

Abstract
We introduce a machine-learning approach to predict the complex non-Markovian dynamics of supercooled liquids from static averaged quantities. Compared to techniques based on particle propensity, our method is built upon a theoretical framework that uses as input and output system-averaged quantities, thus being easier to apply in an experimental context where particle resolved information is not available. In this work, we train a deep neural network to predict the self intermediate scattering function of binary mixtures using their static structure factor as input. While its performance is excellent for the temperature range of the training data, the model also retains some transferability in making decent predictions at temperatures lower than the ones it was trained for, or when we use it for similar systems. We also develop an evolutionary strategy that is able to construct a realistic memory function underlying the observed non-Markovian dynamics. This method lets us conclude that the memory function of supercooled liquids can be effectively parameterized as the sum of two stretched exponentials, which physically corresponds to two dominant relaxation modes.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Understanding the dynamics of supercooled liquids approaching the glass transition represents one of the major challenges in condensed matter science [1–4]. The most striking signature of this phenomenon is the dramatic increase in viscosity or relaxation time upon a relatively mild change in the thermodynamic control parameters. Despite the magnitude of this effect, there are no substantial changes in the microscopic structure of the material, which severely hinders our understanding of the mechanisms underlying the glass transition.
In recent years, machine learning algorithms have been successfully employed to capture subtle changes in the local structure of glassforming materials to create accurate predictors of the dynamics. The first such example is a machine-learned parameter called softness [5–9], which, based on support vector machines and physical intuition, identifies key structural features that strongly correlate with local particle dynamics. Neural networks can also identify local structures [10, 11] and correlate them to local dynamics [12, 13]. Furthermore graph neural networks [14] have shown that the graph structure of each particle's local environment contains significant information to predict its long-time dynamics. It was later demonstrated that more refined observables could be calculated [15] and combined with simpler models to capture the connection between statics and dynamics in glassy systems [16, 17]. Similar results can be achieved even with information theory [18, 19] and dimensionality reduction [19, 20]. Recently, neural networks have also been used to find complex order parameters for glassy dynamics [21]. However all these approaches are based on a particle resolved description of the system, which requires knowledge of the location of every single particle and its precise local environment. Unfortunately these particle resolved quantities are not always easy to measure, and furthermore, single-particle properties do not easily lend themselves to statistical–physical theory development. Hence, a more collective description is often preferred.
Here we propose an alternative approach that is not based on local single-particle features, but instead on system averaged quantities. This approach takes inspiration from collective theories of the glass transition [22–33] that aim to predict the glassiness of the system using collective static observables that do not need to be resolved per particle. The cornerstone of our method consists of rewriting the dynamics of supercooled liquids following the Mori–Zwanzig procedure [22, 34] to obtain a form of a generalized Langevin equation (GLE) called the memory equation [35]. From a mathematical point of view, this equation takes as input the statistically-averaged static structure of the system, mainly through the static structure factor S(k) which is a function of the wave vector k. Using S(k) as the initial boundary condition, the memory equation can then be used to predict the time-dependent dynamics of the system, quantified by the intermediate scattering function  at a given time t. The key bottleneck, however, is finding the exact memory function that governs the dynamics of
at a given time t. The key bottleneck, however, is finding the exact memory function that governs the dynamics of  ; this memory function should account for the dynamical slowdown of supercooled liquids, but its functional form is a priori unknown. After decades of intense research, scientists have been able to solve only approximations of this equation, like mode-coupling theory (MCT) [22, 31, 34, 36–43].
; this memory function should account for the dynamical slowdown of supercooled liquids, but its functional form is a priori unknown. After decades of intense research, scientists have been able to solve only approximations of this equation, like mode-coupling theory (MCT) [22, 31, 34, 36–43].
In this paper, we use machine-learning to approximate the memory function. In particular we discuss two different approaches to the problem: (i) first we train a deep neural-network (DNN) in order to learn the memory equation using data measured from computer simulations of binary mixtures interacting via Lennard–Jones (LJ) or Weeks–Chandler–Andersen (WCA) potentials. In this approach the DNN plays the role of both the memory equation and the memory function itself. (ii) Then we develop an evolutionary strategy (ES) tailored to identify and construct the memory function that produces the dynamics observed in the simulations.
In figure 1 we sketch the concept of our approach. First we collect extensive simulation data for LJ and WCA binary mixtures. For different values of temperature T and density ρ we measure the static structure factor  and the self intermediate scattering function
and the self intermediate scattering function  , where α and β are the indexes to represent the species of the mixture. These averaged descriptors are then given to a DNN that we train to predict the intermediate scattering function for a given
, where α and β are the indexes to represent the species of the mixture. These averaged descriptors are then given to a DNN that we train to predict the intermediate scattering function for a given  , under the assumption introduced in section section 2.1. We show that our DNN achieves excellent performance, thus concluding that the network can learn the memory equation. Next, in order to obtain some physical intuition about the memory function we introduce an ES that, given the intermediate scattering function and the structure of the memory equation, is able to describe the memory function in a parametrized functional form.
, under the assumption introduced in section section 2.1. We show that our DNN achieves excellent performance, thus concluding that the network can learn the memory equation. Next, in order to obtain some physical intuition about the memory function we introduce an ES that, given the intermediate scattering function and the structure of the memory equation, is able to describe the memory function in a parametrized functional form.

Figure 1. Sketch of our machine learning approach based on averaged static descriptors. The static structure factor is the main input of the model and even though it only shows minute changes with the temperature T, the model was trained to predict the abrupt slowdown from these minimal changes. The DNN explained in section 2.1 predicts  from
from  . Instead with our evolutionary strategy (section 2.2) we are able to construct the memory function
. Instead with our evolutionary strategy (section 2.2) we are able to construct the memory function  that produces the observed dynamics.
that produces the observed dynamics.
Download figure:
Standard image High-resolution imageOverall, the results of our model are twofold: we introduce an effective approach that is able to rapidly predict the collective dynamics of the system from static measurements, once the model has been trained. Secondly, we propose a representation of the memory function that may be more convenient, and perhaps more realistic, than some state-of-the-art theories. The function parametrized by our machine-learning algorithm can be informative for future efforts aimed at developing a more quantitative theory of the glass transition. In the next sections we will discuss the mechanism of our machine-learning approach, how to generalize it to other systems, and some implications of our findings.
2. Results
2.1. Dynamics of supercooled liquids from neural networks
We train a multi-layer perceptron (MLP) to predict the dynamics of supercooled liquids from static averaged quantities. The MLP is a fully connected DNN with a simple feed-forward architecture. The dynamics is characterized by measuring the intermediate scattering function  from the simulations (details in section 4.1). Rather than a full k-dependent description of the dynamics, we follow the standard procedure [42, 44, 45] for binary mixtures, which consists in the following steps: (i) we focus only on
from the simulations (details in section 4.1). Rather than a full k-dependent description of the dynamics, we follow the standard procedure [42, 44, 45] for binary mixtures, which consists in the following steps: (i) we focus only on  which is the location of the main peak of SAA
and it is arguably the most descriptive wavenumber for such supercooled mixtures [35], (ii) we consider only the self part of the intermediate scattering function assuming that it also represents the collective dynamics, and (iii) we ignore the mixed term
which is the location of the main peak of SAA
and it is arguably the most descriptive wavenumber for such supercooled mixtures [35], (ii) we consider only the self part of the intermediate scattering function assuming that it also represents the collective dynamics, and (iii) we ignore the mixed term  since
since  . Hence we end up describing the dynamics using
. Hence we end up describing the dynamics using  , where
, where  represents the two species.
represents the two species.
Furthermore, we define  in the following way:
in the following way:

where N is the total number of particles and  is the position of particle i of species α at time t. Our choice of normalization imposes
is the position of particle i of species α at time t. Our choice of normalization imposes  . In our work, this has two advantages: we can now directly compare our prediction of
. In our work, this has two advantages: we can now directly compare our prediction of  with collective theories like MCT under assumptions (i)–(iii), and secondly, our machine learning approach gives more importance to the most glassy (slowest) dynamics, because they are rescaled by a larger factor corresponding to their larger values of
with collective theories like MCT under assumptions (i)–(iii), and secondly, our machine learning approach gives more importance to the most glassy (slowest) dynamics, because they are rescaled by a larger factor corresponding to their larger values of  .
.
The MLP that we use to predict the dynamics takes as input the static structure factor  on a uniform grid of
on a uniform grid of  wave numbers in the range
wave numbers in the range  , including the
, including the  terms, for a total of 300 values of
terms, for a total of 300 values of  (considering the
(considering the  symmetry). In addition the MLP receives the temperature T, the density ρ, a label for the interaction type (i.e. either LJ or WCA), and the logarithm of the time at which it has to predict
symmetry). In addition the MLP receives the temperature T, the density ρ, a label for the interaction type (i.e. either LJ or WCA), and the logarithm of the time at which it has to predict  . With this input–output architecture after training we can easily tune the value of t in the input to reconstruct the full time dependence.
. With this input–output architecture after training we can easily tune the value of t in the input to reconstruct the full time dependence.
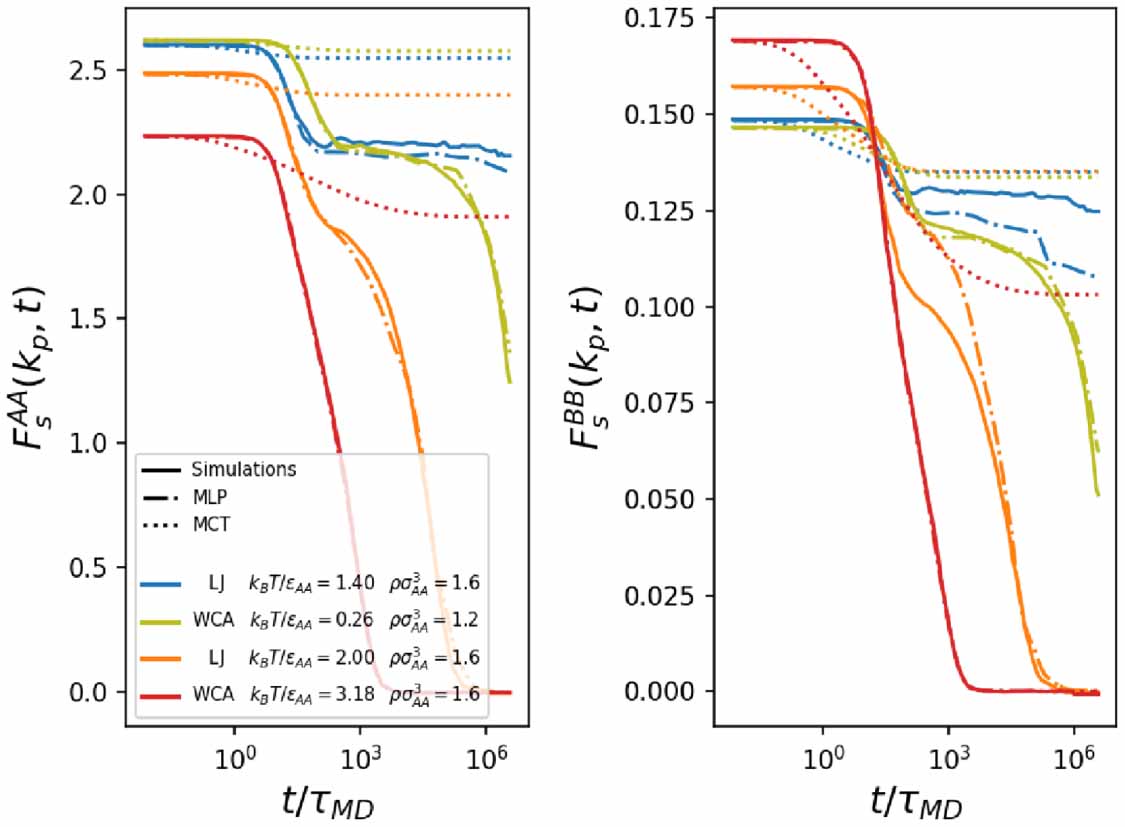
In figure 2 we show that the MLP (detailed in section 4.2) produces good predictions in the full temperature range, from high-temperature liquid to glass on which it was trained. In this figure we also report the results of MCT (dotted lines), which is a theory based on the same static information used as input for the MLP. The results indicate that the MLP significantly outperforms MCT in predicting the realistic dynamics.

Figure 2. Predictions of the multi-layer perceptron (MLP) for the self intermediate scattering function of binary mixtures, for the AA and BB components, normalized as defined in equation (1). We report four state points from the test set (not used for training): the red is a warm liquid, the orange is a supercooled liquid, the yellow is a strongly supercooled liquid and blue is a glass. We compare the MLP (dot-dashed lines) with simulations (solid lines) and mode-coupling theory (dotted line) predictions.
Download figure:
Standard image High-resolution imageTo quantify the performance of the MLP we measure its predictivity on data outside of it training set. The model has been trained using  of the data available while we use the remaining data to evaluate the R2 score:
of the data available while we use the remaining data to evaluate the R2 score:

where  is the sum of squared residuals
is the sum of squared residuals

and  is the total sum of squares
is the total sum of squares

where  represents the mean. Notice that one observation in equations (3) and (4) corresponds to one time
represents the mean. Notice that one observation in equations (3) and (4) corresponds to one time  of
of  for any given T and ρ, so the sum runs over all the temperatures T, densities ρ and times ti
. Moreover, the train/test split is performed separating
for any given T and ρ, so the sum runs over all the temperatures T, densities ρ and times ti
. Moreover, the train/test split is performed separating  of the
of the  LJ/WCA
LJ/WCA states rather than
states rather than  of all the data points, in order to avoid training the MLP using data strongly correlated with the test set.
of all the data points, in order to avoid training the MLP using data strongly correlated with the test set.
A value of R corresponds to a perfect fit, so R2 is an effective measure to evaluate the quality of the model. In figure 3 we report the R2 score as a function of
corresponds to a perfect fit, so R2 is an effective measure to evaluate the quality of the model. In figure 3 we report the R2 score as a function of  , where
, where  is the temperature at which fit-parameter-free MCT predicts the glass transition, reported in table 1. With this normalization we can average simulations at different densities and different pairwise interactions to produce a single curve. In this work we are not interested in the precise estimation of the critical point of MCT for our mixtures, but a more detailed discussion is available in [3, 44, 46]. In the supplementary information we show the root mean squared error (RMSE) for the same data. The trend of the curve shows that the performance of the MLP starts to drop at
is the temperature at which fit-parameter-free MCT predicts the glass transition, reported in table 1. With this normalization we can average simulations at different densities and different pairwise interactions to produce a single curve. In this work we are not interested in the precise estimation of the critical point of MCT for our mixtures, but a more detailed discussion is available in [3, 44, 46]. In the supplementary information we show the root mean squared error (RMSE) for the same data. The trend of the curve shows that the performance of the MLP starts to drop at  , when the two-step relaxation becomes more prominent and thus the intermediate scattering function is a more 'complex' function with more features to predict. At
, when the two-step relaxation becomes more prominent and thus the intermediate scattering function is a more 'complex' function with more features to predict. At  the MLP predictions exhibit pronounced fluctuations, but the predictions are still good on average, as we highlight in the inset of figure 3. Surprisingly at even lower temperatures, when the dynamics is even slower, the performances increase, approaching again the perfect R
the MLP predictions exhibit pronounced fluctuations, but the predictions are still good on average, as we highlight in the inset of figure 3. Surprisingly at even lower temperatures, when the dynamics is even slower, the performances increase, approaching again the perfect R score. This is a consequence of the fact that in the glass the second relaxation happens at
score. This is a consequence of the fact that in the glass the second relaxation happens at  , which is outside the time window that the model observes, so F is characterized by a single relaxation, thus being easier to learn for the model.
, which is outside the time window that the model observes, so F is characterized by a single relaxation, thus being easier to learn for the model.

Figure 3. Performance of the multi-layer perceptron (MLP) in predicting the self-intermediate scattering function of binary mixtures. We report the R2 score as a function of temperature, normalized by  which is the temperature at which mode-coupling theory predicts the glass transition. Its value is averaged over states with similar values of
which is the temperature at which mode-coupling theory predicts the glass transition. Its value is averaged over states with similar values of  and the colored region represents the standard deviation of each bin. A value of 1 represents perfect predictions. In the inset we compare the MLP prediction with the target simulation, for a set with R
and the colored region represents the standard deviation of each bin. A value of 1 represents perfect predictions. In the inset we compare the MLP prediction with the target simulation, for a set with R . We conclude that on average the model predictions are good across the entire temperature range.
. We conclude that on average the model predictions are good across the entire temperature range.
Download figure:
Standard image High-resolution imageTable 1. Temperatures that we use to normalize the data. The values of  correspond to the critical temperature of mode-coupling theory for the WCA and LJ mixtures [3, 44, 46], below which fit-parameter-free MCT predicts that the system is a glass.
correspond to the critical temperature of mode-coupling theory for the WCA and LJ mixtures [3, 44, 46], below which fit-parameter-free MCT predicts that the system is a glass.

|

|

|

|

|
|---|---|---|---|---|
| WCA | 0.74 | 1.77 | 3.49 | 5.10 |
| LJ | 0.90 | 1.87 | 3.53 | 5.10 |
2.1.1. Transferability
2.1.1.1. Temperature transferability
One of the main strengths of machine learning is the possibility to train a model in a more favorable situation (e.g. when there is more data available) and deploy it in a less favorable one. For computer simulations the hardest region to sample is the low temperature regime, because the dynamics is much slower and more time is required to sample all relevant structural rearrangements. This means that it is much easier to collect data at high T than at low T.
Here we show the temperature transferability of our model, i.e. its performance at temperatures different from the training. We report in figure 4 the R2 score when the MLP is trained only using data for  . The RMSE is reported in the supplementary information. As expected the model performs excellently in its training region (solid lines), but outside (dashed lines) its score starts dropping. The results of figure 4 suggest the existence of two regimes: (i) for
. The RMSE is reported in the supplementary information. As expected the model performs excellently in its training region (solid lines), but outside (dashed lines) its score starts dropping. The results of figure 4 suggest the existence of two regimes: (i) for  we have full transferability. It is in fact possible to train the model at high temperature and retain good predictions, as evidenced by the red curve in figure 4. (ii) When
we have full transferability. It is in fact possible to train the model at high temperature and retain good predictions, as evidenced by the red curve in figure 4. (ii) When  the transferability is restricted. In figure 4 we show that the best we can do is to transfer the training at
the transferability is restricted. In figure 4 we show that the best we can do is to transfer the training at  down to
down to  .
.

Figure 4. Temperature transferability of the MLP: we report the R2 score as a function of the temperature. For each curve the model is trained using only temperatures larger than the one corresponding to the rhombus. The solid lines represent the regions in which the model has been trained, while it has never seen data from the dashed line region.
Download figure:
Standard image High-resolution imageOverall we can conclude that our approach is transferable in the (i) MCT regime corresponding to  , while the transferability is very limited in the (ii)
, while the transferability is very limited in the (ii)  activated regime. This low temperature region is in fact characterized by the appearance of heterogeneous activated dynamics and facilitation, that become dominant at low temperature [47, 48]. We hypothesize that this different relaxation mechanism is the reason behind the lack of transferability. In summary, except for the very low temperature region, our approach presents some degree of temperature transferability that we can use to reduce the need for data that are harder to collect.
activated regime. This low temperature region is in fact characterized by the appearance of heterogeneous activated dynamics and facilitation, that become dominant at low temperature [47, 48]. We hypothesize that this different relaxation mechanism is the reason behind the lack of transferability. In summary, except for the very low temperature region, our approach presents some degree of temperature transferability that we can use to reduce the need for data that are harder to collect.
2.1.1.2. Model transferability
We show in this section the performance of the MLP in predicting the dynamics of computer simulations produced with a different interaction than the one the MLP has been trained on. Our library consists of simulation data for binary LJ and binary WCA, so their dynamics is similar at high temperature and/or high density, but it becomes significantly different approaching  . In figure 5 we show the prediction of the MLP when it is trained over LJ and tested over WCA and vice versa, reporting the R2 score as a function of normalized temperature. We see that at
. In figure 5 we show the prediction of the MLP when it is trained over LJ and tested over WCA and vice versa, reporting the R2 score as a function of normalized temperature. We see that at  the MLP produces excellent predictions even when it is trained for a different interaction potential. However the quality drops for very low temperature, when minute differences between the LJ and WCA structures are amplified to enormous differences in dynamics [31, 43, 44, 49–51] and configurational entropy [52–54]. In particular the model performs poorly when it is trained using the WCA potential and tested over the LJ data. This is a consequence of the fact that the LJ model becomes a glass at a higher temperature compared to the WCA model [31, 44, 49], so there is a region where the LJ model is infinitely slower than the WCA.
the MLP produces excellent predictions even when it is trained for a different interaction potential. However the quality drops for very low temperature, when minute differences between the LJ and WCA structures are amplified to enormous differences in dynamics [31, 43, 44, 49–51] and configurational entropy [52–54]. In particular the model performs poorly when it is trained using the WCA potential and tested over the LJ data. This is a consequence of the fact that the LJ model becomes a glass at a higher temperature compared to the WCA model [31, 44, 49], so there is a region where the LJ model is infinitely slower than the WCA.

Figure 5. Model transferability of the MLP. We report the R2 score of the model when tested for a different interaction potential not included in the training. The inset qualitatively shows that R corresponds to acceptable predictions.
corresponds to acceptable predictions.
Download figure:
Standard image High-resolution imageOverall we see that it is possible to use data measured from another system to obtain reliable predictions for a different (but relatively similar) system. However those predictions become unreliable at very low T, when approaching the glass transition.
2.2. ES for the memory function
In the previous section we have seen how to numerically correlate static structural information with the dynamics of the system. Such a deep learning approach however does not tell us much about the physics of the system. Here we employ a physics-informed strategy that is created in order to avoid the application of a black box [55, 56], but instead we bound the machine learning model to play the role of a single physical unknown function: the memory function.
In order to develop this physics-informed strategy we start from the exact memory equation that describes the overdamped dynamics of liquids [35]:

where  is a constant representing the vibrational term [22, 34]. While the equation above is formally exact, unfortunately the memory function
is a constant representing the vibrational term [22, 34]. While the equation above is formally exact, unfortunately the memory function  that appears in the integral is unknown, and thus the equation cannot be solved. MCT is based on an uncontrolled approximation of this memory function that lead to excellent semi-quantitative results [34, 41, 57], but its predictions are not able to exactly capture the full phenomenology of the glass transition [44]. While there are some ways to invert equation (5) [51, 58], and various approaches to numerically estimate the memory function [59–62], there is no consensus on the general form of M. More importantly, most of these procedures to calculate M are very sensitive to noise, thus requiring refined data, and overall they are often computationally expensive.
that appears in the integral is unknown, and thus the equation cannot be solved. MCT is based on an uncontrolled approximation of this memory function that lead to excellent semi-quantitative results [34, 41, 57], but its predictions are not able to exactly capture the full phenomenology of the glass transition [44]. While there are some ways to invert equation (5) [51, 58], and various approaches to numerically estimate the memory function [59–62], there is no consensus on the general form of M. More importantly, most of these procedures to calculate M are very sensitive to noise, thus requiring refined data, and overall they are often computationally expensive.
Here we show that it is possible to effectively parameterize M as a sum of stretched exponentials, whose coefficients can be determined by an evolutionary algorithm. In choosing this exponential representation, we have drawn inspiration from theories such as MCT [22, 63] for which the known (albeit approximate) memory function typically has a similar structure as the intermediate scattering function, combined with the fact that  is known experimentally to behave as a stretched exponential for long times [64]. Thus, we represent the memory function in the following way:
is known experimentally to behave as a stretched exponential for long times [64]. Thus, we represent the memory function in the following way:

which is a sum of  stretched exponentials, for a total of
stretched exponentials, for a total of  parameters for every state. Notice that our parametrization also allows for standard or compressed exponentials, according to the value of
parameters for every state. Notice that our parametrization also allows for standard or compressed exponentials, according to the value of  . As previously discussed (section 2.1), we focus only on
. As previously discussed (section 2.1), we focus only on  , which is usually the most important wavevector in simple glassformers such as the systems studied here.
, which is usually the most important wavevector in simple glassformers such as the systems studied here.
The details of our ES are discussed in section 4.4. Briefly, the ES is an optimization technique inspired by evolution and natural selection. It works by creating new generations of memory functions (parameterized as equation (6)) by cross-breeding the previous generation and adding random mutations. For each of them we then solve the memory equation (equation (5)) obtaining  and then we do one step of evolution favoring the individuals that minimize the following loss function:
and then we do one step of evolution favoring the individuals that minimize the following loss function:

which is the squared difference between predicted and observed dynamics. In the supplementary information we verify that the ES solutions are physically reasonable by replacing the intermediate scattering function with the MCT approximation  and confirming that the ES converges towards
and confirming that the ES converges towards  . Notice however that equation (6) allows unrealistic short time non-monotonic behavior, that we observe sometimes. Overall, we believe that our ES solutions still retain a fair degree of realism.
. Notice however that equation (6) allows unrealistic short time non-monotonic behavior, that we observe sometimes. Overall, we believe that our ES solutions still retain a fair degree of realism.
The results of the ES are reported in figure 6. In panel (a) we show that the ES is able to recover the simulated self intermediate scattering function  that we are targeting. The figure presents four curves that range from the liquid to the glass phase. We have also verified that the ES solution converges to the simulated
that we are targeting. The figure presents four curves that range from the liquid to the glass phase. We have also verified that the ES solution converges to the simulated  for any temperature and density that we have available. Even though we have only focused on
for any temperature and density that we have available. Even though we have only focused on  , we speculate that our approach should work for any value of k since the structure of equations (5) and (6) does not depend on k. Note however that, unlike MCT, this parametrized memory function does not contain explicit couplings among different wave numbers, nor any self-consistent feedback mechanism to drive dynamical slowdown.
, we speculate that our approach should work for any value of k since the structure of equations (5) and (6) does not depend on k. Note however that, unlike MCT, this parametrized memory function does not contain explicit couplings among different wave numbers, nor any self-consistent feedback mechanism to drive dynamical slowdown.

Figure 6. Predictions of the evolutionary strategy (ES) for the memory function of binary mixtures, with focus on the dominant AA component at  . We report four state points at different temperature: the red is a warm liquid, the orange is a supercooled liquid, the yellow is a strongly supercooled liquid and blue is a glass. In (a) we see that the ES (solid) perfectly reproduces the simulations (dot-dashed). In panel (b) we report the memory that the ES uses to reproduce the simulated
. We report four state points at different temperature: the red is a warm liquid, the orange is a supercooled liquid, the yellow is a strongly supercooled liquid and blue is a glass. In (a) we see that the ES (solid) perfectly reproduces the simulations (dot-dashed). In panel (b) we report the memory that the ES uses to reproduce the simulated  (solid) and we compare it to MCT (dotted) which produces instead very bad predictions.
(solid) and we compare it to MCT (dotted) which produces instead very bad predictions.
Download figure:
Standard image High-resolution imageIn figure 6(b) we report the results for the memory function. Following the parametrization introduced in equation (6) the ES is able to converge to memory functions that produce the realistic  of figure 6(a). In particular the memory functions presented in figure 6(b) are obtained setting
of figure 6(a). In particular the memory functions presented in figure 6(b) are obtained setting  . We highlight the differences between the M at which the ES converged, with the MCT approximation (dashed lines), that unsurprisingly overestimates the glassiness of these systems [35, 42, 44]. We conclude that the ES method we introduced is an effective way to obtain a realistic memory function.
. We highlight the differences between the M at which the ES converged, with the MCT approximation (dashed lines), that unsurprisingly overestimates the glassiness of these systems [35, 42, 44]. We conclude that the ES method we introduced is an effective way to obtain a realistic memory function.
Lastly we discuss the physical insights that we can harness from our evolutionary approach. We have seen that the ES converges to the simulated intermediate scattering function if we model the memory function following equation (6). Since equation (5) is exact, we know that the real memory function has to produce the same output as our ES when propagated through equation (5). This means that we can look at the structure of our ES solutions to have some intuition about the real memory. In particular, in figure 7 we report the R2 for different parametrizations containing a different number of stretched exponentials and we verify that a good solution needs at least  . In the supplementary information we also show that the second stretched exponential becomes relevant only approaching the glass transition, in the same range where localized unstable modes become relevant [65], and when energy-driven and entropy-driven activation start to compete [66]. We also know that activation and facilitation become relevant only at very low temperature [47, 48]. This suggests that there are at least two separate relaxation channels that real materials follow while relaxing, with the second channel becoming dominant below
. In the supplementary information we also show that the second stretched exponential becomes relevant only approaching the glass transition, in the same range where localized unstable modes become relevant [65], and when energy-driven and entropy-driven activation start to compete [66]. We also know that activation and facilitation become relevant only at very low temperature [47, 48]. This suggests that there are at least two separate relaxation channels that real materials follow while relaxing, with the second channel becoming dominant below  , i.e. the temperature that is often identified with a crossover [67]. It is important to recall however that the
, i.e. the temperature that is often identified with a crossover [67]. It is important to recall however that the  used in our work is obtained from fit-parameter-free MCT, while other works have considered different definitions of
used in our work is obtained from fit-parameter-free MCT, while other works have considered different definitions of  , and hence these comparisons should be treated with caution.
, and hence these comparisons should be treated with caution.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 7. Performance of the evolutionary strategy in finding the memory function that correctly predicts the dynamics. We parameterize the memory following equation (6), while the different curves correspond to different values of  . We show that
. We show that  is the minimum number of exponentials to achieve good performances, which corresponds to a total of 27 parameters.
is the minimum number of exponentials to achieve good performances, which corresponds to a total of 27 parameters.
Download figure:
Standard image High-resolution image{kind=link}
Moreover, the results derived from the ES may also provide cues for analytical modeling. Models like MCT invoke uncontrolled approximations to solve equation (5). One possibility is the exponential closure that assumes that ![$M^{\alpha\beta}(k,t)\sim \exp\left[-\Omega^2_{\alpha\beta}(k) t\right]$](https://content.cld.iop.org/journals/2632-2153/4/2/025010/revision2/mlstacc7e1ieqn86.gif) . This schematic model is simple enough to be solved analytically, but its results are not satisfying [30, 63, 68–70]. Inspired by our ES we may propose a double stretched-exponential memory defined as
. This schematic model is simple enough to be solved analytically, but its results are not satisfying [30, 63, 68–70]. Inspired by our ES we may propose a double stretched-exponential memory defined as

This schematic model retains a structure of equation (5) similar to the exponential closure, but according to our ES results it should be more appropriate to describe the glassy dynamics, provided that it is properly parametrized. Note however that the correct parametrization would still require numerical fitting (e.g. via an ES). Nonetheless, we argue that our ES strategy can be used to explore different functional forms that may improve upon the conventional MCT closure approximation.
In summary we have defined here a simple approach to determine the memory function M given the self-intermediate scattering function  . The ES is fast and reliable across all the temperatures and densities studied. The results suggest that at least two relaxation channels need to be considered, giving rise to the machine-learning-inspired schematic model of equation (8).
. The ES is fast and reliable across all the temperatures and densities studied. The results suggest that at least two relaxation channels need to be considered, giving rise to the machine-learning-inspired schematic model of equation (8).
3. Discussion
The goal of this study was to show how a neural network can understand and predict the dynamics of supercooled liquids from static information. Our approach is based on averaged quantities such as static structure factors that are easier to measure experimentally, compared to particle resolved ones. We are also able to interpret the mechanism of the machine learning model to gain some physical intuition about the glass transition.
In figures 2 and 3 we show that we can train a MLP to efficiently predict the dynamics (represented by the self intermediate scattering function  ), using only statistically-averaged static information. This implies that dynamical information is encoded in the static structure of the system, similarly to how higher-order correlations are partially encoded into two body structure [50]. Furthermore since the main input of our neural network is the static structure factor
), using only statistically-averaged static information. This implies that dynamical information is encoded in the static structure of the system, similarly to how higher-order correlations are partially encoded into two body structure [50]. Furthermore since the main input of our neural network is the static structure factor  , our results corroborate the idea that two body static correlations when elaborated using an expressive approach like our MLP, are enough to describe the dynamics.
, our results corroborate the idea that two body static correlations when elaborated using an expressive approach like our MLP, are enough to describe the dynamics.
One of the main problems in studying systems close to the glass transition is data collection, because experiments and simulations at deeply supercooled temperatures are slow. We show that our MLP performs relatively well when only high temperature data are provided for training (figure 4) or when the MLP is used to make predictions for different variations of the model that is used for training (figure 5). Unfortunately this transferability drops when the system is approaching the glass transition, because we know that minute changes in the structure correspond to enormous changes in the dynamics. Overall this means that, if the interest is in the liquid regime it is possible to fully exploit the MLP transferability by training the model where data is easily available, but to accurately describe the glassy regime, glassy data is actually required.
We then develop a physics-inspired method to obtain an expression for the memory function that realistically describe our data. Instead of using deep learning as a black box to connect statics to dynamics, we rewrite the dynamics as a memory function and we replace this memory with our machine learning model. Our approach circumvents inverse Laplace transforms, which can be computationally expensive, by using an ES that parametrizes a pre-defined functional form for the memory function. We show in figure 6 that the ES easily converges to memory functions that reproduce the real dynamics observed in simulations.
Our physics-inspired evolutionary approach is also able to give some intuition about the physics. The results in figure 7 let us conclude that the memory function can be effectively parameterized as a sum of two stretched exponentials. We can interpret those two stretched exponentials as two relaxation processes that describe the complex multiscale relaxation of the glassy liquid, and we can also see that only one is needed to describe the liquid phase (SI figure S7). One possible interpretation for the existence of two dominant relaxation channels might be dynamic heterogeneity, i.e. the coexistence of transiently fast and slow groups of particles, which is known to emerge at temperatures below  [6, 12, 47]. However, more work is needed to identify the microscopic physical origins of the two stretched exponentials and to pinpoint the temperature regime where this effect is relevant. This intuition motivates us to explore a schematic model where the memory function is exactly represented as two stretched exponentials, but we leave that for future work.
[6, 12, 47]. However, more work is needed to identify the microscopic physical origins of the two stretched exponentials and to pinpoint the temperature regime where this effect is relevant. This intuition motivates us to explore a schematic model where the memory function is exactly represented as two stretched exponentials, but we leave that for future work.
In conclusion, we have introduced two data-driven tools to evaluate and describe the dynamics of supercooled liquids. The neural network that we propose can be efficiently trained and deployed to predict the self-intermediate scattering function from averaged quantities which are simple to measure experimentally. Lastly we have discussed a way to obtain an effective memory function using an ES, concluding that the memory can be reasonably represented as a sum of two stretched exponentials. We believe that our machine-learning method, once trained, can be efficiently applied to predict the dynamics of many other glass forming mixtures and that data-driven approaches to find suitable functional forms of the memory function may help guide the development of more effective theories to describe the glass transition.
4. Methods
4.1. Computer simulations
The models reported in this paper have been trained and tested using simulation data of two binary mixtures: the Kob–Andersen binary LJ mixture [71] and its WCA truncation [72]. They are three-dimensional  mixtures of particles
mixtures of particles  interacting with each other via
interacting with each other via

where the cutoff radius  is
is  for LJ, and
for LJ, and  is
is  for WCA [72]. The choice of
for WCA [72]. The choice of  secures that
secures that  . As usual [71], we set
. As usual [71], we set  .
.
For these mixtures we perform molecular dynamics simulations in the NVE ensemble using HOOMD-blue [73]. First we equilibrate the system at different densities  and temperatures
and temperatures  We impose periodic boundary conditions and set the box at
We impose periodic boundary conditions and set the box at  while tuning the density by changing the number of particles
while tuning the density by changing the number of particles ![$N\in \left[1200,2000\right]$](https://content.cld.iop.org/journals/2632-2153/4/2/025010/revision2/mlstacc7e1ieqn103.gif) . All the particles have the same mass m. We run the simulations for 108 timesteps of size
. All the particles have the same mass m. We run the simulations for 108 timesteps of size  with
with  , which allows us to sample up to
, which allows us to sample up to  . Notice that the trajectories that are deeply in the glass regime (i.e. where
. Notice that the trajectories that are deeply in the glass regime (i.e. where  ) cannot be fully equilibrated due to the ergodicity breaking that defines the glass transition. Additionally, even though the mixture is designed to avoid crystallization, it is still possible for some specific trajectories to crystallize; in that case we remove such occurrences from our data. Finally, we use the simulated trajectories to calculate the partial static structure factors
) cannot be fully equilibrated due to the ergodicity breaking that defines the glass transition. Additionally, even though the mixture is designed to avoid crystallization, it is still possible for some specific trajectories to crystallize; in that case we remove such occurrences from our data. Finally, we use the simulated trajectories to calculate the partial static structure factors  and the self intermediate scattering functions
and the self intermediate scattering functions  .
.
4.2. MLP
We train a MLP to predict the dynamics of supercooled mixtures from static information. The results reported in section 2.1 are produced by a MLP. The network consists of five hidden layers of size  , interposed by ReLU activation functions, that transform the 304 input features
, interposed by ReLU activation functions, that transform the 304 input features  into the output
into the output  . The MLP is trained for 1000 iterations, taking approximately one hour on a standard Intel i7 CPU. We also use
. The MLP is trained for 1000 iterations, taking approximately one hour on a standard Intel i7 CPU. We also use  loss and Lasso regularization [74] with the adam optimization algorithm [75].
loss and Lasso regularization [74] with the adam optimization algorithm [75].
4.3. Memory equation and MCT
In this paper we numerically solve equation (5), which is called the memory equation [35]. This is an equation of the same class as the GLE and we believe that out method can be tailored to solve a wide category of GLE equations with a structure similar to equation (5), using physical intuition.
In general, it is possible to exactly describe the dynamics of liquids by deriving an expression for

from the solution of the overdamped equation

but unfortunately the memory function  is unknown. Notice that in this paper we are mainly interested in solving equation (5) which corresponds to equation (11) if
is unknown. Notice that in this paper we are mainly interested in solving equation (5) which corresponds to equation (11) if  is replaced with
is replaced with  . We will also assume that the memory function is the same in equations (5) and (11).
. We will also assume that the memory function is the same in equations (5) and (11).
The memory equation can only be solved using some approximations like MCT [22, 31, 34, 37, 38, 43], for this reason we also refer to the MCT equation. The MCT approximation applied to equation (5) consists of the following definition of the memory function:

where  is the density of species α and the vertex function corresponds to
is the density of species α and the vertex function corresponds to

with  .
.
So overall, the inputs for the MCT equation are the bulk density ρ, the temperature T, and the structure factor  . In our numerical solution of the MCT equation we follow all the steps discussed in [31, 41, 43, 45] over a grid of
. In our numerical solution of the MCT equation we follow all the steps discussed in [31, 41, 43, 45] over a grid of  points. As an alternative to the MCT approximation, we also solve equation (5) using equation (6) instead of
points. As an alternative to the MCT approximation, we also solve equation (5) using equation (6) instead of  , from the same inputs. In summary, at any given
, from the same inputs. In summary, at any given  we only require
we only require  as input to predict the microscopic relaxation dynamics of the system, either with MCT or with our parametrization of the memory identified by the ES.
as input to predict the microscopic relaxation dynamics of the system, either with MCT or with our parametrization of the memory identified by the ES.
4.4. ES
ES is a class of machine learning optimization algorithms that are inspired by natural evolution in the following way: at every iteration (or generation), a population of parameters (the genotypes) are perturbed by cross-breeding and mutations and their objective function (fitness) is evaluated. Then the highest scoring parameters are recombined to populate the next generation, iteratively until the objective function is optimized. The huge advantage of this class of algorithms is that they do not require back-propagation, which is particularly useful when the objective function is a complex integro-differential equation like our GLE (equation (5)).
We use covariance matrix adaptation evolution strategy [76] (CMA-ES), a widely known method of the ES class which describes the population by a multivariate Gaussian. The algorithm is available as a python package [77]. Another advantage is that it does not require any hyper-parameter except for the initial condition and the population size represented by the initial variance of the gaussian σ. We then use CMA-ES to find the best function  parametrized as equation (6) that reproduces the real dynamics. In practice at each step we propagate
parametrized as equation (6) that reproduces the real dynamics. In practice at each step we propagate  through equation (5) and we compare its output
through equation (5) and we compare its output  to the real dynamics
to the real dynamics  , evaluating the fitness function
, evaluating the fitness function  (equation (7)) for the evolution. We use as initial condition
(equation (7)) for the evolution. We use as initial condition  and for the initial population we set
and for the initial population we set  . We use Lasso regularization to evaluate equation (7). Usually the procedure converges below an error
. We use Lasso regularization to evaluate equation (7). Usually the procedure converges below an error  within a couple of hours of evolution. Results in figure 7 show that the F predicted by ES is very close to the real dynamics, so we conclude that M is well represented by two stretched exponentials.
within a couple of hours of evolution. Results in figure 7 show that the F predicted by ES is very close to the real dynamics, so we conclude that M is well represented by two stretched exponentials.
Acknowledgments
We thank Ilian Pihlajamaa and Vincent Debets for their careful feedback and useful suggestions related to this work. This work has been financially supported by the Dutch Research Council (NWO) through a START-UP grant (LMCJ) and Vidi grant (LMCJ). M D acknowledges financial supportfrom the European Research Council (ERC Advanced Grant No. ERC-2019-ADV-H2020 884902, SoftML).
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.
Author contributions
S C performed the simulations. S C developed the MLP model. S C, M C, E B developed the ES. S C wrote the paper with the help of M C, E B, M D and L M C J. M D, L M C J provided resources and supervision.
Supplementary data (1.7 MB PDF)