

Abstract
CASA, the Common Astronomy Software Applications, is the primary data processing software for the Atacama Large Millimeter/submillimeter Array (ALMA) and the Karl G. Jansky Very Large Array (VLA), and is frequently used also for other radio telescopes. The CASA software can handle data from single-dish, aperture-synthesis, and Very Long Baseline Interferometery (VLBI) telescopes. One of its core functionalities is to support the calibration and imaging pipelines for ALMA, VLA, VLA Sky Survey, and the Nobeyama 45 m telescope. This paper presents a high-level overview of the basic structure of the CASA software, as well as procedures for calibrating and imaging astronomical radio data in CASA. CASA is being developed by an international consortium of scientists and software engineers based at the National Radio Astronomy Observatory (NRAO), the European Southern Observatory, the National Astronomical Observatory of Japan, and the Joint Institute for VLBI European Research Infrastructure Consortium (JIV-ERIC), under the guidance of NRAO.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Radio astronomy is a discipline that heavily relies on computational resources to image the sky at wavelengths ranging from roughly 10 m to 300 μm (e.g., Condon & Ransom 2016; Thompson et al. 2017). The Common Astronomy Software Applications (CASA) 9 (McMullin et al. 2007) is a software package that enables the calibration, imaging, and analysis of data produced by world-leading radio telescopes.
CASA consists of open-source software for the processing of single-dish and radio interferometric data (Jennison 1958). It consists of a suite of applications implemented in the C++ programming language (Stroustrup 1997) and accessible through an Interactive Python interface (Perez & Granger 2007). The origin of CASA lies in the AIPS++ project (Glendenning 1996; McMullin et al. 2006), which was started in 1992 as the successor of the Astronomical Information Processing System (AIPS) software package (Greisen 2003). The original AIPS++ project was run by a consortium of astronomical institutes, including the Australia Telescope National Facility (ATNF), the National Center for Supercomputing Applications (NCSA) at the University of Illinois, Jodrell Bank Observatory (JBO), the MERLIN/VLBI National Facility (MERLIN/VLBI), the National Radio Astronomy Observatory (NRAO), and the Netherlands Foundation for Research in Astronomy (ASTRON). 10 In 2004, the AIPS++ code was re-organized and migrated to CASA, and the scripting language was changed from Glish (Paxson & Saltmarsh 1993; Schiebel 1996) to Python bindings known as "casapy." At the same time, the core of the AIPS++ libraries formed Casacore (van Diepen & Farris 1994; Casacore Team 2019). 11 Casacore has offered a stable and nearly static platform for many radio synthesis telescopes. It includes a table based storage mechanism designed for astronomical data, a visibility storage framework, fundamental C++ data structures, an image storage format, numerical methods for astronomy, a library for unit and coordinate conversion, and methods to handle images in the Flexible Image Transport System (FITS) format (Pence et al. 2010) using wcslib for coordinate conversions (Calabretta 2011). A consortium led by NRAO started to develop the CASA package, primarily aimed at supporting the Atacama Large Millimeter/submillimeter Array (ALMA) (Wootten & Thompson 2009) and the Karl G. Jansky Very Large Array (VLA) (Thompson et al. 1980; Chandler & Butler 2014), but on a best-effort basis also other radio telescopes. CASA layers advanced calibration, imaging and image analysis along with basic visualization and telescope-specific support on top of the Casacore base. Currently, CASA is the primary data processing software for ALMA and the VLA, and through the versatility of the software and external development collaborations, it is commonly used also for other aperture-synthesis and single-dish radio telescopes.
This paper provides a high-level overview of the CASA software. It is not intended as a complete overview of CASA functionality or of radio processing techniques, but instead allows the readers to familiarize themselves with the principles and philosophy behind the CASA software. In Section 2 we summarize the structure of CASA, the CASA data model, the Application Programming Interface (API), and the comprehensive CASA documentation. Section 3 gives an overview of the different stages of data processing in CASA, both for interferometric and single-dish data. One of the core functionalities of CASA is to support the data calibration and imaging pipelines for ALMA, VLA and the VLA Sky Survey (VLASS), and we briefly discuss this in Section 4. The CASA development process is summarized in Section 5. Section 6 mentions the tentative design of a next-generation CASA package, suitable for data processing with next-generation radio telescopes.
2. The CASA Software
2.1. CASA Structure and Python
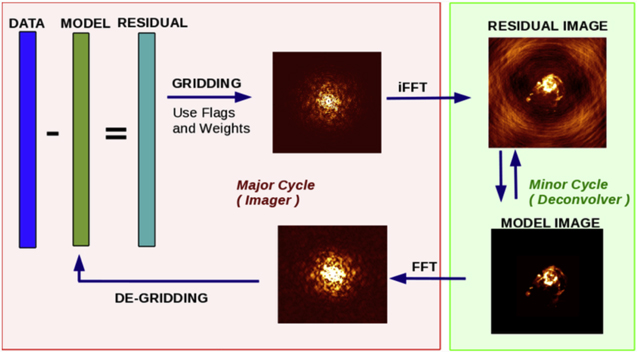
CASA consists of an open-source code library implemented in C++ (Stroustrup 1997), with some parts in Fortran (Backus et al. 1956). It is designed to run on Unix platforms, including certain versions of Linux and macOS. Python is used for scripting and to interact with the software through an Interactive Python (IPython) interface (van Rossum 1995; Perez & Granger 2007). Therefore, CASA uses the standard Python syntax to define variables, lists, indices, etc. CASA has traditionally been distributed as a "monolithic," integrated application, including a Python interpreter and all the libraries, packages and modules (Figure 1). From version 6 onward, CASA is also available in "modular" version through pip-wheel installation, which was introduced together with the switch from Python 2 to Python 3. This provides users with the flexibility to use CASA in their own Python environment.
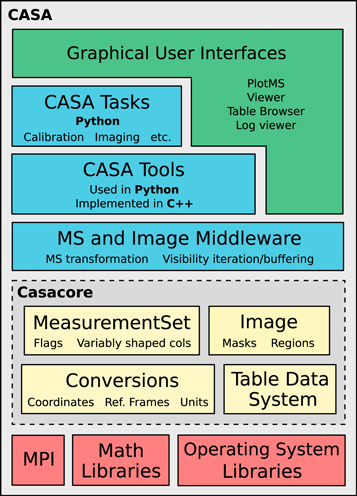
Figure 1. Layer architecture diagram of the monolithic CASA software package. The various terminology is discussed throughout Section 2.
Download figure:
Standard image High-resolution imageInitial versions of the CASA top-level user interface were object-oriented, but it was soon adapted to provide a functional, aggregate interface that is easier for users to handle and reminiscent of the AIPS model. The object-oriented interface remained on the layer below. Since then, within CASA, the suite of applications consists of basic objects called tools that can be called to perform operations on the data, as well as user-friendly tasks (see Section 2.3.2). CASA tasks are small to medium-size applications that use the CASA tools, and that are built as Python functions with a well-defined set of parameters. In this way, both tools and tasks are Python interfaces to the C++ application layer that implements the more computing-intensive science algorithms and features (Figure 1). Further underneath this application layer is the C++ code framework of Casacore, which is an independent package that contains the core data- and image-handling infrastructure (Casacore Team 2019).
The CASA software is designed to facilitate manual interactive and scripted use, as well as batch and pipeline processing. It provides a framework to parallelize processing using multiple cores and computing nodes where available. The history of the present CASA session is displayed in the CASA logger graphical user interface (GUI), and also stored on disk in a casa.log file.
2.2. The MeasurementSet and Data Model
The MeasurementSet (MS) is the database in which interferometric or single-dish data are stored for processing in CASA (Wieringa & Cornwell 1996; Kemball & Wieringa 2000). The MS is essentially a relational database consisting of a Main table containing the bulk data, and a number of sub-tables which store meta-data referenced by the Main table to avoid redundancy and to allow database normalization (Codd 1970). In CASA, the MS is implemented based on the Casacore Table Data System (CTDS; van Diepen 2015, 2020), which is a storage management system that stores each table as a file system directory with a standard set of files, in particular one file per table column. The Main table bulk data can either consist of the interferometric visibilities or single-dish total-power measurements. The Main table rows contain these data chronologically for each time-step, phase-reference direction, spectral window, and baseline, with each row containing a two-dimensional array that represents the polarization and spectral channel axes. The meta-data consist of entries that identify and characterize the recorded data, such as the spectral window parameters or the positions of the antennas (see Kemball & Wieringa 2000).
The MS Main table initially only contains one column with the radio data, named DATA for interferometric data or FLOAT_DATA for single-dish data. When a calibration is applied to the DATA column, a CORRECTED_DATA column is created to contain the calibrated data, leaving the original data untouched. Other columns can be added, such as the MODEL_DATA column, which stores the expected visibility values that represent an image-plane source model. Other standard columns worth mentioning are the FLAG column, which indicates the data flags (Section 3.2); the SIGMA column, which gives the per-channel noise; and the WEIGHT column, which contains the data weights to be used, e.g., when combining different visibilities in imaging.
2.3. Application Programming Interface (API)
CASA provides a Python framework, which includes Python packages that expose CASA's functionality in a functional manner ( casatasks ) and in an object oriented manner ( casatools ). Additional packages provide basic visualization tools. As mentioned in Section 2.1, these packages can be installed directly as part of the user's normal Python environment, or the user can download a monolithic version of CASA (Figure 1), which includes a full Python distribution including an extended IPython shell with task invocation (inp/go) and other extensions. These elements constitute the Application Programming Interface (API) of CASA, which gives users the possibility to configure and extend CASA. An extensive suite of automated tests is used to verify this API for each CASA release.
2.3.1. CASA Configuration and Shell
CASA accepts a variety of configuration options, specified either through configuration files or command line arguments. A configuration file config.py can be edited prior to starting a CASA session, which can be used to set reference data paths, pipeline installation, options for display of GUIs, and more. In addition, a startup.py file can be used to customize the CASA shell, which provides the environment for interactive Python-based data analysis using CASA tasks and tools, as described in Section 2.3.2. The startup.py file allows setting paths, importing Python packages, and executing other Python code to prepare the session.
2.3.2. CASA Tasks, Tools, and GUIs
CASA tools are Python objects that use C++ functions to perform operations on the data. The collection of tools contains a large part of the functionality of CASA, but each tool in itself performs a separate low-level operation. This means that procedures to achieve a typical data analysis objective, such as performing a bandpass calibration, typically need many calls to different tools. To make CASA more user-friendly, higher-level CASA tasks are offered, which are constructed based on the tools and cover a comprehensive set of use-cases for data processing and analysis. A CASA task performs a well defined step in the processing of the data, such as loading, plotting, flagging, calibrating, imaging, or analyzing the data. Each task has a well defined purpose and set of input parameters, which may have a two-layer hierarchy containing sub-parameters.
While CASA tools are Python class objects with methods, CASA tasks can be called as a function with one or more arguments specified, which allows for robust scripting and pipeline use in Python. Where possible and useful, parameters have a specified default value. CASA tasks can also be controlled by setting global parameters. These can be inspected in the terminal via the inp command, before executing the task by typing go. Throughout this paper, we will refer to the names of CASA tasks and tools in bold , and task parameters in italic. For an overview of the tasks and tools that are available in CASA, see CASA Docs. 12
CASA also contains a variety of applications with Graphical User Interfaces (GUIs) to examine visibility data, image products, and meta-data. Two of the most widely used GUIs are plotms , for diagnostic plotting of visibility and calibration-table data, and the CASA viewer , for visualizing image products. More information on data analysis and the use of GUIs in CASA is provided in Section 3.6.
2.3.3. External Data Repository
Each CASA version comes with a minimal repository of binary data that is required for CASA to function properly. In particular the CASA Measures system, which handles physical quantities with a reference frame and performs reference frame conversions, requires valid Earth Orientation Parameters (EOPs) and solar system object ephemerides. These are contained in the "Measures tables." The EOP tables are updated daily by ASTRON, 13 based on the geodetic information from services like the International Earth Rotation and Reference Systems Service (IERS). 14 The ephemeris tables are copied over from the Horizons online solar system data and ephemeris computation service at the Jet Propulsion Laboratory (JPL). 15 Other data that is updated less frequently is also stored in the CASA data repository, such as observatory-specific beam models, correction tables for Jy/K conversion, and files that specify the antenna array configurations for the CASA simulator.
The CASA data repository, and the runtime data therein, is necessarily updated frequently compared to the much sparser schedule by which new CASA versions are released. Operations on recently observed data may need an up-to-date data repository to work correctly. Upon starting a CASA session, it may therefore be necessary to update either the Measures tables or the entire data repository with the most recent version. Routines for handling these external data dependencies are readily available in CASA.
2.4. Parallel Processing
In order to achieve high processing speeds, CASA provides a framework to run tasks and commands in parallel using multiple cores and computing nodes (Roberts et al. 1999; Castro et al. 2017). The CASA Parallelization framework is implemented using the Message Passing Interface (MPI) standard (The MPI Forum 1993). The CASA distribution comes with a wrapper of the MPI executor called mpicasa, which configures the environment to run CASA in parallel. CASA implements parallelization both at the Python and C++ level. Calibration and manipulation tasks, as well as continuum imaging, use Python-level parallelization, while spectral cube imaging uses specific C++ level parallelization.
Imaging in CASA offers parallelization by partitioning along the time axis (for continuum imaging) or frequency axes (for spectral cube imaging), which shortens the overall execution time of gridding, deconvolution, and auto-masking. Certain parts of imaging also use multi-threading to improve performance, e.g., in Fourier transforms.
Several calibration and data-manipulation tasks can be executed in a trivially parallel mode where there is little or no dependency or need for communication between the parallel processes. So far, parallel execution of one CASA session in multiple processes has to be specifically initiated by starting the session using mpicasa instead of casa. However, it is foreseen that in the future parallel processing will become the standard way of reducing data (see Section 6).
2.5. CASA Documentation
The official CASA documentation is the online library of CASA Docs. 16 A version of CASA Docs is published with each official CASA release. CASA Docs describes in detail the functionality of the CASA software. For each task, CASA Docs provides an extensive description, as well as an overview of the parameters that are available for that specific task. The CASA Docs page with the task description and parameter overview can also be opened from within CASA with the command doc(''taskname''). CASA Docs further provides detailed background information, installation instructions, useful examples, release information, and a list of known issues. CASA Docs also includes a CASA Memo and Knowledgebase section.
We note that CASA Docs is not intended to teach users all the fundamentals of radio astronomy. For that, a number of excellent books and review articles are available (e.g., Christiansen & Hogbom 1985; Thompson et al. 1986; Clark 1995; Taylor et al. 1999; Wilson et al. 2013; Condon & Ransom 2016). There is also a comprehensive collection of online tutorials, or "CASA Guides," which provide step-by-step recipes for processing various types of data sets in CASA. 17 Various telescope teams maintain these data processing tutorials for ALMA, VLA, Australia Telescope Compart Array (ATCA; Frater et al. 1992), European VLBI Network (EVN; Zensus & Ros 2015), and CASA simulations. The CASA website 18 contains links to all the information and documentation that CASA offers, including how to download CASA.
3. Data Processing
Figure 2 shows a typical end-to-end workflow diagram for CASA data processing for radio interferometric data. In this Section, we will discuss the different stages of the data processing, including data import and export (Section 3.1), data examination and flagging (Section 3.2), calibration (Section 3.3), data manipulation (Section 3.4), imaging (Section 3.5), visualization and data analysis (Section 3.6), and simulations (Section 3.7). We will address how these stages in the data processing are handled by CASA.

Figure 2. Flow chart of the basic operations that a general user will carry out in a typical end-to-end CASA data processing session.
Download figure:
Standard image High-resolution image3.1. Data Processing I: Import and Export
For importing and exporting data, CASA can handle various file formats. The raw data from ALMA and the VLA are not recorded in an MS with CASA tables, but instead in the Astronomy Science Data Model (ASDM) format, also referred to as the ALMA Science Data Model or Science Data Model (SDM) (Viallefond 2006). The ASDM is an extension of the MS, but also contains all the observatory-specific meta-data. It is implemented in a hybrid format using "Binary Large Objects" for the bulk data and large meta-data subtables, and XML for smaller meta-data subtables. When processing ALMA or VLA data, the first step has to be the import of the (A)SDM into the CASA MS format using the task importasdm . Data from a few other telescopes and astronomical software packages can also be directly imported into a CASA MS, as can any general radio astronomy data stored in the FITS formats UVFITS and FITS-IDI (Wells et al. 1981; Pence et al. 2010; Greisen 2016, 2020).
3.2. Data Processing II: Examination and Flagging
To examine data, CASA offers a range of tasks and GUIs. Task listobs provides a summary of the contents of an MS as ASCII text. A variety of GUI-based tasks and applications permit to plot and select visibilities and meta-data, often interactively or through a scriptable interface. These include plotants , which plots the antenna positions that were used during the observations; browsetable , which permits to inspect and edit the contents of any CASA table and its meta-data; and plotms , which interactively creates diagnostic plots from MSs and calibration tables. The ms and tb tool interfaces allow the extraction of data chunks into numpy arrays, for further examination and visualization using standard Python libraries.
An important application for the visualization and selection of (u,v)-data is "flagging." The term "flagging" or "applying flags" means discarding data that should not be included in the calibration or subsequent scientific analysis, because the data is compromised by known systematic errors or technical issues that happened during observations. These could for example be data from an antenna which line-of-sight to the source was partially blocked ("shadowed") by another antenna, or data from spectral channels at the edge of the receiver band that are particularly noisy. Another important reason for flagging of (u,v)-data is radio frequency interference (RFI; Fridman & Baan 2001; Briggs & Kocz 2005; Ellingson 2005, see also Thompson et al. 2017, and references therein). RFI consists of strong, predominantly human-made radio emission from electrical equipment, such as satellites, television towers, cars, or mobile devices, which contaminates the faint radio signals from astronomical objects. RFI is often limited to well-defined ranges in frequency or time, and the corresponding visibilities can be discarded by flagging the data (e.g., Middelberg 2006; Offringa et al. 2010).
CASA offers several ways to apply flags. Besides the GUI-based applications described above, which permit easy graphical selection and flagging of a sub-set of the visibility data, there is also the all-purpose flagging task flagdata . The task flagdata relies on command-line input for manual data selection and automated algorithms to apply flags. For manual data selection, users can specify antennas, baselines, spectral windows, shadowing limits, and other parameters. In addition, flagdata includes the following automated flagging algorithms:
- 1.clip: flags visibilities associated with ranges in data values. This includes values in the meta-data, such as water vapor radiometer (WVR) or system temperature (Tsys) measurements.
- 2.tfcrop: creates time-averaged spectra of the visibility amplitudes for each field, spectral window, timerange, and baseline. It then fits a polynomial to the bandshape of each spectrum, and subsequently identifies and flags data points that deviate from this polynomial fit. tfcropis optimized for flagging strong, narrow-band RFI.
- 3.rflag: detects outliers based on sliding-window root-mean-square (rms) filters. This means that as the algorithm iterates through the data in chunks of time, it calculates statistics across the time-chunks and applies flags based on user-supplied thresholds.
Flagging does not actually delete data in the MS, but just makes entries in corresponding Boolean arrays inside the MS. A version of this FLAG column can be copied over to a CASA flag versions table, under a separate directory with the extension <msname>.flagversions. This provides backups of the flags, which can be restored to the MS from which they were created, in order to get back to a previous flag version. The CASA task flagmanager allows users to manage different versions of flags in the data.
3.3. Data Processing III: Calibration
3.3.1. Interferometric Calibration
Calibration is the process of correcting the signals measured with an interferometer or single-dish radio telescope for instrumental and environmental propagation factors that corrupted the desired astronomical signal, and transform the data from instrumental units to absolute standard units. This is necessary for making an accurate image of the sky, which can be related to images made by other telescopes and theoretical predictions. In CASA, the calibration process consists of determining a series of complex correction factors and applying these corrections to the visibility measurements of objects of scientific interest. Calibration solutions are typically derived from observations of well-characterized calibrator sources, often radio-bright and unresolved quasars for which a simple visibility model may be assumed, and occasionally solar system objects for absolute flux calibration. In cases where a source in the target-field is bright enough, calibration solutions can often also be obtained or improved through the iterative process of self-calibration, using this target source as the de facto calibrator source (e.g., Pearson & Readhead 1984; Wilkinson 1989; Cornwell & Fomalont 1999).
The MeasurementSet structure in CASA is designed to permit interferometric data to be calibrated following the Measurement Equation (Sault et al. 1996a; Hamaker et al. 1996; Noordam 1996). The Measurement Equation is based on the fact that the visibilities measured by an interferometer have been corrupted by a sequence of multiplicative factors, arising from the atmosphere, antennas, electronics, correlator, and downstream signal-processing. For visibility calibration in CASA, the general Measurement Equation (Sault et al. 1996a; Hamaker et al. 1996) can be written as:

where
V
ij
represents the observed visibility, which is a vector of complex numbers that represents the amplitude and phase of the raw correlations formed among the sampled dual-polarization wavefronts, as received by a pair of antennas (i and j) at each time sample and per spectral channel.  represents the corresponding true visibilities, in a nominally perfect polarization basis (typically either linear or circular), that are to be recovered by the calibration process, and which are proportional to combinations of the true Stokes parameters of the source visibility function (Stokes 1852). Jij
is an operator that represents an accumulation of all corruption factors affecting the correlations on baseline i − j. As written here, Jij
is a Mueller matrix for baseline i − j, formed in most cases from the outer product of a pair of (single-index) antenna-based Jones matrices, Ji
:
represents the corresponding true visibilities, in a nominally perfect polarization basis (typically either linear or circular), that are to be recovered by the calibration process, and which are proportional to combinations of the true Stokes parameters of the source visibility function (Stokes 1852). Jij
is an operator that represents an accumulation of all corruption factors affecting the correlations on baseline i − j. As written here, Jij
is a Mueller matrix for baseline i − j, formed in most cases from the outer product of a pair of (single-index) antenna-based Jones matrices, Ji
:

Each antenna-based Jones matrix, Ji , models the propagation of a signal from a radiation source through to the voltage output of antenna i, and characterizes the net effect on the resulting correlations (Jones 1941; Mueller 1948; Heiles et al. 2001). Factoring Jij in Equation (1) into the most common series of recognized effects, we have:

with the individual terms described in detail below. For just the antenna-based calibration terms, we can write:

The order of terms in Equation (4) reflects the order in which the incoming signal encounters the corrupting effects (from right to left), and in general, terms cannot be arbitrarily reordered, i.e., they do not all algebraically commute. In practice, not all terms need to be considered in all cases, and some (or even most) may be ignored depending upon their relative importance with respect to dynamic range requirements and scientific goals. In aggregate, the calibration terms in the Measurement Equation describe a net effective (imperfect) polarization basis, characterizing the departure from the ideal intended polarization basis of the instrument. The internal algebra and properties of particular calibration terms in some cases depend on the nominal basis, as will the heuristics engaged to solve for or calculate them, and thus also their implementations in CASA. However, the form of the equation as expressed here represents an approximation to the sequence of physical effects encountered by the observed wave front, and is therefore polarization basis-agnostic.
Solving for an antenna-based factor is generally an over-determined problem, since there are only Nant antenna-based factors for Nant(Nant − 1)/2 baselines, per term. The specific calibration terms recognized within the CASA calibration model are as follows:
- 1.Fi : ionospheric effects, including dispersive delay and Faraday rotation (e.g., de Gasperin et al. 2018). Most relevant at low radio frequencies (≲5 GHz), and typically estimated from information on the ionospheric total electron content.
- 2.Ti : tropospheric effects, such as opacity and path-length variations (e.g., Hinder & Ryle 1971), which stochastically affect visibility amplitude and phase, respectively, in a polarization-independent manner. Relevant at all radio frequencies, but most important at higher frequencies, where tropospheric variations set the timescale for calibration. Typically solved from the visibility data themselves, on a calibrator observed periodically near the science target. Estimates may also be obtained from water vapor radiometry (WVR; Rocken et al. 1991; Emrich et al. 2009; Maud et al. 2017).
- 3.Pi : parallactic angle rotation, which describes the orientation of the antennas' polarization in the coordinate system of the sky. Calculated analytically from observational geometry information.
- 4.Ei : effects introduced by properties of the optical components of the telescopes, including gain response as a function of elevation and the net aperture-efficiency scale.
- 5.Di : instrumental polarization response, describing the polarization leakage between feeds. This factor describes the fraction of one hand of nominally received polarization that is detected by the receptor for the other hand, and vice versa. Solved from observations on an appropriately chosen calibrator.
- 6.Gi : general time- and polarization-dependent complex gain response, including phase and amplitude variations due to the signal path between the feed and the correlator, and sometimes including tropospheric and ionospheric effects when not separately factored into Fi and Ti . Solved from the visibility data themselves (like Ti ), Gi includes the scale factor for absolute flux density calibration, by referring solutions to observations of a calibrator with known flux density. In some cases, this scale reconciliation is performed on Ti solutions.
- 7.Bi : the amplitude and phase "bandpass" response introduced by spectral filters and other components in the electronic transmission of the signal. This is effectively a frequency channel-dependent version of Gi . Usually assumed to be stable in time, Bi is solved from calibrator observations with sufficient signal-to-noise ratio per frequency channel.
- 8.Ki : general geometrically parametrized gain phases that are time- and frequency-dependent, such as delay and delay-rate. Includes antenna-position corrections and traditional fringe-fitting.
- 9.Mij : baseline-based correlator (non-closing) errors. When used with extreme care, baseline-based solutions can account for residuals not factorable as antenna-based errors, but this usually indicates a failure to fully and adequately model and calibrate more subtle antenna-based effects, such as instrumental polarization. Once invoked, subsequent antenna-based calibration cannot be further used reliably since the baseline-based term will have absorbed antenna-based information arbitrarily.
Occasionally, specializations of some of these terms are invoked for particular purposes. For example, system temperature calibration is implemented as a variation of bandpass calibration, position angle calibration is implemented as an offset to the Pi term, and cross-hand phase as an offset to the Gi term (but located in front of Di ). In general, the modular implementation of calibration terms in CASA is designed to permit such specializations, where warranted. Additional corrections, such as for direction-dependent widefield or wideband effects, can optionally be invoked during the imaging stage (see Section 3.5.3). 19
3.3.2. Calibration Methodology in CASA
In CASA, solutions for the calibration corrections can be derived using various calibration tasks and tools. The calibration solutions are then stored in separate calibration tables, in a system similar to the MeasurementSet. The most widely used tasks for deriving calibration corrections are:
- 1.gaincal : solves for time- and optionally polarization-dependent (but channel-independent) variations in the complex gains ("phases" and/or "amplitudes"), i.e., Gi and Ti . Also used to derive rudimentary delay corrections, as a variation of Ki .
- 2.bandpass : solves for frequency-dependent complex gains, i.e., Bi .
- 3.fluxscale : applies a scale factor to the Gi or Ti gain solutions from gaincal , according to the gains derived from observations of the flux-density calibrator, on the assumption that the net electronic gain is stable with time. Normally the task setjy is used to set the model visibility amplitude and phase associated with a flux density scale prior to running gaincal and fluxscale .
- 4.polcal : solves for instrumental polarization calibration factors, including leakage, cross-hand phase, and position angle corrections.
- 5.fringefit : solves for delay- and rate-parameterized gain phases for cases where uncertain array geometry and/or distinct clocks limit coherence in frequency and time, as is common in Very Long Baseline Interferometry (VLBI; e.g., Wiesemeyer & Nothnagel 2011). Also supports a dispersive delay term. The implementation of fringefit is described in detail by van Bemmel et al. (2022).
- 6.gencal : derives various calibration solutions from ancillary information stored in the MeasurementSet or otherwise specified or retrieved, including ionosphere, system temperature, antenna position corrections, opacity, gain curves, etc.
- 7.applycal : applies all specified calibration to the MeasurementSet DATA column, according to the order prescribed in the Measurement Equation (Equation (3)), and writes out the CORRECTED_DATA column for imaging.
A range of other tasks and tools for calibration support are available in CASA, including plotweather to plot weather information and estimate opacities, plotbandpass for plotting bandpass information, wvrgcal for WVR-derived gains (Nikolic et al. 2012), and blcal to derive baseline-based gains.
Solving for calibration is a generalized bootstrapping process wherein each additional solved-for component is determined relative to the best available existing information for other calibration terms and the calibrator visibility model. Initially, there may be no prior calibration available (or only a few terms derived from ancillary information), and only point-like visibility models. As new calibration is derived, it may be desirable to revise terms that were solved for earlier in the process. For example, a solution for the bandpass, Bi , may be determined with a provisional time-dependent Gi solution from the same calibrator data (but derived from only a subset of frequency channels without the benefits of a prior Bi solution), and then the Gi solution will be revised and improved using the Bi solution as a prior and all frequency channels for more sensitivity. Algebraically, the prescribed order of calibration terms (4) is respected in all solves. When all relevant calibration terms have been solved-for, their aggregate is applied (with appropriate interpolation) to calibrator and science target data for imaging and deconvolution.
Insofar as the calibration derived from calibrator observations may not precisely characterize corruptions occurring in the science target data (due to time- and direction-dependence), it is often desirable to self-calibrate against the visibility model derived from the initial imaging and deconvolution process, and then re-image to better bootstrap and converge on an optimized net calibration and source model (e.g., Pearson & Readhead 1984; Wilkinson 1989; Cornwell & Fomalont 1999). In some cases, the calibrators may not be perfect point sources, and self-calibration may be used to jointly optimize their visibility model(s), and the calibration derived from them, before proceeding to the science target. The CASA implementation for visibility calibration is designed to support this generalized self-calibration ideal for the iterated revision and convergence of all calibration terms and source model estimates. In practice, the largest benefit is obtained by iterative revision of time-dependent gains, mainly due to the troposphere, and the visibility model of the source.
3.3.3. Single Dish Calibration
The concept of single-dish calibration is different from that of an interferometer. Atmospheric variability that causes phase decoherence in interferometric data is not relevant for single-dish observations, but large-scale atmospheric fluctuations that are resolved out by interferometers yield power in single-dish telescopes. Single-dish telescopes detect and quantify signals in brightness temperature TB (Kelvin). The brightness temperature of an astronomical target can be measured through:

where TON is the on-target measurement, and TOFF is a measurement of the blank sky, taken at roughly the same elevation and time as the target measurement, but ideally absent of any target emission or contaminating sources at the frequencies of interest to the observer. The measured signal includes contributions from sky targets (for TON), cosmic background signals, atmosphere, ground, and the telescope itself, as well as noise from the instrument's electronics. Tsys is the system temperature, which is obtained through an observation of the sky together with measurements of loads with known temperatures that are placed in front of the receiver.
Typical observing modes include Position Switching, by which separate exposures are taken at discrete "ON" and "OFF" positions on the sky, or On-The-Fly mapping, where the telescope smoothly scans the field that contains the "ON" and "OFF" measurements (e.g., O'Neil 2002; Mangum et al. 2007; Sawada et al. 2008). In CASA, the calibration of single-dish data generally requires several steps, namely the application of the Tsys calibration, and of the "sky" calibration, i.e., TOFF. The T values are a function of frequency, hence calibration must be performed in the spectral domain. In addition, in the spectral domain, single-dish data rely on accurate fitting and subtraction of the spectral baseline emission.
Single-dish data in CASA rely on the same MeasurementSet as interferometric data. For single-dish calibration, various CASA tasks can be used that are also suitable for interferometry, such as listobs , flagdata , gencal , and applycal . In addition, a number of dedicated single-dish tasks are available in CASA, including sdcal for calibration, sdgaincal for removing time-dependent gain variations, and sdbaseline for fitting and subtracting a baseline from single-dish spectra.
3.4. Data Processing IV: Data Manipulation
CASA contains a number of tasks that allow manipulation of visibility data. This includes tasks to concatenate, average, split, weight, or regrid data in various ways (e.g., concat , split , statwt , and cvel ), as well as dedicated tasks for Hanning smoothing ( hanningsmooth ), continuum subtraction ( uvcontsub ), model subtraction ( uvsub ), correcting the astronomical positions of targets ( fixplanets ), or shifting the interferometric phase center ( phaseshift ). While historically each step in the manipulation of visibility data was done by individual tasks, currently the multi-purpose task mstransform combines most of the above mentioned functionality, with the possibility of applying each of these transformations separately or together in an in-memory pipeline, thus avoiding unnecessary input/output (I/O) steps. Most of the manipulation of visibility data is done after calibration, but before imaging.
3.5. Data Processing V: Imaging and Deconvolution
3.5.1. Interferometric Imaging
Image reconstruction in radio interferometry (Readhead & Wilkinson 1978; Sramek & Schwab 1989; Cornwell 1995; Frey & Mosoni 2009; Rau et al. 2009) is the process of solving the linear system of equations:

where V TRUE represents visibilities that have been calibrated for direction independent effects through applycal , using the solutions from Equation (3). I is a list of parameters that model the sky brightness distribution, such as an image consisting of pixels. [A] is a measurement operator that encodes the process of how visibilities are generated when a telescope observes a sky brightness I , and is generally given by [Sdd ][F], such that

where [F] represents a 2D Fourier transform (Fourier 1878; Bracewell 2000) and [Sdd ] represents a 2D spatial frequency sampling function that can include direction-dependent instrumental effects. An interferometer has a finite number of array elements, which means that [A] is not invertible because of unsampled regions of the (u, v)-plane. Therefore, this system of equations must be solved iteratively, applying constraints via various choices of image parameterizations and instrumental models.
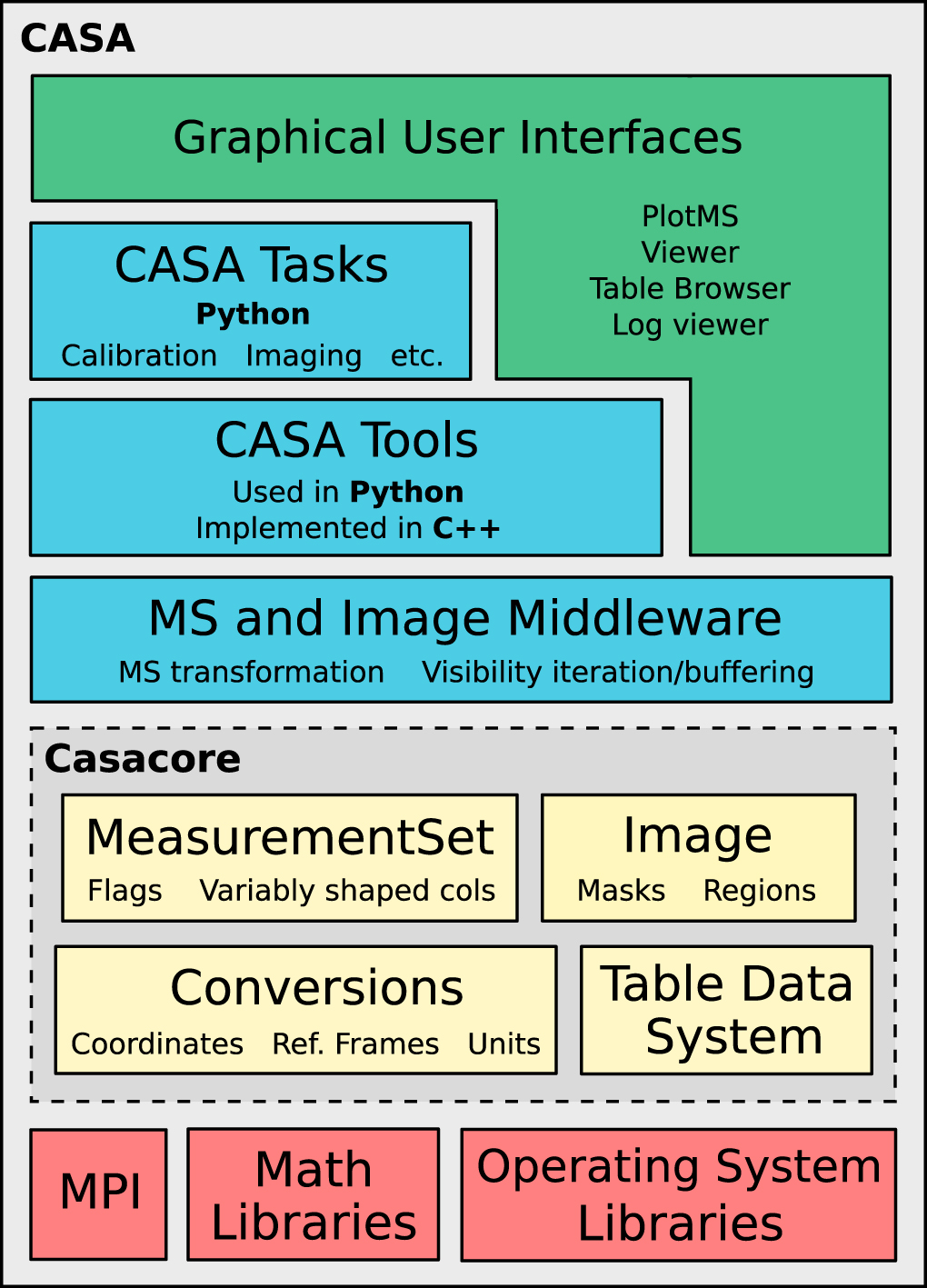
In CASA, this interferometric imaging process consists of converting a list of calibrated visibilities into a raw image, also called a "dirty" image, then "cleaning" this image to obtain an estimate of the true sky model by iterating through a few χ2 minimization steps that evaluate the goodness of fit of the current model with respect to the visibilities, and subsequently constructing the final image product. Under ideal conditions, the dirty image is the true sky brightness convolved with the point-spread-function (PSF) of the instrument and added noise terms (Figure 3). The PSF typically has a complex shape determined by the (u, v)-coverage and interference pattern of the—often sparsely populated—distribution of antennas in the interferometer. Moreover, in reality, the dirty image is based only on the visibilities that are sampled by the interferometer, hence it does not contain the complete information about the true sky brightness distribution. There are several stages to forming a dirty image from interferometric data, including weighting, convolutional resampling, Fourier transformation, and normalization. To obtain the final "clean" image of the source, a model of the true sky brightness distribution is reconstructed from the dirty image and the PSF in a process called "deconvolution" (Cornwell & Braun 1989), and subsequently convolved with a Gaussian that represents the instrumental resolution specified by the main lobe of the PSF. In this Section, we explain those concepts of imaging, weighting, gridding, and deconvolution that are most sensitive to parameters that need to be specified by users in CASA. This includes an overview of how deconvolution and image restoration is implemented in the CASA imaging task tclean .

Figure 3. Convolution of the sky brightness distribution (left) with the instrumental point-spread-function (middle) results in the "dirty" image (right). This example is based on simulated VLA data.
Download figure:
Standard image High-resolution image3.5.2. Weighting Schemes
As part of the imaging process, the visibilities can be weighted in different ways to alter the instrument's natural response function, affecting resolution, sidelobe suppression, and root-mean-square (rms) noise levels. There are three main weighting schemes for radio interferometric data: natural, uniform, and Briggs (robust) weighting (Briggs 1995).
- 1.natural weighting: the data are gridded into (u, v)-cells for imaging, with weights given by the visibility weights in the MeasurementSet. This results in a higher imaging weight for higher (u, v)-density. Natural weighting produces an image with the lowest noise, but often with lower than optimal resolution.
- 2.uniform weighting: the data are first gridded to a number of cells in the (u, v)-plane, and afterwards the (u, v)-cells are re-weighted to have uniform imaging weights. Uniform weighting produces an image with higher resolution, but which has increased noise compared to natural or briggs weighting. Also available in CASA is the option of superuniform weighting, which increases the number of cells to define the (u, v)-plane patch for the weighting renormalization, and by doing so further increases the resolution and noise.
- 3.briggs (robust) weighting: this is a flexible weighting scheme that provides a trade-off between resolution and sensitivity (Briggs 1995). It uses a robustness parameter that takes values between −2.0 (close to uniform weighting) and 2.0 (close to natural weighting). CASA also includes two modified versions of the Briggs weighting scheme, named briggsabs and briggsbwtaper.
- 4.uvtaper: optionally, a multiplicative Gaussian taper can be applied to the spatial frequency grid, in addition to any of the above options. This effectively downweights the longer baselines, decreasing the resolution compared to the original weighting scheme it is applied on top of, and increasing surface brightness sensitivity.
3.5.3. Imaging Mode and Gridding
After visibilities are properly weighted, the next steps in the imaging process of interferometric data consists of gridding, Fourier transformation (Fourier 1878; Bracewell 2000), and normalization of the data. Imaging weights and weighted visibilities are first resampled using gridding convolution functions onto a regular (u, v)-grid in a process called convolutional resampling (Brouw 1975). The result is Fourier-inverted using a fast-Fourier transformation, and subsequently grid-corrected to remove the image-domain effect of the gridding convolution function.
In CASA, the type and shape of the image product is determined by various parameters, including data selection, definition of the spectral mode, and the gridder algorithm. Image products can be continuum images, spectral cubes, or Stokes images, while multiple pointings can be captured into a mosaic image. The standard gridding in CASA relies on prolate spheroidal functions, along with image-domain operators to correct for direction-dependent effects. More sophisticated gridder modes can apply direction-dependent, time-variable and baseline-dependent corrections during gridding in the visibility-domain, by computing the appropriate gridding convolution kernel to use along with the imaging-weights. These gridder modes are superior for certain data sets, like widefield and wideband data, but are more computationally intensive.
Typical imaging modes in CASA include:
- 1.mfs, multi-frequency synthesis imaging: standard continuum imaging, where selected data channels across a (wide) range in frequencies are mapped onto a single wideband image (Conway et al. 1990).
- 2.cube imaging: Standard imaging of spectral lines, where selected data channels are mapped to a number of image channels using various interpolation schemes. Optionally, the image cube can be corrected for Doppler effects and ephemeris tracking.
- 3.
- 4.mosaic imaging: continuum or spectral-line imaging of observations that consist of multiple pointings, producing fields-of-view larger than the primary beam. Options for stitched and joint mosaics are available (e.g., Ekers & Rots 1979; Cornwell 1988; Bremer 1994; Condon et al. 1994; Sault et al. 1996b).
- 5.
- 6.imaging multiple (outlier) fields: large fields imaged as a main field plus multiple (smaller) outlier fields, rather than visibility data being gridded onto one large (u, v)-grid.
- 7.correction for widefield and wideband instrumental effects: high dynamic range imaging of data with a large field-of-view and large fractional bandwidth, by accounting for a number of widefield and wideband effects during gridding. These effects include sky curvature, non-coplanar baselines (Cornwell & Perley 1992), and antenna-based aperture illumination functions that change with time, frequency, and polarization (Sekhar et al.2019).
A-Projection is an example of an advanced gridding algorithm in CASA, which can correct for complex widefield (Bhatnagar et al. 2008) and wideband (Bhatnagar et al. 2013) effects (see also Tasse et al. 2013). This can be critical for sensitive widefield continuum observations, for example those performed using the lower frequency bands of the VLA (e.g., Rau et al. 2016; Schinzel et al. 2019). The aperture illumination function results in a direction-dependent complex gain that causes the primary beam to vary with time, frequency, polarization, and antenna (Jagannathan et al. 2018; Sekhar et al. 2019). These variations may be caused by pointing errors, feed leg structures that break azimuthal symmetry, parallactic angle rotation, and varying dish sizes. These variations in the primary beam are corrected during the gridding using the wideband A-Projection algorithm, which computes gridding convolution functions for each baseline as the convolution of the complex conjugates of two antenna aperture illumination functions (Bhatnagar et al. 2013). In addition, sky curvature and non-coplanar baselines result in a so-called w-term that is not zero, which means that standard 2D imaging applied to such data will produce artifacts around sources away from the phase center. A W-Projection algorithm corrects for the effects introduced by the w-term, using gridding convolution functions that are computed based on the Fourier transform of the Fresnel electro-magnetic wave propagator for a finite set of w-values (Cornwell et al. 2008). The wproject, mosaic, and awproject gridding options implement different approximations and combinations of the A- and W-Projection algorithms.
3.5.4. Deconvolution and Image Reconstruction
Deconvolution refers to the process of reconstructing a model of the sky brightness distribution, given a dirty image and the PSF of the instrument. This process is called deconvolution, because under ideal conditions, the dirty image can be written as the result of a convolution of the true sky brightness and the PSF of the instrument (Figure 3). The concept of deconvolution is a widely used technique in signal and image processing, and explaining the fundamentals is beyond the scope of the current paper (see Cornwell & Braun 1989). Instead, we will give an overview of how the technique of deconvolution and image reconstruction is practically implemented in CASA through the task tclean .
Tclean, CASA's powerful imaging task—The CASA task used for imaging is tclean , which is based on the CLEAN algorithm (Högbom 1974; Schwarz 1978). The tclean task takes the calibrated visibilities from the MS and applies weighting, sampling, Fourier transformation, deconvolution, and image restoration according to inputs specified by the user or pipeline. The output of tclean is a reconstructed image of the astronomical source. In addition, tclean by default also produces various other images that may be useful for subsequent processing or analysis, including images of the derived sky model and residuals, instrumental PSF, primary beam response, and sum of the data weights.
Image reconstruction in CASA follows the CLEAN method by Cotton & Schwab (see Schwab 1984), which consists of an outer loop of major cycles and an inner loop of minor cycles (Figure 4). The major cycle implements transforms between the visibility data and image domain, while the minor cycle represents the deconvolution step that operates purely in the image domain. This method implements an iterative weighted χ2 minimization that solves the measurement equation, but allows for a practical trade-off between the efficiency of operating in the image domain and the accuracy that comes from frequently returning to the ungridded list of visibilities. It also allows for minor cycle algorithms to have their own internal optimization scheme.
{kind=link}
{kind=link}
{kind=link}
Figure 4. Schematic overview of the iterative image reconstruction in the CASA task tclean . The left (red) and right (green) boxes show the major and minor cycle, respectively. After gridding the visibilities and applying an inverse fast Fourier transform (iFFT), deconvolution on the (residual) image is done in the minor cycle. At the end of the minor cycle, the model image is translated back into the (u, v)-domain with a fast Fourier transform (FFT), where it is subtracted from the visibility data at the start of the next major cycle.
Download figure:
Standard image High-resolution image{kind=link}
The minor cycle performs the deconvolution step by separating sky emission from the PSF and building up a model of the true sky brightness distribution. Different algorithms are available in CASA to identify flux components that are to be included in the sky model. These are hogbom, clark, and clarkstokes, which all identify model-components as delta-functions (Högbom 1974; Clark 1980); mem, which is based on the Maximum Entropy Method (Cornwell & Evans 1985); multiscale, which assigns model components at different spatial scales and is useful for images that include extended emission (Cornwell 2008); asp, which is an Adaptive-Scale Pixel algorithm for more flexible multi-scale source modeling (Bhatnagar & Cornwell 2004); and mtmfs or Multi-Term (Multi-Scale) Multi-Frequency Synthesis, which is a multi-scale and multi-term cleaning algorithm optimized for wideband imaging (Rau & Cornwell 2011). Deconvolution begins with a residual image that includes the astronomical signal, PSF, and noise. In this residual image, model components are identified using one of the above algorithms. After the algorithm identifies a model component, the model is updated accordingly and the effect of the PSF is removed by subtracting a scaled PSF from the image at the location of each component. Many such iterations of finding peaks and subtracting PSFs form the minor cycle (Figure 4). This deconvolution step can be performed for the whole image, or across regions of the image as defined with a mask. At the start of the next major cycle, the model of the sky brightness that is derived during the minor cycle is evaluated against the measurement equation and converted into a predicted list of model visibilities, which are then subtracted from the data to form a new residual image.
During the major cycle, a pseudo inverse of [Sdd ][F] is computed and applied to the visibilities. Operationally, weighted visibilities are convolutionally resampled onto a grid of spatial-frequency cells, inverse Fourier transformed, and normalized via user-specified inputs. The accuracy and efficiency of the image reconstruction depends on the algorithms chosen for [Sdd ] and [F], and direction-dependent instrumental effects can be accounted for via carefully constructed convolution functions in CASA (see Section 3.5.3).
Image deconvolution, and the corresponding sequence of major and minor cycles, continues until a user-specified threshold criterion has been reached across the selected region. This threshold can be specified based on a cutoff level or number of interactions, optionally combined with a mask. Such a mask can be constructed a-priori by the user, iteratively after each major cycle, or determined automatically using the auto-multithresh algorithm. The auto-multithresh option evaluates the noise and sidelobe thresholds in the residual image to set an initial mask at the start of each minor cycle and then cascades that mask down to lower signal-to-noise, taking into account the fundamental properties of the image (Kepley et al. 2020).
After deconvolution, the output sky model is restored by a Gaussian function that represents the instrumental resolution specified by the PSF main lobe, but without the sidelobes. This results in a cleaned image of the sky.
The final image can optionally be corrected for the response of the primary beam of the telescope, in case this has not already been done during the gridding stage. This will provide true values of the flux density throughout the field-of-view. Options for wideband primary-beam correction are included within the mosaic and awproject gridders.
3.5.5. Single Dish Imaging
Converting single-dish observations into an image or cube is done almost entirely in the image domain. The single-dish data should be calibrated, according to the process described in Section 3.3.3. The CASA task tsdimaging then converts the single-dish observations into an image or cube by forming and populating the image grid. The convolution kernels that can be used for gridding the image in CASA consist of a boxcar function, Gaussian function, primary beam function, prolate spheroidal wave function, and Gaussian-tapered Bessel function (Mangum et al. 2007). The tsdimaging task by default chooses reasonable values for parameters like pixel size, image dimensions, and spectral resolution, but all these can be adjusted manually in CASA.
3.5.6. Image Combination
Combining interferometric with single-dish data allows for reconstructing the flux of the astronomical source on all spatial scales, including extended emission that is resolved out even by the shortest baselines of the interferometer. Techniques that rely on joint deconvolution (Cornwell 1988; Sault et al. 1996b), either in the image domain (Stanimirovic et al. 1999; Stanimirovic 2002; Pety & Rodríguez-Fernández 2010; Junklewitz et al. 2016; Rau et al. 2019) or in the visibility domain (Kurono et al. 2009; Koda et al. 2011, 2019; Teuben 2019), have been shown to be fruitful for combining single-dish and interferometric data.
CASA contains a dedicated joint deconvolution algorithm for wideband multi-term and mosaic imaging, captured in the CASA task sdintimaging (Rau et al. 2019). Interferometer data are gridded into an image cube and corresponding PSF. The single dish image and PSF cubes are combined with the interferometer cubes in a feathering step (Cotton 2017). This feathering step is based on the CASA task feather , which Fourier transforms the single-dish and interferometric images to a gridded visibility plane and weights them by their spatial frequency response. The joint image and PSF cubes then form inputs to any deconvolution algorithm, be it multi-channel (cube), multi-frequency synthesis (mfs), or multi-term mfs (mtmfs) mode. Model images from the deconvolution algorithm are translated back to model image cubes prior to subtraction from both the single dish image cube and the interferometer data to form a new pair of residual image cubes to be feathered in the next iteration. In the case of wideband mosaic imaging, wideband primary beam corrections are always performed per channel of the image cube, followed by a multiplication by a common primary beam, prior to deconvolution.
The sdintimaging task supports joint deconvolution for spectral cubes as well as multi-term wideband imaging, operates on single pointings as well as joint mosaics, includes corrections for frequency dependent primary beams, and optionally allows the deconvolution of only single-dish images in both cube and (multi-term) mfs mode. An option has also been provided to tune the relative weighting of the single dish and interferometer data alongside the standard weighting schemes used for interferometric imaging.
3.6. Data Processing VI: Analysis and Visualization
CASA also offers a suite of features, mostly in the form of Graphical User Interfaces (GUIs), for the visualization and analysis of radio astronomical data. Various GUIs are available to inspect the raw data and meta-data from the telescopes, including browsetable to display CASA tables, plotants to plot the antenna positions, and plotms to visualize the visibility data (see Section 3.2).
An new tool for visualizing image products is the Cube Analysis and Rendering Tool for Astronomy (CARTA; Comrie et al. 2021), 20 which is an external image visualization and analysis software designed for ALMA, the VLA, and pathfinder telescopes for the Square Kilometre Array (SKA; Lazio 2009). CARTA is developed by a consortium of the Academia Sinica Institute of Astronomy and Astrophysics (ASIAA), the South African Inter-University Institute for Data Intensive Astronomy (IDIA), the National Radio Astronomy Observatory (NRAO), and the Department of Physics at the University of Alberta. CARTA is being developed bearing in mind the increasing demands of next-generation radio telescopes, and will be a standard visualization tool that can be used for data processed with CASA.
3.7. Data Processing VII: Simulations
The capability of simulating observations and data sets from the VLA, ALMA, and other existing and future observatories is an important use-case for CASA. This not only gives users a better understanding of the scientific capabilities and expected output of these telescopes, but also provides benchmarks to test the performance, optimization, and reproducibility of the CASA software. CASA can create simulated MeasurementSets for any interferometric array. For a large number of interferometers, array configuration files of the antenna distributions are readily available in CASA. The tasks available for simulating observations in CASA are:
- 1.simobserve: create simulated MeasurementSets for an interferometric or total power observation with a specific telescope.
- 2.simanalyze: image and analyze simulated MeasurementSet data, including diagnostic images and plots.
- 3.simalma: streamlined combination of simobserve and simanalyze for ALMA data. The simalma task can simulate ALMA observations in one go, including multiple configurations of the main 12 m interferometric array, the 7 m Atacama Compact Array (ACA; Iguchi et al. 2009), and total power measurements.
In addition to these simulation tasks, the simulator methods as part of the CASA tools allow for even greater flexibility and functionality, especially for non-ALMA use-cases. For example, the simulator tools can be used to calculate and apply calibration tables that represent some of the most important corrupting factors, such as atmospheric and instrumental effects.
3.8. Very Long Baseline Interferometry
CASA can also process Very Long Baseline Interferometry (VLBI) data (e.g., Wiesemeyer & Nothnagel 2011), including data from the Very Long Baseline Array (VLBA; Kellermann & Thompson 1985) and European VLBI Network (EVN; Zensus & Ros 2015). The CASA package contains the VLBI-specific tasks fringefit and accor (van Bemmel et al. 2019). The fringefit task determines phase, delay, delay-rate, and optionally dispersive delay solutions, as a function of time and spectral window. This enables correcting the visibility phases for errors introduced by the atmosphere, the signal paths of the instrument, or other pre-calibration factors. The accor task determines the amplitude corrections from the apparent normalization of the mean autocorrelation spectra. This corrects for errors in sampler thresholds during an observation, as caused by the DiFX correlator used by the VLBA (Napier et al. 1994). In addition to fringefit and accor , other tasks that are used for processing normal interferometric data can also handle VLBI data.
Externally, Janssen et al. (2019) built the first generic VLBI calibration and imaging pipeline on top of CASA. This rPICARD VLBI pipeline formed a critical component in the processing of data from the Event Horizon Telescope, which resulted in the first image of a black hole (e.g., Event Horizon Telescope Collaboration et al. 2019a, 2019b; Janssen et al. 2019).
VLBI development for CASA is being led by JIVE in collaboration with NRAO, and is an ongoing effort. The VLBI-specific tools, tasks, and their operation are described in detail in a CASA-VLBI paper by van Bemmel et al. (2022), which complements this current CASA paper.
3.9. Algorithm Research and Development
The features and algorithms within CASA are continually improved as use-cases and needs evolve. Algorithm Research and Development (R&D) is performed in conjunction with the NRAO Algorithm R&D Group, with scientific staff engaged in telescope and pipeline operations, and within the CASA development team. Algorithms that are expected to be incorporated into CASA in the next few years include a wideband version of the Adaptive Scale Pixel (ASP) deconvolution algorithm (Bhatnagar & Cornwell 2004; Hsieh & Bhatnagar 2021), Full Mueller imaging for wide bandwidths (Jagannathan 2018), an automated flagging algorithm based on binning of the (u, v)-data, and a Graphics Processing Unit (GPU) implementation of the widefield A-Projection algorithm (Pokorny 2021).
The CASA team is also developing a new set of GUIs for examining, processing, and simulating data in CASA. Such new GUIs will allow for better integration in Python, and offer usability within Notebook environments (Kluyver et al. 2016).
4. ALMA and VLA Pipelines
One of the core aspects of CASA development is to support various pipelines for the operation of ALMA and the VLA. ALMA maintains both a calibration and an imaging pipeline, which are built on top of CASA (T. Hunter et al. 2022, in preparation; see also Muders et al. 2014; Geers et al. 2019; Masters et al. 2020). These ALMA pipelines are used for automated and customized processing of ALMA data. Different versions of these pipelines are maintained by NRAO for processing data from the VLA and VLA Sky Survey (Kent et al. 2020), as well as the Science Ready Data Products program (Lacy et al. 2020). The pipelines use standard CASA tasks and tool methods, as well as custom-made pipeline tasks and analysis utilities. The ALMA and VLA pipelines, and associated pipeline tasks, are bundled only with select versions of CASA.
CASA also supports the pipeline for processing single-dish data from the Nobeyama 45 m telescope obtained in On-The-Fly observing mode. In addition, the flexibility of the CASA software also allows for creation of custom build tasks and external pipelines, such as the VLBI pipelines mentioned in Section 3.8.
5. Development Process
CASA's development planning is done in conjunction with a stakeholder group containing representatives from current NRAO and ALMA telescopes, pipeline-enabled projects and external users. VLBI and Single-Dish stakeholder inputs are coordinated via our partner developer teams and included in our overall development plans. Stakeholder priorities are then balanced with needs for software maintenance and evolution to prioritize work on a half-yearly timescale, while CASA puts out regular releases on a few-month cadence.
For each feature that is added, standard software development practices are employed, starting with the definition of requirements and specifications prior to development, and ending with internal verification and external validation stages. Verification tests include functional and unit tests written against specifications and aimed at code and interface coverage. We also maintain stakeholder-verification tests targeted toward specific dominant usage modes (i.e., operational pipelines) and are developing performance and benchmarks test-suites. Validation is typically done by external science staff and evaluates applicability to stakeholder use-cases. Some numerical or algorithmic features undergo additional detailed characterization, either by the development team or by external testers, to assess the effectiveness of the implementation for the intended use-cases.
6. Next-Generation CASA
With the massive increase in data rates and volumes that are expected in the era of the next-generation radio telescopes, such as the next-generation VLA (ngVLA; Murphy et al. 2018) and ALMA wideband sensitivity upgrade (Brogan 2019), a next-generation of data processing software needs to be efficient and easily scalable to large computing environments. A design phase has started for a next-generation CASA software, built on top of CASA's next-generation infrastructure. This next-generation CASA is aimed at reducing code complexity and development time, while at the same time increasing reliability, flexibility, and scalability. A prototype implementation of the CASA next-generation infrastructure, currently referred to as CNGI, 21 uses the Zarr storage system (Miles et al. 2020), the Xarray API (Hoyer & Hamman 2017) and the Dask parallel processing framework (Dask Development Team 2016).
7. Conclusions
The Common Astronomy Software Applications (CASA) is a versatile software package for the calibration, imaging, and analysis of data from ALMA, the VLA, and other radio telescopes. CASA aims at maintaining full functionality for the processing of astronomical data produced by aperture-synthesis arrays and single-dish radio telescopes. With comprehensive documentation and a stakeholder-based development process, CASA serves the astronomical community as a leading software for the processing of radio data. With its core aspect of supporting pipelines, and its initiative of developing a modernized software infrastructure to address increasing data rates and scalability, CASA will continue to meet the challenges of handling the ever-increasing complexity of data produced by current and next-generation radio telescopes.
The CASA team is indebted to all our colleagues who have previously been associated with and contributed to the CASA project, and we thank them for their dedicated work over the years. CASA is being developed by an international consortium of scientists and software engineers based at the National Radio Astronomy Observatory (NRAO), the European Southern Observatory (ESO), the National Astronomical Observatory of Japan (NAOJ), and the Joint Institute for VLBI European Research Infrastructure Consortium (JIV-ERIC), under the guidance of NRAO. The CASA team acknowledges its international partners the Academia Sinica Institute of Astronomy and Astrophysics (ASIAA), the CSIRO division for Astronomy and Space Science (CASS), the Netherlands Institute for Radio Astronomy (ASTRON), the Inter-University Institute for Data Intensive Astronomy (IDIA), and the University of Alberta for 3rd-party software (CARTA/Casacore) that CASA both uses and contributes too. We also thank our colleagues at the ALMA, VLA, VLASS, SRDP, and Nobeyama pipeline development teams and science working groups, the ALMA regional centers, and the VLA, VLBA, and Nobeyama instrument teams for their valuable help with code validation, quality control, and user support. The CASA Team is indebted to NRAO's Scientific Computing Group lead by James Robnett, and thankful for IT support by the Computing & Information Services group. We are also grateful for the feedback from the CASA Users Committee and other stakeholders in support of the CASA project. Finally, we sincerely thank the anonymous referee for valuable suggestions that improved this paper. The National Radio Astronomy Observatory is a facility of the National Science Foundation operated under cooperative agreement by Associated Universities, Inc. ALMA is a partnership of ESO (representing its member states), NSF (USA) and NINS (Japan), together with NRC (Canada), MOST and ASIAA (Taiwan), and KASI (Republic of Korea), in cooperation with the Republic of Chile. The Joint ALMA Observatory is operated by ESO, AUI/NRAO and NAOJ. The European VLBI Network is a joint facility of independent European, African, Asian, and North American radio astronomy institutes. This work is supported by the ERC Synergy Grant "BlackHoleCam: Imaging the Event Horizon of Black Holes" (grant 610058). S.S. acknowledges financial support from the Inter-University Institute for Data Intensive Astronomy (IDIA). IDIA is a partnership of the University of Cape Town, the University of Pretoria, the University of the Western Cape and the South African Radio astronomy Observatory.
Software: CASA (https://casadocs.readthedocs.io), Casacore (Casacore Team 2019), CARTA (Comrie et al. 2021), AIPS (Greisen 2003), AIPS++ (McMullin et al. 2006), Python (van Rossum 1995), IPython (Perez & Granger 2007), C++ (Stroustrup 1997), Fortran (Backus et al. 1956).
Footnotes
- 9
- 10
Initial members also included the National Centre for Radio Astrophysics (NCRA) in India and Canada's Herzberg Institute of Astrophysics (HIA).
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21