



Abstract
The mapping of fermionic states onto qubit states, as well as the mapping of fermionic Hamiltonian into quantum gates enables us to simulate electronic systems with a quantum computer. Benefiting the understanding of many-body systems in chemistry and physics, quantum simulation is one of the great promises of the coming age of quantum computers. Interestingly, the minimal requirement of qubits for simulating Fermions seems to be agnostic of the actual number of particles as well as other symmetries. This leads to qubit requirements that are well above the minimal requirements as suggested by combinatorial considerations. In this work, we develop methods that allow us to trade-off qubit requirements against the complexity of the resulting quantum circuit. We first show that any classical code used to map the state of a fermionic Fock space to qubits gives rise to a mapping of fermionic models to quantum gates. As an illustrative example, we present a mapping based on a nonlinear classical error correcting code, which leads to significant qubit savings albeit at the expense of additional quantum gates. We proceed to use this framework to present a number of simpler mappings that lead to qubit savings with a more modest increase in gate difficulty. We discuss the role of symmetries such as particle conservation, and savings that could be obtained if an experimental platform could easily realize multi-controlled gates.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Simulating quantum systems on a quantum computer is one of the most promising applications of small scale quantum computers [1]. Significant efforts have gone into the theoretical development of simulation algorithms [2–6], and their experimental demonstrations [7–12]. Resource estimates [13–15], such as for example for FeMoCo, a model for the nitrogenase enzyme, indicate that simulations of relevant chemical systems may be achieved with relatively modest quantum computing resources [16] in comparison to many standard quantum algorithms [17, 18].
One essential component in realizing simulations of fermionic models on quantum computers is the representation of such models in terms of qubits and quantum gates. Following initial simulation schemes for fermions hopping on a lattice [19], more recent proposals used the Jordan–Wigner [20] transform [3, 7, 21, 22], the Verstraete-Cirac mapping [23], or the Bravyi–Kitaev transform [2] to find a suitable representation. Specifically, the task of all such representations is two-fold. First, we seek a mapping from states in the fermionic Fock space of N sites to the space of n qubits. The fermionic Fock space is spanned by 2N basis vectors  where νj ∈ {0, 1} indicates the presence (νj = 1) or absence (νj = 0) of a spinless fermionic particle at orbital j3
. Such a mapping
where νj ∈ {0, 1} indicates the presence (νj = 1) or absence (νj = 0) of a spinless fermionic particle at orbital j3
. Such a mapping  is also called an encoding [24]. An example of such an encoding is the trivial one in which n = N and qubits are used to represent the binary string
is also called an encoding [24]. An example of such an encoding is the trivial one in which n = N and qubits are used to represent the binary string  . That is
. That is

where ωj = νj in the standard basis  .
.
Second, we need a way to simulate the dynamics of Fermions on these N orbitals. These dynamics can be modeled entirely in terms of the annihilation and creation operators cj and  that satisfy the anticommutation relations
that satisfy the anticommutation relations

with [A, B]+ = AB + BA. Following these relations, the operators act on the fermionic Fock space as




where  is the fermionic vacuum and
is the fermionic vacuum and  . Mappings of the operators cj to qubits typically use the Pauli matrices X, Z, and Y acting on one qubit, characterized by their anticommutation relations
. Mappings of the operators cj to qubits typically use the Pauli matrices X, Z, and Y acting on one qubit, characterized by their anticommutation relations ![${[{P}_{i},{P}_{j}]}_{+}=2{\delta }_{{ij}}{\mathbb{I}}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn8.gif) for all
for all  . An example of such a mapping is the Jordan–Wigner transform [20] given by
. An example of such a mapping is the Jordan–Wigner transform [20] given by


where


It is easily verified that together with the trivial encoding (1) this transformation satisfies the desired properties (2)–(6) and can hence be used to represent fermionic models with qubit systems.
In order to assess the suitability of an encoding scheme for the simulation of fermionic models on a quantum computer, a number of parameters are of interest. The first is the total number of qubits n needed in the simulation. Second, we may care about the gate size of the operators cj and  when mapped to qubits. In its simplest form, this problem concerns the total number of qubits on which these operators do not act trivially, that is, the number of qubits L, on which an operator acts as
when mapped to qubits. In its simplest form, this problem concerns the total number of qubits on which these operators do not act trivially, that is, the number of qubits L, on which an operator acts as  instead of the identity
instead of the identity  , sometimes called the Pauli length. Different transformations can lead to dramatically different performance with respect to these parameters. For both the Jordan–Wigner as well as the Bravyi–Kitaev transform n = N, but we have L = O(n) for the first, while
, sometimes called the Pauli length. Different transformations can lead to dramatically different performance with respect to these parameters. For both the Jordan–Wigner as well as the Bravyi–Kitaev transform n = N, but we have L = O(n) for the first, while  for the second. We remark that in experimental implementations we typically do not only care about the absolute number L, but rather the specific gate size and individual difficulty of the qubit gates each of which may be easier or harder to realize in a specific experimental architecture. For error-corrected quantum simulation, the cost in T-gates is as important to optimize as the circuit depth [25], and quantum devices with restricted connectivity even require mappings tailored to them [26, 27]. Finally, we remark that instead of looking for a mapping for individual operators
for the second. We remark that in experimental implementations we typically do not only care about the absolute number L, but rather the specific gate size and individual difficulty of the qubit gates each of which may be easier or harder to realize in a specific experimental architecture. For error-corrected quantum simulation, the cost in T-gates is as important to optimize as the circuit depth [25], and quantum devices with restricted connectivity even require mappings tailored to them [26, 27]. Finally, we remark that instead of looking for a mapping for individual operators  we may instead opt to map pairs (or higher order terms) of such operators at once, or even look to represent sums of such operators.
we may instead opt to map pairs (or higher order terms) of such operators at once, or even look to represent sums of such operators.
1.1. Results
Here, we propose a general family of mappings of fermionic models to qubit systems and quantum gates that allow us to trade-off the necessary number of qubits n against the difficulty of implementation as parametrized by L, or more complicated quantum gates such as CPhase. Ideally, one would of course like both the number of qubits, as well as the the gate size to be small. We show that our mappings can lead to significant savings in qubits for a variety of examples (see table 1) as compared to the Jordan–Wigner transform for instance, at the expense of greater complexity in realizing the required gates. The latter may lead to an increased time required for the simulation depending on which gates are easy to realize in a particular quantum computing architecture.
Table 1. Overview of mappings presented in this paper, listed by the complexity of their code functions, their qubit savings, qubit requirements (n), properties of the resulting gates and first appearance. Mappings can be compared with respect to the size of plain words (N) and their targeted Hamming weight K. We also refer to different methods that are not listed, as they do not rely on codes in any way [30, 31].
| Mapping | En-/decoding type | Qubits saved | n(N, K) | Resulting gates | Origin |
|---|---|---|---|---|---|
Jordan–Wigner  Parity transform Parity transform |
Linear/linear | None | N | Length-O(n) Pauli strings | [20, 24] |
| Bravyi–Kitaev transform | Linear/linear | None | N | Length-O(log n) Pauli strings | [2] |
| Checksum codes | Linear/ affine linear | O(1) | N − 1 | Length-O(n) Pauli strings | Here |
| Binary addressing codes | Nonlinear/nonlinear | O(2n/K) |

|
 -controlled gates -controlled gates |
Here |
| Segment codes | Linear/nonlinear |

|

|
 -controlled gates -controlled gates |
Here |
At the heart of our efforts is an entirely general construction of the creation and annihilation operators in (3) given an arbitrary encoding  and the corresponding decoding
and the corresponding decoding  . As one might expect, this construction is not efficient for every choice of encoding
. As one might expect, this construction is not efficient for every choice of encoding  or decoding
or decoding  . However, for linear encodings
. However, for linear encodings  , but possibly nonlinear decodings
, but possibly nonlinear decodings  , they can take on a very nice form. While in principle any classical code with the same properties can be shown to yield such mappings, we provide an appealing example of how a classical code of fixed Hamming weight [28] can be used to give an interesting mapping.
, they can take on a very nice form. While in principle any classical code with the same properties can be shown to yield such mappings, we provide an appealing example of how a classical code of fixed Hamming weight [28] can be used to give an interesting mapping.
Two other approaches allow us to be more modest with the algorithmic depth in either accepting a qubit saving that is linear with N, or just saving a fixed amount of qubits for hardly any cost at all.
In previous works, trading quantum resources has been addressed for general algorithms [29], and quantum simulations [30–32]. In the two works of Moll et al and Bravyi et al, qubit requirements are reduced with a scheme that is different from ours. A qubit Hamiltonian is first obtained with e.g. the Jordan–Wigner transform, then unitary operations are applied to it in order taper qubits off successively. The paper by Moll et al provides a straight-forward method to calculate the Hamiltonian, that can be used to reduce the amount of qubits to a minimum, but the number of Hamiltonian terms scales exponentially with the particle number. The notion that our work is based on, was first introduced in [31] by Bravyi et al, for linear en- and decodings. With the generalization of this method, we hope to make the goal of qubit reduction more attainable in reducing the effort to do so. The reduction method is mediated by nonlinear codes, of which we provide different types to choose from. The transform of the Hamiltonian is straight-forward from there on, and we give explicit recipes for arbitrary codes. We can summarize our contributions as follows.
- We show that for any encoding
 there exists a mapping of fermionic models to quantum gates. For the special case that this encoding is linear, our procedure can be understood as a slightly modified version of the perspective taken in [24]. This gives a systematic way to employ classical codes for obtaining such mappings.
there exists a mapping of fermionic models to quantum gates. For the special case that this encoding is linear, our procedure can be understood as a slightly modified version of the perspective taken in [24]. This gives a systematic way to employ classical codes for obtaining such mappings. - Using particle conservation symmetry, we develop 3 types of codes that save a constant, linear and exponential amount of qubits (see table 1 and sections 3.1.1–3.1.3). An example from classical coding theory [28] is used to obtain significant qubit savings (here called the binary addressing code), at the expense of increased gate difficulty (unless the architecture would easily support multi-controlled gates).
- The codes developed are demonstrated on two examples from quantum chemistry and physics.
- 1.The Hamiltonian of the well-studied hydrogen molecule in minimal basis is re-shaped into a two-qubit problem, using a simple code.
- 2.A Fermi–Hubbard model on a 2 × 5 lattice and periodic boundary conditions in the lateral direction is considered. We parametrize and compare the sizes of the resulting Hamiltonians, as we employ different codes to save various amounts of qubits. In this way, the trade-off between qubit savings and gate complexity is illustrated (see table 2).

2. Background
To illustrate the general use of (possibly non linear) encodings to represent fermionic models, let us first briefly generalize how existing mappings can be phrased in terms of linear encodings in the spirit of [24]. Under consideration in representing the dynamics is a mapping for second-quantized Hamiltonians of the form

where  are complex coefficients, chosen in a way as to render H Hermitian. We illustrate the use of such a mapping in the context of quantum simulation in appendix A. For our convenience, we use length-l N-ary vectors
are complex coefficients, chosen in a way as to render H Hermitian. We illustrate the use of such a mapping in the context of quantum simulation in appendix A. For our convenience, we use length-l N-ary vectors ![${\boldsymbol{a}}={({a}_{1},...,{a}_{l})}^{\top }\in {[N]}^{\otimes l}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn29.gif) to parametrize the orbitals on which a term
to parametrize the orbitals on which a term  is acting, and write
is acting, and write ![$[N]=\{1\,,...,\,N\}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn31.gif) . A similar notation will be employed for binary vectors of length l, with
. A similar notation will be employed for binary vectors of length l, with  , deciding whether an operator is a creator or annihilator by the rules
, deciding whether an operator is a creator or annihilator by the rules  and
and  .
.
Every term  is a linear operation
is a linear operation  , with
, with  being the Fock space restricted on N orbitals, the direct sum of all possible antisymmetrized M-particle Hilbert spaces
being the Fock space restricted on N orbitals, the direct sum of all possible antisymmetrized M-particle Hilbert spaces  . Conventional mappings transform states of the Fock space
. Conventional mappings transform states of the Fock space  into states on N qubits, carrying over all linear operations as well
into states on N qubits, carrying over all linear operations as well  .
.
Before we start presenting conventional transformation schemes, we need to make a few remarks on transformed Hamiltonians and notations pertaining to them. First of all, we identify the set of gates  with the term Pauli strings (on n qubits). The previously mentioned Jordan–Wigner transform, obviously has the power to transform (11) into a Hamiltonian that is a weighted sum of Pauli strings on N qubits. General transforms, however, might involve other types of gates. We however have the choice to decompose these into Pauli strings. One might want to do so when using standard techniques for Hamiltonian simulation. In the following, we will denote the correspondence of second-quantized operators or states B to their qubit counterparts C by:
with the term Pauli strings (on n qubits). The previously mentioned Jordan–Wigner transform, obviously has the power to transform (11) into a Hamiltonian that is a weighted sum of Pauli strings on N qubits. General transforms, however, might involve other types of gates. We however have the choice to decompose these into Pauli strings. One might want to do so when using standard techniques for Hamiltonian simulation. In the following, we will denote the correspondence of second-quantized operators or states B to their qubit counterparts C by:  . For convenience, we will also omit identities in Pauli strings and rather introduce qubit labels, e.g.
. For convenience, we will also omit identities in Pauli strings and rather introduce qubit labels, e.g.  and write
and write  . A complete table of notations can be found in appendix G.
. A complete table of notations can be found in appendix G.
Consider a linear encoding of N fermionic sites into n = N qubits given by a binary matrix A such that

and A is invertible, i.e.  . Note that in this case, the decoding given by
. Note that in this case, the decoding given by  is also linear. It is known that any such matrix A, subsequently also yields a mapping of the fermionic creation and annihilation operators to qubit gates [24]. To see how these are constructed, let us start by noting that they must fulfill the properties given in (3)–(6) and (2), which motivates the definition of a parity, a flip and an update set below:
is also linear. It is known that any such matrix A, subsequently also yields a mapping of the fermionic creation and annihilation operators to qubit gates [24]. To see how these are constructed, let us start by noting that they must fulfill the properties given in (3)–(6) and (2), which motivates the definition of a parity, a flip and an update set below:
- 1. anticommutes with the first operators and thus acquires phase .
- 2.A creation operator might be absent (present) in between and , leading the rightmost operator to map the entire state to zero since .
- 3.Given that the state was not annihilated, the occupation of site im has to be changed. This means a creation operator has to be added or removed between and .












These rules tell us what the transform of an operator  has to inflict on a basis state (12). In order to implement the phase shift of the first rule, a series of Pauli-Z operators is applied on qubits, whose numbers are in the parity set (with respect to j ∈ [N]), P(j) ⫅ [N]. Following the second rule we project onto the ±1 subspace of the Z-string on qubits indexed by another [N] subset, the so-called flip set of j, F(j). The update set of j, U(j) ⫅ [N] labels the qubits to be flipped completing the third rule using an X-string
has to inflict on a basis state (12). In order to implement the phase shift of the first rule, a series of Pauli-Z operators is applied on qubits, whose numbers are in the parity set (with respect to j ∈ [N]), P(j) ⫅ [N]. Following the second rule we project onto the ±1 subspace of the Z-string on qubits indexed by another [N] subset, the so-called flip set of j, F(j). The update set of j, U(j) ⫅ [N] labels the qubits to be flipped completing the third rule using an X-string

with  . P(j), F(j) and U(j) depend on the matrices A and A−1 as well as the parity matrix R. The latter is a (N × N) binary matrix which has its lower triangle filled with ones, but not its diagonal. For the matrix entries this means Rij = θij, with θij as the discrete version of the Heaviside function
. P(j), F(j) and U(j) depend on the matrices A and A−1 as well as the parity matrix R. The latter is a (N × N) binary matrix which has its lower triangle filled with ones, but not its diagonal. For the matrix entries this means Rij = θij, with θij as the discrete version of the Heaviside function

The set members are obtained in the following fashion:
- 1.P(j) contains all column numbers in which the jth row of matrix has non-zero entries.
- 2.F(j) contains the column labels of non-zero entries in the jth row of A−1.
- 3.U(j) contains all row numbers in which the jth column of A has non-zero entries.

Note that this definition of the sets differs from their original appearance in [24, 33], where diagonal elements are not included. In this way, our sets are not disjoint, which leads to Z-cancellations and appearance of Pauli-Y operators, but we have generalized the sets for arbitrary invertible matrices, and provided a pattern for other transforms later. In fact, we recover these linear transforms from the general case in appendix F. There we also show explicitly that these operators abide by (2)–(6).
2.1. Jordan–Wigner, parity and Bravyi–Kitaev transform
As an illustration, we present popular examples of these linear transformations, note again that all of these will have n = N. The Jordan–Wigner transform is a special case for  , leading to the direct mapping. The operator transform gives L = O(N) Pauli strings as
, leading to the direct mapping. The operator transform gives L = O(N) Pauli strings as

In the parity transform [24], we have L = O(N) X-strings:


The Bravyi–Kitaev transform [2] is defined by a matrix A [24, 33] that has non-zero entries according to a certain binary tree rule, achieving  .
.
2.2. Saving qubits by exploiting symmetries
Our goal is to be able to trade quantum resources, which is done by reducing degrees of freedom by exploiting symmetries. For that purpose, we provide a theoretical foundation to characterize the latter.
Parity, Jordan–Wigner and Bravyi–Kitaev transforms encode all  states and provide mappings for every
states and provide mappings for every  operator. Unfortunately,they require us to own a N-qubit quantum computer, which might be unnecessary. In fact, the only operator we want to simulate is the Hamiltonian, which usually has certain symmetries. Taking these symmetries into account enables us to perform the same task with n ≤ N qubits instead. Symmetries usually divide the
operator. Unfortunately,they require us to own a N-qubit quantum computer, which might be unnecessary. In fact, the only operator we want to simulate is the Hamiltonian, which usually has certain symmetries. Taking these symmetries into account enables us to perform the same task with n ≤ N qubits instead. Symmetries usually divide the  into subspaces, and the idea is to encode only one of those. Let
into subspaces, and the idea is to encode only one of those. Let  be a basis spanning a subspace
be a basis spanning a subspace  be associated with a Hamiltonian (11), where for every
be associated with a Hamiltonian (11), where for every 
 . Usually, Hamiltonian symmetries generate many such (distinct) subspaces. Under consideration of additional information about our problem, like particle number, parity or spin polarization,we select the correct subspace. Note that particle number conservation is by far the most prominent symmetry to take into account. It is generated by Hamiltonians that are linear combinations of products of
. Usually, Hamiltonian symmetries generate many such (distinct) subspaces. Under consideration of additional information about our problem, like particle number, parity or spin polarization,we select the correct subspace. Note that particle number conservation is by far the most prominent symmetry to take into account. It is generated by Hamiltonians that are linear combinations of products of ![${c}_{i}^{\dagger }{c}_{j}^{\,}\,| \,i,j\in [N]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn71.gif) . These Hamiltonians, originating from first principles, only exhibit terms conserving the total particle number;
. These Hamiltonians, originating from first principles, only exhibit terms conserving the total particle number; . From all the Hilbert spaces
. From all the Hilbert spaces  , one considers the space with the particle number matching the problem description.
, one considers the space with the particle number matching the problem description.
These symmetries will be utilized in the next section: we develop a language that allows for encodings  that reduce the length of the binary vectors
that reduce the length of the binary vectors  as compared to
as compared to  . This means that the state
. This means that the state  will be encoded in
will be encoded in  qubits, since each digit saved corresponds to a qubit eliminated. As suggested by Bravyi et al [31], qubit savings can be achieved under the consideration of non-square, invertible matrices A. However, we will see below that using transformations based on nonlinear encodings and decodings
qubits, since each digit saved corresponds to a qubit eliminated. As suggested by Bravyi et al [31], qubit savings can be achieved under the consideration of non-square, invertible matrices A. However, we will see below that using transformations based on nonlinear encodings and decodings  (the inverse transform defined by A−1 before), we can eliminate a number of qubits that scales with the system size. For linear codes on the other hand, we find a mere constant saving.
(the inverse transform defined by A−1 before), we can eliminate a number of qubits that scales with the system size. For linear codes on the other hand, we find a mere constant saving.
3. General transformations
We here show how second-quantized operators and states, Hamiltonian symmetries and the fermionic basis  are fused into a simple description of occupation basis states. While in this section all general ideas are presented, we would like to refer the reader to the appendices for details: to appendix B in particular, which holds the proof of the underlying techniques. Fermionic basis states are represented by binary vectors
are fused into a simple description of occupation basis states. While in this section all general ideas are presented, we would like to refer the reader to the appendices for details: to appendix B in particular, which holds the proof of the underlying techniques. Fermionic basis states are represented by binary vectors  , with its components implicating the occupation of the corresponding orbitals. Basis states inside the quantum computer, on the other hand, are represented by binary vectors on a smaller space
, with its components implicating the occupation of the corresponding orbitals. Basis states inside the quantum computer, on the other hand, are represented by binary vectors on a smaller space  . These vectors are code words of the former
. These vectors are code words of the former  , where the binary code connecting all
, where the binary code connecting all  and
and  is possibly nonlinear. In the end, an instance of such a code will be sufficient to describe states and operators, in a similar way than the matrix pair (A, A−1) governs the conventional transforms already presented. We now start by defining such codes and connect them to the state mappings.
is possibly nonlinear. In the end, an instance of such a code will be sufficient to describe states and operators, in a similar way than the matrix pair (A, A−1) governs the conventional transforms already presented. We now start by defining such codes and connect them to the state mappings.
Let  be a subspace of
be a subspace of  , as defined previously. For
, as defined previously. For  , we define two binary vector functions
, we define two binary vector functions  , where we regard each component as a binary function
, where we regard each component as a binary function  . Furthermore we introduce the binary basis set
. Furthermore we introduce the binary basis set  , with
, with

All elements in  shall be represented in
shall be represented in  . If for all
. If for all  the binary functions
the binary functions  and
and  satisfy
satisfy  , and for all
, and for all  , then we call the two functions encoding and decoding, respectively. An encoding-decoding pair (
, then we call the two functions encoding and decoding, respectively. An encoding-decoding pair ( ) forms a code.
) forms a code.
We thus have obtained a general form of encoding, in which qubit states only represent the subspace  . The decoding, on the other hand, translates the qubit basis back to the fermionic one:
. The decoding, on the other hand, translates the qubit basis back to the fermionic one:

We intentionally keep the description of these functions abstract, as the code used might be nonlinear, i.e. it cannot be described with matrices  . Nonlinearity is thereby predominantly encountered in decoding rather than in encoding functions, as we will see in the examples obtained later.
. Nonlinearity is thereby predominantly encountered in decoding rather than in encoding functions, as we will see in the examples obtained later.
For any code ( ), we will now present the transform of fermionic operators into qubit gates. Before we can do so however, two issues are to be addressed. Firstly, one observes that we cannot hope to find a transformation recipe for a singular fermionic operator
), we will now present the transform of fermionic operators into qubit gates. Before we can do so however, two issues are to be addressed. Firstly, one observes that we cannot hope to find a transformation recipe for a singular fermionic operator  . The reason for this is that the latter operator changes the occupation of the jth orbital. As a consequence, a state with the occupation vector
. The reason for this is that the latter operator changes the occupation of the jth orbital. As a consequence, a state with the occupation vector  is mapped to
is mapped to  , where
, where  is the unit vector of component j;
is the unit vector of component j;  . The problem is that since we have trimmed the basis,
. The problem is that since we have trimmed the basis,  will probably not be in
will probably not be in  , which means this state is not encoded4
. The action of
, which means this state is not encoded4
. The action of  is, thus, not defined. We can however obtain a recipe for the non-vanishing Hamiltonian terms
is, thus, not defined. We can however obtain a recipe for the non-vanishing Hamiltonian terms  as they do not escape the encoded space being
as they do not escape the encoded space being  -operators. Note that this issue is never encountered in the conventional transforms, as they encode the entire Fock space.
-operators. Note that this issue is never encountered in the conventional transforms, as they encode the entire Fock space.
Secondly, we are yet to introduce a tool to transform fermionic operators into quantum gates. The structure of the latter has to be similar to the linear case, as they mimic the same dynamics as presented in section 2. In general, a gate sequence will commence with some kind of projectors into the subspace with the correct occupation, as well as operators implementing parity phase shifts. The sequence should close with bit flips to update the state. The task is now to determine the form of these operators. The issue boils down to finding operators that extract binary information from qubit states, and map it onto their phase. In other words, we need to find linear operators associated with e.g. the binary function dj, such that it maps basis states  . In any case, we must recover the case of Pauli strings on their respective sets when considering linear codes. For our example, this means the linear case yields the operator
. In any case, we must recover the case of Pauli strings on their respective sets when considering linear codes. For our example, this means the linear case yields the operator  . Using general codes, we are lead to define the extraction superoperation
. Using general codes, we are lead to define the extraction superoperation  , which maps binary functions to quantum gates on n qubits:
, which maps binary functions to quantum gates on n qubits:

The extraction superoperator is defined for all binary vectors  and binary functions
and binary functions  as:
as:





Note that the first two properties imply that the operators ![${\mathfrak{X}}[f],{\mathfrak{X}}[g]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn120.gif) commute and all operators are diagonal in the computational basis. Given that binary functions have a polynomial form, we are now able to construct operators by extracting every binary function possible, for example
commute and all operators are diagonal in the computational basis. Given that binary functions have a polynomial form, we are now able to construct operators by extracting every binary function possible, for example


We firstly we have used (22) to arrive at (26), and then reach (27) by applying the properties (23)–(25) to the respective sub-terms. This might however not be the final Hamiltonian, since the simulation algorithm might require us to reformulate the Hamiltonian as a sum of weighted Pauli strings [4, 5]. In that case, need to decompose all controlled gates. The cost for this decomposition is an increase in the number of Hamiltonian terms, for instance we find  . In general, (24) and (25) can be replaced by an adjusted definition:
. In general, (24) and (25) can be replaced by an adjusted definition:

We will be able to define the operator mappings introducing the parity and update functions,  and
and  :
:


Finally, we have collected all the means to obtain the operator mapping for weight-l operator sequences as they occur in (11):

where θij is defined in (14) and δij is the Kronecker delta. In this expression, we find various projectors, parity operators with corrections for occupations that have changed before the update operator is applied. The update operator  , is characterized by the
, is characterized by the  -vector
-vector 

This is a problem: when summing over the entire  , one has to expect an exponential number of terms. As a remedy, one can arrange the resulting operations into controlled gates, or rely on codes with a linear encoding. If the encoding can be defined using a binary (n × N)-matrix A,
, one has to expect an exponential number of terms. As a remedy, one can arrange the resulting operations into controlled gates, or rely on codes with a linear encoding. If the encoding can be defined using a binary (n × N)-matrix A,  , the update operator reduces to
, the update operator reduces to

In appendix B, we show that (31)–(33) satisfy the conditions (2)–(6). Note that the update operator is also important for state preparation: let us assume that our qubits are initialized all in their zero state, ![$({\bigotimes }_{i\in [n]}| 0\rangle )$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn129.gif) , then the fermionic basis state associated with the vector
, then the fermionic basis state associated with the vector  is obtained by applying the update operator
is obtained by applying the update operator  . Here the vector
. Here the vector  contains all occupied orbitals, such that
contains all occupied orbitals, such that  . Even for nonlinear encodings the state preparation can done with Pauli strings: as the initial state is a product state of all zeros, we can replace operators
. Even for nonlinear encodings the state preparation can done with Pauli strings: as the initial state is a product state of all zeros, we can replace operators ![${\mathfrak{X}}[{\boldsymbol{\omega }}\to {\prod }_{i\in { \mathcal S }\subseteq [n]}\,{\omega }_{i}]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn134.gif) by
by  .
.
In the following we will turn our attention to the most fruitful symmetry to take into account: particle conservation symmetry. While code families accounting for this symmetry are explored in the next subsection, alternatives to the mapping of entire Hamiltonian terms are discussed for such codes in appendix C.
3.1. Particle-number conserving codes
In the following, we will present three types of codes that save qubits by exploiting particle number conservation symmetry, and possibly the conservation of the total spin polarization. Particle-number conserving Hamiltonians are highly relevant for quantum chemistry and problems posed from first principles. We therefore set out to find codes in which  have a constant Hamming weight
have a constant Hamming weight  . Since the Hamming weight is defined as
. Since the Hamming weight is defined as  , it yields the total occupation number for the vectors
, it yields the total occupation number for the vectors  . In order to simulate systems with a fixed particle number, we are thus interested to find codes that implement code words of constant Hamming weight. Note that the fixed Hamming weight K does not necessarily need to coincide with the total particle number M. A code with the latter property might also be interesting for systems with additional symmetries. Most importantly, we have not taken into account the spin-multiplicity yet. As the particles in our system are fermions, every spatial site will typically have an even number of spin configurations associated with it. Orbitals with the same spin configurations naturally denote subsets of the total amount of orbitals, much like the suits in a card deck. An absence of magnetic terms as well as spin–orbit interactions leaves the Hamiltonian to conserve the number of particles inside all those suits. Consequently, we can append several constant-weight codes to each other. Each of those subcodes encodes thereby the orbitals inside one suit. In electronic system with only Coulomb interactions for instance, we can use two subcodes (
. In order to simulate systems with a fixed particle number, we are thus interested to find codes that implement code words of constant Hamming weight. Note that the fixed Hamming weight K does not necessarily need to coincide with the total particle number M. A code with the latter property might also be interesting for systems with additional symmetries. Most importantly, we have not taken into account the spin-multiplicity yet. As the particles in our system are fermions, every spatial site will typically have an even number of spin configurations associated with it. Orbitals with the same spin configurations naturally denote subsets of the total amount of orbitals, much like the suits in a card deck. An absence of magnetic terms as well as spin–orbit interactions leaves the Hamiltonian to conserve the number of particles inside all those suits. Consequently, we can append several constant-weight codes to each other. Each of those subcodes encodes thereby the orbitals inside one suit. In electronic system with only Coulomb interactions for instance, we can use two subcodes ( ,
,  ) and (
) and ( ,
,  ), to encode all spin-up, and spin-down orbitals, respectively. The global code (
), to encode all spin-up, and spin-down orbitals, respectively. The global code ( ), encoding the entire system, is obtained by appending the subcode functions e.g.
), encoding the entire system, is obtained by appending the subcode functions e.g.  Appending codes like this will help us to achieve higher savings at a lower gate cost.
Appending codes like this will help us to achieve higher savings at a lower gate cost.
The codes that we now introduce (see also again table 1), fulfill the task of encoding only constant-weight words differently well. The larger  , the less qubits will be eliminated, but we expect the resulting gate sequences to be more simple. Although not just words of that weight are encoded, we treat K as a parameter—the targeted weight.
, the less qubits will be eliminated, but we expect the resulting gate sequences to be more simple. Although not just words of that weight are encoded, we treat K as a parameter—the targeted weight.
3.1.1. Checksum codes
A slim, constant amount of qubits can be saved with the following n = N − 1, affine linear codes. Checksum codes encode all the words with either even or odd Hamming weight. As this corresponds to exactly half of the Fock space, one qubit is eliminated. This means we disregard the last component when we encode  into words with one digit less. The decoding function then adds the missing component depending on the parity of the code words. The code for K odd is defined as
into words with one digit less. The decoding function then adds the missing component depending on the parity of the code words. The code for K odd is defined as


In the even-K version, the affine vector  , added in the decoding, is removed. Since encoding and decoding function are both at most affine linear, the extracted operators will all be Pauli strings, with at most a minus sign. The advantage of the checksum codes is that they do not depend on K. They can be used even in cases of smaller saving opportunities, like
, added in the decoding, is removed. Since encoding and decoding function are both at most affine linear, the extracted operators will all be Pauli strings, with at most a minus sign. The advantage of the checksum codes is that they do not depend on K. They can be used even in cases of smaller saving opportunities, like  . We can employ these codes even for Hamiltonians that conserve only the Fermion parity. This makes them important for effective descriptions of superconductors [34].
. We can employ these codes even for Hamiltonians that conserve only the Fermion parity. This makes them important for effective descriptions of superconductors [34].
3.1.2. Codes with binary addressing
We present a concept for heavily nonlinear codes for large qubit savings,  , [28]. In order to conserve the maximum amount of qubits possible, we choose to encode particle coordinates as binary numbers in
, [28]. In order to conserve the maximum amount of qubits possible, we choose to encode particle coordinates as binary numbers in  . To keep it simple, we here consider the example of weight-one binary addressing codes, and refer the reader to appendix D for K > 1. In K = 1, we recognize the qubit savings to be exponential, so consider N = 2n. Encoding and decoding functions are defined by means of the binary enumerator,
. To keep it simple, we here consider the example of weight-one binary addressing codes, and refer the reader to appendix D for K > 1. In K = 1, we recognize the qubit savings to be exponential, so consider N = 2n. Encoding and decoding functions are defined by means of the binary enumerator,  , with
, with 


where  is implicitly defined by
is implicitly defined by  . An input
. An input  will by construction render only the jth component of (36) non-zero, when
will by construction render only the jth component of (36) non-zero, when  5
.
5
.
The exponential qubit saving comes at a high cost: the product over each component of  implies multi-controlled gates on the entire register. This is likely to cause connectivity problems. Note that decomposing the controlled gates will in general be practically prohibited by the sheer amount of resulting terms. On top of those drawbacks, we also expect the encoding function to be nonlinear for K > 1.
implies multi-controlled gates on the entire register. This is likely to cause connectivity problems. Note that decomposing the controlled gates will in general be practically prohibited by the sheer amount of resulting terms. On top of those drawbacks, we also expect the encoding function to be nonlinear for K > 1.
3.1.3. Segment codes
We introduce a type of scaleable  codes to eliminate a linear amount of qubits. The idea of segment codes is to cut the vectors
codes to eliminate a linear amount of qubits. The idea of segment codes is to cut the vectors  into smaller, constant-size vectors
into smaller, constant-size vectors  , such that
, such that  . Each such segment
. Each such segment  is encoded by a subcode. Although we have introduced the concept already, this segmentation is independent from our treatment of spin 'suits'. In order to construct a weight K global code, we append several instances of the same subcode. Each of these subcodes codes is defined on
is encoded by a subcode. Although we have introduced the concept already, this segmentation is independent from our treatment of spin 'suits'. In order to construct a weight K global code, we append several instances of the same subcode. Each of these subcodes codes is defined on  qubits, encoding
qubits, encoding  orbitals. We deliberately have chosen to only save one qubit per segment in order to keep the segment size
orbitals. We deliberately have chosen to only save one qubit per segment in order to keep the segment size  small.
small.
We now turn our attention to the construction of these segment codes. As shown in appendix E, the segment sizes can be set to  and
and  . As the global code is supposed to encode all
. As the global code is supposed to encode all  with Hamming weight K, each segment must encode all vectors from Hamming weight zero up to weight K. In this way, we guarantee that the encoded space contains the relevant, weight K subspace. This construction follows from the idea that each block contains equal or less than K particles, but might as well be empty. For each segment, the following de- and encoding functions are found for
with Hamming weight K, each segment must encode all vectors from Hamming weight zero up to weight K. In this way, we guarantee that the encoded space contains the relevant, weight K subspace. This construction follows from the idea that each block contains equal or less than K particles, but might as well be empty. For each segment, the following de- and encoding functions are found for  :
:


where  is a binary switch. The switch is the source of nonlinearity in these codes. On an input
is a binary switch. The switch is the source of nonlinearity in these codes. On an input  with
with  , it yields one, and zero otherwise.
, it yields one, and zero otherwise.
There is just one problem: segment codes are not suitable for particle-number conserving Hamiltonians, according to the definition of the basis  , that we would have for segment codes. The reason for this is that we have not encoded all states with
, that we would have for segment codes. The reason for this is that we have not encoded all states with  . In this way, Hamiltonian terms
. In this way, Hamiltonian terms  that exchange occupation numbers between two segments, can map into unencoded space. We can, however, adjust these terms, such that they only act non-destructively on states with at most K particles between the involved segment. This does not change the model, but aligns the Hamiltonian with the necessary condition that we have on
that exchange occupation numbers between two segments, can map into unencoded space. We can, however, adjust these terms, such that they only act non-destructively on states with at most K particles between the involved segment. This does not change the model, but aligns the Hamiltonian with the necessary condition that we have on  . This is discussed in detail appendix E, where we also provide an explicit description of the binary switch mentioned earlier.
. This is discussed in detail appendix E, where we also provide an explicit description of the binary switch mentioned earlier.
Using segment codes, the operator transforms will have multi-controlled gates as well: the binary switch is nonlinear. However, gates are controlled on at most an entire segment, which means there is no gate that acts on more than  qubits. This an improvement in gate locality, as compared to binary addressing codes.
qubits. This an improvement in gate locality, as compared to binary addressing codes.
4. Examples
4.1. Hydrogen molecule
In this subsection, we will demonstrate the Hamiltonian transformation on a simple problem. Choosing a standard example, we draw comparison with other methods for qubit reduction. As one of the simplest problems, the minimal electronic structure of the hydrogen molecule has been studied extensively for quantum simulation [3, 4] already. We describe the system as two electrons on 2 spatial sites. Because of the spin-multiplicity, we require 4 qubits to simulate the Hamiltonian in conventional ways. Using the particle conservation symmetry of the Hamiltonian, this number can be reduced. The Hamiltonian also lacks terms that mix spin-up and -down states, with the total spin polarization known to be zero. Taking into account these symmetries, one finds a total of 4 fermionic basis states:  . These can be encoded into two qubits by appending two instances of a (N = 2, n = 1, K = 1)-code. The global code is defined as :
. These can be encoded into two qubits by appending two instances of a (N = 2, n = 1, K = 1)-code. The global code is defined as :


The physical Hamiltonian

is transformed into the qubit Hamiltonian

The real coefficients gi are formed by the coefficients hijkl of (42). After performing the transformation, we find




In previous works, conventional transforms have been applied to that problem Hamiltonian. Afterwards, the resulting 4-qubit-Hamiltonian has been reduced by hand in some way. In [11], the actions on two qubits are replaced with their expectation values after inspection of the Hamiltonian. In [30], on the other hand, the Hamiltonian is reduced to two qubits in a systematic fashion. Finally, the case is revisited in [31], where the problem is reduced below the combinatorical limit to one qubit. The latter two attempts have used Jordan–Wigner, the former the Bravyi–Kitaev transform first.
4.2. Fermi–Hubbard model
We present another example to illustrate the trade-off between qubit number and gate cost as well as circuit depth. For that purpose, we consider a simple toy Hamiltonian and demonstrate that a reduction of qubit requirements is theoretically possible. Although we do not want to claim that this scenario is realistic, we present a simple cost model with it, that hints the potential up-scaling of circuit depth and simulation cost, as the number of qubits decreases: we therefore consider the total sum of Pauli lengths of every term, which gives us an idea of the number of two-qubit gates required, and the number of Hamiltonian terms, as we decompose controlled gates (28), which should give us an idea of possible T-gate requirements and simulation depth. Let us start now to describe the model. We consider a small lattice with periodic boundary conditions in the lateral direction. The system shall contain 10 spatial sites, doubled by the spin-multiplicity. The problem Hamiltonian is

with its real coefficients t, U. It exhibits hopping terms along the edges E of the graph in figure 1. The sketch on the left of this figure shows the connection graph of the first 10 orbitals. The other 10 orbitals are connected in the same fashion, and each such site is interacting with its counterpart from the other graph. We aim to populate this model with four Fermions, where the total spin polarization is zero. Two conventional transforms and two transforms based on our codes are compared by the amount of qubits necessary, as well as the size of the transformed Hamiltonian. Note that besides eigenenergies, one might also be interested in obtaining the values of correlation functions, e.g.  , which is done by measuring (qubit) operators obtained with the transform (48). The only difference is that if a correlator maps into unencoded space, it is to be set to zero. As benchmarks, we decompose controlled gates and count the number of resulting Pauli strings. The sum of their total weight constitutes the gate count. Having these two disconnected graphs is an invitation to us to append two codes acting on sites 1–10 and 11–20 respectively. for this example, we consider the following codes:
, which is done by measuring (qubit) operators obtained with the transform (48). The only difference is that if a correlator maps into unencoded space, it is to be set to zero. As benchmarks, we decompose controlled gates and count the number of resulting Pauli strings. The sum of their total weight constitutes the gate count. Having these two disconnected graphs is an invitation to us to append two codes acting on sites 1–10 and 11–20 respectively. for this example, we consider the following codes:
- 1.Jordan–Wigner and Bravyi–Kitaev transform: for comparison, we employ these conventional transforms on our system, with which we do not save qubits. The resulting terms are best obtained by the transforming every Fermion operator in (48) by (13), where the flip, parity and update sets, F(j), P(j), U(j) are determined by the choice of matrices A and A−1, which are binary tree matrices in the the case of the Bravyi-Kitev transform, and identity matrices for the Jordan–Wigner transform.
- 2.Checksum code ⊕ checksum code: knowing that the particle number is conserved, and that spin cannot be flipped, we are free to save 2 qubits in constraining the parity of both, spin-up and -down particles, alike. This is done in appending two (N = 10) checksum codes, where each that acts on only spin-up (spin-down) orbitals, so indices 1–10 (11–20). The code resulting from appending two even checksum codes is linear, and encoding and decoding function feature the matricesHowever, as not the entire Fock space is encoded, we need to perform the operator transform according to (31), where the update operator is defined by (33), where A refers here to the first matrix.
- 3.Segment code ⊕ segment code: knowing the particle number in one 'spin suite' to be 2, we can for both, spin-up and -down orbitals, append two K = 2 segment codes to each other. This equals a total of 4 segment codes, saving 4 qubits. The resulting global code is defined bywhere are the encodings of the subcodes (39), and are occupations on the segements of the total orbital vector . These segments are formed as suggested by the right-hand side of figure 1. For details on the decoding functions and Hamiltonian adjustments, please consider appendix E. The Hamiltonian transform is in the end carried out again by (31) and (33).
- 4.Checksum code segment code: a compromise between the above, in which the spin-up orbitals are transformed via a checksum code, and the spin-down orbitals are transformed via two segment codes. The global code used for the Hamiltonian transformation is the appendage of an (even-weight, N = 10) checksum code and two (K = 2) segment codes, including Hamiltonian adjustments on the spin-down orbitals.









Figure 1. Left: illustration of the Fermi–Hubbard model considered. Lines between two sites, like 1 and 2, indicate the appearance of the term  in the Hamiltonian (48). Periodic boundary conditions link sites 1 and 5 as well as 6 and 10. Sites 11–20 follow the same graph. Right: segmenting of the system; the two blocks are infringed. The gray links are to be adjusted.
in the Hamiltonian (48). Periodic boundary conditions link sites 1 and 5 as well as 6 and 10. Sites 11–20 follow the same graph. Right: segmenting of the system; the two blocks are infringed. The gray links are to be adjusted.
Download figure:
Standard image High-resolution imageNote that from the combinatorial perspective, we could encode the problem with 11 qubits. However, if we append two K = 2 binary addressing codes to each other, the resulting Hamiltonian is on 14 qubits already. The problem is that the resulting Hamiltonian for this case cannot be expressed with decomposed controlled gates due to the high number of resulting terms.
Indeed, table 2 suggests that decomposing the controlling gates might easily lead to very large Hamiltonians with a multitude of very small terms. The gate decomposition appears therefore undesirable. We in general recommend to rather decompose large controlled gates as shown in [35]. However, one also notices that an elimination of up to two qubits comes at a low cost: the amount of gates is not higher than in the Bravyi–Kitaev transform. As soon as we employ segment codes on the other hand, the Hamiltonian complexity rises with the amount of qubits eliminated.
Table 2. Relaxing the qubit requirements for the Hamiltonian (48), where various mappings trade different amounts of qubits. The notation ⊕ is used as two codes for different graphs are appended. We compare different mappings by the amount of qubits. We make comparrisons by the number of Hamiltonian terms and the total weight of the resulting Pauli strings.
| Mapping | Qubits | Gates | Terms |
|---|---|---|---|
| Jordan–Wigner transform | 20 | 232 | 74 |
| Bravyi–Kitaev transform | 20 | 278 | 74 |
| Checksum code ⊕ Checksum code | 18 | 260 | 74 |
| Checksum code ⊕ Segment code | 17 | 4425 | 876 |
| Segment code ⊕ Segment code | 16 | 9366 | 1838 |
5. Conclusion and future work
In this work, we have introduced new methods to reduce the number of qubits required for simulating fermionic systems in second quantization. We see the virtue of the introduced concepts in the fact that it takes into account symmetries on a simple but non-abstract level. We merely concern ourselves with objects as simple as binary vectors, but attribute the physical interpretation of orbital occupations to them. At this level, the mentioned symmetries are easy to apply and exploit. The accounting for the complicated antisymmetrization of the many-body wave function on the other hand is done in the fermionic operators, which to transform we have provided recipes for. In these operator transforms we see room for improvement: we for instance lack a proper gate composition for update operators of nonlinear encodings at this point. We on the other hand have the extraction superoperator  return only conventional (multi)-controlled phase gates. Nonlinear codes would on the other hand benefit from a gate set that includes gates with negative control, i.e. with the (−1) eigenvalue conditioned on
return only conventional (multi)-controlled phase gates. Nonlinear codes would on the other hand benefit from a gate set that includes gates with negative control, i.e. with the (−1) eigenvalue conditioned on  eigenspaces of certain qubits involved. We consider our work to be relevant for quantum simulation with near-term devices, with a limited number of qubits at disposal. Remarks about asymptotic scaling are thus missing in this work, but would be interesting. Also, we have centered our investigations around quantum computers with qubits. The idea behind the generalized operator transforms, however, can possibly be adapted to multi-level systems (qudits). The operator transforms of segment and binary addressing codes, for instance, might simplify in such a setup, if generalized Pauli operators are available in some form.
eigenspaces of certain qubits involved. We consider our work to be relevant for quantum simulation with near-term devices, with a limited number of qubits at disposal. Remarks about asymptotic scaling are thus missing in this work, but would be interesting. Also, we have centered our investigations around quantum computers with qubits. The idea behind the generalized operator transforms, however, can possibly be adapted to multi-level systems (qudits). The operator transforms of segment and binary addressing codes, for instance, might simplify in such a setup, if generalized Pauli operators are available in some form.
Apart from the codes presented, we have laid the foundation for the reader to invent their own. As supplementary material, we include a program to transform arbitrary Hamiltonians from a second-quantized form into Pauli string form, using user-defined codes. In this way we hope that in the long term, many more entries will be added to table 1. The extension of this work to a more general setting for symmetries, in which the latter are generated by groups or sets of operators that commute with the Hamiltonian, is an open task. Furthermore, we are certain that table 1 can be extended into another way: gate relaxations for transforms with n > N have already been shown [2, 23, 26, 36], and we are currently working in that direction.
Acknowledgments
We would like to thank Kenneth Goodenough, Victoria Lipinska, Thinh Le Phuc and Valentina Caprara Vivoli for helpful discussions on how to present our results. We would also like to thank CWJ Beenakker for his support. MS was supported by the Netherlands Organization for Scientific Research (NWO/OCW) and an ERC Synergy Grant. SW was supported by STW Netherlands, an NWO VIDI Grant and an ERC Synergy Grant.
Appendix A.: On quantum simulation
At this point, we discuss quantum simulation in the context of our transformations. Amongst other things, we describe the most simple algorithm for Hamiltonian simulation, and proceed by investigating feasibility issues with our transforms Let us start by explaining how this work fits into the larger frame.
The transformations we have developed are going to be useful to trade quantum resources for quantum simulation of fermionic systems, independent from the concrete quantum algorithms chosen for simulation of the problem. For those problems from quantum chemistry and many-body physics we are usually given a fermionic system and its Hamiltonian. One is then to determine the system's ground state and ground state energy, sometimes parts of its spectrum. Where classical computation is infeasible, we simulate the system inside a quantum computer, on which the problem can be solved with existing algorithms. With either transform (see table 1), the fermionic system is therefore mapped to a system of n qubits. With the operator transform, H turns into  , a sum of weighted
, a sum of weighted  gates, Pauli strings at best. We then apply algorithms like quantum phase estimation [3, 37–39], variational quantum eigensolvers [9, 11, 12, 40] , or adiabatic simulations [6]. All of those algorithms receive ansatz states as inputs and in some way prepare (eigen-) states, while also outputting their energy. The ground state is the state with the lowest energy, and can be then manipulated as it is inside the quantum registers after the simulation. For the remainder of this appendix, we discuss implications of the simulation algorithms onto our transforms Thus we outline some principles, these algorithms rely on: algorithms might require us to simulate the time evolution of our encoded system according to
gates, Pauli strings at best. We then apply algorithms like quantum phase estimation [3, 37–39], variational quantum eigensolvers [9, 11, 12, 40] , or adiabatic simulations [6]. All of those algorithms receive ansatz states as inputs and in some way prepare (eigen-) states, while also outputting their energy. The ground state is the state with the lowest energy, and can be then manipulated as it is inside the quantum registers after the simulation. For the remainder of this appendix, we discuss implications of the simulation algorithms onto our transforms Thus we outline some principles, these algorithms rely on: algorithms might require us to simulate the time evolution of our encoded system according to  . For that purpose, we need to know how to transform the time evolution operator
. For that purpose, we need to know how to transform the time evolution operator  , where
, where  is a time step, into gate sequences. Maybe we even need to apply those evolution conditionally, means as an operation controlled on an auxiliary qubit (register). We thus need to embed
is a time step, into gate sequences. Maybe we even need to apply those evolution conditionally, means as an operation controlled on an auxiliary qubit (register). We thus need to embed  into an algorithm for Hamiltonian simulation.
into an algorithm for Hamiltonian simulation.
Let us now be a bit more concrete, and select such an algorithm. Despite the wide range of theoretical proposals for Hamiltonian simulation algorithms [41–43], only the perhaps simplest scheme appears to be experimentally feasible for digital quantum simulation at the moment. Note that it can only be applied to Hamiltonians that are a sum of Pauli strings with real weights

The idea is to approximate  , by sequences of the exponentiated Pauli strings
, by sequences of the exponentiated Pauli strings  , where
, where  is a time slice of
is a time slice of  . This method is commonly referred to as Trotterization. The numbers, signs and values of the time slices
. This method is commonly referred to as Trotterization. The numbers, signs and values of the time slices  , as well as the ordering of the exponentiated strings, govern the error of the simulation—strategies to minimize that error can be learned from the works of Suzuki [44, 45]. Note that we do not specify whether the Hamiltonian simulation is performed in an analog or digital fashion, however, not all strings σ are feasible to be implemented in an analog fashion. The digital gadget for the exponentiation of Pauli strings, on the other hand, is well known [46]. See figure A1 for an example. We are therefore able to approximately perform a (conditional) simulated time evolution with
, as well as the ordering of the exponentiated strings, govern the error of the simulation—strategies to minimize that error can be learned from the works of Suzuki [44, 45]. Note that we do not specify whether the Hamiltonian simulation is performed in an analog or digital fashion, however, not all strings σ are feasible to be implemented in an analog fashion. The digital gadget for the exponentiation of Pauli strings, on the other hand, is well known [46]. See figure A1 for an example. We are therefore able to approximately perform a (conditional) simulated time evolution with  of the form (A1). Using algorithms like variational eigensolvers, where we do not simulate the time evolution but estimate the Hamiltonian expectation value by measuring its terms, we are in principle not tied to the structure of (A1). However, it is more convenient. Equation (A1) gives us two constraints on how to transform (11).
of the form (A1). Using algorithms like variational eigensolvers, where we do not simulate the time evolution but estimate the Hamiltonian expectation value by measuring its terms, we are in principle not tied to the structure of (A1). However, it is more convenient. Equation (A1) gives us two constraints on how to transform (11).

Figure A1. Implementing  , conditional on qubit 'phase'.
, conditional on qubit 'phase'.  is a real rotation angle, where
is a real rotation angle, where  , is a time slice, and
, is a time slice, and  is the Hamiltonian weight of the string
is the Hamiltonian weight of the string  , as in (A1).
, as in (A1).
Download figure:
Standard image High-resolution imageThe first constraint is that we need to decompose every fermionic operator into Pauli strings, using (28). The total number of Pauli strings resulting can be a problematically high when the underlying codes are highly nonlinear. For Trotterization that means a tremendous increase in length due to the abundance of sequenced Pauli string gadgets, many of them with very small rotation angles (ϕ in figure A1).
The second constraint seems trivial at first: in order to simulate a Hamiltonian, it has to be hermitian. More precisely, it has to be hermitian on the entire  , so the coefficient θσ have to be real. We on the other hand might not even need the entire
, so the coefficient θσ have to be real. We on the other hand might not even need the entire  to encode our physical system. Non-hermicities, meaning complex coefficients θσ, can occur whenever one is careless with the remainder of the qubit space, when the code space is left or states are encoded in an ambiguous way. We here list a few pitfalls that can cause non-hermitian terms to occur after the transform and discuss how to avoid them.
to encode our physical system. Non-hermicities, meaning complex coefficients θσ, can occur whenever one is careless with the remainder of the qubit space, when the code space is left or states are encoded in an ambiguous way. We here list a few pitfalls that can cause non-hermitian terms to occur after the transform and discuss how to avoid them.
- Issues may be caused by codes that are not one-to-one. A one-to-one code has the property: for all . Although we have excluded the one-to-one property from the definition of the codes (taing into account the next item), it assures the hermiticity of the transformed Hamiltonian.
- The encoded basis has a size that is in between 2n and 2n−1, so n qubits provide too much Hilbert space by default. However, we can always add a state to the basis that is mapped to zero by all terms . This state, represented by ν, can have several partners on the code space , for which (i.e. not be mapped one-to-one). For example for particle-number conserving Hamiltonians, we can balance these dimensional mismatches using the vacuum state in such a way, since .
- We encounter this problem when using a code with a Hamiltonian, that is not feasible with it. The segment codes for instance are feasible only for certain adjusted particle-number-conserving Hamiltonians, as we shall see in appendix E.








Appendix B.: General operator mappings
The goal of this appendix is to verify that the fermionic mode is accurately represented by our qubit system. This is divided into three steps: step one is to analyze the action of Hamiltonian terms on the fermionic basis. In the second step, we verify parity and projector parts of (31) to work like the original operators in step one, disregarding the occupational update for a moment. Conditions for this state update are subsequently derived. The update operator (32) is shown to fulfill these conditions in the third step, thus concluding the proof.
B.1. Hamiltonian dynamics
In order to verify that the gate sequences (31) are mimicking the Hamiltonian dynamics adequately, we verify that the resulting terms have the same effect on the Hamiltonian basis. This is done on the level of second quantization with respect to the notation (18): no transition into a qubit system is made. This step serves the sole purpose to quantify the effect of the Hamiltonian terms on the states. To that end, we begin by studying the effect of a singular fermionic operator  on a pure state, before considering an entire term
on a pure state, before considering an entire term  on a state in
on a state in  . As a preliminary, we note that (3)–(6) follow directly from (2), when considering that
. As a preliminary, we note that (3)–(6) follow directly from (2), when considering that

The relations (3)–(6) indicate how singular operators act on pure states in general. We now become more specific and apply these rules to a state  , that is not necessarily in
, that is not necessarily in  , but is described by an occupation vector
, but is described by an occupation vector  . The effect of an annihilation operator on such a state is considered first:
. The effect of an annihilation operator on such a state is considered first:



A short explanation on what has happened: in (B2), cj has anticommuted with all creation operator  that have indexes i < j. Depending on the component νj, a creation operator
that have indexes i < j. Depending on the component νj, a creation operator  might now be to the right of the annihilator cj. If the creation operator is not encountered, we may continue the anticommutations of cj until it meets the vacuum and annihilates the state by
might now be to the right of the annihilator cj. If the creation operator is not encountered, we may continue the anticommutations of cj until it meets the vacuum and annihilates the state by  . Using the anticommutation relations (2), we therefore replace
. Using the anticommutation relations (2), we therefore replace  with
with ![$\tfrac{1}{2}[1-{(-1)}^{{\nu }_{j}}]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn226.gif) when going from (B2) to (B3). Finally, the terms are rearranged in (B4): conditional sign changes of the anticommutations are factored out of the new state with an occupation that is now described by the binary vector
when going from (B2) to (B3). Finally, the terms are rearranged in (B4): conditional sign changes of the anticommutations are factored out of the new state with an occupation that is now described by the binary vector  rather than
rather than  . When considering to apply a creation operator
. When considering to apply a creation operator  on the former state, the result is similar. Alone at step (B3), we have to replace
on the former state, the result is similar. Alone at step (B3), we have to replace  by
by ![$\tfrac{1}{2}[1+{(-1)}^{{\nu }_{j}}]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn231.gif) instead, as now the case of appearance of the creation operator leads to annihilation:
instead, as now the case of appearance of the creation operator leads to annihilation:  . We thus find
. We thus find

We now turn our attention to the actual goal, effect of a Hamiltonian term from (11) on a state in  (this means its occupation vector
(this means its occupation vector  is in
is in  ). We therefore consider a generic operator sequence
). We therefore consider a generic operator sequence  , parametrized by some N-ary vector
, parametrized by some N-ary vector ![${\boldsymbol{a}}\in {[N]}^{\otimes l}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn237.gif) and a binary vector
and a binary vector  , for some length l. With (B4) and (B5), we now have the means to consider the effect such a sequence of annihilation and creation operators. The two relations will be repeatedly utilized in an inductive procedure, as every single operator
, for some length l. With (B4) and (B5), we now have the means to consider the effect such a sequence of annihilation and creation operators. The two relations will be repeatedly utilized in an inductive procedure, as every single operator  of
of  will act on a basis state, one after another. The state's occupation is updated after every such operation. For convenience, we define:
will act on a basis state, one after another. The state's occupation is updated after every such operation. For convenience, we define:



Now, the procedure starts:




We again explain what has happened: first, the rightmost operator, which is either  or
or  depending on the parameter bl, acts on the state according to either (B4) or (B5). We therefore combine the two relations for the absorption of this operator
depending on the parameter bl, acts on the state according to either (B4) or (B5). We therefore combine the two relations for the absorption of this operator  in (B10). In the same fashion, all the remaining operators of the sequence are one-after-another absorbed into the state. The new state is described by the vector
in (B10). In the same fashion, all the remaining operators of the sequence are one-after-another absorbed into the state. The new state is described by the vector  after the update. And the cycle begins anew with
after the update. And the cycle begins anew with  . From (B11) on, we use the notations (B6)–(B8) to describe partially updated occupations. By the end of this iteration, the occupation of the state is changed to
. From (B11) on, we use the notations (B6)–(B8) to describe partially updated occupations. By the end of this iteration, the occupation of the state is changed to  , with the total change
, with the total change  . Also, the coefficients of (B12) take into account sign changes from anticommutations ('parity signs' in (B12)) and the eigenvalues of the applied projections. In its entirety, (B12) denotes the resulting state, and is the main ingredient for the next step.
. Also, the coefficients of (B12) take into account sign changes from anticommutations ('parity signs' in (B12)) and the eigenvalues of the applied projections. In its entirety, (B12) denotes the resulting state, and is the main ingredient for the next step.
B.2. Parity operators and projectors
We are given the operator transform (31) and the state transform (19). We want to show the that the Fermion system is adequately simulated, which means to show that the effect (B12) is replicated by (31) acting on  . This is the goal of the next two steps. We start by evaluating the application of (31) on that state, up to the update operator
. This is the goal of the next two steps. We start by evaluating the application of (31) on that state, up to the update operator  . This means that the operators applied implement two things only: the parity signs of (B12), and the projection onto the correct occupational state. Note that these parity operators and projectors are applied before the update operator in (31):
. This means that the operators applied implement two things only: the parity signs of (B12), and the projection onto the correct occupational state. Note that these parity operators and projectors are applied before the update operator in (31):

We now commence our evaluation:





Let us describe what has happened: in (B15), the extraction property (21) is used, and we arrive at (B16) after using the property  and the definition of the parity function. From there we go to (B17) when we merge the two products and perform rearrangements that make it easy to cast all delta and theta functions into the components of the partially updated occupations
and the definition of the parity function. From there we go to (B17) when we merge the two products and perform rearrangements that make it easy to cast all delta and theta functions into the components of the partially updated occupations  , (B18).
, (B18).
Comparing (B18) to (B12), we notice to have successfully mimicked the same sign changes and and projections, as the coefficients in both relations match. Now it is only left to show that the state update is executed correctly. Naively, one would think that we would need to show that

but this is too strong a statement. It is in fact sufficient to demand

For  , (B19) and (B20) is equivalent. However, it might be the case that
, (B19) and (B20) is equivalent. However, it might be the case that  , so
, so  is not encoded. This mean that (B19) is not fulfilled, since
is not encoded. This mean that (B19) is not fulfilled, since  . It is however not necessary to include
. It is however not necessary to include  in the encoding, as for
in the encoding, as for  , the state will vanish anyways: we know from
, the state will vanish anyways: we know from  , that in this case
, that in this case  must act destructively on that basis state,
must act destructively on that basis state,  . This detail is implemented by the projector part of the transformed sequence (31). These projectors are, as we have just shown, working faithfully like (B12), for the transformed sequence acting on every
. This detail is implemented by the projector part of the transformed sequence (31). These projectors are, as we have just shown, working faithfully like (B12), for the transformed sequence acting on every  with
with  . Hence (B20) is a sufficient condition for the updated state. The proof is completed once we have verified that (B20) is satisfied with the update operator defined as in (32). This is done during the next step.
. Hence (B20) is a sufficient condition for the updated state. The proof is completed once we have verified that (B20) is satisfied with the update operator defined as in (32). This is done during the next step.
B.3. Update operator
The missing piece of the proof is to check that (32) and (33) fulfill the condition (B20). We start by verifying the condition (B20) for (33), which we have presented as special case of (32) for linear encoding functions:  . Using that property, one can in fact derive (33) from (32) directly. We now apply (33) to
. Using that property, one can in fact derive (33) from (32) directly. We now apply (33) to  , but firstly we note that
, but firstly we note that

where  is the jth unit vector of
is the jth unit vector of  . Using (B21) and the linearity of
. Using (B21) and the linearity of  , we find:
, we find:




which shows (B20) for linear encodings.
We now turn our attention to general encodings and prove the same expression for update operators as defined in (32):






which completes the proof. We swiftly recap what has happened: in (B26), we have plugged the definition of (32) into the left-hand side of (B20). In between this equation and (B27), we have evaluated the expectation values of the extracted operators ![${\mathfrak{X}}[{\varepsilon }_{j}^{{\boldsymbol{q}}}]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn268.gif) . From that line to the next, the
. From that line to the next, the  -sum is collapsed over the condition
-sum is collapsed over the condition  . We go from (B28) to (B29) by applying (B21). Once we insert the definition (30) into (B29), it becomes obvious that the condition (B20) is fulfilled. Thus, the entire operator transform is now proven.
. We go from (B28) to (B29) by applying (B21). Once we insert the definition (30) into (B29), it becomes obvious that the condition (B20) is fulfilled. Thus, the entire operator transform is now proven.
Appendix C.: Transforming particle-number conserving Hamiltonians
In this appendix, we examine the richest symmetry to exploit for qubit savings: particle conservation. We begin by introducing the most relevant class of Hamiltonians that exhibit this symmetry, but ultimately the main goal of this appendix is to simplify the operator transform for all such Hamiltonians. Motivated by the compartmentalized recipes of the conventional mappings, (13), we suggest alternatives to the transform (31), that do not depend on the sequence length l.
Let us start by noting how easy it is to state that a Hamiltonian the total number of particles: a Hamiltonian like (11), conserves the total number of particles when every term  has as many creation operators as it has annihilation operators. The lengths l, implicit in the sequences
has as many creation operators as it has annihilation operators. The lengths l, implicit in the sequences  that occur in the Hamiltonian, are thereby determined by the field theory or model, that underlies the problem. The coefficients
that occur in the Hamiltonian, are thereby determined by the field theory or model, that underlies the problem. The coefficients  , on the other hand, are determined by the set of basis functions used. For first-principle problems in quantum chemistry and solid state physics, we usually encounter particle-number-conserving Hamiltonians with terms of weight that is at most l = 4:
, on the other hand, are determined by the set of basis functions used. For first-principle problems in quantum chemistry and solid state physics, we usually encounter particle-number-conserving Hamiltonians with terms of weight that is at most l = 4:

where Uijkl, tij are complex coefficients of the interaction and single particle terms, respectively. In the notation of (11), these coefficients correspond to h(i, j, k, l)(1,1,0,0) and h(i, j)(1,0). The (l = 4) interaction terms usually originate from either magnetism and/or the Coulomb interaction. Even for these (l = 4)-terms, the operator transform (31) is quite bulky, and we in general would like to have a transform that is independent of l. Before we begin to discuss such transform recipes however, we need to set up some preliminaries. First of all, we need to find a suitable code ( ), as discussed in the main part. Ideally, we would encode only the Hilbert space with the correct number of particles, M, but Hilbert spaces of other particle numbers can also be included. Assuming that the Hamiltonian visits every state with the same particle number, we must encode entire Hilbert spaces
), as discussed in the main part. Ideally, we would encode only the Hilbert space with the correct number of particles, M, but Hilbert spaces of other particle numbers can also be included. Assuming that the Hamiltonian visits every state with the same particle number, we must encode entire Hilbert spaces  only. Secondly, we need to reorder the fermionic operators inside the Hamiltonian terms
only. Secondly, we need to reorder the fermionic operators inside the Hamiltonian terms  . The reason for this is, that our goal can only be achieved by finding recipes for smaller sequences of constant length. In order to transform the Hamiltonian terms then, we need to invoke the anticommutation relations (2) to introduce an order in
. The reason for this is, that our goal can only be achieved by finding recipes for smaller sequences of constant length. In order to transform the Hamiltonian terms then, we need to invoke the anticommutation relations (2) to introduce an order in  , such that these small sequences appear as consecutive, distinct blocks. As we shall see, these blocks will have the shape
, such that these small sequences appear as consecutive, distinct blocks. As we shall see, these blocks will have the shape  . So every
. So every  needs to be reordered, such that every even operator is a creation operator, and every odd operator an annihilator. For the (l = 4)-terms in (C1), this reordering means
needs to be reordered, such that every even operator is a creation operator, and every odd operator an annihilator. For the (l = 4)-terms in (C1), this reordering means  .
.
Let us quickly sketch the idea behind that reordering and introduce some nomenclature: instead of considering Hamiltonian terms, we realize that also the terms  also conserve the particle number:
also conserve the particle number:  . Let us act with
. Let us act with  on an encoded state. We consider a state that is not annihilated by
on an encoded state. We consider a state that is not annihilated by  . Its particle number is reduced by one through cj, but then immediately restored by
. Its particle number is reduced by one through cj, but then immediately restored by  . In fact, for a general sequence of that arrangement, every even operator restores the particle number in this way and every odd reduces it. We therefore call the subspace, in which we find the state after an even (odd) number of operators, the even (odd) subspace. Since all l must be even for the Hamiltonian to have particle conservation symmetry, the even subspace is the one encoded. The odd subspace, on the other hand, has one particle less, so it is
. In fact, for a general sequence of that arrangement, every even operator restores the particle number in this way and every odd reduces it. We therefore call the subspace, in which we find the state after an even (odd) number of operators, the even (odd) subspace. Since all l must be even for the Hamiltonian to have particle conservation symmetry, the even subspace is the one encoded. The odd subspace, on the other hand, has one particle less, so it is  , if the even one is
, if the even one is  .
.
C.1. Encoding the two spaces separately
In this ordering, one can find a recipe for a singular creation or annihilation operator. The strategy is to consider a second code for the odd subspace. As before ( ) denotes the code for the even subspace, and now (
) denotes the code for the even subspace, and now ( ) is encoding the odd subspace. The idea is that after an odd operator (which in this ordering is an annihilation operator), the state is updated into the odd subspace. With every even operator (which is a creation operator), the state is updated from the odd subspace back into the even one. We find:
) is encoding the odd subspace. The idea is that after an odd operator (which in this ordering is an annihilation operator), the state is updated into the odd subspace. With every even operator (which is a creation operator), the state is updated from the odd subspace back into the even one. We find:


In (C3),  is defined as in (32), but its counterpart from (C2) is defined by
is defined as in (32), but its counterpart from (C2) is defined by

with the primed functions  defined like (30) and (29), but with (
defined like (30) and (29), but with ( ,
,  ) in place of (
) in place of ( ,
,  ).
).
This method relies on n qubits being feasible to simulate the odd subspace in. That is, however, not always the case. The basis set of  is in general larger than
is in general larger than  , when M > N/2. In this way, the odd subspace can also be larger and even be infeasible to simulate with just n qubits. As a solution, one changes the ordering into odd operators being creation operators, and even ones being annihilators, like
, when M > N/2. In this way, the odd subspace can also be larger and even be infeasible to simulate with just n qubits. As a solution, one changes the ordering into odd operators being creation operators, and even ones being annihilators, like  . This causes the odd subspace to become
. This causes the odd subspace to become  , which has a smaller basis set than
, which has a smaller basis set than  . For that case (
. For that case ( ,
,  ) become the code for the odd subspace, and (
) become the code for the odd subspace, and ( ,
,  ) will be associated to the even subspace in (C2) and (C3).
) will be associated to the even subspace in (C2) and (C3).
The obvious disadvantage is that two codes have to be employed at once. However, the checksum code for instance (section 3.1.1 in the main part), comes in two different flavors already, which can be used as codes for even and odd subspaces, respectively.
C.2. Encoding the building blocks
The building blocks  are guaranteed to conserve the particle number, so the even subspace is conserved. As a consequence, one may consider the possibility to transform the operators as the pairs we have rearranged them into. In this way, we still have a certain compartmentalization of (31). Two special cases are to be taken into account: when i > j, an additional minus sign has to be added, as compared to the i < j case. Also, when i = j, all parity operators cancel and the projectors coincide. We find:
are guaranteed to conserve the particle number, so the even subspace is conserved. As a consequence, one may consider the possibility to transform the operators as the pairs we have rearranged them into. In this way, we still have a certain compartmentalization of (31). Two special cases are to be taken into account: when i > j, an additional minus sign has to be added, as compared to the i < j case. Also, when i = j, all parity operators cancel and the projectors coincide. We find:

with  being the l = 2 version of (32), and
being the l = 2 version of (32), and  and
and  defined as usual by (29) and (30).
defined as usual by (29) and (30).
Appendix D.: Multi-weight binary addressing codes based on dissections
With binary addressing codes, that is codes that are similar to the one presented in section 3.1.2 in the main part, even an exponential amount of qubits can be saved for systems with low particle number, but at the expense of complicated gates. For this appendix, we firstly recap the situation of section 3.1.2 and clarify what binary addressing means. Firstly, some nomenclature is introduced. We then generalize the concept of binary addressing codes to weight K codes, using results from [28]. As an example, we explicitly obtain the K = 2 code.
Suppose we have a system with N = 2r orbitals, and one particle in it. Our goal is to encode the basis state, where the particle is on orbital y ∈ [2r], as a binary number in r qubits. In this way, the state with occupational vector  is encoded as
is encoded as  , with
, with  and
and  . Probing an unknown basis state, a decoding will now have components of the form
. Probing an unknown basis state, a decoding will now have components of the form

Such binary functions output 1 only when  . In our nomenclature, we say that in the basis state
. In our nomenclature, we say that in the basis state  , the particle has the coordinate y. We refer to codes that store particle coordinates in binary form, as binary addressing codes.
, the particle has the coordinate y. We refer to codes that store particle coordinates in binary form, as binary addressing codes.
In the K = 1 case from the main part, the code words just contain the binary representation of one coordinate. The question is now how to generalize the binary addressing codes. For multi-weight codes, we have to have K sub-registers to store the addresses of K particles. Naively, one would want to store the coordinate of each particle in its respective sub-register in binary form, as we have done for K = 1. This however, holds a problem. As the particles are indistinguishable, the stored coordinates would be interchangeable, the code would not be one-to-one. For the binary numbers  and
and  , that represent a coordinate each, this would mean
, that represent a coordinate each, this would mean  . That strategy not only complicates the operator transform, it also leads to a certain qubit overhead, as each plain word has as many code words as there are permutations of K items. Since this naive idea leaves us unconvinced, we abandon it and search for one-to-one codes instead. The key is to consider the coordinates to be in a certain format and this is where [28] comes into play. We proceed by using some relevant concepts of that paper.
. That strategy not only complicates the operator transform, it also leads to a certain qubit overhead, as each plain word has as many code words as there are permutations of K items. Since this naive idea leaves us unconvinced, we abandon it and search for one-to-one codes instead. The key is to consider the coordinates to be in a certain format and this is where [28] comes into play. We proceed by using some relevant concepts of that paper.
Let us consider the coordinates of K particles to be given in the N-ary vector  . Between those coordinates, we have imposed an ordering xi > xj as i > j. Particles cannot share the same orbital, so we are excluding the cases where two coordinates are equal. Using results from [28], we transform the latter into coordinates that lack such an ordering, and where each component is an integer from a different range:
. Between those coordinates, we have imposed an ordering xi > xj as i > j. Particles cannot share the same orbital, so we are excluding the cases where two coordinates are equal. Using results from [28], we transform the latter into coordinates that lack such an ordering, and where each component is an integer from a different range:

Through that transform, each vector  corresponds to a valid vector
corresponds to a valid vector  , and there is no duplication. We now represent the
, and there is no duplication. We now represent the  -coordinates by binary numbers in the code words
-coordinates by binary numbers in the code words  , where
, where  :
:

A geometric interpretation of the process portrays the vector  as a set of coordinates in a K-dimensional, discrete vector space. The vectors allowed by the ordering form thereby a multi-dimensional tetrahedron. The states outside the tetrahedron do not correspond to a valid
as a set of coordinates in a K-dimensional, discrete vector space. The vectors allowed by the ordering form thereby a multi-dimensional tetrahedron. The states outside the tetrahedron do not correspond to a valid  vector, so encoding each coordinate xi in
vector, so encoding each coordinate xi in  qubits would be redundant. We therefore dissect the tetrahedron, and rearrange it into a brick, as it is referred to in [28]. What is actually done is to apply symmetry operations (like point-reflections) on the vector space until the tetrahedron is deformed into the desired shape a K-dimensional, rectangular volume. The fact that the vectors to encode are now all inside a hyper-rectangle is what we wanted to achieve. We can now clip the ranges of the coordinate axes (to
qubits would be redundant. We therefore dissect the tetrahedron, and rearrange it into a brick, as it is referred to in [28]. What is actually done is to apply symmetry operations (like point-reflections) on the vector space until the tetrahedron is deformed into the desired shape a K-dimensional, rectangular volume. The fact that the vectors to encode are now all inside a hyper-rectangle is what we wanted to achieve. We can now clip the ranges of the coordinate axes (to ![$[\lceil \mathrm{log}\tfrac{N}{m}\rceil ]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn327.gif) ) to exclude vectors the vectors outside the brick. As the values on the axes correspond to non-binary addresses, this means that the qubit space is trimmed as well, and we have eliminated all states based on not-allowed coordinates. This is where we now reconnect to our task of finding a code: the
) to exclude vectors the vectors outside the brick. As the values on the axes correspond to non-binary addresses, this means that the qubit space is trimmed as well, and we have eliminated all states based on not-allowed coordinates. This is where we now reconnect to our task of finding a code: the  - and
- and  -functions have to take into account the reshaping process, as only the coordinates
-functions have to take into account the reshaping process, as only the coordinates  have a physical interpretation and can be decoded. The binary addresses in the code words, on the other hand, are representatives of
have a physical interpretation and can be decoded. The binary addresses in the code words, on the other hand, are representatives of  . With with binary logic, the two coordinates have to be reconnected. We illustrate this abstract process on the example of the
. With with binary logic, the two coordinates have to be reconnected. We illustrate this abstract process on the example of the  -code.
-code.
D.1. Weight-two binary addressing code
As an example, we present the weight-two binary addressing code on N = 2r orbitals. The integer r will determine the size of the entire qubit system  , with two registers of size r and r − 1.
, with two registers of size r and r − 1.
With the two registers, a binary vector  with
with  and
and  is defining the qubit basis. In two-dimensions, the brick turns into a rectangle and the tetrahedron into triangle. The decoding function takes binary addresses of the rectangular
is defining the qubit basis. In two-dimensions, the brick turns into a rectangle and the tetrahedron into triangle. The decoding function takes binary addresses of the rectangular  , and transforms them into coordinates in the triangle
, and transforms them into coordinates in the triangle  . The ordering condition implies hereby where to dissect the rectangle: figure D1 may serve as a visual aid, disregarding the excluded cases of
. The ordering condition implies hereby where to dissect the rectangle: figure D1 may serve as a visual aid, disregarding the excluded cases of  , we find for
, we find for ![${y}_{1}\in [N],{y}_{2}\in [N/2]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn340.gif) and
and ![${\boldsymbol{x}}\in {[N]}^{\otimes 2}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn341.gif) :
:

This decoding is translated into a binary functions as follows: the coordinate y1 is represented by the binary vector  and y2 by
and y2 by  . For each component defined by the binary vector
. For each component defined by the binary vector  , we have
, we have

with  as defined in (D3) and we have employed two binary functions S and
as defined in (D3) and we have employed two binary functions S and  . Here, S compares the binary numbers to determine if the coordinates are left of the dissection (a black tile in figure D1)
. Here, S compares the binary numbers to determine if the coordinates are left of the dissection (a black tile in figure D1)

The binary function T, on the other hand, is checking whether a set of coordinates is on a diagonal position (diagonally marked tiles). These excluded cases are mapped to  altogether
altogether

This concludes the decoding function. Unfortunately, the amount of logic elements in the decoding will complicate the weight-two codes quite a bit, and the encoding function is hardly better. The reason for this is to find in the ordering condition: the update operations are conditional on whether we change the ordering of the coordinates represented by  and
and  . This is reflected in a nonlinear encoding function: we remind us that the encoding function is a map
. This is reflected in a nonlinear encoding function: we remind us that the encoding function is a map  , and with
, and with  we find
we find

with  as defined in (D3), and
as defined in (D3), and  .
.

Figure D1. Visualization of the two-dimensional vector space: a valid vector is represented as a colored tile. The left gray tiles and the black ones constitute the triangle, defining all valid vectors  . The marked diagonal tiles are to be excluded from the encoded space. The black tiles and the gray ones on the right of this diagonal form the brick, containing all
. The marked diagonal tiles are to be excluded from the encoded space. The black tiles and the gray ones on the right of this diagonal form the brick, containing all  vectors.
vectors.
Download figure:
Standard image High-resolution imageThe dissecting of tetrahedrons can be generalized for codes of weight larger than two (see again [28]), but as one increases the number of dissections, the code functions are complicated even further.
Appendix E.: Segment codes
In this appendix, we provide detailed information on the segment codes. We firstly concern ourselves with the segmentation of the global code, including a derivation of the segment sizes. In another subsection we construct the segment codes themselves. The last subsection is dedicated to the adjustments one has to make to Hamiltonian, such that segment codes become feasible to use.
E.1. Segment sizes
At this point we want to sketch the idea behind the segment sizes ( ) stated during section 3.1.3 in the main part, but first of all we would like to clearly set up the situation.
) stated during section 3.1.3 in the main part, but first of all we would like to clearly set up the situation.
We consider vectors  to consist of
to consist of  smaller vectors
smaller vectors  of length
of length  , such that
, such that  . We call those vectors
. We call those vectors  segments of
segments of  . The goal is now to find a code (
. The goal is now to find a code ( ) to encode a basis
) to encode a basis  which contains all vectors
which contains all vectors  with Hamming weight K. For that purpose we relate the segment
with Hamming weight K. For that purpose we relate the segment  to a segment of the code space,
to a segment of the code space,  , for all i ∈ [N]. The code space segments constitute the code words in a fashion similar to the previous segmentation of
, for all i ∈ [N]. The code space segments constitute the code words in a fashion similar to the previous segmentation of  :
:  . However, the length of those binary vectors
. However, the length of those binary vectors  is
is  , such that with
, such that with  and
and  , the problem is reduced by
, the problem is reduced by  qubits as compared to conventional transforms. We now introduce the subcodes (
qubits as compared to conventional transforms. We now introduce the subcodes ( ), with which we encode the ith segment
), with which we encode the ith segment  as
as  (see figure E1). Note that we require the subcodes to inherit all the code properties. In this way we guarantee the code properties of the global code (
(see figure E1). Note that we require the subcodes to inherit all the code properties. In this way we guarantee the code properties of the global code ( ) when appending
) when appending  instances of the same subcode:
instances of the same subcode:


Figure E1. Visualization of (E1) for  . The global code (
. The global code ( ) relates the occupation vectors to the global code words
) relates the occupation vectors to the global code words  . The an instance of the subcode (
. The an instance of the subcode ( ) relates ith block in
) relates ith block in  , to the ith segment in the code words,
, to the ith segment in the code words,  .
.
Download figure:
Standard image High-resolution imageThe orbital number being an integer multiple of the block size is of course an idealized scenario. One will probably have to add a few other components in order to compensate for dimensional mismatches.
We now set out to find the smallest segment size  . It should be clear that
. It should be clear that  is a function of the targeted Hamming weight K: this means K determines which segment codes are suitable for the system. The reason for this is that we need to encode all vectors with weight 0 to K inside every segment, taking into account for the up to K particles on the orbitals inside one segment. In order to include weight K vectors, the size of each segment must be at least K. If the segment size would be exactly K, on the other hand, we end up encoding the entire Fock space again. In doing so, we are not making any qubit savings. The segments must thus be larger than K. In other words, we look for an integer
is a function of the targeted Hamming weight K: this means K determines which segment codes are suitable for the system. The reason for this is that we need to encode all vectors with weight 0 to K inside every segment, taking into account for the up to K particles on the orbitals inside one segment. In order to include weight K vectors, the size of each segment must be at least K. If the segment size would be exactly K, on the other hand, we end up encoding the entire Fock space again. In doing so, we are not making any qubit savings. The segments must thus be larger than K. In other words, we look for an integer  , where the sum of all combinations
, where the sum of all combinations  with
with  is smaller equal
is smaller equal 

In the case  , the condition is fulfilled as identity, since exactly half of all
, the condition is fulfilled as identity, since exactly half of all  combinations are included in the sum.
combinations are included in the sum.
E.2. Subcodes
This subsection offers a closer look at the construction of the segment subcodes ( ). Let us start by considering the decoding
). Let us start by considering the decoding  in order to explore the nature of the binary switch
in order to explore the nature of the binary switch  , that occurs in (38). One observes the two (affine) linear
, that occurs in (38). One observes the two (affine) linear  -maps
-maps

to produce together all the vectors with weight equal or smaller than K, if we input all  with
with  into the first, and the remaining cases with
into the first, and the remaining cases with  into the second one. Note that the last component is always zero in outputs of the first function and one in the second. Therefore, the inverse of both maps is always a linear map with the matrix
into the second one. Note that the last component is always zero in outputs of the first function and one in the second. Therefore, the inverse of both maps is always a linear map with the matrix ![$[\ {\mathbb{I}}\ | {{\boldsymbol{I}}}^{\hat{{\boldsymbol{n}}}}]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn402.gif) . We take this inverse as encoding (39), and the two maps (E3) are merged into the decoding (38). In order to switch between these two maps we define the binary function
. We take this inverse as encoding (39), and the two maps (E3) are merged into the decoding (38). In order to switch between these two maps we define the binary function  such that
such that

In general, one can define this binary switch in a brute-force way by

For the case K = 1 ( ), the switch equals
), the switch equals  , and for the code we recover a version of binary addressing codes, where the vector (0, 0, 0) is encoded.
, and for the code we recover a version of binary addressing codes, where the vector (0, 0, 0) is encoded.

In the K = 2 ( ) case, this binary switch is found to be
) case, this binary switch is found to be  .
.
E.3. Hamiltonian adjustments
As mentioned in section 3.1.3, in the main part, segment codes are not automatically compatible with all particle-number-conserving Hamiltonians. We show here, how certain adjustments can be made to these Hamiltonians, such that their action on the space  is not changed, but segment codes become feasible to describe them with. In order to understand this issue, we begin by examining the encoded space. For that purpose we reprise the situation of (E1), where we have append
is not changed, but segment codes become feasible to describe them with. In order to understand this issue, we begin by examining the encoded space. For that purpose we reprise the situation of (E1), where we have append  instances of the same subcode. With segment codes, the basis
instances of the same subcode. With segment codes, the basis  contains vectors with Hamming weights from 0 to
contains vectors with Hamming weights from 0 to  . We have encoded all possible vectors
. We have encoded all possible vectors  with
with  , but although we have some, not all vectors with
, but although we have some, not all vectors with  are encoded. We can illustrate that point rather quickly: each segment has length
are encoded. We can illustrate that point rather quickly: each segment has length  , but the subcode encodes vectors
, but the subcode encodes vectors  with only
with only  . The (global) basis
. The (global) basis  is thus deprived of vectors
is thus deprived of vectors  where for any segment
where for any segment  .
.
We now turn our attention to terms, which, when present in a Hamiltonian, make segment codes infeasible to use. Note, that  -vectors with
-vectors with  , are not corresponding to fermionic states we are interested in. In particular it is a certain subset of states with
, are not corresponding to fermionic states we are interested in. In particular it is a certain subset of states with  , which can lead out of the encoded space (into the states previously mentioned) when acted upon with certain fermionic operators. Let us consider the operator
, which can lead out of the encoded space (into the states previously mentioned) when acted upon with certain fermionic operators. Let us consider the operator  as an example, where i and j are in different segments (let us call these segments A and B). Now a basis state as depicted in figure E2, is not annihilated by
as an example, where i and j are in different segments (let us call these segments A and B). Now a basis state as depicted in figure E2, is not annihilated by  , and leads into a state with 3 particles in segment A. The problem is that the initial state is encoded in the
, and leads into a state with 3 particles in segment A. The problem is that the initial state is encoded in the  segment codes, whereas the updated state (with the 3 particles in A) is not. In general, operators
segment codes, whereas the updated state (with the 3 particles in A) is not. In general, operators  , that change occupations in between segments, will cause some basis states with
, that change occupations in between segments, will cause some basis states with  to leave the encoded space. We can however adjust these terms
to leave the encoded space. We can however adjust these terms  , such that
, such that  , where
, where  is the basis encoded by the segment codes. We now sketch the idea behind those adjustments, before we reconsider the situation of figure E2. Note that after these adjustments have been made to all Hamiltonian terms in question, the segment codes are compatible with the new Hamiltonian. The idea is to switch those terms off for states, that already have K particles inside the segments, to which particles will be added. We have to take care to do this in a way that leaves the Hamiltonian hermitian on the level of second quantization, i.e. we have to adjust the terms
is the basis encoded by the segment codes. We now sketch the idea behind those adjustments, before we reconsider the situation of figure E2. Note that after these adjustments have been made to all Hamiltonian terms in question, the segment codes are compatible with the new Hamiltonian. The idea is to switch those terms off for states, that already have K particles inside the segments, to which particles will be added. We have to take care to do this in a way that leaves the Hamiltonian hermitian on the level of second quantization, i.e. we have to adjust the terms  and
and  into
into  and
and  , such that
, such that  is hermitian. For the K = 2 code of figure E2, we can make the following adjustments:
is hermitian. For the K = 2 code of figure E2, we can make the following adjustments:

Figure E2. (Filled) circles represent (occupied) fermionic orbitals, where K = 2 segment codes are used in the indicated blocks. This occupational case is problematic for the codes, as the operator  acting on this state leaves the encoded space.
acting on this state leaves the encoded space.
Download figure:
Standard image High-resolution image

Appendix F.: Conventional mappings
We now revisit the conventional transforms from section 2 in the main part, and discuss all notations that have been introduced to express it close to the appealing nomenclature of [24, 33]. In particular, we show that the relation (13) is recovered as a special case from (31) and (33). After that, we verify that such constructions satisfy the fermionic anticommutation relations. For now, however, we would like to restate the situation: a linear n = N code, encoding the entire Fock space, is mediated by the quadratic matrices A and  , such that
, such that  and
and  . The matrices are required to be each others inverses, so
. The matrices are required to be each others inverses, so

We now explain the form of the parity, update and flip sets. As the code is linear, the extraction operator is retrieving only Pauli strings following (22) and (24). One finds:


where P(i) and F(i) are the parity and flip sets with respect to i, as we defined them in section 2. The update sets U(i) are obtained from update operators of linear encodings:

In order to derive (13), we would like to point out the commutation relations between Pauli strings  and
and  . These will prove useful in verifying the fermionic commutation relations later. For commutations of update- and flip set strings we find:
. These will prove useful in verifying the fermionic commutation relations later. For commutations of update- and flip set strings we find:


We have used the relation (F1) for the above. Similarly, for commutations of update and parity strings we have:

Finally, we combine (F2)–(F4) with the operator from (31). Using (F5) and (F7) to move every update string  in between the projectors and parity strings of aj and aj+1, we get
in between the projectors and parity strings of aj and aj+1, we get


which is a sequence of the operators (13). The transform of a singular operator is cj(†) is thus derived from (31). Although we have already shown that (31) satisfies (3)–(6), but we now want to show that (13) fulfills the anticommutation relations (2) in particular. In doing so, we generally distinguish the cases i = j and  . For
. For ![${[{c}_{j}^{(\dagger )},{c}_{j}^{(\dagger )}]}_{+}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn445.gif) , we consult (F5) and find
, we consult (F5) and find

We notice that for  , the gate transform of
, the gate transform of 
 properly differs by a minus sign from the transform of
properly differs by a minus sign from the transform of 
 due to (F7). We want to make this observation explicit for the
due to (F7). We want to make this observation explicit for the  case of
case of ![${[{c}_{i}^{},{c}_{j}^{\dagger }]}_{+}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn452.gif) :
:




At last, we find by explicit construction :

Thus, we find ![${[{c}_{i}^{},{c}_{j}^{\dagger }]}_{+}\hat{=}{\delta }_{{ij}}{\mathbb{I}}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn453.gif) , and our construction (13) is in compliance with all relations in (2).
, and our construction (13) is in compliance with all relations in (2).
Appendix G.: Notations
| Symbol | Type | Informal definition |
![$[...]$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn454.gif)
|
Set of integers from 1 to argument | |

|
Correspondence between fermionic operators/states to qubit counterparts | |

|
![${[N]}^{\otimes l}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn457.gif)
|
Length-l N-ary vector describing orbitals in 
|

|
 binary matrix defining a conventional encoding (decoding) binary matrix defining a conventional encoding (decoding) |
|

|

|
Length-l binary vector determining operator types in 
|

|
Basis of a space of Fermions on N orbitals, smaller than the Fock space | |

|

|
Fermionic annihilation (creation) operator |

|
Vector space of n-qubit states | |

|

|
Decoding function |

|

|
Encoding function |

|

|
Update function important for nonlinear encodings, see (30) |

|
Fock space restricted on N orbitals | |

|
subset of [n] | Flip set with respect to orbital j, see (13) |

|

|
Term in a fermionic Hamiltonian, see (11) |

|
Antisymmetrized Hilbert space of M indistinguishable particles on N orbitals | |

|
Identity operator on arbitrary spaces | |
| K | [N] | Targeted Hamming weight of a code |
| l | Length of a sequence of fermionic operators in 
|
|
| L | [n] | Weight of a Pauli string |

|
Linear operators on argument vector space | |
| M | [N] | Total particle number in a system of N orbitals |
| n | Number of qubits | |
| N | Number of orbitals | |

|

|
N-orbital occupation vector representing a fermionic basis state, see (18) |

|

|
Binary vector representing a product state in the n-qubit basis, see (19) |

|

|
Parity function, implementing signs for parity operators |

|
subset of [n] | Parity set of orbital j, see (13) |

|
Set of single-qubit Pauli operators 
|
|

|

|
Change of a vector  by a term by a term 
|
| R | Binary  matrix, with the lower triangle (including diagonal) filled with ones matrix, with the lower triangle (including diagonal) filled with ones |
|
| θij |
![${[N]}^{\otimes 2}\to {{\mathbb{Z}}}_{2}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn496.gif)
|
Discrete version of the Heaviside function, see (14) |

|
 or or 
|
Binary unit vector, just component j is one |
| U(j) | subset of [n] | Update set of orbital j, see (13) |

|

|
Update operator with respect to an occupation of  , see (32) and (33) , see (32) and (33) |

|
subset of 
|
Defines the occupation vectors  implementing the basis implementing the basis  , see (18) , see (18) |

|
![${{\mathbb{Z}}}_{2}^{\otimes N}\to [N]\cup \{0\}$](https://content.cld.iop.org/journals/1367-2630/20/6/063010/revision2/njpaac54fieqn508.gif)
|
Hamming weight of a binary vector, sum of its components |

|

|
Extraction superoperator, maps binary functions into quantum gates, see (20)–(28) |

|
Binary digits 
|
Footnotes
- 3
We slightly abuse the nomenclature of quantum chemistry and molecular physics in merging spatial and spin quantum numbers into one index j, and use it as a label for what we call now the jth orbital.
- 4
'Unencoded state' is actually a slightly misleading term: when we say a state
is not encoded, we actually mean that it cannot be encoded and correctly decoded, so . - 5
For better or worse we have used the binary representation of the orbital indexes. We could however employ any other counting method, i.e. any injective mapping that relates a binary vector representing a qubit basis state to an integer labeling an orbital.


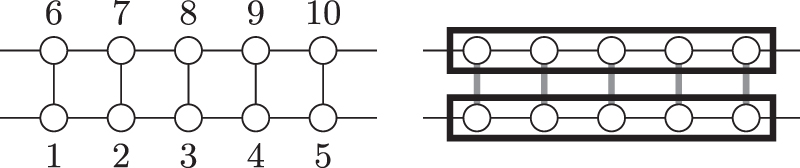{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}