
5. Simulations
In this section, we perform simulations to assess the performances of the proposed algorithms. To reproduce as closely as possible the application setting, the cortical surfaces and the forward operators are taken from the MEG application described in section 6. The details on the extraction and computation of such objects are left to the same section. For the same reason, the signals on the brain space considered here are vector-valued functions, specifically functions from the brain space  to
to  , as is the case in the MEG application. The proposed methodology can be trivially extended to successfully deal with this case, as shown in the following simulations.
, as is the case in the MEG application. The proposed methodology can be trivially extended to successfully deal with this case, as shown in the following simulations.
5.1. Indirectly observed functions
We consider  to be a triangular mesh, with 8k nodes, representing the cortical surface geometry of a subject, as shown on the left panel of figure 1. Each of the 8k nodes will represent a location vj associated with the sampling operator Ψ. The locations of the nodes {vj} on the brain space, the location of the 241 detectors on the sensors space and a model of the subject's head, enable the computation of a forward operator K describing the relation between the signal generated on the locations {vj}, on the brain space, and the signal detected on the 241 sensors in the sensors space. In practice, the signal on each node vj is described by a three dimensional vector, characterized by an intensity and a direction, while the signal detected on the sensors space is a scalar signal. Thus, the forward operator is a 241 × 24k matrix.
to be a triangular mesh, with 8k nodes, representing the cortical surface geometry of a subject, as shown on the left panel of figure 1. Each of the 8k nodes will represent a location vj associated with the sampling operator Ψ. The locations of the nodes {vj} on the brain space, the location of the 241 detectors on the sensors space and a model of the subject's head, enable the computation of a forward operator K describing the relation between the signal generated on the locations {vj}, on the brain space, and the signal detected on the 241 sensors in the sensors space. In practice, the signal on each node vj is described by a three dimensional vector, characterized by an intensity and a direction, while the signal detected on the sensors space is a scalar signal. Thus, the forward operator is a 241 × 24k matrix.
We first want to assess the performances of the proposed model in the case of indirect functional observations belonging to a linear space. To this purpose, we produce synthetic data following the generative model (5). Specifically, on  , we construct the four
, we construct the four  orthonormal vector-valued functions {ψr = (ψr,1, ψr,2, ψr,3) : r = 1, ..., 4}, with
orthonormal vector-valued functions {ψr = (ψr,1, ψr,2, ψr,3) : r = 1, ..., 4}, with  . These represent the PC functions to be estimated. In figure 5 we show the four components of {ψr} and the associated energy maps
. These represent the PC functions to be estimated. In figure 5 we show the four components of {ψr} and the associated energy maps  , with ||⋅|| denoting the Euclidean norm in
, with ||⋅|| denoting the Euclidean norm in  . We then generate m = 50 smooth vector-valued functions {xl} on
. We then generate m = 50 smooth vector-valued functions {xl} on  by
by

where {zlr} are i.i.d realizations of the four independent random variables {zr ∼ N(0, γr) : r = 1, ..., 4}, with γ1 = 32, γ2 = 2.52, γ3 = 22 and γ4 = 1.

Figure 5. From top to bottom the components and the energy maps of the PC functions ψ1, ..., ψ4.
Download figure:
Standard image High-resolution imageThe functions {xl} are sampled at the 8k nodes, and the forward operator is applied to the sampled values, producing a collection of vectors {yl} each of dimension 241, the number of active sensors. Moreover, on each entry of the vectors {yl}, we add Gaussian noise with mean zero and standard deviation σ, for different choices of σ, to reproduce different signal-to-noise ratio regimes.
In the following, we compare the PC model (7) to an alternative approach that we call the naive approach. In fact, the individual functions {xl} could be estimated from {yl} by use of classical inverse problem estimators. Here, we adopt the estimates  defined as
defined as

where each  is defined in such a way that it balances the fitting term and the regularization term in (20). Due to the fact that f is vector-valued,
is defined in such a way that it balances the fitting term and the regularization term in (20). Due to the fact that f is vector-valued,  is defined as
is defined as

with  denoting the components of f. The same penalty operator is also adopted to generalize to vector-valued functions the PC models introduced in sections 3 and 4. In this approach, the constant λ is chosen independently for each of the m functions by partitioning the 241 detectors in roughly equally sized K = 2 groups and applying K-fold cross-validation. The criterion for the optimal λ is the average reconstruction error, on the sensors space, computed on the validation groups. Once we obtain the estimates
denoting the components of f. The same penalty operator is also adopted to generalize to vector-valued functions the PC models introduced in sections 3 and 4. In this approach, the constant λ is chosen independently for each of the m functions by partitioning the 241 detectors in roughly equally sized K = 2 groups and applying K-fold cross-validation. The criterion for the optimal λ is the average reconstruction error, on the sensors space, computed on the validation groups. Once we obtain the estimates  we can compute the estimated PC functions {ψr} by applying classical multivariate PC analysis on the reconstructed objects
we can compute the estimated PC functions {ψr} by applying classical multivariate PC analysis on the reconstructed objects  .
.
The estimates are compared to those of the proposed PC function model, as described in algorithm 1, with 15 iterations. Note that, instead, a tolerance could be fixed to test if the algorithm has converged. However, 15 iterations give satisfactory convergence levels in our simulations and application studies. We partition the m observations in equally sized K = 2 groups and perform K-fold cross-validation for the choice of the penalty. Specifically, we choose the coefficient λ that minimizes the sensors space reconstruction error, on the validation groups.
To evaluate the performances of the two approaches, we generate 100 datasets as previously detailed. The quality of the estimated rth PC function is then measured with  . The results are summarized in the boxplots in figure 6, for two different signal-to-noise ratios, where the Gaussian noise has standard deviation σ = 5 and σ = 10. In figure 7 we show an example of a signal on the brain space corrupted with the specified noise levels.
. The results are summarized in the boxplots in figure 6, for two different signal-to-noise ratios, where the Gaussian noise has standard deviation σ = 5 and σ = 10. In figure 7 we show an example of a signal on the brain space corrupted with the specified noise levels.

Figure 6. On the left, a summary of the results in a medium signal-to-noise ratio regime. On the right, a summary of the results in a low signal-to-noise ratio regime. Each boxplot displays the paired differences of the estimation errors  between the estimates of the two steps naive method and those obtained by applying algorithm 1. A paired difference greater than 0 indicates that, for the dataset in question, algorithm 1 has performed better than the two steps naive approach.
between the estimates of the two steps naive method and those obtained by applying algorithm 1. A paired difference greater than 0 indicates that, for the dataset in question, algorithm 1 has performed better than the two steps naive approach.
Download figure:
Standard image High-resolution image
Figure 7. From left to right, the energy map of a generated function xl, the associated signal yl on the sensors space with respectively no additional error, Gaussian error of standard deviation σ = 5 and Gaussian error of standard deviation σ = 10.
Download figure:
Standard image High-resolution imageThe boxplots highlight the fact that the proposed approach provides better estimates of the PC functions (i.e. lower estimation errors  ), when compared to the naive approach. Differences in the estimation error are higher in a low signal-to-noise regime, as it is for the estimation of the fourth PC function, where intuitively, the low variance associated to the PC function makes it more difficult to distinguish this structured signal from the noise component. Also surprising is the stability of the estimates of the proposed algorithm across the generated datasets, as opposed to the naive approach of reconstructing the functional observations independently, which instead returns multiple particularly unsatisfactory reconstructions. An example of such reconstructions is shown in figure 8.
), when compared to the naive approach. Differences in the estimation error are higher in a low signal-to-noise regime, as it is for the estimation of the fourth PC function, where intuitively, the low variance associated to the PC function makes it more difficult to distinguish this structured signal from the noise component. Also surprising is the stability of the estimates of the proposed algorithm across the generated datasets, as opposed to the naive approach of reconstructing the functional observations independently, which instead returns multiple particularly unsatisfactory reconstructions. An example of such reconstructions is shown in figure 8.

Figure 8. On the first row the energy maps of the true four PC components to be estimated, on the second row the estimations given by the two steps naive method, and on the third row the reconstructions obtained by applying algorithm 1.
Download figure:
Standard image High-resolution image5.2. Indirectly observed covariance functions
In this section, we consider  to be a 8k nodes triangular mesh, this time representing a template geometry of the cortical surface, which is shown in figure 10. This contains only the geometric features common to all subjects. Moreover, each subject's cortical surface is also represented by a 8k nodes triangular surface, which is used, together with the locations of the 241 detectors on the sensors space, and the head model, to compute a forward operator Ki for the ith subject. The 8k nodes of each subject's triangular mesh are in correspondence with the 8k nodes of the template mesh
to be a 8k nodes triangular mesh, this time representing a template geometry of the cortical surface, which is shown in figure 10. This contains only the geometric features common to all subjects. Moreover, each subject's cortical surface is also represented by a 8k nodes triangular surface, which is used, together with the locations of the 241 detectors on the sensors space, and the head model, to compute a forward operator Ki for the ith subject. The 8k nodes of each subject's triangular mesh are in correspondence with the 8k nodes of the template mesh  . This allows the model to be defined on the template
. This allows the model to be defined on the template  .
.

Figure 9. On the top row, the energy maps of ψ1, ..., ψ4. On the bottom row the energy maps of the estimates  obtained by applying algorithm 2.
obtained by applying algorithm 2.
Download figure:
Standard image High-resolution imageAs in the previous section, we construct four  orthonormal functions
orthonormal functions  . The energy maps of
. The energy maps of  are shown in figure 9. We generate synthetic data from model (6) as follows:
are shown in figure 9. We generate synthetic data from model (6) as follows:

where zi1, ..., zi4 are i.i.d realizations of the four independent random variables  , with γ1 = 32, γ2 = 2.52, γ3 = 22 and γ4 = 1. The matrix-valued form of the covariance functions arises from the fact that the observed functions on the brain space are vector-valued. Subsequently, we construct the point-wise evaluations matrices
, with γ1 = 32, γ2 = 2.52, γ3 = 22 and γ4 = 1. The matrix-valued form of the covariance functions arises from the fact that the observed functions on the brain space are vector-valued. Subsequently, we construct the point-wise evaluations matrices  , from which the correspondent covariance matrices on the sensors space are defined as
, from which the correspondent covariance matrices on the sensors space are defined as

The term  is an error term, where Ei is an s × s matrix with each entry that is an independent sample from a Gaussian distribution with mean zero and standard deviation 5. We then apply algorithm 2 with 15 iterations, feeding in input
is an error term, where Ei is an s × s matrix with each entry that is an independent sample from a Gaussian distribution with mean zero and standard deviation 5. We then apply algorithm 2 with 15 iterations, feeding in input  . The results are shown in figure 9, in terms of energy maps of the reconstructed functions
. The results are shown in figure 9, in terms of energy maps of the reconstructed functions  . These are a close approximation of the underlying functions
. These are a close approximation of the underlying functions  . The fidelity measure
. The fidelity measure  of such estimates is 6.8 × 10−2, 6.1 × 10−1, 6.8 × 10−1 and 7.4 × 10−1, for ψ1, ..., ψ4 respectively, which is comparable in term of order of magnitude to the results obtained in the case of PCs of indirectly observed functions. Across the generation of multiple datasets, results are stable, with the exception of few situations where the cross-validation approach suggests a penalization coefficient λ that under-smoothes the solution, due to very similar associated signals on the sensors space of the under-smoothed solution and the real solution. However, the cross-validation is only a possible approach to the choice of the penalization constant, and many other options have been proposed in the inverse problems literature (Vogel 2002). Some of these, however, involve visual inspection.
of such estimates is 6.8 × 10−2, 6.1 × 10−1, 6.8 × 10−1 and 7.4 × 10−1, for ψ1, ..., ψ4 respectively, which is comparable in term of order of magnitude to the results obtained in the case of PCs of indirectly observed functions. Across the generation of multiple datasets, results are stable, with the exception of few situations where the cross-validation approach suggests a penalization coefficient λ that under-smoothes the solution, due to very similar associated signals on the sensors space of the under-smoothed solution and the real solution. However, the cross-validation is only a possible approach to the choice of the penalization constant, and many other options have been proposed in the inverse problems literature (Vogel 2002). Some of these, however, involve visual inspection.

Figure 10. Top side and bottom side views of the template triangular mesh  composed of 8k nodes.
composed of 8k nodes.
Download figure:
Standard image High-resolution image6. Application
In this section, we apply the developed models to the publicly available human connectome project (HCP) young adult dataset (Van Essen et al 2012). This dataset comprises multi-modal neuroimaging data such as structural scans, resting-state and task-based functional MRI scans, and resting-state and task-based MEG scans from a large number of healthy volunteers. In the following, we briefly review the pre-processing pipeline, applied to such data by the HCP, to ultimately facilitate their use.
6.1. Pre-processing
For each individual a high-resolution 3D structural MRI scan has been acquired. This returns a 3D image describing the structure of the gray and white matter in the brain. Gray matter is the source of large parts of our neuronal activity. White matter is made of axons connecting the different parts of the gray matter. If we exclude the sub-cortical structures, gray matter is mostly distributed at the outer surface of the cerebral hemispheres. This is also known as the cerebral cortex.
By segmentation of the 3D structural MRI, it is possible to separate gray matter from white matter, in order to extract the cerebral cortex structure. Subsequently a mid-thickness surface, interpolating the mid-points of the cerebral cortex, can be estimated, resulting in a 2D surface embedded in a 3D space that represents the geometry of the cerebral cortex. In practice, such a surface, sometimes referred to as cortical surface, is a triangulated surface. Moreover, from the 3D structural MRI, a surface describing the individuals' head can be extracted. The latter plays a role in the derivation of the model for the electrical/magnetic propagation of the signal from the cerebral cortex to the sensors. An example of the cortical surface of a single subject, is shown on the right panel in figure 1, instead the associated head surface and MEG sensors positions are shown on the left panel of the same figure.
Moreover, a surface based registration algorithm has been applied to register each of the extracted cortical surfaces to a triangulated template cortical surface, which is shown in figure 10. Post registration, the triangulated template cortical surface is sub-sampled to a 8k nodes surface. Moreover, the nodes on the cortical surface of each subject are also sub-sampled to a set of 8k nodes in correspondence to the 8k nodes of the template. For each subject, a 248 × 24k matrix, representing the forward operator, has been computed with FieldTrip (Oostenveld et al 2011) from its head surface, cortical surface and sensors position. Such a matrix relates the vector-valued signals in  , on the nodes of the triangulation of the cerebral cortex, to the one detected from the sensors, consisting of 248 magnetometer channels.
, on the nodes of the triangulation of the cerebral cortex, to the one detected from the sensors, consisting of 248 magnetometer channels.
With the aim of studying the functional connectivity of the brain, for each subject, three 6 min resting state MEG scans have been performed, of which one session is used in our analysis. During the 6 min, data are collected from the sensors at 600k uniformly distributed time-points. Using FieldTrip, classical pre-processing is applied to the detected signals, such as low quality channels and low quality segments removal. Details of this procedure can be found in the HCP MEG reference manual. Moreover, we apply a band pass filter, limiting the spectrum of the signal to the [12.5, 29] Hz, also known as the beta waves. For the signal of each channel we compute its amplitude envelope (see figure B.1) which describes the evolution of the signal amplitude. The measure of connectivity between channels that we adopt in this work is the covariance of the amplitude envelopes. Other connectivity metrics, such as phase-based metrics, have been proposed in the literature (see Colclough et al 2016, and references therein).
6.2. Analysis
Here we apply the population model introduced in section 4.2 to the HCP MEG data. The first part of the analysis focuses on studying dynamic functional connectivity of a specific subject. For this purpose, we subdivide the 6 min session in n = 40 consecutive intervals. Each of these segments is used to compute a covariance matrix in the sensors space, resulting in n covariance matrices S1, ..., Sn. In this setting, we have one forward operator K = K1 =⋯= Kn. The aim is understanding the main modes of variation of the functional connectivity on the brain space of the subject. Thus, algorithm 2, with 20 iterations, is applied to S1, ..., Sn to find the PC covariance functions.
A regularization parameter λ common to all the PC components is chosen by inspecting the plot of the regularity of the first R = 10 PC covariance functions ( ) versus the residual norm, for different choices of the parameter. This is a version of the L-curve plot (Hansen 2000) and is shown on the left panel of figure B.2. Here we show the results for λ = 102, in the appendices we show the results for λ = 10. The energy maps of the estimated
) versus the residual norm, for different choices of the parameter. This is a version of the L-curve plot (Hansen 2000) and is shown on the left panel of figure B.2. Here we show the results for λ = 102, in the appendices we show the results for λ = 10. The energy maps of the estimated  ,
,  and
and  resulting from the analysis are shown in figure 11. These are associated with the first three PC covariance functions
resulting from the analysis are shown in figure 11. These are associated with the first three PC covariance functions  ,
,  and
and  . High intensity areas, in yellow, indicate which areas present high average interconnectivity, either by means of positive or negative correlation in time.
. High intensity areas, in yellow, indicate which areas present high average interconnectivity, either by means of positive or negative correlation in time.

Figure 11. Top side and bottom side views of the estimated energy maps  ,
,  and
and  obtained by applying algorithm 2 to the covariance matrices computed from the MEG resting state data of a single subject on n = 40 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps. On the top right panel we highlight with red circles the areas with high average interconnectivity, which correspond to the neighborhoods of the red crossed vertices in the plot of the energy map of ψ1.
obtained by applying algorithm 2 to the covariance matrices computed from the MEG resting state data of a single subject on n = 40 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps. On the top right panel we highlight with red circles the areas with high average interconnectivity, which correspond to the neighborhoods of the red crossed vertices in the plot of the energy map of ψ1.
Download figure:
Standard image High-resolution imageIn figure 12, we show the plot of variances associated with each time segment, describing the variation in time of the PC covariance functions, hence the variation in interconnectivity. The variance can be either defined on the sensors space, by normalizing the PC covariance functions  , with K the forward operator, or on the brain space, by normalizing the PC covariance functions on the brain space
, with K the forward operator, or on the brain space, by normalizing the PC covariance functions on the brain space  . Due to the presence of invisible dipoles, which are dipoles that display zero magnetic field on the sensors space, the two norms can be quite different, leading to different average variances for each PC covariance function. Due to the high sensitivity of the source space variances on the choice of the regularization parameter, we focus on the estimated variances on the sensors space.
. Due to the presence of invisible dipoles, which are dipoles that display zero magnetic field on the sensors space, the two norms can be quite different, leading to different average variances for each PC covariance function. Due to the high sensitivity of the source space variances on the choice of the regularization parameter, we focus on the estimated variances on the sensors space.

Figure 12. Plots of the segment-specific variances of the first R = 10 PC covariance functions. On the left, the estimated variances on the sensors space, on the right, the estimated variances on the brain space.
Download figure:
Standard image High-resolution imageWe have also applied our model to the covariances obtained by subdividing the MEG session in n = 80 segments. As expected the PC covariance functions, shown in figure B.5 are very similar. However, the variances, in figure B.4, show higher variability in time, which can be partially explained by the fact that shorter time segments lead to covariance estimates that have higher variability.
The second part of the analysis focuses on applying the proposed methodology to a multi-subject setting. Specifically, n = 40 different subjects are considered. For each subject, the 6 min scan is used to compute a covariance matrix, resulting in n covariance matrices S1, ..., Sn. The template geometry in figure 10 is used as a model of the brain space. Algorithm 2 is then applied to find the PC covariance functions on the template brain, associated with S1, ..., Sn. We run the algorithm for 20 iterations, and choose the regularizing parameter to be λ = 102 by inspecting the L-curve plot in the right panel of figure B.2. The results for λ = 10 are shown in the appendices. The energy maps of the estimated functions  ,
,  and
and  and the associated first three covariance functions
and the associated first three covariance functions  ,
,  and
and  , are shown in figure 13. High intensity areas, in yellow, indicate which areas present high average connectivity. In figure 14, we show the subject-specific associated variances, both in the sensors space and the brain space.
, are shown in figure 13. High intensity areas, in yellow, indicate which areas present high average connectivity. In figure 14, we show the subject-specific associated variances, both in the sensors space and the brain space.

Figure 13. Top side and bottom side views of the estimated energy maps  ,
,  and
and  obtained by applying algorithm 2 to the covariance matrices computed from the MEG resting state data of n = 40 different subjects. On the right panel, the covariance functions associated with these energy maps.
obtained by applying algorithm 2 to the covariance matrices computed from the MEG resting state data of n = 40 different subjects. On the right panel, the covariance functions associated with these energy maps.
Download figure:
Standard image High-resolution image
Figure 14. Plots of the subject-specific variances associated with the first R = 10 PC covariance functions. On the left, the estimated variances on the sensors space, on the right, the estimated variances on the brain space.
Download figure:
Standard image High-resolution imageThe presented methodology opens up the possibility to understand population level variation in functional connectivity, and indeed, whether, just as we need different forward operators for individuals (due to anatomical differences), we should also be considering both population and subject-specific connectivity maps when analyzing connectivity networks. In fact, it is of interest to note that in both the single and multi-subject settings, the areas with high interconnectivity, displayed in yellow in figures 11 and 13, seem to be at least partially overlapping with the brain's default network (Buckner et al 2008, Yeo et al 2011). The brain's default network consists of the brain regions known to have highly correlated hemodynamic activity (i.e. highest functional connectivity levels), and to be most active, when the subject is not performing any specific task. An image of the spatial configuration of the default network can be found, for instance, in figure 2 of Buckner et al (2008). From the plots of the associated variances in the sensors space (left panel of figures 12 and 14) we can see that these areas are also the ones that show high variability in connectivity across time or across subjects. This might suggest that the brain's default network is also the brain region that shows among the highest levels of spontaneous variability in connectivity.
The plots of the variances on the brain space (right panel of figure 14), when compared to those on the sensors space (left panel of figure 14), demonstrate that these type of studies are highly sensitive to the choice of the regularization, not only in terms of spatial configuration of the results, but also in terms of estimated variances on the brain space. With a naive 'first reconstruct and then analyze' approach, where the reconstructed data on the brain space replace those observed on the sensors space, this issue could go unnoticed, as the variability that does not fit the chosen model is implicitly discarded in the reconstruction step and does not appear in the subsequent analysis. Also, importantly, our analysis deals with statistical samples that are entire covariances, overcoming the limitations of seed-based approaches, where prior spatial information is required to choose the seed. Seed locations are usually informed by fMRI studies and this comes with the risk of biasing the analysis when comparing electrophysiological networks (MEG) and hemodynamic networks (fMRI).
In general, care should be taken when drawing conclusions from MEG studies. Establishing static and dynamic functional connectivity from MEG data remains challenging, due to the strong ill-posedness of the inverse problem. It is known that other variables, such as the choice of the frequency band or the choice of the connectivity metric can influence the analysis. While the choice of the neural oscillatory frequency band could be seen as an additional parameter in MEG functional connectivity studies, there is no general agreement on the choice of the connectivity metrics (Gross et al 2013). It is important to highlight that in this paper we focus on methodological contributions to the specific problem of reconstructing and representing indirectly observed functional images and covariance functions.
7. Discussion
In this work we introduce a general framework for the reconstruction and representation of covariance operators in an inverse problem context. We first introduce a model for indirectly observed functional images in an unconstrained space, which outperforms the naive approach of solving the inverse problem individually for each sample. This model plays an important role in the case of samples that are indirectly observed covariance functions, and thus constrained to be positive semidefinite. We deal with the non-linearity introduced by such constraint by working with unconstrained representations, yet incorporating spatial information in their estimation. The proposed methodology is finally applied to the study of brain connectivity from the signals arising from MEG scans.
The models proposed here can be extended in many interesting directions. From an applied prospective, it is of interest to apply them to different settings, not necessarily involving neuroimaging, where studying second order information has been so far prohibitive. Direct examples are second order analysis of the dynamics of meteorological observations, such as temperature. Another possible application is the study of the dynamics of ocean currents, where the irregularity of the spatial domain, and its complex boundaries, can be easily accounted for thanks to the manifold representation approach in our models.
From a modeling point of view, it is of interest to take a step further toward the integration of the inverse problems literature with the approach we adopt in this paper. For instance, penalization terms that have been shown to be successful in the inverse problems literature, e.g. total variation penalization, could be introduced in our models.
Acknowledgments
The authors would like to thank the anonymous reviewers and the member of the Editorial Board for their useful and constructive comments.
Appendix A.: Discrete solutions
Proof of proposition 1. We want to find a minimizer  , given z with ||z|| = 1, of the objective function in (7):
, given z with ||z|| = 1, of the objective function in (7):

An equivalent formulation of a minimizer  of such objective function is given by satisfying the equation
of such objective function is given by satisfying the equation

for every  (see Braess 2007, chapter 2). Moreover, such minimizer is unique if
(see Braess 2007, chapter 2). Moreover, such minimizer is unique if  is positive definite. Given that for a closed manifold
is positive definite. Given that for a closed manifold  ,
,  iff f is a constant function (Dziuk and Elliott 2013), the positive definiteness condition is equivalent to assuming that
iff f is a constant function (Dziuk and Elliott 2013), the positive definiteness condition is equivalent to assuming that  , the kernel of
, the kernel of  , does not contain the subspace of p-dimensional constant vectors.
, does not contain the subspace of p-dimensional constant vectors.
Moreover, we can reformulate equation (22) in a form that involves only first-order derivatives by integration by parts against a test function. We then look for a solution in the discrete space  , i.e. finding
, i.e. finding 

for all φ, w ∈ V. The operator  is the gradient operator on the manifold
is the gradient operator on the manifold  . The gradient operator
. The gradient operator  is such that
is such that  , for w a smooth real function on
, for w a smooth real function on  and
and  , takes value on the tangent space at v. We denote with ⋅ the scalar product on the tangent space.
, takes value on the tangent space at v. We denote with ⋅ the scalar product on the tangent space.
We recall here the definition of the κ × κ matrices to be  and
and  . Note that requiring (23) to hold for all φ, w ∈ V is equivalent to requiring that (23) holds for all φ, w that are basis elements of V, thus exploiting the basis expansion formula (11) we can characterize (23) with the solution of the linear system
. Note that requiring (23) to hold for all φ, w ∈ V is equivalent to requiring that (23) holds for all φ, w that are basis elements of V, thus exploiting the basis expansion formula (11) we can characterize (23) with the solution of the linear system

where  and
and  are the basis coefficients of f ∈ V and g ∈ V, respectively. Solving (24) in
are the basis coefficients of f ∈ V and g ∈ V, respectively. Solving (24) in  leads to
leads to

□
Proof of proposition 2. We want to find a minimizer  , given {zi} with
, given {zi} with  , of the objective function in (14):
, of the objective function in (14):

Comparing (26) with (21) it is evident that by following the same steps of the proof of proposition 1 we obtain the desired result, which is

□
Appendix B.: Application—additional material
Here we present further material complementing the analysis in section 6. In figure B.1 we show the amplitude envelope computed from a filtered version of a signal detected by an MEG sensor. The covariance of the amplitude envelopes across different sensors is the measure of connectivity used in this work.

Figure B.1. Amplitude envelope (in red) of the filtered signal (in blue) detected by an MEG sensor.
Download figure:
Standard image High-resolution imageIn figure B.2 we show the L-curve plots associated with the PC covariance models applied to the dynamic and multi-subject functional connectivity studies.

Figure B.2. Plots of the regularity of the first R = 10 PC covariance functions, measured as  versus the residual norm in the data, for different choices of log(λ). On the left panel, the plot refers to the dynamic connectivity study, on the right panel the plot of the multi-subject connectivity study.
versus the residual norm in the data, for different choices of log(λ). On the left panel, the plot refers to the dynamic connectivity study, on the right panel the plot of the multi-subject connectivity study.
Download figure:
Standard image High-resolution image
Figure B.3. Energy maps of the estimated  ,
,  and
and  obtained by applying algorithm 2, with lower regularization (λ = 10), to the covariance matrices computed from the MEG resting state data of a single subject on n = 40 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps.
obtained by applying algorithm 2, with lower regularization (λ = 10), to the covariance matrices computed from the MEG resting state data of a single subject on n = 40 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps.
Download figure:
Standard image High-resolution imageIn figures B.3 and B.4 we show respectively the plots of the estimated PC covariance functions and associated variances from the dynamic functional connectivity study on n = 40 segments with regularization parameter λ = 10.
In figures B.5 and B.6 we show the estimated PC covariance functions and associated variances from the dynamic functional connectivity study on n = 80 time segments with regularization parameter λ = 102.

Figure B.4. Plots of the segment-specific variances of the first R = 10 PC covariance functions in time when a smaller regularization parameter is chosen (λ = 10).
Download figure:
Standard image High-resolution image
Figure B.5. Energy maps of the estimated  ,
,  and
and  obtained by applying algorithm 2, with λ = 102, to the covariance matrices computed from the MEG resting state data of a single subject on n = 80 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps.
obtained by applying algorithm 2, with λ = 102, to the covariance matrices computed from the MEG resting state data of a single subject on n = 80 consecutive time intervals. On the right panel, the covariance functions associated with these energy maps.
Download figure:
Standard image High-resolution image
Figure B.6. Plots of the segment-specific variances of the first R = 10 PC covariance functions in time, with λ = 102, when the MEG resting state data is split into n = 80 consecutive time intervals.
Download figure:
Standard image High-resolution image
Figure B.7. Energy maps of the estimated  ,
,  and
and  obtained by applying algorithm 2, with lower regularization (λ = 10), to the covariance matrices computed from the MEG resting state data of n = 40 different subjects. On the right panel, the covariance functions associated with these energy maps.
obtained by applying algorithm 2, with lower regularization (λ = 10), to the covariance matrices computed from the MEG resting state data of n = 40 different subjects. On the right panel, the covariance functions associated with these energy maps.
Download figure:
Standard image High-resolution image
Figure B.8. Plots of the subject-specific variances associated with the first R = 10 PC covariance functions computed from n = 40 subject, with regularization parameter λ = 10.
Download figure:
Standard image High-resolution imageIn figures B.7 and B.8 we show the estimated PC covariance functions and associated variances from the multi-subject functional connectivity study on n = 40 subjects with regularization parameter λ = 10.
Footnotes
- 5
More precisely, we have that
, i.e. the series converges uniformly in mean-square. - 6
Formally, these are weak derivatives, hence uniquely defined almost everywhere (i.e. up to a set of measure zero) and are always evaluated in an integral form (see Dziuk and Elliott 2013, for further details).

{kind=link}
{kind=link}
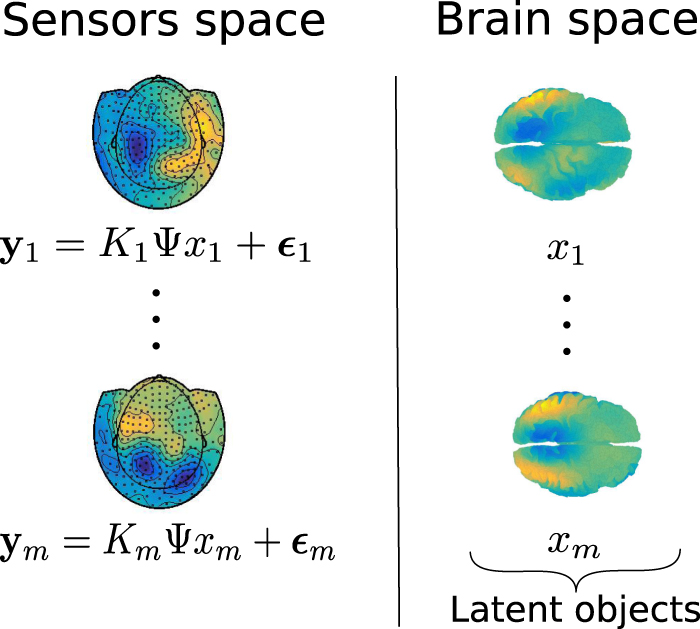{kind=link}
{kind=link}
{kind=link}
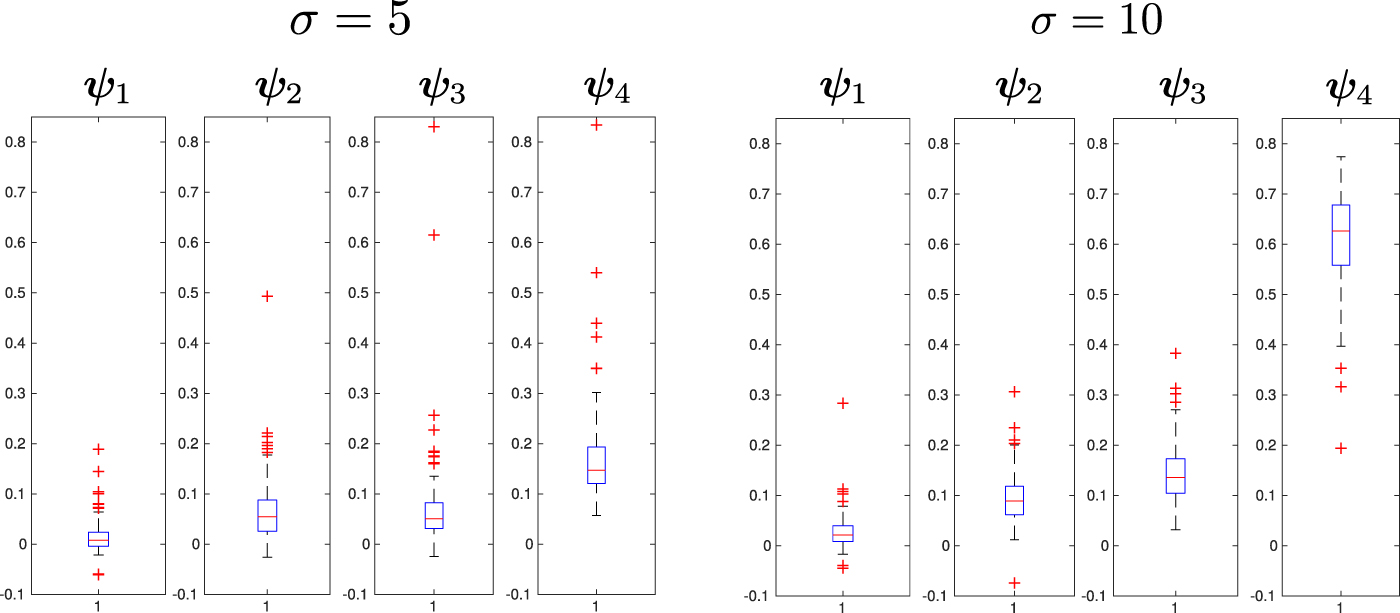{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}