
Abstract
Quantum machine learning (QML) is a rapidly growing area of research at the intersection of classical machine learning and quantum information theory. One area of considerable interest is the use of QML to learn information contained within quantum states themselves. In this work, we propose a novel approach in which the extraction of information from quantum states is undertaken in a classical representational-space, obtained through the training of a hybrid quantum autoencoder (HQA). Hence, given a set of pure states, this variational QML algorithm learns to identify—and classically represent—their essential distinguishing characteristics, subsequently giving rise to a new paradigm for clustering and semi-supervised classification. The analysis and employment of the HQA model are presented in the context of amplitude encoded states—which in principle can be extended to arbitrary states for the analysis of structure in non-trivial quantum data sets.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
In recent years, the amalgamation of quantum mechanics and machine learning (ML) has instigated extensive research into the field of quantum machine learning (QML) [1]. With fault-tolerant quantum computation far from realisable in the near future, one of the areas in which researchers are looking for quantum advantage are variational algorithms. These variational approaches have demonstrated robustness in the regime of noisy intermediate-scale quantum devices, thus being a contender to first demonstrate quantum advantage [2]. With applications in QML variational methods most commonly employ a parameterised quantum circuit (PQC) [3, 4], where parameters are classically optimised in a feedback loop routine between optimiser and PQC.
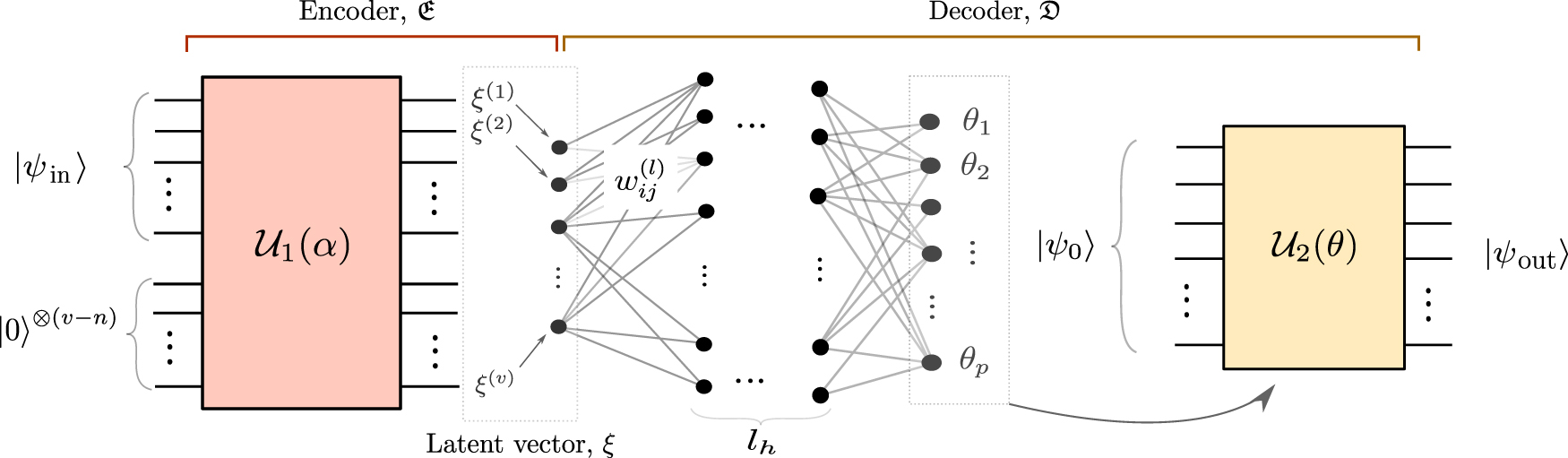
Generally, QML methods can be categorised into two distinct groups: (i) models that obtain advantage through the learning of classical data—once embedded into a quantum system—or (ii) the learning of purely quantum data sets. This paper focuses on the latter task, and proposes an approach in which the learning of quantum states can be undertaken in a classical representational space. This allows for novel approaches to cluster and classify quantum states based on their classical representations. Such representations will be formed from the employment of—what we have termed—a hybrid quantum autoencoder (HQA), illustrated in figure 1(c).

Figure 1. (a) An autoencoder, where black dots represent neurons, and lines represent their weighted inputs/outputs (appendix  and
and  are unitary operators. Here the latent vector is an inaccessible compressed quantum state. (c) Structure of the HQA. The encoder is composed of a QNN that is measured to return a classical latent vector,
are unitary operators. Here the latent vector is an inaccessible compressed quantum state. (c) Structure of the HQA. The encoder is composed of a QNN that is measured to return a classical latent vector,  . The decoder employs an ANN and a QNN to return quantum state. The output of all autoencoders, (a), (b) & (c) are trained to match any input from a particular data set.
. The decoder employs an ANN and a QNN to return quantum state. The output of all autoencoders, (a), (b) & (c) are trained to match any input from a particular data set.
Download figure:
Standard image High-resolution imageClassically, an autoencoder is a specific artificial neural network (ANN) architecture that is trained to return its input as its output, whilst undergoing a crucial funnelling of its degrees of freedom [6] (shown in figure 1(a)). This funnelling process generates compressed representations of data points that belong to a particular group of data.
The autoencoder is composed of two maps: an encoder, e, and decoder, h, that are both approximated using ANNs (a discussion on ANNs relevant to this work is presented in appendix  and outputs a lower dimensional latent vector,
and outputs a lower dimensional latent vector,  , such that,
, such that,  . The decoder performs the inverse,
. The decoder performs the inverse,  . Subsequently, the autoencoder (both h and e) is trained to approximate
. Subsequently, the autoencoder (both h and e) is trained to approximate  for any
for any  in the data set. This would be trivial for if
in the data set. This would be trivial for if  and
and  had equal dimensionality; however, in the case where
had equal dimensionality; however, in the case where  , the autoencoder is forced to encode the most important aspects of the input,
, the autoencoder is forced to encode the most important aspects of the input,  , into the latent space. The latent vector,
, into the latent space. The latent vector,  , is in essence a representation of
, is in essence a representation of  in the lower dimensional representational space of
in the lower dimensional representational space of  .
.
The main advantage of an autoencoder is that it is able to learn complex compression strategies through an unsupervised learning process. Such a process requires a human to have minimal prior information regarding the data set. Hence, it is often used in the context of denoising and compressing data that lack obvious methods of dimensionality reduction. Quantum autoencoders (QAEs) (figure 1(b)), discussed further in section 2.2, are direct analogues and hence provide non-trivial compression maps for quantum states to a subset of its Hilbert space.
In essence, both ML and QML algorithms exploit the tendency that data aggregates in a low dimensional sub-manifold over the vast space of possible data points. We describe the data as lying on a sub-manifold to emphasise the fact that infinitesimal tangential translations, result in remaining on the sub-manifold. It should be noted that, although in mathematics a manifold has a more formal definition, in ML it is used to describe a set of points that can be well approximated by considering only a small number of degrees of freedom, embedded in a higher-dimensional space [6]. This manifold hypothesis is essential so that data points have a neighbourhood of highly similar examples that can be accessed by applying small transformations to traverse the manifold. Hence, the main objective of a QAE is to learn the sub-manifold that describes a particular set of quantum states. The HQA in particular, represents the sub-manifold in an accessible classical vector space.
Quantum states can be represented as positive semi-definite operators on a complex Hilbert space,  , known as density matrices. Theoretically, one can imagine putting the elements of the density matrix through a classical ML algorithm to find similarities between quantum states or even classify states. However, the information stored in quantum states is notoriously inaccessible without exponential resources to characterise each (through quantum state tomography (QST) [7, 8]). The HQA, in figure 1(b), gets around this by using an encoder that is trained to output classical information about important aspects of a quantum state. This quantum to classical transformation is extreme in its dimensionality reduction, as for a pure input state we have
, known as density matrices. Theoretically, one can imagine putting the elements of the density matrix through a classical ML algorithm to find similarities between quantum states or even classify states. However, the information stored in quantum states is notoriously inaccessible without exponential resources to characterise each (through quantum state tomography (QST) [7, 8]). The HQA, in figure 1(b), gets around this by using an encoder that is trained to output classical information about important aspects of a quantum state. This quantum to classical transformation is extreme in its dimensionality reduction, as for a pure input state we have  where
where  is the dimension of the classical space by measuring the n number of qubits. Hence one can see that if the state is able to be reconstructed from the classical space, then the classical space can only describe a relatively small set of quantum states. Nonetheless, the classical real space represents a manifold in
is the dimension of the classical space by measuring the n number of qubits. Hence one can see that if the state is able to be reconstructed from the classical space, then the classical space can only describe a relatively small set of quantum states. Nonetheless, the classical real space represents a manifold in  that can be learned with the construction of the HQA. It will be seen that it is this perspective that distinguishes the HQA from the QAEs explored in literature thus far.
that can be learned with the construction of the HQA. It will be seen that it is this perspective that distinguishes the HQA from the QAEs explored in literature thus far.
At this point, it is important to address the classical shadows created in shadow tomography [9–12], where a set of random single-qubit Pauli measurements form a classical representation of a quantum state. The aim of shadow tomography is to approximate a state with the idea that many linear functions of states can be predicted with a relatively small set of the Pauli measurements. However, a crucial distinction to the autoencoder structure presented in this paper, is that classical representations generated by the HQA look to store characteristics that distinguish training instances, rather than information about the state itself. Furthermore, given a set of training instances, the HQA is able to generate a classical representational space—in contrast to classical representations of states generated in shadow tomography.
This paper is structured such that we first provide background into quantum neural networks (QNNs) and QAEs in section 2; before then constructing the HQA in section 3. This is then followed by applications of clustering and classification in section 4, including results from numerical simulations.
2. Background
2.1. Quantum neural networks
QNNs are the extension of ANNs to QML. The precise form of the QNN, however, is quite non-trivial as it would need to take advantage of unique quantum mechanical properties while also retaining the non-linear functional features of classical ANNs [13]. Hence, there are various proposals for QNN designs that claim similar non-linear dissipative dynamics of ANNs, but are yet to present clear quantum advantage [14–17]. In this paper, the implementation of the HQA will use the simplest design of a QNN: a PQC coupled with a specified observable. The choice of QNN, however, is arbitrary to the overall approach of the HQA (as shown in figure 1(c)). Hence a fair comparison of QNN complexity and expressibility—for the construction of the HQA specifically—is left for future work.
PQCs form the basis of hybrid quantum–classical algorithms that optimise a quantum circuit with respect to a problem-dependent cost function [18]. The optimisation is performed classically to determine a better estimate of parameters which define a variational circuit. The optimisation in this work is performed using the parameter shift rule [19], elaborated in appendix
Since any quantum circuit can be defined as a gate sequence  , the m parameters of the circuit are the set of θi
which parameterise the unitaries. We define the measurement of a PQC as a function
, the m parameters of the circuit are the set of θi
which parameterise the unitaries. We define the measurement of a PQC as a function  , mapping the gate parameters to an expectation value,
, mapping the gate parameters to an expectation value,

where  is a predetermined observable (most commonly a Pauli-Z) and ρ0 is an initial arbitrary state of the circuit. For consistency, the state before measurement will have notation,
is a predetermined observable (most commonly a Pauli-Z) and ρ0 is an initial arbitrary state of the circuit. For consistency, the state before measurement will have notation,  as evident from the second line in equation (1). It should be noted that this functional form of the variational circuits hides the fact that on real devices, repeated measurements of the circuit are required to obtain this expectation value. As a result, there is a natural statistical uncertainty to the estimated
f, determined by the number of samples taken of the circuit. Caution is thus required when constructing algorithms that require arbitrarily large numerical precision of f. These algorithms may have promising results in state-vector simulations, but become computationally infeasible to measure on real quantum devices.
as evident from the second line in equation (1). It should be noted that this functional form of the variational circuits hides the fact that on real devices, repeated measurements of the circuit are required to obtain this expectation value. As a result, there is a natural statistical uncertainty to the estimated
f, determined by the number of samples taken of the circuit. Caution is thus required when constructing algorithms that require arbitrarily large numerical precision of f. These algorithms may have promising results in state-vector simulations, but become computationally infeasible to measure on real quantum devices.
The optimisation of PQCs remain an area of research as it is not clear that employing classical optimisers will result in optimal solutions for quantum cost function landscapes. This has given rise to works suggesting optimisers that are aware of the underlying quantum structure of quantum states [20–22]. Furthermore, there exist limitations of barren plateaus in deep PQC-based algorithms, as initially realised in [23]. Here, the suppression of gradient with increasing depth of circuit, has also been shown to be linked to the expressibility of PQCs [24]. Critically, shallow circuits are not immune either, with an exponential suppression of gradients with increasing number of qubits [25]. In addition to barren plateaus, PQCs are seen to exhibit narrow gorges [25] which is the occurrence of the existence of cost landscape minima in narrow wells that get steeper with increasing depth. The effects are not only seen with an increase in qubits, but arise due to entanglement [26], certain cost functions [25, 27], and noise [28].
These phenomena clearly have implications on QAEs that employ PQCs and have been shown to be more pronounced for global loss functions—such as a fidelity-based loss [25]. Addressing this problem, there has been recent work employing the generalised quantum natural gradient—over the standard gradient—to train fidelity loss-based variational algorithms without barren plateaus [29]. However, this method requires a lower bound to the fidelity against the initial state, that is independent of the number of qubits and is therefore largely dependent on the chosen quantum data set {ρin}. As with many variational quantum algorithms, trainability for larger number of qubits is an active area of research. We therefore aim to emphasise the approach of the HQA algorithm, over its exact implementation.
2.2. Quantum autoencoders
Many recent works involving QAEs build on the structure first proposed by Romero et al [5], using shallow PQCs to compress quantum states. In [30], QNNs are of the form in [31] to construct a QAE that successfully denoises Greenberger–Horne–Zeilinger states which are subject to spin-flip and random unitary noise errors. Recently, there has been further enhancements with a projected-QAE model to improve the recovery of fidelity for an ensemble of pure states [32]. In [33], a QAE is constructed using approximate quantum adders that are obtained with classical genetic algorithms as opposed to more commonly used gradient methods for parameter optimisation.
All such applications work on the process of funnelling quantum states into a lower dimensional Hilbert space. This naturally returns compressed representations that disregard both stochastic noise fluctuations and irrelevant degrees of freedom. It is important to note that the set of states are assumed to have support on a subset of its Hilbert space,  . The existence of such support is not guaranteed, but is instead common in many sets of quantum states, due to symmetries inherent to physical processes. For example, in [5] a QAE is classically simulated to show the compression of ground states of the Hubbard model and molecular Hamiltonians.
. The existence of such support is not guaranteed, but is instead common in many sets of quantum states, due to symmetries inherent to physical processes. For example, in [5] a QAE is classically simulated to show the compression of ground states of the Hubbard model and molecular Hamiltonians.
QAEs have been experimentally realised for the compression of qutrits with photons in [34] and the compression of two-qubit states into two single-qubit states in [35]. Furthermore experimental realisation of the QAE via quantum adders has been shown in [36]. These QAEs are promising, but are nonetheless distinct to the HQA proposed in this paper. Specifically, the HQA aims to generate a classical representation of the  sub-manifold for classical analysis. Hence, not only can the data be compressed, but the compressed representation is an accessible classical vector that can be analysed.
sub-manifold for classical analysis. Hence, not only can the data be compressed, but the compressed representation is an accessible classical vector that can be analysed.
There are clear limitations on an autoencoder's ability to compress data. On the compression rate of QAEs, there exist not only a fundamental limit due to the degrees of freedom in a dataset, but a quantum limitation related to the von Neumann entropy of the density operator representing the ensemble of training states [5]. In [37], it is further elaborated that the compressibility is related to the eigenvalues of the weighted ensemble density matrix. Crucially, this theoretical limit is intrinsic to all possible compression strategies and QAEs.
3. The hybrid quantum autoencoder
3.1. Design
This paper proposes a novel variation of the QAE that we have termed a HQA. The hybrid nature of this model arises from the incorporation of both ML, in the form of classical ANNs, as well as QML, through the use of PQC-based QNNs. Figure 2 illustrates the overall design of the model which is a combination of (i) an encoder that takes a quantum state from Hilbert space  to a subset of the real vector space
to a subset of the real vector space  of dimension
of dimension  , and (ii) a decoder that performs the inverse of such an operation. In general, though quantum states are positive semidefinite (trace = 1) operators ρ on
, and (ii) a decoder that performs the inverse of such an operation. In general, though quantum states are positive semidefinite (trace = 1) operators ρ on  , the HQA is equipped to identify only pure states. Hence, we associate the vector |ψa
⟩ to the pure state ρa
:= |ψa
⟩⟨ψa
|. Mathematically, the encoder and decoder have the form of a map,
, the HQA is equipped to identify only pure states. Hence, we associate the vector |ψa
⟩ to the pure state ρa
:= |ψa
⟩⟨ψa
|. Mathematically, the encoder and decoder have the form of a map,


where ![$\mathcal{V}={[-1,1]}^{v}$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn31.gif) is termed the latent space and
is termed the latent space and  is referred to as the latent vector—analogous to the terminology used when dealing with classical autoencoders. This vector is in essence a classical representation of the quantum state—a perfect representation if
is referred to as the latent vector—analogous to the terminology used when dealing with classical autoencoders. This vector is in essence a classical representation of the quantum state—a perfect representation if  is achieved. This indicates that the information of state |ψin⟩ was preserved in the latent vector to then be recreated without any loss of information. In information theory this is lossless encoding of information into a compressed latent space.
is achieved. This indicates that the information of state |ψin⟩ was preserved in the latent vector to then be recreated without any loss of information. In information theory this is lossless encoding of information into a compressed latent space.

Figure 2. Illustration of the PQC-based HQA constructed through the combination of an encoder,  , and decoder,
, and decoder,  . With input
. With input  , there are (v − n) ancilla qubits. The latent space in the diagram is defined as the vector of dimension v, formed from the expectation values of all qubits in register, ξ = (ξ(1), ..., ξ(v)), where ξ(i) = ⟨Zi
⟩ and Zi
is the Z-pauli operator acting on the ith qubit. The PQC architecture of both
, there are (v − n) ancilla qubits. The latent space in the diagram is defined as the vector of dimension v, formed from the expectation values of all qubits in register, ξ = (ξ(1), ..., ξ(v)), where ξ(i) = ⟨Zi
⟩ and Zi
is the Z-pauli operator acting on the ith qubit. The PQC architecture of both  and
and  are shown in appendix
are shown in appendix
Download figure:
Standard image High-resolution imageThough the functional form of the encoder and decoder are defined, the models themselves have not been specified. As seen in figure 2, the encoder  is a PQC parameterised by a vector, α. The PQC receives some state |ψin⟩, and applies unitary
is a PQC parameterised by a vector, α. The PQC receives some state |ψin⟩, and applies unitary  on the combined system of the input state with (v − n) ancilla qubits. From this circuit, the Z expectation value of every qubit is measured, to then form the latent vector ξ,
on the combined system of the input state with (v − n) ancilla qubits. From this circuit, the Z expectation value of every qubit is measured, to then form the latent vector ξ,

where  , Zi
is the Z-Pauli operator acting on the ith qubit and α parameterises the PQC that will be optimised. The set of ξ = (ξ(1), ..., ξ(v)) forms the latent vector which is identified as the classical representation of an input quantum state. With inspiration from shadow tomography [11, 12], it is possible to enlarge the latent space with further X and Y expectation values. However, we leave this for future work. Following the encoder, the decoder is extremely similar to the one defined in equation (4). However, this time it is a mapping that returns a quantum state when given a latent vector,
, Zi
is the Z-Pauli operator acting on the ith qubit and α parameterises the PQC that will be optimised. The set of ξ = (ξ(1), ..., ξ(v)) forms the latent vector which is identified as the classical representation of an input quantum state. With inspiration from shadow tomography [11, 12], it is possible to enlarge the latent space with further X and Y expectation values. However, we leave this for future work. Following the encoder, the decoder is extremely similar to the one defined in equation (4). However, this time it is a mapping that returns a quantum state when given a latent vector,

where  is the functional from of the ANN that is parameterised by
is the functional from of the ANN that is parameterised by  (discussed in appendix
(discussed in appendix
It is important to note, both encoder and decoder have hyper-parameters (such as the number of parameters that define the PQCs, the number of neurons and depth of the ANN, etc) for which one must optimise. From here on we will assume that these hyper-parameters are accounted, realising that there is possible future work in rigorously addressing the exact optimisation for this HQA model.
Now that we have defined the encoder and decoder, the HQA model,  , is the combination defined as,
, is the combination defined as,

where we will refer to the output of the HQA as  . Though the HQA looks as though it is a single run through both the encoder and decoder, there is an implicit sub-routine for the encoder where the PQC must be sampled multiple times to obtain ξ.
. Though the HQA looks as though it is a single run through both the encoder and decoder, there is an implicit sub-routine for the encoder where the PQC must be sampled multiple times to obtain ξ.
Now that the components of the HQA have been pieced together, the model is trained to copy the input such that |ψout⟩ ≈ |ψin⟩. To do this we find a measure that can identify the distance between quantum states which will be the foundation of the HQA cost function. There are many possible ways in which to construct a sensible loss function, the one which we will be considering is one minus the fidelity  between the model output and the expected training output. Hence for a chosen training data set of K quantum states,
between the model output and the expected training output. Hence for a chosen training data set of K quantum states,  , and the fidelity defined as
, and the fidelity defined as  , we define a loss,
, we define a loss,

where

is the average fidelity across all the training instances. In practice, the learner does not calculate the loss over all training instances per iteration, but rather a small batch or even over a single instance. This is because, (i) it is computationally expensive having a loss function that sums over all training instances, and (ii) doing so may result in over-fitting to the training data.
The fidelity between two states is maximum when input states are identical, and minimum when they are orthogonal. Hence, the aim is to maximise the fidelity to achieve |ψin⟩ ≈ |ψout⟩, and thereby minimise the loss, which lies in the range [0, 1]. This is a natural choice for a loss function, as the fidelity is a common distance measure between quantum states. The fidelity has also successfully been used for the construction of denoising QAEs [30] and is hence a great starting point for the construction of the HQA loss function. Selecting a method to measure the fidelity now becomes a hyper-parameter of the model—for which this paper will use the swap test (discussed in appendix
Using the swap test, we can make an estimate of the training complexity. The sampling complexity per iteration (derivation in appendix

where  is the number of parameters in the encoder and
is the number of parameters in the encoder and  in the decoder, ɛξ
= Δξi
is the uncertainty in each component of the latent vector
in the decoder, ɛξ
= Δξi
is the uncertainty in each component of the latent vector  , and ɛfid is the uncertainty in the fidelity measurement. The required ɛξ
and ɛfid is quite non-trivial and in this work, we use infinite precision for the measured expectation values. This non-triviality will become evident when dealing with the application in section 4, where the HQA is fundamentally unable to learn some states due to their stochasticity.
, and ɛfid is the uncertainty in the fidelity measurement. The required ɛξ
and ɛfid is quite non-trivial and in this work, we use infinite precision for the measured expectation values. This non-triviality will become evident when dealing with the application in section 4, where the HQA is fundamentally unable to learn some states due to their stochasticity.
3.2. Order in latent space
Now that the HQA has been constructed, one can observe the powerful nature of representing states in a classical latent space. Training the HQA gives rise to order in latent space that is created purely through matching the input quantum state to the output. In other words, even though we are not supplying the HQA with information about the states trained directly, the model is able to learn these differences and form patterns in latent space. It is this order that we can exploit to apply ML learning techniques to cluster and classify states in section 4.
The HQA is trained for a training set of quantum states  that have underlying symmetry. In this paper,
that have underlying symmetry. In this paper,  will correspond to a set of distinct amplitude encoded Gaussian states that can be easily analysed.
will correspond to a set of distinct amplitude encoded Gaussian states that can be easily analysed.
A Gaussian distribution is defined as,

where μ and σ are the mean and standard deviation respectively. Quantising this function for N equally spaced values in the range ![$\mu \in \left[-\frac{N}{2},\frac{N}{2}\right]$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn54.gif) ,
, ![$\sigma \in \left(0,\frac{N}{3}\right]$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn55.gif) , we have
, we have  where i ∈ {0, 1, ..., N − 1} and ⌈a⌉ is the ceiling function that returns the smallest integer above or equal to a. Now that we have discrete distribution,
where i ∈ {0, 1, ..., N − 1} and ⌈a⌉ is the ceiling function that returns the smallest integer above or equal to a. Now that we have discrete distribution,  , it can be encoded into the N = 2n
amplitudes of a n-qubit quantum state,
, it can be encoded into the N = 2n
amplitudes of a n-qubit quantum state,

where  is the normalisation constant. The ability for such encoded states to be variationally encoded has been shown in [39].
is the normalisation constant. The ability for such encoded states to be variationally encoded has been shown in [39].
With this set of distinct quantum states, the HQA is employed to generate a classical latent space that represents the subset in which these states lie. Automatic differentiation is assumed through this unsupervised model to update the PQC parameters in the encoder and the weights of the ANN that determine the decoder. The PQC architecture of  and
and  are shown in appendix
are shown in appendix
In figure 3(a), we see that training convergence is robust to latent space dimension, with similar loss evolution for all v. However, in figure 3(b), larger v is seen to decrease the loss in testing. As expected we see greater expressibility of the quantum state with a larger latent space.

Figure 3. An ensemble of 12 HQA models, with a 5 qubit input state, were averaged for each data point in the two figures. (a) Illustration of the running loss as a HQA was trained with identical samples for various latent sizes. A bin size of 100 was used for plot. (b) Performance of the HQA as the latent space dimensionality is increased. It is important to note that (b) shows the average loss of 1000 testing instances sampled from a continuous range, ![$\hat{\mu }\in [\frac{-N}{2},\frac{N}{2}]$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn61.gif) and
and ![$\hat{\sigma }\in [0,\frac{N}{2}]$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn62.gif) . Whereas the loss displayed in (a),
. Whereas the loss displayed in (a),  , is the running loss during training, averaging over a batch size of 2.
, is the running loss during training, averaging over a batch size of 2.
Download figure:
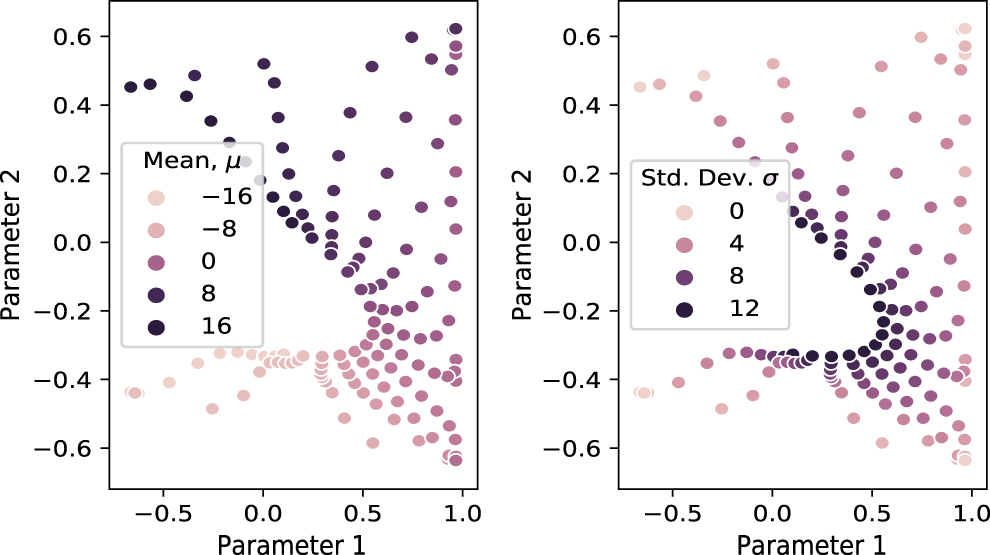
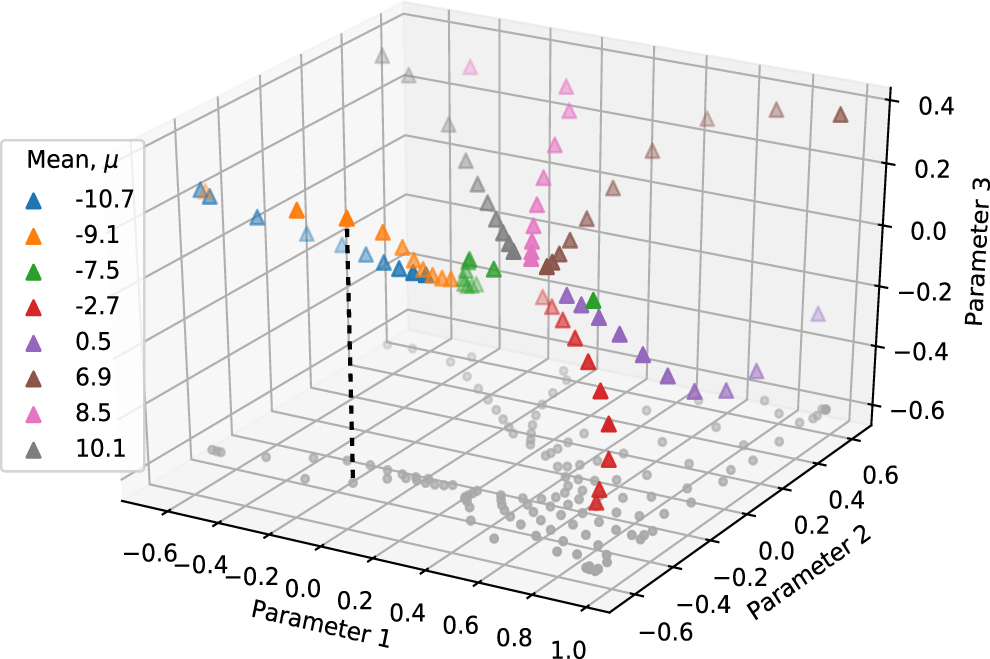
Standard image High-resolution imageOnce trained, to analyse this model we can apply only the trained encoder,  , to an input quantum state and observe its location in latent space—this latent vector is what we refer to as the classical representation of the input quantum state. An illustration of this process is shown in figure 4. The latent vector can then be obtained for all the amplitude encoded Gaussian states used for training, and then plotted. Figure 5 shows such a plot for n = 5 and a latent size, v = 12 where first two components (or parameters) of the vector are illustrated. This figure shows that Gaussian encoded states are distributed with a pattern distinguishing their mean and standard deviations. In this specific example, we see that an outward radial movement in the presented latent space corresponds to decreasing the standard deviation; and a positive polar rotation corresponds to increasing the mean. Such elegance is evident from patterns in the original set of quantum states; the two degrees of freedom: μ and σ. However, these patterns have the ability to be extremely non-trivial to visualise and this can be seen when we extend the results of figure 5 to a 3rd dimension as shown in figure 6. Hence this non-triviality suggests the use of ML to learn patterns in latent space.
, to an input quantum state and observe its location in latent space—this latent vector is what we refer to as the classical representation of the input quantum state. An illustration of this process is shown in figure 4. The latent vector can then be obtained for all the amplitude encoded Gaussian states used for training, and then plotted. Figure 5 shows such a plot for n = 5 and a latent size, v = 12 where first two components (or parameters) of the vector are illustrated. This figure shows that Gaussian encoded states are distributed with a pattern distinguishing their mean and standard deviations. In this specific example, we see that an outward radial movement in the presented latent space corresponds to decreasing the standard deviation; and a positive polar rotation corresponds to increasing the mean. Such elegance is evident from patterns in the original set of quantum states; the two degrees of freedom: μ and σ. However, these patterns have the ability to be extremely non-trivial to visualise and this can be seen when we extend the results of figure 5 to a 3rd dimension as shown in figure 6. Hence this non-triviality suggests the use of ML to learn patterns in latent space.

Figure 4. Once trained, one can use the encoder, to obtain the classical representation of a given quantum state:  . This latent vector of dimension v, can subsequently be plotted using a subset its components.
. This latent vector of dimension v, can subsequently be plotted using a subset its components.
Download figure:
Standard image High-resolution image
Figure 5. Figures show a HQA trained with Gaussian distributions over five qubits and a latent space dimension, v = 12. Noting that the HQA is not explicitly supplied with information about the states, the model can be seen to decode states into latent space, such that patterns are formed based on aspects of the trained distributions. Here we observe patterns formed in latent space distinguishing the mean and standard deviation of the Gaussian amplitude encoded states.
Download figure:
Standard image High-resolution image
Figure 6. Illustration of the Gaussian distributions displayed with two parameters in figure 5, extended to a 3rd dimension. Its projection onto parameter 1 & 2 space is shown in grey. Note: only some of the states with chosen means are plotted.
Download figure:
Standard image High-resolution imageIt is not necessarily true that patterns will be visible when plotting the first two parameters of latent space. A plot of, say, the 9th and 10th latent parameters shows no patterns at all, as points seem to all congregate on a line or point. This indicates that these latent parameters are not being used to distinguish the quantum states, suggesting that a possible dimensionality reduction is possible for the latent space. This is where one can use principal component analysis (PCA) [6] that will both, allow for a clearer understanding of how the latent space is used, and also transform the space so that the most principal components can be plotted.
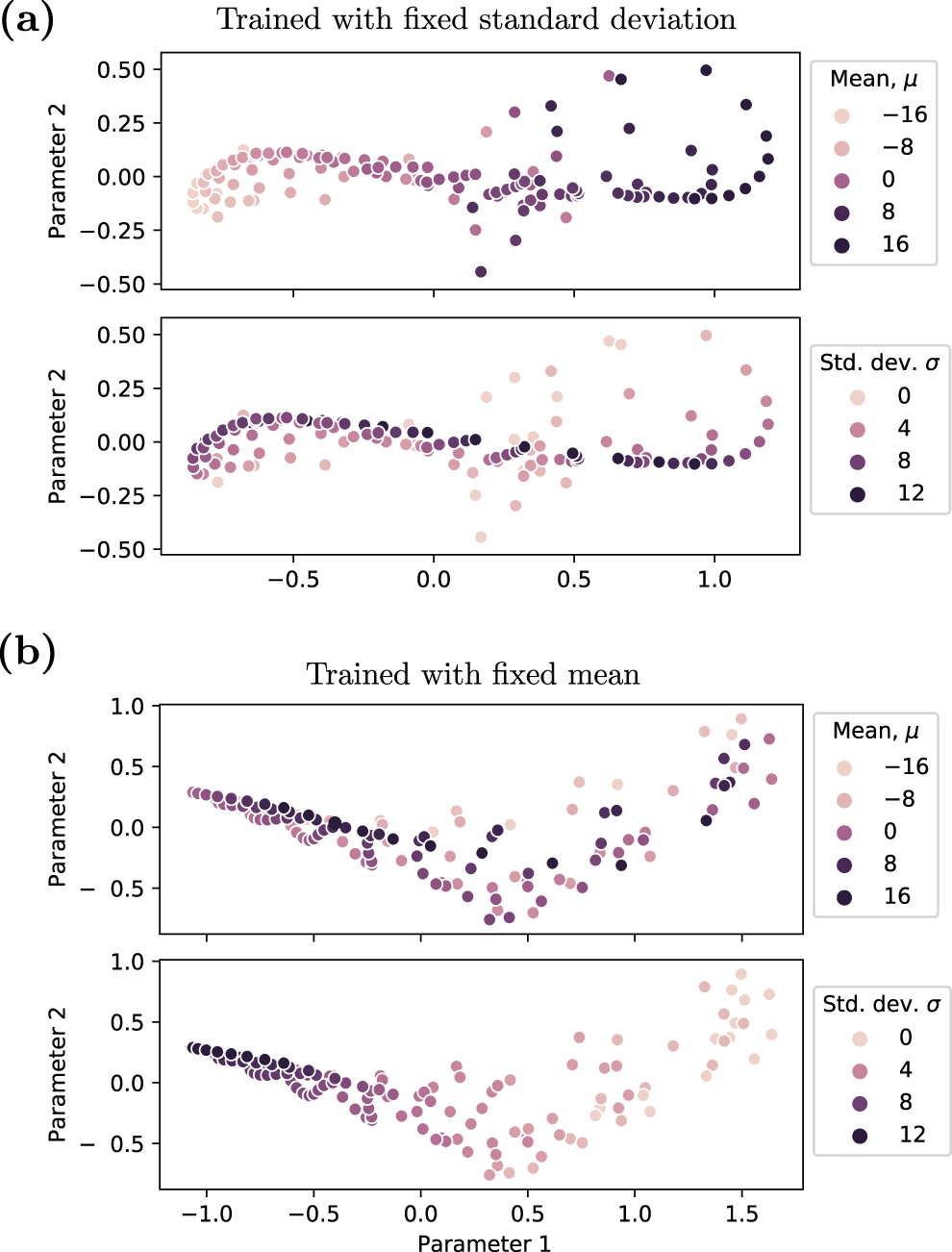
Now that we have identified a method of systematically analysing latent space, we can ask the question of whether this pattern would still occur if one simply trained on Gaussians with different mean values. Or similarly, if the model was built on training on Gaussians with only varying standard deviations. The results of doing so are shown in figure 7 where the two most principal components from PCA dimensionality reduction are plotted. The formation of patterns in latent space can only be observed when training has seen the variations in state. For example, in figure 7 where only μ was varied and σ was kept constant, there is order formed distinguishing μ but not σ. The opposite occurs where the training is switched. This suggests the HQA naturally attempts to allocate areas of similar quantum states without the need for additional supervision. In the context of applications, this is extremely useful as one can exploit the latent space location of a particular unknown state in reference to other known states—where similarity was before not necessarily obvious. In general, this means that we can infer information about states by applying ML algorithms to the states in latent space, as will be explored in section 4.

Figure 7. (a) The distribution of Gaussian amplitude encoded states in latent space when the HQA is trained with varying mean, but fixed standard deviation of σ = 3. (b) Illustrates the reverse, with training over a range of standard deviations but with a fixed mean, μ = 0. Both figures employ a HQA with a latent size of 12 over a five qubit amplitude encoded state. The two parameters shown are in the direction of the two most principle components which accounts for 55% of the variation in (a) and 71% of the variation in (b). This variation refers to the spread of data in the plotted components. One should also note, since the latent space has been transformed to the basis of the two principle components, the parameters of the latent space are not necessarily between −1 and 1.
Download figure:
Standard image High-resolution image4. Application
It is evident that clear patterns emerge in latent space from training Gaussian distributions. An extension to merely observing these patterns is obtaining information about quantum states through their latent representation. This includes both, understanding what it means for states to be located near each other in latent space, and also seeing if one can infer information about states using ML on their latent space representation.
In order to test these methods, we construct a toy problem involving two classes of states. We define amplitude encoded skewed Gaussian distributions of the form,

where di
is the amplitude of the ith orthogonal state,  is a Gaussian distribution, vi
= max{0, a ⋅ i + b} is a linear function, and we have the class label definitions
is a Gaussian distribution, vi
= max{0, a ⋅ i + b} is a linear function, and we have the class label definitions

where η ∈ [0, 1] is a uniform stochastic term that fluctuates as a distribution is called for training or testing.
To illustrate the power of the HQA, we introduce the artificial objective of clustering states by either smooth or non-smooth, simply from applying classical ML techniques to their latent space representations. However, before one can obtain these representations, one needs to train the HQA, raising the question of selecting training instances. In general, there is no clear answer to how one should proportion the training instances between the two classes. However, it was seen in section 3.2 that order was formed when the HQA had seen different distributions, without which the latent representations appear to not separate deferring distributions. Hence we look at two HQAs: (i) one that is trained with only smooth states, and (ii) a HQA trained with both classes in equal proportion. An important point to know here is that the HQA will fundamentally not be able to reproduce the states with the applied stochastic term as the set of such distributions is far too large. Nevertheless, it will be shown—through both clustering and classification—that the HQA does not need to recreate states perfectly to be useful in the context of ML in latent space.
Post the HQA training, it is possible to analyse the latent representations of the quantum states that are obtained by applying  on a sample of the states (the results of which are shown in figure 8). Using both classes of distributions for training, constructs a HQA (figure 8(b)) that is still able to allocate regions of varying mean in its principal components. However, the HQA trained on only smooth states lacks this order (figure 8). Interestingly, minor components of the vector clearly distinguish the two classes of states, regardless of its training.
on a sample of the states (the results of which are shown in figure 8). Using both classes of distributions for training, constructs a HQA (figure 8(b)) that is still able to allocate regions of varying mean in its principal components. However, the HQA trained on only smooth states lacks this order (figure 8). Interestingly, minor components of the vector clearly distinguish the two classes of states, regardless of its training.

Figure 8. Two HQA models are constructed with seven qubit input states and a latent size of v = 12. Figure (a) shows the actual location of states in latent space when the HQA model is trained with only smooth states of skewed Gaussians. While (b) shows a similar result, however, in this case where the HQA is trained on both classes. Both (a) and (b) include plots for the principal and minor components of the latent vector. In total, 1600 states are plotted, split evenly between the classes.
Download figure:
Standard image High-resolution imageHaving constructed classes of states, in this section we will look at (i) clustering states based on their latent representations, and (ii) providing an enhancement on classifying quantum states with semi-supervised learning. The applications are explored with two instances of trained HQAs, giving rise to two unique latent space representations. Though HQAs will vary depending on initial conditions and the order of data points trained, we observe similar (though not identical) results for the applications of clustering and classification when repeated with different HQAs.
4.1. Clustering
In classical ML the most common algorithm for clustering is kmeans [41] (also referred to Lloyd's algorithm) which attempts to find clusters in a data set by observing some classical distance measure (an introduction to kmeans is presented in appendix  where N = 2n
. In addition, the authors exploit the fact that kmeans can be expressed as a quadratic programing problem which can be solved using a quantum adiabatic algorithm. In [43], an approach is presented with efficient quantum methods of calculating the Euclidean distance. Alternatively, the quantum approximate optimisation algorithm (QAOA) [44] is used in [45], for clustering by association to the maximum cut problem.
where N = 2n
. In addition, the authors exploit the fact that kmeans can be expressed as a quadratic programing problem which can be solved using a quantum adiabatic algorithm. In [43], an approach is presented with efficient quantum methods of calculating the Euclidean distance. Alternatively, the quantum approximate optimisation algorithm (QAOA) [44] is used in [45], for clustering by association to the maximum cut problem.
Many of the methods in literature suffer from requiring QST techniques to classically obtain clusters, which is not required when using the HQA. We define a method of clustering states using classical representations generated by the HQA, after which classical clustering algorithms are used on a space that is exponentially smaller.
For the classical clustering of latent space, it is required that a more sophisticated method than kmeans is used. There are many advanced clustering methods that allow non-linear clustering [46], but in general such clustering is not natural. In this work we will use Gaussian mixture modelling which is an extension of the kmeans clustering algorithm that has the flexibility to change the importance of certain parameters of the vector [47]—kmeans simply uses a Euclidean measure of distance.
The predicted labels from clustering latent space are shown in figure 9. The results show remarkable agreement with true labels when considering the minor components of the latent vector: 85.1% accuracy for the HQA trained with only smooth states and 84.4% accuracy for the HQA trained with both classes. On the other hand, clustering based on the principal components are seen to amount to guessing the class of state. The reason for this is evident when looking at the principal components. Fitting using all components is seen to identify clusters relating to the mean of the distributions (grouping negative and positive means), which is also a valid clustering outcome from an unsupervised viewpoint. Such a deficiency is attributed, not to a limitation of the algorithm, but rather to the non-uniqueness of the task's solution.

Figure 9. These figures show the prediction results of clustering on the latent space representations of quantum states. The classical clustering was done using Gaussian mixture modelling, post the training of the HQA. The clustering fits were taken using: (i) all components and, (ii) the last four minor components (least principal components). The plot shows four possible clustering outcomes by also distinguishing the HQA model trained with only smooth states in (a), and the HQA trained with both classes in (b). Each of the four outcomes, have plots showing the predictions in both the principal and minor components. Observe that we have identical latent spaces from the two HQA models shown in figure 8. However, here we have principal and minor components grouped next to each other with only the class label—and not the Gaussian means—distinguished. Note: the class labels of smooth and non-smooth are added later, as clustering merely predicted two groups of blue and orange.
Download figure:
Standard image High-resolution imageAt this point, one should retrace the steps of this clustering method in the context of an application. It is conceivable that a quantum experiment is conducted that produces quantum states about which the user has no information. This stream of states could hence be used for the training of the HQA. Importantly, however, one should note that a single sample of a quantum state is not sufficient. There is both, the sub-routine for the encoder, as well as the fidelity computation, that requires multiple copies of the state being produced from the experiment. Once a level of convergence has been reached, a clustering algorithm—such as kmeans or Gaussian mixture modelling—could be used on the latent representations of these states to identify possible groups. Finally, one can learn to identify—possibly highly non-trivial—distinctions between quantum states. This was shown in the distinction between smooth and non-smooth states, however more work is required to extend such a method to further applications.
4.2. Semi-supervised classification
In a similar process to using classical clustering methods on latent space, we now use classical supervised learning models to classify quantum states. Specifically two ML algorithms are used: support vector machine (SVM) [48] and logistic regression (LR) [49]. These are both supervised learning algorithms that are successfully used for classification. The former attempts to obtain a separating hyper-plane splitting the smooth and non-smooth classes, while the latter is a form of binary regression. It is enough for the reader to understand that these are supervised learning algorithms that are fundamentally linear, but where the SVM can be extended to non-linear decision boundaries with the use of, what is called, a kernel. The decision boundaries of these models are shown in figure 10.

Figure 10. Decision boundaries of classical ML classifiers: SVM and LR. The SVM has an additional hyper-parameter, known as the kernel. Three different kernels are also shown: linear, polynomial (in this case degree of 3) and radial basis function (RBF). For polynomial and RBF kernels, points were fit with γ = 5. The results shown here are for a subset of the latent points (minor components fitted and plotted) generated from the HQA trained with both classes of states (results from figure 8).
Download figure:
Standard image High-resolution imageSplitting the 1600 classical data points (seen in figure 8) in a 3:10 testing/training ratio, the SVM and LR models are trained in two ways: (i) on all components of the latent vectors, and (ii) on just the principal components. The accuracy on the test data for all these variations (including kernel) is shown in table 1.
Table 1. Results of the binary classification problem of distinguishing smooth and non-smooth states from their latent space representations. This is done for two HQA models, with (n, v) = (7, 12), that identify different latent vectors: a HQA trained on only smooth and another HQA trained on both. The accuracy is simply defined as the proportion of correct classifications on a separate group of test data (size = 480). Importantly, both the SVM and the LR models are by no means optimised for the performance in this classification problem. Rather, these classical models are used as an illustration of the possibility of classifying states based on their latent space representation. For completeness, the hyper-parameters used for SVM are: C = 1.0 and γ = 2 (Linear), 20 (RBF). Finally, PCA reduction takes the four most principal components from the latent vector. The PCA reduced space accounts for 55% of the variance for HQA trained on both classes and 48% trained only smooth.

|
In general, both SVMs with non-linear kernels are seen to have a higher classification accuracy than LR. This makes sense, as the distribution of states on latent space was seen to be highly non-linear. More importantly however, from the performance of the SVM, the interesting result is that the HQA trained on only the smooth distributions, is comparable to the HQA trained on both when considering all components of the vector. At the same time, the HQA trained on both classes performs better when considering ML on only the principal components. To understand this behaviour, we realise that the HQA model attempts to separate states in only a few principal components. This means that when both classes were used for training the HQA, this separation was identifiable by the algorithm.
Considering all components, the polynomial kernel SVM with a HQA trained on only smooth distributions has a 0.95 accuracy rate. This occurs as a result of the non-smooth distributions—that were not seen by the HQA—being stored off the learned manifold and into the distinct unutilised regions of the latent space. It was hence easy for both ML algorithms to distinguish between the classes, with even a linear decision boundary from LR achieving an accuracy of 0.87.
These are significant results to keep in mind, however, not necessarily the most natural use of the HQA. If such a classification of quantum states was the main objective given a set of labelled states, one could instead—potentially—train the encoder  rather than an entire HQA. However, the power of the HQA comes down to its ability to be trained unsupervised—i.e. without any labelling of the states that are being fed. For example, it is possible to train a HQA with the output states of some quantum experiment without knowing anything about the states themselves. Post-training one would only be required to label a few states and simply perform classical ML to obtain a working quantum state classifier. The reason that this works lies with the ability of the HQA to learn a manifold in which relevant states lie. Such a manifold is far smaller than the space of all states, hence requiring far fewer labelled instances to train. In ML literature, this process is known as semi-supervised learning, where only a portion of instances are labelled but where the unlabelled instances are also able to help with the overall classification process.
rather than an entire HQA. However, the power of the HQA comes down to its ability to be trained unsupervised—i.e. without any labelling of the states that are being fed. For example, it is possible to train a HQA with the output states of some quantum experiment without knowing anything about the states themselves. Post-training one would only be required to label a few states and simply perform classical ML to obtain a working quantum state classifier. The reason that this works lies with the ability of the HQA to learn a manifold in which relevant states lie. Such a manifold is far smaller than the space of all states, hence requiring far fewer labelled instances to train. In ML literature, this process is known as semi-supervised learning, where only a portion of instances are labelled but where the unlabelled instances are also able to help with the overall classification process.
5. Conclusion
QML algorithms are yet to conclusively demonstrate advantage in the NISQ-era. There remain crucial problems that must be resolved for the application of these methods on real devices. One such problem is the emergence of barren plateaus and narrow gorges in gradient-based optimisation. This is common to most models that involve the optimisation of PQCs and is hence critical that it is solved for the specific HQA design implemented in this work. A general limitation of qubit-based devices is the requirement of repeated measurements in order to obtain continuous values up to a finite sampling imprecision. It is however possible to apply similar principles to vontinuous–variable quantum devices [50] for a more efficient measurement of continuous latent space vectors. This approach is left for future work, in align with the QML models proposed in [51]. Finally, the effect of noise on the HQA requires further research, with potential robustness seen from training stochastic states.
Due to these problems, it was important that the proposal of the HQA was made arbitrary in its specific implementation (as illustrated in figure 1(c)). Therefore, the crucial aspect of this work is the proposed paradigm of learning quantum states through the application of ML techniques on their classical representations—representations that are generated through training a HQA.
To demonstrate its successful application, the HQA was constructed using PQCs on a training set of Gaussian amplitude encoded states. Patterns—associated with the mean and standard deviation of the Gaussian encoded quantum state—were visually recognisable in their latent space representations. The emergence of order in latent space was exploited for the implementation of clustering and semi-supervised classification. In the context of (non-)smooth states (defined in equation (13)), we were able to achieve 84% accuracy for clustering and 93% for classification. Though the accuracy is highly problem dependent, the applied states under question had non-trivial distinctions and hence demonstrates the robustness of this clustering and classification approach.
Finally, it is assumed that an end-to-end application of the HQA will involve a set of training states obtained from supplemental quantum algorithms—such as the quantum variational eigensolver [3]. In [5] the constructed QAE is classically simulated to compress ground states of the hydrogen molecule with various r. Furthermore, there have been attempts for entanglement classification [52, 53], a process which can potentially employ variational methods. Recently, QAEs were suggested for use in low-rank state fidelity estimation [54], for which the structured classical latent space constructed by the HQA could be exploited. Unique from employing classical shadows to represent states, the HQA can also be used to generate new quantum states by traversing the learned classical latent space. These examples motivate further uses of the HQA from the contrived application studied in this work. Nonetheless, the novel paradigm proposed in this paper, lays the framework for a unique approach to extracting information and obtaining underlying structure from sets of quantum states.
Acknowledgments
The authors acknowledge the support provided by the University of Melbourne through the establishment of an IBM Network Quantum Hub at the University. CDH is supported by a research grant from the Laby Foundation. The large number of simulations required for this work were made feasible through access to the University of Melbourne's High Performance Computer, Spartan [55]. The HQA implementation was carried out employing the QML framework provided by the PennyLane [56] library.
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.
Appendix A.: Artificial neural network
The idea of ANNs was first proposed in 1957 in an attempt to mimic the way in which the human brain processes visual data [57]. Since then, the use of ANNs has been ubiquitous in many fields ranging from, image classification to numeric calculations in computationally expensive regions of phase-space [58]. It is important to note that ANNs are also regularly used in the context of unsupervised algorithms and in all cases, play the ubiquitous role of a function approximator.
Though ANNs come in various architectures, their fundamental unit is the neuron that accept inputs  and outputs a scalar known as the activation, a, of that neuron. It has the mathematical form,
and outputs a scalar known as the activation, a, of that neuron. It has the mathematical form,

where wi
is the weighting for input xi
and b is a bias term. These parameters will be tuned in the learning stage of the model such that the outputs correspond to the labels of the inputs. The function σ is known as the activation function which is a non-linear mapping ![$\sigma :\mathbb{R}\to [0,1]$](https://content.cld.iop.org/journals/2058-9565/7/1/015020/revision2/qstac3c53ieqn71.gif) , that outputs the activation of a neuron. In practice common activation functions include sigmoid, hyperbolic tan, rectified linear unit functions [6]. A network of these neurons form an ANN, with the output neurons commonly giving a probability distribution over the possible classifications. There are many different types of architectures for the way in which the neurons can be connected, but a common example is the feed-forward ANN, shown in figure 11. The layered fashion of the feed-forward ANN means that the whole network has a relatively simple mathematical form,
, that outputs the activation of a neuron. In practice common activation functions include sigmoid, hyperbolic tan, rectified linear unit functions [6]. A network of these neurons form an ANN, with the output neurons commonly giving a probability distribution over the possible classifications. There are many different types of architectures for the way in which the neurons can be connected, but a common example is the feed-forward ANN, shown in figure 11. The layered fashion of the feed-forward ANN means that the whole network has a relatively simple mathematical form,

where we have,  is the sum of previous layer neurons appropriately weighted by matrix
is the sum of previous layer neurons appropriately weighted by matrix  . These weights are, most commonly, learned through gradient optimisation.
. These weights are, most commonly, learned through gradient optimisation.

Figure 11. The structure for a feed-forward ANN.
Download figure:
Standard image High-resolution imageThe real utility of ANNs is in their ability to learn and approximate any continuous function with sufficient data. The universal approximation theorem states that a feed-forward neural network with a single hidden layer is able to approximate any continuous function on  [59]. It is important to note that non-linear activation functions are required—without which we have a complex linear model. This is evident from equation (A2) where it can be that linear σi
implies a linear f as function compositions preserve linearity. The non-trivial aspect is that there is no restriction on the non-linearity of the activation function and how this relates to the number of neurons required in the hidden layer. Due to this universality of function approximation, ANNs do not have the same hyper-parameter tuning problem as other ML models. Hyper-parameters refer to parameters of the model that must be identified by the user—such as the number of neurons in the case of an ANN. The hyper-parameter that an ANN does not require is a choice of the type of decision boundary, which in other models is crucial. At the same time a significant problem with ANNs its tendency to approximate too closely the training instances rather than generalising upon these data points. This is known in ML literature as over-fitting and there are regularisation techniques to mitigate this problem.
[59]. It is important to note that non-linear activation functions are required—without which we have a complex linear model. This is evident from equation (A2) where it can be that linear σi
implies a linear f as function compositions preserve linearity. The non-trivial aspect is that there is no restriction on the non-linearity of the activation function and how this relates to the number of neurons required in the hidden layer. Due to this universality of function approximation, ANNs do not have the same hyper-parameter tuning problem as other ML models. Hyper-parameters refer to parameters of the model that must be identified by the user—such as the number of neurons in the case of an ANN. The hyper-parameter that an ANN does not require is a choice of the type of decision boundary, which in other models is crucial. At the same time a significant problem with ANNs its tendency to approximate too closely the training instances rather than generalising upon these data points. This is known in ML literature as over-fitting and there are regularisation techniques to mitigate this problem.
Appendix B.: The parameter shift rule
In this paper the computation of quantum gradients of continuous parameters are computed using parameter-shift differentiation proposed in [60]. It is shown that the analytical gradient of a variational circuit, f, defined in equation (1), can be found when it is composed of gates of the form  , where they are generated by a Hermitian operator G with strictly two eigenvalues ±r. It is shown that ∂μ
f can be estimated using two additional evaluations of the quantum device by placing either gates
, where they are generated by a Hermitian operator G with strictly two eigenvalues ±r. It is shown that ∂μ
f can be estimated using two additional evaluations of the quantum device by placing either gates  in the original circuit next to the gate that we are differentiating. Since for unitarily generated one-parameter gates we have
in the original circuit next to the gate that we are differentiating. Since for unitarily generated one-parameter gates we have  , we simply have a shift of the parameters by
, we simply have a shift of the parameters by  to find the gradient,
to find the gradient,

This is aptly named the parameter shift rule. For generator G with more than two eigenvalues this strategy fails; however one is able to use an ancilla qubit and perform a decomposition of the derivative of the gate to obtain a gradient as elaborated in [19]. As an important additional benefit, the parameter-shift rule has been shown to hold on noisy quantum devices [61]. Furthermore, recent works have attempted to generalise this method of obtaining an analytic gradient for more intricate unitaries using stochastic techniques [62].
Having acquired the derivative of parameters in VQCs, one is now able to explore its use in QML—especially hybrid models involving both classical and quantum processing units. The ability to compute gradients of VQCs means that it is possible to attach a VQC and ANN as components of a larger ML algorithm, over which the back-propagation algorithm will still be applicable (shown in figure 12). To implement these models, an open-source Python3 software framework for hybrid quantum–classical optimisation and ML, termed PennyLane [56], is used. The library interfaces with popular ML libraries such as Tensorflow, PyTorch, autograd while also providing APIs for the access of publicly available quantum devices such as those by Rigetti and IBM—alleviating some of the tedious programing.

Figure 12. Diagram of an example hybrid QML algorithm, with the combination of an ANN and a PQC. For simplicity, both models only have a single parameter that is trained. For input, x, and label, y, the diagram highlights the derivatives required for the update of each parameter using the back-propagation algorithm.
Download figure:
Standard image High-resolution imageAppendix C.: PQC architecture
The decomposition unitary  need not be understood in terms of the commonly used single and two qubit circuit gates. Rather, they can be generalised to any tunable parameter in a particular quantum device and optimised accordingly. Though this is possible for specific devices, this paper will address PQCs from a general perspective, such that
need not be understood in terms of the commonly used single and two qubit circuit gates. Rather, they can be generalised to any tunable parameter in a particular quantum device and optimised accordingly. Though this is possible for specific devices, this paper will address PQCs from a general perspective, such that  is composed of only single and two qubits gates, with parameters θ defining the rotation on single qubit gates. Though
is composed of only single and two qubits gates, with parameters θ defining the rotation on single qubit gates. Though  can, in theory, be set as a random set of U3 gates and CNOT gates, it is generally desired to have a pattern of gates so that one can compare and generalise PQCs made from certain patterns. These patterns will be referred to as PQC architectures, separate from device architectures that describes the physical qubit layout of a device. In this work, we employ an alternating structure of rotation layers and entangling layers, as shown in figure 13.
can, in theory, be set as a random set of U3 gates and CNOT gates, it is generally desired to have a pattern of gates so that one can compare and generalise PQCs made from certain patterns. These patterns will be referred to as PQC architectures, separate from device architectures that describes the physical qubit layout of a device. In this work, we employ an alternating structure of rotation layers and entangling layers, as shown in figure 13.

Figure 13. The architecture is defined by alternating rotation and entangling layers—with q number of such repetitions. Here, RY := exp(−iYθ), where Y is the Pauli-Y operator. With only nearest neighbour couplings, such a structure is also known as a hardware efficient ansatz.
Download figure:
Standard image High-resolution imageAppendix D.: Swap test
To measure the fidelity between two coherent quantum states, one can introduce an ancilla qubit and use the swap test. To find the overlap between an output state,  , and a reference state,
, and a reference state,  , one repeatedly measures the ancilla qubit from the circuit shown in figure 14. This works since the state before measurement is,
, one repeatedly measures the ancilla qubit from the circuit shown in figure 14. This works since the state before measurement is,

Now measuring the ancilla qubit in the Z-basis, the probability of measuring eigenvalue, z = ±1 is,

where we have used  due to orthogonality and the normalisation condition, ∑i
|ψi
|2 = 1. Similarly for the
due to orthogonality and the normalisation condition, ∑i
|ψi
|2 = 1. Similarly for the  states. Therefore by measuring and recording the ancilla qubit enough times, we can work out the overlap between the two states in terms of the probability Pr(z = ±1),
states. Therefore by measuring and recording the ancilla qubit enough times, we can work out the overlap between the two states in terms of the probability Pr(z = ±1),

Under certain conditions, such a measure is equivalent to the mean-squared error (MSE) between amplitudes encodings, though in general it is a far stronger statement. The MSE Loss,  , can in this context be written as,
, can in this context be written as,

where again we have made a simplification using the fact that ψi
and ϕi
are normalised. This means that minimising the fidelity implies the minimisation of  —with the assumption that the amplitudes of the two states are non-negative real values. This can be shown by using the triangle inequality on equation (D3) to show that
—with the assumption that the amplitudes of the two states are non-negative real values. This can be shown by using the triangle inequality on equation (D3) to show that  revealing that the maximisation of the fidelity implies the minimisation of
revealing that the maximisation of the fidelity implies the minimisation of  in equation (D4). However, the fidelity statement is stronger due to the inequality. It should, however, be noted that the swap test requires large numbers of SWAP gates, and hence further research is required to enhance this fidelity measurement.
in equation (D4). However, the fidelity statement is stronger due to the inequality. It should, however, be noted that the swap test requires large numbers of SWAP gates, and hence further research is required to enhance this fidelity measurement.

Figure 14. This is a circuit diagram depicting the swap test algorithm that is used to compute the overlap, |⟨ϕ|ψ⟩|2 through repeated measurements of the ancilla qubit.
Download figure:
Standard image High-resolution imageAppendix E.: Training complexity
Given the particular design of the HQA (proposed in section 3.1), one can obtain a complexity for the training process. Each evaluation of the HQA would require  samples to determine the latent vector and Mswap samples to obtain the fidelity. We can relate the error in fidelity, ɛfid, to Mswap such that we have
samples to determine the latent vector and Mswap samples to obtain the fidelity. We can relate the error in fidelity, ɛfid, to Mswap such that we have  . This relation relies on the fact that the swap test measurement is a Bernoulli trial. Similarly, we relate the uncertainty in the latent vector components to the number of encoder samples:
. This relation relies on the fact that the swap test measurement is a Bernoulli trial. Similarly, we relate the uncertainty in the latent vector components to the number of encoder samples:  , where
, where  ξ
is the uncertainty in each component of the latent vector.
ξ
is the uncertainty in each component of the latent vector.
A single evaluation of the HQA requires  samples. However, training requires the calculation of gradients through the parameter shift rule (Section B). Specifically, one must obtain the gradients with respect to all parameters in the model:
samples. However, training requires the calculation of gradients through the parameter shift rule (Section B). Specifically, one must obtain the gradients with respect to all parameters in the model:  ,
,  and
and  , where αi
are the
, where αi
are the  encoder parameters, wij
are the ANN parameters (weights) and θi
are the
encoder parameters, wij
are the ANN parameters (weights) and θi
are the  decoder parameters. The gradient evaluations are of the form,
decoder parameters. The gradient evaluations are of the form,



where the output of the encoder,  , becomes the input to the ANN, f, and the output of the ANN becomes θi
. Note, only αi
and wij
are optimised, but we also require the gradient with respect to θi
.
, becomes the input to the ANN, f, and the output of the ANN becomes θi
. Note, only αi
and wij
are optimised, but we also require the gradient with respect to θi
.
Sampling a quantum circuit is required to obtain the gradients  and
and  .
.  must be calculated for all
must be calculated for all  parameters and
parameters and  must be calculated for all
must be calculated for all  parameters. The number of circuit samples required for
parameters. The number of circuit samples required for  and
and  , is proportional to
, is proportional to  and Mswap, respectively. In addition, an evaluation of the HQA is required for the calculation of the loss for that particular iteration. This therefore requires an additional
and Mswap, respectively. In addition, an evaluation of the HQA is required for the calculation of the loss for that particular iteration. This therefore requires an additional  samples. Putting all this together we have sampling complexity per iteration of,
samples. Putting all this together we have sampling complexity per iteration of,

Appendix F.: Kmeans clustering
Clustering is an unsupervised ML algorithm that attempts to group a set of data points into distinct clusters. The most commonly used clustering algorithm is the kmeans algorithm (or Lloyd's algorithm) [41]—used mainly due to its elegance and simplicity.
Kmeans is an iterative algorithm that partitions a data set into k groups. The algorithm works as follows:
- (a)Select k points randomly from the set to act as seed clusters,

- (b)Assign each data point in the set,, to the closest cluster based on some distance measure .
- (c)Average the group of points associated with each cluster, to form k new clusters.
- (d)Go back to 2, or stop when no reassignments of data points from their cluster groups are made.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note that the distance measure, D, is arbitrary but usually chosen to be the Euclidean distance. The average of the mth cluster group, with M associated data points  , is taken as
, is taken as  .
.