

Abstract
This paper analyses the efficiency of various frequency cepstral coefficients (FCC) in a non-speech application, specifically in classifying acoustic impulse events-gunshots. There are various methods for such event identification available. The majority of these methods are based on time or frequency domain algorithms. However, both of these domains have their limitations and disadvantages. In this article, an FCC, combining the advantages of both frequency and time domains, is presented and analyzed. These originally speech features showed potential not only in speech-related applications but also in other acoustic applications. The comparison of the classification efficiency based on features obtained using four different FCC, namely mel-FCC (MFCC), inverse mel-frequency cepstral coefficients (IMFCC), linear-frequency cepstral coefficients (LFCC), and gammatone-frequency cepstral coefficients (GTCC) is presented. An optimal frame length for an FCC calculation is also explored. Various gunshots from short guns and rifle guns of different calibers and multiple acoustic impulse events, similar to the gunshots, to represent false alarms are used. More than 600 acoustic events records have been acquired and used for training and validation of two designed classifiers, support vector machine, and neural network. Accuracy, recall and Matthew's correlation coefficient measure the classification success rate. The results reveal the superiority of GFCC to other analyzed methods.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
With the growing prevalence of shootings in public areas and the rise in gun ownership among citizens over all around the world, the demand for autonomous systems capable of detecting and identifying dangerous events like a gunshot is growing not only in public spaces, e.g. hospitals, campuses, hospitals, parks, or government buildings not mentioning traditional military applications. Existing surveillance technologies, like cameras or drones, in combination with physical security measures, such as guards or patrol officers, offer limited protection and may prove inadequate in certain situations. In such scenarios, an automatic acoustic-based detection system holds an advantage over the described methods. The advantage of such an automatic acoustic system lies in the ability to detect, localize and effectively classify the type of acoustic event and, in a case of a gunshot, even estimate the caliber of a gun. Acoustic surveillance systems have the potential to identify dangerous events in various environments and, when strategically placed, to track the source of continuous threats. Such a system has been introduced and described by the authors in [1]. The crucial parameters for the autonomous acoustic surveillance system to correctly identify the acoustic event, such as a gunshot, are features extracted from the recorded acoustic impulse signal used for classification.
The acoustic pattern of a gunshot can be characterized by two phenomena, muzzle blast, caused by an explosive charge creating hot, high-pressure gases to expand as acoustic energy from the gun barrel, which has a pattern similar to the N letter, and, in case of a supersonic projectile, shock wave, caused by combinations of compression and expansion shock. The shock wave, also called N-wave, for its specific look, propagates in a conic shape in a perpendicular trajectory, away from the bullet trajectory. An example of a muzzle blast and a shock wave is in figure 1.

Figure 1. (a) Muzzle blast (b) Shock wave.
Download figure:
Standard image High-resolution imageIn figure 1(a), there is an 'N-pattern' characterized for muzzle blast that lasts about 5 ms. The gunshot was taken from a CZ BREN2 rifle gun of caliber 5.56 NATO with an SD ammunition of a velocity of approx. 320 m s−1. Figure 1(b) shows an 'N-wave' corresponding to a shock wave that lasts <3 ms. The gunshot was fired from CZ 75 SP-01 Phantom (9 mm Luger) with a shell velocity of approx. 380 m s−1. A more detailed explanation of the gunshot theory can be found in [2–5]. The acoustic response of a gunshot depends on many factors: the barrel caliber, barrel length, type of bullet and its velocity, the chemical properties of the propellant, or environmental conditions such as air temperature, air humidity, wind speed, and direction. All these factors affect the resulting pattern. In addition, the environment where the shot was fired may also affect the shape of the recorded pattern. In dense areas, reflections and diffractions caused by objects or the ground itself can significantly alter the pattern [6]. Since gunshot characteristics are a complex problem and are determined by many factors, commonly used methods for feature extraction from acoustic impulse signals based on the time or frequency domain cannot be reliably applied. Considering the gunshot as an impulse signal, traditional frequency domain signal processing methods such as spectral analysis rather provide the acoustic characteristic of the surrounding environment than the pattern of a gunshot [7]. The characteristic N-pattern of a gunshot is also affected by many phenomena that cause it to change due to, for example, nonlinear dispersion effects. In case of a supersonic projectile, the shock wave completely dissipates once the projectile velocity drops below the supersonic velocity or hits an obstacle. In dense areas where multiple acoustic reflections may occur, this can further prevent reliable application of wavelet methods [8, 9]. Furthermore, examining the power spectra of gunshots of different calibers recorded at the same distance precludes the use of a simple filtering method [10].
This article directly follows on from the authors work presented in [1], where authors introduced the complete system for the detection, localization and classification of impulse acoustic events. It has been revealed the gunshot pattern due to its complexity cannot be reliably detected using common time or frequency domain methods. Therefore, the authors introduced novel two stage detection algorithm. Firstly, the recorded audio signal is pre-processed in the time domain with the algorithm based on a median filter, which is able to detect the impulse in the signal to the signal-to-noise ratio up to 5 dB. The second stage perform calculation of the mel-frequency cepstral coefficients (MFCC) which are used as a features for the classification of the impulse event, a gunshot more specifically, into individual calibers. The presented system is fully automated, is capable to localize and identify the source of the event and it does not require a human operator, therefore its operational costs are incomparably lower in comparison with commercially available systems [11–14].
In the article [1], it has been also shown the signal processing method based on MFCC originally used in other acoustic applications can be reliably used for a gunshot recognition. The method was tested on a various gunshots taken in the same military area shooting range with the promising results.
In this article authors comparing the effectivity of the various frequency cepstral coefficients (FCC) in a gunshot detection and recognition applications and testing the optimal frame length with an acoustic signal going to be processed with the FCC. The emphasis has been put not only on a variety of and impulse acoustic event but also on a diversity of an environment where the events has been recorded. The introduced methods are MFCC, Inverse MFCC (IMFCC), Linear-FCC (LFCC), and Gammatone-frequency Cepstral Coefficients (GTCC). These FCC showed very good performance in speech recognition tasks, but recently it has also been used in various acoustic applications such as music genre classification, animal sounds classification, or environmental sound recognition.
Since the recorded audio signal is not a stationary waveform, framing the signal must be performed as a first step of every feature extraction method. This enables the representation of non-stationary audio waveforms, by their nature, as stationary frames of the signal. In commonly used methods for audio signal processing such as speech, music genre, animal, or ambient sound recognition, the typical frame length is from 10 ms to 40 ms [15–19].
Therefore, the optimal length of the frame for feature extraction using cepstral analysis is also part of the experiment. Taking into account the time duration of all gunshot phenomena, including reflections and time delays between muzzle blast and shockwave for measured bullet speeds and distances and with regard to a variety of false alarms, three different sizes of the frames with the acoustic signal have been tested, 15 ms, 30 ms and 50 ms.
Presented experiments use the extracted features by the four different FCC to identify and classify various acoustic impulse signals into false alarms and gunshots, and in the case of a gunshot, into the individual calibers. As a classifier, a support vector machine (SVM) classifier and a neural network (NN) are used, and a metric for their success evaluation includes Accuracy, Recall and Matthew's Correlation Coefficient.
The paper is organized as follows. Section 2 introducing the selected methods for the feature extraction. Section 3 explaining data acquisition and their processing, the examples of the impulse events are shown and detailed description of the methods is presented and discussed. Section 4 contains the results of the experiment followed by Section 5, where the results are discussed. The conclusion and future work directions are outlined in the section 6.
2. Feature extraction method
The analysis of the gunshot pattern described in the Introduction section revealed its complexity. It has been shown that conventional methods for feature extraction may not work reliably. Therefore, more complex processing offering the advantages of both time and frequency domains shows the direction of reliable identification of a gunshot and its classification into individual calibers. This can be done using methods based on a cepstral analysis. Cepstral analysis combines both time and frequency domains, and cepstral features possess several advantages, including source-filter separation, conciseness, and orthogonality, making them convenient for training machine learning algorithms [20–22]. It already proved its effectiveness in feature extraction in another acoustic field, speech-oriented applications.
The best-known and commonly used method for feature extraction based on cepstral coefficients which apply fast Fourier transform (FFT), filters, and power spectra, is MFCC. MFCC has a wide range of uses in audio spectral characteristics applications focusing on the identification of speech and speaker, music-genre classification, or classification of sounds in general [23–28]. These cepstral coefficients are based on a mel-frequency spacing of the filters bank and its energies. It mimics the audio perception of a human ear. The filter bank applied for feature extraction can use the base mel-frequency filter bank or its modifications, LFCC or inverse mel-frequency (IMFCC) filter banks [29]. Another two cepstral coefficients, derived from Linear prediction coefficients, are linear prediction cepstral coefficients (LPCC) and perceptual linear prediction coefficients (PLPC). LPCC is mainly used in noise elimination [30] or music genre classification [31], or speech recognition [32]. PLPC involves critical band spectral resolution, equal-loudness curve, and intensity loudness power law [20]. These cepstral coefficients are mainly used for animal sound classification [29], emotion identification [30], and speech recognition systems [33]. The last two cepstral coefficients are both derived from the human auditory response and the analysis performed in the cochlea [34]. Greenwood function cepstral coefficients are primarily used for animal and bird sound identification and classification [20], and GTCC are considered the most noise-robust features in audio recognition applications. The extraction of GTCC is similar to MFCC but is based on the gammatone filter bank, which output is the frequency-time domain representation of an acoustic signal. Unlike MFCC, the GTCC are more robust against noise. The main applications of GTCC are environmental sound identification and speech recognition [35].
To summarize the above, the most efficient cepstral coefficients in environmental and general ambient sound recognition and classification are MFCC and its modifications and GTCC. In these applications, some studies favor GTCC, some studies favor MFCC over GTCC [34, 36], or [37].
This study focuses on an efficiency comparison of these methods and their modifications in gunshot identification and classification. It also exploring a different sizes of frame which is used for features calculation. All the cepstral coefficients feature extraction methods used the same approach as shown in figure 2.

Figure 2. The block diagram of the feature extraction algorithms.
Download figure:
Standard image High-resolution imageThe input audio signal is firstly split into short time frames. The frames are usually set to be from 10 ms up to 50 ms long, and it can have an effect on the resulting effectivity of the extracted features for classification [38–44]. Subsequently, FFT is calculated. To minimize the discontinuity of the framed signal, each frame is windowed by multiplying each frame by a hamming window. The spectra are then filtered by a filter bank, calculating a nonlinear rectification function to the filtered signal (log or power function), and, finally, the discrete cosine transform is performed. As a result, cepstral coefficients, which will be served as features extracted from audio signals for later classification, are calculated.
3. Data acquisition and processing
To assess the effectiveness of the proposed feature extraction methods, multiple acoustic impulse events, including gunshots and false alarms, which pattern is similar to gunshots, have been recorded and processed.
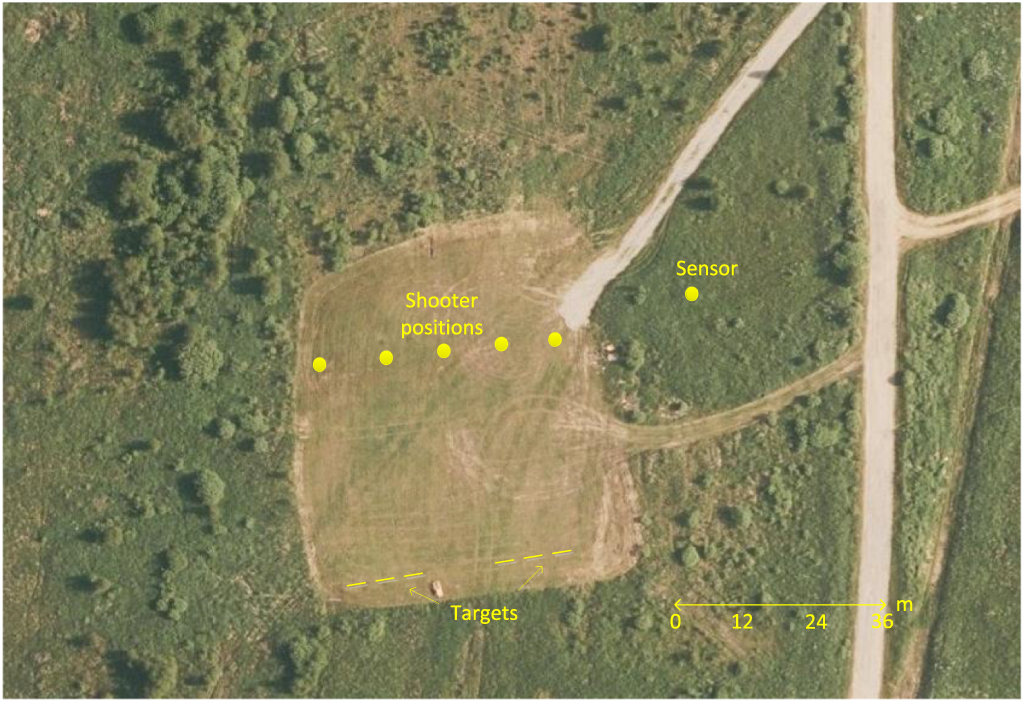
For a gunshot recordings, experiment on a military shooting range in Czechia were conducted. The experiment involved recordings of four different types of firearms gunshots from various distances from the sensor. The military shooting range where all gunshots experiments was taken is in figure 3. It worth nothing to mention the clear visibility of the sensor to all of shooters positions.

Figure 3. The scheme of the shooting range where the experiments were taken.
Download figure:
Standard image High-resolution image9 mm short gun, 5.56 NATO rifle gun, .22 short gun, and 7.62 mm Tokarev short gun were recorded as a representation of gunshot patterns. During the experiment, each weapon was used with the same ammunition type (i.e. speed of the bullet). The ammunition type used covered both subsonic and supersonic speeds close to the speed of the sound, ranging from vmin ≈ 280 m s−1 to vmax ≈ 380 m s−1.
For the purpose of verifying the correct recognition of gunshots from other impulse environmental sounds, a diverse impulse acoustic event having a similar pattern to a gunshot has been selected to provide the basis for false alarms. The emphasis has been placed on selecting events that can be mistaken for a gunshot.
All recorded events has been captured by PreSonus PRM1 electret microphone and digitized by Rubix 44 USB audio Interface with 24-bit analogue-to-digital converter and with the sampling frequency of fs = 48 kHz. The distance between the acoustic event and the microphone was approx. from 20 m to 60 m in the case of gunshots and an in much closer distance of approx. units of meters in a case of false alarms to achieve similar amplitude intensity as for gunshots. About 500 impulse acoustic events have been recorded and processed to test the individual feature extraction methods based on cepstral coefficients. The overview of all events and their amounts is in table 1. In the case of gunshots, there is also a bullet muzzle velocity v presented.
Table 1. An overview of samples.
| Class | Number of samples |
|---|---|
| 9 mm (v ≈ 380 m s−1) | 101 |
| 5.56 NATO SD (v ≈ 320 m s−1) | 131 |
| 7.62 mm Tokarev (v ≈ 280 m s−1) | 72 |
| .22 (v ≈ 300 m s−1) | 78 |
| False alarms | 107 |
A simple impulse-type pre-detection algorithm based on a modified median filter preprocess recorded and digitized acoustic signal and splits it into the adjustable frame length. More details about the algorithm implementation can be found in [1].
Measured acoustic patterns example for all four tested gunshots are presented in figure 4. The figure shows the detail of a filtered acoustic signal where the peak was detected and its near vicinity with no reflections.

Figure 4. An example of measured patterns of a gunshots.
Download figure:
Standard image High-resolution imageThe selected false alarms are represented by hand claps, bubble wraps popping, hand slams, door slams and other kind of slams. In general, the events which have the similar acoustic response as a gunshot. All of the other sounds have been recorded by the authors using the same way as in the case of gunshots.
An example of the gunshot pattern and selected false alarm similarity is presented in figures 5 and 6. Figure 5 shows a recorded acoustic pattern corresponding to subsonic shots (5.56 NATO SD ammunition) and its details—muzzle blast at times approx. 0.05 s (taken at a distance of 50 m) and 0.4 s (taken at a distance of 30 m).

Figure 5. Acoustic pattern corresponding to a 5.56 NATO SD ammunition.
Download figure:
Standard image High-resolution image
Figure 6. Acoustic pattern corresponding to a door slam.
Download figure:
Standard image High-resolution imageWhile figure 6 depicts the acoustic pattern of a door slam recorded from a much closer distance of approx. 4 m. An N-shaped pattern typical for a gunshot is clearly visible in a time of approx. 0.2 s.
Upon comparing both Figures, it becomes evident that the acoustic pattern produced by gunshots and that of a door slam could be mistaken for each other if we solely rely on detecting the N-shaped pattern. Last but not least, figure 7 shows an example of recorded gunshot taken in a noisy environment.

Figure 7. Signal corresponding to a gunshot taken by a .22 caliber in a noisy environment.
Download figure:
Standard image High-resolution imageAgain, it can be seen, without a particular signal processing it cannot be possible to detect correctly a gunshot.
As a part of the experiment, different lengths of the frames containing the detected acoustic peak are considered. From the complexity of a gunshot, the speed of bullets (from speed of the sound for temperature of 30 °C v30°C ≈ 350 m s−1 to a maximum supersonic speed of bullet speed of vbullet ≈ 380 m s−1) used in the experiment and the distances between the shooter and the recording device (up to 60 m), the shortest frame size has been set to 15 ms. Taking into account the reflections and the acoustic pattern length of false alarms, additional two frame sizes of 30 ms, and 50 ms, have been tested to compare the effectivity of the presented feature extraction methods.
After framing the signal, the frames are multiplied by a hamming window, and FFT is performed. Using the FFT and by applying a filter bank, individual FCCs are calculated as shown in figure 2. The previous experiments with acoustic signals [1, 38, 42, 45, 46] showed the optimal numbers of filters are about 20–30 filters. Therefore, the filter bank with 26 filters was designed and applied. The number of filters was chosen as a trade-off between classification accuracy and filter bank calculation complexity. The bandwidth of the filter bank starts at fmin = 1 Hz and ends at fmax = 24 kHz for all four methods, MFCC, IMFCC, LFCC, and GTCC. The implemented filter banks based on mel-frequency are shown in figure 8. The frequency characteristic of the Gammatone filter bank is in figure 9.

Figure 8. mel-frequency filter bank.
Download figure:
Standard image High-resolution image
Figure 9. Frequency characteristic of Gammatone filter bank.
Download figure:
Standard image High-resolution imageThe implementation of all functions and algorithms described above has been done by authors in the MATLAB software. More details about the implementation can be found in [47, 48].
The calculated 26 cepstral coefficients are then used as features for a SVM classifier with a polynomial kernel of second order and a NN with 20 layers (an input layer, 18 hidden layers, and an output layer). The layers were trained using the Levenberg-Marquardt training method and MATLAB NN training tool [49]. Both designed classifiers were tested for an effectivity comparison of the four different FCC in acoustic impulse events detection.
4. Results
As shown in table 1, four types of gunshots and various types of false alarms with similar pattern to a gunshot have been recorded, processed and classified to test the efficiency of the individual cepstral coefficients and the optimal frame length of the input data. In this way, five classes for the multi-label classification task are set: 0 (false alarms), 1 (9 mm), 2 (5.56 NATO SD), 3 (7.62 mm Tokarev), and 4 (.22). The 26 extracted features for four FCC methods for each sample has been divided into training and testing data sets.
Approx. 75% of samples from each class (four gunshots classes and false alarms class) were used for training and validation, and the rest (≈25%) were used for testing. The training process was performed using the MATLAB Neural Fitting tool, where the data division to training, validation, and testing groups was random. The Levenberg–Marquardt optimization algorithm for training was selected because of a relatively limited number of data. mean squared error was has been used as a performance measure, and MEX function for calculations [50]. The resulting NN was trained after 370 iterations. The overview of all sample numbers used for testing and training is in table 2.
Table 2. An overview of samples.
| Class number | Class | Number of samples for training | Number of samples for testing |
|---|---|---|---|
| 0 | False alarms | 86 | 21 |
| 1 | 9 mm | 70 | 31 |
| 2 | 5.56 NATO SD | 100 | 31 |
| 3 | 7.62 mm Tokarev | 55 | 17 |
| 4 | .22 | 60 | 18 |
The experiment results for all the feature extraction methods, and both classifiers (SVM and NN) are presented in the following figures and tables.
Figure 10 depicts confusion matrices of all four FCC feature extraction methods for the SVM classifier and for all three frame lengths of 15 ms, 30 ms and 50 ms.

Figure 10. Confusion matrixes for SVM classifier and all three frame sizes.
Download figure:
Standard image High-resolution imageBased on the confusion matrices calculated above, some patterns of the methods are clearly visible. The mel-frequency-based cepstral coefficients have similar results. On the other hand, Gammatone-FCC show a much more promising score. Also, it is visible that with the increasing frame length, the classification is more successful. The resulting confusion matrices for the NN classifier are in figure 11.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 11. Confusion matrixes for NN classifier and all three frame sizes.
Download figure:
Standard image High-resolution image{kind=link}
These confusion matrices confirm the results obtained with the SVM classifier. It shows the dominance of GTCC over the mel-frequency type cepstral coefficients. Also, it reveals that the NN tends to classify better than SVM for some of the classes in the performed tests.
Using the proper metrics calculated from confusion matrixes, it is possible to closely examine the results and understand the presented feature extraction methods and the different frame lengths' overall effectiveness. This allows to reveal which methods and its parameters are more efficient in our case of usage.
The metrics used for an evaluation were Accuracy (ACC) (1), Recall (RLC), also known as sensitivity (2), and Matthews' correlation coefficient (MCC) (3) [51].



where T stands for true, F stands for false, P stands for positive, and N stands for negative.
Tables 3 and 4 present results for the first two classes, 9 mm, and 5.56 NATO SD ammunition, with a velocity close to the speed of the sound and with a similar pattern to each other (see figure 4).
Table 3. Classification results for a 9 mm class.
| Frame length | Feature extractor | SVM | NN | SVM | NN | SVM | NN |
|---|---|---|---|---|---|---|---|
| ACC (%) | ACC (%) | RLC (%) | RLC (%) | MCC (-) | MCC (-) | ||
| 15 ms | MFCC | 83,90 | 85,59 | 80,65 | 67,74 | 0,62 | 0,62 |
| LFCC | 83,90 | 83,90 | 80,65 | 64,52 | 0,62 | 0,57 | |
| IMFCC | 85,59 | 90,68 | 83,87 | 87,10 | 0,66 | 0,77 | |
| GTCC | 93,22 | 97,46 | 87,10 | 93,55 | 0,82 | 0,93 | |
| 30 ms | MFCC | 84,75 | 87,29 | 67,74 | 87,10 | 0,60 | 0,70 |
| LFCC | 87,29 | 83,90 | 70,97 | 70,97 | 0,66 | 0,59 | |
| IMFCC | 85,59 | 92,37 | 67,74 | 80,65 | 0,62 | 0,80 | |
| GTCC | 97,46 | 98,31 | 90,32 | 93,55 | 0,93 | 0,96 | |
| 50 ms | MFCC | 84,75 | 93,22 | 74,19 | 90,32 | 0,61 | 0,83 |
| LFCC | 88,98 | 86,44 | 77,42 | 77,42 | 0,71 | 0,66 | |
| IMFCC | 89,83 | 90,68 | 74,19 | 80,65 | 0,73 | 0,76 | |
| GTCC | 97,46 | 99,15 | 90,32 | 96,77 | 0,93 | 0,98 |
Table 4. Classification results for a 5.56 NATO SD class.
| Frame length | Feature extractor | SVM | NN | SVM | NN | SVM | NN |
|---|---|---|---|---|---|---|---|
| ACC (%) | ACC (%) | RLC (%) | RLC (%) | MCC (-) | MCC (-) | ||
| 15 ms | MFCC | 87,29 | 88,98 | 61,29 | 61,29 | 0,65 | 0,71 |
| LFCC | 87,29 | 90,68 | 61,29 | 74,19 | 0,65 | 0,75 | |
| IMFCC | 87,29 | 89,83 | 61,29 | 67,74 | 0,65 | 0,73 | |
| GTCC | 93,22 | 98,31 | 83,87 | 96,77 | 0,82 | 0,96 | |
| 30 ms | MFCC | 86,44 | 92,37 | 74,19 | 80,65 | 0,65 | 0,80 |
| LFCC | 87,29 | 89,83 | 74,19 | 80,65 | 0,67 | 0,74 | |
| IMFCC | 87,29 | 92,37 | 74,19 | 90,32 | 0,67 | 0,81 | |
| GTCC | 98,31 | 99,15 | 100 | 100 | 0,96 | 0,98 | |
| 50 ms | MFCC | 88,98 | 94,92 | 80,65 | 83,87 | 0,72 | 0,87 |
| LFCC | 91,53 | 89,83 | 83,87 | 80,65 | 0,78 | 0,74 | |
| IMFCC | 94,92 | 94,07 | 90,32 | 83,87 | 0,87 | 0,84 | |
| GTCC | 98,31 | 99,15 | 100 | 100 | 0,96 | 0,98 |
It is evident that all three mel-frequency type cepstral coefficients have very similar results. In comparison, GTCC achieved a much better score in almost all cases. Also, it is visible that with the increasing frame length, classification success is getting more accurate. On the other hand, a longer frame could contain more reflections typical for the place where the sensor is located, and, therefore, it will include an acoustic impulse response of the local reverberant environment. This will cause the frame to more likely contain more information about the acoustical surroundings than the gunshot itself. The achieved results also favor NN over the SVM classifier in most cases.
Tables 5 and 6 show results of another two resembling gunshot patterns—7.62 Tokarev and .22 ammunitions. The results are presented in Tables 5 and 6 confirm the superiority of the GTCC over the other FCC and the slightly better classification success of the NN and for a longer frame length.
Table 5. Classification results for a 7.62 mm Tokarev class.
| Frame length | Feature extractor | SVM | NN | SVM | NN | SVM | NN |
|---|---|---|---|---|---|---|---|
| ACC (%) | ACC (%) | RLC (%) | RLC (%) | MCC (-) | MCC (-) | ||
| 15 ms | MFCC | 95,76 | 94,07 | 83,33 | 77,78 | 0,83 | 0,77 |
| LFCC | 95,76 | 96,61 | 83,33 | 88,89 | 0,83 | 0,87 | |
| IMFCC | 94,07 | 95,76 | 77,78 | 83,33 | 0,77 | 0,83 | |
| GTCC | 98,31 | 99,15 | 94,44 | 94,44 | 0,93 | 0,97 | |
| 30 ms | MFCC | 97,46 | 98,31 | 88,89 | 94,44 | 0,90 | 0,93 |
| LFCC | 96,61 | 95,76 | 83,33 | 83,33 | 0,86 | 0,83 | |
| IMFCC | 96,61 | 97,46 | 88,89 | 88,89 | 0,87 | 0,90 | |
| GTCC | 99,15 | 100 | 94,44 | 100 | 0,97 | 1 | |
| 50 ms | MFCC | 94,92 | 98,31 | 83,33 | 94,44 | 0,80 | 0,93 |
| LFCC | 97,46 | 94,92 | 88,89 | 83,33 | 0,90 | 0,80 | |
| IMFCC | 97,46 | 97,46 | 88,89 | 88,89 | 0,90 | 0,90 | |
| GTCC | 100 | 100 | 100 | 100 | 1 | 1 |
Table 6. Classification results for a .22 class.
| Frame length | Feature extractor | SVM | NN | SVM | NN | SVM | NN |
|---|---|---|---|---|---|---|---|
| ACC (%) | ACC (%) | RLC (%) | RLC (%) | MCC (-) | MCC (-) | ||
| 15 ms | MFCC | 94,07 | 94,07 | 70,59 | 70,59 | 0,75 | 0,75 |
| LFCC | 94,07 | 95,76 | 70,59 | 76,47 | 0,75 | 0,82 | |
| IMFCC | 93,22 | 95,76 | 64,71 | 76,47 | 0,70 | 0,82 | |
| GTCC | 97,46 | 98,31 | 88,24 | 94,12 | 0,89 | 0,93 | |
| 30 ms | MFCC | 96,61 | 98,31 | 82,35 | 88,24 | 0,86 | 0,93 |
| LFCC | 96,61 | 95,76 | 82,35 | 76,47 | 0,86 | 0,82 | |
| IMFCC | 96,61 | 97,46 | 82,35 | 88,24 | 0,86 | 0,89 | |
| GTCC | 98,31 | 99,15 | 94,12 | 94,12 | 0,93 | 0,97 | |
| 50 ms | MFCC | 94,07 | 98,31 | 70,59 | 88,24 | 0,75 | 0,93 |
| LFCC | 96,61 | 94,07 | 82,35 | 70,59 | 0,86 | 0,75 | |
| IMFCC | 97,46 | 97,46 | 88,24 | 88,24 | 0,89 | 0,89 | |
| GTCC | 99,15 | 99,15 | 94,12 | 94,12 | 0,97 | 0,97 |
It can also be seen if there is no variability in an environment and the same gun is used, the results are significantly better than in cases of 9 mm and 5.56 NATO SD classes taken by multiple firearms.
The overall worst results from all five classes are shown in table 7. It is caused by the significant variability of recorded false alarms and its intended similarity to gunshot patterns of all types. Nevertheless, the same scenario as in gunshot-type classes is apparent. The GTCC gives the best results from all four feature extraction methods, confirming the superiority over the Gammatone-based methods. Again, longer frames are more successful in the classification. Since most of the false alarms have been recorded in closed spaces, thus its recordings contain many reflections. Therefore, longer frames include more extracted patterns for a classifier.
Table 7. Classification results for a False alarm class.
| Frame length | Feature extractor | SVM | NN | SVM | NN | SVM | NN |
|---|---|---|---|---|---|---|---|
| ACC (%) | ACC (%) | RLC (%) | RLC (%) | MCC (-) | MCC (-) | ||
| 15 ms | MFCC | 83,05 | 76,27 | 66,67 | 76,19 | 0,48 | 0,43 |
| LFCC | 83,05 | 82,20 | 66,67 | 76,19 | 0,48 | 0,51 | |
| IMFCC | 83,90 | 80,51 | 71,43 | 66,67 | 0,52 | 0,44 | |
| GTCC | 97,46 | 98,31 | 100 | 100 | 0,92 | 0,95 | |
| 30 ms | MFCC | 94,07 | 93,22 | 95,24 | 76,19 | 0,82 | 0,76 |
| LFCC | 91,53 | 87,29 | 95,24 | 71,43 | 0,76 | 0,59 | |
| IMFCC | 93,22 | 93,22 | 95,24 | 85,71 | 0,80 | 0,78 | |
| GTCC | 98,31 | 98,31 | 100 | 100 | 0,95 | 0,95 | |
| 50 ms | MFCC | 91,53 | 94,92 | 76,19 | 95,24 | 0,71 | 0,84 |
| LFCC | 91,53 | 92,37 | 85,71 | 80,95 | 0,73 | 0,74 | |
| IMFCC | 88,14 | 93,22 | 80,95 | 95,24 | 0,64 | 0,80 | |
| GTCC | 98,31 | 99,15 | 100 | 100 | 0,95 | 0,97 |
In case of need for individual false alarms classification, like glass breaking or a human scream from another impulse event like hand claps or various slams, a significantly larger dataset containing a sufficient amount from each of these individual events has to be recorded and used for a proper training of a classifier. However, results similar to those achieved for a gunshot classification can be expected for individual cepstral coefficients. On the other hand, the optimal frame length can vary since some of these events can last for a longer period of time. From this, it can be said that the longer frames should offer better results.
However, in this article, the focus is on identification and classification effectiveness using various cepstral coefficients of gunshots only, and thus, the classification success into individual false alarm classes is not subject to this study.
5. Discussion
All five tested classes indicate the superiority of the GTCC feature extraction method over the mel-frequency type feature extraction methods. The mel-frequency type triangular magnitude response filter cuts the frequencies outside the filter in contrast with the smooth shape of the Gammatone magnitude filter, which has an increased overlap of the filters and includes more spectral information about the acoustic signal. The Matthews' correlation coefficient is well over 0.90 for GTCC in almost all cases for both classifiers. This is confirmed by very high Recall values, which indicate the correct detection of true positives and show the suitability of the GTCC in gunshot identification and classification.
The classification algorithm also tested the optimal length of the frame with the detected acoustic impulse event for given distances between the sensor and the event/gunshot. The results revealed that longer frames showed better results across both classifiers. The optimal frame length for acoustic gunshot detection depends on the distance between the sensor (up to ≈100 m) and the shooter; for a bullet's speed, traveling about the speed of sound should be about 30–50 ms long. The longer frames can cause the extracted features to contain more likely information about the acoustic surroundings than about the gunshot itself. On the other hand, a frame that is too short can lose some of the critical information about the event, skipping some of the phenomena produced by a gunshot. This is, again, confirmed by the resulting RLC and MCC values.
Finally, the NN classifier produced better results than the SVM classifier across almost all the frame lengths and all four types of feature extraction algorithms.
In general SVM find linear or in our case a nonlinear (the second order polynomial kernel) decision boundaries that separate classes based on the support vectors, which may not capture as much complexity. On the other hand, the NN can learn complex decision boundaries that can capture intricate relationships within the data. Another possible reasons can be NN have a greater capacity to learn from noisy data and generalize well to unseen examples. It needs to be said the classification success of the classifier depends on the size and variability of the training set. However, under the same conditions, the NN will surpass the SVM classifier slightly.
6. Conclusion
The article introduced the classification of acoustic impulse signals-gunshots, and compared classification success across four feature extraction methods based on cepstral coefficients. The tested methods were MFCC, IMFCC, LFCC, and GTCC, which were primarily used for speech or ambient sound recognition applications. Various frame lengths are also presented as input parameters for the feature extraction method. Three different frame lengths of 15 ms, 30 ms, and 50 ms were tested to show the optimal frame length. Finally, two machine learning classification algorithms were implemented: SVMs and NNs. The experiment included four different gun calibers: 9 mm, 5.56 NATO SD, 7.62 mm Tokarev, and .22, and a set of false alarms consisting of impulse events with similar acoustic patterns to gunshots. These false alarms included slams, slaps, bubble wraps popping, etc. The experiment results revealed the dominance of the GTCC classification accuracy compared to the others, mel-frequency type cepstral coefficients. Moreover, the results showed the optimal frame length with the detected acoustic impulse event to be 30–50 ms. Last but not least, the NN outperforms the SVM classifier in almost all cases. In conclusion, it can be assessed that GTCC gives the best results in a non-speech recognition application, such as gunshot detection.
In the future, the authors will focus on a more significant variability of weapon calibres and a greater variety of environments where shooting will be carried out and focus on an NN design.
Data availability statement
The data cannot be made publicly available upon publication due to legal restrictions preventing unrestricted public distribution. The data that support the findings of this study are available upon reasonable request from the authors.