


ABSTRACT
We describe an algorithm that can adaptively provide mixture summaries of multimodal posterior distributions. The parameter space of the involved posteriors ranges in size from a few dimensions to dozens of dimensions. This work was motivated by an astrophysical problem called extrasolar planet (exoplanet) detection, wherein the computation of stochastic integrals that are required for Bayesian model comparison is challenging. The difficulty comes from the highly nonlinear models that lead to multimodal posterior distributions. We resort to importance sampling (IS) to estimate the integrals, and thus translate the problem to be how to find a parametric approximation of the posterior. To capture the multimodal structure in the posterior, we initialize a mixture proposal distribution and then tailor its parameters elaborately to make it resemble the posterior to the greatest extent possible. We use the effective sample size (ESS) calculated based on the IS draws to measure the degree of approximation. The bigger the ESS is, the better the proposal resembles the posterior. A difficulty within this tailoring operation lies in the adjustment of the number of mixing components in the mixture proposal. Brute force methods just preset it as a large constant, which leads to an increase in the required computational resources. We provide an iterative delete/merge/add process, which works in tandem with an expectation–maximization step to tailor such a number online. The efficiency of our proposed method is tested via both simulation studies and real exoplanet data analysis.
Export citation and abstract BibTeX RIS
1. INTRODUCTION
Since the beginning of recorded time, we have wondered whether we are alone or whether there are other planets that might support life. The scientific quest for extrasolar planets (exoplanets) began in the mid 19th century, but it was only as recent as 1992 that astronomers have been able to confirm the existence of other planetary systems.
The most productive technique for detecting exoplanets is the radial velocity (RV) method, which uses Doppler shifts of lines in the star's spectrum to measure the line-of-sight velocity component of the reflex motion of the star in response to the planet's gravitational pull. The presence of a planet orbiting a star will lead to a periodic wobble in the star's RV, but if there are no planets present the expected velocity is constant, although measurements fluctuate because of stellar jitter or other systematic sources, e.g., starspots. Here, we focus on analyzing reflex motion data.
The primary question of whether there are no planets or one or more can be formulated as a model selection problem, where the collection of models includes the zero-planet model  , one-planet
, one-planet  , two-planet
, two-planet  , and so on. These models can be analytically specified according to Newtonian mechanics, but they are strongly nonlinear, yielding complex, multimodal likelihood surfaces over parameter spaces ranging in size from a few dimensions to dozens of dimensions.
, and so on. These models can be analytically specified according to Newtonian mechanics, but they are strongly nonlinear, yielding complex, multimodal likelihood surfaces over parameter spaces ranging in size from a few dimensions to dozens of dimensions.
As more high-quality exoplanet RV data were released, they fueled new interest in Bayesian algorithms, which can fully and accurately account for diverse sources of uncertainty in the context of complex models. In Bayesian statistics, the posterior probability of a model requires accurately calculating the integrated or marginal likelihood, which, in the context of an exoplanet, is extremely challenging; see Clyde & George (2004) for a general overview or Clyde et al. (2007) for some of the issues that arise in astronomy. Most of the existing methods estimate the marginal likelihoods based on the Markov Chain Monte Carlo (MCMC) output. For example, Ford used MCMC with random walk proposals (Ford 2005, 2008), and Gregory utilized parallel tempering MCMC to perform orbit modeling (Gregory 2005); Gregory's approach uses a control system to tune the proposal parameters in a pilot run, and he has augmented his algorithm to include parameter updates based on genetic algorithms (Gregory 2011). Balan & Lahav applied an approximate adaptive Metropolis random walking algorithm to the problem (Balan & Lahav 2009). Tuomi used the more rigorous adaptive metropolis algorithm of Haario et al. (2001) for posterior sampling (Tuomi 2011), and to calculate marginal likelihoods needed for comparing planet and no-planet models, he used the algorithm of Chib & Jeliazkov (2001) that estimates marginal likelihoods from MCMC output.
There are computationally burdensome tasks that would be challenging to pursue with existing algorithms due to the various tuning parameters or parameterization choices to explore. As more and more exoplanet data have been increasingly generated, current algorithms are inefficient and can be complex for more wide-ranging analyses on data that may signify absent or ambiguous evidence for planets. In these cases, the likelihood surface becomes more complex than it is for strong-signal cases. The above concern motivates us to research a new easy-to-implement algorithm that more efficiently explores the Bayesian posterior distributions for exoplanet models.
In this paper we develop an algorithm with significantly improved computational efficiency and less complexity for users in terms of algorithm tuning. In contrast to existing posterior sampling methods based on MCMC, our algorithm is developed within the framework of importance sampling (IS), which in theory can give an optimal estimate of the marginal likelihood in terms of bias and variance. Our algorithm is characterized by its unique adaptive mechanism for tailoring a prescribed mixture proposal that is then used to approximate the posterior.
A very preliminary version of our algorithm has been reported in Loredo et al. (2012), wherein the algorithm is termed annealing adaptive IS. In contrast to Loredo et al. (2012), which just reveals several illustrative simulation results of the algorithm, this paper will introduce the most updated version of the algorithm in detail. Further, we apply the algorithm to analyze many real data, and the results are revealed here for the first time.
The remainder of this paper is organized as follows. In Section 2, we briefly review IS and how it is used to estimate marginal likelihoods for model selection. In Section 3, we describe the proposed algorithm, termed adaptive annealed importance sampling (AAIS), which is used for adaptive exploration and approximation to the posteriors of exoplanet models. We evaluate its performance through several simulations. The population Monte Carlo (PMC) method, an adaptive IS approach that has recently been used in astrophysics, is involved for performance comparison. In Section 4 an overview of the RV models and related likelihood functions and priors is provided. In Section 5, we apply the proposed algorithm while analyzing data sets of several real star systems with one or more planets. A simulated RV data set is used to re-evaluate the performance of AAIS in the context of exoplanets. Finally, we conclude with a discussion of possible extensions of the method in Section 6.
2. IMPORTANCE SAMPLING FOR MARGINAL LIKELIHOOD ESTIMATION
IS (Geweke 1989) is a Monte Carlo technique for estimating stochastic integrals, such as the marginal likelihoods required for Bayesian model comparison. Given a proposal distribution q that is absolutely continuous with respect to the posterior, the marginal likelihood of model  is re-expressed as an expectation with respect to q:
is re-expressed as an expectation with respect to q:

where θ denotes the parameter of  ,
,  the likelihood function, and
the likelihood function, and  the prior. Given a random sample of size N drawn from q, θ1, ..., θN, an unbiased and consistent Monte Carlo estimate of the marginal likelihood is
the prior. Given a random sample of size N drawn from q, θ1, ..., θN, an unbiased and consistent Monte Carlo estimate of the marginal likelihood is

where

is termed the importance weight in what follows.
The efficiency of IS depends largely on how closely the proposal q approximates the posterior in the shape. The efficiency of approximation can be monitored by the effective sample size (ESS; Kong et al. 1994), which is defined as

where  . The ESS takes values between 1 and N. The maximum ESS value appears iff all importance weights are equal, which indicates that q is the same as the posterior in shape. The other extreme happens if all but one of the importance weights are zero, which leads to a minimum ESS value of 1. The ESS is shown to be a convenient way to interpret the level of inequality in the weights.
. The ESS takes values between 1 and N. The maximum ESS value appears iff all importance weights are equal, which indicates that q is the same as the posterior in shape. The other extreme happens if all but one of the importance weights are zero, which leads to a minimum ESS value of 1. The ESS is shown to be a convenient way to interpret the level of inequality in the weights.
We can construct confidence intervals of the marginal likelihood estimate using its asymptotic normality, which gives

where  takes the value of the variance of
takes the value of the variance of  in Equation (2). An approximate 95% confidence interval is just
in Equation (2). An approximate 95% confidence interval is just  . Note that the above error estimate is only reliable when the ESS value is big enough. If the ESS is very low, it indicates a big discrepancy between the proposal and the target, which leads to a bad particle approximation to the target; thus, the information extracted from the particles is not qualified for calculating the confidence intervals.
. Note that the above error estimate is only reliable when the ESS value is big enough. If the ESS is very low, it indicates a big discrepancy between the proposal and the target, which leads to a bad particle approximation to the target; thus, the information extracted from the particles is not qualified for calculating the confidence intervals.
A number of things can go wrong in the process of proposal construction. If the proposal function has thinner tails than the posterior, the estimate of the marginal likelihood will tend to be unstable because the importance weights can be arbitrarily large; on the other hand, if the proposal function has much fatter tails than the posterior, too many of the random samples will be drawn from the tails, resulting in a seemingly stable but biased estimate. The best case is a proposal function with slightly heavier tails than the posterior. Of course, asymptotically it should not matter which proposal function is used; for samples of a practical size, though, a poor choice can be disastrous.
These problems are only compounded in high-dimensional settings where the posterior is often extremely complicated. Unless one is very lucky indeed, it is usually very difficult to get accurate results in real-life situations with dimensions greater than three.
In the following section, we describe an adaptive method for tailoring a mixture of student's t-distributions to approximate the posterior in shape. The resulting mixture distribution is shown to be an efficient proposal function, even for complicated multimodal posteriors whose parameter space ranges in size from a few dimensions to dozens of dimensions.
3. THE PROPOSED ADAPTIVE ANNEALED IMPORTANCE SAMPLING ALGORITHM
In this section, we describe the proposed AAIS algorithm, which adaptively constructs a mixture approximation to the posterior. We use an ESS calculated based on the IS draws (see Equation (4)) to measure the degree of approximation. Then the goal is just to tailor a mixture proposal to produce an ESS value as large as possible.
In what follows, we denote the posterior by p(·). To capture the multimodal structure in p(·), we initialize a mixture proposal distribution:

where  denotes the tunable model parameter, m the index of mixing components, M the number of mixing components, f the density function of the mixing component, ξ the parameter of f, α the probability mass that satisfies αm > 0, and
denotes the tunable model parameter, m the index of mixing components, M the number of mixing components, f the density function of the mixing component, ξ the parameter of f, α the probability mass that satisfies αm > 0, and  . The task is to tailor the value of ψ to make q resemble p to the greatest extent possible with heavier tail structures. The heavy tail property of q is ensured by utilizing the Student's t-distribution as a mixing component.
. The task is to tailor the value of ψ to make q resemble p to the greatest extent possible with heavier tail structures. The heavy tail property of q is ensured by utilizing the Student's t-distribution as a mixing component.
To begin with, a sequence of intermediate target density functions, p1(·), p2(·), ..., pI(·), is built up, in which

where ψ0 is an initialized parameter value of q, and 0 = λ1 ⩽ ... ⩽ λI = 1 is the temperature ladder. An appropriate temperature ladder makes the target density evolve smoothly from an initialized mixture density q(· |ψ0) to p(·). See Section 3.5 for approaches to design an efficient temperature ladder. The proposed scheme updates ψ iteratively, in which a single, say the ith, iteration consists of the following operations.
- 1.Draw independent and identically distributed (i.i.d) random samples
 from q(· |ψi − 1).
from q(· |ψi − 1). - 2.Calculate the importance weightsand then normalize the weights
- 3.Update the value of ψi − 1 with the following steps.
- 4.If i < I, set i = i + 1 and go to step 1 to start a new iteration, otherwise the algorithm ends here.



As is shown, this algorithm is built on a series of annealed target distributions. Provided that an efficient temperature ladder is used, the transition between any pair of neighboring target densities will be smooth. So only one iteration of EM is included in Step 3(d), in order to make a slight adjustment for ψ.
3.1. Delete Negligible Components
The "negligible components" are components that have negligible impact on the proposal function. Their probability masses are much smaller than the others. Based on the principle of survival of the fittest, we delete up to a fixed number of components whose probability masses are smaller than a given threshold Tdelete. We then increase the probability masses of the surviving components proportionally with respect to their original values to guarantee that their summation is 1.
3.2. Merge Overlapped Components
This procedure merges overlapped components according to a criterion we term mutual information. The objective is to avoid the coexistence of mixing components that are too overlapped in the proposal, so as to find a more reasonable parsimonious mixture representation of the posterior. To introduce the concept of mutual information, first assume that there are N equally weighted samples  drawn from a mixture density function q(·). According to the Monte Carlo principle, q(·) can be approximated by an empirical point-mass function as
drawn from a mixture density function q(·). According to the Monte Carlo principle, q(·) can be approximated by an empirical point-mass function as

where δ(θ) denotes the delta-Dirac mass function located at θ. Denoting  (m|θn) the posterior mass in the event that θn belongs to component m, we have
(m|θn) the posterior mass in the event that θn belongs to component m, we have

It is intuitive that the components j, k contain completely overlapped information, if the identity (j|θn) = (k|θn) is satisfied for n = 1, 2, ..., N. Based on this heuristic, the mutual information between components j, k is defined as

where Zm = ((m|θ1), ..., (m|θN))T, the superscript T denotes the transposition operation, || · || the Euclidean norm, and  . Here, 1n denotes the n-dimensional column vector with all elements being 1.
. Here, 1n denotes the n-dimensional column vector with all elements being 1.
Note that ![${{\mathsf MI}}(j,k)\in [-1,1], j,k\in \lbrace 1,\ldots,M\rbrace ^2$](https://content.cld.iop.org/journals/0067-0049/213/1/14/revision1/apjs496757ieqn17.gif) , and
, and  iff the jth and kth components are identical. Within the IS framework, each data point θn is associated with an importance weight, wn. Correspondingly
iff the jth and kth components are identical. Within the IS framework, each data point θn is associated with an importance weight, wn. Correspondingly  becomes
becomes  , and the mutual information between j, k turns to be
, and the mutual information between j, k turns to be

where diag(·) denotes the diagonal matrix with elements in the parentheses.
For each pair of two components j, k, if  is bigger than a given threshold Tmerge, we merge them into one using the following operations:
is bigger than a given threshold Tmerge, we merge them into one using the following operations:



and then we subtract one for M.
3.3. Add New Necessary Components
This procedure is developed for exploring the posterior, especially the parameter subspace that is indeed important for the posterior but has been neglected in q so far. We add new components centered at the samples of the highest importance weights, and tune their parameters for exploring local structures of the posterior.
We denote the highest weight sample using θs, s ∈ {1, 2, ⋅⋅⋅, N}. First, we compute the ESS based on current IS draws, and compare it with a given threshold ESSthr. If the current ESS is smaller than ESSthr, we perform the add operation as follows.
- 1.Design a trial density function ftrial(·) to approximate the local structure of the target function around θs.
- 2.Build up a trial mixture proposal qtrial by combining ftrial(·) with q as qtrial = αtrialftrial + (1 − αtrial)q, where 0 < αtrial < 1 denotes the initial probability mass specified to ftrial. Denote the parameter of qtrial by ψtrial.
- 3.Use qtrial as the proposal function and perform IS. Then, we select out the particle with the highest importance weight and label it. We then update ESS based on current IS draws. If the new ESS value is bigger than the older one, it means that the add operation is useful for increasing the ESS value, so we update ψ = ψtrial and and go to step 1; otherwise, go to the next step.
- 4.Update ψ via an iteration of the EM operation, which is presented in Section 3.4.
- 5.Perform IS again and update the location of θs.
- 6.Calculate ESS. If the current ESS is bigger than a given threshold ESSthr, end this procedure; otherwise, go to Step 1.


A crucial issue of the above operation is how to explore the local region around the highest weight sample. It is clear intuitively that we must get some samples from the interesting region for exploration. We do this in Step 1 via a routine IS procedure that provides a Monte Carlo estimate of that local region. The parameter of ftrial is then updated to let ftrial resemble the local shape of the target function.
3.4. EM operations for Student's t-mixture
In the mixture defined by Equation (6), we select the mixture components to be Student's t-distributions, whose heavy-tail property is desirable for constructing IS proposal densities. When a d dimensional random variable Y follows the multivariate Student's t-distribution  with center μ, positive definite inner product matrix Σ, and degrees of freedom v ∈ (0, ∞], the density function of Y is shown to be
with center μ, positive definite inner product matrix Σ, and degrees of freedom v ∈ (0, ∞], the density function of Y is shown to be

where

denotes the Mahalanobis squared distance from Y to μ with respect to Σ. Substituting fm(θ|η) with  in Equation (6), we get the Student's t-mixture model:
in Equation (6), we get the Student's t-mixture model:

for which the adjustable parameters include M, μm, Σm, αm, m = 1, 2, ..., M. Based on a weighted sample set  , the E and M steps update values of αm, μm, and Σm in q as (Cappé et al. 2008)
, the E and M steps update values of αm, μm, and Σm in q as (Cappé et al. 2008)
E step:

M step:


where

and Cn = (θn − μm)(θn − μm)T, is calculated by Equation (11), d is the dimension of θ, and A' is an updated value of A. More details about the EM operation can be found, for example, in Mclachlan & Krishnan (1997) and Mclachlan & Peel (2000).
3.5. On Initialization Issues and Tuning Parameters of the Algorithm
Here, several guidelines for initialization and specification of the involved tuning parameters of the algorithm are provided.
The AAIS algorithm is started by initializing the proposal q(· |ψ0), which is in the form of a Student's t-mixture, defined by Equation (19). It is practical to select q(· |ψ0) to be a dispersive distribution over the parameter space, if there is no prior knowledge about the posterior before running the algorithm. We argue that the efficiency of the algorithm is not dependent on the initial value of ψ0, as discussed in Section 3.7. This argument has also been corroborated by several simulation studies. For example, in the Rastrigin case in Section 3.8.1, a single-mode initialization with only one component results in a final proposal that approximates a highly multimodal posterior.
In every iteration, say the ith one, the annealing temperature λi needs to be specified. Here, we present an adaptive approach to determine λi online. First, note that the annealed target density pi(θ) is a function of λ, as shown in Equation (7). pi(θ) then determines the importance weights of the importance samples drawn from proposal q(· |ψi − 1). Since there is a certain relationship between the ESS and the importance weights through Equation (4), the ESS can be treated as a function of λ. We denote the function as

where the subscript identifies the iteration index. Based on λi − 1, λi is specified by

where ESSi − 1 is calculated based on importance weights that are associated with pi − 1(θ), and β ∈ (0, 1) is a parameter controlling the extent to which pi(·) differs from pi − 1(·). Empirically, we select β = 0.8 to guarantee a smooth transition from pi − 1(·) to pi(·).
The annealing temperature ladder can also be specified empirically in an offline manner. The linear incremental ladder, e.g., [0.1, 0.2, ..., 0.9, 1], the exponential incremental ladder, e.g., [0.0001, 0.001, 0.01, 0.1, 1], and the hybrid ladder, e.g., [0.0001, 0.001, 0.01, 0.1, 0.4, 0.7, 1] are all candidate choices for practical use. The efficiency of each choice can be monitored by the accompanying ESS outputs of every iteration of the algorithm. In our experimental studies, we just adopt the offline methods for saving computing resources.
Tdelete is the single tuning parameter in the delete operation, and its value is set online. The guideline is to guarantee that Tdelete ≪ 1/M. For example, if there is now 104 mixing components in the proposal, it is then reasonable to set Tdelete = 10−6, but if there are only three components, then a value 1/100 is effective enough for use.
In the merge operation, the tuning parameter Tmerge should be specified beforehand. Tmerge denotes a quantization for the greatest overlapping level allowed among the mixing components. An empirical choice for Tmerge is 0.85.
In the add operation, the trial component ftrial is in the form of Student's t, as shown in Equation (17). The only parameter that needs to be artificially specified is Σtrial. A typical choice is just to specify Σtrial to be a unit diagonal matrix for simplicity, unless there is any available prior knowledge on the local structure around the highest weight IS draw. The probability mass of the new added component, i.e., αtrial, is initially set as the averaged probability mass of the mixing components.
In setting ESSthr and the particle size N, we mainly consider the dimensions and complexity of the problem. For less than three-dimensional (3D) cases, we empirically set ESSthr = 0.9N with N = 4 × 103; for four- to seven-dimensional cases, an empirical choice is ESSthr = 0.4N with N = 104; for eight- to twelve-dimensional cases, ESSthr = 0.3N with N = 2 × 105 is usually set. The highest dimensional case for which the algorithm has been evaluated is the computation of the marginal likelihood of a three-planet model whose parameter is 17 dimensions. For that case, we set ESSthr = 0.2N and N = 106.
3.6. A Discussion on the delete/merge/add Procedures
Regarding the delete/merge/add operations described above, one may wonder what the effects of each one are on the other two. For example, is it possible that the new added component just happens to meet the condition of merging or deleting, or can these three operations be interchangeable? We argue that the add operation is independent of the other two. According to our algorithm design, the new added component is always located around the highest weight sample, whose location is separated from the well-supported area of the parameter space. Basically, the new added component is unlikely to meet the condition of merging. The initialized probability mass of the newly added component can be strictly controlled to guarantee that the new component cannot be deleted upon its generation. In summary, the add operation can be performed prior to or after any one of the other two. However, the delete operation should be performed prior to the other two. This can prevent the algorithm from spending unnecessary computing resources on the negligible components. Since only a limited number of negligible components are allowed to be deleted in one iteration, the new proposal q(·) are guaranteed to be effective.
3.7. Connections to Existing Methods
The proposed AAIS algorithm has connections to existing adaptive IS (AIS) methods, e.g., Evans (1991), Oh & Berger (1993), Cappé et al. (2008, 2004), and West (1993), to name just a few. Such AIS methods are featured in an iterative manner in which the proposal function is updated.
Recently, a state-of-the-art AIS algorithm called PMC has been used in the area of astrophysics (Kilbinger et al. 2010; Wraith et al. 2009). PMC was first proposed in statistical literature (Cappé et al. 2004, 2008). The appeal of PMC lies in the usage of a flexible mixture type proposal and a simple EM-based mechanism to tune the mixture parameter, which makes it an efficient approach to handle some multimodal posteriors. The shortcomings of PMC accompany its merit. First, in the PMC algorithm, the number of mixing components is restricted to be a pre-determined constant, which is clearly a strong limitation. Furthermore, PMC totally relies on an EM mechanism to update the parameter values of the mixture proposal, while EM itself is a local optimization/searching technique whose efficiency largely depends on the initialization. Thus, the efficiency of the algorithm is highly dependent on the initial choice of the proposal, which has already been pointed out by Kilbinger et al. (2010).
The proposed AAIS algorithm distinguishes itself from existing AIS methods (including PMC) in the following aspects.
First, instead of approximating the posterior p(·) directly, as in AIS, the new algorithm seeks to tailor a prescribed proposal to approximate a series of annealed distributions (pi(·) in Equation (7)) one by one.
Second, in the AAIS algorithm a set of newly developed operations termed delete, merge, and add is proposed to work in tandem with the EM procedure to tailor the number of mixing components online.
The combination of the embedded annealing strategy and the developed delete/merge/add operations creates a real difference between the proposed AAIS algorithm and the other existing AIS methods. The annealed distributions provide a smooth intermediate transition from the initial proposal to the posterior, while there is a good chance that the initial proposal differs greatly from the posterior in shape. The delete/merge/add processes fill gaps in the EM method by providing a way to tailor the number of mixture components online, by virtue of which the limitation stemming from the local property of the EM is broken. With the aid of the delete/merge/add operations, the annealing strategy truly comes into play, giving AAIS the desired global searching property and making the efficiency of the algorithm not dependent on the initialization.
For complicated posteriors, e.g., the Rastrigin function as introduced in Section 3.8.1, which has massive peaky modes, it is shown that PMC is not able to discover the overall structure of the posterior, even if the mixing component number is preset to be a large value. We argue that the above phenomenon stems from the inherent local searching property of PMC.
3.8. Simulation Studies
In this section, we perform simulation studies to test the capability of the developed AAIS method in exploring and approximating complex posteriors.
3.8.1. Example 1: Rastrigin Function
The Rastrigin function is a typical example of a nonlinear and highly multimodal function, which is widely used as a performance test problem for optimization algorithms, e.g., in Mühlenbein et al. (1991). The Rastrigin function is defined by

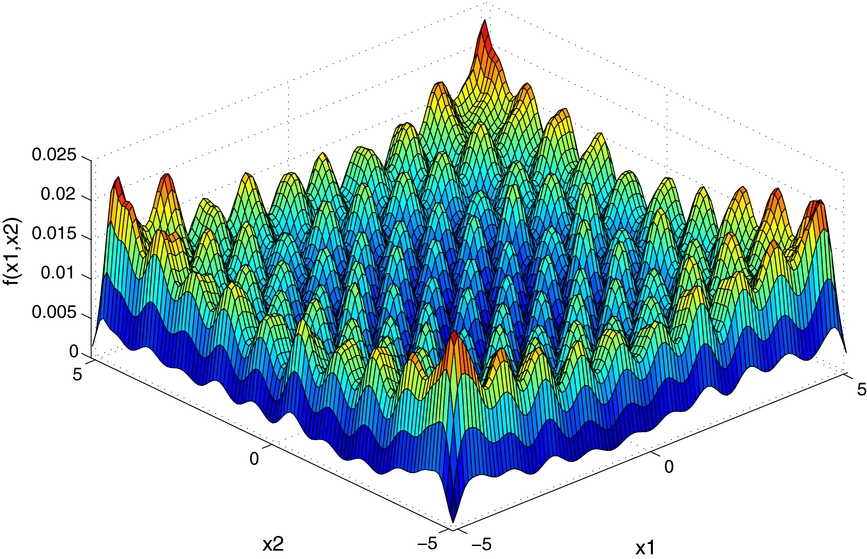
where d denotes dimensions. The global minimum f(x*) = 0 at x* = (0, ⋅⋅⋅, 0). As usual, the function is evaluated on the hypercube xi ∈ [ − 5.12, 5.12] for all i = 1, ⋅⋅⋅, d. It is shown in Figure 1 in its two-dimensional (2D) form.

Figure 1. 2D Rastrigin function.
Download figure:
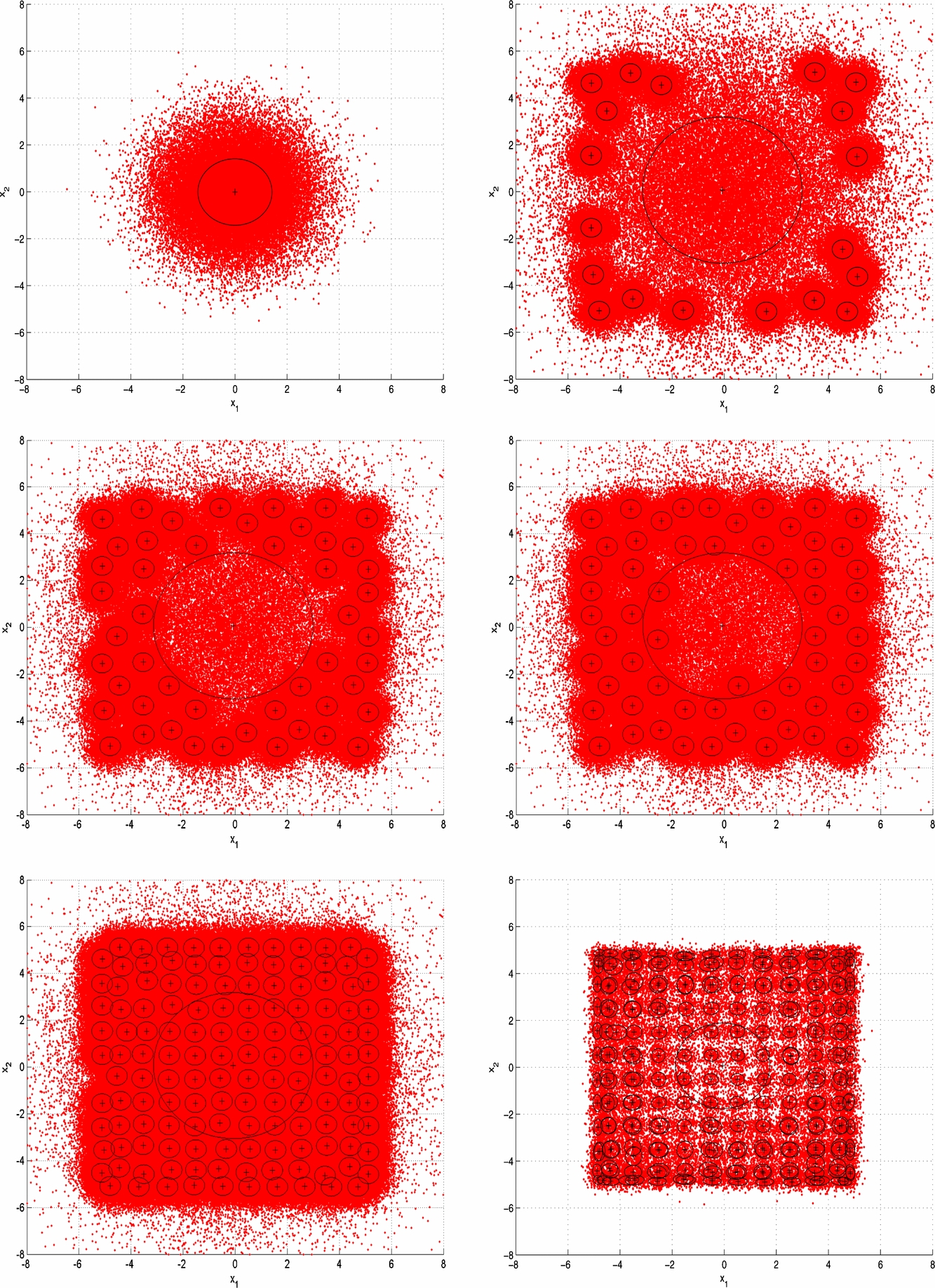
Standard image High-resolution imageHere, we set the target function to be proportional to the 2D Rastrigin function, i.e., p(θ)∝f(x), θ≜x. The purpose is to test the capability of our AAIS algorithm in dealing with highly multimodal target distributions. The mixture proposal final output of an example run of the AAIS is shown in Figure 2. In this example run, the AAIS algorithm is initialized with only one component; its intermediate sampling and proposal output are shown in Figure 3. As can be seen, the AAIS algorithm adaptively tunes the number of surviving components and finally gives an accurate estimate of the shape of the posterior.

Figure 2. AAIS output mixture proposal density in the 2D Rastrigin experiment.
Download figure:
Standard image High-resolution image
Figure 3. 2D Rastrigin function example: intermediate sampling results of the AAIS algorithm in six iterations of an example run. The top-left panel shows the sampling result of the first iteration, the top right corresponds to the second iteration, the middle left the third iteration, the middle right the fourth iteration, the bottom left shows result of the fifth iteration, and the bottom right is the final result. The contours represent the location, scale, and shape of the components in the T-mixture proposal, which are drawn at one standard deviation from the means in each of the major and minor axis directions.
Download figure:
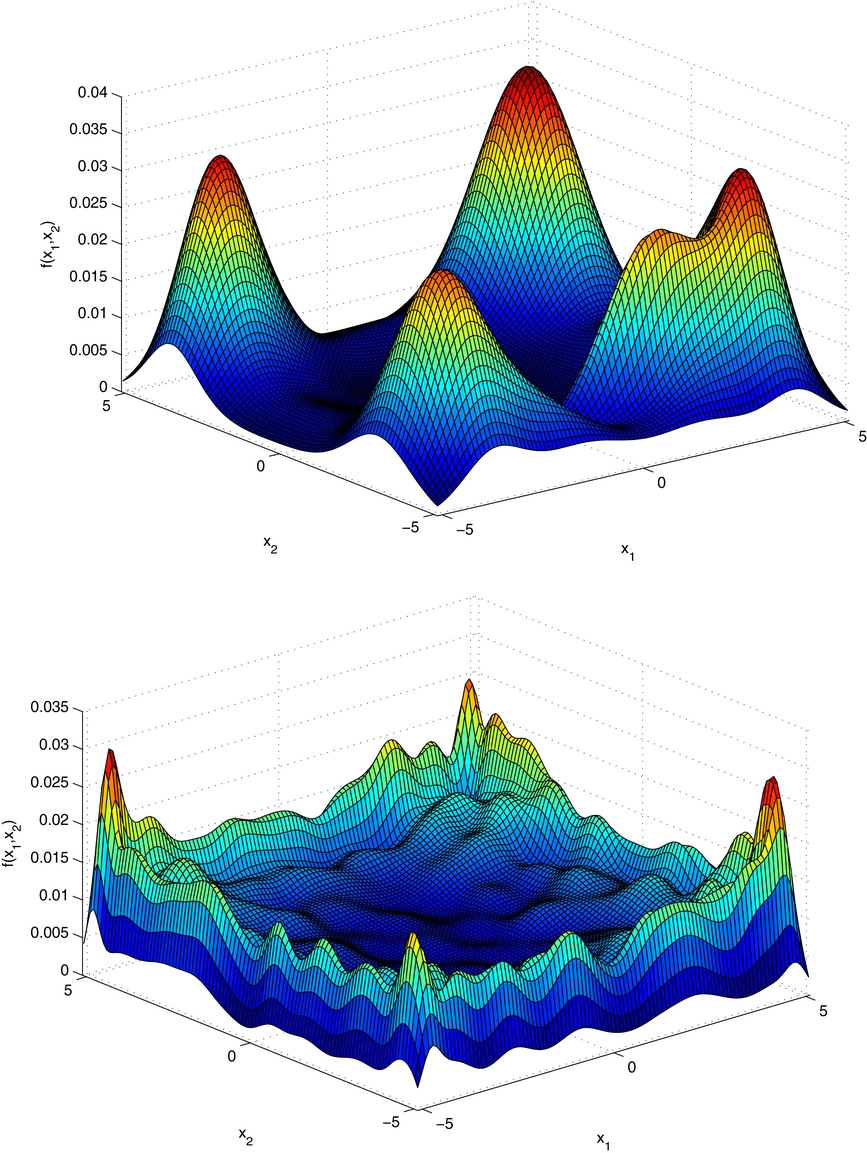
Standard image High-resolution imageIn order to compare the performance of the AAIS with that of PMC, the mixture proposal function output by a typical run of PMC is presented in Figure 4. It is shown that the result is highly dependent on the initialization and that the PMC algorithm is incapable of discovering the overall structure of the posterior, which corroborates arguments made in Section 3.7.

Figure 4. PMC output mixture proposal density in the 2D Rastrigin experiment. The upper and lower plots are associated with different initializations made for the proposal mixture function. The upper one corresponds to five mixture components and the bottom one to 100 components.
Download figure:
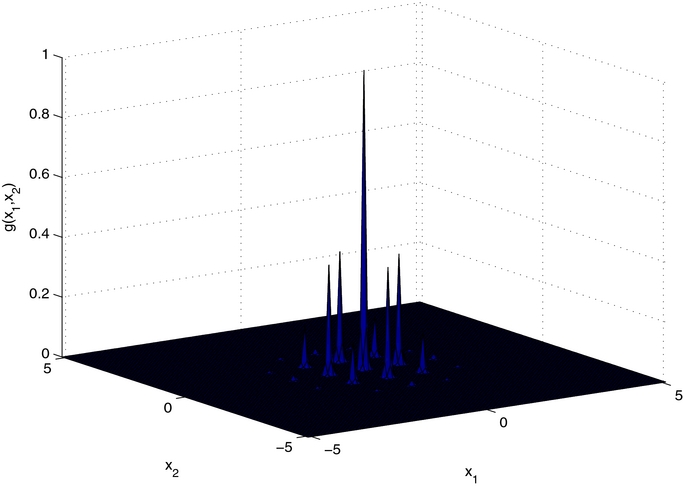
Standard image High-resolution imageNow we consider the application of AAIS for finding the global minimum of the ten-dimensional Rastrigin function. As the algorithm always tends to sample/explore areas with higher density values, it is natural to adapt it to search maxima rather than minima. So we transform the Rastrigin function to g(x) = exp (− f(x)), and then the task becomes looking for the global maxima. The transformed function is shown in Figure 5 in its 2D form. We evaluate the function values corresponding to all those samples generated during the running process of the algorithm and then output the one with the biggest function value as the final solution. The AAIS algorithm is equipped with a temperature ladder [0.0001, 0.001, 0.01, 0.1, 0.2, 0.4, 0.8, 1] and a particle size N = 105. The truly global maximum 1 is only reached at x* = (0, ⋅⋅⋅, 0), but the algorithm could find a solution better than 0.99 in 8 out of 10 runs, with an overall best solution being 0.9976 with corresponding x = [0.0004, −0.0014, −0.0014, −0.0016, 0.0005, 0.0001, 0.0007, −0.0010, −0.0004, −0.0018]. In the other two runs, the AAIS algorithm always found one of the local minima.

Figure 5. Transformed 2D Rastrigin function.
Download figure:
Standard image High-resolution image3.8.2. Example 2: Three-dimensional Flared Helix
Here, the posterior is simulated to be proportional to a cylindrical function with a standard Gaussian cross-section (in (x, y)) that has been deformed (in z) into a helix with varying diameters. The helix performs three complete turns. The shape of this function is illustrated in Figure 6. The function is normalized to integrate to exactly 60. We wonder if the shape of the output mixture proposal from AAIS can match that of the posterior.

Figure 6. Simulated 3D flared helix target distribution.
Download figure:
Standard image High-resolution imageFor AAIS, we initialize the proposal q with 10 equally weighted mixing Student's t components, whose centers are uniformly distributed over the parameter space. Ten iterations of the algorithm are performed with a linear incremental ladder [0.1, 0.2, ..., 0.9, 1]. The PMC algorithm (Cappé et al. 2008) is also included for performance comparison. We initialize PMC the same as for AAIS, and also run it with 10 iterations to output the final proposal function.
In Figure 7 we plot 2000 random samples drawn from the mixture proposals outputted by AAIS and PMC, respectively. It is shown that AAIS successfully explored those three complete turns, while PMC missed the last half turn in the helix function.

Figure 7. 3D flared helix example. Left: random samples drawn from the proposal output by the AAIS algorithm. Right: random samples drawn from the proposal output by the PMC algorithm (Cappé et al. 2008). In the diagonal, the curves are kernel density estimates of the posterior samples.
Download figure:
Standard image High-resolution imageWe then test if the proposed AAIS can give a good estimation of the integral of the test function. The benchmark PMC algorithm is also included for comparison. We show the results in Table 1. It is shown that AAIS performs much better than PMC, as it gives a much more accurate estimate to the real answer.
Table 1. 3D Flared Helix Example
| ESS/N | Estimate of the Integral (Real Answer is 60) | |
|---|---|---|
| AAIS | 0.4459 | 59.7 ± 2.0 |
| PMC | 0.1525 | 47.2 ± 3.3 |
Note. Quantitative performance comparison.
Download table as: ASCIITypeset image
3.8.3. Example 3: Outer Product of Seven Univariate Densities
Here, our concern is whether good results gained from the above 2D and 3D examples imply good results in a high-dimensional target function with two or more target modes. To test this concern, we use as a target function the outer product of seven univariate distributions normalized to integrate to exactly 1. These seven distributions are as follows:
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7..







Here,  denotes the gamma distribution,
denotes the gamma distribution,  the normal distribution,
the normal distribution,  the skew-normal distribution,
the skew-normal distribution,  the Student's t-distribution,
the Student's t-distribution,  denotes the beta distribution, and ε(· |λ) the exponential distribution. Dimension 2 has two modes bracketing a deep ravine, dimension 4 has one low, broad mode that overlaps a second sharper mode, and dimension 7 has three distinct, well-separated modes. Only dimension 5 is symmetric. There is a range of tail behavior as well, from Gaussian to heavy-tailed.
denotes the beta distribution, and ε(· |λ) the exponential distribution. Dimension 2 has two modes bracketing a deep ravine, dimension 4 has one low, broad mode that overlaps a second sharper mode, and dimension 7 has three distinct, well-separated modes. Only dimension 5 is symmetric. There is a range of tail behavior as well, from Gaussian to heavy-tailed.
We initialize for AAIS 50 equally weighted mixing components. The centers of these components for each dimension are uniformly distributed over [ − 10, 10]. A linear incremental ladder [0.1, 0.2, ..., 0.9, 1] is used. We include PMC here for performance comparison, which is initialized identically, and run with 10 iterations.
In Figure 8 we depict the scatter plot of random samples drawn from the resulting mixture proposals outputted by AAIS and PMC, respectively. It is shown that the proposed AAIS algorithm manages to find all the modes in the target function, while PMC fails to detect the target modes in the second and seventh dimension.

Figure 8. Seven-dimensional outer product example. Top: random samples drawn from the proposal output by the proposed AAIS algorithm. Bottom: random samples drawn from the proposal output by the PMC algorithm (Cappé et al. 2008). In the diagonal, the curves are kernel density estimates of the samples.
Download figure:
Standard image High-resolution imageFor this case, AAIS also gives an accurate estimate to the integral of the target function, as shown in Table 2.
Table 2. Seven-dimensional Outer Product Example
| ESS/N | Estimate of the Integral (Real Answer is 1) | |
|---|---|---|
| AAIS | 0.4948 | 1.0011 ± 0.0303 |
| PMC | 0.2454 | 0.4675 ± 0.0246 |
Note. Quantitative performance comparison.
Download table as: ASCIITypeset image
4. RV MODELS, MARGINAL LIKELIHOOD, AND PRIORS
In a two-body system such as a star and planet, the pair rotates together about a point lying somewhere on the line connecting their centers of mass. If one of the bodies (the star) radiates light, the frequency of this light measured by a distant observer will vary cyclically with a period equal to the orbital period. This Doppler effect is understood well enough that astronomers can translate between a frequency shift and the star's velocity toward or away from earth.
4.1. RV Models
If a star does not host any orbiting planets, then the RV measurements will be roughly constant over any period of time, varying due to the "stellar jitter," the random fluctuations in a star's luminosity, or fluctuations stemming from other systematic sources, e.g., starspots. In the zero-planet model, the ith element of the RV data, vi, is Gaussian-distributed as

with mean C and variance  . C denotes the constant center-of-mass velocity of the star relative to earth, s the square root of the "stellar jitter," and the additional variance component
. C denotes the constant center-of-mass velocity of the star relative to earth, s the square root of the "stellar jitter," and the additional variance component  is a calculated error of vi due to the observation procedure.
is a calculated error of vi due to the observation procedure.
In  ,
,

where ▵V(ti|ϕ) is the velocity shift caused by presence of the planet. Such a velocity shift is a family of curves parameterized by a five-dimensional vector ϕ≜(K, P, e, ω, μ0) as follows:

where T(t) is the "true anomaly at time t" given by

and E(t) is called the "eccentric anomaly at time t," which is the solution to the transcendental equation

In the above expressions, K denotes the velocity semi-amplitude, P the orbital period, e the eccentricity (0 ⩽ e ⩽ 1), ω the argument of periastron (0 ⩽ ω ⩽ 2π), and μ0 the mean anomaly at time t = 0, (0 ⩽ μ ⩽ 2π). The parameters C, K, and s have the same unit as velocity, the velocity semi-amplitude K is usually restricted to be non-negative to avoid identification problems, and C may be positive or negative. The eccentricity parameter e is unitless, with e = 0 corresponding to a circular orbit, and a larger e means more eccentric orbits. Periastron is the point at which the planet is closest to the star and the argument of periastron ω measures the angle at which we observe the elliptical orbit. The mean anomaly μ is the angular distance of a planet from periastron.
If there are p ⩾ 1 planets, the expected velocity is C + ▵V(ti|ϕ1, ..., ϕp). The overall velocity shift ▵V is the summation of velocity shifts of each individual planet, i.e.,

4.2. Marginal Likelihood
Given competing models  ,
,  , ...,
, ...,  , we do Bayesian model selection to determine the number of planets. Bayesian model selection requires calculation of marginal likelihoods. Taking
, we do Bayesian model selection to determine the number of planets. Bayesian model selection requires calculation of marginal likelihoods. Taking  , for example, its marginal likelihood is calculated as
, for example, its marginal likelihood is calculated as

where v≜(v1, ...vn), n is the sample size of the RV observations, θp the parameter of  , Θp the value space of θp,
, Θp the value space of θp,  the prior, and
the prior, and  the likelihood. It is worth noting that, without forced identifiability (i.e., not imposing any order on the planetary parameters) there are at least p! modes in the likelihood; therefore, the likelihood value should be divided by p!. Bayes Factors for comparing the p planet model to the 0 planet model can be expressed as
the likelihood. It is worth noting that, without forced identifiability (i.e., not imposing any order on the planetary parameters) there are at least p! modes in the likelihood; therefore, the likelihood value should be divided by p!. Bayes Factors for comparing the p planet model to the 0 planet model can be expressed as

The posterior of the p planet model is calculated with

where  is the prior odds of having p planets to 0 planet. We present the related priors in the following subsection.
is the prior odds of having p planets to 0 planet. We present the related priors in the following subsection.
4.3. Priors
We adopt priors recommended in (Ford & Gregory 2006; Bullard 2009) due to their approximate realism and mathematical tractability. For all models under investigation, the prior of C is uniformly distributed over an interval [Cmin , Cmax ] defined by a lower limit Cmin and upper limit Cmax of C, with Cmax > Cmin , i.e.,

log (smin + s) is uniformly distributed over the interval [log (smin ), log (smax )]:

The joint prior on (C, s2) can be viewed as a modified independent Jeffrey's prior as Cmin → −∞, Cmax → ∞, smin → 0, smax → ∞, which leads to well-defined posterior distributions and Bayes Factors even in the limit.
For a p > 0 planet model, without other prior information, each pair of ϕi and ϕj (i ≠ j, i, j ∈ [1, p]) have identical independent priors. As in (Ford & Gregory 2006; Bullard 2009), we specify an independent prior for elements of each ϕj, j = 1, 2, ..., p in a transformed parameter space:

leading to  . The Poincaré variables x and y greatly reduce the very strong correlations between μ0 and ω, which is particularly important for low eccentricity orbits, where the parameters are nearly unidentifiable. The use of z further reduces correlations between the parameters ω and μ0 when e ≪ 1, but has little effect for large e. Bullard (2009) recommended using the log transformation of P and K because the posteriors are more Gaussian in these coordinates, which led to improved posterior simulation. In the transformed parameter space, the prior distribution for ϕ is
. The Poincaré variables x and y greatly reduce the very strong correlations between μ0 and ω, which is particularly important for low eccentricity orbits, where the parameters are nearly unidentifiable. The use of z further reduces correlations between the parameters ω and μ0 when e ≪ 1, but has little effect for large e. Bullard (2009) recommended using the log transformation of P and K because the posteriors are more Gaussian in these coordinates, which led to improved posterior simulation. In the transformed parameter space, the prior distribution for ϕ is

for  ,
,  , x2 + y2 < 1, and 0 ⩽ z ⩽ 2π, where the normalizing constant is
, x2 + y2 < 1, and 0 ⩽ z ⩽ 2π, where the normalizing constant is

We list the constants used in the specification of the prior in Table 3, which are set based on physical realities (e.g., an orbit with too small a period will result in the planet getting consumed by the star).
Table 3. Prior Hyperparameters for the Distribution of ϕp
| Pmin | 1 day | Pmax | 1000 yr |
| Kmin | 1 m s−1 | Kmax | 2128 m s−1 |
| Cmin | −2128 m s−1 | Cmax | 2128 m s−1 |
| smin | 1 m s−1 | smax | 2128 m s−1 |
Download table as: ASCIITypeset image
5. EXOPLANET DATA ANALYSIS
We apply the proposed AAIS algorithm to analyze real data originating from several star systems such as Star HD 73526, HD 217107, HD 37124, and 47 Ursae Majoris (47 UMa). To begin with, a simulated RV data set is used to evaluate the efficiency of the proposed algorithm.
5.1. Simulated RV Data Case
We simulate 10 RV observations from a star hosting one planet with P = 100 days, K = 20 ms−1, e = 0.5, μ0 = 1, C = 0, and s = 1.5. The corresponding periodogram is shown in Figure 9. Then, we run the AAIS algorithm to estimate parameters of the single-planet model  and predict the RV curve during the observation period. In Figure 10, the predicted RV curve along with the corresponding credible interval is compared with the true RV curve. As is shown, the true RV answer falls within the ±1 standard error (68%) credible interval of the prediction almost everywhere, which confirms the accuracy of the parameter estimation. The marginal likelihoods of
and predict the RV curve during the observation period. In Figure 10, the predicted RV curve along with the corresponding credible interval is compared with the true RV curve. As is shown, the true RV answer falls within the ±1 standard error (68%) credible interval of the prediction almost everywhere, which confirms the accuracy of the parameter estimation. The marginal likelihoods of  ,
,  , and
, and  are estimated by AAIS to be 4.74 × 10−45, 3.14 × 10−16, and 4.95 × 10−17, respectively. So the corresponding Bayes factors are
are estimated by AAIS to be 4.74 × 10−45, 3.14 × 10−16, and 4.95 × 10−17, respectively. So the corresponding Bayes factors are  ,
,  , which supports the existence of a single planet.
, which supports the existence of a single planet.

Figure 9. Periodogram for the simulated RV data.
Download figure:
Standard image High-resolution image
Figure 10. Simulated RV data case. The estimated RV curve along with ±1 standard error confidence interval calculated by AAIS based on  . Error bars show simulated RV observations, including internal uncertainties.
. Error bars show simulated RV observations, including internal uncertainties.
Download figure:
Standard image High-resolution image5.2. Star HD 73526 Data Released in Tinney et al. (2003)
Tinney et al. released this data set and claimed to support an orbit of 190.5 ± 3.0 days (Tinney et al. 2003). Gregory then did a Bayesian re-analysis on this data set and reported three possible orbits, with periods  ,
,  , and
, and  days, respectively (Gregory 2005). Gregory also discussed the possibility of an additional planet and reported that the Bayes factor is less than 1 when comparing
days, respectively (Gregory 2005). Gregory also discussed the possibility of an additional planet and reported that the Bayes factor is less than 1 when comparing  with
with  (Gregory 2005).
(Gregory 2005).
We use the proposed AAIS algorithm to estimate the marginal likelihoods of  ,
,  , and
, and  , respectively. The result is summarized in Table 4. These estimates are reliable, which is indicated by the performance metric ESS/N, which is also included in Table 4. The resulting Bayes Factors are shown in Table 5, which supports
, respectively. The result is summarized in Table 4. These estimates are reliable, which is indicated by the performance metric ESS/N, which is also included in Table 4. The resulting Bayes Factors are shown in Table 5, which supports  the most. This result is consistent with conclusions made in Tinney et al. (2003) and Gregory (2005).
the most. This result is consistent with conclusions made in Tinney et al. (2003) and Gregory (2005).
Table 4. HD 73526 Tinney et al. (2003) Data Case: Estimated Marginal Likelihoods.
| Marginal Likelihood | ESS/N | |
|---|---|---|
 |
5.9013 × 10−50 ± 5.1325 × 10−52 | 0.9320 |
 |
4.4886 × 10−41 ± 3.2093 × 10−42 | 0.5698 |
 |
1.5511 × 10−42 ± 3.2878 × 10−43 | 0.3458 |
Download table as: ASCIITypeset image
Table 5. HD 73526 (Tinney et al. 2003) Data Case: Estimated Bayes Factors
BF |
BF |
|---|---|
| 7.606 × 108 | 0.03456 |
Download table as: ASCIITypeset image
Focusing on  , we investigate the posterior by drawing random samples from its approximation proposal given by AAIS. We show a scatter plot of the samples in Figure 11. It is clear that there are two modes in the period P, which are
, we investigate the posterior by drawing random samples from its approximation proposal given by AAIS. We show a scatter plot of the samples in Figure 11. It is clear that there are two modes in the period P, which are  and
and  , respectively.
, respectively.

Figure 11. HD 73526 (Tinney et al. 2003) data case. The scatter plot of the random samples is drawn from the approximated posterior of  .
.
Download figure:
Standard image High-resolution image5.3. Star HD 73526 Data Released in Tinney et al. (2006)
Tinney et al. released another data set on the star HD 73526 (Tinney et al. 2006), which contains more RV data components than in Tinney et al. (2003). Such a data set was claimed to have two planets (Tinney et al. 2006).
We estimate the marginal likelihoods of  ,
,  ,
,  , and
, and  , respectively, via the proposed AAIS algorithm. The result is shown in Table 6. The estimates are reliable, as indicated by the metric ESS/N. The resulting Bayes Factors are listed in Table 7, and indicate that it most likely has two planets.
, respectively, via the proposed AAIS algorithm. The result is shown in Table 6. The estimates are reliable, as indicated by the metric ESS/N. The resulting Bayes Factors are listed in Table 7, and indicate that it most likely has two planets.
Table 6. HD 73526 (Tinney et al. 2006) Data Case: Calculated Marginal Likelihoods
| Marginal Likelihood | ESS/N | |
|---|---|---|
 |
8.9566 × 10−77 ± 1.0852 × 10−78 | 0.9510 |
 |
5.8519 × 10−70 ± 1.7077 × 10−71 | 0.6545 |
 |
4.8122 × 10−65 ± 1.4284 × 10−66 | 0.2034 |
 |
1.7981 × 10−72 ± 2.6248 × 10−73 | 0.1281 |
Download table as: ASCIITypeset image
Table 7. HD 73526 (Tinney et al. 2006) Data Case: Calculated Bayes Factors
BF |
BF |
BF |
|---|---|---|
| 6.534 × 106 | 8.233 × 104 | 3.737 × 10−8 |
Download table as: ASCIITypeset image
We then examine the posterior of  by drawing random samples from its approximation proposal given by AAIS. We show the scatter plot of such samples in Figure 12. Two distinct modes in P appear to be
by drawing random samples from its approximation proposal given by AAIS. We show the scatter plot of such samples in Figure 12. Two distinct modes in P appear to be  and
and  , respectively.
, respectively.

Figure 12. HD 73526 (Tinney et al. 2006) data case. The scatter plot of the random samples is drawn from the approximated posterior of  .
.
Download figure:
Standard image High-resolution imageWhen investigating the posterior of  , we separate parameters allocated to each planet and then plot random draws from the approximated posteriors output by the AAIS in Figure 13. Based on such random draws, we estimate the periods of the two planets via IS, obtaining
, we separate parameters allocated to each planet and then plot random draws from the approximated posteriors output by the AAIS in Figure 13. Based on such random draws, we estimate the periods of the two planets via IS, obtaining  and
and  , respectively.
, respectively.

Figure 13. HD 73526 (Tinney et al. 2006) data case. The scatter plot of the random samples is drawn from the approximated posterior of  . The top panel corresponds to the first planet, and the bottom panel corresponds to the second planet.
. The top panel corresponds to the first planet, and the bottom panel corresponds to the second planet.
Download figure:
Standard image High-resolution imageUtilizing IS, we calculate the minimum mean squared estimates (MMSEs) of the RV curves corresponding to each model under investigation, and then plot them In Figure 14. The RV observations are also involved for reference. As is shown, the RV estimate yielded by  fits the real data best.
fits the real data best.

Figure 14. HD 73526 (Tinney et al. 2006) data case. Error bars only include internal uncertainties. The estimated RV curves are based on  ,
,  , and
, and  , respectively.
, respectively.
Download figure:
Standard image High-resolution image5.4. Star HD 217107 Data
Star HD 217107 data was released in Vogt et al. (2005) and it was claimed to have two planets.
We analyze such data using our AAIS method. The estimates of marginal likelihoods of  ,
,  ,
,  , and
, and  are listed in Table 8. These estimates are reliable, as indicated by the sufficiently large values of ESS/N. The resulting Bayes Factors are listed in Table 9, which shows that
are listed in Table 8. These estimates are reliable, as indicated by the sufficiently large values of ESS/N. The resulting Bayes Factors are listed in Table 9, which shows that  beats
beats  ,
,  , and
, and  .
.
Table 8. HD 217107 (Vogt et al. 2005) Data Case: Calculated Marginal Likelihoods
| Marginal Likelihood | ESS/N | |
|---|---|---|
 |
3.6492 × 10−168 ± 7.0150 × 10−169 | 0.9644 |
 |
3.7389 × 10−141 ± 0.6077 × 10−142 | 0.6448 |
 |
3.0897 × 10−108 ± 1.0011 × 10−109 | 0.4119 |
 |
8.9191 × 10−159 ± 1.7736 × 10−160 | 0.1142 |
Download table as: ASCIITypeset image
Table 9. HD 217107 (Vogt et al. 2005) Data Case: Calculated Bayes Factors
BF |
BF |
BF |
|---|---|---|
| 1.025 × 1027 | 8.264 × 1032 | 2.887 × 10−51 |
Download table as: ASCIITypeset image
5.5. Star HD 37124 Data
Star HD 37124 was claimed to have three planets (Vogt et al. 2005). We re-analyze the associated RV data with the proposed AAIS algorithm. The estimates of the marginal likelihoods are listed in Table 10. Indicated by ESS/N, the results are somewhat reliable. The resulting Bayes Factors are presented in Table 11, and support the conclusion of Vogt et al. (2005) that it most likely has three planets.
Table 10. HD 37124 (Vogt et al. 2005) Data Case: Estimated Marginal Likelihoods
| Marginal Likelihood | ESS/N | |
|---|---|---|
 |
2.0889 × 10−110 ± 2.1857 × 10−112 | 0.9427 |
 |
1.0717 × 10−106 ± 1.3077 × 10−107 | 0.1737 |
 |
1.9830 × 10−97 ± 1.1451 × 10−98 | 0.1798 |
 |
2.9228 × 10−84 ± 1.2563 × 10−85 | 0.1305 |
Download table as: ASCIITypeset image
Table 11. HD 37124 (Vogt et al. 2005) Data Case: Estimated Bayes Factors
BF |
BF |
BF |
|---|---|---|
| 5.13 × 103 | 1.850 × 109 | 1.474 × 1013 |
Download table as: ASCIITypeset image
In Figure 15, we plot the estimated RV curves corresponding to  ,
,  , and
, and  , respectively. As is shown, the RV curve estimated by
, respectively. As is shown, the RV curve estimated by  fits the real observations best.
fits the real observations best.

Figure 15. HD 37124 (Tinney et al. 2006) data case. Error bars only include internal uncertainties. Top left: MMSE estimates of the RV curve using  . Top right: MMSE estimates of the RV curve using
. Top right: MMSE estimates of the RV curve using  . Bottom: MMSE estimates of the RV curve using
. Bottom: MMSE estimates of the RV curve using  .
.
Download figure:
Standard image High-resolution image5.6. The 47 Ursae Majoris (47 UMa) Data
These 47 UMa data has been analyzed in Gregory & Fischer (2010). We re-analyze the associated RV data set using our AAIS algorithm. We show the estimated marginal likelihoods in Table 12 and the Bayes factors in Table 13. We obtain reliable estimates of marginal likelihoods of  ,
,  , and
, and  , as indicated by ESS/N. However, the marginal likelihood estimate for
, as indicated by ESS/N. However, the marginal likelihood estimate for  is unreliable, because the corresponding ESS/N is only 0.0089. Based on the above results, we can say that it is more likely to have two planets than zero or one planet, but there is a lot of uncertainty on whether there is a third planet. In contrast, Gregory & Fischer (2010) concluded that there is a third planet, even though there is a larger uncertainty on the estimate of the period for the third planet than for the others. Scheduling and collecting new observations should be helpful in reducing the above uncertainties. A preliminary version of the proposed AAIS algorithm has been reported in Loredo et al. (2012), which addressed ongoing work on adaptive scheduling of exoplanet observations. We plan to perform a detailed study of the proposed algorithm for application in scheduling new observations. The results will be reported in a future publication.
is unreliable, because the corresponding ESS/N is only 0.0089. Based on the above results, we can say that it is more likely to have two planets than zero or one planet, but there is a lot of uncertainty on whether there is a third planet. In contrast, Gregory & Fischer (2010) concluded that there is a third planet, even though there is a larger uncertainty on the estimate of the period for the third planet than for the others. Scheduling and collecting new observations should be helpful in reducing the above uncertainties. A preliminary version of the proposed AAIS algorithm has been reported in Loredo et al. (2012), which addressed ongoing work on adaptive scheduling of exoplanet observations. We plan to perform a detailed study of the proposed algorithm for application in scheduling new observations. The results will be reported in a future publication.
Table 12. 47 UMa (Gregory & Fischer 2010) Data Case: Estimated Marginal Likelihoods
| Marginal Likelihood | ESS/N | |
|---|---|---|
 |
2.0198 × 10−1004 ± 9.2572 × 10−1006 | 0.1002 |
 |
3.4400 × 10−896 ± 3.10 × 10−897 | 0.5643 |
 |
1.3500 × 10−816 ± 1.77 × 10−817 | 0.3324 |
 |
2.8970 × 10−825 ± 9.1623 × 10−825 | 0.0089 |
Download table as: ASCIITypeset image
Table 13. 47 UMa (Gregory & Fischer 2010) Data Case: Estimated Bayes Factors
BF |
BF |
BF |
|---|---|---|
| 1.703 × 10108 | 3.924 × 1079 | ? |
Note. "?" means a strong uncertainty.
Download table as: ASCIITypeset image
In Figure 16, we plot the estimated RV curves corresponding to  and
and  , respectively. It is clear that the RV estimate of
, respectively. It is clear that the RV estimate of  fits the real data much better than
fits the real data much better than  .
.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 16. 47 UMa (Gregory & Fischer 2010) data case. Error bars only include internal uncertainties. Left: MMSE estimate of the RV curve using  . Right: MMSE estimate of the RV curve using
. Right: MMSE estimate of the RV curve using  .
.
Download figure:
Standard image High-resolution image{kind=link}
6. DISCUSSIONS AND CONCLUSIONS
In the context of exoplanet detection, the calculation of marginal likelihoods that are required for Bayesian model selection is a crucial computational issue. The major challenge in computation comes from the highly nonlinear exoplanet models, which lead to complicated multimodal structures in the posteriors, whose parameter space ranges in size from a few dimensions to dozens of dimensions.
In this paper, we propose a very efficient algorithm, called AAIS, that is capable of adaptively exploring and approximating complex posteriors. It is shown that this approach facilitates simulating draws by IS from multimodal joint posterior distributions, and provides an effective and easy-to-implement way for estimating marginal likelihoods that are required for Bayesian model selection. We applied our algorithm to analyze a bunch of real exoplanet observations that have been released in the literature. The results have corroborated the efficiency of this new method.
Currently, with limited computational resources, our algorithm can handle posteriors whose parameter space ranges up to 17 dimensions (corresponding to the three-planet model), but will struggle with higher dimensional cases with more than three planets. We plan to continue to revise the algorithm to make it capable of handling more complicated posteriors that may appear in practice. We are also interested in applying AAIS to analyze more of the latest real data sets if such data are released and available. A most preliminary version of AAIS has been used to provide a computational tool for adaptive scheduling of observations, as reported in Loredo et al. (2012). We will perform a detailed study of the algorithm for application in scheduling new observations. The results will be reported in a future publication.
The author appreciates the insightful comments and suggestions given by the anonymous reviewers. This work was mainly supported by the National Science Foundation of the U.S. under grant No. 0507481. The author also appreciates discussions with his colleagues when he was with Department of Statistical Science at Duke University as a research scholar. This work was partly supported by the National Natural Science Foundation (NSF) of China under grant No. 61302158, the Provincial Science and Technology Plan (NSF) of Jiangsu province under grant No. BK20130869, the Natural Science Research Project for Colleges and Universities in Jiangsu province under grant No. 13KJB520019, and the Scientific Research Foundation of Nanjing University of Posts and Telecommunications under grant No. NY213030.