

Abstract
The curse of dimensionality associated with the Hilbert space of spin systems provides a significant obstruction to the study of condensed matter systems. Tensor networks have proven an important tool in attempting to overcome this difficulty in both the numerical and analytic regimes.
These notes form the basis for a seven lecture course, introducing the basics of a range of common tensor networks and algorithms. In particular, we cover: introductory tensor network notation, applications to quantum information, basic properties of matrix product states, a classification of quantum phases using tensor networks, algorithms for finding matrix product states, basic properties of projected entangled pair states, and multiscale entanglement renormalisation ansatz states.
The lectures are intended to be generally accessible, although the relevance of many of the examples may be lost on students without a background in many-body physics/quantum information. For each lecture, several problems are given, with worked solutions in an ancillary file.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
One of the biggest obstacles to the theoretical and numerical study of quantum many-body systems is the curse of dimensionality, the exponential growth of the Hilbert space of quantum states. In general this curse prevents efficient description of states, providing a significant complexity barrier to their study. Despite this, physically relevant states often possess additional structure not found in arbitrary states, and as such do not however exhibit the pathological complexity, allowing them to be efficiently described and studied.
Tensor networks have proven to be an incredibly important technique in studying condensed matter systems, with much of the modern theory and numerics used to study these systems involving tensor networks.
In the numerical regime, tensor networks provide variational classes of states which can be efficiently described. By, for example, minimising the energy over one of these classes, one can learn a great deal about the low-energy behaviour some physical system of interest. The key variational classes are: matrix product states (MPS), projected entangled pair states (PEPS), and multiscale entanglement renormalisation ansatz (MERA). Due to their importance, and prevalence in the literature, we devote a chapter to each of these.
By studying the structure and properties of classes tensor networks, for example MPS, one can learn a great deal about the types of states which they can describe. Tensor network states therefore provide an important analytic framework for understanding the universal properties of classes of states which possess particular properties, such as those which only support certain entanglement or correlation structures.
In addition to their application to many-body physics, tensor networks can also be used to understand many of the foundational results in quantum information. The understanding of concepts such as quantum teleportation, purification, and the church of the larger Hilbert space, can be understood relatively simply when the tensor network framework is utilised. Some examples of this are presented in section 3. These lectures aim to introduce, and make familiar, the notation conventionally used for tensor network calculations. As a warm up, we present some key quantum information results in this notation.
After introducing the class of MPS, we present some of the key properties, as well as several analytic matrix product states examples, which can serve as useful toy models. To demonstrate the analytic power of MPS we will then consider a key result in condensed matter theory: the classification of one-dimensional phases. This serves as an example of a result which, within the tensor network formalism, can be much more succinctly and clearly explained than it can in more standard linear algebraic notation.
When utilising tensor networks numerically, algorithms must be designed which, for example, minimise the energy of some Hamiltonian over the variational class. We introduce two such algorithms, namely DMRG and TEBD, which are particularly prevalent. These have become standard tools in numerical many-body physics.
We then introduce the class of PEPS, a class designed for two-dimensional many-body systems. We discuss some of the properties, and some of the challenges to simulating using this class of networks.
Finally, we introduce another class, MERA, which can be utilised for the study of gapless one-dimensional (and higher!) systems. This class has many interesting properties, including an interpretation as a renormalisation group. This has sparked interest in a wide range of fields, from quantum information to string theory.
2. Introduction to tensor network notation
One of the primary reasons that tensor networks are so useful is the straightforward and transparent notation usually used to describe them. Using a graphical language, the structure is manifest. Many general properties of the objects under study, particularly quantum states, can be identified directly from the structure of the network needed to describe them.
Tensor network notation (TNN) can be considered a generalisation of Einstein summation notation. In this lecture we will define tensor networks, starting with an introduction to tensors and the operations we can perform upon them.
2.1. Tensors
Tensors are a generalisation of vectors and matrices. A d-dimensional vector can be considered an element of  , and a
, and a  -dimensional matrix an element of
-dimensional matrix an element of  . Correspondingly a rank-r tensor of dimensions
. Correspondingly a rank-r tensor of dimensions  is an element of
is an element of  . We can clearly see that scalars, vectors and matrices are all therefore rank 0, 1 and 2 tensors respectively.
. We can clearly see that scalars, vectors and matrices are all therefore rank 0, 1 and 2 tensors respectively.
In tensor network notation a single tensor is simply represented by a geometric shape with legs sticking out of it, each corresponding to an index, analogous to the indices of Einstein notation. For example a rank-four tensor R can be represented as

In some contexts the shape used and direction of the legs can imply certain properties of the tensor or index—for a general network however, neither carry any special significance. When representing quantum states, it is often convenient to use the direction of legs to denote whether the corresponding vectors live in the Hilbert space ('kets') or its dual ('bras'). By adhering to this convention, certain prohibited contractions can be easily disallowed, such as a contraction between two kets. This is notationally analogous to the convention of upper and lower denoting co- and contra-variant indices in the Einstein or Penrose notation (a specialised form of TNN) employed in the study of general relativity or quantum field theory.
Because quantum mechanics, in contrast to general relativity, is complex, care has to be taken with complex conjugation. This is usually indicated either by explicitly labelling the tensor or adopting some index convention, such as flipping a network (upward and downward legs being exchanged) carrying an implicit conjugation.
2.2. Tensor operations
The main advantage in TNN comes in representing tensors that are themselves composed of several other tensors. The two main operations we will consider are those of the tensor product and trace, typically used in the joint operation of contraction. As well as these two operations, the rank of a tensor can be altered by grouping/splitting indices.
2.2.1. Tensor product.
The first operation we will consider is the tensor product, a generalisation of the outer product of vectors. The value of the tensor product on a given set of indices is the element-wise product of the values of each constituent tensor. Explicitly written out in index notation, the binary tensor product has the form:

Diagrammatically the tensor product is simply represented by two tensors being placed next to each other. As such the value of a network containing disjoint tensors is simply the product of the constituent values.

2.2.2. Trace.
The next operation is that of the (partial) trace. Given a tensor A, for which the xth and yth indices have identical dimensions ( ), the partial trace over these two dimensions is simply a joint summation over that index:
), the partial trace over these two dimensions is simply a joint summation over that index:

Similar to Einstein notation, this summation is implicit in TNN, indicated by the corresponding legs being joined. An advantage over Einstein notation is that these summed-over indices need not be named, making the notation less clunky for large networks. For example, consider tracing over the two indices of a rank-3 tensor:

One property of the trace we can trivially see from this notation is that of its cyclic property. By simply sliding one of the matrices around—which only changes the placement of the tensors in the network, and therefore not the value—we can cycle the matrices around (being careful of transpositions), proving  .
.

Whilst this serves as a trivial example, the higher rank equivalents of this statement are not always so obvious, and the fact that these properties hold 'more obviously' in TNN is often useful.
2.2.3. Contraction.
The most common tensor operation used is contraction, corresponding to a tensor product followed by a trace between indices of the two tensors. An example would be the contraction between two pairs of indices of two rank-3 tensors, which is drawn as:

Familiar examples of contraction are vector inner products, matrix-vector multiplication, matrix-matrix multiplication, and the trace of a matrix:
| Conventional | Einstein | TNN |
|---|---|---|
 |
 |
 |
 |
 |
 |
| AB |  |
 |
 |
 |
 |
2.2.4. Grouping and splitting.
Rank is a rather fluid concept in the study of tensor networks. The space of tensors  and
and  are isomorphic as vector spaces whenever the overall dimensions match (
are isomorphic as vector spaces whenever the overall dimensions match ( ). Using this we can extend concepts and techniques only previously defined for vectors and matrices to all tensors. To do this, we can group or split indices to lower or raise the rank of a given tensor respectively.
). Using this we can extend concepts and techniques only previously defined for vectors and matrices to all tensors. To do this, we can group or split indices to lower or raise the rank of a given tensor respectively.
Consider the case of contracting two arbitrary tensors. If we group together the indices which are and are not involved in this contraction, this procedure simply reduces to matrix multiplication:

It should be noted that not only is this reduction to matrix multiplication pedagogically handy, but this is precisely the manner in which numerical tensor packages perform contraction, allowing them to leverage highly optimised matrix multiplication code.
Owing to the freedom in choice of basis, the precise details of grouping and splitting are not unique. One specific choice of convention is the tensor product basis, defining a basis on the product space simply given by the product of the respective bases. The canonical use of tensor product bases in quantum information allows for the grouping and splitting described above to be dealt with implicitly. Statements such as  omit precisely this grouping: notice that the tensor product on the left is a
omit precisely this grouping: notice that the tensor product on the left is a  dimensional matrix, whilst the right hand-side is a 4-dimensional vector. The 'tensor product' used in quantum information is often in fact a Kronecker product, given by a true tensor product followed by just such a grouping.
dimensional matrix, whilst the right hand-side is a 4-dimensional vector. The 'tensor product' used in quantum information is often in fact a Kronecker product, given by a true tensor product followed by just such a grouping.
More concretely, suppose we use an index convention that can be considered a higher-dimensional generalisation of column-major ordering. If we take a rank n + m tensor, and group its first n indices and last m indices together to form a matrix

where we have defined our grouped indices as


where  is the dimension of the xth index of type i(j). When such a grouping is given, we can now treat this tensor as a matrix, performing standard matrix operations.
is the dimension of the xth index of type i(j). When such a grouping is given, we can now treat this tensor as a matrix, performing standard matrix operations.
An important example is the singular value decomposition (SVD), given by  . By performing the above grouping, followed by the SVD, and then splitting the indices back out, we get a higher dimensional version of the SVD
. By performing the above grouping, followed by the SVD, and then splitting the indices back out, we get a higher dimensional version of the SVD

So long as we choose them to be consistent, the precise method by which we group and split is immaterial in this overall operation. As a result we will keep this grouping purely implicit, as in the first equality equation (2.8). This will be especially useful for employing notions defined for matrices and vectors to higher rank objects, implicitly grouping then splitting. Graphically the above SVD will simply be denoted

where U and V are isometric ( ) across the indicated partitioning, and where the conjugation in
) across the indicated partitioning, and where the conjugation in  is included for consistency with conventional notation and also taken with respect to this partitioning. We will refer to such a partitioning of the indices in to two disjoint sets as a bisection of the tensor.
is included for consistency with conventional notation and also taken with respect to this partitioning. We will refer to such a partitioning of the indices in to two disjoint sets as a bisection of the tensor.
Aside 1 (Why do we care so much about the singular value decomposition?). One of the main uses of tensor networks in quantum information is representing states which belong to small but physically relevant corners of an otherwise prohibitively large Hilbert space, such as low-entanglement states. The central backbone of this idea is that of low matrix-rank approximations. Suppose we have some matrix, and we want the ideal low matrix-rank approximation thereof. Eckart and Young [1] showed that if we measure error in the Frobenius norm, then trimming the singular value decomposition is an ideal approximation. Specifically take  to be the SVD of X, then the trimmed version of X is given by
to be the SVD of X, then the trimmed version of X is given by

where S(k) has had all but the largest k singular values set to zero (i.e. has matrix-rank k), then Eckart-Young theorem says that  for all Y of matrix-rank k. Mirsky further generalised this result in [2] to show optimality in all unitarily invariant norms. Whenever we use the term trim, we are referring to this very method of low-rank approximation.
for all Y of matrix-rank k. Mirsky further generalised this result in [2] to show optimality in all unitarily invariant norms. Whenever we use the term trim, we are referring to this very method of low-rank approximation.
2.3. Tensor networks
Combining the above tensor operations, we can now give a single definition of a tensor network. A tensor network is a diagram which tells us how to combine several tensors into a single composite tensor. The rank of this overall tensor is given by the number of unmatched legs in the diagram. The value for a given configuration of external indices, is given by the product of the values of the constituent tensors, summed over all internal index labellings consistent with the contractions. A generic example of this is given below:

2.4. Bubbling
Whilst tensor networks are defined in such a way that their values are independent of the order in which the constituent tensors are contracted, such considerations do influence the complexity and practicality of such computations. Tensor networks can be contracted by beginning with a single tensor and repeatedly contracting it against tensors one-at-a-time.
The order in which tensors are introduced and contracted is known as a bubbling. As the bubbling is performed the network is swallowed into the stored tensor, until only the result remains.
Many networks admit both efficient and inefficient bubblings, highlighting the need for prudence when planning out contractions. Take for example a ladder-shaped network (we'll see a few of these in the following lectures). One bubbling we may consider is to contract along the top of the ladder, then back along the bottom. Showing both this bubbling, as well as the partially contracted tensor that is kept in memory (in red), we see this bubbling looks like:


The scaling of this procedure is however quite unfavourable; consider a ladder of length n. At the midpoint of this contraction, when the top has been contracted, the tensor being tracked has rank n, and thus the number of entries is scaling exponentially with n. As such the memory and time footprints of this contraction are also exponential, rendering it infeasible for large n. If however we contract each rung in turn, the tracked tensor has a rank never more than 3, giving constant memory and linear time costs.


The memory footprint at any step during the contraction corresponds to the product of the dimensions of each leg passing through the boundary of the contracted region (see the red legs in equation (2.18)). Whilst the above ladder arrangement possesses both good and bad bubblings, some networks possess an underlying graph structure that does not admit any efficient contraction ordering. A good example of this is the 2D grid; due to the 2D structure of this lattice, it is clear that the contracted region must, somewhere near the middle of the contracting procedure, have a perimeter on the order of  where n is the number of tensors. As a result such contractions generically take exponential time/memory to perform. An example of a high cost step during such a bubbling is shown below, with the prohibitively large perimeter indicated by the red legs.
where n is the number of tensors. As a result such contractions generically take exponential time/memory to perform. An example of a high cost step during such a bubbling is shown below, with the prohibitively large perimeter indicated by the red legs.

Although the bubblings we have depicted here involve picking a single tensor and contracting others into it one-by-one, this will frequently not be the most efficient order; often a multibubbling approach is faster.
Pfeifer et al [3] provides code which allows for finding optimal bubbling order for networks of up to 30–40 tensors. This code interfaces with that provided in [4] and [5], providing a complete tensor network package.
2.5. Computational complexity
Above we've described that there exist networks which stymie the specific contraction procedures we've outlined. In this section we'll see that there also exist networks for which there are complexity theoretic obstructions which do not allow for any contraction procedure to be efficient.
We will now consider the computational complexity associated with tensor network contractions. Whilst all of the tensor networks we will consider in later lectures constitute memory-efficient representations of objects such as quantum states, not all permit efficient manipulation. This demonstrates that how one wishes to manipulate a tensor network is an important part of considering them as ansätze.
Whilst algorithms which can speed up tensor network contractions by optimising the bubbling used [3–5], as discusssed above, the underlying computational problem is  -complete [6, 7]
-complete [6, 7]
Even ignoring the specific bubbling used, the complexity of the overall contraction procedure can also be shown to be prohibitive in general. Consider a network made from the binary tensors e and n. The value of e is 1 if and only if all indices are identical, and zero otherwise, whilst n has value 1 if and only if all legs differ and 0 otherwise. Take an arbitrary graph, and construct a tensor network with an e tensor at each vertex and n tensor in the middle of each edge, with the connectedness inherited from the graph.
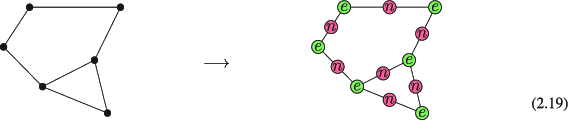
By construction, the non-zero contributions to the above tensor network correspond to an assignment of index values to each vertex (enforced by e) of the original graph, such that no two neighbouring vertices share the same value (enforced by n). If each index is q-dimensional this is a vertex q-colouring of the graph, and the value of the tensor network corresponds to the number of such q-colourings. As determining the existence of a q-colouring is an  -complete problem [8], contracting this graph is therefore
-complete problem [8], contracting this graph is therefore  -complete [9]. Indeed similar constructions exist for tensor networks corresponding to
-complete [9]. Indeed similar constructions exist for tensor networks corresponding to  and other
and other  -complete problems [10]. As we will see later in section 7, there also exists a quantum hardness result which shows approximate contraction to be
-complete problems [10]. As we will see later in section 7, there also exists a quantum hardness result which shows approximate contraction to be  -hard, putting it inside a class of problems not believed to be efficiently solvable on even a quantum computer.
-hard, putting it inside a class of problems not believed to be efficiently solvable on even a quantum computer.
Problems 1. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.Consider the following tensors, in which all indices are three-dimensional, indexed from 0:
 Calculate the value of the following tensor network:
Calculate the value of the following tensor network: - 2.In this question we are going to consider expanding out a contraction sequence, in a manner which would be needed when coding up contractions. Given a network, and an associated bubbling, we wish to write out a table keeping track of the indices of the current object, the tensor currently being contracted in, the indices involved in that contraction, and new indices left uncontracted. For example for the networkwhere the bubbling is performed in alphabetical order, then the table in question looks likeFor the tensor network
Current Tensor Contract New — A — B α γ C δ construct a corresponding table, where contraction is once again done in alphabetical order. - 3.
- (a)Calculate the contraction of the tensor network in equation (2.19) for bond dimension 3, i.e. calculate the number of three-colourings of the corresponding graph.
- (b)Using the e and n tensors from section 2.5, come up with a construction for a tensor network which gives the number of edge colourings. For a planar graphs, construct an analogous network to count face colourings.
- (c)Using tensor networks, determine the minimum number of colours required to vertex and edge colour the below graph (known as the chromatic number and index respectively).
- 4.Much like the singular value decomposition, given a bisection of the indices we can consider norms of tensors.
- (a)Does the operator norm depend on the bisection, i.e. are the operator norms across any two bisections of the same tensor necessarily equal?
- (b)What about the Frobenius norm? If they can differ, give an example, if not draw a tensor network diagram that shows it to be manifestly independent of bisection.
- 5.Write out the Einstein notation corresponding to the network in equation (8.1).










3. Quantum information examples
In this lecture we will cover a few examples of concepts in quantum information which can be better understood in tensor network notation. This lecture won't serve as much as an introduction to these concepts, but instead as a Rosetta stone for those familiar with quantum information and not with TNN. For a more thorough introduction to quantum information see the textbooks of [11–13] or lecture notes of [14, 15]. We note that for the study of open quantum systems, a more specialised form of TNN was developed in [16].
3.1. Bell state and the Bell basis
The Bell basis forms a convenient orthonormal set of two qubit states that exhibit maximal entanglement. The standard notation for this basis is

The first of this basis,  , we shall denote
, we shall denote  and simply refer to as the Bell state. Thought of as a matrix,
and simply refer to as the Bell state. Thought of as a matrix,  is proportional to the one qubit identity,
is proportional to the one qubit identity,

In tensor network notation, this is represented simply as a line connecting its two legs.

Next we will define  to be the vectorisation of an operator O, such that
to be the vectorisation of an operator O, such that  .
.

Given this definition, we can see that the Bell basis simply corresponds to a vectorisation of the Pauli operators

Thus we see that the Bell basis is intimately linked to the Pauli operators, with the Euclidean inner product on Bell basis states corresponding to the Hilbert–Schmidt inner product on Paulis.
3.2. Quantum teleportation
Given this notation for the Bell basis, we can now understand Quantum Teleportation in TNN. The idea here is for two parties (Alice and Bob, say) to share a Bell state. Given this shared resource of entanglement, we then allow Alice to perform local operations on her half of the pair, and an arbitrary fiducial qubit. After transmitting only two classical bits, Bob can then correct his half of the pair such that he recovers the state of the original fiducial qubit, successfully teleporting the data within.
The procedure for teleportation goes as follows. First Alice performs a projective measurement in the Bell basis on both the fiducial qubit and her Bell qubit. The result of this measurement is then (classically) transmitted to Bob, requiring two communication bits. Bob then performs the corresponding Pauli on his Bell qubit, correcting the influence of the measurement. Taking the fiducial state to be  , and supposing the measurement outcome corresponds to
, and supposing the measurement outcome corresponds to  , then this procedure gives Bob a final state of
, then this procedure gives Bob a final state of  :
:

where A1 and A2 correspond to the single qubit registers of Alice, and B to Bob's qubit. In tensor network notation this can be clearly seen:



where the dashed line indicates the physical separation of the two parties.
As such we can see that  is correctly transmitted for any measurement outcome p, each of which is seen with probability 1/4. Thus we see that in spite of the non-deterministic intermediary states, the overall procedure is deterministic. Analogous procedures can work for p being elements of any set of operators which are orthonormal with respect to the Hilbert–Schmidt inner product, e.g. higher dimensional Paulis.
is correctly transmitted for any measurement outcome p, each of which is seen with probability 1/4. Thus we see that in spite of the non-deterministic intermediary states, the overall procedure is deterministic. Analogous procedures can work for p being elements of any set of operators which are orthonormal with respect to the Hilbert–Schmidt inner product, e.g. higher dimensional Paulis.
3.2.1. Gate teleportation.
The idea behind gate teleportation is similar to regular teleportation, but utilises a general maximally entangled state instead of the Bell state specifically. Suppose we prepare a maximally entangled state  corresponding to a unitary U, and post select on a Bell basis measurement of
corresponding to a unitary U, and post select on a Bell basis measurement of  , followed by a correcting unitary Cp, then Bob ends up with the state:
, followed by a correcting unitary Cp, then Bob ends up with the state:




If we take  then Bob receives
then Bob receives  for all measurement outcomes, i.e.
for all measurement outcomes, i.e.  . If U is a Clifford operator5, this correction is also a Pauli, making the procedure no more resource intensive in terms of the gates used than standard teleportation.
. If U is a Clifford operator5, this correction is also a Pauli, making the procedure no more resource intensive in terms of the gates used than standard teleportation.
An example of where this is useful is in the case where Paulis can be reliably performed, but Cliffords can only be applied non-deterministically. Gate teleportation allows us to prepare the  first, simply retrying the non-deterministic procedure until it succeeds. Once this has succeeded, we can use gate teleportation to apply this unitary on the data state using only Pauli operations. As such we can avoid needing to apply non-deterministic gates directly on our target state, endangering the data stored within.
first, simply retrying the non-deterministic procedure until it succeeds. Once this has succeeded, we can use gate teleportation to apply this unitary on the data state using only Pauli operations. As such we can avoid needing to apply non-deterministic gates directly on our target state, endangering the data stored within.
3.3. Purification
For a given mixed state ρ, a purification is a pure state  which is extended into a larger system (the added subsystem is known as the purification system), such that the reduced density on the original system is ρ. One such purification is given by
which is extended into a larger system (the added subsystem is known as the purification system), such that the reduced density on the original system is ρ. One such purification is given by  , which can be simply seen by considering the corresponding tensor networks. The definition of the state is
, which can be simply seen by considering the corresponding tensor networks. The definition of the state is

which gives a reduced density of

By dimension counting, it can be shown that the above purification is unique up to an isometric freedom on the purification system, i.e. all purifications are of the form  where
where  . Equivalently all purifications can be considered to be proportional to
. Equivalently all purifications can be considered to be proportional to  , where
, where  is some maximally entangled state other than the Bell state.
is some maximally entangled state other than the Bell state.
3.4. Stinespring's Dilation theorem
Stinespring's Theorem says that any quantum channel  —a completely positive trace preserving (CPTP) map—can be expressed as a unitary map V acting on a larger system followed by a partial trace, i.e.
—a completely positive trace preserving (CPTP) map—can be expressed as a unitary map V acting on a larger system followed by a partial trace, i.e.

Physically this means that dynamics of an open system is equivalent to those of a subsystem of a larger, closed system—the founding tennet of the Church of the Larger Hilbert Space. Any CPTP map can be represented by a set of Kraus operators Ki such that

In TNN this looks like

where the transposition in the Hermitian conjugate is done with respect to the horizontal legs, and the upper leg corresponds to the virtual index i.
Next we define the tensor U as

where we can see that U is an isometry ( ), which we can think of as a unitary V with an omitted ancilla
), which we can think of as a unitary V with an omitted ancilla

Using this, and partial tracing over the upper index, we get the Stinespring Dilation Theorem as desired:





Problems 2. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.Consider the inverse of teleportation. Alice wishes to send classical bits to Bob, and possesses a quantum channel through which she can send Bob qubits. How many bits of information can be communicated in a single qubit? For simplicity consider the case where Bob can only perform projective measurements.
- 2.Suppose Alice and Bob initially shared a Bell pair. Does this pre-shared entanglement resource boost the amount of classical information that can be successfully communicated, and if so by how much? Hint: Notice that the four possible Bell states differ by a Pauli acting on a single qubit.
4. Matrix product states
Now that we have established the notation, the remaining lectures will examine some key tensor networks and algorithms for strongly interacting quantum many body systems. We begin with one dimensional models.
Matrix product states (MPS) are a natural choice for efficient representation of 1D quantum low energy states of physically realistic systems [17–22]. This lecture will begin by motivating and defining MPS in two slightly different ways. We will then give some analytic examples of MPS, demonstrating some of the complexity which can be captured with this simple network. Some simple properties of MPS will then be explained, followed by a generalisation of the network to operators rather than pure states.
Let  be the (completely general) state of N qudits (d dimensional quantum system). The state is completely specified by knowledge of the rank-N tensor C.
be the (completely general) state of N qudits (d dimensional quantum system). The state is completely specified by knowledge of the rank-N tensor C.
By splitting the first index out from the rest, and performing an SVD, we get the Schmidt decomposition

where  are the Schmidt weights and
are the Schmidt weights and  and
and  are orthonormal sets of vectors. Graphically this looks like
are orthonormal sets of vectors. Graphically this looks like

where λ is a diagonal matrix containing the Schmidt weights.
The α-Rényi entropy is given by

where ρ is some density matrix. Note that the entanglement rank S0 is simply the (log of the) number of nonzero Schmidt weights and the von Neumann entropy is recovered for  . We also note that the Schmidt weights now correspond precisely to the singular values of the decomposition equation (4.2), and so these values capture the entanglement structure along this cut.
. We also note that the Schmidt weights now correspond precisely to the singular values of the decomposition equation (4.2), and so these values capture the entanglement structure along this cut.
We can now perform successive singular value decompositions along each cut in turn, splitting out the tensor into local tensors M, and diagonal matrices of singular values λ quantifying the entanglement across that cut.



By now contracting6 the singular values tensors  into the local tensors M(i) we get the more generic form
into the local tensors M(i) we get the more generic form

This is the matrix product state. It is not yet clear that we have done anything useful. The above construction is both general and exact, so we have the same number of coefficients in an arguably much more complicated form.
Suppose however we consider states for which the entanglement rank across any bisection of the chain is bounded. In particular, suppose that only D of the Schmidt weights were non-zero. Then we can use the MPS form to take advantage of this by truncating the λ matrix to make use of this property. In particular, any state with a so-called strong area law such that  for some constant c along any bipartition can be expressed (exactly) using an MPS with only
for some constant c along any bipartition can be expressed (exactly) using an MPS with only  coefficients. As discussed in section 6, there are many relevant states for which an area law for the von Neumann entropy (
coefficients. As discussed in section 6, there are many relevant states for which an area law for the von Neumann entropy ( ) is sufficient to guarantee arbitrarily good approximation with an MPS of only
) is sufficient to guarantee arbitrarily good approximation with an MPS of only  bond dimension [17–19].
bond dimension [17–19].
In TNN, the name matrix product state is a misnomer, as most tensors involved are in fact rank-3. The uncontracted index is referred to as the physical index, whilst the other two are virtual, bond or matrix indices. For reasons of convenience, as well as to capture periodic states most efficiently, the MPS ansatz is usually modified from equation (4.7) to

or in the translationally invariant case

Note that in this form the matrix indices are suppressed and matrix multiplication is implied. The graphical form of this MPS is

4.1. 1D projected entangled pair states
In addition to the above construction, MPS can (equivalently) be viewed as a special case of the projected entangled pair states (PEPS) construction [18, 23, 24]. This proceeds by laying out entangled pair states  on some lattice and applying some linear map
on some lattice and applying some linear map  between pairs
between pairs

where

is the chosen entangled pair. In section 7, we will generalise this construction to arbitrary dimensions and arbitrary lattices.
It is clear that this construction is equivalent to the tensor network construction by letting  . We can write the linear map
. We can write the linear map  as
as

The tensor A is exactly the MPS tensor introduced above, and the choice of entangled pair ensures that the A tensor corresponding to a pair of PEPS 'projectors' applied to the Bell state above is exactly the contraction of the corresponding A tensors:


Thus, we see that the two descriptions are equivalent, and interchanged through the applications of local unitaries to the virtual indices of A or equivalently changing the maximally entangled pair in the PEPS.
We note that this should not generally be seen as a practical preparation procedure. Generically the PEPS tensors will map states down into a non-trivial subspace, with the physical implementation of this requiring post-selected measurements. If one of these fails, we need to go back and begin the construction from the start, meaning this procedure is not generally scalable.
4.2. Some MPS states
4.2.1. Product state.
Let

This gives the state  , as does
, as does

4.2.2. W state.
What state do we get when we set

and we choose the boundary conditions of the MPS to be

We have  ,
,  ,
,  and
and ![${\rm Tr}[A_1X]=1$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn082.gif) , so we get
, so we get

the W-state [18].
4.2.3. GHZ state.
If we choose  and
and  , or the equivalent MPS tensor
, or the equivalent MPS tensor

then we get the Greenberger-Horne-Zeilinger (GHZ) state [18]

4.2.4. AKLT state.
Suppose we wish to construct an SO(3) symmetric spin-1 state [21, 22, 25]. Let  be the SO(3) invariant singlet state. Let
be the SO(3) invariant singlet state. Let  be the projector onto the spin-1 subspace
be the projector onto the spin-1 subspace

The advantage is that the spin operators on the corresponding systems pull through  , meaning it commutes with rotations. Let
, meaning it commutes with rotations. Let  be the spin vector on the spin-1 particle, and
be the spin vector on the spin-1 particle, and  the spin vector on the ith qubit, then this means:
the spin vector on the ith qubit, then this means:






with the same holding for SY. Thus the state obtained after this projection is fully SO(3) symmetric, but has a nontrivial entanglement structure (which would not be obtained if the state was simply a singlet at each site for example).
This state has many interesting properties. We can write a 2-local Hamiltonian for which this is the ground state. Let  be the projector onto the spin-2 subspace of a pair of spin-1 particles. This operator has eigenvalues {0,1}.
be the projector onto the spin-2 subspace of a pair of spin-1 particles. This operator has eigenvalues {0,1}.  annihilates an adjacent pair of spin-1 particles, since they are built from two spin-1/2s and a spin-0, so have no overlap with the spin-2 subspace. It is simple to check that on periodic boundary conditions the ground state of
annihilates an adjacent pair of spin-1 particles, since they are built from two spin-1/2s and a spin-0, so have no overlap with the spin-2 subspace. It is simple to check that on periodic boundary conditions the ground state of  is unique (and gapped).
is unique (and gapped).
If we examine the action of rotations about the three axes of the spin-1, we see that

In particular,  ,
,  ,
,  . In section 5 we will see that this tells us the AKLT state is in a nontrivial symmetry protected topological (SPT) phase.
. In section 5 we will see that this tells us the AKLT state is in a nontrivial symmetry protected topological (SPT) phase.
4.2.5. Cluster state.
It is convenient to write a bond dimension 2 MPS for this state where a physical site contains a pair of spins. Let

or equivalently the map from virtual to physical spin-1/2 particles

where the entangled pairs are in the Bell state  . The map
. The map  corresponds to the circuit
corresponds to the circuit

Notice in this case our PEPS tensor  simply corresponds to unitary circuit. As such this is one of the exceptional cases in which the PEPS description can be considered a scalable preparation procedure.
simply corresponds to unitary circuit. As such this is one of the exceptional cases in which the PEPS description can be considered a scalable preparation procedure.
Given an explicit MPS description of this state, we can now back out a Hamiltonian for which it is a ground state, allowing us to infer certain properties.
The initial state is constructed from entangled pairs  , and is the unique ground state of the Hamiltonian
, and is the unique ground state of the Hamiltonian

Applying the circuit (between Bell pairs with first qubit odd and second even), we see that this transforms to


This is precisely the cluster state Hamiltonian. The physical symmetry of this model is  , where
, where  and
and  . Pushing this backwards through the circuit, we see that it is equivalent to act on the virtual spins with
. Pushing this backwards through the circuit, we see that it is equivalent to act on the virtual spins with  and
and  .
.
This action tells us that, just like the AKLT state, the cluster state possesses SPT order.
4.3. MPS properties
MPS form a vanishingly small corner of the full Hilbert space, and thus we cannot hope to use them to approximate arbitrary states. If physically relevant states correspond to those which can be well approximated by MPS, and MPS manifest the same non-generic properties as these physical states, then they represent an extremely useful tool to study these systems.
4.3.1. Decay of correlations.
We have already seen that MPS have bounded levels of entanglement, manifesting as strict area laws. We will now investigate the type of correlations which can be represented. Let  be some operator for which we wish to compute the two point correlator
be some operator for which we wish to compute the two point correlator

where the subscript denotes the site at which the operator  is applied. Graphically this expectation value is written as:
is applied. Graphically this expectation value is written as:

We refer to the object

as the  -transfer matrix. Note that we usually just refer to
-transfer matrix. Note that we usually just refer to  as the transfer matrix and simply denote it
as the transfer matrix and simply denote it  .
.
The correlator (in the thermodynamic limit) can then be written as


where VL and VR are the dominant left and right eigenvectors of  respectively. The only change required when calculating longer range correlators is inserting higher powers of
respectively. The only change required when calculating longer range correlators is inserting higher powers of  in equation (4.41). The decay of correlators is therefore controlled by the eigenvalues of
in equation (4.41). The decay of correlators is therefore controlled by the eigenvalues of  . We can normalise A so that the dominant eigenvalue of
. We can normalise A so that the dominant eigenvalue of  is 1, with the rest lying inside the unit disk. Thus any correlator can either decay exponentially with distance or be constant. Thus we see that MPS can only capture states with exponentially decaying correlations [22].
is 1, with the rest lying inside the unit disk. Thus any correlator can either decay exponentially with distance or be constant. Thus we see that MPS can only capture states with exponentially decaying correlations [22].
4.3.2. Gauge freedom.
Not all MPS represent different physical states [18]. The set of transformations of the description (i.e. the MPS) which leaves the physical state invariant are known as gauge transformations. In the case of MPS, these correspond to basis transformations on the virtual level:



where  . Note that M is only required to have a left inverse, so can be rectangular and enlarge the bond dimension.
. Note that M is only required to have a left inverse, so can be rectangular and enlarge the bond dimension.
Another freedom is blocking. We can combine several MPS tensors  into a single effective tensor Bk, on a larger physical region
into a single effective tensor Bk, on a larger physical region
A number of canonical forms exist which partially gauge fix the MPS description. One of the most common is the left-isometric or left-canonical form (with right-isometric or right-canonical defined analogously). Here the MPS tensors obey


This is most useful on open boundary systems where a simple algorithm exists to put any MPS into this form. It is frequently used in numerical applications, in particular when using variational minimisation to optimise an MPS description of a ground state (DMRG), a mixed left/right isometric form is used.
Putting an MPS into this form is a partial gauge fixing. The remaining freedom is that of a unitary7 on the virtual level, rather than general invertible matrix. This technique is heavily used in tensor network algorithms as a method of increasing numerical stability.
4.4. Renormalising matrix product states
When we renormalise a system, we usually think about attempting to write down an effective model at a longer length scale which captures the low energy portion of the original model. This can be achieved by blocking sites together, then discarding degrees of freedom to ensure the description remains useful. In the MPS, blocking can be achieved by simply contracting tensors together. How to discard only high energy degrees of freedom is a challenging question. MPS allows us to avoid having to answer this question all together [26].
Since we care only about expectation values of operators, we can work entirely in the transfer matrix picture. Blocking sites together simply consists of taking products of transfer matrices

with sandwiched operators  being renormalised similarly. Note that the dimension of
being renormalised similarly. Note that the dimension of  remains D4 at all times, so we never need to worry about discarding degrees of freedom. We can also use transfer matrices formed from different MPS to get off-diagonal terms of the form
remains D4 at all times, so we never need to worry about discarding degrees of freedom. We can also use transfer matrices formed from different MPS to get off-diagonal terms of the form  .
.
4.5. Mixed states and many body operators
As described above, an MPS can be used to represent a pure state. How is a mixed state represented in this language?
Let ![$\vert {\psi{[A]}} \rangle $](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn119.gif) be some (pure) MPS state. We can write the density matrix corresponding to
be some (pure) MPS state. We can write the density matrix corresponding to ![$\vert {\psi{[A]}} \rangle $](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn120.gif) as
as


The reduced density matrix on some subset of spins R will therefore be represented as


where we have used the left and right normal forms to bring in the boundary terms.
The above network is an example of what is referred to as matrix product operators (MPOs) [21, 27, 28]. The general form of MPOs we will be considering is

In addition to being used to represent density matrices, MPOs can be used to represent a large class of many body operators, including small depth quantum circuits and local Hamiltonians. For example, the transverse field Ising Hamiltonian

can be represented on a line with the (operator valued) matrix

and end vectors

The Hamiltonian on N sites is then obtained as

The Heisenberg model

can be obtained in the same fashion with

More generally, an MPO can be used to represent any operator which does not increase the Schmidt rank of any state too much. An existing explicit analytic construction of MPOs for 1D local Hamiltonians, as well as a new generalisation for higher dimensional Hamiltonians, is covered in more detail in appendix A.
Problems 3. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.Describe the state given by an MPS with tensorwhere index ordering is as shown and indices 1 and 2 are combined. Boundary conditions require inserting a Pauli Z before closing periodic BCs, similar to equation (4.19).
- 2.Describe the state given by the MPS whose only nonzero components arewhere the left and right boundary conditions are.Hint: Writing out the matrices corresponding to fixing the physical index might help!
- 3.Describe the qudit state given by the MPSwhere, denotes addition mod d, the left boundary condition is , and the right boundary is for some .
- 4.Let be some group. Describe the operator given by the MPO with
where the left boundary condition is, the right boundary is for some , and denotes group multiplication.
- 5.Suppose the local basis is labelled by particle number. What is the action of the following operator (bond dimension linearly increasing left to right)?with left vector and right vector .
- 6.Write an MPO for the transverse-field-cluster HamiltonianHint: This can be done with bond dimension 4.
- 7.Use the ideas of MPSs and MPOs to prove that depth quantum circuits can be simulated efficiently on a classical computer.




















5. Classifying gapped phases in 1D
Matrix product states are extremely useful in both analytic and numerical applications. One of the most powerful results in the field of tensor network analytics is a complete classification of gapped phases in 1D.
To begin this lecture, we will introduce quantum phases. We will then argue that in the absence of symmetry constraints, all MPS are in the same phase. Finally, we will show how symmetries change this classification. Whilst interesting in it's own right, this material also serves to demonstrate the analytic power of TNN.
5.1. Quantum phases
The classical definition of a phase, or more particularly a phase transition, is usually associated to some nonanalytic behaviour of the free energy density

where  is some vector of parameters of the model (pressures, masses, coupling strengths, etc) and H the Hamiltonian of our system. Clearly when we take the quantum limit (
is some vector of parameters of the model (pressures, masses, coupling strengths, etc) and H the Hamiltonian of our system. Clearly when we take the quantum limit ( ), the free energy is simply the ground state energy. A quantum phase transition is thus associated with the ground state [29].
), the free energy is simply the ground state energy. A quantum phase transition is thus associated with the ground state [29].
At a classical phase transition, correlations become long ranged

where the averages are taken with respect to some thermal distribution. We therefore say that a thermal (classical) phase transition is driven by thermal fluctuations, where the variance measures the increasingly long range of these fluctuations. A quantum phase transition also has divergent correlation length, however there is no thermal average— the statistics are purely quantum in origin [29].
A classical phase corresponds to a range of deformations of H and β which can be made without causing nonanalyticities in the free energy f. Likewise, a quantum phase transition occurs where the ground state energy becomes nonanalytic (in the thermodynamic limit) as a function of some Hamiltonian parameters (not temperature this time!). Suppose we have a continuous family of quantum Hamiltonians  . The lowest energy levels generically act in one of the following ways [29]:
. The lowest energy levels generically act in one of the following ways [29]:

On the left, there is no phase transition, whilst on the right a transition occurs when the roles of the ground and first excited states cross.
For our purposes, a phase transition will be associated with a gapless point in the spectrum. Therefore, we will say that two states  and
and  are in the same phase if there is a continuous family of Hamiltonians
are in the same phase if there is a continuous family of Hamiltonians  such that
such that  is the ground state of H(0),
is the ground state of H(0),  is the ground state of H(1), and the gap remains open for all
is the ground state of H(1), and the gap remains open for all ![$\lambda\in[0, 1]$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn143.gif) .
.
An equivalent notion is finite time evolution under a local Hamiltonian [30]. Two states are in the same phase if they can be interconverted by time evolution for a finite period. This is linked to the possibility of one state naturally evolving into the other.
It is simpler, and essentially equivalent, to ask which states can be interconverted by a local quantum circuit of depth constant in the system size [20, 31]. We will work within this framework. One may also ask the more complicated question of how phases change if we impose a symmetry; if we insist that all of the Hamiltonians  commute with some symmetry group
commute with some symmetry group  . In the circuit picture, this corresponds to restricting the gate set to only gates which commute with this symmetry [31–33].
. In the circuit picture, this corresponds to restricting the gate set to only gates which commute with this symmetry [31–33].
5.2. Injective MPS
In this lecture, we will restrict ourselves to the case of injective MPS [18, 34]. If we assume the MPS is in left canonical form

then injective MPS are those for which the identity is the unique eigenvalue 1 left eigenvector of the transfer matrix. Moreover this means that there exists a unique full-rank8 density matrix ρ which is a 1 right eigenvector, i.e.


These MPS correspond to unique gapped ground states of local Hamiltonians [35]. The arguments we will present here generalise to non-injective MPS, however they become very technical.
5.3. No topological order
We will refer to states which cannot be connected by any constant depth local circuit as being in distinct topological phases, or having distinct topological order. This is to distinguish them from the symmetric phases we will discuss later in this lecture. In fact, we will see that there are no nontrivial topological phases in 1D [20].
Let Aj define some injective MPS, and construct the transfer matrix  9
9

As discussed in the previous lecture, this can be used to renormalise the MPS. Taking products of this transfer matrix corresponds to blocking sites of the original MPS. Since the MPS is injective, the leading eigenvalue of  is 1 and all other eigenvalues are strictly smaller. Therefore, by taking the kth power of the transfer matrix, we obtain a new transfer matrix which is
is 1 and all other eigenvalues are strictly smaller. Therefore, by taking the kth power of the transfer matrix, we obtain a new transfer matrix which is

where  is the second eigenvalue of the transfer matrix and ρ is the fixed point of the channel. This transfer matrix can be decomposed to give a new effective MPS tensor describing the long wavelength physics
is the second eigenvalue of the transfer matrix and ρ is the fixed point of the channel. This transfer matrix can be decomposed to give a new effective MPS tensor describing the long wavelength physics

On the regions we blocked together, we could have first applied a unitary to the state without changing the blocked transfer matrix. Since we only required a constant number of sites to be blocked to achieve this MPS tensor, this unitary freedom is restricted to a constant depth unitary circuit—precisely the equivalence we wish to allow.
Now, let V be some unitary which acts as  on the state given by
on the state given by  and arbitrarily on the rest of the space. We can now use this to apply two circuit layers to the MPS
and arbitrarily on the rest of the space. We can now use this to apply two circuit layers to the MPS

which completely disentangles the MPS, giving the state  .
.
Notice that this was all achieved by simply blocking a constant number of sites together, so we have only used a constant depth quantum circuit. Therefore, all injective MPS are in the same (topological) phase as the product state, and therefore each other.
5.4. Symmetry respecting phases
The proofs in this section are translated into TNN from [34].
Since there are no nontrivial topological phases, we will now examine what happens when a symmetry restriction is imposed on the allowed gates. Let  be some symmetry group for a state which acts on-site as
be some symmetry group for a state which acts on-site as  for each
for each  , where ug is a unitary representation of
, where ug is a unitary representation of  acting on a single site. Recall that for ug to be a representation, we must have
acting on a single site. Recall that for ug to be a representation, we must have

for all  .
.
Let A be an MPS tensor such that ![$\vert {\psi[A]} \rangle $](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn159.gif) is symmetric, meaning that
is symmetric, meaning that ![$U_g \vert {\psi[A]} \rangle ={\rm e}^{{\rm i}\phi_g}\vert {\psi[A]} \rangle $](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn160.gif) for all
for all  . We will now examine how this symmetry is realised on the MPS tensor itself.
. We will now examine how this symmetry is realised on the MPS tensor itself.
We require an understanding of the action of unitaries on the physical level of an MPS, and when they can be 'pushed through' to act on the virtual level. There, they won't be touched by the action of constant depth symmetric circuits on the physical legs, so any properties associated with the virtual action of the symmetry will be an invariant of the phase.
We require two lemmas.
Lemma 1. Let u be some unitary and A an injective MPS tensor. Then the largest eigenvalue λ of the u-transfer matrix

is contained within the unit disk.
Proof. Let  (note that we are not assuming that this is unitary) be a left eigenvector of
(note that we are not assuming that this is unitary) be a left eigenvector of 

We therefore get for some density matrix ρ

Once again let ρ be the (unique) right eigenvector of  with eigenvalue 1. We can view the above expression as an inner product between two vectors
with eigenvalue 1. We can view the above expression as an inner product between two vectors

We can now apply the Cauchy-Schwarz inequality across the dotted line, giving



where the vertical lines indicate absolute value. Thus we have

and so  . □
. □
Lemma 2. Equality is achieved in lemma 1 if and only if there exists a unitary v and an angle θ such that

Proof. First we prove the 'if' direction. Assume that equation (5.19) holds. Then



and so we have found a left eigenvector  of
of  with a modulus 1 eigenvalue of
with a modulus 1 eigenvalue of  .
.
Now we prove the 'only if' direction. Assume there exists a left eigenvector  with eigenvalue of modulus 1, then the Cauchy-Schwarz inequality equation (5.15) must become an equality. Therefore, there is some scalar α such that
with eigenvalue of modulus 1, then the Cauchy-Schwarz inequality equation (5.15) must become an equality. Therefore, there is some scalar α such that

Taking the norm of each side as vectors, we have



Therefore,  , so
, so  .
.
Since ρ is full rank, it is invertible, so

Now, rearranging this and left multiplying by  , we have
, we have



We therefore see that  is a left eigenvector of the transfer matrix
is a left eigenvector of the transfer matrix  with norm-1 eigenvalue. By assuming injectivity however we require that the only norm-1 eigenvalue is the non-degenerate +1 eigenvalue, whose left eigenvector is the identity. Thus we conclude v is, after rescaling, unitary, and that equation (5.19) therefore holds. □
with norm-1 eigenvalue. By assuming injectivity however we require that the only norm-1 eigenvalue is the non-degenerate +1 eigenvalue, whose left eigenvector is the identity. Thus we conclude v is, after rescaling, unitary, and that equation (5.19) therefore holds. □
So far, we have established that a unitary u can be 'pushed through' the MPS tensor if and only if the u-transfer matrix has an eigenvalue of unit magnitude. We will now show that u is a local symmetry if and only if it can be pushed through. This will complete our understanding of the action of local symmetries on MPS tensors.
Theorem 1 (Symmetries push through). Let  be a group. A unitary representation ug is a local symmetry if and only if
be a group. A unitary representation ug is a local symmetry if and only if

for vg unitary and  .
.
Proof. If equation (5.31) holds, it is clear that ug is a symmetry since vg is simply a gauge transformation on the MPS.
Let

be the reduced density matrix on k sites, where ρ is the right fixed point of  . By construction,
. By construction,  , but
, but  will generically be mixed, so
will generically be mixed, so  . Recall that the purity of a density matrix is lower bounded by the inverse of the matrix-rank, i.e.
. Recall that the purity of a density matrix is lower bounded by the inverse of the matrix-rank, i.e.  . Since our reduced density matrix is obtained from a bond dimension D MPS, it has rank at most D2. Therefore
. Since our reduced density matrix is obtained from a bond dimension D MPS, it has rank at most D2. Therefore



where the second equality holds because ug is a local symmetry.
Here, the left and right boundary vectors ( and ρ) are independent of the number of sites upon which
and ρ) are independent of the number of sites upon which  is supported, so this inequality holds for all k. This can only be the case if
is supported, so this inequality holds for all k. This can only be the case if  has an eigenvalue of magnitude 1, as it would otherwise have to possess exponential decay. From lemma 2, this implies that there exists some unitary vg and an angle
has an eigenvalue of magnitude 1, as it would otherwise have to possess exponential decay. From lemma 2, this implies that there exists some unitary vg and an angle  such that
such that

which completes the proof. □
We now investigate the properties of the virtual action of the symmetry. As discussed above, if we apply a constant depth circuit with symmetric gates to the MPS (i.e. mapping us to any other state in the phase), we can push the symmetry action first through the circuit and then onto the virtual level. Therefore, any properties it has will be an invariant of the phase.
Aside 2 (Projective representations). Let  be some group. A (linear) representation ug obeys
be some group. A (linear) representation ug obeys

This is not the most general way of acting with a group however. We could also ask for

where ![$\omega[g, h]={\rm e}^{{\rm i}\phi[g, h]}$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn187.gif) is a scalar which depends on both g and h independently. This is known as a projective representation. One might ask whether this is simply a more complicated way of writing a linear representation. Maybe we can rephase vg to obtain equation (5.37). Let
is a scalar which depends on both g and h independently. This is known as a projective representation. One might ask whether this is simply a more complicated way of writing a linear representation. Maybe we can rephase vg to obtain equation (5.37). Let ![$\beta[g]$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn188.gif) be some phase depending only on g then after a rephasing
be some phase depending only on g then after a rephasing ![$v_g\mapsto \beta[g]v_g$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn189.gif) , we have
, we have

We say that ω and  are equivalent if they are related in this way, so
are equivalent if they are related in this way, so

A projective representation is therefore equivalent to a linear representation if the phases can be completely removed, i.e. there exists a β such that

As you will show in problems 4, there are projective representations which are not equivalent to any linear representation.
Suppose we act with ug followed by uh on the MPS tensor, then

We could also have combined  before pushing through, which tells us
before pushing through, which tells us

Therefore

so  is equivalent to a linear representation. We can split this across the tensor product, telling us that in general
is equivalent to a linear representation. We can split this across the tensor product, telling us that in general

where ω is some phase. We cannot say anything about the phase in this case, since anything would be cancelled by tensoring with the conjugate.
The only freedom we have to change vg within a phase is local rephasing, therefore the equivalence classes of ω label the different phases of injective MPS with a symmetry restriction. These equivalence classes are indexed by the so-called second group cohomology class of the group  , an object usually written as
, an object usually written as  [24, 30].
[24, 30].
Problems 4. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.The group has the presentation . Show that the Pauli matrices form a projective representation of .Hint: let and show that , where ω is some phase.
- 2.Determine the factor system for the Pauli matrices.
- 3.Show that the Pauli projective representation is not equivalent to a linear representation.Hint: xz = zx, can we rephase vx and vz to make?
- 4.Recall from section 4.2 that the symmetry of the cluster state is, with the action on the MPS tensor being
What can we conclude about the cluster state?




![$v_gv_h=\omega[g, h]v_{gh}$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn199.gif)
![$\omega[g, h]$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn200.gif)



6. Tensor network algorithms
One area in which tensor networks have had exceptional practical success is in low-temperature simulation of condensed matter systems. A relatively well-understood toy model is finding ground states of one-dimensional spin systems. Even under the assumption of a local Hamiltonian, this seemingly narrow problem retains  -completeness [36] (a quantum analogue of
-completeness [36] (a quantum analogue of  ), dashing any hope of general simulation, even on a quantum computer. Whilst this may at first seem like a significant problem, many 'physically realistic' systems don't exhibit this prohibitive complexity. Tensor networks can be used to exploit, and to a certain extent understand, this structure.
), dashing any hope of general simulation, even on a quantum computer. Whilst this may at first seem like a significant problem, many 'physically realistic' systems don't exhibit this prohibitive complexity. Tensor networks can be used to exploit, and to a certain extent understand, this structure.
As discussed previously, states of low entanglement are well represented in the form of MPS. If we consider the case of local and gapped Hamiltonians, it has been shown that the relevant ground states cannot be highly entangled [19, 37–40] (see [41] for a review). This restricted entanglement means that such states admit efficient MPS approximations [17], and moreover that they may be efficiently approximated [40, 42–45], showing that the presence of the gap causes the complexity to plummet from  -complete all the way down to
-complete all the way down to  , removing the complexity barrier to simulation. We note that despite the challenges, both complexity theoretic and physical, in applying MPS to gapless models, they have been successfully utilised for this purpose [46–48].
, removing the complexity barrier to simulation. We note that despite the challenges, both complexity theoretic and physical, in applying MPS to gapless models, they have been successfully utilised for this purpose [46–48].
More concretely, the way in which we plan to approximate the ground state is by minimising the Rayleigh quotient of the Hamiltonian H (the energy) over some restricted domain  to yield an approximate ground state
to yield an approximate ground state  given as
given as

As we know that the exact solution is well-approximated by MPS, we will restrict ourselves to the domain  of MPS of a bounded bond dimension. The idea behind DMRG and TEBD is to start in some MPS state10 then variationally move along this domain, minimising the energy as we go. The difference between both methods is the manner in which this variation step is performed, with DMRG and TEBD taking more computational and physical approaches respectively.
of MPS of a bounded bond dimension. The idea behind DMRG and TEBD is to start in some MPS state10 then variationally move along this domain, minimising the energy as we go. The difference between both methods is the manner in which this variation step is performed, with DMRG and TEBD taking more computational and physical approaches respectively.
Although the algorithms we discuss here are designed for finding MPS ground states, they can be adaped to simulate time evolution [49, 50], find Gibbs states [51], or optimise other operators acting on a statespace of interest [52].
6.1. DMRG (the computer scientist's approach)
By far the most studied and successful of the algorithms in the field is DMRG. For clarity we will be restricting ourselves to finite DMRG, though there do exist thermodynamic variants. DMRG is an umbrella term which encompasses several similar algorithms, the algorithm we will discuss here is a simplified but nonetheless effective example. As the introduction of this algorithm in [53] pre-dates TNN, its description has historically been presented in a far more physically motivated and technically complicated manner. Due to the corresponding shift in interpretation, the original acronym now holds little relevance to the modern tensor network interpretation of DMRG, and so for clarity we intentionally omit defining precisely the expansion of DMRG as an acronym. For a full review in pre-TNN notation see [54], and see [21] for a TNN treatment.
Representing the Hamiltonian by an MPO, optimising the Rayleigh quotient over MPS looks like the following:

The difficulty is that as we need the contraction of these MPS tensors; the overall objective function is highly non-linear, but it does however only depend quadratically on each individual tensor. The key heuristic behind DMRG is to exploit the simplicity of these local problems, approximating the multivariate (multi-tensor) optimisation by iterated univariate (single tensor) optimisations.
Note that while the DMRG algorithm we are going to outline only calculates ground states, related generalisations exist which can be used to simulate excited states, dynamics etc.
6.1.1. One-site.
The simplest interpretation of the above sketch of DMRG is known as DMRG1 (or one-site DMRG). For a fixed site i, the sub-step involves fixing all but a single MPS tensor, which is in turn optimised over, i.e.

In TNN these step look like:

Next we define the environment tensors


which correspond to taking closed tensor networks—the expectation values of H and the I respectively—and removing the objective tensor. Given these environments, the sub-step in equation (6.4) becomes

Vectorising this equation yields

Finally we can simplify the denominator of this objective function by appropriately gauge-fixing our MPS to be in canonical form. By putting the parts of the MPS left of our site in left-canonical form, and those to the right in right-canonical form, then we get that  simply reduces to the identity:
simply reduces to the identity:

Given this canonicalisation, the problem thus reduces to

As  is Hermitian, this optimisation has a closed form solution given by the minimum eigenvector11 of
is Hermitian, this optimisation has a closed form solution given by the minimum eigenvector11 of  . By sweeping back and forth along the chain, solving this localised eigenvector problem, and then shifting along the canonicalisation as necessary, we complete our description of the algorithm.
. By sweeping back and forth along the chain, solving this localised eigenvector problem, and then shifting along the canonicalisation as necessary, we complete our description of the algorithm.
The main advantage of DMRG1 is that the state stays within the MPS manifold without the bond dimension growing, meaning that the algorithm is greedy12. This strict restriction on the bond dimension can however be a double-edged sword; this means that there is no particularly convenient method of gently growing the bond dimension as the algorithm runs13, and no information is gained regarding the appropriateness of the choice of bond dimension. Both of these problems are addressed in turn by the improved, albeit slightly more complicated, DMRG2 algorithm.
6.1.2. Two-site.
The idea with DMRG2 is to block two sites together, perform an optimisation in the vein DMRG1, then split the sites back out. This splitting process gives DMRG2 its power, allowing for dynamic control of the bond dimension, as well as providing information about the amount of error caused by trimming, which helps to inform the choice of bond-dimension.
First an optimisation is performed:

which can once again be solved by taking the minimum eigenvector of an environment tensor with respect to two sites,  , once again in mixed canonical form. After this the two-site tensor is split apart by performing an SVD14 and a bond trimming:
, once again in mixed canonical form. After this the two-site tensor is split apart by performing an SVD14 and a bond trimming:

This trimmed SVD has two key features. Firstly the bond dimension to which we trim could be higher than that we originally started with, allowing us to gently expand out into the space of higher bond dimension MPS. Secondly we can use the truncated singular values to quantify the error associated with this projection back down into the lower bond dimension space, better informing our choice of bond dimension.
6.2. TEBD (the physicist's approach)
Time-evolving block decimation (TEBD) [58, 59] is a tensor network algorithm that allows the dynamics of 1D spin systems to be simulated. By simulating imaginary-time-evolution low-temperature features such as the ground state may be calculated as well.
To simulate imaginary-time-evolution, we need to approximate the imaginary-time-evolution operator  . The problem here is that whilst we may have an efficient representation of H, any exponential of it will not necessarily have a succinct representation. Take the example of a two-body Hamiltonian with corresponding imaginary-time-evolution operator
. The problem here is that whilst we may have an efficient representation of H, any exponential of it will not necessarily have a succinct representation. Take the example of a two-body Hamiltonian with corresponding imaginary-time-evolution operator

and hi is an interaction term acting on spins i and i + 1. Whilst H has a constant Schmidt rank, admitting an efficient representation as an MPO,  generically has exponential bond dimension for almost all τ.
generically has exponential bond dimension for almost all τ.
Let  denote the sum of terms hi for odd(even) i. As all the terms within
denote the sum of terms hi for odd(even) i. As all the terms within  are commuting,
are commuting,  can be efficiently computed and represented. The problem of approximating
can be efficiently computed and represented. The problem of approximating  can therefore be reduced to the problem of approximating
can therefore be reduced to the problem of approximating  when only terms of the form
when only terms of the form  and
and  can be computed.
can be computed.
The central mathematical tool to TEBD are the exponential product approximations. The first order of these approximation is the Suzuki-Trotter formula, which approximates the total evolution by simply evolving each subsystem:

It turns out there exist entire families of such approximations [60], though for our purposes we will just illustrate the procedure for Suzuki-Trotter.
The TEBD algorithm works by approximating the imaginary-time-evolution operator by the above exponential product formulae, applying it to a given MPS, and trimming the bond dimension to project back down into the space of MPS.
Our approximation to the imaginary-time-evolution operator is given by a product of layers containing only nearest-neighbour two-site operators, meaning we need only be able to contract these operators into our MPS. Suppose we want to apply an operator U to the spins at sites i and i + 1. The idea is to apply the operator, contract everything into a single tensor, then once again use an SVD trimming to truncate the bond dimension back down.

The benefits this trimming procedure gave to DMRG2—namely control over bond dimension growth and quantification of trimming errors—are also seen in TEBD. As the above procedure is entirely localised, TEBD also admits a large amount of parallelisation, not typically available to DMRG.
6.3. Implementation
From-scratch implementation of these simple algorithms can be achieved with relative ease, however several high performance libraries exist for research level simulations. We direct the interested reader to investigate ITensor [61] (C+ +), evoMPS [62] (Python), Matrix Product Toolkit [63] (C+ +), uni10 (C+ +) [64], Tensor Operations [65] (Julia) among others. A simple tensor class can also be easily written in MATLAB.
Problems 5. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.Consider the critical transverse Ising modelFor open boundary conditions, it is known that the ground state energy as a function of n has the form [66]for some integers α and β. Using either DMRG or TEBD, estimate the ground state energy for several chain lengths and calculate α and β.
- 2.



7. Projected entangled pair states
Many of the ideas behind MPS generalise to higher dimensions via projected entangled pair states or PEPS [22, 23]. We will see how this is a misnomer in two ways, there is not necessarily a projector and there is not necessarily an entangled pair.
We begin by recalling the PEPS description of matrix product states, then generalise this to two dimensional models. After giving several examples, we will examine the properties of PEPS, identifying both the similarities and differences to MPS.
7.1. One dimensional systems: MPS
We have already seen the PEPS construction in 1D. Let  be some (usually) entangled pair and
be some (usually) entangled pair and  some linear map. Then
some linear map. Then

where

is the chosen entangled pair. As we saw, we have a large choice in the exact description we use. We can transform the local basis of each spin in the entangled pair by any (left) invertible matrix

since we can modify  to compensate
to compensate

One thing to note is that  does not necessarily need to be a valid quantum state. We usually leave it unnormalised for convenience.
does not necessarily need to be a valid quantum state. We usually leave it unnormalised for convenience.
In addition to this gauge freedom, we have additional choices in the description. We could use entangled triplets for example. Let  , then we could choose our PEPS to be
, then we could choose our PEPS to be

Clearly this doesn't offer any more descriptive power than using entangled pairs. Suppose we have some PEPS projector  acting on pairs, then we can extend this to a
acting on pairs, then we can extend this to a  acting on triplets by
acting on triplets by

In the other direction, we can build a product of triplets using a minor modification of the GHZ MPS presented above and then use  to build our state of interest.
to build our state of interest.
7.2. Extending to higher dimensions
The extension from one to higher dimensional systems proceeds straightforwardly. We will discuss the simple case of a hypercubic lattice, but the framework can be carried out on any graph. In particular, we will restrict to 2D.
As before, we allow  to be some entangled pair. The PEPS is built as the natural generalisation to 2D
to be some entangled pair. The PEPS is built as the natural generalisation to 2D

where

is some linear operator from the virtual to the physical space.
Clearly there is a large amount of gauge freedom in this description as there was in the 1D case. Any invertible transformation of each virtual spin can be compensated in the definition of the PEPS 'projector'  , analogous to equation (7.4).
, analogous to equation (7.4).
As in the MPS, one may ask whether using different entanglement structures leads to greater descriptive power. It is easy to see that this is not the case in general. Suppose we choose to lay down plaquettes in a GHZ state and then act with PEPS projectors between plaquettes.

We can use a standard PEPS to prepare this resource state, so any state which can be prepared from this 'projected entangled plaquette' construction can be prepared from a PEPS at small additional cost.
7.3. Some PEPS examples
We will now look at several example PEPs.
7.3.1. Product state.
We have already seen this example in 1D. Exactly the same thing works in 2D, for example take

7.3.2. GHZ state.
Directly generalising the 1D case, we can use

to build the GHZ state.
7.3.3. RVB state.
Let D = 3 be the bond dimension and let

for  , as well as all rotations on the virtual level, be the only nonzero elements of the PEPS tensor. Suppose we tile these tensors and project the dangling indices onto the
, as well as all rotations on the virtual level, be the only nonzero elements of the PEPS tensor. Suppose we tile these tensors and project the dangling indices onto the  state. What is the resulting physical state?
state. What is the resulting physical state?
This state is known as the resonating valence bond state [22, 67, 68] and consists of a superposition of all complete tilings of the lattice with maximally entangled pairs

where

Aside 3 (Kitaev's Toric code). Kitaev's Toric code [69] is a canonical example of a topologically ordered model Here we will construct a Hamiltonian with the code space as the ground space of the model. The ground state of this Hamiltonian is the superposition of all closed loops of flipped spins.
We place qubits on the edges of a square lattice.

We wish to create a Hamiltonian with closed loop states (of flipped spins) as the ground state. Suppose all spins are initially in the  state. Then around every vertex v place an interaction
state. Then around every vertex v place an interaction

To be in the ground state of this term, the number of edges flipped to  neighbouring a given vertex must be even. Drawing edges carrying flipped spins in red, we can trace the effect of this on the lattice
neighbouring a given vertex must be even. Drawing edges carrying flipped spins in red, we can trace the effect of this on the lattice

We can see that on a square graph, requiring an even number of edges incident on each vertex enforces that all of our loops are closed.
At this point, our ground space contains all states with only closed loops. We want an equal superposition of all closed loop states. This is achieved by placing an interaction around plaquettes or squares on the lattice, which convert between loop states. To be an eigenstate, all loop states reachable from the vacuum state must be in the superposition. At each plaquette p, place an interaction

This has the desired effect. Placing the interaction at the indicated plaquette performs the following transformation of loops

It's not hard to convince yourself that all loop states can be reached from the empty state, so all closed loop patterns must be in the superposition. The final Hamiltonian is

and the ground state is an equal superposition over all closed loop states:

Note that the Toric code Hamiltonian is usually presented in the  basis rather than the
basis rather than the  basis.
basis.
7.3.4. Toric code ground state.
The simplest way to construct a PEPS for the toric code uses the structure of the ground state. The PEPS tensor is constructed to ensure the superposition of closed loop patterns is achieved upon contraction. The most natural way to achieve this it to write a single tensor for every second plaquette rather than each site.
We begin by adding new edges to the lattice. These edges will become the bonds in the tensor network.

where the plaquettes are numbered for clarity.
Recall that the ground state is built using loops of  in a background of
in a background of  . We choose the state of the added edges such that the loop pattern is preserved
. We choose the state of the added edges such that the loop pattern is preserved

where  indicates a spin in the
indicates a spin in the  state on that edge. We choose the following convention when it is ambiguous
state on that edge. We choose the following convention when it is ambiguous

which makes everything consistent.
Interpreting these added edges as bonds in a tensor network, we obtain a PEPS tensor for every second plaquette in the original lattice with four physical indices. The nonzero components are

where  . In this tensor the straight legs indicate virtual indices, and the wavy legs physical indices, specifically the four qubits on the given plaquette. The network looks as below, with the dotted lines representing the original lattice:
. In this tensor the straight legs indicate virtual indices, and the wavy legs physical indices, specifically the four qubits on the given plaquette. The network looks as below, with the dotted lines representing the original lattice:

This tensor simply ensures that if adjacent physical indices are in the  state, i.e. carrying a loop, then the virtual index between them does not carry a loop which would leave the plaquette. Conversely, if only one is in the
state, i.e. carrying a loop, then the virtual index between them does not carry a loop which would leave the plaquette. Conversely, if only one is in the  state, the loop must leave the plaquette.
state, the loop must leave the plaquette.
Since an even number of the virtual bonds must be in the  state for the tensor entry to be nonzero, the PEPS tensor has a property called
state for the tensor entry to be nonzero, the PEPS tensor has a property called  -injectivity [35]. This means that there is a symmetry on the virtual level
-injectivity [35]. This means that there is a symmetry on the virtual level

This turns out to be closely related to the topological order present in this model.
7.4. 2D cluster state and the complexity of PEPS
Let D = 2 be the bond dimension and let

be the only nonzero elements of the PEPS tensor. The physical state generated is the 2D cluster state, a universal resource for measurement based quantum computing [70, 71].
If we could efficiently take the inner product between PEPS (i.e. contract a square grid network), then we can clearly classically simulate single qubit post selected measurements by simply contracting rank 1 projectors onto the physical indices of these PEPS tensors. This shows us that we cannot contract even simple PEPS states efficiently, unless post-selected quantum computing can be classically simulated ( ) [72].
) [72].
7.4.1. Numerical PEPS.
Although we will not discuss the details of numerical implementation of PEPS algorithms, we note that the status is not as dire as the previous section would imply. In many practical situations, approximate contraction of PEPS networks can be achieved in both the finite [73] and infinite [74, 75] system size limits.
7.5. Properties of PEPS
Above, we saw a number of properties of 1D PEPS or MPS. We will now see which properties hold in two dimensions. One might naïvely expect MPS and more general PEPS to share similar properties. As we will see below, these two tensor network states share qualitatively different properties, both in terms of the physics the corresponding states exhibit, and in the computational power of the tensor networks.
Aside 4 (Tensor network for classical partition function). Let ![$H[s]=\sum_{\langle i, j\rangle }h[s_i, s_j] $](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn252.gif) be some classical Hamiltonian. We frequently want to calculate the partition function
be some classical Hamiltonian. We frequently want to calculate the partition function ![$\mathcal{Z}=\sum_{\{s\}}{\rm e}^{-\beta H[s]}$](https://content.cld.iop.org/journals/1751-8121/50/22/223001/revision1/aaa6dc3ieqn253.gif) for such a system at a temperature β. We can use a simple tensor network to help.
for such a system at a temperature β. We can use a simple tensor network to help.
Define the two tensors

Placing a D tensor at every classical spin and an M tensor corresponding to each interaction, the following network evaluates to the partition function.

Thermal expectation values can be calculated by inserting local tensors into this network. For example

where

has been inserted at site n.
Notice that by combining D and M tensors, the partition function can be described with a single tensor

Let

where  , the classical Ising model. The tensor Q then simplifies to
, the classical Ising model. The tensor Q then simplifies to

7.5.1. Algebraic decay of correlations.
As we saw above, MPS can only capture states with exponential decay of correlations (or constant correlations of course). We will now see if this holds in the case of PEPS. We can build a PEPS state corresponding to a classical partition function by modifying the above construction [67]. Let

or equivalently combine these into

This defines a PEPS state

Note this is a pure state, and not a thermal state. It is however not normalised, with  . Correlation functions computed using this state are equal to those computed using classical statistical physics. Suppose we were to consider a classical model with a thermal phase transition (such as the Ising model above). Such a model will exhibit algebraic decay of correlations at the critical temperature, implying that the corresponding PEPS does as well. Thus we can see that unlike MPS, the states described by PEPS can exhibit algebraic decay of correlations.
. Correlation functions computed using this state are equal to those computed using classical statistical physics. Suppose we were to consider a classical model with a thermal phase transition (such as the Ising model above). Such a model will exhibit algebraic decay of correlations at the critical temperature, implying that the corresponding PEPS does as well. Thus we can see that unlike MPS, the states described by PEPS can exhibit algebraic decay of correlations.
7.5.2. Gauge freedom.
The gauge freedom of a PEPS tensor is a simple generalisation of the MPS freedom. As before, we can block tensors together without changing the global state. In addition, we can perform the following transformation (on a translationally invariant PEPS):

where N and M are invertible matrices.
Recall that in the MPS case, we could use this freedom to bring the tensors into a canonical form. This cannot be done exactly in the case of PEPS, though there do exist numerical methods to bring PEPS into approximate canonical forms [76].
Problems 6. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.What is the PEPS tensor required to build the GHZ state on the honeycomb lattice where spins reside on vertices?
- 2.Which 2 qubit gate is obtained by contracting the following tensors along the horizontal index?
- 3.The cluster state can be prepared from the all state by applying CZ between all adjacent spins. Show that equation (7.20) indeed gives the cluster state.Hint: Consider the decomposition of a gate given in the above problem.
- 4.Investigate how logical operators on the physical spins of the Toric code can be pulled onto the virtual level of the PEPS. Can you see why-injectivity is so important for topologically ordered PEPS?
- 5.Convince yourself that evaluating expectation values on the PEPS constructed from a classical partition function indeed reproduces the thermal expectation values.



8. Multiscale entanglement renormalisation ansatz
MPS are extremely useful for understanding low energy states of 1D quantum models. Despite this, they cannot capture the essential features of some important classes of states. In particular, they cannot reproduce the correlations seen in gapless ground states. Recall that MPS always have exponentially decaying correlations, whereas gapless ground states generically support correlations with power law decay. Similarly MPS also have a strict area law for entanglement entropy, where gapless states admit a logarithmic divergence. The multiscale entanglement renormalisation ansatz is a tensor network designed to overcome these problems.
As mentioned in section 6, although MPS do not naturally support the kind of correlations expected in critical models, they have been successfully applied for the study of such systems nonetheless. Using MPS for this purpose requires families of MPS of increasing bond dimension to examine how the correlations behave. The MERA state functions differently. As we will discuss, a single MERA state can naturally capture the physics of a gapless ground state.
Here, we will present the tensor network as an ansatz and argue that it is well suited to representing ground states of gapless Hamiltonians in 1D. Suppose the state can be written as

where

As we will see, these constraints on the tensors have both a physical and computational impact. Note that the u and w tensors do not have to be identical, although we frequently restrict to this case if we expect translationally and scale invariant states. The class of states which are expressed as equation (8.1) are known as multiscale entanglement renormalisation Ansatz (MERA) states [77–81].
Although we will not discuss it here, the MERA can be straightforwardly generalised to higher dimensional systems [82–85]. Unlike PEPS, the network can be efficiently optimised in higher dimensions, although the scaling makes the numerics very challenging!
8.1. Properties of MERA
8.1.1. Logarithmic violation of the area law.
One of the key properties realised in the MERA which cannot be realised in MPS is a scaling of entanglement entropy. This is easily seen by bond counting. Recall that if n bonds must be broken to separate a region from the rest of the network, the maximum entanglement entropy that can be supported is  , where D is the bond dimension. Recall that in the case of MPS any reduced state on a contiguous region can be removed by cutting n = 2 bonds.
, where D is the bond dimension. Recall that in the case of MPS any reduced state on a contiguous region can be removed by cutting n = 2 bonds.
By inspecting the diagram

it is straightforward to see that to remove a block of N physical indices from the rest of the network,  bonds must be cut. This shows that the maximum entropy scales as
bonds must be cut. This shows that the maximum entropy scales as  [77, 78].
[77, 78].
8.1.2. Power law decay of correlations.
Using the constraints on the tensors (equation (8.2)), we can simplify the evaluation of a two point correlator on a MERA state [79].




Note that the length scale behaviour of the correlator is completely determined by the application of a superoperator

where the w tensor can be viewed as a set of Kraus operators

obtained by grouping the indices indicated.
Thus,  is a completely positive, unital map and all eigenvalues λ of
is a completely positive, unital map and all eigenvalues λ of  are
are  . We can bring operators separated by N sites together by applying
. We can bring operators separated by N sites together by applying 
 times. Considering eigenoperators of the
times. Considering eigenoperators of the  superoperator, the correlator acts as
superoperator, the correlator acts as

where  ,
,  are known as scaling dimensions, where
are known as scaling dimensions, where  is the corresponding eigenvalue of
is the corresponding eigenvalue of  . Therefore, a MERA state can support algebraic decay of correlations. Although this discussion required the operators to be placed at special sites, it can be easily generalised.
. Therefore, a MERA state can support algebraic decay of correlations. Although this discussion required the operators to be placed at special sites, it can be easily generalised.
8.1.3. Efficient manipulation.
As described in section 2.5, a good tensor network ansatz should fulfil two properties. First, it should be efficiently storable. All of the networks we have discussed thus far have this property, as only a small number of coefficients are required to represent these states. The second property is more subtle; one should be able to extract physical data efficiently. Although this works for the 1D MPS network, it fails for 2D PEPS states; the contractions required to calculate expectation values of local operators is incredibly hard.
It turns out the MERA has both of these properties. One can efficiently store the state data, and, thanks to the constraints in equation (8.2), one can efficiently compute local expectation values and correlators. We have already seen how this works. The isometric constraints ensure that local operators on the physical level of the network are mapped to local operators on the higher levels [86]. Therefore, computing expectation values only requires manipulation of a small number of tensors in the causal cone of the operator

where the shaded region indicates the causal cone of the five site operator on the physical level indicated in yellow. Notice that the number of tensors on each subsequent level does not grow. Indeed, after a single layer of tensors, the operator becomes a three site operator, and the range never grows. Thus, we see that the layers of the MERA act to map local operators to local operators.
8.2. Renormalisation group transformation
Much of the discussion above concerned interpretation of the layers of the MERA as Kraus operators, defining a unital CP map on local operators. Evaluating expectation values can be seen as application of many superoperators followed by the inner product with some state on a smaller number of sites

where  is a map from 3N−j spins to 3N−j/3 spins. This can be seen as a renormalisation group or scale transformation. The state
is a map from 3N−j spins to 3N−j/3 spins. This can be seen as a renormalisation group or scale transformation. The state  is supported on 3N−j spins, and contains only the physical data necessary to understand the physics on that length scale. As we saw, if O is a local operator,
is supported on 3N−j spins, and contains only the physical data necessary to understand the physics on that length scale. As we saw, if O is a local operator,  is easy to evaluate. This allows us to understand the effective operator as a function of length scale [77, 79, 80].
is easy to evaluate. This allows us to understand the effective operator as a function of length scale [77, 79, 80].
The thermodynamic or macroscopic observables can be seen as the operators obtained by applying a formally infinite number of MERA layers to the high energy or microscopic observables. Thus, the macroscopic physics, or phase structure, is determined by fixed points of the maps  . Some particularly interesting states are the scale invariant states. If the MERA tensors are all the same after some layer, the state is scale invariant. For these states, we do not expect the physics to change as a function of length or energy scale. The fixed point observables of these states are particularly simple to understand, and distinct scale invariant states characterise the different phases.
. Some particularly interesting states are the scale invariant states. If the MERA tensors are all the same after some layer, the state is scale invariant. For these states, we do not expect the physics to change as a function of length or energy scale. The fixed point observables of these states are particularly simple to understand, and distinct scale invariant states characterise the different phases.
Since there is no characteristic length scale set by either the spectral gap or correlation length, gapless ground states are expected to be scale invariant. The MERA therefore allows us to understand the long range physics of these states incredibly efficiently [79, 86]. Another way to achieve a scale invariant state is to have zero correlation length—these states characterise gapped phases.
8.3. AdS/CFT
In the appropriate limit, the low energy physics of the gapless spin chains considered here is described by a conformal field theory (CFT) [87, 88]. The physics of CFTs is thought to be related to gravitational theories in one additional dimension [89–91].
This duality can be observed in the MERA network [92–94]. Imposing the graph metric on the MERA, we find a discretised anti-de Sitter (AdS) metric [92], whilst the edge theory is a 'discretised' CFT. In addition to being a concrete realisation of the holographic principle, the MERA/CFT duality provides avenues towards designing quantum error correcting codes [95].
We note that the AdS/MERA connection remains an open research question. Limits on the ability of MERA states to replicate physics on scales less than the AdS radius have been shown [94]. Additionally, whether the geometry is best understood as anti-de Sitter [92] or de Sitter [93] is currently unclear. Whatever the status, the connection is intriguing. We encourage the interested reader to explore the rapidly expanding literature on the topic [94–103].
8.4. Some simple MERA states
8.4.1. Product state.
Let

and  .
.
If we build  layers using these tensors, we end up with a state on N sites. The network still has a free index at the top, so we need to define a one-index 'top tensor' T to obtain the final state. Let
layers using these tensors, we end up with a state on N sites. The network still has a free index at the top, so we need to define a one-index 'top tensor' T to obtain the final state. Let  . The state obtained is
. The state obtained is  .
.
8.4.2. GHZ state.
Let

and  . Let the top tensor be
. Let the top tensor be  . The state obtained is
. The state obtained is  .
.
8.4.3. Cluster state.
It is more convenient to define the cluster state on a binary MERA than a ternary. Place two spins at each site and let

where  is a controlled-Z gate and H is the Hadamard. If we pick a top tensor
is a controlled-Z gate and H is the Hadamard. If we pick a top tensor  , we obtain the cluster state on periodic boundary conditions.
, we obtain the cluster state on periodic boundary conditions.
8.4.4. Gapless states.
Recently, a family of analytic MERA for the critical point of the transverse field Ising model was proposed [104]. One can also use numerical techniques to obtain a MERA approximation to the ground state of a local Hamiltonian however. Here, we will present some physical data obtained for a model known as the transverse field cluster model [105]. In particular, we will present the ground state energy and the decay exponents ( in equation (8.10)).
in equation (8.10)).
This model is most straightforwardly defined with a pair of spin half particles at each site. The Hamiltonian for this model is

This is the cluster state Hamiltonian with transverse fields and an additional interaction with variable strength. The Hamiltonian remains gapless for a range of values of λ, over which the ground state energy varies continuously as seen in figure 1(a). The decay exponents also vary over this range, meaning that the thermodynamic physics or RG fixed point is dependent on λ. These exponents can easily be extracted from an optimised MERA by finding the eigenvalues of the  superoperator in equation (8.8). The MERA results are shown in figure 1(b).
superoperator in equation (8.8). The MERA results are shown in figure 1(b).

Figure 1. (a) Ground state energy density extracted from a ternary MERA after optimising the tensors to locally minimise the energy. (b) Correlation decay exponents for the transverse field cluster model obtained from a ternary MERA. Reprinted figure with permission from [105], copyright 2015 by the American Physical Society.
Download figure:
Standard image High-resolution imageFigures reproduced from [105].
Problems 7. Solutions in supplementary material (stacks.iop.org/JPhysA/50/223001/mmedia).
- 1.Can you find a MERA for the W state?
- 2.What state is given by the MERA with and top tensor ?
- 3.The above state is the ground state of the Hamiltonianon periodic boundary conditions. Is that clear? Can you find a unitary U2j−1,2j which transforms this Hamiltonian into
- 4.Act with the above transformation U on the MERA tensor to obtain another MERA tensor. What is this state?
- 5.What is the maximum range of thermodynamic observables in a ternary MERA scheme?
- 6.What does the reduced density matrix on a few sites of the MERA look like? Notice that it corresponds to the top tensor being passed through a CPTP map several times, this is usually called the descending superoperator.
- 7.Do tree tensor networks (i.e. MERA for) have any area law violation on contiguous regions?






Acknowledgments
We thank everyone who stayed awake for the presentation of these lectures in January of 2016 at the Australian Institute of Nanoscience. We thank Stephen Bartlett, Andrew Doherty, Christopher Granade, Robin Harper, Marco Tomamichel, Dominic Williamson, and especially Doriane Drolet and David Tuckett, for their input. For suggesting that we give these lectures and editorial assistance, we give special thanks to Chris Ferrie. We acknowledge support from the Australian Research Council via the Centre of Excellence in Engineered Quantum Systems (EQuS), project number CE110001013.
Much of the material was reproduced from memory after one of the authors attended the Tensor Network Summer School at Universiteit Gent in 2015.
Appendix. PEPOs for local Hamiltonians: the 'particle decay' construction
In numerical algorithms such as DMRG, operators such as Hamiltonians are often represented in the form of Matrix Product Operators (MPO) in 1D, and Projected Entangled Pair Operators (PEPO) in 2D and higher, as seen below. For highly structured Hamiltonians, such as those which are local and translation invariant, an analytic MPO construction of such operators is known in 1D [21]. In this section we review this, and outline a generalisation which allows for local Hamiltonians (and even slightly less structured operators) to be optimally expressed as a PEPOs in arbitrary spatial dimensions.

Much like in equations (4.54) and (4.58) we are going to omit the physical indices, as such we will consider MPO tensors to be (operator-valued) matrices, and PEPO tensors to be (operator-valued) rank-2D tensors in D spatial dimensions.
In this section we will need to specify individual tensor values, as well as the values of a tensor network for a specific index designation. For brevity, we will therefore omit the legs in our diagrams, indicating specific entries in a tensor by a  surrounded by the index values. For example the identity is given by i
surrounded by the index values. For example the identity is given by i  i = 1 for all i. To make the constructions more clear we will also allow for non-numeric index values, and denote the index set by I.
i = 1 for all i. To make the constructions more clear we will also allow for non-numeric index values, and denote the index set by I.
A.1. 1D
In this notation, if we label our indices  , then the transverse Ising model Hamiltonian given in equation (4.54) is given by
, then the transverse Ising model Hamiltonian given in equation (4.54) is given by


where the boundary terms fix the far left and right indices to  and
and  respectively.
respectively.
One common interpretation of this construction is in terms of finite-state automata, with the index values corresponding to the automaton states, and the non-zero index values to the transition rules. The automaton moves from left to right15, with the boundary vectors setting the initial state to  and final state to
and final state to  . With only these restrictions, the automaton can transition from
. With only these restrictions, the automaton can transition from  to
to  either directly (giving the field term −hZ), or via 1 (giving the Ising term −JXX) at any location.
either directly (giving the field term −hZ), or via 1 (giving the Ising term −JXX) at any location.
To make the higher dimensional generalisation clear we will slightly modify this finite-state automata language, to that of particles and their decay. We can think of → as a right-moving particle, and · as the vacuum. The first two transition rules (A.1) correspond to both the vacuum and particle being stable states, with the remaining transitions (A.2) to valid decay routes of the particle. Thus we can interpret the value of the overall MPO as being a superposition over all decays, with each corresponding to a term in the Hamiltonian.
A.1.1. Heisenberg model.
Suppose we wish to construct a Hamiltonian containing multiple two-body terms, such as the Heisenberg anti-ferromagnet, which contains the terms −JXXX, −JYYY, −JZZZ, as well as a field −hZ. An MPO of this model is given in standard notation in equation (4.58).
Added Hamiltonian terms can be accommodated in this construction by extra decay chains. Take our index set to be  and our MPO to have terms:
and our MPO to have terms:





Again equations (A.3) correspond to stable vacuum and particles, and each of the transition rules equations (A.4)–(A.7) to each term in the Hamiltonian.
A.1.2. Cluster model.
The Cluster Hamiltonian contains three body terms of the form ZXZ. Larger terms such as this can be accommodated by longer decay chains. Take an index set  and include the standard stable vacuum/particle terms as well as
and include the standard stable vacuum/particle terms as well as

By combining the above two techniques, we can construct arbitrary local Hamiltonians.
A.2. 2D and higher
In higher dimensions we can use a similar construction. Suppose we want to construct a 2D field Hamiltonian, consisting of a Z at every site. Take our index set to be  . Our typical stable vacuum/particle terms that we will always include now become
. Our typical stable vacuum/particle terms that we will always include now become

For the field Hamiltonian we need only allow for a simple particle decay of

As for the boundary conditions, along the top, right and bottom boundaries we will once again fix the only non-zero indices to be the vacuum  . Along the left edge, the boundary condition is a virtual W-state (see equation (4.18)) on indices
. Along the left edge, the boundary condition is a virtual W-state (see equation (4.18)) on indices  , i.e. the equal superposition of all single-particle states. As such we can see that all the non-zero contributions to the Hamiltonian are of the form:
, i.e. the equal superposition of all single-particle states. As such we can see that all the non-zero contributions to the Hamiltonian are of the form:

As with 1D, by introducing intermediary states and different decay rules, arbitrary local Hamiltonians in any dimension can be similarly constructed. For example suppose we wanted a 9-body plaquette term of the form:

Take  and our non-trivial decay modes to be
and our non-trivial decay modes to be

then we can see that the non-zero contributions to the Hamiltonian are of the form

A.3. Other examples
Below are several more example of Hamiltonian constructed by the above method.
A.3.1. Toric code (Wen plaquette).

A.3.2. Quantum compass model/Bacon–Shor code.

A.3.3. 2D transverse Ising.

A.3.4. 2D cluster state.

Footnotes
- 5
The Cliffords are the group of unitaries which map Paulis to Paulis under conjugation.
- 6
Into precisely which tensor the singular values are contracted can be important, and relates to gauge fixing the MPS, see section 4.3.2.
- 7
If you include the ability to expand the bond dimension then this grows to an isometric freedom.
- 8
Were ρ not full rank we could reduce the bond dimension such that it were without changing any observables in the thermodynamic limit.
- 9
Note that
is the 'Liouville superoperator' form of the channel (equation (5.4)) - 10
Typically a random MPS is sufficient in practice, though one could use an educated guess if available.
- 11
If we had not canonicalised the MPS then a closed form solution still exists in the form of the generalised eigenvector of
and , but in general the cost of canonicalisation is well-justified by the increased stability it yields. - 12
A greedy algorithm is one which solves local problems, such that the cost function (energy in this case) monotonically decreases.
- 13
- 14
Whilst other factorisations such as QR and LU can also be used, SVD is preferred over other rank-revealing decompositions due to the optimality of singular value truncation as a low-rank approximation (see aside 1).
- 15
Though a right-to-left convention is more commonly used in this 1D construction, a left-to-right convention will prove useful for consistency with the higher dimensional construction.




{kind=link}