




Abstract
In this era of large-scale spectroscopic stellar surveys, measurements of stellar attributes ("labels," i.e., parameters and abundances) must be made precise and consistent across surveys. Here, we demonstrate that this can be achieved by a data-driven approach to spectral modeling. With The Cannon, we transfer information from the APOGEE survey to determine precise  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn3.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn4.gif) from the spectra of 450,000 LAMOST giants. The Cannon fits a predictive model for LAMOST spectra using 9952 stars observed in common between the two surveys, taking five labels from APOGEE DR12 as ground truth
from the spectra of 450,000 LAMOST giants. The Cannon fits a predictive model for LAMOST spectra using 9952 stars observed in common between the two surveys, taking five labels from APOGEE DR12 as ground truth  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn7.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn8.gif) , and K-band extinction
, and K-band extinction  . The model is then used to infer
. The model is then used to infer  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn12.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn13.gif) for 454,180 giants, 20% of the LAMOST DR2 stellar sample. These are the first
for 454,180 giants, 20% of the LAMOST DR2 stellar sample. These are the first ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn14.gif) values for the full set of LAMOST giants, and the largest catalog of
values for the full set of LAMOST giants, and the largest catalog of ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn15.gif) for giant stars to date. Furthermore, these labels are by construction on the APOGEE label scale; for spectra with S/N > 50, cross-validation of the model yields typical uncertainties of 70 K in
for giant stars to date. Furthermore, these labels are by construction on the APOGEE label scale; for spectra with S/N > 50, cross-validation of the model yields typical uncertainties of 70 K in  , 0.1 in
, 0.1 in  , 0.1 in
, 0.1 in ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn18.gif) , and 0.04 in
, and 0.04 in ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn19.gif) , values comparable to the broadly stated, conservative APOGEE DR12 uncertainties. Thus, by using "label transfer" to tie low-resolution (LAMOST R ≈ 1800) spectra to the label scale of a much higher-resolution (APOGEE R ≈ 22,500) survey, we substantially reduce the inconsistencies between labels measured by the individual survey pipelines. This demonstrates that label transfer with The Cannon can successfully bring different surveys onto the same physical scale.
, values comparable to the broadly stated, conservative APOGEE DR12 uncertainties. Thus, by using "label transfer" to tie low-resolution (LAMOST R ≈ 1800) spectra to the label scale of a much higher-resolution (APOGEE R ≈ 22,500) survey, we substantially reduce the inconsistencies between labels measured by the individual survey pipelines. This demonstrates that label transfer with The Cannon can successfully bring different surveys onto the same physical scale.
Export citation and abstract BibTeX RIS
1. Label Transfer Using The Cannon
A diverse suite of large-scale spectroscopic stellar surveys have been measuring spectra for hundreds of thousands of stars in the Milky Way. Among them are APOGEE (Majewski et al. 2015), Gaia-ESO (Gilmore et al. 2012), GALAH (De Silva et al. 2015), LAMOST (Zhao et al. 2012), RAVE (Kordopatis et al. 2013), SEGUE (Yanny et al. 2009), and Gaia (Gaia Collaboration 2016) with its radial velocity spectrometer. Stellar spectra are also obtained by surveys as side products: for example, SDSS has many more stellar spectra beyond SEGUE, obtained in the original survey and subsequent (non-SEGUE) phases like BOSS and eBOSS.
These surveys target different types of stars, in different parts of the sky, and at different wavelengths. For example, APOGEE observes in the near-infrared and targets predominantly giants in the dust-obscured mid-plane of the Galaxy, whereas GALAH observes in the optical and targets predominantly nearby main-sequence stars. In addition, they observe at different resolutions and employ different data analysis methodologies to derive, from spectra, a set of labels characterizing each star. In our work, we use the term "label" to collectively describe the full set of stellar attributes, physical parameters and element abundances like  ,
,  ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn22.gif) , and [X/H]. We adopt this term from the supervised machine learning literature, as our methodology (The Cannon) is an adaptation of supervised learning to suit the particulars of stellar spectra.
, and [X/H]. We adopt this term from the supervised machine learning literature, as our methodology (The Cannon) is an adaptation of supervised learning to suit the particulars of stellar spectra.
The suite of spectroscopic surveys are complementary in their spatial coverage and scientific motivation, and there is enormous scientific promise in combining their results. However, diversity is also the reason why surveys cannot be rigorously stitched together at present: different pipelines measure substantially different labels for the same stars (e.g., Smiljanic et al. 2014). For example, Chen et al. (2015) compared the three stellar parameters  ,
,  , and
, and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn25.gif) between APOGEE and LAMOST, two of the most ambitious ongoing surveys, and found consistency in the photometrically calibrated
between APOGEE and LAMOST, two of the most ambitious ongoing surveys, and found consistency in the photometrically calibrated  but systematic biases in
but systematic biases in  and
and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn28.gif) , as Figure 1 shows for 9952 objects observed and analyzed by both surveys. Furthermore, when Lee et al. (2015) used the SEGUE pipeline to measure parameters (including
, as Figure 1 shows for 9952 objects observed and analyzed by both surveys. Furthermore, when Lee et al. (2015) used the SEGUE pipeline to measure parameters (including ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn29.gif) and [C/Fe]) from LAMOST spectra, they found that the physical scale of SEGUE labels is systematically offset from that of other surveys, like APOGEE. The SEGUE pipeline could only be straightforwardly applied to the LAMOST spectra because the two surveys are qualitatively very similar, e.g., in their resolution and wavelength coverage.
and [C/Fe]) from LAMOST spectra, they found that the physical scale of SEGUE labels is systematically offset from that of other surveys, like APOGEE. The SEGUE pipeline could only be straightforwardly applied to the LAMOST spectra because the two surveys are qualitatively very similar, e.g., in their resolution and wavelength coverage.
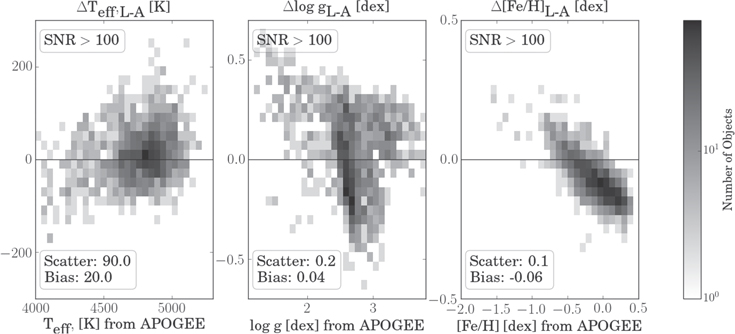
Figure 1. Systematic offsets in the labels  ,
,  , and
, and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn32.gif) that were derived by the LAMOST ("L") and APOGEE ("A") pipelines, respectively. There are significant biases in
that were derived by the LAMOST ("L") and APOGEE ("A") pipelines, respectively. There are significant biases in  and
and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn34.gif) . Shown for the 2183 stars that have been observed and analyzed by both surveys, and that have LAMOST spectra with S/N > 100. S/N values were calculated for each spectrum by taking the median of the flux-uncertainty ratio across all pixels.
. Shown for the 2183 stars that have been observed and analyzed by both surveys, and that have LAMOST spectra with S/N > 100. S/N values were calculated for each spectrum by taking the median of the flux-uncertainty ratio across all pixels.
Download figure:
Standard image High-resolution imageAlthough such systematic label offsets may not be surprising for two surveys with disjoint wavelength coverage and very different spectral resolutions (see Section 2), labels are ultimately characteristics of stars and not of observations, and must therefore be unbiased and consistent between surveys to within the stated error bars. To that end, better techniques must be developed for bringing different surveys onto the same label scale.
We approach this problem of intersurvey systematic biases by using The Cannon (Ness et al. 2015), a new data-driven method for measuring stellar labels from stellar spectra in the context of large spectroscopic surveys. Ness et al. (2015) describe the method in detail; we direct the reader to this paper for details on what distinguishes this particular data-driven technique from others, and more specifically what distinguishes it from the MATISSE method (Recio-Blanco et al. 2006). Here, we recapitulate the fundamental assumptions and steps of The Cannon in the context of bringing surveys onto the same scale, and describe the procedure more concretely in Sections 3 and 4.
Presume that Survey X and Survey Y are two spectral surveys that are not (yet) on the same label scale: their individual pipelines measure inconsistent labels for objects observed in common, as in Figure 1. Presume further that there are good reasons to trust the labels of Survey X more than those of Survey Y. This could be, for example, because Survey X has higher spectral resolution and higher S/N. Our goal is to resolve the systematic inconsistencies by bringing Survey Y onto Survey X's label scale. Ultimately, we want a model that can directly infer labels from Survey Y's spectra that are consistent with what would be measured by the Survey X pipeline from the corresponding Survey X spectra.
The Cannon relies on a few key assumptions: that stars with identical labels have very similar spectra, and that spectra vary smoothly with label changes. In other words, the continuum-normalized flux at each pixel in a spectrum is a smooth function of the labels that describe the object. The function that takes the labels and predicts the flux at each wavelength of the spectrum is called the "spectral model," fitting for the coefficients of the spectral model is the goal of the first step, the "training" step.
In the training step, The Cannon uses the objects that have both spectra from Survey Y and labels from Survey X. The spectra and corresponding "reference labels" are used to fit for the spectral model coefficients at each pixel of the spectrum independently. The spectral model characterizes the flux at each pixel of a Survey Y spectrum as a function of corresponding Survey X labels, and predicts what the spectrum of an object observed in Survey Y would look like given a set of labels from Survey X.
In the second step, the "test" step, this model is used to derive likely labels for any (similar) object given its spectrum from Survey Y, including those not observed by Survey X. Note that if the Survey X pipeline has measured a dozen labels precisely and the Survey Y pipeline has only measured three, we can in principle use our model to infer extra, previously unknown labels from Survey Y spectra; we dub this process of transferring knowledge of labels from one survey to another "label transfer." Note also that in this approach, Survey X enters only through its labels, not the data (spectra, light curves, or otherwise) from which these labels were derived, and Survey Y enters only through its spectra. This distinguishes our approach from traditional cross-calibration techniques such as multilinear fitting. Although the outcome of this process (consistent labels for a set of stars observed in common between two surveys) is the same as in traditional cross-calibration, we make no use of the labels from the Survey Y pipeline. In a sense, cross-calibration is a byproduct of our label transfer analysis.
Note that this procedure does not require that the two surveys have any overlapping wavelength regions; indeed, that is one of its strengths. However, this also means that caution must be taken when transferring labels from one survey to another. One could imagine trying to measure a new label from a wavelength regime that has no sensitivity to that label. In that case, The Cannon could still "learn" to predict the label via astrophysical correlations with other labels. Thus, the model should always be inspected for astrophysical plausibility. The interpretability of the model is another strength of our approach, as addressed in Section 3 and especially Figure 5.
In this work, we take APOGEE to be Survey X and LAMOST to be Survey Y. We select APOGEE as the source of the trusted stellar labels because it is the higher-resolution survey (R ≈ 22,500 versus R ≈ 1800 for LAMOST). We use four post-calibrated labels from APOGEE DR12, as measured by the ASPCAP pipeline (García Pérez et al. 2015):  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn37.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn38.gif) . We also use the K-band extinction
. We also use the K-band extinction  ; while not strictly an intrinsic property of the stars, it is a "label" in the sense that it is an immutable property of the stellar spectrum when observed from our location in the Galaxy. We decided to include extinction in constructing the model because the objects in the reference set (in the Galactic mid-plane) include visual extinctions up to
; while not strictly an intrinsic property of the stars, it is a "label" in the sense that it is an immutable property of the stellar spectrum when observed from our location in the Galaxy. We decided to include extinction in constructing the model because the objects in the reference set (in the Galactic mid-plane) include visual extinctions up to  ≈ 3.5 (
≈ 3.5 ( ≈ 0.4). This impacts some of the optical spectra in the training step and in the test step, not only by reddening, but also by dust and gas absorption features.
≈ 0.4). This impacts some of the optical spectra in the training step and in the test step, not only by reddening, but also by dust and gas absorption features.
Note that what we call ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn42.gif) in this work is stored under the header PARAM_M_H in DR12. We use this value so that all four labels have gone through the same post-calibration procedure, but refer to it as
in this work is stored under the header PARAM_M_H in DR12. We use this value so that all four labels have gone through the same post-calibration procedure, but refer to it as ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn43.gif) rather than [M/H] because it has been calibrated to the
rather than [M/H] because it has been calibrated to the ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn44.gif) of star clusters (Mészáros et al. 2013), and in order to be consistent with the terminology from LAMOST.
of star clusters (Mészáros et al. 2013), and in order to be consistent with the terminology from LAMOST.
Of course, our key assumption—that stars with identical labels have very similar spectra—is only an approximation. In this case, we assume that any two stars with near-identical  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn47.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn48.gif) , and
, and  have near-identical spectra, regardless of spatial position (e.g., R.A. and decl.) or other properties (e.g., individual element abundances). This approximation should be a very good one, however, because the shape of each spectrum should be dominated by these five labels. This is supported by the quality of the model fit, e.g., as illustrated in Figure 10.
have near-identical spectra, regardless of spatial position (e.g., R.A. and decl.) or other properties (e.g., individual element abundances). This approximation should be a very good one, however, because the shape of each spectrum should be dominated by these five labels. This is supported by the quality of the model fit, e.g., as illustrated in Figure 10.
The 11,057 objects measured in common between APOGEE and LAMOST constitute the possible reference set for the training step; in practice, we use 9952 of these objects to fit for the spectral model. Then, we apply this model to infer both new labels for the reference set, as well as labels for the remaining 444,228 LAMOST giants in DR2 not observed by APOGEE. By construction, these labels are tied to the APOGEE scale.
Like cross-calibration techniques, our label transfer approach with The Cannon is fundamentally limited by the quality and breadth of the available reference set. In this case, the set of common objects happens to be entirely giants, and we are therefore limited to applying our model to the giants in LAMOST DR2, which is why we must discard such a large fraction (80%) of our sample. Indeed, the Cannon model is only applicable within the label range in which it has been trained, and even then there is inevitably some extrapolation because we are not training on a set of labels that comprehensively describe a stellar spectrum. We return to this issue in Section 4, and direct the reader to Section 5.4 of Ness et al. (2015) for additional discussion of the issue of extrapolation in The Cannon and to Section 6 of Ness et al. (2015) for avenues for future improvement.
This work is an implementation of the general procedure that is described in detail in Ness et al. (2015). The primary distinguishing feature is how the LAMOST spectra were prepared for The Cannon, and we describe that process in Section 2.1. The fact that it performs well for spectra at very different wavelength regimes and resolutions illustrates the general applicability of this procedure to large uniform sets of stellar spectra, given a suitable reference set.
2. Data: LAMOST Spectra and APOGEE Labels
The Large sky Area Multi-Object Spectroscopic Telescope (LAMOST) is a low-resolution (R ≈ 1800) optical (3650–9000 Å) spectroscopic survey. The second data release (DR2; Luo et al. 2016) is public and consists of spectra for over 4.1 million objects, as well as three stellar labels ( ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn52.gif) ) for ∼2.2 million stars. Although the survey does not select for a particular stellar type, many of the stars are red giants; the population of K giants numbers 500,000 in DR2 (Liu et al. 2014). Moreover, >100,000 red clump candidates have been identified in the DR2 catalog (Wan et al. 2015). Stellar labels for the LAMOST spectra are derived by the LAMOST Stellar Parameter pipeline (LASP; Wu et al. 2011a, 2011b; Luo et al. 2016). LASP proceeds via two steps. In the first step, the Correlation Function Initial (CFI; Du et al. 2012) calculates the correlation coefficients between the measured spectrum and spectra from a synthetic grid, and finds the best match. This first-pass coarse estimate serves as the starting guess for the second step, which makes use of the Université de Lyon Spectroscopic Analysis Software (ULySS; Koleva et al. 2009; Wu et al. 2011b). In ULySS, each spectrum is fit to a grid of model spectra from the ELODIE spectral library (Prugniel & Soubiran 2001; Prugniel et al. 2007). These model spectra are a linear combination of nonlinear components, optically convolved with a line-of-sight velocity distribution and multiplied by a polynomial function. Improved surface gravity values have been obtained for the metal-rich giant stars via cross-calibration with asteroseismically derived values from Kepler (Liu et al. 2015).
) for ∼2.2 million stars. Although the survey does not select for a particular stellar type, many of the stars are red giants; the population of K giants numbers 500,000 in DR2 (Liu et al. 2014). Moreover, >100,000 red clump candidates have been identified in the DR2 catalog (Wan et al. 2015). Stellar labels for the LAMOST spectra are derived by the LAMOST Stellar Parameter pipeline (LASP; Wu et al. 2011a, 2011b; Luo et al. 2016). LASP proceeds via two steps. In the first step, the Correlation Function Initial (CFI; Du et al. 2012) calculates the correlation coefficients between the measured spectrum and spectra from a synthetic grid, and finds the best match. This first-pass coarse estimate serves as the starting guess for the second step, which makes use of the Université de Lyon Spectroscopic Analysis Software (ULySS; Koleva et al. 2009; Wu et al. 2011b). In ULySS, each spectrum is fit to a grid of model spectra from the ELODIE spectral library (Prugniel & Soubiran 2001; Prugniel et al. 2007). These model spectra are a linear combination of nonlinear components, optically convolved with a line-of-sight velocity distribution and multiplied by a polynomial function. Improved surface gravity values have been obtained for the metal-rich giant stars via cross-calibration with asteroseismically derived values from Kepler (Liu et al. 2015).
APOGEE is a high-resolution (R ≈ 22,500), high-S/N (S/N ≈ 100), H-band (15200–16900 Å) spectroscopic survey, part of the Sloan Digital Sky Survey III (Eisenstein et al. 2011; Majewski et al. 2015). Observations are conducted using a 300 fiber spectrograph (Wilson et al. 2010) on the 2.5 m Sloan Telescope (Gunn et al. 2006) at the Apache Point Observatory (APO) in Sunspot, New Mexico (USA) and consist primarily of red giants in the Milky Way bulge, disk, and halo. The most recent data release, DR12 (Alam et al. 2015; Holtzman et al. 2015), comprises spectra for >100,000 red giant stars together with their basic stellar parameters and 15 chemical abundances. The parameters and abundances are derived by the ASPCAP pipeline, which is based on chi-squared fitting of the data to 1D LTE models for seven labels:  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn55.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn56.gif) ,
, ![$[{\rm{C}}/{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn57.gif) ,
, ![$[{\rm{N}}/{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn58.gif) , and micro-turbulence (García Pérez et al. 2015). The best-matching synthetic spectrum for each star is found using the FERRE code (Allende Prieto et al. 2006).
, and micro-turbulence (García Pérez et al. 2015). The best-matching synthetic spectrum for each star is found using the FERRE code (Allende Prieto et al. 2006).
2.1. Preparing LAMOST Spectra for The Cannon
To be used by The Cannon, any spectroscopic data set must satisfy the conditions laid out in Ness et al. (2015). The spectra must share a common line-spread function, be shifted to the rest frame, and be sampled onto a common wavelength grid with uniform start and end wavelengths. The flux at each pixel of each spectrum must be accompanied by a flux variance that takes error sources such as photon noise and poor sky subtraction into account; bad data (e.g., regions with skylines and telluric regions) must be assigned inverse variances of zero or very close to zero. Finally, the spectra do not need to be continuum normalized, but they must be normalized in a consistent way that is independent of S/N; more precisely, the normalization procedure should be a linear operation on the data, so that it is unbiased as (symmetric) noise grows.
Preparatory steps were necessary to make the raw LAMOST spectra satisfy these criteria. First, the displacement from the rest frame was calculated for each spectrum using the redshift value provided in the data file header, and the spectra shifted accordingly. (The redshift values are derived within the LAMOST data pipeline from their cross-correlation procedure.) Spectra were then resampled onto the original grid using linear interpolation. After shifting, we applied lower and upper wavelength cuts and sampled all spectra onto a common wavelength grid spanning 3905–9000 Å. All of these operations were performed on both the flux and inverse variance arrays.
Each spectrum was normalized by dividing the flux at each  by
by  , which was derived by an error-weighted, broad Gaussian smoothing:
, which was derived by an error-weighted, broad Gaussian smoothing:
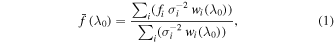
where fi is the flux at pixel i,  is the uncertainty at pixel i, and the weight
is the uncertainty at pixel i, and the weight  is drawn from a Gaussian
is drawn from a Gaussian
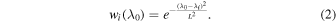
L was chosen to be 50  , much broader than typical atomic lines.
, much broader than typical atomic lines.
To emphasize, this "normalization" is in no sense "continuum normalization," and is different from the standard normalization used in spectral analysis. Our goal in preparing the spectra in this way is to simplify the modeling procedure by removing overall flux, flux calibration, and large-scale shape changes from the spectra.
The procedure is illustrated in Figure 2, which shows three spectra corresponding to a sample reference object: its APOGEE spectrum, its LAMOST spectrum overlaid with its Gaussian-smoothed "continuum," and its final "normalized" LAMOST spectrum.
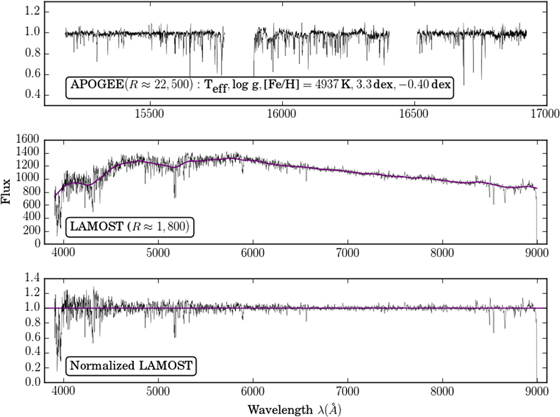
Figure 2. Spectra of a sample reference object (2MASS ID 2M07101078+2931576). The top panel shows the normalized APOGEE spectrum (with its basic stellar labels) and the middle panel shows the raw LAMOST spectrum overlaid with the Gaussian-smoothed version of itself. The bottom panel shows the resulting "normalized" spectrum, determined by dividing the black line by the purple line in the middle panel. The Cannon operates on the normalized spectrum in the bottom panel, although note that this "normalization" is different from the standard normalization used in spectral analysis. APOGEE and LAMOST spectra are qualitatively very different, in wavelength coverage and resolution.
Download figure:
Standard image High-resolution image3. The Cannon Training Step: Modeling LAMOST Spectra as a Function of APOGEE Labels
In the training step, as described in Section 1, The Cannon uses objects observed in common between the two surveys of interest. These common objects, used to train the model, are called reference objects. For each reference object, The Cannon uses the spectra from one survey (in this case, LAMOST) and the corresponding "trusted labels" from the other survey (in this case, APOGEE). These data—spectra from one survey, labels from the other—are used to fit a predictive model independently at each wavelength of a (LAMOST) spectrum. Given a set of APOGEE labels, this model seeks to predict every pixel of a LAMOST spectrum for a star with those properties.
To select reliable reference objects, we make a number of quality cuts to the full set of 11,057 objects in common between LAMOST DR2 and APOGEE DR12. We eliminate stars with unreliable  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn66.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn67.gif) , or
, or  as described in Holtzman et al. (2015). This involves excising the 677 objects with
as described in Holtzman et al. (2015). This involves excising the 677 objects with  < 3500 or
< 3500 or  > 6000, with
> 6000, with ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn71.gif) < 0.1 dex, or with ASPCAPFLAG set. This leaves 10,380 objects.
< 0.1 dex, or with ASPCAPFLAG set. This leaves 10,380 objects.
Furthermore, a reliable reference object is by definition one that can be captured by the spectral model. So, we run an iteration of The Cannon on the 10,380 objects from the first cut: we train the model and use it to infer new labels for all 10,380 objects. We excise the 428 objects (<0.5%) whose difference from the reference (APOGEE) value in any label is greater than four times the scatter in that label. This leaves 9952 objects of the original 11,057. These cuts, sensible but somewhat ad hoc, still leave a very extensive set of reference objects.
The label space of the remaining reference set is well-sampled, as seen in Figures 3 and 4. Figure 3 shows the distribution of the remaining 9952 reference objects in (LAMOST  , LAMOST
, LAMOST  ) label space. The black points in the background are the full LAMOST DR2 sample, with their values from the LAMOST pipeline. The overlaid colored points are the reference objects; in the left panel, they are shown with their LAMOST pipeline values, and in the right panel, they are shown with their APOGEE pipeline values. It is only the APOGEE labels, shown as colored dots in the right panel, that are used in the training step.
) label space. The black points in the background are the full LAMOST DR2 sample, with their values from the LAMOST pipeline. The overlaid colored points are the reference objects; in the left panel, they are shown with their LAMOST pipeline values, and in the right panel, they are shown with their APOGEE pipeline values. It is only the APOGEE labels, shown as colored dots in the right panel, that are used in the training step.

Figure 3. LAMOST DR2 (black points), overlaid with the reference set of 9952 objects (colored points) used to train the spectral model. These colored points are objects that have been observed by both LAMOST and APOGEE; in the left panel, they are shown with their LAMOST pipeline values, and in the right panel, they are shown with their APOGEE pipeline values. It is the values in the right panel that are used to train the spectral model.
Download figure:
Standard image High-resolution imageFigure 4 again shows the distribution of labels for the 9952 reference objects, this time for each label individually. The values from the LAMOST pipeline are shown in yellow and the corresponding values from the APOGEE pipeline are shown in purple. The APOGEE (purple) values comprise the reference set, which means that they are used to train the spectral model.
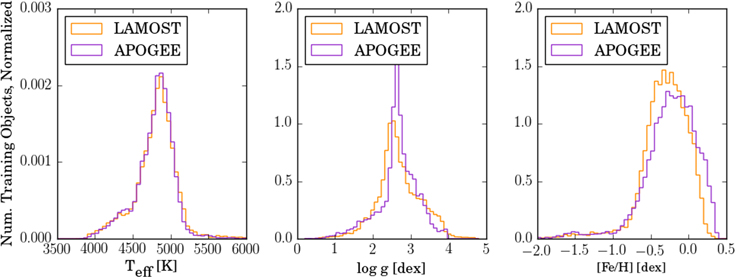
Figure 4. Distribution of labels for the 9952 training objects, values from LAMOST DR2 in yellow and values from APOGEE DR12 in purple. The purple (APOGEE) values are used to train the spectral model.
Download figure:
Standard image High-resolution imageThe Cannon uses the reference objects to fit for a spectral model that characterizes the flux in each pixel of the (normalized) spectrum as a function g of the labels of the star. In this case, the flux  for a spectrum n at wavelength λ in the LAMOST survey (L) can be written as
for a spectrum n at wavelength λ in the LAMOST survey (L) can be written as

where  is the set of spectral model coefficients at each wavelength λ of the LAMOST spectrum and
is the set of spectral model coefficients at each wavelength λ of the LAMOST spectrum and  is some (possibly complex) function of the full set of labels from APOGEE. The noise model is
is some (possibly complex) function of the full set of labels from APOGEE. The noise model is ![${\rm{noise}}=[{s}_{\lambda }^{2}+{\sigma }_{n\lambda }^{2}]\,{\xi }_{n\lambda }$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn77.gif) , where each
, where each  is a Gaussian random number with zero mean and unit variance. The noise is thus a root-mean-square (rms) combination of two contributions: the inherent uncertainty in the spectrum from, e.g., instrument effects and finite photon counts (
is a Gaussian random number with zero mean and unit variance. The noise is thus a root-mean-square (rms) combination of two contributions: the inherent uncertainty in the spectrum from, e.g., instrument effects and finite photon counts ( ), and intrinsic scatter in the model at each wavelength (sλ). This intrinsic scatter can be thought of as the expected deviation of the spectrum from the model at that pixel, even in the limit of vanishing measurement uncertainty. Handling uncertainties by fitting for a noise model independently at each pixel is a key feature of The Cannon and distinguishes it from traditional machine learning methods.
), and intrinsic scatter in the model at each wavelength (sλ). This intrinsic scatter can be thought of as the expected deviation of the spectrum from the model at that pixel, even in the limit of vanishing measurement uncertainty. Handling uncertainties by fitting for a noise model independently at each pixel is a key feature of The Cannon and distinguishes it from traditional machine learning methods.
Following Ness et al. (2015), we presume that the model g can be written as a linear function of  :
:
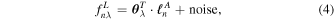
corresponding to the single-pixel log-likelihood function
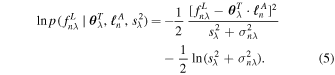
For this work, once more as in Ness et al. (2015), we use a quadratic model such that  is
is
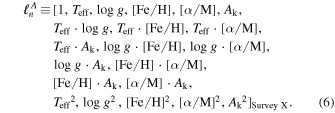
The training step thus consists of holding the labels in the label vector  fixed (these are the reference labels) and optimizing the log-likelihood to solve for the coefficients
fixed (these are the reference labels) and optimizing the log-likelihood to solve for the coefficients ![$[{\theta }_{\lambda },{s}_{\lambda }^{2}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn83.gif) independently at every pixel. For a fixed scatter value, optimization is a pure linear-algebra operation (weighted least squares). Currently, we optimize for the scatter by stepping through a grid of scatter values.
independently at every pixel. For a fixed scatter value, optimization is a pure linear-algebra operation (weighted least squares). Currently, we optimize for the scatter by stepping through a grid of scatter values.
Figure 5 shows the leading (linear) coefficient for each label as a function of wavelength, as well as the scatter as a function of wavelength. The magnitude of the leading coefficient can be thought of as the sensitivity of a particular pixel to that particular label. Thus, Figure 5 is a way to visualize which regions of the spectrum are (as determined by The Cannon) important for which labels. We find that  ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn86.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn87.gif) all have strong sensitivity to well-known spectral features such as Mg i, Na i D, and the Ca ii triplet.
all have strong sensitivity to well-known spectral features such as Mg i, Na i D, and the Ca ii triplet.
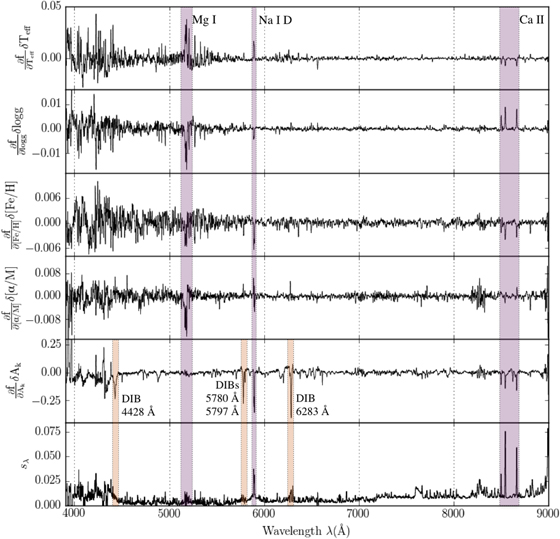
Figure 5. Leading (linear) coefficients and scatter from the best-fit spectral model, with prominent features labeled. These coefficients indicate how sensitive each pixel in the spectrum is to each of the labels. In the top four panels, note peaks at well-known spectral features such as the Mg i triplet around 5170 Å and the Ca ii triplet around 8600 Å. In the fifth panel, note peaks at well-known diffuse interstellar bands (DIBs). The coefficients are scaled by the approximate errors in the labels (91.5 K in  , 0.11 in
, 0.11 in  , 0.05 in
, 0.05 in ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn90.gif) and
and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn91.gif) ; Holtzman et al. 2015).
; Holtzman et al. 2015).
Download figure:
Standard image High-resolution imageInterestingly, we find that  has strong sensitivity not only to the Na i D doublet, but also to features that correspond to known diffuse interstellar bands (DIBs). The strongest of these DIBs are indicated by the orange lines in the lower panels of Figure 5. DIBs are absorption features that appear to arise from diffuse interstellar material; see Sarre (2006) and Herbig (1995) for extensive reviews. Over 400 have been detected to date, mostly at optical wavelengths, but their origin remains uncertain (Herbig 1993; Hobbs et al. 2008). DIB strength has been found to correlate well with extinction and the column density of neutral hydrogen (Friedman et al. 2011). In addition, some DIBs seem to have correlated strengths, which suggests a shared origin (McCall et al. 2010; Friedman et al. 2011). Large-scale studies of DIBs (e.g., Yuan & Liu 2012) hold promise for learning not only about their origin but also for mapping their environment; Zasowski et al. (2015) used DIBs in APOGEE infrared spectra to find that DIB strength is linearly correlated with extinction and thus a powerful probe of the structure and properties of the ISM. It is therefore perhaps not surprising that The Cannon learned to associate
has strong sensitivity not only to the Na i D doublet, but also to features that correspond to known diffuse interstellar bands (DIBs). The strongest of these DIBs are indicated by the orange lines in the lower panels of Figure 5. DIBs are absorption features that appear to arise from diffuse interstellar material; see Sarre (2006) and Herbig (1995) for extensive reviews. Over 400 have been detected to date, mostly at optical wavelengths, but their origin remains uncertain (Herbig 1993; Hobbs et al. 2008). DIB strength has been found to correlate well with extinction and the column density of neutral hydrogen (Friedman et al. 2011). In addition, some DIBs seem to have correlated strengths, which suggests a shared origin (McCall et al. 2010; Friedman et al. 2011). Large-scale studies of DIBs (e.g., Yuan & Liu 2012) hold promise for learning not only about their origin but also for mapping their environment; Zasowski et al. (2015) used DIBs in APOGEE infrared spectra to find that DIB strength is linearly correlated with extinction and thus a powerful probe of the structure and properties of the ISM. It is therefore perhaps not surprising that The Cannon learned to associate  with DIB strength; features in the leading coefficients plot include well-known DIBs, e.g., at 4428, 4882, 5780, 5797, 6203, 6283, 6614, and 8621 Å. Note that the DIBs in the Cannon model are effectively smeared across the radial velocity dispersion of the training sample.
with DIB strength; features in the leading coefficients plot include well-known DIBs, e.g., at 4428, 4882, 5780, 5797, 6203, 6283, 6614, and 8621 Å. Note that the DIBs in the Cannon model are effectively smeared across the radial velocity dispersion of the training sample.
4. The Cannon Test Step: Deriving New Stellar Labels from LAMOST Spectra
In the training step (Section 3) we treated the labels from APOGEE  as known and solved for the coefficients
as known and solved for the coefficients  of the spectral model. Now, in the test step, we take these spectral model coefficients and solve for new labels
of the spectral model. Now, in the test step, we take these spectral model coefficients and solve for new labels  (as opposed to
(as opposed to  ) based on the spectra
) based on the spectra  for each test object n. For a model that is quadratic in the labels, like ours, this consists of nonlinear optimization. We use Python's curve_fit routine from the scipy library, which uses the Levenberg–Marquardt algorithm. We use seven starting points in label space to assure convergence.
for each test object n. For a model that is quadratic in the labels, like ours, this consists of nonlinear optimization. We use Python's curve_fit routine from the scipy library, which uses the Levenberg–Marquardt algorithm. We use seven starting points in label space to assure convergence.
Before deriving new stellar labels for LAMOST objects, we test our model using a "leave- -out" cross-validation test. We split the 9952 reference objects into eight groups, by assigning each one a random integer between 0 and 7. We leave out each group in turn, and train a model on the remaining seven groups. We then apply that model to infer new labels for the group that was left out. At the end of this process, each of the 9952 reference objects has a new set of labels determined by The Cannon, from a model that was not trained using that object.
-out" cross-validation test. We split the 9952 reference objects into eight groups, by assigning each one a random integer between 0 and 7. We leave out each group in turn, and train a model on the remaining seven groups. We then apply that model to infer new labels for the group that was left out. At the end of this process, each of the 9952 reference objects has a new set of labels determined by The Cannon, from a model that was not trained using that object.
4.1. Cross-validation
Figure 6 shows the results of cross-validation. It shows four labels ( ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn102.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn103.gif) ) determined by The Cannon directly from LAMOST spectra, plotted against the corresponding APOGEE (reference) labels, which were determined by ASPCAP directly from APOGEE spectra. For completeness, we show the output for extinction in the final panel (light purple). Note that, in this work, we consider extinction as a "nuisance" label: we fit for it in order to more reliably determine the four other labels, but the question of how to use The Cannon to reliably determine extinction values from spectra is beyond the scope of this work.
) determined by The Cannon directly from LAMOST spectra, plotted against the corresponding APOGEE (reference) labels, which were determined by ASPCAP directly from APOGEE spectra. For completeness, we show the output for extinction in the final panel (light purple). Note that, in this work, we consider extinction as a "nuisance" label: we fit for it in order to more reliably determine the four other labels, but the question of how to use The Cannon to reliably determine extinction values from spectra is beyond the scope of this work.

Figure 6. Cross-validation of The Cannon's label transfer from APOGEE to LAMOST. Shown are the APOGEE labels of all reference objects compared to the labels derived from LAMOST data by The Cannon in the test step. We emphasize that no object in this figure was used to train the model that inferred its labels. The tight one-to-one correlations in the  ,
,  and
and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn106.gif) panels reflect the quality of the label transfer. The bottom right panel shows how well The Cannon is able to transfer the new label
panels reflect the quality of the label transfer. The bottom right panel shows how well The Cannon is able to transfer the new label ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn107.gif) from APOGEE. The success with which the cross-validation reproduces the reference labels serves to justify our application of this method to a more extensive LAMOST sample. For completeness, we include extinction as a fifth panel, but emphasize that ours is not a reliable method for inferring extinction from LAMOST spectra. The scatter and bias values represent spectra with S/N > 50.
from APOGEE. The success with which the cross-validation reproduces the reference labels serves to justify our application of this method to a more extensive LAMOST sample. For completeness, we include extinction as a fifth panel, but emphasize that ours is not a reliable method for inferring extinction from LAMOST spectra. The scatter and bias values represent spectra with S/N > 50.
Download figure:
Standard image High-resolution imageThe low scatter and bias in the ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn108.gif) panel (bottom right) shows how well The Cannon transferred a new label to the LAMOST data set. The scatter in all four labels for the objects with S/N > 50 LAMOST spectra (roughly half of the objects) is comparable to the typical uncertainties from ASPCAP, which are 91.5 K in
panel (bottom right) shows how well The Cannon transferred a new label to the LAMOST data set. The scatter in all four labels for the objects with S/N > 50 LAMOST spectra (roughly half of the objects) is comparable to the typical uncertainties from ASPCAP, which are 91.5 K in  , 0.11 in
, 0.11 in  , and around 0.05 in both
, and around 0.05 in both ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn111.gif) and
and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn112.gif) (Holtzman et al. 2015). (To clarify, the model was trained on and applied to objects of all S/N values; we are simply quoting scatter values for objects with S/N > 50. The dependence of scatter with S/N is shown in Figure 8.) Note that the scatter in the
(Holtzman et al. 2015). (To clarify, the model was trained on and applied to objects of all S/N values; we are simply quoting scatter values for objects with S/N > 50. The dependence of scatter with S/N is shown in Figure 8.) Note that the scatter in the ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn113.gif) derived from the LAMOST spectra is very similar to the precision in
derived from the LAMOST spectra is very similar to the precision in ![$[\alpha /\mathrm{Fe}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn114.gif) inferred indirectly for the SEGUE G-dwarfs by Bovy et al. (2012), based on SDSS spectra at similar resolution, wavelength coverage, and S/N. Note also that the discontinuity in
inferred indirectly for the SEGUE G-dwarfs by Bovy et al. (2012), based on SDSS spectra at similar resolution, wavelength coverage, and S/N. Note also that the discontinuity in ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn115.gif) is present in the reference set (because of the existence of two physical alpha sequences, the alpha-enhanced and alpha-poor sequences) and recovered in the test step, despite the fact that the model itself is in no way bimodal. The model is a quadratic function: nothing about it encourages a separation of these populations. Thus, this represents further physical verification of the model's accuracy.
is present in the reference set (because of the existence of two physical alpha sequences, the alpha-enhanced and alpha-poor sequences) and recovered in the test step, despite the fact that the model itself is in no way bimodal. The model is a quadratic function: nothing about it encourages a separation of these populations. Thus, this represents further physical verification of the model's accuracy.
This information is represented as residuals in Figure 7; a direct comparison with Figure 1 shows a significant improvement in scatter and a dramatic reduction of systematic differences between the labels derived from LAMOST and APOGEE spectra, particularly in  and
and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn117.gif) . The intersurvey biases in the three labels have all but vanished, demonstrating that we have successfully measured APOGEE-scale labels directly from LAMOST spectra, thus bringing the two surveys onto the same scale. Note also that the scatter (at a given S/N) has been reduced considerably: The Cannon can also measure more precise labels from the low-resolution LAMOST spectra (Ness et al. 2015).
. The intersurvey biases in the three labels have all but vanished, demonstrating that we have successfully measured APOGEE-scale labels directly from LAMOST spectra, thus bringing the two surveys onto the same scale. Note also that the scatter (at a given S/N) has been reduced considerably: The Cannon can also measure more precise labels from the low-resolution LAMOST spectra (Ness et al. 2015).
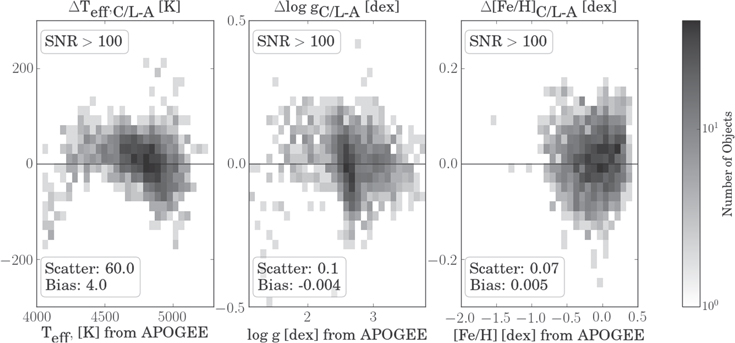
Figure 7. Comparison between The Cannon output and APOGEE reference labels. Shown here are labels for the 9952 objects in the reference set, objects measured in common between LAMOST and APOGEE. The systematic differences between labels determined by The Cannon from LAMOST spectra and by ASPCAP from APOGEE spectra have been almost completely eliminated (see Figure 1). The values from The Cannon also show a substantially reduced scatter with respect to the APOGEE labels, presumed to be ground-truth here.
Download figure:
Standard image High-resolution imageIn both Figures 6 and 7, there is a clear turn-off at low temperatures,  ≲ 4250. Our model in this regime is limited by the fact that ASPCAP labels are less reliable at these lower temperatures, so we urge caution when using labels for objects at lower temperatures. We return to this in Sections 4.2 and 5.
≲ 4250. Our model in this regime is limited by the fact that ASPCAP labels are less reliable at these lower temperatures, so we urge caution when using labels for objects at lower temperatures. We return to this in Sections 4.2 and 5.
Furthermore, The Cannon performs more precisely at low S/N than the LAMOST pipeline, as seen in Figure 8. Here, for an S/N metric, we define " ." We quantify S/N in the g-band because the leading coefficients show that decisive information comes from this regime. Furthermore, the error bar and S/N should reflect the variance of each pixel around the best-fit model; thus, the
." We quantify S/N in the g-band because the leading coefficients show that decisive information comes from this regime. Furthermore, the error bar and S/N should reflect the variance of each pixel around the best-fit model; thus, the  of a model that fits well (in this case, the model from The Cannon) should roughly equal the number of pixels in the spectrum, 3626. Instead, the
of a model that fits well (in this case, the model from The Cannon) should roughly equal the number of pixels in the spectrum, 3626. Instead, the  led us to find that the errors and S/N in the spectra needed to be adjusted by a factor of three. Thus,
led us to find that the errors and S/N in the spectra needed to be adjusted by a factor of three. Thus,  represents the S/N in the g-band, multiplied by three.
represents the S/N in the g-band, multiplied by three.

Figure 8. S/N dependence of the scatter between APOGEE DR12 labels and the corresponding labels measured from LAMOST spectra by The Cannon (purple points) and LASP (yellow points). The Cannon represents a substantial improvement from the LAMOST pipeline in the three labels that the APOGEE and LAMOST pipelines measure in common, and the model behaves well with decreasing S/N. The performance improvement is generally steeper than the inverse of the S/N. Note that we are using our own value for  , which does not reflect the reported LAMOST error bar.
, which does not reflect the reported LAMOST error bar.
Download figure:
Standard image High-resolution imageFigure 9 provides verification that the label transfer in  and
and  has led to astrophysically plausible results. It compares the (
has led to astrophysically plausible results. It compares the ( ,
,  ) distribution for all reference objects using their labels from the APOGEE pipeline, from the LAMOST pipeline, and from the Cannon model for the LAMOST data. Both the morphology of the red clump and of the giant branch shows that the Cannon labels are physically much more plausible than the pipeline labels derived from the same LAMOST data.
) distribution for all reference objects using their labels from the APOGEE pipeline, from the LAMOST pipeline, and from the Cannon model for the LAMOST data. Both the morphology of the red clump and of the giant branch shows that the Cannon labels are physically much more plausible than the pipeline labels derived from the same LAMOST data.
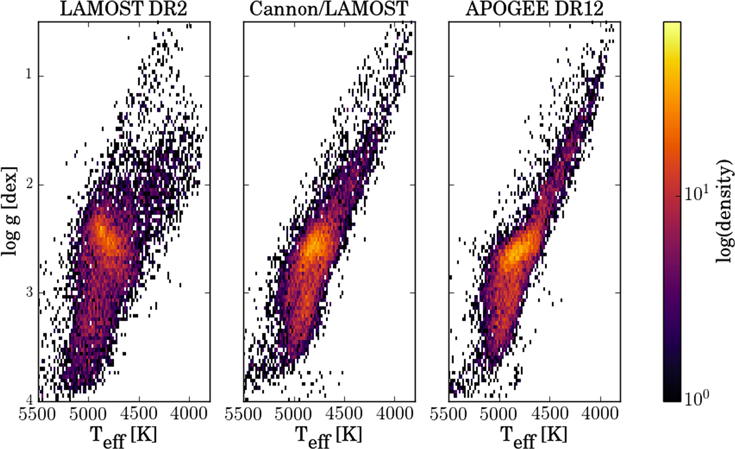
Figure 9. Astrophysical verification of the labels derived by The Cannon model for LAMOST data: the panel show the distribution of all reference objects in the ( ,
,  ) plane, using their LAMOST DR2 labels (left), Cannon labels from LAMOST spectra (center), and APOGEE DR12 labels (right). The distribution of Cannon labels is not only much more similar to ASPCAP's labels, but also much more physically plausible, exhibiting a tighter red clump and a more well-defined upper giant branch.
) plane, using their LAMOST DR2 labels (left), Cannon labels from LAMOST spectra (center), and APOGEE DR12 labels (right). The distribution of Cannon labels is not only much more similar to ASPCAP's labels, but also much more physically plausible, exhibiting a tighter red clump and a more well-defined upper giant branch.
Download figure:
Standard image High-resolution imageFinally, the "goodness of fit" can be quantified by a  value that takes into account uncertainty in the data and scatter in the model. This
value that takes into account uncertainty in the data and scatter in the model. This  essentially amounts to a comparison between the model spectrum and the data. This is visualized in Figure 10, which compares the data to the Cannon model spectrum for a randomly selected LAMOST object, centered on the Mg i triplet. The spectra line up nearly perfectly, to within the uncertainties in the data and scatter in the model. This demonstrates that the model, with the five labels we are fitting for, is an excellent description of LAMOST spectra. The success of cross-validation motivates and justifies the application of the model to LAMOST objects that have not been observed by APOGEE.
essentially amounts to a comparison between the model spectrum and the data. This is visualized in Figure 10, which compares the data to the Cannon model spectrum for a randomly selected LAMOST object, centered on the Mg i triplet. The spectra line up nearly perfectly, to within the uncertainties in the data and scatter in the model. This demonstrates that the model, with the five labels we are fitting for, is an excellent description of LAMOST spectra. The success of cross-validation motivates and justifies the application of the model to LAMOST objects that have not been observed by APOGEE.
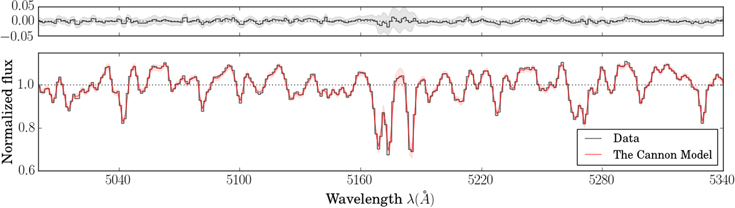
Figure 10. Sample model spectrum: a portion of the (Cannon-)normalized spectrum for a randomly selected star in the validation set, centered on the Mg i triplet. The best-fit model spectrum is in red and the data is in black. The residuals are plotted in the top panel. To emphasize, this object was not used to train the model that inferred its labels.
Download figure:
Standard image High-resolution image4.2. Application to LAMOST DR2
We now turn to applying the spectral model to DR2 objects that were not observed by APOGEE. The Cannon cannot extrapolate to regimes of ( ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn134.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn135.gif) ) label space that are completely different from those represented in the reference set, as shown in Ness et al. (2015). We believe that it is the bounds of the training labels that limit the applicability of the model, rather than the distribution of the training labels. This is because the label distribution is not sparse; the reference set densely populates the training label space (see Figures 3 and 4). In addition, the model is quadratic and is therefore fit smoothly across the label space.
) label space that are completely different from those represented in the reference set, as shown in Ness et al. (2015). We believe that it is the bounds of the training labels that limit the applicability of the model, rather than the distribution of the training labels. This is because the label distribution is not sparse; the reference set densely populates the training label space (see Figures 3 and 4). In addition, the model is quadratic and is therefore fit smoothly across the label space.
So, we restrict our test set to LAMOST DR2 objects that are reasonably close to the reference set in label space. To do so, we define a "label-distance" D from the reference objects in label space, exploiting here the fact that all test objects have (initial) stellar label estimates from the LAMOST pipeline. The label-distance of a LAMOST test object (in LAMOST label space; subscript L) and a reference object (in APOGEE label space; subscript A) is
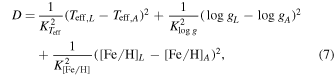
where we have normalized by the approximate uncertainty in each label:  ,
,  , and
, and ![${K}_{[\mathrm{Fe}/{\rm{H}}]}=0.10$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn138.gif) . We then calculate an object's label-distance from the reference set by taking the average of its label-distances to the 10 nearest reference objects.
. We then calculate an object's label-distance from the reference set by taking the average of its label-distances to the 10 nearest reference objects.
We use these label-distances to define the regime within which a LAMOST DR2 object was deemed a feasible test object. The label-distance cut was determined by running the test step of The Cannon on 3000 random objects in LAMOST DR2. This showed that there is a particular label-distance (roughly 2.5, as defined in Equation (7)) at which the giant-branch and main-sequence populations separate: since the reference set comprises only giants, stars on the giant branch are closer to the reference set in label space than stars on the main sequence. As expected, running these 3000 objects through the test step (using The Cannon to try and reproduce their reference labels) demonstrated that The Cannon was better able to reproduce the training labels for stars within this label-distance than for stars outside this label-distance.
Thus, we use this label-distance cut to inform our choice of test objects: we select those with a label-distance to the reference set of less than 2.5. Effectively, this is a way to select only giants; we are restricted to giants because these happen to be the objects with reference labels. Figure 11 shows 14,000 random stars in the ( ,
,  ) plane (colored points), on top of the entire LAMOST DR2 sample (see Figure 3): a label-distance cut at 2.5 neatly separates the giants (to which the spectral model applies) from the main-sequence stars.
) plane (colored points), on top of the entire LAMOST DR2 sample (see Figure 3): a label-distance cut at 2.5 neatly separates the giants (to which the spectral model applies) from the main-sequence stars.
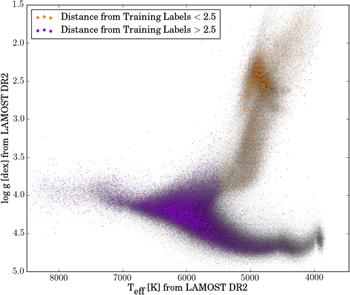
Figure 11. Label-distance from reference set. (Black) all LAMOST DR2 points in ( ,
,  ) space, with (Color) 14,000 objects overlaid, color-coded by their distances from the reference label space. For the test step, we choose objects whose distances are less than 2.5, which amounts to effectively selecting giant stars. The fact that our reference set consists only of giants restricts the applicability of our model to this regime; that is, in this work we only apply the model to the orange points. The structure seen in the lower main sequence is presumably an artifact of the LAMOST analysis.
) space, with (Color) 14,000 objects overlaid, color-coded by their distances from the reference label space. For the test step, we choose objects whose distances are less than 2.5, which amounts to effectively selecting giant stars. The fact that our reference set consists only of giants restricts the applicability of our model to this regime; that is, in this work we only apply the model to the orange points. The structure seen in the lower main sequence is presumably an artifact of the LAMOST analysis.
Download figure:
Standard image High-resolution imageWe define the test set as all LAMOST DR2 objects with a label-distance from the reference set of <2.5. After using the spectral model to infer new labels, we excise objects for which the convergence either failed or resulted in a fit with reduced  > 10 (fewer than 0.1% of the objects). This leaves 444,228 stars (giants), not including the reference set. Figure 12 shows the (
> 10 (fewer than 0.1% of the objects). This leaves 444,228 stars (giants), not including the reference set. Figure 12 shows the ( ,
,  ) plane for 44,000 of these objects (those within the window −0.1 < [Fe/H] < 0.0, chosen simply for clarity). The values measured by The Cannon form a much cleaner and more well-defined red clump and upper giant branch, illustrating the improvement in precision we have achieved by transferring labels from APOGEE.
) plane for 44,000 of these objects (those within the window −0.1 < [Fe/H] < 0.0, chosen simply for clarity). The values measured by The Cannon form a much cleaner and more well-defined red clump and upper giant branch, illustrating the improvement in precision we have achieved by transferring labels from APOGEE.

Figure 12. Precision of the new labels: the ( ,
,  ) plane for the ∼44,000 test objects in a narrow
) plane for the ∼44,000 test objects in a narrow ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn148.gif) window: −0.1 <
window: −0.1 < ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn149.gif) < 0.0. The left panel shows the values from the LAMOST DR2 catalog, as determined by LASP. The right panel shows the values from The Cannon applied to the same spectra. The labels from The Cannon are clearly much more precise and astrophysically plausible, exhibiting a more well-defined red clump and upper giant branch.
< 0.0. The left panel shows the values from the LAMOST DR2 catalog, as determined by LASP. The right panel shows the values from The Cannon applied to the same spectra. The labels from The Cannon are clearly much more precise and astrophysically plausible, exhibiting a more well-defined red clump and upper giant branch.
Download figure:
Standard image High-resolution imageThe newly inferred labels for all of the 444,228 objects, together with the Cannon labels for the reference set and their associated formal uncertainties (from the covariance matrix), are available in a FITS format and an excerpt is shown in Table 1. This table includes the first ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn150.gif) values measured for the full set of LAMOST giants. We note that
values measured for the full set of LAMOST giants. We note that ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn151.gif) has been previously measured for roughly 1% of this sample, using the SEGUE pipeline (Lee et al. 2015). As mentioned previously, this could be done because SEGUE and LAMOST have very similar resolution and wavelength coverage. We emphasize that the approach with The Cannon does not rely on surveys having any overlapping wavelength coverage, or even comparable spectral resolution.
has been previously measured for roughly 1% of this sample, using the SEGUE pipeline (Lee et al. 2015). As mentioned previously, this could be done because SEGUE and LAMOST have very similar resolution and wavelength coverage. We emphasize that the approach with The Cannon does not rely on surveys having any overlapping wavelength coverage, or even comparable spectral resolution.
Table 1.
Stellar Labels ( ,
,  ,
, ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn154.gif) , and
, and ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn155.gif) ) for 454,180 Stars, Inferred by The Cannon Directly from LAMOST Spectra
) for 454,180 Stars, Inferred by The Cannon Directly from LAMOST Spectra
| LAMOST ID |
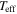
|
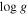
|
![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn158.gif)
|
![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn159.gif)
|
σ(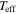 ) ) |
σ(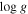 ) ) |
σ(![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn162.gif) ) ) |
σ(![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn163.gif) ) ) |
Red. |
|---|---|---|---|---|---|---|---|---|---|
| (K) | (dex) | (dex) | (dex) | (K) | (dex) | (dex) | (dex) |

|
|
| spec-55859-F5902_sp01-034 | 4899 | 3.15 | −0.597 | 0.207 | 48 | 0.08 | 0.053 | 0.024 | 0.62 |
| spec-55859-F5902_sp01-136 | 5279 | 3.08 | −0.838 | 0.206 | 145 | 0.29 | 0.177 | 0.075 | 0.57 |
| spec-55859-F5902_sp01-202 | 4884 | 3.25 | −0.383 | 0.225 | 36 | 0.06 | 0.040 | 0.016 | 0.82 |
| spec-55859-F5902_sp01-207 | 4882 | 3.43 | −0.252 | 0.186 | 39 | 0.06 | 0.043 | 0.017 | 0.88 |
Note. Column 1 is the unique LAMOST FITS name of the object in the format spec− _
_ –
– , which can be resolved at the LAMOST DR2 website (dr2.lamost.org). Columns 2–5 are the labels from The Cannon, Columns 6–9 are the formal errors on those labels from the covariance matrix in the Cannon model fit, and the final column is the reduced
, which can be resolved at the LAMOST DR2 website (dr2.lamost.org). Columns 2–5 are the labels from The Cannon, Columns 6–9 are the formal errors on those labels from the covariance matrix in the Cannon model fit, and the final column is the reduced  . Note that the reduced
. Note that the reduced  values are low by a factor of ∼3 because the random component of the errors in the LAMOST spectra is overestimated (see Section 4).
values are low by a factor of ∼3 because the random component of the errors in the LAMOST spectra is overestimated (see Section 4).
Download table as: ASCIITypeset image
We further emphasize that at lower temperatures,  ≲ 4250, our model is less reliable, as shown in Figures 6 and 7. Thus, we urge caution when using the catalog for objects in this temperature regime, which is roughly 3% of the sample.
≲ 4250, our model is less reliable, as shown in Figures 6 and 7. Thus, we urge caution when using the catalog for objects in this temperature regime, which is roughly 3% of the sample.
In addition to the formal uncertainties from the covariance matrix, there are a number of sources of uncertainty that we now address. First, the discreteness (that is, the incomplete and sparse coverage) of the reference set induces an uncertainty in the final estimation of the labels. To estimate the strength of this effect, we create 20 different spectral models by bootstrap-sampling from the set of reference objects. For each set, we run the cross-validation as described in Figure 6. A subset of the test set has 20 different label estimates, and we adopt the standard deviation of these measurements to reflect the uncertainties of these new LAMOST labels. With such a large training sample with which to fit the spectral model, the values are negligible: 4.4 K for  , 0.012 dex for
, 0.012 dex for  , 0.0060 dex for
, 0.0060 dex for ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn173.gif) , and 0.0042 dex for
, and 0.0042 dex for ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn174.gif) .
.
Furthermore, there is a contribution from the uncertainties in the labels used to train the model, which we do not account for in this version of The Cannon. Thus, although we only report the formal uncertainty in Table 1, the number is certainly an underestimate. The spread in the cross-validation (see Section 4.1, and Figures 6 and 8) provides an estimate of the uncertainties. It is important to recall, however, that "uncertainty" here is the departure from the APOGEE value. Our goal is to make measurements consistent with the APOGEE scale; we cannot improve upon the accuracy of the reference system.
4.3. The [α/M] Map of the Milky Way from LAMOST
The full astrophysical verification and exploitation of the new set of labels for the LAMOST DR2 giants is beyond the scope of the paper. Here, we give some initial indication of what will be enabled, by showing the (![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn175.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn176.gif) ) plane (Figure 13) and the distribution of
) plane (Figure 13) and the distribution of ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn177.gif) in galactic latitude and longitude (Figure 14) for all LAMOST DR2 giants. This is by far the largest set of giants with the
in galactic latitude and longitude (Figure 14) for all LAMOST DR2 giants. This is by far the largest set of giants with the ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn178.gif) abundance label. As Figure 14 shows, the combination of the two surveys overcomes a limitation of many previous analyses of the abundance-dependent Galactic disk structure (see e.g., Rix & Bovy 2013): most large surveys have either extensive coverage at high Galactic latitudes with sparse sampling in the Galactic plane or vice versa. The distribution in the (
abundance label. As Figure 14 shows, the combination of the two surveys overcomes a limitation of many previous analyses of the abundance-dependent Galactic disk structure (see e.g., Rix & Bovy 2013): most large surveys have either extensive coverage at high Galactic latitudes with sparse sampling in the Galactic plane or vice versa. The distribution in the (![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn179.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn180.gif) ) plane looks very plausible, exhibiting the α-enhanced and the low-α sequences, and the spatial distribution beautifully exhibits the low-alpha, chemically late, young population in the mid-plane and at large radii, and the alpha-enhanced, rapidly enriched, old population in the thick disk (high latitudes) and Galactic center.
) plane looks very plausible, exhibiting the α-enhanced and the low-α sequences, and the spatial distribution beautifully exhibits the low-alpha, chemically late, young population in the mid-plane and at large radii, and the alpha-enhanced, rapidly enriched, old population in the thick disk (high latitudes) and Galactic center.
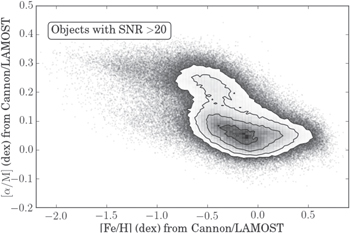
Figure 13. (![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn181.gif) ,
, ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn182.gif) ) plane, showing the labels determined by The Cannon for 305,694 of the 454,180 objects: those with LAMOST spectra S/N > 20. The raw values are shown as grayscale points and the contours (made from logarithmic bins) are at 0.5σ, 1σ, 1.5σ, and 2σ. These are the first
) plane, showing the labels determined by The Cannon for 305,694 of the 454,180 objects: those with LAMOST spectra S/N > 20. The raw values are shown as grayscale points and the contours (made from logarithmic bins) are at 0.5σ, 1σ, 1.5σ, and 2σ. These are the first ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn183.gif) values measured for the full set of LAMOST giants, and by far the largest set of giants with this abundance label. Figure made using code from Foreman-Mackey et al. (2016).
values measured for the full set of LAMOST giants, and by far the largest set of giants with this abundance label. Figure made using code from Foreman-Mackey et al. (2016).
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 14. Distribution on the sky (in Galactic coordinates) of the full set of objects with consistently measured ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn184.gif) : the top panel shows the full APOGEE sample with ≈100,000 objects, and the bottom panel shows these values combined with 454,180
: the top panel shows the full APOGEE sample with ≈100,000 objects, and the bottom panel shows these values combined with 454,180 ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn185.gif) inferred by The Cannon from the LAMOST spectra. The much more extensive area coverage of the LAMOST data is immediately apparent. One can clearly see how the low-α stars, presumably a younger population from more slowly enriched gas, is concentrated toward the mid-plane. The α-enhanced stars, mostly a rapidly enriched, old population, are found in the thick disk and halo (at high latitudes) as well as in the outer Galactic bulge; the arrow on the right denotes the Galactic center. This illustrates the promise of survey label transfer for stitching together a more complete stellar population picture of the Galaxy.
inferred by The Cannon from the LAMOST spectra. The much more extensive area coverage of the LAMOST data is immediately apparent. One can clearly see how the low-α stars, presumably a younger population from more slowly enriched gas, is concentrated toward the mid-plane. The α-enhanced stars, mostly a rapidly enriched, old population, are found in the thick disk and halo (at high latitudes) as well as in the outer Galactic bulge; the arrow on the right denotes the Galactic center. This illustrates the promise of survey label transfer for stitching together a more complete stellar population picture of the Galaxy.
Download figure:
Standard image High-resolution image{kind=link}
As this represents the first (and only) attempt to measure ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn186.gif) for most of these objects, we cannot prove that these values are "correct" in an absolute sense. In particular, we cannot know whether the test set falls within the
for most of these objects, we cannot prove that these values are "correct" in an absolute sense. In particular, we cannot know whether the test set falls within the ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn187.gif) range of the reference set, or whether The Cannon is extrapolating outside the
range of the reference set, or whether The Cannon is extrapolating outside the ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn188.gif) range of the reference set. We do not believe that this is a significant issue, as spectra should be dominated by
range of the reference set. We do not believe that this is a significant issue, as spectra should be dominated by  ,
,  , and
, and ![$[\mathrm{Fe}/{\rm{H}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn191.gif) . This is supported by Figures 13 and 14 and the fact that, in the test step, the model does an excellent job of predicting the spectra as quantified by the low
. This is supported by Figures 13 and 14 and the fact that, in the test step, the model does an excellent job of predicting the spectra as quantified by the low  values and visualized in Figure 10. Our paper stands as the only prediction of this label—and the best one that can be made by The Cannon given the available overlap (training) set. We encourage future observations to test these predictions.
values and visualized in Figure 10. Our paper stands as the only prediction of this label—and the best one that can be made by The Cannon given the available overlap (training) set. We encourage future observations to test these predictions.
In addition, The Cannon is certainly not the only possible way to measure alpha-enhancement values from LAMOST spectra, and this may not be the best measurement possible with The Cannon. In particular, allowing the model to fit for extinction via DIBs in the spectrum may be problematic, because the DIBs are in a different velocity frame from the star. In a future paper, it may be worth exploring masking the DIBs from the spectrum. For now, we simply seek to demonstrate that alpha-enhancement values can be measured from these spectra using a data-driven technique to transfer values from the APOGEE label system. Unlike traditional cross-calibration methods, a method like The Cannon that transfers information from one survey to another does not rely on both survey pipelines measuring a set of parameters; we can measure alpha enhancement despite the fact that the LAMOST pipeline has not attempted to measure those values, because we build a spectral model directly from APOGEE data.
5. Discussion
We have demonstrated that The Cannon can be used to put two spectroscopic stellar surveys with very different experimental setups (wavelength coverage, resolution) onto the same label (stellar parameter and chemical abundance) scale by training a spectral model on the set of objects observed in common between the surveys. We used LAMOST and APOGEE as our example, and showed that we can greatly reduce the systematic differences between labels measured using the two individual survey pipelines. We can also boost the precision of the label estimates for the data set of less resolution and S/N (LAMOST in this case). By training our model to infer APOGEE-scale stellar labels directly from LAMOST spectra, we can also transfer new labels from one survey to another: here we derived ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn193.gif) for the full set of LAMOST giants for the first time.
for the full set of LAMOST giants for the first time.
There are substantial benefits to using The Cannon for label transfer. As described in Ness et al. (2015), The Cannon is very fast: for 9952 objects, on a regular computer, the training step took a few minutes and the test step for 444,228 test objects (i.e., the label determination) took a few hours. In addition, The Cannon requires no physical models and performs well at low S/N and low resolution: in this case, we were able to measure labels of comparable precision to APOGEE (at least, to ASPCAP's stated precision; see Ness et al. 2015) from LAMOST's substantially lower resolution and lower S/N spectra (see Figure 8). Finally, because The Cannon fits for a set of model coefficients independently at each wavelength of the spectrum, there is a straightforward way to investigate the information content of a particular wavelength regime and determine where and how information about a particular label is encoded (see Figure 5).
This label transfer effort was both enabled and severely limited by the reference set. The large number of objects with reliable labels (9952) measured in common between the two surveys enabled us to fit for a spectral model, but the incomplete label coverage restricted the applicability of the model to only 454,180, roughly 20% of the several million LAMOST objects. Furthermore, the quality of the reference labels at low  restricted our ability to reliably model spectra in that regime (see Section 4.1). To take full advantage a data-driven approach like The Cannon, it is essential for surveys to measure objects in common that have high-fidelity labels comprehensively spanning the label space of interest.
restricted our ability to reliably model spectra in that regime (see Section 4.1). To take full advantage a data-driven approach like The Cannon, it is essential for surveys to measure objects in common that have high-fidelity labels comprehensively spanning the label space of interest.
Clearly, The Cannon holds promise for bringing other overlapping surveys onto the same label scale (e.g., RAVE, SEGUE, GALAH, Gaia-ESO). Looking ahead, Gaia will provide a billion low-resolution spectra. By the time these spectra become available, over a million of these objects will have spectroscopic labels determined by much higher-resolution ground-based spectra. This offers a tremendous opportunity for transferring high-quality spectral labels to low-resolution Gaia spectra, if not with the present version of The Cannon then with the basic underlying ideas of data-driven spectral modeling.
It is a pleasure to thank Jo Bovy (U. Toronto), Andy Casey (IoA Cambridge), Morgan Fouesneau (MPIA), Evan Kirby (Caltech), Branimir Sesar (MPIA), and Yuan-Sen Ting (Harvard) for valuable discussions and assistance. A.Y.Q.H. is grateful to the community at the MPIA for their support and hospitality during the period in which most of this work was performed. The authors would like to thank two anonymous referees for their detailed and constructive feedback, which greatly improved the strength and clarity of the paper.
A.Y.Q.H. was supported by a Fulbright grant through the German-American Fulbright Commission and a National Science Foundation Graduate Research Fellowship under grant No. DGE1144469. M.K.N. and H.W.R. have received funding for this research from the European Research Council under the European Union's Seventh Framework Programme (FP 7) ERC Grant Agreement n. [321035]. D.W.H. was partially supported by the NSF (grant IIS-1124794), NASA (grant NNX08AJ48G), and the Moore-Sloan Data Science Environment at NYU. C.L. acknowledges the Strategic Priority Research Program "The Emergence of Cosmological Structures" of the Chinese Academy of Sciences, grant No. XDB09000000, the National Key Basic Research Program of China 2014CB845700, and the National Natural Science Foundation of China (NSFC) grants No. 11373032 and 11333003.
Guoshoujing Telescope (the Large Sky Area Multi-Object Fiber Spectroscopic Telescope LAMOST) is a National Major Scientific Project built by the Chinese Academy of Sciences. Funding for the project has been provided by the National Development and Reform Commission. LAMOST is operated and managed by the National Astronomical Observatories, Chinese Academy of Sciences.
Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS website is www.sdss.org.
SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, the Chilean Participation Group, the French Participation Group, Harvard-Smithsonian Center for Astrophysics, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatory of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University.
Facilities: Sloan (APOGEE spectrograph) - Sloan Digital Sky Survey Telescope, LAMOST - .
After the completion and submission of our paper, Li et al. (2016) also demonstrated that ![$[\alpha /{\rm{M}}]$](https://content.cld.iop.org/journals/0004-637X/836/1/5/revision1/apjaa563aieqn195.gif) can be realiably measured from LAMOST spectra. They developed a technique for this measurement using template matching and an extension of the LAMOST Stellar Pipeline
can be realiably measured from LAMOST spectra. They developed a technique for this measurement using template matching and an extension of the LAMOST Stellar Pipeline
The code used to produce the results described in this paper was written in Python and is available online in an open-source repository: www.github.com/annayqho/TheCannon. An archival copy has been preserved with Zenodo (Ho et al. 2016).