
Abstract
The rapid rise of nanotechnology has resulted in a parallel rise in the number of products containing nanomaterials. The unusual properties that nano forms of materials exhibit relative to the bulk has driven intense research interest and relatively rapid adoption by industry. Regulatory agencies are charged with protecting workers, the public, and the environment from any adverse effects of nanomaterials that may also arise because of these novel physical and chemical properties. They need data and models that allow them to flag nanomaterials that may be of concern, while balancing potential stifling of commercial innovation. Roadmaps for the future of safe nanotechnology were defined more than a decade ago, but many roadblocks identified in these studies remain. Here, we discuss the roadblocks that are still hindering the effective application of informatics and predictive computational nanotoxicology methods from providing more effective guidance to nanomaterials regulatory agencies and safe-by-design rationale for industry. We describe how developments in high throughput synthesis, characterization, and biological assessment of nanomaterials will overcome many of these roadblocks, allowing a clearly defined roadmap for computational design of effective but safe-by-design nanomaterials to be realized.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
It is clear that the field of nanotechnology is advancing very rapidly; the number of published papers is increasing approximately exponentially from a total of 4550 by 2000 to a total of 326 925 by 2020, a >70-fold increase (WoS title search 'nanotech* OR nanopart* OR nanomater*'). This compares with materials generally for which the number of publications has grown <4-fold, and biomaterials whose publications have grown <5-fold in the same period (WoS title search material* and WoS title search biomaterial*), see figure 1.
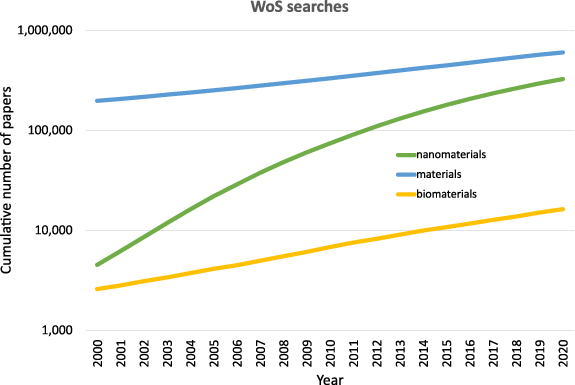
Figure 1. Relative increase in cumulative publications in nanotechnology relative to those in materials generally, and biomaterials.
Download figure:
Standard image High-resolution imageProducts taking advantage of the unique properties of nanomaterials are also increasing rapidly. While obtaining an accurate estimate of the number of new products is quite difficult, one source has listed in excess of 5000 products are currently on the market that contain nanomaterials (https://nanodb.dk/en/), up from 1860 in 2015 [1]. Policymakers and regulatory agencies responsible for safe use of these materials are struggling to balance occupational health and safety (OH&S) and environmental risk against overregulation of the industry that stifles innovation, the so-called underregulation vs overregulation dilemma. Underregulation occurs when regulations are not sufficiently stringent to protect public and environmental health. For example, dietary supplements were underregulated in the United States (US), before the passing of dietary supplement legislation, because existing legal frameworks did not properly protect the public from risks these products posed. Overregulation occurs when regulations are more stringent than required to protect public and environmental health, causing negative effects on consumer autonomy, industry, and the economy. For example, HIV/AIDS activists argued that strict Food and Drug Administration (FDA) regulations for drug testing and approval were preventing patients from accessing to life-saving medications [2, 3].
Nanomaterials research is generating many new materials. They are incorporated into products faster than safety data and mechanistic knowledge relating to adverse health or environmental impacts can be generated. Consequently, regulators are seeking faster methods of obtaining guidance on potentially problematic nanomaterials, through accelerated synthesis and biological screening [4, 5], surrogate assays involving omics technologies [6–9], and by exploiting the impressive developments in artificial intelligence (AI), particularly machine learning (ML) [10–13], that have occurred in the past decade. Clearly, most of these are platform technologies that have been deployed successfully in multiple science and technology areas. Nanotechnology is leveraging developments in omics technologies, robotics and automation, and combinatorial synthesis to obtain larger and richer data sources for regulatory decision making and design of safer products containing nanomaterials.
As with small molecule drug candidates and biomaterials, testing of all possible nanomaterials that might be incorporated into products is infeasible due to the time and cost of doing so. There is also increasing pressure on industry to reduce or eliminate animal testing for ethical reasons. Consequently, computational methods have become an increasingly important, complementary technology for design and development of drugs, biomaterials, and nanomaterials and for guiding regulatory decisions [14–17]. For nanomaterials, as with small molecule drug candidates and biomaterials, computational models are an important way of predicting potential adverse effects, understanding the mechanisms by which these materials interact with biology, identifying which nanomaterials should be subject to stricter regulation, and providing a rationale for building 'safe-by-design' principles into new nanomaterials and the products containing them.
This paper discusses the major roadblocks holding back the wider exploitation of computational methods for these purposes. It covers the commercial nanomaterials that interact with humans, animals and the environment incidentally during manufacture, use, and disposal, not nanomaterials deliberately administered for diagnostic and therapeutic purposes in medicine. Recent reviews summarize progress in medical applications of nanomaterials for readers interested in these aspects [18–25].
1. Differences between the properties of nanomaterials, bulk materials and biomaterials
The most general definition of a nanomaterial, compared to the same material in bulk, is that it has at least one dimension <100 nm. Nanoobjects can be quite complex and require more specific classification. They were originally classified by Gleiter [26], but this scheme did not account for the diverse dimensions of fullerenes, nanotubes or nanoflowers. Thus, Pokropivny and Skorokhod reported a classification scheme for zero-, one-, two- and three-dimensional (0D, 1D, 2D, and 3D) materials [27] based on the number of nanomaterials dimensions that lie outside the nanoscale (⩽100 nm) range (figure 2). 0D nanomaterials have all dimensions within the nanoscale (⩽100 nm, nanoparticles or nanospheres), 1D nanomaterials have one dimension outside the nanoscale (nanotubes, nanorods, nanofibres, and nanowires), and 2D nanomaterials have two dimensions outside the nanoscale (graphene, nanofilms, nanolayers, and nanocoatings). 3D nanomaterials are distributed forms of nanoscale objects that are not confined to the nanoscale in any dimension (powders, dispersions of nanomaterials, bundles of nanowires, nanotubes and multi-nanolayers, or nanoporous materials) so are more complex. Similarly, International Standards Organization (ISO) terminologies for nano-objects (ISO/TS 80004-2:2015) define nanoplates and nanoribbons as having one and two dimensions in the nanoscale but are significantly larger in the other dimensions. ISO/TS 80004-4:2011 defines nanostructured entities more complex these simple nano-objects, e.g. a nanocomposite is a solid material containing at one or more physically or chemically distinct regions with at least one dimension in the nanoscale. Nanofoams are a liquid or solid matrix filled with a gaseous phase in which one of the two phases has nanoscale dimensions. Conversely, a nanoporous material is a solid material containing nanoscale pores or cavities. The regulatory term nanoforms was defined in 2019 to distinguish between compositionally similar nanomaterials of different sizes, shapes, or coatings.
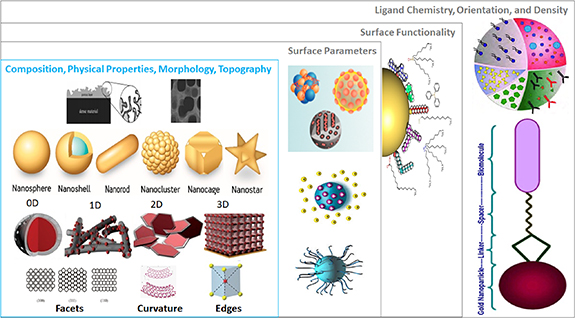
Figure 2. Overview of characteristic properties of nanomaterials (gold-based in this example) showing the different 0D, 1D, 2D, and 3D shapes, cores, sizes and its distribution, surface functionalizations, and types of bonding. Creative Commons Attribution (CC BY) license from Lynch et al [28].
Download figure:
Standard image High-resolution imageSize is a major property that impacts strongly on nanomaterials behaviour and function because the surface to volume ratio of particles is inversely proportional to particle size. Thus, the main distinguishing features of nanomaterials relative to bulk materials are their much larger surface areas, their ability to transport readily and be taken up by cells, their potentially complex shapes summarized above, and the fact that they are distributions of physicochemical properties (rather than single values) that are often challenging to measure reliably.
2. Implications of these differences for application of ML to nanomaterials regulation
The simplification is often made that another distinguishing feature of nanomaterials is their ability to attract a macromolecular or ion coating or corona. This coating is often dynamic, changing over time and as the particle moves between different environmental compartments.
However, bulk materials and biomaterials also become coated with these molecules in complex environments like serum, plasma, or environmental streams, albeit with much smaller surface contributions than for nanomaterials. The fact the nanomaterials are distributions of physicochemical properties, can be large and topographically complex, and can be altered dynamically by their environments present specific challenges for developing ML models linking these properties to biological impacts that we discuss in more detail below.
3. Prior nanosafety roadmaps
There have been a number of important Roadmaps for safe use of nanomaterials proposed in the past decade. The first comprehensive list of milestones was compiled at the COST (European Cooperation in Science and Technology)-sponsored exploratory workshop on Quantitative Nanostructure Toxicity Relationships in Maastricht in 2011 [29]. The nanomaterials-specific milestones identified in this roadmap and later reviews included:
- better characterization of materials for biological activity experiments,
- development of nanomaterials-specific descriptors,
- development of high throughput in vitro methods for measuring relevant endpoints and interactions of nanoparticles with plasma proteins,
- improved methods for tracking nanoparticles in the body,
- improved data storage, sharing and mark-up languages,
- generation of more in vivo data,
- generation of models to predict nanoparticle corona in diverse environments,
- elucidation of mechanisms of entry of nanoparticles into cells,
- development of ML models of in vitro and in vivo effects of nanoparticles suitable for regulatory purposes,
- and development of nanoparticle fingerprints for regulators to classify nanomaterials into hazard classes.
While these were research-driven milestones in the roadmap, they have been directly or indirectly influential in driving research agendas in Europe and the US in particular. This initial Maastricht roadmap led directly to European Union (EU) funding of the COST Action MODENA and has been cited in Government policies on the safe use of nanomaterials (United Kingdom (UK) Parliamentary Office of Science and Technology POSTNOTE Number 562 October 2017 Risk Assessment of Nanomaterials). The roadmap was influential in funding of several other related COST Actions and, more recently, Horizon 2020 projects on nanosafety. Subsequent publications have also reinforced the importance of the above milestones and issues to progress in the safe use of nanomaterials [30–44]. Some milestones in the roadmap for future of safe nanotechnology we identify in this review are the same or similar to those proposed up to a decade ago because progress against these prior milestones has been slower than expected. This is due to a number of factors discussed in more detail below, including slower than anticipated uptake of high throughput synthesis and characterization technologies, consequential dearth of large and robust data sets for training ML models, and limited development of efficient and interpretable specific descriptors for nanomaterials. Thus, most milestones are carried forward and still need to be addressed properly in the future. To this end, The EU and US Roadmap for Nanoinformatics 2030 for computational prediction of potential adverse effects of nanomaterials was published recently by Haase and Klaessig [45]. This defined a similar set of milestones to those listed above.
The majority of the 2, 5, and 10 year milestones defined in the Maastricht workshop (figure 3) have not been achieved, many of the most important ones remain. The reasons for this, and how they can be overcome, constitute the main focus of this review. To help address these issues, a number of large projects have been funded by the EU Horizon 2020 program that aim to establish networks of researchers to develop computational tools for use in nanosafety prediction, e.g. NanoReg2 (https://nanoreg2.eu), NanoSolveIT (https://nanosolveit.eu) [26] and SABYDOMA (www.sabydoma.eu) and generation of relevant data e.g. NanoHarmony (https://nanoharmony.eu). One of the greatest challenges facing regulators is how to design and implement a regulatory process that is robust enough to deal with a rapidly diversifying system of manufactured nanomaterials over time. The NanoReg2 project will couple structure-based design to the regulatory process using ideas and data from value chain implementation studies. It will establish this paradigm as a fundamental method for validating novel manufactured nanomaterials based on the widely accepted grouping strategies for nanomaterials. NanoSolveIT will implement a nanoinformatics-driven decision-support strategy based on innovative in silico methods, models and tools to identify critical characteristics of nanomaterials responsible for their adverse effects on human health and the environment and for their utility in high-tech applications. SABYDOMA develops new methodology for safe-by-design using control systems. Screening at the point of production feeds back to modify the design of nanomaterials in an evolutionary optimization process. NanoHarmony develops test guidelines for eight nanomaterials endpoints identified as regulatory priorities. It also coordinates collection, exchange, and use of available data for test method development via a sustainable researcher network. These regulatory priority endpoints are: bioaccumulation; toxicokinetics; quantification of biological samples; intestinal fate; ecotoxicology; solubility and dissolution rate; surface chemistry; and dustiness. The projects discussed are only three of eleven H2020 funded projects on toxicity of nanomaterials from a total of 67 H2020 projects related to toxicology in all fields (www.fabiodisconzi.com/open-h2020/per-topic/toxicology/list/index.html)

Figure 3. Two, five, and 10 year milestones from the 2012 Maastricht COST workshop. Used with permission from Winkler et al [29].
Download figure:
Standard image High-resolution imageA very recent, seminal paper stressed the need for a sustainable nanotechnology system governance for European society [27, 46]. Other regulatory and standardization communities (e.g. FDA, Environmental Protection Agency (EPA), European Chemicals Agency (ECHA), ISO and Organisation for Economic Co-operation and Development (OECD)) are strongly committed to development of validated methods for characterizing as-received intrinsic properties and medium-dependent extrinsic properties of nanomaterials, and to identifying the exposure/hazard posed by nanomaterials to humans and the environment [27]. These agencies, and the recent body of literature, have highlighted the major issues and milestones required for progress towards rational, safe use of nanomaterials. Consequently, this paper will focus on the main issues holding back the application of AI and ML methods to the prediction of adverse biological effects of nanomaterials. The primary adverse biological effects are cell viability, metabolic activity, oxidative stress, inflammation and genotoxicity. The most important remaining roadblocks that hinder generation of predictive models of nanomaterials properties with broad domains of applicability for use in regulation and safe-by design relate to data, description of nanomaterials, descriptors, and domain of applicability.
3.1. Data
Machine learning methods offer great promise for modelling and prediction of beneficial and adverse properties of nanomaterials. This is because they are fast, do not rely on underlying mechanistic models, use open source accessible technologies, and have proven effective in modelling patterns in complex data in many other domains [13]. Being data driven methods, they are critically dependent on the information used to generate them. Data quantity, quality, diversity, and range are all important for generating robust and predictive ML models with broad domains of applicability.
3.1.1. Data quantity
Nanosafety research projects are still hampered by lack of sizable data sets, largely due to the time, cost, and animal and human ethics issues involved with collecting them. Compared to the measurement of properties of single, well-defined organic molecules or even those of pristine nanomaterials free of the influence of biological environments, assessing properties of nanomaterials that change over time or in different biological fluids is less standardized and more technically challenging [27]. Computational models and read across (imputation) methods are used to 'fill in the gaps' in data sets [47], but making more data available is clearly preferable. Robotics and automation are making large inroads into other areas of science and technology, reviewed recently by Liu et al for materials generally [48], so should generate similar impacts in nanotoxicology. Within the past decade, methods have been reported for high throughput synthesis of nanomaterials [49–51], accelerated characterization of their physicochemical properties [52], and fast in vitro toxicity screening [53–60]. Further development, adoption, and application of these high throughput methods should greatly increase the amount of nanomaterials data in the future.
3.1.2. Data quality
Apart from the size of data sets, as with other types of materials, there are often problems with the reliability of data from experiments on the physicochemical and biological effects of nanomaterials. The same time, cost and ethics issues that limit the amount of data, also effect the number of experimental replicates that can be done. This impacts data quality, signal-to-noise ratio, and occurrence and treatment of outliers. Reproducibility in science has become a key issue in the past few years, with recent studies specifically focusing on nanomaterials. Several research groups have published methods for improving the reproducibility of synthesis of nanomaterials [61–64]. The reproducibility of nanomaterials bioassays has been addressed by Petersen et al [65] and the role of materials provenance on reproducibility has been discussed by Baer et al [66]. Clearly, experiments are more difficult to perform on nanomaterials compared to small organic molecules because of the variations in size and shape, agglomeration behaviour, and corona formation inherent in nanomaterials. The effects of corona formation on experimental reproducibility have been studied by Galmarini et al [67].
3.1.3. Data diversity
Finally, widely applicable models of potential adverse properties of nanomaterials need to be trained on data derived from diverse types of nanomaterials and as wide a range of relevant biological endpoints as feasible (see also Domain). The need for systematic studies of diverse nanomaterials morphologies, types and endpoints has been stressed in recent papers [68, 69].
3.2. Description
The first step in addressing nano-safety issues is characterizing nanomaterials in relevant biological environments (describing the so-called biologically relevant entity) so that subsequent examinations can be linked to specific features of nanostructures. Nanoparticles can agglomerate, dissolve, have photocatalytic properties, and form persistent or dynamic complexes with biological molecules or ions. These properties can substantially affect the biological behaviour of nanomaterials [70–75]. While some progress has been made with regard to when, where, and how to characterize nanomaterials, this remains to be a challenge because the novel properties of nanomaterials that differ from those of the bulk materials may change significantly under different conditions and/or over time. These dynamic properties of nanomaterials are highly sensitive to the surrounding environment and the properties may interact (i.e. are interrelated), making the characterization process even more complicated (e.g. the zeta potential of nanoparticles varies greatly depending on whether they are pristine or in different types of biological fluids).
Ideally, the physicochemical characterization of nanomaterials should be performed in relevant biological matrices because pristine nanomaterials become modified upon introduction to biological fluids [76]. The surfaces of nanomaterials are immediately covered by biological components, resulting in the formation of bio-corona that modifies materials characteristics such as particle size, surface charge and state of aggregation [77]. The corona varies with environment and over time because more abundant macromolecules that bind first are gradually replaced by less abundant but more tightly bound macromolecules. More research is needed on how the physicochemical properties of nanomaterials (e.g. size, surface chemistry, dissolution, aggregation, etc) change as a function of biological conditions and whether these transformations make nanomaterials more or less toxic than their pristine form. This will provide more detailed information on biological effects of nanomaterials that can be used by regulators to more accurately assess the risks that they pose to the human or environmental health.
Fortunately, significant progress is being made in characterizing the nanoparticle corona as a function of nanomaterials physicochemical properties and the environment in which they are found. A number of studies in the past year have reported a range of spectroscopic, mass spectrometric, and chromatographic methods for characterizing nanoparticle coronas, some of which can be used to study the dynamic properties of biocoronas (figure 4) [78–87]. These data have enabled development of explanatory and potentially predictive models of nanoparticle corona composition [88–93] and dynamic behaviour that form the basis for rational design and development of nanomaterials that attract little or no corona [94].
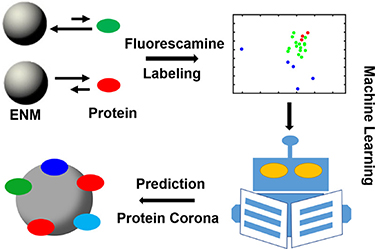
Figure 4. Use the fluorescence change from fluorescamine labelling of proteins, in the absence or presence of nanomaterials, as a novel descriptor to train ML models of corona formation. Fluorescence correlated with abundance of corresponding proteins in the corona on diverse nanomaterials. Used with permission from Duan et al [92].
Download figure:
Standard image High-resolution imageSolubility and biopersistence of nanomaterials in biological fluids are other key considerations that need to be addressed in nanosafety evaluation, since they directly influence internal exposure to a nanomaterial. The biological activity of soluble nanomaterials may be largely due to the dissolved material rather than the particle per se, e.g. ZnO. The rate of dissolution is affected by nanoparticle physical form (e.g. particle size, shape, coating, core doping) potentially providing methods for rational control of dissolution to minimize adverse biological effects [95]. Despite its critical importance, it is still unclear which nanomaterials characteristics affect solubility and particularly, biopersistence [96, 97]. More research is also required to understand how nanomaterials dissolution in biological fluids or persistence in the body influence biodistribution and biological impacts, and how this can be modified by formulation, coatings, or other methods.
3.3. Descriptors
Molecular descriptors, mathematical entities that encode relevant structural and physicochemical properties of nanomaterials, can be generated by theoretical methods or by standardized experiments. They are one of the most important elements in computational modelling studies in medicinal/environmental chemistry, toxicology, pharmacology, genomics and drug design [98–100]. Computed theoretical descriptors that capture important structural properties of nanomaterials provide diverse sources of chemical properties and a broad coverage of the vast chemical property space describing all possible nanomaterials. Experimentally derived descriptors (e.g. size shape, solubility, agglomeration, etc) are of very limited use in ML models of biological effects of nanomaterials, not only because of their time and resource intensiveness (even using high throughput methods), but also because they are not available for designed or otherwise hypothetical materials not yet synthesized [101].
A large number of theoretically well-founded and chemically interpretable descriptors can now be directly calculated from molecular structure using various commercial and open-source software packages [102]. However, almost all existing molecular descriptors and fingerprints currently used are not nano-specific, rather have been 'borrowed' from the pharmaceutical domain for organic small molecules. Some of these descriptors are not directly applicable to nanomaterials due to the polydispersity of nanoparticle physical properties, the size and shape of nanomaterials, incomplete characterization of their compositions, and their complex interactions with each other and with biological macromolecules and ions. In other words, the interfacial properties of nanomaterials are highly affected by external conditions, and hence, cannot be simply reflected by their composition or chemical structure.
The specificity of nanoscale properties and the lack of nano-specific molecular descriptors that can capture them constitutes a long-recognized but still only-partially addressed roadblock. Clearly there is a strong need for better descriptors for nanomaterials, providing an important challenge for researchers, but progress in this area has been disappointingly slow. However, interesting developments in deep learning have shown that imaging and related methods coupled with deep learning algorithms may provide a paradigm shift in the way nano-specific descriptors are generated for training predictive models in the future. For example, Russo et al [103] used convolutional neural networks (CNNs) to encode complex nanostructures into data structures suitable for machine learning modelling. Nanostructures were represented by virtual molecular projections, a multidimensional digitalization of nanostructures, and used as input data to train predictive CNN models of nanoparticle biological properties. The CNN neurons recognized distinct nanostructure features critical to activities and physicochemical properties (figure 5). Russo et al proposed that this 'end-to-end' deep learning approach effectively digitizes complex nanostructures for data-driven ML models and that it can be applied to rationally design nanoparticles with desired activities.

Figure 5. Virtual molecular projection and CNN modelling. (A) The 3D coordinates of atoms in a nanoparticle are projected to 2D, based on atom types. (B) The CNN modelling framework. The 2D molecular projections are processed by sequentially stacked convolution and pooling layers that abstract features and reduce data dimensions. A fully connected layer links the convolution–pooling layers to predict the experimental properties of nanoparticles. Reprinted with permission from Russo et al [103]. Copyright (2020) American Chemical Society.
Download figure:
Standard image High-resolution imageApart from their efficacy in ML models, another important property of nanomaterials descriptors (and descriptors more generally) is interpretability. That is, how easily can the most important descriptors controlling biological responses, identified by ML models, be used to rationally design improved materials and to understand the mechanisms by which they elicit their biological properties. Interpretable descriptors can be related easily to chemically recognizable features in nanomaterials. This is an important, ongoing issue for ML modelling of physicochemical and biological properties of molecules and materials generally [100]. Traditional molecular descriptors currently used in ML models are often arcane, and new descriptors are needed can be easily interpreted in terms of their biological (e.g. toxicity), physical (e.g. photocatalysis, solubility) and interaction (e.g. agglomeration, corona structure) properties. To this end, research by De et al and Sizochenko and coworkers has described new methods for encoding the properties of nanomaterials that are both efficient and interpretable [104, 105]. De et al used a set of 23 descriptors obtained from the periodic table or derived from them. These included the molecular weight of a metal oxide, number of oxygen atoms, metal electronegativity, metal oxidation state, number of valence electrons and atomic number. These were found to be as effective as descriptors generated by time consuming quantum chemical methods. Sizochenko et al used a 'liquid drop' model for nanoparticles in which a nanoparticle is represented as a spherical drop in which atoms or molecules are densely packed, and the density of cluster is equal to mass density (figure 6). It distinguishes the nanoparticles' surface molecules from the other molecules in volume. They also employed a simplex representation of molecular structure to encode the first level of organization of nanoparticles. Here, any molecule can be represented as a system of different simplexes (fragments of fixed composition and topology) that differentiate atoms in a simplex by their type and other properties such as electronegativity, lipophilicity, van der Waals interactions, etc.
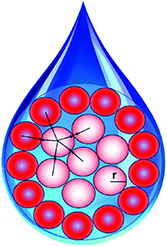
Figure 6. Liquid drop model of nanoparticles showing interactions between molecules located in the core (white circles and the surface of the nanoparticle (red circles)). Reproduced from Sizochenko et al [104] with permission from The Royal Society of Chemistry.
Download figure:
Standard image High-resolution imageText string representations of molecular entities, such as SMILES and InChI, are being used increasingly to generate descriptors for ML models, often in conjunction with deep learning algorithms that generate latent features from them. InChI keys are textual identifiers for chemical substances that provide a standard way to encode molecular information. The recent report of the first definition of NInChI (an InChI representation for diverse types of nanomaterials) suggests their potential for use as unique identifiers for database searches. As they encode essentially all relevant properties of complex nanomaterials in a hierarchical and compact text format, they should allow generation of new types of nanospecific descriptors that incorporate the complex structures, different nanoforms of the same material, diverse types of nanomaterials, and provenance information [28].
New 'surrogate' methods of generating information useful for modelling properties of nanomaterials are showing considerable promise. Spectroscopic, mass spectrometric, proteomic, and genomic 'fingerprints' of nanomaterials, and/or the effects they have on biological systems, can serve as useful descriptors when coupled with efficient sparse feature selection methods that identify a small pool of most relevant features. These have proven very useful in modelling the biological properties of other types of materials. For example, ion mass profiles generated by Time-of-Flight Secondary Ion Mass Spectrometry (ToF-SIMS) are very useful surface chemistry descriptors for ML models [106]. Given the importance of surface chemistry to nanomaterials, it is very likely such surface analysis fingerprints will prove equally useful for generating robust ML models of nanomaterials properties.
Quantitative fingerprint information can also be extracted from microscopy images of nanomaterials, which then can be used to train predictive models. Although the idea of image-based nanodescriptors has been around for more than a decade [107], it still is not routinely used in molecular descriptor calculation tools, and remains at a more conceptual rather than practical level, with a few exceptions such as recently-released NanoXtract image analysis tool [108]. This uses electron microscopy images to generate 18 image nanodescriptors such as area, perimeter length, roughness, aspect ratio, and concavity/convexity (figure 7).
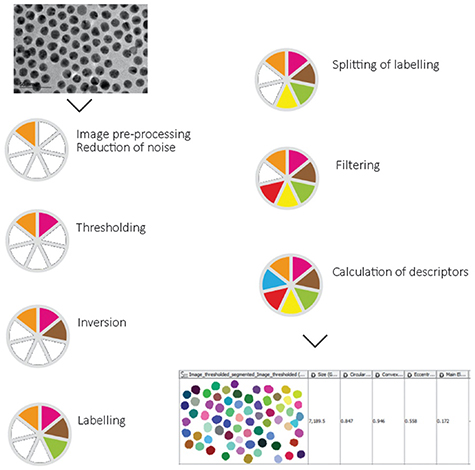
Figure 7. Schematic workflow of the image processing steps for NanoXtract nanoparticle image analysis. Used with permission from Varsou et al [108].
Download figure:
Standard image High-resolution imageAnother recent and novel approach is the use of information entropy to characterize distributions of nanoparticles [109]. The development of more sophisticated image analysis approaches and the application of image-based nanodescriptors is expected to evolve in the near future with the adaptation of existing tools to nanospecific needs. The predictive power of ML models can be boosted by incorporation of experimental fingerprints from surrogate analyses. However, in common with other experiment-based descriptors, these approaches are not useful for predicting the biological properties of nanomaterials not yet synthesized.
Predictive models of biological effects of nanomaterials can also provide insight into how nanomaterials generate their biological effects, but only if the descriptors that constitute the model are physically or chemically interpretable. Therefore, special attention must be given to the interpretability as well as efficacy of nano-descriptors so that they can be used to develop models that are both predictive and explanatory.
3.4. Domain
Clearly, ML models are necessarily trained using limited datasets that cover a restricted range of physicochemical and biological properties. The relative dearth of large and diverse training datasets is one of the main limitations to the wide use of ML models of nanomaterials biological properties. Computational models are most useful for predicting the properties of nanomaterials that exist in, or near, their domains of applicability, the multidimensional space defined by the descriptors and biological responses of data used to train the models. When using these models for interpolation (e.g. to fill in gaps of studies using partial factorial design of experiments) or extrapolation close to the model domain, the predictions are generally reliable. The further predictions are made from the domain of applicability of the model, the less reliable the predicted properties will be. New modelling algorithms such as Nearest neighbour Gaussian Processes [110], and existing ML methods that exploit Bayesian statistics [111, 112], can provide estimates of the reliability of the predictions. As larger, more diverse data sets become available, and ML methods better able to estimate the prediction uncertainties are adopted, 'out of domain' issues should diminish.
The problem of predicting relevant in vivo responses to nanomaterials are likely to persist for some time. Generation of experimental in vivo data is particularly restricted by ethical, time, and cost issues. By using efficient design of experiment methods, the number of in vivo experiments can be minimized, and ML models could be used to predict in vivo responses to other nanomaterials within their domains of applicability. However, realistically, the limitations of experimental in vivo testing will remain or may become even tighter, so we are unlikely to see large increases in the amount of available in vivo data. However, ongoing development of surrogate bioassays, such as gene expression profiles (toxicogenomics) or new phenotypic assays, should identify assays that correlate better with in vivo responses than current in vitro assays do. Rapid advances in intrinsically high throughput 'omics' methods, transcriptomics, proteomics and metabolomics can generate large, rich datasets on the responses of cells or organisms to nanomaterials exposure [113, 114]. ML modelling methods could exploit these data in two main ways: using these expression profiles as descriptors to better predict in vivo responses; and using computed nanodescriptors to model the relationships between physicochemical properties of nanomaterials and important omics signatures or pathways identified through expression profiling. For example, Furxhi et al used physicochemical descriptors for nanomaterials and experimental exposure conditions, cell line, cell type and tissue to model biological outcomes from genome wide studies using Bayesian networks [115]. Dysregulated genes were identified using fold change on exposure to nanomaterials, and Gene Ontology analysis functionally annotated the selected genes with the relevant biological effects. The model predicted the impact on 9 different biological pathways with a binary accuracy of 80%–100% (50% is random chance). The Ahmad group has also been active in using ML to model toxicological properties of nanomaterials using omics data. They recently reviewed the potential of combining integrative omics with machine learning to profile nanomaterials and model their biological impact for safety and risk assessment [116–118]. Metabolomics now allows study of metabolic dysregulation in biological cells, tissues, and living objects caused by exposure to nanomaterials. Untargeted metabolomics (metabolic fingerprinting) can be valuable for risk assessment of nanomaterials. Genomic and metabolic fingerprints, used in conjunction with sparse feature selection and feature importance methods, can be used to train predictive and interpretable ML models of the possible adverse biological properties of nanomaterials.
Hybrid ML modelling methods, where experimental in vitro assay results and nanodescriptors are used to model limited in vivo data and allow it to be leveraged more widely and reliably, show promise [119, 120]. For example, Lee and co-workers reported that molecular descriptors for drugs combined with in vitro basal cytotoxicity was more successful in predicting human acute toxicity than descriptors or in vitro results alone [121]. Recent developments in high throughput surrogate methods for assessing nanomaterials toxicity have been comprehensively reviewed by Collins and co-workers [59].
3.5. Future of the roadmap
If the roadblocks detailed above can be removed or at least reduced, the nanotoxicity field will have available to it a relatively large number of substantial, diverse, and relevant data sets, and a suite of efficient nano-specific descriptors. There are a large number of efficient and well-validated ML algorithms available that can be trained by such data and descriptors to generate robust and useful models of important toxicological endpoints. Recent reviews have highlighted the role specific ML methods play in modelling nanotoxicity data [10, 122–126]. For example, Brown and co-workers wrote a review focusing on: using ML to analyse and extract new insights from large nanoscience data sets; applying ML to accelerate material discovery, particularly the use of active learning to guide experimental design; and the science behind memristive devices that can be used for hardware implementation of ML [127]. Ahmad et al have recently reviewed the application of deep learning ML methods to modelling of nanomaterials properties relevant to nanosafety (figure 8) [117].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 8. Characteristics and architectures of deep neural networks (DNNs), CNNs, and recurrent neural networks (RNNs). Reproduced from Ahmad et al [117] with permission from The Royal Society of Chemistry.
Download figure:
Standard image High-resolution image{kind=link}
There is still a paucity of scientists with multidisciplinary domain knowledge required to apply new technological developments to (computational) nanotoxicology. Relatively few researchers are being rigorously trained in skills needed to develop robust models of possible adverse effects of nanomaterials and probe mechanistic aspects of nanomaterials biology interactions. Large multidisciplinary teams are the dominant paradigm in many areas of science, and nanosafety is no exception. The new H2020 initiatives referred to above, building on EU COST Actions before them, are helping build this critical mass—similar initiatives exist in the US [128] and Asia e.g. Asia Nanos Forum (www.asia-anf.org/working-groups/nano-safety-risk-management/).
With advances in the quantitative detection of small particles in complex samples, it has become clear that a wide range of processes and tools release nano-sized particles into the environment. The ability of some nanoparticles to pass through biological membranes opens up new possibilities in diagnostics and therapies but poses serious questions about human health risks associated with nanomaterial exposure. Experimental nanotoxicology, and its complementary computational equivalent, are making important contributions to understanding interactions of nanomaterials with biological systems, predicting possible adverse effects, developing safe-by-design methods for industry, and providing data and models to support regulatory decisions.
Computational nanotoxicology supports human health risk assessment of nanomaterials by integrating, unifying, and completing empirical evidence. However, the chemical and physical complexity of nanomaterials will continue to make modelling and prediction of relevant biological and mechanisms impacts a mathematical and computational challenge. Subtle differences in nanomaterials properties may dramatically affect in vitro and in vivo responses. When coupled with the dynamic behaviour of the biologically relevant form of specific nanomaterials in different media, considerably more effort is needed to model nanomaterials properties relative to a bulk material or small organic molecules with precisely defined structures and properties.
In summary, to overcome these challenges, future research should focus on:
- development of improved computable, nanospecific, interpretable descriptors that represent unique and biologically relevant features of nanomaterials,
- collection of post-transformational characterization data measured under conditions that mimic all relevant exposure scenarios,
- development of models that can robustly predict the composition of the corona as a function of biological medium and time,
- generation of large, information rich surrogate data sets and nanomaterials fingerprints based on imaging, surface analysis methods, proteomics, transcriptomics and related fields,
- adoption of relevant sparse feature selection algorithms and deep learning methods that can generate and identify relevant nanomaterials features from a large pool of possibilities,
- generation of larger sets of reliable in vitro and in vivo toxicity data for model development and calibration; further development of hybrid in vivo models based on molecular, physicochemical, and high throughput in vitro data,
- creation of robust, searchable and self-updating databases that facilitate sharing and comparison of data on nanotoxicology,
- training of researchers with both domain expertise and data analytics background, and establishment of tight networks of computational nanotoxicology researchers.
Predictions are difficult, especially about the future, and especially in light of the failure to achieve the milestones in the roadmap developed almost 10 years ago. With these caveats, a roadmap capable of addressing the above nanomaterials research challenges should be achievable within a decade. Impressive developments in ML methods and applications, especially deep learning, will overcome some of the issues identified in the review. On the one hand, these methods require a lot of data. On the other hand, they may simplify the development of nanospecific descriptors and may be amenable to using raw data in new way. Finally, publication of negative results from toxicological studies is critically important for the generation of cumulative knowledge in nanoscience, because no-adverse-effect is a positive result in nanosafety, and models need to understand what nanoparticle features produce adverse effects and which do not. In this way the dream of rational 'safe-by-design' nanomaterials will become increasingly realized. It is interesting to speculate how quickly these new, exciting potential solutions to computational nanotoxicology roadblocks will be adopted, and whether the next decade will indeed see a golden age of safe use of nanotechnologies that will enrich the lives of us all.
Acknowledgments
C O K would like to acknowledge financial support from TUBITAK (BIDEB 2232, Project No. 118C229).