

Abstract
Recently, deep learning based methods appeared as a new paradigm for solving inverse problems. These methods empirically show excellent performance but lack of theoretical justification; in particular, no results on the regularization properties are available. In particular, this is the case for two-step deep learning approaches, where a classical reconstruction method is applied to the data in a first step and a trained deep neural network is applied to improve results in a second step. In this paper, we close the gap between practice and theory for a particular network structure in a two-step approach. For that purpose, we propose using so-called null space networks and introduce the concept of  -regularization. Combined with a standard regularization method as reconstruction layer, the proposed deep null space learning approach is shown to be a
-regularization. Combined with a standard regularization method as reconstruction layer, the proposed deep null space learning approach is shown to be a  -regularization method; convergence rates are also derived. The proposed null space network structure naturally preserves data consistency which is considered as key property of neural networks for solving inverse problems.
-regularization method; convergence rates are also derived. The proposed null space network structure naturally preserves data consistency which is considered as key property of neural networks for solving inverse problems.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
We study the solution of inverse problems of the form

Here  is a linear operator between Hilbert spaces
is a linear operator between Hilbert spaces  and
and  , and
, and  models the unknown data error (noise), which is assumed to satisfy the estimate
models the unknown data error (noise), which is assumed to satisfy the estimate ![$ \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\noise}{\xi} \snorm{\noise } \leqslant \delta $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn007.gif) for some noise level
for some noise level  . We consider a possibly infinite-dimensional function space setting, but the approach and results apply to a finite dimensional setting as well.
. We consider a possibly infinite-dimensional function space setting, but the approach and results apply to a finite dimensional setting as well.
We focus on the ill-posed (or ill-conditioned) case where, without additional information, the solution of (1.1) is either highly unstable, highly underdetermined, or both. Many inverse problems in biomedical imaging, geophysics, engineering sciences, or elsewhere can be written in such a form (see, for example [7, 22]). For its stable solution one has to employ regularization methods, which are based on approximating (1.1) by neighboring well-posed problems, which enforce stability, accuracy, and uniqueness.
1.1. Regularization methods
Any method for the stable solution of (1.1) uses, either implicitly or explicitly, a priori information about the unknowns to be recovered. Such information can be that  belongs to a certain set of admissible elements
belongs to a certain set of admissible elements  or that it has small value of some regularizing functional. The most basic regularization method is probably Tikhonov regularization, where the solution is defined as a minimizer of the quadratic Tikhonov functional
or that it has small value of some regularizing functional. The most basic regularization method is probably Tikhonov regularization, where the solution is defined as a minimizer of the quadratic Tikhonov functional

Other classical regularization methods for solving linear inverse problems are filter based methods [7], which include Tikhonov regularization as special case.
In the last couple of years variational regularization methods including TV regularization or  regularization became popular [22]. They also include classical Tikhonov regularization as special case. In the general version, the regularizer
regularization became popular [22]. They also include classical Tikhonov regularization as special case. In the general version, the regularizer ![$ \newcommand{\edot}{\,\cdot\,} \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\e}{{\rm e}} \frac{1}{2} \norm{\edot }^2 $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn012.gif) is replaced by general convex and lower semi-continuous functionals.
is replaced by general convex and lower semi-continuous functionals.
In this paper, we develop a new regularization concept that we name  -regularization method. Roughly spoken, a
-regularization method. Roughly spoken, a  -regularization method is a tuple
-regularization method is a tuple  where (for a precise definition see definition 2.3)
where (for a precise definition see definition 2.3)
 is the set of admissible elements, defined by the function Φ;
is the set of admissible elements, defined by the function Φ;- are continuous mappings;
- is a suitable parameter choice;
- For any we have as .






Note that for some cases is might be reasonable to take  multivalued. For the sake of simplicity here we only consider the single-valued case. Classical regularization methods are special cases of
multivalued. For the sake of simplicity here we only consider the single-valued case. Classical regularization methods are special cases of  -regularization methods in Hilbert spaces where
-regularization methods in Hilbert spaces where  . A typical regularization method is in this case given by Tikhonov regularization, where
. A typical regularization method is in this case given by Tikhonov regularization, where  . Here and in the following
. Here and in the following  denotes the identity on
denotes the identity on  .
.
1.2. Solving inverse problems by neural networks
Very recently, deep learning approaches appeared as alternative, very successful methods for solving inverse problems (see, for example [2–6, 8, 10, 12, 15, 25–28]). In most of these approaches, a reconstruction network  is trained to map measured data to the desired output image.
is trained to map measured data to the desired output image.
Various reconstruction networks have been introduced in the literature. In the two-step approach, the reconstruction networks take the form  where
where  maps the data to the reconstruction space (reconstruction layer or backprojection; no free parameters) and
maps the data to the reconstruction space (reconstruction layer or backprojection; no free parameters) and  is a neural network (NN) whose free parameters are adjusted to the training data. In particular, so called residual networks
is a neural network (NN) whose free parameters are adjusted to the training data. In particular, so called residual networks  where only the residual part
where only the residual part  is trained [11] show very accurate results for solving inverse problems [3, 6, 12, 13, 16, 18, 21, 26]. Another class of reconstruction networks learns free parameters in iterative schemes. In such approaches, a sequence of reconstruction networks
is trained [11] show very accurate results for solving inverse problems [3, 6, 12, 13, 16, 18, 21, 26]. Another class of reconstruction networks learns free parameters in iterative schemes. In such approaches, a sequence of reconstruction networks  is defined by some iterative process
is defined by some iterative process  where
where  is some the initial guess,
is some the initial guess,  are networks that can be adjusted to available training data, and
are networks that can be adjusted to available training data, and  are updates based on the data and the previous iterates [2, 14, 15, 23].
are updates based on the data and the previous iterates [2, 14, 15, 23].
Further existing deep learning approaches for solving inverse problems are based on trained projection operators [5, 8], or use neural networks as trained regularization term [17].
While the above deep learning based reconstruction networks empirically yield good performance, none of them is known to be a convergent regularization method. In this paper, we use a new network structure (null space network) that, when combined with a classical regularization of the Moore Penrose inverse is shown to provide a convergent  -regularization method with rates. One of the reviewers of this manuscript kindly brought to our attention that the null space network structure actually has been introduced already by Mardani and collaborators in [19, 20] in a finite dimensional setting. We extend the use of the null space network to operators with non-closed range and analyze its stable approximation in the context of regularization methods.
-regularization method with rates. One of the reviewers of this manuscript kindly brought to our attention that the null space network structure actually has been introduced already by Mardani and collaborators in [19, 20] in a finite dimensional setting. We extend the use of the null space network to operators with non-closed range and analyze its stable approximation in the context of regularization methods.
1.3. Proposed null space networks and main results
As often argued in the recent literature, deep learning based reconstruction approaches (especially using two-stage networks) lack data consistency, in the sense that outputs of existing reconstruction networks fail to accurately predict the given data. In order to overcome this issue, in this paper, we introduce a new network, that we name null space network. The proposed null space network takes the form

The function  , for example, can be defined by a neural network according to definition 3.2. Note that
, for example, can be defined by a neural network according to definition 3.2. Note that  equals the projector onto the null space
equals the projector onto the null space  of
of  . Consequently, the null space network
. Consequently, the null space network  satisfies the property
satisfies the property  for all
for all  . This yields data consistency, which means that the equation
. This yields data consistency, which means that the equation  is invariant among application of a null space network (compare figure 1).
is invariant among application of a null space network (compare figure 1).

Figure 1. Sketch of the action of a null space network  that maps points
that maps points  to more desirable elements in
to more desirable elements in  along the null space of
along the null space of  . The component
. The component  is invisible in the data
is invisible in the data  , whereas the part
, whereas the part  can be found by applying the pseudoinverse
can be found by applying the pseudoinverse  to the data
to the data  .
.
Download figure:
Standard image High-resolution imageSuppose  are some desired output images and let
are some desired output images and let  be a trained null space network that approximately maps
be a trained null space network that approximately maps  to
to  . (See the appendix for a possible training strategy.) In this paper, we show that if
. (See the appendix for a possible training strategy.) In this paper, we show that if  is any classical
is any classical  -regularization, then the two-stage reconstruction network
-regularization, then the two-stage reconstruction network

yields a  -regularization with
-regularization with  . To the best of our knowledge, these are first results for regularization by neural networks. Additionally, we will derive convergence rates for
. To the best of our knowledge, these are first results for regularization by neural networks. Additionally, we will derive convergence rates for  on suitable function classes.
on suitable function classes.
The intuition behind using the null space network in the two-stage approach (1.4) is that only invisible information in  should be learned by the network, whereas the visible part in
should be learned by the network, whereas the visible part in  should be kept (compare figure 1). Moreover, in the case that
should be kept (compare figure 1). Moreover, in the case that  has non-closed range then the visible part
has non-closed range then the visible part  will be be sensitive with respect to data perturbation. These instabilities with respect to noise can exactly be addressed by a regularizing family
will be be sensitive with respect to data perturbation. These instabilities with respect to noise can exactly be addressed by a regularizing family  of continuous operators that converge pointwise to
of continuous operators that converge pointwise to  in the limit
in the limit  .
.
1.4. Outline
This paper is organized as follows. In section 2 we develop a general theory of  -regularization and introduce the notion of
-regularization and introduce the notion of  -generalized inverse (definition 2.1) and
-generalized inverse (definition 2.1) and  -regularization methods (definition 2.3) generalizing the classical Moore–Penrose generalized inverse and regularization concept. We show convergence (see theorem 2.4) and derive convergence rates (theorem 2.8) that include regularization via the null space networks as a special case. In section 3 we introduce the null-space networks and extend the convergence results in the special case of the null space network (theorems 3.4 and 3.5). Possible strategies for training a nullspace network are described in the appendix. The paper concludes with an outlook presented in section 4.
-regularization methods (definition 2.3) generalizing the classical Moore–Penrose generalized inverse and regularization concept. We show convergence (see theorem 2.4) and derive convergence rates (theorem 2.8) that include regularization via the null space networks as a special case. In section 3 we introduce the null-space networks and extend the convergence results in the special case of the null space network (theorems 3.4 and 3.5). Possible strategies for training a nullspace network are described in the appendix. The paper concludes with an outlook presented in section 4.
2. A theory of -regularization

In this section, we introduce the novel concepts of  -generalized inverse and
-generalized inverse and  -regularization. We derive a general class of
-regularization. We derive a general class of  -regularization for which we show convergence and derive convergence rates.
-regularization for which we show convergence and derive convergence rates.
Throughout this section, let  be a linear bounded operator and
be a linear bounded operator and  be Lipschitz continuous and define
be Lipschitz continuous and define

The prime example is  being a null space network with a neural network function
being a null space network with a neural network function  . This case will be studied in the following section. The results presented in this section apply to general Lipschitz continuous functions
. This case will be studied in the following section. The results presented in this section apply to general Lipschitz continuous functions  whose image is contained in
whose image is contained in  .
.
2.1. -regularization methods

In the following we denote by  the Moore–Penrose generalized inverse of
the Moore–Penrose generalized inverse of  , defined by
, defined by ![$ \newcommand{\ran}{{\rm ran}} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\Ao}{\mathbf A} \dom(\Ao^{+}) := \ran\skl{\Ao} \oplus \ran\skl{\Ao}^\bot$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn093.gif) and
and

It is well known [7] that ![$ \newcommand{\set}[1]{{\left\{#1\right\}}} \newcommand{\signal}{x} \newcommand{\data}{y} \newcommand{\XX}{X} \newcommand{\Ao}{\mathbf A} \newcommand{\e}{{\rm e}} \set{\signal \in \XX \mid \Ao^*\Ao \signal =\Ao^* \data} \neq \emptyset$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn094.gif) if and only if
if and only if ![$ \newcommand{\ran}{{\rm ran}} \newcommand{\skl}[1]{(#1)} \newcommand{\data}{y} \newcommand{\Ao}{\mathbf A} \data \in \ran\skl{\Ao} \oplus \ran\skl{\Ao}^\bot$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn095.gif) . In particular,
. In particular,  is well defined, and can be found as the unique minimal norm solution of the normal equation
is well defined, and can be found as the unique minimal norm solution of the normal equation  .
.
Classical regularization methods aim for approximating  . In contrast, the null space network will recover different solutions of the normal equation. For that purpose, we introduce the following concept.
. In contrast, the null space network will recover different solutions of the normal equation. For that purpose, we introduce the following concept.
Definition 2.1 ( -generalized inverse). We call
-generalized inverse). We call  the
the  -generalized inverse of
-generalized inverse of  if
if

Recall that for any  , the solution set of the normal equation
, the solution set of the normal equation  is given by
is given by  . Hence
. Hence  gives a particular solution of the normal equation, that can be adapted to a training set. The
gives a particular solution of the normal equation, that can be adapted to a training set. The  -generalized inverse coincides with the Moore–Penrose generalized inverse if and only if
-generalized inverse coincides with the Moore–Penrose generalized inverse if and only if  for all
for all  in which case
in which case  .
.
Lemma 2.2. The  -generalized inverse is continuous if and only if
-generalized inverse is continuous if and only if  is closed.
is closed.
Proof. If  is closed, then classical results show that
is closed, then classical results show that  is bounded (see for example [7]). Consequently,
is bounded (see for example [7]). Consequently,  is bounded too. Conversely, if
is bounded too. Conversely, if  is continuous, then the identity
is continuous, then the identity  implies that the Moore–Penrose generalized inverse
implies that the Moore–Penrose generalized inverse  is bounded and therefore that
is bounded and therefore that  is closed. □
is closed. □
Lemma 2.2 shows that as in the case of the classical Moore–Penrose generalized inverse, the  -generalized inverse is discontinuous in the case that
-generalized inverse is discontinuous in the case that  is not closed. In order to stably solve the equation
is not closed. In order to stably solve the equation  we therefore require bounded approximations of the
we therefore require bounded approximations of the  -generalized inverse. For that purpose, we introduce the following concept of regularization methods adapted to
-generalized inverse. For that purpose, we introduce the following concept of regularization methods adapted to  .
.
Definition 2.3 ( -regularization method). Let
-regularization method). Let ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} \skl{\Ro_\al}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn126.gif) be a family of continuous (not necessarily linear) mappings
be a family of continuous (not necessarily linear) mappings  and let
and let ![$ \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\YY}{Y} \al^\star \colon \skl{0, \infty} \times \YY \to \skl{0, \infty}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn128.gif) . We call the pair
. We call the pair ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} (\skl{\Ro_\al}_{\al >0}, \alpha^\star)$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn129.gif) a
a  -regularization method for the equation
-regularization method for the equation  if the following hold:
if the following hold:
- .
- .
![$ \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\set}[1]{{\left\{#1\right\}}} \newcommand{\skl}[1]{(#1)} \newcommand{\data}{y} \newcommand{\YY}{\rm{dom(A^+)}} \forall \data \in \YY \colon \lim_{\delta\to 0} \sup \set{\al^\star\skl{\delta, y^\delta} \mid y^\delta \in \YY \wedge \snorm{y^\delta- y} \leqslant \delta } =0$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn133.gif)
![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\set}[1]{{\left\{#1\right\}}} \newcommand{\skl}[1]{(#1)} \newcommand{\data}{y} \newcommand{\YY}{\rm{dom(A^+)}} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\nun}{\boldsymbol{\Phi}} \forall \data \in \YY \colon \lim_{\delta\to 0} \sup \set{\snorm{\Ao^{\nun} y - \Ro_{\al^\star\skl{\delta, y^\delta}} y^\delta} \mid y^\delta \in \YY \wedge \snorm{y^\delta- y} \leqslant \delta } =0$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn135.gif)
In the case that ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} (\skl{\Ro_\al}_{\al >0}, \alpha^\star)$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn136.gif) is a
is a  -regularization method for
-regularization method for  , then we call the family
, then we call the family ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} \skl{\Ro_\al}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn139.gif) a regularization of
a regularization of  and
and  an admissible parameter choice.
an admissible parameter choice.
In our generalized notation, a classical regularization method for the equation  corresponds to a
corresponds to a  -regularization method for
-regularization method for  . Further note that the null space assumption is required for
. Further note that the null space assumption is required for  with
with  being a solution of
being a solution of  instead of being any element. We consider this data consistency property central for solving inverse problems with neural network based reconstruction methods.
instead of being any element. We consider this data consistency property central for solving inverse problems with neural network based reconstruction methods.
2.2. Convergence analysis
The following theorem shows that the combination of a null space network and a regularization method of  yields a regularization of
yields a regularization of  .
.
Theorem 2.4. Let  be a linear operator and
be a linear operator and  be Lipschitz continuous. Moreover, suppose
be Lipschitz continuous. Moreover, suppose  is any classical regularization method for
is any classical regularization method for  . Then, the pair
. Then, the pair  with
with  is a
is a  -regularization method for
-regularization method for  . In particular, the family
. In particular, the family  is a regularization of
is a regularization of  .
.
Proof. Because  is a
is a  -regularization method,
-regularization method, 
![$ \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\skl}[1]{(#1)} \newcommand{\sset}[1]{\{#1\}} \newcommand{\YY}{Y} { \YY {{\rm ~und~}} \snorm{y^\delta- y} \leqslant \delta \}} =0$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn163.gif) . Let
. Let  be a Lipschitz constant of
be a Lipschitz constant of  . For any
. For any  we have
we have

Consequently

In particular,  is a regularization of
is a regularization of  . □
. □
A wide class of  -regularization methods can be defined by a regularizing filter.
-regularization methods can be defined by a regularizing filter.
Definition 2.5. A family ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn170.gif) of functions
of functions ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Ao}{\mathbf A} g_\al \colon [0,\norm{\Ao^*\Ao}] \to \R $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn171.gif) is called a regularizing filter if it satisfies
is called a regularizing filter if it satisfies
- For all , is piecewise continuous;
- ;
- .


![$ \newcommand{\al}{\alpha} \newcommand{\la}{\lambda} \newcommand{\sabs}[1]{{\left\vert#1\right\vert}} \newcommand{\set}[1]{{\left\{#1\right\}}} \newcommand{\skl}[1]{(#1)} \newcommand{\e}{{\rm e}} \exists C >0 \colon \sup \set{\sabs{\la g_\al \skl{\la}} \mid \al >0 \wedge \la \in [0,||\boldsymbol{\rm{A^*A}}||]} \leqslant C$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn176.gif)
![$ \newcommand{\al}{\alpha} \newcommand{\la}{\lambda} \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\skl}[1]{(#1)} \newcommand{\Ao}{\mathbf A} \forall \la \in (0,\norm{\Ao^*\Ao}] \colon \lim_{\al \to 0} g_\al \skl{\la} = 1/\la$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn178.gif)
Corollary 2.6. Let ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn179.gif) be a regularizing filter and define
be a regularizing filter and define ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \newcommand{\Ao}{\mathbf A} \newcommand{\Bo}{\mathbf B} \Bo_\al := g_{\al} \kl{\Ao^*\Ao} \Ao^*$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn180.gif) . Then
. Then  is a regularization of
is a regularization of  .
.
Proof. The family  is a regularization of
is a regularization of  ; see [7]. Therefore, according to theorem 2.4,
; see [7]. Therefore, according to theorem 2.4,  is a regularization of
is a regularization of  . □
. □
Basic examples of filter based regularization methods are Tikhonov regularization, where  , and truncated singular value decomposition where
, and truncated singular value decomposition where

Classical regularization methods are based on approximating the Moore–Penrose inverse. The following result shows that  -regularization methods are essentially continuous approximations of
-regularization methods are essentially continuous approximations of  .
.
Proposition 2.7. Let ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} \skl{\Ro_\al}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn190.gif) be a family of continuous mappings
be a family of continuous mappings  .
.
- (a)If pointwise as , then the family is a regularization of .
- (b)Suppose that is a regularization of and that there exists a parameter choice that is continuous in the first argument. Then pointwise as .
![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\nun}{\boldsymbol{\Phi}} \newcommand{\re}{{\rm Re}} \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} \to \Ao^{\nun}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn192.gif)

![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} \skl{\Ro_\al}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn194.gif)

![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\Ro}{\mathbf R} \skl{\Ro_\al}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn196.gif)


![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\nun}{\boldsymbol{\Phi}} \newcommand{\re}{{\rm Re}} \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} \to \Ao^{\nun}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn199.gif)

- (a)If pointwise, then pointwise. Hence, classical regularization theory implies that is a regularization of . We have and, according to theorem 2.4, the family is a regularization of .
- (b)We havewhich shows that is a regularization of . Together with standard regularization theory this shows that pointwise as . Consequently, converges pointwise to . □
![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\nun}{\boldsymbol{\Phi}} \newcommand{\re}{{\rm Re}} \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} \to \Ao^{\nun}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn201.gif)
![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\ran}{{\rm ran}} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\Po}{\mathbf P} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\nun}{\boldsymbol{\Phi}} \newcommand{\re}{{\rm Re}} \Po_{\ran(\Ao^{+})} \circ \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} \to \Po_{\ran(\Ao^{+})} \circ \Ao^{\nun} = \Ao^{+}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn202.gif)








![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\ran}{{\rm ran}} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\Po}{\mathbf P} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\re}{{\rm Re}} \Po_{\ran(\Ao^{+})} \circ \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} \to \Ao^{+}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn210.gif)

![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\ran}{{\rm ran}} \newcommand{\dom}{{\rm dom}} \newcommand{\skl}[1]{(#1)} \newcommand{\rest}[2]{{#1}\vert_{#2}} \newcommand{\XX}{X} \newcommand{\Po}{\mathbf P} \newcommand{\Ao}{\mathbf A} \newcommand{\Ro}{\mathbf R} \newcommand{\Id}{{\rm Id}} \newcommand{\nun}{\boldsymbol{\Phi}} \newcommand{\re}{{\rm Re}} \rest{\Ro_\al}{\dom \skl{\Ao^{+}}} = (\Id_{\XX}+\nun) \circ \Po_{\ran(\Ao^{+})} \circ \rest{\Ro_\al}{\dom \skl{\Ao^{+}}}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn212.gif)

2.3. Convergence rates
Next we derive quantitative error estimates. For that purpose, we assume in the following that ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \newcommand{\Ao}{\mathbf A} \newcommand{\Bo}{\mathbf B} \Bo_\al = g_{\al} \kl{\Ao^*\Ao} \Ao^*$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn214.gif) is defined by the regularizing filter
is defined by the regularizing filter ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn215.gif) . We use the notation
. We use the notation  as
as  where
where ![$ \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\YY}{Y} \al^\star \colon \YY \times \skl{0, \infty} \to \skl{0, \infty}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn218.gif) and
and  to indicate there are positive constants
to indicate there are positive constants  such that
such that  .
.
Theorem 2.8. Suppose  and let
and let ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn223.gif) be a regularizing filter such that there exist constants
be a regularizing filter such that there exist constants  with
with
- ;
- .
![$ \newcommand{\al}{\alpha} \newcommand{\la}{\lambda} \newcommand{\abs}[1]{\left\vert#1\right\vert} \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\kl}[1]{\left(#1\right)} \newcommand{\Ao}{\mathbf A} \forall \al >0 \; \forall \la \in [0, \norm{\Ao^*\Ao}]\colon \la^\mu \abs{1- \la g_\al \kl{\la}} \leqslant c_1 \alpha ^\mu$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn226.gif)
![$ \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \forall \al \in(0, \al_0) \colon \snorm{g_\al}_\infty \leqslant c_2/ \al$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn228.gif)
Consider the  -regularization method
-regularization method  and set
and set

Moreover, let ![$ \newcommand{\al}{\alpha} \newcommand{\skl}[1]{(#1)} \newcommand{\YY}{Y} \al^\star \colon \skl{0, \infty} \times \YY \to \skl{0, \infty}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn231.gif) be a parameter choice (possible depending on the source set
be a parameter choice (possible depending on the source set  ) that satisfies
) that satisfies  as
as  . Then there exists a constant
. Then there exists a constant  such that
such that

In particular, for any  we have the convergence rate result
we have the convergence rate result ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\Ro}{\mathbf R} \snorm{\Ro_{\al^\star(\delta,y^\delta)} (y^\delta) - \signal } = \mathcal{O}(\delta^{\frac{2\mu}{2\mu+1}})$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn237.gif) .
.
Proof. We have ![$ \newcommand{\ran}{{\rm ran}} \newcommand{\kl}[1]{\left(#1\right)} \newcommand{\Po}{\mathbf P} \newcommand{\Ao}{\mathbf A} \newcommand{\M}{{\mathcal M}} \newcommand{\nun}{\boldsymbol{\Phi}} \Po_{\ran(\Ao^{+})} \M_{\mu, \rho, \nun} = \kl{\Ao^*\Ao}^\mu \kl{\overline{B _\rho (0)}} $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn238.gif) and
and  . Suppose
. Suppose  and
and  with
with ![$ \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\data}{y} \newcommand{\Ao}{\mathbf A} \snorm{\Ao \signal - \data^\delta} \leqslant \delta$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn242.gif) . Under the given assumptions,
. Under the given assumptions,  is an order optimal regularization method on
is an order optimal regularization method on ![$ \newcommand{\kl}[1]{\left(#1\right)} \newcommand{\Ao}{\mathbf A} \kl{\Ao^*\Ao}^\mu \kl{\overline{B _\rho (0)}} $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn244.gif) , which implies (see [7])
, which implies (see [7])

for some constant  independent of
independent of  ,
,  . Consequently, we have
. Consequently, we have

where  is the Lipschitz constant of
is the Lipschitz constant of  . Taking the supremum over all
. Taking the supremum over all  and
and  with
with ![$ \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\data}{y} \newcommand{\Ao}{\mathbf A} \snorm{\Ao \signal - \data^\delta} \leqslant \delta$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn252.gif) yields (2.5). □
yields (2.5). □
Note that the filters ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn253.gif) of the truncated SVD and the Landweber iteration satisfy the assumptions of theorem 2.8. In the case of Tikhonov regularization, the assumptions are satisfied for
of the truncated SVD and the Landweber iteration satisfy the assumptions of theorem 2.8. In the case of Tikhonov regularization, the assumptions are satisfied for  . In particular, under the assumption (resembling the classical source condition)
. In particular, under the assumption (resembling the classical source condition)

we obtain the convergence rate ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\Ro}{\mathbf R} \snorm{\Ro_{\al^\star(\delta,y^\delta)} (y^\delta) - \signal } = \mathcal{O}(\delta^{1/2})$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn255.gif) .
.
3. Deep null space learning
Throughout this section let  be a linear bounded operator. In this case, we define
be a linear bounded operator. In this case, we define  -regularizations by null-space networks. We describe a possible training strategy and derive regularization properties and rates. For the following recall that the projector onto the kernel of
-regularizations by null-space networks. We describe a possible training strategy and derive regularization properties and rates. For the following recall that the projector onto the kernel of  is given by
is given by  .
.
3.1. Null space networks
We work with layered feed forward networks in infinite dimensional spaces, although more complicated networks can be applied as long as their Lipschitz constant is finite. As the error estimates depend on the Lipschitz constant it is also desirable that the Lipschitz constant is not too large. Neural network functions in infinite dimensional spaces can be found in [1, 9, 17] and the references therein. Nevertheless, while the notion of neural networks is standard in a finite-dimensional setting, no established definition seems available for general Hilbert spaces. Here we use the following notation in Hilbert space notion.
Definition 3.1 (Layered feed forward network). Let  and
and  be Hilbert spaces. We call a function
be Hilbert spaces. We call a function  defined by
defined by

a layered feed forward neural network function of depth  with activations
with activations  if
if
- (N1) are Hilbert spaces with and ;
- (N2) are affine, continuous;
- (N3) are continuous.





Usually the nonlinearities  are fixed and the affine mappings
are fixed and the affine mappings  are trained. In the case that
are trained. In the case that  is a function space, then a standard operation for
is a function space, then a standard operation for  is the ReLU (the rectified linear unit),
is the ReLU (the rectified linear unit), ![$ \newcommand{\set}[1]{{\left\{#1\right\}}} {\rm ReLU} (x) := \max \set{x,0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn274.gif) , that is applied component-wise, or ReLU in combination with max pooling which takes the maximum value
, that is applied component-wise, or ReLU in combination with max pooling which takes the maximum value ![$ \newcommand{\abs}[1]{\left\vert#1\right\vert} \newcommand{\set}[1]{{\left\{#1\right\}}} \max\set{\abs{x(i)} \colon i \in I_k}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn275.gif) within clusters of transform coefficients. Note that in the typical case of
within clusters of transform coefficients. Note that in the typical case of  -spaces the elements are equivalence classes of functions. In this case, any representative has to be selected for the application of
-spaces the elements are equivalence classes of functions. In this case, any representative has to be selected for the application of  , which is clearly independent of the chosen representative. The network in definition 3.1 may in particular be a convolutional neural network (CNN); see [17] for a definition of CNNs in Banach spaces. In a similar manner, one could define more general feed forward networks in Hilbert spaces, for example following the notion of [24] in the finite dimensional case.
, which is clearly independent of the chosen representative. The network in definition 3.1 may in particular be a convolutional neural network (CNN); see [17] for a definition of CNNs in Banach spaces. In a similar manner, one could define more general feed forward networks in Hilbert spaces, for example following the notion of [24] in the finite dimensional case.
We are now able to formally define the concept of a null space network.
Definition 3.2. A function  is called a null space network if it has the form
is called a null space network if it has the form  where
where  is any Lipschitz continuous neural network function.
is any Lipschitz continuous neural network function.
An example for the null space network with  as defined in (3.1). We however again point out that
as defined in (3.1). We however again point out that  could be a more general Lipschitz continuous neural network function for which the results below equally hold. For the sake of clarity of presentation, we use the simple definition 3.1 of layered neural networks.
could be a more general Lipschitz continuous neural network function for which the results below equally hold. For the sake of clarity of presentation, we use the simple definition 3.1 of layered neural networks.
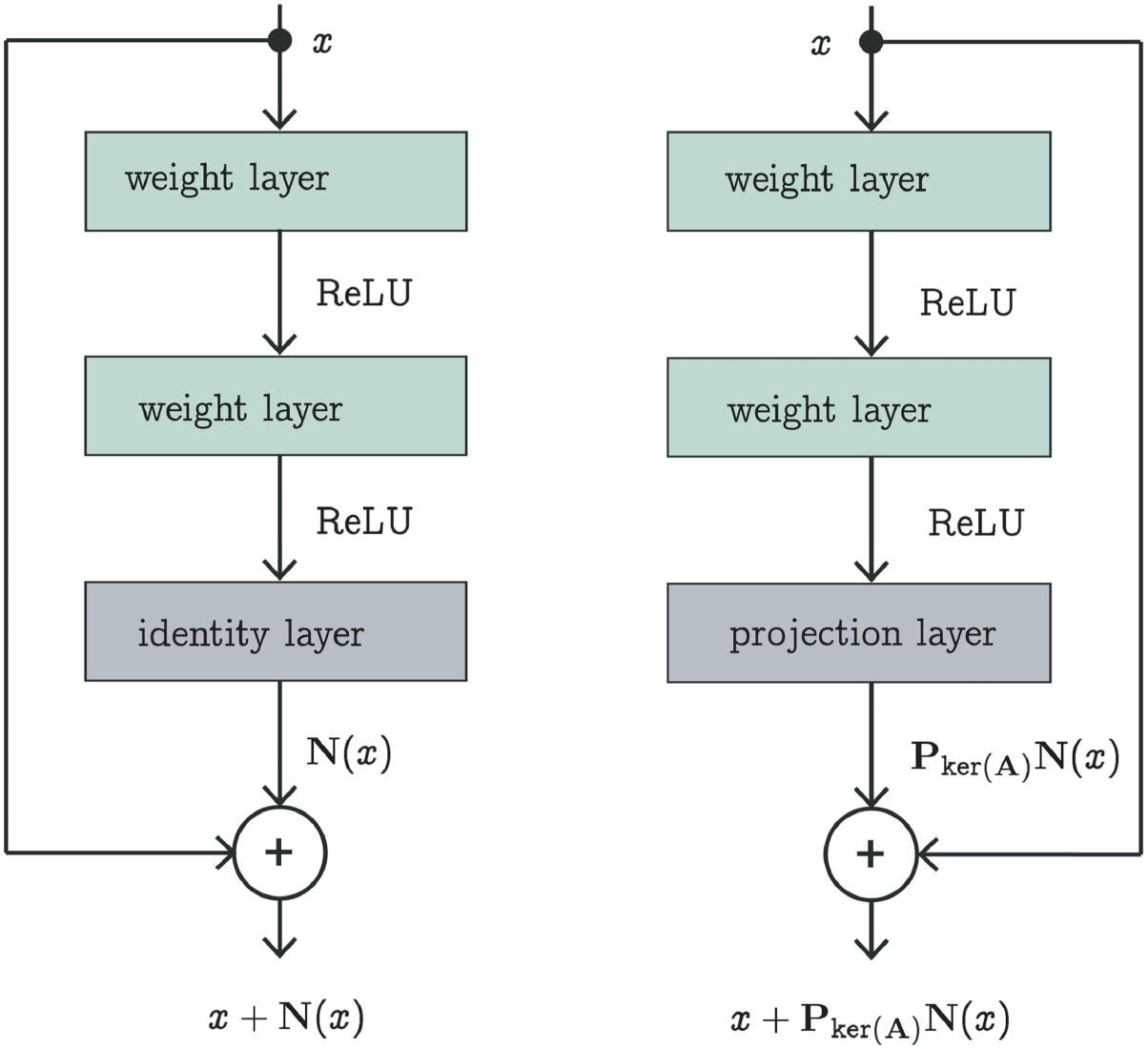
An example of a standard residual network  and a layered null space network
and a layered null space network  both with depth
both with depth  (i.e. two weight layers) are shown in figure 2.
(i.e. two weight layers) are shown in figure 2.

Figure 2. Standard residual network (left) versus null space network (right). The only difference is the projection layer on  after the last weight layer.
after the last weight layer.
Download figure:
Standard image High-resolution imageRemark 3.3. Throughout the following we assume that  is a given null-space network. Following the deep learning philosophy, the network would be selected from a parameterized family
is a given null-space network. Following the deep learning philosophy, the network would be selected from a parameterized family  based on given training data. A possible training strategy is presented in appendix. The results below hold for any null space network where the Lipschitz constant is finite. It is widely accepted that the Lipschitz constant in typically trained networks is reasonably small. As the error constant depends on the Lipschitz constants of the network it is desirable to keep the Lipschitz constant small. The proposed training strategy also accounts for this issue in the layered neural networks according to definition 3.1.
based on given training data. A possible training strategy is presented in appendix. The results below hold for any null space network where the Lipschitz constant is finite. It is widely accepted that the Lipschitz constant in typically trained networks is reasonably small. As the error constant depends on the Lipschitz constants of the network it is desirable to keep the Lipschitz constant small. The proposed training strategy also accounts for this issue in the layered neural networks according to definition 3.1.
Another simple way of constructing a null space network is to add a data consistency layer to an existing network. To be specific, let  be any trained network. Then one obtains a null space network by considering
be any trained network. Then one obtains a null space network by considering

Moreover, one can easily show that ![$ \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Ao}{\mathbf A} \newcommand{\nsn}{\mathbf{L}} \norm{x - \nsn \Ao^{+} \Ao x } \leqslant \norm{x - \nsn_0 \Ao^{+} \Ao x} $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn290.gif) for every
for every  . Hence the null space network is always better in terms of reconstruction error than the original network for recovering
. Hence the null space network is always better in terms of reconstruction error than the original network for recovering  from data
from data  .
.
3.2. Convergence and convergence rates
Let  be a null-space network, possibly trained as described in appendix by approximately minimizing (A.1). Any such network belongs to the class of functions
be a null-space network, possibly trained as described in appendix by approximately minimizing (A.1). Any such network belongs to the class of functions  by taking
by taking  . Consequently, the convergence theory of section 2 applies. In particular, theorem 2.4 shows that a regularization
. Consequently, the convergence theory of section 2 applies. In particular, theorem 2.4 shows that a regularization  of the Moore–Penrose generalized inverse defines a
of the Moore–Penrose generalized inverse defines a  -regularization method via
-regularization method via  . Additionally, theorem 2.8 yields convergence rates for the regularization
. Additionally, theorem 2.8 yields convergence rates for the regularization  of
of  .
.
In some cases, the projection  might be costly to be computed exactly. For that purpose, in this section we derive more general regularization methods that include approximate evaluations of
might be costly to be computed exactly. For that purpose, in this section we derive more general regularization methods that include approximate evaluations of  .
.
Theorem 3.4. Let  be a null space network and set
be a null space network and set  . Suppose
. Suppose  is a regularization method for
is a regularization method for  . Moreover, let
. Moreover, let  be a family of bounded operators on
be a family of bounded operators on  with
with ![$ \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\Po}{\mathbf P} \newcommand{\Qo}{\mathbf Q} \newcommand{\Ao}{\mathbf A} \snorm{\Qo_\al - \Po_{\ker(\Ao)}} \to 0$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn310.gif) as
as  . Then, the pair
. Then, the pair  with
with

is a  -regularization method for
-regularization method for  . In particular, the family
. In particular, the family  is a regularization of
is a regularization of  .
.

The claim follows from theorem 2.4. □
Theorem 3.5. Let  be a null space network and set
be a null space network and set  . Let
. Let  , suppose
, suppose ![$ \newcommand{\al}{\alpha} \newcommand{\kl}[1]{\left(#1\right)} \kl{g_\alpha}_{\al >0}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn320.gif) satisfies the assumptions of theorem 2.8, and let
satisfies the assumptions of theorem 2.8, and let  be a family of bounded operators on
be a family of bounded operators on  with
with ![$ \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\Po}{\mathbf P} \newcommand{\Qo}{\mathbf Q} \newcommand{\Ao}{\mathbf A} \snorm{\Qo_\al - \Po_{\ker(\Ao)}} = \mathcal{O}(\alpha^\mu)$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn323.gif) . Consider the regularization
. Consider the regularization  with
with

Then, the parameter choice  yields the convergence rate results
yields the convergence rate results ![$ \newcommand{\R}{{\mathbb R}} \newcommand{\al}{\alpha} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\Ro}{\mathbf R} \snorm{\Ro_{\al^\star(\delta, y^\delta)} (y^\delta) - \signal } = \mathcal{O}(\delta^{\frac{2\mu}{2\mu+1}})$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn326.gif) for any
for any  .
.
Proof. Follows from the estimate (3.4) with  and theorem 2.8. □
and theorem 2.8. □
One might use  as a possible approximation to
as a possible approximation to  for some function
for some function  . In such a situation, one can use existing software packages (for example, for the filtered backprojection algorithm and the discrete Radon transform in case of computed tomography) for evaluating
. In such a situation, one can use existing software packages (for example, for the filtered backprojection algorithm and the discrete Radon transform in case of computed tomography) for evaluating  and
and  .
.
4. Conclusion
In this paper, we introduced the concept of null space networks that have the form  , where
, where  is any neural network function (for example a deep convolutional neural network) and
is any neural network function (for example a deep convolutional neural network) and  is the projector onto the kernel of the forward operator
is the projector onto the kernel of the forward operator  of the inverse problem to be solved. The null space network shares similarity with a residual network that takes the general form
of the inverse problem to be solved. The null space network shares similarity with a residual network that takes the general form  . However, the introduced projector
. However, the introduced projector  guarantees data consistency which is an important issue when solving inverse problems.
guarantees data consistency which is an important issue when solving inverse problems.
The null space networks are special members of the class of functions  that satisfy
that satisfy  . For this class, we introduced the concept of
. For this class, we introduced the concept of  -generalized inverse
-generalized inverse  and
and  -regularization as point-wise approximations of
-regularization as point-wise approximations of  on
on  . We showed that any classical regularization
. We showed that any classical regularization  of the Moore–Penrose generalized inverse defines a
of the Moore–Penrose generalized inverse defines a  -regularization method via
-regularization method via  . In the case of null space networks where
. In the case of null space networks where  , we additionally derived convergence results using only approximation of the projection operator
, we additionally derived convergence results using only approximation of the projection operator  . Additionally, we derived convergence rates using either exact or approximate projections.
. Additionally, we derived convergence rates using either exact or approximate projections.
To the best of our knowledge, the obtained convergence and convergence rates are the first regularization results for solving inverse problems with neural networks. Future work has to be done to numerically test the null space networks for typical inverse problems such as limited data problems in CT or deconvolution and compare the performance with standard residual networks, iterative networks or variational networks.
Acknowledgment
The work of MH and SA has been supported by the Austrian Science Fund (FWF), project P 30747-N32.
Appendix. Possible network training
We may train the null space network  to (approximately) map elements to the desired class of training phantoms. For that purpose, fix the following:
to (approximately) map elements to the desired class of training phantoms. For that purpose, fix the following:
- is a class of training phantoms;
- For all fix the nonlinearity ;
- are finite-dimensional spaces of affine continuous mappings;
- is the set of all NN functions of the form (3.1) with .






{kind=link}
{kind=link}
We then consider null space network  where
where  . To train the null space networks we propose to minimize the regularized error functional
. To train the null space networks we propose to minimize the regularized error functional  defined by
defined by

where  is of the form (3.1) and
is of the form (3.1) and  is the linear part of
is the linear part of  and
and  is a regularization parameter.
is a regularization parameter.
Network training aims at making  small, for example, by gradient descent. Clearly
small, for example, by gradient descent. Clearly ![$ \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Lo}{\mathbf{L}} \newcommand{\e}{{\rm e}} \prod_{\ell=1}^L \norm{\Lo_\ell}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn371.gif) is an upper bound on the Lipschitz constant of
is an upper bound on the Lipschitz constant of  . By the inequality of arithmetic and geometric means, the sum
. By the inequality of arithmetic and geometric means, the sum ![$ \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Lo}{\mathbf{L}} \newcommand{\e}{{\rm e}} \sum_{\ell=1}^L \norm{\Lo_\ell}$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn373.gif) essentially bounds the product
essentially bounds the product ![$ \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Lo}{\mathbf{L}} \newcommand{\e}{{\rm e}} \prod_{\ell=1}^L \norm{\Lo_\ell} $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn374.gif) . Therefore, the Lipschitz constant of the finally trained network will stay reasonably small. Alternatively, one can directly use the product of the Lipschitz constants
. Therefore, the Lipschitz constant of the finally trained network will stay reasonably small. Alternatively, one can directly use the product of the Lipschitz constants ![$ \newcommand{\norm}[1]{{\left\Vert#1\right\Vert}} \newcommand{\Lo}{\mathbf{L}} \newcommand{\e}{{\rm e}} \prod_{\ell=1}^L \norm{\Lo_\ell} $](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn375.gif) as regularization term in (A.1), but using the sum of the Lipschitz constants seems more in line with standard practice.
as regularization term in (A.1), but using the sum of the Lipschitz constants seems more in line with standard practice.
Note that it is not required that (A.1) is exactly minimized. Any trained network where ![$ \newcommand{\N}{{\mathbb N}} \newcommand{\snorm}[1]{\Vert#1\Vert} \newcommand{\signal}{x} \newcommand{\XX}{X} \newcommand{\Ao}{\mathbf A} \newcommand{\Id}{{\rm Id}} \newcommand{\NN}{\mathbf{N}} \newcommand{\e}{{\rm e}} \frac{1}{2} \sum_{\ell=1}^L \snorm{\signal_n - (\Id_{\XX} + \Ao^{+} \Ao \NN) (\Ao^{+} \Ao \signal_n) }^2$](https://content.cld.iop.org/journals/0266-5611/35/2/025008/revision2/ipaaf14aieqn376.gif) is small yields a null space network
is small yields a null space network  that does, at least on the training set, a better job in estimating
that does, at least on the training set, a better job in estimating  from
from  than the identity.
than the identity.
Alternatively, we may train a regularized null space network  to map the regularized data
to map the regularized data  (instead of
(instead of  ) to the outputs
) to the outputs  . This yields the modified error functional
. This yields the modified error functional

Trying to minimize  may be beneficial in the case that many singular values are small but do not vanish exactly. The regularized version
may be beneficial in the case that many singular values are small but do not vanish exactly. The regularized version  might be defined by truncated SVD or Tikhonov regularization.
might be defined by truncated SVD or Tikhonov regularization.