
Abstract
Objective. To simultaneously deblur and supersample prostate specific membrane antigen (PSMA) positron emission tomography (PET) images using neural blind deconvolution. Approach. Blind deconvolution is a method of estimating the hypothetical 'deblurred' image along with the blur kernel (related to the point spread function) simultaneously. Traditional maximum a posteriori blind deconvolution methods require stringent assumptions and suffer from convergence to a trivial solution. A method of modelling the deblurred image and kernel with independent neural networks, called 'neural blind deconvolution' had demonstrated success for deblurring 2D natural images in 2020. In this work, we adapt neural blind deconvolution to deblur PSMA PET images while simultaneous supersampling to double the original resolution. We compare this methodology with several interpolation methods in terms of resultant blind image quality metrics and test the model's ability to predict accurate kernels by re-running the model after applying artificial 'pseudokernels' to deblurred images. The methodology was tested on a retrospective set of 30 prostate patients as well as phantom images containing spherical lesions of various volumes. Main results. Neural blind deconvolution led to improvements in image quality over other interpolation methods in terms of blind image quality metrics, recovery coefficients, and visual assessment. Predicted kernels were similar between patients, and the model accurately predicted several artificially-applied pseudokernels. Localization of activity in phantom spheres was improved after deblurring, allowing small lesions to be more accurately defined. Significance. The intrinsically low spatial resolution of PSMA PET leads to partial volume effects (PVEs) which negatively impact uptake quantification in small regions. The proposed method can be used to mitigate this issue, and can be straightforwardly adapted for other imaging modalities.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Prostate specific membrane antigen (PSMA) positron emission tomography (PET) is an imaging modality typically used to detect prostate cancer (Afshar-Oromieh et al 2015). PSMA ligands accumulate not only in prostate tissue, but also in the salivary glands, lacrimal glands, liver, spleen, kidneys, and the colon (Israeli et al 1994, Trover et al 1995, Wolf et al 2010, Schwarzenboeck et al 2017), leading to undesirable dose in these healthy regions (Israeli et al 1994, Trover et al 1995, Wolf et al 2010). However, this typically unwanted uptake can be utilized to investigate intra-salivary gland parenchyma, which is an area of active research in the context of radiotherapy treatment planning (Buettner et al 2012, van Luijk et al 2015, Clark et al 2018).
Quantifying uptake statistics in the relatively small size of salivary glands is difficult, due to partial volume effects (PVEs) associated with the intrinsically low resolution of PET imaging (Marquis et al 2023), which is typically over 5 mm (Pan et al 2019). PVEs in PET images primarily correspond to spill-over between image voxels due to the positron range and point-spread function of the scanner (Erlandsson et al 2012). Patient motion and Poisson-distributed noise due to low photon counts further exacerbates blur in PET images. While official SNMMI guidelines recommend using the maximum standard uptake value (SUVmax) in single voxels for uptake metrics (Fendler et al 2017), maximum uptake values are affected by 'spill-in' from neighbouring voxels and would be expected to differ within small volumes if PVEs could be mitigated.
There have been attempts to mitigate partial volume effects in PET images using analytical methods (Alpert et al 2006, Šroubek et al 2009, Erlandsson et al 2012, Guérit et al 2015, Hansen et al 2023), with most traditional approaches involving estimation of the point spread function. These methods are not applicable in the case of collaborative studies involving multiple scanners, or where the point spread function is unknown.
The ill-posed problem of simultaneously estimating the theoretical 'deblurred' image, x , along with the spread-function or blur kernel, k , from the original image y ( y = x ∗ k ), is referred to as blind deconvolution. Traditional maximum a posteriori (MAP)-based methods for solving blind deconvolution require estimation of prior distributions for the kernel and deblurred image and specialized optimization techniques to avoid convergence towards a trivial solution. MAP-based methods are governed by the equation

where Pr( y ∣ k ∣ x ) is the fidelity term likelihood and Pr( x ) and Pr( k ) are the priors of the deblurred image and blur kernel, respectively. Many prior models have been suggested (Chan and Wong 1998, Levin et al 2009, Krishnan et al 2011, Liu et al 2014, Ren et al 2016, Zuo et al 2016), but are generally hand-crafted and insufficient for accurate modelling of x and k (Ren et al 2020).
In 2020, Ren et al (2020) developed 'neural blind deconvolution' for estimating the deblurred image and blur kernel from 2D natural images using two neural networks which are optimized simultaneously, as opposed to traditional MAP-based methods which generally employ alternating optimization to avoid a trivial solution (Ren et al 2020). This is a self-supervised deep learning method that does not involve a separate training set, but instead learns to predict deblurred images independently for each image. Neural blind deconvolution was shown to out-perform (Ren et al 2020) other traditional methods in terms of peak signal-to-noise ratio, SSIM, and error ratio.
In this work, we build off of the development of 2D neural blind deconvolution (Ren et al 2020, Kotera et al 2021), implementing changes to the network architecture and optimization procedures for suitability with 3D PSMA PET medical images. We also modify the architecture to accomodate simultaneous supersampling to enhance spatial resolution.
2. Methods
2.1. Retrospective patient data set
Full-body [18F]DCFPyL PSMA PET/CT images were de-identified for 30 previous prostate cancer patients (mean age 68, age range 45–81; mean weight: 90 kg, weight range 52–128kg). Patients had been scanned, two hours following intravenous injection, from the thighs to the top of the skull on a GE Discovery MI (DMI) scanner. The mean and standard deviation of the injected dose was 310 ± 66 MBq (minimum: 182 MBq, maximum: 442 MBq). PET images were reconstructed using VPFXS (OSEM with time-of-flight and point spread function corrections) (number of iterations/subsets unknown, pixel spacing: 2.73/3.16 mm, slice thickness: 2.8/3.02mm). The scan duration was 180 s per bed position. For appropriate comparison of voxel values between patients, patient images were all resampled to a slice thickness of 2.8 and pixel spacing of 2.73 using linear interpolation. Helical CT scans were acquired on the same scanner (kVP: 120, pixel spacing: 0.98 mm, slice thickness: 3.75 mm).
Images were cropped to within 6 slices below the bottom of the submandibular glands and 6 slices above the top of the parotid glands. Cropping was employed to avoid exceeding time constraints and the 6 GB memory of the NVIDIA GeForce GTX 1060 GPU used for training. Registered CT images were used to contour parotid and submandibular glands for calculating uptake statistics. Limbus AI (Wong et al 2021) was used for preliminary auto-segmentation of the glands on CT images, which were then manually refined by a single senior Radiation Oncologist, Jonn Wu. Contours were used to calculate uptake statistics within salivary glands. Images were normalized to the maximum voxel value prior to deblurring, and afterwards rescaled to standard uptake values normalized by lean body mass (SUVlbm). Lean body mass was estimated from patient weight and height using the Hume formula (Hume 1966).
2.2. Overview of neural blind deconvolution
Neural blind deconvolution, as first demonstrated by Ren et al (2020), estimates a deblurred version, x , of an actual image, y , by training neural networks on a case-specific basis. Specifically, two neural networks, Gx and Gk are trained to predict x , and a blur kernel, k , whose convolution together yields a close estimate of the original image, y . The use of neural networks for image prediction was motivated by the work of Ulyanov et al on deep image priors (Ulyanov et al 2020) which defines

where θx and θk represent trainable model parameters of Gx and Gk , respectively. The following implicit constraints exist on network outputs which are satisfied automatically due to the networks' architectures.

Previously, Ren et al (2020), Kotera et al (2021) such networks were trained using a loss function including a mean squared error (MSE) fidelity term along with regularization terms, R( x , k ), where

The mathematical formulation of our problem differs slightly as we have adapted Gx to yield an output image, x which is twice as large as y in each dimension to accomplish supersampling. Our x is then linearly downsampled to the original image size, x ↓, before being convolved with the kernel. Furthermore, we incorporate a component of mean absolute error into our loss function's fidelity term

This can be written in terms of the model parameters θx and θk as

which can then be optimized via backpropagation of loss gradients.
2.3. Model architecture
Neural blind deconvolution was originally demonstrated on 2D images using a 'U-Net' (Ronneberger et al 2015)-style, symmetric, multiscale, autoencoder network for Gx and a shallow fully-connected network for Gk . We built off of this methodology while implementing some notable changes to optimize model performance on PSMA PET images. A schematic diagram of the network design is shown in figure 1.
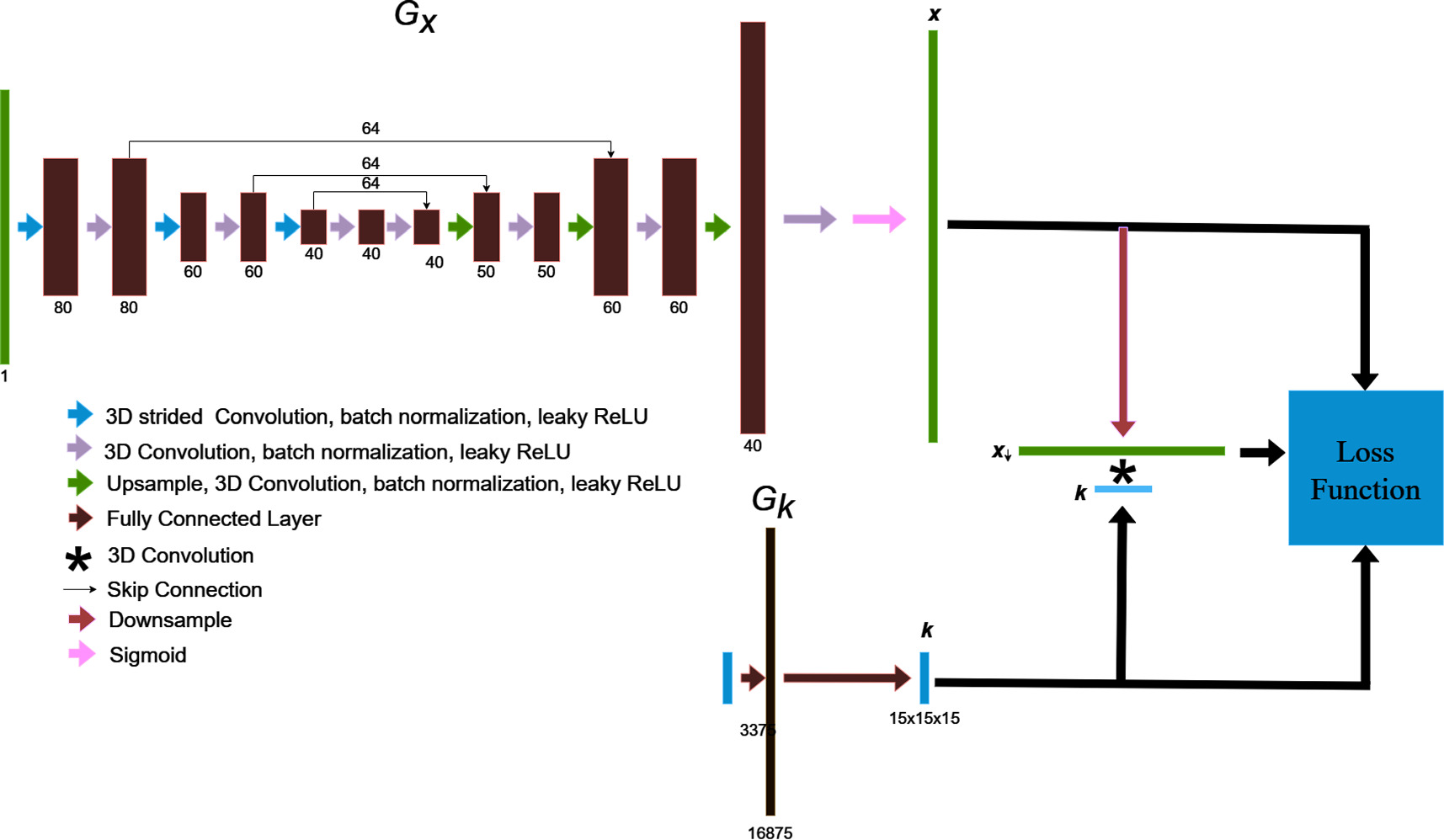
Figure 1. The blind deconvolution architecture used for deblurring PSMA PET images is illustrated. Gx is an asymmetric, convolutional auto-encoder network for predicting the deblurred image, x , and Gk is a fully-connected network for predicting the blur kernel, k . The convolution of x and k is trained to match the original image by using back-propagated model gradients from the loss function for iterative optimization.
Download figure:
Standard image High-resolution image2.3.1. Gx architecture
All operations involving Gx were adapted for use with 3D images. The network includes only 3 layers in the encoder-decoder series (as opposed to 5 in Ren et al's implementation) (Ren et al 2020). A decrease in network layers is justified by the low resolution of PET images, which requires a smaller receptive field than needed for high-resolution images to localize edge features (Horwath et al 2019). An additional layer was added to the end of the decoder section, including an upsampling operation, and double convolution, to output a final x twice as large in each dimension as the original input. This design allows x to be simultaneously supersampled and deblurred within the blind deconvolution process.
Rather than iteratively increasing channels towards deeper regions of the encoder and decoder, we found that reversing the design such that the channel count decreases towards inward regions of the network produced favourable results. For each double convolution, the first strided convolution decreases the image size by a factor of 2. We included a high number of skip connection channels (64), as it was found to improve prediction accuracy.
Furthermore, we scaled the final sigmoid layer used in previous versions of neural blind deconvolution (Ren et al 2020, Kotera et al 2021), as a regular sigmoid constrains the x to have the same maximum value as y . This is not necessarily true, nor expected for the case of partial volume effect correction. We therefore scaled the final layer by 3/2.
2.3.2. Gk architecture
Gk is a single layer perceptron, whose architecture Ren et al (2020) found to outperform the auto-encoder style design of Gx for the case of predicting the kernel. Model input is a one-dimensional vector of length 3375, which is fed through a fully connected layer with 16,875 nodes, to an output of length 3375 which is passed through a SoftMax operation before being reshaped into a 15 × 15 × 15 3D kernel image. The softmax function ensures that kernel voxels sum to unity, and has the form:

2.4. Loss function and optimization
It was unnecessary to form distinct training and validation sets as needed in supervised learning algorithms. Neural blind deconvolution is a type of 'zero shot' (Shocher et al 2018) self-supervised learning algorithm, which utilises deep learning without requiring prior model training. Instead, parameters of Gx and Gk are optimized separately for each individual patient to predict the deblurred images. The algorithm for updating network weights to predict deblurred PSMA PET images is summarized in table 1.
Table 1. The optimization algorithm for updating network weights to predict deblurred PSMA PET images. This algorithm builds off of Ren et al's proposed joint optimization algorithm (Ren et al 2020) and implements modifications suggested by Kotera et al (2021).
| Network optimization algorithm |
|---|
| Input: original PSMA PET image, y |
| Output: deblurred PSMA PET image, x , and blur kernel, k |
| Pre-training |
| 1. Downsample y to 1/2 resolution |
| 2. Initialize input z x from uniform distribution to match size of y |
| 3. Initialize z k as size 7 × 7 × 7 Gaussian kernel with standard deviation of two voxels |
| 4. for i = 1 to 1000: |
5. 
|
6. 
|
| 7. Compute loss and back-propagate gradients |
| 8. Update Gi x and Gi k using the ADAM optimizer (Kingma and Ba 2017) |
9.  , , 
|
10. Upsample
k
by 11/7 and downsample
x
by a factor of 
|
11. Downsample
y
by  to match new convolution size to match new convolution size |
| 12. z x = x , z k = k |
| 13. Repeat steps 4 through 9 |
14. Upsample
k
by 15/11 and downsample
x
by a factor of 
|
| 15. z x = x , z k = k |
| Main Training |
| 16. for i = 1 to 5000: |
17. 
|
18. 
|
| 19. Compute loss and back-propagate gradients |
| 20. Update Gi x and Gi k using the ADAM optimizer (Kingma and Ba 2017) |
21.  , , 
|
The main optimization procedure consisted of 5000 iterations broken into 3 stages, stage 1: 0 ≤ step <300, stage 2: 300 ≤ step <2000, stage 3: 2000 ≤ step <3500, stage 4: step ≥3500. 5000 iterations was chosen as it had been used in previous neural blind deconvolution methods, and furthermore because we found this number of iterations to be sufficient for the training loss to level out. We implemented a multi-scale pre-training procedure similar to the method recommended by Kotera et al (2021). This involves initially training Gx
and Gk
to predict
x
and
k
using 2 × downsampled PSMA PET images, which are then upsampled by  and used as input for a second round of pre-training. The output is then upsampled back to the original size to serve as inputs for the regular training stage. We further modified the procedure such that after every upsampling during pre-training, the models, Gx
and Gk,
are trained to predict their own inputs for 100 iterations, which was sufficient to allow training in the next scale to begin by predicting upsampled versions of the predictions in the previous layer. The size of
k
varies with the size of
x
, such that three kernel sizes are used, 7 × 7 × 7, 10 × 10 × 10, and the original size 15 × 15 × 15. For the downsampled pre-training of
x
and
k
, 1000 iterations were used in each stage. This number of iterations was chosen to allow the pre-training image to approximately converge to its final estimate. The initial input vector for Gk
was a Gaussian Kernel with a standard deviation of two voxels, and the initial input vector for Gx
was a pseudorandom-generated array, sampled from a uniform distribution. The loss function components for each stage are summarized in table 1. The parameters of Gx
and Gk
were updated using the ADAM optimizer (Kingma and Ba 2017).
and used as input for a second round of pre-training. The output is then upsampled back to the original size to serve as inputs for the regular training stage. We further modified the procedure such that after every upsampling during pre-training, the models, Gx
and Gk,
are trained to predict their own inputs for 100 iterations, which was sufficient to allow training in the next scale to begin by predicting upsampled versions of the predictions in the previous layer. The size of
k
varies with the size of
x
, such that three kernel sizes are used, 7 × 7 × 7, 10 × 10 × 10, and the original size 15 × 15 × 15. For the downsampled pre-training of
x
and
k
, 1000 iterations were used in each stage. This number of iterations was chosen to allow the pre-training image to approximately converge to its final estimate. The initial input vector for Gk
was a Gaussian Kernel with a standard deviation of two voxels, and the initial input vector for Gx
was a pseudorandom-generated array, sampled from a uniform distribution. The loss function components for each stage are summarized in table 1. The parameters of Gx
and Gk
were updated using the ADAM optimizer (Kingma and Ba 2017).
It was previously reported by Kotera et al (2021) that adopting a total variation (TV) loss term biases outputs towards a trivial solution during the initial stages of training, but improves image quality as predictions near the final, correct solution. We experienced similar findings, and therefore implemented a TV loss term only after the first 2000 iterations. After the first 3500 iterations, the fidelity term of the loss function transitions from a combination of MSE and MAE to the structural similarity index metric, which was also found to boost performance during final stages (Kotera et al 2021).
During the first 300 iterations of training, we employed registered computed tomography (CT) images to provide anatomical guidance. This was implemented by including a SSIM loss term involving x and a CT texture map of the grey level run length matrix (GLRLM) with a long run emphasis, computed with pyradiomics (van Griethuysen et al 2017). We opted to use the texture map as opposed to the regular CT image as CT texture maps have been demonstrated to have a closer correlation with PSMA PET uptake (Sample et al 2023) than regular CT images. CT guidance was discontinued after the first 300 steps of training to prevent competition with the fidelity term as outputs move closer towards final estimates. A previous study using traditional MAP-based blind deconvolution of PET images demonstrated the utility of magnetic resonance images for guiding optimization (Guérit et al 2016, Song et al 2019, Gillman et al 2023).
A cumbersome challenge in performing a blind deconvolution is avoiding a trivial solution, x * k = x *δ = y (Chaudhuri et al 2014, Perrone and Favaro 2014, Yu et al 2019). It is therefore necessary to impose regularization on kernel predictions. Previously, Ren et al (2020), Kotera et al (2021) applied an ℓ2 norm constraint to the kernel to avoid convergence to a delta function. We also applied an ℓ2 norm term; however, we only penalized kernel values larger than 0.7, to avoid a trivial solution while not penalizing small- to mid-range values in the kernel.
2.5. Patient analysis
Ground truth deblurred patient images were not available, and we therefore adopted a variety of strategies and metrics for evaluating the quality of deblurred patient images and the model's ability to predict accurate blur kernels.
Two quantitative blind image quality metrics were compared between x and y . First, the Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) score (Mittal et al 2012) was used, which varies between 0 and 100, indicating the lowest and highest possible image quality, respectively. BRISQUE takes an input image and computes a set of features using the distribution of intensity and relationships between neighbouring voxels. It then predicts its image quality from its predicted deviation from a natural, undistorted image. Second, images were compared using the contrastive language-image pre-training (CLIP) metric (Wang et al 2022) which varies between 0 and 1. CLIP is a multi-modal (language and vision) neural network trained with millions of image/text pairs. The model can be used for predicting both image quality and image caption quality. The clip network predicts image quality by ranking the applied captions 'good photo' and 'bad photo'. CLIP was compared with numerous other quality metrics and was found to perform second to only BRISQUE.
The theoretical blur kernel of PET images has a component resulting from the point spread function of the scanner, as well as other limitations and patient motion. Since all PET images were acquired on the same scanner, with the same image collection protocol, it is expected that predicted blur kernels should have high inter-patient similarity, Kernels were compared between patients quantitatively by taking the inner product of normalized kernel images. To validate the ability of neural blind deconvolution to accurately recover blur kernels, rather than arbitrary or semi-random shapes imposed by the loss function/optimization, we generated four types of 'pseudokernels' and convolved them with previously deblurred images, which were then fed back into the blind deconvolution model. Predicted kernels were then compared with pseudokernels visually and by taking inner products. Generated pseudokernel shapes included a regular Gaussian, and 3 Gaussians skewed in the x, y, and z direction.
2.6. Phantom analysis
The deblurring methodology was further tested using PET images acquired using the Quantitative PET Prostate Phantom (Q3P) (Fedrigo et al 2024). The phantom had been developed for a previous study (Fedrigo et al 2022) and included a set of 'shell-less' spheres (3-16 mm diameters) of 22NaCl infused epoxy resin. The positron energy via 22Na decay is similar to that from 18F (220.3 keV and 252 keV respectively) (Jødal et al 2014, 2012), making 22Na suitable for approximating the decay seen in [18F]DCFPyL PET. The phantom contains eight spheres with diameters of 16mm, 14 mm, 10 mm, 8 mm, 7 mm, 6 mm, 5 mm, and 3 mm arranged evenly in a coaxial ring and 50 mm from the radial centre of the phantom. The spheres were prepared with a 22Na concentration of 57.6 kBq ml−1 to represent lesion concentrations from an analysis of patients imaged with [18F]DCFPyL PET (Fedrigo et al 2022). By the time of acquisition, activity concentrations had decayed to approximately 31 kBq ml−1. To establish realistic background concentration, the phantom was filled with a background concentration of 2 kBq ml−1. To account for Poisson noise, the phantom was imaged for five noise realizations (2.5min scan time) using a 5-ring Discovery MI PET/CT scanner. Phantom images were reconstructed using VPFXS (8 subsets, 4 iterations, 6.4 mm filter) using the clinical scanner console. The phantom specifications and image acquisition process are described in further detail by Fedrigo et al (2024)
Phantom images were deblurred using the same neural blind deconvolution methodology applied to patient images. However, registered CT images of phantoms did not exist and therefore texture features could not be included during early stages of optimization. As regions of high uptake within the phantom were all spherically symmetric, there was inherent ambiguity in the extent of blurring. This is because multiple combinations of blur kernels and 'deblurred' images can be convolved to produce highly similar observed images. This ambiguity is broken when shapes of arbitrary differing shapes are included in images, as in the case of patient acquisitions. To mitigate this challenge, we modified the final layer of Gx to produce maximum values of 1.1× the maximum voxel in the original image, rather than 1.5×. This did not present physical challenges, as the maximum voxel value was approximately equal to the known activity concentration in the largest sphere.
Phantom spheres were contoured via two methods. First, a single fixed threshold that minimized the total difference between contoured and actual sphere volumes was determined separately for original and deblurred images. Second, variable thresholds were determined for each sphere size individually. Thresholds were expressed as a fraction of the maximum voxel value within a given region, and values between 0.2 and 0.8 (0.01 step size) were tested. Regions were defined by all voxels connected to the maximum voxel within a given sphere and greater than the given threshold. Actual volumes are referred to as V0. The 3 mm sphere was not included in the analysis as it was poorly defined on original and deblurred images.
Activity concentration uniformity was first compared in original and deblurred sphere images by plotting intensity profiles. Recovery coefficients (RCs) for the mean, median, and maximum activity concentration (RCmean,  ) were also determined. These were defined as
) were also determined. These were defined as

where ah,true is the ground truth activity concentration for each sphere determined in a previous study (Fedrigo et al 2022), and stat = {mean, median, max}. The mean inner product between combinations of phantom kernels was calculated. The difference in total activity within deblurred and original images was assessed.
3. Results
3.1. Patient analysis
Deblurred images had higher BRISQUE and CLIP scores than original images upsampled using nearest-neighbours, linear, quadratic, and cubic interpolation. These results are summarized in table 2.
Table 2. Blind image quality metrics, CLIP and BRISQUE are compared for original (
y
) and deblurred (
x
) PSMA PET images. For appropriate comparison, y was upsampled by 2 in each dimension to match the size of
x
. In the first column,
y
is upsampled using nearest neighbours interpolation to remain visually identical. We also compared the quality of
y
when upsampled using linear, quadratic and cubic interpolation ( ,
, ,
, ).
).
| Original | Polynomial interpolation | Proposed method | |||
|---|---|---|---|---|---|
| y |

|

|

| x | |
| CLIP | 0.19 ± 0.03 | 0.33 ± 0.05 | 0.32 ± 0.05 | 0.32 ± 0.05 | 0.39 ± 0.04 |
| BRISQUE | 75.8 ± 8.1 | 89.6 ± 5.4 | 85.0 ± 6.3 | 84.8 ± 6.32 | 90.5 ± 7.5 |
Maximum intensity projections of x , k , x * k , and y are shown for a single patient in figure 2 and visual comparisons of original and deblurred PET image slices including parotid glands and submandibular glands are shown for 3 different patients in figure 3. Maximum intensity projection images are shown through the head and neck in figure 4.
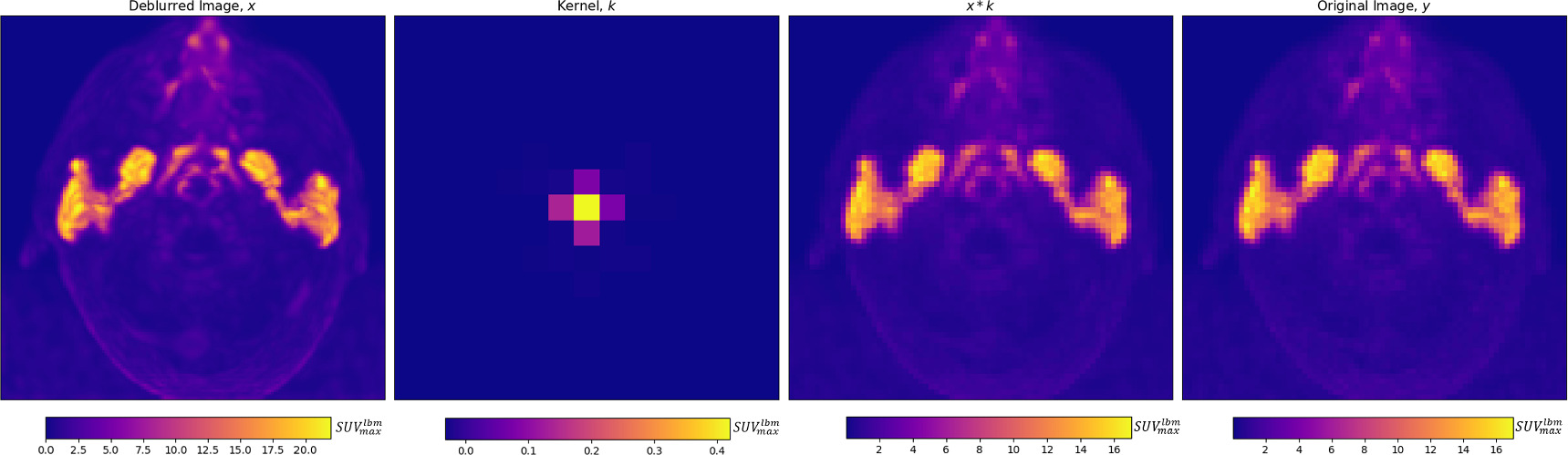
Figure 2. From left to right, for an individual patient, a deblurred maximum intensity projection image, and axial projection of the predicted kernel are shown, along with the maximum intensity projection of the convolution of the deblurred image and kernel, which is trained to match the original image, on the right. The inferior aspect of the tubarial glands are visible between the parotid glands.
Download figure:
Standard image High-resolution image
Figure 3. Axial slices intersecting parotid glands (left) and submandibular glands (right) for 3 different patients are shown on original and deblurred images.
Download figure:
Standard image High-resolution image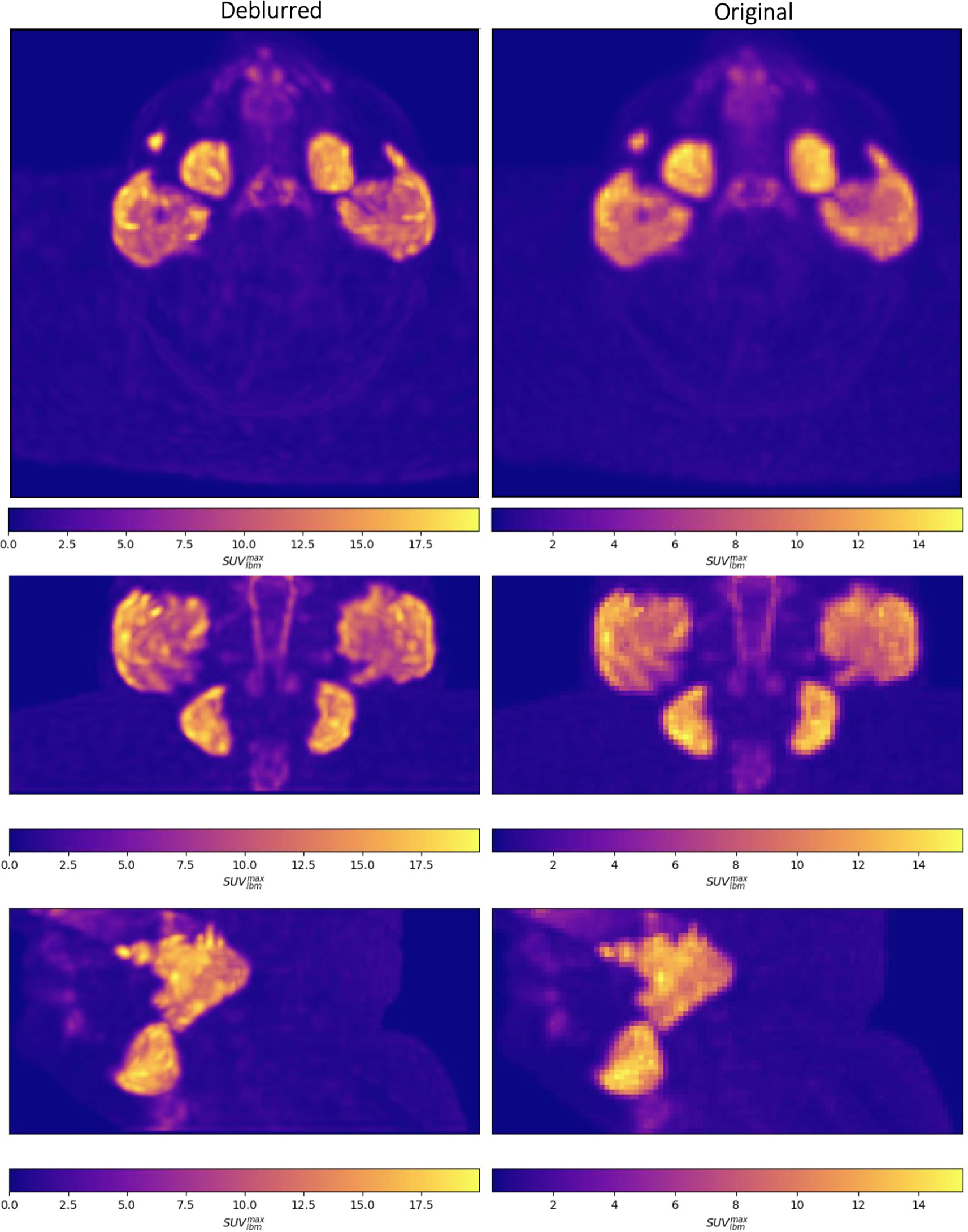
Figure 4. Maximum intensity projections of deblurred (left) and original (right) PSMA PET images are shown through the head and neck in the axial (top), coronal (middle) and sagittal (bottom) planes.
Download figure:
Standard image High-resolution imagePredicted blur kernels displayed relatively low inter-patient variability, having a mean inner product between different patients of 0.73. Projections of the mean predicted kernel onto the three standard cartesian planes are found in figure 5. Predicted kernels were mostly symmetric while having small inter-patient deviations in skewness. The distribution of kernel voxels in various patient directions is summarized in table 3, with maximum variation found in the anterior–posterior direction. Kernels were found to display a centred peak, which rapidly fell off to less than 0.01 when two voxels from the center in any direction.

Figure 5. The mean predicted kernel is projected onto the 3 standard patient planes. The predicted blur kernel was found to be mostly symmetric.
Download figure:
Standard image High-resolution imageTable 3. The fraction of the kernel contained within a plane oriented in each Cartesian direction and intersecting the center of the kernel image, averaged over all patients. For example, the average blur kernel has a sum of 0.52 anterior to the center point.
| Anterior | Posterior | Superior | Inferior | Left | Right |
|---|---|---|---|---|---|
| 0.52 ± 0.07 | 0.48 ± 0.07 | 0.49 ± 0.05 | 0.51 ± 0.05 | 0.51 ± 0.05 | 0.49 ± 0.05 |
The mean absolute difference of the total activity found within all voxels of original and deblurred images varied by less than 0.05 ± 0.07%. The predicted blurred image, x * k , and the original image, y , had a MAE and MSE of 0.013 ± 0.004 and 0.003 ± 0.001 SUVlbm, respectively.
Pseudokernels applied to deblurred PET images were predicted well, with mean inner products of predicted and generated pseudokernels above 0.90 for each of the 4 types of pseudokernel applied (regular Gaussian, and skewed Gaussian along 3 patient axes). These results are displayed in figure 6.
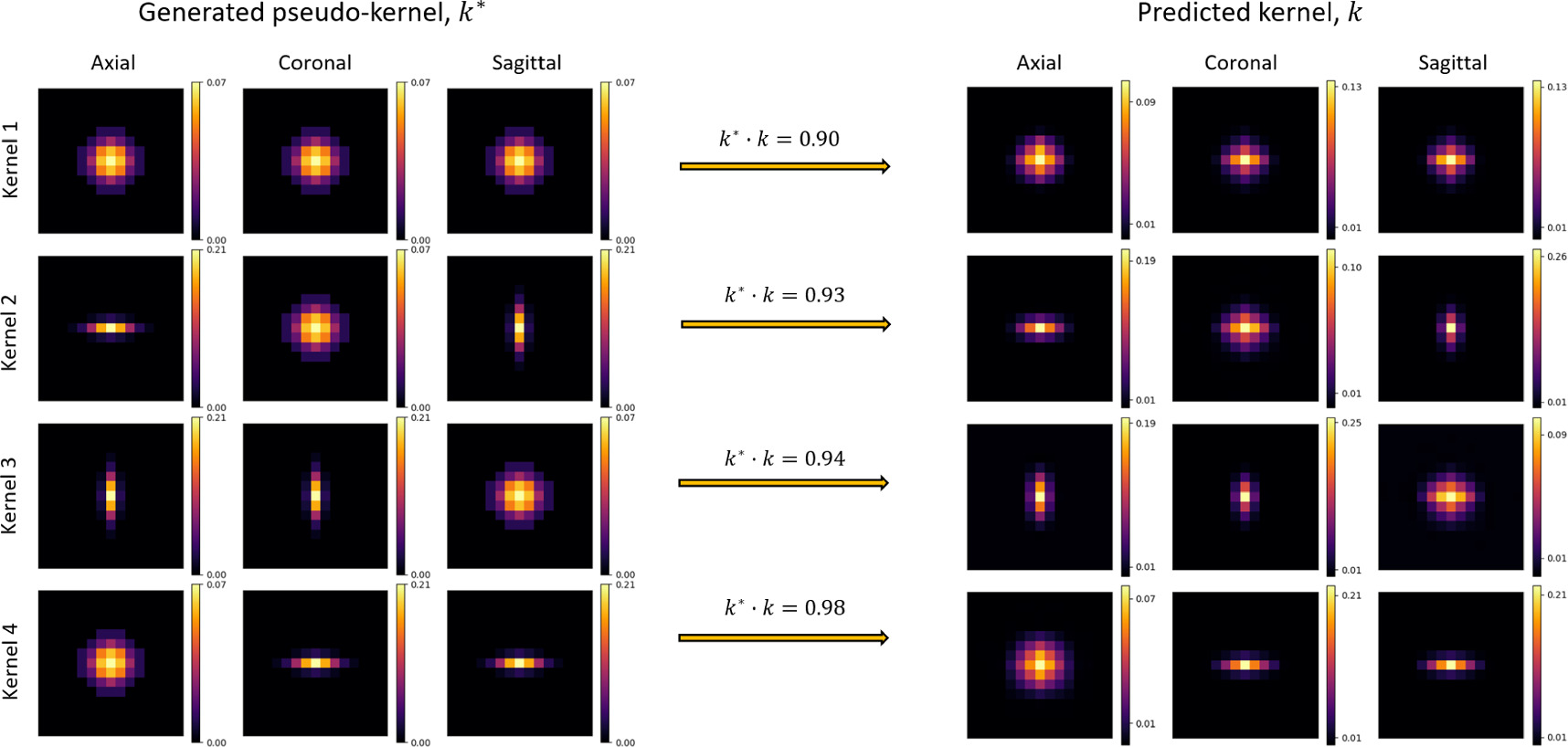
Figure 6. To validate the model's ability to predict accurate blur kernels, 4 variously skewed pseudokernels were applied to deblurred images before re-running the blind deconvolution. Generated pseudokernels (k*, left) and their corresponding predicted kernel (k, right) are shown in separate rows for each of the 4 pseudokernel shapes, in axial, coronal, and sagittal image slices. The dot-product of normalized kernels, k* · k, was used to assess kernel similarity.
Download figure:
Standard image High-resolution imageDeblurred images appeared to be visually sharper than original images. Since x is double the size of y , we upsampled y using nearest-neighbours, linear, quadratic, and cubic interpolation for comparison's sake. Side by side images are found in figure 7.

Figure 7. Predicted deblurred images, x are twice the original resolution, and we therefore tested whether perceived improvements in image quality were only due to the size difference by upsampling the original image using nearest neighbours, linear, quadratic, and cubic interpolation. The deblurred image (right) appeared to have the best quality.
Download figure:
Standard image High-resolution imageCohort uptake statistics within CT-defined salivary glands, calculated using both original and deblurred images, are listed in table 4. Maximum uptake values in both parotid and submandibular glands were significantly higher in deblurred images (p < 0.01), and mean uptake values were insignificantly higher. Uptake plots are shown over corresponding lines through the parotid glands in figure 8. The gradient of uptake from 0.5 SUVlbm to the full width at half-maximum (FWHM) is approximately twice as steep for deblurred images than their original counter-parts. The deblurred images display internal heterogeneity within parotid and submandibular glands that appears unresolved in original images. Axial, coronal and sagittal slices of fusion PET/CT images are shown for both deblurred and original images in figure 9.

Figure 8. An axial slice through the original (left) and deblurred (right) PSMA PET images, intersecting the parotid glands is shown, along with a red line whose corresponding uptake plot is shown directly below each image. Uptake plots for deblurred and original images are displayed together at the bottom. The deblurred images are found to have smaller partial volume effects, as demonstrated by a more rapid ascent to the full width at half maximum, as shown on lateral edges. In this case, the rise to FWHM was twice as steep in the deblurred images.
Download figure:
Standard image High-resolution image
Figure 9. From top to bottom, axial, coronal, and sagittal image slices are shown for both deblurred (left) and original (right) PSMA PET/CT fusion images.
Download figure:
Standard image High-resolution imageTable 4. PSMA PET uptake statistics in CT-defined salivary glands are summarized using both original and deblurred images.
| Parotid | Submandibular | |||||
|---|---|---|---|---|---|---|
| original | Deblurred | p-value | original | Deblurred | p-value | |

| 16.2 ± 4.6 | 21.0 ± 6.2 | p < 0.001 | 15.9 ± 3.9 | 20.2 ± 5.2 | p < 0.001 |

| 7.1 ± 1.9 | 6.7 ± 1.8 | p < 0.001 | 7.1 ± 1.8 | 7.8 ± 2.2 | p < 0.001 |
3.2. Phantom analysis
Axial MIPs and slices of original and deblurred phantom images are shown in figure 10. Activity concentrations were more localized within spheres after deblurring. This was most pronounced in small spheres (≤10 mm). In larger spheres, the activity concentration had higher uniformity after deblurring as seen in signal versus distance plots (across axial slices in both y and x directions) in figure 11. Figure 11 also shows ROI masks defined for each sphere using variable thresholds (table 5). Deblurred and supersampling images resulted in ROIs with higher symmetry. The total activity concentration in phantom images was unaltered after deblurring (p > 0.61).
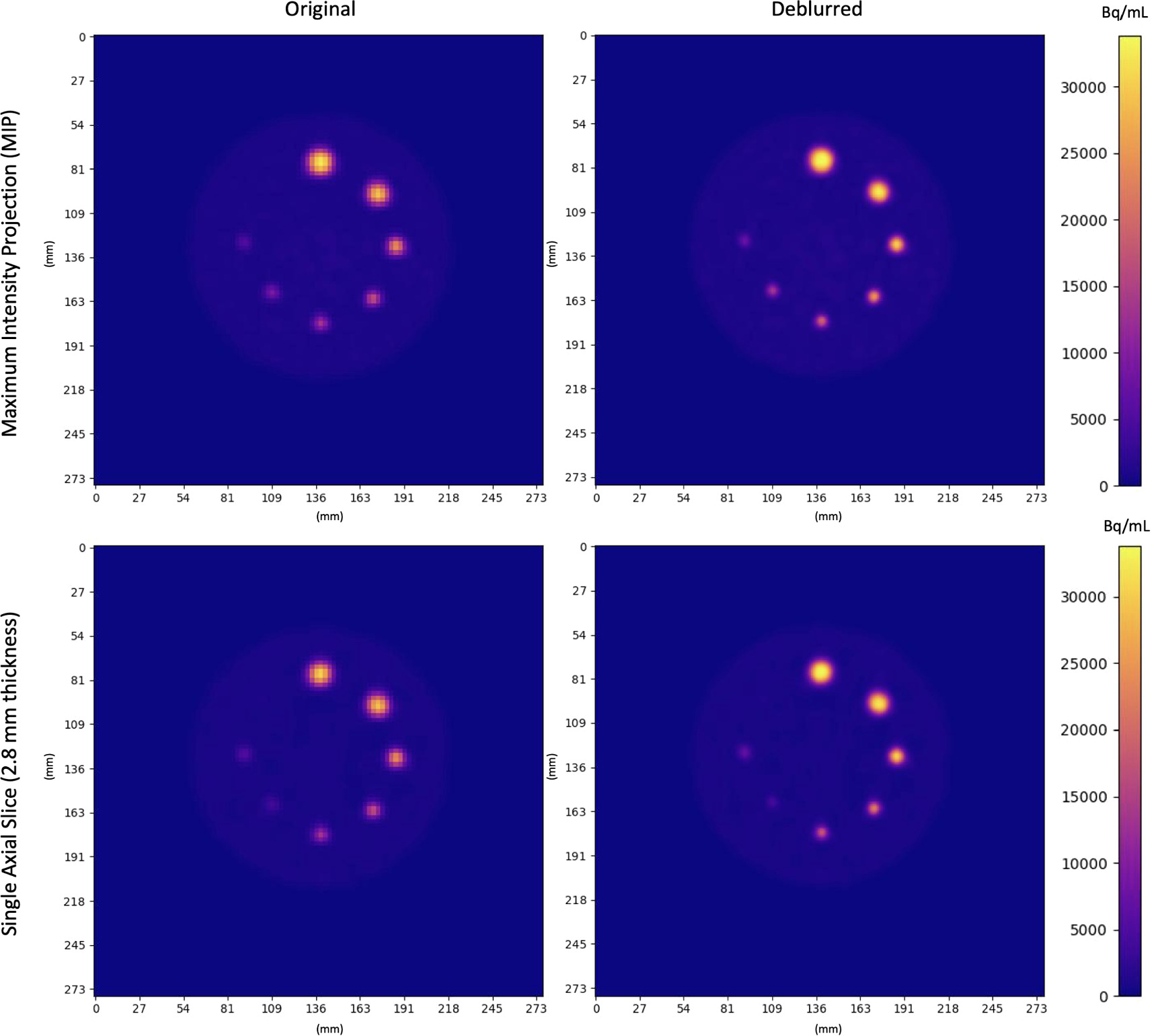
Figure 10. Original and Deblurred PET images of the Q3P phantom. Coplanar spheres containing uniform 22NaCl activity concentrations fused in epoxy resin are seen in a single axial slice. Clockwise from the top sphere, diameters were 16 mm, 14 mm, 10 mm, 8 mm, 7 mm, 6 mm, 5 mm. Spheres appear more homogeneous and localized (especially in smaller regions) after deblurring.
Download figure:
Standard image High-resolution image
Figure 11. Axial slices of 22NaCl infused epoxy spheres in phantom images for original and deblurred images are shown, along with masks corresponding each sphere's best variable threshold for contouring accurate volumes (blue). From top to bottom, sphere diameters are: 16 mm, 14 mm, 10 mm, 8 mm, 7 mm, 6 mm, 5 mm. Activity concentration plots versus distance across each volume in the coronal and sagittal direction are shown to the right, corresponding to red lines shown in PET images.
Download figure:
Standard image High-resolution imageTable 5. Volume and recovery coefficient statistics for 22NaCl infused epoxy spheres in original and deblurred images are shown for volumes determined using a single fixed threshold (top) or a variable threshold determined separately for each sphere size (bottom). Deblurring decreased thresholded volume error, and raised recovery coefficients of the mean, median, and maximum activity concentration. Deblurring increased overestimation of the maximum activity concentration in 16 and 14 mm spheres.
| Single fixed threshold | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Diameter (mm) | Threshold (%) | V/V0 | RCmean | RCmedian | RCmax | |||||
| Original | Deblurred | Original | Deblurred | Original | Deblurred | Original | Deblurred | Original | Deblurred | |
| 16 | 42 | 38 | 0.83 ± 0.01 | 0.94 ± 0.01 | 0.71 ± 0.01 | 0.76 ± 0.01 | 0.69 ± 0.01 | 0.75 ± 0.02 | 1.05 ± 0.01 | 1.10 ± 0.02 |
| 14 | 42 | 38 | 0.80 ± 0.02 | 0.86 ± 0.02 | 0.65 ± 0.01 | 0.72 ± 0.01 | 0.62 ± 0.01 | 0.70 ± 0.01 | 0.99 ± 0.01 | 1.11 ± 0.02 |
| 10 | 42 | 38 | 0.88 ± 0.05 | 0.85 ± 0.05 | 0.47 ± 0.02 | 0.58 ± 0.02 | 0.43 ± 0.02 | 0.55 ± 0.02 | 0.75 ± 0.02 | 0.94 ± 0.02 |
| 8 | 42 | 38 | 1.3 ± 0.08 | 1.10 ± 0.05 | 0.34 ± 0.01 | 0.45 ± 0.02 | 0.33 ± 0.01 | 0.41 ± 0.02 | 0.50 ± 0.02 | 0.76 ± 0.03 |
| 7 | 42 | 38 | 1.7 ± 0.05 | 1.4 ± 0.20 | 0.24 ± 0.01 | 0.32 ± 0.02 | 0.22 ± 0.04 | 0.30 ± 0.02 | 0.40 ± 0.01 | 0.55 ± 0.04 |
| 6 | 42 | 38 | 2.3 ± 0.14 | 2.0 ± 0.42 | 0.17 ± 0.01 | 0.23 ± 0.02 | 0.16 ± 0.01 | 0.21 ± 0.01 | 0.28 ± 0.01 | 0.39 ± 0.03 |
| 5 | 42 | 38 | 6.6 ± 0.52 | 4.0 ± 0.45 | 0.10 ± 0.01 | 0.14 ± 0.01 | 0.08 ± 0.01 | 0.13 ± 0.01 | 0.16 ± 0.01 | 0.24 ± 0.01 |
| Variable thresholds | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Diameter (mm) | Threshold (%) | V/V0 | RCmean | RCmedian | RCmax | |||||
| Original | Deblurred | Original | Deblurred | Original | Deblurred | Original | Deblurred | Original | Deblurred | |
| 16 | 36 | 35 | 0.98 ± 0.02 | 1.00 ± 0.02 | 0.66 ± 0.01 | 0.73 ± 0.02 | 0.63 ± 0.01 | 0.73 ± 0.02 | 1.05 ± 0.01 | 1.10 ± 0.02 |
| 14 | 36 | 33 | 0.98 ± 0.02 | 1.00 ± 0.02 | 0.60 ± 0.01 | 0.67 ± 0.01 | 0.56 ± 0.01 | 0.64 ± 0.01 | 0.99 ± 0.01 | 1.11 ± 0.02 |
| 10 | 41 | 34 | 0.98 ± 0.07 | 0.99 ± 0.05 | 0.45 ± 0.02 | 0.54 ± 0.01 | 0.42 ± 0.02 | 0.51 ± 0.02 | 0.75 ± 0.02 | 0.94 ± 0.02 |
| 8 | 54 | 41 | 1.00 ± 0.03 | 1.98 ± 0.05 | 0.37 ± 0.01 | 0.46 ± 0.02 | 0.35 ± 0.01 | 0.44 ± 0.02 | 0.50 ± 0.02 | 0.76 ± 0.03 |
| 7 | 52 | 47 | 1.02 ± 0.11 | 0.98 ± 0.20 | 0.28 ± 0.01 | 0.38 ± 0.02 | 0.27 ± 0.01 | 0.35 ± 0.02 | 0.40 ± 0.01 | 0.55 ± 0.04 |
| 6 | 59 | 56 | 1.00 ± 0.10 | 1.00 ± 0.23 | 0.22 ± 0.01 | 0.28 ± 0.02 | 0.21 ± 0.01 | 0.27 ± 0.01 | 0.28 ± 0.01 | 0.39 ± 0.03 |
| 5 | 79 | 67 | 1.21 ± 0.13 | 1.02 ± 0.13 | 0.15 ± 0.01 | 0.20 ± 0.01 | 0.15 ± 0.01 | 0.19 ± 0.01 | 0.16 ± 0.01 | 0.24 ± 0.01 |
RCmean, RCmedian, and RCmax increased for each sphere upon deblurring (table 5). Small sphere volumes were thresholded with higher volumetric accuracy, and ROI contouring using a single fixed threshold was made more effective for minimizing total volume error over all sphere sizes after deblurring (figure 12). In particular, a single fixed threshold characterized small spheres more effectively after deblurring. In both original and deblurred images, the maximum activity concentration in 16 mm and 14 mm exceeded actual activity levels. Deblurring increased this overestimation by approximately 5% (table 5). Table 5 includes recovery coefficients and volumes of thresholded phantom regions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 12. Volume and concentration statistics for 22NaCl infused epoxy spheres in phantom images for original and deblurred images. The top row corresponds to sphere statistics determined using volumes defined with a single fixed threshold, while the bottom row corresponds to statistics determined with individual thresholds determined for each sphere size. Spheres defined using deblurred/supersampled images had lower volume discrepancies, and higher recovery coefficients (RCs) of mean, median, and maximum activity concentration. Error bars indicate standard deviations over the 5 consecutively acquired phantom images.
Download figure:
Standard image High-resolution image{kind=link}
Deblurred images of all separate phantom acquisitions were similar, with a mean inner product of 0.93 ± 0.04 between distinct kernels. The shape and size of the mean kernel determined for phantom images was similar to that found for patient images.
4. Discussion
Based on blind image quality metrics and visual appearance, neural blind deconvolution helped mitigate PVEs and improve overall image quality. Quality improvements were a demonstrated result of the blind deconvolution process, and not only standard upsampling, as shown by comparing results with original images upsampled using various orders of polynomial interpolation. The intrinsically low spatial resolution of PET imaging, and consequent PVEs (Bettinardi et al 2014), render PVE correction a necessary task when quantifying uptake in small image regions. Furthermore, PVE correction of PET images has been shown to increase the statistical significance of correlations between uptake bio-markers and various clinical endpoints and prognostic indices (Hatt et al 2011, 2012, 2013, Ohtaka 2013, Gallivanone et al 2014).
Predicted blur kernels were consistent with anticipated sizes and shapes, being small (generally no more than 3 voxels across in any direction with values larger than 0.01) and mostly symmetric. By observing uptake fall-off at body borders in original images, it appears that PVEs cause small spill-out to distances larger than one voxel, but neural blind deconvolution did not detect such small blur components. For model validation, it was essential that predicted kernels were similar between patients. The observed low, but non-zero, inter-patient variability of predicted kernels was as expected. Kernel distributions arise from an unknown combination of the point spread function, scanner limitations, patient motion and other artifacts.
The model's demonstrated ability to predict the shape of pseudokernels convolved with previously deblurred images validated its ability to predict various kernel shapes rather than simply Gaussian shapes. All generated pseudokernel shapes were predicted with high accuracy, but it is notable that the highest accuracy (mean inner product = 0.98) was found for pseudokernel's that were stretched onto primarily one axial slice, and all kernel's stretched onto primarily one axis were predicted with a higher accuracy than the symmetric Gaussian kernel. This may be due to the slightly larger slice spacing than pixel spacing (ratio of 1.025), as it is unclear what mechanism in the model architecture would result in increased predictive power of axially flattened kernels.
The methodology was further validated on phantom images. Activity was more concentrated within spheres and recovery coefficients were higher after deblurring. Use of a single fixed threshold for defining regions had lower volume error for small regions after deblurring and greater fine detail in small spheres is observable in figures 10 and 11. These findings, along with improvements in blind image quality metrics and sharpened ROI uptake boundaries support the ability of this method to improve image quality. It is particularly important to further explore the affect of deblurring on the SUVmax in lesions, as deblurring led to overestimation of the maximum activity concentration within large spheres. This effect may have been due to the spherical symmetry of phantom lesions, which leads to ambiguity in the determination of a theoretical deblurred image and blur kernel. Overestimation of activity concentrations in large phantom spheres suggest that maximum uptake values in deblurred parotid and submandibular glands may be overestimated. Further exploration of this technique on phantom data with various shapes and sizes could help to understand limitations of this methodology.
An advantage of neural blind deconvolution over traditional blind deconvolution methods (Guérit et al 2016) for mitigating PVEs in PET images is that it does not require prior assumptions of the PSF to be imposed. A review of various blind deconvolution algorithms (excluding neural blind deconvolution) applied to natural images (Levin et al 2009) found that the shift-invariant assumption for the blur kernel is often incorrect, which possibly explains a portion of the variance seen in predicted kernels. The proposed method assumes a uniform blur kernel, such that the image can be modelled as y = x * k . However, it is known that PET image blur is dependent on radial distance from the isocentre (radial astigmatism) (Moses 2011, Derenzo et al 1981), so this methodology could likely be improved by modifying the training algorithm to incorporate a spatially varying kernel. However, due to the static nature of the PET scanner, it is likely that this variance is less pronounced here than in cases of natural image acquisition using hand-held devices.
Previous approaches to super-resolution of PSMA PET images typically seek to reconstruct images of standard quality using lower than standard doses (Kennedy et al 2006, Hu et al 2019, Deng et al 2022, Yoshimura et al 2022). These methods use supervised learning to train models to predict known'ground truth' high resolution images from their lower resolution counterparts. Other approaches acquire standard images at multiple points of view and attempt to reconstruct single images of supersampled resolution (Chang et al 2009). In contrast, the present approach seeks to supersample reconstructed images of standard quality to higher than standard resolution, using a self-supervised learning technique. Therefore, ground truth images do not exist for a direct comparison of real and predicted high resolution images. We therefore relied on assessing improvements in blind image quality metrics, and testing kernel similarity between patients and the model's ability to accurately predict pseudokernels.
To directly compare the present method with previous supersampling techniques (Kennedy et al 2006, Hu et al 2019, Deng et al 2022, Yoshimura et al 2022), a potential study could acquire both low and high resolution PSMA PET images, and then apply the present method to the low resolution images. The acquired 'high resolution' images could then be compared with predicted values. This allows for direct quantification of supersampling quality.
The performance of neural blind deconvolution on 2D natural images was previously found to out-perform other deblurring approaches (Ren et al 2020, Kotera et al 2021). A difference between applying deblurring approaches to PET images vs natural images is that the blur kernel for natural images is primarily due to motion, and 'still' natural images can typically be taken as ground-truth images. However, the blur kernel of PSMA PET images typically have a primary component due to intrinsic properties of the scanner. . This makes it especially challenging to assess deblurring approaches applied to PET images. It was not possible to directly assess the accuracy of predicted blur kernels, as true blur kernels are unknown, and can only be estimated from the scanner's point spread function, which is a source of uncertainty that burdens traditional blind deconvolution a posteriori analyses.
A great advantage of self-supervised learning over supervised learning deep learning algorithms is that a large training set is unnecessary. This is especially important in the case of PSMA PET deblurring, PSMA PET is relatively expensive to acquire (Song et al 2022), making it difficult to acquire large datasets. A self-supervised approach to super-resolution of PET images using generative adversarial networks (Song et al 2020) has had demonstrated success, despite its use of 2D rather than 3D convolutions.
While in the traditional U-Net architecture as well as previous neural blind deconvolution studies, the channel count increases towards deeper regions of the encoder and decoder (Ronneberger et al 2015, Ren et al 2020, Kotera et al 2021), we discovered that larger channel counts towards outside regions of the network, decreasing towards the bottom of the encoder and decoder, performed most accurately. Furthermore, including a large number of skip connection channels (64 each) greatly improved performance. This is likely due to increased high-level feature extraction at the top of the network allowing for ultimately better image reconstruction, along with bottle-necking in deeper regions leading to improved learning of important features (Goodfellow et al 2016). Our modelling power was limited by time and GPU resources, and we were unable to test whether scaling all channel counts further could improve results. The model code is available for download online (Sample 2023).
Image quality appeared higher within the high uptake regions of salivary glands as well as other low uptake regions. Before adopting the combination of MAE and MSE used in the loss function, we used only MSE as in previous literature (Ren et al 2020, Kotera et al 2021), but found that this lent itself poorly to the highly skewed distribution of PSMA PET uptake. Adding in MAE allowed appropriate penalization of discrepancy in lower-uptake regions, leading to higher overall quality. We found that decreasing the number of autoencoder layers in Gx from 5 to 4 or 3 had no perceived affect on the model's predictive power, and opened up GPU memory for more channels to be added to the remaining layers. We experimented with various numbers of hidden layers and channel counts in Gk and found that a single layer with 5 times the number of channels in the flattened kernel image worked best.
PET imaging suffers from intrinsically low resolution, resulting in apparent partial volume effects. We have demonstrated neural blind deconvolution to be a viable post-reconstruction method for mitigating these effects. As opposed to traditional maximum a posteriori methods for estimating deblurred images, neural blind deconvolution allows for simultaneous estimation of x and k without convergence towards a trivial solution. We have built off of previously demonstrated 2D natural image architectures (Ren et al 2020, Kotera et al 2021) to create a suitable architecture for 3D PET images. Use of CT images for guiding blind deconvolution relies on accurate image registration. The GLRLM with a long-run emphasis was used rather than the original CT im age, due to its lower contrast which matches PSMA PET better, and due to our previous findings which demonstrated a strong correlation between PSMA PET uptake and the CT GLRLM (Sample et al 2023). Initially, a joint entropy loss function was used rather than SSIM, however, this relies on voxel-binning which causes problems during gradient calculation for back-propagation. Regularization of the kernel was necessary for avoiding a trivial solution. However, once a MSE penalty was applied to kernel values greater than 0.7, the model converged to non-trivial solutions for all patients. Maximum kernel values were generally less than 0.4, so our kernel constraint did not arbitrarily constrain the maximum value found in predicted kernels to a set value.
This analysis was performed on a dataset of previously reconstructed images, without access to raw scanner data. VPFXS had been previously chosen for clinical image reconstruction over BSREM/Q.Clear (Sah et al 2017, Teoh et al 2015) for consistency across scanners (which did not all have access to BSREM/Q.Clear reconstruction algorithms). The voxel size is an important acquisition parameter whose modification is sure to affect model performance. The dependence of model performance on voxel size would make for an interesting future study. Many other acquisition and model parameters can be further fine-tuned for optimal performance. Future studies seeking to enhance PSMA PET with neural blind deconvolution should maintain a consistent voxel size across patients for the sake of comparison.
PSMA PET uptake is heavily biased towards the salivary glands in the head and neck. A previous study has demonstrated heterogeneous uptake of PSMA-PET in parotid glands (Sample et al 2023), and mitigating partial volume effects using neural blind deconvolution appears to make this effect more pronounced. The tubarial glands (Valstar et al 2021) appeared with greater definition in deblurred images, as two distinct regions of high uptake. Maximum uptake regions were better localized in deblurred images, resulting in increased overall maximum values, as well as slight increases in whole-gland means. These results are too be expected, due to mitigated spill-out and spill-in of voxel values around maximum values, and spill-out near gland edges. The total activity in original and deblurred images remained constant, which was necessary in the context of PET imaging. Originally, we included a separate total activity constraint in the loss function, but found this redundant since our fidelity term accomplished this goal.
Supersampling during neural blind deconvolution is not limited to double scaling, and the demonstrated model architecture can easily be amended for accommodating additional resizing. Furthermore, the methodology could be adapted for kernels to be first convolved with deblurred images before downsampling to compute the fidelity loss. Our methodology was limited by time and computation resources.
Deblurring and supersampling PSMA PET images was motivated by the challenge of quantifying uptake in small spatial regions of images, such as the salivary glands, where partial volume effects become increasingly problematic. PSMA PET has high ligand accumulation in the parotid glands (Israeli et al 1994, Trover et al 1995, Wolf et al 2010), and has been suggested to relate to whole-gland functionality (Klein Nulent et al 2018, Mohan et al 2020, Zhao et al 2020). Heterogeneity of PSMA PET uptake trends in salivary glands can be analysed with greater fine detail brought out by deblurring/supersampling. PSMA PET has the unique potential to quantitatively investigate salivary gland physiology, which could potentially lead to better understanding of their functionality as relevant for radiotherapy treatment planning.
PSMA PET is primarily used for detecting and staging prostate cancer, and deblurring/supersampling with neural blind deconvolution could improve fine detail in small lesions, leading to better localization. This methodology has the potential to improve target localization for treatment planning and reduce the rate of false negative lesion detection. Greater localization ability will lead to better estimation of lesion volumes and better monitoring of treatment outcomes. Use of SUVmean over SUVmax will likely be necessary for characterising regions of interest as super-resolution algorithms continue to develop and gain clinical confidence, as the SUVmax is more sensitive to partial volume effects in small regions.
5. Conclusion
In this work, we have adapted neural blind deconvolution for simultaneous PVE correction and supersampling of 3D PSMA PET images. PVE correction allows for fine detail recovery within the imaging field, such as uptake patterns within salivary glands. Leveraging the power of deep learning without the need for a large training data set or prior probabilistic assumptions makes neural blind deconvolution a powerful PVE correction method. Our results demonstrate improvements in the method's ability to improve image quality over other commonly used supersampling techniques. The model code is available online for further studies (Sample 2023).
Acknowledgments
This work was supported by the Canadian Institutes of Health Research (CIHR) Project Grant PJT-162216.
Data availability statement
The data that support the findings of this study are openly available at the following URL/DOI: https://github.com/samplecm/neural_blind_deconv_PSMA.
Ethical statement
This retrospective study was approved by the BC Cancer Agency Research Ethics Board (H21-00518-A001). Participants had provided written consent in prior studies for their data to be further analyzed and for subsequent results to be published.