
Abstract
Interaction control presents opportunities for contact robots physically interacting with their human user, such as assistance targeted to each human user, communication of goals to enable effective teamwork, and task-directed motion resistance in physical training and rehabilitation contexts. Here we review the burgeoning field of interaction control in the control theory and machine learning communities, by analysing the exchange of haptic information between the robot and its human user, and how they share the task effort. We first review the estimation and learning methods to predict the human user intent with the large uncertainty, variability and noise and limited observation of human motion. Based on this motion intent core, typical interaction control strategies are described using a homotopy of shared control parameters. Recent methods of haptic communication and game theory are then presented to consider the co-adaptation of human and robot control and yield versatile interactive control as observed between humans. Finally, the limitations of the presented state of the art are discussed and directions for future research are outlined.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Traditional robotic manipulators, such as those used in the automotive industry, are potentially dangerous to human workers and thus are kept separated from them (figure 1(a)). Inspired by the benefits of human–human interaction ([1], figure 1(b)), robotic systems have been increasingly used to work in physical interaction with humans (figures 1(c)–(h)). In these contact robots, the physical interaction arises directly, or through an object such as when carrying a large object together. Contact robots offer a broad range of new opportunities for application in various fields such as manufacturing, microfabrication, or shared driving [2], as well as in a number of medical contexts, such as surgery [3] and neurorehabilitation [4].

Figure 1. Examples of interaction control. (a) Traditional industrial manipulators are separated from human workers. (b) Humans can carry out tasks efficiently together by relying on haptic communication. (c) Robot-assisted neurorehabilitation of the hand function (from National University of Singapore and Imperial College London). (d) Collaborative robot for manufacturing (from Jožef Stefan Institute, Ljubljana, Slovenia). (e) Using the Symbition exoskeleton (from University of Twente) to facilitate mobility. (f) Intelligent gravity support for ergonomic manufacturing (reproduced with permission from EJ Colgate). Reproduced with permission from EJ Colgate. (g) Human–robot interaction for versatile operation in construction, showing two robots assisting in bolting the timber beams. Reproduced with permission. A project member manually bolts the timber beams together that have been jointly preplaced by the two robots. Photo: NCCR Digital Fabrication/Roman Keller. (h) Teleoperated 'three hand surgery' using a soft endoscope equipped with tools (from Nanyang Technical University, Singapore, reproduced with permission).
Download figure:
Standard image High-resolution imageFor instance, teleoperation can enable an operator to carry out actions in remote, inaccessible or hazardous environments, such as long-distance space exploration activities, micro/nano-world manipulation or surgical operations. Robot systems designed for collaborations with human workers, often termed collaborative robots, can carry out tasks that are difficult to perform ergonomically when unassisted or otherwise uneconomical to automate [5, 6], or that require close proximity to human operators [7]. Robotic systems are also developed to facilitate physical rehabilitation [8–12] and sport training.
Historically, human–robot interaction consisted of developing safe strategies to use a robot in the proximity of humans, but not in contact with them [13]. For instance, the presence and location of humans detected from machine vision or infrared maps can be used to determine safe areas for the robot to move in and avoid collisions. To better decide how to safely and efficiently assist a human operator the robot can implement predictive assistive behaviours, rather than simply engaging with reactive behaviours, for example by inferring the operator's motion target intent to help guide their movement to the goal.
This intent can be inferred through observation of the operator's motion during the interaction, and may also incorporate prior knowledge of the task being performed. In tasks requiring physical contact between the human and robot, sensory cues such as interaction forces, motion and electrophysiological activities can provide information about the human operator's intents, that are unobservable for a purely vision-guided interaction.
Furthermore, recent studies have revealed a number of performance benefits when humans physically interact and collaborate while performing a common task [1, 14]. In particular, it has been shown that human partners share their motion plan through haptic sensing (the synthesis of touch and force sensing), which they use to improve own performance [15–17]. This highlights the potential for contact robots to rely on haptic communication, the exchange of haptic information, to identify the human operator motion plan and improve interaction control [18, 19]. Dedicated techniques developed in signal processing and machine learning (ML), such as linear quadratic estimation (LQE), dynamic movement primitives (DMP), Gaussian processes, etc, can be used to identify a partner's control.
Another major aspect of interaction control concerns how to share the effort between the robot and its user. Many interaction control methods tend to assign fixed roles of leader and follower to the human and the robot (such as in teleoperation [20]) or conversely to provide a fixed dynamic environment imposed on the user (such as in robot-assisted physical training [21]). However, while the human will automatically learn the robot control scheme and adapt to it [15, 22], the robot may also adapt its control to the human based on knowledge acquired through haptic communication. By understanding the human user control and using appropriate control theory or ML algorithms, the robot may develop appropriate interaction strategies to share effort considering their respective strengths [23, 24].
This paper reviews techniques for the interaction control of a contact robot with its human operator, focusing on the mechanical interaction and the exchange of haptic information (through the interaction force and tactile information). Compared to previous recent review papers (such as [23, 25]), this paper uses a systematic framework based on a dynamic model, cost functions, and control laws to compare various algorithms and describe future control designs. It also considers human neuromechanical control [26] as a key factor to intent estimation when interacting with a human partner. This includes recent studies on the physical interaction between humans that reveal how haptic communication is used to model the partner and improve interaction control [1, 15, 27]. These results underline the critical role of motion intent to shape the interaction between two agents.
The techniques of interaction control for contact robots can be described as an onion structure, with layers built around the core of its human user's intention detection (figure 2). Based on interaction data and a-priori information, a contact robot may read the motion/control intent. This information can be used to adapt the robot's behaviour unilaterally, or to develop interactive control considering the human natural co-adaptation.

Figure 2. Control for contact rich human–robot interactions can be described in terms of layered dependencies, with each layer building on the last to enhance the overall interactive capability of the robot system. At the core is the sensor data of the interaction and prior information. This data can then be processed into intents and task inferences, that can then be used for control adaptations and interactive behaviours.
Download figure:
Standard image High-resolution imageThe sections in the rest of the paper correspond to this structure. Section 2 formalizes the interaction control dynamics framework between a robot and its human user. The physical model of the human–robot system interacting with the environment forms the basis for how state updates through sensing are used to adapt the robot behaviour. The systems and techniques to identify the intent of the human operator are then described in section 3. Section 4 describes the various schemes developed during the last decades to adapt the interaction in a contact robot. Section 5 then discusses tools to analyse human–robot co-adaptation and to create interactive control between these two agents. Finally in section 6 limitations of the current state of the art are analysed and future research directions are identified,
2. Human–robot control dynamics
2.1. Interaction dynamics
We consider physical human–robot interaction through a direct kinaesthetic interface (e.g. an exoskeleton), through a commonly held object (e.g. in co-manipulation), or through a haptic device (e.g. for teleoperation). All these interactions can be described using the dynamic model:

expressing that the robot control command
u
and human motor command
u
h
drive the task dynamics  , where
x
is position vector and all variables are functions of time. Depending on the context of the aforementioned different interactions,
x
may represent the position of the collaboratively held object in co-manipulation, the position of the follower robot in teleoperation, or the joint angles of an exoskeleton. Moreover, although the above model describes interaction between a human and a robot, it can be extended to modelling of human–human or robot–robot interaction.
, where
x
is position vector and all variables are functions of time. Depending on the context of the aforementioned different interactions,
x
may represent the position of the collaboratively held object in co-manipulation, the position of the follower robot in teleoperation, or the joint angles of an exoskeleton. Moreover, although the above model describes interaction between a human and a robot, it can be extended to modelling of human–human or robot–robot interaction.
Without loss of generality, we assume that the robot control includes feedforward and feedback components:

where t represents the time. The feedforward component v uses prior knowledge of the system acquired through learning or identification to compensate for the (typically nonlinear) task dynamics. The feedback component w uses online evaluation of control performance to react in an appropriate way to unexpected situations:

where  is the motion target (a desired position or trajectory) and
is the motion target (a desired position or trajectory) and  are feedback gain matrices corresponding to stiffness and viscosity. Note that these feedback matrices can be updated to deal with uncertainties in the system, e.g. using adaptive control [28]. This gives a general form of feedforward and feedback components, which can be modified in different conditions and for different systems.
are feedback gain matrices corresponding to stiffness and viscosity. Note that these feedback matrices can be updated to deal with uncertainties in the system, e.g. using adaptive control [28]. This gives a general form of feedforward and feedback components, which can be modified in different conditions and for different systems.
Human motor control can be modelled similarly:

In this case
w
h
corresponds to the viscoelastic response to perturbations relative to the planned trajectory due to muscle mechanical properties and reflexes, where both the stiffness  and viscosity
and viscosity  increase with the motor command magnitude
increase with the motor command magnitude  [26].
[26].
2.2. Estimating the human user's intent
If the human parameters are not considered by the robot and the human does not consider the robot, they are in a relationship of co-activity where each of the two agents considers only themself [29]. Interaction via co-activity may work well if the robot and human carry out independent and complementary subtasks, e.g. an intelligent gravity support device enabling a human operator to move a workpiece in a horizontal plane with little effort (figure 1(f), [30]). However, when the robot and human work on the same task in an uncoordinated way, this may lead to inefficient interaction, instability or failure [31]. Therefore, it is critical for contact robots to consider the interaction dynamics with their users. To collaborate with a human operator, the robot should know or predict some elements of their movement or their control, usually referred to as intent estimation in physical human–robot interaction literature.
Estimating the human motion intent requires modelling their neuromechanical control. Let us consider a nonlinear stochastic framework recently introduced to model human motor control with feedforward and feedback components and considering the inherent sensorimotor noise [32, 33]. In this framework, the feedforward control component  corresponds to minimization of the expected cost (for visibility we drop the h
subscript in
corresponds to minimization of the expected cost (for visibility we drop the h
subscript in  ):
):

where  are weighting matrices and T is the terminal time of the planned motion. This cost function expresses human sensorimotor control as a trade-off between information (through
are weighting matrices and T is the terminal time of the planned motion. This cost function expresses human sensorimotor control as a trade-off between information (through  ) and energy (from
v
) [34].
) and energy (from
v
) [34].
The feedback component  can be computed using a linearization of the human motor command dynamics, by minimizing the cost:
can be computed using a linearization of the human motor command dynamics, by minimizing the cost:

where  indicates that task completion takes longer than the planned motion. For linear feedback, this optimal control method is called linear quadratic regulation (LQR). When the time window
indicates that task completion takes longer than the planned motion. For linear feedback, this optimal control method is called linear quadratic regulation (LQR). When the time window ![$[0,T_+]$](https://content.cld.iop.org/journals/2516-1091/4/3/032004/revision4/prgbac8193ieqn13.gif) moves forward, minimizing the cost Cw
yields model predictive control, which can be used for nonlinear systems and include various constraints [35, 36]. In equation (6) the current movement
moves forward, minimizing the cost Cw
yields model predictive control, which can be used for nonlinear systems and include various constraints [35, 36]. In equation (6) the current movement  is estimated by minimizing the square error prediction:
is estimated by minimizing the square error prediction:

For a linear system this yields linear quadratic estimation (LQE) or Kalman filtering, which, combined with LQR (assuming independent Gaussian noise), yields linear quadratic Gaussian control.
This model can predict human arm movements in various visual and dynamic conditions [32, 33]. However it requires knowledge of the neuromechanical parameters that will depend on the user and on their action. The many parameters involved in such complex model can only be indirectly observed by the robot through interaction responses or biosignal analysis, and would be difficult to identify during movement. On the other hand, it is possible to extract information from the human user in realtime directly from interaction data without a formal model. For instance, the data-driven technique of [37] could accurately predict a simple arm reaching movement for over 300 ms in advance, by comparing the ongoing movement with individual movement patterns. However it does not generalize to other movements.
Therefore, various approaches between these two model-based and data-driven extremes have been developed to learn the human user's motion intent. These methods, based on signal processing, ML and control theory, will be presented in section 3. They represent attempts to address the trade-off between a prediction based on simple models with few parameters that can be efficiently identified and run in realtime (but have limited generalization ability), and on more complex models offering the versatility necessary to be used for various tasks (but are difficult to realize).
2.3. Human–robot interaction control
How should the robot consider detected information on the human user's motion and share the control with them? For instance, in the case of exoskeleton control, it can be desirable to yield 'transparent' interaction by offering little resistance, or to provide assistance along the user's planned movement. In contrast, to avoid reaching vital areas, a surgical robot may have to take the lead in order to keep the tool away from these areas [38]. Different tasks will require interaction behaviours between these extremes, defined according to a task-specific higher-order logic [39], which we describe by:
- desired task objectives, e.g. stable interaction, reaching a task target
x
d
(that can be different from
 ) or tracking a desired force trajectory
f
d
;
) or tracking a desired force trajectory
f
d
; - a desired (fixed or varying) relationship between and .



Using these control notations of section 2.1, section 4 will describe typical approaches for contact robots to adapt to the human user developed in the literature.
The robot control should further consider the adaptation of the human to dynamic environments [40, 41] or the interaction to human partners as was observed in [1, 16]. The bilateral adaptation between human and robot (or other pair of agents such as human–human and robot–robot) can be modelled/designed using game theory (GT) as reported in section 5.
3. Human intent estimation
Intent estimation can refer to many methods and approaches, encompassing topics such as activity recognition, safety systems, etc. In physical human–robot interactions, using intent detection to generate a forward prediction of an ongoing or future motion enables the robot to actively participate in the interaction. This enables many new behaviours over passive interactions, such as compensating for inertial effects to reduce the effort required from the user to move with the robot, for instance when using an exoskeleton system [42]. We consider here three categories of intent estimation that are particularly relevant to the modelling and control of physical human–robot interactions:
- (a)motion intent from movement kinematics and system dynamics, e.g. inferring the intended motion target so that the robot can actively guide the human towards the goal;
- (b)action intent from discrete action sets, e.g. for selecting an appropriate grasp type for a prosthetic based on electromyography (EMG) signals;
- (c)task-level intent, e.g. given knowledge of the overall goal task, a robot can provide corrective actions that contradict the human's current intended motion, as might be used in a rehabilitation context.
A mixture of these approaches may be used within one system to manage different aspects of a task; however, these categories partition the different approaches reasonably well based on the underlying methods used, which range from control and signal processing methods to various ML methods.
3.1. Motion intent estimation
Motion intent estimation must involve some form of assumption over the human movement and/or use some state estimation technique to provide a forward prediction of the current motion, typically over a relatively short time horizon, with the goal of directly adapting the robot control dynamics to better suit the interaction.
Early work on motion and dynamics based intent estimation considered collaborative transport problems, where a human–robot team is tasked with moving an object together ([43, 44], figure 3). Earlier modelling of this shared movement assumed human motion during the interaction to be maximally smooth, as in the average of reaching arm movements, and can be modelled as a fifth order polynomial (minimizing the magnitude of time derivative of the acceleration) [45]. More recent works have sought to apply this model for human–robot interaction, by considering individual motion characteristics [46]. While this model presents a convenient parameterization, its validity is limited to reaching arm movements, and it fails at accurately predicting movements with constraints, such as when picking/deposing an object, or during interaction with the environment [26].

Figure 3. Moving a shared load is an example of a contact task where intent estimation can be incorporated in a number of ways. Intent estimation can be used for (i) gain matching between the human and robot to provide a more natural interaction ( K h and K ), (ii) inferring the desired movement direction and speed through online estimation from the interaction dynamics at the robot end-effector ( f int ), or (iii) assisting with following a desired path from a learned trajectory ( x d ).
Download figure:
Standard image High-resolution imageOther approaches to motion intent estimation for contact robots are based on the interaction force/torque  which can be measured through a sensor at the interface [47]. Using the model structure of section 2.1, the human control input can be defined by (i) virtual control gains and (ii) a virtual human target
which can be measured through a sensor at the interface [47]. Using the model structure of section 2.1, the human control input can be defined by (i) virtual control gains and (ii) a virtual human target  representing the motion intent:
representing the motion intent:

In this expression, the virtual gains  can be measured or computed from human neuromechanical models [26], learned using average population data, or just assumed a practical value, e.g. to match the robot control gains.
can be measured or computed from human neuromechanical models [26], learned using average population data, or just assumed a practical value, e.g. to match the robot control gains.  can then be estimated from this equation using LQE.
can then be estimated from this equation using LQE.
Data driven methods have been considered to estimate the human reaching target during a physical human–robot interaction limb guiding task. In [48], a radial basis function neural network was inserted in the impedance control loop to compensate for the unknown dynamics of the human limb in contact with the robot in an online-adaptive manner, which provides an estimate of the human motion target. ML techniques for biosignal analysis can be used for human motion intent prediction. For instance, EMG signals can be used to estimate human motion in 3D space, with recurrent neural network architectures yielding better results than a support vector regression or a non-recurrent network architecture [49]. In [50], a deep convolutional neural network was used to estimate interaction force from EMG, potentially avoiding the need to incorporate interaction force sensors to facilitate human–robot physical interaction. However, prediction based on EMG signals will suffer from their large inter-trials variability and noise [26].
3.2. Action intent estimation
Action intent estimation can be used to modulate the type of human–robot interaction, by providing a discrete action set that the robot can choose from based on observations of the human user. It aims to enable more complex and task-specific interactions that would be impossible by only considering the interaction dynamics as found in motion intent estimation. This form of intent is typically concerned with a longer time horizon than motion intent estimation, and generally requires a higher logic beyond (not represented in the notation of section 2.1).
For example, a subacute stroke patient may not be able to open the hand alone and thus want to control a hand exoskeleton system with their forearm EMG signals. Their EMG signals may be degraded so could not be used to derive a continuous control command to the robot, but a simple thresholding method is generally sufficient to infer the intended action [51]. In comparison, EEG has also been used in this study, but did not exhibit superior performance and is more complex to set up. Another example is when the robot body is covered with an electronic tactile sensing skin which the human user can touch to elicit 'event-like' actions [52, 53].
Other recent approaches have applied ML methods to classify intended actions. This might involve using sensing which is not directly relevant to the main task, but offers a communication route between the human and robot. An example of this is processing bicep and tricep EMG signals with a multilayer perceptron to yield discrete 'move up' and 'move down' control signals during a collaborative lifting task (figure 3) [54]. This allows the robot to interact with the human even while lifting a completely compliant object, e.g. a loose piece of rope, where there would not be a dynamic interaction at the human–robot interface for motion intent estimation approaches, without applying a stretching force on the rope.
3.3. Task intent estimation
Intent estimation at the task-level can give a robot partner prior knowledge of the overall task or goal that they should try to achieve, enabling further complex human–robot interactions. Rather than considering the next moment or action as seen in motion or action intent estimation, task-level intent estimation may consider a full expected trajectory representing an objective behaviour the robot should try replicated with their partner.
Consider a human–robot team performing a peg-in-hole type task. One approach to modelling the control requirements for completing this task is to assume that accurate positioning of the robot end-effector is required specifically at the insertion stage of the task, but not necessarily while initially moving the robot to the approximate region of the hole. If the robot were to have a high control gain through out the task, it would be possible for the human to position the robot accurately, but not do this particularly quickly or with low-effort, as the high-level of damping used in the robot controller would resist changes in motion. Some control heuristics can mitigate the issue, for example a robot could provide high gain during slow movements to help with accuracy [55]; however, this will limit movement in all directions and will not necessarily guide the user. Instead, task intent estimation can allow for varying controller gains in a task-relevant manner [56–61]. In the case of [58], for a peg-in-hole type task a minimal intervention controller is defined based on a learned task representation that results in the robot behaving compliantly during free-space movements while moving toward the hole, then engaging in a task-directed stiffness as it performs the insertion stage of the task, offering resistance in directions of motion that do not align the peg co-axially with the hole, with the overall effect of reducing both robot and human effort.
Providing the robot with knowledge of the task-level intent also enables the robot to act autonomously, creating opportunities for robot adaptation, for example as a means of compensating for noisy communications during teleoperation by providing a fall-back behaviour [62], or as a means of gradually taking over execution of the task as the robot system gains confidence in the learned task representation [63–65]. Alternating between human control and robot autonomy is discussed further in section 4.
A representation of a task can simply be a known and fixed trajectory, but it is often required from a robot to learn a representation of the task that can be adapted to different conditions. There is a large body of prior work detailing how such representations can be learned to enable robots to perform new tasks [57, 66–70]. A general overview is presented here, along with a description of how such representations can be used for intent estimation in physical human–robot interactions. As summarised in [70], learning a task specifically involves learning a policy, which is a mapping:

between observed states
x
s
and/or contexts
s
to an action
a
. In the context of robot task learning for intent estimation, these output actions can represent different levels of action, from (a) low-level actions, such as direct motor commands, motion targets, or system gains, to (b) full trajectories of these low-level actions,
τ
, or (c) abstract high-level task actions that represent a series of trajectories to perform some sequence of tasks, e.g. 'pick up the cup'. A policy can either be deterministic,  , or stochastic, where actions are drawn from a policy distribution conditioned on current states and contexts,
, or stochastic, where actions are drawn from a policy distribution conditioned on current states and contexts, ![$\boldsymbol{a} \sim \mathbf{\pi}[\boldsymbol{a}|(\boldsymbol{s},\boldsymbol{x}_s)]$](https://content.cld.iop.org/journals/2516-1091/4/3/032004/revision4/prgbac8193ieqn23.gif) .
.
There are many approaches for deriving a policy for robot control. ML for robot control most commonly considers behavioural cloning and reinforcement learning (RL).
3.3.1. Behavioural cloning
Describes methods where the robot uses data samples of input observed states and the corresponding output actions to directly produce a map between states and actions as described in equation (9).
In systems where labelled data sets for a task are provided through physical interaction with a human partner, a behavioural cloning system might also be described as a learning from demonstration system [67]. Here, a dataset of N demonstrations,  , is provided. The demonstration dataset consists of N-trajectories,
τ
, contexts,
s
, and optionally reward signals,
, is provided. The demonstration dataset consists of N-trajectories,
τ
, contexts,
s
, and optionally reward signals,  , that specify the performance of the observed trajectory in the context of the goal task,
, that specify the performance of the observed trajectory in the context of the goal task,  . Each trajectory is defined by a sequence of features,
. Each trajectory is defined by a sequence of features, ![$\boldsymbol{\tau} = [\boldsymbol{\phi}_0, \ldots, \boldsymbol{\phi}_T]$](https://content.cld.iop.org/journals/2516-1091/4/3/032004/revision4/prgbac8193ieqn27.gif) , representing the system state at each time step. A common assumption for learning a policy from human-provided demonstrations is that the observed human-provided features represent the true goal policy, i.e. an expert policy. The robot learner's goal is then to minimize the difference between the distribution over the observed expert features,
, representing the system state at each time step. A common assumption for learning a policy from human-provided demonstrations is that the observed human-provided features represent the true goal policy, i.e. an expert policy. The robot learner's goal is then to minimize the difference between the distribution over the observed expert features,  , and the distribution of features observed from the learner's policy,
, and the distribution of features observed from the learner's policy,  :
:

where D is some similarity measure between the expert and learner feature distributions, where the learner's policy is typically learned using some supervised learning method [70]. An example that follows this paradigm and is commonly used in robot learning systems is the Gaussian Mixture Model. The GMM is a general probabilistic learning method which encodes the provided data set as a joint distribution between the input and output states,  . Actions can be generated from this joint distribution through a Gaussian Mixture Regression which computes the conditional distribution for the output given an input vector
. Actions can be generated from this joint distribution through a Gaussian Mixture Regression which computes the conditional distribution for the output given an input vector  [57, 58]. While behavioural cloning generally does not involve the learning agent generating new data for learning in undemonstrated regions (as found in RL), many methods have been developed to represent underlying invariances in a task with the learned model such that the robot can generate effective trajectories in previously unobserved task conditions [58, 71, 72]. An additional advantage to a GMM-based representation is that the encoded covariance data may be used for modulating the robot impedance in a task-directed manner [58]. These methods have been applied to a variety of tasks with contact robots, including collaborative object movement [73], converting human-human demonstrations to human–robot task policies [74].
[57, 58]. While behavioural cloning generally does not involve the learning agent generating new data for learning in undemonstrated regions (as found in RL), many methods have been developed to represent underlying invariances in a task with the learned model such that the robot can generate effective trajectories in previously unobserved task conditions [58, 71, 72]. An additional advantage to a GMM-based representation is that the encoded covariance data may be used for modulating the robot impedance in a task-directed manner [58]. These methods have been applied to a variety of tasks with contact robots, including collaborative object movement [73], converting human-human demonstrations to human–robot task policies [74].
A common alternative approach to probabilistic methods for robot task learning uses motion primitives to represent tasks. In particular, dynamic movement primitives (DMP) yields a method that uses a single demonstration to encode a task as a dynamical system such that the robot will converge to a specified goal state from the current state [75]. The task-specific trajectory is incorporated to the dynamical system through a learned forcing function, which seeks to reproduce the provided demonstration exactly. Examples of DMPs in the field of contact robots include object-handover tasks [76], and predictive modelling of human motion for robust exoskeleton control [77]. Recent works have considered extensions and combinations of probabilistic, motion primitive, and kernel based learning methods, to address issues such as high-dimensioned state spaces, e.g. with Kernelised Movement Primitives [78, 79].
3.3.2. Reinforcement learning (RL)
While there has been a number of developments to improving the generalization of behaviour cloning, these supervised learning methods are typically not robust in conditions that deviate from the demonstrated conditions [70]. RL presents an alternate paradigm to task learning that enables a robot to learn a policy for a sequential decision making process where the environment dynamics are unknown [80, 81]. Generally, RL involves the robot interacting with the environment using its current policy, collecting state observations and possibly rewards, until it reaches some termination condition or state.
A key distinction from behavioural cloning methods is that this process can be achieved without any data being provided to the robot on the task that must be performed. Instead the robot can perform explorative actions in the task space to discover an optimal policy. While there have been great advances in perception and learning state representations in the field of deep learning that have enhanced RL [82], the expense and risk involved in pure exploration based data collection for real-world human–robot interactions is a significant bottleneck for deploying RL in real-world robotics [68, 83].
Rather than beginning learning from scratch, task demonstrations can be incorporated to accelerate learning by reducing the policy search space through offline learning, often called inverse reinforcement learning (IRL) [84]. Rather than learning a direct mapping between states and actions, the learning process attempts to infer the demonstrator's reward function, such that the robot can learn a policy that can generalise more effectively through exploration. In addition to the reduction in computational cost, this can serve to reduce the risk involved with a pure unstructured exploration approach to determining a task policy for a robot that must come in to contact with the environment or a human partner [68].
As highlighted in [85], the availability of task-relevant data is critical for enabling effective RL to take place. As discussed above, pure exploration of a task policy in the real world is typically not feasible, given the high number of samples required and safety concerns around random policy exploration. Key areas of research that aim to address this issue even more efficiently than IRL are sim-to-real transfer learning, and zero-/one-/few-shot learning. In sim-to-real transfer learning, the goal is to learn a policy in simulation, where data is cheap and exploration is safe, then transfer this policy to a real robot system for deployment [86, 87]. Practically, this encounters many challenges due to the gap between simulated and real-world task environments. Few-shot learning then aims to address the challenges of deploying robots on new tasks in the real-world by leveraging policies learned for previously learned similar tasks [88–90].
3.4. Mutual human–robot learning
With both behavioural cloning and RL based approaches to task learning for contact robots, the human operator should usually be the reference and thus have a leading role in the learning process. This can be done by using an incremental approach to modify a repeated motion with a GUI or through direct physical interaction [91–93], which can yield more accurate and smoother action. Many task learning methods can use the physical interaction with the human operator to transfer and refine expert demonstrations by directly pushing or pulling the contact robot along the desired task trajectories during behavioural cloning [67].
Physical interactions can also enable the human to provide online corrective actions during a RL process [94]. It is also possible to directly incorporate the coadaptation that takes place when a human and robot are learning to perform a new task collaboratively [95]. Here, a human and a robot collaborate to complete a ball maze task, where the teleoperated commands sent to the robot by the human are included in the RL state observations. Incorporating the human in the learning offers the opportunity for co-learning to occur, where as the human improves at the task the robot can adapt its own policy to better interact with them, and vice-versa.
When learning a control policy that involves interacting with a human partner that is also learning a policy, neglecting to consider the human adaptation could result in a covariate shift in the task distribution that makes the learned model ineffective at providing an accurate estimation of the human's intent [70, 95], unless this co-adaptation is explicitly accounted for. There is much scope for investigating the dynamic interaction that takes place between partners learning a task, with previous works modelling this problem between a human and a robot as a noisy communication process [96–98]. A game-theoretic control perspective is presented on this topic in section 5.
In addition to the challenge of co-adaptive learning, when considering learning processes that must directly interact with, and involve human partners, there are some key points to note. First, as data is collected through real-world interaction with a human partner, data collection is an expensive process. This results in the need for learning methods that are effective with limited data. Second, humans exhibit a wide range of physical properties that can make determining appropriate control commands for physical interactions difficult, particularly given the data collection limitations. It has been shown that population-level models of human motion can perform poorly, thus requiring model personalization [37, 99].
4. Robot control adaptation
Using elements of the human user's control that can be identified as discussed in the previous section, the robot can adapt its control according to an interaction strategy. Using the modelling of section 2.1, this control adaptation can be implemented on the robot motion target, control input or on the control gains (figure 3), as will be presented in this section. Extending the approach of [100], we define a homotopy of human–robot interaction behaviours:

where  denote the robot and human targets
denote the robot and human targets  , control inputs
, control inputs  or gains
or gains ![$\left([\boldsymbol{K},\boldsymbol{B}],[\boldsymbol{K}_h,\boldsymbol{B}_h]\right)$](https://content.cld.iop.org/journals/2516-1091/4/3/032004/revision4/prgbac8193ieqn35.gif) , and
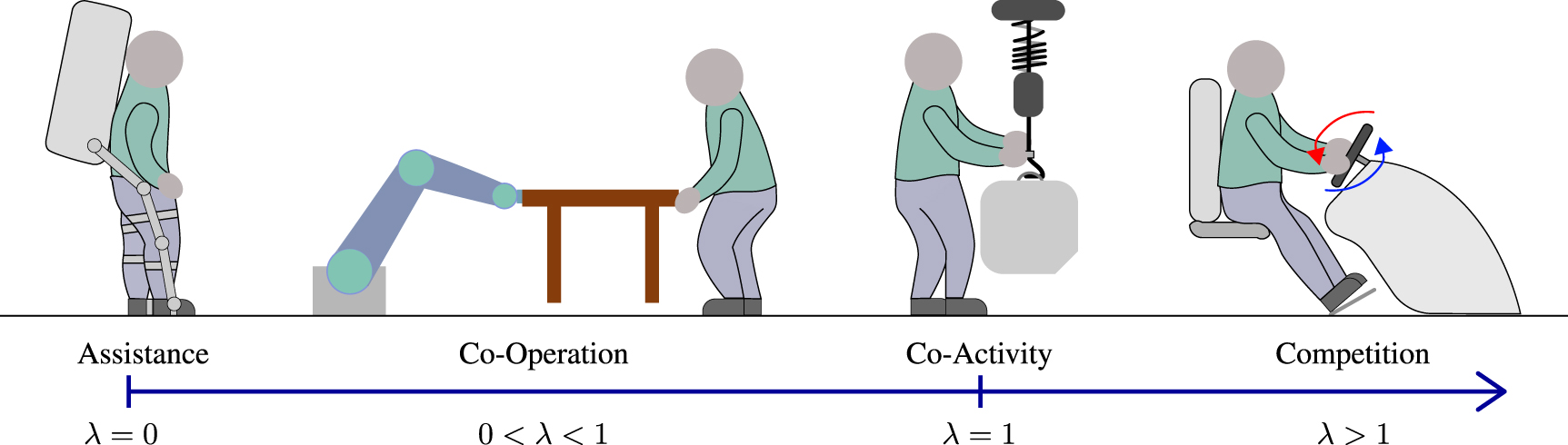
, and  is a nominal parameter. As illustrated in figure 4, this continuous parameter's representation can describe the typical interaction behaviours introduced in [101] by varying λ. λ = 0 corresponds to Assistance, λ = 1 to Co-activity,
is a nominal parameter. As illustrated in figure 4, this continuous parameter's representation can describe the typical interaction behaviours introduced in [101] by varying λ. λ = 0 corresponds to Assistance, λ = 1 to Co-activity,  to Cooperation and λ > 1 to Competition. For example, when
ξ
stands for motion target in a load sharing task in figure 3, competition refers to the case where human's and robot's targets are in opposite directions, assistance is when two targets are identical and cooperation is the case between competition and cooperation. Note that the motion target is defined in a body-fixed coordinate system, i.e. the origin is at the current position. The works analysed in this section are summarized in table 1.
to Cooperation and λ > 1 to Competition. For example, when
ξ
stands for motion target in a load sharing task in figure 3, competition refers to the case where human's and robot's targets are in opposite directions, assistance is when two targets are identical and cooperation is the case between competition and cooperation. Note that the motion target is defined in a body-fixed coordinate system, i.e. the origin is at the current position. The works analysed in this section are summarized in table 1.

Figure 4. Typical human–robot interaction strategies defined by the continuum of their adaptation using λ as described in equation (11) [47], and examples of their applications: a lower-limb exoskeleton provides walk assistance to the human user (assistance), a robot manipulator moves a table with the human (co-operation), a collaborative robot holds an object to allow the human to move it horizontally (co-activity), and the steering wheel provides resisting forces to the human driver when an obstacle is detected (competition).
Download figure:
Standard image High-resolution imageTable 1. Robot control adaptation.
| Assistance (λ = 0) | Cooperation ( ) ) | Coactivity (λ = 1) | Competition (λ > 1) | |
|---|---|---|---|---|
Robot target ( , ,  , ,  ) ) | [105–110]: same as human motion target, adaptive/iterative learning control [57, 60, 111, 112]: probabilistic models | [47]: interdependent motion targets | [47]: independent motion targets | [47, 102, 103]: opposite motion target |
Robot control command ( , ,  , ,  ) ) | [118, 119, 121, 122]: minimization of human control command | [100, 115–117]: supplement to human control command ( ) [118, 119, 121, 122]: interdependent control commands ( ) [118, 119, 121, 122]: interdependent control commands ( ) ) | [118, 119, 121, 122]: independent control commands | |
Robot gain ( , ,  , ,  ) ) | [5, 132–135]: identical to human gain | [125, 127, 128]: interaction stability | [31, 117, 129–131, 134, 143–146]: complementary gain adaptation | |
| Metrics for performance evaluation | Trajectory tracking error, force tracking error, task completion time | Trajectory tracking error, human effort, task completion time, human–robot disagreement | Task completion time | Force tracking error, distance to obstacles, impact force |
4.1. Adaptation of robot target
4.1.1. Competition
One embodiment of competition is when the robot target  is opposite to the direction of the human target
is opposite to the direction of the human target  (
( in equation (11)). Taking into account human performance, a rehabilitation robot may deliberately challenge the trainee by amplifying their movement errors to improve the outcomes of physical therapy [102]. Furthermore, if human movement or behaviour can be predicted, the robot can plan its motion in time to respond to the situation overseen by the human [47, 103].
in equation (11)). Taking into account human performance, a rehabilitation robot may deliberately challenge the trainee by amplifying their movement errors to improve the outcomes of physical therapy [102]. Furthermore, if human movement or behaviour can be predicted, the robot can plan its motion in time to respond to the situation overseen by the human [47, 103].
4.1.2. Assistance
Many works on human–robot interaction assume that the human has better perception and decision abilities than the robot and so should have a leading role. Using impedance control [104], the robot can be assigned a passive follower role by setting its stiffness to zero. To make the robot proactively follow the human user, the robot target  can be set as the human target:
can be set as the human target:

(corresponding to equation (11) with  and λ = 0), requiring to estimate
and λ = 0), requiring to estimate  as has been discussed in section 3.1.
as has been discussed in section 3.1.
The control community uses adaptive control and iterative learning control to estimate  and adapt
and adapt  [105–110], while the ML community uses probabilistic models to encode
[105–110], while the ML community uses probabilistic models to encode  and decode it for adaptation of
and decode it for adaptation of  [57, 60, 111, 112]. These two approaches may have complementary advantages: the modelling in control theory has more intuitive physical meanings and the system performance can be analysed in rigour; while the ML method takes system uncertainties into account, which are inevitable in a human–robot interaction system.
[57, 60, 111, 112]. These two approaches may have complementary advantages: the modelling in control theory has more intuitive physical meanings and the system performance can be analysed in rigour; while the ML method takes system uncertainties into account, which are inevitable in a human–robot interaction system.
4.1.3. Cooperation
When the robot and human have different targets, switching between them to pass the leading role has been considered in several works, see [107]. However, very few works have explored the intermediate behaviours between leading (corresponding to Competition or Co-activity) and submission (through the Assistance behaviour). Initial effort has been made in [47] to continuously adapt  according to
according to  from competition, cooperation to assistance, depending on the task and system's state. There are also works to realize cooperation by adapting the controller
u
r
, as discussed in the following section.
from competition, cooperation to assistance, depending on the task and system's state. There are also works to realize cooperation by adapting the controller
u
r
, as discussed in the following section.
4.2. Adaptation of robot control command
Many early works use this strategy to address safety in robot-assisted surgery. In these works, a robot controller  (setting λ = 1 in equation (11)) is designed based on the knowledge of the task and environment, without necessarily considering the human partner's behaviour. Virtual fixtures in the form of force fields have been proposed to keep away from dangerous areas (with a repulsive force) or guide movement (through an attractive force) [20, 113, 114].
(setting λ = 1 in equation (11)) is designed based on the knowledge of the task and environment, without necessarily considering the human partner's behaviour. Virtual fixtures in the form of force fields have been proposed to keep away from dangerous areas (with a repulsive force) or guide movement (through an attractive force) [20, 113, 114].
In equation (1),
u
can be adapted with
u
h
to modulate the interaction between the robot and human. For instance, to increase the human user's loading capability or reduce their effort, an exoskeleton can provide an assistive force or torque with (setting  and
and  in equation (11)):
in equation (11)):

can be modulated according the context of a task [100]. Dynamic role allocation can be thus be implemented by adapting
u
depending on
u
h
. In [115] where a robot and a human move a table to a target position without a specified path, it is shown that an adaptive role strategy is superior to a constant role strategy in terms of reduced human effort and task completion time, although human users prefer the constant role. While no explicit relationship between
u
and
u
h
is predefined, adaptation of  according to
u
h
is studied for a collaborative search and rescue task [116]. Similar to that in [117], the robot tries to reach its own target when there is no human input and gives up its leading role to the human partner when they intervene.
according to
u
h
is studied for a collaborative search and rescue task [116]. Similar to that in [117], the robot tries to reach its own target when there is no human input and gives up its leading role to the human partner when they intervene.
In systems where it is possible to evaluate the confidence level of the robot  in performing a task, a higher-order logic can be used [118] to modulate the command between an active component (corresponding to the known part) and a passive component (for the unknown part), yielding the nominal controller equation (11):
in performing a task, a higher-order logic can be used [118] to modulate the command between an active component (corresponding to the known part) and a passive component (for the unknown part), yielding the nominal controller equation (11):

Typically, the active part  may be implemented as elastic guidance along a planed trajectory and the passive part
may be implemented as elastic guidance along a planed trajectory and the passive part  as damping yielding to caster dynamics and stabilising the system. Using the above strategy, haptic assistance is investigated for tele-operation in [119], which mimics the human decision-making process and improves performance compared to no assistance [120].
as damping yielding to caster dynamics and stabilising the system. Using the above strategy, haptic assistance is investigated for tele-operation in [119], which mimics the human decision-making process and improves performance compared to no assistance [120].
A finite-state machine based role exchange (RE) mechanism is discussed in [121, 122] in the context of virtual haptic board game, where the dominant role and associated control level are dynamically changed according to rendered stiffness.
4.3. Adaptation of robot gain
4.3.1. Interaction stability
Many early literature about adaptation of the robot's gains concerns the interaction stability, which is not surprising as stability is critical to ensure safety for human-in-the-loop systems. Passivity is a widely adopted criterion to guarantee the interaction stability [123], based on which the robot is controlled using an impedance model with fixed robot gains [124]. Such a conservative controller makes the robot behave as a passive follower and it generally increases the human physical load. Many works propose adapting the robot control gains to provide the human user assistance and reduce their effort while ensuring interaction stability. One popular approach is to increase the robot's damping at low velocity in order to ensure stability and decrease it at high velocity to lower the robot's hindrance to the human [125, 126]. A similar idea of adapting robot damping is found in [55, 127, 128], but the adaptation is triggered according to the change of the human force and the estimated human arm stiffness. With some knowledge about the human gains K h , the robot gains can be updated to guarantee complementary stability [129]. Using the estimated interaction stiffness (corresponding to human gains), human–robot interaction stability can be investigated using Lyapunov theory [130], then the robot damping parameters can be adapted to ensure stability [131].
In above works, the robot plays a follower role without motion target, reducing the feedback controller in equation (3) to  . This controller with only a damping term makes the robot behave like a 'brake' which dissipates the system energy. While this is useful in ensuring system stability, it increases the human user effort. By having its own motion target, the robot can provide rich interaction behaviours as are needed in various applications, yielding more options about how to regulate the relationship between
. This controller with only a damping term makes the robot behave like a 'brake' which dissipates the system energy. While this is useful in ensuring system stability, it increases the human user effort. By having its own motion target, the robot can provide rich interaction behaviours as are needed in various applications, yielding more options about how to regulate the relationship between  and
K
h
, as detailed in the following sections.
and
K
h
, as detailed in the following sections.
4.3.2. Assistance
This type of interaction can be described by (setting  and λ = 0 in equation (11)):
and λ = 0 in equation (11)):

which indicates that the robot has a similar controller gain as the human. One direct application of this interaction is to transfer the human operator's variable impedance to the robot so that it can duplicate the operator's movement [5, 132, 133]. In collaborative manipulation of an object along the same direction [134, 135], the robot's impedance is set the same as the human partner's so that motion synchronization is achieved and the object load is equally shared between the human and robot.
4.3.3. Competition and complementary control
This type of interaction can be described by (setting λ = 2 and  in equation (11)):
in equation (11)):

where K 0 is a predefined matrix corresponding to the task specification. If K 0 overrides K h , the robot will either provide complementary assistance to the human, or compete with them. How should this interaction behaviour be implemented? Let us consider two cases: when the knowledge of a higher-level task objective is predefined, and when it is not.
In physical rehabilitation [136], the task target is usually predefined and the robot is expected to complement the human partner's force required to complete the task. In this case, it is not necessary to explicitly define
K
0 and one can use the error to the task target to indirectly evaluate the human performance. Therefore, the robot's gains or impedance parameters can be increased when the task cannot be achieved by the human and decreased otherwise [137–139]. This control strategy is closely related to adaptive control [140] and iterative learning control [138, 141, 142]. It is also possible to predefine
K
0 as a controller gain that can achieve the known task target [31]. Then, in an extreme case where the human user's gain  , according to equation (16) the robot will provide sufficient actuation with
, according to equation (16) the robot will provide sufficient actuation with  to complete the task; in the dual case where
to complete the task; in the dual case where  , the robot will not provide any actuation with
, the robot will not provide any actuation with  ; in a case where
; in a case where  , the robot will resist the human movement with
, the robot will resist the human movement with  . In this rehabilitation application, the motion targets of the robot and human are the same as the task target, i.e.
. In this rehabilitation application, the motion targets of the robot and human are the same as the task target, i.e.  . In the case where
. In the case where  , researchers used the criterion in equation (16) to adapt the robot's leading role in various applications. In human–robot handshaking [143], the authors used a hidden Markov model to determine if the human partner is in passive or active state based on the human limb parameters: if the human partner is passive, then the robot gain is set at a high value to follow its own reference trajectory; otherwise at a low value to make the robot follow the human lead. In a collaborative sawing task [134], the human partner's arm stiffness is estimated using EMG signal and the robot's stiffness was adapted according to equation (16) to provide complementary assistance.
, researchers used the criterion in equation (16) to adapt the robot's leading role in various applications. In human–robot handshaking [143], the authors used a hidden Markov model to determine if the human partner is in passive or active state based on the human limb parameters: if the human partner is passive, then the robot gain is set at a high value to follow its own reference trajectory; otherwise at a low value to make the robot follow the human lead. In a collaborative sawing task [134], the human partner's arm stiffness is estimated using EMG signal and the robot's stiffness was adapted according to equation (16) to provide complementary assistance.
When the knowledge of a higher-level task objective is not available, the decision making for the robot may become tricky. In co-manipulation tasks [117, 144–146], the robot impedance is adjusted to a high value in a routine task without human's intervention, and automatically decreases when the human partner wants to take over the lead for fine tuning of the robot's path or dealing with unexpected situations, e.g. obstacle avoidance. This means that the robot gives up leading to the human when there is a conflict. This is based on a hypothesis that the human's decision should prevail, which may be questionable in some cases. For example, in shared driving of a car [147] or of a wheelchair [148], the robot should take over the leading role when it perceives an obstacle that the human user does not see. Note that a competition behaviour is inherently used when the robot and human have different motion targets, but enhancing the competition by adapting  according to the human parameters has not been studied in the literature, which we believe is worth further investigation.
according to the human parameters has not been studied in the literature, which we believe is worth further investigation.
4.3.4. Adaptation of
K
according to or
u
h

Other works do not prescribe a relation with
K
h
, but adapt
K
in a heuristic ways related to  or
u
h
. For example, in [55], the robot's damping parameter is adapted according to the derivative of the human's applied force to make the interaction more transparent. In [149, 150], a probabilistic task model is established through learning by demonstration and used by the robot to predict the human behaviour in a collaborative task. The human force is used as an indicator of the disagreement between the predicted and actual human behaviors and to adapt the robot's controller gains to either follow its own reference trajectory or be compliant to the human partner. In [151], by estimating the human user's intentional walking direction, the cane robot's mass and damping parameters are adapted with less resistance to the human user in the walking direction and more in the perpendicular direction.
or
u
h
. For example, in [55], the robot's damping parameter is adapted according to the derivative of the human's applied force to make the interaction more transparent. In [149, 150], a probabilistic task model is established through learning by demonstration and used by the robot to predict the human behaviour in a collaborative task. The human force is used as an indicator of the disagreement between the predicted and actual human behaviors and to adapt the robot's controller gains to either follow its own reference trajectory or be compliant to the human partner. In [151], by estimating the human user's intentional walking direction, the cane robot's mass and damping parameters are adapted with less resistance to the human user in the walking direction and more in the perpendicular direction.
5. Interactive control
The two previous sections have reported techniques to adapt the control of contact robots to the human user in a unilateral way, based on information about their motion intent gained from haptic sensing. However, there is ample experimental evidence that humans automatically adapt to their dynamic environment [26, 40, 152]. This means that the user of a contact robot will likely also adapt to its interaction. It has been further observed that when humans carry out connected actions such as transporting and manipulating objects together or in tango dancing, they continuously exchange sensory information to adapt their control and improve their performance [14–16, 153]. How to consider these human motor adaptations? Could contact robots interact and co-adapt with their user as interacting humans do? The techniques that have been developed in recent years to address these questions will be presented in the next three subsections. Figure 5 summarizes the sensorimotor interaction between the human and robot agents, specifying how motion intention and adaptation can be used to develop (bilateral) interactive control.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. System diagram summarizing intent estimation, interactive control, and control adaptation in human–robot interaction. The subscript h distinguishes the human operator's from the robot's variables.  is a task-dependent state vector, used for feedback control.
is a task-dependent state vector, used for feedback control.  represents the task-dependent state estimated partner's target.
represents the task-dependent state estimated partner's target.  then represents an estimated state target, used to shape the interaction between the partners. Finally, both partners execute a command on the shared environment,
then represents an estimated state target, used to shape the interaction between the partners. Finally, both partners execute a command on the shared environment,  .
.
Download figure:
Standard image High-resolution image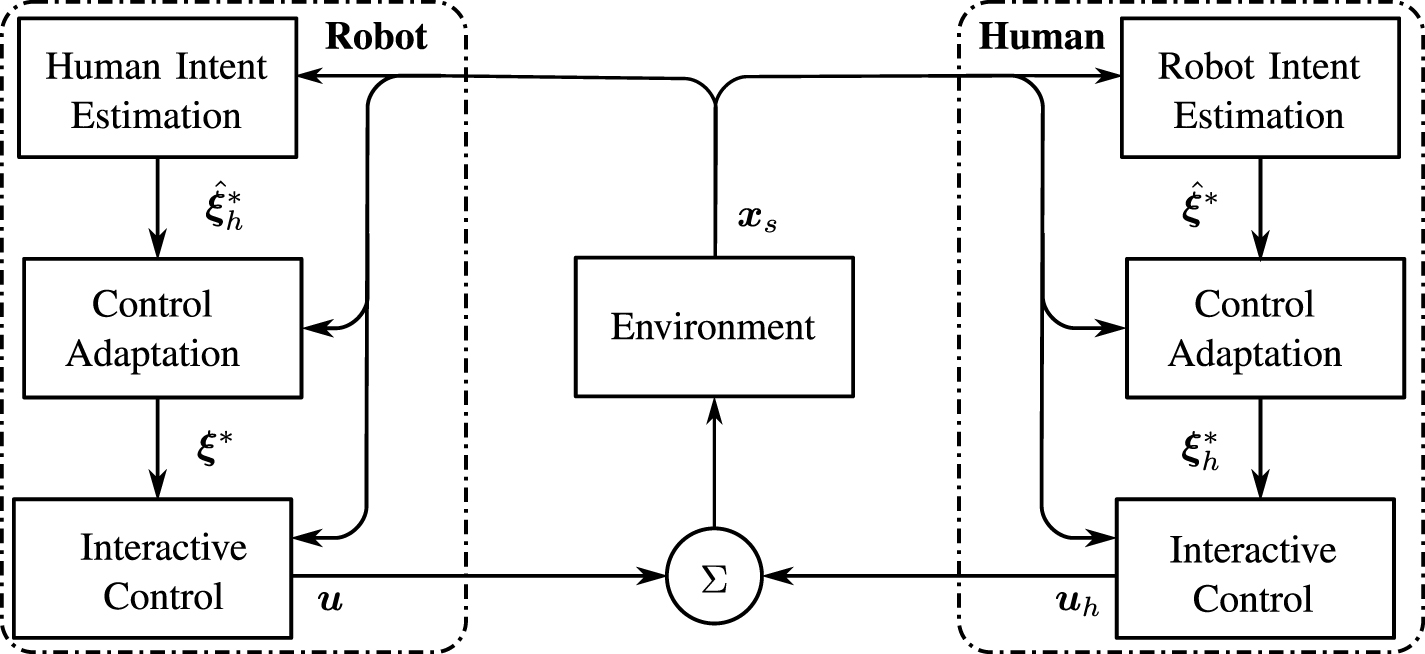{kind=link}
5.1. Sensory augmentation
Humans can combine haptic information from the interaction with another human or with a robot carrying out the same task to improve the accuracy of their own visual sensing [15]. Section 3 has presented techniques enabling a contact robot to detect the motion intent of its user from the interaction force, the common position or other haptic information. The robot can combine this haptic information with information from its other sensors such as camera, ultrasonic, radio-frequency identification. This can improve performance and in turn provide more accurate information to the human user. This interactive control strategy was implemented on a tracking task carried out with a human and a robot equipped with position and force sensors, where it exhibited increased accuracy with the additional interaction information [19]. Study of performance on groups of two, three and four connected humans [16] suggests that the benefit of this sensory augmentation approach increases with the group size, which may transfer to groups of humans and robots interacting with each other.
5.2. The game theory of interactive control
How should two interactive agents such as a contact robot and its human user, both able to read the other's motion intent, share the effort to carry out a common task? Differential GT [154] is a mathematical construct that can be used to investigate the control of these two interacting agents and yield appropriate control. While the human operator may wish to operate the robot according to their planed movement, the robot controller should be able to detect a novice or tired operator and compensate for their shortcomings. Mathematically, the robot will try to minimize its error and effort, as well as the estimated error and effort of the human, computed from a model of the human motor control:

where Q , Q h , R , R h are matrices weighting the error to effort costs. The constraint conditions for minimizing equation (17) are subject to equation (1). This system of equations from non-cooperative GT determines the Nash equilibrium. Using the estimated intent and gain estimated from the human side, the robot can consider the human control by further regulating its control gains.
Following this approach, [155, 156] discuss the strategy design to overcome conflicting intents between human and autonomous vehicle. GT-based controllers for shared driving have been developed in [2, 157, 158], where however the human driver's controller is assumed to be known. A method to identify the human partner's control during movement and compute the Nash equilibrium is developed in [31, 159]. This results in improved stability and reduced gains relative to co-activity implemented with one LQR controller for each of the human and robot [31]. Inverse optimal control [160, 161] and Q-learning RL [162] have also been used to identify the human's cost function for a game theoretic robot controller.
The Nash equilibrium models the situation where the human and robot cannot trust each other. When the operator gets accustomed to the robot's behaviour and knows that it can assist them, the interaction may correspond more to the Stackelberg equilibrium [163, 164] in which the human becomes dominant. Correspondingly the human cost Ch is first minimized, yielding a solution which is then used to minimize the robot cost C. This has been applied to model human driving control in [165, 166]. In situations where the human and robot consider both of their tasks simultaneously, this cooperative game can be modelled through the Pareto equilibrium where effort tradeoffs both the human and robot tracking errors. This was applied to an object transportation task in [167].
5.3. Flexible interaction behaviour through negotiation theory
The GT concept has been used in [101] to specify and classify the human–robot interaction behaviours of figure 4, which have been implemented in [31]. However, the relationship may arguably vary during operation according to changes in the dynamic environment, with human's fatigue, etc. Therefore, the human–robot relationship should be dynamically modified with a higher level decision process that:
- allows for different perceived information levels and limited communication channels,
- reflects the decision-making and reasoning process explicitly, and
- allows for iterations until the determinate agreement is obtained.
This can be implemented using negotiation theory [168, 169] providing an iteration process between two agents considering both intent and effort levels and leading to co-adaptation in three steps. Utility cost functions  are first computed to evaluate respective offers
are first computed to evaluate respective offers  based on which acceptance will be decided:
based on which acceptance will be decided:

Concession (assistance), tit-for-tat (cooperation and co-activity) and competition are defined in the context of negotiation theory [170] and have been considered to solve collaborative and conflict situations in haptic human–robot interaction [171], which correspond to the cases of λ = 0,  and λ > 1 in figure 4. A feasible opponent model including intent and utility function parameter estimation has been developed based on optimization subject to multiple constraints [172], which does not require prior determination of hypotheses in Bayesian learning [173, 174]. Event-based game is considered to explicitly reflect the negotiation process with complete information of system dynamics in [175], where each player is able to access others' cost functions (i.e. strategies) and then determine the associated strategy. With the support of touchpad-like interface, a butterfly negotiation model allows for multiple goal-directed levels of human–machine interaction [176].
and λ > 1 in figure 4. A feasible opponent model including intent and utility function parameter estimation has been developed based on optimization subject to multiple constraints [172], which does not require prior determination of hypotheses in Bayesian learning [173, 174]. Event-based game is considered to explicitly reflect the negotiation process with complete information of system dynamics in [175], where each player is able to access others' cost functions (i.e. strategies) and then determine the associated strategy. With the support of touchpad-like interface, a butterfly negotiation model allows for multiple goal-directed levels of human–machine interaction [176].
6. Limitations and future directions
Contact robots offer many opportunities for interaction with the human user, which have been and are still being extensively investigated. A great deal of progress has been achieved in the development of interaction control systems for contact robots in recent years, as has been reviewed above. In this section we would like to identify a number of open questions and directions to further research and developments.
First, despite abundant effort in the literature, interaction control is still constrained by limited capabilities of intent estimation. Critical to detect motion intent of the human operator is the model of their sensorimotor control. Models should be developed with few parameters that can be identified during movement, while representing the major characteristics of human neuromechanics [26].
While human intent can be represented in different forms, the communicated information in physical human–robot interactions first consists of the interaction force, position, velocity, etc. This sensory information can be combined with the robot's sensing to extract maximum knowledge about the ongoing task as was described under sensory augmentation in section 5.1. Intent estimation is mathematically looking for the single right solution from multiple (or indefinite) possibilities, which is challenging given limited available information. This may be facilitated by using multi-modality interaction integrating other information exchange such as vision, natural language, etc [177].
There are significant gains to be made by the sensing and analysis of biosignals of the human operator to improve the intent estimation. For EMG signals for example, methods are required for handling the diversity of the signals across tasks, the non-stationarity of signals over time and experience, and the variation of signals across human users. High-density EMG coupled with advanced signal processing and ML may provide maximum information about the neural signals in a non-invasive way [178]. Advances would also be provided by practical interfaces, for example wearable interfaces that can be easily donned such as EMG bracelets [179]. Other techniques to acquire signals stemming from muscle activities, such as wearable ultrasound devices, are being developed [180].
It is necessary to develop better task representations for performing and learning interacting in more complex tasks, as discussed in section 3.3. This is not a problem specific to contact robots, and rather corresponds to a diverse range of applications and use cases. A core problem for learning task representations from interaction data is the causal confusion challenge whereby purely observational data does not help learn an accurate model of the underlying system [181], and so more explicit models of how observed variables are related to the underlying phenomenon are required to separate cause and effect in observations. Another fundamental issue in learning task representations is that of covariate shift, where the nature of the underlying task changes over time and the original model no longer performs well [70]. This has implications on the task-specific nature of learning task representations from demonstrations or observations, where a robot system can be limited to performing one task, or a limited set of tasks based on what it has been shown previously.
Humans are able to generalize learning, for example the learning of a small bicycle as a child automatically transfers to the driving of any larger bicycle when one grows [182]. Similarly, an emerging area of research which may help improve the generality of assistance that can be provided by contact robotics is that of meta-learning, whereby data from an unbounded set of tasks can be incorporated to a general model that can then be rapidly adapted to a new unobserved task [183]. Applying such task learning methods to contact robotics could allow for generally assistive robot systems that can more easily shift from task to task, with minimal re-training or adaptation required.
On the control side, it has been discussed that there is an opportunity to integrate control theory and ML. Among many other reasons, one is that the current control theory for physical human–robot interactions is mainly limited to a single task, e.g. moving an object from one position to another, while ML has been used to deal with multiple tasks. However, one shortcoming of ML is lack of strict analysis of system stability and performance, which is crucial to physical human–robot interactions. It is important to investigate how to combine their complementary advantages.
Regarding the interaction behavior, a lot of effort has been made on cooperation between human and robot, but not explicitly on competition. Therefore, we want to draw attention on the cases where the robot may have alternative objective or criteria for executing the overall goal that conflicts with the human intent. This is because competition is inherent to many applications where it is used to prevent human errors such as virtual fixtures for obstacle avoidance. Versatile physical human–robot interactions may be developed by adapting between assistance and competition according to human input.
As we have seen above, many works in physical human–robot interaction have considered the human partner as a system to identify, without considering their own adaptation to the robot. How will this co-adaptation affect interaction stability? Will a new model considering co-adaptation improve prediction of human behaviours and even guide the modulation of human learning? Works discussed in section 5 have presented preliminary results, but have not addressed adequately how human adaptation can be modelled and integrated to robot adaptation. Conversely, researchers in the field of human motor control mainly focus on the human side. Some results could already be used to design human-like robotic control strategies, but more benefits can be expected by considering human–robot co-adaptation, which is thus worth further study.
Last but not least, there are still relatively few works on how human users perceive the mechanical interaction with a robot. In general, it was found that operators prefer interacting with a predictable behaviour than with human-like control or even with a human [184, 185]. However, this does not mean that human-like behaviours should be avoided. Traditional contact robots have used either trajectory guidance such as in rehabilitation robots or caster dynamics for collaborative tasks such as carrying an object together [186]. However it was shown that this modifies the behaviour and interferes with learning [36], in contrast to human-like interaction control [187]. Furthermore, the potential of distinct interactive control strategies such as proposed in [101] has not been well exploited yet.
Acknowledgments
The work was supported in part by the UK EPSRC Grant Nos. EP/T006951/1 and EP/R026092/1; the EC H2020 COST ACTION TD16116, EC H2020 ICT 871803 CONBOTS, FETOPEN 829186 PH-CODING and ICT 871767 REHYB programme grants; and the Slovenian Research Agency P2-0076.
Data availability statement
No new data were created or analysed in this study.