

Abstract
Many real-world problems, like modelling environment dynamics, physical processes, time series etc involve solving partial differential equations (PDEs) parameterised by problem-specific conditions. Recently, a deep learning architecture called Fourier neural operator (FNO) proved to be capable of learning solutions of given PDE families for any initial conditions as input. However, it results in a time complexity linear in the number of evaluations of the PDEs while testing. Given the advancements in quantum hardware and the recent results in quantum machine learning methods, we exploit the running efficiency offered by these and propose quantum algorithms inspired by the classical FNO, which result in time complexity logarithmic in the number of evaluations and are expected to be substantially faster than their classical counterpart. At their core, we use the unary encoding paradigm and orthogonal quantum layers and introduce a new quantum Fourier transform in the unary basis. We propose three different quantum circuits to perform a quantum FNO. The proposals differ in their depth and their similarity to the classical FNO. We also benchmark our proposed algorithms on three PDE families, namely Burgers' equation, Darcy's flow equation and the Navier–Stokes equation. The results show that our quantum methods are comparable in performance to the classical FNO. We also perform an analysis on small-scale image classification tasks where our proposed algorithms are at par with the performance of classical convolutional neural networks, proving their applicability to other domains as well.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
1.1. Fourier neural network
Solving partial differential equations (PDEs) has been a crucial step in understanding the dynamics of nature. They have been widely used to understand natural phenomena such as heat transfer, modelling the flow of fluids, electromagnetism, etc.
Each PDE is an equation, along with some initial conditions, for which the solution is a function f of space and time (x, t), for instance. A PDE family is determined by the equation itself, such as Burgers' equation or Navier–Stokes equation. An instance of a given PDE family is the aforementioned equation along with a specific initial condition, represented, for instance, as  . Modifying this initial condition leads to a new PDE instance and, therefore, to a new solution
. Modifying this initial condition leads to a new PDE instance and, therefore, to a new solution  . Note also that the solution is highly dependent on some physical parameters (i.e. viscosity in fluid dynamics).
. Note also that the solution is highly dependent on some physical parameters (i.e. viscosity in fluid dynamics).
In practical scenarios, a closed-form solution for most PDE families' instances is difficult to find. Therefore, classical solvers often rely on discretising the input space and performing many approximations to model the solution. A large number of computations for each PDE instance are required, depending on the chosen resolution of the input space.
Recently, considerable effort in research for approximating a PDE's solution is based on neural networks. The main idea is to let a neural network become the solution of the PDE by training it either for a fixed PDE instance or with various instances of a PDE family. The network is trained in a supervised way by trying to match the same solutions as the ones computed with classical solvers. The first attempts [1, 2] were aimed at finding the PDE's solution  for an input (x, t) given a specific initial condition (one PDE instance), and later [3–5] to a specific discretisation resolution for all instances of a PDE family. For the first case, once trained, the neural network can output solution function values at any resolution for the instance it was trained on. However, it has to be optimized for each instance (new initial condition) separately. In the latter case, the neural network can predict solution function values for any instance of the PDE family but for a fixed resolution on which it was trained.
for an input (x, t) given a specific initial condition (one PDE instance), and later [3–5] to a specific discretisation resolution for all instances of a PDE family. For the first case, once trained, the neural network can output solution function values at any resolution for the instance it was trained on. However, it has to be optimized for each instance (new initial condition) separately. In the latter case, the neural network can predict solution function values for any instance of the PDE family but for a fixed resolution on which it was trained.
A recent proposal named Fourier neural network [6] overcame these limitations and posed the problem as learning a function-to-function mapping for parametric PDEs. Parametric PDEs are families of PDEs for which the initial condition can be seen as parametric functions. Given any initial condition function of one such PDE family sampled at any resolution, the neural network can predict the solution function values at the sampled locations.
The input is usually the initial condition  itself. It is encoded as a vector of a certain length
itself. It is encoded as a vector of a certain length  by sampling it uniformly at
by sampling it uniformly at  locations x of the input space, given some resolution. This input is also called an evaluation of the initial condition function. The number of samples
locations x of the input space, given some resolution. This input is also called an evaluation of the initial condition function. The number of samples  is key in analysing the computational complexity as it is the neural network input size. Note that sometimes the initial condition is also sampled for several times t as well. The output of the neural network is the corresponding PDE's solution
is key in analysing the computational complexity as it is the neural network input size. Note that sometimes the initial condition is also sampled for several times t as well. The output of the neural network is the corresponding PDE's solution  applied at all x sampled and for a fixed t. Experiments on widely popular PDEs showed that it was effective in learning the mapping from a parametric initial condition function to the solution operator for a family of PDEs.
applied at all x sampled and for a fixed t. Experiments on widely popular PDEs showed that it was effective in learning the mapping from a parametric initial condition function to the solution operator for a family of PDEs.
The method proposes a Fourier Layer (FL) repeated several times. It consists of a Fourier Transform (FT), then a multiplication with a trainable matrix (also called a linear transform, and an Inverse Fourier Transform (IFT) operation, and ends with a standard non-linearity. This is similar to the convolution operation as it also translates to multiplication in the Fourier domain. However, a key feature of the FL is the fact that one can keep only some part of the data before the IFT, corresponding to the lowest frequency in the Fourier domain, reducing the amount of information and computational resources.
The major bottleneck which might hinder the scalability of this classical Fourier neural operator (FNO) is its time complexity, limited by the classical FT and IFT operations inside the FL. Indeed, their time complexity is  with a classical computer (single-threaded), where
with a classical computer (single-threaded), where  is the input size (number of samples). For a multi-threaded classical scenario (say p threads), the best possible theoritical time-complexity of the FT will be approximately
is the input size (number of samples). For a multi-threaded classical scenario (say p threads), the best possible theoritical time-complexity of the FT will be approximately  (for the case when work is almost equally distributed). In most real-world use cases,
(for the case when work is almost equally distributed). In most real-world use cases,  is expected to be quite high for learning precisely the solution of a PDE family. To be more precise, we will see that each input, a vector of size
is expected to be quite high for learning precisely the solution of a PDE family. To be more precise, we will see that each input, a vector of size  , is first modified and reshaped to become a matrix of size
, is first modified and reshaped to become a matrix of size  (see figure 1).
(see figure 1).  is named channel dimension, and usually
is named channel dimension, and usually  . This matrix will be the actual input of the FL. Thus, even for a practical multi-threaded scenario where limited cores are availble leading to
. This matrix will be the actual input of the FL. Thus, even for a practical multi-threaded scenario where limited cores are availble leading to  , the complexity of FFT can be at-best sublinear in
, the complexity of FFT can be at-best sublinear in  (depending on
(depending on  ).
).

Figure 1. Overview of the Fourier neural network. Each initial condition  is sampled
is sampled  times and modified via a trainable matrix P to become a matrix of size
times and modified via a trainable matrix P to become a matrix of size  . Then, T Fourier Layers (green block) are applied sequentially. In this paper, we are designing quantum circuits to implement the Fourier Layers. Each Fourier Layer consists of a row-wise Fourier Transform (FT), followed by a column-wise multiplication with trainable matrices labelled W, and the row-wise inverse Fourier transform (IFT). We only apply the inner matrix multiplications to the first K columns (also called modes) and leave the others unchanged or replaced by 0 s before the IFT. Finally, a reverse operation with a trainable matrix Q is performed to obtain the output
. Then, T Fourier Layers (green block) are applied sequentially. In this paper, we are designing quantum circuits to implement the Fourier Layers. Each Fourier Layer consists of a row-wise Fourier Transform (FT), followed by a column-wise multiplication with trainable matrices labelled W, and the row-wise inverse Fourier transform (IFT). We only apply the inner matrix multiplications to the first K columns (also called modes) and leave the others unchanged or replaced by 0 s before the IFT. Finally, a reverse operation with a trainable matrix Q is performed to obtain the output  as a discretized vector. The trainable parts are updated with Gradient Descent until the outputs correspond to the actual solutions of the PDE.
as a discretized vector. The trainable parts are updated with Gradient Descent until the outputs correspond to the actual solutions of the PDE.
Download figure:
Standard image High-resolution image1.2. Quantum algorithmic proposals
Quantum computing has gained popularity due to its potential for faster performance than its classical counterpart. Among the most famous quantum algorithms is the exponentially faster quantum fourier transform (QFT), although probably only attainable with long-term quantum computers. Similarly, other long-term quantum algorithms for machine learning have been proposed [7–9].
More recently, several developments in learning techniques based on near-term quantum computing were proposed. The initial demonstrations of these algorithms involved experiments on small-scale quantum hardware [10–13], which established their effectiveness in extracting patterns. Following this, many works [14, 15] proposed small-scale implementations of fully connected quantum neural networks on near-term hardware. Other proposals [16] for deploying convolution-based learning methods on quantum devices showed effective training in practice. Furthermore, [17] proposed quantum-hardware implementation for generative adversarial networks. A different approach, where the inputs are encoded as unary states, using the two-qubit quantum gate reconfigurable beam splitter (RBS) was proposed in a recent work [18]. This encoding gave rise to the use of orthogonal properties of pure quantum unitaries, as proposed in [19, 20] for training, for instance, orthogonal feed-forward networks to damp the gradient-based issues while learning. It used a pyramid-shaped (or other architectures) circuit based on parameterised RBS gates to implement a learnable orthogonal matrix as compared to the existing classical approaches, which offer approximate orthogonality at the cost of increased training time. This orthogonality in neural networks results in much smoother convergence and also lesser parameters, as shown by [21] for feed-forward neural networks and [22] for convolutional nets. The effectiveness of these orthogonal quantum networks was further shown in another work on medical image classification [19] problem.
In this work, we develop quantum algorithms to implement the FNO. In particular, we propose three circuits equivalent to or close to the FL (See the green box in figure 1). The remaining parts of the FNO can be adapted using existing techniques [19].
At the core of our circuit, we develop a new QFT suited for near-term hardware and specific quantum data encoding, and an implementation for Controlled Parameterized Circuits. Termed as unary-QFT, which transforms only the unary states into the Fourier domain. Under the assumption that a quantum hardware with appropriate connectivity is available, allowing parallel inference of fixed quantum gates to certain disjoint qubit pairs, it provides with an exponential speedup compared to the classical operation (assuming a practical classical scenario where  ). This is a widely plausible scenario in the near future since even current quantum hardwares like ones based on cold atoms do allow parallel operations on qubits (1,2), (3,4),
). This is a widely plausible scenario in the near future since even current quantum hardwares like ones based on cold atoms do allow parallel operations on qubits (1,2), (3,4),  , (n-1,n). We have built it upon the recently developed idea [18, 19] of encoding inputs to unary quantum states and applying orthogonal transformations only on these unary-basis states via learnable quantum circuits. Using this, we adapt the classical Fourier neural network [6] and propose several quantum algorithms to learn the functional mapping from the initial condition function of a PDE instance to the corresponding solution function.
, (n-1,n). We have built it upon the recently developed idea [18, 19] of encoding inputs to unary quantum states and applying orthogonal transformations only on these unary-basis states via learnable quantum circuits. Using this, we adapt the classical Fourier neural network [6] and propose several quantum algorithms to learn the functional mapping from the initial condition function of a PDE instance to the corresponding solution function.
The circuit proposed in this work is inspired by the widely popular butterfly diagram used for the fast Fourier transform (FFT) [23]. Then, we propose an implementation of controlled butterfly-shaped learnable quantum circuits for applying the linear transform (trainable matrix multiplications) in the Fourier domain. This results in three quantum circuits inspired by the classical FL, which are faster than the classical operation or, said differently, require fewer parameters for the same architecture, thereby boosting their scalability. Given the matrix input of the FL dimension  , where
, where  corresponds to the number of samples per PDE, and
corresponds to the number of samples per PDE, and  correspond to the channel dimension, the order of depth and gate complexities corresponding to FL and proposed algorithms is shown in table 1. In an ideal quantum learning scenario, the depth complexity should also correspond to the runtime complexity for the quantum algorithm. However, the current parameterized quantum circuits have a classical control which means parameters need to be loaded to this classical control and if this operation is not done in parallel in the final QPU architectures, then it the runtime complexity would have sequential execution complexity of this operation. Since the bottleneck classical operation (FT) and the corresponding quantum operation (QFT) does not involve parameterized options, under the above discussed assumption of parallel execution of gates on QPUs, the depth complexity can be approximately taken as runtime complexity of quantum algorithms. It is possible that in many practical scenarios the above assumptions might not be perfectly applicable where gate complexity might play a significant role in deciding runtime complexity. This might be a key limitation of our proposed algorithms.
correspond to the channel dimension, the order of depth and gate complexities corresponding to FL and proposed algorithms is shown in table 1. In an ideal quantum learning scenario, the depth complexity should also correspond to the runtime complexity for the quantum algorithm. However, the current parameterized quantum circuits have a classical control which means parameters need to be loaded to this classical control and if this operation is not done in parallel in the final QPU architectures, then it the runtime complexity would have sequential execution complexity of this operation. Since the bottleneck classical operation (FT) and the corresponding quantum operation (QFT) does not involve parameterized options, under the above discussed assumption of parallel execution of gates on QPUs, the depth complexity can be approximately taken as runtime complexity of quantum algorithms. It is possible that in many practical scenarios the above assumptions might not be perfectly applicable where gate complexity might play a significant role in deciding runtime complexity. This might be a key limitation of our proposed algorithms.
Table 1. Comparison of the order of time/depth complexities (O) of the proposed circuits with the existing classical Fourier Layer (FL). Here  denotes the sampling dimension,
denotes the sampling dimension,  denotes the channel dimension where
denotes the channel dimension where  and K (usually in the range 4–16) denotes the maximum number of modes allowed [6]. This implies that the proposed quantum algorithms would be faster than the classical method. Each quantum circuit requires
and K (usually in the range 4–16) denotes the maximum number of modes allowed [6]. This implies that the proposed quantum algorithms would be faster than the classical method. Each quantum circuit requires  qubits and K independent parallel circuits are required by the Parallelised QFNO.
qubits and K independent parallel circuits are required by the Parallelised QFNO.
| Method | #Qubits | #Circuits | Gate complexity | Depth complexity |
|---|---|---|---|---|
| Classical FL | — | — | — |
 + + log( log( ) ) |
| Parallel QFL |
 + + 
| K |
 log( log( )+ )+ log( log( ) ) |
 + + log( log( ) ) |
| Sequential QFL |
 + + 
| 1 |
 log( log( )+ )+ log( log( ) ) |
 + + log( log( ) ) |
| Composite QFL |
 + + 
| 1 | ( +K)log( +K)log( +K)+ +K)+ log( log( ) ) | log( +K)+ +K)+ log( log( ) ) |
The first algorithm corresponds to the quantum counterpart of the classical operation, where the middle trainable matrix is an orthogonal one. The other two algorithms are modifications of the first circuit with lower circuit depth to mitigate the fact the near-term quantum hardware might still be too noisy.
We have simulated all the three proposed quantum algorithms on all the three PDEs evaluated, as in the classical FNO paper [6], namely Burgers' equation, Darcy's flow equation and Navier–Stokes equation, on the synthetic datasets used in that paper. We have also simulated our quantum algorithms against the convolutional neural networks (CNNs) on several benchmark datasets for image classification. In all the experiments, the three quantum algorithms perform similarly and also show accuracies comparable to state-of-the-art classical methods.
1.3. Contributions
To summarize, the contributions of this work are the following:
- We propose a new quantum circuit for performing a QFT on an input encoded as a superposition of unary states.
- Using this unary-QFT, we propose three quantum circuits with a provable equivalence or approximation to the classical FL. These circuits can be sequentially combined to form a quantum version of a trainable Fourier neural network for solving Parametric PDEs.
- We provide an in-depth analysis of the computational complexity of the circuits and prove their logarithmic time complexity with respect to
 (input dimension) under certain assumptions, compared to the linear time complexity of the classical counterpart.
(input dimension) under certain assumptions, compared to the linear time complexity of the classical counterpart. - We benchmark results, showing the effectiveness of the proposed quantum algorithms, against their classical equivalent, for solving several PDEs or even classifying images from well-known datasets.

2. Classical FNO
For solving a PDE, we are provided with a dataset where each instance is a set of the initial conditions of the family of the PDE. This initial condition is represented as a parameterised function and is sampled at various locations to generate the input. The neural network's output corresponding to this initial condition is trained to be the value of the solution  for that instance at the same locations and for a given t. The FNO [6] tries to learn this functional mapping from the initial condition function to the solution function for this PDE family. This implies that given a set of initial conditions sampled at various locations as input to the FNO, it has to predict the solution function values at all these locations for any PDE instance in the test set. An overview of the FNO is given as figure 1.
for that instance at the same locations and for a given t. The FNO [6] tries to learn this functional mapping from the initial condition function to the solution function for this PDE family. This implies that given a set of initial conditions sampled at various locations as input to the FNO, it has to predict the solution function values at all these locations for any PDE instance in the test set. An overview of the FNO is given as figure 1.
We recall that each input of the FNO is a parametric initial condition, seen for instance as a function of space  . This function is sampled at
. This function is sampled at  locations and forms a vector in
locations and forms a vector in  that is later modified by a trainable matrix P to become a matrix
that is later modified by a trainable matrix P to become a matrix  . We denote
. We denote  the channel dimension and usually
the channel dimension and usually  . The matrix A will be the input of the first FL and its size will be maintained for each following FL. As shown in figure 1, the FNO consists of a sequence of FLs. Without loss of generality, we will denote
. The matrix A will be the input of the first FL and its size will be maintained for each following FL. As shown in figure 1, the FNO consists of a sequence of FLs. Without loss of generality, we will denote  to be the input of any FL.
to be the input of any FL.
Each FL starts by transforming its input matrix to the Fourier domain. It applies a FT on each column of the input matrix A. The resulting matrix has the same dimension, and we will refer to its  columns as modes to emphasize their presence in the Fourier basis. After the FT, we apply a learnable matrix multiplication to the first K modes, i.e. the first K columns among
columns as modes to emphasize their presence in the Fourier basis. After the FT, we apply a learnable matrix multiplication to the first K modes, i.e. the first K columns among  (see figure 1). The original proposal indicates to crop the remaining modes by replacing them with 0. In our quantum proposal, we will let the remaining modes untouched rather than cropping them. The final operation is an Inverse Fourier Layer (IFT) which transforms the matrix back to the input space. Note that in the original proposal, the authors apply in parallel a direct convolution to the input, and both outputs are merged (Not shown in figure 1). In our quantum proposals, we discard this convolution part for simplicity, without any impact on the experimental accuracy.
(see figure 1). The original proposal indicates to crop the remaining modes by replacing them with 0. In our quantum proposal, we will let the remaining modes untouched rather than cropping them. The final operation is an Inverse Fourier Layer (IFT) which transforms the matrix back to the input space. Note that in the original proposal, the authors apply in parallel a direct convolution to the input, and both outputs are merged (Not shown in figure 1). In our quantum proposals, we discard this convolution part for simplicity, without any impact on the experimental accuracy.
In this work, we propose several quantum algorithms for mimicking the FL and name these circuits Quantum Fourier Layer (QFL). We name the resulting neural network as a Quantum Fourier neural operator (QFNO). As the other parts of the FNO (P and Q matrix multiplications from figure 1) are easier to adapt with existing quantum techniques [19], we have not focused our work on them. Next, we will formulate the analytic expression of the FL's output, in order to prove its correspondence to QFL.
Fourier layer We now discuss the mathematical details of the classical FL for a 1D PDE case (e.g. Burgers equation), showing the inputs and outputs of each transformation involved. For each PDE instance, the input is denoted as  , where
, where  denotes the number of channels per sample in the input and Ns
corresponds to the number of samples for this instance (initial condition function).
denotes the number of channels per sample in the input and Ns
corresponds to the number of samples for this instance (initial condition function).
Regarding notation, the elements of A are aij
, its rows are ai
while its columns are aj
. We denote the output corresponding to this classical operation as  , and its elements, columns, and rows as yij
, yi
, and yj
respectively. As the quantum matrices are orthogonal and the l2-norm of any quantum state vector is 1, we consider the input A such that
, and its elements, columns, and rows as yij
, yi
, and yj
respectively. As the quantum matrices are orthogonal and the l2-norm of any quantum state vector is 1, we consider the input A such that  . Enforcing this condition is easy and does not have any significant impact on the optimization process.
. Enforcing this condition is easy and does not have any significant impact on the optimization process.
Going further, a FT is applied to this input along each row of size  :
:

where ![$a_i = (a_{ij})_{j\in [1,N_\mathrm{s}]}$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn79.gif) . We can also define
. We can also define ![$\hat{a}^{j} = (\hat{a}_{ij})_{i\in[1,N_\mathrm{c}]}$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn80.gif) . Let
. Let  be the resulting matrix.
be the resulting matrix.
Denoting the maximum number of modes with K, the intermediate linear transform is in fact a multiplication with a 3-tensor  . Each
. Each  corresponds to the
corresponds to the  matrix of W, indexed along the last dimension, and corresponding to
matrix of W, indexed along the last dimension, and corresponding to  mode (see figure 1). In the quantum implementation later, we will consider matrices Wk
to be orthogonal, as this naturally occurs in quantum circuits. We multiply the tensor W to the first K modes (along the
mode (see figure 1). In the quantum implementation later, we will consider matrices Wk
to be orthogonal, as this naturally occurs in quantum circuits. We multiply the tensor W to the first K modes (along the  dimension) of the
dimension) of the  . Said differently, for each
. Said differently, for each  , the jth column of
, the jth column of  is multiplied by Wj
, resulting in the following output
is multiplied by Wj
, resulting in the following output

Let  , we can rewrite the previous vector as
, we can rewrite the previous vector as

In the original classical proposal [6], the rest of the modes are discarded (replaced by zeros). In the quantum case, it will be simpler to let the other modes unchanged. We found that this choice does not impact the performance.
Finally, we apply the IFT operation on this transformed input, row by row. It results in the following output for each row i :

where  is the ith component of
is the ith component of  . In conclusion, the overall time complexity of the FL (FT + Matrix Multiplications + IFT) should be
. In conclusion, the overall time complexity of the FL (FT + Matrix Multiplications + IFT) should be  . This runtime can be improved if we consider a distributed algorithm, considering the current availability of efficient GPUs. By parallelising classical operations, we can achieve the FL in
. This runtime can be improved if we consider a distributed algorithm, considering the current availability of efficient GPUs. By parallelising classical operations, we can achieve the FL in  . Note however that the dominant term remains the same as
. Note however that the dominant term remains the same as  and K is usually a constant.
and K is usually a constant.
3. Quantum algorithmic tools
In this section, we introduce quantum tools necessary to build the QFL in section 4. These tools are meant to be implemented on near-term quantum computers, with modularity so that they can be useful for other applications.
We first introduce the matrix unary amplitude encoding, a fast way to load a matrix as a quantum state. Then, we develop a new quantum circuit to apply a QFT on the unary basis states. Finally, we present learnable quantum orthogonal layers, the equivalent of learnable weight matrices in classical neural networks.
We introduce here a quantum gate that will be common to the next tools: the 2-qubit RBS gates [24], parameterised by a single parameter θ. The RBS gate has the following unitary:

It can be observed that it modifies  and
and  , while it performs the identity operation on
, while it performs the identity operation on  and
and  . The RBS, therefore, preserves the hamming weight of the input state. In particular, any superposition of the unary basis (states with hamming weight 1), is kept in this basis through a circuit made of RBS gates. Its implementation depends on the quantum hardware considered.
. The RBS, therefore, preserves the hamming weight of the input state. In particular, any superposition of the unary basis (states with hamming weight 1), is kept in this basis through a circuit made of RBS gates. Its implementation depends on the quantum hardware considered.
Now, we will discuss an identity for these RBS gates and use it in the coming section to implement controllable parameterised circuits made of these gates.
Proposition 3.1. Given two qubits, applying an RBS gate on them with angle θ, followed by a Z gate on any one of them is equivalent to applying a Z gate on the same qubit followed by an RBS gate with angle  on the two qubits (figure 2).
on the two qubits (figure 2).
Proof. Let us first look at the circuit shown in figure 2(a). Equation (6) shows the calculation for the final unitary corresponding to the left-hand side:

and equation (7) shows the same for the right-hand side:

where both the equations finally arrive at the same unitary matrix, thereby proving the identity. A similar calculation for the circuit shown in figure 2(b) verifies its correctness. □

Figure 2. RBS identities.
Download figure:
Standard image High-resolution image3.1. Data encoding in the unary basis
As seen in section 2, the input of each classical FL is a matrix A. As we are about to propose quantum circuits to process this data, we need a method to encode these matrices as quantum states. We chose to encode data as amplitude-encoded states, a superposition of basis states with amplitudes that correspond to the data itself. We chose the unary basis, namely the computational basis vectors that have a hamming weight of 1, e.g.  with the 1 on the ith qubit. This choice of basis is motivated by its ability to implement near term encoding for vectors and matrices. It also allows performing tractable linear algebra tasks with provable guarantees. Higher order basis states can be used [25] but are not the focus of this work.
with the 1 on the ith qubit. This choice of basis is motivated by its ability to implement near term encoding for vectors and matrices. It also allows performing tractable linear algebra tasks with provable guarantees. Higher order basis states can be used [25] but are not the focus of this work.
Given an input matrix  , its quantum state once loaded should be:
, its quantum state once loaded should be:

To load a matrix in such a way, we use a quantum circuit made of two registers (one for the rows, the other for the columns) as shown in figure 3 from [20]. It uses subcircuits from [18] that load vectors in the unary basis. For instance, a row  is loaded as
is loaded as  . We can get rid of the normalization factors if we assume or preprocess the vectors and matrices to be normalised.
. We can get rid of the normalization factors if we assume or preprocess the vectors and matrices to be normalised.

Figure 3. Quantum circuit for loading a matrix  as a quantum state on the unary basis. Each white square is a circuit to load a vector. ai
is the ith row of A. The circuit starts with the state
as a quantum state on the unary basis. Each white square is a circuit to load a vector. ai
is the ith row of A. The circuit starts with the state  .
.
Download figure:
Standard image High-resolution imageOn the n-qubits top register, we first load the vector made of the norm of each row  . On the d-qubits lower register, we sequentially load and unload each row Ai
in a controlled fashion. Details can be found in [20].
. On the d-qubits lower register, we sequentially load and unload each row Ai
in a controlled fashion. Details can be found in [20].
With the right connectivity, the circuit to load a vector of size n has depth  , hence loading a matrix
, hence loading a matrix  requires a circuit of depth
requires a circuit of depth  .
.
The main advantages of using unary encoded states are:
- It is possible to efficiently construct amplitude encodings of classical data (vectors) in the unary basis in logarithmic depth.
- Starting with unary encoded states and using only Hamming weight preserving gates, one can restrict the size of the Hilbert space we work in, which prevents Barren Plateaus and other concentration phenomena that prevent QML in practice [26].
On the other hand, the number of qubits required is linear in the vector size. In other words, unary and general binary encodings provide a trade off between the number of qubits (linear versus logarithmic) and circuit depth (logarithmic versus linear). Last, one should look at the unary encodings as a special case of fixed Hamming weight encodings. We can use these more general encodings together with the Compound Circuit to perform compound matrix operations that can model higher order interactions. These operations are much harder to simulate classically as the Hamming weight increases, while the quantum complexity remains the same.
3.2. Unary QFT
QFT, one of the most impactful algorithms found in quantum computing literature, provides an exponential speedup compared to classical computing. It performs the discrete Fourier transform over the entire 2n -dimensional Hilbert space. In this work, we propose a new quantum circuit that performs the discrete Fourier transform over the unary basis states. This allows for a shallow-depth quantum circuit adapted to our quantum data encoding presented in the previous section.
The classical algorithm for performing FFT uses a butterfly-shaped diagram [23], shown in figure 4. Our goal is to inspire from the classical FFT diagram and perform the same operation with quantum circuits. Namely, the unitary matrix, once restricted to the unary basis, must implement the FFT matrix. With an input  , The FFT matrix Fn
is given by:
, The FFT matrix Fn
is given by:

Figure 4. Diagram of the Cooley–Tukey algorithm [23], performing the classical FFT on an input  . Each white box performs an elementary radix-2 operation with the root of unity
. Each white box performs an elementary radix-2 operation with the root of unity  .
.
Download figure:
Standard image High-resolution image

where  is the
is the  -root of unity raised to some power k based on the position of the radix. Note that Fn
is not unitary, but its scaled version
-root of unity raised to some power k based on the position of the radix. Note that Fn
is not unitary, but its scaled version  , is unitary. Therefore, we will implement the scaled version using our quantum circuit. As shown in figure 4, the input x is permuted, which we will have to take into account when loading data quantumly.
, is unitary. Therefore, we will implement the scaled version using our quantum circuit. As shown in figure 4, the input x is permuted, which we will have to take into account when loading data quantumly.
The classical FFT algorithm is decomposed into several radix-2 operations (figure 4). Each one itself is a matrix multiplication which transforms the input ![$[a, b]$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn117.gif) into
into ![$[a+\omega^k b, a-\omega^k b]$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn118.gif) . In matrix multiplication terms, each of these operations applies the matrix
. In matrix multiplication terms, each of these operations applies the matrix  .
.
Quantumly, we want to reproduce the idea of the classical FFT diagram. It results in the circuit shown in figure 5. To reproduce the action of the radix-2 transforms (scaled by a factor of  to make it unitary) on two qubits, we use one single qubit gate and one RBS gate (equation (5)). The single qubit gate is a phase gate
to make it unitary) on two qubits, we use one single qubit gate and one RBS gate (equation (5)). The single qubit gate is a phase gate  applied on the top qubit only. Then, we apply an RBS gate with an angle of
applied on the top qubit only. Then, we apply an RBS gate with an angle of  . Overall, this applies the following unitary:
. Overall, this applies the following unitary:

Figure 5. Quantum circuit for implementing a Fourier Transform on the unary basis. Single qubit gates are phase gates. Vertical lines are RBS gates with  angle. It reproduces the classical FFT butterfly circuit (figure 4) by replacing each radix-2 operation with the phase gate followed by the RBS gate. The input must be a vector
angle. It reproduces the classical FFT butterfly circuit (figure 4) by replacing each radix-2 operation with the phase gate followed by the RBS gate. The input must be a vector  encoded in the unary basis, with the right permutation. The output will be
encoded in the unary basis, with the right permutation. The output will be  .
.
Download figure:
Standard image High-resolution image

The above unitary, once restricted to the unary basis, namely  (middle rows and columns) in the case of two qubits, is exactly the desired radix operation :
(middle rows and columns) in the case of two qubits, is exactly the desired radix operation :  .
.
We apply these operations exactly in the manner of the classical FFT architecture. For an n-dimensional vector, we would thus require n qubits,  depth and
depth and  gates.
gates.
The Unary-QFT is meant to be applied on a unary quantum state, after a vector data loader for instance. Note that the input to the circuit needs to be the permuted version of the vector. This is a fixed permutation, and we can construct our data loader accordingly.
Finally, it is simple to apply the IFT in a similar way, named Unary-IQFT. It is simply the inverse of the above circuit (figure 5), along with the right permutation of the input data.
In the rest of this work, we will use the following equations. Given a normalized real vector  , and its FT
, and its FT  , the QFT operation in unary basis and its inverse, the IQFT operation, can be defined as follows:
, the QFT operation in unary basis and its inverse, the IQFT operation, can be defined as follows:

The classical FFT time complexity is  for a n-bit input on a single CPU. Indeed, it consists in applying
for a n-bit input on a single CPU. Indeed, it consists in applying  times
times  butterfly operations. Our quantum unary FT requires n qubits and has
butterfly operations. Our quantum unary FT requires n qubits and has  gates, but can run in
gates, but can run in  timesteps in a single QPU. Indeed, when the connectivity allows it, gates acting on different qubits are applied simultaneously, for example this is indeed the case for trapped ion or cold atom quantum hardware.
timesteps in a single QPU. Indeed, when the connectivity allows it, gates acting on different qubits are applied simultaneously, for example this is indeed the case for trapped ion or cold atom quantum hardware.
3.3. Quantum circuits as trainable linear transforms
To mimic the learnable part of the FL, we need to perform quantumly some sort of matrix multiplication in the unary basis. With this in mind, we propose to use Quantum Orthogonal Layers [19], namely parameterised quantum circuits using hamming-weight preserving gates only. In our case, we are consequently ensured to preserve the superposition in the unary basis, before applying the final IFT. The unitary considered have real values and once restricted to the unary basis, correspond to orthogonal matrices, hence their name. In the context of the FL, we are now able to apply a learnable linear transform (see section 2), by implementing orthogonal matrix multiplications with trainable parameters.
Several circuits are possible, but we will mostly use the Butterfly circuit shown in figure 6: it has the same layout as the previous Unary-QFT (section 3.2), and for this reason has a logarithmic depth if the hardware connectivity allows to simultaneously apply quantum gates acting on different pairs of qubits, as is already the case for trapped ion and cold atoms hardware. For an input  , the Butterfly quantum circuit has
, the Butterfly quantum circuit has  parameterised gates. The corresponding matrices, once restricted to the unary basis, lie in a subgroup of orthogonal matrices. Other circuits, with nearest-neighbours qubits connectivity, are also usable in our case. They differ in their expressivity, number of parameters, and depth.
parameterised gates. The corresponding matrices, once restricted to the unary basis, lie in a subgroup of orthogonal matrices. Other circuits, with nearest-neighbours qubits connectivity, are also usable in our case. They differ in their expressivity, number of parameters, and depth.

Figure 6. Parameterised quantum circuits with a butterfly shape will take the role of the linear transforms (matrix multiplications) in the Fourier Layer. Given complete hardware connectivity, their depth is logarithmic in the number of qubits.
Download figure:
Standard image High-resolution imageIn the next sections, we will detail how to apply such circuits in a controlled fashion. This will become useful as K such orthogonal matrix multiplications will be applied on the first K modes (see section 2), after the FT.
4. Quantum circuits for FL
Using the circuits from the previous section as building blocks, we propose three quantum circuits for classical FL, named Sequential (section 4.1), Parallel (section 4.2), and Composite (section 4.3) QFL respectively. These quantum circuits are differentiated based on how the intermediate matrix multiplications in the classical FL are implemented using the learnable quantum circuit. We compare their computational complexities (see table 1) and their efficiency in practice in the following sections.
To reproduce the classical FL (see section 2) using quantum circuits, we need the final quantum state to correspond to the result of the classical FL, as shown in equation (4). Therefore, we expect ideally a quantum output state of the following form:

which simply means that the matrix y is encoded in the unary basis, as is equation (8), and yij
is the jth component of the resulting vector yi
defined in equation (4). Note that there are no normalization factors in the above equation, as the rows of the matrix  are assumed normalized, and the normalisation is preserved through the circuit.
are assumed normalized, and the normalisation is preserved through the circuit.
For our three quantum circuit proposals- the Sequential circuit (4.1), the Parallel circuit (4.2), and the Composite circuit (4.3)-we will compare their output quantum state to the desired one (equation (12)), showing how well we are able to replicate the classical operation.
Our conclusions are the following: the Sequential circuit is returning the desired output  but might have a prohibitive depth for near-term application. On the other hand, both Parallel and Composite circuits are designed to have a shorter depth, at the cost of producing a slightly different quantum output. Interpreting these alternative outputs is complicated, and numerical simulations in section 5 will assess their quality.
but might have a prohibitive depth for near-term application. On the other hand, both Parallel and Composite circuits are designed to have a shorter depth, at the cost of producing a slightly different quantum output. Interpreting these alternative outputs is complicated, and numerical simulations in section 5 will assess their quality.
The three proposals are closely related, as shown in figures 7, 9 and 10. All circuits start with  , where the top and lower registers are used respectively to encode the Nc
rows and the Ns
columns of the input matrix A. Indeed, all circuits start by loading the input matrix A as explained in section 3.1. We recall that
, where the top and lower registers are used respectively to encode the Nc
rows and the Ns
columns of the input matrix A. Indeed, all circuits start by loading the input matrix A as explained in section 3.1. We recall that  is the number of samples that are used to encode each initial condition function of the PDE, as a vector.
is the number of samples that are used to encode each initial condition function of the PDE, as a vector.  is another dimension we use to extend this vector as a matrix. We usually have
is another dimension we use to extend this vector as a matrix. We usually have  . After this step, the Unary-QFT from section 3.2 is applied on the lower register. At the very end, the inverse QFT is applied similarly, followed by a measurement of both registers. Between the two FTs lies the core difference between the three proposals: the implementation of the K matrix multiplications (see figure 1 and section 2). This part is a trade-off between circuit depth, circuit repetitions, and correspondence with the classical FL.
. After this step, the Unary-QFT from section 3.2 is applied on the lower register. At the very end, the inverse QFT is applied similarly, followed by a measurement of both registers. Between the two FTs lies the core difference between the three proposals: the implementation of the K matrix multiplications (see figure 1 and section 2). This part is a trade-off between circuit depth, circuit repetitions, and correspondence with the classical FL.

Figure 7. Sequential-QFL: The proposed Sequential Quantum Circuit, which replicates the classical FNO operation from figure 1(if we measure at the end). Further details regarding it are given in section 4.1. The yellow box comprises a controlled parameterized circuit having jth qubit ( ) of the lower register as the controlling qubit.
) of the lower register as the controlling qubit.
Download figure:
Standard image High-resolution image4.1. Sequential circuit for FL
This first proposal is represented as figure 7. As explained, the Sequential circuit starts by loading the input matrix A, which in general is itself the output of the previous FL. Therefore, the first part of the circuit is nothing else than the circuit displayed in figure 3. Its depth is  . The resulting state is:
. The resulting state is:

To follow the classical operation, the FT should be applied to each of the rows. Thus, we apply the Unary-QFT operation on the lower register, currently encoding a superposition of these row vectors.
We first rewrite the previous state as:

And then apply the QFT operation, as in equation (11), to the lower register:

where  corresponds to the classical, row-wise, FT of A. Note that the resulting state has kept its superposition in the unary basis.
corresponds to the classical, row-wise, FT of A. Note that the resulting state has kept its superposition in the unary basis.
Next, we realize the learnable linear transform, namely K matrix multiplications, as in the middle of the classical FL (figure 1). Each matrix Wk
, to follow the classical notations from section 2, will now become an orthogonal matrix in the quantum case. This multiplication is done with the parameterised quantum circuits from section 3.3, which preserves the unary basis. We choose to use the learnable butterfly circuit from figure 6, for its shallow depth. As explained before, applying these learnable circuits effectively applies an orthogonal matrix multiplication in the unary basis. The main challenge, which will differentiate the three proposals, consists in applying these matrix multiplications to the first K columns  , independently. Contrary to the previous QFT, the linear transform should act on the columns, encoded in the upper register.
, independently. Contrary to the previous QFT, the linear transform should act on the columns, encoded in the upper register.
As shown in figure 7, we propose to apply sequentially K such parameterised circuits  (butterfly circuits) on the top register. To ensure independent transformations are applied on each column
(butterfly circuits) on the top register. To ensure independent transformations are applied on each column  , we propose a controlled implementation of the parameterised circuit, or, a Controlled parameterised Circuit. It applies the parameterised circuit to the upper register only when a particular qubit of the lower register is not in the activated state (
, we propose a controlled implementation of the parameterised circuit, or, a Controlled parameterised Circuit. It applies the parameterised circuit to the upper register only when a particular qubit of the lower register is not in the activated state ( ). For the circuit Pj
, controlled by jth qubit of the lower register, this controlled implementation begins with the application of circuit Pj
on the upper register, followed by the application of Controlled Z-gates to certain qubits in the upper register if the jth qubit in the lower register is in state
). For the circuit Pj
, controlled by jth qubit of the lower register, this controlled implementation begins with the application of circuit Pj
on the upper register, followed by the application of Controlled Z-gates to certain qubits in the upper register if the jth qubit in the lower register is in state  . This can be seen as a controlled implementation of some matrix UZ
(see figure 7) and thus, we denote this transformation by CUZ
.
. This can be seen as a controlled implementation of some matrix UZ
(see figure 7) and thus, we denote this transformation by CUZ
.
The set of qubit indices for applying these Z-gates are selected using the following rule: each RBS-gate of the parameterized circuit
Pj
has a
Z-gate applied to exactly one of its two qubits. For instance, if Pj
has nearest neighbour connectivity, then the desired set can be the set of even or odd qubit indices. Subsequently, we apply another parametrized circuit, similar to Pj
, on the upper register, but this time reversing the order in which the RBS gates are applied, denoting this circuit by  . Finally, we repeat the controlled Z-gate operations on the same qubits. This completes the implementation of the controlled parameterised circuit. Let us now see how this implementation achieves the desired task.
. Finally, we repeat the controlled Z-gate operations on the same qubits. This completes the implementation of the controlled parameterised circuit. Let us now see how this implementation achieves the desired task.
Figure 8 shows the controlled version of the parameterized circuit from figure 6. Here, the lowest qubit controls all the Z-gates and thus, is the controlling qubit for the parameterized circuit. The complete circuit includes the parameterized circuit (Pj
) followed by controlled Z-gates on some of the qubits (CUZ
). These qubits are selected using the following criterion: Every RBS-gate in the circuit has exactly one of its two qubits lying in this set. Finally, the circuit Pj
is applied again but this time the order of RBS-gate is reversed ( ). Denoting the angles
). Denoting the angles ![$[\theta_1, \theta_2,...., \theta_{M}]$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn155.gif) by
by  , where M is the total number of parameterized RBS-gates in Pj
, and writing the circuit Pj
as
, where M is the total number of parameterized RBS-gates in Pj
, and writing the circuit Pj
as  , the following relation holds between Pj
and
, the following relation holds between Pj
and  :
:

where  denotes the conjugate transpose of Pj
.
denotes the conjugate transpose of Pj
.

Figure 8. parameterised Butterfly Circuit followed by Z gates on certain qubits and its flipped version around the vertical axis. The dash-enclosed region shows the last layer RBS gates of the parameterised circuit being cancelled out by first layer RBS gates in its flipped version, using the RBS identities in figure 2. Similarly for the second last layer after the last layer is cancelled out and so on. Thus, eventually, only Z gates will remain.
Download figure:
Standard image High-resolution imageBefore proceeding further on the implementation of the controlled parameterised circuit, we first discuss a claim below regarding the existence of UZ for any possible parameterized butterfly circuit.
Claim 4.1. For an N-qubit butterfly-shaped parameterised circuit described in section 3, with N = 2a
for any whole number a, there exists a set of qubit indices  such that every RBS-gate in the circuit has exactly one of its qubits' index lying in this set.
such that every RBS-gate in the circuit has exactly one of its qubits' index lying in this set.
Proof. We show this proof by recurrence. We first establish the base case for a = 1 (or N = 2). For this we know  will be either {1} or {2}. □
will be either {1} or {2}. □
Now, it is given that  exists for some a > 1. Since
exists for some a > 1. Since  consists of exactly one of the qubit index for every RBS-gate, then indices not in
consists of exactly one of the qubit index for every RBS-gate, then indices not in  (denoted by
(denoted by  ) cannot have any RBS-gate between them. Also, since exactly one of every RBS-gate indices is in
) cannot have any RBS-gate between them. Also, since exactly one of every RBS-gate indices is in  , therefore the other index lies in
, therefore the other index lies in  . Thus,
. Thus,  is also a solution set for this problem. Now, if we combine the two
is also a solution set for this problem. Now, if we combine the two  qubit circuits (corresponding to
qubit circuits (corresponding to  and
and  ), then we see that there is no new connection on the index set
), then we see that there is no new connection on the index set  . Thus, this can correspond to the set
. Thus, this can correspond to the set  . Hence, we proved that if
. Hence, we proved that if  exists, then
exists, then  also exists.
also exists.
Going further, we now use Identity 3.1 for RBS gates to arrive at the following equation:

Using this, we arrive at the following relation:

Thus, it can be observed that when the lowest qubit in figure 8 is in state  , each RBS gate in the last layer of PK
is being cancelled out by the RBS gate in the first layer of
, each RBS gate in the last layer of PK
is being cancelled out by the RBS gate in the first layer of  . After this, the second last layer operations get cancelled by the second layer of
. After this, the second last layer operations get cancelled by the second layer of  and finally only Z-gate operations (UZ
) will remain. Finally, the application of another CUZ
unitary results in UZ
being re-applied to the upper register and using
and finally only Z-gate operations (UZ
) will remain. Finally, the application of another CUZ
unitary results in UZ
being re-applied to the upper register and using  , we can conclude that the state of the upper register is preserved. Thus, applying X-gate on the lowermost qubit again retains the initial state before the application of this circuit.
, we can conclude that the state of the upper register is preserved. Thus, applying X-gate on the lowermost qubit again retains the initial state before the application of this circuit.
On the other hand, when the lowest qubit is in state  , no Z-gates are applied, and the initial state of the remaining qubits is transformed by PK
and
, no Z-gates are applied, and the initial state of the remaining qubits is transformed by PK
and  . This corresponds to a controlled version of a parameterised circuit, namely
. This corresponds to a controlled version of a parameterised circuit, namely  . Note that it is slightly different from applying a controlled Pj
only, whose implementation remains an open question.
. Note that it is slightly different from applying a controlled Pj
only, whose implementation remains an open question.
Let us now apply the Controlled version of P1 on the state in equation (15). After re-arranging terms and applying P1, it can be written as:

Now, on applying the CUZ
unitary using the first qubit of the lower register as the control (applied when this qubit is in state  ), the state becomes:
), the state becomes:

Now, applying the flipped circuit  transforms the state to:
transforms the state to:

Using  from equation (18), the state reduces to:
from equation (18), the state reduces to:

Finally, repeating the controlled application of UZ leads to:

Applying K such controlled circuits, where the jth circuit on the upper register is controlled by jth qubit in the lower register, and re-arranging the terms in the last equation leads to the following state:

We now want to compare the state obtained in equation (24) to the classical output of the FNO from equation (3), before the final IFT. We recall that in the classical case, each of the first K columns  was multiplied by an independent matrix Wj
. In the quantum case, we need to understand if the same operation is applied, and with which matrix
was multiplied by an independent matrix Wj
. In the quantum case, we need to understand if the same operation is applied, and with which matrix  .
.
For all ![$j \in [1,K]$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn188.gif) , we saw in equation (24) that
, we saw in equation (24) that  was applied to the unary encoding of
was applied to the unary encoding of  . We denote respectively by
. We denote respectively by  and
and  the unary matrix of Pj
and
the unary matrix of Pj
and  . Each matrix is the
. Each matrix is the  submatrix of the whole unitary of size
submatrix of the whole unitary of size  , corresponding to the basis states of unary vectors (see section 3.3). Therefore, considering only the top register, the jth operation
, corresponding to the basis states of unary vectors (see section 3.3). Therefore, considering only the top register, the jth operation  corresponds to the sub-matrix
corresponds to the sub-matrix  :
:

This matrix  is the quantum implementation corresponding to the matrix Wj
used in the implementation of classical FNO (equation (3)). The overall matrix
is the quantum implementation corresponding to the matrix Wj
used in the implementation of classical FNO (equation (3)). The overall matrix  can be decomposed into
can be decomposed into  vectors
vectors ![$\hat{a}^j = (\hat{a}_{ij})_{i\in[1,N_\mathrm{c}]}$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn201.gif) . Then, for the first K vectors
. Then, for the first K vectors  we will have
we will have  , where this
, where this  is the quantum counterpart for one used in classical FNO. Thus, the state after these controlled parameterised circuits can be written as:
is the quantum counterpart for one used in classical FNO. Thus, the state after these controlled parameterised circuits can be written as:

Finally, the output state of this circuit after IQFT on the lower register becomes:

Since  =
=  , where
, where  , this implies that jth component of IFT would be same as the coefficient of jth state in IQFT. From this, we can conclude that the state in equation (12) is equivalent to the state in equation (27) and thus, this circuit replicates the classical operation. Finally, let us now discuss the depth complexity of this circuit.
, this implies that jth component of IFT would be same as the coefficient of jth state in IQFT. From this, we can conclude that the state in equation (12) is equivalent to the state in equation (27) and thus, this circuit replicates the classical operation. Finally, let us now discuss the depth complexity of this circuit.
Depth complexity (d). Based on the discussion of the Sequential QFL circuit, it can be divided into four parts : (a) unary loading of the input matrix ( ), (b) applying QFT on the lower register (
), (b) applying QFT on the lower register ( ), (c) applying K Controlled Parameterised Circuits on the upper register (
), (c) applying K Controlled Parameterised Circuits on the upper register ( ) and (d) applying inverse QFT on the lower register (
) and (d) applying inverse QFT on the lower register ( ). Thus, the depth of the complete Sequential QFL circuit becomes:
). Thus, the depth of the complete Sequential QFL circuit becomes:

4.2. Parallelised circuit for FL
For the Sequential QFL discussed in the previous subsection, the depth complexity of the learnable part is linear in the number of modes (K). Given the multiplicative noise model for NISQ devices, this linear dependence might hinder learning. A helpful modification then can be parallelising the learnable butterfly circuits, which can make the learning in the presence of noise more efficient and reduce the circuit's depth complexity. Figure 9 shows this modified version of the Sequential QFL, consisting of K quantum circuits operating in parallel and each implementing only one learnable circuit controlled by one of the top K qubits in the lower register. As all the circuits up to the learnable part are similar to the sequential circuit, we can directly write the state after the QFT using equation (15), as:

where the index k denotes the  parallel circuit and
parallel circuit and  ,
,  denote the coefficient
denote the coefficient  , state
, state  corresponding to this
corresponding to this  circuit respectively. Also, in the
circuit respectively. Also, in the  parallel circuit, the learnable butterfly part is controlled by the
parallel circuit, the learnable butterfly part is controlled by the  qubit of the lower register. We recall that the parameterised circuit applied on the top register is effectively mapping the vector
qubit of the lower register. We recall that the parameterised circuit applied on the top register is effectively mapping the vector  to
to  (see equation (27)) and thus, we can write the updated state of the circuits as:
(see equation (27)) and thus, we can write the updated state of the circuits as:

Now, applying IQFT on the lower register in each of the circuits independently:

We denote coefficients of this state corresponding to  circuit by
circuit by  and thus re-writing it as:
and thus re-writing it as:

where all of the  are explicitly given by using the equation for the FT as follows:
are explicitly given by using the equation for the FT as follows:

Similarly, writing cij for the sequential circuit discussed in the paper (using equation (27)):

Comparing the above two equations leads to the observation that coefficients in equation (34) would not be a subset of coefficients in equation (33), and there is no closed-form classical processing/transformation to achieve this. Thus, this parallel circuit results in a somewhat different operation which might be intuitively similar to the sequential circuit, but the output is different. However, section 5 shows that this conceptually similar operation is also effective in dealing with PDEs/Images and is expected to be more efficient than the sequential circuit for a noisy scenario. Also, if we remove the IQFT operation from this circuit and instead apply the classical IFT, measuring after equation (30), we get the following K
 matrices after applying the square root operation:
matrices after applying the square root operation:

where  and
and  have been defined previously. In case we combine
have been defined previously. In case we combine  from all of the K matrices with
from all of the K matrices with ![$(\hat{a}^j)_{j\in[K+1, N_\mathrm{s}]}$](https://content.cld.iop.org/journals/2058-9565/9/3/035026/revision2/qstad42ceieqn229.gif) from any of the K matrices, suppose the first one, it leads to the following
from any of the K matrices, suppose the first one, it leads to the following  matrix:
matrix:

which is exactly the same as equation (3). Thus, this modified circuit (without the IQFT), followed by some classical post-processing and IFT, can replicate the classical FL operation.

Figure 9. Parallel QFL: parallelised version of the Sequential Quantum Circuit to minimize the depth of the learning part, thus making it more efficient when deployed on noisy hardware. For each mode (out of the top K) in the transformed input, there is a different circuit to perform the parameterised matrix transform.
Download figure:
Standard image High-resolution imageDepth complexity (d). Given that the only difference compared to the Sequential QFL is the parallel implementation of the controlled parameterised circuits as against sequential, the depth complexity of this circuit can be derived by substituting K = 1 in equation (37):

and a total of K independent quantum circuits are required to execute this circuit.
4.3. Composite circuit for FL
As highlighted in the previous subsection, the depth of the parameterised part of the sequential circuit might make the learning process difficult on currently available noisy quantum hardware. Even though the Parallelised QFL can deal with this, its requirement of K independent  qubit circuits might not be possible in many cases.
qubit circuits might not be possible in many cases.
Therefore, we propose a new operation corresponding to the learnable part of the sequential circuit and term the resulting overall circuit as the Composite QFL. It significantly decreases the learnable part's depth complexity while requiring only one quantum circuit with ( ) qubits. Here, instead of applying the K-controlled parameterised circuits, we span a single, more extensive parameterised circuit over the upper register (
) qubits. Here, instead of applying the K-controlled parameterised circuits, we span a single, more extensive parameterised circuit over the upper register ( qubits) and top K qubits in the lower register. Figure 10 shows the diagram for this circuit. Note that the upper and lower registers are unary independently, before the parametrized circuit.
qubits) and top K qubits in the lower register. Figure 10 shows the diagram for this circuit. Note that the upper and lower registers are unary independently, before the parametrized circuit.

Figure 10. Composite-QFL: Variant of the Sequential-QFNO where instead of controlled butterfly circuits, there is a Composite Butterfly Circuit spanning the upper register and top K qubits of the lower register.
Download figure:
Standard image High-resolution imageIf we jointly consider the upper and lower registers, the states are in a superposition over the hamming weight two basis states. However, we will consider the upper register and just the top K qubits from the lower register, in that case, the states can be in a superposition over hamming weight one and two basis states. Given that the RBS gates are hamming weight preserving, the state after applying the parameterized circuit will also be a superposition of hamming weight one and two basis states.
Note that the input superposition cannot have all the possible basis states with hamming weights 1 and 2 for the top  qubits. For instance, it does not comprise unary states for which the 1 is in the lower K qubits. Similarly, for hamming weight 2, it does not comprise states with both the 1 s in top
qubits. For instance, it does not comprise unary states for which the 1 is in the lower K qubits. Similarly, for hamming weight 2, it does not comprise states with both the 1 s in top  or bottom K qubits. In contrast, the output superposition can have any of the hamming weight 1 or 2 states. Recall that the number of possible hamming weight 1 states for these
or bottom K qubits. In contrast, the output superposition can have any of the hamming weight 1 or 2 states. Recall that the number of possible hamming weight 1 states for these  qubits is
qubits is  and hamming weight 2 states is
and hamming weight 2 states is  .
.
Let us now discuss the application of parameterised circuits on these  qubits. The complete unitary B will be a
qubits. The complete unitary B will be a  block diagonal matrix with each block corresponding to a subspace with fixed hamming weight [25],
block diagonal matrix with each block corresponding to a subspace with fixed hamming weight [25],  , where Bi
correspond to the block diagonal unitary for subspace with hamming weight i. Since our input has hamming weight 1 or 2, we only care about unitaries B1 and B2. B1 will be of size
, where Bi
correspond to the block diagonal unitary for subspace with hamming weight i. Since our input has hamming weight 1 or 2, we only care about unitaries B1 and B2. B1 will be of size  and B2 of
and B2 of  .
.
Given the circuit is similar to the sequential circuit till the QFT operation, the state of this circuit after QFT would be the same as the one in equation (15). We now separate this complete state into two sets of states corresponding to hamming weight 1 and 2:

where the first term corresponds to the superposition of hamming weight two basis states  and similarly the second term corresponds to the superposition of hamming weight one basis states
and similarly the second term corresponds to the superposition of hamming weight one basis states  . On application of the parameterised circuit, the unitary B1 will act on
. On application of the parameterised circuit, the unitary B1 will act on  and B2 on
and B2 on  .
.
Let us first focus on the term corresponding to  . It does not contain the states where the qubits in the upper register are all 0 and the 1 lies in the top K qubits of the lower register. It implies that the coefficients of all these states should be taken as zero. Therefore, the state corresponding to this
. It does not contain the states where the qubits in the upper register are all 0 and the 1 lies in the top K qubits of the lower register. It implies that the coefficients of all these states should be taken as zero. Therefore, the state corresponding to this  can also be written as:
can also be written as:

where  denotes the state corresponding to no ones in the upper
denotes the state corresponding to no ones in the upper  register and
register and  denotes the hamming weight 2 states for the lower register, where i and j denote the positions of 1. Similarly, if we consider the first term in equation (38), corresponding to
denotes the hamming weight 2 states for the lower register, where i and j denote the positions of 1. Similarly, if we consider the first term in equation (38), corresponding to  , we further have to include states where both ones are in the upper register or both ones in the top K of the lower register. These new states again would have zero coefficients. As a result, we can write the term corresponding to
, we further have to include states where both ones are in the upper register or both ones in the top K of the lower register. These new states again would have zero coefficients. As a result, we can write the term corresponding to  in equation (38) as:
in equation (38) as:

This results in a total of  states.
states.
Let us now discuss the application of parameterised circuit (B1, B2) on the  and
and  states in equations (39) and (40) respectively. For the hamming weight 1 basis, the application of parameterised circuit (B1) is already discussed in section 4.1. For notational consistency, we denote this operation as a multiplication with matrix
states in equations (39) and (40) respectively. For the hamming weight 1 basis, the application of parameterised circuit (B1) is already discussed in section 4.1. For notational consistency, we denote this operation as a multiplication with matrix  . It results in the transformed coefficients
. It results in the transformed coefficients  :
:

Furthermore, we also apply a post-select operation to preserve the basis, selecting only the states with a non-zero coefficient before applying the B1.
On similar lines as hamming weight 1 basis, for the hamming weight 2 case, the application of parameterised circuit (B2) can be interpreted as multiplication by the matrix  where
where  . Based on a recent work on subspace states [25], if the parameterised circuit has a nearest neighbour connectivity, then the matrix B2 is the compound order 2 matrix [27] of B1. Therefore, for this case, each of its elements will correspond to the determinant of a
. Based on a recent work on subspace states [25], if the parameterised circuit has a nearest neighbour connectivity, then the matrix B2 is the compound order 2 matrix [27] of B1. Therefore, for this case, each of its elements will correspond to the determinant of a  submatrix of W1:
submatrix of W1:

for some  . For the butterfly-shaped circuit, we are not limited to nearest neighbour connectivity and thus, W2 has to be extracted from the complete unitary (
. For the butterfly-shaped circuit, we are not limited to nearest neighbour connectivity and thus, W2 has to be extracted from the complete unitary ( ) only. After applying this unitary B2 on
) only. After applying this unitary B2 on  , their transformed coefficients cij
are:
, their transformed coefficients cij
are:

Similar to the case of hamming weight 1, here also we use a post-select operation to discard the states which initially had coefficients zero thereby preserving the basis.
Combining the transformed  ,
,  states and applying IQFT on the lower register, the final output state of this circuit is:
states and applying IQFT on the lower register, the final output state of this circuit is:

We term the overall circuit, when parameterised circuit has nearest neighbour connectivity (pyramid-shaped), as the Composite Circuit (Compound) having depth complexity 
 and for butterfly shaped as the Composite Circuit (Butterfly) having depth complexity
and for butterfly shaped as the Composite Circuit (Butterfly) having depth complexity  .
.
4.4. Learning and expressivity
Classical vs. Quantum. The quantum learning models here have their learnable part as orthogonal matrices, as they are built up from parameterized quantum gates. This indeed changes the learning process and the expressivity, in theory. Since in the classical operations any matrix can be used, the quantum case will be less expressive. In practice, this constrain on degrees of freedom can have both advantages and disadvantages. It has been shown that imposing orthogonality can result in a more uniform spectrum of weights and a more stable training due to a smaller and better structured search space [21]. The quantum models inheriting natural orthogonality can provide these advantages. Also, since they can match the performance of classical methods with fewer parameters due to structural constraints/assumptions, they can also be a better alternative in overfitting cases. A contrasting effect of these constraints can be limited expressivity of the proposed quantum methods as compared to the classical counterparts. First, note that any matrix can be embedded into an orthogonal one of double the size, so we do not consider this constraint very important. Moreover, while the pyramid circuit can cover all possible classical orthogonal matrices [28], the butterfly circuit can further limit this expressivity since it has fewer parameters. It is an interesting future direction to explore the set of matrices that can be simulated by these butterfly circuits.
In classical orthogonal deep learning, training the weight matrices while keeping them orthogonal was a major difficulty [21]. However after the introduction of quantum-inspired orthogonal matrices such as in [20, 28] the classical orthognal training has also become efficient:  complexity, which corresponds to the number of tunable parameters. Quantumly, with a pyramid circuit the number of gates is also
complexity, which corresponds to the number of tunable parameters. Quantumly, with a pyramid circuit the number of gates is also  , with a depth of O(n), depending on the hardware connectivity and on how the classical control of those parametrized is applied. For a butterfly circuit, the depth is
, with a depth of O(n), depending on the hardware connectivity and on how the classical control of those parametrized is applied. For a butterfly circuit, the depth is  . Finally, for the Composite quantum FNO, computation is performed on a higher hamming weight sub-basis of the Hilbert space, therefore the gap between classical and quantum complexity increases, opening a path for larger separations [25].
. Finally, for the Composite quantum FNO, computation is performed on a higher hamming weight sub-basis of the Hilbert space, therefore the gap between classical and quantum complexity increases, opening a path for larger separations [25].
Sequential vs. Parallel vs. Composite. For noiseless cases, like usual supervised learning classical simulation, we believe that the Parallel Circuit should be at par with the Sequential Circuit. However, on a quantum hardware having noise, in a complicated task where deeper networks are required, we believe the Parallel one can significantly outperform the Sequential one. For the Compound Circuit, we believe that if it is tuned properly, it can perform at par with the Sequential one due to its higher expressivity. However, for highly complex tasks, the Compound Circuit's training might be more difficult and computationally expensive where it might suffer in performance.
In terms of expressivity, we showed that Sequential and Parallel circuits are performing almost similar operations and require the same number of parameters as well. They would be exactly the same if the Parallel circuit measurement was done before the final IQFT, and a classical IFT was applied in the right way. That being said, it is hard to know which one is more expressive than the other at this point of the analysis. For the Composite circuit, we believe it can be more expressive since we do not limit the interaction between the qubits as in the first two circuits.
5. Experiments
This section analyses our proposed quantum algorithms for solving PDEs and image classification tasks. We compare them against the state-of-the-art in both the domains, i.e. classical Fourier networks (for PDEs) and CNNs (for image classification), for both tasks. All the details related to architecture and hyperparameters are provided at the end of the paper. All the experiments shown in this section are simulated, i.e. the quantum operations have been simulated using classical matrices corresponding to quantum unitaries, since the currently available quantum hardware is too noisy for circuits of such size. However, we expect the upcoming generations of quantum hardware to support experiments of such scale. Also, the Butterfly version of the Composite Circuit, i.e. Composite Circuit (Butterfly), has been used for all the experiments.
5.1. PDEs
We show results on all the three PDEs used in the classical FL paper [6]: Burgers' equation, Darcy's Flow equation and Navier–Stokes equation using the datasets proposed in that paper. All of these equations were designed for modelling the flow of fluids and have found their applications in other domains as well. We abstractly describe the three tasks. For equations and other details, please refer to [6]. We analyse the performance of the trained networks across different resolutions (Ns ) for the first two and for different viscosity values for the third.
Burgers' equation. It is a 1D-PDE for modelling fluid motion and is expressed as follows:

with  corresponding to the fluid viscosity and u0 denoting the initial condition function for this PDE family. We need to learn the mapping from this u0 to the function at time one
corresponding to the fluid viscosity and u0 denoting the initial condition function for this PDE family. We need to learn the mapping from this u0 to the function at time one  , for a given viscosity.
, for a given viscosity.
Figure 11(left) shows the comparison of relative error in estimating this mapping among the classical FL, classical CNNs and proposed quantum circuits for the FLs, across different resolutions. The quantum circuits perform comparably to the classical FL and are much better than classical CNNs.

Figure 11. Left: performance comparison (relative error as used in [6]) of the classical Fourier networks, CNNs and the three circuit proposals for a quantum Fourier layer on the Burgers 1D PDE equation across different resolutions. The quantum Fourier circuits are quite close to the performance of the classical Fourier baseline and much better than classical CNNs in minimizing the error. Right: same comparison on the Darcy's 2D PDE for different resolutions. A similar relative performance is observed where the error in CNNs is much larger and is increasing w.r.t. resolution, whereas the error in the other four (3 quantum circuits and classical layer) is quite similar.
Download figure:
Standard image High-resolution imageDarcy's Flow equation. In this case, it is a 2D PDE with the following equation:

where a(x) is the diffusion coefficient, f(x) is the forcing function and u(x) is the solution function. The aim here is to learn the mapping  given the forcing function f(x). All of them are functions of positional coordinates only. Figure 11(right) shows the relative error for the 2D-version of all the methods in solving this PDE, across different resolutions. Here also the three quantum circuits and the classical FL show similar performance, consistent across resolutions, and the CNNs show much worse results, with their error increasing with resolution.
given the forcing function f(x). All of them are functions of positional coordinates only. Figure 11(right) shows the relative error for the 2D-version of all the methods in solving this PDE, across different resolutions. Here also the three quantum circuits and the classical FL show similar performance, consistent across resolutions, and the CNNs show much worse results, with their error increasing with resolution.
Navier–Stokes equation. We now consider the 2D Navier–Stokes equation which is as follows:

where w corresponds to vorticity, w0 being the initial vorticity, ν is the viscosity, u is a velocity field and f(x) is some sort of a forcing function. The aim here is to model the fluid vorticity up to instant  given the vorticity up to time 10. Figure 12(a) shows the performance comparison for this equation between our proposed circuits and classical methods. It shows the convergence comparison for this family with viscosity ν fixed to
given the vorticity up to time 10. Figure 12(a) shows the performance comparison for this equation between our proposed circuits and classical methods. It shows the convergence comparison for this family with viscosity ν fixed to  for all the methods. Here, again, it can be observed that all the proposed circuits and the classical Fourier method perform significantly better than CNNs. Also, from table 2, the sequential circuit performs similarly to classical method and the others converge at a slightly higher error.
for all the methods. Here, again, it can be observed that all the proposed circuits and the classical Fourier method perform significantly better than CNNs. Also, from table 2, the sequential circuit performs similarly to classical method and the others converge at a slightly higher error.

Figure 12. Left: convergence comparison for the Navier–Stokes equation with  , trained for 500 epochs. Right: performance comparison of the CNNS, classical Fourier layer and the proposed quantum circuits on the MNIST dataset. It can be observed that all of them perform quite similarly, classical CNNs being the best.
, trained for 500 epochs. Right: performance comparison of the CNNS, classical Fourier layer and the proposed quantum circuits on the MNIST dataset. It can be observed that all of them perform quite similarly, classical CNNs being the best.
Download figure:
Standard image High-resolution imageTable 2. Comparison of parameters required by one layer of the proposed circuits and the existing classical Fourier Layer along with error analysis for different ν and T values for the 2D case of a Navier–Stokes equation.
| Method | Classical FNO | Sequential QFNO | Parallelised QFNO | Composite QFNO |
|---|---|---|---|---|
| Parameters | 294 912 | 23 040 | 23 040 | 6144 |
 ; T = 50 ; T = 50 | 0.0139 | 0.0148 | 0.0167 | 0.0186 |
 ; T = 30 ; T = 30 | 0.1603 | 0.1618 | 0.1633 | 0.1660 |
 ; T = 20 ; T = 20 | 0.1601 | 0.1615 | 0.1626 | 0.1638 |
5.2. Image classification
We further compare our proposed Quantum algorithms on the downstream image classification tasks on benchmark datasets including the MNIST, FashionMNIST [30] and PneumoniaMNIST [29] datasets. The MNIST dataset consists of grayscale images corresponding to digits from 0 to 9 (both included), having a resolution of  . The task is to predict the digit for a given input image. Similarly, for FashionMNIST also there is a 10-way classification task into various categories of clothing, using
. The task is to predict the digit for a given input image. Similarly, for FashionMNIST also there is a 10-way classification task into various categories of clothing, using  grayscale images. On the other hand, PneumoniaMNIST involves a binary classification task into positive or negative for a given grayscale image.
grayscale images. On the other hand, PneumoniaMNIST involves a binary classification task into positive or negative for a given grayscale image.
For this comparison, we have used the 2D versions of all the architectures–our quantum FNO, the classical FNO and the CNNs. Figures 12(b) and 13 show the epochs (x-axis) v/s accuracy (y-axis) plot for this evaluation. It can be observed that our proposed algorithms outperform the classical FNO and converge in close proximity (w.r.t. accuracy) to the classical CNNs, with Sequential QFL being almost comparable to the classical CNNs. This shows that the proposed QFLs are comparable in performance to the state-of-art in the vision domain as well along with solving PDEs, thereby broadening the scope of their applicability.

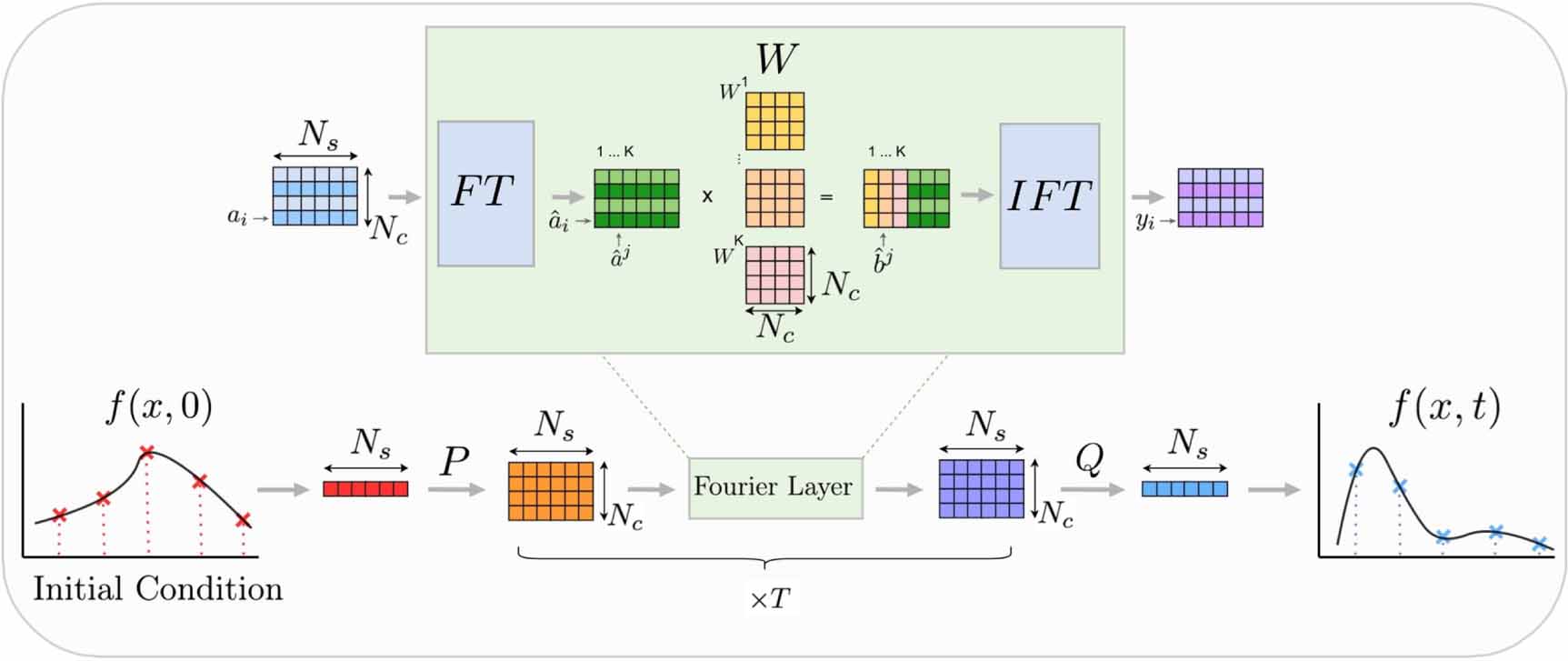{kind=link}
{kind=link}
{kind=link}
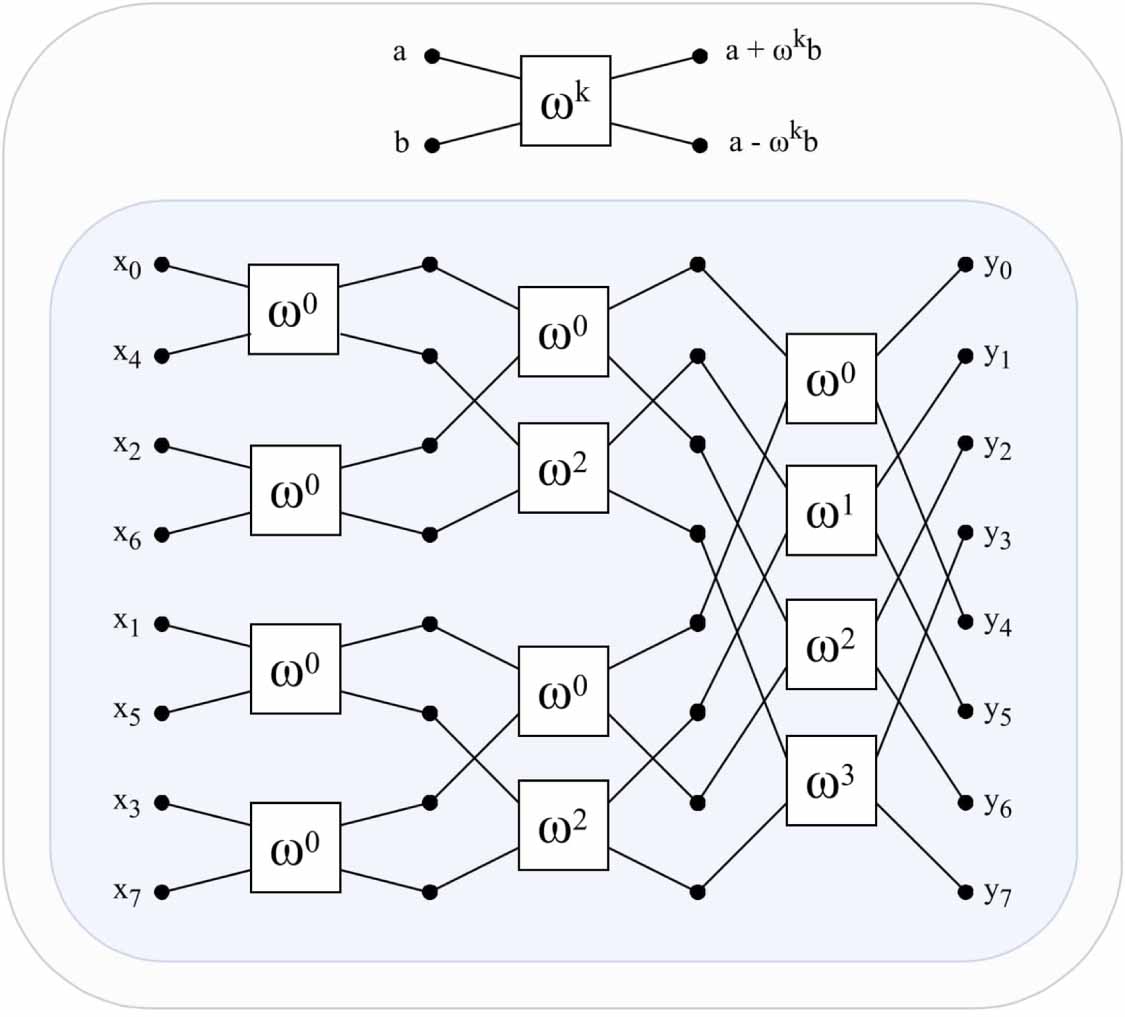{kind=link}
{kind=link}
{kind=link}
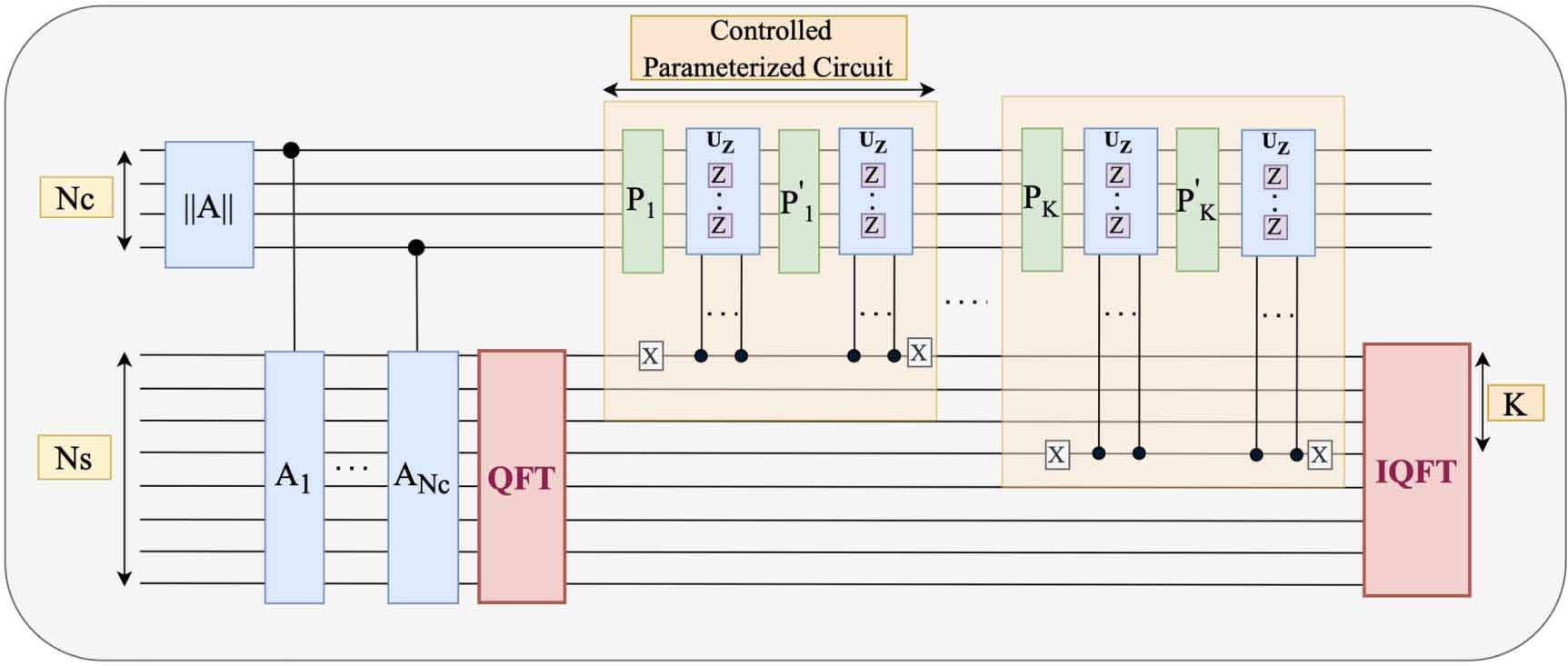{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
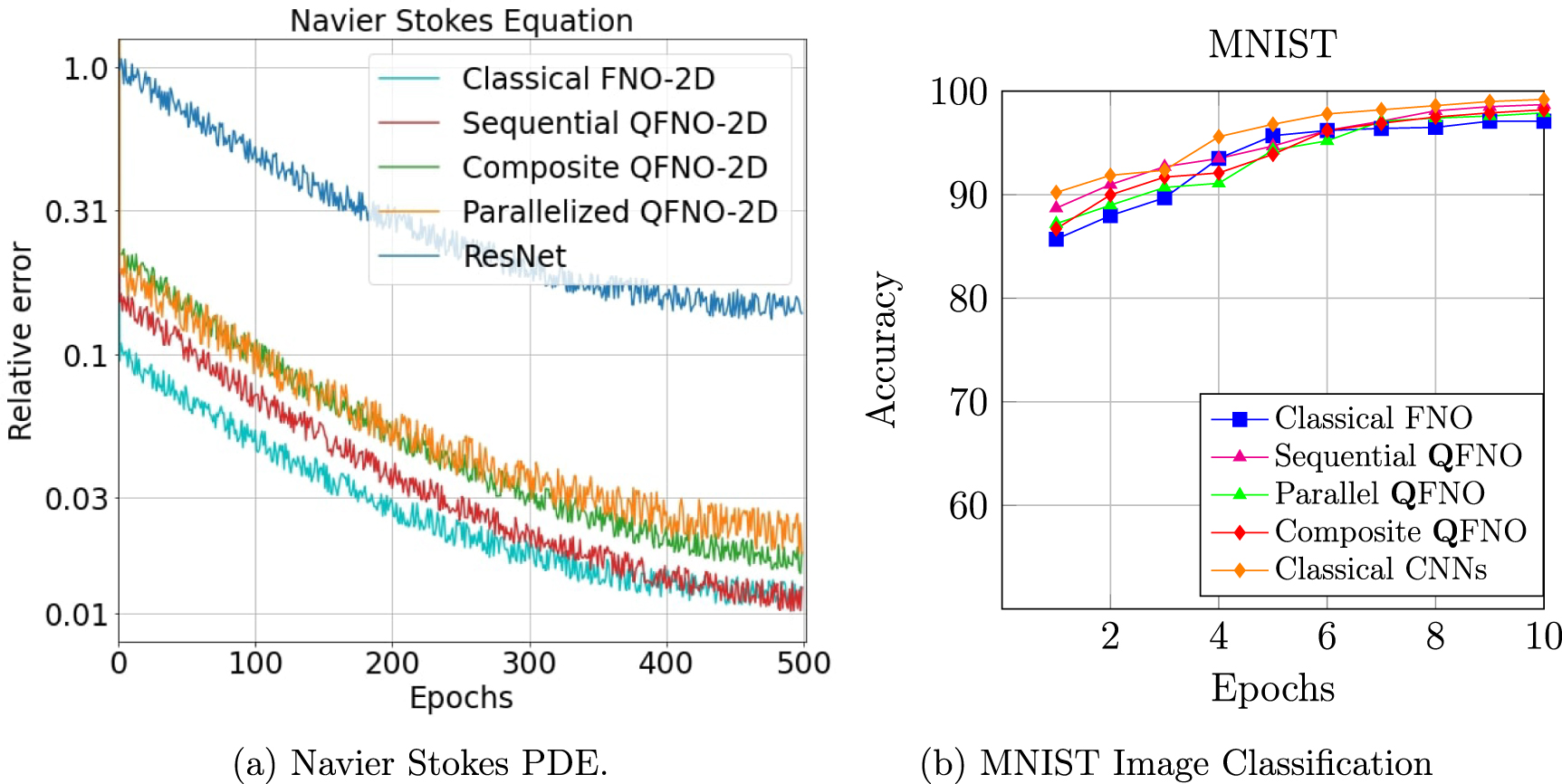{kind=link}
Figure 13. Left: performance comparison of the CNNS, classical Fourier layer and the proposed quantum circuits on the Pneumonia-MNIST [29] dataset. The performance of CNNs is somewhat noisy here whereas it is smoother in the case of the sequential circuit, both converging to a similar value. The composite quantum circuit and the classical Fourier baseline are also quite close to the CNNs in convergence. Right: same comparison on the FashionMNIST [30] data. Here, a significant difference in the performance is observed with CNNs being the best followed by the Sequential circuit.
Download figure:
Standard image High-resolution image{kind=link}
6. Conclusion
We proposed a quantum algorithm to carry out the recently proposed classical FNO on quantum hardware. We further proposed two more quantum algorithms, which perform a different operation than the classical one and can be much more efficiently deployed on noisy quantum hardware. Experimental results further confirm that the proposed quantum neural networks perform efficiently in both solving PDEs and image classification. The sequential network quite matches the best-performing classical algorithm (which is the CNNs for images and the classical FL for PDEs) on both tasks.
An interesting future direction can be further developing the learning process of the composite network so that it can perform better than the sequential network while at the same time being more efficient to deploy. The composite network intuitively performs a kind of attention mechanism (as done in [20]) that learns how to mix the mappings performed on each of the top K modes and understanding how this mixing works can provide new ideas for improving it.
Data availability statement
The data that support the findings of this study are openly available at the following URL/DOI: https://medmnist.com/.