

Abstract
I present a didactical project, introducing the concept of information with all its interdisciplinary ramifications to students of physics and the neighbouring sciences. Proposed by Boltzmann as entropy, information has evolved into a common paradigm in science, economy, and culture, superseding energy in this role. As an integrating factor of the natural sciences at least, it lends itself as guiding principle for innovative teaching that transcends the frontiers of the traditional disciplines and emphasizes general viewpoints. Based on this idea, the postgraduate topical lecture presented here is intended to provide a firm conceptual basis, technically precise but versatile enough to be applied to specific topics from a broad range of fields. Basic notions of physics like causality, chance, irreversibility, symmetry, disorder, chaos, complexity can be reinterpreted on a common footing in terms of information and information flow. Dissipation and deterministic chaos, exemplifying information currents between macroscopic and microscopic scales, receive special attention. An important part is dedicated to quantum mechanics as an approach to physics that takes the finiteness of information systematically into account. Emblematic features like entanglement and non-locality appear as natural consequences. The course has been planned and tested for an audience comprising, besides physicists, students of other natural sciences as well as mathematics, informatics, engineering, sociology, and philosophy. I sketch history and objectives of this project, provide a resume of the course, report on experiences gained teaching it in various formats, and indicate possible future developments.
Export citation and abstract BibTeX RIS

Content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
This work has been presented for the first time at a symposium dedicated to the problem of how to incorporate complexity into teaching, a concept that has influenced large parts of science during the last decades but hardly been established in classrooms and lecture halls. It reports on the objectives and the conception of a course on a subject closely related to complexity—information—and some practical experiences made teaching this material.
The curricula offered by a typical physics department of a university or college are traditionally characterized by a high degree of compartmentalization: 'Theoretical Solid-State Physics', 'Quantum Optics', 'Experimental High-Energy Physics' are standard lecture titles that reflect a structure motivated by phenomenological criteria or mere tradition. Correspondingly, the formation of a professional physicist is not very broad, not intended to form generalists. At the same time, conscience is increasing that a wider perspective, the ability to work in teams 'across the Two Cultures', comprising representatives of different disciplines, is a highly desired competence in the academy as well as in the industry. The demand is growing for courses that contribute to this component of education, oriented in transversal concepts and broad syntheses, as the integration of a studium generale and similar offers in innovative curricula shows. However, they mostly appear as separate endeavours, not interlocked with the technical courses proper. As necessary and welcome as such initiatives are, they do not couple specialized to holistic teaching. What is needed is rather a reorganization of the traditional contents, presenting them as elements of a larger enterprise, stimulating students to form a coherent whole of the diverse pieces of a puzzle they are confronted with during their studies.
The teaching project put forward in this article is intended to contribute to this objective, inevitably based on personal background and preferences and certainly reflecting the conditions and requirements of a physics department as principal platform for its realization. I shall present the course in three steps, an external approach, recalling in section 2 the motivations and the historical background that led to its conception, then from inside, providing a bird's eye view of its contents in section 3, and terminating from outside again in section 4, with experiences made teaching the course under various circumstances and with some plans for follow-up projects.
2. Motivation and history
Ideas to develop a course on the role of information in physics and in the neighbouring sciences go back to a personal anecdote, during my postgraduate studies. One day, driven by curiosity, I randomly browsed journal volumes just returned from the bookbinder to the department library, and stumbled into an article that immediately enthraled me: in a seminal paper, Shaw [1] interprets deterministic chaos in terms of a directed flow of information from invisible microscopic scales to macroscopic magnitude. The idea not only stimulated the choice of my principal area of scientific interest. It also left me deeply convinced that information flows in time, in space, and between scales constitute an extraordinarily powerful tool to understand a vast range of phenomena on a common footing, not only in physics but also in the neighbouring sciences.
This virtue alone would render it a suitable subject for an interdisciplinary course. In this respect, information has much in common with a related category, energy: physical by nature, it applies to a huge variety of situations even, and in particular, outside the scientific context. In fact, both concepts share a dichotomy between a precise meaning in physics, including a quantitative definition, and a rather elastic usage in everyday language, depending on context. In both cases, their penetration into common vocabulary can be traced back to a historical development: the history of science and technology on the one hand and the general political, social, and economic development on the other are not unrelated. Obviously, science depends on economic and social boundary conditions. At the same time, major progress achieved in science and technology can have significant repercussions on life in general. While small steps usually go unnoticed by the public, grand epochs in the history of science correlate with concomitant global changes in the society, often but not necessarily coinciding with scientific revolutions in the sense of Kuhn [2]. The following table is a crude attempt to draw such long-term parallels during the last 600 years, not attempting precision nor completeness:
| Centuries | Era | Characteristic quantity | Characteristic devices | Paradigms | Prevailing socio economic model |
|---|---|---|---|---|---|
| 16–17 | Mechanistic | Force | Wedge, lever, pulley, toothwheel, clock, print | Universe as clock-work, celestial mechanics, Laplace's demon | Agriculture, manufacture |
| 18–19 | Thermo dynamic | Energy | Watermill, windmill, steam engine, combustion motor | Energy conservation, thermodynamic systems, Maxwell's demon | Industrial |
| 20–21 | Informatic | Information | Telegraph, telephone, computer | The world as computer/network | Post-industrial knowledge society |
It also indicates how the last three eras have been accompanied by simultaneous technological progress, reflected in novel devices being invented and entering daily life. In particular, returning to central concepts like energy and information, they have played the role of universal metaphors, applied not only in their original field but to just about every subject that invited for scientific interpretation. In a similar way as Laplace and his contemporaries interpreted all of nature as a deterministic mechanism, as 'cosmic clockwork', we are accustomed to associate organs and their functions to engines or parts thereof, to compare our brains with computers and genetic control with algorithms (figure 1). In short, information is fashionable [3–7]. The category penetrates our life from the TV news till the purchase of a computer or a cell phone. Counting word frequencies in contemporary documents, future palaeontologists may well identify 'information' as a cultural leitfossil of our time. From time to time, science produces concepts which help understanding our ambient world from a new angle. 'Information' is one such case.
Given its paramount importance, combined with its potentials as an integrating factor between the sciences (figure 2), the plan emerged to develop a topical lecture dedicated to this subject. Intended as a novel pedagogic approach to physics and related curricula, the course aims at the following didactical objectives:
– Surmount traditional fences between disciplines.
– Focus teaching on common structures and unifying concepts.
– Emphasize analogies and invite to finding new ones.
This means that, by contrast to traditional physics lectures, a comprehensive idea plays the guiding role, in a wider sense than just a formalism like Newton's laws or Maxwell's equations. The overall objective is to demonstrate the unifying power of the concept of information. More specific phenomena and categories are only addressed as case studies to illustrate and substantiate the general reasoning. The teaching strategy, adapting it to an interdisciplinary content and a wider audience, also has to leave the traditional scheme of theoretical-physics lectures behind, replacing or complementing, e.g., detailed derivations by qualitative arguments, often based on analogies [8] and even on their direct visualization (represented in this report by numerous illustrations).

Figure 1. The Jacquard weaving loom (1805) is probably the first man-made tool generating patterns from a digital memory medium, astonishingly similar to the punch cards of the 20th century. It continues to serve as a metaphor to explain reproducible pattern formation controlled by digital data, for example the genetic control of embryonic development [9].
Download figure:
Standard image High-resolution image'The concept of information in physics', as a tentative title, is sufficiently wide to accommodate various related subjects along with the initial nucleus, classical and quantum chaos in terms of information flows. As a minimum objective on the semantic level, the course should foster a conscious, precise usage and critical analysis of the category. Beyond that, two main thematic threads, inspired by chaology, pervade the entire course.
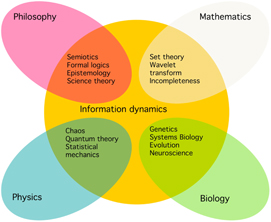
Figure 2. Information dynamics overlaps significantly with the neighbouring sciences, mathematics, physics, and biology, as well with humanities such as philosophy and hermeneutics, and of course with computer science and other branches of engineering (not shown).
Download figure:
Standard image High-resolution imageThe flow of information, in space and in time, among systems, and between scales, beyond its static features, has an enormous explanatory power. Elementary properties of flows, such as a global conservation of the flowing quantity, imply a host of phenomena which otherwise would appear unrelated. In view of the prevailing role of this idea, the course might well be titled 'The information cycle', referring by analogy to the hydrological cycle.
The rise of the theory of deterministic chaos could have been perceived as a decisive step to replace chance as an essential element of the foundations of, in particular, statistical physics. It was frustrated by the insight that precisely quantum mechanics, otherwise considered as a stronghold of insurmountable unpredictability, prevents truly chaotic behaviour. The analysis of this surprising outcome, known as 'quantum chaos', triggered a number of profound insights into the character and origin of random processes in physics. Indeed, clarifying concepts around determinism versus chance, causality, prediction, and disorder, particularly in quantum mechanics, is another objective of this teaching project: another subtitle could read 'Classical randomness and quantum determinism'.
Quantum mechanics is of central relevance for the course, if only because it is indispensable to account for the smallest scales where the core of physical information processing goes on. In fact, the progress achieved in quantum optics in the last decades suggests an alternative view of quantum mechanics, based on information, a contemporary approach that may eventually supersede the Copenhagen interpretation which has dominated the field for almost a century. Quantum information and computation are among the buzzwords associated with the information era—it cannot be the intention of the course, though, to contribute to publicity for quantum high technology. Rather, it should provide a conceptual basis solid enough to enable an independent view, even a critical perspective, towards overly optimistic scenarios.
This does not mean that computation in general should not be featured: forming a direct complement of information as a key notion, the computer is used as a standard metaphor for a wide class of dynamical processes. In this sense, the course as sketched till here could be subtitled 'natural systems as information processors', to be succeeded by a section on 'computers as natural systems'. This second part, reading the metaphor backwards, is intended to analyse devices, man-made for computation purposes, as natural systems: technical tools obeying physical, e.g., thermodynamic, laws and liable to corresponding fundamental limits concerning energy consumption, accuracy and reliability, speed, and more. Moreover, it demonstrates the full power of the analogy by applying it likewise to 'natural computing' in genetic processes, to fictitious ballistic computers, and, last but not least, to quantum computation.
Thanks to the open-minded spirit at Universidad Nacional de Colombia, favouring innovation and experiment in teaching, I could implement this project and test it under real-life conditions. I summarize my experiences in section 4.
3. Outline of the course
The following subsections present a synopsis of the lecture, summarizing chapter by chapter their central themes and their functions for the course as a whole. The programme comprises two parts with ten sections in total:

Figure 3. René Magritte's painting 'La trahison des images' (1928–1929) illuminates the distinction between an object and a symbol representing it from an artist's point of view: an image of a pipe is not a pipe; one cannot smoke it. ©ADAGP, Paris 2014.
Download figure:
Standard image High-resolution imagePart 1: Natural systems as information processors
- 1.The concept of information.
- 2.Simple applications.
- 3.Epistemological aspects.
- 4.Information in physics: general aspects.
- 5.Information in classical Hamiltonian dynamics.
- 6.Thermodynamic entropy flow: chaos versus dissipation.
- 7.Fluctuations, noise, and microscopic degrees of freedom.
- 8.Information and quantum mechanics: digitalizing the microcosm.Part 2: Computers as natural systems
- 9.Physical aspects of computing.
- 10.Quantum computation and quantum algorithms.
3.1. The concept of information
Keywords:
– The three dimensions of information: syntactic, semantic, pragmatic; language and metalanguage; the meaning of 'meaning'.
– Boltzmann's versus Shannon's definitions; units.
– Sign; entropy and negentropy; actual versus potential information.
– Relative, conditional, mutual information; Bayes' law.
– Information and correlations; redundancy.
– Defining information in vectors and functions.
– Analogue versus digital: resolving the dichotomy.
The introductory chapter serves to mediate between the meaning of the concept familiar to the participants—mixing colloquial use and precise quantitative thermodynamic definitions—and the analysis developed in the course. Following an outline of the historical background, much as in section 2 above, the concept is embedded in a broader philosophical context. In particular, the triad of syntactic, semantic, and pragmatic information is expounded. Almost throughout the course, information is used in its physical meaning, i.e., reduced to syntactic information. The categories of sender, message, and receiver, often considered as inseparably connected to information [6], in fact come into play only on the semantic level. Notwithstanding, the emergence of semantics in natural history is a fascinating issue to be addressed at least briefly (figure 3). It can be associated to the onset of genetic coding, thus coincides with the origin of life on earth. According to the standard view of molecular evolution, the appearance of massive long-term memory media in the form of free RNA molecules even preceded the decisive step towards semantics, its association to the linear sequence of amino acid chains. Later cases of languages emerging in the course of evolution, from chemical signalling by pheromones through mimicry in insects through conceptual language in humans, are important to keep in mind as well.
Precise quantitative definitions [10, 11] are presented with due care for details. Boltzmann's primordial definition of entropy hinges on his crucial notion of complexion, referring to the repertoire of distinguishable states of a system. It is scrutinized further applying it to various contexts where information is quantified. Shannon's extension of Boltzmann's entropy to probabilistic processes then serves as the starting point for all quantitative discussions throughout the course, without major modification or adjustment to the specific context. To be sure, entropy is frequently understood in a more restricted thermodynamical sense, as the information contained in the random motion of microscopic particles manifest as heat. However, this distinction is diffuse and obliterates the universality of the concept. Therefore, the two notions, entropy and information, are used interchangeably wherever no confusion is caused.
A subtle point concerning the sign of information leads to ambiguity and deserves special attention to be cleared up. I suggest the following distinction:
– Potential information, Ipot, refers to the measure of the set of states accessible to the system, all boundary conditions, restrictions, etc taken into account. Equivalent to Boltzmann's entropy, it measures the disorder remaining in the system or the lack of knowledge on its state.
– Actual information, Iact, refers to the knowledge an observer, a measurement, a theory ..., has on the state of the system. It measures the part of its state space excluded by these constraints and is analogous to the concept of negentropy coined by Schrödinger [12].
Potential and actual information do not have opposite sign (both are positive), but add up to a constant sum, Ipot + Iact = Itot = const, so that the simultaneous changes of both quantities are indeed opposed, ΔIpot = −ΔIact. The total information, Itot, is a measure of the entire repertoire of states the system disposes of, its 'universe'. It is not free of a subjective component, depending, e.g., on the maximum resolution available to determine the state of the system.
The remainder of this chapter introduces basic properties of Shannon's information, such as additivity, and refines it to more specific quantities like relative and conditional information and redundancy [10]. A distinction frequently discussed in the literature [13] is that between analogue and digital signals, continuous and discrete quantities. This apparently unbridgeable contrast already looses acuity if reconsidered in the light of Fourier analysis. It finally resolves in the context of quantum mechanics (see section 3.8 below) where the equivalence between the two forms of information arises naturally.
Large part of the material contained in this chapter is amply referenced in the literature. Nevertheless it is included in order to render the course self-contained, to introduce notations and fix conventions of usage.
3.2. Simple applications
Keywords:
– Number systems.
– Propositional logics, Boolean algebra, and set theory.
– Logical inference as a discrete dynamical process.
– The genetic code.
– The Central Dogma: directed information flow from genome to proteome to phenotype.
The second section presents a number of specific examples how to apply the quantities defined previously. It also gives a first impression of the versatility of the approach, spanning the wide range from propositional logics to genetics.
An information-theoretic analysis of number systems illustrates, besides elementary features, the notion of hierarchies of scales, following Nicolai Hartmann's 'levels of reality' [14]. Much as in the decimal system, digits can alternatively represent units, tenths, hundredths, etc, similar levels of resolution can be discerned in many other contexts: a novel can be subdivided into chapters which in turn consist of paragraphs, of sentences, ... words, ... letters, down even to pixels of print and smaller units. Physics analyses a piece of metal as a macroscopic object, in terms of crystal domains, unit cells, ions, atoms, elementary particles, ending presently at quarks and leptons. Biology sets in at the level of super-organisms (e.g., ant states), followed by individual organisms, organs, tissues, cells, cell organelles, macromolecules, before joining physics at the level of molecules and ions. In all these cases, the respective information contents In of each level n of the hierarchy add up to the total information as if they were distinct subsystems, Itot = ∑n In (figure 4).

Figure 4. Hierarchies of structures are abundant in science as well as in daily life, where elementary items at the nth level resolve into a set of smaller parts at the subsequent, (n + 1)th level, providing a finer resolution. Disregarding correlations, the information contents of each level just add up to the total information of the structure at hand.
Download figure:
Standard image High-resolution imageThe bottom and top of a hierarchy, its lowest and uppermost levels, depend on context and convention. They are of course limited by the state of research at any given time; some hundred years ago physics considered atoms as the smallest units and galaxies as the largest known structures. In biology, progress has been even more impressive, extending the range to molecular cell biology below and to ecosystems above.

Figure 5. An inference a → b is logically valid if and only if the implication a ⊃ b (or ¬a ∨ b) is a tautology, i.e., is true for all interpretations of a and b, independent of contingent facts [15]. Translated to set theory, this means that A ⫅ B (Ac ∪ B = U, the universal set), or |A| ≤ |B| in terms of set magnitudes. An equivalent inequality in terms of information content is Ipot(B) ≥ Ipot(A).
Download figure:
Standard image High-resolution imageA less known insight to be put forward in this chapter is a homomorphism between information measures, set theory, and formal logics. The link between information and set theory can be grasped intuitively by associating information measures to the fraction of a system's state space that is occupied by a specific state A, corresponding to the potential information Ipot(A) alluded to above. At the same time, the magnitude |A| of this subset of the total state space can be quantified according to set theory. In this way, they become at least monotonous functions of one another, if not proportional. To relate set theory to formal logics, in turn, define sets by a common property of their elements, say x ∈ A iff (if and only if) the assertion a(x) is true. With this convention, logical inference translates into a relation between sets: the implication a → b is a tautology [15] iff the inclusion A ⫅ B applies to the corresponding sets (figure 5). This requires that |B| ≤ |A|, hence Ipot(B) ≥ Ipot(A). It means that in a logical inference chain, the potential information associated to each step can only increase (knowledge can only decrease), in accordance with the general rule that logical inference is independent of contingent facts [15]. This surprising yet plausible rule is closely related to an information-theoretic characterization of causal chains, see section 3.3 below, another analogy imparted by information.

Figure 6. An inference chain can be characterized as a sequence of propositions ... → an → an+1 → an+2 → ..., where the entropy increases monotonously at each step and no information on reality is gained: ... ≤ In ≤ In+1 ≤ In+2 ≤ ....
Download figure:
Standard image High-resolution imageA similar relationship arises between binary logical operators, Boolean algebra, and the logical gates underlying digital electronics [16]. In particular, it allows to apply this homomorphism in practical tasks, such as constructing circuits that perform certain logical operations, and to implement them in devices as simple as combinations of switches.
The genetic code, as a paramount biological application, is not only included for its implications for virtually all aspects of life. It is also a striking example for the close analogy between man-made digital technology and the way life itself stores and processes information. Moreover, the translation of DNA sequences via RNA into proteins may be considered as the invention of semantics by nature [17]. No older natural process is known that could have been interpreted in terms of meaning. A particularly intriguing aspect of this phenomenon, bearing not only on the storage of information but even on its directed flow, is the so-called Central Dogma, asserting that genetic information can only be transmitted from DNA to RNA to protein to phenotype, but not in the opposite direction. Originally conceived as antithesis to Lamarckism, dominating genetics unchallenged for decades, it is presently being undermined 'from within' by recent results on epigenetics [18], indicating an inheritance of acquired traits.
Moreover, the genetic code provides an illustrative case of discreteness on the molecular level. The distinction of digital versus analogue data is often discussed (see, e.g., [13]) as a fundamental difference. A more profound analysis, however, reduces it to a mere question of representation. Fourier analysis, for example, readily allows transforming a given data set between discrete and continuous form. The relevant quantity, invariant under such changes of coding, turns out to be the total information content, measured, e.g., as the number of independent real coefficients. The most radical realization of this principle in is in fact quantum mechanics, where the same underlying information capacity (in terms of the Hilbert space dimension or the number of qubits) can be reflected in diverse forms of discretization, smearing, etc of observables, see section 3.8.
3.3. Epistemological aspects
Keywords:
– Redundancy, data compression, and scientific induction.
– Randomness; algorithmic complexity and its non-calculability.
– Gödel's theorem and incompleteness; epistemological implications; incompleteness and the controversy reductionism versus holism.
– Self-reference and limits of prediction; self-fulfilling prophecy.
– Causality and information flow; causal explanation and prediction; final versus causal explanation.
– Accumulation of information in adaption and evolution; information gathering and utilizing systems (IGUSs); learning and information flow in ontogeny and phylogeny.
Epistemology and theory of science do not belong to the syllabus of physics; contemplating how science proceeds and is possible in the first place goes on outside the natural sciences. In the context of information, though, it suggests itself to ignore this rule: apparently a digression, a section on epistemology not only provides deep insight on how science works, it also bears directly on a central subject of the course, randomness. Yet another question renders this chapter essential: confronted with Shannon information, uninitiated persons tend to object, 'This definition merely counts the quantity of symbols, it does not take their relevance into account, the real news value of the message'. Indeed, not even refined concepts like redundancy and correlations are able to reproduce our intuitive ability to tell random symbol strings and ordered sequences apart, a distinction that is at the heart of scientific induction. Even the most successful and convincing attempt till now to quantify randomness, algorithmic complexity, turns out to be fundamentally flawed: the impossibility to prove randomness is deeply related to Gödel's Incompleteness Theorem [19, 20], a milestone of 20th century intellectual history. The opportunity to include it in a course on information in physics is unique and justifies addressing what may well challenge the participants' analytical capacity more than any other topic along the programme. The section is complemented by specific considerations around pertinent concepts like prediction and explication. It is the only section within the course where the semantic dimension of information plays a major role.
The concept of algorithmic complexity [21, 22] can be introduced referring to a recent achievement of data processing: data compression. Computer users have an intuition what data compression is good for and where it is efficient. An appropriate first step is to confront them with two binary sequences such as [21]
A: 010101010101010101010101010101
B: 100111011000100110000001010111
and to ask, 'which one appears random, which one ordered, and why?' A typical answer would refer to a simple rule that allows to reproduce sequence A,
print '01'
repeat n times
while for sequence B, no such rule suggests itself, besides the trivial answer
print '100111011000100110000001010111'
repeat 1 time.
Algorithmic complexity formalizes and quantifies this idea, measuring the length of the shortest possible algorithm that allows to reproduce a given symbol sequence. It qualifies as random if and only if this shortest algorithm is (at least) as long as the sequence itself, that is, if it proves incompressible.
Apparently random sequences (which however, unlike B, do allow for a plausible extrapolation) are often used in intelligence tests, asking to identify the correct continuation among several choices. Some will find it, others not: there is a subjective component to the criterion of being patterned, finding a suitable compression may depend on the intelligence of the beholder. A sequence may resist all attempts to decode it, till a future genius finds the solution. Mathematical rigour would require to prove irreducibility, objectifying the criterion. Unfortunately, it turns out (and can be proven) that such a proof is impossible, if it is to be shorter than the sequence in question. The proof in itself would inevitably contain exactly the missing shorter algorithm which allegedly cannot exist. This self-referential structure resembles the reasoning behind Gödel's proof of his incompleteness theorem [19, 20]. Indeed it has been shown that the two theorems (non-provability of randomness, incompleteness of certain attempts to axiomatize mathematics, respectively) share crucial elements [22].
The above caveat concerning the length of the proof is decisive: it implies by reverse that randomness can well be proven or disproven if sufficiently long algorithms are admitted. Similarly, Gödel only denies that, e.g., the consistency of number theory could be proven 'from within', in a kind of logical bootstrap (figure 7). Indeed, properties of less powerful systems can be assessed in the framework of more powerful ones. In this way, the incompleteness theorem and related principles induce an order relation among formal systems, not unlike to how the relation 'A can be emulated on B' between two information-processing systems [4] induces a hierarchy of computational capacity.

Figure 7. This drawing by artist Saul Steinberg succinctly visualizes the idea of a 'logical bootstrap', the self-reference underlying paradoxical sentences like 'All the Cretans are liars' ascribed to Epimenides the Cretan, and analysed at depth in Gödel's Incompleteness Theorem. Saul Steinberg, Untitled, Copyright 1945, Ink on Paper. Originally published in Steinberg S 1945 All in Line © The Saul Steinberg Foundation/Artists Rights Society (ARS), New York.
Download figure:
Standard image High-resolution imageGödel's proof is a striking example of insight achieved by a human brain but inaccessible to automated formal reasoning. It has given rise to speculations about a fundamental inferiority of artificial as compared to natural intelligence, posing the question exactly where the human brain succeeds but artificial intelligence fails. The ability to find patterns within a given symbol sequence or, more generally, spatio-temporal structures that allow to compress its information content, is at the heart of algorithmic complexity. At the same time, it is an established concept in cognitive science: feature detection abounds in species with a central nervous system and is often crucial for their survival. Imitation forms a natural analogue of emulation and implies a similar relation of superiority. Human beings are masters in recognizing patterns; categorization in conceptual languages hinges on this capacity. In this sense, human brains are highly optimized 'correlation detectors', organizing the chaotic flood of sensory data. Pattern recognition cannot be completely automatized. From elementary manifestations, such as prey generating behavioural patterns unpredictable by predators, to its highest expression, hypothesizing scientific theories, it needs a high degree of creativity. Detecting order in apparently random structures itself seems to require the ability to create randomness.
Algorithmic randomness deals with finite sequences like A and B above. Prima facie, it is not concerned with extrapolating them, possibly to infinite length, as in scientific induction. That there is an immediate relationship becomes evident, once a principle of epistemological parsimony ('Occam's razor') is invoked [23]: among two competing hypotheses, prefer the simplest, the one requiring less unjustified assumptions. It clearly favours the shortest algorithm sufficient to reproduce the known part of the sequence as basis for its extrapolation.
For a living organism, obtaining and optimizing predictions of the future is an even more important application of pattern recognition than organizing sensory data. It is probably this particular selection pressure that produced the highly efficient nervous systems providing this ability in higher animals. Referring to the general ability of life not only to react to the past but to anticipate the future, theoretical biologist Robert Rosen has coined the notion of 'anticipatory systems' [24]. Besides physical factors like climate, for most species the environment comprises, above all, conspecifics and members of other species, plants and animals, some of which may be equipped with their own cognitive apparatus. Anticipating the behaviour of living elements of the environment may well pose the bigger challenge, by far, than forecasting physical conditions.
The task of predicting predictors leads back to a problem concerning the information exchange between systems in general. What if the predictor forms part of the same system it pretends to predict? Obviously, a feedback arises from prediction to predictor. The phenomenon is known and relevant far beyond the biological context. Self-fulfilling prophecy has occupied literature at least from the classical king Oedipus saga [25] onwards. Most democracies prohibit the publication of election polls shortly before elections in order to prevent this effect. The opposite case, self-destroying prophecy, may be desired in turn in the prediction of future catastrophes concerning, e.g., global warming.

Figure 8. 'Mise en abyme' ('thrown into the abyss') is the technical term for images, texts, ..., containing a replica of themselves. They are examples of the challenge to store the initial conditions of a given system within this same system as input for a prediction of its own future behaviour.
Download figure:
Standard image High-resolution imageAn elementary argument against the possibility of reliable self-prediction refers to the mere problem how to store the antecedents (initial conditions) within the predicting system. They inevitably include the present state of the predictor itself, comprising its own memory, which in turn ... etc ad infinitum (figure 8). The issue has entered literature as well, as in Laurence Sterne's 18th century novel Tristram Shandy [26]. It plays a central role in the discussion about scopes and limits of brain research: is the human brain able to understand itself [27]?
The challenge alluded to above, to predict the behaviour of intelligent beings, increases with the capacity of these systems to anticipate and outperform the prediction. An arms race develops, not unlike the competition between the intelligence services of hostile powers. There is little doubt that this competition has been particularly fierce already in early hominids. A convincing hypothesis states that the resulting evolutionary pressure is responsible for the exceedingly rapid growth of their brains which finally led to Homo sapiens sapiens [28].
It seems that in anticipatory systems, information flows backward in time: future facts get known before they occur and, triggering actions of the observer in the present, elicit effects that precede their cause in time [24, 32], apparently contradicting causality: an event A qualifies as the cause of the effect B only if two necessary conditions are fulfilled [29]:
- i.All the information contained in B is already present in A, Iact(A) ≥ Iact(B).
- ii.A precedes B in time, tA ≤ tB.
As an immediate consequence, causal chains are characterized by a monotonous decrease of actual information, resembling inference chains in this respect (see figure 6). With discrete replaced by continuous time, they turn out to be analogous also to leaky communication channels. In this context, lecturers fond of fancy science-fiction constructs may refer to time travel: implying information flow backwards in time, it is incompatible with causality.
In numerous fields such as biology, medicine, engineering, psychology, and law a type of explanation is very common which apparently reverses this order: final (functional, teleological) explanations. They answer 'why'-questions by providing a justification, a future objective rather than a past cause, interpreting 'why' as 'what for' [30]. In biology, in particular, organs and behaviours are explained by pointing out their function, their purpose, their survival value [31, 32]. Their validity is often questioned, contrasting them with areas like physics where the above two criteria apply rigorously. However, they can be reconciled with causality if the process of evolutionary adaption is taken into account. The emergence of physiological or behavioural patterns, both in phylogeny and in individual development, can be considered as the result of repeated trial-and-error processes: trial structures are tested against reality and selected according to whether or not they help solving a given problem. The preferred solutions are stored in genetic (adaption) or neural memory (learning) and then recursively optimized by varying the already achieved useful structure in finer details. In this way, a 'virtuous circle' arises which in each iteration unconditionally follows causal laws (figure 9). It is only the long-term result of this optimization that appears to anticipate a 'desired' future event as its explanans. It is a characteristic feature of biological systems that chains of concatenated final explanations ('A is good for B which enables C in order to obtain D ...') do not end in a Grand Final Objective of All Life, but tend to close in circles. This circularity, cast by Rosen [24, 32] in the aphorism 'Life is closed under efficient cause', has far-reaching implications for ethics and religion.

Figure 9. Final (functional) explanations, abundant in biology, seem to contradict causality. They imply information flowing backwards in time, but can be reconciled with the rigorous criteria of causal explanation by unfolding them as the repeated action of variation and selection: physiological structures, behavioural patterns, tools arising from trial-and-error anticipate the intended effect, hence can be explained as being 'intended' to fulfil a specific purpose.
Download figure:
Standard image High-resolution imageThis argument contracts trial-and-error processes as de facto causal chains to hypothetical functional relations (figure 9). Implying an effective flow of information from the outside world towards the memory of an organism, it has repercussions beyond its immediate context. It allows to understand, in particular, how relevant knowledge on the environment can accumulate in the genome, apparently contradicting the Central Dogma. Likewise, it provides a convincing scheme to interpret neural learning in a way that avoids a direct capture of incoming sensory data in the style of the Nuremberg funnel [27]. In both cases, hypotheses are generated within, in a creative act [33], to form an information current inside-out. Nevertheless, combined with selection and feedback, in effect information on the outside world can enter and be stored.
From the broader perspective of information flow, the question arises in how far intelligent, 'anticipatory', systems play a special role in nature that cannot even be subsumed in categories like chaotic behaviour as prototypical source of unpredictability. The issue has been contemplated by biologists and physicists; Wheeler, Gell-Mann, and Zurek coined the notion of IGUS [33–35] (figure 10). It generalizes natural intelligence to an abstract model of adaptive anticipatory behaviour, processing information in a way different from all other physical systems even outside thermal equilibrium. Chaotic systems only amplify small causes to large effects. By contrast, IGUS are able to receive data through their sensory organs, on subatomic to cosmic scales and from spatially and temporally remote sources (figure 10). They store, process and connect these data in a complex manner and use limbs and communication organs to elicit consequences again far out in space and time, forming dense nodes in the network of information flows. Exploring and learning, IGUS detect minute loopholes in phase space connecting a desired but nearly inaccessible state to more frequently visited regions, and to zero in to this state as an unexpected solution of a survival task, a phenomenon ranging from funnelled energy landscapes in protein folding to human technology.

Figure 10. Information gathering and utilizing systems (IGUS) provide a general conceptual frame for systems which, like most living organisms, receive data on their environment from sources possibly far away in space and time, store and process them forming cross-connections even between completely uncorrelated facts, to trigger effects that again can be spatially and temporally very remote from the IGUS.
Download figure:
Standard image High-resolution imageIn this way, the presence of IGUS induces phenomena that are perfectly compatible with basic physical laws but extremely improbable from the viewpoint of statistical physics: for example, an asteroid approaching Earth and detected by humankind might be destroyed by a projectile launched from the threatened planet1 . The event could be perceived by other intelligent beings as evidence for the presence of IGUS in the solar system. In this sense, IGUS prove qualitatively more complex and unpredictable than even chaotic systems.
The concepts of IGUS and adaption also shed new light on the discrepancy between free will and determinism. Drawing on a more and more sophisticated internal representation of the outside world and correspondingly refined strategies to exploit its laws, an organism will achieve increasing agreement between its objectives and the effects of actions undertaken to reach them. Subjectively, observed facts will coincide ever closer with intentions. As a result, the border between auto-determined self and independent external world is blurred and pushed outwards. It creates an impression of freedom of will that is consistent with, even depends on, the validity of deterministic laws.
3.4. Information in physics: general aspects
Keywords:
– The computer as a metaphor.
– Information versus energy.
– Entropy, causality, irreversibility, symmetry, chance, disorder in terms of information.
– Information sources versus information sinks.
After having reached out towards subjects barely related to physics, such as theoretical biology or cognitive science, the subsequent sections return the course to more familiar ground. The examples discussed above should have demonstrated the enormous integrative force of the concept of information. With this background, various basic notions in physics can now be interpreted coherently, revealing unexpected common facets. To name but a few [34],
| Entropy | Information applied to thermodynamic systems and processes |
|---|---|
| Causality | Absence of information infiltrating from unknown sources |
| Irreversibility | Unrecoverable loss of information (on the initial conditions) |
| Symmetry | Redundancy of spatial and/or temporal structure |
| Chance | Event or process generating information not accessible before |
| Disorder | Static randomness, structure lacking symmetry |
Those terms that refer to dynamical processes, like causality, chance, irreversibility, deserve a closer look, involving the sophisticated mathematical tools available for classical and quantum mechanics. Before going into detail in sections 3.5–3.8, a versatile tool to study information flows should be introduced which can serve as a link between general conceptual analysis and physics: Bayesian networks [29]. It is common in physics to reduce flow fields which, properly speaking, form a continuum in space, to discrete channels. This is an appropriate idealization, for example, in the description of electr(on)ic circuits and occurs naturally in the formation of rivers. In an analogous manner, communication channels concentrate information currents into discrete networks defined by their topology (connectivity) and directionality, while their detailed geometry is irrelevant. The flow in networks can be discussed in terms of links, nodes, meshes ..., obeying sum rules, hierarchies, etc. In recent years, network analysis has become a very active field in statistical physics2 .
Bayesian networks allow to visualize directly most of the concepts alluded to above (figure 11). In this perspective, causal chains appear, e.g., as sequences of communication channels where information can be lost on the way (sinks of information current) but not enter, and random events inversely as sources injecting entropy into the network (figure 11(a)). As in circuit theory and in hydrodynamics, a decisive condition for this kind of analysis is the validity of sum rules. They mark the difference between the deterministic dynamical laws dominating microscopic physics, as in classical Hamiltonian and quantum mechanics, and the probabilistic rules applying to macroscopic phenomena.

Figure 11. Bayesian networks [29] reduce complex information flows to networks of discrete communication channels with well-defined connectivity, to be analysed in terms of links, nodes, currents, sum rules etc. For example, random events appear in a Bayesian network as sources of information currents (a). Causal explanations reconnect such dead rear ends of causal chains to the rest of the network (b).
Download figure:
Standard image High-resolution image3.5. Information in classical Hamiltonian dynamics
Keywords:
– Review of Hamiltonian dynamics and the symplectic formalism; time evolution generated by canonical transformations.
– Canonical transformations conserve information.
– The problem of unbounded information content (Gibbs' paradox); the problem of unbounded propagation speed (special relativity).
With Hamiltonian mechanics, classical physics reached a climax of perfection, given its mathematical beauty and rigour. As a reminder for physics students and a minimum introduction for other participants, the course provides a brief synopsis of basic elements of the Hamiltonian formalism, such as symplectic geometry and canonical transformations (see, e.g., [36]). The objective is to arrive at a conservation law of crucial importance for the discussion of information flows in Hamiltonian systems: the preservation of the total entropy content under canonical transformations, hence under any time evolution generated by Hamiltonian dynamics. Information being defined in terms of phase-space volume, as in Boltzmann's entropy, this invariance is a corollary of the conservation of phase-space volume in Hamiltonian systems (Liouville's theorem). Introducing the phase-space probability density ρ(r) and the information flow (current density) as the phase-space velocity j = dr/dt weighted with the entropy density, ρI = −kBρlnρ, i.e., jI = jρI, allows to state conservation laws as a continuity equation for entropy density and flow, ∂ρI/∂t + ∇ · jI = 0.
Conservation of entropy is but one facet of the invariance of Hamiltonian mechanics under time reversal. The absence of a preferred direction of time in the microscopic equations of motion has a surprising and counterintuitive consequence for the concept of causality: without time arrow, cause and effect become interchangeable, and causality looses a crucial part of its meaning.
As evident as entropy conservation appears, concluding from microscopic equations of motion, it is in stark contrast to the second law of thermodynamics which predicts its permanent growth. This aporia will be addressed in section 3.7. There is, however, another hallmark of classical physics related to information content that finally led to its replacement by quantum mechanics: in what is known as Gibbs' paradox [37], J Willard Gibbs argued as early as 1875, when classical physics still stood unshaken, that Boltzmann's entropy is not an extensive quantity and in fact can take arbitrarily large values even for a finite system at finite temperature. His argument hinges on the distinguishability of molecules underlying all classical statistics. If their internal states form a continuum, then even infinitesimal differences suffice to discern two molecules. Taken to the extreme, the complete specification of the internal state requires an infinite amount of information, letting entropy diverge without bound. It needed the radical changes brought about by quantum theory to overcome this crisis and to put statistical mechanics on more solid ground (see section 3.8).

Figure 12. Hamiltonian systems with a mixed phase space where regular and chaotic dynamics coexist, the generic case, typically exhibit nested self-similar structures. (a)–(e) show subsequent amplifications, each by a factor of ca. 400, of the respective regions marked in pink (arrows) for the Hénon map. The similarity of the structures is evident. The process could continue ad infinitum, analogous to the mise-en-abyme phenomenon featured in figure 8(a), revealing an unlimited supply of information upon closing in to ever finer resolution. Reproduced with permission from [38], figure 3.
Download figure:
Standard image High-resolution imageThe problem got revived in a more recent development, the study of deterministic chaos in particular in Hamiltonian systems. While in Gibbs' argument, the continuum of distinguishable internal states of a molecule is just a hypothetical assumption, it becomes immediately manifest in the context of chaotic dynamics: as one of its symptoms, self-similar structures in phase space (figure 12) arise which illuminate Gibbs' point from a new perspective. They provide striking evidence that finer and finer details exist down to arbitrarily small scales which would allow to distinguish dynamical states of molecules, hence require an infinite amount of information to be specified.

Figure 13. The Bernoulli map x → x' = 2x (mod 2) (a) is arguably the simplest mathematical example of a chaotic system, generating an information of 1 bit per step. A suitable model for the Bernoulli map, in turn, which reproduces the same randomizing effect by the same mechanism, is a popular procedure to mix playing cards (b). The discrete nature of the cards even allows to visualize quantum suppression of chaos in a rudimentary form.
Download figure:
Standard image High-resolution image3.6. Thermodynamic entropy flow: chaos versus dissipation
Keywords:
– Dissipation as phase-space contraction.
– Chaos as phase-space expansion.
– Information balance in dissipative systems.
– Self-similarity, fractal dimension, and information density.
On the face of it, Hamiltonian mechanics is incompatible with such everyday phenomena as dissipation and other irreversible processes. Sophisticated reasoning and modelling is needed to reconcile the two levels. It appears much more natural to incorporate, as traditional approaches like Aristotelian physics did, friction as constituent part of the theory. The price to be paid, however, is high: it includes in particular the loss of crucial conservation laws such as Liouville's theorem. In Newtonian physics, the phase space volume initially occupied can shrink to zero, so that an entire family of initial conditions converges to one identical final state. If it is known with certainty while the initial conditions are distributed according to some probability, entropy decreases from some positive value to zero. The contraction of phase space results in an outward information current on the macroscopic level. Retrodiction of the initial state becomes increasingly imprecise, memory is lost [1].
The opposite process, an increase of phase-space volume and thus of entropy, can be associated to a general phenomenon as well: chaos (figure 13). While in the case of dissipation, knowledge of the final state of a process does not provide enough data to reconstruct its initial state to the same accuracy, the converse is true for chaotic systems [1]. Here, knowledge of the initial state does not allow to predict the final state with the same resolution, a situation known as the butterfly effect. While the underlying dynamical laws can be perfectly deterministic, the practical impossibility to make predictions beyond a certain time range leads to an effective indeterminism.
Dissipation and chaos form a pair of mutually inverse processes, related by time reversal (figure 14). The former corresponds to a contraction of phase space with concomitant loss of information, the latter to phase-space expansion and information gain. In fact, the stretching of phase space is only one of two constituent features of chaotic behaviour: if the total available state space is bounded, expansion must eventually be balanced by an opposing mechanism: the folding of phase space compensates for its expansion, erasing information on large scales at least at the same rate as it is injected on small scales (figure 15). Combining the two simultaneous processes, a picture emerges of chaos as an elevator permanently lifting information from small to large dimensions.

Figure 14. Dissipation and chaos form a pair of converse processes: while for dissipation (a), a contraction of phase-space volume results in a loss of potential information, I(t2) < I(t1) for t2 > t1, phase-space expansion leads to an information gain in the case of chaotic dynamics (b), I(t2) > I(t1).
Download figure:
Standard image High-resolution image
Figure 15. Chaotic dynamics is characterized by two complementary processes occurring simultaneously: while the state space is stretched, injecting information locally, it is also folded as a whole, erasing information globally (a). Their repeated action (b) leads to a continuous uplift of information from small to large scales. Original drawings reproduced from [1]. Reproduced with permission from [1], figures 24 and 25.
Download figure:
Standard image High-resolution imageOpening the view to larger scales, the entropy flow from the Sun to its planets, driving, e.g., the evolution of life on Earth, can be interpreted like dissipation as a top-down information current. Conversely, Prigogine's 'dissipative structures' in non-equilibrium systems [39] break symmetries by amplifying microscopic fluctuations. They form a bottom-up entropy flow analogous to chaos.
As an important complement to this section, a quantitative account of fractal structures and their information content should be included. It can be extended to a general discussion of the intimate relationship between information and dimension, as is manifest, e.g., in the concept of information dimension [40].
3.7. Fluctuations, noise, and microscopic degrees of freedom
Keywords:
– Noise and information.
– Fluctuations and noise.
– The second law of thermodynamics.
– The fluctuation–dissipation theorem (FDT).
Friction generates heat. This everyday observation, as innocuous as it appears, resolves the general question how energy is conserved in dissipative processes where it escapes from macroscopic motion: interpreting heat as kinetic energy of microscopic degrees of freedom, friction merely transfers energy to small scales where it is no longer directly visible. Einstein, seeing clearly this connection, cast it in the form of his FDT [40]. It states a quantitative relation between the energy dissipated in macroscopic motion and the random jitter of the microscopic components of matter.
Conservation of energy and of information, even if they are independent laws, coincide in many respects: the interpretation of friction as an energy transfer from macroscopic to microscopic freedoms carries over to entropy. It suggests to understand the FDT similarly as reflecting information currents between macro- and microstates. In this way, it indicates how the entropy balance on the large is to be reconciled with the conservation of phase-space volume addressed in section 3.5: the injection of entropy into the microscopic freedoms, visible in thermal fluctuations, compensates for the macroscopic loss.
Using 'scales' and 'freedoms' indiscriminately is in fact an abuse of terms. The principal features of deterministic chaos can already be studied in models comprising only few degrees of freedom, even in maps of the unit interval onto itself [41]. Thermodynamics, by contrast, deals with large numbers of particles. The randomness generated by chaotic dynamics is not of the same nature as thermal noise. While in deterministic chaos, the output time series can be traced back to a low-dimensional initial condition, the interaction between many particles introduces an additional element of disorder in thermal systems.
Indeed, Brownian motion, the random quivering of particles of intermediate size induced by thermal fluctuations, has become a paradigm of noise. Generally, noise is treated in statistical physics as the complementary information that fills the gap between what is known about a system (the actual information Iact, see section 3.1) and its total information capacity Itot, following Jayne's maximum-entropy principle [42]. The continuous increase of entropy in thermal systems and similarly in technical processes like repeated copying or communication via imperfect channels, amounts to an accumulated action of noise. Classifications like white, coloured, Gaussian ... noise can be understood as concepts combining pure randomness with a few parameters with known values, like mean and first moment, in well-defined distributions or ensembles.
A macroscopic physical manifestation of noise is diffusion: coarse-graining details and levelling out sharp gradients, it erases all structures in a distribution that could be read as a signal (figure 16). In this way, it counteracts the contraction of phase space caused by dissipation. Taking into account the coupling of these two antagonistic processes by the FDT, an equilibrium between entropy flows from microscopic to macroscopic scales and vice versa will eventually arise. It prevents distributions from approaching sharp points (delta functions) or steps (Theta functions) that amount to an infinite information content.

Figure 16. Diffusion, a paradigm for irreversibility, blurs and eventually erases distinct patterns in a distribution, replacing the initial information gradually by random noise. It occurs in thermodynamics as well as in technical processes like repeated copying or communication via noisy channels. (a)–(d) show a density distribution, in the initial state (a) and after successive applications of a filter simulating diffusion (b)–(d).
Download figure:
Standard image High-resolution imageCombining all these considerations around information exchange between different scales, a pattern emerges that resembles convection cells and subduction zones above a hot surface (figure 17): while as dominating tendency, macroscopic information is absorbed by microscopic freedoms and turned into heat, isolated chaotic processes lift information from small to large dimensions where they become visible and are perceived as unpredictable events.

Figure 17. Combining the information flows top-down, macro–micro, in dissipation, and bottom-up, from small to large scales in deterministic chaos, a pattern of counter directed 'vertical' currents emerge which resemble convection cells in hydrodynamics.
Download figure:
Standard image High-resolution imageThe preferred time arrow we observe thus appears to be rooted in the combination of two crucial effects: the existence of information flows both from large to small and from small to large scales, and the fact that the universe has been born in a state of imbalance where structures on the largest scales prevailed [4, 33].
3.8. Information and quantum mechanics: digitalizing the microcosm
Keywords:
– Standard formulations of quantum mechanics.
– Heisenberg's uncertainty relation, a fundamental upper bound of information density in phase space.
– The density operator, von-Neumann entropy, and their properties.
– Unitary transformations conserve information.
– Quantum suppression of chaos.
The preceding discussion leaves a crucial question open: how is information processed on the smallest scales, on the bottom level of natural computation where the laws of quantum mechanics supersede classical physics? To fill this gap, a section on the specific way quantum systems process information is indispensable.
The question cannot be answered by merely extrapolating classical mechanics to atomic and molecular dimensions. Scale matters in information dynamics, as the considerations concerning Gibbs' paradox have shown. Entropy diverges if an unlimited information density is assumed. A drastic modification of classical mechanics was required to fix this problem and related anomalies which by the end of the 19th century led to a profound crisis of classical physics.
The way out of the impasse followed closely Thomas Kuhn's scheme of scientific revolution [2]: quantum mechanics, the new paradigm, provides a radical answer, lifting physics to a new level of self-consistency. The limitation of the information density to a finite value, given by Planck's quantum of action h = 2πħ, can even be considered as the one central axiom of quantum mechanics from where to unfold most of its more specific predictions, including the most paradoxical ones. Imposing a fundamental bound to an information-related quantity, it is closely related to special relativity: the vacuum speed of light forms an absolute limit only if understood as an upper bound for the group velocity of waves, or more generally, the propagation of information. Quantum mechanics reformulates the fundamental laws of physics under the strict verdict that the density of information is finite. It is close in spirit to signal-processing theories based on finite available data sets and coincides with many of their consequences.
The common nucleus of all quantum uncertainty relations is in fact a mathematical theorem [10]: if a finite data set is represented simultaneously, say, in time t and frequency ω (or position and wavenumber, ...), the respective uncertainties Δt and Δω are bounded from below by Δt Δω ≥ 2π, a dimensionless number, the size of a so-called Gabor cell [10]. This theorem becomes a law of physics once, e.g., frequency ω is replaced by energy E = ħω, so that the mathematical bound takes the physical form Δt ΔE ≥ 2πħ, involving Planck's constant. The uncertainty relations impose an objective limit for the information content of a system and are not a mere subjective restriction owing to imperfections, however insurmountable, of the measuring equipment.
Quantum mechanics is frequently reduced to quantization, often understood as discretization or pixelization, and the contrast quantum versus classical is simplified to discrete versus continuous. This is inappropriate and misleading. Quantum mechanics does not imply the discreteness of any specific quantity. The density of eigenstates in phase space, one per Planck cell of size 2πħ, as a fundamental limit does not even require a particular shape of these cells. Depending on the system at hand, they can be rectangular (potential box), elliptic (harmonic oscillator), or take any other, even arbitrarily irregular, shape. As a consequence, only in particular cases does the compartmentalization of phase space result in the discretization of an observable quantity.
While in this respect, quantum theory revolutionized classical physics, it agrees perfectly with Hamiltonian mechanics in another important aspect: the time evolution of closed systems, the way they process information, is invariant under time reversal and preserves the total entropy content. Following John von Neumann, a pioneer who anticipated an information-based approach to quantum theory, entropy can be defined in quantum mechanics in a way closely analogous to Shannon's definition [43]. Quantum mechanics replaces canonical transformations, which generate the time evolution of classical systems in phase space, by unitary transformations of Hilbert space, the state space in quantum physics. Von Neumann's entropy is invariant under the action of unitary transformations, just as Hamiltonian mechanics conserves classical entropy. This implies in particular that the apparent incompatibility of the second law with the fundamental microscopic physics is by no means restricted to classical mechanics. Worse even, the possibility offered by quantum mechanics to quantify the information content of every state renders the contradiction even more inescapable.
Both features taken together, finite information density and conservation of entropy, however, also indicate how to remove the classical inconsistencies. The picture developed above of counter-directed information flows—dissipation as sink, chaos as source of entropy—suggests there should be a ground level where the paternoster lift turns around. Where classical physics appears fathomless, quantum mechanics inserts the missing bottom. In the case of chaotic dynamics, consequences are particularly drastic: if information is permanently conveyed up from a limited source, the supply will eventually run out. That is exactly what happens: after a finite time, closed quantum systems cease to be chaotic. They become periodic—no more surprise, no further entropy is produced. The time for this breakdown to occur depends on the output rate (the Lyapunov exponent) and the supply (system size). In this rigorous sense, chaos in quantum mechanics cannot exist. So far about bottom-up information currents.
This is true, however, only for strictly closed systems. It is a commonplace, though, that closed systems are an idealization and practically do not exist. Even a minimum interaction suffices to enable an exchange of information between systems, however slow. For this reason, dissipation is so ubiquitous: there is always a loophole for entropy to escape—and to enter where it is in short supply. Chaos combined with dissipation exemplifies the interplay of these two processes, seen from a quantum viewpoint. On the one hand, uncertainty destroys the hallmark of dissipative chaos, strange attractors with a self-similar (fractal) geometry (figure 18). Viewed from sufficiently close, approaching the scale of Planck's constant, the infinitely fine structure disappears and gives way to smooth distributions [44, 45]. However, this does not occur on a fixed raster, as if rendering the attractor on a computer screen with low resolution. Rather, the coarsening adapts to the shape of the attractor at hand. At the same time, including dissipation restores chaotic structures in the time evolution, injecting the missing information whose scarcity dries out chaos in closed quantum systems. On a timescale independent of the breakdown discussed above, dissipative quantum chaos restores irregular, aperiodic motion [44, 45].

Figure 18. The Zaslavsky map is a standard model for dissipative chaos, exhibiting a strange (self-similar) attractor (a). Treating the same model as a quantum system, the strange attractor loses its self-similarity. The infinitely fine classical details are replaced by a structure that is smooth on the scale of Planck's constant (b). After [44]. Reprinted from [44], figure 11, Copyright (1990), with permission from Elsevier.
Download figure:
Standard image High-resolution imageWhence the information that revives chaotic irregularity? Microscopic models of quantum dissipation coincide in their basic setup: the system of interest, for example a chaotic model with a few dimensions, is coupled to an environment comprising an infinite number of degrees of freedom, often modelled following specific prototypes, for example the modes of the quantized electromagnetic field (or quantum vacuum for short). In this system, permeating virtually the entire universe, quantum uncertainty is manifest in a zero-point energy of its normal modes. The finite energy contained even in their ground states, in turn, is observable as vacuum fluctuations, a remainder of thermal fluctuations which persists down to zero absolute temperature.
In this way, the image of rising and descending information currents is complemented by a picture of what is going on at the bottom where these flows connect: the quantum vacuum acts as a huge universal garbage dump where all lost information finally ends, the bits of an archive deleted on some computer as much as the emphatic words of Julius Caesar, the echo of a supernova somewhere in the Universe just as the roar of Triassic monsters, and is recycled to surface eventually as fresh quantum randomness.
Quantum mechanics not only resolves information-related inconsistencies of classical physics, it also implies unexpected consequences not related to the failures of its precursor. Akin to the twin paradox of special relativity, emblematic quantum features such as entanglement, nonlocality, and action at a distance, combined in the Einstein–Podolsky–Rosen (EPR) paradox (figure 19), have sparked decades of debate among physicists and philosophers. However, interpreting quantum mechanics as a theory of finite information, they appear as natural, inevitable results. An account of quantum physics along these lines, complementing Bohr's Copenhagen interpretation by a contemporary approach, has been proposed by Anton Zeilinger [46], the Austrian pioneer in experimental evidence of entanglement. Earlier attempts in this direction include work of Carl-Friedrich von Weizsäcker [47, 48] and of James A Wheeler [49].

Figure 19. An electron (e−) and a positron (e+) generated simultaneously, e.g., from a sufficiently energetic photon, in a spontaneous creation, are called an Einstein–Podolsky–Rosen (EPR ) pair for a particular correlation between their spins se− and se+: conservation of angular momentum implies the sum rule se− + se+ = 0. The two spins are undetermined till they are measured and take specific directions. The individual results for each spin are a typical quantum random process, both orientations are equally probable and cannot be predicted. The sum rule, however, requires invariably that the two spins take opposite signs. This anticorrelation occurs instantaneously between the two measurements. It does not violate causality, though: no information is transmitted. Rather, the two particles, despite their growing spatial separation, form a single indivisible qubit that is set with the measurement.
Download figure:
Standard image High-resolution imageWhile largely analogous to classical information according to Boltzmann or Shannon, von Neumann's entropy is different in a decisive point: there is an absolute zero for quantum entropy, a lower bound that is missing in the classical case. No more can be known, no less can remain open about a system than if it is in a pure state. This amounts to zero entropy; it takes positive values if the system is not in a pure state. Quantum mechanics not only limits the maximum information content of a closed system, it also implies a lower bound. The minimum is a single bit, a system that can take only one of two possible states. Quantum systems as small as that, such as spins, are often called 'qubits'. The crucial point is that an isolated two-state system cannot carry more information, either.
It is tempting to imagine this elementary quantum of information to be also associated to a single indivisible point-like particle, e.g., an electron. In fact, this expectation is unfounded. The fundamental property, an information content of 1 bit, can well refer to a system that consists of two or more spatially distributed parts: the subsystems become entangled. The prototypical case are EPR pairs, for example an electron and a positron generated simultaneously in a decay process. Their total internal angular momentum is zero, so that their spins must take opposite orientations. Together they form a single qubit, shared by two particles that move arbitrarily far apart in space. It can be manipulated, in particular oriented in a specific direction, operating on only one of the two particles. Once fixed, the spin orientation involves both particles simultaneously, it occurs nonlocally. This process does not contradict causality, there is no 'spooky action at a distance', as Einstein put it: no information is transmitted from one system to another; a single qubit just takes a definite value that can be observed at different places.
This situation sheds light, too, on quantum-mechanical measurement and the fundamental randomness ascribed to it, a matter of fierce debate since the advent of quantum mechanics. As long as the two particles remain isolated as a pair, the sign of their common spin does not take any definite value. Performing a measurement on the system forces the spin to assume a specific direction. This creates 1 bit of information that did not exist before; the conservation of entropy in closed systems requires that it cannot come from the EPR pair itself. As in the case of quantum chaos with dissipation, the only possible source is the environment the pair couples to when it interacts with the measurement apparatus. This indicates that in the random outcome of the measurement, information is not created from nothing, either. It merely amplifies a fluctuation of the quantum vacuum or the degrees of freedom of the apparatus to macroscopic visibility. Robert Laughlin, in his monograph 'A different universe. Reinventing physics from the bottom down' [50], compares this situation with a radio station where in the dead season, in lack of true news, editors start interviewing each other.
The common feature that renders these quantum paradoxes comprehensible is the fact that a limited amount of information, a single bit in the extreme, is shared by parts of a system that are distributed in space. It is the paucity, not abundance, of this resource that leads to entanglement and to counterintuitive effects.
3.9. Computers as physical systems
Keywords:
– Computation as a physical process.
– The Turing machine.
– Universal computation.
– Reversible and irreversible operations; ballistic and Brownian computers.
– Landauer's physical limits of computation.
Analogies are symmetric relations [8]. The metaphor underlying this essay, comparing natural systems to computers, actually has two sides: while the preceding sections elucidate computation-like features in nature, the remaining part highlights the natural conditions dominating computers. After all, entropy is a physical quantity, its storage and transport in computers underlies the same fundamental constraints, such as energy conservation, as in 'natural' systems. In the words of Rolf Landauer [51]: information is physical.
As an initial insight, the distinction between computers on the one hand and natural systems on the other is no more than a convention. In particular, where computation means simulation, these roles become interchangeable: water waves serve to simulate light, but light waves can also be used to simulate wavelets on a water surface. Electrons in a metal resemble cold atoms in optical lattices. Inversely, they allow to anticipate the behaviour of particles in standing laser fields. Microwaves in superconducting cavities are analogous to wave functions in quantum billiards. Measuring their eigenmodes and their frequencies can outperform double-accuracy numerical calculations, adding a third tier of simulation.
If indeed this distinction is pointless, what in fact are the criteria that qualify a technical system to be called a computer in the more limited colloquial meaning? The following general conditions are expected to apply:
– The nominal state space is finite and discrete.
– Time proceeds in discrete steps.
– The time evolution, apart from contingent input from keyboards, other computers, etc, follows deterministic state-to-state transition laws.
More restrictive criteria, like a binary code or a hardware built from silicon-based electronic circuits, are not necessary; a mechanical calculator and even an abacus are acceptable as computers.
These last two examples show that the notion of a nominal state space is decisive. Abaci and mechanical calculators are evidently macroscopic physical systems where all relevant variables are continuous, not discrete. Time advances continuously, anyway. As man-made objects, computers are natural systems embedded in human culture. Their states, besides comprising physical variables, bear symbolic meanings, subject in turn to norms and conventions. An elementary example is a two-state, on–off switch (figure 20): taken as a mechanical system, it can assume a continuum of states associated to the spatial position of the switch. It is constructed, though, such that its mechanical potential is bistable. The switch will fall into one of its two minima, corresponding to the nominal states 'off' versus 'on', and, sufficiently strong friction provided, stay there. The barrier separating them must be sufficiently high to prevent switching by thermal fluctuations but low enough to be surmounted by a fingertip.

Figure 20. An ordinary switch exemplifies a basic principle of digital computing: the two states of the device, e.g., 'off' versus 'on', should be controlled by a bistable potential with two minima separated by a barrier, sufficiently high so as to prevent a mere thermal excitation from changing the state of the device, of a typical magnitude kBT (T denoting temperature), yet low enough to allow for switching by an intentional external pulse.
Download figure:
Standard image High-resolution imageThis construction already represents basic physical traits of a computer. Within a continuous state space, the nominal states are marked by steep potential minima, separated by barriers chosen such that with high probability, a control impulse, but no thermal fluctuation, will trigger a transition. As a consequence, every irreversible change of state results in dissipating as much energy as amounts to the barrier height ΔE, which in turn must exceed the mean thermal energy kBT by far (kB denoting Boltzmann's constant, T temperature, see figure 20).
Evidently, such losses occur as soon as stored information is deleted. The erasure of one bit generates at least kB ln 2 of entropy, converting an energy kBT ln 2 into heat [51]. In fact, most logical operations have the same consequence. Binary operations like AND, OR, EQUIVALENCE etc that map a pair of Boolean variables onto a single one, can in general not be inverted uniquely since one of the two input bits is lost. They constitute irreversible processes, hence generate as much entropy and heat as a mere deletion.
A computer in the colloquial sense therefore inevitably represents a dissipative system, not only for possible friction between its parts. Classifying its asymptotic states in the terminology of dynamical systems theory [52], it can only comprise point attractors (single states eventually reached by the system) or limit cycles (a periodic sequence of states the system terminates in, figure 21). By contrast, strange attractors with fractal geometry are not compatible with a finite discrete state space. Digital computers thus provide qualitative classical models for the quantum suppression of chaos, except for the fact that their state space forms a rigid raster while quantum distributions in phase space can take any shape.

Figure 21. Digital computers have a discrete state space comprising only a finite number of distinct states. This requires their dynamics to start repeating itself after a finite number of steps (in the absence of external input from keyboards etc). In the case of dissipative computing, final states can be point attractors (a) or limit cycles (b). In reversible computing (c) and (d), the state space initially occupied cannot contract, a limit cycle comprises as many states as led into it. In both cases, chaotic behaviour is excluded.
Download figure:
Standard image High-resolution imageHowever, the standard modus operandi of a digital computer, as outlined here, is not the only possibility. The idea of reversible, frictionless computation enjoyed considerable attention at the time when the basic design of quantum computers emerged [53]. In quantum computation (see the subsequent section 3.10), it is of vital importance to preserve coherence, dissipation is absolutely forbidden. The loss of information in binary logical operations can in fact be avoided by saving one of the input bits which, combined with the output, allows to restore the other input. Quite some creativity has been devoted, at the same time, to conceiving ballistic mechanical computers that operate with only negligible friction between their moving parts [53], the only purpose of such fictitious devices being to demonstrate the feasibility of computation without generating entropy. Having a finite discrete state space in common with conventional dissipative computers, they cannot simulate chaotic dynamics.
Classical reversible computers share a fundamental problem with their quantum counterparts: due to the verdict not to contract different inputs to a single output, they cannot exploit redundancy as a strategy to prevent and correct errors. Therefore, the error frequency increases linearly with the computation time or the number of operations realized. It can be reduced by slowing down the processing speed, resulting in a trade-off with performance.
Computing devices built by human beings are not the first examples of tools or organs brought about in the course of evolution with the principal function to store and/or process information. As has been mentioned above, RNA and DNA can already be considered as digital memory devices. Likewise, replication and transcription constitute copying operations, as a rudimentary instance of computation. They even work with astonishing accuracy, given that they go on in molecular systems exposed to thermal noise at physiological temperature. Inspired by such natural systems, the idea of Brownian computers emerged, where thermal fluctuations drive a system through a sequence of logical-like operations. In order to achieve a well-defined direction of the process, a finite gradient has to be imposed. To avoid a concomitant energy loss, this gradient can be made arbitrarily small, again on the expense of computational speed.
Inherent thermodynamic limitations are by no means the only aspects where physics constrains digital computing. Also quantum mechanics and special relativity have tangible effects. Their general discussion, linking computer science back to physics, has been pioneered by Landauer [51]. Summarizing these issues, the following problems remain largely open:
Accuracy.
– How many operations can be performed before they merge with noise?
– What is the minimum energy dissipated per operation?
Speed.
– How does relativity limit the speed of information processing?
– How does thermodynamics limit the speed of information processing?
– What is the trade-off between accuracy and speed of computation?
Size.
– What is the maximum density of information storage, in (phase) space?
– Which physical limits exist, if any, for the scaling-up of computers?
– What is the maximum capacity of a communication line?
3.10. Quantum computation
Keywords:
– Quantum versus classical computing.
– Quantum dense coding and quantum parallelism.
– Quantum gates.
– Decoherence and error correction.
– Deutsch's and Shor's algorithm, quantum fast Fourier transformation.
After visionary initial steps by theoreticians like Richard Feynman in the early 1980s [54], quantum computation enjoyed a hype in the first years of the 21st century, driven by fast progress in experimental quantum optics and a concomitant theoretical development bringing together physicists, mathematicians, and computer scientists. Meanwhile, enthusiasm has somewhat waned in view of the formidable technical problems that remain to be solved, but a certain fascination survives. It is nourished by the perspective of exploring a completely new construction principle for computers that appears to offer possibilities inaccessible to classical computation. Buzzwords like 'quantum teleportation' and 'quantum cryptography' produced their effect.
Given the flood of recent literature on the subject, it cannot be the purpose of the course to add yet another introduction to quantum computation or to contribute to propaganda in its favour. The topic is nevertheless included because it illuminates certain facets of the way quantum systems store and process information from a relatively applied point of view, contrasting it with the way similar tasks are solved on the classical level.
Another crucial difference not yet mentioned between Hilbert space, the state space of quantum systems, and the phase space of classical mechanics is that quantum states are endowed with a phase, besides their position in Hilbert space, equivalent to a real vector. By contrast to the direction of the state vector, this additional variable with the characteristics of an angle is not related to any directly observable physical quantity. Notwithstanding, it does play a role in an emblematic quantum phenomenon, interference. Like other waves, quantum (matter) waves can superpose and thus interfere constructively or destructively. This alternative is decided by the relative phase of the superposed waves, ranging from plain addition to mutual annihilation. The phase determines the sign (more generally, a direction in the complex plane) associated to each component of a Hilbert-space vector, while information measures only take their magnitude into account.
The decisive question in the context of information processing is: can this variable be utilized like any other state-space coordinate, adding a dimension that is not accounted for in classical measures of entropy and information such as Boltzmann's or Shannon's, respectively?
A brief comparison already reveals that the quantum phase cannot be treated as an information-carrying state variable, i.e., one more Hilbert-space dimension:
- –A quantum system cannot be in a 'phase state'. Rather, the phase forms part of the description of its state.
- –The phase is not directly observable, hence cannot be entered as input or read out as output from a macroscopic device.
- –It does not form a pair with a complementary, canonically conjugate state variable; there is no uncertainty relation involving the phase.
To be sure, there exist operators with the properties of an angle, as a cyclic spatial coordinate which fulfils a corresponding commutation relation with a quantized angular momentum. The phase is of a different nature. In fact, there are alternative representations of quantum mechanics, like Wigner's [55], where quantum coherence is encoded in features other than phases. Claiming that information can be stored in the phase is misleading, at best.
Physical reality can be attributed to the phase only as far as it is involved in superposition processes. This does not exclude taking advantage of it as a resource in computation, though not in the same way as a common Hilbert-space dimension. As soon as a quantum system is forced to assume a specific state among several alternatives, such as in output processes, the phase is lost and with it its potential to participate in the computation. Till then, the system can be kept pending between alternatives and process them simultaneously; they remain latently present in the quantum state without becoming individually manifest. The gist of quantum programming is to exploit this resource as far as possible, optimizing protocols and input and output procedures accordingly.
Obviously, a system's capacity to store and process information increases with its size. In order to obtain an extensive variable, proportional to the number of involved degrees of freedom, Boltzmann made his entropy depend logarithmically on the spatial size accessible to each freedom and the resolution available to measure its position, etc. Classically, the information thus increases linearly with the number of subsystems and logarithmically with their size. The same is true in quantum mechanics. Quantum computers consist of qubits, each one contributing two dimensions to Hilbert space, but can be perfectly compared to systems described by continuous observables like position and momentum, if only the Hilbert-space dimension is finite. The relevant unit in phase space, a Planck cell, amounts to one dimension of Hilbert space. Quantum coincides with classical entropy in that it grows logarithmically with the state-space dimension, hence linearly with the number of qubits.
The advantage of quantum computing appears only in a subtler detail: quantum dense coding [43] does in fact not refer to the storage capacity as such but to the way qubits are addressed. With a basis comprising entangled states, the entire content can be accessed operating only on a single subsystem. This feature reflects again that in quantum mechanics, subsystems are not necessarily associated to qubits one to one.
The variety of alternatives encoded in a single entangled initial state can be processed in parallel in a quantum computer till a result is read out, reducing the initial superposition to a single option. A lead over classical computing can only be gained as far as it is advantageous to have the results of the same algorithm, applied simultaneously to several inputs, latently ready, till one of them needs to be finally saved or processed further. There exist a number of tasks that fulfil this condition and serve as prototypes to demonstrate the virtues of quantum computation. They range from finding the parity of the outputs of a binary operation (Deutsch's algorithm) through factorization of natural numbers (Shor's algorithm) through sophisticated problems like fast Fourier transform. Quantum parallelism is already being applied to other tasks, such as network search engines, using parallel architecture on conventional platforms [56].
Quantum dense coding and quantum parallelism make essential use of the quantum phase, thus depend on its faithful conservation during all operations. Quantum computers must preserve the coherence of the quantum states they are processing, that is, phase correlations must not be perturbed. This requires above all that the system remain isolated from its environment while operating. As pointed out in the context of classical computing, even binary operations systematically discard one of their two input bits. For this reason, the exclusive use of reversible logic is vital for quantum computation. In analogy to reversible classical gates, quantum gates perform unitary transformations on qubits which in principle could be restored by applying the same operation backwards to the output—not to enable an 'undo' at any time, but to avoid the entropy generated by converting the unused bit into heat. Usually, the complementary output bits are not processed further but kept idle till the algorithm terminates.
In this way, the information loss inherent in logical operations can be circumvented. It proves much more difficult, however, to suppress natural decoherence through the coupling of the central processing unit (CPU), typically implemented employing microscopic particles like single electrons or nuclei [43, 57], to the ambient world. Apparently a mere technical problem, it turns out to be almost prohibitive. Initially, the CPU must be prepared from outside in a predetermined quantum state. Upon completing the computation, it must be observed by measurement to extract the output. Both tasks require strong interaction with the macroscopic device containing the quantum CPU. Phase coherence is inextricably related to the limited information content of a small isolated quantum system. Any leak, any minute contact with the environment will allow this vacuum to be filled with entropy entering from outside.
Equivalently, decoherence can be analysed in terms of entanglement. As soon as a quantum system prepared in a superposition of many states, as in quantum computation, interacts with the ambient world, they exchange information. The central system will leave a trace in the environment, in particular in its phases, while loosing internal coherence. This process occurs likewise in measurements and in unintentional decoherence, irrespective of whether the imprint of the central system is observed or not: entanglement is transferred from the central system to the environment.
It is intriguing to return from this specific close look onto quantum computation to the broader viewpoint of information processing in natural quantum systems. Seth Lloyd's 'Programming the Universe' interprets the world as a huge quantum computer in [4], quite in the spirit of the analogy promoted in this report. A host of related questions arise: does nature perform quantum parallel processing? If so, given that no system is perfectly isolated, how do they preserve coherence? Why is entanglement is largely eliminated on molecular scales and beyond, i.e., whence classical behaviour? How is this phenomenon related to the exchange of information between subsystems? In particular, why did humans, as macroscopic IGUS (see section 3.7), perceive the world as a classical system, missing quantum effects completely till the advent of sophisticated experimental equipment? Why has nature, in developing brains as its high-end computing devices, opted for classical information processing, dispensing with the benefits of quantum computation (or has it)? Going to larger scales even, is the Universe as a whole a closed system, hence in a pure quantum state, maybe globally entangled?
Recent research activities shed light onto this complex from different sides. Stimulated by technological challenges arising around quantum computation, standard models of quantum dissipation, in quantum optics and solid-state physics, are being revised: how are the parts of a system disentangled once it gets coupled to a reservoir, how does this process induce, in turn, entanglement with and within the reservoir? In quantum chemistry, the idea, prevailing for decades, is questioned that the functional dynamics of enzymes can be analysed on basis of Newtonian mechanics alone. Evidence accumulates that quantum coherence not only survives within their active core but is even vital for their biological function [58]. Questions concerning large-scale structures of the universe are increasingly studied in terms of quantum information.
4. Experiences and perspectives
4.1. Teaching experience
Parts of the material presented here have been conceived for the first time in various seminars, talks, and informal discussions. In the course of time, the idea took shape they might be combined to a coherent story, possibly as a topical lecture. At the same time, it was clear that the intended subject was certainly not addressed in existing physics curricula, graduate or postgraduate.
It came as a positive surprise that the Physics Department of Universidad Nacional de Colombia in Bogotá considered my proposal and agreed to implement the course in its postgraduate programme. In an emerging country struggling with formidable social and economic problems, it is already an achievement to have physics departments functioning properly. It is truly remarkable if in addition, teaching projects are accepted that may well fail.
The course might have been integrated within an existing class of lectures on interdisciplinary subjects, linking physics to history, economy, arts etc, popular among students as a soft component within the curriculum. 'The concept of information in physics' has not been relegated to this category but offered as a standard lecture, not compulsory but with the usual requirements to be graded.
This offered the opportunity to introduce some modifications of the common pedagogical pattern of theoretical physics courses, besides the innovative contents. Following a scheme intermediate between lecture and seminar, students were encouraged to work out short talks on sundry topics, too special to be addressed in the course proper. They include
– Time–frequency representations and the wavelet transform.
– Increase of information content from genome to proteome to phenotype.
– Adaption as accumulation of knowledge: genetic, epigenetic, and cultural heredity.
– Self-fulfilling prophecy: from king Oedipus to the quantum Zeno effect.
– Algorithmic complexity and Gödel's theorem.
– Einstein's FDT and Nyquist's formula.
– The quantum Baker map.
– The Turing machine and universal computation.
– Decoherence and error correction in quantum computation.
– Standard algorithms of quantum computing.
Besides these student seminars, worked out and presented by small teams, the course is accompanied by written exercises, to provide feedback on the learning process and to practice methods and concepts. Much in the style of traditional problem sets in theoretical physics, they cover, however, a wider class of tasks, including design exercises as well as logical and conceptual questions to be solved in the form of mini essays rather than derivations. A typical problem set is reproduced in appendix A.2. Of course, exercises can only cover those parts of the contents that form established canonical knowledge. Open or controversial issues are not suitable for this purpose.
In this format, the course is calculated for 16 weeks of two 2 h sessions each (i.e., 64 h in total). Initially, it has been restricted to physics students proper, attracting an audience of 10–15 students every two or three semesters. In general, the unconventional concept was accepted with enthusiasm. A frequent misunderstanding, however, is worth mentioning: students may be attracted by the keyword 'quantum information' in the announcement (see appendix A.1) and enrol mainly to be introduced to quantum computation. Learning with the first lessons that this is not the idea, they loose interest or leave altogether. Typically however, after a few weeks to adapt to the unfamiliar style and interdisciplinary scope, the majority begins to enjoy a learning experience very different from their everyday routine.
As a major improvement after several rounds strictly within physics, the course was opened to a wider audience. Students of biology and philosophy were admitted within to their own curriculum, not only as mere listeners. Notably the biologists contributed valuable expertise in topics related to the life sciences and appreciated, in turn, the opportunity to reconsider aspects of their discipline from a new angle. As a next step, further disciplines, such as mathematics and computer science, will be included.
In 2010, Philippe Binder of the University of Hawaii and I had the opportunity to read the course under unique, ideal conditions. It was invited as a mini-course in a summer-school organized by the German Scholar Foundation (Studienstiftung des deutschen Volkes). The Foundation supports highly-gifted students economically and academically. In summer-schools, complementary knowledge is provided in timely, often cross-disciplinary topics. In our case, it was possible to attract students from mathematics, informatics, biology, and philosophy, besides physics. Adapting the programme to this format, frontal teaching was replaced by guided discussions, backed-up by student seminars. According to feedback, the course was a full success. For us, it was a unique opportunity to share our ideas with an audience of exceptionally gifted future researchers.
Teaching this course is a challenge for the lecturer as it requires solid knowledge in subjects far outside physics. At the same time, leaving the routine of physics lectures behind provides a truly rewarding experience.
4.2. Open questions and loose ends
The course presented here represents a snapshot of mental work in progress. Notwithstanding, considerable effort has been made to base it as far as possible on uncontroversial, approved knowledge. It is a hallmark of insight, however, to trigger more questions than it answers. The task to cast the material in a coherent teachable form and discussions with students during the course provoked questions and revealed inconsistent or incomplete reasoning, concerning technical details or posing problems of far-reaching character we cannot hope to solve in the near future. It is encouraging and fascinating to observe how part of these open problems appear as emerging research subjects in physics, computer science, cognitive science, and biology.
The following list represents but an incomplete and unsystematic selection of open problems that deserve further reflection or await fresh results of experimental and theoretical research to be settled:
- –Universality of information/entropy: as a fundamental tenet, the course treats the concepts of information and entropy as equivalent, applying to subjects outside physics, from formal logics to genetics. Is this assumption legitimate or do we use indiscriminately what in fact are distinct categories?
- –
- –Gödel's incompleteness theorem has led some researchers to the conclusion that human thinking has an uncatchable advance over artificial intelligence. One of the suspects is creativity: what renders it distinct from mere random generation, in the refined sense of algorithmic complexity?
- –Genetic mutations are an emblematic case of randomness, providing the creativity that enables evolution to find innovative solutions. What exactly is the physical origin of the random changes manifest in genetic variability: thermal fluctuations of DNA or RNA molecules, quantum uncertainty [59], or yet another mechanism on a higher level in genetic information processing?
- –The predictions of Einstein's FDT indicate at least the simultaneous presence of a two-way information traffic between macroscopic and microscopic freedoms. Does this include a quantitative equivalence, at least in an equilibrium situation (stationary state) [60]?
- –Combining statistical mechanics with quantum physics, a consistent picture emerges how dissipation dumps information into the quantum vacuum and chaos lifts it up to large scales. Is there a similar top level at cosmic scales where the information flow turns, like a paternoster in the attic?
- –There is some evidence, however inconclusive, that the average complexity of organisms increased systematically in the course of evolution. Can this tendency be corroborated, e.g., by improving the paleological data base or refining the concept of organismic complexity? If so, is it an inherent feature of evolution, maybe driven by the entropy flow within the solar system?
While the information age approaches maturity, a new paradigm emerges. The World Wide Web not only revolutionizes global economy and culture, it also gives rise to an extremely complex network of information flows whose organization and controlled growth challenge engineers and physicists. This process already stimulated the creation of new concepts which in turn invite to be generalized, fertilizing fields such as molecular biology, brain research, and many-body physics. Focusing on information dynamics, the present project anticipates this recent development and prepares students for its analysis.
4.3. Perspectives and future plans
Seeing this project advance from first sketches to its implementation as a course was a stimulating experience. It encourages to apply the same ideas to future projects or to create new proposals along similar lines:
- –The general conception, combining a decidedly interdisciplinary subject with an approach aimed at scientific precision and objectivity, has proven suitable for science curricula anticipating future professional and academic developments. Other topics could well be addressed in a similar style, e.g.,
- –Epistemology and cognition, a contemporary scientific view.
- –Determinism versus free will: physics, psychology, social and legal aspects.
- –Complexity.
- –Interaction with the participants revealed a demand for lecture notes covering the entire material, as a monograph on a semi-popular level, to be used as a stand-alone reader or as a textbook accompanying the course. Even taking recent books of similar scope into account [3–7], the present approach appears sufficiently distinct to warrant a publication of its own.
Acknowledgments
I thank Carlos Maldonado (Universidad del Rosario, Bogotá, Colombia) for organizing the workshop that gave rise to this work. Philippe Binder (University of Hawaii at Hilo, USA) has accompanied the entire project with stimulating ideas and critical remarks. I am grateful for his encouragement and support.
Appendix
A.1. Announcement 'The concept of information in physics'
The general announcement of 'The concept of information in physics' comprises an outline, indicating objectives and content of the course, a programme with contents in keywords and estimated durations of every section, a bibliography, and the evaluation scheme (figure A.1).

Figure A.1. The general announcement of 'The concept of information in physics'.
Download figure:
Standard image High-resolution imageA.2. Sample problem sets
The course has been accompanied by written exercises following the traditional scheme of problem sets for physics lectures, but including a wider range of tasks beyond quantitative calculations. Figure A.2 shows two typical problem sets.

{kind=link}
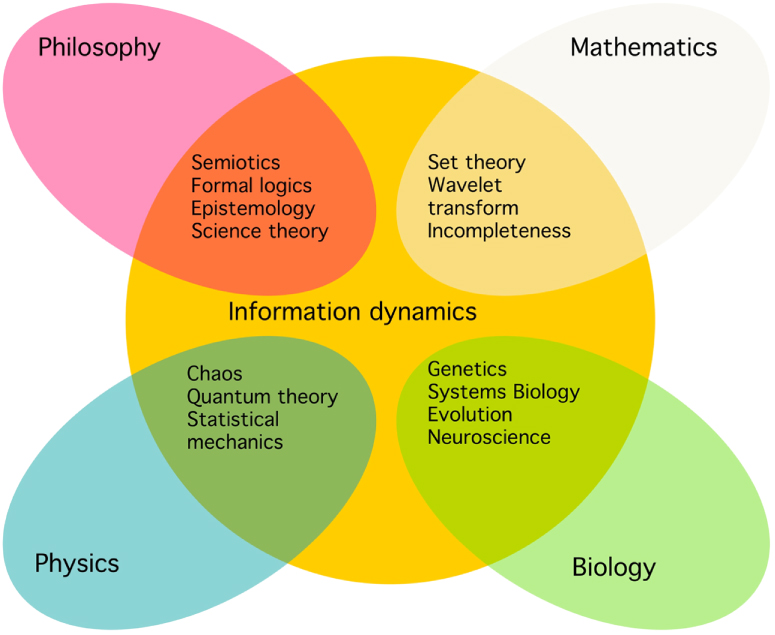{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure A.2. Two typical problem sets from the course.
Download figure:
Standard image High-resolution image{kind=link}
Footnotes
- 1
See, e.g., NASA's Deep Impact Mission that culminated in the partial destruction of comet Tempel I on 4 July 2015 (www.jpl.nasa.gov/missions/deep-impact/).
- 2
See, e.g., the 2014 workshop 'Causality, Information Transfer and Dynamical Networks', at the Max Planck Institute for the Physics of Complex Systems (MPIPKS), Dresden, Germany (www.mpipks-dresden.mpg.de/~cidnet14/).