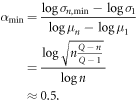Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
Taylor's law describes the fluctuation characteristics underlying a complex system in which the variance of an event within a time span grows by a power law with respect to the mean. The previous paper, Taylor's Law for Linguistic Sequences and Random Walk Models (Tanaka-Ishii and Kobayashi 2018), appeared in Journal of Physics Communications and described a new way to apply Taylor analysis to texts. The method was applied to over 1100 texts across 14 languages. The results showed how the Taylor exponents of natural-language written texts were consistently around 0.58, thus being universal.
Experimentally, the Taylor exponent α is known to take a value within the range of 0.5 ≤ α ≤ 1.0 across a wide variety of domains, including finance, meteorology, agriculture, and biology. The previous paper shows how this is the case for language.
The Taylor exponent is analytically proven to be 0.5 for an independent and identically distributed (i.i.d.) process. The paper also shows a case when 1.0 is reached. This Addendum provides two additional cases of rare word alignment for α = 0.5 and α = 1.0. These cases provide an understanding to interpret the value of the exponent of a real text.
Consider dividing a text of length N into Q segments of length Δt, i.e., N = QΔt. Suppose that Q is sufficiently large.
First of all, if a word only appears once in the entire text, then μ1 and σ1 are calculated as follows.
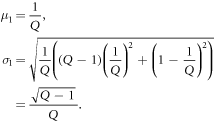
For words that appear n(≪Q) times in a text, there are two extreme possibilities: when the n words are all in the same segment, and on the other hand, when the n words are all in different segments.
When the n words all appear in the same segment, then σ becomes the largest for this case, as follows.
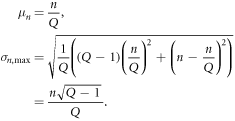
Because the extreme of such a case occurs when n = 1, α is 1, as follows.
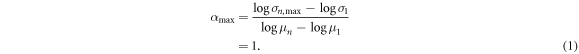
On the other hand, when the n words all appear in different segments, then σ becomes the smallest, as follows.
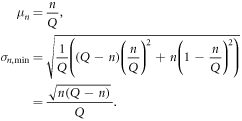
Because the extreme of such a case occurs when n = 1, α is 0.5, as follows.