
Abstract
Analytic continuation maps imaginary-time Green's functions obtained by various theoretical/numerical methods to real-time response functions that can be directly compared with experiments. Analytic continuation is an important bridge between many-body theories and experiments but is also a challenging problem because such mappings are ill-conditioned. In this work, we develop a neural network (NN)-based method for this problem. The training data is generated either using synthetic Gaussian-type spectral functions or from exactly solvable models where the analytic continuation can be obtained analytically. Then, we applied the trained NN to the testing data, either with synthetic noise or intrinsic noise in Monte Carlo simulations. We conclude that the best performance is always achieved when a proper amount of noise is added to the training data. Moreover, our method can successfully capture multi-peak structure in the resulting response function for the cases with the best performance. The method can be combined with Monte Carlo simulations to compare with experiments on real-time dynamics.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Analytic continuation is an important problem in computational quantum many-body physics [1, 2]. For quantum many-body systems, a variety of methods, ranging from perturbation approximations to quantum Monte Carlo algorithms, are performed in imaginary time and only produce imaginary-time Green's function [3–5]. Nevertheless, to compare with real-time responses measured in experiments, we need the response function or the closely related spectral function  from which the response function can be calculated. On the other hand, the spectral function and the Matsubara frequency representation of the imaginary-time Green's function,
from which the response function can be calculated. On the other hand, the spectral function and the Matsubara frequency representation of the imaginary-time Green's function,  , are related by [6, 7]
, are related by [6, 7]

Hence this relation is crucial to analytically continue the imaginary-time Green's function to real time that connects numerical results to experimental observations.
However, extracting  form the above relation, equation (1), is a difficult problem. Although the mapping from
form the above relation, equation (1), is a difficult problem. Although the mapping from  to
to  is linear, the coefficients decrease and approach zero as Ω increases, making the inverse of such mapping ill-conditioned [8–10]. That is to say, a small noise embedded in
is linear, the coefficients decrease and approach zero as Ω increases, making the inverse of such mapping ill-conditioned [8–10]. That is to say, a small noise embedded in  can be significantly amplified and lead to huge errors in the evaluated
can be significantly amplified and lead to huge errors in the evaluated  . Since
. Since  obtained by various numerical methods inevitably contains noise, thus obtained
obtained by various numerical methods inevitably contains noise, thus obtained  always has large errors, which makes the comparison with experimental measurements unreliable. This is the intrinsic difficulty in the analytic continuation [8–10].
always has large errors, which makes the comparison with experimental measurements unreliable. This is the intrinsic difficulty in the analytic continuation [8–10].
Many methods have been developed to address this problem. One of the most popular approaches is the maximum entropy (MaxEnt) method which aims to find the most probable  that maximizes an entropy functional [11–18]. However, the method is biased toward Gaussian type spectral functions, and sharp peaks or edges in the spectral function can be easily missed. Several stochastic methods have then been proposed to recover these singular features [19–25]. Nevertheless, these stochastic methods are usually time-consuming [28]. Many of the existing methods also rely on prior physical information. For instance, relying on the conjecture of holographic duality and the insight from gravity physics, the analytic continuation has also been applied to study quantum critical dynamics [26].
that maximizes an entropy functional [11–18]. However, the method is biased toward Gaussian type spectral functions, and sharp peaks or edges in the spectral function can be easily missed. Several stochastic methods have then been proposed to recover these singular features [19–25]. Nevertheless, these stochastic methods are usually time-consuming [28]. Many of the existing methods also rely on prior physical information. For instance, relying on the conjecture of holographic duality and the insight from gravity physics, the analytic continuation has also been applied to study quantum critical dynamics [26].
The fast development of applying machine learning methods to physics problems offer a new route to address this problem. The neural network (NN) is a useful tool to express functional mapping that can also tolerant errors. Nevertheless, the neural-network-based methods have only been discussed in few recent works on the analytic continuation problem [27–30]. While these method offer new promise, lots of issues remain open. Especially, since the difficulty of the analytic continuation roots in the amplification of the noise, one basis question is whether we should add noise into the training data and, if so, what is the proper amplitude of the noise. To the best of our knowledge, this issue has not been well studied before. In this work, we systematically study the noise effect in the training dataset. The key finding is that the NN's performance can be significantly enhanced when a proper amount of noise is added to the data.
2. Framework
Below we first introduce our general framework that includes both the training data preparation and the training scheme.
To prepare training data, we need to include a variety of spectral functions  . For each given type of
. For each given type of  , the corresponding imaginary-frequency Green's function
, the corresponding imaginary-frequency Green's function  can be generated according to equation (1). Each pair of
can be generated according to equation (1). Each pair of  contributes one sample in the dataset. Since both the input and the output of NN are discrete, we shall first discretize
contributes one sample in the dataset. Since both the input and the output of NN are discrete, we shall first discretize  and
and  . We discretize Ω into Nout number of points
. We discretize Ω into Nout number of points  in a proper range of Ω, and we normalize
in a proper range of Ω, and we normalize  to
to  such that
such that  . Then, the output spectral function
. Then, the output spectral function  is represented by a discretized vector
is represented by a discretized vector  . For the input Green's function,
. For the input Green's function,  where
where  and β is set as unity.
and β is set as unity.  is generally a complex number. To mimic the inevitable noise in the calculated
is generally a complex number. To mimic the inevitable noise in the calculated  from various numerical methods, we add a randomly sampled noise individually for each point ωn
, i.e.
from various numerical methods, we add a randomly sampled noise individually for each point ωn
, i.e.

where noise δ and  satisfy a Gaussian distribution with zero mean and standard deviation η. The input Green's function
satisfy a Gaussian distribution with zero mean and standard deviation η. The input Green's function  is then represented by a discretized vector
is then represented by a discretized vector ![$\{\textrm{Re}[\tilde{\mathcal{G}}(i\omega_n)],\textrm{Im}{[}\tilde{\mathcal{G}}(i\omega_n) {]} {|} \{n = 1,\dots,N_{\textrm{in}}\}\}$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn29.gif) .
.
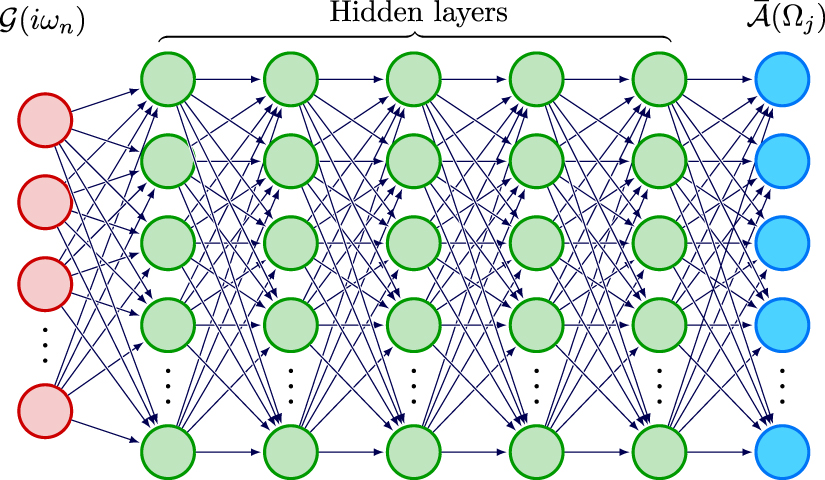
The multi-layer fully connected NN used in this work is depicted in figure 1. The input layer is the discretized  , and the output layer is the discretized
, and the output layer is the discretized  . The training process is carried out with the Adam optimizer [31], and the Kullback-Leibler divergence is used as the training loss function, which is defined as
. The training process is carried out with the Adam optimizer [31], and the Kullback-Leibler divergence is used as the training loss function, which is defined as

where t labels samples in the dataset.  are the labels and
are the labels and  are the outputs of the NN. After training, the mean absolute error on the testing set is chosen to evaluate the performance, which is defined as
are the outputs of the NN. After training, the mean absolute error on the testing set is chosen to evaluate the performance, which is defined as

Here the summation runs over all samples in the testing dataset, and  is the product of the dimension of the output and the number of samples in the testing dataset. For all training processes, 105 number of training samples and
is the product of the dimension of the output and the number of samples in the testing dataset. For all training processes, 105 number of training samples and  testing samples are prepared.
testing samples are prepared.

Figure 1. Schematic of the fully-connected NN for the analytic continuation problem. The first layer (red) denotes the input of discretized imaginary-time Green's function ![${\textrm{Re}}/{\textrm{Im}}[\mathcal{G}(i\omega_n)]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn36.gif) . The last layer (blue) denotes the output of discretized spectral function
. The last layer (blue) denotes the output of discretized spectral function  . In between, there are five hidden layers (green) with the same number of neurons as the output layer.
. In between, there are five hidden layers (green) with the same number of neurons as the output layer.
Download figure:
Standard image High-resolution image3. Results
Below we will present our results on two cases, one on synthetic spectral functions and the other on the transverse field Ising model.
3.1. Synthetic spectral functions
We generate the synthetic spectral function as a summation of Gaussian distributions.

Here  denotes a Gaussian distribution centered at µ with width σ, that is
denotes a Gaussian distribution centered at µ with width σ, that is

The coefficients λi
take random value in ![$[0,1]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn41.gif) under the constraint
under the constraint  , which ensures the normalization condition
, which ensures the normalization condition  . Here the maximum number of Gaussian components is three. The mean value µ of each Gaussian distribution ranges from
. Here the maximum number of Gaussian components is three. The mean value µ of each Gaussian distribution ranges from ![$[-6,6]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn44.gif) and the width σ ranges from
and the width σ ranges from ![$[0.1,4]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn45.gif) . Since these synthetic spectral functions are made of Gaussian components, their corresponding imaginary-frequency Green's function
. Since these synthetic spectral functions are made of Gaussian components, their corresponding imaginary-frequency Green's function  can be exactly calculated according to equation (1).
can be exactly calculated according to equation (1).
After training, the performance of the NN is measured by the mean absolute value  on the testing dataset. Here we add noise with amplitude ηtest into the testing dataset in order to mimic the inevitable noise in numerical simulations.
on the testing dataset. Here we add noise with amplitude ηtest into the testing dataset in order to mimic the inevitable noise in numerical simulations.  is plotted in figure 2(a) for different values of ηtest. Smaller of
is plotted in figure 2(a) for different values of ηtest. Smaller of  indicates better performance of the trained NN. Figure 2(a) shows that, if ηtrain is below ηtest,
indicates better performance of the trained NN. Figure 2(a) shows that, if ηtrain is below ηtest,  becomes large and the NN does not perform well.
becomes large and the NN does not perform well.  approaches the optimal performance when
approaches the optimal performance when  . Then,
. Then,  slowly increases when
slowly increases when  .
.

Figure 2. The performance is measured by the mean absolute error  when the trained NN are applied to the testing dataset. The NN are trained with a given training dataset with noise strength ηtrain, and
when the trained NN are applied to the testing dataset. The NN are trained with a given training dataset with noise strength ηtrain, and  is plotted against ηtrain. (a) Synthetic spectral function. Different curves correspond to different noise strength ηtest of the testing dataset. (b) The transverse field Ising model. The quantum Monte Carlo simulation generates the testing dataset with unknown noise strength.
is plotted against ηtrain. (a) Synthetic spectral function. Different curves correspond to different noise strength ηtest of the testing dataset. (b) The transverse field Ising model. The quantum Monte Carlo simulation generates the testing dataset with unknown noise strength.
Download figure:
Standard image High-resolution imageFigure 3(a) shows a concrete typical example in the testing dataset with noise amplitude  . Here we show the NN results with and without noise in the training data, and we also show results from the MaxEnt method for comparison. As one can see, both the MaxEnt method (brown dotted line) and the NN results without noise (green dot-dashed line) miss the first peak. The MaxEnt method tends to generate a smooth and simple distribution with minimal singularities. In contrast, the results can be significantly improved when noise is added into the training data and when the noise amplitude is comparable with that in the test data. The blue dashed line shows that the NN result with
. Here we show the NN results with and without noise in the training data, and we also show results from the MaxEnt method for comparison. As one can see, both the MaxEnt method (brown dotted line) and the NN results without noise (green dot-dashed line) miss the first peak. The MaxEnt method tends to generate a smooth and simple distribution with minimal singularities. In contrast, the results can be significantly improved when noise is added into the training data and when the noise amplitude is comparable with that in the test data. The blue dashed line shows that the NN result with  can successfully capture both positions, amplitudes, and widths of two peaks in the spectral function, with tiny error compared with the exact results (solid red line). Hence, we show that our NN can successfully predict the spectral function, and the performance of the NN can be enhanced by adding noise properly into the training dataset.
can successfully capture both positions, amplitudes, and widths of two peaks in the spectral function, with tiny error compared with the exact results (solid red line). Hence, we show that our NN can successfully predict the spectral function, and the performance of the NN can be enhanced by adding noise properly into the training dataset.

{kind=link}
{kind=link}
Figure 3. Predictions of the NN. Red solid lines are the exact spectral functions. Blue dashed lines are the result of NN trained with the dataset with optimal noise. Green dot-dashed lines are the result of NN trained without noise. The brown dotted lines are the result of the maximum entropy method. (a) Shows an example from synthetic spectral functions, and (b) shows an example from the transverse field Ising model.
Download figure:
Standard image High-resolution image{kind=link}
3.2. The transverse field Ising model
For synthetic spectral functions, we know precisely the amount of noise we add into the testing dataset. However, noise is always unavoidably generated from numerical simulations and its amplitude is generally not precisely known. To address such situations, we consider the one-dimensional transverse field Ising model, whose Hamiltonian reads

where  are the standard Pauli operators on site l. Here g is the transverse field strength, J is the coupling along z-direction which will be set as a unit below, and the boundary condition is taken to be periodic. Since this model can be solved exactly by mapping to free fermions using the Jordan–Wigner transformation, closed analytic forms of both
are the standard Pauli operators on site l. Here g is the transverse field strength, J is the coupling along z-direction which will be set as a unit below, and the boundary condition is taken to be periodic. Since this model can be solved exactly by mapping to free fermions using the Jordan–Wigner transformation, closed analytic forms of both  and
and  can be obtained (see appendix
can be obtained (see appendix  , which contributes one sample to the training dataset. For the testing dataset, the imaginary-time Green's function
, which contributes one sample to the training dataset. For the testing dataset, the imaginary-time Green's function  is computed using a Worm-type quantum Monte Carlo method (see appendix
is computed using a Worm-type quantum Monte Carlo method (see appendix  are still obtained by the exact mapping to free fermions under the same parameters q and g.
are still obtained by the exact mapping to free fermions under the same parameters q and g.
Figure 2(b) shows  as a function of ηtrain. In this case, it also shows a clear minimum around
as a function of ηtrain. In this case, it also shows a clear minimum around  . This result means that the most proper noise strength also exists, even though the intrinsic numerical noise in the testing dataset may not be Gaussian type. With the optimum noise strength, the trained NN outputs the best prediction for the testing dataset produced by the quantum Monte Carlo simulations. One example is shown in figure 3(b). Compared with the synthetic spectral function shown in figure 3(a), the spectral function of the transverse field Ising model is much more singular and contains sharp edges. Moreover, a dark continuum [33], a finite region with vanishing
. This result means that the most proper noise strength also exists, even though the intrinsic numerical noise in the testing dataset may not be Gaussian type. With the optimum noise strength, the trained NN outputs the best prediction for the testing dataset produced by the quantum Monte Carlo simulations. One example is shown in figure 3(b). Compared with the synthetic spectral function shown in figure 3(a), the spectral function of the transverse field Ising model is much more singular and contains sharp edges. Moreover, a dark continuum [33], a finite region with vanishing  , exists between the two peaks. With the optimal noise strength, the trained NN correctly resolves both the positions and height of the two peaks, the locations of the sharp edges and the dark continuum. In comparison, the MaxEnt method fails to capture these features of the spectral function. The NN trained without noise also produces two peaks, but the fluctuations are much stronger, especially in the dark continuum.
, exists between the two peaks. With the optimal noise strength, the trained NN correctly resolves both the positions and height of the two peaks, the locations of the sharp edges and the dark continuum. In comparison, the MaxEnt method fails to capture these features of the spectral function. The NN trained without noise also produces two peaks, but the fluctuations are much stronger, especially in the dark continuum.
4. Summary and outlook
In summary, we have developed a NN-based method for analytic continuation. The training data is generated either from synthetic Gaussian type spectral functions or by the exact solution of the transverse field Ising model, where the analytic continuation can be done analytically. The validity of this method is demonstrated with data obtained from quantum Monte Carlo simulations. The main finding of this work is that a proper amount of noise has to be added to the training data in order to reach optimal performance. Our NN-based method can be easily applied to perform analytic continuation of Monte Carlo results from other models, such as the Bose–Hubbard model and the anisotropic Heisenberg models, and compare the analytic continuation results with experimental measurements of real-time dynamics, such as quantum simulation experiments with ultracold atomic gases.
Acknowledgments
We thank Lei Wang for helpful discussions. This work is supported by NSFC Grant No. 11904190 (J Y), 11734010 (H Z), and Beijing Outstanding Young Scientist Program (H Z).
Data availability statement
The data that support the findings of this study are openly available at the following URL/DOI: https://github.com/jy19Phy/Noise-Enhanced-Neural-Networks-for-Analytic-Continuation.
Appendix A.: Exact solution for the transverse Ising model
For the transverse Ising model, it is possible to obtain the analytic expressions of both the imaginary-time Green's function and the spectral function. The first step is to rotate the spins along the y-axis for negative 90 degrees which defines the following new spin operators  ,
,

The next step is to perform the standard Jordan–Winger transformation that maps spin operators to fermion operators  and
and 

where  is the fermion occupation operator at site m. In terms of these fermionic operators, the resulting Hamiltonian of equation (7) is quadratic,
is the fermion occupation operator at site m. In terms of these fermionic operators, the resulting Hamiltonian of equation (7) is quadratic,

The boundary condition becomes  where L is the number of sites and
where L is the number of sites and  is the fermion parity operator. After a phase rotation of the operator
is the fermion parity operator. After a phase rotation of the operator  by
by  , in momentum space the Hamiltonian assumes the form
, in momentum space the Hamiltonian assumes the form

where the prime means summation over different pairs of k and −k except for k = 0, d is the lattice spacing, and  with L being the lattice size. One can then easily diagonalize the Hamiltonian by the standard Bogoliubov transformation, resulting in a free fermion Hamiltonian
with L being the lattice size. One can then easily diagonalize the Hamiltonian by the standard Bogoliubov transformation, resulting in a free fermion Hamiltonian

where  (
( ) is the new fermion creation (annihilation) operator of momentum mode k and
) is the new fermion creation (annihilation) operator of momentum mode k and  is the corresponding quasi-particle energy. The explicit expression of the Bogoliubov transformation reads
is the corresponding quasi-particle energy. The explicit expression of the Bogoliubov transformation reads

where θk
is determined by ![$\tan2\theta_k = J\sin(kd)/[g-J\cos(kd)]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn78.gif) .
.
We choose to study the imaginary-time spin-spin correlation function along the x-direction,

where  is the imaginary-time Heisenberg operator and
is the imaginary-time Heisenberg operator and  denotes the time-ordering operator. This correlator corresponds to the density-density correlation function in terms of the Jordan–Wigner fermion
denotes the time-ordering operator. This correlator corresponds to the density-density correlation function in terms of the Jordan–Wigner fermion  . Since the Hamiltonian equation (A3) or (A5) is quadratic, the correlator can be evaluated using Wick's theorem. After a tedious but straightforward calculation, the momentum and frequency representation of the correlator
. Since the Hamiltonian equation (A3) or (A5) is quadratic, the correlator can be evaluated using Wick's theorem. After a tedious but straightforward calculation, the momentum and frequency representation of the correlator  ,
,

which takes the following explicit form

Here fk
is the Fermi–Dirac distribution function  and
and  is the even Matsubara frequency where
is the even Matsubara frequency where  . With the analytical formula of
. With the analytical formula of  , we can then analytically perform the analytic continuation and read out the spectral function,
, we can then analytically perform the analytic continuation and read out the spectral function,

In conclusion, both the Green's function or the correlator  and the spectral function
and the spectral function  can be evaluated exactly according to equations (A9) and (A10) for each g, with J being the energy unit. For preparation of the training dataset, setting temperature
can be evaluated exactly according to equations (A9) and (A10) for each g, with J being the energy unit. For preparation of the training dataset, setting temperature  and interaction strength g ranging from 0.5 J to 2.0 J with interval 0.1 J. For each parameter g, the momentum q will be discretized into
and interaction strength g ranging from 0.5 J to 2.0 J with interval 0.1 J. For each parameter g, the momentum q will be discretized into ![$(0, 0.01, 2\pi]$](https://content.cld.iop.org/journals/2632-2153/3/2/025010/revision2/mlstac6f44ieqn90.gif) and setting d as the unit length. Here in this transverse problem,
and setting d as the unit length. Here in this transverse problem,  does not obey the normalization relation
does not obey the normalization relation  . Thus the mean-square error is adopted for the training process.
. Thus the mean-square error is adopted for the training process.
Appendix B.: Quantum Monte Carlo simulation of the transverse Ising model
We closely follow reference [32] to map spin operators into hard-core boson operators such that the resulting partition function can be efficiently sampled by the Worm algorithm [34, 35]. We first perform a spin rotation around the y-axis for 90 degrees and the spin rotational operators  is defined as
is defined as

For the negative rotation, the corresponding boson Hamiltonian in this time can be written as a sum of the kinetic term  and the potential energy term
and the potential energy term  ,
,

where


and

Here we have omitted unimportant constants. Employing the expansion

where  is the imaginary time ordering operator and
is the imaginary time ordering operator and  . In the Fock basis a typical term (out of 2n
terms) in the nth order expansion of the partition function reads
. In the Fock basis a typical term (out of 2n
terms) in the nth order expansion of the partition function reads

since the matrix element of the both hopping and pair creation/annihilation is one. Here  is the potential energy of the hard-core bosons at imaginary time τ. As is clear from equation (B6), the weight of the configuration is positive and can be sampled by the Monte Carlo method. Following the detailed update procedures in [32], the partition function can be efficiently sampled by Worm-type algorithms. The imaginary-time Green's function
is the potential energy of the hard-core bosons at imaginary time τ. As is clear from equation (B6), the weight of the configuration is positive and can be sampled by the Monte Carlo method. Following the detailed update procedures in [32], the partition function can be efficiently sampled by Worm-type algorithms. The imaginary-time Green's function  defined in equation (A7) just corresponds to
defined in equation (A7) just corresponds to  asides from unimportant constants. Since
asides from unimportant constants. Since  is diagonal in the Fock basis, the statistics can be easily accumulated in Monte Carlo simulations. We perform the simulation with system size L = 100 at various values of transverse field g to prepare the training and testing datasets.
is diagonal in the Fock basis, the statistics can be easily accumulated in Monte Carlo simulations. We perform the simulation with system size L = 100 at various values of transverse field g to prepare the training and testing datasets.