



ABSTRACT
Improving the capabilities of detecting faint X-ray sources is fundamental for increasing the statistics on faint high-z active galactic nuclei (AGNs) and star-forming galaxies (SFGs). We performed a simultaneous maximum likelihood point-spread function fit in the [0.5–2] keV and [2–7] keV energy bands of the 4 Ms Chandra Deep Field South (CDFS) data at the position of the 34,930 CANDELS H-band selected galaxies. For each detected source we provide X-ray photometry and optical counterpart validation. We validated this technique by means of a ray-tracing simulation. We detected a total of 698 X-ray point sources with a likelihood  (i.e., >2.7σ). We show that prior knowledge of a deep sample of optical–NIR galaxies leads to a significant increase in the detection of faint (i.e., ∼10−17 cgs in the [0.5–2] keV band) sources with respect to "blind" X-ray detections. By including previous X-ray catalogs, this work increases the total number of X-ray sources detected in the 4 Ms CDFS, CANDELS area to 793, which represents the largest sample of extremely faint X-ray sources assembled to date. Our results suggest that a large fraction of the optical counterparts of our X-ray sources determined by likelihood ratio actually coincides with the priors used for the source detection. Most of the new detected sources are likely SFGs or faint, absorbed AGNs. We identified a few sources with putative photometric redshift z > 4. Despite the low number statistics and the uncertainties on the photo z, this sample significantly increases the number of X-ray-selected candidate high-z AGNs.
(i.e., >2.7σ). We show that prior knowledge of a deep sample of optical–NIR galaxies leads to a significant increase in the detection of faint (i.e., ∼10−17 cgs in the [0.5–2] keV band) sources with respect to "blind" X-ray detections. By including previous X-ray catalogs, this work increases the total number of X-ray sources detected in the 4 Ms CDFS, CANDELS area to 793, which represents the largest sample of extremely faint X-ray sources assembled to date. Our results suggest that a large fraction of the optical counterparts of our X-ray sources determined by likelihood ratio actually coincides with the priors used for the source detection. Most of the new detected sources are likely SFGs or faint, absorbed AGNs. We identified a few sources with putative photometric redshift z > 4. Despite the low number statistics and the uncertainties on the photo z, this sample significantly increases the number of X-ray-selected candidate high-z AGNs.
Export citation and abstract BibTeX RIS
1. INTRODUCTION
The scientific return of deep X-ray surveys is maximized in those regions of the sky intensively covered by longer wavelength observations. For example, the study of the accretion and star formation processes and their cosmic evolution is routinely performed by combining observations obtained in the X-ray and in the optical and near-infrared bands. It is widely accepted that all bulged galaxies host supermassive black holes (SMBHs) in their centers and that a fraction of them, roughly of the order of a few percent, show some kind of nuclear activity. Luminous X-ray emission is a clear signature of nuclear activity produced in the vicinity of the central black hole (BH). Also, non-active galaxies emit X-ray light at luminosities much lower than those produced by active galactic nuclei (AGNs) due to stellar-driven processes such as accretion onto binaries and supernova remnants. As a consequence, X-ray luminosity is also a probe of star formation rate (SFR, Fabbiano 1989; Ranalli et al. 2005; Mineo et al. 2012; Basu-Zych et al. 2013). Clusters of galaxies, AGNs, and star-forming galaxies (SFGs) are the three main ingredients of the extragalactic cosmic X-ray background (CXB). Chandra and XMM-Newton surveys were able to resolve a large fraction of the extragalactic CXB in discrete sources. The yet unresolved fraction is thought to be made up of a mix of faint SFGs at moderate to high redshifts and low-luminosity AGNs.
The selection of sizable samples of faint AGNs is fundamental to understanding AGN evolution and to constraining models of SMBH formation, especially at high-z. So far, X-ray surveys have sampled the bright end (LX ≥ 1043) of the AGN X-ray luminosity function (XLF) up to z ∼ 5 (see, e.g., Hasinger 2008; Ebrero et al. 2009; Aird et al. 2010; Ueda et al. 2014; Vito et al. 2014; Miyaji et al. 2015). At higher redshifts, only a handful of very bright AGNs powered by massive BHs are known, but the low-luminosity tail of the XLF remains unknown. These "missing" BHs are the key to understanding the mass build-up of SMBHs in the first Gyr of the universe and to improving our understanding of their formation and early evolution. In fact, the mechanism of SMBH formation is still a matter of debate since their growth up to ∼109 M⊙ by z ∼ 7 (Mortlock et al. 2011) cannot be explained by Eddington limited accretion onto ordinary stellar remnant seed BHs in such a short time. This problem can be solved by invoking the formation of massive BH seeds at z ≥ 10 or supercritical accretion episodes (Madau et al. 2014).
Theorists are debating whether the SMBH seeds were formed by the collapse of an early generation of stars (called Population III, POPIII) or from the direct collapse of pristine gas clouds (direct collapse black holes, DCBHs). The endpoint of the evolution of a POPIII star is a ∼101–2 M⊙ BH, whereas a DCBH can easily reach ∼105–6 M⊙ at z ≥ 10 (Yue et al. 2013). Volonteri (2010) predicts that, if the main SMBH seeding mechanism was a DCBH, then the number density of low-luminosity AGNs should rapidly decline at z ≥ 3, whereas if the seeding mechanism was mainly due to POPIII stars, then the number density of low-luminosity AGNs at z ≥ 3 should decline more slowly. Unfortunately there is no direct observational evidence of SMBH seeds, though indirect arguments based on the X-ray and near-IR backgrounds (see, e.g., Kashlinsky et al. 2012; Cappelluti et al. 2013; Yue et al. 2013) or stacking (Treister et al. 2013) suggest that significant progresses may be obtained by a synergic multi-wavelength approach.
By combining Chandra 2 Ms deep X-ray observations (Luo et al. 2008) and optical/near-infrared images in the z, K, and IRAC images in the GOODS-MUSIC field along with F160W data in the Early Release Science region (ERS, Grazian et al. 2011), Fiore et al. (2012) pushed the formal detection limits of the X-ray images at deeper levels using the optical near-infrared images as priors. Giallongo et al. (2015) improved the method outlined above using 4 Ms Chandra data and F160W GOODS images. The optical/near-infrared priors have then been used to select high-redshift (z > 4) AGNs and evaluate their impact on the reionization history of the universe (Giallongo et al. 2015). Pushing the limits of deep Chandra surveys toward ultra-faint fluxes would also allow us to boost the detections of faint (Lehmer et al. 2012) normal (SFG) galaxies, which start to outnumber AGNs around 10−17 erg cm−2 s−1 in the 0.5–2 keV band. The detection of additional very faint X-ray sources and their identification in the optical/NIR may lead to the discovery of moderate redshift (z ∼ 1–2) SFGs and improve the current knowledge of the cosmic evolution of binaries in galaxies. The evolution of SFGs has been mostly determined via stacking of optically selected samples (Basu-Zych et al. 2013). Stacking is a powerful tool, however, the outcomes of these investigations are strongly influenced by the choice of the reference sample. Samples of X-ray-detected SFGs are available only up to z ∼ 1.3 (Mineo et al. 2014), making it difficult to perform a direct determination of their evolution around and beyond the peak of cosmic star formation at z ∼ 2–3. In order to increase these sample sizes, we need to boost our efficiency in detecting faint sources by developing new source detection techniques.
Unfortunately, the sky area sensitive to extremely faint fluxes (and luminosities) is very small and therefore only a handful of faint sources (either high-z AGNs or SFGs) have been detected so far. While we cannot push the flux limit to fainter fluxes, we can develop methods that allow us to increase the efficiency of source detections.
The method described in this paper is conceptually similar to that followed by Giallongo et al. (2015) and originally proposed in Fiore et al. (2012), but differs from standard methods usually adopted in the literature. The most recent and comprehensive discussion is reported in Hsu et al. (2014) where the optical/NIR counterparts are searched within the X-ray positional error box. The method proposed here maximizes the number of CANDELS sources with an X-ray counterpart. The advantage here is that, thanks to the unprecedented depth of WFC3 images (down to mAB ∼ 29–30 in H band), almost all of the counterparts of the X-ray sources are already detected in the CANDELS H-band catalog. In fact, the likelihood that a Chandra source has a counterpart with H magnitude below the detection limit of WFC3 is very low. Moreover, in this paper we take advantage of the superb Chandra angular resolution and astrometric accuracy, which guarantees the capability of associating a very large fraction of X-ray sources with optical/NIR counterparts in Hubble Space Telescope (HST) images (Xue et al. 2011; Civano et al. 2012; Hsu et al. 2014). As mentioned above, a well established method in the literature is to assign a counterpart to the X-ray detection with the likelihood ratio (LR) technique (see, e.g., Ciliegi et al. 2005; Brusa et al. 2007; Civano et al. 2012). Here we employ the LR technique to evaluate the reliability of our source detection, counterpart assignment, and to complement our catalog in the few cases where our method fails. Other authors used a similar approach but validated the associations with a Bayesian analysis (e.g., Hsu et al. 2014). The CDFS/GOODS-S was observed by HST-WFC3/ACS in the Cosmic Assembly Near-Infrared Extragalactic Legacy Survey (CANDELS) which incorporates a wide 0.048 deg2 observation plus the so-called Hubble Ultradeep Field (UDF) and, thanks to its extraordinary sensitivity, reaches H-band depth of mAB ≃ 28 (Guo et al. 2013).
The outstanding quality of the HST CANDELS catalog, combined with the sub-arcsecond angular Chandra resolution, makes it possible to directly perform a point-spread function (PSF) fitting of X-ray data at the position of each HST source.
The overall approach is similar to that pioneered by Fiore et al. (2012), but it benefits from improved detection techniques and homogeneous treatment of the data as well as from extensive simulations. Even though, at the time of this writing, a large fraction of the ultra-deep 7 Ms Chandra observations in the CDFS have been performed, we rely on the 4 Ms data set (Xue et al. 2011, hereafter X11), with a flux limit Slim ∼ 10−17 erg s−1 cm−2 in the 0.5–2 keV (i.e., log(L) = 42.6 erg s−1 at z = 6) since it allows a more robust comparison with published data. The additional observations in the CDFS are used as an a posteriori test.
Throughout the paper we adopt a concordance lambda cold dark matter (Λ-CDM) cosmology with ΩΛ = 0.7, Ωm = 0.3, and H0 = 70  km s−1 Mpc−1. Unless otherwise stated, errors are quoted at the 1σ level.
km s−1 Mpc−1. Unless otherwise stated, errors are quoted at the 1σ level.
2. OBSERVATIONS AND DATA ANALYSIS
The 4 Ms CDFS consists of 23 observations described in Table 1 of Luo et al. (2008) plus another 31 pointings described in X11 for a total exposure of ∼4 Ms. For the purpose of this paper we employed only observations taken with a focal temperature of ≤−120°C since at higher T the background cannot be modeled with our technique (see below). Differently from Luo et al. (2008) and X11, because of higher detector temperature, we discarded Chandra OBS-ID 1431/0-1, ending up with a total exposure time of ∼3.8 Ms.
For every pointing, level 1 data were reprocessed using the chandra_repro software in CIAO and CALDB 4.6.1 released by the Chandra team. Spurious signals from cosmic rays and instrumental features have been removed as well as time intervals with flaring particle background. After cleaning, the effective exposure time is ∼3.6 Ms. Astrometry has been improved by matching a high-significance X-ray source catalog with the Guo et al. (2013) catalog in the H magnitude range 15 < mAB < 23. Images were created in the [0.5–2] and [2–7] keV energy bands, respectively. In the same bands we created exposure maps at effective energies of 1.2 and 3.2 keV, respectively. Both images and exposure maps have a bin size of 0 5. In the same energy bands we created background maps by using the CXC blank fields library. Above 9.5 keV, the mirror effective area of Chandra is basically zero; this means that the events accumulated at those energies are due to noncosmic (particle) interactions with the detector and the satellite. The level of noncosmic flux is variable because of several factors (e.g., solar activity), but its spectral shape is constant in time (Hickox & Markevitch 2006). Thus, in order to obtain a realistic particle background, it is sufficient to rescale the maps in any band by the ratio of the [9.5–12] keV number of events in the templates to the [9.5–12] keV number of events in the real event file (see below for a more detailed treatment).
5. In the same energy bands we created background maps by using the CXC blank fields library. Above 9.5 keV, the mirror effective area of Chandra is basically zero; this means that the events accumulated at those energies are due to noncosmic (particle) interactions with the detector and the satellite. The level of noncosmic flux is variable because of several factors (e.g., solar activity), but its spectral shape is constant in time (Hickox & Markevitch 2006). Thus, in order to obtain a realistic particle background, it is sufficient to rescale the maps in any band by the ratio of the [9.5–12] keV number of events in the templates to the [9.5–12] keV number of events in the real event file (see below for a more detailed treatment).
While precise in estimating the particle background, this method may introduce a bias in the determination of the level of purely cosmic diffuse background. Blank field event files contain a certain level of galactic background. In fact, by construction, blank field files are produced by averaging source-removed event files of extragalactic fields and randomizing the position of the remaining photons in order to remove clustering features of background fluctuations (Cappelluti et al. 2012). The CDFS is a high-latitude field and its background is well approximated in the blank field file library. However, since we assume that the particle background is well modeled by the method described above, the level of galactic and solar system CXB could be over- or underestimated. For that reason, after masking for X11-detected sources, we computed the following quantity

where  (E, d) and
(E, d) and  (E, b) are the total number of CXB photons in the energy band E in the data and in the blank field files in any given pointing, respectively. This quantity, scaled to account for the source's masked area, is the number of over- or underestimated local CXB photons in our maps. The ΔCXB photons are then redistributed across the field of view and the detector according to the energy-dependent exposure map. In this way, we expect a good agreement between the real and the modeled background. A full description of the method can be found in Hickox & Markevitch (2006). The images created with this method suffer from Poissonian random noise and cannot be adopted as background models. For these reasons, the assembled mosaic of background maps has been smoothed by using a Gaussian filter with σ = 20''.
(E, b) are the total number of CXB photons in the energy band E in the data and in the blank field files in any given pointing, respectively. This quantity, scaled to account for the source's masked area, is the number of over- or underestimated local CXB photons in our maps. The ΔCXB photons are then redistributed across the field of view and the detector according to the energy-dependent exposure map. In this way, we expect a good agreement between the real and the modeled background. A full description of the method can be found in Hickox & Markevitch (2006). The images created with this method suffer from Poissonian random noise and cannot be adopted as background models. For these reasons, the assembled mosaic of background maps has been smoothed by using a Gaussian filter with σ = 20''.
3. SOURCE DETECTION WITH cmldetect
Here we briefly summarize our source detection method and the main features of the detection software. We employed a modified version of the XMM-SAS tool emldetect. A description of the algorithm and of the statistical theory behind it can be found in Johnson & Wichern (2007). While several authors have used cmldetect to analyze Chandra surveys (see, e.g., Puccetti et al. 2009; Krumpe et al. 2015), the major step forward here is the employment of WFC3-HST galaxies as priors to improve the efficiency with faint sources and to facilitate the identification process.
This code has been initially developed for ROSAT and XMM-Newton, and it was adapted (Puccetti et al. 2009; Krumpe et al. 2015) for use with Chandra with a customized version of the software cmldetect that makes use of a Chandra PSF-library and the XMM-SAS infrastructure. Unlike the XMM-Newton PSF, the Chandra PSF does not depend exclusively on energy and off-axis angle, but also depends on the azimuthal position. Such a feature cannot be handled by the XMM-SAS infrastructure; thus, in order to allow the software to work with Chandra, we created an ad hoc PSF library by averaging over all the azimuthal angles of the PSF templates in energy and off-axis angle bins. This approximation has been proven effective in several Monte Carlo simulations and on real data within the Chandra COSMOS survey (Puccetti et al. 2009). Moreover, since the geometry of the 4Ms CDFS mosaic is such that the roll angles are basically random, in this way, the azimuthal PSF dependence is smeared out and the approximation adopted in our PSF library carefully represents the real data.
Given an input list of source positions, simultaneous maximum likelihood PSF fits to the event distribution on the detector are performed in all energy bands at the same time. Since the Chandra CDFS 4 Ms observations have aim points separated by <1', we employ the cumulative mosaic image and we fixed the mean pointing position at α = 03h 32m 28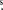 06, δ = −27° 48' 26'' as a reference optical axis.
06, δ = −27° 48' 26'' as a reference optical axis.
The most important fit parameters are the source location, source extent (beta model core radius), and source count rates. Sources with overlapping PSFs are fitted simultaneously. The maximum allowed number of sources that can be fitted simultaneously is limited to 10, and it is ruled by the parameter nmaxfit which sets the maximum number of sources that are considered simultaneously. After some trial, we set nmaxfit = 5 as a compromise between the deblending performance and the computational times, which become impracticable for larger values.
Two parameters determine the image region on which a source fit is performed: ecut determines the size of the sub-image around each source used for fitting and scut determines the radius around each source in which other input sources are considered for multi-PSF fitting. Both ecut and scut are given as encircled energy fractions (EEFs) of the calibration PSF. For our purposes, we fixed ecut = 0.68 scut = 0.9 as in Puccetti et al. (2009).
All detection likelihoods are transformed to equivalent likelihoods  (
( ) (see the XMM emldetect manual15
) corresponding to the case of two free parameters to allow comparison between detection runs with different numbers of free parameters:
) (see the XMM emldetect manual15
) corresponding to the case of two free parameters to allow comparison between detection runs with different numbers of free parameters:

where P is the incomplete Gamma function, n is the number of energy bands involved, ν is the number of degrees of freedom of the fit (ν = 3 + n if task parameter fitextent = yes16
, and ν = 2 + n otherwise), and  where C is the statistics defined by Cash (1979). The equivalent detection likelihoods obey the simple relationship
where C is the statistics defined by Cash (1979). The equivalent detection likelihoods obey the simple relationship

where p is the probability for a random Poissonian fluctuation to have caused the observed source counts. Note that for very small numbers of source counts (less than ≈9 counts, Cash 1979), this relation likely does not hold and thus the low count regime must be tested with ad hoc simulations.
For this work, the input list for cmldetect was made by the positions of the 34,930 CANDELS GOODS-S WFC3 selected sources (Guo et al. 2013) on a total area of 0.048 deg2. The details of the parameters adopted and the properties of the resulting catalogs are described later in Section 5. Here we focus on the detection process and the association with input priors.
As a first step, we fixed the source position (parameter fitposition = no in cmldetect) to the input value, while the source flux was the only free parameter. The fit was performed in the [0.5–2] keV and [2–7] keV energy bands simultaneously. Thus, by construction, the equivalent likelihood from which we set the threshold is that of the [0.5–7] keV band. For our purposes we did not search for extended sources, thus we set fitextent = no. We first apply a preliminary threshold at  whereas the final threshold for the catalog is chosen only after the simulations (see below). Due to PSF blurring, bright sources are observed on several pixels, especially off-axis; the same X-ray source could be the counterparts of several CANDELS galaxies. If there are more than five candidates with our multi-PSF fitting software, it could happen that at the location of bright sources and on their PSF wings, the software could find more detections. If the source is detected with more than 400 counts (i.e., <10% of all the sources in the 4 Ms CDFS; see below), within 90% of the PSF radius we keep only the detection with the higher
whereas the final threshold for the catalog is chosen only after the simulations (see below). Due to PSF blurring, bright sources are observed on several pixels, especially off-axis; the same X-ray source could be the counterparts of several CANDELS galaxies. If there are more than five candidates with our multi-PSF fitting software, it could happen that at the location of bright sources and on their PSF wings, the software could find more detections. If the source is detected with more than 400 counts (i.e., <10% of all the sources in the 4 Ms CDFS; see below), within 90% of the PSF radius we keep only the detection with the higher  and remove the other(s) from the catalog. At lower counts levels, a visual inspection does not show any obvious cases of multiple sources.
and remove the other(s) from the catalog. At lower counts levels, a visual inspection does not show any obvious cases of multiple sources.
Although the astrometry of Chandra is calibrated to be precise within 05, offsets between the X-ray and the near-IR position may exist and lead to additional errors in the determination of the X-ray flux. To verify this effect and to provide the best possible coordinates for the X-ray centroid, we then released the constraints on the position of the X-ray emission by letting cmldetect run with fitposition = yes. In doing so, we realized that the internal structure of cmldetect software loses track of the actual ID of the prior during the multi-source fit within the PSF EEF parameters set by scut and ecut. Since this is crucial information, we had to correct for this effect a posteriori, so by querying the software developer17
and after testing the procedure, we assigned again the source to the prior that is closer to the X-ray centroid. This is not meant to assign a counterpart to the X-ray source, but simply to keep track of the input prior source. However, we have also found that in some cases the revised position of the X-ray centroid is significantly shifted with respect to the position of the original prior. This is shown in Figure 1, where we show the displacement between the best fit and input CANDELS source positions. We note that for ∼80% of the sources the X-ray centroid is consistent with the position of the input source within 1'', although there is a tail at larger offsets (i.e., ≃20% at >10 and <10% at >15).

Figure 1. Left: the separation between the input position and the best fit X-ray centroid in arcseconds., shown in red for sources with  and in blue for those with
and in blue for those with  . Right: the off-axis angle distribution of the sources with an input vs. output position smaller than (blue filled histogram) and larger than (red histogram) 1'' compared to that of the whole sample (black filled histogram).
. Right: the off-axis angle distribution of the sources with an input vs. output position smaller than (blue filled histogram) and larger than (red histogram) 1'' compared to that of the whole sample (black filled histogram).
Download figure:
Standard image High-resolution imageThis effect depends strongly on two quantities: the position in the field and the X-ray intensity. Indeed, as one can notice in the right panel of Figure 1, the majority of the sources with large offset are objects detected at low significance ( ) and at off-axis angles >4'–5' (see Figure 1).
) and at off-axis angles >4'–5' (see Figure 1).
This is not entirely surprising—it is well known that the image quality of the Chandra images on the GOODS-South field degrades significantly at large offset from the center, most notably due to a significant degradation of the PSF, which leads to a lower positional accuracy. It also indicates that the centering of X-ray sources becomes difficult at low signal-to-noise ratio (S/N).
To investigate the origin of this shift, we have visually inspected all the relatively few (≃30) sources that have an offset larger than 1'' but are also detected at good S/N ( ), i.e., those for which the X-ray position can be determined unambiguously. We have verified that in most cases the large shift is due to some error in the determination of the X-ray centroid, usually due to the poor PSF at wide distances from the center (most of these sources are indeed close to the image edges) or to tensions between the position in the soft-X and hard-X images. In nearly all cases, however, the association with the optical prior is robust since the true X-ray center is actually close to the optical center. However, at this stage of the analysis, the association of a prior with an X-ray source should not be considered an identification but simply as a test of the robustness of the procedure.
), i.e., those for which the X-ray position can be determined unambiguously. We have verified that in most cases the large shift is due to some error in the determination of the X-ray centroid, usually due to the poor PSF at wide distances from the center (most of these sources are indeed close to the image edges) or to tensions between the position in the soft-X and hard-X images. In nearly all cases, however, the association with the optical prior is robust since the true X-ray center is actually close to the optical center. However, at this stage of the analysis, the association of a prior with an X-ray source should not be considered an identification but simply as a test of the robustness of the procedure.
To better scrutinize the reliability of our procedure and the origin of possible systematic effects, we have designed a set of simulations and a comparison with other approaches to source detection, which are described in the following sections.
4. CANDELS X-RAY SIMULATIONS
The production of a source catalog requires a deep knowledge of its statistical properties as well as its limitations. In particular, a fundamental property of a catalog is the selection function and the contamination from spurious detections. The best way to evaluate these characteristics is to test the procedure on a sample of simulated sources whose properties are known a priori. Also, carefully simulating the property of the instrument is fundamental to evaluating the quality of the catalog. In this section we present the statistical properties of our catalog as well as validation of the quality of the method.
4.1. Simulated Galaxies and AGN Samples
Detecting X-ray sources using optical/NIR priors is a relatively new procedure (see, e.g., Fiore et al. 2012) which needs specifically designed simulations to validate its photometric accuracy and source detection yield. Every CANDELS galaxy was assigned an X-ray flux and folded into a ray-tracing model of AXAF response to X-rays (MARX) simulation to mimic the Chandra performance. In order to reproduce in a realistic way our mock sample, we created artificial X-ray fluxes of CANDELS galaxies from the estimated L8–1000 μm by using ad hoc scaling relations between LIR and LX (see below). Infrared luminosities (LIR, from 8 to 1000 μm) are predicted for all galaxies in the catalog starting from their observed photometric redshift, their stellar mass (Santini et al. 2014), their UVJ rest-frame colors, and their observed (or extrapolated from the spectral energy distribution (SED)) UV luminosity (1500 Å). We first split our sample into actively star-forming and quiescent galaxies using the UVJ color–color selection (Williams et al. 2009). Quiescent galaxies are given zero LIR. For SFGs, we predict their total SFR assuming that they follow the redshift-dependent SFR–M* correlation, the so-called "main sequence" of SFGs, using the observed relation from Schreiber et al. (2015) and adding a 0.3 dex random scatter, mimicking the observed dispersion of the SFR–M* correlation. We convert the rest-frame UV luminosity into a non-obscured SFR, using the formula introduced in Daddi et al. (2004) and subtract it from the predicted SFR to recover only the dust-obscured component. Finally, we convert this remaining SFR into LIR using the formula of Kennicutt (1998). In order to derive the X-ray luminosity of galaxies, we adopted the prescription of Basu-Zych et al. (2013), which relates z and SFR to LX for SFGs. Galaxies with a predicted [0.5–2] keV flux <10−20 (cgs) were flagged with SX = 0.
A fraction of CANDELS galaxies could be AGNs, which are powerful X-ray sources. In order to include AGN X-ray emission in our sample, we divided the sample into Δ(z) = 0.1 redshift bins and in every bin we assigned an AGN flux (SAGN) to a fraction of galaxies consistent with that expected by the Gilli et al. (2007) population synthesis model down to 10−20 erg s−1 cm−2. We point out that with this method the luminosity function of X-ray AGNs is correctly reproduced, but the random choice of the AGN host galaxy does not allow us to obtain the correct optical/NIR luminosity distribution of the simulated X-ray source counterparts. As a result, we may typically assign AGNs to galaxies that are fainter than the real AGN hosts.
In Figure 2 we show the simulated log N–log S of X-ray sources derived with this method compared with the number counts measured by Lehmer et al. (2012).

Figure 2. Comparison of the simulated [0.5–2] keV cumulative number counts log N–log S for SFGs (red continuous line) and AGNs (blue continuous line) with the measurements of Lehmer et al. (2012) in the CDFS (black filled circles). The total model SFG+AGN is plotted as a black continuous line.
Download figure:
Standard image High-resolution image4.2. Ray-tracing Events Simulation
To simulate the CANDELS X-ray sources we employed the ray-tracing software MARX, which provides a detailed ray-trace simulation of Chandra observations and can generate standard FITS event files and images as output. It reproduces the Chandra mirror system and all focal plane detectors including ACIS-I. The pointing direction, boresight, roll angle, and dithering were reproduced to simulate all the 34,930 CANDELS sources. Every input source was assigned a photon X-ray spectrum modeled as a simple power law with Γ = 1.4 plus galactic absorption with NH = 7 × 1019 cm−2 (Dickey & Lockman 1990) and a normalization derived from its flux. For every galaxy, the software produces the expected number of events as a function of energy by randomly drawing them from their spectral distribution. Every photon has been spread on the detector according to the actual PSF template from calibration at any given energy and radial/azimuthal coordinates. Detector response was reproduced within MARX and pixel randomization was also applied. Dithering of the satellite was also taken into account by using an internal MARX model. Since the software can handle one source and one pointing per run, we produced 54 event files for every galaxy. All the 34,930 source event files simulated over 54 pointings were co-added and reprojected onto the same tangent point. For every pointing, the background in the energy band [E] was estimated with the technique described by Hickox & Markevitch (2006) by randomly extracting events from the blank field background files so that ![${B}_{\mathrm{sim}}[E]=\tfrac{{B}_{d}[9.5\mbox{--}12]}{{B}_{m}[9.5\mbox{--}12]}{B}_{m}[E]$](https://content.cld.iop.org/journals/0004-637X/823/2/95/revision1/apj523523ieqn14.gif) where, Bsim[E] is the number of background events in the energy band [E], Bd[9.5–12] is the number of events in the real data in the [9.5–12] keV energy band, Bm[9.5–12] is the number of events in the blank field event files in the [9.5–12] keV energy band, and Bm[E] is the number of events in the blank field event files in [E] energy bands, respectively. The sources and the background simulations were then merged in a single event file and images were produced.
where, Bsim[E] is the number of background events in the energy band [E], Bd[9.5–12] is the number of events in the real data in the [9.5–12] keV energy band, Bm[9.5–12] is the number of events in the blank field event files in the [9.5–12] keV energy band, and Bm[E] is the number of events in the blank field event files in [E] energy bands, respectively. The sources and the background simulations were then merged in a single event file and images were produced.
4.3. Method Reliability: Source Detection on Simulated Maps
We use these simulations to test the detection procedure and to verify its efficiency. Synthetic images were produced from the simulated event files in the [0.5–2] keV, [2–7] keV, and [0.5–7] keV energy bands with a spatial binning of 05. Similarly, we used the resampled blank field background maps described in Section 4.2 to create background maps in the same energy band and with the same spatial binning as in images. Background maps were smoothed with a Gaussian kernel with σ = 20''. As exposure maps we employed those computed for the real data.
We ran a source detection on the simulated images with the same parameters as the real data. In the real data, in ∼20% of the cases, the actual detected source is found more than 1'' away from the galaxy flagged as a prior. By making use of our simulations, we checked this fraction and found the same result. We first notice that the values of  of most of the detected sources improve significantly by fitting of the position (i.e., by using fitposition = yes compared to fitposition = no). As in the real data, the fraction of sources for which we find a >1'' displacement between the prior and the best fit X-ray centroid shows a strong radial dependency. At off-axis angles <4'–5', the number of such sources is of the order of 5% while, at larger off-axis angles, this fraction is of the order of 30%. Since the only difference between center and off-center in the simulations is the degraded PSF, we conclude that a larger fraction of the X-ray centroids at relatively large off-axis angles is significantly displaced from the priors due to PSF degradation.
of most of the detected sources improve significantly by fitting of the position (i.e., by using fitposition = yes compared to fitposition = no). As in the real data, the fraction of sources for which we find a >1'' displacement between the prior and the best fit X-ray centroid shows a strong radial dependency. At off-axis angles <4'–5', the number of such sources is of the order of 5% while, at larger off-axis angles, this fraction is of the order of 30%. Since the only difference between center and off-center in the simulations is the degraded PSF, we conclude that a larger fraction of the X-ray centroids at relatively large off-axis angles is significantly displaced from the priors due to PSF degradation.
We can use the simulations to verify the accuracy of our procedure in determining the correct prior. This is not straightforward since in our simulations an X-ray flux is assigned to all the SFGs in the input sample. Most of them have fluxes that are very small, definitely below the detection limit, but also non-zero. To take this into account, we used the statistical approach used in Cappelluti et al. (2007), which compares the input and output catalogs of the simulations using the match in both position and flux. We evaluated how many "prior" sources are the actual counterparts of the detected X-ray sources by cross-correlating our output catalog with the input one by minimizing the following quantity (Cappelluti et al. 2007):

where X, Y are the coordinates on the detector and S is the flux in the [0.5–7] keV band, respectively. This estimator is also known as Mahalanobis distance (Johnson & Wichern 2007). The subscripts "in" and "out" stand for input and output catalogs, respectively. As a first result, we find that for ∼2% and ∼8% of the detected sources, on- and off-axis respectively, the actual counterpart is not the prior.
We also tested the accuracy of the photometry: in Figure 3 we show the [0.5–2] keV input versus output counts. As in Puccetti et al. (2009) the output/input counts ratio is consistent with 1 and spread according to a Poissonian distribution. At faint fluxes, the distribution appears to be skewed toward high Cout/Cin ratios because of a sort of Malmqvist bias—i.e., we do not plot objects with a low parameter in Figure 3.

Figure 3. Photometry efficiency test on the simulations. The input vs. output source counts.
Download figure:
Standard image High-resolution imageThese simulations are able to guide us in the choice of a crucial parameter, namely the detection threshold. To this aim, we have to compute the expected number of background fluctuations detected as sources as a function of the detection likelihood  . We did this by running a source detection using a randomized image of the modeled background as the X-ray map and the CANDELS catalog as input. In this way, the number of detections can be considered an estimate of the overall number of spurious detections in the real data. In Figure 4 we show the cumulative distribution of the ratio between the spurious sources detected in these simulations and the real sources detected in the data as a function of the
. We did this by running a source detection using a randomized image of the modeled background as the X-ray map and the CANDELS catalog as input. In this way, the number of detections can be considered an estimate of the overall number of spurious detections in the real data. In Figure 4 we show the cumulative distribution of the ratio between the spurious sources detected in these simulations and the real sources detected in the data as a function of the  parameter. Since the goal of this paper is to push the limit of deep fields beyond the actual one and maximize the detection of faint sources, we estimate that an acceptable spurious fraction should not be higher than 5%, compared to the usually adopted values of ∼1%–2%. This fraction corresponds to values
parameter. Since the goal of this paper is to push the limit of deep fields beyond the actual one and maximize the detection of faint sources, we estimate that an acceptable spurious fraction should not be higher than 5%, compared to the usually adopted values of ∼1%–2%. This fraction corresponds to values  and translates into a minimum flux detection significance of ∼2.7σ (Equation (2)). This is similar to the value reached with blind detections at comparable background levels (Luo et al. 2008; Xue et al. 2011).
and translates into a minimum flux detection significance of ∼2.7σ (Equation (2)). This is similar to the value reached with blind detections at comparable background levels (Luo et al. 2008; Xue et al. 2011).

Figure 4. Fraction of spurious detections in the GOODS-S field as a function of the detection likelihood as determined by our Monte Carlo simulations in the [0.5–7] keV band.
Download figure:
Standard image High-resolution imageFinally, we checked whether the simulated background carefully represents the actual level. In fact, we know that the real background fluctuations (Cappelluti et al. 2012) are not randomly distributed, but are strongly correlated. However, the simulated background is relatively smooth and uniform and this could introduce a bias in the spurious fraction estimate. For that reason, we performed a source detection on the real data masked for the detected sources according to the PSF size at the source location. The umasked part of the image can be considered a fair estimate of the real background. We then produced a catalog of 34,930 positions drawn from the real catalog by randomly placing the artificial sources in an annulus with inner and outer radii 5''–10'' from the real prior sample of sources, respectively. In this way we preserve the spatial distribution of the CANDELS sources in the input catalog, but we do not overlap real sources. We then ran our source detection on this masked image by using the random sample described above as the input catalog. We repeated this procedure 20 times. All these detections are nothing but random background fluctuations which would enter the catalog as spurious sources. The results found with this test are fully consistent with those obtained with the randomized background images.
We then computed the selection function of our detection procedure by evaluating the ratio of the number of retrieved input sources with respect to that of input ones in bins of intrinsic input flux of  = 0.1. The resulting cumulative histogram is smoothed with a filter width of
= 0.1. The resulting cumulative histogram is smoothed with a filter width of  S = 0.3. The final sky coverage is shown in Figure 5. Note that here we present the sky coverage with respect to the intrinsic (and not the detected) flux of the X-ray sources.
S = 0.3. The final sky coverage is shown in Figure 5. Note that here we present the sky coverage with respect to the intrinsic (and not the detected) flux of the X-ray sources.

Figure 5. Sky area vs. input flux selection function plot for our sample in two sub-bands compared with that of Lehmer et al. (2012). The red and the blue continuous lines represent the selection functions in the [0.5–2] keV and [2–7] keV energy bands, respectively. The red dashed and the blue dashed lines represent the selection functions from Lehmer et al. (2012) in the [0.5–2] keV and [2–7] keV energy bands, respectively. Hard-band fluxes have been extrapolated to [2–10] keV fluxes.
Download figure:
Standard image High-resolution imageThe results are compared with those of Lehmer et al. (2012) obtained with a Bayesian method for flux calculation and for blind X-ray source detection in the CDFS. As expected, the faintest recovered sources detected with the two methods have a similar flux, but our method yields a steeper selection function at faint fluxes. As an example, in the [0.5–2] keV band, with a threshold  (see below) in the faintest fractions of a decade of fluxes our method can recover about a factor of five more sources. This is particularly evident in the [0.5–2] keV energy band, but not so much in the [2–7] keV band. This is due to the fact this method takes advantage of the highest angular resolution of Chandra at low energies.
(see below) in the faintest fractions of a decade of fluxes our method can recover about a factor of five more sources. This is particularly evident in the [0.5–2] keV energy band, but not so much in the [2–7] keV band. This is due to the fact this method takes advantage of the highest angular resolution of Chandra at low energies.
In summary, in this work we have explored the advantages of using a prior-based search for X-ray sources in the GOODS-South field, issuing the cmldetedct software. This evidence allows us to draw the first conclusions about the quality of this method: (a) at off-axis angles <4', for 98% of the sources the prior galaxy is likely to be the counterpart of the X-ray source, (b) at off-axis angles >4' (i.e., if the PSF HEW > 15), the prior sources and the relative detected X-ray sources are significantly displaced in 20% of the cases, but for 92% of the sources, the prior galaxy is likely to be the counterpart of the X-ray source, (c) the source detection quality is improved by fitting the position of the X-ray centroid, and (d) using a deep optical catalog as a prior increases the probability of detecting a faint X-ray source compared with that of a blind detection based on background fluctuations. To some extent, the limitations in this approach are certainly due to the complex nature of the X-ray data in the CDFS area, which degrade at large distances from the center. However, some of these limitations can be due to the specific performances of cmldetect, which was not originally designed to be used in this way. In future works we plan to adapt other prior-based software for photometry (such as T-PHOT, Merlin et al. 2015) to the case of X-ray data.
5. X-RAY CATALOG ASSEMBLY
Armed with the results of the simulations described above, we have obtained the final catalog in the GOODS-South field. In this section, we summarize the procedure finally adopted and the comparison with other approaches.
5.1. The Prior-based Catalog
We run the source detection on the 4 Ms CDFS data [0.5–2] keV and [2–7] keV bands simultaneously and the likelihood is computed in the [0.5–7] keV band. We used the positions of the 34,930 sources detected by Guo et al. (2013) in the CANDELS GOODS-S area as the input catalog and set fitposition = no and we imposed a  = 4.98 threshold in the resulting [0.5–7] keV energy band. In this way we preselected 735 sources, some of which corresponded to the same X-ray source. We then fitted the position of the sources to determine the best possible X-ray centroid of each detected source. At this threshold, we detected 698 unique sources in the ∼0.048 deg2 of the CANDELS GOOD-S area analyzed by Guo et al. (2013). We considered only point sources and we did not fit the extension of the sources. Sources falling within the region of groups/clusters detected by Finoguenov et al. (2015) were visually inspected individually. For every source, we determined the source counts and the count rate as an output of the detection algorithm, the background level, the PSF 90% EEF, and the
= 4.98 threshold in the resulting [0.5–7] keV energy band. In this way we preselected 735 sources, some of which corresponded to the same X-ray source. We then fitted the position of the sources to determine the best possible X-ray centroid of each detected source. At this threshold, we detected 698 unique sources in the ∼0.048 deg2 of the CANDELS GOOD-S area analyzed by Guo et al. (2013). We considered only point sources and we did not fit the extension of the sources. Sources falling within the region of groups/clusters detected by Finoguenov et al. (2015) were visually inspected individually. For every source, we determined the source counts and the count rate as an output of the detection algorithm, the background level, the PSF 90% EEF, and the  in the [0.5–2] keV, [2–7] keV and [0.5–7] keV energy bands, respectively. Count rates were converted into fluxes by assuming a simple power-law spectrum with Γ = 1.4 plus a Galactic absorption NH = 7 × 1019 cm−2 (Dickey & Lockman 1990). The energy conversion factors (ECFs) were computed with the online tool Chandra PIMMS. The response of the ACIS-I detector varied significantly across the Chandra lifetime; for this reason, we computed the ECFs for every pointing's epoch and then weight-averaged them according to the exposure time. As a result, we obtained a count rate to flux ECF of 5.32 × 10−12 erg cm−2 in the [0.5–2] keV band and 2.71 × 10−12 erg cm−2 to convert the [2–7] keV count rate into a [2–10] keV flux. The full band count rate, counts, and fluxes are the sums of those in the two sub-bands, respectively. As mentioned above, the overall significance of the detection is measured with the cumulative [0.5–7] keV energy band net counts, thus for some sources the parameters in the [0.5–2] keV, [2–7] keV sub-bands may not be accurate. For this reason, the fluxes of the sources for which the sub-band detection has a significance lower than the threshold (
in the [0.5–2] keV, [2–7] keV and [0.5–7] keV energy bands, respectively. Count rates were converted into fluxes by assuming a simple power-law spectrum with Γ = 1.4 plus a Galactic absorption NH = 7 × 1019 cm−2 (Dickey & Lockman 1990). The energy conversion factors (ECFs) were computed with the online tool Chandra PIMMS. The response of the ACIS-I detector varied significantly across the Chandra lifetime; for this reason, we computed the ECFs for every pointing's epoch and then weight-averaged them according to the exposure time. As a result, we obtained a count rate to flux ECF of 5.32 × 10−12 erg cm−2 in the [0.5–2] keV band and 2.71 × 10−12 erg cm−2 to convert the [2–7] keV count rate into a [2–10] keV flux. The full band count rate, counts, and fluxes are the sums of those in the two sub-bands, respectively. As mentioned above, the overall significance of the detection is measured with the cumulative [0.5–7] keV energy band net counts, thus for some sources the parameters in the [0.5–2] keV, [2–7] keV sub-bands may not be accurate. For this reason, the fluxes of the sources for which the sub-band detection has a significance lower than the threshold ( 4.98) in the specific sub-band should be used with care. Although all the sources have
4.98) in the specific sub-band should be used with care. Although all the sources have  in the [0.5–7] keV band, we report 534 and 285 significant detections in the [0.5–2] keV and [2–7] keV energy bands, respectively. We define these sources as N(
in the [0.5–7] keV band, we report 534 and 285 significant detections in the [0.5–2] keV and [2–7] keV energy bands, respectively. We define these sources as N( 4.98) in Table 1. Among these, 352 sources are detected in the [0.5–2] keV but not in the [2–7] keV band, 106 sources in the [2–7] keV but not in the [0.5–2] keV, and only 61 sources have a significant detection in the [0.5–7] keV energy band and no significant counterpart in the sub-bands N(
4.98) in Table 1. Among these, 352 sources are detected in the [0.5–2] keV but not in the [2–7] keV band, 106 sources in the [2–7] keV but not in the [0.5–2] keV, and only 61 sources have a significant detection in the [0.5–7] keV energy band and no significant counterpart in the sub-bands N( 4.98). In Table 1 we briefly summarize the properties of the X-ray catalog presented here.
4.98). In Table 1 we briefly summarize the properties of the X-ray catalog presented here.
Table 1. Number of Detections
| [0.5–2] keV | [2–7] keV | [0.5–7] keV | |
|---|---|---|---|
N( 4.98) 4.98) |
531 | 285 | 698 |
n( 4.98) 4.98) |
352 | 106 | 61 |
| N(X11) | 466 | 254 | 527 |
| N(X11+C15) | * | * | 784 |
| Slim | 0.11 | 0.87 | 0.89 |
Note. From top to bottom:  is the actual number of significant detections in the three energy bands,
is the actual number of significant detections in the three energy bands,  is the number of sources significantly detected in a given energy band only (plus the full band), N(X11) is the number of X11 significant detections in the three energy bands, N(X11 + C15) is the total number of unique X-ray sources detected in the CANDELS GOODS-S area by X11 and in this work, and Slim is the flux limit in each band in units of ×10−16 erg cm−2 s−1. "*" means not applicable.
is the number of sources significantly detected in a given energy band only (plus the full band), N(X11) is the number of X11 significant detections in the three energy bands, N(X11 + C15) is the total number of unique X-ray sources detected in the CANDELS GOODS-S area by X11 and in this work, and Slim is the flux limit in each band in units of ×10−16 erg cm−2 s−1. "*" means not applicable.
Download table as: ASCIITypeset image
5.2. The Comparison with Previous Catalogs
In the same area, X11 detected 527 X-ray sources by using the same X-ray data set. They used a purely blind X-ray detection without prior knowledge of the actual counterparts. Among these, 466, 254, and 527 are detected in the [0.5–2] keV, [2–7] keV, and [0.5–7] keV bands, respectively (N(X11) in Table 1). A simple positional match between the two catalogs with a 2'' matching radius returns 443 sources in common: 252 detected with our method only and 85 detected only by X11. In Figure 7 we show the distribution of the distances between the X-ray centroids found here and those of X11: the average shift is ∼05. By merging our catalog with that of X11 we bring the total number of X-ray-detected sources in the CANDELS-GOOD-S area to 784.
As a safety check we cross-matched the counterpart catalog of Hsu et al. (2014) with ours for the 443 sources in common with X11. If we consider all the sources with a secure association in our catalog, we find the same association in 90% of the cases. Three quarters of the remaining have an off-axis angle >4'. The likely reason for this discrepancy is the different method used for the X-ray centroid estimate: our method versus the completely different method adapted by Hsu et al. (2014) for assigning the counterpart to the X-ray sources. We compared the fluxes properties of the 443 sources in common with those presented by X11. In Figure 6 we show the comparison of the [0.5–2] keV fluxes measured by us and those of X11. There is very good agreement between the measurements, and the mean of the ratio of the two measurements is ∼0.98. Our count rate to flux conversion (which uses a fixed spectral slope) is different from that of X11, who used a spectral index obtained from the hardness ratio for each source. This leads to an intrinsic dispersion in the two measurements that has no clear trend with flux.

Figure 6. [0.5–2] keV fluxes measured here compared with those of X11 for the common above-threshold sources.
Download figure:
Standard image High-resolution image
Figure 7. Angular separation between the 443 sources in common with the catalog of X11.
Download figure:
Standard image High-resolution imageWe also checked the 85 sources detected by X11 only. Among them, 62 have been detected by our software, but with  , thus they did not satisfy the selection criterion for being included in the catalog. The remaining 28 unmatched sources are all at the very faint limit of their catalog. Therefore, 28/571 X11 sources are not found with our method even at
, thus they did not satisfy the selection criterion for being included in the catalog. The remaining 28 unmatched sources are all at the very faint limit of their catalog. Therefore, 28/571 X11 sources are not found with our method even at  3. We can explain this small fraction of "missed" sources with statistical fluctuations among the two catalogs or, alternatively, they could belong to the sample of extended sources (see, e.g., Finoguenov et al. 2015).
3. We can explain this small fraction of "missed" sources with statistical fluctuations among the two catalogs or, alternatively, they could belong to the sample of extended sources (see, e.g., Finoguenov et al. 2015).
We also performed a visual inspection of the newly detected sources in this paper with the public deeper observations in the CDFS. At the time of this writing, ∼5.9 Ms of data are available in the archive. Among the 698 sources detected in this work, only a handful of very faint objects seem to be undetected by visual inspection. Their number is consistent with the expected spurious fraction (5%).
5.3. Validation of the Prior Matching
As we have shown above, our method potentially suffers from some uncertainties, as shown by the relatively large fraction of objects that are detected at large distances from the priors, especially for faint sources at off-axis angles >4'. According to our simulations, a fraction of the detected X-ray sources may not be associated with the input prior at large off-axis angles.
It is therefore interesting to explore the more traditional technique for identifying counterparts of X-ray sources without priors, namely the LR technique of Sutherland & Saunders (1992). We followed the procedure of Brusa et al. (2005, 2007) adapted for Chandra by Civano et al. (2012). For a given candidate counterpart with magnitude m at a distance r from the X-ray source, the likelihood ratio LR is defined as the ratio between the probability that the source is the correct identification and the corresponding probability for a background, unrelated object  , where q(m) is the expected magnitude m distribution function of the real optical counterpart candidates, f(r) is a two-dimensional Gaussian probability distribution function (PDF) of the positional errors, and n(m) is the surface density of background objects with magnitude m. The distribution of the local background objects, n(m), was computed from each of the three input catalogs using the objects within a 5''–10'' annulus around each X-ray source. We chose a 5'' inner radius in order to avoid the presence of true counterparts in the background distribution and a 10'' outer radius to exclude the counterparts of other nearby X-ray sources.
, where q(m) is the expected magnitude m distribution function of the real optical counterpart candidates, f(r) is a two-dimensional Gaussian probability distribution function (PDF) of the positional errors, and n(m) is the surface density of background objects with magnitude m. The distribution of the local background objects, n(m), was computed from each of the three input catalogs using the objects within a 5''–10'' annulus around each X-ray source. We chose a 5'' inner radius in order to avoid the presence of true counterparts in the background distribution and a 10'' outer radius to exclude the counterparts of other nearby X-ray sources.
The function q(m) has been estimated from our data as follows. We first computed q'(m) = [number of sources with magnitude m within 3''] – [expected number of background sources with magnitude m in a 3'' circle]. The choice of a 3'' radius is dictated by the requirement of maximizing the statistical significance of the overdensity around the X-ray sources. A smaller radius would include in the analysis only a fraction of the true identifications and the q(m) distribution would be more affected by Poissonian noise. A larger radius would increase the number of background sources.
As extensively described in Brusa et al. (2007), with this procedure, q(m) is underestimated at faint magnitudes. At fainter magnitudes, the number density of CANDELS sources within the search radius of each X-ray source is artificially smaller than that expected from the whole sample n(m). The reason for this biased estimate is the presence of a large number of moderately bright CANDELS counterparts within the X-ray centroids. These sources could occupy a non-negligible fraction of the X-ray counterpart search area, making it difficult to detect faint background objects. Such a bias would produce an unrealistic negative q(m), which would prevent us from using the LR procedure at faint magnitudes. In order to correctly estimate n(m) at faint magnitudes, we have randomly extracted from the CANDELS catalog 1500 NIR sources with the same expected magnitude distribution of the X-ray source counterparts. Then we computed the background surface density around these random samples of galaxies. Indeed, we found that the n(m) computed in this way is consistent with the first measured n(m) at F160W < 24.5 and much smaller than it at faint magnitudes. Therefore, the input n(m) in the likelihood procedure was the global one for F160W < 24.5 and that derived with this analysis for F160W > 24.5. This allowed us to associate several very faint counterparts with X-ray sources that would have been missed without this adjustment to the procedure. In Figure 8, we show the observed magnitude distribution of the objects in the 1.6 μm catalog within a radius of 3'' around each X-ray source (solid histogram), plotted together with the expected distributions of background objects in the same area (red solid histogram). The smoothed difference between these two distributions is the expected distribution of the counterparts (q'(m), black curve) before normalization. The q(m) is obtained by normalizing q'(m) to 1.

Figure 8. Top: the black solid histogram is the magnitude distribution of all the Guo et al. (2013) sources within 3'' from our X-ray centroids. The red solid histogram is the expected background magnitude distribution of sources in an annulus with an inner radius of 5'' and an outer radius of 10'' from the X-ray source. The blue dashed histogram is the resulting, non-normalized, q(m) distribution adopted to compute the LR. The black continuous line is the adopted q(m).
Download figure:
Standard image High-resolution imageFor the probability distribution of positional errors, f(r), we adopted a Gaussian distribution with standard deviation,  , where σopt is the positional uncertainty for the optical sources that we assumed to be 01 for all the sources. σX was set to RADEC_ERR, which is the error in the centroid provided by cmldetect. The RADEC_ERR in our catalog spans from ∼01 to ∼15 We also added a 025 systematic (half Chandra pixel) to take into account pixelation effects. Having determined the values of q(m), f(r), and n(m), we computed the LR value for all the sources within 3'' of the 698 X-ray centroids. As in Civano et al. (2012) and Brusa et al. (2005) we had to choose the best likelihood threshold value (Lth) for LR to discriminate between spurious and real identifications. Lth must be small enough to avoid missing too many real identifications so that the completeness of the sample is high and large enough to keep the number of spurious identifications low and increase the identification reliability. Extensive simulations indicate that the trade-off is obtained for R = C ∼ 0.89 corresponding to Lth = 0.75. As a result, 698 sources have at least a counterpart within the search radius but only for 608 does the association pass the LR test. With this threshold, 529 X-ray sources have 1 significant counterpart with LR > Lth, 74 have 2, and 9 have 3 counterparts, respectively. For 90 sources we do not have a significant counterpart association and they are flagged with FLAG_ASSOC = 2 in the catalog. However, in many cases, having multiple counterparts does not imply that the identification is not secure. In order to resolve multiple associations, we computed the distribution of the LR among the possible counterparts of the same X-ray source (Civano et al. 2012).
, where σopt is the positional uncertainty for the optical sources that we assumed to be 01 for all the sources. σX was set to RADEC_ERR, which is the error in the centroid provided by cmldetect. The RADEC_ERR in our catalog spans from ∼01 to ∼15 We also added a 025 systematic (half Chandra pixel) to take into account pixelation effects. Having determined the values of q(m), f(r), and n(m), we computed the LR value for all the sources within 3'' of the 698 X-ray centroids. As in Civano et al. (2012) and Brusa et al. (2005) we had to choose the best likelihood threshold value (Lth) for LR to discriminate between spurious and real identifications. Lth must be small enough to avoid missing too many real identifications so that the completeness of the sample is high and large enough to keep the number of spurious identifications low and increase the identification reliability. Extensive simulations indicate that the trade-off is obtained for R = C ∼ 0.89 corresponding to Lth = 0.75. As a result, 698 sources have at least a counterpart within the search radius but only for 608 does the association pass the LR test. With this threshold, 529 X-ray sources have 1 significant counterpart with LR > Lth, 74 have 2, and 9 have 3 counterparts, respectively. For 90 sources we do not have a significant counterpart association and they are flagged with FLAG_ASSOC = 2 in the catalog. However, in many cases, having multiple counterparts does not imply that the identification is not secure. In order to resolve multiple associations, we computed the distribution of the LR among the possible counterparts of the same X-ray source (Civano et al. 2012).
If such a ratio is larger than the median (LRmax/LRi), then we define the association as secure. In other cases the association is flagged (FLAG_ASSOC = −1) as ambiguous and the CANDELS ID number of all the candidate counterparts is listed in the catalog in LR order. Secure identifications are flagged with FLAG_ASSOC = 1. After this procedure we have 552 secure identifications, 56 ambiguous ones (double to triple), 90 are not secure identifications, and 3 are unidentified (likely spurious X-ray detections). In Table 2 we summarize the results of our identification procedure. As expected, we observe that the fraction of ambiguous and unsecure identifications increases with the off-axis angle.
Table 2. Results of Our LR Identification Procedure
| Class | Number | % |
|---|---|---|
| Secure | 552 | 79.1% |
| Ambiguous | 56 | 8.0% |
| Not secure | 90 | 12.9% |
Download table as: ASCIITypeset image
In Figure 9 we show the distribution of the distance between the X-ray centroid and the best counterpart in the CANDELS catalog. This distribution peaks at ∼025 and sharply declines down to 2''.

Figure 9. Distribution in arcseconds of the distances between the X-ray centroid and the optical counterpart for secure identifications.
Download figure:
Standard image High-resolution imageWe can finally compare the results of the prior-based photometry with this LR technique. We find that the results are nicely consistent. Indeed, 545/552 (∼98.7%) of the secure identifications are associated with the input prior CANDELS ID and 43/57 in the case of ambiguous sources. We note that this comparison cannot be performed for 90/698 sources, i.e., 13% of the sources, for which the LR does not yield any result.
We point out that the majority of the sources for which the counterpart is flagged as not secure and is not coincident with the prior are found, on average, with  and at large off-axis angles; thus they also have broad PSFs. In particular, at off-axis angles <4', the fraction of sources for which the counterpart is not the prior is <1%, whereas at off-axis angles >4', this is ∼9%. We added a flag, FLAG_PRIOR, which has value of 1 for off-axis angles <4', or
and at large off-axis angles; thus they also have broad PSFs. In particular, at off-axis angles <4', the fraction of sources for which the counterpart is not the prior is <1%, whereas at off-axis angles >4', this is ∼9%. We added a flag, FLAG_PRIOR, which has value of 1 for off-axis angles <4', or  10, and 2 for off-axis angles >4',
10, and 2 for off-axis angles >4',  10. If FLAG_PRIOR = 1, one can safely use the prior source as the actual counterpart. Otherwise, one should check if the results of the LR yield another counterpart. In our simulations the AGN X-ray flux is randomly assigned to a CANDELS galaxy; thus we could not test the LR because the AGN magnitude distribution was the same as that that of background sources. If a source with no prior was simulated, it would not be detected; however, the only source of potential errors is the high probability that a source is detected by chance given a random prior within ecut. To evaluate this, we performed the following test. To avoid contamination by bright sources, we selected 1847 prior candidates within 4'' of the 500 faintest detected sources. From that catalog, we removed the sources that we identified as "BEST_ID" and ran the source detection on 455 of them which had more than one counterpart. We removed a posteriori from the 1847 input sources the actual counterpart of each X-ray source and ran the source detection. As a result, we have detected only 169/455 detections above the threshold with
10. If FLAG_PRIOR = 1, one can safely use the prior source as the actual counterpart. Otherwise, one should check if the results of the LR yield another counterpart. In our simulations the AGN X-ray flux is randomly assigned to a CANDELS galaxy; thus we could not test the LR because the AGN magnitude distribution was the same as that that of background sources. If a source with no prior was simulated, it would not be detected; however, the only source of potential errors is the high probability that a source is detected by chance given a random prior within ecut. To evaluate this, we performed the following test. To avoid contamination by bright sources, we selected 1847 prior candidates within 4'' of the 500 faintest detected sources. From that catalog, we removed the sources that we identified as "BEST_ID" and ran the source detection on 455 of them which had more than one counterpart. We removed a posteriori from the 1847 input sources the actual counterpart of each X-ray source and ran the source detection. As a result, we have detected only 169/455 detections above the threshold with  4.98. For these sources, the recovered X-ray centroid is consistent with that obtained with the master prior catalog. We repeated the LR test and for 99.5% of the secure matches, the best candidate was still BEST_ID. While an evaluation of ecut is not straightforward, we note that the sources not detected by this test are, as expected, those whose priors had distances from the X-ray centroid that were larger than or similar to ecut.
4.98. For these sources, the recovered X-ray centroid is consistent with that obtained with the master prior catalog. We repeated the LR test and for 99.5% of the secure matches, the best candidate was still BEST_ID. While an evaluation of ecut is not straightforward, we note that the sources not detected by this test are, as expected, those whose priors had distances from the X-ray centroid that were larger than or similar to ecut.
5.4. Catalog Column Descriptions
Our catalog is available in machine readable format at http://www.astrodeep.eu/data/ and on VizieR (http://cds.u-strasbg.fr). Here we describe the columns in the online catalog.
- NID: ID of the X-ray source.
- PRIOR_ID: CANDELS ID of the optical source used as the prior for the X-ray source detection.
- FLAG_PRIOR: flag to determine the reliability of the association with a prior.
- BEST_ID: CANDELS ID of the primary optical counterpart of the X-ray source from LR.
- SECOND: CANDELS ID of the second best optical counterpart of the X-ray source from LR.
- FLAG_ASSOC: quality of the identification flag.
- RA_X: best fit R.A. in decimal degree units of the X-ray centroid.
- DEC_X: decl. in decimal degree units of the X-ray centroid.
- RADEC_ERR: 1D error on the X-ray centroid position (arcseconds).
- SEP: distance from the best optical counterpart.
- SCTS_FULL: [0.5–7] keV counts.
- SCTS_FULL_ERR: 1σ [0.5–7] keV counts error.
- SCTS_SOFT: [0.5–2] keV counts.
- SCTS_SOFT_ERR: 1σ [0.5–2] keV counts error.
- SCTS_HARD: [2–7] keV counts.
- SCTS_HARD_ERR: 1σ [2–7] keV counts error.
 _FULL: -ln(p) determined in the [0.5–7] keV band.
_FULL: -ln(p) determined in the [0.5–7] keV band.- _SOFT: -ln(p) determined in the [0.5–2] keV band.
- _HARD: -ln(p) determined in the [2–7] keV band.
- FLUX_FULL:[0.5–10] keV flux in erg cm−2 s−1 in units 10−16.
- FLUX_FULL_ERR 1σ :[0.5–10] keV flux error in erg cm−2 s−1 in units 10−16.
- FLUX_SOFT:[0.5–2] keV flux in erg cm−2 s−1 in units 10−16.
- FLUX_SOFT_ERR 1σ :[0.5–2] keV flux error in erg cm−2 s−1 in units 10−16.
- FLUX_HARD: [2–10] keV flux in erg cm−2 s−1 in units 10−16.
- FLUX_HARD_ERR 1σ :[2–10] keV flux error in erg cm−2 s−1 in units 10−16.
- RATE_FULL:[0.5–7] keV count rate in ph cm−2 s−1.
- RATE_FULL_ERR 1σ :[0.5–7] keV count rate error in ph cm−2 s−1.
- RATE_SOFT:[0.5–2] keV count rate in ph cm−2 s−1.
- RATE_SOFT_ERR 1σ :[0.5–2] keV count rate error in ph cm−2 s−1.
- RATE_HARD:[2–7] keV count rate in ph cm−2 s−1.
- RATE_HARD_ERR 1σ :[2–7] keV count rate error in ph cm−2 s−1.
- HR1: hardness ratio.
- HR1_ERR: hardness ratio error.
- OFFAX: off-axis angle in arcminutes.
- RA_OPT: best fit R.A. in decimal degree units of the best CANDELS counterpart.
- DEC_OPT: decl. in decimal degree units of the best CANDELS counterpart.
- m160: F160W AB magnitude.
- Spec_z: spectroscopic redshift from Santini et al. (2014).
- Photo_z: photometric redshift from Santini et al. (2014).
- Photo_z_H: photometric redshift from Hsu et al. (2014).
- X11: source ID in X11.18
- H14: source ID in Hsu et al. (2014).



6. GENERAL PROPERTIES OF THE X-RAY SAMPLE
Here we present a preliminary overview of the properties of newly detected X-ray sources; a more complete analysis will be presented in a forthcoming dedicated paper. In the upper left panel of Figure 10 (left), we show the [0.5–10] keV flux of our detections versus the F160W magnitude of their counterparts for the whole sample and for the new detected sources. As expected, the new sources are fainter than the whole sample, and the brightness distribution of their counterparts peaks at fainter magnitudes. In particular, the whole sample of counterparts has  = 23.1, whereas for the new sources,
= 23.1, whereas for the new sources,  = 24.3.
= 24.3.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 10. Top left panel: the S0.5–10 vs. the F160W AB magnitude for the whole sample (black open circles) and for new sources (red open circles). The inset shows the F160W AB magnitude distribution for the whole sample (black histogram) and for new sources (red histogram). Top right panel: the S0.5–10 vs. HR for the whole sample (black open circles) and for new sources (red open circles). The horizontal dashed lines represent the expected HR for a power-law spectrum with varying spectral index Γ = −0.5–2.5 from top to bottom. The green filled circles are the average HR in ΔLog(S) = 0.25 flux bin for the whole sample, and the blue filled circles are the same for new sources. Lower left panel: the photo-zdistribution for the whole sample (black filled histogram) and for new sources (red filled histogram) compared with the fiducial redshift distribution of X11 (blue filled histogram). Lower right panel: photo-z vs. L0.5–10 for the whole sample (black open circles) and for new sources (red open circles).
Download figure:
Standard image High-resolution image{kind=link}
In the upper right panel of Figure 10 we show the X-ray colors as a function of the [0.5–10] keV flux. The X-ray color, or hardness ratio, is defined as HR =  , where H and S are the count rates in the [2–7] keV and [0.5–2] keV energy bands, respectively.
, where H and S are the count rates in the [2–7] keV and [0.5–2] keV energy bands, respectively.
The whole sample has an average hardness ratio of ∼−0.1 (green points) corresponding to a power-law spectrum with photon index  = 1.4 The new sources have a slightly harder average hardness ratio
= 1.4 The new sources have a slightly harder average hardness ratio  ∼ 0.0–0.5 (blue points). This difference, although marginally significant, suggests that the new population may include a large number of obscured AGNs.
∼ 0.0–0.5 (blue points). This difference, although marginally significant, suggests that the new population may include a large number of obscured AGNs.
The luminosities of the low-redshift sources are as low as 1040 erg s−1 (see the bottom right panel of Figure 10), indicating that the bulk of the z < 1 population is due to star-forming galaxies and low-luminosity obscured AGNs.
An updated catalog of X-ray sources detected in the CDFS with blind standard methods was recently assembled (Hsu et al. 2014), merging various catalogs: X11, Luo et al. (2008), Virani et al. (2006), and Rangel et al. (2013). In the CANDELS area, 11 sources were not detected by Hsu et al. (2014) (all of them in X11). Out of 11 sources, six are recovered in our catalog. As a consequence, the Hsu et al. (2014) catalog contains 5 sources that were not detected either by us or X11. Therefore, the total number of bonafide X-ray sources in the CANDELS GOODS area is 789.
Finally, we cross-correlated our catalog with the photo-z catalog presented by Santini et al. (2014). In the lower left panel of Figure 10 we show the photo-z distribution for the new and old X-ray source populations compared with that of X11. Such a catalog has been derived by computing the weighted average of the PDFs obtained by several teams using galaxy templates. This could be a problem for some of our sources since their powerful X-ray emission indicates AGN activity and therefore a nuclear contamination of the SED. For these sources the photo-z may not be reliable; however, since Hsu et al. (2014) measure the photo-z by including AGN contamination in the fit, we included their photo-z for the sources in common. We note that the bulk of our new X-ray sources lie at z ∼ 1–3 and, remarkably, we find 9 highly reliable (FLAG_ASSOC = 1) candidates with photo-z ≥ 4, 2 with spec-z ≥ 4 (and photo-z < 4) and another 4 with photo-z ≥ 4 but FLAG_ASSOC = 2 in the CANDELS catalog. We point out that source NID = 624, detected on the tail of a bright off-axis X-ray source, could be a spurious detection. Eight of them are in common with the X11 and Giallongo et al. (2015) catalogs. In Table 3 we report all the high-z candidates and mark those already detected by Giallongo et al. (2015) and X11. The high-z candidates are likely to be AGNs with luminosities of the order of 1043−43.5 erg s−1. Another source in common with Giallongo et al. (2015) is CANDELS ID = 29323 (NID = 495) with photo-z = 9.73, however, the photo-z of this source is dominated by artifacts in the SED and it is not reported in Table 3. The high-z candidate sources that are not in common with Giallongo et al. (2015) and X11 are in general (except one, NID624) faint and just above the threshold. Interestingly, Giallongo et al. (2015) detected more (22) candidate z > 4 X-ray sources; this is apparently in contrast with our findings. We searched our raw catalog, which includes sources down to  = 3, and retrieved 17/22 sources within 2'' from our X-ray centroid. Although found at low threshold, with our method we cannot exclude at a significance level of ∼95% that these sources (at least in this band) are background fluctuations at the position of CANDELS galaxies. Therefore, we can explain such a discrepancy with the fact that the two methods adopt different thresholds and different energy bands. In fact, whereas we used standard energy ranges, Giallongo et al. (2015) chose the energy band that could maximize the S/N. The analysis of the full Chandra data set, known as the 7 Ms, will provide further clues and will be the subject of a future investigation. Finally, we want to point out that in the catalog of Hsu et al. (2014), none of our seven high-z candidates in common with theirs has a photo-z > 4. Although this requires a deeper investigation, a similar result was found by Weigel et al. (2015) who did not find any z > 5 source in the same area.
= 3, and retrieved 17/22 sources within 2'' from our X-ray centroid. Although found at low threshold, with our method we cannot exclude at a significance level of ∼95% that these sources (at least in this band) are background fluctuations at the position of CANDELS galaxies. Therefore, we can explain such a discrepancy with the fact that the two methods adopt different thresholds and different energy bands. In fact, whereas we used standard energy ranges, Giallongo et al. (2015) chose the energy band that could maximize the S/N. The analysis of the full Chandra data set, known as the 7 Ms, will provide further clues and will be the subject of a future investigation. Finally, we want to point out that in the catalog of Hsu et al. (2014), none of our seven high-z candidates in common with theirs has a photo-z > 4. Although this requires a deeper investigation, a similar result was found by Weigel et al. (2015) who did not find any z > 5 source in the same area.
Table 3. Candidate z > 4 X-Ray Sources Based on Photo-z
| NID | PRIOR_ID | FLAG_ASSOC |

|
FLUX_FULL | Spec_z | Photo_z | Photo_z_H | X11 |
|---|---|---|---|---|---|---|---|---|
| 624a | 28496 | 1 | 52.09 | 1.39 × 10−15 | −9.0 | 6.045 | −99.0 | −99 |
| 306 | 4760 | 2 | 7.54 | 6.32 × 10−17 | −9.0 | 5.78 | −99.0 | −99 |
| 295b | 20765 | 1 | 9.38 | 5.73 × 10−17 | −9.0 | 5.229 | 2.6389 | 521 |
| 341 | 25825 | 2 | 5.78 | 3.48 × 10−16 | −9.0 | 5.145 | −99.0 | −99 |
| 216b | 19713 | 1 | 9.81 | 8.01 × 10−17 | −9.0 | 4.842 | 3.0113 | 392 |
| 572b | 4356 | 1 | 66.05 | 8.66 × 10−16 | −9.0 | 4.703 | 1.7139 | 485 |
| 599b | 16822 | 1 | 230.46 | 9.09 × 10−16 | −9.0 | 4.521 | 3.2327 | 371 |
| 59 | 4466 | 1 | 5.59 | 2.23 × 10−17 | −9.0 | 4.498 | −99.0 | −99 |
| 510b | 273 | 2 | 8.90 | 5.91 × 10−16 | 4.762 | 4.488 | 0.1374 | 403 |
| 272 | 14537 | 1 | 5.25 | 1.33 × 10−16 | −9.0 | 4.331 | −99.0 | −99 |
| 400 | 24833 | 1 | 5.47 | 2.84 × 10−16 | −9.0 | 4.079 | −99.0 | −99 |
| 575 | 24636 | 2 | 28.07 | 6.68 × 10−16 | −9.0 | 4.054 | 3.699 | 602 |
| 238 | 4209 | 1 | 8.69 | 6.63 × 10−17 | 4.724 | 3.123 | −99.0 | −99 |
| 571 | 23382 | 1 | 31.88 | 7.93 × 10−16 | 4.379 | 2.294 | 2.4261 | 534 |
Notes.
aPossibly spurious source on the tail of a bright off-axis X-ray source. bSource detected by Giallongo et al. (2015) and Fiore et al. (2012).Download table as: ASCIITypeset image
7. CONCLUSION AND SUMMARY
In this paper we have presented a new X-ray source catalog in the GOODS-S area based on the 4 Ms Chandra CDFS data. For the first time we produced a catalog with both a maximum likelihood PSF fitting technique based on prior HST galaxy detections as well as an "a posteriori" LR test to confirm the association. The method is tested through extensive Monte Carlo ray-tracing simulations using state-of-the-art knowledge of the SFR–LX scaling relation for SFGs and AGN population synthesis models for the CXB.
In this paper we developed and tested a technique based on optical/near-IR priors to fully exploit the deep observations in the Chandra Deep Field South. The detection of faint X-ray sources at the limit of the Chandra capabilities is based on two approaches. Recently, thanks to ultra-deep multi-wavelength surveys with HST, such as CANDELS, combined with the high angular resolution of Chandra, some authors proposed using the entire three-dimensional data cube (position and energy) and searching for X-ray counts at the position of high-z galaxies in the GOODS-South survey, assuming that the angular resolution of Chandra is good enough to accurately locate the position of the X-ray sources.
These approaches complement the previously widely adopted one based on either wavelets (see, e.g., X11) or PSF fitting (Puccetti et al. 2009) of candidate sources selected among the most significant background fluctuations. The X-ray selected samples are then matched with optical/NIR catalogs and the actual counterpart of the X-ray sources are assigned using the LR techniques, which balances the distance source/counterpart and the underlying magnitude distribution of the counterparts.
Here we applied both methods to the X-ray 4Ms data of the GOODS-South region. We first performed a PSF fitting on a sample of HST-WFC3-selected galaxies down to a magnitude limit where we reasonably expect to identify most of the X-ray source counterparts. Our results, validated by simulations, indicate that by using priors, we can detect objects down to a lower likelihood threshold than in previous works. As a result, we end up increasing the number of faint source detections (Figures 4 and 5).
We also performed an LR analysis using well established techniques to associate the detected sources with the optical catalog. The overall result is that through the LR test, we can confirm that among the ∼83% of sources for which a secure match is found, at off-axis angles <4', the counterpart determined by the LR is coincident with the prior in ∼99% of the cases. This fraction drops to 92%–93% at larger off-axis angles. The prior is the actual counterpart of the identified sources, on average, in 96% of the cases. This observational finding is confirmed by extensive simulations. For the remaining 17% (i.e., 90 not secure, 14 ambiguous, and 7 secure for which the prior and the LR counterpart do not match), we cannot draw any conclusions on the identity of the counterpart.
After fitting the X-ray centroid, the LR test suggests that the use of priors ensures the detection of the correct counterpart in at least 87% of cases. For the remaining 13%, the X-ray centroid is significantly displaced from the optical source or the objects are at large (>4') off-axis angles. Although it is not always possible to firmly associate HST and Chandra sources without running an LR analysis, we note that at least for sources with FLAG_ASSOC = 1 that the counterpart is coincident with the prior in 98% of the cases if we consider the inner portion of the field of view θoff-axis < 4'. At larger off-axis angles, this fraction drops to 92%.
Our method significantly improves the efficiency in the detection of faint X-ray sources in deep X-ray surveys by taking advantage of the precise HST positions. Indeed, 257 new X-ray sources are discovered down to a flux of ∼1(8) × 10−17 erg cm−2 s−1 in the [0.5–2] keV ([0.5–10] keV) energy band.
The final catalog contains 698 X-ray sources selected in the [0.5–7] keV energy range. Five hundred fifty-two have a secure match with the CANDELS catalog. By cross-matching the current catalog with those published in the literature we were able to estimate that the number of unique X-ray sources in the CANDELS GOODS-S area sums 789. Based on photo-z and a few spectro-z sources with high-redshifts z > 4, 15 candidate AGN are identified. Six of them are in common with results from Giallongo et al. (2015), and the counterparts of 4 FLAG_ASSOC = 2 sources are ambiguous. Although the discrepancy with previous results (Giallongo et al. 2015) can be explained as due to different approaches and thresholds adopted, we conclude that the actual number of X-ray selected AGNs at z > 5 remains very sensitive to the details of the analysis and ultimately needs deeper and better data to be robustly measured. Also, since other authors using different approaches obtain different results than those reported in the official catalog (e.g., Hsu et al. 2014; Weigel et al. 2015), we want to point out that a discussion of the photo-z quality included in our catalog is beyond the scope of this paper and it will be discussed elsewhere.
Indeed, the method presented and extensively discussed in this paper may be obviously extended to many other X-ray surveys where deep optical/NIR HST ancillary data are available and may significantly boost the legacy value of these programs. We point out that the most rewarding scientific return of the method is obtained if it is applied to surveys designed to have a constant PSF and a sharp core, such as the COSMOS Legacy and the UDS Chandra fields.
N.C. acknowledges the Yale University YCAA Prize Postdoctoral Fellowship program. We acknowledge the contribution of the EC FP7 SPACE project ASTRODEEP (Ref. No: 312725). ASTRODEEP is a FP7-funded, coordinated and comprehensive program of (i) algorithm/software development and testing, (ii) data reduction/release, and (iii) scientific data validation/analysis aimed at making Europe the world leader in the exploitation of the deepest multi-frequency astronomical survey data. N.C. acknowledges Marcella Brusa and Francesca Civano for discussions about the LR technique. N.C. thanks Roberto Gilli and Cristian Vignali for insightful discussions. N.C. also thanks Mara Salvato for discussions about photo-z quality and Hermann Brunner for his valuable assistance with cmldetect. J.S.D. acknowledges the support of the European Research Council through the award of an Advanced Grant. N.C. kindly acknowledges M.M. Lozio for useful discussions. We especially thank the anonymous referee for the useful comments that significantly improved this paper.
Facilities: HST (WFC3) - Hubble Space Telescope satellite, CXO (ACIS) - Chandra X-ray Observatory satellite.
Footnotes
- 15
- 16
If fitextent = yes, the sources are also fitted with a convolution of beta or Gaussian profiles with the PSF and if the likelihood obtained is significantly larger than that obtained with the PSF only, the source is classified as extended.
- 17
H. Brunner (2016, private communication).
- 18
Sources in the X11 supplementary catalog have been number with their ID+1000.