
Abstract
The quantum Boltzmann machine (QBM) is a generative machine learning model for both classical data and quantum states. Training the QBM consists of minimizing the relative entropy from the model to the target state. This requires QBM expectation values which are computationally intractable for large models in general. It is therefore important to develop heuristic training methods that work well in practice. In this work, we study a heuristic method characterized by a nested loop: the inner loop trains the β-variational quantum eigensolver (β-VQE) by Liu et al (2021 Mach. Learn.: Sci. Technol.2 025011) to approximate the QBM expectation values; the outer loop trains the QBM to minimize the relative entropy to the target. We show that low-rank representations obtained by β-VQE provide an efficient way to learn low-rank target states, such as classical data and low-temperature quantum tomography. We test the method on both classical and quantum target data with numerical simulations of up to 10 qubits. For the cases considered here, the obtained QBMs can model the target to high fidelity. We implement a trained model on a physical quantum device. The approach offers a valuable route towards variationally training QBMs on near-term quantum devices.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The study of quantum information technologies has shown to be a fruitful discipline for the discovery of novel algorithms and computing applications. It is expected that quantum algorithms will outperform their classical counterparts on several tasks of practical relevance, such as factoring large prime numbers and simulating quantum many-body systems. Over the last decade, scientists have been exploring if quantum algorithms can also offer advantages in machine learning. While this has been answered in the affirmative [1, 2], the theoretical performance benefits will materialize only when large-scale fault-tolerant quantum computers become available.
In the context of near-term quantum computing, a plethora of variational quantum algorithms (VQAs) for machine learning tasks have been investigated [3–5]. In VQAs, one solves the computational problem by choosing an ansatz, typically a parameterized quantum circuit, and then optimizes its parameters with respect to a suitable objective function. Applications of VQAs include finding ground states of small molecules, combinatorial optimization, classification, and generative modeling.
In this paper, we continue this line of research and propose a VQA for training quantum Boltzmann machines (QBMs) [6, 7]. QBMs are generative models inspired by quantum Ising models and can be used for both classical and quantum data. In QBM training, the goal is to find the weights of a Hamiltonian ansatz, such that its thermal state best approximates the target density matrix [8, 9]. The QBM training depends on the ability to prepare and compute properties of a thermal state, which is intractable in general [10]. It is therefore key to develop efficient heuristic methods that work well in practice; indeed, even classical Boltzmann machines are intractable and must be trained by efficient heuristics such as contrastive divergence [11]. In this work, we employ the recently proposed β-variational quantum eigensolver [12] (β-VQE) to approximate the QBM properties.
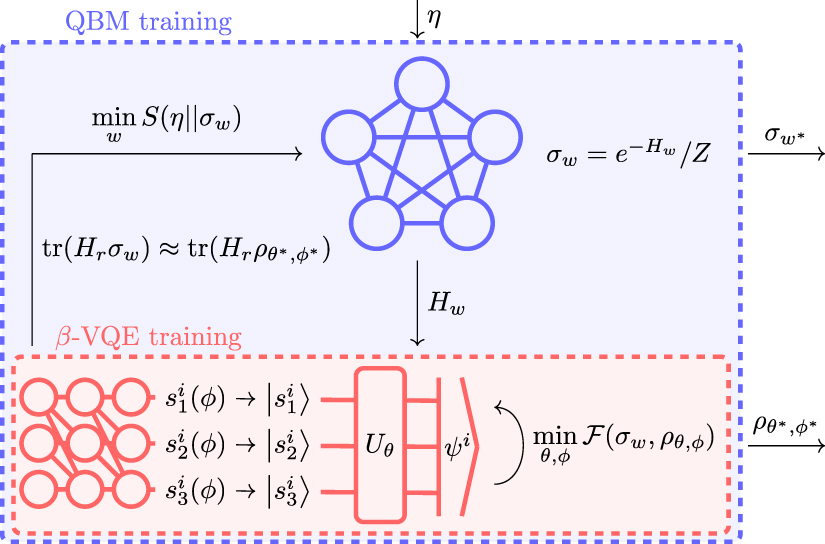
β-VQE represents a mixed density matrix as a combination of a classical probability distribution and a parameterized quantum circuit. Computational basis states are randomly sampled and used as input for the circuit, where they are transformed into quantum states. β-VQE has been experimentally demonstrated on a superconducting quantum computer [13]. The purpose of our work is to provide evidence that β-VQE can be successfully exploited for the training of QBMs on classical and quantum data sets to high accuracy. The algorithm is illustrated in figure 1 along with some empirical statevector simulation results on a classical data set.

Figure 1. Illustration of the nested-loop algorithm for QBM training. In the outer loop (blue box) we optimize the quantum relative entropy S from the QBM model σw
to the target η. This step utilizes an approximation to the QBM statistics,  , which is provided by the inner loop (red box). In the inner loop we optimize the variational free energy
, which is provided by the inner loop (red box). In the inner loop we optimize the variational free energy  of the β-VQE ansatz
of the β-VQE ansatz  with the QBM Hamiltonian Hw
. At the end of training, we output the QBM model and its β-VQE approximation.
with the QBM Hamiltonian Hw
. At the end of training, we output the QBM model and its β-VQE approximation.
Download figure:
Standard image High-resolution imageSeveral other techniques have been proposed for QBM training: quantum annealing [7], variational imaginary time evolution [14], the eigenstate thermalization hypothesis [15], pure thermal shadows [16], and others [17, 18]. Most of these approaches have not been demonstrated as they require a fault-tolerant quantum computer [15–18]. On the other hand, the few approaches that have been demonstrated on real hardware [7, 14] incur a significant overhead in terms of ancilla qubits. Remarkably, the approach studied here is near-term and uses the same number of qubits as the number of variables in the data set. We deploy our trained model by preparing and sampling it on IBM Kolkata device.
We equip the algorithm with additional features and rules of thumb that reduce the overall computational cost. Firstly, it is possible to use a limited number of computational basis states in β-VQE, yielding a low-rank approximation. We provide evidence that this is especially useful for classical target data. Secondly, since small updates in parameter space during QBM training lead to small steps in density matrix space, we introduce a natural warm-start strategy for β-VQE. We observe that warm-start yields faster convergence, possibly avoiding barren plateaus [19] by keeping the solution close to a local minimum at all times. Finally, we find that a circuit depth scaling linearly with the system size is sufficient to get accurate results. For the dataset we use, the β-VQE approximation resulted in a difference in fidelity of  compared QBM training using the exact gradient, regardless of system size, suggesting that this method is scalable.
compared QBM training using the exact gradient, regardless of system size, suggesting that this method is scalable.
2. Methods
2.1. Quantum Boltzmann machines
The QBM [6, 7] is defined as the n-qubit Gibbs state (mixed density matrix)

with  the partition function, β > 0 the fixed inverse temperature and Hw
a parameterized Hamiltonian. In this work, we consider Hamiltonians of the form
the partition function, β > 0 the fixed inverse temperature and Hw
a parameterized Hamiltonian. In this work, we consider Hamiltonians of the form

which consists of a sum of a polynomial number of non-commuting qubit-operators Hr with weights wr . The specific form of the operators Hr does not matter at this point and will be given in the result section below. The quantum Hamiltonian Hw generalizes the role of the energy function in a classical Boltzmann machine [20].
In order to find the optimal weights  , we aim to minimize the quantum relative entropy
, we aim to minimize the quantum relative entropy

from σw
to the target density matrix η [8, 9]. This information-theoretic measure generalizes the classical Kullback–Leibler divergence to density matrices and has nice properties for the QBM model ansatz, e.g. the logarithm cancels the exponential in equation (1). The target η is either some quantum system with unknown Hamiltonian Ht
at finite temperature, i.e.  , or a classical data set embedded into a quantum state.
, or a classical data set embedded into a quantum state.
The optimization of  can be done with gradient descent. By noticing that only the second term in equation (3) depends on wr
, and using Duhamel's formula for the derivative of a matrix exponential [21], we obtain the partial derivatives
can be done with gradient descent. By noticing that only the second term in equation (3) depends on wr
, and using Duhamel's formula for the derivative of a matrix exponential [21], we obtain the partial derivatives

Similar to the classical case [20], the gradient is given by the difference between statistics under the data density matrix η and the model density matrix σw . The data statistics do not change during training and need to be obtained only once. However, the QBM statistics change after every iteration of gradient descent and must be recomputed. The QBM density matrix σw in equation (1) is given by the matrix exponential of the Hamiltonian, whose dimension scales exponentially in the number of qubits. This means that computing the full density matrix becomes computationally intractable for larger system sizes.
While the classical BM has the same exponential scaling of the number of states, there exist several approximation algorithms that can effectively compute the necessary statistics, often based on Markov-chain Monte Carlo [22]. However, for quantum systems, no general MCMC methods exist due to the negative sign problem for non-stoquastic models [23, 24]. Since the QBM is not restricted to the stoquastic domain and can include spin-glass models, quantum Monte Carlo is not an option in general. In the following section, we review the β-VQE method that with help of a quantum computer can be used to potentially circumvent this issue.
2.2. Classical data embedding
The QBM can be trained on classical and quantum data. Since classical data is not naturally represented in density matrices, the data is embedded in a quantum system. There are various ways to do this. We use the pure-state embedding presented in [9]. From a classical data set  , the empirical probability distribution is constructed counting the relative occurrence of each binary vector in the data,
, the empirical probability distribution is constructed counting the relative occurrence of each binary vector in the data,  . We create a pure quantum state representation from the empirical distribution by mapping the n-dimensional binary vector
s
i
to a spin-
. We create a pure quantum state representation from the empirical distribution by mapping the n-dimensional binary vector
s
i
to a spin- system with n particles. Each 1 in
s
i
corresponds with a particle in the spin-up state
system with n particles. Each 1 in
s
i
corresponds with a particle in the spin-up state  and each 0 to a particle in spin-down state
and each 0 to a particle in spin-down state  in the σz
basis. Let:
in the σz
basis. Let:

The quantum state is obtained by taking the superposition of all spin states corresponding to the binary vectors with coefficients equal to  , i.e.
, i.e.  . The density matrix embedding is then constructed by taking the outer product of this state,
. The density matrix embedding is then constructed by taking the outer product of this state,

2.3. β-VQE
Recently, Liu et al [12] proposed a variational method to represent a mixed density matrix called β-VQE. It combines a classical network with a quantum circuit (figure 1) into a parameterized density matrix ansatz given by

Here  is a parameterized probability distribution over binary states implemented by a classical network, e.g. a parameterized Bernoulli distribution or an autoregressive network [25]. The binary states are then used as inputs for a parameterized quantum circuit Uθ
, which transforms them into quantum states. The combined system
is a parameterized probability distribution over binary states implemented by a classical network, e.g. a parameterized Bernoulli distribution or an autoregressive network [25]. The binary states are then used as inputs for a parameterized quantum circuit Uθ
, which transforms them into quantum states. The combined system  can accurately represent finite-temperature Gibbs states of quantum spin systems, e.g. see [12]. Here we aim to see if it can be used for the wide range of Hamiltonians needed to train the QBM on quantum and classical data.
can accurately represent finite-temperature Gibbs states of quantum spin systems, e.g. see [12]. Here we aim to see if it can be used for the wide range of Hamiltonians needed to train the QBM on quantum and classical data.
The optimal parameters of  for a fixed QBM Hamiltonian Hw
are found by minimizing the variational free energy
for a fixed QBM Hamiltonian Hw
are found by minimizing the variational free energy

This is equivalent to minimizing the quantum relative entropy from σw
to  . The minimization can be done with gradient descent on the classical network and quantum circuit parameters simultaneously. The required gradients [12] are given by
. The minimization can be done with gradient descent on the classical network and quantum circuit parameters simultaneously. The required gradients [12] are given by

for the circuit, and

for the classical network. Here we used a control variate to reduce the variance as in [12]:  and
and  . For quantum gates of the form
. For quantum gates of the form  where G is a Pauli operator, the gradient w.r.t. the circuit parameters, equation (9), reduces to a parameter shift rule: a weighted sum of energy expectation values [26]. Suppose the circuit is a product of L such gates, i.e.
where G is a Pauli operator, the gradient w.r.t. the circuit parameters, equation (9), reduces to a parameter shift rule: a weighted sum of energy expectation values [26]. Suppose the circuit is a product of L such gates, i.e.  . Then
. Then

where for convenience,  and
and  .
.
Computation of the gradient is tractable on a quantum computer if the sum is approximated by sampling a polynomial number of bitstrings from pφ (s), and if there is no barren plateau in the optimization landscape [19]. The gradient w.r.t. the parameters of the classical network, equation (10), has the form of a standard weighted entropy gradient, which for classical networks can be efficiently approximated from sampling [27].
2.4. Truncated-rank β-VQE
We propose a slight modification of the sampling approach for the gradients originally presented in [12]. Instead of randomly sampling from all computational basis states, we choose the R states with the highest probability and renormalize pφ on those states. This results in a β-VQE density matrix of rank R

In the following, we refer to this as truncated-rank β-VQE. As an immediate consequence, the gradients for the variational free energy equations (9) and (10) are also truncated for this model. This means that we can heuristically choose a small R so that the optimization can be performed at a reduced computational cost.
2.5. Training QBMs with the nested-loop algorithm
We now describe the nested-loop algorithm to train a QBM with a truncated rank β-VQE. Recall that the aim is to train the QBM so that it resembles some target data embedded in η. This is schematically shown in figure 1. The algorithm starts with a simple ansatz for the QBM Hamiltonian Hw
, e.g. a Heisenberg XXZ model or a random spin-glass model. In the inner loop, the β-VQE ansatz  is trained to represent the QBM σw
by minimizing equation (8). In the outer loop,
is trained to represent the QBM σw
by minimizing equation (8). In the outer loop,  is used to compute approximate QBM statistics
is used to compute approximate QBM statistics  . These are used for training the QBM by gradient descent with equation (4).
. These are used for training the QBM by gradient descent with equation (4).
Since Hw
changes only slightly between two QBM iterations, we use a warm-start strategy for the parameters  of the β-VQE ansatz
of the β-VQE ansatz  between the steps of the outer loop. We reuse the converged parameters of
between the steps of the outer loop. We reuse the converged parameters of  in one β-VQE inner loop as the initial parameters for the next β-VQE inner loop. Hence, while the β-VQE has to run for a relatively long time in the first inner loop, we find that it converges much faster in subsequent iterations.
in one β-VQE inner loop as the initial parameters for the next β-VQE inner loop. Hence, while the β-VQE has to run for a relatively long time in the first inner loop, we find that it converges much faster in subsequent iterations.
The total number of statistic estimations of the nested-loop algorithm is of order

Here nQBM is the number of QBM iterations for convergence to some fixed accuracy,  the number of β-VQE iterations, R the rank of the β-VQE, and nθ
the number of circuit parameters.
the number of β-VQE iterations, R the rank of the β-VQE, and nθ
the number of circuit parameters.
3. Numerical results
Using the nested-loop algorithm, we train QBMs on both classical and quantum data. We use the Hamiltonian ansatz

where w and  are weights, and
are weights, and  is the n-qubit Pauli operator acting on qubit i. We initialize the weights randomly from a normal distribution with mean 0 and standard deviation
is the n-qubit Pauli operator acting on qubit i. We initialize the weights randomly from a normal distribution with mean 0 and standard deviation  . The weights are trained in the outer loop using gradient descent with a momentum parameter
. The weights are trained in the outer loop using gradient descent with a momentum parameter  .
3
The ansatz taken for Hw
determines the precise models that the QBM can represent. Not every state in the Hilbert space can be represented by this ansatz. Therefore, there might be target data that can not be exactly modeled. We define this as a model mismatch.
.
3
The ansatz taken for Hw
determines the precise models that the QBM can represent. Not every state in the Hilbert space can be represented by this ansatz. Therefore, there might be target data that can not be exactly modeled. We define this as a model mismatch.
For the β-VQE, we implement the classical network pφ
with a variational auto-encoder (VAE) [25] made of a hidden layer of 50 neurons. For the quantum circuit Uθ
, we use a checkerboard pattern of general SU(4) unitaries with periodic boundary conditions. One layer of this ansatz is shown in figure 2(a). Each SU(4) unitary is implemented via a decomposition into CNOT gates and single-qubit rotations following [28]. This is illustrated in figure 2(b). We define the circuit depth d as the number of repetitions of such a layer. This gives a total number of circuit parameters  . We determine the optimizer settings, e.g. the learning rate, for each target data set separately, and give them below. As the stopping criterion for the inner loop, we use a target precision ε on the β-VQE gradient (equations (9) and (10)). In addition, we also set a maximum number of iterations
. We determine the optimizer settings, e.g. the learning rate, for each target data set separately, and give them below. As the stopping criterion for the inner loop, we use a target precision ε on the β-VQE gradient (equations (9) and (10)). In addition, we also set a maximum number of iterations  for the inner loop, in order to avoid very long convergence times. To quantify the model performance, we compute the Uhlmann-Jozsa fidelity between the QBM and the target state, given by
for the inner loop, in order to avoid very long convergence times. To quantify the model performance, we compute the Uhlmann-Jozsa fidelity between the QBM and the target state, given by

This fidelity satisfies all of Jozsa's axioms, described in [29]. Importantly, fidelity is an intensive property, as opposed to the quantum relative entropy. Thus it is a useful measure for comparing performance on different system sizes.

Figure 2. Parameterized quantum circuit used for the β-VQE. (a) shows a single layer of a four-qubit ansatz. It consists of a checkerboard pattern of general SU(4) unitaries with periodic boundary conditions. (b) The SU(4) unitaries are implemented as three CNOT gates and 15 single-qubit rotations. This is a special case of the decomposition given in figure 2 of [28].
Download figure:
Standard image High-resolution imageBy means of classical statevector simulations, we show that with these settings we are able to train QBMs to high accuracy on both classical and quantum data. Afterward, we train a small QBM using noisy and noise-free quantum simulators of real quantum hardware and sample the final QBM on the real device.
3.1. Classical data results
The classical data we consider in this paper is introduced in [30]. A patch of 160 connected ganglion cells from the salamander retina is connected to a multi-electrode array, where the activity of multiple neurons is recorded simultaneously. The ganglion cells are then exposed to 297 repeats of a movie. Every timeframe of 20 ms, the activity for each neuron is recorded and denoted by a 1 (spike) or a 0 (no spike), resulting in a binary vector of size 160 for each time frame. Each iteration of the movie consists of 953 timeframes.
We selected subsets of the ganglion cells with high mutual information (MI). This selection procedure is described in detail in appendix  , resulting in a set of
, resulting in a set of  binary vectors. Other iterations of the movie are grouped per 10 to form test sets, resulting in 26 separate test sets. Consequently, all timeframes occur in an equal ratio within the training set and the test sets. Since many test sets are available, this provides an excellent method for testing how well the QBM generalizes to unseen data.
binary vectors. Other iterations of the movie are grouped per 10 to form test sets, resulting in 26 separate test sets. Consequently, all timeframes occur in an equal ratio within the training set and the test sets. Since many test sets are available, this provides an excellent method for testing how well the QBM generalizes to unseen data.
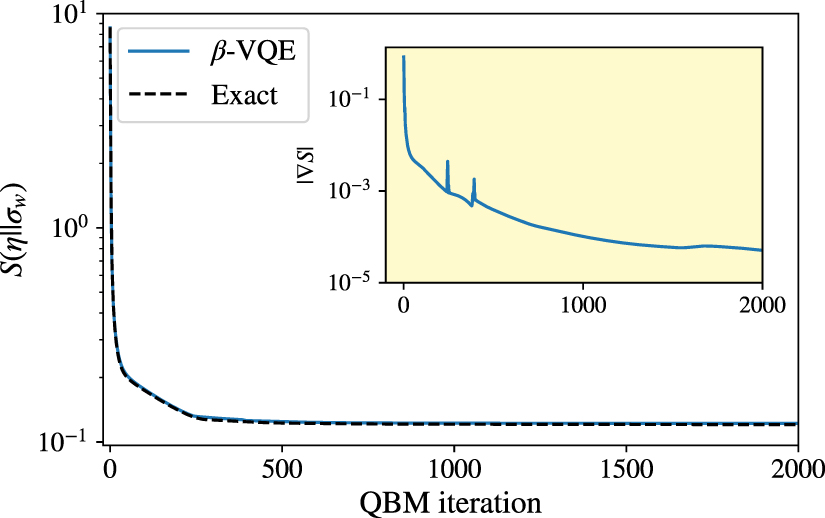
In figure 3, we show the convergence of the quantum relative entropy during training. We observe that  decreases monotonically and saturates at S = 0.12. This is close to the value obtained from learning with the exact gradient (dashed line). To compare these results to classical models, the QBM probability distribution over classical states can be obtained through projection, i.e.
decreases monotonically and saturates at S = 0.12. This is close to the value obtained from learning with the exact gradient (dashed line). To compare these results to classical models, the QBM probability distribution over classical states can be obtained through projection, i.e.  . We can then directly compare the classical relative entropy, or KL-divergence, to the classical BM. The QBM achieved a KL-divergence of 0.010 on the training data. In contrast, the classical BM only achieves a KL-divergence of 0.022 when fully converged. These results generalize well to unseen data. The QBM outperforms the classical BM, achieving a lower KL-divergence on all test sets. A histogram of the results is shown in appendix
. We can then directly compare the classical relative entropy, or KL-divergence, to the classical BM. The QBM achieved a KL-divergence of 0.010 on the training data. In contrast, the classical BM only achieves a KL-divergence of 0.022 when fully converged. These results generalize well to unseen data. The QBM outperforms the classical BM, achieving a lower KL-divergence on all test sets. A histogram of the results is shown in appendix

Figure 3. Convergence of the QBM training on the training set  of the classical salamander retina data of size n = 8 using rank R = 16 and depth d = 8. The nested-loop algorithm closely approximates exact QBM gradient optimization in this setting. The inlay shows the size of the gradient. The QBM achieves a quantum relative entropy of S = 0.12. A classical relative entropy, or KL-divergence, of 0.010 is achieved on the training set, which is significantly lower than the classical BM that achieves a KL-divergence of 0.022. The corresponding fidelity for the QBM is F = 0.998, compared to F = 0.269 for the classical BM.
of the classical salamander retina data of size n = 8 using rank R = 16 and depth d = 8. The nested-loop algorithm closely approximates exact QBM gradient optimization in this setting. The inlay shows the size of the gradient. The QBM achieves a quantum relative entropy of S = 0.12. A classical relative entropy, or KL-divergence, of 0.010 is achieved on the training set, which is significantly lower than the classical BM that achieves a KL-divergence of 0.022. The corresponding fidelity for the QBM is F = 0.998, compared to F = 0.269 for the classical BM.
Download figure:
Standard image High-resolution imageNote that the norm of the gradient, shown in the inset of figure 3, is  , which is still significantly nonzero. In contrast, the classical BM can be trained until the norm of the gradient reaches machine precision. The convergence of the QBM was numerically studied in [9] as a function of the rank of the target state η where it was shown that convergences deteriorates with lower rank. It has been shown that later training iterations tend to increase the magnitude of the weights, akin to lowering the effective temperature of the QBM. During this phase, the ground state of the QBM,
, which is still significantly nonzero. In contrast, the classical BM can be trained until the norm of the gradient reaches machine precision. The convergence of the QBM was numerically studied in [9] as a function of the rank of the target state η where it was shown that convergences deteriorates with lower rank. It has been shown that later training iterations tend to increase the magnitude of the weights, akin to lowering the effective temperature of the QBM. During this phase, the ground state of the QBM,  , already accurately represents the target state despite the nonzero gradient, achieving better results than the classical BM. This is also reflected by the high fidelity of F = 0.998 between the ground state and the target.
, already accurately represents the target state despite the nonzero gradient, achieving better results than the classical BM. This is also reflected by the high fidelity of F = 0.998 between the ground state and the target.
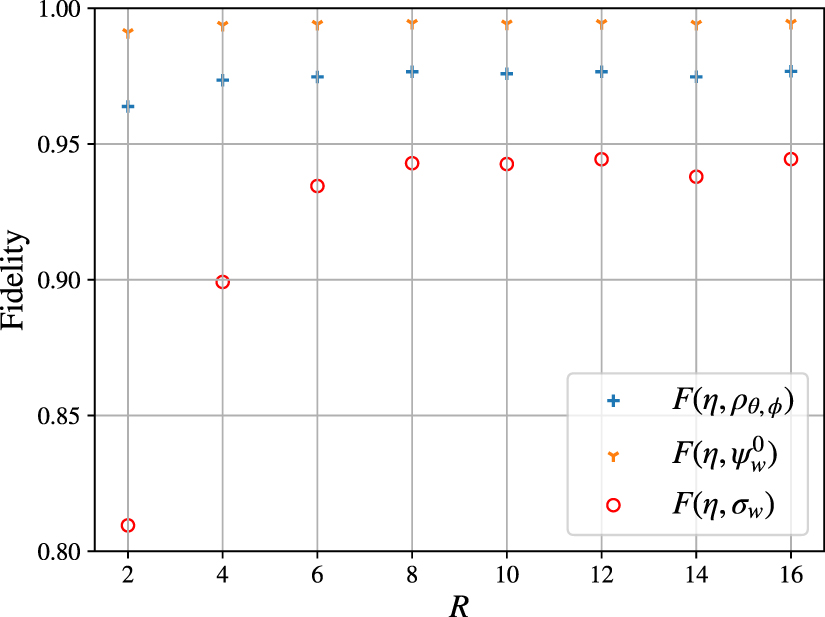
We investigate some important aspects of the learning algorithm, starting with the rank used in the truncated-rank β-VQE inner loop. In figure 4 we show the fidelity for different states obtained at the end of our algorithm. The fidelity between the QBM and η, indicated by the blue crosses, increases substantially with increased β-VQE rank, even though the target is a pure state. This might seem counter-intuitive but is a direct result of the low-rank approximation of the gradient. For a very low rank β-VQE, the approximation to the gradient becomes vanishingly small once the ground state accurately approximates the target pure state. During that stage, the exact σw is still very mixed, but the gradient is approximated as if it were close to a pure state. Conversely, when a higher rank approximation is used, the gradient is still nonzero even if the ground state of σw closely resembles the target pure state, allowing the QBM to converge further towards a pure state. The fidelity between the target and the ground state of the QBM is depicted in figure 4 by the yellow triangles. High fidelity of F > 0.99 is achieved with as few as two samples.

Figure 4. Fidelity achieved with different β-VQE rank R and depth d = n on salamander retina data of size n = 8. The β-VQE achieves fidelities  even with small R. While the full QBM state σw
is still mixed resulting in a lower fidelity, the ground state
even with small R. While the full QBM state σw
is still mixed resulting in a lower fidelity, the ground state  achieves a fidelity of
achieves a fidelity of  in all cases. σw
can be turned into a pure state by multiplying the weights by a large constant factor.
in all cases. σw
can be turned into a pure state by multiplying the weights by a large constant factor.
Download figure:
Standard image High-resolution imageAnother important aspect is the scaling of the performance of the algorithm with the number of features (qubits) n. In order to investigate this, we train the QBM on subsets of the salamander retina data of different sizes. We set the circuit depth equal to the number of features, which was heuristically found to be a good rule of thumb, see appendix

Figure 5. Fidelity for different system sizes using rank  and depth d = n. For all sizes, a fidelity of F > 0.98 is achieved between the target state and the ground state of the QBM. The fidelity drops for larger system sizes, which is due to model mismatch between the QBM and the target. The error on the fidelity introduced by the β-VQE is of order
and depth d = n. For all sizes, a fidelity of F > 0.98 is achieved between the target state and the ground state of the QBM. The fidelity drops for larger system sizes, which is due to model mismatch between the QBM and the target. The error on the fidelity introduced by the β-VQE is of order  .
.
Download figure:
Standard image High-resolution image3.2. Quantum data results
In our second example, we train a QBM to model quantum data. As target state η we take the finite temperature Gibbs state  with
with

with  ,
,  , and β = 1. Quantum data taken from systems at finite temperatures is usually characterized by a high rank. However, we show that the β-VQE can be used to get an efficient low-rank approximation to the target state. We train the QBM with the nested-loop algorithm, again analyzing the effect of the rank. The results for the quantum data are shown in figure 6. In contrast to the results for classical data shown in figure 4, we require a higher rank approximation to obtain a high fidelity. By increasing the rank, the β-VQE is more capable of representing the mixed QBM state. In the truncated-rank β-VQE, one has the freedom to increase the rank freely during training, at the cost of a higher computational demand. For mixed target states, it can be efficient to start out with a low-rank approximation for early iterations of the outer loop, when only a rough approximation of the QBM gradient is sufficient for training, and increase the rank as the gradient approaches zero.
, and β = 1. Quantum data taken from systems at finite temperatures is usually characterized by a high rank. However, we show that the β-VQE can be used to get an efficient low-rank approximation to the target state. We train the QBM with the nested-loop algorithm, again analyzing the effect of the rank. The results for the quantum data are shown in figure 6. In contrast to the results for classical data shown in figure 4, we require a higher rank approximation to obtain a high fidelity. By increasing the rank, the β-VQE is more capable of representing the mixed QBM state. In the truncated-rank β-VQE, one has the freedom to increase the rank freely during training, at the cost of a higher computational demand. For mixed target states, it can be efficient to start out with a low-rank approximation for early iterations of the outer loop, when only a rough approximation of the QBM gradient is sufficient for training, and increase the rank as the gradient approaches zero.

Figure 6. Fidelity achieved between the target XXZ model η of size n = 8 and the QBM using the nested-loop algorithm, as a function of the rank of the β-VQE using depth d = n. The black line represents the fidelity between the model and an exact fixed rank approximation, and as such represents the best achievable fidelity for the corresponding fixed rank β-VQE.
Download figure:
Standard image High-resolution image3.3. Training QBM with the nested loop in practice
All the simulations in previous sections assume access to the exact quantum state. This is possible via classical statevector simulations which are intractable in general. To overcome this, one can execute the required circuits on a quantum computer. This introduces two new sources of error. First, the quantum computer is affected by various sources of hardware noise [31, 32]. While little information is available on the noise for a specific quantum chip, we believe this noise is biased in general. Thus, this is a source of error that cannot be completely mitigated by taking many measurements. Second, the output statistics are approximated from a finite number of shots (measurements). This is important, for example, when estimating the gradient of β-VQE in equation (9). When hardware noise is absent, the error due to a finite number of shots (M) scales as  . In this section, we take a closer look at these sources of errors in the context of QBM training.
. In this section, we take a closer look at these sources of errors in the context of QBM training.
We use Qiskit [33] to simulate both the noise-free and noisy hardware. For the noisy hardware simulations, we use the fake provider module from Qiskit to mimic the behavior of IBM's quantum devices. We use a subset of the salamander retina data of size n = 4 and the Hamiltonian ansatz given in equation (14). For β-VQE we truncate the rank to R = 2 and use the circuit in figure 2 with a depth of d = 2.
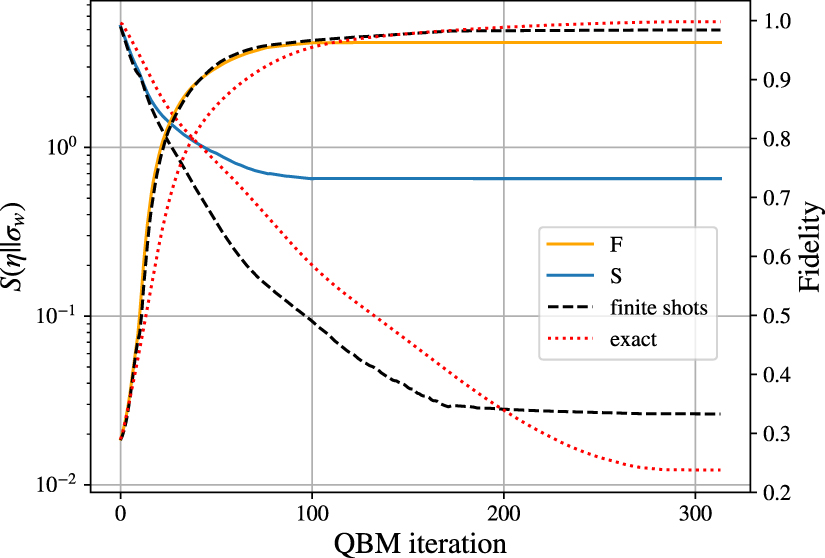
Figure 7 compares the QBM training in three different settings in terms of estimating the expectation values: using exact values, using a noise-free quantum simulator with 5000 shots, and finally using a noisy quantum hardware simulator with 5000 shots. The FakeKolkata backend from Qiskit, which mimics the behavior of IBM's ibmq_kolkata device, is used to produce the noisy hardware results.

Figure 7. Quantum relative entropy and fidelity during QBM training on the classical salamander retina data target of size n = 4 by using exact expectation values (red doted line) and using a noise-free (dashed black line) and a noisy (solid lines) quantum simulator with finite shots to approximate the expectation values. We use the truncated β-VQE with R = 2 and d = 2. To produce noisy hardware results, Qiskit's FakeKolkata backend is used, which mimics the noisy behavior of IBM's ibmq_kolkata device. We use 5000 shots for approximating the expectation values present in estimating the variational free energy, and its gradient using the parameter shift rule. While there is a significant difference between relative entropies, the fidelities are very similar. A fidelity of 0.983 and 0.962 is achieved in noise-free and noisy hardware cases with finite shots respectively. When using exact expectation values, a fidelity of 0.998 is achieved.
Download figure:
Standard image High-resolution imageAs expected, the learning stops earlier in the presence of noise. An increase in the noise causes the errors introduced by the β-VQE algorithm to reach the size of the QBM gradient faster. The size of the error compared to the size of the gradient is shown in figure 8 for the noisy and noise-free quantum simulators, when both are using the same number of shots to approximate the expectation values. As expected, a higher (lower) quantum relative entropy (fidelity) is achieved using a noisy hardware compared to a noise-free one.

Figure 8. The mean size  of the QBM gradient (blue) and the mean size of the error ε introduced by the β-VQE approximation (orange) during the training in the noise-free (top panel) and noisy (bottom panel) quantum simulators. The training process and model ansatz here is exactly the same process that we have used to make the plots for noise-free and noisy quantum simulators with finite shots in figure 7. The QBM converges until the error introduced by the β-VQE becomes the dominant factor of the gradient. The error decreases initially but finally fluctuates around
of the QBM gradient (blue) and the mean size of the error ε introduced by the β-VQE approximation (orange) during the training in the noise-free (top panel) and noisy (bottom panel) quantum simulators. The training process and model ansatz here is exactly the same process that we have used to make the plots for noise-free and noisy quantum simulators with finite shots in figure 7. The QBM converges until the error introduced by the β-VQE becomes the dominant factor of the gradient. The error decreases initially but finally fluctuates around  in the noise-free quantum simulator case as expected. In the noisy quantum simulator case the error ε is larger, which forces the training to stop earlier than the noise-free quantum simulator case. The resulting QBM has a higher quantum relative entropy as shown in figure 7.
in the noise-free quantum simulator case as expected. In the noisy quantum simulator case the error ε is larger, which forces the training to stop earlier than the noise-free quantum simulator case. The resulting QBM has a higher quantum relative entropy as shown in figure 7.
Download figure:
Standard image High-resolution imageFinally, we deploy the QBM model trained using the FakeKolkata backend on the corresponding real quantum hardware device, ibmq_kolkata. We sample the thermal state in the computational basis and compare its KL-divergence to the target distribution. The target distribution is resampled a number of times in order to obtain different test sets. The results are shown in figure 9. As expected, the ibmq_kolkata (red bars) yields KL-divergences higher than those of the noise-free quantum simulator (blue bar). However, deploying the same QBM model on another IBM device, ibmq_perth (yellow bars), results in a KL-divergence about twice as high as using ibmq_kolkata, demonstrating the recent improvements made to noise reduction in quantum hardware. We expect that further advancements in noise reduction will contribute significantly to improving these results. Note that QBM models trained in the noisy setting are to some extent bound to the specific hardware [7] (data not shown). Further investigation is needed to examine how hardware noise affects QBM training by increasing the number of qubits.

Figure 9. KL divergence to the target salamander retina data for probability distributions obtained from real noisy quantum hardware and noise-free quantum simulator. We use a system size of n = 4 and a rank R = 2 and depth  -VQE. In the real quantum hardware cases, the resulting β-VQE is implemented on the physical quantum devices ibmq_kolkata and ibm_perth, and the final probability distributions is obtained using sampling. As it is clear from the figure, sampling from the physical devices results in a higher KL divergence compared to the noise-free quantum simulator case due to the noise present in the current quantum devices. Parameters for ibmq_kolkata and ibm_perth are obtained by simulating the QBM training with the FakeKolkata and FakePerth backend respectively. The crosses denote the KL divergence on the training set, and the histogram shows the KL divergence on test sets.
-VQE. In the real quantum hardware cases, the resulting β-VQE is implemented on the physical quantum devices ibmq_kolkata and ibm_perth, and the final probability distributions is obtained using sampling. As it is clear from the figure, sampling from the physical devices results in a higher KL divergence compared to the noise-free quantum simulator case due to the noise present in the current quantum devices. Parameters for ibmq_kolkata and ibm_perth are obtained by simulating the QBM training with the FakeKolkata and FakePerth backend respectively. The crosses denote the KL divergence on the training set, and the histogram shows the KL divergence on test sets.
Download figure:
Standard image High-resolution image4. Discussion and conclusion
Training QBMs by minimizing the quantum relative entropy with gradient descent requires calculating the difference in statistics between the target and the model. In general, this is intractable because it involves computing exact Gibbs state expectation values. This has been shown to be QMA-hard [10], which means that even a quantum algorithm could take exponential time. We show that the β-VQE can be used as an efficient heuristic for obtaining the gradient in practice, closely approximating QBM training with the exact gradient. When combined with the QBM training loop, we dubbed this the nested-loop training algorithm.
The QBM trained with the nested-loop algorithm outperforms the classical BM, achieving a significantly lower KL-divergence. In comparing the two models, it should be noted that the QBM has about three times as much parameters as the classical BM. However, the classical BM is a subset of the QBM using only diagonal σz terms, and as such can only represent a diagonal state regardless of the amount of parameters used. Furthermore, note that the results in this paper are indicative of the improvements that the QBM can achieve over classical models, and do not necessarily represent the best possible results. Both the QBM and the BM results can be improved by adding hidden variables [17, 22, 34], at a higher computational cost.
When the target is constructed from classical data, we find that the QBM can be trained using a low-rank version of β-VQE. This is also observed for quantum data originating from low-temperature systems. For high-temperature quantum systems, a high rank is needed to achieve high fidelity. Yet, for the data considered here, we find numerically that a circuit depth scaling linearly with the system size is sufficient. We also find that a warm-start strategy for β-VQE can significantly reduce the overall computational cost. The nested-loop algorithm provides a method for training the QBM on near-term quantum devices.
The nested-loop algorithm is a synergy between two models, where the advantages of one model compensate for the weakness of the other. Having two model density matrices, σw
and  , may seem redundant, and one may wonder why the β-VQE is not used to represent the data directly. However, optimization of the β-VQE on the data density matrix directly requires computing the fidelity, and hence the overlaps between quantum states. This is intractable for large system sizes. The QBM serves as an intermediary, providing a local parameterized Hamiltonian that can be evaluated on a circuit. Similarly, the β-VQE provides the low-rank approximation necessary to train the QBM. Previous experiments with rank-one approximations for QBM training have revealed that this leads to problematic level crossings that prohibit convergence, even in the case where the target distribution can be well approximated with a rank-one density matrix. An example is shown in appendix
, may seem redundant, and one may wonder why the β-VQE is not used to represent the data directly. However, optimization of the β-VQE on the data density matrix directly requires computing the fidelity, and hence the overlaps between quantum states. This is intractable for large system sizes. The QBM serves as an intermediary, providing a local parameterized Hamiltonian that can be evaluated on a circuit. Similarly, the β-VQE provides the low-rank approximation necessary to train the QBM. Previous experiments with rank-one approximations for QBM training have revealed that this leads to problematic level crossings that prohibit convergence, even in the case where the target distribution can be well approximated with a rank-one density matrix. An example is shown in appendix
At the end of training, the user is left with two density matrix representations of the target state. Depending on the purpose, either one can be used as a final approximation to the data. For quantum tomography the QBM state σw
is most useful, revealing a possible candidate for the underlying Hamiltonian. For classification and generative tasks, one might directly use the β-VQE density  .
.
Alternative methods for approximating Gibbs states could act as an inner loop instead of the β-VQE [12]. Recently, a new method for generating Gibbs states was introduced called the Noise-Assisted Variational Quantum Thermalization [35] (NAVQT), where noisy quantum gates thermalize a pure state. While their idea is promising, the β-VQE achieved better results on models with randomized parameters. Several other approaches rely on preparing a purification on a larger system [36, 37], including the thermofield double (TFD) state [38, 39]. The Gibbs state is obtained from the pure state by tracing out the additional subsystem. Evidently, this demands a significant increase in the number of qubits needed, up to doubling the system size for the TFD. This computational demand makes it less suitable for the QBM inner loop that has to be evaluated many times during training. In contrast, the β-VQE is initiated with a mixture of classical states. For target systems that are not very mixed, the truncated β-VQE needs only a few states to obtain an accurate approximation, especially for a pure target state. Nevertheless, purification methods could be preferable for high-temperature target systems that are close to maximally mixed. For such systems, the β-VQE needs to sample over a significant portion of the Hilbert space to obtain accurate results, whereas purification methods still need only a single state in a system size twice as large. Finally, the classical networks considered in β-VQE provide a more tractable and expressive latent space than the product state ansatzes considered in earlier work [39, 40], making it suitable for QBM training.
Acknowledgments
We thank Samuel Duffield and Kirill Plekhanov for fruitful discussions. We thank Manu Compen for earlier collaborations on rank-one QBM training. This publication is part of the 'Quantum Inspire—the Dutch Quantum Computer in the Cloud' project (NWA.1292.19.194) of the NWA research program 'Research on Routes by Consortia (ORC)', which is funded by the Netherlands Organization for Scientific Research (NWO).
Data availability statement
No new data were created or analysed in this study.
Appendix A: Salamander retina data
For training on the classical salamander retina data, we select subsets of various sizes n with high MI. We initialize the dataset by selecting the pair of neurons that have the highest pairwise MI between all neuron pairs. Subsequently, the neuron that has the highest MI with the existing subset is selected and added. This is repeated until a dataset of the desired size is constructed.
As shown in [9], the QBM with exact gradient computation outperforms the classical BM on this data set. We reproduce these results for the QBM trained with the nested-loop algorithm. The QBM achieves a lower KL-divergence on all test sets. A histogram of these results is shown in figure 10.

Figure 10. Histogram of KL-divergences for both the QBM and classical BM on the salamander retina data of size n = 8. We used a β-VQE of rank R = 16 and depth d = 8. The crosses denote the results on the training set and the histograms show the results on the test sets. The nested-loop QBM outperforms the classical BM, achieving a lower KL-divergence on all test sets.
Download figure:
Standard image High-resolution imageAppendix B: Circuit-depth analysis
In this section, we assume the QBM in the outer loop is fixed to the Heisenberg XXZ model in equation (16) with β = 1. We then analyze the effect of circuit depth in β-VQE which, as a reminder, is executed in the inner loop to approximate the QBM.
We use the exact gradient in equation (9) and increase the circuit depth from 3 to 8 layers. We compute the Uhlmann-Jozsa fidelity in equation (15) between the β-VQE and the QBM. The results are shown in figure 11. Clearly, deeper circuits can achieve higher fidelity. We emphasize however that increasing the circuit depth is computationally expensive as the resulting circuits contain more parameters to train. A circuit depth of 8 is sufficient to obtain F > 0.98.

Figure 11. Fidelity between the QBM and the target Heisenberg XXZ model in equation 16 of size n = 8 for different circuit depths. A rank  -VQE was used.
-VQE was used.
Download figure:
Standard image High-resolution imageAppendix C: Rank-one QBM training
For targets encoding classical data, the QBM usually converges to a rank-one solution. Thus, one may wonder if it is possible to train the QBM using only the ground state to approximate the gradient. This would provide an opening to using various methods of ground state approximation. We find that using a rank-one approximation does not work in general due to problematic level crossings. As the QBM converges, level crossings between the ground state and the first excited state can occur. Consequentially, the ground state approximation of the gradient changes drastically between two iterations. This is troublesome if the gradient after the level crossing again directs the model back over the level crossing. In such a case, one can only converge closer to the exact point of degeneracy, and at that point, it is not possible to train the QBM further using the ground state approximation. Such a case is plotted in figures 12 and 13.

Figure 12. Convergence of the QBM trained using a rank-one approximation on salamander retina data of size n = 8. We used a β-VQE of rank R = 1 and depth d = 8. Problematic level crossings prevent further convergence.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 13. Top: Spectral gap of the QBM during training on salamander retina target state of size n = 8 using a rank R = 1 approximation of depth d = 8. After a level crossing is passed, the QBM converges towards the point of degeneracy Bottom: Spectral gap of the QBM during training on the same salamander retina target state using a rank R = 16 depth  -VQE in the nested-loop algorithm. The QBM now smoothly converges.
-VQE in the nested-loop algorithm. The QBM now smoothly converges.
Download figure:
Standard image High-resolution image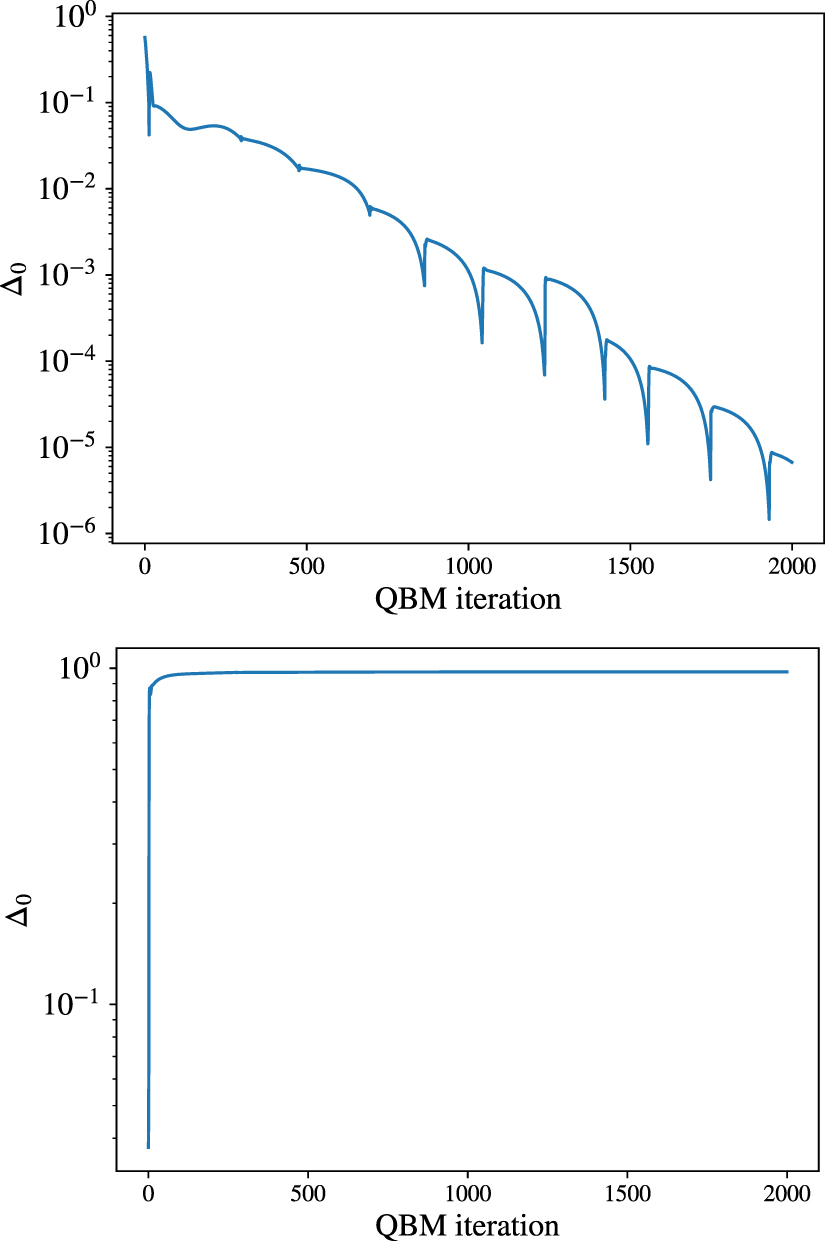{kind=link}
One might see the resemblance between the spikes in the norm of the gradient in figure 12 (inset) and the two spikes in figure 3 (inset). However, they are due to different events. For rank-one training in figure 12 the spikes coincide with the level crossings shown in in figure 13. Instead, for the truncated-rank β-VQE the system is always gapped. In this case, the spikes are due to the high momentum and variable learning rate that we use during training. These settings accelerate training, especially for rank-one targets. But, sometimes, they cause the QBM to overshoot the optimal point, causing the spikes.
Footnotes
- 3
While the specifics of the update scheme do not noticeably change the quality of the final result, we find that they do have a large impact on the number of outer loop iterations needed to get there. Fast convergence was usually achieved with a variable learning rate that is increased by 1% after every iteration as long as the cost function decreased, and halved if the cost function increased, combined with some momentum.