


Abstract
The heat capacity of a given probe is a fundamental quantity that determines, among other properties, the maximum precision in temperature estimation. In turn, is limited by a quadratic scaling with the number of constituents of the probe, which provides a fundamental limit in quantum thermometry. Achieving this fundamental bound with realistic probes, i.e. experimentally amenable, remains an open problem. In this work, we tackle the problem of engineering optimal thermometers by using networks of spins. Restricting ourselves to two-body interactions, we derive general properties of the optimal configurations and exploit machine-learning techniques to find the optimal couplings. This leads to simple architectures, which we show analytically to approximate the theoretical maximal value of and maintain the optimal scaling for short- and long-range interactions. Our models can be encoded in currently available quantum annealers, and find application in other tasks requiring Hamiltonian engineering, ranging from quantum heat engines to adiabatic Grover's search.




Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Our ability to measure temperature in quantum systems is currently being pushed to new regimes [1–4]. At the experimental level, ultraprecise temperature measurements of gases at the lowest temperatures in the Universe are possible [5, 6], and new methods for thermometry with probes of atomic size are being developed. Relevant examples include nanodiamonds acting as thermometers of living cells [7, 8], nanoscale electron calorimeters based on the absorption of single quanta of energy [9–11], and single-atom thermometry probes [12–14]. At the theoretical level, progress has been made in the understanding of ultraprecise thermometry via quantum probes in equilibrium [15–23] and out-of-equilibrium states [24–34]. Crucially, the energy structure of optimal thermometers has been revealed [35–38], suggesting that the precision can grow quadratically with the number of constituents [39]. There is however still a gap between such theoretical bounds and state-of-the art experimental implementations, which is crucial to address to exploit the full potential of quantum thermometry.
Due to its generality and practical relevance, we consider in this work equilibrium thermometry [4]. In this case, the probe is assumed to be well described by a thermal state at the temperature T that is being estimated. Then, the error ΔT of any measurement on the probe is bounded by [40, 41]:

where is the heat capacity of the probe, and ν the number of repetitions of the experiment—see section 2 for a precise definition of the quantities involved. Intuitively speaking, a high heat capacity ensures that the energy of the probe highly varies with T, thus enabling the detection of small temperature variations.

An optimal probe for equilibrium thermometry is hence the one with the highest heat capacity. The ultimate limits to this problem were set by Correa et al in [35] by finding the maximum given an arbitrary Hamiltonian of dimension D. The spectrum of such an optimal probe consists in an effective two-level system, with a single ground state and an exponential degeneracy of the excited level. The resulting optimal heat capacity reads . If we consider that the probe consists of N bodies of dimension d (hence ), then becomes [35, 39]:





This expression shows a quadratic scaling with the number of constituents N, to be confronted with the typical extensive behaviour of the heat capacity (i.e. linear in N). This quadratic scaling is reminiscent of the well-known Heisenberg limit in quantum metrology [42], although it should be realised that the advantage here arises due to the interacting nature of the probe's Hamiltonian, and not from the presence of entanglement in the probe. Mok et al [37] provides a specific N-spin interacting Hamiltonian that can saturate (2), which however requires N-body interactions. A natural question therefore arises:
- Q:Can we reach the ultimate limit (2) via realistic Hamiltonians, i.e. featuring two-body and local interactions?
A natural approach to address Q is to consider probes at the verge of a thermal phase transition, where the heat capacity can scale superextensively with N [43–48]. Previous studies with spin systems close to criticality exemplify the potential of phase transitions for thermometry [45, 46, 48] but do not come close to the ultimate limit (2). For small values of N, proposals for optimal probes have also been considered with spin chains [27, 37] or interacting fermionic systems [49]. Yet, despite promising progress, none of the above approaches leads to a general answer to Q and hence to the possibility of approaching a quadratic precision in quantum thermometry.
To address Q, we consider as a platform a generic system of spins with two-body interactions, such as those currently programmable in quantum annealers. Their open system dynamics is starting to be studied [50–54], and they represent flexible physical devices with a high degree of control. More specifically, we consider a Hamiltonian of the form:

where is the i-th classical spin of the system 9 . We then maximise over all control parameters hi and Jij (with different constraints on their locality and strength). To tackle the exponential complexity of this task, we use advanced numerical techniques, commonly employed in the Machine-Learning community, to discover ansatzes for the form of optimal probes. We then combine these numerical ansatzes with physical insights to analytically prove that can display the quadratic scaling of equation (2), with a slightly worse prefactor that depends on the locality of the Hamiltonian (3), thus answering affirmatively Q. These results add on recent applications of Machine-Learning based techniques in the field of quantum thermodynamics [55–62], as well as in other domains, including protein folding [63], many-body problems [64–66], geosciences [67], algorithm discovery [68].



In figure 1, we illustrate the type of results obtained. The heat capacity of any spins system is upper-bounded by the fundamental bound (red line, and equation (2) with d = 2), however the maximum heat capacity obtainable with N non interacting spins simply corresponds to N times the maximum heat capacity of a single spin (green line). The use of interactions can enhance . Nevertheless, standard interacting spin-networks such as the 1D Ising model in the figure (purple dots) show an extensive scaling of in the limit of large N, hence losing their advantage. In contrast, we find optimal spin-network architectures (3) that approximate for all N, see e.g. the Star model as an example of the architectures discussed in the next sections (blue dots in figure 1).





Figure 1. Maximum heat capacity , as a function of in a log-log plot, of spin-based thermometers. The red line corresponds to the mathematical bound (2) on any system with dimension (for a formal definition, see equation (8)), which shows a quadratic scaling in terms of the number N of total spins employed. Our optimal spin-network architecture, the 'Star model', provides the highest heat capacity for Hamiltonians of the form (3) when , and can reach the mathematical bound (2) in the large N limit. This is to be compared with the extensive scaling of standard models, such as the 1D Ising chain. The green line delimits the region accessible with non-interacting spins, and simply corresponds to , 0.44 being the maximum heat capacity of a single spin.









Download figure:
Standard image High-resolution imageThe rest of the paper is structured as follows. In section 2 we review equilibrium thermometry, and we analyse the fundamental properties of the optimal energy spectra for the maximization of . In section 3 we move to the case of physically realistic probes (3), we present the derivation and analysis of our optimal thermometer models, and then discuss their implementation and properties. In section 4 we describe other relevant models which we use for performance comparison. Finally in section 5 we conclude and discuss future directions and applications of this work. The appendix contains details of the numerical methods employed, technical analytical derivations, and complementary analysis of our results. The code written to perform the machine-learning based optimization is available upon request (see the "Data availability statement").

2. Equilibrium thermometry and properties of optimal spectra
Let us consider a sample at some unknown temperature T, corresponding to the inverse temperature (herafter we set for simplicity). To assess β, we let the sample weakly interact with a probe described by its Hamiltonian H. After a sufficiently long time, it is assumed that the probe will reach a Gibbs state, fully determined by H and β:



By measuring the energy of , it is possible to infer β (hence the temperature T). Let us note that projective energy measurements were shown to be optimal for temperature estimation [35, 41]. In particular, the Cramer–Rao bound [69] specific to the case of temperature estimation at equilibrium [3, 4] can be exploited to estimate the minimal error ΔT. More precisely, for a number ν of identically and independently distributed (i.i.d.) repetitions of the experiment, ΔT has a mean square value that is bounded by equation (1), that is . It is therefore clear that the maximum precision one can get in estimating the temperature T by measuring the energy of the probe at equilibrium with the sample is determined by the heat capacity . This is formally defined as the variation in mean energy of the probe per temperature change unit, i.e.




In terms of the eigensystem of the probe's Hamiltonian H, the state populations of read , with and . In the energy eigenbasis of the probe, it is easy to verify from equation (5) that the heat capacity is proportional to the energy variance of the Gibbs state:







where D is the dimension of the Hilbert space. Such expression clarifies that the heat capacity only depends on the spectrum of the Hamiltonian H and inverse temperature β. It is important for the following to note the scale invariance , with . This allows us to express all energies in units of β, and to simply refer to the heat capacity as a function of a adimensional Hamiltonian , as . In the following, we will omit the tilde and simply use adimensional units, writing . We also emphasize that a global energy shift does not affect neither the Gibbs state nor the heat capacity as .






2.1. Optimal spectrum for equilibrium thermometry
From equation (1), we see that an optimal probe for thermometry is the one with maximum heat capacity . The maximization of of a generic D-dimensional system at thermal equilibrium has been carried out in [35] assuming full-control on the Hamiltonian and its spectrum,



The resulting optimal spectrum consists of a single ground state and a -degenerate excited state, that is


with an optimal gap E = x in temperature units that satisfies the transcendental equation . The corresponding heat capacity is [35]. This expression gives in the asymptotic regime of large probes () , hence . For a probe made up of N constituents, each with local dimension d, so that , we recover the Heinsenberg-like scaling in equation (2).






2.2. Properties of optimal spectra
In order to understand the origin of the desired scaling , we now discuss the relevant features of the spectrum equation (9) in its optimal configuration, as well as possible perturbations of it. This will be relevant for cases in which a physical realization (e.g. using equation (3)) can approximate equation (9), but not exactly. Specifically, we prove that a large class of spectra can exhibit the Heisenberg-like scaling of the heat capacity, when the following 3 properties are satisfied:


P1: exponential degeneracy. The spectrum has a two-level structure with single ground state, and a first excited level that is exponentially degenerate (in N), with a gap that can be tuned.
P2: bandwidth tolerance. The engineering of the effective two-level spectrum, and in particular of the bandwidth of the first excited level, can tolerate a relative precision of .

P3: tolerance to additional energy levels. The presence of other energy levels does not necessarily deteriorate the maximal value of and its scaling. In particular: i) high energy levels (i.e. above the first excited level) do not decrease the maximal heat capacity, while ii) energy levels below the first excited have an exponentially small contribution to the heat capacity, provided that their total degeneracy is (at most) polynomial in N, and their gap to the ground level increases (at least) linearly in N.

A schematic representation of the class of spectra satisfying the above three properties is given in figure 2. We now provide an intuitive understanding of these properties.
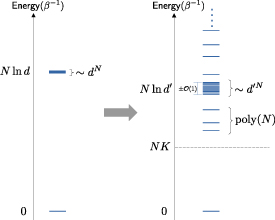
Figure 2. (Left) The idealized model (9). (Right) we prove that any Hamiltonian featuring a spectrum of the form respecting properties P1-P2-P3 (see details in text) can exhibit a scaling of the maximal heat capacity.


Download figure:
Standard image High-resolution imageThe importance of the exponential degeneracy of the first excited state (P1) can be appreciated from the degenerate model equation (9) and its corresponding ground state probability for the Gibbs state (in units of β), , which can be expressed as


For small energy gaps E and large D, the value of p0 tends to 0 as meaning that in the thermal state, almost all the population is spread evenly in the degenerate excited subspace. When the gap reaches , , while for larger values it increases to , and the excited levels become empty. The width of this transition is of order , and it is the point where the system experiences the peak in heat capacity; in fact, for smaller (larger) values of E, the energy variance is suppressed exponentially, given that the whole population collapses to the excited subspace (ground state). At the peak of the heat capacity, approximately half of the population is in the ground state, and half is spread in the degenerate level. If the degeneracy is exponential in N, the optimal gap is linear in N, and the resulting energy variance equation (7) scales quadratically. According to this observation, the exponential (in N) degeneracy of the first excited level is the first main ingredient for a system to exhibiting such quadratic scaling of the heat capacity. Furthermore, we notice that at a formal level, the same scaling is obtained whenever for some , which leads to P1. Notice however that any physical implementation of such a conceivably highly fine-tuned two-level probe will be susceptible to noise. The resulting deviation will cause a broadening of the ideally degenerate excited level into a band. In appendix
![${\sim}\textrm{Exp}[E]/(D-1)$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn58.gif)











Finally, it is possible to show that the quadratic scaling of the heat capacity is preserved even in the presence of additional 'undesired' energy levels, provided that property P3 is satisfied.
More precisely, consider two Hamiltonians, H1 with dimension , and H2 with dimension . H1 has 1 ground state and a k1-degenerate excited state, , while H2 has the same spectrum and additional k2 excited states above, , with . Assuming control over the first excited gap E, we prove in appendix






This property guarantees that additional excess levels above the k1-degeneracy of H1 can only increase the maximal heat capacity. As a consequence, as the system size grows, any model featuring an exponential degeneracy of the first excited level and a tunable gap will show the desired Heisenberg-like scaling of the heat capacity. The control over E, while keeping , can easily be obtained, for example by rescaling all the parameters of H1 or H2 globally. For what concerns additional levels below the first excited, it is enough to notice that if their total number is of order for finite k, and their gap from the ground state energy is bounded between NK and (), their total contribution to the variance (7) scales as , and is therefore suppressed for large N.




![$\mathcal{O}(N^{k+2} \exp[-\beta NK])$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn79.gif)
3. Optimal spin-network thermometers
We recall that, without any restriction on the possible interactions among the N spins, it is possible to generate the Hamiltonian equation (9) and to saturate the theoretical maximum value of the heat capacity (see e.g. [37], where the authors make use of arbitrary N-body interactions). The question Q we address in this work is whether it is possible to achieve the optimal scaling if we restrict ourselves to physically motivated 2-body Hamiltonians given by equation (3). In such spin-systems, we have , where N is the total number of spins, thus the ultimate limit equation (2) reads




for large N. Below, we demonstrate that the answer to our main question is positive. We show that it is possible to design a thermal probe ('Star model', section 3.1) consisting of N interacting spins with two-body interactions that approximates the maximum value of the thermal sensitivity equation (12). We further prove that a thermal probe ('Star-chain model', section 3.2) with two-body and local interactions can be designed with a heat capacity exhibiting the same scaling as equation (12) with a prefactor that can be made arbitrarily close to the Star model. Moreover, in section 3.3 we show that the Star-chain model can be realized on currently available quantum annealers. Finally, in section 3.4 we analyze the scaling of the Hamiltonian parameters in these configurations, and the effect of constraints on the absolute value of the parameters.

3.1. Star model
We now search for thermal probes, consisting of spin networks with two body interactions, that maximize the heat capacity. We maximized over the parameters hi
and Jij
employing equation (7) and constraining H to be of the form (3). Notice that such problem is numerically hard due to (i) its nonconvexity, (ii) the number of optimization parameters that scales quadratically in N, and (iii) the number of spin configurations that scales exponentially. As such, first attempts based on simpler techniques such or gradient descent with momentum [70] estimating the gradients with finite-differences, and the gradient-free covariance matrix adaptation evolution strategy [71], would get stuck in sub-optimal local maxima with a substantially lower , not exhibiting the Heisenberg-like scaling. We thus decided to use tools commonly employed in Machine Learning, i.e. we implemented the optimization in PyTorch that allows us to compute the exact gradients of the negative heat capacity using backpropagation [72], and we used the Adam optimizer [73] (see appendix


After repeating the optimization for different total numbers of spins N, a recurrent pattern emerges (cf appendix

with , corresponding to a single spin () that is coupled uniformly to all the other ones. A representation of this Star model is shown in figure 3.



Figure 3. (a), (b): Machine learned Hamiltonian parameters (3), for T = 1 and N = 7. (a) shows the local field hi as a function of the spin index, while (b) shows the Jij parameters (color) as a function of the site indices i and j. The resulting model that emerges, sketched in (c), is (13). It consists of a single central spin (corresponding to spin nr. 2 in (a), (b), and orange circle in (c)) with a different local magnetic field and that interacts (gray lines) with all the other N − 1 spins homogeneously (black circles) resulting in a Star-shaped connectivity.

Download figure:
Standard image High-resolution imageThe resulting spectrum has 2 main classes of eigenstates. The first class consists of -degenerate evenly spaced states with energy


corresponding to the first spin being up, i.e. , and k spins up among the remaining N − 1 ones. The second class consists of the first spin being down . In this the second term in (13) becomes null, independently of the value of all the other spins , and we get a -degenerate excited state with energy





That is, thanks to the simple topology and choice of the couplings in equation (13), the first spin acts as an 'on-off' switch for the effective magnetic field on the remaining spins, generating an exponential degeneracy of the level. The partition function of the Star model can be solved analytically, being the sum of the two partition functions corresponding to , i.e.




This expression can be used to efficiently compute all the relevant thermodynamic quantities of the model (cf appendix D.1). Moreover, it is easy to see that by choosing b > 0 and , one ensures


corresponding to a single ground state, and -degenerate first excited level. By saturating , one gets , corresponding to a degeneracy for the first excited state 10 (for a visual representation, see figure 4). Notice that property P3 (11) ensures that such a model can achieve at least the heat capacity , that is






In the asymptotic limit, we get

which becomes indistinguishable from the theoretical bound , see equation (12) and shown in figures 1 and 9 below. In appendix A.3, we provide a table with the optimal values of the Hamiltonian parameters (see equation (13)) and the corresponding value of given by numerical optimization.


![$\mathcal{C}^\textrm{Star[N]}_\textrm{max}$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn106.gif)

Figure 4. Spectrum of the Star model (13) (for N = 9). eigenvalues form a binomial spectrum (14), while the other eigenvalues are completely degenerate (15). The gap between the ground energy and the exponentially degenerate level approximately coincides with the optimal gap of the ideal spectrum (9) for [35] (red line), as expected from the discussion in section 3.1.




Download figure:
Standard image High-resolution image3.2. Star-chain model
As the Star model arises from an unconstrained numerical optimization of for Hamiltonians of the form (3) (cf above section 3.1 and appendix



Here α is the index identifying the central spin of each Star-like sub-unit (orange circles in the figure), while selects the i-th spin in each sub-unit (black circles), i.e.


Short-range interactions are guaranteed by considering a fixed value of m. The partition function of the Star-chain model can be computed analytically (cf appendix D.3),

where , , and . From the spectral point of view, this model guarantees a degeneracy for each energy level with down α-spins. In particular, when all the α-spins are down, i.e. , corresponding to a 2mn
degeneracy. Moreover, if the couplings J are negative and strong enough to force all the n
α-spins to be the same (for a detailed analysis of the needed coupling strengths, see section 3.4 and appendix
















which leads to This shows that is essentially quadratic in , i.e.
![$\mathcal{C}^{\text{Star-chain}[N]}_\textrm{max}\sim (\ln (2^{mn}+mn))^2/4$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn131.gif)



Equation (24) makes clear how large values of m increase the achievable heat capacity, (see appendix A.3 for the optimal values of and the corresponding Hamiltonian parameters). For , the Star-chain model coincides with the Star model (n = 1, cf figures 3 and 5). Let us note that short-range interactions impose a maximum m, but this one only impacts the prefactor of the quadratic scaling. Hence, it does not change the quadratic scaling of demonstrated with the Star-chain model.




Figure 5. Representation of the Star-chain model (20). The total number of spins is . The orange circles represent the α-spins, coupled to each other through the blue lines, while the black circles represent the -spins coupled to their respective α-spin through the gray lines. The values of the local fields hi and coupling terms Jij are reported in the figure.


Download figure:
Standard image High-resolution image3.3. Implementation in the Chimera graph
Quantum annealers are devices governed by programmable quantum spin Hamiltonians, therefore representing a natural platform to test our findings. Interestingly, the topology of the interactions of the Star-chain model with m = 3 (cf figure 5) can be embedded into the Chimera graph (cf figure 6) of the D-Wave annealing quantum processor 11 . This means that, as from (24), a programmable spin network in the Chimera graph can reach at least of the ultimate bound (12). Remarkably, numerical optimization of for the Chimera model results indeed in the Star-chain model with m = 3 represented in figure 6 (see appendix A.5). Notice also that there exists new architectures of the D-Wave annealers, such as the Pegasus graph [74–76], which can reach higher connectivities, and therefore higher values of m for which the Star-chain Hamiltonian can be embedded. Such optimal thermometer probes could be used, for example, to precisely measure the surrounding effective temperature of the annealer (to be compared with the cryostat temperature), and overall to gain a better understanding of the D-Wave annealer as an open quantum system [50, 51, 77, 78].




Figure 6. Embedding of the Star-chain model for m = 3 (see figure 5) into the Chimera graph, which is used by D-Wave Systems 11 . As in figure 5, orange circles represent the α-spins, coupled to each other through the blue lines, while black circles represent the -spins coupled to the respective α-spin through the gray lines. Dotted lines represent unused couplings of the Chimera architecture (i.e. where ).


Download figure:
Standard image High-resolution imageLet us emphasize a specificity of both the Star and Star-chain models, that may become relevant for practical applications. For both models, it is enough to measure a single spin to perform temperature estimation. In the regime of large N, the only relevant energy levels contributing to the Gibbs state are the ground level, and the first excited level (higher excited levels are exponentially suppressed in the statistics, cf appendix D.2 and previous discussions). We can distinguish between these two cases by simply measuring the value of for the Star model (13), or any of the in the Star-chain model (20).


3.4. Scaling and constraints on the strength of the interactions
While the results presented above are very promising, one challenging requirement of the optimal configurations is the strength of the interactions between the constituents. This one becomes increasingly demanding for large N. For instance, engineering the optimal spectrum for the Star model with a first-excited state degeneracy requires the scaling and as N grows (see 'unconstrained' dots in figure 7(a)), accompanied by a relative precision for both parameters (cf section 3.1 and appendix




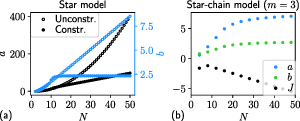
Figure 7. Parameter scaling of the Star model (a) and Star-chain model for m = 3 (b) in their configurations that maximise (we obtain nearly identical values of for both cases). In the 'unconstrained' case (empty circles), b increases linearly with N, and a quadratically. This corresponds to the optimal choice of section 3.1. In the 'constrained' case (full circles), it is possible to find solutions in which b is limited by a constant, while a increases linearly. These solutions preserve the same numerical value of , and are found optimizing the heat capacity over a and b, and choosing as initial point for the optimization b = 2.2 and .





Download figure:
Standard image High-resolution imageHowever, as we show in appendix D.1, there exist solutions that are mathematically sub-optimal but numerically indistinguishable in terms of , with much more favorable scaling of the Hamiltonian parameters. In fact, even when limiting b to be bounded by a constant, it is possible to achieve the desired quadratic scaling of , arbitrarily close to the optimal value equation (19). These solutions feature a finite b, whose precise value becomes irrelevant, and a linear scaling of , which admits a relative precision (see appendices





Finally, it is possible to use the machine learning optimization method to maximize over all possible Hamiltonians of the form equation (3) with the additional constraint for the parameters to be bounded (see appendix A.2 for details). Our numerical optimization leads to configurations that are too complex and case-dependent to be discussed in generality. However, the resulting maximal heat capacities seem to indicate that a quadratic scaling is still possible under such constraints, see figure 8.



Figure 8. Comparison of the heat capacity, as a function of N, on a linear scale (a), and on a log-log scale (b). The 'bound' curves represent numerical maximizations of the general spin Hamiltonian (3), where all parameters are constrained to be in a certain interval, i.e. , with c shown in the legend. The red and black lines are reference quadratic and linear scalings.
![$h_i, J_{ij}\in [-c,c]$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn160.gif)
Download figure:
Standard image High-resolution image4. Comparison to alternative models
In figure 9, we compare the maximum values of the heat capacity for different models of spin Hamiltonians, as the number of spins N grows. The Star and Star-chain models show a quadratic scaling in N that eventually surpasses all standard models—such as the Ising model in 1D, as well as a model of uniform 'all-to-all' interactions. The latter show instead the standard thermodynamic extensive scaling, i.e. linear in N, of the heat capacity. Below, we briefly describe each of the relevant alternative models to which our results obtained for the Star and Star-chain models have to be compared.


Figure 9. Performance of the optimal spin-based thermometers found in this work as a function of . Our optimal architectures, 'Star model' and 'Star-chain model' demonstrate a quadratic scaling of the maximal heat capacity in terms of the number N of total spins employed. This is to be compared with the extensive scaling of standard models, such as the 1D Ising chain, or the All-to-all model described in the text. For (see the inset for the heat capacity zoomed around small values of ), the Star model provides the highest heat capacity for Hamiltonians of the form (3) and can reach the mathematical bound (8) (red line in the plot) in the large N limit. The Star-chain model has a similar behaviour while only using short-range interaction, and it can be programmed on current quantum annealers (cf section 3.3). A detailed description and discussion of all the models we consider is given in the text.







Download figure:
Standard image High-resolution image4.1. Ising lattices
The 1D Ising model is arguably the simplest candidate for an interacting-spin thermometry probe. For N spins, it is defined by the Hamiltonian

where we choose periodic boundary conditions . The heat capacity for this model can be efficiently computed with standard techniques [79]. Numerically maximization leads consistently to homogeneous interactions and local fields . As expected, an Ising chain probe will at most achieve a linear scaling in N of the heat capacity, as seen in figure 9. Note that a 2-dimensional Ising model can achieve a slightly higher scaling at criticality, i.e. [80, 81], while the 3-dimensional Ising model has using critical scaling [82].





4.2. All-to-all symmetric model
Another relevant model for this work is a model with all-to-all interactions, completely symmetric under permutations. Its Hamiltonian takes then the form

It describes a complete graph with homogeneous interactions J > 0 and local fields h > 0. Taking the systems' symmetries into account, we get the following -degenerate eigenenergies for up-spins:



As shown in appendix

4.3. k-SAT model and the exponential degeneracy
Finally, we notice that in [83, 84], a Hamiltonian replicating a global AND-operation between M logical bits (represented by M spins) was introduced, with the aid of M ancillary spins. Such Hamiltonian was proposed as the basic element to build general models to solve k-SAT problems [85]. We will thus refer to it as the k-SAT model. A logical AND identifies a single string (without loss of generality, the string given by , M times) with an energy different from the energy associated to all the other logical strings. Formally, this spectrum coincides with the ideal two-level degenerate model (9), and therefore the Hamiltonian proposed in [83, 84] exhibits the desired quadratic scaling of the maximum , more precisely (cf figure 9). The construction uses a total of spins (the neglected levels correspond to energies that can be made arbitrarily high, see [83]), that is, an overhead of . The Star and Star-chain models achieve similar degeneracies while using a much smaller overhead, i.e. a 1-spin overhead for the Star model and a -spins overhead for the Star-chain model. In table 1, we compare these models in terms of the excited-level degeneracy and scaling of , as well as the locality of the interactions.





![$\mathcal{C}_\textrm{max}^{k-\textrm{SAT}[N]} = \mathcal{C}^\textrm{opt}(2^\frac{N}{2})$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn182.gif)




Table 1. Models recreating an effective spectrum with a single ground state and an exponentially degenerate first excited level. With the same total number N of spins, the k-Sat model 'sacrifices' half of them to obtain a degeneracy, while the Star model has a single spin overhead ( degeneracy), and the Star-chain a overhead ( degeneracy). Moreover, the Star-chain model can be realised with short-range interactions.




| Model | 1st excited deg. | Asymptotic | Short-range? |
|---|---|---|---|
| k-Sat [83] | |||
| Star | |||
| Star-chain | ✓ |









5. Conclusions and outlook
In this work, we addressed the problem of maximizing the heat capacity of physically realisable quantum systems, which amounts to engineer the best probe for temperature estimation in the context of equilibrium thermometry [4]. Using a combination of analytical derivations, Machine-Learning methods, and physical insights, we explore the design space of spin Hamiltonians with two-body interactions and local magnetic fields, discovering Hamiltonians with star-shaped topology that can approach the theoretical maximum of in the limit of large systems. Additionally, we showed that an arbitrarily good approximation can be achieved when requiring these interactions to be short-ranged. The models emerging from such optimisation achieve a Heisenberg-like scaling of the sensitivity, without the use of entanglement, contrary to the well-known case of phase estimation in quantum optics [42]. Remarkably, these models show a simple architecture of the interactions that make them ideal probes also for adaptive temperature estimation schemes [39, 86]. We further showed that the models we found can be embedded in currently available quantum annealers 11 , making them highly attractive both from a theoretical and experimental points of view. These results pave the way to the physical realization of ultra-sensitive spin-based thermometers, valid also for alternative experimental platforms such as cold atoms [87], NV centers [88], and Rydberg atoms [89]. Of particular interest is the use of these engineered optimal spin-network thermal probes for ultracold gases [13, 21–23, 32].


In terms of Hamiltonian spectrum engineering, we showed that the essential requirement for an optimal thermal probe made of N constituents is the presence of a single ground state and an exponential degeneracy of the first excited level. This effective two-level spectrum also appears in other problems, in which we speculate that our work might have application, such as protein folding modelling [90, 91], adiabatic Grover's search [92–94], energy based boolean computation [83], and quantum heat engines [82, 95–98].
An interesting challenge for the future is to characterise the relaxation timescale τrel of the optimal probes derived here, see also [94, 95]. Due to critical slowdown, we expect a trade-off between large heat capacity and slowness of the relaxation process. It hence remains a relevant open question if a similar Hamiltonian engineering can be performed taking as a figure of merit , which would also have important consequences in the optimization of thermal engines [82, 95–98]. At the same time, it is worth emphasising that when time is a resource for thermometry 12 , optimal non-equilibrium protocols require the same effective two-level structure of the models presented in this work, as recently shown in [38]. Another challenge is to move beyond the weak coupling assumption behind (4), and consider the optimisation of thermometer probes for the more general mean force Gibbs state [99–101].

Acknowledgments
We thank Rosario Fazio for fruitful discussions. P A is supported by the QuantERA II programme, that has received funding from the European Union's Horizon 2020 research and innovation programme under Grant Agreement No 101017733, by the Austrian Science Fund (FWF), project I-6004, by 'la Caixa' Foundation (ID 100010434, Grant No. LCF/BQ/DI19/11730023), and by the Government of Spain (FIS2020-TRANQI and Severo Ochoa CEX2019-000910-S), Fundacio Cellex, Fundacio Mir-Puig, Generalitat de Catalunya (CERCA, AGAUR SGR 1381). F N gratefully acknowledges funding by the BMBF (Berlin Institute for the Foundations of Learning and Data—BIFOLD), the European Research Commission (ERC CoG 772230) and the Berlin Mathematics Center MATH+ (AA1-6, AA2-8). P A E gratefully acknowledges funding by the Berlin Mathematics Center MATH+ (AA1-6, AA2-18). G H and M P L acknowledge funding from the Swiss National Science Foundation through a starting Grant PRIMA PR00P2_179748 and an Ambizione Grant No. PZ00P2-186067, and through the NCCR SwissMAP.
Data availability statement
The code used to generate these results can be provided upon request to the authors. All data that support the findings of this study are included within the article (and any supplementary files).
Appendix A: ADAM optimization and the emergence of the Star (and Star-chain) models
In this appendix we explain how we carried out the numerical optimization of the heat capacity using methods that are commonly employed in machine learning.
Let us consider an arbitrary Hamiltonian that depends on a set of parameters θ. The θ parameters could be, for example, the hi and Jij parameters in equation (3). Our aim is to determine the value of the parameters θ that maximize the heat capacity of the system. As discussed in the main text, this is equivalent to maximizing the Hamiltonian variance of the thermal state given in equation (7).


In machine learning, it is common to minimize a 'loss function' that depends on a set of parameters. One way to determine the value of θ that minimizes is to use gradient descent. This consists of starting from a random value of the parameters θ, computing the gradient , and updating the parameters according to




where α > 0 is the so-called 'learning rate' that determines how large of a step we take in parameter space in the opposite direction of the gradient. If α is small enough and is differentiable, then it is guaranteed that ; reiterating this gradient descent step many times, we will reach a local minimum.


However, this method is prone to getting stuck in local minima, may take many iterations to converge, and choosing appropriate values of α is not always straightforward. An alternative to the update rule in equation (A1) is given by ADAM (Adaptive Moment Estimation) [73]; this method was empirically found to converge better in a variety of problem. As equation (A1), it only requires the calculation of the gradient at each iteration, but it improves over it in various ways, so we refer to [73] for details.
In order to find the parameters θ that maximize the heat capacity of the system described by , we use as loss function


such that minimizing the loss function corresponds to maximizing the Hamiltonian variance. We then start from a random choice of θ and use the ADAM optimization method to minimize the loss function. We compute the gradient of the variance using backpropagation [72], which is a common machine learning algorithm that automatically computes the gradient of a function in a given point. In particular, we use the PyTorch framework to compute the Hamiltonian variance of the thermal state, its gradient, and to perform the ADAM optimization using the default hyperparameters.
We now display some of the results we found with this method in different classes systems.
A.1. N Spin Hamiltonian
In this subsection we show how the Star model emerged from the numerical optimization considering the N spin Hamiltonian given in equation (3), and we provide some details on the optimization method. The optimization was carried out as described above considering and as the θ parameters. Both are initialized randomly between −1 and 0. We performed separate optimizations for , finding the All-to-All model for , and the Star model for . For , the results were found running a single optimization with fixed learning rate α = 0.001 for 60000 steps (although most optimizations converge much sooner). However, for , this choice would sometimes get stuck in local minima. For , we ran the optimization multiple times as detailed above, and chose the model with the largest heat capacity. For , to avoid getting stuck in local minima, we used a common technique in Machine Learning, which consists of scheduling the learning rate, i.e. of varying it at each optimization step. In particular, we used the 'CyclicLR' scheduler of PyTorch that varies the learning rate in a triangular fashion between a minimum and a maximum value. For N = 14, we chose and , and halved the amplitude of the triangle at every repetition (such that, asymptotically, the learning rate converges to . The number of steps during the 'up phase' of the triangle was chosen to be 6000. For N = 15, we chose and without halving the amplitude of the triangle at every repetition. Also in this case the 'up phase' consists of 6000 steps.
















To show the emergence of the Star model, in figure 10 we show the values of hi and of Jij found with our numerical method for N = 4 (left panels), N = 7 (middle panels), and N = 9 (right panels). The upper panels show hi as a function of the site index , while the lower panels show the value of Jij (the color) as a function of the site indices i and j. Since Jij is only defined for i < j, a white square is shown when such condition is not satisfied.

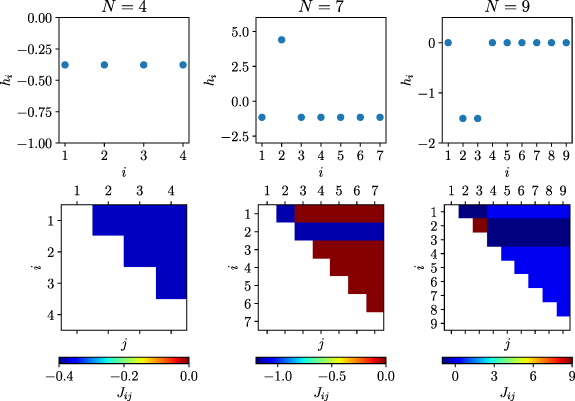
Figure 10. Values of hi and of Jij found with our numerical method for N = 4 (left panels), N = 7 (middle panels), and N = 9 (right panels). The upper panels show hi as a function of the site index , while the lower panels show the value of Jij (the color) as a function of the site indices i and j. Since Jij is only defined for i < j, a white square is shown when such condition is not satisfied.

Download figure:
Standard image High-resolution imageAs we can see, for N = 4 all parameters take the same value ( for every i and j); this corresponds to the All-to-All model described in equation (26) with . For N = 7, we see that all spins are interchangeable except for a single privileged spin corresponding to i = 2. Indeed, , while , and Jij is non null, and equal to −1.15, only when i or j are equal to 2. This is precisely the Star model as described in equation (13) with a ≈ 4.41 and . For N = 9, we find a model where all spins are interchangeable, except for two privileged spins corresponding to . Indeed, except for . Also when both i and j are not 2 or 3, while , and when i or j are 2 or 3, but not both. The Hamiltonian of this model can be written as












and schematically represented as in figure 11 with a ≈ 8.96 and . Interestingly, it can be seen that has the same exact spectrum as , and therefore the same heat capacity. Therefore, while they are physically two different models, they have identical characteristics as thermometers.




Figure 11. Schematic representation of the Hamiltonian given in equation (A3).

Download figure:
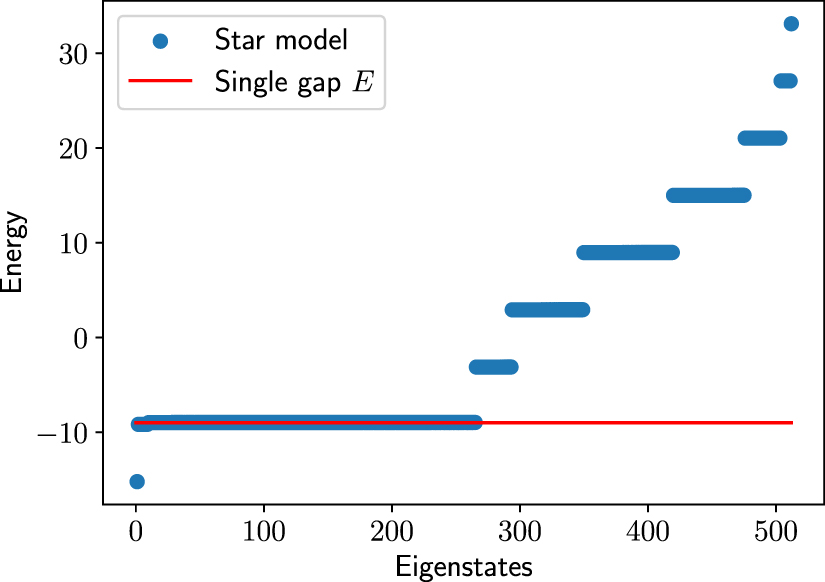
Standard image High-resolution imageAt last, in figure 12 we analyze the spectrum of the Star model corresponding to N = 9. The individual eigenenergies are plotted as dots on the y-axis. For comparison, we plot as a red line the value of E (measured from the ground state energy) that maximizes the heat capacity of the degenerate Hamiltonian (see equation (9)) for N = 9. As expected, there is a single ground state, a highly degenerate first excited state (with a degeneracy approximately given by half of the states), and further excited states with a binomial degeneracy. Interestingly, and as suggested by the Lemma of appendix B, the value of E is quite similar to the energy of the highly degenerate first excited state.


Figure 12. Spectrum of the Star model, found with the numerical optimization for N = 9, represented as dots with the corresponding energy on the y-axis. The red line represents the energy E (measured from the ground state energy) that maximizes the heat capacity of the degenerate Hamiltonian (see equation (9)) for N = 9.

Download figure:
Standard image High-resolution imageA.2. N Spin Hamiltonian with bounded parameters
In this subsection we discuss how we performed the optimization of the heat capacity of N spins with an additional bound on the magnitude of the parameters that lead to the 'bound' curves in figure 8. In particular, we wish to maximize equation (3) with respect to hi and Jij , with the additional constraint that

where c > 0 is a real constant.
Since our method works well for unconstrained optimizations, we introduce the following parameterization

where xi and yij are real parameters. Since the hyperbolic tangent produces values in , the parameterization of equation (A5) guarantess to satisfy the constraint in equation (A4) for any value of xi and yij .
![$[-1,1]$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn246.gif)
We therefore apply the same optimization described above, but choosing and as our unconstrained optimization parameters θ, instead of and .




In particular, the orange and green dots in figure 8 were produced the following way. We initialize the and parameters randomly in the interval . Then, for each value of , we repeat the optimization 12 times, choosing the one with the highest heat capacity. In particular, 6 repetitions are performed with learning rate α = 0.01, and 6 with α = 0.03. For , we do the same but choosing as learning rates respectively α = 0.01 and α = 0.003.


![$[-1.5, 1.5]$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn253.gif)


A.3. Optimal values for the Star model and the Star-chain
In this subsection we provide some details regarding the heat capacity maximization in the Star and Star-chain models. In particular, in tables 2 and 3 we provide the explicit values plotted in figure 7.
Table 2. Values of the parameters of the Star and Star-chain models, that optimize the heat capacity, plotted in figure 7 (see caption of figure 7) for details. The second half of the parameters are given in table 3.
| Star model (unconstr.) | Star model (constr.) | Star-chain model | |||||
|---|---|---|---|---|---|---|---|
| N | a | b | a | b | a | b | J |
| 2 | −0.711 | 0.711 | −0.711 | 0.711 | — | — | — |
| 3 | 0.000 | 0.797 | −0.136 | 0.752 | — | — | — |
| 4 | 0.894 | 0.894 | 0.578 | 0.810 | 0.578 | 0.810 | −1.600 |
| 5 | 2.015 | 1.007 | 1.518 | 0.897 | — | — | — |
| 6 | 3.398 | 1.133 | 2.797 | 1.020 | — | — | — |
| 7 | 5.070 | 1.267 | 4.482 | 1.173 | — | — | — |
| 8 | 7.052 | 1.410 | 6.553 | 1.340 | 1.964 | 1.101 | −1.191 |
| 9 | 9.358 | 1.560 | 9.041 | 1.520 | — | — | — |
| 10 | 11.998 | 1.714 | 13.722 | 1.905 | — | — | — |
| 11 | 14.977 | 1.872 | 17.489 | 2.123 | — | — | — |
| 12 | 18.297 | 2.033 | 20.311 | 2.216 | 3.504 | 1.559 | −1.612 |
| 13 | 21.960 | 2.196 | 22.760 | 2.263 | — | — | — |
| 14 | 25.967 | 2.361 | 25.032 | 2.289 | — | — | — |
| 15 | 30.318 | 2.527 | 27.208 | 2.304 | — | — | — |
| 16 | 35.013 | 2.693 | 29.322 | 2.314 | 4.953 | 2.021 | −2.038 |
| 17 | 40.053 | 2.861 | 31.397 | 2.320 | — | — | — |
| 18 | 45.438 | 3.029 | 33.444 | 2.324 | — | — | — |
| 19 | 51.168 | 3.198 | 35.473 | 2.326 | — | — | — |
| 20 | 57.243 | 3.367 | 37.490 | 2.328 | 5.720 | 2.267 | −2.468 |
| 21 | 63.664 | 3.537 | 39.495 | 2.329 | — | — | — |
| 22 | 70.431 | 3.707 | 41.493 | 2.329 | — | — | — |
| 23 | 77.543 | 3.877 | 43.488 | 2.329 | — | — | — |
| 24 | 85.001 | 4.048 | 45.477 | 2.329 | 6.164 | 2.411 | −2.903 |
Table 3. Continuation of the parameters displayed in table 2.
| Star model (unconstr.) | Star model (constr.) | Star-chain model | |||||
|---|---|---|---|---|---|---|---|
| N | a | b | a | b | a | b | J |
| 25 | 92.805 | 4.218 | 47.465 | 2.329 | — | — | — |
| 26 | 100.956 | 4.389 | 49.451 | 2.329 | — | — | — |
| 27 | 109.452 | 4.560 | 51.436 | 2.329 | — | — | — |
| 28 | 118.294 | 4.732 | 53.420 | 2.329 | 6.452 | 2.504 | −3.336 |
| 29 | 127.483 | 4.903 | 55.404 | 2.329 | — | — | — |
| 30 | 137.018 | 5.075 | 57.388 | 2.330 | — | — | — |
| 31 | 146.899 | 5.246 | 59.371 | 2.329 | — | — | — |
| 32 | 157.127 | 5.418 | 61.354 | 2.328 | 6.649 | 2.568 | −3.767 |
| 33 | 167.701 | 5.590 | 63.339 | 2.329 | — | — | — |
| 34 | 178.621 | 5.762 | 65.324 | 2.329 | — | — | — |
| 35 | 189.887 | 5.934 | 67.310 | 2.329 | — | — | — |
| 36 | 201.500 | 6.106 | 69.295 | 2.329 | 6.790 | 2.614 | −4.195 |
| 37 | 213.460 | 6.278 | 71.280 | 2.329 | — | — | — |
| 38 | 225.766 | 6.450 | 73.267 | 2.329 | — | — | — |
| 39 | 238.418 | 6.623 | 75.254 | 2.329 | — | — | — |
| 40 | 251.417 | 6.795 | 77.241 | 2.329 | 6.896 | 2.648 | −4.622 |
| 41 | 264.762 | 6.967 | 79.230 | 2.329 | — | — | — |
| 42 | 278.453 | 7.140 | 81.218 | 2.329 | — | — | — |
| 43 | 292.492 | 7.312 | 83.206 | 2.329 | — | — | — |
| 44 | 306.876 | 7.485 | 85.196 | 2.329 | 6.979 | 2.676 | −5.047 |
| 45 | 321.607 | 7.657 | 87.187 | 2.330 | — | — | — |
| 46 | 336.685 | 7.830 | 89.176 | 2.330 | — | — | — |
| 47 | 352.109 | 8.002 | 91.167 | 2.330 | — | — | — |
| 48 | 367.879 | 8.175 | 93.158 | 2.330 | 7.046 | 2.697 | −5.472 |
| 49 | 383.996 | 8.348 | 95.150 | 2.330 | — | — | — |
| 50 | 400.460 | 8.520 | 97.141 | 2.330 | — | — | — |
All three optimizations are carried out using the Adam optimizer for 6000 steps and backpropagation to compute the gradients as described in appendix A, but we only optimize over the a and b parameters of the Star model, and over the a, b and J parameters of the Star-chain model.
In particular, the 'unconstrained' case of the Star model was optimized fixing the condition , and optimizing only over b. The initial value is set to b = 6, and the learning rate is set at α = 0.01. In the 'constrained' case of the Star model, we optimize over a and b choosing as initial values and b = 2.2, and learning rate α = 0.001. In the Abel model with m = 3, we optimize over a, b and J. For N = 4, we choose as initial values a = 3.5, b = 1.55 and . For higher values of N, we choose as initial values the parameters that maximize the previous optimization. We set the learning rate at α = 0.003.



A.4. Quantum N Spin Hamiltonian
In this subsection, we employ our numerical optimization method to maximize the heat capacity of the most generic two-body spin Hamiltonian, namely

where and are arbitrary parameters. Since the heat capacity only depends on the spectrum of the Hamiltonian, we can perform arbitrary unitary operations to without changing its spectrum, thus its heat capacity. Choosing local unitary transformations of the form




where θµ are three suitable angles, we can always rotate into an operator proportional only to . Therefore, applying the appropriate unitary transformation on each spin site, we obtain the Hamiltonian



where and are arbitrary parameters.


In this subsection, without loss of generality, we optimize equation (A8) considering and as optimization parameters θ. We performed a separate optimization for with a fixed learning rate α = 0.001, performing 20000 optimization steps, and starting from random initial values of the parameters uniformly distributed between 0 and 1. In all cases, we found values of the heat capacity that are identical (up to numerical errors) to the values found considering the N spin Hamiltonian with only σz , i.e. the model, given by equation (3), considered in the previous subsection. Furthermore, these solutions also have the same spectrum found in the previous subsection. However, they are not the same model: indeed, the optimal values of that we find are non-zero when and . This can be understood in the following way: since the spectrum and the heat capacity are invariant under unitary transformations, we can apply any unitary transformation to the Star model to generate different models that display the same spectrum and heat capacity. Therefore, there is an infinitely large class of systems with the same optimal heat capacity, and our optimization method converges randomly to one of these solutions.






As an example, in figure 13 we plot the spectrum, hi , and (for ), that we found for N = 9, in the same style as in figures 10 and 12. As we can see, there is some structure in for that privileges a specific spin index (number 8 in this case). However, it is clear that this model is different from the N spin Hamiltonian with only σz . Nonetheless, we see that the spectrum, and thus the heat capacity, is essentially the Star spectrum (compare the first panel of figure 13 with figure 12). The very small discrepancies are due to the numerical optimization method that reached parameters near the local minima, but not exactly. As previously anticipated, the 'noisyness' that is visible in many panels can be explained by the infinite number of models that yield the same spectrum, such that the numerical method converges to a random one based on the initial stochastic choice of the parameters.





Figure 13. Optimization results for the quantum spin Hamiltonian in equation (A8) for N = 9. The first row shows the spectrum and the hi as in figures 10 and 12. Each of the lower 9 panels displays , for all combinations of , as a function of the site index i and j (similar to figure 10). Since is only defined for i < j, a white box is plotted when such condition is not fulfilled.



Download figure:
Standard image High-resolution imageA.5. D-Wave annealer Hamiltonian
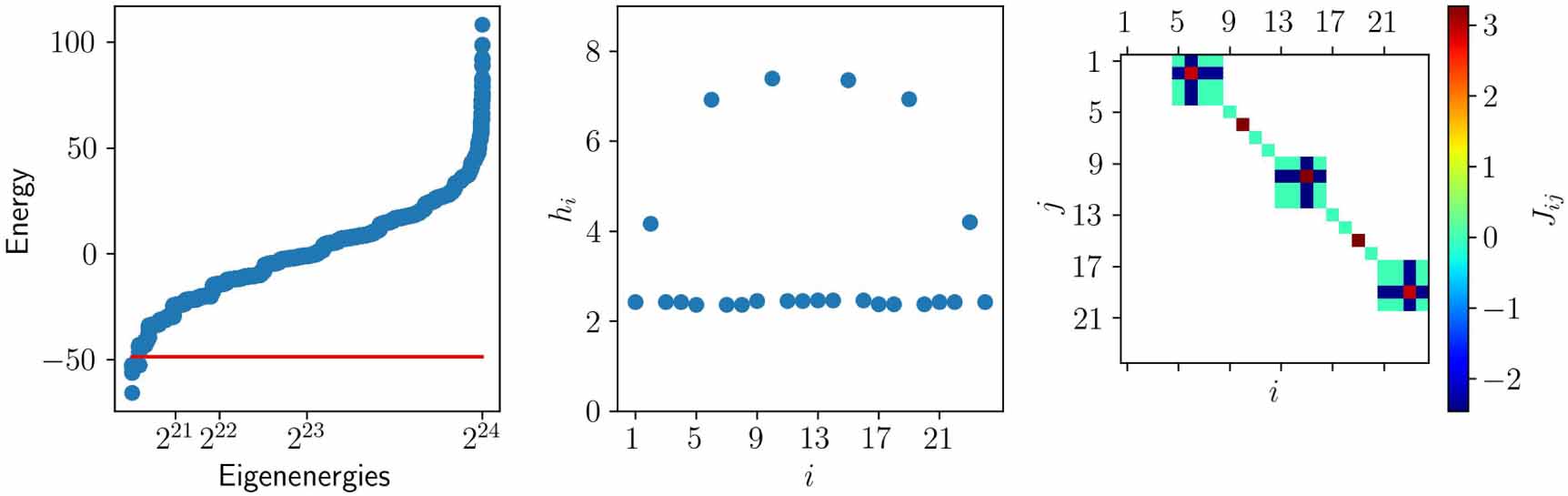
In this subsection we consider a spin Hamiltonian as in equation (3) with only terms, but we constrain the optimization to reflect the topology of the interactions of D-Wave annealers. In particular, we consider the Chimera graph as in figure 6, and we focus on 3 units, i.e. 24 spins. This corresponds to excluding the lower right unit of figure 6. Mathematically, we enforce elements of Jij to be null whenever a connection between spin i and j is not present in the topology, and then we minimize the loss function considering the non-null and parameters as θ. We use the Star optimization method for 20 000 steps at a fixed learning rate, and randomly initializing the parameters between −1.5 and 1.5. In fact, we ran the optimization 3 times: once with α = 0.01, and twice with α = 0.03. This yielded values of the heat capacity between 39.99 and 41.57.



In figure 14 we show the numerical results that we found in the optimization run that yielded the largest heat capacity (corresponding to . The first panel shows the spectrum in the same style as figure 12, while the second and third panels show the values of hi and Jij as in figure 13. To better understand the results, we applied a local unitary flip of in all sites where (which does not change the spectrum, thus the heat capacity). This amounts to changing the sign of hi whenever hi is negative, and correspondingly changing the sign of Jij and Jji for all j. The indexing of the spins is such that the first unit is described by , the second by , and the third by . Furthermore, spins of the first unit are coupled to spins of the second unit, and spins of the second unit are coupled to spins are the third unit (see non-white boxes in the last panel of figure 14).











Figure 14. Optimization results for the Chimera graph topology of the interactions of D-Wave annealers with 3 units (24 spins). The first panel shows the spectrum of the model as in figure 12, while the second and third panels show the values of hi and of Jij as in figure 10. Since Jij is only defined for i < j and when spins i and j are coupled according to the Chimera graph shown in figure 6, a white box is plotted whenever Jij is not defined.
Download figure:
Standard image High-resolution imageAs we can see, this model is very similar to the Star-chain model with m = 3 embedded into the Chimera graph as in figure 6. Indeed, there are two privileged spins per unit (corresponding to spins in the first unit, in the second, and in the third). These are represented in orange in figure 6. These spins have a larger on-site potential as compared to all other ones (see middle panel of figure 14), and they are each coupled to 3 spins within the same unit (see the 'dark blue crosses' in the last panel of figure 14). Furthermore, the three units are linked to each other through these privileged spins (see the two brown isolated dots in the last panel of figure 14).



Appendix B: A small Lemma of (Property 2)
In this appendix we prove a theoretical Lemma that leads to Property 2 in the main text, section 2.2. The Lemma considers two Hamiltonians, H1 and H2, such that H1 has a single ground state and a k1-degenerate excited state ( levels in total), while H2 has the same spectrum and additional k2 excited states above (totaling levels) that is,




with . Consider now the realistic situation in which these Hamiltonians are controlled via internal coupling parameters , such as is the case of our work. The Lemma has two assumptions: i) it is possible to control the first excited gap , contemporary to keeping the additional α-levels above ii) . A simple scenario in which these assumptions are satisfied is the simple Hamiltonian . Under these assumptions, the Lemma states that the maximal achievable heat capacity with H2 is always larger than the maximum heat capacity obtainable with H1.






B.1. Proof of the lemma
When computing the variance of the energy in a thermal state, global shifts in the energy do not matter. For this reason we rewrite the same Hamiltonians putting the k1 levels to zero, i.e.



with and .


We now use temperature units β = 1, to simplify the discussion. The thermal states are therefore

Let us call and the corresponding ground state populations,



Notice that they both depend on the value of E, which we omit in the following for simplicity. It is easy to compute the heat capacity (equivalently, the energy variance) as

For what concerns H2 instead (calling pα the population of the level Eα )

with

where the inequalities follow from B being trivially positive, while A corresponds to the variance of an Hamiltonian having levels Eα with population pα and all the rest of the population being at an energy = 0. It follows that


Finally, let us compare the maximal value of the heat capacity in the two cases. Let's call the optimal value for the Hamiltonian H1, which induces a ground state population equal to , i.e.



It suffices to conclude now by noticing that is an increasing function of E and is always smaller than , cf equation (B7). This means that



Therefore one can choose which will lead to and therefore from (B11)



concluding the proof.
Appendix C: Parametric scaling and noise-tolerance
In this section we estimate the strength and the precision that is needed in the engineering of the Hamiltonian parameters (3) in order to achieve the optimal Heisenberg-like scalings (19), (12) and (24) of the models described in the main text. For simplicity, we will work in adimensional units in which β = 1.
C.1. Bandwidth tolerance in the degenerate model
As we argued in section 2.1, the main property that optimal models satisfy in order to reach the optimal scaling of the maximal heat capacity, is that of generating a single ground state and an exponentially-degenerate first excited level, i.e. approximating the degenerate Hamiltonian (9) in the best possible way, as well as possibly having additional higher energy levels (cf lemma in appendix B). However, in any physical realization, the resulting spectrum will have imperfections, when compared to (9). In particular, the exponentially-degenerate level might split into a bandwidth, or the overall gap might be shifted. Here we estimate the noise tolerance to such imprecisions in the first excited level.

C.1.1. Uniform shift
Consider first the case in which there is no splitting in the D − 1 first excited levels, but a uniform error, that is

and the value of E is not exactly the optimal energy gap. We show here that as far as the imprecision does not scale with the dimension, the heat capacity behaves smoothly. We know, infact, that the optimal value of E, for large dimensions is . (cf main text and [35]). Suppose now that


Then, the resulting adimensional variance of the flat Hamiltonian with degenerate excited states and gap E can be computed given the ground state probability


It follows that


The leading term of the asymptotic energy variance, for large dimension is given, for , by , i.e. recovering the results of [35] (see also main text, equation (2) and section 2.1). Moreover, from expression (C4) we see immediately that in order to keep such scaling, the denominator needs to be suppressed such that is bounded. This implies that the relative noise tolerance of the energy gap is given by





where we used that, in the case of N constituents the dimension of the system is exponential in N. That is, the relative error ε should scale as . Given , this is equivalent to the absolute error being bounded by a constant



C.1.2. Single eigenstate shift and bandwith tolerance
We now analyse the case in which the highly degenerate first excited level splits into separate energies. That is, consider a D-dimensional Hamiltonian with a single ground state and levels contained in a bandwith δ, i.e. (w.l.o.g. we can shift the ground-state energy to be negative, and the degenerate bandwith to be centered around 0)


Computing the energy variance, we obtain

with


Notice now that the term A is always positive, while the first term, is the leading term in the degenerate model in which (cf main text and [35])


It is then easy to show that, similarly to (C4), as far as the Ei levels are small and do not scale with the dimension, the optimal N2 scaling is preserved. This is easily seen as , while B in case is bounded as



It follows that the leading term, remains dominant and the heat capacity achieves the N2 scaling, as far as is finite. This is guaranteed by the fact that



and therefore

C.2. Consequences for the Star and Star-chain
In the above subsection we estimated the noise tolerance of the energy spectrum of the degenerate Hamiltonian (9) in order for the heat capacity to be close to its optimal value and maintain the Heisenberg-like scaling . The results indicate that the error in the spectral engineering should be constant while N (and therefore the dimension D) grows. In terms of relative precision, as the optimal spectrum has a first excited gap , this means a relative precision in the engineering of the spectrum around the optimal values.



However, the spectrum of the Hamiltonian is a function of its parameters (3). In this subsection, we analyse what precision is needed in our main models, (13) and (20) and how the estimation of the noise tolerance is reflected in the Hamiltonian parameters.



C.2.1. Reduction to

First, for generic considerations, we notice that we limit ourselves to estimate the noise tolerance in the Star model only, because there is an exact mapping between the Star-chain and the Star model, in the limit of strong couplings −J, i.e. given (we allow a small relaxation in the Star-chain model, i.e. we assume different magnetic fields aα on the spins, which is useful in the following analytical derivation, but does not significantly change the spectral properties of the model)


in the limit of high J, as explained in the main text, only configurations in which are allowed, and therefore the effective Hamiltonian spectrum, up to an irrelevant global shift, becomes


where is a formal spin that has value +1 when (similarly for −1), and . The above (C16) formally coincides with the Star model (13)




if one identifies . Moreover the mapping preserves the parametrization in b, while in the gets mapped to a in the above equation. One could therefore assume to be zero for all αs except one, , such that the mapping between the two models is complete and the parameterization is formally the same by mapping .





C.2.2. Parametric scaling an noise-tolerance of in the optimal-degeneracy configuration

We thus consider here the Hamiltonian (13)


As mentioned in the main text, by choosing and , it is ensured the presence of a single ground state at energy E0, a -degenerate level at energy and a 2nd excited, N − 1-degenerate level E1 as








The optimal degeneracy of is reached when , but it is not necessary for the model to achieve its N2 scaling of for the heat capacity . For simplicity, consider the choice . The first excited gap is, in this case





This means that, for such choice of parameters, in the asymptotic limit of large N, one has , and consequently . That is, b has a linear scaling in N and a has a quadratic scaling in N. This happens even if we relax the assumption of . In that case, it remains valid that




therefore b scales at least linearly in N and a at least quadratically, as it satisfies .

For what concerns the parametric error-tolerance for a and b in , notice that we estimated above the gap-error tolerance, which results to be constant (cf appendix C.1), that is, one should have


with bounded by a constant. From the above expression is easy to see that, if treated as independent, b can have an error , while for a the admitted error is . It follows that both the relative error for a and b is inversely quadratic




C.2.3. Noise-tolerance in the degeneracy-suboptimal configurations
In the subsection above, we considered the case in which the Star model (C18) is forced in its optimal configurations satisfying an exponentially-degenerate first excited level, i.e. . We saw that this imposes a linear scaling on b and quadratic scaling on a, and a relative error of order on both parameters. However, it is possible to show, as we do in appendix D.1, that (slightly) suboptimal solutions exist, featuring a bounded value of b , while still achieving quadratic scaling of . In fact, these solutions can have to be arbitrarily close to its optimal value (19)). While referring the reader to appendix D.1 for the details, it is enough for our purposes to notice that, in such solutions, b can take any finite value larger than a certain treshold , while, the gap between and E0 still approximates the optimal value









The exact finite value of b is not important in this case, and can be taken as given. It follows that in such configurations, while , while scales linearly. Consequently we can obtain the error that is admitted on a in these configurations. It follows, given equation (C27) and the fact that the optimal gap has a fixed bandwidth tolerance (cf C.1), that a similar noise scaling applies to a, i.e.




C.2.4. Subtler sources of parameter-noise
Finally, notice that in the implementation of a more general error could arise. That is, the actual tuning of the parameters of the generic spin Hamiltonian (3)


to be converted into assumes all for i > 1 and j > 1. Moreover, assuming (realistically) these contributions to be null, the resulting Hamiltonian is



The Star model assumes . Noise in the couplings might however affect this constraint. The main consequence would be a splitting of the level due to the fact that the configurations with would have a binomial spectrum




The bandwidth splitting of is therefore characterized by


where the allowed constant bandwidth was derived above C.1. It follows that, in general the error of each spin should be of order , i.e.



For what concerns

its scaling and relative error tolerance are the same as b, that is (C26) for the optimal degeneracy case appendix C.2.2, or 'irrelevant' for the suboptimal configurations discussed above in appendix C.2.3.
Appendix D: Analytics for the Star model and Star-chain model
In this appendix we provide additional analytics regarding the two main models presented in the main text, i.e. the Star model (13) and the Star-chain (20).
D.1. Partition function for the Star model
Given the energies and degeneracies indicated in section 3.1, we can exactly compute the partition function for the Star model (13),
![$Z = {\textrm{Tr}}[e^{-\beta H}]$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn384.gif)

The partition function is


where the first term correspond to the binomial part of the spectrum (i.e. for ), while the second term correspond to the degeneracy that is obtained for . The above expression can be manipulated into




and can be used to compute efficiently relevant quantities such as the average energy, the free energy etc as from standard statistical mechanics. In particular the average energy is given by

Similarly the heat capacity, or energy variance, is given by

which for the Star model can be expressed analytically by substituting (D2)

in temperature units where β = 1.
D.2. Statistics of the energy levels, exponential suppression above the degeneracy, and slightly suboptimal configurations with better parameter scaling
In this section we analyze the statistics of the energy levels of the Star model. As we argued in appendix C.2.1, the Star-chain model becomes equivalent to the former in the limit of large .

The probability of a given energy outcome in from a Gibbs state is, in temperature units β = 1, given by

Z being the partition function, which for the Star model is, from (D3), in temperature units β = 1,

Without loss of generality, it is possible to shift all energies in order to have = 0 for simplicity. Given that , this is equivalent to multiplying the partition function with a factor e−a . That is, in this case the spectrum reduces to





and the partition function becomes

Notice that it is possible to identify three contributions to Z', i.e.

corresponding respectively to the weight of the ground state, degenerate level, and all the binomial levels above E0, i.e.



We now prove that in the optimal configurations, all the statistics of the Star model resides in and , while the remaining is exponentially suppressed, as far as b grows (at least) logaritmically. Moreover, in the optimal configurations, we know from the main text and from appendix D.1 that , and therefore in such case one has . Finally, as far as b grows faster than , all the statistical contribution from the other levels is suppressed. This can be seen from equation (D16) and








which, for large N, tends to

For example, in the optimal configuration of the Star model, grows linearly in N and the whole contribution of the statistics from all levels , is suppressed exponentially as



D.3. Star-chain: partition function and spectrum
D.3.1. Partition function of the Star-chain
Remarkably, the Star-chain model at equilibrium can be exactly solved, in the sense that it is possible to compute analytically its partition function, using the transfer matrix method, which is used in standard solutions of the 1D Ising model [102]. Consider the Star-chain Hamiltonian

The partition function is given by definition as

where is the -long vector given by and is summed over all possible values ±1 of all the spins. It is therefore possible to separate the two classes of spins by defining




To compute the partition function we can consider

Moreover for fixed , we can re-express the second sum as



We now notice that, when fixing it is possible to solve the sum over by using the fact that




It follows that can be seen as a matrix (corresponding to the four elements ) ,




Finally, notice that the partition function is given by (cf (D23) and (D24))

where and are the two eigenvectors of W, that are, in temperature units β = 1,




Substituting these values in (D29) constitutes the analytical expression of the partition function for the Star-chain model.
D.3.2. Spectrum of the Star-chain
In this subsection we will build analytical considerations on the energy spectrum of the Star-chain model. Consider again the Hamiltonian

Here indices the privileged spins, and the 'subordinate spins' of each α-spin, for a total of spins. Also, we can take the 'Star-choice' that guarantees degeneracy. We are left with





We separated the term as it is the one that breaks the permutation symmetry (for cyclic boundary conditions it has only cyclic symmetry). Such term needs therefore all its 2n levels to be resolved. The remaining part is permutationally symmetric and therefore has a spectrum that can be computed efficiently. Define


It follows that

Then, for the remaining spins, notice that there are that do not contribute to the energy due to their α-spin being down, and the interaction of the form . For the same reason, all the remaining one see an effective magnetic field equal to 2b. We therefore define



It follows that

Putting all the pieces together, we cannot coarse grain easily the 2n degeneracy of the configurations, but we can simplify the remaining degeneracy by writing down the energy levels as


with fixed by the configuration , , and degeneracy (for each -configuration) equal to





Appendix E: All-to-All model
Consider the following model of an N-spin Hamiltonian.

where h and J are two coefficients. This model consistently emerged from numerical optimisation of for small number of spins, up to N = 5. Moreover, the Hamiltonian (E1) model is completely symmetric under permutations of the spins' operators. This helps in expressing its spectrum as a function of the total number k of spins up, having (it follows that N − k spins are in the opposite configuration, )




each level with degeneracy

It follows that the partition function is given by

From numerical optimization (cf appendix A.1), it appears that the optimal values of h and J that maximise in this model satisfy the relation


Under such hypothesis, the above expression (E2) for the energy levels can be written as

which clarifies explicitly the ground state being and the fact that all the levels above form a spectrum that is parabolic in k, with a first excited level corresponding to and k = 0, with total degeneracy .


![$\text{deg}[E_{k = 0}]+\text{deg}[E_{k = N-1}] = N+1$](https://content.cld.iop.org/journals/2058-9565/9/3/035008/revision2/qstad37d3ieqn430.gif)
Footnotes
- 9
In the appendix, we consider also the case of fully quantum-mechanical spin Hamiltonians. However, the numerical optimization, for N up to 9, suggests that there is no advantage in considering the most general two-body Hamiltonian with arbitrary off-diagonal interactions involving also σx and σy terms (see appendix A.4 for details).
- 10
We conjecture that is the maximal achievable degeneracy of the first excited level, in Hamiltonians of the form equation (3) with a single ground state.
- 11
D-wave systems (available at: www.dwavesys.com/).
- 12
In this case, full relaxation to equilibrium is clearly suboptimal, and optimal protocols take place when the probe is in an out-of-equilibrium state (see e.g. [4]).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}