


Abstract
We provide a short introduction to the field of topological data analysis (TDA) and discuss its possible relevance for the study of complex systems. TDA provides a set of tools to characterise the shape of data, in terms of the presence of holes or cavities between the points. The methods, based on the notion of simplicial complexes, generalise standard network tools by naturally allowing for many-body interactions and providing results robust under continuous deformations of the data. We present strengths and weaknesses of current methods, as well as a range of empirical studies relevant to the field of complex systems, before identifying future methodological challenges to help understand the emergence of collective phenomena.
Export citation and abstract BibTeX RIS
1. Introduction
Take a cloud of points in a D-dimensional space. The points could correspond to the coordinates of individuals in a space of attributes, such as their age, income and height. Or the positions of birds in the sky. Or the locations of McDonalds in a city. Or a sample of coordinates in phase space for a dynamical system. This type of data is prevalent in a variety of domains, including many areas of Physics, and several mathematical tools have been developed to reveal information hidden in their noisy patterns and to reduce the system dimensionality. Important families of methods include principal component analysis [1], looking for dominant directions to explain the variance in the data, geometric or k-nearest neighbour graphs [2], where pairs of points are connected if they are sufficiently close, or their fractal dimension [3] revealing the self-similarity of the data. Each tool reveals a certain aspect of the data, putting emphasis on either statistics, connections or geometry. Topological data analysis (TDA) provides an alternative set of tools that extracts topological features from the data that are invariant under certain transformations, and aims at characterising its shape by means of its number of cavities, holes or voids [4–6] (see figure 1). TDA can be seen as an extension of the aforementioned families of methods, and intuitively understood in terms of networks with non-binary interactions with a geometrical flavour.
TDA has gained popularity in the field of data mining and has been applied to data in a broad range of disciplines. The main purpose of this paper is to investigate its potential advantages and limitations for the study of complex systems. To do so, we first provide a short introductory guide for complex systems scientists to TDA, clarifying underlying concepts, with a particular focus on the theory of simplicial complexes and persistent homology, and pointing to relevant introductory bibliography. We then present salient results of applications of TDA to examples of complex systems. Finally, we try to delineate situations when these tools might be of relevance and identify steps to turn TDA from a set of computational tools to a framework for a science of complex topology.

Figure 1. Generators of the first homology groups for a triangulation of the torus. The torus has two 1-dimensional holes, the one surrounded by the blue cycle and the one surrounded by the red cycle, so H1 has two elements, which are the equivalence classes of 1-cycles. For example the two red cycles (and any similar cycle on the torus) are in the same equivalence class because they 'surround the same hole' while the blue cycle (and any other similar) are in the other equivalence class of H1. The Betti numbers are β0 = 1 (one connected component), β1 = 2 (two 1-dimensional holes surrounded by a chain of edges), β2 = 1 (one void enclosed within the surface).
Download figure:
Standard image High-resolution image2. TDA in a nutshell
The field of geometry studies properties of an object that are invariant under rigid motion, such as the angles in a triangle or the curvature of a surface. Topology studies instead invariants under continuous deformations, called homotopies, that can be understood as the stretching and shrinking of an object. The larger set of transformations leads to a characterisation of the shape of a topological space. TDA offers computational tools to translate raw data into structured sets of simplicial complexes that can be analysed by means of topological theory. The output of the algorithm provides topological metrics characterising the empirical data and ways to compare different datasets.
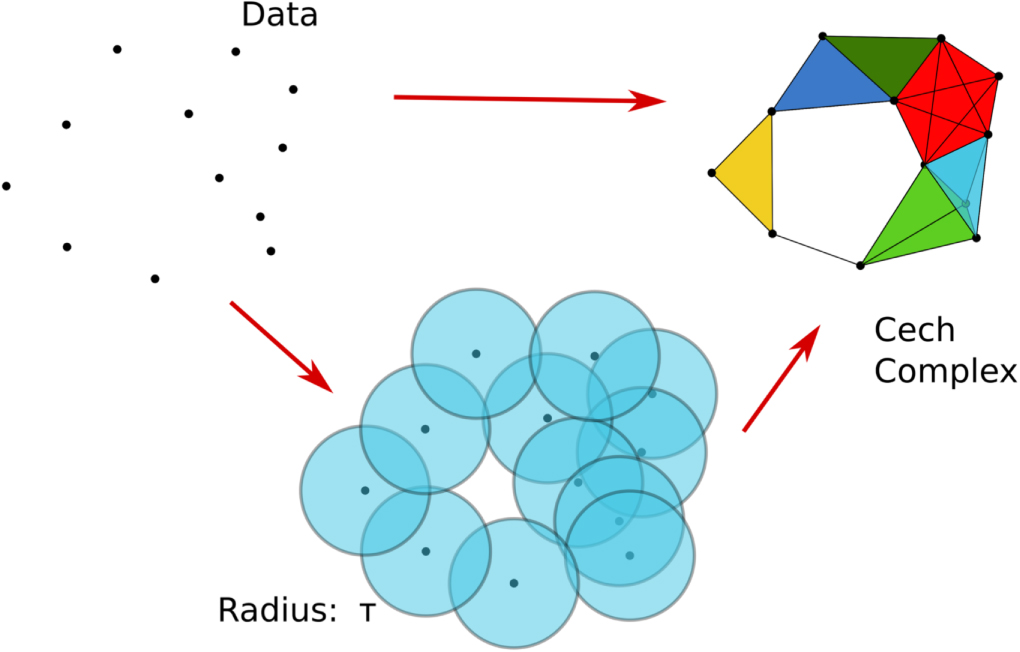
To introduce these ideas more formally, let us consider the canonical example of a set of N points embedded in a metric space, as mentioned in the introduction (see figure 2). We fix a distance τ and say that two data points i and j are connected if balls of radius τ with centres at i and j have a non-empty intersection. Similarly, three points form a triangle if the three corresponding balls have a point in common, and so on. This construction is called a Čech complex, a particular type of simplicial complex for metric spaces [7]. A close alternative construction is the Vietoris–Rips complex, where we form a k simplex whenever k + 1 points are pairwise within distance τ [8]. Clearly, a Vietoris–Rips complex with given τ has more simplices than a Čech Complex on the same N points with τ/2 threshold. There are other ways to build complexes from data, but, for the time being, let us assume that the object has been built. Formally, one calls simplex a convex hull of affinely independent points and its faces are simplices based on subsets of points. Then an abstract simplicial complex is a set of simplices with the following rules:
- Every face of a simplex in a complex is in the complex.
- The non-empty intersection of two simplices is a face of each of them.
Clearly the Čech complex verifies the properties of an abstract simplicial complex. By definition, the dimension of a simplex is equal to the number of its vertices minus one. Note that this quantity should not be confused with the dimension of the original metric space. Thus a single node is a 0-simplex, an edge is a 1-simplex, etc. Let us now take a simplicial complex and the set K of all k-simplices, for some fixed dimension k. A k-chain is defined as the formal sum  for σi ∈ K and ai in some field F. A common convention is to take ai ∈ Z2, so that the chain either contains a certain simplex, or not. It is clear that, for a fixed object and dimension, a set of chains is a vector space Ck.
for σi ∈ K and ai in some field F. A common convention is to take ai ∈ Z2, so that the chain either contains a certain simplex, or not. It is clear that, for a fixed object and dimension, a set of chains is a vector space Ck.

Figure 2. Example of a fixed set of points completed to a Čech complex with radius τ.
Download figure:
Standard image High-resolution imageTake a simplex ![$\sigma =[{v}_{0},{v}_{1},\,\ldots \,,{v}_{k}]$](https://content.cld.iop.org/journals/0143-0807/40/1/014001/revision2/ejpaae790ieqn2.gif) in a complex. By definition, all of its faces also belong to the complex. This is true, in particular, for faces of dimension k − 1. This property, illustrated in figure 3, permits to define a boundary operator
in a complex. By definition, all of its faces also belong to the complex. This is true, in particular, for faces of dimension k − 1. This property, illustrated in figure 3, permits to define a boundary operator ![${\delta }_{k}(\sigma )={\sum }_{i}{(-1)}^{i}[{v}_{0},\,\ldots \,,{v}_{i}^{{\prime} },\,\ldots \,,{v}_{k}]$](https://content.cld.iop.org/journals/0143-0807/40/1/014001/revision2/ejpaae790ieqn3.gif) , where
, where  indicates that vertex vi is deleted from the list. The corresponding transformation defines a linear homomorphism from Ck to
indicates that vertex vi is deleted from the list. The corresponding transformation defines a linear homomorphism from Ck to  . In words the boundary operator maps a simplex to a formal sum of its faces, so for example the boundary of a triangle is simply the sum of its edges. It can be shown that
. In words the boundary operator maps a simplex to a formal sum of its faces, so for example the boundary of a triangle is simply the sum of its edges. It can be shown that  for any complex d. These concepts allow one to define a k-chain c (for cycle) as a simplex verifying δk(c) = 0 and a k-chain b (for boundary) if
for any complex d. These concepts allow one to define a k-chain c (for cycle) as a simplex verifying δk(c) = 0 and a k-chain b (for boundary) if  such that δk+1 (d) = b. Let Bk be the set of all k-boundaries and Zk the set of all k-cycles, then we have
such that δk+1 (d) = b. Let Bk be the set of all k-boundaries and Zk the set of all k-cycles, then we have  and, due to linearity of δ, they are actually subgroups.
and, due to linearity of δ, they are actually subgroups.
The last paragraph clearly shows that the mathematics of simplicial complexes are far more challenging than those of networks, for instance. For more through introductions on the topic, we point the reader to references such as [6, 9–11]. Let us instead focus on the computational tools that emerge from these formal definitions and what can be learnt from them. As a first step, we define the kth homology group  δk+1. By construction, two simplicial complexes obtained from different datasets are topologically equivalent, and are said to have the same shape, if they produce the same homology groups. The kth homology group directly provides an important, interpretable quantity, as its rank gives the kth Betti number, equal to the number of k-dimensional holes in the topological fabric.
δk+1. By construction, two simplicial complexes obtained from different datasets are topologically equivalent, and are said to have the same shape, if they produce the same homology groups. The kth homology group directly provides an important, interpretable quantity, as its rank gives the kth Betti number, equal to the number of k-dimensional holes in the topological fabric.

Figure 3. The boundary operator of a 2-simplex returns the formal sum of its edges. Arrows represent orientation.
Download figure:
Standard image High-resolution imageIn an applied setting, an important aspect is that the construction of the simplicial complex depends on the value of certain parameters, and that the choice of the value can not be done a priori. Take the value of τ in a Čech complex for instance. Increasing values of τ lead to larger and larger simplices, until a simplex made of the N points is formed, but what value of τ should be chosen? This will depend on the kind of data and on what is the object of investigation, but clearly the choice will affect the shape of data and the resulting analysis using topological tools. Persistent homology [4, 8, 12] is a way to consider the information obtained from all values of parameters, and to represent into an understandable and easy-to-interpret form.

{kind=link}
{kind=link}
{kind=link}
Figure 4. A visual summary of the many ways in which simplicial complexes can be built: from a cloud of data points, from a network and from a hypergraph. The simplicial complex represented in the figure corresponds to the hypergraph on its left.
Download figure:
Standard image High-resolution image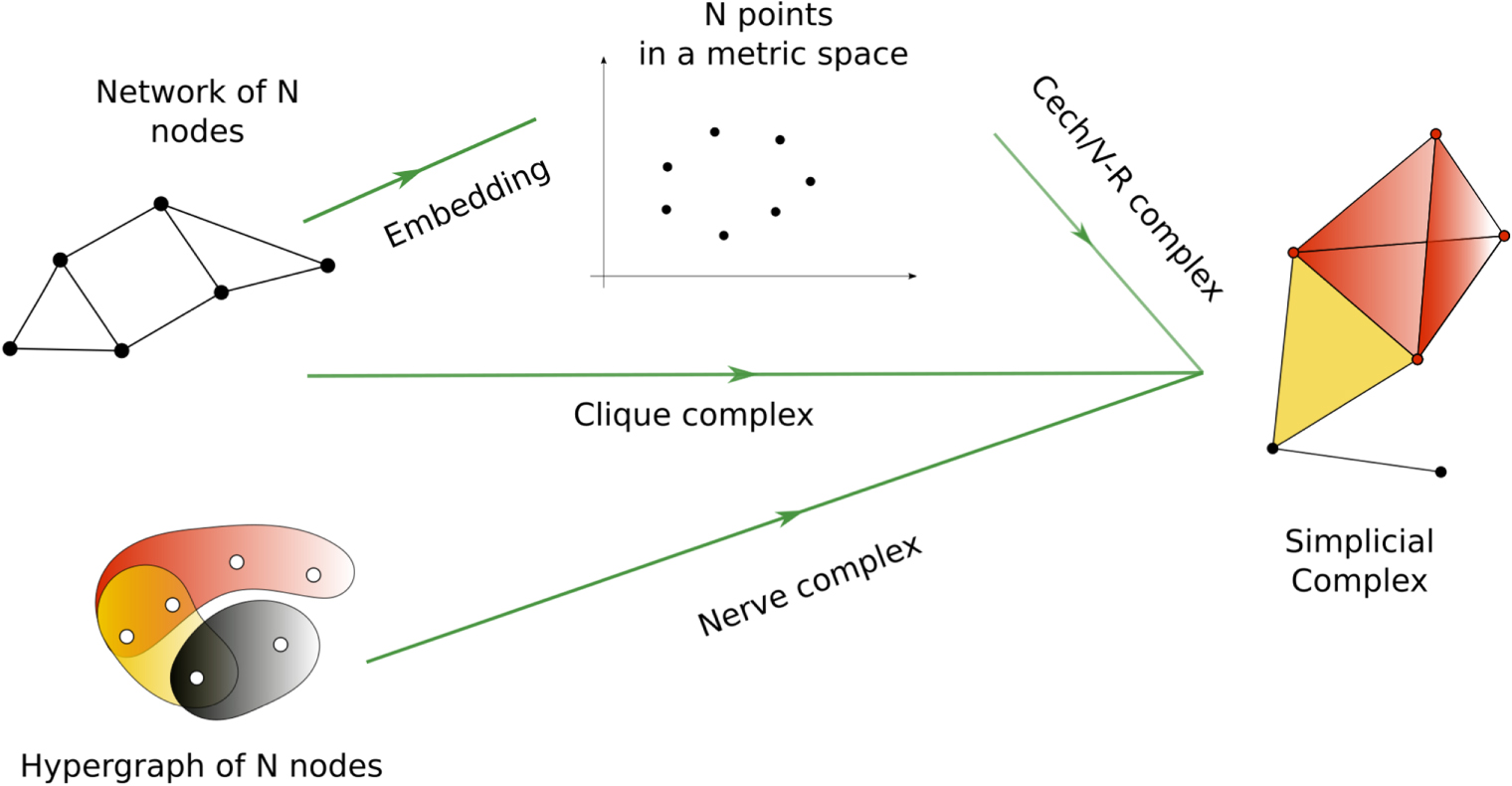{kind=link}
For the purpose of this discussion, let us consider again a Čech complex for the sake of simplicity. As τ increases, more and more simplicies are formed in the complex but, as no simplices are deleted, if a cycle exists for τ = τ1, then it will be present for all τ > τ1. Along the way, new cycles can also appear as well as new boundaries. Homology groups thus evolve when τ changes and persistent homology aims at extracting information from this evolution. Tuning the value of τ for a Čech complex is an example of the general idea of filtrations. By definition, a filtration is a nested sequence of simplicial complexes  , which implies a partial order on simplices. By looking at homology groups for different values of the filtration, we may track when holes appear (birth) and disappear (death), which can be visualised by means of so-called barcodes. The length of the parameter interval between the death and the birth of a hole is called its persistence. It is usually assumed that holes with long persistence convey important information about the system, while short ones are associated to noise, but there are cases in which short-lived holes may convey important information [13]. Note that the filtration can be performed on other model parameters, for instance on the time when a hole appears or disappears [14], in the case of temporal data, or on the weight of a simplex, in the case of weighted simplices [15]. Another important concept is that of persistence landscape [16]. Persistence landscapes are piecewise-linear functions, defined in a separable Banach space, that convey the information about births and deaths of homological cycles during the filtration. The great advantage they offer with respect to other visualisations (e.g. barcodes) is that it is possible to compute average landscapes over different datasets and also to define an Lp distance between landscapes, which allows to do statistical analysis on mesoscale structures [17].
, which implies a partial order on simplices. By looking at homology groups for different values of the filtration, we may track when holes appear (birth) and disappear (death), which can be visualised by means of so-called barcodes. The length of the parameter interval between the death and the birth of a hole is called its persistence. It is usually assumed that holes with long persistence convey important information about the system, while short ones are associated to noise, but there are cases in which short-lived holes may convey important information [13]. Note that the filtration can be performed on other model parameters, for instance on the time when a hole appears or disappears [14], in the case of temporal data, or on the weight of a simplex, in the case of weighted simplices [15]. Another important concept is that of persistence landscape [16]. Persistence landscapes are piecewise-linear functions, defined in a separable Banach space, that convey the information about births and deaths of homological cycles during the filtration. The great advantage they offer with respect to other visualisations (e.g. barcodes) is that it is possible to compute average landscapes over different datasets and also to define an Lp distance between landscapes, which allows to do statistical analysis on mesoscale structures [17].
3. From networks to simplicial complexes for complex systems
The operation leading to Čech complex is clearly reminiscent of the notion of geometric graph [2]. In the latter, a network is constructed from points in a metric space via a threshold, and pairs of nodes are connected by an edge. Note that the relations between networks and geometry are both-ways. Complementary to geometric graphs, aiming at defining networks from geometrical data, many network methods aim at embedding nodes on a metric space. Important examples include hyperbolic embedding methods [18], that naturally produce heterogeneous degree distributions and strong clustering in complex networks, where the nodes are assigned a location in an hyperbolic space. The resulting embedding can then be used to help routing information on the network for instance. Spectral embeddings such as diffusion maps [19] also play an important role. Related to the notion of kernel on graphs [20], they allow one to project networks a lower-dimensional spaces and to define distance or similarity matrices between nodes. The latter can then be exploited to cluster the nodes, e.g. by means of k-means, in order to reveal modules hidden in the original network [21].
Despite these connections with geometry, most of the emphasis in network science is put on the existence of pairwise edges between nodes in an abstract space, and on indirect paths of interactions formed by a succession of edges. This focus on connectivity has led to important contributions in our understanding of complex systems, as networks naturally provide a bridge between structure and dynamics [22]. For instance, certain types of interaction networks tend to facilitate diffusion, or to allow for complex dynamical regimes. Important structural properties include the degree distribution, as the existence of high degree nodes provides shorter paths and accelerates diffusive processes [23], the over-representation of motifs that allow for local reinforcement in the dynamics [24], and community structure, as the presence of dense communities is associated to different time scales for the dynamics and allows for the coexistence of different states [25]. More importantly, complex systems are composed by large numbers of interacting elements, and network science thus provides a universal language, applicable to a variety of domains, in order to decipher the myriads of connections in the system.
Despite these successes, network science also has important limitations that may prevent it to properly represent the complexity of real-world interacting systems. Moreover, these limitations become more and more apparent with the availability of rich datasets, allowing to track paths of diffusion in systems, and the temporal characteristics of the system evolution [26]. For these reasons, different attempts are currently developed in order to provide appropriate models for higher-order networks [27]. One of those models builds on TDA and represents systems as simplicial complexes. From our previous discussion on the Čech complex, it is clear that an important difference between networks and simplicial complexes is the possibility to encode higher-order interactions, involving more than two nodes. Simplicial complexes thus provide an alternative to hypergraphs [28], where many-body interactions can also be encoded but, at the same time, they put a particular emphasis on the underlying the geometrical nature of system. For these reasons, simplicial complexes appear to be a good candidate to model and analyse systems composed of many elements, interacting via many-body interactions, and expected to have a strong geometrical nature. When adopting a TDA approach, it is crucial to remember that the underlying assumption of TDA is that the shape of data matters, and that the existence of a lower-dimensional embedding may correspond to underlying symmetries or constraints in the system. A good example would be noisy observations of a dynamical system in a periodic orbit. TDA naturally provides tools to detect and quantify such recurrent motion. In that case, the identification of voids in the data points indeed gives us critical information about the system behaviour. In this direction, [29] introduced a method to reconstruct the phase space of a real-world dynamical system from time series using simplicial complexes, which preserve the topology of the state space. In that case, short-lived holes may be interpreted as temporary inaccessible subspaces of the state space, while persistent holes as permanent obstacles to the dynamics. It is also important to bear in mind the additional conceptual and computational costs associated to TDA, as the number of faces rapidly explodes even in fairly small systems.
Before turning to a presentation of tools and their applications, note that there exist different ways by which data points can be encoded into simplicial complexes (see figure 4). The first type of encoding deals with points embedded into a metric space, as discussed above, for which standard methods like the Čech complex and the Vietoris–Rips complex can be built. There exist also many situations when the system has the structure of a hypergraph, with nodes interacting via non-binary interactions, and where the hypergraph can be modelled as a simplicial complex, called a nerve complex. Potential applications can be found in chemistry, with biochemical reactions may involve more than two species in a reaction [30], and social systems, where group interactions naturally appear in collaboration [31] and contact [32] networks. In that case, each clique of size d in the hypergraph leads to the a simplex of dimension d − 1, as well as all its intrinsic simplicies. Finally, simplicial complexes can also be used to analyse standard networks. A first method consist in embedding the nodes in a metric space, as was discussed earlier in this section, and then to construct, for example, a Čech complex. For a spectral embedding, the underlying geometry of the problem would thus be associated to the dominant eigenvectors of the network. Alternatively, a clique-complex can be constructed by associating each clique in the network to a simplex.
4. Important tools
The first algorithm for the computation of persistent homology was provided by [16], which allowed computation over a particular field, the field  , and was later extended for computation over general fields [33]. Algorithms for computing homology are based on the reduction algorithm, which we briefly describe here following [33]. The boundary operator
, and was later extended for computation over general fields [33]. Algorithms for computing homology are based on the reduction algorithm, which we briefly describe here following [33]. The boundary operator  can be represented by an integer matrix Mk with entries in {−1, 0, 1}, where columns are the k-simplices and rows are the (k − 1) simplices. The null space of Mk corresponds to Zk and the range-space to Bk−1. The reduction algorithm uses elementary row and column operations to reduce Mk to its Smith normal form
can be represented by an integer matrix Mk with entries in {−1, 0, 1}, where columns are the k-simplices and rows are the (k − 1) simplices. The null space of Mk corresponds to Zk and the range-space to Bk−1. The reduction algorithm uses elementary row and column operations to reduce Mk to its Smith normal form  ,
,

The computation of the Smith normal form in all dimensions is sufficient to characterize the homology of the complex, as  and
and  , so the Betti number can be computed as
, so the Betti number can be computed as

The vector space defined above captures the homology of a single complex, while a filtration is constituted by many complexes. To compute persistent homology, one needs to find a basis that is compatible across the entire filtration, which can be shown to exist [33]. A simplified version of the reduction algorithm over a general field is given in [33]. In the worst case, its complexity is cubic in the number of simplices. Other algorithms have been developed for the reduction of the matrix representation of the boundary operator, and while some of them can be faster for some specific datasets, the complexity remains cubic in general.
Several publicly available software packages implement reduction and persistence homology: javaPlex [34], Perseus [35], Dionysus [36], PHAT [37], DIPHA [38], Gudhi [39], ripser [40] and jHoles [41]. A comparison of their performance [6], tested on real and synthetic datasets, concluded that the fastest package overall are ripser, Gudhi and DIPHA, while javaPlex is the easiest and best software for a beginner, as long as the analysis is done on small complexes.
5. Application of TDA
In recent years the number of contributions relying on TDA tools is rapidly increasing, as TDA provides alternative and complementary tools in many disciplines dealing with complex systems. The discipline that is possibly benefiting the most from the adoption of TDA is neuroscience: after the network paradigm proved successful for studying a multitude of problems, the adoption of simplicial complexes and the consequent relaxation of the simplifying assumption that all can be counted for by dyadic relationships seems the natural step forward considering the inherently complex and rich structure of neural systems [11, 42, 43]. Several works exploit the fact that a study of homological cycles through persistent homology provides a way to detect differences between neural systems, in terms of their mesoscale structures. For example [44] finds evidence of different brain activity in two states: under the effect of a psychedelic drug and with a placebo. The homological features of brain functional networks in the two cases are significantly different, with an increased integration between cortical region in the altered state. Developing on the same methodology, [45] shows that measures of edges importance in homological cycles complement the information provided by standard graph metrics. TDA has also proved useful to understand the structure of the brain, [46] finds that homologycal cycles in structural brain networks link regions of early and late evolutionary origin. A related stream of works uses persistence landscape distance to detect changes in functional brain networks during learning of a simple motor task [13], and the functional equivalence between imagery and perception [47], providing empirical evidence that functional equivalence is higher for highly hyp-notisable individuals, a scenario that was suggested by behavioural studies but could not be confirmed by means of standard computational tools. This result serves as an example of the ability of TDA to identify significant features that would have remained blurred with standard methods, including networks methods. Other examples of applications include studies on how topology of brain arteries changes with age [48], how information flows in cortical microcircuits in response to stimuli [49], how the homological features of connectivity for hyperactivity disorder and autism spectrum are different compared to healthy cases [50], how speech-related brain regions connectivity changes in different scenarios of speech perception [51], and the topological differences between epileptic and healthy EEG signals [52].
The physics of granular media is another field that benefited from both network science and TDA methods (for a thorough review see [53]). Granular media are characterised by dissipative interactions between particles, which prevent them from reaching standard thermal equilibria. In a granular packing, the forces between adjacent particles are represented by a weighted network, where the weight is proportional to the the ongoing force. The resulting networks can be analysed after being turned into simplicial complexes. For instance, homological holes in force networks of granular systems help identifying structural defects of the material [54] and persistence diagrams identify differences in the structure of compressed granular materials in presence or absence of frictions [55, 56]. Even simple measures as Betti numbers provide a quantitative basis to differentiate between frictional and frictionless systems [57], but persistent homology proves to be more effective in identifying more subtle differences between systems. As an example, in the force networks of a tapped system composed of disks and pentagons, Betti numbers allow one to distinguish between the shapes [58], but persistent homology allows to quantify finer differences that would otherwise have been indistinguishable [59].
Another area of growing interest is that of machine learning and, more specifically, that of neural networks and deep-neural networks. This set of methods have proven to be extremely successful at recognising patterns in noisy data, despite the fact that they take, as an input, single data points or pixels. A promising research direction is to combine TDA with neural networks, by using shapes identified by TDA as input data in the machine learning framework. This technical aspect is far from trivial, as persistent diagrams, for instance, contain a variable number of intervals, while a structured input of a fixed size is typically required in machine learning. One possible solution is through the use of persistence landscapes which, coupled with convolutional neural networks, leads to so-called called a persistent convolutional neural network model [60]. The key here is the piecewise linearity of persistence landscapes that makes back-propagation straightforward. A successful application of this methodology is in music classification, where an incorporation of the shape of audio signals helped to outperform the state of the art methods. As a next step, [61] proposed to project persistence diagrams on a fixed-size collection of structure elements, to let the algorithm decide which information to consider in the training, with excellent results for the classification of the shapes of 2D objects. There exist other ways by which TDA and machine learning can be integrated, as in [62], where the authors use weights of convolutional networks at different training steps as an input for TDA, and many more ways are expected to come in this rapidly evolving field of research.
The applications of TDA in other fields of science are more sparse and fragmented, but several examples show its growing interest and its potential in a range of problems. Several works aim at classifying weighted networks in terms of the persistence of their homological structures [15]. This is the case in biology, for instance, where the method proved successful in identifying high-survival breast cancers [63] and in deciphering noisy biological signals those in electromyographic data [64]. Persistent homology has also been used in genomic datasets to identify evolutionary patterns of RNA viruses [65]. Applications in finance and economics include the detection of crisis in financial markets [66], a description of the connectivity of the banking networks using Betti numbers [67], and a classification of countries in terms of the homology of their trade networks [68]. In computational social science, works have identified patterns of international communities in mobile phone data [69]. Other research areas include dynamical systems, through the study of contagions maps [70], continuum percolation [71] and scientometrics, to understand scientific collaborations [72, 73] and co-occurrences relations of concepts in scientific articles [14].
6. Perspectives
The study of networks has emerged as a science through the development of different facets that feed each other: the design of algorithms, the identification of ubiquitous patterns, the identification of mechanism leading to the emergence of these patterns, and an understanding on how they affect the behaviour of the system. As an example, take the modular organisation of complex networks, which has led to the design of efficient community detection algorithms, a quantification of modularity in a variety of systems, the identification, amongst others, of evolutionary mechanisms driving the formation of communities, and a study of their impact on synchronisation and diffusion [74]. The combination of these findings have helped capture the evasive nature of complex systems. For TDA to achieve a similar status as a building block of the science of complex systems, much remains to be done. As we have discussed, much attention has been dedicated, so far, at the design of computational methods and the study of empirical systems. In this direction, different tools from network science have been generalised to simplicial complexes, for instance centrality measures [75, 76]. However, large sections of this programme remain overall unexplored. A central yet intriguing notion is that of hole. Assuming that a system presents certain properties about the temporal properties and size of its holes, we still lack understanding of the impact of these holes on the function and behaviour of the system. Likewise, where does the complex topology emerge? Can we find simple rules that explain why various datasets from complex systems can be efficiently characterised by means of TDA, as several empirical studies suggest?
As we have written before, we believe that TDA is a promising research venue in situations where the salient features of a system are its connectivity and geometrical patterns. It is thus unsurprising that a majority of successes associated to TDA have been found in neuroscience. Similarly, another promising field of study, still relatively unexplored, would the study of complex urban systems, as cities also present a multi-scale inter-connected organisation and their morphology plays a crucial role in the functioning [77]. In terms of impact on dynamics, finally, interesting research directions include the study of higher-order analogs of the graph Laplacian, called the Hodge Laplacian, which could provide mathematical grounds for the study of diffusion on simplicial complexes [78]. Together with these considerations, the increasing popularity of TDA is calling for a clarification of the relation between network concepts and simplex geometry [79] and a quantification of the statistical significance of topological features, which motivates models of random simplicial complexes [80–82], stochastic models of growing complexes [83, 84].