

Abstract
The inverse Ising problem, or the learning of Ising models, is notoriously difficult, as evaluating the partition function has a large computational cost. To quickly solve this problem, inverse formulas using approximation methods such as the Bethe approximation have been developed. In this paper, we employ the tree-reweighted (TRW) approximation to construct a new inverse formula. An advantage of using the TRW approximation is that it provides a rigorous upper bound on the partition function, allowing us to optimize a lower bound for the learning objective function. We show that the moment-matching and self-consistency conditions can be solved analytically, and we obtain an analytic form of the approximate interaction matrix as a function of the given data statistics. Using this solution, we can compute the interaction matrix that is optimal to the approximate objective function without iterative computation. To evaluate the accuracy of the derived learning formula, we compared our formula to those obtained by other approximations. From our experiments on reconstructing interaction matrices, we found that the proposed formula gives the best estimates in models with strongly attractive interactions on various graphs.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
While Ising models have been widely used in statistical physics [1], they are also frequently applied to the modeling of real-world data, such as the modeling of neural spike train data [2], protein structures [3], and genome regulation [4]. In these applications, an Ising model must learn parameters (i.e. an interaction matrix and local external fields) such that the model can reproduce the distribution of the given data. This kind of learning problem associated with Ising models is known as the inverse Ising problem, in contrast to the direct problem, in which expectation values are computed by given model parameters. The inverse Ising problem, as well as the direct problem, is generally hard to solve exactly because of the intractable summation appearing in the partition function. Thus, many researchers have developed efficient approximation methods to solve the inverse Ising problem [5].
On the one hand, many iterative methods, for example, the gradient ascent method following Monte Carlo sampling, have been developed to solve the inverse Ising problem. However, in most cases of iterative methods, the number of iterations needed to obtain the required accuracy is not known in advance. Moreover, Monte Carlo computation typically requires a large number of iterations to converge.
On the other hand, noniterative methods for inverse Ising problems have also been developed. For example, an inverse formula based on the Bethe approximation was derived [6, 7]. The Bethe approximation [1], which is equivalent to belief propagation [8], was first applied to the direct Ising problem [9]. Together with the linear response relation [10], an analytic expression of the expectation values or the correlation matrix was obtained as a function of the model parameters. Surprisingly, it was later found that the analytic expression for the correlations can be inversely solved to obtain the interaction matrix [6, 7]. This analytic solution is an interaction matrix that is a function of the data statistics, which enables us to obtain the optimal interaction matrix in the Bethe approximation without iterations.
In this study, instead of the Bethe approximation, we use the tree-reweighted (TRW) approximation to obtain an approximate solution for the inverse Ising problem. The TRW approximation was developed to improve the accuracy and convergence of a belief propagation algorithm [11]. In contrast to the ordinary belief propagation algorithm, the TRW free energy is provably convex with respect to the variational parameters. Moreover, the approximate partition function computed by the TRW approximation gives a rigorous upper bound on the exact partition function. Thus, the TRW approximation gives a lower bound on the exact log-likelihood function when learning a model [12]. Although the use of this lower bound for learning has been proposed in a previous study [12], it has not yet been applied to derive an analytic inverse formula in the Ising model, which is the main contribution of this study.
The remainder of this paper is organized as follows. In section 2, we introduce the Ising model and define its direct and inverse problems. In section 3, we review the TRW approximation and introduce the TRW free energy. Using the TRW free energy, we analytically obtain the inverse formula for the Ising model that optimizes the rigorous lower bound on the exact log-likelihood in section 4. In section 5, we briefly summarize some previous inverse formulas and conduct experiments to compare the proposed inverse formula and the previous inverse formulas. Conclusions and suggestions for future work are provided in section 6.
2. Ising model and the inverse problem
Prior to describing the inverse Ising problem, we begin with the definition of the Ising model to fix the notation. Let si ∈ {−1, +1}(i = 1, ..., N) denote random spin variables and s = {s1, ..., sN }. In an Ising model, these spin variables interact with each other via pairwise interactions. The energy function of an Ising model is defined by

where J = {Jij } is the symmetric interaction matrix and h = {hi } is the external field. The probability distribution over the spin variables s in this Ising model is given by the Boltzmann distribution,

where the partition function

is defined to normalize the distribution.
Note that we generally assume that the interaction matrix and the external field are not uniform. In this case, the model corresponds to the spin glass system in condensed matter physics. Moreover, we allow the model to have connections on an arbitrary graph, e.g. a multidimensional lattice graph or a fully connected graph (Sherrington–Kirkpatrick model). The connectivity information is embedded in the matrix elements of J, where Jij = 0 indicates that there is no connection between si and sj .
Despite the simplicity of the Ising model, it is generally difficult to compute the correlations of the spins under the distribution (2) with the given parameters J and h unless an approximation or a sampling-based method is employed. This difficulty of the 'direct' (i.e. inference) problem is due to the intractability of the summation over the spin variables. Note that the same summation appears in the partition function Z, and if we can obtain the partition function as a function of the parameters, we can readily compute the correlations by differentiating ln Z with respect to the parameters.
Next, we formulate the inverse Ising problem as follows. Let {s(1), ..., s(D)} be a given set of observed spin variables. The goal of the inverse problem is to infer the optimal parameters J* and h*, which reproduce the probability distribution of the given dataset. Specifically, the optimal parameters are obtained as maximum-likelihood estimators for the following log-likelihood function:

Here,  denotes an expectation value with respect to the given dataset
denotes an expectation value with respect to the given dataset  , and Φ(J, h) = ln Z(J, h) is the log partition function. As with the direct problem, solving the inverse problem requires computing the summation appearing in the log-likelihood or the partition function, which is intractable in general.
, and Φ(J, h) = ln Z(J, h) is the log partition function. As with the direct problem, solving the inverse problem requires computing the summation appearing in the log-likelihood or the partition function, which is intractable in general.
To further see the connection between the direct and inverse problems, we reformulate the inverse problem as follows. Differentiating the objective function l(J, h) with the parameters J and h and setting the gradients to zero, we obtain the equations for the optimal parameters, J*, h*, as

These equations yield the well-known moment-matching conditions for maximum-likelihood estimates [13]. The moments computed in the model (right-hand side) are matched by the statistics of the data (left-hand side). The following sections make use of moment-matching conditions to solve the inverse problem. We estimate moments by applying the TRW approximation introduced in the next section and then solve the moment-matching conditions with respect to the parameters.
3. Tree-reweighted approximation
In this section, we describe the TRW approximation [11] for the Ising model. Exploiting the convexity of the log partition function Φ, the TRW approximation gives us an upper bound on the log partition function. This upper bound can be obtained by minimizing the TRW free energy, which is similar to the Bethe free energy in the Bethe approximation. A summary of the TRW approximation and the TRW free energy is given as follows, and for a full discussion, please refer to [11].
3.1. Upper bound on the partition function
First, let us observe that the log partition function is a convex function of the parameter J. This is easily verified by computing its second derivative:

Note that the right-hand side is a covariance matrix of {si sj }. Because a covariance matrix is positive-semidefinite, equation (6) implies that the log partition function Φ is a convex function of J.
Next, we introduce spanning trees. Let E denote the set of edges of the given model, where E = {(i, j) ∈ 1, 2, ..., N|i < j, Jij
≠ 0}. A spanning tree T is a subgraph defined by a subset of E, T ⊂ E, such that T is a connected tree graph and all the spins have edges in T. Let  be the set of all spanning trees of E. We assign an arbitrary probability distribution ρ(T) over the spanning trees in
be the set of all spanning trees of E. We assign an arbitrary probability distribution ρ(T) over the spanning trees in  exhibiting nonnegativity and normalization, where ρ(T) ⩾ 0 and
exhibiting nonnegativity and normalization, where ρ(T) ⩾ 0 and  .
.
For each spanning tree  , the partition function Φ(J(T), h) is defined by substituting the parameter J in Φ(J, h), with J(T) satisfying the conditions
, the partition function Φ(J(T), h) is defined by substituting the parameter J in Φ(J, h), with J(T) satisfying the conditions


Note that J(T) is not unique. We can choose various parameter sets that satisfy these conditions.
Finally, we are ready to determine the upper bound on the log partition function Φ(J, h). Using the convexity of Φ(J, h) in equation (6), the upper bound on Φ(J, h) can be obtained by applying Jensen's inequality,

where we use equation (8). The upper bound in equation (9) depends on the choice of ρ(T) and J(T). To use the upper bound to approximate the partition function, the upper bound should be close to the true value of the partition function. Thus, we need to optimize the parameters to tighten the upper bound. In fact, the optimal upper bound can be obtained by minimizing the TRW free energy.
3.2. Tree-reweighted free energy
We consider optimizing the upper bound (9) when ρ(T) is given. Naively, to obtain the optimal upper bound, we have to solve the optimization problem with respect to the parameters J(T) for all  under the constraints in equations (7) and (8). However, the main theorem in the TRW approximation states that the optimal bound can be obtained by minimizing the TRW free energy [11],
under the constraints in equations (7) and (8). However, the main theorem in the TRW approximation states that the optimal bound can be obtained by minimizing the TRW free energy [11],

Here, the pseudomarginals q = {qi , qij } that satisfy



for all i and (i, j) ∈ E are the variational parameters. The TRW free energy FTRW(q, J, h; ρ) is then defined by

where the energy term  and the entropy term
and the entropy term  are
are


respectively. Here, we define the entropies of the pseudomarginals as ![${H}_{ij}[{q}_{ij}]=-{\sum }_{{s}_{i},{s}_{j}}{q}_{ij}({s}_{i},{s}_{j})\mathrm{ln}\enspace q({s}_{i},{s}_{j})$](https://content.cld.iop.org/journals/1742-5468/2022/2/023406/revision1/jstatac50b1ieqn10.gif) and
and ![${H}_{i}[{q}_{i}]=-{\sum }_{{s}_{i}}{q}_{i}({s}_{i})\mathrm{ln}\enspace q({s}_{i})$](https://content.cld.iop.org/journals/1742-5468/2022/2/023406/revision1/jstatac50b1ieqn11.gif) . We also define the edge appearance probabilities ρij
. We also define the edge appearance probabilities ρij

where νij
(T) is the indicator function: νij
(T) = 1 if (i, j) ∈ T and νij
(T) = 0 otherwise. Intuitively, ρij
is the probability of the appearance of edge (i, j) over all spanning trees  .
.
Mathematically, the TRW free energy is the dual objective function of the primal optimization problem. While the number of variables J(T) in the primal problem is proportional to the number of spanning trees T (e.g.  in the fully connected graph), the number of variables q in the TRW free energy is
in the fully connected graph), the number of variables q in the TRW free energy is  . Thus, the optimization problem is drastically simplified and becomes feasible.
. Thus, the optimization problem is drastically simplified and becomes feasible.
To use the TRW approximation to obtain approximate statistics  , etc (i.e. the direct problem), we have to find the optimal q that minimizes the TRW free energy FTRW(q, J, h; ρ). The pseudomarginals approximate the marginal probability of a single spin and joint probability of two spins:
, etc (i.e. the direct problem), we have to find the optimal q that minimizes the TRW free energy FTRW(q, J, h; ρ). The pseudomarginals approximate the marginal probability of a single spin and joint probability of two spins:


Fortunately, the optimal q is unique because the TRW free energy is a convex function of q [11]. To find the optimal q, an iterative algorithm [11] that is similar to the belief propagation algorithm used in the Bethe approximation can be used [8]. In the following section, however, instead of using the belief propagation-like algorithm, we directly solve the equation where the gradient of the TRW free energy is zero.
3.3. Relation to the Bethe free energy
In this subsection, we briefly review the Bethe approximation and show its relation to the TRW approximation. In the Bethe approximation, the true probability distribution (2) is approximated by marginal probabilities qij and qi as

The approximate distribution Q(s) is optimized by minimizing the Kullbuck–Leibler divergence between Q(s) and P(s) with respect to q as variational parameters. This minimization problem is equivalent to minimizing the Bethe free energy:

where  is defined by in equation (15), and
is defined by in equation (15), and

where di is the number of spins connected to a spin si .
Obviously, with ρij = 1 for all edges, the TRW free energy is reduced to the Bethe free energy. However, note that this does not mean that the TRW approximation includes the Bethe approximation. The choice of ρij = 1 is invalid unless the graph is a tree. Additionally, note that the Bethe free energy does not give an upper bound for the partition function, nor is it convex.
4. Derivation of the TRW inverse formula
Using the TRW upper bound  , we obtain a lower bound for the objective function for the inverse problem (4):
, we obtain a lower bound for the objective function for the inverse problem (4):

In the TRW approximation, we maximize the lower bound lTRW(J, h) instead of the exact objective function l(J, h).
By differentiating the approximate objective function with respect to the parameters and setting them to zero, ∂lTRW/∂Jij = ∂lTRW/∂hi = 0, we obtain the analog of the moment-matching conditions in equation (5):

In the pseudomoment-matching conditions (24), the right-hand sides are the approximate expectation values to be computed in the TRW approximation.
We now calculate the explicit solution JTRW of the pseudomoment-matching conditions (24). To evaluate  and
and  , we first address the minimum of the TRW free energy FTRW(q, J, h; ρ).
, we first address the minimum of the TRW free energy FTRW(q, J, h; ρ).
Given that all the random variables are binary, we parameterize the pseudomarginals qi , qij by the mean value mi and covariance cij as follows:


By substituting these equations into the TRW free energy (14), we obtain the optimal solutions  by solving ∂FTRW/∂mi
= ∂FTRW/∂cij
= 0.
by solving ∂FTRW/∂mi
= ∂FTRW/∂cij
= 0.
Following the case of the Bethe approximation, we can eliminate cij from the equations ∂FTRW/∂mi = ∂FTRW/∂cij = 0 by applying the cavity methods [14, 15], and we derive a self-consistency equation for mi as

where  and
and

We can obtain an approximate expectation value  by a solution to the self-consistency equation (27).
by a solution to the self-consistency equation (27).
We next evaluate the two-point correlation  . A consistent approach is the use of the linear response relation [10]:
. A consistent approach is the use of the linear response relation [10]:

The left-hand side of equation (29) is the derivative of the optimal solution  , while with the application of the pseudomoment-matching conditions (24), the right-hand side is the covariance C of the given data:
, while with the application of the pseudomoment-matching conditions (24), the right-hand side is the covariance C of the given data:

To evaluate ∂mi /∂hj , we take the mj -derivative of both sides of equation (27),

Because equation (30) states that ![${[{C}^{-1}]}_{ij}=\partial {h}_{i}/\partial {m}_{j}$](https://content.cld.iop.org/journals/1742-5468/2022/2/023406/revision1/jstatac50b1ieqn25.gif) , we obtain the following from equation (31) for any i ≠ j:
, we obtain the following from equation (31) for any i ≠ j:

Finally, by solving quartic equation for  , we obtain an approximate solution to the inverse Ising problem:
, we obtain an approximate solution to the inverse Ising problem:

where  and
and

Note that in the inverse formula (33), mi
and Cij
are not variational parameters in the TRW free energy, but they are the mean value and covariance of the spin si
computed by the given data,  and
and  , respectively. The inverse formula (33) gives the approximate parameter J = {Jij
} as a function of data statistics mi
and Cij
. For the estimation of h = {hi
}, if needed, we can solve equation (27) for hi
as a function of mi
and the estimated Jij
.
, respectively. The inverse formula (33) gives the approximate parameter J = {Jij
} as a function of data statistics mi
and Cij
. For the estimation of h = {hi
}, if needed, we can solve equation (27) for hi
as a function of mi
and the estimated Jij
.
4.1. Relation to the Bethe inverse formula
As mentioned in section 3.3, the TRW approximation is reduced to the Bethe approximation by setting ρij = 1 for all i and j. Thus, we can obtain the inverse formula in the Bethe approximation [6, 7] by setting ρij = 1 in the TRW inverse formula (33) as

where

Note again that the choice of ρij = 1 is valid only if the graph structure of the model is a tree and the TRW approximation is equivalent to the Bethe approximation in the models with tree graphs.
5. Numerical experiments
5.1. Experiment settings
In this section, we experimentally evaluate the inverse formula in the TRW approximation by comparing it to similar inverse formulas obtained by other approximations, the independent-pair (IP), Bethe, and density-consistency (DC) approximations. We first briefly describe the IP and DC approximations.
In the IP approximation [16], only the effects of a pair of spins si and sj are taken into account in the computation of the interaction Jij , which leads to the formula:

Note that the IP approximation corresponds to the Bethe approximation without the linear response relation.
In the DC approximation, the density consistency approximation [21] for estimation of merginal probabilities is applied to the inverse Ising problem, which results in the following closed-form solution [20]

where

Interestingly, by replacing Σij → Cij , we obtain the Sessak–Monnason (SM) formula [17], which uses small-correlation expansion of the entropy function. Experimentally, we observed the SM formula behaved similarly to the DC formula, but gave slightly worse result than the DC formula, which is consistent to the observation in [20]. We therefore omitted the result of the SM inverse formula in the following for simplicity.
To evaluate the accuracy of the inverse formulas, we attempt to reconstruct an interaction matrix from the statistics of the sampled data. The experimental method is described as follows: we construct an Ising model with a certain graph structure and randomly generated parameters Jij
and hi
. Using the Monte Carlo sampling method, we compute the mean value  and covariance
and covariance  for each model
1
. By substituting mi
and Cij
into the inverse formulas, we reconstruct the interaction matrices Jij
. Finally, we measure the errors of the reconstructed interaction Jij
by comparing it to the true interaction
for each model
1
. By substituting mi
and Cij
into the inverse formulas, we reconstruct the interaction matrices Jij
. Finally, we measure the errors of the reconstructed interaction Jij
by comparing it to the true interaction  by using the normalized distance:
by using the normalized distance:

The smaller ΔJ is, the better the reconstruction is.
The graph structures and parameters are summarized as follows. We use four types of graph structures: random three-regular, two-dimensional lattice, three-dimensional lattice, and fully connected graphs. We set the numbers of spins N to 20, 7 × 7, 4 × 4 × 4, and 16 for the four graphs. We set two types of interactions for each graph: attractive and mixed. To generate the parameters, we use the uniform distribution U with a given interaction strength ω > 0, and for all  ,
,

for the attractive models and

for the mixed models. The bias parameter hi is drawn by hi ∼ U[−0.05, 0.05] for both the attractive and mixed settings.
5.2. The edge appearance probabilities
To use the TRW inverse formula, the edge appearance probability ρij
must be set. Ideally, we should choose the optimal ρij
that maximize the approximate objective function (23). However, because we do not have the closed-form solution of the optimal ρij
, we need iterative, restricted optimization to obtain the optimal solution. Instead, we propose two simple choices of ρij
that do not need iterative computations. The first is a uniform choice,  [11], where N and |E| are the number of the spins and edges, respectively.
[11], where N and |E| are the number of the spins and edges, respectively.
The second choice is more heuristic and inspired by the optimization algorithm in the direct problem [11]. We pick the most important spanning tree T(max), and assign probabilities as ρ(T(max)) = 1 and ρ(T) = 0, ∀ T ≠ T(max), which results in the edge appearance probability,

As T(max), we use the maximum spanning tree, i.e. a spanning tree that has maximum sum of edge weights among all spanning trees. Here, we use the mutual information Iij
as a weight of the edge (i, j), where Iij
= −Hij
[qij
] + Hi
[qi
] + Hj
[qj
]. When the moment-matching condition is satisfied, we can compute Iij
by statistics mi
and Cij
using equations (25) and (26). To find the maximum spanning tree, we use Kruscal's algorithm of the order  implemented in the package NetworkX [22]. Since zero elements in ρij
is problematic in the TRW formula, we use the smoothed version,
implemented in the package NetworkX [22]. Since zero elements in ρij
is problematic in the TRW formula, we use the smoothed version,

where 0 < α < 1 is a parameter. We set α = 0.5 and use  as the second choice of ρij
.
as the second choice of ρij
.
5.3. Results
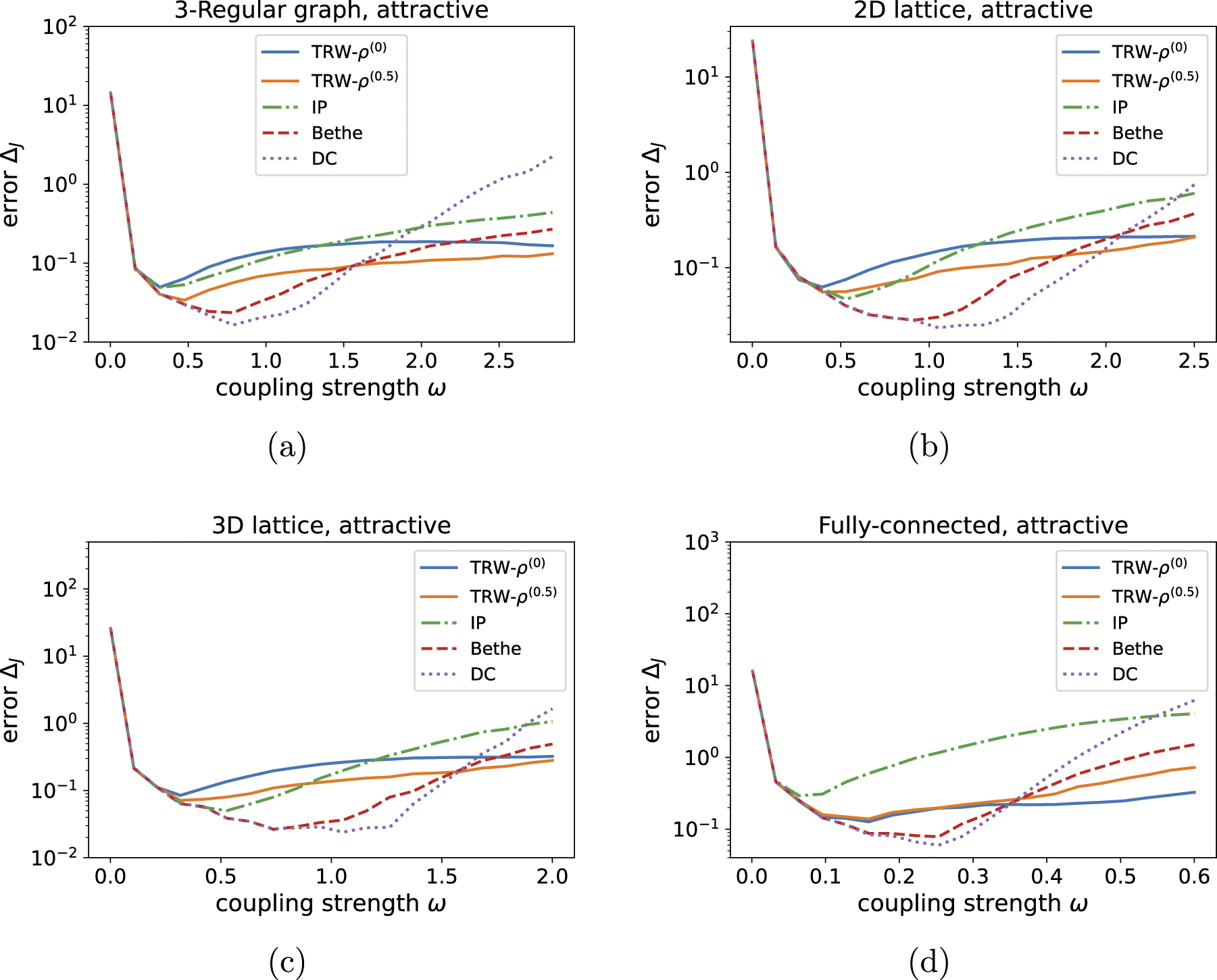
In figure 1, we show the reconstruction result for the attractive-interaction models. For all the graph structures and the inverse formulas, the error measurement ΔJ becomes large in the regions with small interaction strength ω. This is because in such small ω regions, the statistical uncertainty of the mean and covariance primarily dominates the errors, and the differences in the inverse formulas are completely eliminated [6, 19].

Figure 1. Reconstruction errors in the attractive-interaction models with coupling strength ω for the (a) three-regular, (b) two-dimensional lattice, (c) three-dimensional lattice, and (d) fully connected graphs.
Download figure:
Standard image High-resolution imageWhen ω is nonzero, the differences between the inverse formulas become large. For all settings, the IP approximation typically gives the worst results. For the strongly attractive interactions, the proposed TRW approximation yields reasonable errors compared to the Bethe and DC inverse formulas. We next compare the uniform and weighted parameter settings of the TRW formulas, TRW-ρ(0) and TRW-ρ(0.5) respectively. For the sparse graphs, i.e. the regular and lattice graphs, TRW-ρ(0.5) was better than TRW-ρ(0), while TRW-ρ(0) was better than TRW-ρ(0.5) for the fully-connected graph. This is reasonable because for sparse graphs, a maximum spanning tree has a large responsibility in reconstruction of parameters, therefore giving a large weight to the maximum spanning tree may be helpful for the good reconstruction. On the other hand, for dense graphs, many spanning trees are important for the reconstruction, thus treating all the trees equally may make the reconstruction better. Especially, for large ω, TRW-ρ(0.5) gave the best results for the regular and lattice graphs, and TRW-ρ(0) gave the best for the fully-connected graph among all the inverse formula.
In figure 2, we show the reconstruction results for the mixed-interaction models. For the mixed interactions, the Bethe and DC approximations yield the best results for the lattice and fully-connected graphs in the region of large ω. For the three-regular graph, TRW-ρ(0.5) and the Bethe formula were the best in the region of large ω. Comparing TRW-ρ(0) and TRW-ρ(0.5), we found the same tendency with the attractive case, i.e. TRW-ρ(0.5) was better for the sparse graphs, but the superiority of TRW-ρ(0) for the fully-connected graph was not clear and it showed almost the same accuracy with TRW-ρ(0.5). Also for the fully-connected graph, the results of the both TRW approximations became comparable to those of the Bethe and DC approximations when the interactions are strong.

{kind=link}
Figure 2. Reconstruction errors in the mixed-interaction models with coupling strength ω for the (a) three-regular, (b) two-dimensional lattice, (c) three-dimensional lattice, and (d) fully-connected graphs.
Download figure:
Standard image High-resolution image{kind=link}
6. Conclusion
Aiming at faster and more accurate learning, we developed a new, iteration-free formula for the inverse Ising problem. Following a previous study using the Bathe approximation [6], we combined the linear response relation and the pseudomoment-matching conditions to derive the inverse formula. However, we used the TRWfree energy rather than the Bethe free energy. The advantage of using the TRW free energy over the Bethe free energy is twofold. The first advantage is that the TRW free energy is convex, allowing us to find the global optimal solution. The second advantage is that we can optimize a rigorous lower bound on the likelihood function using the optimal value of the TRW free energy. We analytically obtained the TRW inverse formula (33), which gives the interaction matrix as a function of the edge appearance probabilities ρij as well as the statistics of the input datasets mi and Cij . Using this formula, we could compute the approximate interaction matrix with the same computational complexity as in the Bethe approximation (35).
In order to use the TRW formula, we need to fix the edge appearance probability ρij
. We proposed two settings,  and
and  . For
. For  , all edges are treated equivalently, while for
, all edges are treated equivalently, while for  , the edges in the maximum spanning tree are biased to have more weights. We called the TRW approximation with
, the edges in the maximum spanning tree are biased to have more weights. We called the TRW approximation with  and
and  as TRW-ρ(0) and TRW-ρ(0.5), respectively.
as TRW-ρ(0) and TRW-ρ(0.5), respectively.
We compared the proposed TRW inverse formula to others in interaction reconstruction experiments in models with attractive and mixed interactions on various graph structures. We found that the TRW-ρ(0.5) gave the best accuracy in models with large attractive interactions for the regular and lattice graphs, while the TRW-ρ(0) was the best for the fully-connected graph. In particular, for the fully connected graph, the TRW-ρ(0) formula showed overwhelmingly good reconstructions compared to the Bethe and DC approximations. In contrast, for mixed-interaction matrices (i.e. the elements were both positive and negative), the best estimations were typically obtained by the Bethe and DC approximations. However, the TRW-ρ(0.5) formula gave the best results with large interactions on the regular graph.
We also found limitations to using the TRW inverse formula. The first limitation was the negative argument of the square root in the inverse formula (33): empirically, we found that when the interactions and biases were large, mi also became large, and the argument tended to become negative, which resulted in the failure of the TRW approximation. Note that this limitation is also present in the Bethe inverse formula [6]. The second limitation was singular correlation matrices: if a correlation matrix was singular, we could not compute its inverse and could not use the TRW inverse formula. This situation was seen when the number of samples was too small or when the interaction was too large. The TRW, Bethe and DC inverse formulas all have this limitation. Interestingly, the IP inverse formula does not experience singular correlation matrices. The third limitation was that we needed the information of graph structure in advance to use the TRW inverse formula, because the graph structure is required in order to set ρij . This limitation restricts the TRW formula from the applications such as estimation of a graph structure from data.
Although we demonstrated that the TRW inverse formula is useful, some open questions should be addressed for future improvements and practical applications. First, the TRW inverse formula has the free parameter ρij
, which was fixed to  and
and  in our experiments. There is no doubt that optimizing ρij
improves the accuracy of the inferred interactions. In fact, a method to obtain the optimal ρij
value that minimizes the upper bound ΦTRW(J, h; ρ) has been previously discussed in the context of direct problems [11]. However, it is difficult to obtain an optimal value by analytically solving equations, and we must perform iterative computations. Even though it is difficult to analytically obtain the optimal value, there may be an easy but efficient choice of ρij
that is superior to the choices used in this study. It is also interesting to optimize the parameter α in
in our experiments. There is no doubt that optimizing ρij
improves the accuracy of the inferred interactions. In fact, a method to obtain the optimal ρij
value that minimizes the upper bound ΦTRW(J, h; ρ) has been previously discussed in the context of direct problems [11]. However, it is difficult to obtain an optimal value by analytically solving equations, and we must perform iterative computations. Even though it is difficult to analytically obtain the optimal value, there may be an easy but efficient choice of ρij
that is superior to the choices used in this study. It is also interesting to optimize the parameter α in  in equation (44).
in equation (44).
Another question is the extension of the inverse formula to models with hidden variables such as restricted Boltzmann machines. The introduction of hidden variables makes the model drastically simpler and recognizable to a human being. We may directly extend the inverse formula to include hidden variables, or we may use the inverse formula in a step of expectation-maximization-like algorithms to reduce the computational cost.
Finally, we are interested in applying TRW approximation and the proposed inverse formula to physics. The partition function dominates the physical properties of a system, such as phase transitions and critical phenomena. Thus, the TRW approximation, which can give a rigorous bound for the partition function, may be applicable to the mathematical analysis of physical models. The proposed formulation, with which we analyzed the exact solution of the TRW free energy, may also be useful for providing new insights into statistical and mathematical physics.
Acknowledgments
We are grateful to anonymous reviewers for helpful comments that significantly improved the paper. Part of this paper is based on results obtained from a project commissioned by the New Energy and Industrial Technology Development Organization (NEDO). This work was supported by JSPS KAKENHI Grant Nos. JP18K18117 and JP18K11488, and the INOUE ENRYO Memorial Grant, TOYO University. Some of the material in this paper has been reused from our preliminary conference paper, 'An Analytic Solution to the Inverse Ising Problem in the Tree-reweighted Approximation', in IEEE Proceedings, 2018, with permission, © 2022 IEEE.
Footnotes
- 1
We used the PyMC3 package [18] for the Monte Carlo simulation.