
Abstract
Quantum computers have the potential to outperform classical computers in a range of computational tasks, such as prime factorisation and unstructured searching. However, real-world quantum computers are subject to noise. Quantifying noise is of vital importance, since it is often the dominant factor preventing the successful realisation of advanced quantum computations. Here we propose and demonstrate an interleaved randomised benchmarking protocol for measurement-based quantum computers that can be used to estimate the fidelity of any single-qubit measurement-based gate. We tested the protocol on IBM superconducting quantum processors by estimating the fidelity of the Hadamard and T gates—a universal single-qubit gate set. Measurements were performed on entangled cluster states of up to 31 qubits. Our estimated gate fidelities show good agreement with those calculated from quantum process tomography. By artificially increasing noise, we were able to show that our protocol detects large noise variations in different implementations of a gate.
Export citation and abstract BibTeX RIS

Content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Quantum computers employ the non-classical features of quantum mechanics, such as superposition and entanglement, to substantially speed up certain computational tasks such as prime factorisation [1], unstructured searching [2], simulating many body systems [3], machine learning [4] and combinatorial optimisation [5]. In the circuit model, quantum computing is performed by explicitly applying unitary operations (or gates) from a universal set [6, 7]. Measurement-based quantum computing is a competing model, where the entire computation is carried out by performing adaptive single-qubit measurements on an entangled resource state [8–11]. Hence, provided that the entangled resource state can be generated, quantum computing can be reduced to performing single-qubit measurements and multi-qubit entangling operations do not need to be performed on demand. This is highly advantageous in linear optical systems [12–14], where these entangling operations cannot be performed deterministically. Measurement-based quantum computing also has benefits in physical systems such as superconducting systems [15], cold atoms [16] and quantum dots [17], where the entangled resource state is easy to generate, since the qubits to be entangled are spatially close to each other. In our work, we focus on measurement-based quantum computing and the benchmarking of quantum gates in this model.
Irrespective of the quantum computing model or the physical system used, however, experimental realisations of quantum computers are subject to noise. Characterising the noise is important, since noise is often the dominant factor preventing the successful realisation of advanced quantum algorithms on near-term quantum computers [18–20]. A complete characterisation of errors on a quantum computer can be obtained by performing quantum process tomography for all its elementary operations (or hardware implemented gates) and calculating the associated gate fidelities [21–24]. However, this is very resource intensive, since the number of experiments that need to be performed grows exponentially with the number of qubits. This method also requires that state preparation and measurement errors are negligible, which is rarely the case in current hardware. Randomised benchmarking, which provides a partial characterisation of errors, avoids both these problems [25].
Standard randomised benchmarking can be used to estimate the average gate fidelity of a set of gates on a quantum computer (usually the Clifford group or a subset thereof) [26–37]. Interleaved randomised benchmarking can be used to estimate the fidelity of individual Clifford gates [38–40]. Special interleaved randomised benchmarking protocols for estimating the fidelity of non-Clifford gates such as the T gate have been proposed [41, 42]. Since the Clifford gates together with the T gate form a universal set, these protocols enable fidelity estimation of individual gates from a universal set.
Both standard and interleaved randomised benchmarking have been implemented in a great variety of physical systems. These include trapped ions [34, 39, 43], superconducting systems [38, 44–47], nuclear magnetic resonance quantum processors [48], cold atoms [49, 50] and quantum dots [51]. Several variations of randomised benchmarking have also recently been demonstrated in trapped ions [52] and superconducting systems [53, 54].
Simple adaptations of standard randomised benchmarking have been suggested for measurement-based quantum computers [55]. In this paper we expand on the work of [55] and propose an interleaved randomised benchmarking protocol for measurement-based quantum computers. In our measurement-based interleaved randomised benchmarking protocol, any single-qubit measurement-based 2-design can be used to estimate the fidelity of any single-qubit measurement-based gate. We test our protocol by using the approximate measurement-based 2-design proposed and studied in our previous work [56] to estimate the fidelity of the Hadamard gate and the T gate on remotely accessible IBM superconducting quantum computers [57]. Even though IBM quantum computers are primarily optimised for quantum computing in the circuit model, a variety of measurement-based protocols have been successfully implemented on these systems [20, 56, 58]. The IBM quantum computers were chosen for our experiments, since systems optimised for quantum computing in the measurement-based model, such as PsiQuantum's photonic systems, are not readily accessible and other cloud-based systems optimised for the circuit model, such as IonQ's trapped ions, had too few qubits to prepare the large entangled resource states required for our protocol at the time of starting the experiments.
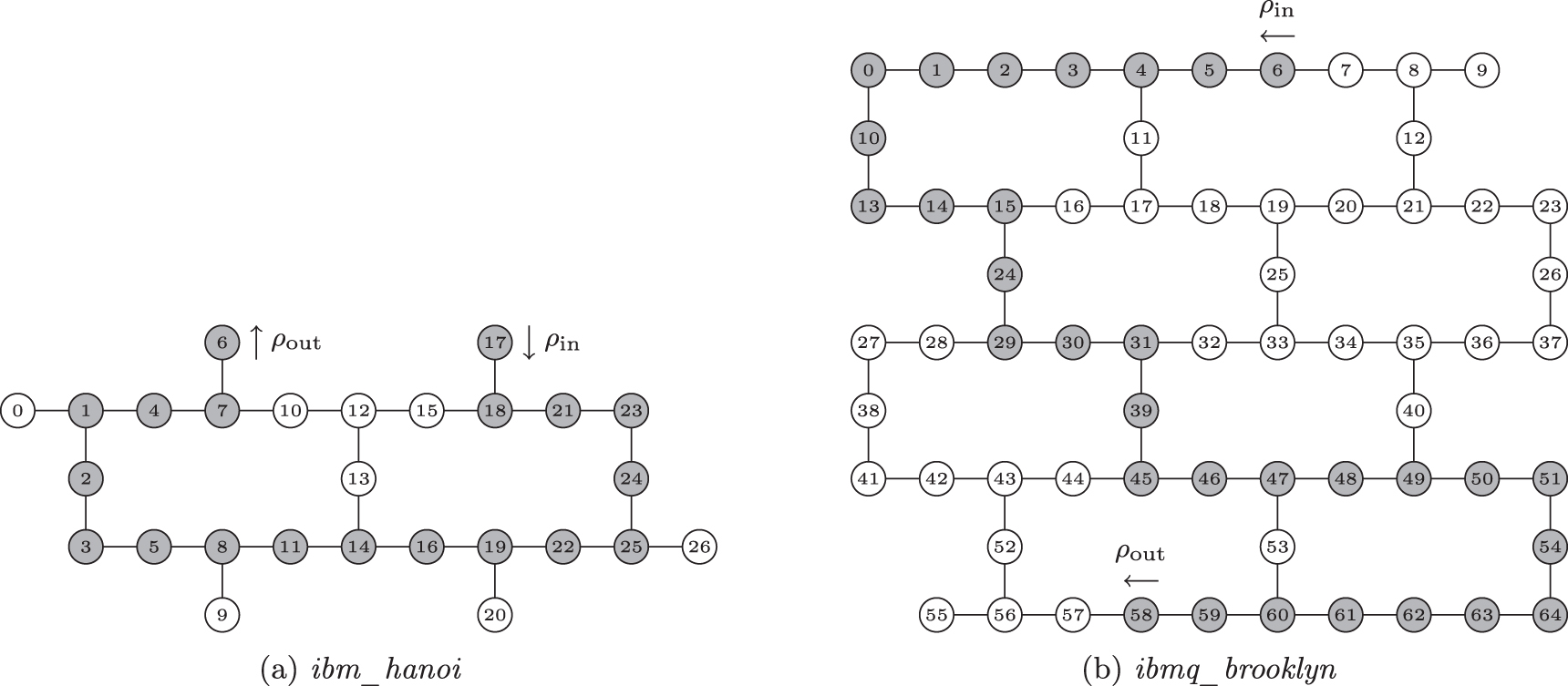
Since the Hadamard gate and the T gate form a universal single-qubit set [59], our experiments provide a proof-of-concept demonstration of fidelity estimation of measurement-based gates from a universal single-qubit set. In our demonstration, we use entangled resource states of up to 19 qubits on the ibm_hanoi quantum processor (see figure 1(a)) and entangled resource states of up to 31 qubits on the ibmq_brooklyn quantum processor (see figure 1(b)). In our previous work [56], in which we implemented single-qubit measurement-based t-designs on IBM processors, the implementations were not tested on any application and the entangled resource states used did not exceed six qubits. This work therefore demonstrates significant progress in practical quantum computing on superconducting systems in the measurement-based model.

Figure 1. Qubit topologies of the processors used in our demonstration, with the qubits used shaded grey.
Download figure:
Standard image High-resolution imageIn all the experiments, estimated gate fidelities show good agreement with gate fidelities calculated from process tomography results. Our study highlights the usefulness of IBM quantum processors for single-qubit measurement-based quantum computing and shows how to practically characterise noisy quantum logic gates in this setting. The results of our work contribute to the ongoing goal of building up to advanced multi-qubit quantum computing on noisy intermediate scale quantum processors using the measurement-based model.
Our paper is structured as follows. In section 2, we summarise single-qubit measurement-based quantum computing, single-qubit measurement-based t-designs and interleaved randomised benchmarking. In section 3, we present our measurement-based interleaved randomised benchmarking protocol. In section 4, we discuss adjustments to the protocol that are required for implementation on the IBM quantum processors. A description of the experiments performed and the results obtained is presented in section 5. A summary of the work and concluding remarks are given in section 6. Supplementary material is included, in which further details about the experiments are given.
2. Background
2.1. Measurement-based quantum computing
In the measurement-based model, quantum computing is realised by performing adaptive single-qubit measurements on an entangled resource state such as the cluster state [8–11]. In particular, 2D cluster states are entangled resource states for universal quantum computing [10] and fault-tolerant quantum computing can be achieved using 3D cluster states [60]. Here we concentrate on linear cluster states, which are entangled resource states for single-qubit measurement-based quantum computing [61]. A n-qubit linear cluster state is prepared on a linear array of n qubits by preparing each qubit in the state  and then applying controlled phase gates CZ = diag(1, 1, 1, − 1) between neighbouring qubits.
and then applying controlled phase gates CZ = diag(1, 1, 1, − 1) between neighbouring qubits.
We briefly summarise measurement-based processing with linear cluster states [56]. The measurement-based protocol for implementing unitary operations with a n-qubit linear cluster state is illustrated in figure 2. The first qubit is prepared in the input state,  , to which the implemented unitary operation is to be applied. The remaining qubits are prepared in the state
, to which the implemented unitary operation is to be applied. The remaining qubits are prepared in the state  (Step 1), and qubits are then entangled by applying controlled phase gates between neighbouring qubits (Step 2). Each qubit i ∈ {1,...,n − 1} is then measured at an angle ϕi
in the Pauli XY plane, that is in the basis
(Step 1), and qubits are then entangled by applying controlled phase gates between neighbouring qubits (Step 2). Each qubit i ∈ {1,...,n − 1} is then measured at an angle ϕi
in the Pauli XY plane, that is in the basis  with
with  . Each measurement is equivalent to applying the unitary operation
. Each measurement is equivalent to applying the unitary operation

to  , where mi
∈ {0, 1} is the measurement outcome (occurring with probability
, where mi
∈ {0, 1} is the measurement outcome (occurring with probability  for all mi
), X is the Pauli X operation, H is the Hadamard gate and
for all mi
), X is the Pauli X operation, H is the Hadamard gate and  is a z-rotation by the angle ϕi
. Hence, these measurements result in the nth qubit being prepared in the output state,
is a z-rotation by the angle ϕi
. Hence, these measurements result in the nth qubit being prepared in the output state,  (Step 3), with
(Step 3), with

and where
ϕ
and
m
denote ordered lists of angles and measurement outcomes (occurring with probability  for all
m
) respectively.
for all
m
) respectively.

Figure 2. A review of measurement-based processing using a n-qubit linear cluster state. Reproduced from [56]. CC BY 4.0. Step 1 depicts the initialisation of the qubits. Step 2 depicts the entangled cluster state (after controlled phase gates have been applied between neighbouring qubits) in addition to the measurements performed on each qubit. Step 3 depicts the state resulting from the measurements.
Download figure:
Standard image High-resolution imageEven though the implemented unitary operation is probabilistic and depends on the measurement outcomes, any deterministic quantum computation can be realised by employing adaptive measurement feedforward [11, 61]. In particular, unitary operations which are deterministic up to a single known Pauli gate can be implemented by performing the measurements on qubits 1 to n − 1 sequentially and allowing future measurement angles to depend on past measurement outcomes. The desired quantum computation is then realised deterministically by applying the required and known Pauli correction to qubit n.
We now give explicit measurement-based implementations of the Hadamard gate and the T = diag(1, eiπ/4) gate. When all measurement outcomes are zero, the 2-qubit linear cluster state with the measurement angle ϕ1 = 0 implements the Hadamard gate and the 3-qubit linear cluster state with the measurement angles  and ϕ2 = 0 implements the T gate. When non-zero measurement outcomes occur, the desired gate can still be implemented by applying the appropriate Pauli correction to the final qubit [61]. In particular, the Pauli X operation must be applied to implement the Hadamard gate when m1 = 1. For the T gate, the Pauli X operation must be applied when m1 = 0 and m2 = 1, the Pauli Y operation must be applied when m1 = 1 and m2 = 1, and the Pauli Z operation must be applied when m1 = 1 and m2 = 0. Hence the Hadamard gate and the T gate can be realised deterministically with fixed measurement angles and a Pauli correction, and in these specific cases do not require adaptive measurement feedforward. However, implementations of more complicated deterministic operations, such as arbitrary single-qubit rotations, require both adaptive measurement feedforward and a Pauli correction [10].
and ϕ2 = 0 implements the T gate. When non-zero measurement outcomes occur, the desired gate can still be implemented by applying the appropriate Pauli correction to the final qubit [61]. In particular, the Pauli X operation must be applied to implement the Hadamard gate when m1 = 1. For the T gate, the Pauli X operation must be applied when m1 = 0 and m2 = 1, the Pauli Y operation must be applied when m1 = 1 and m2 = 1, and the Pauli Z operation must be applied when m1 = 1 and m2 = 0. Hence the Hadamard gate and the T gate can be realised deterministically with fixed measurement angles and a Pauli correction, and in these specific cases do not require adaptive measurement feedforward. However, implementations of more complicated deterministic operations, such as arbitrary single-qubit rotations, require both adaptive measurement feedforward and a Pauli correction [10].
2.2. Measurement-based t-designs
A unitary t-design is a pseudorandom ensemble of unitary operators of which the statistical moments match those of the uniform Haar ensemble either approximately or exactly up to some finite order t. The expectation of any  with respect to the Haar measure on the unitary group U(d), where d = 2 for single qubits, is defined by
with respect to the Haar measure on the unitary group U(d), where d = 2 for single qubits, is defined by

Thus formally an ensemble of unitaries {pi
, Ui
} is an exact unitary t-design if for all 

and {pi
, Ui
} is an  -approximate t-design if there exists an such that for all
-approximate t-design if there exists an such that for all 

where the matrix inequality A ≤ B holds if B − A is positive semidefinite [62, 63]. We are primarily interested in unitary 2-designs, which are sufficient for randomised benchmarking [28].
In addition to being entangled resource states for measurement-based quantum computing (see section 2.1), linear cluster states can be used to implement single-qubit t-designs by entirely foregoing adaptive measurement feedforward and Pauli corrections, that is by fixing the measurement angles
ϕ
and considering the ensemble of unitaries {p
m
, U
m
(
ϕ
)} for all
m
. In particular, the 6-qubit linear cluster state with the measurement angles ϕ1 = 0,  ,
,  ,
,  and ϕ5 = 0 implements an exact 2-design [62] and the 5-qubit linear cluster state with the measurement angles ϕ1 = 0,
and ϕ5 = 0 implements an exact 2-design [62] and the 5-qubit linear cluster state with the measurement angles ϕ1 = 0,  ,
,  and ϕ4 = 0 implements an approximate 2-design with = 0.5 [56]. In our previous work we implemented both the exact measurement-based 2-design and the approximate measurement-based 2-design on IBM processors [56]. Neither implementation passed our test for a 2-design under the test conditions set. However, the test results showed that the approximate 2-design implementation more closely resembled a 2-design than the exact 2-design implementation as a result of reduced noise for the smaller 5-qubit cluster state. This is why we use the approximate 2-design, and not the exact 2-design, in our randomised benchmarking experiments in this work (presented in section 5). We note that the implications of performing randomised benchmarking with an -approximate 2-design, as opposed to an exact 2-design, are not yet well understood theoretically. However, numerical investigations have shown that the estimated fidelity obtained when using an exact 2-design can differ from the estimated fidelity obtained when an exact 2-design is not used [35]. We find that the results obtained with the approximate 2-design are consistent with those obtained using quantum process tomography.
and ϕ4 = 0 implements an approximate 2-design with = 0.5 [56]. In our previous work we implemented both the exact measurement-based 2-design and the approximate measurement-based 2-design on IBM processors [56]. Neither implementation passed our test for a 2-design under the test conditions set. However, the test results showed that the approximate 2-design implementation more closely resembled a 2-design than the exact 2-design implementation as a result of reduced noise for the smaller 5-qubit cluster state. This is why we use the approximate 2-design, and not the exact 2-design, in our randomised benchmarking experiments in this work (presented in section 5). We note that the implications of performing randomised benchmarking with an -approximate 2-design, as opposed to an exact 2-design, are not yet well understood theoretically. However, numerical investigations have shown that the estimated fidelity obtained when using an exact 2-design can differ from the estimated fidelity obtained when an exact 2-design is not used [35]. We find that the results obtained with the approximate 2-design are consistent with those obtained using quantum process tomography.
2.3. Interleaved randomised benchmarking
Unitary 2-designs can be used in interleaved randomised benchmarking, which provides an estimate of the Haar-averaged fidelity of a noisy implementation of a unitary operation or gate [38]. The Haar-averaged fidelity of a noisy implementation of an ideal gate G is defined by

where  is the channel representing the ideal implementation of G and
is the channel representing the ideal implementation of G and  is the channel representing the noisy experimental implementation of G [55]. The average gate error is then given by
is the channel representing the noisy experimental implementation of G [55]. The average gate error is then given by  , which is useful for quantifying the overall reliability of the implementation. However, for some applications, such as determining thresholds for fault-tolerant quantum computing, the worst case error is required [64]. For these applications, the average gate error can be used to obtain bounds on the worst case error [24, 65–67].
, which is useful for quantifying the overall reliability of the implementation. However, for some applications, such as determining thresholds for fault-tolerant quantum computing, the worst case error is required [64]. For these applications, the average gate error can be used to obtain bounds on the worst case error [24, 65–67].
We briefly review the interleaved randomised benchmarking protocol proposed by Magesan et al [38], in which the fidelity of individual Clifford gates [68] can be estimated. However, we relax the restriction to Clifford gates and review a variation of the protocol in which any single-qubit unitary 2-design  can be used to estimate the fidelity of any single-qubit unitary operation or gate G. Section III A of [69] explains that the interleaved method of [38] holds for the variation of the protocol reviewed here. The only benefit of the restriction to Clifford gates is that the inverse of a sequence of Clifford gates can be efficiently computed on a classical computer as a result of the Gottesman–Knill theorem [70]. Restricting the protocol to single-qubit gates has the same benefit, since any single-qubit system can be efficiently simulated on a classical computer [61]. The key assumptions of the protocol are that noise from any gate is time-independent, noise from the 2-design
can be used to estimate the fidelity of any single-qubit unitary operation or gate G. Section III A of [69] explains that the interleaved method of [38] holds for the variation of the protocol reviewed here. The only benefit of the restriction to Clifford gates is that the inverse of a sequence of Clifford gates can be efficiently computed on a classical computer as a result of the Gottesman–Knill theorem [70]. Restricting the protocol to single-qubit gates has the same benefit, since any single-qubit system can be efficiently simulated on a classical computer [61]. The key assumptions of the protocol are that noise from any gate is time-independent, noise from the 2-design  is gate-independent and noise from the inverse of any sequence of gates is independent of the sequence.
is gate-independent and noise from the inverse of any sequence of gates is independent of the sequence.
Randomised benchmarking relies heavily on a unitary 2-design's ability to transform an arbitrary noise channel into a depolarising channel [29, 30, 38], a property which was studied extensively in our previous work [71]. In interleaved randomised benchmarking, two experiments are performed, namely an experiment to determine the reference depolarising noise parameter pref and an experiment to determine the interleaved depolarising noise parameter pint. These parameters are then used to estimate the Haar-averaged gate fidelity using

where d = 2 for single qubits.
The reference depolarising noise parameter pref is determined as follows:
- 1.Prepare the qubit in an arbitrary, but fixed, initial state
 .
. - 2.Choose m unitary operators uniformly at random from the 2-design and apply the resulting sequence of operators, Um
⋯ U2
U1, to the state ρ.
- 3.Compute and apply the inverse of the sequence of gates applied in step 2.
- 4.Measure the qubit in the basis. This measures the probability that the initial state is unchanged by the sequence applied in step 2 followed by its inverse (known as the survival probability).
- 5.
- 6.Repeat steps 1 to 5 for different sequence lengths m and extract the reference depolarising noise parameter pref by fitting the resulting data for Fref(m) versus m to the exponential decay modelThe parameters Aref and Bref absorb state preparation and measurement errors, as well as the error of the inverse applied in step 3. The relation between the number of repetitions chosen in step 5 and confidence intervals for the extracted parameters is discussed in [65].




The interleaved depolarising noise parameter pint is determined as follows:
- 1.Prepare the qubit in the same fixed initial state.
- 2.Choose m unitary operators uniformly at random from the 2-design and apply the interleaved sequence GUm
⋯ GU2
GU1 to the state ρ.
- 3.Compute and apply the inverse of the sequence of gates applied in step 2.
- 4.Measure the qubit in the basis. This once again measures the survival probability.
- 5.Repeat steps 1 to 4 for a fixed m and average the survival probability over the different sequences to obtain the sequence fidelity Fint(m).
- 6.Repeat steps 1 to 5 for different m and extract the interleaved depolarising noise parameter pint by fitting the resulting data for Fint(m) versus m to the exponential decay model




3. Measurement-based interleaved randomised benchmarking protocol
We now present an interleaved randomised benchmarking protocol for measurement-based quantum computers (which is an extension of the standard randomised benchmarking protocol proposed for measurement-based quantum computers by Alexander et al [55]). In particular, we explain how the experiments to determine the reference and interleaved depolarising noise parameters (described in section 2.3) can be implemented on a single-qubit measurement-based quantum computer. To this end, let  be a single-qubit measurement-based 2-design implemented by a (k + 1)-qubit linear cluster state with the fixed measurement angles
ϕ
= (ϕ1,...,ϕk
) and let G be a single-qubit measurement-based gate implemented by a (ℓ + 1)-qubit linear cluster state with the measurement angles
θ
= (θ1,...,θℓ
) (possibly requiring both adaptive measurement feedforward and a Pauli correction).
be a single-qubit measurement-based 2-design implemented by a (k + 1)-qubit linear cluster state with the fixed measurement angles
ϕ
= (ϕ1,...,ϕk
) and let G be a single-qubit measurement-based gate implemented by a (ℓ + 1)-qubit linear cluster state with the measurement angles
θ
= (θ1,...,θℓ
) (possibly requiring both adaptive measurement feedforward and a Pauli correction).
On a measurement-based quantum computer, the reference depolarising noise parameter pref can be determined as follows:
- 1.For a given sequence length m, prepare a (mk + 1)-qubit linear cluster state. This chooses the initial state to be the Pauli X eigenstate, which is the natural choice for measurement-based quantum computing.
- 2.Repeat the measurement pattern ϕ = (ϕ1,...,ϕk ) m times along the length of the cluster state. This implements the desired random sequence, Um ⋯ U2 U1, where the inherent randomness of the measurement-based process ensures that each Ui is chosen uniformly at random from the 2-design. Since the measurement angles are fixed, the mk measurements can be performed simultaneously. The measurement outcomes can be used to determine which sequence of gates was implemented.
- 3.Compute the inverse of the sequence of gates implemented in step 2 and apply this inverse by performing a measurement basis rotation on the final qubit. The inverse is applied in this way, and not as a measurement-based operation, to ensure that noise from the inverse is independent of the sequence.
- 4.Measure the final qubit in the Pauli X basis,.
- 5.Repeat steps 1 to 4 for a fixed sequence length m and determine Fref(m).
- 6.Repeat steps 1 to 5 for different sequence lengths m and fit the resulting data for Fref(m) versus m to equation (8).



On a measurement-based quantum computer, the interleaved depolarising noise parameter pint can be determined as follows:
- 1.For a given m, prepare a (m(k + ℓ) + 1)-qubit linear cluster state.
- 2.Repeat the measurements (ϕ1,...,ϕk , θ1,...,θℓ ) m times along the length of the cluster state. This implements the desired interleaved sequence, GUm ⋯ GU2 GU1. Since adaptive measurement feedforward may be required for the implementation of G, the m(k + ℓ) measurements need to be performed sequentially. If Pauli corrections are required, these can be applied after each set of k + ℓ measurements, by performing a measurement basis rotation, before proceeding with the next set of k + ℓ measurements.
- 3.Compute the inverse of the sequence of gates implemented in step 2 and apply this inverse by performing a measurement basis rotation on the final qubit.
- 4.Measure the final qubit in the Pauli X basis,.
- 5.Repeat steps 1 to 4 for a fixed m and determine Fint(m).
- 6.Repeat steps 1 to 5 for different m and fit the resulting data for Fint(m) versus m to equation (9).

4. Adjustments to protocol for implementation on IBM processors
Since IBM quantum processors did not support dynamic circuit execution at the time of performing the experiments, our measurement-based interleaved randomised benchmarking protocol had to be adjusted to enable implementation on the IBM hardware available at the time. Without dynamic circuit execution, it is not possible to include the inverse (step 3 of the experiments to determine the depolarising noise parameters) in the required quantum circuits, since the inverse depends on the sequence being implemented in step 2, which is only known once the measurements have been performed. One solution is to construct a different circuit for each possible inverse, run each circuit a sufficient number of times to obtain the random sequence corresponding to the implemented inverse, and then use post-selection to eliminate runs in which this desired sequence was not obtained. Since there are 2n
possible inverses for the sequences implemented by performing measurements on a (n + 1)-qubit linear cluster state, we would need 2n
different circuits, and since each random sequence occurs with probability  , all but 1 in every 2n
runs would be eliminated, and each of the 2n
circuits would need to be run at least 2n
times to have a reasonable chance of obtaining the sequence corresponding to the implemented inverse. Hence the number of runs required for post-selection scales like 22n
, which is generally prohibitively expensive.
, all but 1 in every 2n
runs would be eliminated, and each of the 2n
circuits would need to be run at least 2n
times to have a reasonable chance of obtaining the sequence corresponding to the implemented inverse. Hence the number of runs required for post-selection scales like 22n
, which is generally prohibitively expensive.
We therefore employ an alternative strategy in our randomised benchmarking experiments in section 5. We perform full quantum state tomography on the final qubit (after performing the measurements in step 2 of the experiments to determine the depolarising noise parameters) for each of the possible measurement outcomes, apply the correct inverse for each implemented sequence to the appropriate constructed density matrix by performing matrix multiplication, and then extract the survival probability from each resulting density matrix. Since each of the 2n
random sequences implemented by performing measurements on a (n + 1)-qubit linear cluster state occurs with probability  , the associated circuit must be run 3(500)(2n
) times to obtain 500 data points for tomography (which requires 3 basis measurements) for each of the 2n
possible measurement outcomes. Hence the circuit must be run 3(500)(2n
)/8000 = 3(2n
)/16 times if each run has 8000 shots. In the experiments in section 5, 8192 shots (the maximum number of allowed shots on IBM quantum processors at the time of starting the experiments) were used for each run, instead of just 8000 shots, to increase the likelihood of obtaining at least 500 data points for tomography even when the measurement outcomes are not uniform as a result of noise. Although this method has the disadvantage that the inverse is performed through classical post-processing, and not as a quantum mechanical operation, it scales like 2n
, which is much better than post-selection, which scales like 22n
. Since we assume that noise from the inverse is independent of the sequence, noise from the inverse would in any case not affect the depolarising noise parameters which are used to estimate the fidelity, and so performing the inverse through classical post-processing does not affect the results.
, the associated circuit must be run 3(500)(2n
) times to obtain 500 data points for tomography (which requires 3 basis measurements) for each of the 2n
possible measurement outcomes. Hence the circuit must be run 3(500)(2n
)/8000 = 3(2n
)/16 times if each run has 8000 shots. In the experiments in section 5, 8192 shots (the maximum number of allowed shots on IBM quantum processors at the time of starting the experiments) were used for each run, instead of just 8000 shots, to increase the likelihood of obtaining at least 500 data points for tomography even when the measurement outcomes are not uniform as a result of noise. Although this method has the disadvantage that the inverse is performed through classical post-processing, and not as a quantum mechanical operation, it scales like 2n
, which is much better than post-selection, which scales like 22n
. Since we assume that noise from the inverse is independent of the sequence, noise from the inverse would in any case not affect the depolarising noise parameters which are used to estimate the fidelity, and so performing the inverse through classical post-processing does not affect the results.
Since adaptive measurement feedforward cannot be implemented without dynamic circuit execution either, our protocol could only be used to estimate the fidelity of measurement-based gates which can be implemented with fixed measurement angles and a Pauli correction (such as the 2-qubit Hadamard gate and the 3-qubit T gate given in section 2.1) on the IBM quantum hardware available at the time of performing the experiments. As the Pauli corrections required in the interleaved sequences depend on the measurement outcomes, these also cannot be performed without dynamic circuit execution. We therefore average the survival probability, not only over the different random unitaries, but also over the different byproducts that result from omitting the Pauli corrections, when calculating the interleaved sequence fidelity in the experiments in section 5. When applying the inverse of an interleaved sequence with matrix multiplication, the inverse of each individual byproduct is applied, as determined by the measurement outcomes.
5. Experiments
5.1. Implementation of protocol
We implemented our measurement-based interleaved randomised benchmarking protocol, with the adjustments discussed in section 4, first on the ibm_hanoi quantum processor, a 27-qubit superconducting IBM quantum computer. Details of the qubits used can be found in supplementary material I. We used the 5-qubit approximate measurement-based 2-design proposed in our previous work [56] (see section 2.2) to estimate the fidelity of the 2-qubit measurement-based implementation of the Hadamard gate and the 3-qubit measurement-based implementation of the T gate given in section 2.1 on the ibm_hanoi quantum processor. To this end, we implemented reference sequences with lengths m ∈ {1, 2, 3} and interleaved sequences with m ∈ {1, 2, 3}. For each m (reference or interleaved), we prepared the required linear cluster state, performed the appropriate single-qubit measurements on all but the final qubit, and then performed full quantum state tomography on the final qubit for each of the possible measurement outcomes to infer the output state for each corresponding random sequence. As an example, the quantum circuit for the implementation of the interleaved sequence for the 3-qubit T gate with m = 1, which requires a 7-qubit linear cluster state, is shown in figure 3. The largest number of qubits was used for the implementation of the interleaved sequence for the 3-qubit T gate with m = 3, which required (m(k + ℓ) + 1) = (3(4 + 2) + 1) = 19 qubits, as shown in figure 1(a).

Figure 3. Quantum circuit for the implementation of the interleaved sequence for the 3-qubit T gate with m = 1 on the ibm_hanoi quantum processor. The angle  and 'out' represents the different basis measurements used to perform quantum state tomography on the final qubit.
and 'out' represents the different basis measurements used to perform quantum state tomography on the final qubit.
Download figure:
Standard image High-resolution imageSince controlled phase gates are not supported at the hardware level on IBM quantum processors, linear cluster states were prepared using Hadamards and controlled not gates, instead of Hadamards and controlled phase gates, as recommended by Mooney et al [73]. This prevented redundant Hadamards, which would have unnecessarily increased noise, from being introduced during transpilation. Since qubits can only be measured in the computational basis,  , on IBM processors, single-qubit measurements at an angle ϕ in the Pauli XY plane were carried out by applying Rz
(ϕ), followed by a Hadamard, and measuring the qubit in the computational basis.
, on IBM processors, single-qubit measurements at an angle ϕ in the Pauli XY plane were carried out by applying Rz
(ϕ), followed by a Hadamard, and measuring the qubit in the computational basis.
To obtain the data required to determine the sequence fidelity (Fref(m) or Fint(m)) for a given m, the relevant circuit was run 3(2n )/16 times with 8192 shots (see section 4) on the ibm_hanoi quantum processor (where n is the number of single-qubit measurements performed on the (n + 1)-qubit linear cluster state in the implementation). The data (counts) obtained in repeated runs were combined and grouped according to measurement outcomes. The output density matrix for each random sequence was then constructed from the tomography data obtained for the corresponding set of measurement outcomes. To ensure that the density matrices constructed from the data are physical (i.e. that they are Hermitian and have a trace of 1) we employed qiskit's built-in method [74], which uses maximum-likelihood estimation to find the closest physical density matrix to a density matrix constructed from tomography data. The appropriate inverse was then applied to each density matrix and the survival probability was extracted from each resulting density matrix. The sequence fidelity (Fref(m) or Fint(m)) presented for a given m in section 5.2 is the average of these survival probabilities, and the error is given by the standard deviation.
In interleaved randomised benchmarking experiments, sequence fidelities are typically determined for sequence lengths up to m = 80 or longer [38, 46]. Here, the resources required to implement longer sequences prevented us from considering sequence lengths beyond m = 3. For example, the implementation of the interleaved sequence for the 3-qubit T gate with m = 3 required a 19-qubit linear cluster state and the relevant circuit had to be run 3(218)/16 = 49152 times to obtain the data required to determine the sequence fidelity. Since this is already extremely resource intensive, longer sequences would not be feasible, as the number of runs required grows exponentially with the length of the sequence. Hence, even though the adjustments discussed in section 4 have enabled us to obtain data for a proof-of-concept demonstration, dynamic circuit execution remains essential for the efficient scaling of our measurement-based interleaved randomised benchmarking protocol in future.
5.2. Results for universal gates
Sequence fidelities obtained to estimate the fidelity of the 2-qubit measurement-based implementation of the Hadamard gate and the 3-qubit measurement-based implementation of the T gate (a universal single-qubit set), using the 5-qubit approximate measurement-based 2-design of [56], on the ibm_hanoi quantum processor are shown in figure 4. The large uncertainties in the sequence fidelities reflect the gate-dependence of noise from the approximate measurement-based 2-design [56]. A Monte Carlo method which takes these uncertainties into account was used to fit the reference and interleaved sequence fidelities to the exponential decay model given by equations (8) and (9) respectively. The fitting procedure used, the fitting constraints imposed and the estimation of Haar-averaged gate fidelities from the fitting parameters are discussed in supplementary material II. The estimated fidelity of the 2-qubit measurement-based implementation of the Hadamard gate is (0.977± 0.073) and the estimated fidelity of the 3-qubit measurement-based implementation of the T gate is (0.972 ± 0.070). The large uncertainties in the estimated fidelities can be attributed both to the large uncertainties in the sequence fidelities and to the small number of sequence fidelities. It is unclear to what extent the use of an -approximate 2-design, as opposed to an exact 2-design, contributed to the large uncertainties in the estimated fidelities. It is also not clear how is related to these uncertainties or how the relation is affected by the Monte Carlo method used to estimate the fidelities.

Figure 4. Sequence fidelities F(m) obtained for m ∈ {1, 2, 3} to estimate the fidelity of the 2-qubit measurement-based implementation of the Hadamard gate and the 3-qubit measurement-based implementation of the T gate, using the 5-qubit approximate measurement-based 2-design of [56], on the ibm_hanoi quantum processor. Reference and interleaved sequence fidelities were fit to equations (8) and (9) respectively (see supplementary material II). (a) Hadamard gate shows the reference sequence fidelities (in blue) and the interleaved sequence fidelities for the 2-qubit Hadamard gate (in red). (b) T gate shows the same reference sequence fidelities (in blue) and the interleaved sequence fidelities for the 3-qubit T gate (in red).
Download figure:
Standard image High-resolution imageWe now compare the fidelities estimated using our measurement-based interleaved randomised benchmarking protocol to fidelities calculated from process tomography results. To this end, we performed quantum process tomography on each of the three respective sets of qubits of the ibm_hanoi quantum processor on which the 2-qubit Hadamard gate and the 3-qubit T gate were implemented in the interleaved sequences, and used the results to calculate the Haar-averaged gate fidelity of each of the three implementations of the 2-qubit Hadamard gate and the 3-qubit T gate. Further details about the process tomography method used, the implementation of the method and the calculation of Haar-averaged gate fidelities from process tomography results are given in supplementary material III. Fidelities obtained for the three different implementations of the 2-qubit Hadamard gate, on the three different sets of qubits used in the interleaved sequences, range from 0.948 to 0.972. For the 3-qubit T gate, the fidelities obtained from process tomography results range from 0.928 to 0.939.
For both gates, the uncertainty of the gate fidelity calculated using process tomography results is smaller than the uncertainty of the gate fidelity estimated using our measurement-based interleaved randomised benchmarking protocol. We also note that the estimated fidelities are slightly larger than those obtained using process tomography results. Nevertheless, the agreement between our estimated gate fidelities and the gate fidelities calculated from process tomography results is somewhat remarkable considering that we used a very weak approximate 2-design [56], the implementation of this 2-design on the IBM quantum processors did not even pass our test for an approximate 2-design for all states [56], noise from this 2-design is not entirely gate-independent [56] and the fitting parameters were inferred from very few sequence fidelities (only three). This clearly demonstrates the robustness of interleaved randomised benchmarking. It also provides motivation for considering weak approximate 2-designs, such as the one proposed in our previous work [56]. It is unclear to what extent the use of a weak -approximate 2-design, as opposed to an exact 2-design, contributed to the over-estimation of gate fidelities. However, one would expect that in general, an increase in results in an increase in the positive difference between the estimated gate fidelity and the gate fidelity determined from process tomography results.
5.3. Noisier gates
We next investigate the extent to which our measurement-based interleaved randomised benchmarking protocol is able to detect noise variations in different measurement-based implementations of a gate. To this end, we artificially increase noise in the measurement-based implementations of the Hadamard gate and the T gate. One option is to perform the single-qubit measurements in these measurement-based implementations at measurement angles which deviate from the required measurement angles. However, this has the disadvantage that it is not easy to predict whether a measurement-based gate will be more or less noisy than the measurement-based 2-design used to estimate its fidelity. We therefore artificially increase noise in the measurement-based implementations of the Hadamard gate and the T gate by increasing the length of the linear cluster states used in the implementations.
Note that the 3-qubit linear cluster state with the measurement angles ϕ1 = 0 and ϕ2 = 0 implements the identity operation when all measurement outcomes are zero. By appending this measurement-based implementation of the identity operation to the 2-qubit Hadamard gate and the 3-qubit T gate given in section 2.1, we obtain measurement-based implementations of the Hadamard gate and the T gate with longer cluster states. In particular, when all measurement outcomes are zero, the 4-qubit linear cluster state with the measurement angles ϕ1 = 0, ϕ2 = 0 and ϕ3 = 0 implements the Hadamard gate and the 5-qubit linear cluster state with the measurement angles  , ϕ2 = 0, ϕ3 = 0 and ϕ4 = 0 implements the T gate. Furthermore, provided that all measurement outcomes are zero, the 6-qubit linear cluster state with the measurement angles ϕ1 = 0, ϕ2 = 0, ϕ3 = 0, ϕ4 = 0 and ϕ5 = 0 also implements the Hadamard gate and the 7-qubit linear cluster state with the measurement angles
, ϕ2 = 0, ϕ3 = 0 and ϕ4 = 0 implements the T gate. Furthermore, provided that all measurement outcomes are zero, the 6-qubit linear cluster state with the measurement angles ϕ1 = 0, ϕ2 = 0, ϕ3 = 0, ϕ4 = 0 and ϕ5 = 0 also implements the Hadamard gate and the 7-qubit linear cluster state with the measurement angles  , ϕ2 = 0, ϕ3 = 0, ϕ4 = 0, ϕ5 = 0 and ϕ6 = 0 also implements the T gate. When non-zero measurement outcomes do occur, the desired gate can be realised by simply applying the appropriate Pauli correction to the final qubit [61], that is, these implementations all use fixed measurement angles and a Pauli correction and do not require adaptive measurement feedforward.
, ϕ2 = 0, ϕ3 = 0, ϕ4 = 0, ϕ5 = 0 and ϕ6 = 0 also implements the T gate. When non-zero measurement outcomes do occur, the desired gate can be realised by simply applying the appropriate Pauli correction to the final qubit [61], that is, these implementations all use fixed measurement angles and a Pauli correction and do not require adaptive measurement feedforward.
We estimated the fidelity of the 4-qubit and 6-qubit measurement-based implementations of the Hadamard gate and the 5-qubit and 7-qubit measurement-based implementations of the T gate, using the 5-qubit approximate measurement-based 2-design of [56], on the ibmq_brooklyn quantum processor, a 65-qubit superconducting IBM quantum computer. Details of the qubits used are provided in supplementary material IV. We once again implemented reference sequences with lengths m ∈ {1, 2, 3} and interleaved sequences with m ∈ {1, 2, 3}, for each of the gates considered. The ibmq_brooklyn quantum processor was used for these experiments, instead of the ibm_hanoi quantum processor, as the ibm_hanoi quantum processor has too few qubits to implement some of the required sequences, such as the interleaved sequence for the 7-qubit T gate with m = 3, which requires a 31-qubit linear cluster state, as shown in figure 1(b). Sequences were implemented, classical post-processing was done to determine the survival probability for each random sequence and sequence fidelities were calculated in the same way as in the experiments on the ibm_hanoi quantum processor (see section 5.1).
The only difference in the experiments on the ibmq_brooklyn quantum processor is that for the interleaved sequences for the measurement-based gates defined here, we need not perform quantum state tomography for each of the possible measurement outcomes to infer the output state for each random interleaved sequence. This can be understood as follows. For the 2-qubit Hadamard gate and the 3-qubit T gate there is a one-to-one correspondence between the outcomes of single-qubit measurements in the measurement-based implementations and the random byproducts that result from omitting the Pauli corrections. This results in a one-to-one correspondence between random measurement outcomes and random interleaved sequences, since the random interleaved sequences consist of random unitary operators interleaved with random byproducts. In contrast, there are 8, 16, 32 and 64 possible outcomes for the single-qubit measurements performed in the respective 4-qubit, 5-qubit, 6-qubit and 7-qubit measurement-based implementations defined here, but there are only four possible byproducts, corresponding to the four possible Pauli corrections, for each implementation. As a result, there is no longer a one-to-one correspondence between random measurement outcomes and random interleaved sequences. Therefore, to infer the output state for each random interleaved sequence, we need not perform quantum state tomography for each of the possible measurement outcomes, since tomography data obtained for different measurement outcomes which correspond to the same random interleaved sequence can be grouped.
We note that, for the interleaved sequences for the measurement-based gates defined here, it is in fact not feasible to perform quantum state tomography for each of the possible measurement outcomes, since the number of possible measurement outcomes grows exponentially with the length of the cluster state. For example, the circuit implementing the interleaved sequence for the 7-qubit T gate with m = 3 would need to be run 3(230)/16 ≈ 201 million times to obtain the data required to perform tomography for each of the possible measurement outcomes. By performing tomography for each random interleaved sequence, and grouping tomography data obtained for different measurement outcomes corresponding to the same random sequence, we were able to drastically reduce the number of times each circuit had to be run. In particular, to obtain the data required to determine the interleaved sequence fidelity for a given m, for the 4-qubit, 5-qubit, 6-qubit and 7-qubit measurement-based gates defined here, the relevant circuit was run the same number of times as for the 3-qubit T gate (see section 5.1), since the number of possible byproducts, and therefore the number of random interleaved sequences, is the same as for the 3-qubit T gate.
Sequence fidelities obtained to estimate the fidelity of the 4-qubit Hadamard gate and the 5-qubit T gate, using the 5-qubit approximate measurement-based 2-design of [56], on the ibmq_brooklyn quantum processor are shown in figure 5. Furthermore, sequence fidelities obtained to estimate the fidelity of the 6-qubit Hadamard gate and the 7-qubit T gate are shown in figure 6. Table 1 shows the estimated gate fidelities, as well as the range of Haar-averaged gate fidelities calculated from process tomography results (see supplementary material III). Both the estimated gate fidelities and the gate fidelities obtained from process tomography results decrease as the length of the cluster state in the implementation increases, which reflects the expected increase in noise resulting from increasing the length of the cluster state. This shows that, even with very little data, our measurement-based interleaved randomised benchmarking protocol is able to detect large noise variations in different measurement-based implementations of a gate.

Figure 5. Sequence fidelities F(m) obtained for m ∈ {1, 2, 3} to estimate the fidelity of the 4-qubit measurement-based implementation of the Hadamard gate and the 5-qubit measurement-based implementation of the T gate, using the 5-qubit approximate measurement-based 2-design of [56], on the ibmq_brooklyn quantum processor. Reference and interleaved sequence fidelities were fit to equations (8) and (9) respectively (see supplementary material II). (a) Hadamard gate shows the reference sequence fidelities (in blue) and the interleaved sequence fidelities for the 4-qubit Hadamard gate (in red). (b) T gate shows the same reference sequence fidelities (in blue) and the interleaved sequence fidelities for the 5-qubit T gate (in red).
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 6. Sequence fidelities F(m) obtained for m ∈ {1, 2, 3} to estimate the fidelity of the 6-qubit measurement-based implementation of the Hadamard gate and the 7-qubit measurement-based implementation of the T gate, using the 5-qubit approximate measurement-based 2-design of [56], on the ibmq_brooklyn quantum processor. Reference and interleaved sequence fidelities were fit to equations (8) and (9) respectively (see supplementary material II). (a) Hadamard gate shows the reference sequence fidelities from figure 5 (in blue) and the interleaved sequence fidelities for the 6-qubit Hadamard gate (in red). (b) T gate shows the same reference sequence fidelities from figure 5 (in blue) and the interleaved sequence fidelities for the 7-qubit T gate (in red).
Download figure:
Standard image High-resolution image{kind=link}
Table 1. Haar-averaged gate fidelities obtained for the different measurement-based gates on the ibmq_brooklyn quantum processor. 'Est Fidelity' shows the fidelity estimated using our measurement-based interleaved randomised benchmarking protocol. 'Fidelity Range' shows the range of fidelities calculated from process tomography results obtained for the three different sets of qubits used in the interleaved sequences (see supplementary material III).
| Gate | Est Fidelity | Fidelity Range |
|---|---|---|
| 4-qubit Hadamard gate | 0.894 ± 0.092 | 0.831–0.895 |
| 5-qubit T gate | 0.849 ± 0.085 | 0.821–0.851 |
| 6-qubit Hadamard gate | 0.820 ± 0.079 | 0.693–0.835 |
| 7-qubit T gate | 0.791 ± 0.081 | 0.702–0.803 |
6. Conclusion
We proposed an interleaved randomised benchmarking protocol for measurement-based quantum computers, which is an extension of the standard randomised benchmarking protocol proposed for measurement-based quantum computers by Alexander et al [55]. In our measurement-based interleaved randomised benchmarking protocol, any single-qubit measurement-based 2-design can be used to estimate the fidelity of any single-qubit measurement-based gate. Future work could involve developing interleaved randomised benchmarking protocols in which multi-qubit measurement-based 2-designs [63] can be used to estimate the fidelity of multi-qubit measurement-based gates. Obstacles that would need to be overcome in this regard include computing the inverse of a random multi-qubit sequence, since multi-qubit systems cannot generally be efficiently simulated on a classical computer, and applying this inverse in such a way that noise from the inverse is independent of the sequence, since the inverse of a multi-qubit sequence cannot be applied by performing a single-qubit measurement basis rotation. Random measurement-based Clifford gates may help in this regard, where they may be used to bound the fidelity of non-Clifford gates that form a universal set [69]. Another option is to combine Clifford group and Pauli group gates within the interleaved sequence of a measurement-based non-Clifford gate [42]. Future work investigating the implications of performing randomised benchmarking with an approximate 2-design, as opposed to an exact 2-design, is also needed, since it is still unknown whether exact multi-qubit measurement-based 2-designs exist.
We tested our protocol by using the approximate measurement-based 2-design proposed in our previous work [56] to estimate the fidelity of measurement-based implementations of the Hadamard gate and the T gate (a universal single-qubit set) on the remotely accessible IBM superconducting quantum computers. Since IBM processors did not support dynamic circuit execution at the time of performing the experiments, our protocol had to be adjusted to enable implementation on the superconducting quantum hardware available at the time. In particular, it was not possible to implement the inverse of a random sequence as a quantum mechanical operation without dynamic circuit execution, since the sequence, and therefore its inverse, is only known after the required single-qubit measurements have been performed. By preparing linear cluster states of up to 31 qubits, performing single-qubit measurements on all but the final qubit, performing quantum state tomography on the final qubit to infer the output state for each random sequence, and by using classical post-processing to apply the inverse of each sequence and extract the survival probability, we were able to determine reference sequence fidelities for sequence lengths m ∈ {1, 2, 3} and interleaved sequence fidelities for m ∈ {1, 2, 3} for each of the gates considered.
In our adjusted protocol, the resources required to obtain the data needed to determine the sequence fidelity scale exponentially with the length of the sequence, which is why the number of sequence fidelities determined here is much smaller than in typical interleaved randomised benchmarking experiments [38, 46]. Hence, even though our adjustments have enabled us to obtain data for a proof-of-concept demonstration, dynamic circuit execution remains essential for the efficient scaling of our measurement-based interleaved randomised benchmarking protocol. We note that our measurement-based interleaved randomised benchmarking protocol could be implemented as presented in section 3, without any adjustments, on a measurement-based architecture or a circuit-based architecture which supports dynamic circuit execution. A measurement-based architecture or a circuit-based architecture which supports dynamic circuit execution would therefore eliminate the exponential scaling with sequence length as well as the need for quantum state tomography and classical post-processing. Recent work on circumventing dynamic circuit execution on IBM processors for the measurement-based model via a delayed choice strategy [58] is an interesting direction, although such a strategy comes at the expense of adding further entangling gates, which may introduce additional noise. Dynamic circuit execution is thus an important addition to IBM processors for the measurement-based model, and the recent addition thereof opens up many opportunities for quantum computing in the measurement-based model.
In all the experiments, estimated gate fidelities show good agreement with gate fidelities calculated from process tomography results. Even though some gate fidelities are slightly over-estimated and the uncertainties of estimated gate fidelities are larger than the uncertainties of those calculated from process tomography results, the experimental results clearly demonstrate the robustness of interleaved randomised benchmarking if one takes into consideration that we used a very weak approximate 2-design [56], the implementation of this 2-design on the IBM quantum processors did not even pass our test for an approximate 2-design for all states [56], noise from this 2-design is not entirely gate-independent [56] and the fitting parameters were inferred from very few sequence fidelities. Furthermore, by artificially increasing noise in the measurement-based implementations of the Hadamard gate and the T gate, we were able to show that, even with very little data, our measurement-based interleaved randomised benchmarking protocol is able to detect large noise variations in different measurement-based implementations of a gate. Our work highlights the usefulness of cloud-based superconducting systems for single-qubit measurement-based quantum computing and shows how to practically characterise noisy quantum logic gates in this setting. In future experiments, our protocol could be implemented on custom-built linear optical systems [12–14, 75–78], one of the most promising physical systems for measurement-based quantum computing.
Acknowledgments
We acknowledge the use of IBM Quantum services for this work. The views expressed are those of the authors, and do not reflect the official policy or position of IBM or the IBM Quantum team. We thank Taariq Surtee and Barry Dwolatzky at the University of Witwatersrand and Ismail Akhalwaya at IBM Research Africa for access to the IBM processors through the Q Network and Africa Research Universities Alliance. This research was supported by the South African National Research Foundation, the University of Stellenbosch, and the South African Research Chair Initiative of the Department of Science and Innovation and the National Research Foundation.
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.
Supplementary material (0.3 MB PDF)