
Abstract
The trade-off between the number of friendships and the closeness of friendships of humans arises due to the limitations of time and cognitive capacities for communication. This trade-off distinguishes asynchronous text communication through the internet (lightweight communication) from face-to-face communication and the social grooming of primates (elaborate communication). This study modelled communication as messaging flows driven by edge and node activations to investigate micro-mechanisms that realise the trade-off law and the differences between the two types of communications. We observed the emergence of five patterns of social structures depending on the strengths of the two types of activations, namely, edge and node activations. The two patterns that show known statistics on empirical studies, such as the trade-off and power-law distributions of closeness, emerged around a threshold between elaborate and lightweight communications, where network structures qualitatively changed. A balance between edge and node activations shifts one pattern (elaborate communication) to another pattern (lightweight communication). Consequently, relation networks that communicate through lightweight communication become less clustered. These results suggest how communication systems construct different social structures, e.g., the impact of popularising the internet.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Social animals, particularly humans, develop social relationships through communication, such as grooming and conversation, for survival and reproductive success [1, 2]. Several new communication methods, such as e-mails, micro-blogs, social networking services (SNS), avatar chat applications, and video call communications, have been developed for human society. These methods have produced changes in social relationship structures [3].
Previous studies [3–7] observed a power law in the distributions, which show the frequency of message passing in such communications. People often send messages to some specific one in a biased manner. Intimate relationships can be established in this way [3, 8]. In the previous study [9], these friend relationships are classified into primary, intimate, best and good friends, etc in a hierarchical manner. The group size distributions follow geometric series in several datasets on social relationships [2]. The bias in the distributions is realised with a trade-off between the number of the relationships and the strength of the relationships [3, 10, 11].
Functional components are reflected in the features of network structure. People and other animals tend to cooperate with their close partners [12–16]. A few fixed relationships, i.e., limited close relationships, help to keep reciprocal relationships [17, 18]. In contrast, people often obtain novel information via weak relationships that connect different communities [1, 19–22]. We can observe the power law in the messaging in any type of communication [3–7]. On the contrary, we observe different types of social structures along with those types[3]. There is a report [3], which says that social structures are evaluated, which describes the relation between the number of relationships and strength of relationships. The law is described by the equation, C = kqa , where k and q are the number of relationships and the mean strength of these relationships, respectively, and C is the cost of the maintenance or creation of the social relationships. The trade-off parameter a reveals two types of communication methods that qualitatively differ by the threshold a = 1. The different communication method types form different social relationship structures.
Strong relationships can be established easily if the exponent a is small (0 < a < 1) [3]. In the several data set on real communications, e.g. F2F, telephone and baboon grooming, the exponent, a, is in the range between 0 and 1, 0 < a < 1 [3]. Several of these cases involve common features, strong temporal and spatial limitations, and high messaging cost. Previous study [3] classified such communication as elaborate communication. People establish intimate relationships via elaborate communication which creates better impressions [23–25]. The reverse causality is also true in humans. They communicate more in an elaborate manner if they share close relationships [26].
In contrast, cases with a larger exponent (1 < a) often produce weak social relationships [3]. Examples include twitter, e-mail, and SNS, i.e., recently developed communication tools. Several of these ones are asynchronous systems with low communication cost (lightweight communication).
We aim to investigate how human communication behaviour generates a qualitative difference between communication methods based on the trade-off between the number of relationships and the strength of relationships. In this study, we investigate the relationship between social structures and communication types by using an agent-based model of artificial society considering elaborate and lightweight communications [27] and discuss possible connections between social structures and the types of communication. This model enables a discussion of the trade-off parameter a, as shown in a previous work [27]. In this paper, we focus on the relationships between the parameter a and social network structures. Additionally, we improve the evaluation of a for approximating the a in the previous study [3]. In concrete terms, we introduce a unit of window (refer to the statistical values section for details) and use all relationships (the previous study removes weak relationships as noise). After introducing the model, we present the results that demonstrate both the power law in communication frequency and the trade-off law between the number of relationships and the strength of relationships. Next, we show the relationships between the trade-off parameter a and social network structures. Finally, we discuss the observed patterns.
2. Materials and methods
2.1. Model
Agents communicate with each other by sending messages in our artificial society model. The messaging strengthens the relationships between them. We set two types of memory for messaging histories, in each agent (figure 1): histories of receiving events and histories of senders. The histories of receiving events enhance the agent's messaging frequency, regardless of the senders. The histories of senders enhance the messaging frequency to the specific senders. Agents having perfect memory with all senders will communicate only with intimate communication partners. In the case of no memory on senders, agents will send much more messages to randomly selected ones after receiving messages. Here, we refer to these two types of activations as node activation and edge activation, respectively. Agents send messages to someone randomly, with the node activation, like information cascade [28]. On the contrary, agents send messages to the sender as a reply, with edge activation [28, 29].

Figure 1. Two types of activation patterns.
Download figure:
Standard image High-resolution imageAgent i has a messaging tendency λij to another agent j. The tendency can be expressed by the equation
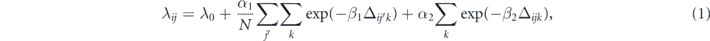
where N is the number of agents, Δijk is the elapsed time from the kth signal from j to i; λ0 is the background tendency; and the other parameters, α1, α2, and β1, β2, are the weights on the node and edge activations and forgetting coefficient, respectively. That is, α indicates the activation impact upon receiving, and β indicates the forgetting speed.
We introduce the upper limit L of the number of simultaneous messages; i.e., the time and cognitive capacities of an agent are finite [30–32]. With the tendency λij , agents choose L other agents in the roulette selection method and send messages to them if the tendency λij is sufficiently large (∑j λij > L). Otherwise, agent i sends a message to j by interpreting λij in terms of probability.
At each step, specific agents are selected as receivers for all the agents, and messages are sent.
2.2. Parameter settings
We conducted experiments with fixed parameters α1 = 10.0 and α2 = 10.0. Subsequently, we tested some values {10cn } (c = 0.25, n = −12, ..., 7) for β1 and β2, respectively. Values for α1 and α2 were simultaneously tested, and no significant difference from the original case could be observed (see figure A1). We iterated T = 1000 steps with these parameters. The number of agents was N = 1000, and the limit was L = 5.
2.3. Statistical values
To characterize the steady state in each test, we took stats only on the latter duration; T > 500. We confirmed that the data in the cases with 1500 ⩽ T ⩽ 2000 did not differ from those in the case of 500 ⩽ T ⩽ 1000. Thus, the results show the values in the steady states.
For statistics, we computed some values according to the previous study [3] as follows: (1) the strength of the relationships, wij , which is the number of activation windows from agent i to j (figure 2). (2) the summation of the strength of the relationships of agent i, mi = ∑j wij , (3) the number of relationships or edges of agent i, ki , (4) the mean strength of the relationship of agent i, qi = mi /ki , and (5) the available social capital of agent i, Ci , which is the total number of activation windows, where the window size s is 8 steps.

Figure 2. Strength of the relationship from i to j (wij ) counted as the number of activation windows h, where i sends messages one or more times. In this figure, wij = 4. This result represents a day in the previous work [3]; i.e., wij is the total number of days on which i sends messages one or more times to individual j.
Download figure:
Standard image High-resolution imageThe window shows the difference in time scales between messaging and life rhythm, such as a day. The difference in the trade-off parameter a emerges depending on how people distribute their limited communication resources, such as time and cognitive resources, in a window [3].
Exponent a was evaluated along the linear regression, log ki = a log qi + b log Ci [3]. We classified exponents with a one-sided test into three classes, a < 0, 0 < a < 1, 1 < a, if the p-value was sufficient, ⩽0.05; otherwise, we classified them as a = 0 or a = 1.
2.4. Normalisation of the number of relationships
There are some reports on the magic number of relationships in human society with a variety of communication methods [33–37]. Some previous studies [33, 36, 37] have shown the possibility that this magic number does not depend on communication tools (it is approximately 150, known as Dunbar's number). In contrast, other studies have pointed out the possibility that online social networks change the magic number (approximately 65 [34] and 200–300 [35]). At all events, these magic numbers do not seem to extremely increase, i.e., at most ∼O(102) . This finding is attributed to the limitations of the time and cognitive capacities for communication [3, 33, 36].
In this paper, as previously mentioned, we defined the number of edges, k, which shows the relative magnitude of relationship diversity, for convenience. We also normalised the strength of the relationships with the value, k, as follows:  , where
, where  . Consequently,
. Consequently,  (i.e. (1/N)∑j
k'j
= 1),
(i.e. (1/N)∑j
k'j
= 1),  , and
, and  . In the following section, we indicate w', k', m', and q' as w, k, m, and q, respectively.
. In the following section, we indicate w', k', m', and q' as w, k, m, and q, respectively.
3. Results
Figure 3(a) shows the phase diagram of the trade-off parameter a. The other parameters also showed similar trends (L = 2 (figure A2) and 10 (figure A3), s = 5 (figure A4) and 40 (figure A5). This finding describes the five classes of exponent a on β1 and  with the fixed parameters α1 and α2, which included both elaborate communication (0 < a < 1) and lightweight communication (1 < a).
with the fixed parameters α1 and α2, which included both elaborate communication (0 < a < 1) and lightweight communication (1 < a).

Figure 3. Results of the simulation experiments.
Download figure:
Standard image High-resolution imageFigure 3(b) shows a heat map of the Gini coefficient based on the relationship strengths wij . This map shows that heavily biased relationship strength distributions were realised in the balanced region between the forgetting coefficients β1 and β2. This area included both types of communication (0 < a < 1 and 1 < a). In this area, a was approximately 1 (figure 4(a)), which is the threshold between elaborate communications and lightweight communications.

Figure 4. Peak of the Gini coefficient and the rapid increase of the clustering coefficient around the threshold a = 1. The high-Gini-coefficient region showed mixed patterns 3 and 4. The red lines represent a = 1.
Download figure:
Standard image High-resolution imageFigure 3(c) shows the directed weighted clustering coefficients (local total clustering coefficients) [38]. The other directed weighted clustering coefficients (local cycle clustering coefficients, local in clustering coefficients, and local out clustering coefficients) showed similar trends. These results show that node activation (low β1 and high β2) promoted highly clustered networks (figure 5(a)). In contrast, edge activation (high β1 and low β2) formed poorly clustered networks (figure 5(b)). This clustering coefficient showed a phase transition by a as a threshold of a = 1 (figure 4(b)). A high Gini coefficient was observed around the critical point (figure 4(c)).

Figure 5. Higher clustering observed in a network with node activation than in a network with edge activation. Node activation can create feedback loops; that is, it facilitates ternary relationships (a). In contrast, edge activation reinforces node-to-node relationships (b); that is, it facilitates only binary relationships.
Download figure:
Standard image High-resolution imageConsequently, we classified this region into five sub-regions according to the categories of a (figure 3(a)) and high/low regions of Gini and clustering coefficients (figures 3(b) and (c), respectively), which are characterised by five typical patterns, as shown in figure 3(d). These are the a < 0 region (pattern 1), the 1 < a, low Gini coefficient, and clustering coefficient region (pattern 2), the 1 < a, high Gini coefficient, and around the boundary of clustering coefficient region (pattern 3), the 0 < a < 1, high Gini coefficient, and around the boundary of clustering coefficient region (pattern 4), and the 0 < a < 1, low Gini coefficient, and high clustering coefficient (pattern 5). The findings presented in figure 3(d) differ from those of previous work [27] due to the improved calculation of a.
Both features, i.e., the power law in the relationship strengths w and the trade-off between the number of relationships and the strength of these relationships, were confirmed in patterns 3 and 4.
Figure 6 shows the relationship strength distributions. In these plots, we employed the parameters, (56.23, 56.23), (10.0, 0.01), (1.0, 0.178), (0.056, 0.001), and (0.001, 0.178), for β1 and β2 in the five respective patterns. We confirmed the power law in patterns 3 and 4. In all degree distributions, we observed Poissonian; i.e., these networks have no significant feature in the degree distribution.

Figure 6. Typical distributions of w on each pattern. Figures (c)–(e) show the log–log plots of the distributions of w as they are skewed. Note that we cannot compare the horizontal axis w among figures (a)–(e) owing to the normalisation based on Dunbar's number.
Download figure:
Standard image High-resolution imageFigure 7 shows the relationships between the strength of social relationships and the number of social relationships. In these plots, we employed the same parameters shown in figure 6. Their a values were −0.909(0.000), 4.750(0.000), 1.100(0.000), 0.904(0.000), and 0.909(0.000) (their p-values are shown in parentheses). The trade-off law C = kqa was confirmed between the number of social relationships and the strength of the social relationships in patterns 2, 3, 4, and 5.

Figure 7. Scatter plots of log k and log q. These figures show log10 k/log10 C and log10 q/log10 C to remove the effect of covariate C from the relationships between k and q. The blue lines are regression lines.
Download figure:
Standard image High-resolution imageWe observed five patterns. In pattern 1, exponent a became negative (a = −0.901), as shown in figure 7. As the forgetting coefficients β1 and β2 were very large, the messaging tendency λij did not increase and λij ∼ λ0. Consequently, the correlated k and q increased owing to the number of activations based on λ0. This pattern indicates that messaging is considered a Poisson process (figure 6(a)) due to random messaging. Consequently, there was no specific relationship between the number of relationships and the strength of these relationships in social communication.
In patterns 2–5, we confirmed a higher tendency (see figure A6), λij , which indicates that the memory in each agent affects the messaging frequency, wij , and thus the number and strength of social relationships.
In pattern 2, the exponent was largely positive (a = 5.165). The forgetting coefficient β1 was large, whereas β2 was small. These values of β1 and β2 indicate that node activation was quickly lost, whereas edge activation lasted for a longer period. Therefore, some specific edges were strongly activated, as shown in figure 6(b). In contrast, in principle, node activation did not grow with the limitation of messages L. Consequently, the trade-off was very strong as the messages in each window were concentrated to a few edges, as, for example, when people have a chat with a few close friends all day.
In patterns 3 and 4, the trade-off between the number of social relationships and the strength of social relationships was observed, as shown in figures 7(c) and (d), where a was 1.100 and 0.904, respectively. These messaging frequencies showed power-law distributions (figures 6(c) and (d)). Both patterns emerged around the critical point a = 1 (figure 4), i.e., a high-Gini-coefficient region, where β1 and β2 were balanced and β1 was slightly greater than β2. Additionally, the node and edge activations of pattern 3 were weaker than those of pattern 4.
The transition from pattern 3 to pattern 4 appeared to arise with a decrease in β2, i.e., with strengthening edge activation. In the transition region, i.e., around the critical point, the network structures changed. The Gini coefficients increased with an increase in a (correlation coefficient: 0.411(0.000) when 0.9 < a < 1.1). The clustering coefficients decreased with an increase in a (correlation coefficient −0.820(0.000) when 0.9 < a < 1.1). The networks of pattern 4 were less biased of closeness and more clustered than those of pattern 3.
Thus, in the transition between pattern 3 and pattern 4, the clustered coefficients increased with strengthening edge activation, in contrast to extreme situations (figure 5). Around the critical point, such as the balanced region between edge activations and node activations, edge activation may have reinforced some specific ternary relationships, i.e., clusters, by converging the messaging of agents. In contrast, node activation appeared to facilitate the scattering and loss of agents' messaging as this activation sends messages to random partners. Consequently, pattern 4 showed more highly clustered networks than pattern 3.
In pattern 5, a small exponent (a = 0.909), 0 < a < 1 (figure 7(e)), was observed once more. The forgetting coefficient β1 was smaller than that in patterns 3 and 4, which caused stronger node activation. In the parameter region, the messaging frequency, λij , showed random messaging. The frequency distribution followed exponential one, as shown in figure 6(e).
For the analysis of information spreading in generated networks in this model, we examined bootstrap percolation, which is an activation process in networks [39]. In an initial step, nodes are activated with the probability p. Inactive nodes become active if their neighbours' effects exceed the threshold κ, where we assume that the effect sizes from j to i are wji
. Node i is activated when  , where Vi
is node i's active neighbours
3
. Activated nodes remain active forever. High p and low κ facilitate information spreading across the whole network. We conducted this iteration process to reach equilibrium.
, where Vi
is node i's active neighbours
3
. Activated nodes remain active forever. High p and low κ facilitate information spreading across the whole network. We conducted this iteration process to reach equilibrium.
In bootstrap percolation on networks, there are 1st- and 2nd-order phase transitions with two critical points depending on the network structures [39, 40]. Around the critical point of the 1st-order transition and 2nd-order phase transition, the number of iterations and the second giant active component, respectively, show maximum values [39].
We observed both phase transitions on the generated networks in our model (figure 8; refer to figure A7 for more cases). There are two cases. Figure 8(a) shows that 1st- and 2nd-order phase transitions occurred. On the other hand, figure 8(b) shows that only 1st-order transition occurred.

Figure 8. Typical cases of the results of bootstrap percolation. These figures show the mean (points) and standard deviation (error bars) of 10 trials. The red lines show pN. In pattern 4 with κ = 2 (figure (b)), the number of active components is always 1; i.e., the 2nd giant active component size does not exist.
Download figure:
Standard image High-resolution imageWhich case occurs depends on the patterns (figure 9). On the networks in patterns 2 and 3, 1st- and 2nd-order phase transitions occurred. In contrast, in patterns 1, 4, and 5, only the 1st-order phase transition occurred.

Figure 9. Critical points of 1st- (black) and 2nd- (blue) order phase transitions for patterns 1–5. In these plots, we used the same parameters as in figure 6.
Download figure:
Standard image High-resolution imageCritical points and the number of iterations to reach equilibrium depend on the patterns (figures 9 and 10, respectively). The values of p and κ on the 1st-order critical points represent the ease of information spreading across the whole network. Information spreading occurred most easily with pattern 2; i.e., p and κ in 1st-order phase transitions were lowest and highest, respectively, followed in order by patterns 3, 4, 5, and 1. On the other hand, the fastest information spreading, i.e., the number of iterations during 1st-order phase transitions, was lowest in pattern 5, followed in order by patterns 4, 3, 2, and 1 (figures 10 and A7(b)). The ease of information spreading was negatively correlated with fast information spreading, excluding pattern 1.

Figure 10. The number of iterations to reach the equilibrium point for patterns 1–5. The color of this figure is logarithmic the number of iterations.
Download figure:
Standard image High-resolution imageThese results are explained by the following reasons: strong connections easily activated connected agents, and sparse networks slowed information spreading (pattern 2). Conversely, high-clustered networks accelerated information spreading and lacked specific strong connections, making information spreading uncertain (pattern 5). This scenario was true for the intermediate cases (patterns 3 and 4) between these extreme cases. On the networks in pattern 4, information spread more slowly and certainly than in pattern 3.
4. Discussion
We investigated how communication types explain social structure using an agent-based model. In the model, agents communicate depending on two types of memory, memory dedicated to message receiving events and memory dedicated to senders, which can realise various communication settings. Although it is often difficult to observe cognitive processes directly, the proposed approach can estimate cognitive mechanisms from the social structure or communication features. Simultaneously, communication logs, which contain information on the social structures or communication features, may realise to investigate the cognitive mechanisms of some specific communication tools.
Humans use multiple types of communication and construct social structures via various communication tools in both real space and cyber space [3]. Therefore, unknown communication tools can create different possible social relationships. Artificial societies are useful to explore these unknown possibilities that may serve as either opportunities or risks.
We constructed a straightforward communication model with two types of memory mechanisms, as the first step towards such an approach, for explaining some existing communication laws. Our model showed five different patterns realised with different forgetting coefficients, β1 and β2.
Among these patterns, known statistics were observed in patterns 3 and 4, i.e., power-law distributions of closeness [3–7] and the trade-off between the number of friendships and the closeness of friendships [3, 7]. These patterns were realised around the critical point a = 1 in the phase transition of the network structures. These networks were rapidly less clustered with an increase in a. Around the critical point, closeness (edge weights of the networks) was strongly biased; consequently, its distribution showed a power law. This region was observed in the condition in which the two forgetting coefficients were moderately mixed.
This result suggests an underlying phase transition in the social network structures by a, which depends on the communication methods. This result also suggests that human communication might be realised around the critical point a = 1, regardless of the communication methods. These phenomena may be explained from the perspective of cognitive mechanisms, such as memory and activation, related to communication.
Pattern 4 (0 < a < 1) showed less biased closeness and more clustered networks than pattern 3 (1 < a). This finding suggests that elaborate communication, such as F2F, telephone, and baboon grooming [3], facilitates the clustering of social networks. The popularisation of lightweight communication methods, such as SNS and e-mails, may facilitate person-to-person relationships regardless of friendships. The closeness of networks on lightweight communication may be biased. It is possible that the popularisation of lightweight communication methods has not affected ego-network sizes (number of relationships of humans) [33, 36]. On the other hand, our results may show that such communication methods have changed social network structures by maintaining the ego-network sizes.
Pattern 4 showed a weaker trade-off and was realised when the forgetting coefficient for the sender (β2) functions better. This result indicates that agents have a stronger memory of senders than that of receiving events. In the real world, this pattern is observed in communication methods, such as F2F, telephone, and baboon grooming [3]. People who adopt these communication methods may tend to concentrate their communication resources on relationships in particular groups and may have clustered ego-networks.
In contrast, pattern 3 showed a strong trade-off between the number of social relationships and the strength of social relationships. It was realised when the forgetting coefficient for receiving events and senders, particularly for the senders, functions worse. This situation occurred when the agents had a weaker memory of the senders. Additionally, the memories of receiving events and senders in pattern 3 were weaker than those in pattern 4. In the real world, this pattern is observed in communication methods, such as twitter, e-mail, and SNS [3]. This communication generated less clustered ego-networks. On these ego networks, the closeness distributions were more biased than those of elaborate communication. This finding suggests that people communicate with other people, regardless of whether these people are friends of their friends, in a lightweight communication system. Networks of online information flow, i.e., communication in a lightweight communication system, have fewer ternary connections [41, 42].
Unknown situations were observed in patterns 1, 2, and 5.
Pattern 1 showed independent Poisson process. This pattern is observed with the higher forgetting coefficients, β1 and β2. This means that communication is very rare and sparse. The firm social relationships can not be established.
At one extreme, the situation with an immense forgetting coefficient β1 was observed in pattern 2. In this case, agents had strong memories of the senders. The relationship was strongly fixed consequently. In this situation, very sparse and static social networks would emerge. The trade-off between the number of relationships and closeness is very strong in these networks.
At the other extreme, the agents only have a memory of receiving events. They can not have a memory for senders, in this pattern, 5. As we can expect, we did not confirm strong specific relationships. The exponential distributions in the messaging frequency support this. Consequently, pattern 5 generates dense and clustered networks. The trade-off between the number of relationships and closeness is weak in such networks. This type of society can be realised in a limited situation, where the community is very small, such as immigrant communities [8]. In these small communities, people may interact with others regardless of closeness.
The difference in the network structure within patterns 2–5 emerged as a difference in the information spreading dynamics. After bootstrap percolation on patterns 2 and 3, biased closeness and less-clustered networks were observed. In the network, 1st- and 2nd-order phase transitions occurred. In contrast, after bootstrap percolation on patterns 4 and 5 in networks, less-biased closeness and clustered networks were observed, and only 1st-order phase transitions occurred. These results suggest that there is a qualitative difference between 1 < a (patterns 2 and 3) and 0 < a < 1 (patterns 4 and 5) due to network structures. In undirected and unweighted networks (Kleinberg's spatial networks [39] and scale-free networks [40]), whether 2nd-order phase transition occurs depends on the clustering of networks. In contrast, a few strong connections in directed and weighted networks (e.g., patterns 2 and 3) seemed to have a key role in a 2nd-order phase transition.
This difference between patterns 2–5 affects the ease and speed of information spreading. The bootstrap percolation process is the process of conforming with the connection of others' opinions [43, 44].
Information is more likely spread on patterns 2 and 3 in networks, particularly pattern 2, where agents were affected by a few close relationships. People tend to be affected by such relationships, in contrast to influencers who are weakly connected with people on social media [45, 46]. These networks require the number of iterations for information spreading across the whole network as information only traverses strong paths [20] due to a few strong connections. This result suggests that the popularisation of lightweight communication can facilitate the global spread of information via close relationships.
On the other hand, information spreads quickly in patterns 4 and 5, particularly pattern 5, as information spreading on networks with unbiased weights is fast because information spreads through a variety of paths [20]. However, the information is less likely to spread on such networks. On these networks, agents were affected by many relationships, which are not specific strong connections.
Note that this finding does not mean that information spreads through elaborate communication at a shorter time than that of lightweight communication, as elaborate communication tends to require more time than lightweight communication in an iteration. For example, in social media (lightweight communication method), people can quickly share information with many people with just one click; i.e., an iteration time of lightweight communication would be shorter than that of elaborate communication.
The relationships between parameter settings (α1, α2, β1 and β2) and trade-off parameter a differed with the previous work [27], which evaluated a the exclusion of windows and weak edges as noises compared with this study. This result may suggest the importance of (1) considering a difference in time scales between messaging and life rhythms and (2) using complete communication datasets, which include rare communication history.
In the real world, our societies primarily appear similar to patterns 3 or 4. If such a situation is based on our preferences and is healthy, we can guide our society to hopeful states by considering the balance between our two memory types. If we wish to explore new types of societies, we can also challenge these extremes. As we already possess rich technology for developing various communication tools and social relationships, the degree of freedom of design in our society has also expanded.
The power law of social relationships has emerged under the conditions of costs for creating and maintaining the strengths of social relationships [11]. In the proposed model, considering the effects of communication cost on the power law would provide further insight.
The communication and social relationships of people are affected by the world. The artificial society model and insights of this paper might be helpful for preserving human nature as they can provide insight into how people create and maintain comfortable/useful social relationships.
Data availability statement
No new data were created or analysed in this study.
: Appendix.
See figures A1, A2, A3, A4, A5, A6 and A7.

Figure A1. Linear dependencies of α1 and α2 in the phase diagram for a (figure 3(a)). The vertical and horizontal cells show the changes in α1 and α2, respectively. Fixed values were used for α1 = 10.0 and α2 = 10.0.
Download figure:
Standard image High-resolution image
Figure A2. Results of the simulation experiments (L = 2).
Download figure:
Standard image High-resolution image
Figure A3. Results of the simulation experiments (L = 10).
Download figure:
Standard image High-resolution image
Figure A4. Results of the simulation experiments (s = 5).
Download figure:
Standard image High-resolution image
Figure A5. Results of the simulation experiments (s = 40).
Download figure:
Standard image High-resolution image
Figure A6. Heat maps of the mean number of messages sent. The light blue region shows that the agents were well activated.
Download figure:
Standard image High-resolution image
Figure A7. Results of bootstrap percolation. These figures show the mean (points) and standard deviation (error bars) of 10 trials. The horizontal cells show the changes in the activation threshold κ. The vertical cells show patterns 1–5. In most cases excluding large κ and small p, the number of giant active components is 1. Therefore, when information did not spread, the sizes of giant active components were pN, which was the number of initial active nodes.
Download figure:
Standard image High-resolution imageFootnotes
- 3

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}