



Abstract
Feedback control is an essential component of many modern technologies and provides a key capability for emergent quantum technologies. We extend existing approaches of direct feedback control in which the controller applies a function directly proportional to the output signal (P feedback), to strategies in which feedback determined by an integrated output signal (I feedback), and to strategies in which feedback consists of a combination of P and I terms. The latter quantum PI feedback constitutes the analog of the widely used proportional-integral feedback of classical control. All of these strategies are experimentally feasible and require no complex state estimation. We apply the resulting formalism to two canonical quantum feedback control problems, namely, generation of an entangled state of two remote qubits, and stabilization of a harmonic oscillator under thermal noise under conditions of arbitrary measurement efficiency. These two problems allow analysis of the relative benefits of P, I, and PI feedback control. We find that for the two-qubit remote entanglement generation the best strategy can be a combined PI strategy when the measurement efficiency is less than one. In contrast, for harmonic state stabilization we find that P feedback shows the best performance when actuation of both position and momentum feedback is possible, while when only actuation of position is available, I feedback consistently shows the best performance, although feedback delay is shown to improve the performance of a P strategy here.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The maturation of quantum technologies relies heavily on the development of advanced quantum measurement and control solutions. For this purpose, many concepts and solutions developed in classical control theory and practice can be carried over to the quantum domain. Recent examples of useful application of classical control concepts in the context of quantum systems are Lyapunov control [1–5], LQG control [6–10], risk-sensitive control [11–13], and filtering and smoothing for estimation and control [14–25].
Feedback control is particularly important for applications such as error correction, cooling, and stabilization of quantum systems. Feedback becomes most interesting when the control signals can be applied to a quantum system at timescales that are comparable to the timescale of the measurement. In this case, one must model the effects of intrinsic time evolution, measurement (including quantum backaction) and feedback control all at the same time, which results in interesting and complex dynamics. This typically leads to a description in terms of a continuous-in-time stochastic dynamical equation for the density matrix of the quantum system. The simplest type of feedback, in which the feedback operation is directly proportional to the measurement signal at the same time, leads to Markovian evolution of the system [26, 27]. This proportional feedback (often termed 'direct' feedback) has been applied in theoretical analysis of many problems including state stabilization and cooling [28–32], quantum error correction [33–35], state purification [36, 37] and generation of entangled states [38–41] and squeezed states [42], and has also been experimentally demonstrated [43–46]. Recent work has extended quantum feedback control beyond proportional feedback to implementations based on estimation of the quantum state [47–49], implementations using stochastic noise sources [50], and to implementations using the most general form of feedback that does not include a time-delayed proportional term [51]. In the latter framework, referred to as proportional and quantum state estimation (PaQS) feedback, the feedback operator can equivalently be expressed as a sum of independent deterministic and stochastic contributions. This approach has also been extended to multiple measurement and feedback operators [41]. In several instances, locally optimal feedback laws have been derived [6, 7, 39, 51–54], with global optimality being shown in a smaller number of cases [39, 53, 54].
As is the case for complex classical systems, the implementation of advanced, and particularly of optimal, feedback control solutions can be challenging, due to instrumentation and computation demands. Therefore, it is important to also develop heuristic control solutions in the quantum domain. In this paper we adapt one of the most widely used classical control heuristics, proportional-integral, referred to as PI feedback control [55], to the quantum domain. In the classical domain both P and PI feedback are subsets of proportional, integral, derivative (PID) control, which includes options for modulating the feedback signal with both integrals and derivatives of the measurement signal, in addition to simple multiples of this. In classical PID control, the feedback signal is proportional to the function
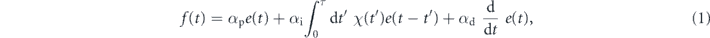
where e(t) is an error signal that is usually derived from the measurement at time t, and αp, αi, αd are real coefficients that dictate the relative weights of the proportional, integral and derivative information, respectively, in forming the control law at any time. These weights are usually tuned empirically to achieve good control performance, since their optimal values cannot be computed a priori except for very simple systems. Intuitively, the integral portion is used to compensate for unused parts of the measurement signal at earlier times—integration can increase the signal to noise ratio, can decrease the amount of time it takes to reach the steady-state, and can decrease overshoot of the desired set point. The third component of equation (1), derivative control, can increase the stability of a result by suppressing slow deviations away from the desired target—here the derivative attempts to anticipate the direction of change in the error. While PID control is not known to be optimal in any general setting, it has proven to be a very useful framework for formulating heuristic control laws in practice [55].
In this paper we address the extension of the first two components of PID control to the quantum domain, formulating a quantum PI feedback law and analyzing the relative benefits of quantum PI, I, and P feedback in two canonical problems for quantum control, namely generation of entanglement between remote qubits using local Hamiltonians and non-local measurements, and state stabilization of the harmonic oscillator in an external environment. In contrast to some earlier studies of these systems [6, 39, 53], our feedback implementations for these problems do not require any state estimation and only rely on simple integrals of the measured signal. We allow for a time delay in the implementation of P feedback, as originally proposed by Wiseman [27]. A time delay between obtaining the measurement signal and implementing a feedback operation reflects common experimental constraints and is often regarded as being detrimental to proportional feedback [56, 57]. However we shall see that in the case of state stabilization of the harmonic oscillator, a time delay introduces additional flexibility of feedback that can be beneficial when the feedback control operations are restricted. We also examine the robustness of P feedback with respect to uncertainties in the time delay, in particular, to increases in the time delay beyond the ideal values for each protocol.
In general, our findings for these two classes of implementations show that adding an integral component to quantum feedback control can be useful in some but not all settings. This is different from the classical setting where adding an integral component to feedback control is almost universally beneficial [55]. The different behavior of quantum systems can be rationalized by recalling a key difference between quantum and classical settings, which is the unavoidable presence of stochastic measurement noise in quantum systems. In classical systems measurement noise can be minimized and even sometimes eliminated. However for quantum systems, any information gain from a measurement necessarily comes at the cost of added noise on the system. The proportional component of feedback can be very effective at minimizing the impact of this added noise. In special cases, including entanglement generation for two qubits with unit efficiency measurements [53] and the harmonic oscillator state stabilization with both position and momentum controls [6], P feedback can be used to cancel the measurement noise. However, when this is not possible or when there are additional noise sources, we find that I feedback, or a combination of I and P feedback, can be more effective than P feedback.
We note that rigorous analysis of a quantum version of full PID control within the input–output analysis of controlled quantum stochastic evolutions has been recently presented by Gough [58, 59]. In the current study of practical implementations, we do not investigate the full PID control in the quantum setting because the singular nature of the quantum measurement record makes the derivative terms ill-behaved and thus not useful for practical control implementations without further modifications. See references [31, 32] for interesting applications of derivative-based feedback.
The remainder of the paper is organized as follows. Section 2 introduces notation and presents the general equation for PI feedback. Section 3 discusses the control of entanglement of two remote qubits via a half-parity measurement and local feedback operations. Here we find that I feedback and PI feedback both show improved performance over P feedback alone. Section 4 investigates the control of state stabilization of a harmonic oscillator in a thermal environment, using feedback control on either both oscillator quadratures or a single quadrature. When control over both quadratures is possible, P feedback is found to perform better than pure I feedback control. When control over only the position quadrature is available, we find that time delay in P feedback can be beneficial, by allowing an approximation of the average momentum of the state that can be used to generate a good control law. However, despite this improvement of delayed P feedback over the direct, i.e., instantaneous, setting, a pure I feedback control strategy is nevertheless found to give better performance under the conditions of thermal damping. In both sections 3 and 4 we compare the results with prior work employing state estimation based feedback, and also analyze the robustness of the control law with respect to non-ideal time delay values. We close with a discussion and outlook for further work in section 5.
2. Formalism
In this section, we will develop the formalism for a quantum system under continuous-in-time measurement (e.g., homodyne detection) and PI feedback control. Figure 1 shows a block diagram of the feedback system that we aim to model. We define ρ to be the state of the system, H the intrinsic Hamiltonian, c the variable-strength measurement operator, and η the measurement efficiency. We will set ℏ = 1 throughout the paper.

Figure 1. Schematic block diagram of PI feedback control of a quantum system. First, the result of a continuous measurement on a quantum system is compared with a target value to form an error signal. This error signal is used to form two signals: (i) a scaled version obtained by multiplication by a real coefficient αp ⩾ 0, and (ii) a smoothed version obtained by integrating over a time interval and multiplication by a real coefficient αi ⩾ 0. These two signals are then additively combined and then used to condition actuation of the quantum system by an operator F.
Download figure:
Standard image High-resolution imageThe dynamics of the system conditioned on the measurement record, but without feedback control, is described by the following Itô stochastic master equation (SME) [60]:
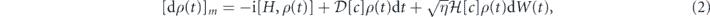
where dW(t) are Wiener increments (Gaussian-distributed random variables with mean zero and autocorrelation  ). The superoperators
). The superoperators  and
and  in this equation are defined as
in this equation are defined as ![$\mathcal{D}\left[A\right]\rho \equiv A\rho {A}^{{\dagger}}-\frac{1}{2}\left({A}^{{\dagger}}A\rho +\rho {A}^{{\dagger}}A\right)$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn4.gif) and
and ![$\mathcal{H}\left[A\right]\rho \equiv A\rho +\rho {A}^{{\dagger}}-\mathrm{Tr}\left[\left(A+{A}^{{\dagger}}\right)\rho \right]\rho $](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn5.gif) . The corresponding measurement current can be written as [60]
. The corresponding measurement current can be written as [60]
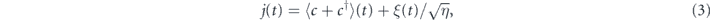
where ξ(t) ≡ dW/dt is a white noise process. To emphasize the link between the measurement current and the conditional state evolution, the last term in equation (2) is sometimes written as ![$\eta \left(j\left(t\right)-\langle c+{c}^{{\dagger}}\rangle \left(t\right)\right)\mathcal{H}\left[c\right]\rho \left(t\right)\mathrm{d}t$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn6.gif) .
.
Before adding the feedback, we first define the error signal by analogy with classical PID control, as
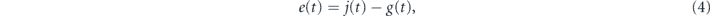
where g(t) is the setpoint or goal. This is often the desired value of the observable ⟨c + c†⟩(t) but could also be another target function. g(t) is assumed to be a smoothly varying or constant function. Then the PI feedback operator in the quantum setting takes the form
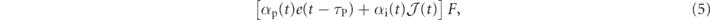
with some Hermitian operator F. Here αp(t) and αi(t) are time-dependent proportional and integral coefficients, respectively. This differs from classical PID control where the control coefficients are time-independent. Here, we will allow for time-dependence that is deterministic and independent of the measurement current, although in the following we will drop the time index on these coefficients for conciseness unless we wish to emphasize the time-dependence. We have also included the freedom of having a time delay τP > 0 in the proportional component. While this is often viewed as an experimental constraint on implementation of quantum feedback control protocols that is detrimental to performance [56, 57], we shall see below that for the harmonic oscillator state stabilization problem this can be used constructively to improve performance (subsection 4.2).  is the integrated error signal,
is the integrated error signal,
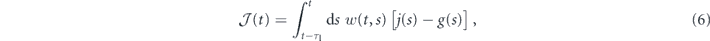
where w is a smooth integration kernel that can be used to vary the contribution of the measurement current at past times, and τI is the integration time. We shall assume the kernels are L2 integrable and normalize them such that  . Time-homogeneous kernels just depend on the time separation, w(t, s) → w(t − s). Typically, w(t, s) decays with t − s and puts decreasing weight on measurement results from further in the past.
. Time-homogeneous kernels just depend on the time separation, w(t, s) → w(t − s). Typically, w(t, s) decays with t − s and puts decreasing weight on measurement results from further in the past.
The action of this PI feedback only is captured by the following dynamics of the system density matrix ρ(t):
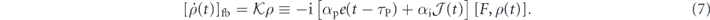
We now combine equations (2) and (7) to derive the SME for evolution under measurements and the PI feedback, using the general formalism developed in reference [27] and its extension to smoothed feedback signals in references [27, 61]. For convenience we define the commutator superoperator F× as F×ρ ≡ [F, ρ]. The time-evolved state after an infinitesimal time dt is given by
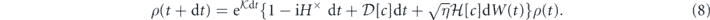
Note that this form ensures causality, since the feedback acts after the evolution due to measurement. The infinitesimal evolution equation is then obtained by expanding the exponential  in a Taylor series up to order dt. The first and second order terms in this expansion are:
in a Taylor series up to order dt. The first and second order terms in this expansion are:
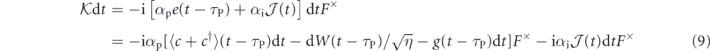
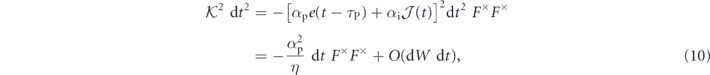
where to write the second line in each equality we have expanded e(t) = j(t) − g(t), used the definitions j(t) (equation (3)),  (equation (6)), and the Ito rule dW(s)dW(t) = δ(t − s)dt.
(equation (6)), and the Ito rule dW(s)dW(t) = δ(t − s)dt.
Therefore, discarding all terms less than order dt, the evolution for the system conditioned on the measurement and subsequently acted upon by the PI feedback control is
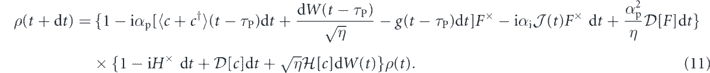
Multiplying this expression out and again discarding all terms smaller than O(dt), we find the following evolution for feedback with delay in the P component, τP > 0, is given by

For the zero time delay case, we go back to equation (11), set τP = 0 and again multiply the expression out and discard terms smaller than O(dt) to get [26, 62]
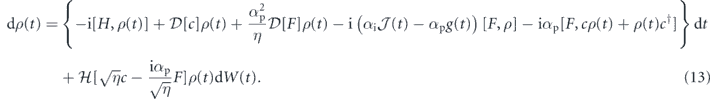
Note that in general it is not possible to obtain equation (13) by setting τP = 0 in equation (12). With zero time delay, the correlation between the feedback noise and measurement noise creates an order dt term (proportional to [F, cρ(t) + ρ(t)c†]) that is not present in the presence of time delay.
The two SMEs in equations (12) and (13) represent the evolution of the quantum system conditioned on a continuous measurement record, together with PI feedback based on that record. Examining the terms proportional to αi, it is evident that the integral feedback component just adds a generator of time-dependent unitary evolution to the system dynamics. This is in contrast to proportional feedback, which in addition to adding coherent evolution terms, also adds a dissipative evolution term and for τP = 0 also modifies the stochastic evolution term (the term proportional to dW in equation (11)). This reflects the difference that in proportional feedback, the delta-correlated noise is directly fed back at each time instant, whereas in integral feedback, the feedback action is conditioned on a smoothed, tempered signal and thus is able to generate a conventional (time-dependent) Hamiltonian term. Note that while the latter is not necessarily smoothly varying in time, its increments are O(dt). We emphasize that these SMEs model feedback that requires no state estimation (usually a computationally expensive task), and thus are more suitable for application to experimental implementations. However, P feedback with τP = 0 will always be an approximation since any measurement and feedback loop will have finite delay. The τP = 0 limit is a good approximation if the delay is small compared to the intrinsic system evolution time scales.
In this work, we simulate the above stochastic differential equations (SDE) describing evolution under PI feedback with a generalized Euler–Maruyama method. In the usual Euler–Maruyama method [63], one generates a Wiener noise increment dW(t) for each time step [t, t + dt] and then updates the state according to the stochastic differential equation. In our generalized Euler–Maruyama method, for each time t we keep a record of the noise up to time τ = max(τI, τP) in the past, i.e., dW(t), dW(t − dt), ...dW(t − τ)). Then dW(t − τP) is accessible and  can be calculated at each time t. The state is then updated according to the SME equation (11) as usual. We normalize the density matrix at each time step to compensate for numerical round-off errors.
can be calculated at each time t. The state is then updated according to the SME equation (11) as usual. We normalize the density matrix at each time step to compensate for numerical round-off errors.
3. Two-qubit entanglement generation
In this section, we compare the performance of P feedback, I feedback, and PI feedback for the task of generating an entangled two-qubit state with a local Hamiltonian and non-local measurement. This non-trivial state generation task was first addressed by measurement-based control with post-selection [64–66], then by P feedback and discrete feedback [39, 53] and most recently by PAQS control [51]. For perfect measurement efficiency η = 1, the proportional feedback strategy with time-dependent αp(t), was shown in reference [53] to be globally optimal among all protocols that have constant measurement rate. In this case, the measurement noise can be exactly canceled and the evolution converges deterministically to the target state. In the following, we consider the case where the measurement efficiency is not unity and the simplified setting where the feedback coefficients αp and αi are assumed to be time-independent. In this experimentally relevant setting, P feedback is not known to be globally optimal. Furthermore, the two-qubit system under measurement and feedback is not linear and therefore is representative of a more general class of quantum systems, in contrast to the linear setting of harmonic oscillator stabilization treated in the next section. This non-linearity makes analytical arguments for optimal feedback laws difficult and therefore we must resort to a numerical study. However, we ask the question: whether its advantageous to combine P and I feedback?
Consider two qubits subject to an intrinsic Hamiltonian H = h1σz1 + h2σz2 and subject to negligible decoherence. In the following we will assume h1 = h2 = h. We measure the half-parity of the qubits [65], which allows a non-local implementation between remote qubits [64]. The relevant measurement operator c is
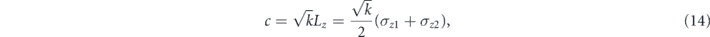
where k is the measurement strength and the associated measurement current is
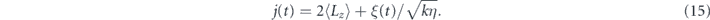
The control goal is to stabilize the system in an entangled state, when starting from a simple product state, |↑⟩ ⊗ |↑⟩ ≡ |↑↑⟩. Given the exchange symmetry of the intrinsic Hamiltonian and the measurement operator (we will be careful to also maintain this symmetry with the feedback operator below), and since the initial state is exchange symmetric, we will remain in the symmetric triplet subspace of two qubits throughout the evolution. This subspace is spanned by the states  ,
,  , and
, and  . Our goal is to evolve to, and stabilize the system in, the entangled state |T0⟩. As in reference [39] we use the intuition of rotating the system in the symmetric subspace and choose a local feedback operator
. Our goal is to evolve to, and stabilize the system in, the entangled state |T0⟩. As in reference [39] we use the intuition of rotating the system in the symmetric subspace and choose a local feedback operator  . Applying a Lx rotation can bring |T±1⟩ closer to |T0⟩.
. Applying a Lx rotation can bring |T±1⟩ closer to |T0⟩.
Since the control goal in this case is to prepare the state |T0⟩, and the deterministic part of the measurement under this state, ⟨T0|Lz|T0⟩ is zero, we may set the goal to be g(t) = ⟨T0|Lz|T0⟩ = 0 ∀ t. Hence our error signal is e(t) = j(t). Thus, we obtain the SME that describes the evolution of the two-qubit system for both τP = 0 (equation (A1)) and τP > 0 (equation (A2)) as shown in appendix
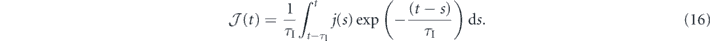
To assess the relative performance of the feedback strategies, we will look at the steady state average populations of the three triplet states as well as the average concurrence measure of entanglement. Given a two-qubit density operator ρ, the populations of the triplet states are given by  , and the concurrence is defined as [67, 68]
, and the concurrence is defined as [67, 68]
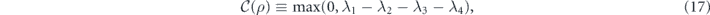
where λ1,..., λ4 are the (non-negative) eigenvalues, in decreasing order, of the Hermitian matrix  with
with  the spin flipped state of ρ.
the spin flipped state of ρ.
Figure 2 shows these measures of the average evolution of the two-qubit system for the initial state |T1⟩, under the strategies of P feedback [αp = 1, αi = 0, panels (a) and (b)], I feedback [αp = 0, αi = 1, panel (c)], and PI feedback with a specific combination of αp and αi [panel (d)]. The parameters of the system are h = 0.1, k = 1, η = 0.4. The choice of k sets the units for the other rates in the model, η was chosen to be consistent with current experimental capabilities [64], and we vary h later to see its effect on the conclusions drawn. The results in this section are for the |T1⟩ initial state. We have also simulated the protocols and their steady states starting from any mixture of product states in the triplet manifold (the initial states simplest to prepare in experiments) and the results are similar to those shown here for the |T1⟩ initial state.
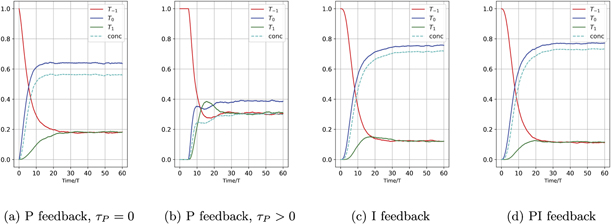
Figure 2. Average evolution of a two-qubit system under feedback control with Hamiltonian h = 0.1. (a) Shows the proportional feedback with αp = 0.2 and τP = 0; (b) proportional feedback with αp = 0.2 and τP = 5; (c) integral feedback with αi = 0.2 and τI = 3; (d) combination of proportional feedback with αp = 0.03 and integral feedback with αi = 0.17, τI = 3. (a) is calculated by dropping the stochastic terms in equation (A1). (b) is calculated by averaging over 8000 trajectories simulated with equation (A2). (c) and (d) are calculated by averaging over 8000 trajectories simulated with equation (A1). For all plots the measurement efficiency is η = 0.4 and the initial state is taken to be the unentangled state T1. The long time value of concurrence in (c) is ∼0.7196 ± 0.0028 and in (d) is ∼0.7289 ± 0.0028.
Download figure:
Standard image High-resolution imageFigures 2(a) and (b) show the evolution under P feedback, with and without a time delay. We expect that there is little benefit in introducing a time delay in proportional feedback in this example, since there is no information in prior measurement currents that is germane to the control goal. Indeed this expectation is borne out by these figures; the performance of the time-delayed feedback is worse than without a time delay, τP = 0. Figure 2(c) shows the performance under I feedback. The value of the integration time τI can be numerically optimized to yield maximum concurrence. The plot in figure 2(c) uses τI = 3, which is a near-optimal value for concurrence.
Comparing figure 2(c) with figures 2(a) and (b), it is evident that in the case of inefficient measurements, η < 1, an I feedback strategy is able to produce a significantly higher steady state average concurrence and target T0 population than a P feedback strategy. Finally, in figure 2(d) we show the average behavior for a specific combination of P and I feedback, i.e., of PI feedback, with αp = 0.03 and αi = 0.17. This combined PI feedback strategy performs slightly better than the pure I feedback strategy, thus outperforming both P and I strategies (the long time value of concurrence in figure 2(c) is ∼0.7196 ± 0.0028 and in figure 2(d) is ∼0.7289 ± 0.0028). We have plotted here the results of just one choice of αp and αi that combines P and I feedback. This particular choice was made to show that PI feedback can outperform P and I feedback based on a more general analysis of mixing the two types of feedback that we will detail below. Note that the total feedback strength has been kept constant across all the settings shown in figure 2, specifically at αi + αp = 0.2, in order to have a fair comparison. We also emphasize that these plots show average values of the state populations and concurrence, where the averages are computed over 8000 evolution trajectories. For efficiency η = 0.4, since none of these protocols achieves cancellation of the measurement noise, the individual trajectories of triplet state populations and concurrence show fluctuations for all four feedback strategies.
Analysis of single trajectories reveals insight into the better performance of the I feedback strategy relative to the P feedback strategies. Representative trajectories of the triplet state populations under I feedback and P feedback with zero time delay are shown in figure 3. In general, the evolution under both feedback strategies drives the system towards the |T0⟩ state. The population T0 can reach the value 1 and remain there for some time period until a measurement noise fluctuation entering through the feedback term is large enough to drive it down. Under P feedback, we are conditioning feedback on the raw measurement and thus the T0 population fluctuations can be large, which results in more frequent transitions out of the target state |T0⟩. In contrast, the integral component in the I feedback strategy smooths out the measurement current fluctuations, which reduces the probability of the feedback term kicking the system out of the target |T0⟩ state. Consequently, as we analyze in detail below the ensemble average of the triplet population, ![$\mathbb{E}\left[{T}_{0}\right]$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn19.gif) , will be larger for the integral control strategy than for the proportional control strategy.
, will be larger for the integral control strategy than for the proportional control strategy.

Figure 3. Single trajectories of triplet state populations for proportional feedback (τP = 0) and integral feedback (τI = 3). The measurement efficiency η = 0.4 and initial state is an unentangled state T1.
Download figure:
Standard image High-resolution imageTo understand this in more quantitative terms, we have given the evolution of these triplet populations and the associated off-diagonal elements of the density matrix in the triplet subspace under general PI feedback in appendix
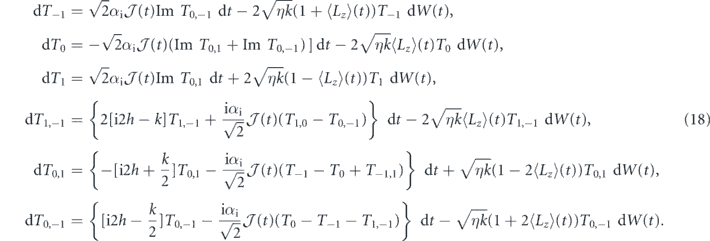
We suppress the time index of Ti and Ti,j here for notational conciseness. We cannot take the ensemble average (to obtain the average evolution) by simply dropping the stochastic terms in this case, because  and Ti and Ti,j are correlated by virtue of the dependence of both on past Wiener increments. Moreover, due to their nonlinearity we cannot solve these equations directly. However, we can use the following argument to show that equation (18) has a (unstable) steady state when T0 = 1. Suppose at some time, T0 reaches 1 and we have T1 = T−1 = 0 (and thus ⟨Lz⟩ = 0). Then the coherences T1,−1, T0,1, T0,−1 will be approximately zero also (since all populations other than T0 are zero). As a result, in the above equations dT−1 = dT0 = dT1 = dT1,−1 ≈ 0, and the only coherences that evolve are given by
and Ti and Ti,j are correlated by virtue of the dependence of both on past Wiener increments. Moreover, due to their nonlinearity we cannot solve these equations directly. However, we can use the following argument to show that equation (18) has a (unstable) steady state when T0 = 1. Suppose at some time, T0 reaches 1 and we have T1 = T−1 = 0 (and thus ⟨Lz⟩ = 0). Then the coherences T1,−1, T0,1, T0,−1 will be approximately zero also (since all populations other than T0 are zero). As a result, in the above equations dT−1 = dT0 = dT1 = dT1,−1 ≈ 0, and the only coherences that evolve are given by  . These coherences are generated by a non-zero
. These coherences are generated by a non-zero  , and then go on to generate non-zero populations in the undesired states T−1 and T1. This perturbation away from the desired state is weak because of two factors: (i)
, and then go on to generate non-zero populations in the undesired states T−1 and T1. This perturbation away from the desired state is weak because of two factors: (i)  can be made small when T0 = 1, since the deterministic position of j(t) is zero, and the averaging integral will dampen the fluctuations dW(t) over the period τI, and (ii) the coherences are dampened at a rate k/2, and therefore even when coherences are generated by non-zero
can be made small when T0 = 1, since the deterministic position of j(t) is zero, and the averaging integral will dampen the fluctuations dW(t) over the period τI, and (ii) the coherences are dampened at a rate k/2, and therefore even when coherences are generated by non-zero  , they can be quickly dampened by the measurement induced dephasing before they generate non-zero populations in the undesired states.
, they can be quickly dampened by the measurement induced dephasing before they generate non-zero populations in the undesired states.
It is clear that the integration time τI is an important parameter for the integral control strategy. Optimization of this parameter involves a tradeoff between smoothing and time delay in the feedback action as τI increases. Specifically, we can expect that a longer integration time τI will improve the concurrence, due to the reduced fluctuations, but because the signal is being averaged over a longer time window, it will take longer for deviations away from the target value to affect the averaged value, resulting in a time delay in the feedback action. To illustrate the resulting trade-off between short and long integration time choices, figure 4(a) plots the steady state average concurrence as a function of the filter integration time τI for I feedback. Note that the τI = 0 reference value refers to the proportional feedback strategy with no delay. The generic behavior shown here is found for any value of the feedback strength αi, i.e., for all αi values we see that the concurrence shows a maximum value at a non-zero optimal filter integration time. This optimal value of τI decreases as the control parameter αi increases (not shown). We also find that the system takes increasingly longer times to reach steady state as the feedback strength αi goes to zero, or as τI gets larger.
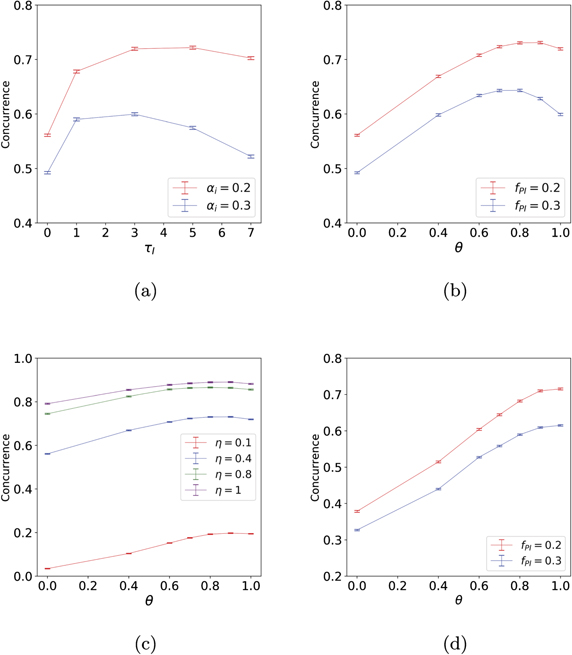
Figure 4. Steady state average concurrence dependence on integration time and relative weight of P and I control in PI control, measured by the mixing ratio θ, equation (19). For all calculations shown here, the initial state is taken to be the unentangled state T1 and all results are averaged over 8000 trajectories. (a) Steady state average concurrence vs integration time τI for pure integral (I) control, for intrinsic Hamiltonian parameters h1 = h2 = h = 0.1, measurement efficiency η = 0.4 and two different integral feedback coefficient values αi. (b) Steady state average concurrence vs mixing ratio θ for intrinsic Hamiltonian parameters h1 = h2 = h = 0.1, measurement efficiency η = 0.4 and PI feedback with different values of total feedback strength fPI. For fPI = 0.3 (blue line), the integration time for the integral component is τI = 1, for fPI = 0.2, (red line) τI = 3. (c) Steady state average concurrence vs the mixing ratio θ for intrinsic Hamiltonian parameters h1 = h2 = h = 0.1, and total feedback strength fPI = 0.2 with integration time τI = 3, under various values of measurement efficiency. (d) Steady state average concurrence vs. mixing ratio θ for intrinsic Hamiltonian parameters h1 = h2 = h = 0.5, and measurement efficiency η = 0.4 under PI feedback. For fPI = 0.3 (blue line) the integration time parameter is τI = 1 and for fPI = 0.2 (red line), τI = 3. The key difference with panel (b) is that here h = 0.5, and in this case I feedback is superior to any mixture of P and I feedback.
Download figure:
Standard image High-resolution imageFinally, we explore in more detail the possibility of full PI feedback, i.e., combining proportional and integral feedback for the problem of entangled state generation with inefficient measurements in this two qubit system. In figure 2(d) we already showed that there was a small benefit to combining both strategies for a particular set of coefficients. To study the performance of the combined strategy more systematically, we write
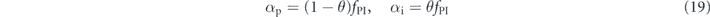
where fPI is the total feedback strength and θ ∈ [0, 1] is a mixing ratio quantifying the combination of the two strategies. In figure 4(b) we now plot the steady state average concurrence versus this strategy mixing ratio θ for PI feedback, while keeping the total feedback strength fPI constant. The plot shows the existence of an optimal mixing ratio θo located between ∼0.7 and ∼0.9, i.e., the optimal strategy is to have mostly integral control with some admixture of proportional control. The precise value of this optimal mixing ratio depends on the total feedback strength fPI. However, as shown in figure 4(c), θo is quite robust to variations in efficiency. Note that the maximum concurrence obtained by this PI feedback strategy for perfect efficiency, η = 1, is less than that obtained using the globally optimal P feedback strategy with time-dependent proportionality constant αp(t) [39, 53].
These results show that the advantage of PI control relative to pure I or pure P control increases as the total feedback strength parameter fPI increases. This can be seen by comparing the difference in steady state average concurrence between P, I and PI with optimal θo for fPI = 0.2 (red line) and fPI = 0.3 (blue line) in figure 4(b). Finally, we note that the optimal mixing ratio also depends on the system Hamiltonian, in particular, the value of h. In this case, for larger values of h, the optimal mixing parameter θo → 1 and the optimal feedback strategy becomes just I feedback. We show the concurrence versus θ curves for h = 0.5 in figure 4(d), for comparison with figure 4(b).
4. Harmonic oscillator state stabilization
State stabilization of a quantum harmonic oscillator is a canonical quantum feedback control problem that has been studied for several decades [6, 10, 29, 52, 69]. This problem has many practical applications, including the cooling and manipulation of trapped cold ions [70] or atoms [71], and cooling of nanoscale [72] or even macroscopic [73, 74] mechanical systems. Purely proportional feedback control schemes have been developed for this problem [6, 29, 52, 69]. In the following, we investigate whether adding integral control adds any benefit in terms of control accuracy.
The system is a quantum harmonic oscillator with mass m and angular frequency ω. We apply a continuous measurement of the oscillator position x with strength k (i.e.,  in the notation of the section 2) and efficiency η. The SME describing the system under measurement is [52]
in the notation of the section 2) and efficiency η. The SME describing the system under measurement is [52]
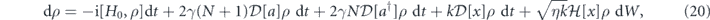
where H0 = p2/(2m) + mω2x2/2, p is the oscillator momentum operator and a is the annihilation operator. The terms proportional to γ describe damping and excitation due to coupling to a bosonic thermal bath with mean occupation N. The associated measurement signal is
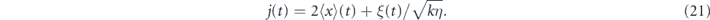
We shall consider two types of feedback for this system. First, we consider linear feedback in both x and p, in which case we have two feedback operators:

We will attach (time-dependent) proportional coefficients (αp1, αp2) and integral coefficients (αi1, αi2) to each of these feedback operators. The total feedback operator is then
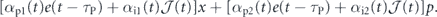
Applying F1 is usually considerably easier than F2, since the former corresponds to applying a force on the oscillator. Therefore, we will also consider the setting where only F1 is available, in which case we have only the coefficients αp1, αi1. Given the simplicity of the harmonic system, it is possible to set up analytic candidate control laws that are specified in terms of choices for the coefficients αp1, αp2, αi1, αi2, and to then assess whether they are consistent with P, I or PI feedback. The SMEs of harmonic oscillator for both cases (τP > 0 and τP = 0) are given by equations (B1) and (B2) in appendix
In the simplest setting where the system starts in a Gaussian state, the state remains Gaussian when evolved according to the above measurement and feedback dynamics since all operators acting on the density matrix are linear or quadratic in x, p [6, 52]. A Gaussian state is completely determined by its first moments ( ) and second moments (
) and second moments ( ,
,  ,
,  ). The evolution of the second moments under the above measurement, thermal damping, and feedback is independent of the feedback, and evolve deterministically, independent of the measurement noise, ξ(t) [6]. The equations of motion for the second moments are given by equation (C1) in appendix
). The evolution of the second moments under the above measurement, thermal damping, and feedback is independent of the feedback, and evolve deterministically, independent of the measurement noise, ξ(t) [6]. The equations of motion for the second moments are given by equation (C1) in appendix
Under the measurement and feedback dynamics described in equations (B1) and (B2), the evolution of the first moments are given by tr[x dρ(t)] and tr[p dρ(t)]:
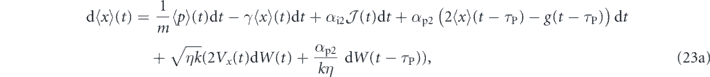
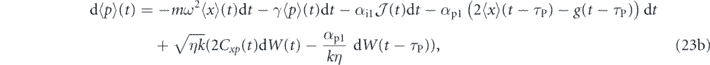
where τP ⩾ 0. In the limit of zero time delay, the equations of motion for the first moments are the same as above, with τP = 0 (this reduction for the evolution of the first moments of the quadratures is a special case since as noted above, taking τP = 0 in equation (12) does not yield equation (13)).
Our overall control goal is state stabilization, where the aim is to center the state at an arbitrary stationary (time-independent) value of the two quadrature means in the rotating frame of the oscillator, notated (Xg, Pg). In the laboratory frame this control goal is specified by the mean quadrature values (xg(t), pg(t)), which are related to (Xg, Pg) by the transformation
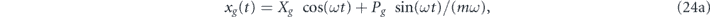
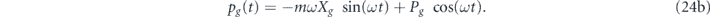
We note that the oscillator cooling problem [6] can be viewed as a special case of this state stabilization with the control goal (Xg = 0, Pg = 0).
The evolution of the first order moments in the rotating frame is given by
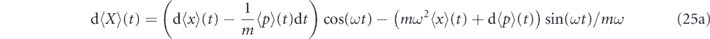
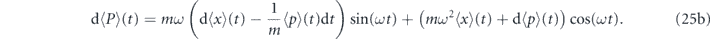
For later convenience we define the deviations from the target mean values in the rotating frame by  and
and  and put these deviations together in a vector
and put these deviations together in a vector ![$Z\left(t\right)\equiv {\left[\tilde {X}\left(t\right),\tilde {P}\left(t\right)\right]}^{\mathsf{T}}$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn32.gif) .
.
We must choose an error signal, e(t), that is based on this control goal and the measurement signal that we have access to. According to the description above, there are two components to the target state in this problem, one for each quadrature of the oscillator, i.e., Xg and Pg. However, since our measurements are made in the laboratory frame and we measure only the x-quadrature, from now on we shall specify the goal function to be g(t) = 2xg(t), so that the error signal is then e(t) = j(t) − 2xg(t).
Finally, we note that in this work we shall restrict ourselves to the regime of weak measurement and damping k, γ ≪ mω2, where the measurement extracts some information about the system at each timestep but does not completely distort the harmonic evolution. Similarly, the system is under-damped by the thermal bath. In this limit, it is valid to still define the characteristic period of the oscillator as T = 2π/ω.
In the following subsections we consider first the case of x measurement with feedback controls in both x and p (section 4.1) and then the case of x measurement with feedback control only in x (section 4.2).
4.1. x and p control
We now analyze the case of x measurement with feedback controls in both x and p.
4.1.1. Proportional feedback
We first consider proportional feedback only, i.e., αi1 = αi2 = 0 in equation (23). We shall show that the quadrature expectations of any state can be driven to the target values (Xg, Pg) by setting αp1(t) = 2kηCxp(t), αp2(t) = −2kηVx(t) and τP = 0. However, in order to compensate for the thermal damping, we also need to add a term γ(xg(t)p + pg(t)x) to the Hamiltonian H0 (note that this is not a feedback term, since it is not dependent on the measurement record). The evolution of the first moments of the oscillator with these settings is given in equations (C2) in appendix  and
and  evolve as:
evolve as:
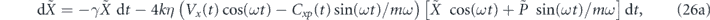
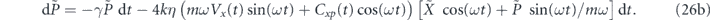
We now see that our choice of proportional feedback coefficients αp1(t) and αp2(t) has allowed the feedback to completely cancel all measurement noise contributions (captured by the dW terms), resulting in deterministic equations for the evolution of the mean values ⟨x⟩(t) and ⟨p⟩(t). The fact that such cancellation is possible was already noted in the early studies of feedback cooling of quantum oscillators [6]. In addition, as we shall prove explicitly below, these coefficients make use of the thermal and measurement induced dissipation to steer the system to the target quadrature mean values.
Figure 5(a) shows the evolution of the mean values of the quadratures in the rotating frame under this control law for an arbitrary initial state (specified in the caption). The evolution behavior suggests that this proportional control law yields exponential convergence to the goal quadrature values. To understand why this particular control law works and to prove the exponential nature of the convergence to the target state, we begin by noting that the coefficients in the system of differential equations in equation (26) display fast oscillations through the cos(ωt) and sin(ωt) terms, while the changes in the other time-dependent terms, Vx(t), Vp(t) and Cxp(t) are small over the timescale of these oscillations. Therefore we may approximate this evolution by another system with new coefficients defined by time-averaging the coefficients in equation (26) over one oscillator period T, and treating all time-varying quantities other than cos(ωt) and sin(ωt) as constants. For example,  since
since  , and Cxp(t)sin(ωt)cos(ωt) ≈ 0 since
, and Cxp(t)sin(ωt)cos(ωt) ≈ 0 since  . We refer to this approximation as period-averaging, but note that it is equivalent to the rotating wave approximation, since it amounts to dropping fast rotating terms in the evolution operator in the rotating frame. In appendix
. We refer to this approximation as period-averaging, but note that it is equivalent to the rotating wave approximation, since it amounts to dropping fast rotating terms in the evolution operator in the rotating frame. In appendix  (recall that
(recall that ![$Z\left(t\right)={\left[\tilde {X}\left(t\right),\tilde {P}\left(t\right)\right]}^{\mathsf{T}}$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn39.gif) ), with
), with
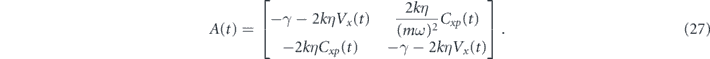
The deviation from the target mean values at time t is given by  . The matrix A(t) has eigenvalues
. The matrix A(t) has eigenvalues  , for which the real parts are negative for all t. Hence, this is a stable system that converges exponentially towards the
, for which the real parts are negative for all t. Hence, this is a stable system that converges exponentially towards the  fixed point. We may view the
fixed point. We may view the  as a vector Lyapunov function guaranteeing the stability of the final state [75]. This shows that for this choice of proportional feedback parameters one can completely cancel the measurement noise and obtain a deterministic system that exponentially stabilizes an arbitrary initial state.
as a vector Lyapunov function guaranteeing the stability of the final state [75]. This shows that for this choice of proportional feedback parameters one can completely cancel the measurement noise and obtain a deterministic system that exponentially stabilizes an arbitrary initial state.
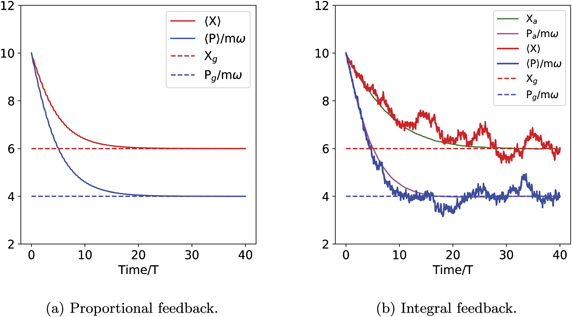
Figure 5. Evolution of expectation values of the quadratures of an oscillator in the rotating frame, subject to continuous measurement, x and p feedback control and thermal damping. The parameters of the system are as follows: m = ω = N = 1, γ = k = mω2/(50), η = 0.4. The initial state is set to ⟨X⟩ = 10, ⟨P⟩ = 10mω and the target values are set to Xg = 6, Pg = 4mω (marked by dotted lines in both subfigures). For these simulations we used dt = T/250 = 0.0251. (a) Proportional feedback. The equations for ⟨X⟩, ⟨P/mω⟩ are deterministic (equation (26)) and converge exponentially to the target values. (b) Integral feedback. The characteristic time τI for the exponential filter is set to 0.15T. The red and blue solid lines show the evolution of the expectations ⟨X⟩, ⟨P/mω⟩, for one trajectory. This evolution is now subject to measurement noise and is not deterministic (equation (29)). The green and purple lines show the behavior of the ensemble average over 1000 trajectories,  and
and  . The maximum standard deviation of the trajectories ⟨X⟩(t) and ⟨P⟩(t) increases with τI, saturating at 0.7610 at long times.
. The maximum standard deviation of the trajectories ⟨X⟩(t) and ⟨P⟩(t) increases with τI, saturating at 0.7610 at long times.
Download figure:
Standard image High-resolution imageThe P feedback strategy developed above requires τP = 0, a condition that is experimentally challenging to achieve due to the finite bandwidth of any feedback control loop. Therefore, we have also tested the performance of the feedback law when τP > 0, on order to investigate the robustness of this strategy. The effect of finite time delay on individual trajectories and on the average state evolution is shown in appendix  and
and  , still converge to the target values, although over a longer timescales than for the ideal τP = 0 setting [here
, still converge to the target values, although over a longer timescales than for the ideal τP = 0 setting [here ![$\mathbb{E}\left[\cdot \right]$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn48.gif) denotes an expectation over trajectories (measurement outcomes)]. However, the individual trajectories no longer converge for finite τp values, and fluctuate around the target values. A detailed analysis of this behavior is given in appendix
denotes an expectation over trajectories (measurement outcomes)]. However, the individual trajectories no longer converge for finite τp values, and fluctuate around the target values. A detailed analysis of this behavior is given in appendix
4.1.2. Integral feedback
Now we examine the dynamics obtained by setting αp1 = αp2 = 0 in equation (23), which corresponds to applying only integral control. The measurement current j(t) provides a noisy estimate of the oscillator position, so it is necessary to filter this in order to obtain a smoothed estimate of the error signal e(t). We use the following exponential filter with memory τI:
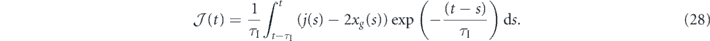
Our choices for the coefficients αi1 and αi2 in the presence of such an integral filter are motivated by the same factor as in the P feedback case above, namely to cancel as much of the measurement noise as possible. While it is not possible to do this exactly with I feedback, we show below that the choice αi1(t) = 2kηCxp(t) and αi2(t) = −2kηVx(t) does provide exponential convergence of the quadratures to their target values on average. As in the proportional feedback case, we also add a term γ(xg(t)p + pg(t)x) to the Hamiltonian H0 to compensate for thermal damping.
The evolution of d⟨x⟩ and d⟨p⟩ with these feedback settings is given in appendix  and
and  yields:
yields:

A typical evolution (trajectory), started from the same initial state as for the P feedback above, is shown in figure 5(b). We now see random fluctuations in the evolution of the quadrature expectations because the measurement noise has not been exactly cancelled by the I feedback. Indeed this is now not possible, since the measurement noise term dW(t) is arbitrarily varying while the integral feedback term is not. Consequently, single trajectories will fluctuate around the target values, preventing perfect state stabilization of individual evolutions. However, the average values of the quadratures (marked by the solid lines labeled Xa and Pa/mω in figure 5(b)) do converge exponentially to the goal values. In figure 5(b) and in subsequent figures where we show stochastic trajectories, we will state the 'maximum standard deviation' at steady state for these trajectories. The standard deviations of ⟨X⟩(t) and ⟨P⟩(t) (calculated over multiple trajectories) are the same but time-dependent and oscillatory at long times. However, this standard deviation is within a narrow range and thus we quote the maximum value over a time window in the steady state region (which is defined as when  and
and  reach constant values).
reach constant values).
To analyze this behavior and prove the exponential convergence of the average over trajectories, we again write equation (29) in matrix form as dZ(t) = AZ(t)dt + b(t)dt + c(t)dW(t), with
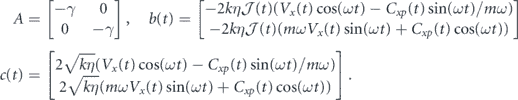
The solution to this system can be formally written as
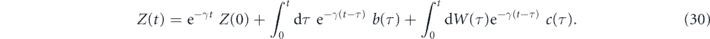
Note that as before, the second order moments evolve slower than cos(ωt), sin(ωt). Furthermore, since  is a smoothed measurement current, it also evolves slowly on the timescale of an oscillator period, T. Thus, we may neglect the second term since the integral over the rapidly oscillating sinusoidal terms will average to zero for t ≫ T. We cannot make the same argument for the third term, since dW(t) does not have finite variation over any interval. This third term is in fact what causes fluctuations of individual quadrature trajectories around their setpoint values in figure 5(b). However, note that since c(τ)e−γ(t−τ) is a non-anticipating function (alternatively, an adapted process that depends only on current and prior times, and independent of the Wiener process), we may conclude that the third term vanishes when averaged over many trajectories, i.e.,
is a smoothed measurement current, it also evolves slowly on the timescale of an oscillator period, T. Thus, we may neglect the second term since the integral over the rapidly oscillating sinusoidal terms will average to zero for t ≫ T. We cannot make the same argument for the third term, since dW(t) does not have finite variation over any interval. This third term is in fact what causes fluctuations of individual quadrature trajectories around their setpoint values in figure 5(b). However, note that since c(τ)e−γ(t−τ) is a non-anticipating function (alternatively, an adapted process that depends only on current and prior times, and independent of the Wiener process), we may conclude that the third term vanishes when averaged over many trajectories, i.e.,  [76]. This leaves only the first, exponentially decaying term, for the average quadrature values and is therefore the reason for the exponential convergence of the ensemble average to the target values. This analysis also shows that the rate of convergence is slower for I feedback than for P feedback, for which there is an additional contribution of −2kηVx(t) to the convergence rate, see equation (27).
[76]. This leaves only the first, exponentially decaying term, for the average quadrature values and is therefore the reason for the exponential convergence of the ensemble average to the target values. This analysis also shows that the rate of convergence is slower for I feedback than for P feedback, for which there is an additional contribution of −2kηVx(t) to the convergence rate, see equation (27).
This first analysis of control of state stabilization for the harmonic oscillator has shown that when access to both x and p control is given, the performance of purely proportional feedback with zero time delay is not improved by adding integral feedback. Indeed, both P and I feedback strategies converge exponentially to the target state when an ensemble average over I feedback trajectories is taken. This shows that state estimation [6] is not necessary to drive a harmonic oscillator to an arbitrary quantum state in the presence of thermal noise. However, when comparing the P and I strategies, it is evident that the P feedback is advantageous for two reasons. The first is that with zero time delay there exists a proportional feedback law that can perfectly cancel the measurement noise perturbations to the system for each individual trajectory, whereas this can only be approximately canceled under an integral feedback strategy for an individual trajectory, resulting in fluctuations about the target mean quadrature values for any given trajectory. The second is a faster convergence for P feedback. Given the superior performance of P feedback over I feedback in this setting, we conclude that is not advantageous to consider a more general PI feedback protocol when P feedback with zero time delay is possible.
For time delays greater than the ideal τP = 0 the stabilization performance of P feedback strategy degrades, with individual trajectories fluctuating around the target quadrature expectation values and these fluctuations having greater variance as the time delay is increased, although the ensemble average still converges to the target state (appendix
4.2. x control only
Our second analysis of control of state stabilization for the harmonic oscillator considers the case of x measurement with only a single control, namely feedback control in x. Under x control only, we set αp2 = αi2 = 0, and therefore have a single feedback operator, F1 = x.
4.2.1. Proportional control
As before, we first consider proportional control alone, i.e., αi1 is also set to zero. Our feedback operator is x, and thus the feedback applies a force. Ideally we want this force to be proportional to −(⟨p⟩(t) − pg(t)) in order to cancel the measurement noise. However, since we are measuring only the position, we do not have direct access to the momentum observable. This is manifest in the dynamical equations in equation (23) by the fact that the only deterministic term involving αp1 is the term −αp1(2⟨x⟩(t − τP) − g(t − τP))dt in the equation for d⟨p⟩(t). This term does not appear to be useful for controlling the oscillator momentum, because it contains information about ⟨x⟩ rather than ⟨p⟩. Indeed, we find that the trajectories for evolution of the mean values do not show convergent behavior when implementing proportional x feedback with τP = 0. Noting that for a harmonic oscillator the average position and momentum have a T/4 relative delay (see also [52]), in the weak measurement and damping limit (k, γ ≪ mω2) we can take a delayed signal term ⟨x⟩(t − T/4) to be a good approximation to the scaled oscillator momentum −⟨p⟩(t)/(mω). This allows formulation of a good control law based on delayed proportional feedback with τP = T/4. One can then follow the same line of reasoning outlined above in section 4.1 to tune the strength and offset of the feedback coefficient in order to achieve noise cancellation. Specifically, we set αp1 = −2kηVxmω with τP = T/4. We similarly add a term γpg(t)x to H0 in order to compensate for thermal damping. Note that full compensation of the effects of thermal damping requires adding a term γ(xg(t)p + pg(t)x), however, consistent with the assumption in this subsection that there is no direct control over the oscillator momentum, we add only the term γpg(t)x. The resulting dynamical equations for the mean quadratures are given in appendix
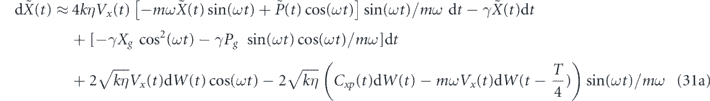
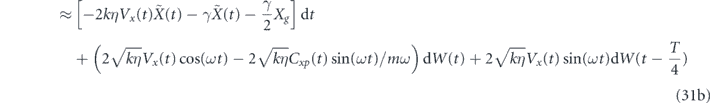
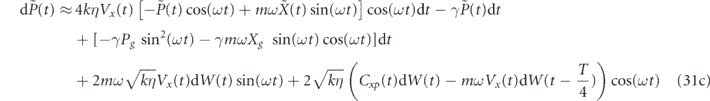
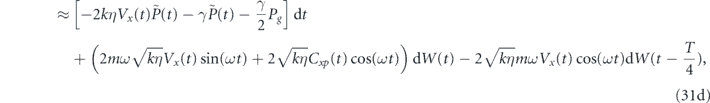
where in the second line of each equation we have applied the period-averaging approximation to the deterministic terms, and regrouped the stochastic terms.
The inability to actuate the oscillator momentum in this situation introduces two negative features into these equations relative to equation (26), for which both x and p control are available. The first is that we cannot perfectly cancel the measurement noise, resulting in the presence of stochastic terms. The second is that we cannot simply compensate for the thermal damping of oscillator momentum by adding a term γxgp to H0. This leads to the  and
and  terms in the period-averaged equations. The first point is not a serious hindrance to stabilization, because in the weak measurement limit the effect of the noise is small and leads primarily to fluctuations around the target values. However, the second point is more serious, since the inability to suppress thermal damping means that the system will be driven to a state that is different from the target state. In appendix
terms in the period-averaged equations. The first point is not a serious hindrance to stabilization, because in the weak measurement limit the effect of the noise is small and leads primarily to fluctuations around the target values. However, the second point is more serious, since the inability to suppress thermal damping means that the system will be driven to a state that is different from the target state. In appendix
With this compensation trick solving the thermal damping issue for this constrained control setting, we can obtain very good stabilization behavior of individual trajectories to the desired target values, with relatively small fluctuations about these, as shown in figure 9(a) in appendix
As in the case of x and p actuation, this P feedback strategy requires a precise value for the feedback loop time delay τP. Here the desired value of τP is non-zero, and is thus experimentally less demanding to realize than the ideal P feedback strategy with x and p actuation for which τP = 0 (section 4.1.1). However, it might still be challenging to engineer a feedback loop with a precise value of delay τP = T/4. To assess the robustness of the strategy with respect to uncertainties in τP, we also analyzed the stabilization performance of this P feedback strategy for larger time delays, i.e., τP = T/4 +  . Results for several values of are shown in appendix > 0. The fluctuations of individual trajectories of quadrature expectation increase with , and there is also a bias in the long-time values of these expectations; i.e., the ensemble average values
. Results for several values of are shown in appendix > 0. The fluctuations of individual trajectories of quadrature expectation increase with , and there is also a bias in the long-time values of these expectations; i.e., the ensemble average values  and
and  do not converge to the target values. This error in convergence is appreciable even for offsets as small as = 0.05T and increases with .
do not converge to the target values. This error in convergence is appreciable even for offsets as small as = 0.05T and increases with .
4.2.2. Integral control
We now study the case of integral feedback when only one feedback operator is available, again choosing F1 = x. On setting αp2 = αi2 = αp1 = 0 in equation (23), it is apparent that the only control handle into the system now comes from the  term. As we learned above, the key to stabilizing the system with F1 = x alone is to construct an estimator of the oscillator momentum. For P feedback we used a time delay to achieve this. Here we will construct an estimator with the integral filter.
term. As we learned above, the key to stabilizing the system with F1 = x alone is to construct an estimator of the oscillator momentum. For P feedback we used a time delay to achieve this. Here we will construct an estimator with the integral filter.
Following Doherty et al [52], we first modulate the measurement signal to form estimates of the oscillator quadrature deviations in the rotating frame:
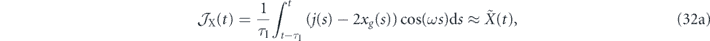
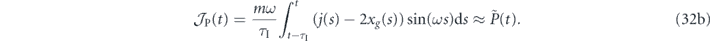
Using equation (24) these integrals of the measurement record can be combined to yield an estimator of the error between ⟨p⟩(t) and pg(t):
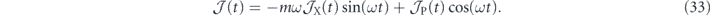
We choose αi1(t) = 4kηVx(t) to achieve measurement noise cancellation and convergence to the target state. The resulting dynamic evolution of the quadrature means are given in appendix
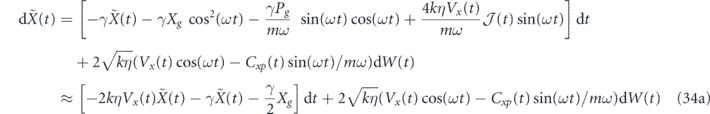
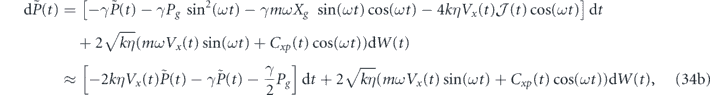
where in the second line of each equation we have used the period-averaging approximation and the approximations  and
and  .
.
These equations have the same form as equation (31), including exactly the same deterministic terms. Therefore, as shown in appendix
Both the P and I feedback trajectories shown in figure 9 show stochastic noise. Since the feedback in the integral strategy is conditioned on a tempered version of the noise instead of on the instantaneous noise, we can expect that this smoothing of the noise should give the integral strategy a relative advantage over the purely proportional strategy here. While the noise does appear smaller in the I trajectory (compare figure 9(b) with 9(a)), it is difficult ascertain the effect of this on the overall performance of the control strategy by examining single trajectories. To enable a quantitative comparison between the performance of the two control strategies in this situation, we therefore define the following average error metric that quantifies the deviation from the control goals when averaged over all measurement trajectories:
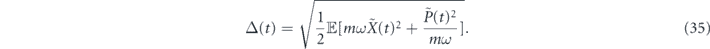
We estimate this error by simulating a large ensemble of trajectories with P or I feedback control. In figure 6 we plot the long-time value of this average error, i.e., when it reaches a constant value, as a function of the measurement efficiency, η. This plot shows that I feedback consistently gives a smaller error and thus performs better than P feedback over essentially the full range of measurement efficiency η.
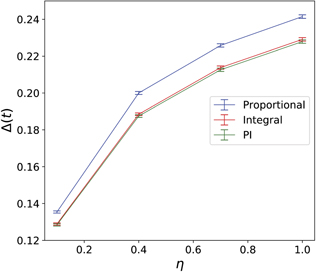
Figure 6. The long time control error, Δ(t → ∞), as a function of the measurement efficiency, η, for the case of feedback with F1 = x actuation only. The P feedback with time delay strategy is shown in blue, the I strategy is shown in red, and the PI strategy with θ = 0.8 (see main text for explanation of this mixing ratio θ) is shown in green. The parameters of the harmonic oscillator are m = ω = N = 1, k = γ = mω2/50, and the target values are set to Xg = 6, Pg/mω = 4. For P feedback, the time delay is τP = T/4. For I feedback, the integration time parameter is τI = T/2. The error is calculated in all cases by averaging over 20 000 trajectories.
Download figure:
Standard image High-resolution imageIn summary, when we only have access to the F1 = x control operator, we do not have sufficient control degrees of freedom to follow the strategy of both cancelling the noise and engineering convergence to the target values, as was possible for P feedback in section 4.1. However, we have seen that by forming momentum estimators (via use of time delay in the P feedback case, and via integral approximations of the quadratures in the I feedback case), we can still achieve effective control, with exponential convergence as before. We find that with this approach, both P and I feedback achieve similar control accuracy, with I feedback performing slightly better on average and the difference increasing with greater measurement efficiency η. Moreover, both of these P and I feedback strategies show the same rate of convergence to the target quadrature mean values, as is evident from the fact that (within the period-averaging approximation) equations (31) and (34) have the same deterministic terms. However, neither of these strategies guarantee convergence of individual trajectories. Also we note that the P feedback strategy is very sensitive to the exact value of the time delay, for which the ideal value is τP = T/4. Deviations from this ideal value result in inadequate stabilization performance, with failure to reach the target state even on average.
Given the similar performance of P and I feedback in this scenario and the lack of robustness of P feedback to variations in the time delay, one might not expect a significant benefit to combining the two to construct a PI feedback strategy. To assess this, we write  and
and  where αp1(t) and αi1(t) are the values determined above, and θ ∈ [0, 1] is a mixing ratio quantifying the combination of the two strategies. In figure 6 we plot the long time control error for θ = 0.8 (the long time control error is minimum, and almost the same, for any value of θ in the interval [0.8, 1]) and note that indeed, there is little statistically significant benefit to combining P and I feedback in this scenario.
where αp1(t) and αi1(t) are the values determined above, and θ ∈ [0, 1] is a mixing ratio quantifying the combination of the two strategies. In figure 6 we plot the long time control error for θ = 0.8 (the long time control error is minimum, and almost the same, for any value of θ in the interval [0.8, 1]) and note that indeed, there is little statistically significant benefit to combining P and I feedback in this scenario.
5. Discussion and conclusions
We have presented and implemented a formalism for modeling proportional and integral (PI) feedback control in quantum systems for which, as in the case of classical PI feedback control, we allow the feedback to be tuned from a purely proportional feedback strategy (P feedback, including the possibility of delay) to a purely integral feedback (I feedback), with a combined strategy at any point in between (PI feedback). In this approach both proportional and integral feedback components are defined in terms of the measurement outcomes only, i.e., no dependence on knowledge of the quantum state is assumed. Consequently we did not seek globally optimal protocols, rather the best performance within the options of P, I, and PI feedback, given the ability to feedback quantum operations based only on the measurement record. For a given implementation we then first compared the performance of separate P feedback and I feedback control strategies, with and without the presence of time delay in the former, and then carried out a PI feedback strategy, following an assessment of whether or not this might be beneficial.
We implemented this quantum PI feedback approach in this work for two canonical quantum control problems, namely entanglement generation of remote qubits by non-local measurements with local feedback operations, and stabilization of a harmonic oscillator to arbitrary target values of its quadrature expectations when subject to thermal noise.
Our first case study was the generation of entanglement by measurement of collective operators of two non-interacting qubits, combined with local feedback operations, for arbitrary measurement efficiency η ⩽ 1 and time-independent proportionality constant αp. Unlike the situation for η = 1 and more general time-dependent P feedback [39], our more restricted—but experimentally relevant—case is unable to completely cancel measurement noise, regardless of the value of η. Here we found that an I feedback strategy can improve on P feedback and achieve superior performance, essentially because an I strategy is able to formulate a smoothed estimate of the error signal by means of the integral filter. This situation is reminiscent of PI feedback control in classical systems [55] and this case provides strong motivation for the formulation of a general PI feedback law that combines the P and I feedback strategies. We numerically determined an optimal mixing ratio between P and I feedback for this problem of remote entanglement generation, showed that this optimal value can depend on the overall feedback strength and system Hamiltonian, and demonstrated that PI feedback can be beneficial over both the I and P feedback strategies in some cases.
In the case of the harmonic oscillator, as in previous work on cooling of a harmonic oscillator [6], we studied two settings of feedback control based on measurement of the position degree of freedom x, which is generally easier to measure than the momentum p. In the first setting, it is possible to actuate both x and p degrees of freedom of the oscillator, while in the second regime it is possible to only actuate x, i.e., to apply a force. The first setting allows formulation of a P feedback strategy that can perfectly cancel the measurement backaction noise entering the system, resulting in a deterministic evolution of the average state [6]. In this setting, adding a Hamiltonian drive to compensate for thermal damping results in a P feedback strategy that allows any state to be exponentially driven to the target quadrature expectation values, without any measurement induced fluctuations. In contrast, while an I feedback strategy that is exponentially convergent can also be formulated, integral feedback terms are regular and cannot completely cancel the measurement noise. This results in a somewhat slower rate of stabilization and considerable fluctuations in the quadrature expectations for individual trajectories, implying that a PI feedback strategy is not as effective as a P feedback strategy with zero time delay. However the ensemble average does converge exponentially to the target quadratures, indicating zero bias of the ensemble in the long-time quadrature expectations.
In the second harmonic oscillator setting, with control only over the x degree of freedom, complete cancellation of the measurement noise can no longer be made, even in a P feedback strategy. However, by using a time delay in P feedback and integral filters in I feedback to obtain estimates of the time-dependent oscillator momentum, we found that it is nevertheless still possible to formulate good feedback control laws that achieve exponential convergence of quadrature expectation values on average, with relatively small measurement noise induced fluctuations of individual trajectories around their target values. In this case, we consistently found a small advantage of I feedback over P feedback for all efficiencies η, with the former also showing smaller fluctuations around the goal. This was seen to stem from the fact that I feedback can derive a smoother estimate of the oscillator momentum through use of an integral filter, and thus allows us to engineer a system with more controlled and smaller fluctuations around the target quadrature mean values.
Thus for the harmonic oscillator state stabilization, we find the best performance with a pure P strategy when both x and p controls are available, and the best performance with a pure I feedback strategy when only x control is available. We found little significant advantage in formulating a general mixed PI feedback strategy for the harmonic oscillator state stabilization. Although we make no claims about the optimality of any of these feedback control strategies for the harmonic oscillator, a significant feature of our analysis is the proof that all of them lead to exponential convergence of the expectation values of the oscillator quadratures to their goal values. We emphasize that this convergence analysis has been restricted to the parameter regime where a period-averaging (i.e., rotating wave) approximation is valid. It is possible that this landscape of PI feedback performance could change outside this regime, which is a potential topic for further study.
We also examined the robustness of the P feedback strategies to imperfect time delay, investigating the effects of larger values of τP than specified by the ideal control law. We found that the harmonic oscillator state stabilization example when both x and p actuation are available is the most robust to finite time delays, with the quadrature expectations at long time having zero bias from their target values (i.e.,  and
and  ), but with fluctuations from the target values that increase with time delay. Meanwhile, both the harmonic oscillator with only x actuation and the two qubit remote entanglement example are very sensitive to deviations of τP away from the ideal specified value, with performance degrading rapidly as the deviation increases. For the latter cases, the I feedback strategy will therefore be preferred when the perfect time delay condition cannot be met.
), but with fluctuations from the target values that increase with time delay. Meanwhile, both the harmonic oscillator with only x actuation and the two qubit remote entanglement example are very sensitive to deviations of τP away from the ideal specified value, with performance degrading rapidly as the deviation increases. For the latter cases, the I feedback strategy will therefore be preferred when the perfect time delay condition cannot be met.
These case studies reveal a key difference between the benefits of PI feedback in the quantum and classical domains. In the quantum case, there is an unavoidable correlation between the noise experienced by the system and the noise in the measurement signal. This is not always the case in classical systems, where the 'process noise' that the system experiences is often independent of the measurement noise. This difference means that P feedback strategies can play a unique and potentially more powerful role in the quantum domain than they typically do in the classical domain. In particular, in some circumstances, depending on the feedback actuation degrees of freedom, a P feedback strategy can perfectly cancel the noise that the system experiences, while an I feedback strategy can only approximately cancel this noise. Of course, one can get the same behavior in special classical systems, e.g., linear systems with zero process noise. In cases where this perfect cancellation is not possible, whether this is due to time delay or other constraints on the feedback action, we saw that I feedback can outperform P feedback, because it provides a smoothed version of the measurement/process noise. This beneficial value of I feedback is similar to that seen in classical PI feedback control.
Several possibilities for extending this work are immediately evident. Firstly, formulating optimal forms of PI feedback in the quantum domain would be beneficial, even for paradigmatic systems that are analytically tractable like the harmonic oscillator example treated here. The results in the current work indicate that such optimality studies would be particularly useful for feedback control in situations with inefficient measurements (see e.g., [54]). Secondly, the development of heuristic methods for tuning the optimal proportions of P and I feedback for any system, analogous to those that exist for classical PI feedback control [55] is an interesting direction. Here, it would be of interest to determine the optimal strategies under constraints of finite measurement and feedback bandwidth, in contrast to the infinite bandwidth controls implicitly assumed in this work, but still without state estimation. Exploration of robust methods to address the implementation of differential control terms to allow implementation of quantum PID control would also be valuable. Finally, our demonstration of the beneficial effects of integral control strategies for generation of entangled states of qubits under inefficient measurements within the range of current capabilities [64], indicate good prospects for experimental demonstration of quantum PI feedback in the near future.
Acknowledgments
HC acknowledges the China Scholarship Council (Grant 201706230189) for support of an exchange studentship at the University of California, Berkeley. HL, FM, and KBW were supported in part by the DARPA QUEST program. LM was supported by the National Science Foundation Graduate Fellowship Grant No. 1106400 and the Berkeley Fellowship for Graduate Study. MS was supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, under the Quantum Computing Application Teams. Sandia National Laboratories is a multimission laboratory managed and operated by National Technology & Engineering Solutions of Sandia, LLC, a wholly owned subsidiary of Honeywell International Inc., for the U.S. Department of Energy's National Nuclear Security Administration under contract DE-NA0003525. This paper describes objective technical results and analysis. Any subjective views or opinions that might be expressed in the paper do not necessarily represent the views of the U.S. Department of Energy or the United States Government.
Appendix A.: Two-qubit entanglement generation
The SME that describes the evolution of the two-qubit system for τP = 0 is
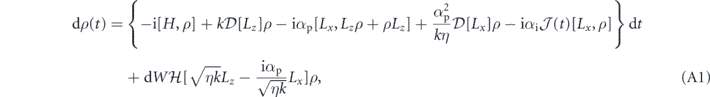
and for τP > 0
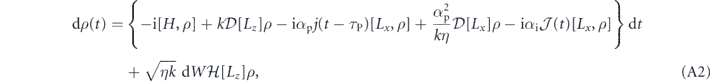
where αp and αi are the proportional and integral feedback coefficients, and as mentioned in the main text above, we have set the goal g(t) = ⟨T0|Lz|T0⟩ = 0.
In this appendix we write in full the non-linear stochastic equation of motion of the triplet state populations and coherences for the two-qubit example treated in the main text. We keep things general and do not assume h1 = h2 in this appendix.
The measurement current is
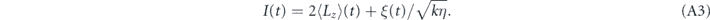
We denote the populations of the triplet and singlet two-qubit states as T± = tr(ρ|T±⟩⟨T±|), T0 = tr(ρ|T0⟩⟨T0|), and TS = tr(ρ|S⟩⟨S|). If the initial state is in the triplet subspace, the subsequent evolution will stay within this subspace under the action of the half-parity measurement and local feedback operations ∝σx1 + σx2.
The evolution of the triplet state populations is given by
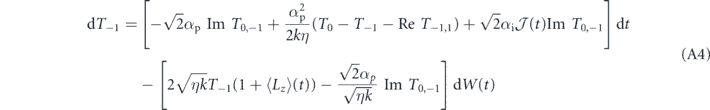
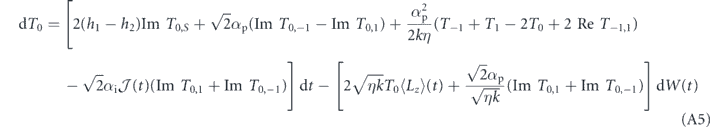
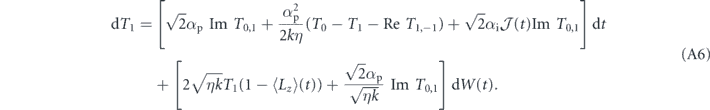
The corresponding coherence terms within the triplet subspace are

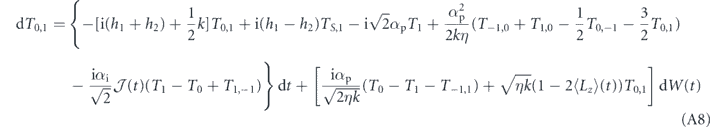
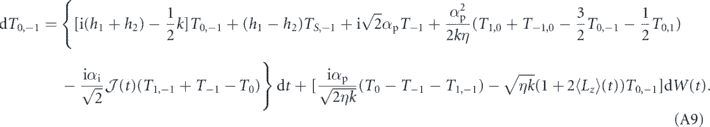
Ts,i are coherences with the singlet state, which come into play if h1 ≠ h2.
This system of nonlinear SDEs cannot be solved for directly, except in the special case of P feedback with zero time delay, i.e., αp > 0, αi = 0, τP = 0. In this case, the SDEs are Markovian and we can directly get the evolution equations for the ensemble average by simply discarding the stochastic terms [77]. In this case, we can solve for the steady state of  to get
to get
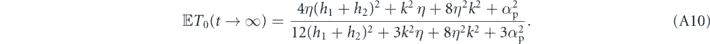
This expression shows that the steady state average population in the desired state increases with decreasing αp. However, from simulations we also see that the system takes longer to converge to the steady state as αp decreases. Finally, we note that ![$\mathbb{E}\left[{T}_{0}\left(t\to \infty \right)\right]{< }1$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn67.gif) always.
always.
Appendix B.: SME of harmonic oscillator
For τP > 0, the evolution of the system with PI feedback control is obtained from equation (12) as
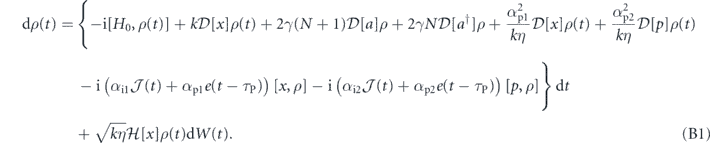
For τP = 0, the evolution of the system with PI feedback control is obtained from equation (13) as

In both cases g(t) is a goal that we define in the main text, with e(t) the corresponding error signal. The proportional feedback component is the same as in reference [6], except that in this work we also consider a time delay τP > 0 in the feedback loop.
Appendix C.: Equations for first and second moments of harmonic oscillator under PI feedback
A.1. Second moments
The equations of motion of the second moments of the oscillator can be derived by evaluation of tr[Vx dρ(t)] = tr[(x − ⟨x⟩)2dρ(t)], etc. These evolve as
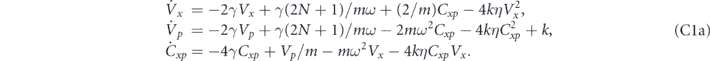
Note that there is no dependence of these equations on the first moments, the feedback operator or on the measurement record. Figure 7 shows representative evolution of these second moments for system parameters used in the main text (m = ω = N = 1, k = γ = 1/50, η = 0.4).
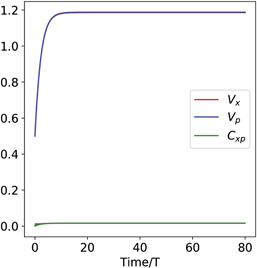
Figure 7. Example evolution of harmonic oscillator second order moments according to equation (C1) for m = ω = N = 1, k = γ = 1/50, η = 0.4.
Download figure:
Standard image High-resolution imageA.2. First moments: x and p control, proportional feedback
The evolution of the first moments of the oscillator with x and p actuation and proportional feedback with the feedback coefficients specified in section 4.1.1 is given by
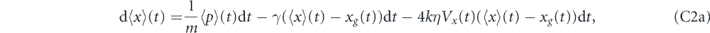
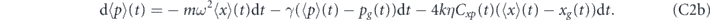
A.3. First moments: x and p control, integral feedback
The evolution of the first moments of the oscillator with x and p actuation and integral feedback with the feedback coefficients specified in section 4.1.2 is given by
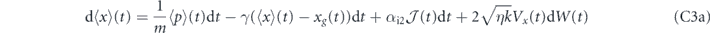
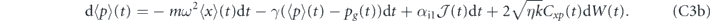
A.4. First moments: x control, proportional feedback
The evolution of the first moments of the oscillator with x actuation only and proportional feedback with the feedback coefficients specified in section 4.2.1 is given by
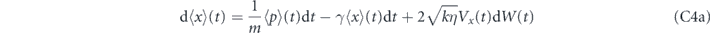
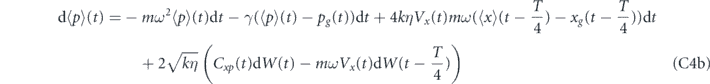
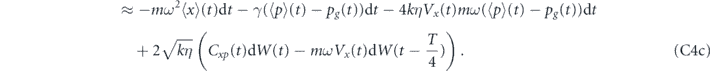
A.5. First moments: x control, integral feedback
The evolution of the first moments of the oscillator with x actuation only and integral feedback with the feedback coefficients specified in section 4.2.2 is given by
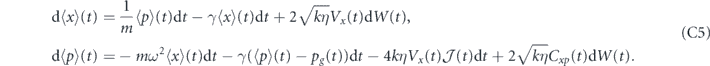
Appendix D.: Quality of the period-averaging approximation
Here we evaluate the quality of the period-averaging approximation used in section 4 of the main text. Consider the deterministic evolution of the oscillator mean deviations  and
and  in equation (26), and its period-averaged approximation in equation (27). In figure 8 we plot the evolution of the oscillator means in the rotating frame, X(t) and P(t), under the exact dynamical equation and its period-averaged approximation for oscillator parameters m = ω = N = 1, κ = γ = 1/50, η = 0.4, initial conditions X0 = P0 = 10, and target values Xg = 6, Pg = 4. We see that there is very good agreement between the exact and approximate evolution.
in equation (26), and its period-averaged approximation in equation (27). In figure 8 we plot the evolution of the oscillator means in the rotating frame, X(t) and P(t), under the exact dynamical equation and its period-averaged approximation for oscillator parameters m = ω = N = 1, κ = γ = 1/50, η = 0.4, initial conditions X0 = P0 = 10, and target values Xg = 6, Pg = 4. We see that there is very good agreement between the exact and approximate evolution.
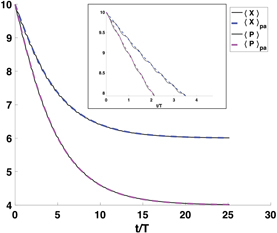
Figure 8. Evolution of X and P quadratures in the rotating frame of an oscillator subject to x and p proportional feedback controls, under the exact evolution (solid, black lines) and the period-averaged evolution (dashed, colored lines). The system parameters are m = ω = N = 1, κ = γ = 1/50, η = 0.4, initial conditions X0 = P0 = 10, and target values Xg = 6, Pg = 4. The inset is a zoom into the early time scale when the deviation between exact and approximate evolution is greatest.
Download figure:
Standard image High-resolution imageAppendix E.: Steady-state compensation for harmonic oscillator with x actuation only
As stated in the main text, under x actuation only, time-delayed proportional feedback results in the following evolution equations for the deviations in the rotating frame:
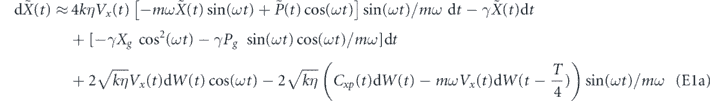
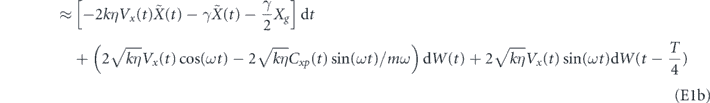
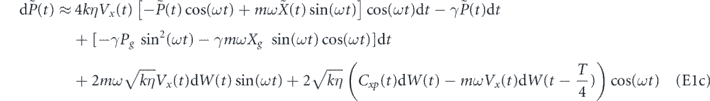
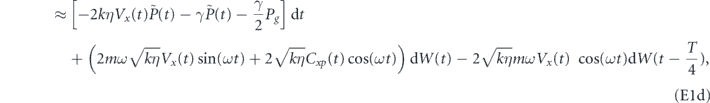
where in the second line of each equation we have applied the period-averaging approximation of section 4 to the deterministic terms, and regrouped the stochastic terms.
We will show below that this system is driven to a steady state with ensemble average quadrature values (where the ensemble average is taken over many trajectories) given by ![$\mathbb{E}\left[\langle X\rangle \left(t\to \infty \right)\right]=\alpha {X}_{g}$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn70.gif) and
and ![$\mathbb{E}\left[\langle P\rangle \left(t\to \infty \right)\right]=\beta {P}_{g}$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn71.gif) , with α < 1 and β < 1.
, with α < 1 and β < 1.
Inspection of equation (E1) shows that one can correct this incorrect ensemble average steady state of the evolution by scaling the target quadrature mean values Xg and Pg to compensate for α, β, if these two coefficients can be determined. To do this, we write the solution of equation (E1) under the period-averaging approximation in matrix form as
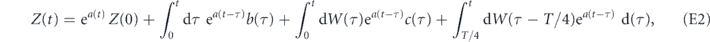
with
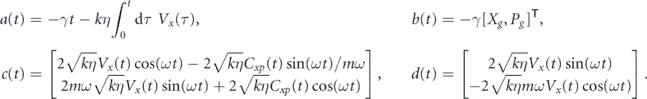
The first term is exponentially decaying to zero. The second term provides a deterministic offset from zero at long times, which is exactly what leads to the α, β scaling factors in the steady state. The third and fourth terms generate fluctuations on all trajectories. However, since ea(t−τ) c(τ) and ea(t−τ) d(τ) are non-anticipating functions (they are independent of the Wiener process), both of these terms will be zero when the expectation value over different measurement realizations are taken. Therefore, we can solve for the ensemble average steady state by dropping the stochastic terms and evaluating the t → ∞ value of equation (E2) (or equivalently dropping the stochastic terms from equations (E1b) and (E1d) and solving for the steady state). Doing this yields  , where
, where  is the steady state of this second moment. We note that this expression for α and β is approximate, because we have solved for the steady state from equation (E2) which was derived under the period-averaged evolution and we also assumed that ⟨x⟩(t − T/4) ≈ ⟨p⟩(t)/mω in formulating our control law. However, both of these approximations are very well justified in the γ, κ ≪ mω limit, so that the corresponding expressions provide excellent estimates of the average steady state for the trajectory. Knowing the values of α, β(=α), we can then compensate for the thermal damping by setting
is the steady state of this second moment. We note that this expression for α and β is approximate, because we have solved for the steady state from equation (E2) which was derived under the period-averaged evolution and we also assumed that ⟨x⟩(t − T/4) ≈ ⟨p⟩(t)/mω in formulating our control law. However, both of these approximations are very well justified in the γ, κ ≪ mω limit, so that the corresponding expressions provide excellent estimates of the average steady state for the trajectory. Knowing the values of α, β(=α), we can then compensate for the thermal damping by setting  and
and  , where
, where  are the true target values of the quadrature means1. Note that this implies a similar rescaling of the laboratory frame target values, i.e.,
are the true target values of the quadrature means1. Note that this implies a similar rescaling of the laboratory frame target values, i.e.,  ,
,  (figure 9).
(figure 9).
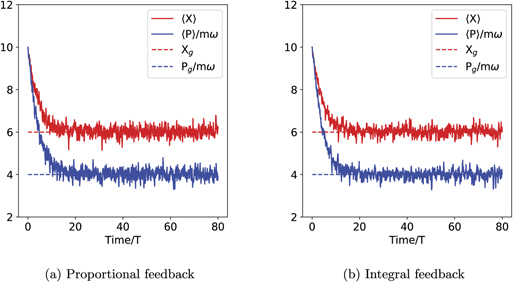
Figure 9. Evolution of X and P quadratures in the rotating frame of an oscillator subject to an x feedback Hamiltonian alone (representative individual trajectories). The parameters of the oscillator are as follows: m = ω = N = 1, η = 0.4, k = γ = mω2/(50). The initial state is set to ⟨X⟩ = 10, ⟨P/mω⟩ = 10 and the target values are Xg = 6, Pg = 4mω (marked by dotted lines in both panels). For these simulations we used dt = T/500 = 0.0126. (a) Proportional feedback control, simulated by equation (31) with time delay τP = T/4. Maximum standard deviation of ⟨X⟩ and ⟨P/mω⟩ in steady state is 0.2420. (b) Integral feedback control, simulated by equation (34) with τI' = T/2. Maximum standard deviation of ⟨X⟩ and ⟨P/mω⟩ in steady state is 0.2395. The steady state compensation in terms of the α, β discussed in the text is incorporated into both of these simulations, with α = β ≈ 0.7434.
Download figure:
Standard image High-resolution imageAppendix F.: Harmonic oscillator stabilization: effect of time delays on P feedback strategies
For the harmonic oscillator state stabilization example presented in the main text, we derived effective P feedback strategies in the case of x and p actuation, and of x actuation only. In the former case, the P feedback strategy required zero time delay, τP = 0, while in the latter, formulating a momentum estimate required a time delay of τP = T/4.
Given that any real feedback loop will have some time delay, and that sometimes it is difficult to make this delay small compared to the natural timescales of the system being controlled, we study the impact of larger-than-desired time delays on the P feedback strategies in this appendix, to examine their robustness with respect to variations in τP.
F.1. x and p control
In the case where x and p actuation is available, figure 5(a) of the main text shows that the ideal P feedback strategy with τP = 0 achieves deterministic and exponential convergence of the quadrature expectations to their target values. In figure 10 we show the behavior of the quadrature expectations for finite delay times, τP > 0. The trajectories are very different from the case of τP = 0, showing increasing noise as τP increases. This is expected, since with a finite time delay we no longer exactly cancel the measurement-induced fluctuations. While the ensemble average of the trajectories still converges to the target state (left panels of figure 10), albeit at a slower rate than for τP = 0, individual trajectories fluctuate around the target quadrature values. Thus with τP > 0 the long-time behavior of the quadrature expectations has zero bias from the target values (i.e.,  and
and  ), but non-zero variance.
), but non-zero variance.
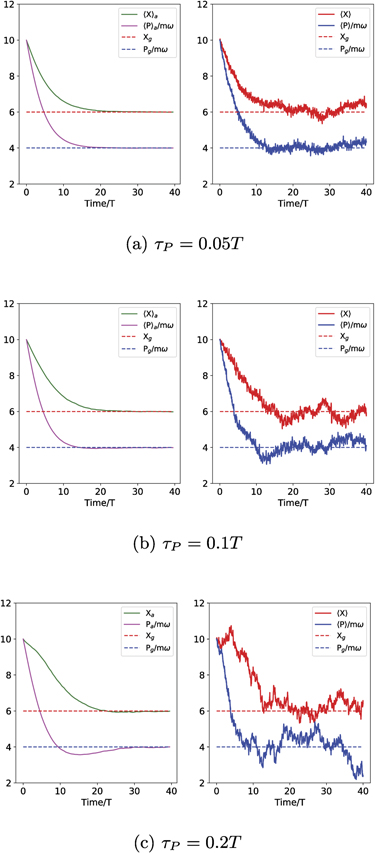
Figure 10. The effect of time delays on the P feedback law when x and p actuation are available (section 4.1.1). The subfigures show three values for the time delay. The left panel in each subfigure shows the ensemble average of the quadrature expectations,  and
and  over 1000 trajectories, and the right panel shows a representative trajectory. The maximum standard deviation of the trajectories at long times are 0.245, 0.397, 0.837, for τP = 0.05T, 0.1T, 0.2T, respectively.
over 1000 trajectories, and the right panel shows a representative trajectory. The maximum standard deviation of the trajectories at long times are 0.245, 0.397, 0.837, for τP = 0.05T, 0.1T, 0.2T, respectively.
Download figure:
Standard image High-resolution imageThe zero bias property of the quadrature expectations from their target values at long times can be proved rigorously. We return to the equations of motion for the quadratures in the presence of finite time delay, equation (25), transform to the rotating frame and then, consistent with averaging over an ensemble of trajectories, drop the stochastic terms to obtain coupled deterministic equations for the deviations  and
and  . This is all done while retaining a finite value of τP. Following the notation of the main text, we then arrive at
. This is all done while retaining a finite value of τP. Following the notation of the main text, we then arrive at
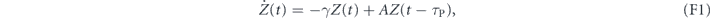
where ![$Z\left(t\right)={\left[\tilde {X}\left(t\right)-{X}_{g},\tilde {P}\left(t\right)-{P}_{g}\right]}^{\mathrm{T}}$](https://content.cld.iop.org/journals/1367-2630/22/11/113014/revision2/njpabc464ieqn85.gif) and
and
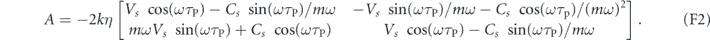
Note that we have replaced the second moments by their time-independent steady state values since we are going to be considering the long-time behavior of the system; Vx(t) → Vs, Vp(t) → Vs, Cxp(t) → Cs. Consider the Laplace transform of Z(t):  . The final value theorem says:
. The final value theorem says:
The Laplace transform of equation (F1) is given by
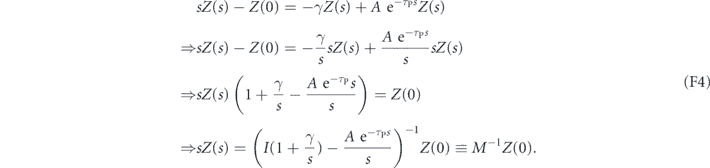
Assuming for simplicity that m = ω = 1 (as in the main text), we have
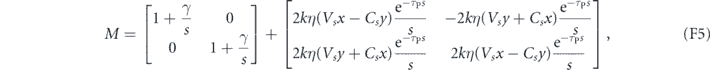
where x = cos(τP) and y = sin(τP). M−1 can be explicitly computed and written as

It then follows that
since all matrix elements of Minv go to constant values as s → 0, while minv goes to zero s → 0, so that lims→0 M−1 = 0.
F.2. x control only
In the case where only x actuation is available, figure 9(a) shows that the ideal P feedback strategy with τP = T/4 achieves exponential convergence of the quadrature expectations to their target values, with a restricted amount of noise on the individual trajectories. In figure 11 we now show the behavior of the quadrature expectations when the time delay is not exactly equal to T/4, i.e., for τP = T/4 + with > 0. We see that in this situation the stabilization performance degrades for all values of —the quadrature expectations deviate from their targets in expectations (show a bias) and the fluctuations in individual trajectories increase with . Thus the performance of the time-delayed P feedback strategy with x control only is less robust to deviations from the ideal τP value than that of the P feedback strategy with both x and p control.
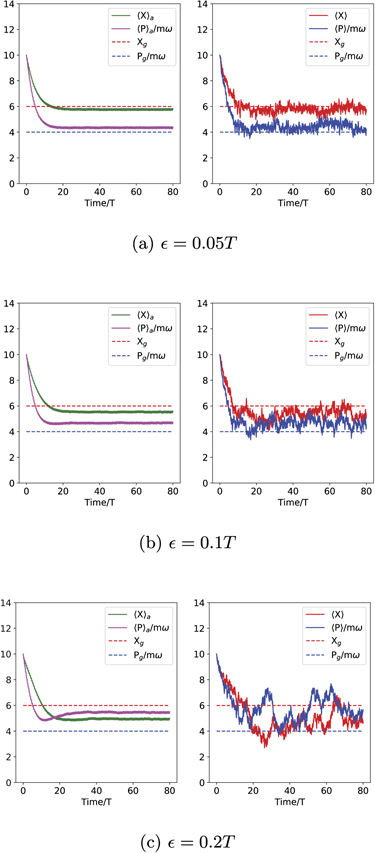
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 11. The effect of time delays on the P feedback law when only x actuation is available (section 4.2.1). The subfigures show three values for the time delay τP = T/4 + . The left panel in each subfigure shows the ensemble average of the quadrature expectations,  and
and  over 1000 trajectories, and the right panel shows a representative trajectory. The maximum standard deviation of the trajectories at long times are 0.314, 0.453, 0.863, for = 0.05T, 0.1T, 0.2T, respectively.
over 1000 trajectories, and the right panel shows a representative trajectory. The maximum standard deviation of the trajectories at long times are 0.314, 0.453, 0.863, for = 0.05T, 0.1T, 0.2T, respectively.
Download figure:
Standard image High-resolution image{kind=link}
Footnotes
- 1
We note that using such steady state compensation can be an alternative to the strategy of introducing deterministic terms in the Hamiltonian to cancel thermal damping effects, i.e., an alternative to adding one or both of the terms γ(xg(t)p+pg(t)x) in the Hamiltonian.