

Abstract
Limited data exists on emissions from agriculture-driven deforestation, and available data are typically uncertain. In this paper, we provide comparable estimates of emissions from both all deforestation and agriculture-driven deforestation, with uncertainties for 91 countries across the tropics between 1990 and 2015. Uncertainties associated with input datasets (activity data and emissions factors) were used to combine the datasets, where most certain datasets contribute the most. This method utilizes all the input data, while minimizing the uncertainty of the emissions estimate. The uncertainty of input datasets was influenced by the quality of the data, the sample size (for sample-based datasets), and the extent to which the timeframe of the data matches the period of interest. Area of deforestation, and the agriculture-driver factor (extent to which agriculture drives deforestation), were the most uncertain components of the emissions estimates, thus improvement in the uncertainties related to these estimates will provide the greatest reductions in uncertainties of emissions estimates. Over the period of the study, Latin America had the highest proportion of deforestation driven by agriculture (78%), and Africa had the lowest (62%). Latin America had the highest emissions from agriculture-driven deforestation, and these peaked at 974 ± 148 Mt CO2 yr−1 in 2000–2005. Africa saw a continuous increase in emissions between 1990 and 2015 (from 154 ± 21–412 ± 75 Mt CO2 yr−1), so mitigation initiatives could be prioritized there. Uncertainties for emissions from agriculture-driven deforestation are ± 62.4% (average over 1990–2015), and uncertainties were highest in Asia and lowest in Latin America. Uncertainty information is crucial for transparency when reporting, and gives credibility to related mitigation initiatives. We demonstrate that uncertainty data can also be useful when combining multiple open datasets, so we recommend new data providers to include this information.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence.
Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Emissions from land use change, and particularly deforestation have had a major impact on global carbon budgets (Le Quéré et al 2015). The net flux of carbon from land use and land cover change between 1990 and 2010, was 12.5% of anthropogenic carbon emissions (Houghton et al 2012). Most of these emissions resulted from forest loss (Le Quéré et al 2015). Reducing deforestation can potentially play a large role in efforts to limit global temperature increases (Zarin et al 2016, Wollenberg et al 2016), through mechanisms such as reducing emissions from deforestation and forest degradation and the role of conservation, sustainable management of forests and enhancement of forest carbon stocks in developing countries (REDD+). Information on what drives deforestation can provide input for policies such as REDD+, as actions to reduce deforestation should directly address the specific drivers (Salvini et al 2014). In order to be eligible for payments related to REDD+, reporting standards which include providing information on uncertainties related to emissions estimates must be adhered to. Uncertainty information is also a requirement for national greenhouse gas inventories (IPCC 2006). Uncertain estimates make informed choices on mitigation approaches difficult, and also threaten the credibility of initiatives which seek to address these emissions (Pelletier et al 2015), such as REDD+.
Emissions from deforestation have been estimated using a variety of methods and data sources (Houghton et al 2012). Most approaches use activity data (area estimates for land use change) and emissions factors (changes in carbon stock due to a land use transition, expressed per unit area). Input data for these estimates includes ground observations, usually derived from forest inventory data, and remote sensing data. Countries report detailed information on deforestation, and this is compiled every 5 years in the Global Forest Resources Assessments (FRA) (FAO 2017). Data used in the FRA include both inventory-based and remote-sensing-based estimates. Remote sensing data are considered particularly useful for forest monitoring (De Sy et al 2012, Goetz et al 2015). Increased access to remote sensing data (through for example the opening of the Landsat archive), allowed for the production of multiple estimates of activity data and emissions factors. Besides the IPCC Tier 1 default factors providing the average forest biomass per ecozone, which may not always fit the country circumstances (Avitabile et al 2011), emission factors can be derived from several maps of forest carbon density (see for example: Avitabile et al 2016, Baccini et al 2012, Saatchi et al 2011, Zarin et al 2016, Tyukavina et al 2015). Sample data are also useful for regional assessments of deforestation and emissions factors (De Sy et al 2015, Achard et al 2014). Since datasets use different input data types and methodologies (see for example: Harris et al 2012b, Mitchard et al 2013, Grace et al 2014, Grainger 2008), a large number of different estimates exist, which can be confusing for policy makers (Harris et al 2012a). Currently, there is a lack of comprehensive data on the agricultural drivers of deforestation. De Sy (2016) however, produced estimates of the fraction of deforestation which is driven by agriculture using a sample-based approach. The synthesis by Hosonuma et al (2012) also provides estimates based on country reported data, but the data have large uncertainties, so making conclusions from their findings is difficult. Gibbs et al (2010) also provide information on the dynamics between agriculture and forests, and conclude that 83% of agriculture expansion between 1980 and 2000 was into forests. Since forest loss worldwide as well as in the tropics is mainly driven by agricultural expansion (Kissinger et al 2012), our study aims at providing a quantitative assessment of agriculture-driven deforestation including uncertainties.
Forest loss is one of the most uncertain components of global carbon budget (Houghton et al 2012, Canadell et al 2010). Many datasets do not provide uncertainty information (for example the FRA). Remote sensing derived estimates often provide information about the uncertainties of datasets, but different methods result in different outcomes (see for example Schepaschenko et al 2017). Many estimates do not indicate how the results were calculated, or do not use uncertainties to provide better estimates (Olofsson et al 2013). Uncertainty can be quantified using empirical and statistical approaches (for example in the case of remote sensing; pixel level uncertainty estimates, or map accuracies), and also expert judgement. The IPCC and other sources provide guidelines on how to produce and report these estimates (GOFC-GOLD 2016, IPCC 2006). It is not only the input datasets for which uncertainty data is required, but also the final emissions estimates. This means that uncertainty for the input datasets must be correctly combined to produce the emission uncertainty (for example when using activity data with an emissions factor).
Our objectives are to (1) quantify uncertainty associated with input datasets (activity data and emissions factors) used in emissions calculations; (2) calculate a best estimate of emissions from deforestation and agriculture-driven deforestation based on the most certain datasets, to compare trends in space and time; (3) calculate the uncertainty of the best emissions estimates, and identify the input component which contributes most to uncertainty, and (4) to make recommendations for use/selection of data and further improvements on the estimation of emissions from deforestation.
2. Data and methods
For 91 countries in the tropics, CO2 emissions from all deforestation (D) and from only agriculture-driven deforestation (ADD) were calculated. Agriculture-driven deforestation, a subset of deforestation, is defined as deforestation where the follow-up land-use is agriculture. Agriculture is defined broadly in this study, and includes subsistence agriculture, and large-scale pastures, as well as tree crops (De Sy et al 2015, Hosonuma et al 2012). A land-use definition of gross deforestation from the FAO was therefore used (see appendix S1 available at stacks.iop.org/ERL/13/014002/mmedia) to assess if the change was driven by agriculture. It was assumed that emissions resulted from loss of above- and below-ground biomass, a fraction of which remained (or is replaced by new biomass) following deforestation. The datasets and data availability are described in table 1 and figure 1.
Table 1. Description of input data for emissions estimates from deforestation and agriculture-driven deforestation.
| 'Abbreviation' Source | Description |
|---|---|
| Deforestation area (A) | |
| 'FRA' The Global Forest Resource Assessment (FAO 2015) | Country reported data on gross area of deforestation (deforestation), and net changes in forest area (net). Uses FAO forest land-use definition of forests and forest change. Net data cover the years 1990–2000, 2000–2005, 2005–2010, 2010–2015; and deforestation 1988–1992, 1998–2002, 2003–2007, 2008–2012. |
| 'RSS' Remote Sensing Survey (FAO and JRC 2012) | A sample-based dataset comprising 10 km × 10 km squares at intersections of every degree line of latitude and longitude. FAO forest land-use definition of forests and forest change are used. Data cover the years 1990–2000, and 2000–2005. |
| 'Kim' (Kim et al 2015) | Map based on 30 m resolution Landsat data. Forest-cover loss in forests >30% canopy cover, and parcels >1 ha. Data cover the years 1990–2000, 2000–2005, and 2005–2010. |
| 'Hansen' (Hansen et al 2013) | Map based on 30 m resolution Landsat data of gross forest cover loss. 10% canopy cover threshold for forests and 0% for deforestation. Data from 2000–2014 (all years) are available. |
| Forest biomass (CB) | |
| 'Baccini' (Baccini et al 2012) | Map of biomass in aboveground woody vegetation (AGB) in the tropics at a 500 m resolution. In this study, AGB with a conversion factor from Saatchi et al (2011) is used to calculate BGB. The map is representative of the time period 2007–2008. |
| 'Saatchi' (Saatchi et al 2011) | Map of forest carbon contained in AGB and BGB in the continental tropics at a 1 km resolution. The map is representative of the early 2000s. |
| 'Avitabile' (Avitabile et al 2016) | Map of biomass in aboveground woody vegetation (AGB) in the tropics at 1 km resolution obtained by the integration of the Baccini and Saatchi maps with an extensive reference dataset. In this study, AGB with a conversion factor from Saatchi et al (2011) is used to calculate BGB. The map is representative of the 2000s. |
| Lost biomass fraction (fCBAgri/fCBLU) | |
| 'De Sy1' (De Sy 2016)/(FAO and JRC 2012)/(Zarin et al 2016)/(Hansen et al 2013) | Deforested areas of the RSS dataset were interpreted using high resolution satellite imagery to assess the land use after deforestation (follow-up land-use). For this study follow-up land uses were aggregated to agriculture (fCBAgri) or to other land uses (fCBLU). The fraction of biomass lost due to forest conversion were derived from a 30 m biomass map from Zarin et al (2016). The Hansen dataset was used as an additional forest mask. Data cover the years 1990–2000. |
| Agriculture-driven deforestation fraction (fAAgri) | |
| 'Hosonuma' (Hosonuma et al 2012) | Literature, country reports, and the country forest transition curve provided information on the drivers of deforestation. Most data are representative of the years 2000–2010. |
| 'De Sy2' (De Sy 2016)/(FAO and JRC 2012) | The deforested areas of the RSS dataset were interpreted using high resolution satellite imagery to assess the follow-up land-use. Data cover the years 1990–2005. |

Figure 1. Number of datasets available per country per component (a), (b), and (c) for 2000–2005.
Download figure:
Standard image High-resolution imageEmissions were calculated from activity data and an emission factor. Activity data were deforestation area (A) for D, and for ADD, they also included the agriculture driver fraction (fAAgri), representing the fraction (f) of forest area replaced by agricultural land use. The emissions factor comprised: the carbon in above- and below-ground forest biomass (AGB + BGB; converted to CO2) (CB) (before deforestation), and the fraction of this biomass which is lost on the land following deforestation in either all land uses (fCBLU), or only agricultural land uses (fCBAgri) (equations (1) and (2))
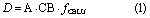
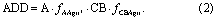
The deforestation area (A) datasets use different definitions of deforestation, and some are more suited to our purposes than others (table 2). The datasets not matching our (the FAO) deforestation definition needed to be harmonized (see Keenan et al 2015). Three differences in the definitions make the estimates thematically mismatched; (1) the use of a net change, rather than only forest loss data, (2) the use of a land cover rather than land use definition and (3) only accounting losses in forest with a tree cover larger than 30% rather than using the 10% threshold. The data were harmonized using available data from which the mismatch was estimated (see appendix S1 for details).
Table 2. Suitability of area data to estimate agriculture-driven deforestation in this study.
| Dataset | Characteristics |
|---|---|
| FRA | Some countries have gross deforestation data which matches the FAO definition, and all time periods are covered, but net rather than gross data is provided in many cases. |
| RSS | Some countries have few sample units, so data are generally best suited to regional estimates, however the deforestation definition matches ours. Data are only available for the first two time periods. |
| Kim | Few countries have data available, and the dataset uses a land cover rather than land use definition, and canopy cover threshold differs. Data cover the entire time period. |
| Hansen | Land cover definition rather than land use, however data for all canopy covers are available, so our chosen threshold can be used. Data cover the last three time periods. |
Outputs were generated for four time periods between 1990 and 2015. The variable A was assumed to be potentially dynamic over the time periods, but the other variables were assumed to remain constant (though uncertain).
For each component (x) (only A, CB, and fAAgri, as fCBLU, and fCBAgri only had one available estimate) a best estimate ( ) was calculated using a weighted mean of available datasets. This weighted mean (
) was calculated using a weighted mean of available datasets. This weighted mean ( ) was calculated (equation (3)), with weights (wi) being proportional to the inverse of the error variance (σi2) for the Ith dataset (so more certain estimates have larger weights) (equation (4)). Variance for the weighted mean (σ2x) is then calculated (equation (5))
) was calculated (equation (3)), with weights (wi) being proportional to the inverse of the error variance (σi2) for the Ith dataset (so more certain estimates have larger weights) (equation (4)). Variance for the weighted mean (σ2x) is then calculated (equation (5))
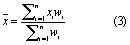
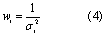
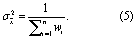
We produced time-series of A by starting with the best estimate of A at the country level calculated for the 2000–2005 period, since most data are available for this time period. The variable A is then reconstructed forwards and backwards from this starting point. In other words, estimates of A for other periods were only used to identify the relative difference to the time periods 2000–2005 and not their absolute values. The trend for the change between periods 1990–2000 and 2000–2005 was calculated from either or both FRA and RSS. The trend for the change between periods 2000–2005 and 2005–2010, and between 2005–2010 and 2010–2015 was calculated from either or both FRA and Hansen. Kim was not included in this part of the analysis, since few countries were covered in that study. Where two datasets were used, a weighted average was used,with weights (equation (4)), relating to the uncertainty of each dataset. The mean of the weights for the two time periods relevant to the trend was used (i.e. trend between 2000–2005 and 2005–2010 would use a mean of the weights of the two time periods 2000–2005 and 2005–2010).
Table 3. Error sources leading to uncertainty in the datasets.
| Type of error | Explanation |
|---|---|
| Lack of data | Data do not cover the required time period, but data from other time periods are available and were used to fill the gap in data lacking time periods by the data provider, or in this study. |
| Measurement-error: data quality | Data may be approximated based on limited information, for example a country may lack the capacity to report forest area accurately, as they lack recent satellite data, or do not have recent forest inventories. Where visual interpretation of satellite data is used to produce information, there is an error associated with this process. |
| Measurement-error: Adjustment for thematic mismatch or bias | Area of deforestation data were harmonized and the adjustment leads to error, as the true value of the thematic mismatch is unknown. Likewise, forest biomass data were adjusted for bias (see appendix S1 for details), which also introduces error. |
| Statistical sampling error | The effect of the sampling size, and the variability between sample units contribute to errors in the estimate. |
2.1. Identifying and quantifying uncertainty
The terms error and uncertainty, are often used interchangeably (Taylor 1997, Heuvelink 2005), and in this study both are used; error to represent the difference between an estimate and the true value, and uncertainty to represent a quantification of the distribution of error. If uncertainty information is not available, potential error sources contributing to uncertainty were identified and the magnitude of each source estimated for each input dataset. All datasets were assessed for the broad causes of uncertainty described by the IPCC (2006) (summarized in table 3).
For each country, the uncertainties identified in each dataset are defined for each time period (table 4).
Table 4. Causes of error considered (✓) in each dataset.
| Data source/type of error | FRA | RSS | Hansen | Kim | Avitabile | Baccini | Saatchi | De Sy1 | De Sy2 | Hosonuma |
|---|---|---|---|---|---|---|---|---|---|---|
| Data use/type | Deforestation area (A) | Forest biomass (CB) | Lost biomass fraction (fCBAgri/fCBLU) | Agriculture-driven deforestation fraction (fAAgri) | ||||||
| Lack of data | ✓a | ✓cd | ✓cd | ✓ad | ||||||
| Measurement-error: data quality | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Measurement-error: adjustment for thematic mismatch or bias | ✓e | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Statistical sampling error | ✓ | ✓ | ✓ | |||||||
eonly 'net' data; a = 1990–2000; c = 2005–2010; d = 2010–2015 (no letter indicates that uncertainty applies to all time periods).
For many datasets,it was not possible to quantify uncertainty using data (e.g. with statistical approaches), so data from additional sources and expert judgement were used (appendix S2).
The overall uncertainty (σ2) was calculated by combining the uncertainties associated with each error source (σi2) (i...n) (equation (6)). Where all terms (error sources) are assumed to additively contribute to total uncertainty
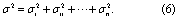
Following guidelines from the IPCC, upper and lower estimates correspond to a 95% confidence interval (CI), as a percent of the mean (IPCC 2006) (equation (7))
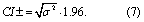
In case the estimate for the area of deforestation (A) was zero for a particular country, when calculating the confidence interval, A was substituted by the mean deforestation estimate from other (non-zero) time-periods in that dataset.
2.2. Propagating uncertainty
Once errors have been calculated for each dataset, they must be propagated to derive uncertainties for D and ADD. Errors associated with the inputs were assumed to be independent, normally distributed, and without bias. We used the exact equation for the variance of the product of three and four independent random variables (Goodman 1962) (equations (8) and (9)) to calculate the output variance (σ2)
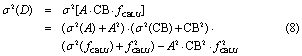
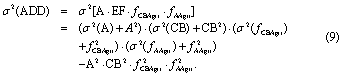
2.3. Contribution of input uncertainty to uncertainty of the emissions estimate
The contribution of each component was assessed as the reduction in the output variance when the corresponding input variance was set to zero. In other words, we recalculated (equations (8) and (9)) multiple times, setting for each recalculation one of σ2 (A), σ2 (CB), σ2 (fCBLU) or σ2(fCBAgri), σ2(fAAgri) to zero. The lowest outputvariance for which the variance of that element (A, CB, fCBLU or fCBAgri, fAAgri) is set to zero, is the one with the largest contribution to the uncertainty.
Some of the uncertainty estimates were based on expert judgment. We used a sensitivity analysis to explore how a different judgement would alter the uncertainty of the final value. Initial assumptions (section 2.1), were compared to three adjustments (table 5). For each adjustment, the emissions are recalculated, and the change in emissions estimate uncertainty calculated.
Table 5. Parameters for the sensitivity analysis. The original expert judgement, and adjusted uncertainties as a % of the estimate) for several sources of uncertainty are shown.
| Assumptions made for errors/type of error | Original expert judgement | Adjustment 1 (high extrapolation error) | Adjustment 2 (high visual interpretation error) | Adjustment 3 (high error from adjustment for thematic mismatch or bias) |
|---|---|---|---|---|
| Lack of data | 15 | 30 | 15 | 15 |
| Measurement-error: visual interpretation error | 5 | 5 | 30 | 5 |
| Measurement-error: adjustment for thematic mismatch or bias | 3 | 3 | 3 | 30 |
Table 6. The number of countries whose trend of deforestation area (A) was derived from each dataset or combination of datasets.
| 1990–2000 and 2000–2005 | 2000–2005 and 2000–2005 | 2005–2010 and 2010–2015 | |
|---|---|---|---|
| Datasets used to derive the trends | |||
| FRA | 21 | 5 | 4 |
| RSS | 1 | – | – |
| FRA and RSS | 69 | – | – |
| Hansen | – | 1 | 1 |
| FRA and Hansen | – | 85 | 86 |
| Dataset with the highest contribution to the trend | |||
| FRA | 27 | 46 | 53 |
| RSS | 64 | – | – |
| Hansen | – | 45 | 38 |
3. Results
3.1. Data selection
We usedall available datasets to calculate emissions giving higher weight to the most certain dataset available. Figure 2 shows the weight given to the datasets for each component, based on their uncertainty.

Figure 2. Contribution (%) of (a) FRA, (b) RSS, (c) Kim, and (d) Hansen to estimates of A, and of (e) Baccini, (f) Saatchi, and (g) Avitabile to estimates of CB, and of (h) Hosonuma, and (i) De Sy2 to estimates of fAAgri in 2000–2005.
Download figure:
Standard image High-resolution imageFigure 2 is driven by both the availability of data, and the weight of each dataset. For component A, RSS and FRA have the highest weighting for the most countries (33 each). Large countries (Brazil, India, China) tend to have a higher weighting for the RSS data, since they have a larger number of sample units, which increases the certainty of the data. The weighting of the RSS data is also driven by the variability in the proportion of deforestation in each sample within a country. Countries which have better data (indicated by higher capacities, or access to better data and support), for example the majority of countries in South and Central America, have a higher weighting for the FRA data. In Africa, more countries (20 out of 43 countries) have the highest weighting for the Hansen data. These tend to be countries with lower capacity, and relatively few RSS sample units. Kim consistently gets low weightings, as although the uncertainties in terms of the CI when expressed as a percent of the estimation are the same as Hansen, the estimates tend to be higher, so variances are also higher. For the biomass in forests, these datasets generally have a more equal weighting, however the Avitabile dataset is more certain, and carries the highest weight in 85 of the 91 countries. For the remaining 6 countries, Saatchi has the highest weight. For the fraction of deforestation which is driven by agriculture, in 43 out of 91 countries only the Hosonuma data are available. For the remaining countries, most (42 of 48) have a higher weight for the Hosonuma data. The countries where De Sy2 has a higher weight are larger countries, which as a result have more sample units (Brazil, India, Mexico, Namibia, Venezuela and Zambia).
3.2. Trend in area of deforestation
The area of deforestation is dynamic and drives most of the trend of the emissions calculations. Between the first two time periods (1990–2000 and 2000–2005), RSS more frequently has the highest weighting. The last two trends (between the last three periods) show a more even distribution, where FRA and Hansen are almost equally likely to contribute the most to the estimate of deforestation. However FRA tends to dominate in Latin America and Asia, while Hansen dominates in Africa, with the exception of some countries including Democratic Republic of Congo, South Africa, and Madagascar most notably (figure 3, table 6).

Figure 3. Contribution (%) of FRA to the trend of deforestation area (A) between (a) 1990–2000 and 2000–2005, (b) 2000–2005 and 2005–2010, and (c) 2005–2010 and 2010–2015, RSS to the trend between (d) 1990–2000 and 2000–2005, and Hansen to the trend between (e) 2000–2005 and 2005–2010, and (f) 2005–2010 and 2010–2015.
Download figure:
Standard image High-resolution imageThe trends for the same time period derived from two different datasets (either FRA and RSS or FRA and Hansen) can disagree in the direction or the magnitude of the change. This difference can be relatively large (mean absolute trend difference is 1.47), with the FRA and RSS being on average more different (absolute difference of 1.9 between the periods 1990–2000 and 2000–2005), and FRA and Hansen being more similar. In many cases, the trend direction is the same for both datasets, and the trend between the last time periods (2005–2010 and 2010–2015) has the most agreement from the contributing datasets, with only 16% of countries having conflicting trends. For the trend between the first two time periods (1990–2000 and 2000–2005) 28% of countries have conflicting trends from FRA and RSS.
A number of countries in Asia have the highest agriculture-driven deforestation between 1990 and 2005. In Africa, the majority of countries had their highest period of agriculture-driven deforestation in 2010–2015 (figure 4).

Figure 4. Period (years) of highest agriculture-driven deforestation.
Download figure:
Standard image High-resolution image3.3. Emissions from deforestation and agriculture-driven deforestation
Latin America is the greatest contributor to global emissions from deforestation and agriculture-driven deforestation, while Africa is the lowest but shows a continual growth in emissions (figure 5). In Africa, the highest emission rates (412 ± 75 Mt CO2 yr−1) occur in the 2010–2015 period, whereas for Latin America the emissions peaked during 2000–2005 (971 ± 148 Mt CO2 yr−1) and decreased afterwards. Overall, the highest annual emission rates (1792 ± 133 Mt CO2 yr−1) occurred in 2005–2010, with the lowest in 1990–2000 (1511 ± 174 Mt CO2 yr−1). Although Brazil's emissions have declined since 2005, these emissions still dominate in the region. Emissions from agriculture-driven deforestation are on average 72% of emissions from all deforestation. This is highest in Latin America (78%), and lowest in Africa (62%). In Asia it is 67%. The remainder of Latin America has the highest proportion of agriculture-driven deforestation (94%), and Indonesia has the lowest (52%).

Figure 5. Annual emissions from agriculture-driven deforestation (Mt CO2), in (a) Africa, Latin America and Asia and (b) a breakdown of those groups to Democratic Republic of the Congo (DRC), humid tropical Africa, the remainder of Sub-Saharan Africa, Brazil, Pan-Amazon, the remainder of Latin America, Indonesia, mainland South and South-east Asia, and insular Southeast Asia. Error bars represent the 95% confidence intervals (or range which represents the uncertainty around the estimate) for emissions from agriculture-driven deforestation and total deforestation. The regions are defined by Tyukavina et al (2015).
Download figure:
Standard image High-resolution image3.4. Uncertainties
The uncertainty of the emissions estimates of agriculture-driven deforestation range between ± 24.9 to ± 283.1% of the estimate, with a mean of ± 62.4% per country (figure 6). The uncertainty for estimates of emissions from deforestation range from ± 10.7 to ± 260.9%, with a mean of ± 29%. At the country level, typically Latin America has lower uncertainties than Africa or Asia, however the highly forested countries in Asia and Africa (for example Indonesia and Democratic Republic of Congo) also have lower uncertainties. Uncertainties for agriculture-driven deforestation emissions are higher than uncertainties for deforestation emissions (figure 5). When country uncertainties are aggregated, uncertainties for emissions are higher in Asia ( ± 22.5% for ADD and ± 7.7% for D), followed by Africa ( ± 16.7% for ADD and ± 6.1% for D), and Latin America ( ± 15.9% for ADD and ± 6.1% for D). Uncertainties for global aggregates are ± 11.4% for ADD and ± 4.3% for D.

Figure 6. Uncertainty ( ± %, which represents a 95% CI) of estimates of emissions from agriculture-driven deforestation. The colour scale is in quantiles (equal frequency of observations per group, in order to better show the differences between countries).
Download figure:
Standard image High-resolution imageFor estimates of emissions from deforestation, A is more frequently the largest contributor to the uncertainty, and fCBLU is more frequently the smallest contributor. In the case of emissions from agriculture-driven deforestation, fAAgri is more frequently the largest contributor to the uncertainty, and CB is more frequently the smallest contributor. This pattern is clear in all continents, with some exceptions, including a number of countries in Latin America, wherethe forest biomass fraction and lost biomass fraction contribute to a relatively large amount of the uncertainty (figure 7).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 7. Contribution (%) to uncertainty of estimates of emissions from deforestation (D) (left side of figure) from (a) A, (b) CB, (c) fCBLU, and emissions from agriculture-driven deforestation (ADD) (right side of figure) from (d) A, (e) CB, (f) fCBAgri, and (g) fAAgri. The darker colours therefore represent the main sources of uncertainty in the two emissions estimates.
Download figure:
Standard image High-resolution image{kind=link}
Sensitivity analysis was implemented to determine how changes to the uncertainty estimates for each input variable influence the uncertainty of the emissions estimates. Increasing the estimated uncertainty associated with the adjustment for the thematic mismatch leads to the largest change in the uncertainty of the emissions estimate, and increasing the extrapolation error leads to the smallest change to the uncertainty. A 10 fold increase in the uncertainty related to the adjustment of the thematic mismatch or bias leads to a ± 17.74% change in the final uncertainty estimate, which accounts for 63.73% of the original uncertainty for emissions from agriculture-deforestation. Doubling the extrapolation error from ± 15% to ± 30% leads to the smallest change in uncertainty for deforestation emissions; only ± 0.37%, which accounts for 1.5% of the original uncertainty estimate (appendix S2).
4. Discussion
We firstly compare the results of this study to the results of other studies. Then we discuss several implications from this study.
4.1. Deforestation estimates
In general, our results for area of forest loss are similar (73–108%) to other published data (see appendix S3 for details). All the studies used in the comparison use a land cover definition, and thus report forest losses in land where there is no change in use, which would not be included in our study. Our emissions from deforestation are 52–75% lower than those from other studies because we take into account the new biomass which replaces forest biomass, or the biomass from the forest which remains on the land, whereas other studies assume that all the biomass is lost following deforestation. This makes a large difference in Asia, where due to tree crops often replacing forests, the biomass lost is replaced by more new biomass than in other land use conversions. The definition of forests can also explain some of the differences. Tyukavina et al (2015) have a higher canopy cover threshold (25%), while Harris et al (2012b) look at the removal of any forest cover. This particular difference would lead to an underestimation from our study in comparison to Tyukavina et al (2015), and an overestimation in comparison to Harris et al (2012b). Achard et al (2014) distinguishes between forests and tree cover mosaics (>70% and 30–70% tree cover respectively), and also 'other wooded land' (OWL). OWL is defined as 'all other woody vegetation (height <5 m), including shrubs and forest regrowth'. OWL is also likely to be found in dry forests, which are difficult to measure, and there is more disagreement over their extent (Bastin et al 2017). Data from Achard et al (2014) used for the comparison could include OWL which is not included in the definition of forests in this study, so we would expect this to lead to higher results from Achard et al (2014). The results for South and Central America are more in agreement in these two studies than those for Africa and Asia. Proportionately, according to Achard et al (2014) there is more OWL in Africa: 58% of the total forest in 2010, in comparison to South and Central America and South East Asia, which have 18% and 31%, so this could explain the differences.
4.2. Data selection for emissions estimates
The best combination of data for emissions estimates differed from country to country (figures 2 and 3). Input data were weighted according to their uncertainty, and these weights can guide decision makers on data selection in similar contexts to this study. It should also be noted that in addition to the uncertainty of the dataset influencing the weight, the magnitude of the estimate also influences the weight. For example, the Kim dataset consistently had lower weights than Hansen, even though the two datasets had similar percent confidence intervals, due to the higher estimates of Kim. For biomass, the Avitabile dataset is most often selected, unless it is not available, where Saatchi is selected. However all datasets have similar uncertainties so could all be considered useful. For the agriculture-driver fraction, the results of this study suggest that only large countries should use De Sy2 above the Hosonuma data. We however suggest that an individual examination of both datasets at the national level may lead to different conclusions about the reliability of the datasets. In fact, both Hosonuma and De Sy2 were found to have large uncertainties.
4.3. Reducing emissions from agriculture-driven deforestation
The urgent need to limit global temperature increases below 2 °C will require actions to reduce all emissions sources, and as a major source of deforestation emissions, reducing agricultural expansion into forests should be considered as a mitigation priority. Latin America currently has the largest emissions from the regions in this study, however emissions have been reducing over the period of the study (figures 4 and 5). Africa has seen a consistent increase in emissions between 1990 and 2015, as predicted by past studies (Barnes 1990). Countries or regions with the largest increase in emissions could be targeted for mitigation actions, for example DRC which saw a large increase between 1990 and 2005, and humid Africa which saw a large increase between 2005 and 2015. In order to address agriculture-driven deforestation, targeted interventions should be developed which address specific agricultural activities. In these cases, interventions in the agriculture sector to mitigate emissions from agriculture-driven deforestation can be effective. Areas with either a yield gap which can be reduced, or with available degraded land which can potentially be rehabilitated have been highlighted for their mitigation potential (Carter et al 2015). There is some debate on the conditions under which these agricultural interventions will be successful (see for example Angelsen and Kaimowitz 2001), however implementation of forest protection activities (such as REDD+) are highlighted as being essential to ensure that forests are protected (Mertz and Mertens 2017). Although in all the countries included in this study, agriculture was found to be the largest driver of deforestation, it could be the case that in the future other drivers become more important, and we acknowledge the need to monitor all drivers. In this paper we do not address emissions related to other carbon pools (such as soil), or indirect emissions for example those related to the life cycle of agricultural products (which may lead to further deforestation). These will result in additional emissions above those considered in this study. Additionally we do not include emissions from forest degradation, which may be significant as estimated by (Baccini et al 2017), and can also result from agriculture.
4.4. Limitations of this study
Estimates of the trend in area of deforestation were provided by two datasets for each time period, and were in some cases very different (section 3.2). We used a weighted mean to prioritize the most certain estimate, however in the case that the two datasets predict an opposite trend (one increasing and one decreasing), the weighted average will thus produce a trend which is closer to 1, which may not reflect the actual trend. This effect will be most seen in the first time period, where there is more disagreement between datasets. Another challenge in this study was the production of comparable uncertainty estimates. Using uncertainties from the data providers themselves, could lead to better results. The current method relies on assumptions about the uncertainties related to the datasets, as many were lacking information or had uncertainty information which could not be used in this study. Our research estimated uncertainties which aimed to capture all the sources of error for each dataset, and it could be that errors exist which were not included in the study. In some cases, expert judgement was used to quantify the uncertainty, which may be erroneous. However sensitivity analysis confirmed (section 3.4) that in many cases the change in uncertainty was not large following a change in the assumptions which were based on expert judgement. Hence, if our uncertainty estimates based on expert judgement are incorrect, this will not substantially influence the overall uncertainty estimates. Additional uncertainties exist in the ancillary data are used to harmonize the datasets (due to thematic mismatch) but we chose not to include those uncertainties, as they are unknown, although some error is assumed to be included during harmonization. Future studies could explore this further. Lack of available data also limited the study. Only the area dataset was considered to be dynamic, with the remaining datasets assumed to be constant over time. Because there is not available data over time for emissions factors or drivers of deforestation, we were not able to capture this dynamic in our end results. This means that the trend in emissions is determined mainly by the area data, and in reality it may be influenced by changes over time in the other inputs, for example emissions factors.
4.5. Reducing uncertainties in estimates of emissions from agriculture-driven deforestation
Uncertainties associated with our estimates of D and ADD are in some cases very high at the country level (for example Uruguay is ± 182% for ADD), although the average for ADD is much lower (± 62%) (figure 6). Large uncertainties are in line with findings in Houghton et al (2012), and Roman-Cuesta et al (2016) who found that uncertainties from forest loss contribute to 98% of the uncertainty of AFOLU emissions, while only contributing to 69% of the emissions. The authors recommend that uncertainties are reported in future datasets (to increase transparency), and that improvements in datasets (increased certainty) should be pursued. Since area data and agriculture-driver factors are the least confident, improvement in the uncertainties related to these estimates will also provide the greatest reductions in uncertainties of emissions estimates. There are two ways to address these uncertainties when reporting for mechanisms such as REDD+. Either the upstream uncertainties are reduced by improving the input datasets, or the emissions estimates are adjusted downstream, by discounting or reducing the estimates (a conservative approach) to avoid overestimating emissions reductions (Pelletier et al 2015). The findings of this study suggest that the upstream adjustments should be made to avoid having to implement downstream adjustments, which reflect negatively on the credibility of the mechanism.
Acknowledgments
This research is part of CIFOR's Global Comparative Study on REDD+ (www.cifor.org/gcs). The funding partners that have supported this research include the Norwegian Agency for Development Cooperation (Norad) [grant no. QZA-16/0110 No. 1500551] and the International Climate Initiative (IKI) of the German Federal Ministry for the Environment, Nature Conservation, Building and Nuclear Safety (BMUB) [grant no. KI II 7—42206–6/75], and the CGIAR Research Program on Forests, Trees and Agroforestry (CRP-FTA), and Climate Change Agriculture and Food Security (CCAFS) with financial support from the CGIAR Fund Donors. The authors thank Louis Verchot for his contribution to the inception of the paper and his helpful insights on the topic; Mathieu Decuyper, Ben Devries and Johannes Reiche for technical assistance; and Erika Romijn for providing data. The authors thank two anonymous reviewers for their comments which have substantially improved the manuscript.