



Abstract
We derive an equality for non-equilibrium statistical mechanics in finite-dimensional quantum systems. The equality concerns the worst-case work output of a time-dependent Hamiltonian protocol in the presence of a Markovian heat bath. It has the form 'worst-case work = penalty—optimum'. The equality holds for all rates of changing the Hamiltonian and can be used to derive the optimum by setting the penalty to 0. The optimum term contains the max entropy of the initial state, rather than the von Neumann entropy, thus recovering recent results from single-shot statistical mechanics. Energy coherences can arise during the protocol but are assumed not to be present initially. We apply the equality to an electron box.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. General introduction
Average values of quantities are not always typical values. In non-equilibrium nano and quantum systems this is often the case, with, for example, the work output of a protocol having a significant probability of deviating from the average. Hence, in these important systems, statements about averages have limited use when it comes to predicting what will happen in any given trial; the fluctuations need to be discussed explicitly. Two key relations concerning fluctuations in work, Crooks' theorem [1] and Jarzynski's Equality [2], have been studied extensively theoretically and experimentally. These theorems hold for any speed of changing the Hamiltonian, the thermalization can be partial or negligible during the protocol. Amongst other things the theorems can be used to determine free energies of equilibrium states from non-equilibrium experiments.
A recently developed alternative approach is single-shot statistical mechanics [3–12], inspired by single-shot information theory [13, 14]. The focus is on statements that are guaranteed to be true in every trial, rather than on average behaviors. For example, one can ask whether a process's work output is guaranteed to exceed some threshold value (such as an activation energy), or whether a process's work cost is guaranteed not to exceed some threshold value (beyond which the system may break from dissipating heat). These statements concern the worst-case work of a process. A key realization is that the optimal worst-case work is determined not by the von Neumann/Shannon entropy of the initial state, but rather the max entropy, which is the logarithm of the number of non-zero eigenvalues of the density matrix. Thus, which entropy one should use in statements about optimal work depends on which property of the work probability distribution one is interested in.
Single-shot statistical mechanics began with almost no a priori relation to fluctuation theorems. Promising links were made in [6, 15]. In [15] it was shown that Crooks' theorem can be used to make statements about worst-case work. This created the beginnings of a bridge between Crooks' theorem and results in single-shot papers. We here complete the bridge, showing that key expressions concerning optimal worst-case work from [3, 5, 6] follow from Crooks' theorem plus some extra thought. To our knowledge this is a new and unexpected result. We moreover generalize them by giving an equality for the worst-case work. The equality governs time-varying Hamiltonian protocols, including fast ones, assuming Markovian heat baths and a weak restriction on the strength of any initial quench. The initial state is taken to be diagonal in the energy eigenbasis, though not necessarily thermal, and energy coherences can arise during the protocol. Figure 1 illustrates the set-up. The equality has the form 'worst-case work = penalty—optimum,' with the penalty term guaranteed to be non-negative such that the optimum can be derived by setting the penalty to zero. We believe this concrete link to fluctuation theorems will give significant impetus to single-shot statistical mechanics, allowing it to harness results from the highly developed fluctuation theorem approach. As a demonstration we apply the result to an electron box experiment described in the fluctuation theorem formalism [16–18]. We begin by defining the general set-up.

Figure 1. Setup: a working-medium, a battery from which work is taken or given to and a single heat bath. The battery system alters the Hamiltonian of the working-medium, depicted with the blue arrow shifting an energy level. The heat bath induces jumps between the system energy levels, depicted by the red arrow.
Download figure:
Standard image High-resolution image2. Trajectory model
The physical scenario is depicted in figure 1. For concreteness, we shall use the following explicit model (and later discuss other possible models). A protocol will be a sequence of elementary changes: (i) changes of the Hamiltonian and (ii) thermalizations. We shall initially assume there is a finite number of such steps (but later show that the continuum limit is well-defined and corresponds to a master equation, at least in the discrete-classical case). The Hamiltonian is parameterized by 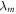 , with m an integer that labels the step.
, with m an integer that labels the step.
1. Hamiltonian changes map 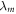 to
to 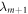 . We follow [19] in supposing there is an energy measurement in the instantaneous energy eigenbasis at the beginning and end of each Hamiltonian-changing step. In a given realization the system then evolves from
. We follow [19] in supposing there is an energy measurement in the instantaneous energy eigenbasis at the beginning and end of each Hamiltonian-changing step. In a given realization the system then evolves from 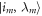 to
to 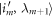 , where im labels the energy eigenstate. This costs work given by the energy difference:
, where im labels the energy eigenstate. This costs work given by the energy difference:  . An important special case is
. An important special case is 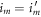 , which arises in the quasi-static (quantum adiabatic) limit, as well as if the energy eigenbasis is constant and only the energy eigenvalues change; this can be termed the discrete-classical case.
, which arises in the quasi-static (quantum adiabatic) limit, as well as if the energy eigenbasis is constant and only the energy eigenvalues change; this can be termed the discrete-classical case.
2. Thermalizations map 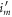 to
to 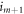 , cost no work, and preserve the Hamiltonian:
, cost no work, and preserve the Hamiltonian: 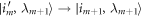 . For notational simplicity let us label this as
. For notational simplicity let us label this as 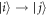 with energy
with energy 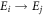 . We do not assume that the system thermalizes fully but that the hopping probabilities respect thermal detailed balance:
. We do not assume that the system thermalizes fully but that the hopping probabilities respect thermal detailed balance: 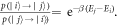 The energy change
The energy change  from such a step is called heat, Qm.
from such a step is called heat, Qm.
A trajectory is the time-sequence of energy eigenstates occupied: 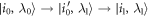
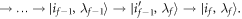
The probability of a given trajectory is accordingly, assuming a Markovian heat bath,
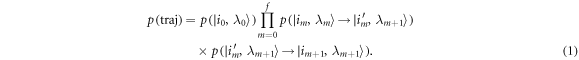
A trajectory's inverse is the reverse of the sequence. The inverse corresponds, in the discrete-classical case, to the Hamiltonian changes running in reverse, from 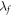 to
to 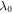 , and to the same thermalizations as in the forward protocol, with the sequence exactly inverted. This process is termed the reverse process. Beyond the discrete-classical case, the Hamiltonian changes corresponding to the reverse process are defined such that
, and to the same thermalizations as in the forward protocol, with the sequence exactly inverted. This process is termed the reverse process. Beyond the discrete-classical case, the Hamiltonian changes corresponding to the reverse process are defined such that  . Our results will hold under that condition. There are at least two ways of satisfying that condition: (i) Simply let the unitary of the corresponding elementary step in the reverse process be
. Our results will hold under that condition. There are at least two ways of satisfying that condition: (i) Simply let the unitary of the corresponding elementary step in the reverse process be 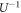 , where U is that of the forward process, (ii) apply a suitable 'time-reversal' operator Θ to all states and operators involved, as in [19]. The reverse trajectory is then the reverse sequence of the time-reversed energy eigenstates:
, where U is that of the forward process, (ii) apply a suitable 'time-reversal' operator Θ to all states and operators involved, as in [19]. The reverse trajectory is then the reverse sequence of the time-reversed energy eigenstates: 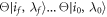 , with the condition
, with the condition 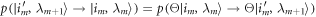 being satisfied, as time reversal implies taking the complex conjugate of the states, in a preferred basis, and the transpose of the time-evolution in the same basis:
being satisfied, as time reversal implies taking the complex conjugate of the states, in a preferred basis, and the transpose of the time-evolution in the same basis: 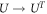 . The condition is thus satisfied as
. The condition is thus satisfied as 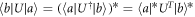 .
.
A given trajectory has some work cost 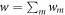 , in line with the definition of the Hamiltonian-changing steps. The inverse trajectory has work cost
, in line with the definition of the Hamiltonian-changing steps. The inverse trajectory has work cost 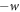 . A given protocol on a given initial state induces a probability distribution over trajectories, with an associated probability distribution over work p(w). The forward and reverse protocols give rise to
. A given protocol on a given initial state induces a probability distribution over trajectories, with an associated probability distribution over work p(w). The forward and reverse protocols give rise to 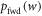 and
and 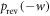 respectively.
respectively.
If the initial density matrices of the forwards and reverse processes are both thermal, 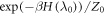 and
and 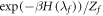 , Crooks' theorem holds [19]:
, Crooks' theorem holds [19]:
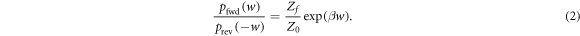
(To derive it take the ratio of equation (1) and the corresponding reverse trajectory expression. Apply thermal detailed balance and the equality of reverse hopping probabilities for the Hamiltonian-changing steps. Sum over trajectories with the same w, and note that the reverse of a trajectory has the same work up to a minus sign [19].)
3. Worst-case work
The central object of our interest is the worst-case work
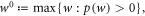
also known as the guaranteed work [7]. In physical situations this will have a finite upper bound as no battery has infinite energy. The worst-case value may be realized by a very unlikely trajectory. It is then natural to consider the worst-case work of a subset of trajectories 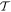 :
:
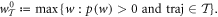
4. One-shot relative entropies
The standard relative entropy is ![$D(\rho | | \sigma ):= -\mathrm{Tr}(\rho [\mathrm{log}\rho -\mathrm{log}\sigma ])$](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn32.gif) [20], wherein logdenotes (in this paper) the natural logarithm, or ln. This D belongs to a class of relative entropies known as the Rényi relative entropies, parameterized by
[20], wherein logdenotes (in this paper) the natural logarithm, or ln. This D belongs to a class of relative entropies known as the Rényi relative entropies, parameterized by 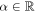 . We shall use two other members of that family: the (classical version of the)
. We shall use two other members of that family: the (classical version of the)  -relative entropy
-relative entropy 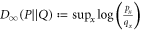 and the 0-relative entropy
and the 0-relative entropy 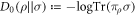 , wherein
, wherein 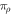 projects onto the support of ρ [21]. These are called one-shot relative entropies, as they arise naturally in one-shot (or single-shot) information theory [13, 14, 21].
projects onto the support of ρ [21]. These are called one-shot relative entropies, as they arise naturally in one-shot (or single-shot) information theory [13, 14, 21].
5. Worst-case work from Crooks
It was shown in [15] that one can recover an expression for the worst-case work w0 from Crooks' theorem equation (2). Consider the equality of Crooks' theorem (for values of w such that 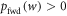 ) and select the value for w which maximizes the lhs (and thus the rhs) [15]:
) and select the value for w which maximizes the lhs (and thus the rhs) [15]:
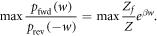
The rhs is monotonic in w, so maximizing the rhs over the support of 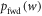 leads to the maximum w-value w0. Taking the logarithm and recalling the
leads to the maximum w-value w0. Taking the logarithm and recalling the 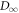 definition yields:
definition yields:
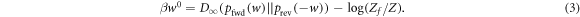
Note that this derivation assumes Crook's theorem which does not in general hold for athermal initial states.
6. Equality for worst-case work
Consider an initial state  , and a protocol of thermalizations and Hamiltonian changes with initial and final Hamiltonians
, and a protocol of thermalizations and Hamiltonian changes with initial and final Hamiltonians  and
and  respectively. This induces a work probability distribution p(w) and an associated w0. We shall derive an equality of the form
respectively. This induces a work probability distribution p(w) and an associated w0. We shall derive an equality of the form 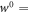 penalty—optimum.
penalty—optimum.
We consider initial states of form 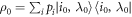 , i.e., diagonal in the energy eigenbasis though not necessarily thermal (energy coherence may still arise during the protocol). We take
, i.e., diagonal in the energy eigenbasis though not necessarily thermal (energy coherence may still arise during the protocol). We take 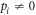 . This is because we wish to avoid divergences from dividing by pi. (See [22] for an alternative approach to this divergence problem.)
. This is because we wish to avoid divergences from dividing by pi. (See [22] for an alternative approach to this divergence problem.)
To apply Crooks' theorem (equation (2)) here, even though the initial state is not assumed to be thermal, our approach is as follows. For example, if one has a degenerate two-level system, the thermal state is 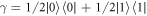 . If one instead had
. If one instead had 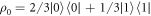 , the worst-case work would be the same as for γ. This follows because the set of trajectories with non-zero probability is the same in both cases, as can be seen from equation (1) which gives the probability of a trajectory. Given a
, the worst-case work would be the same as for γ. This follows because the set of trajectories with non-zero probability is the same in both cases, as can be seen from equation (1) which gives the probability of a trajectory. Given a 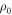 , we will find a corresponding thermal state with the same worst-case work and apply Crooks' theorem to that.
, we will find a corresponding thermal state with the same worst-case work and apply Crooks' theorem to that.
An important practical consideration which makes this more subtle is that some pi may be negligible and even arbitrarily close to 0. It is natural to exclude trajectories starting in those states when calculating the worst-case work. We therefore divide the initial energy eigenstates into two sets. One set is the one of interest: 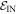 . The set of the other eigenstates, we call
. The set of the other eigenstates, we call 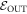 , corresponding to those we shall exclude when calculating the worst-case work. The probability of being in
, corresponding to those we shall exclude when calculating the worst-case work. The probability of being in 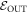 is given by
is given by
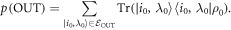
We define 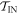 as the set of possible (
as the set of possible (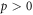 ) trajectories beginning in
) trajectories beginning in 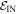 . Similarly, we define
. Similarly, we define 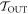 as the set of possible trajectories beginning in
as the set of possible trajectories beginning in 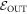 . Recall that each trajectory corresponds to some work value. We call the worst-case work of
. Recall that each trajectory corresponds to some work value. We call the worst-case work of 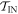 ,
, 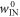 . This cannot be worse than the worst-case over all trajectories:
. This cannot be worse than the worst-case over all trajectories: 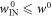 .
.
Let us design an associated thermal state that yields the same worst-case work as 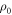 :
:  . Later, we show that this is indeed the case, under an additional mild assumption. The associated thermal state has the same Hamiltonian as the system apart from the OUT levels. We define the Hamiltonian as
. Later, we show that this is indeed the case, under an additional mild assumption. The associated thermal state has the same Hamiltonian as the system apart from the OUT levels. We define the Hamiltonian as 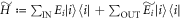 , changing the energies of the states in
, changing the energies of the states in 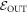 to new ones,
to new ones, 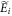 , such that
, such that 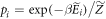 , and leaving the other energy levels the same. The thermal state associated with that Hamiltonian is then
, and leaving the other energy levels the same. The thermal state associated with that Hamiltonian is then
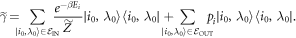
The definition implies that
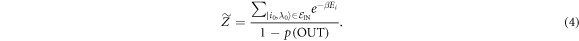
This partition function differs from that of the actual Hamiltonian 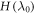 .
.
In this scenario with 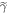 as the initial state and the
as the initial state and the 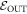 levels lifted, the protocol is the same as in the actual scenario, except that initially the energies of the states in
levels lifted, the protocol is the same as in the actual scenario, except that initially the energies of the states in 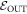 are lowered down to the levels of the actual Hamiltonian of interest. The worst-case work of this scenario is called
are lowered down to the levels of the actual Hamiltonian of interest. The worst-case work of this scenario is called 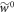 . Under a mild additional restriction on protocols considered, roughly speaking that the worst-case work is bounded from below—as is the case for physically realizable protocols (see Methods), we then have
. Under a mild additional restriction on protocols considered, roughly speaking that the worst-case work is bounded from below—as is the case for physically realizable protocols (see Methods), we then have
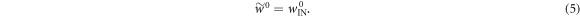
To get 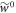 from Crooks' theorem (equation (2)) we shall make use of equation (3) from [15]. This applies in the scenario with
from Crooks' theorem (equation (2)) we shall make use of equation (3) from [15]. This applies in the scenario with 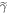 as the initial state, as Crook's theorem holds in that scenario (see discussion around equation (2)), and thus
as the initial state, as Crook's theorem holds in that scenario (see discussion around equation (2)), and thus
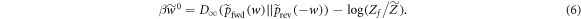
7. Main result
Combining equation (6) and equation (5) we have
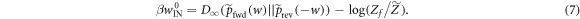
Thus the worst case work of the trajectories of interest 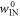 is this equal to (kT times) a relative entropy minus (the logarithm) of the ratio of two partition functions, one of which encodes information about how many of the initial energy eigenstates have negligible occupation probability.
is this equal to (kT times) a relative entropy minus (the logarithm) of the ratio of two partition functions, one of which encodes information about how many of the initial energy eigenstates have negligible occupation probability.
8. Discussion
Note that equation (7) has the form
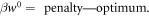
The penalty is essentially given by the difference between the forward and reverse distributions, quantified by D∞. The optimum one can hope for, with a given initial state and given initial and final Hamiltonian, is to set the penalty to 0 (as relative entropies are non-negative), which leaves 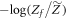 . This term is more negative the smaller the support of ρ is and the lower the final energies are relative to the initial ones. This optimum is achieved by a protocol in [7].
. This term is more negative the smaller the support of ρ is and the lower the final energies are relative to the initial ones. This optimum is achieved by a protocol in [7].
We now consider the optimum term in two important special cases where the single-shot entropy of the initial state emerges. To simplify the considerations we here set 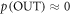 , although our full expressions do not assume that to be the case. The 'epsilonics' are dealt with explicitly in the Methods. (i) Consider firstly the special case of
, although our full expressions do not assume that to be the case. The 'epsilonics' are dealt with explicitly in the Methods. (i) Consider firstly the special case of 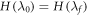 which has been studied in the single-shot statistical mechanics literature. Then
which has been studied in the single-shot statistical mechanics literature. Then 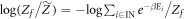 . This can be rewritten, informally, using the definition of D0 in the technical introduction and noting that the sum is only over IN levels, as
. This can be rewritten, informally, using the definition of D0 in the technical introduction and noting that the sum is only over IN levels, as 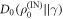 , where
, where 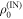 is
is 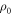 with the probability tail in OUT cut off—this is made general and precise in the discussion on smooth relative entropies in appendix
with the probability tail in OUT cut off—this is made general and precise in the discussion on smooth relative entropies in appendix
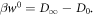
(Recall D∞ concerns work distributions and D0 states.) (ii) Further restricting the Hamiltonian such that 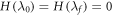 , we have
, we have 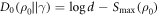 (noting
(noting 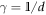 and recalling
and recalling 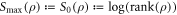 . This recovers the known results from [3, 5, 6] that these are optimal in the respective cases. The message is that it is the max entropy Smax which determines the optimal worst-case work, rather than the von Neumann entropy. If one defines thermodynamic entropy in terms of optimally extractable worst-case work, it is the max entropy which should be used.
. This recovers the known results from [3, 5, 6] that these are optimal in the respective cases. The message is that it is the max entropy Smax which determines the optimal worst-case work, rather than the von Neumann entropy. If one defines thermodynamic entropy in terms of optimally extractable worst-case work, it is the max entropy which should be used.
To make the connection to physics clear, we apply the results to a recent realization of a Szilard engine with an electron box [16–18]. A great advantage of using this trajectories model from the fluctuation theorem approach is that it allows the application of single-shot results to such experiments. We described the set-up in figure 2 and in the Methods section, we analyze what controls the penalty term D∞ in this scenario. We also describe in the Methods how the penalty term, up to vanishing probabilistic error, goes to 0 in the isothermal quasistatic limit.
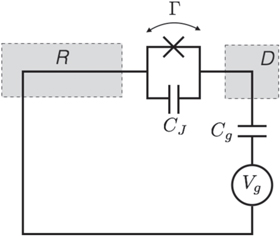
Figure 2. An 'electron box' (D) coupled to a metallic electrode (R) via tunneling and the capacitor with capacitance CJ, and to the gate electrode via the capacitor with Cg. The gate voltage Vg controls the number of excess electrons in the electron box, N. At low temperatures N is restricted to two possible values associated with 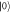 and
and 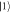 , with relative energy
, with relative energy 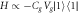 . The electrode R plays the role of a heat bath, with tunneling in/out of D corresponding to thermal excitation/relaxation. Experimentally the work and heat can be measured by probing the charge on D in real time [16–18].
. The electrode R plays the role of a heat bath, with tunneling in/out of D corresponding to thermal excitation/relaxation. Experimentally the work and heat can be measured by probing the charge on D in real time [16–18].
Download figure:
Standard image High-resolution imageAs described in the trajectories section, these results also apply if the evolution includes unitaries that create energy coherences, including sudden changes of the energy eigenbasis such that a state that was orginally an energy eigenstate is now classified as a superposition of energy eigenstates. Such coherences are normally viewed as associated with entropy production and extra work costs. We note an interesting counter-example. Working within this trajectory model, suppose 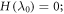
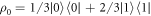 , and
, and 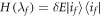 . If the energy eigenstates stay the same throughout such that
. If the energy eigenstates stay the same throughout such that 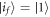 , the worst-case work is
, the worst-case work is 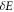 , and it has probability 2/3 (even if the shift is done quickly). If instead the Hamiltonian eigenstates change such that
, and it has probability 2/3 (even if the shift is done quickly). If instead the Hamiltonian eigenstates change such that 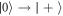 , and
, and 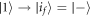 then the worst-case work is still
then the worst-case work is still 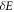 , corresponding to outcome
, corresponding to outcome 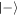 of the final energy measurement. However the probability of this can be as low as 1/2 (if H is changed suddenly
of the final energy measurement. However the probability of this can be as low as 1/2 (if H is changed suddenly 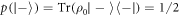 ). This shows that the probability of the worst case can actually be improved (lowered) by coherence due to a sudden change of the Hamiltonian. This improvement comes at the cost of randomizing the work distribution.
). This shows that the probability of the worst case can actually be improved (lowered) by coherence due to a sudden change of the Hamiltonian. This improvement comes at the cost of randomizing the work distribution.
The derivation of the main result relies very little on the specifics of the trajectory model. It would e.g. also go through with the quantum-jump type model in [23, 24]. That model uses no intermediate projective measurements on the system but rather on the heat bath, as is natural in quantum optics.
9. Summary and outlook
We showed that in any protocol with a time-varying Hamiltonian and thermalizations, the worst-case work takes the form of 'penalty—optimum'. The model we used could be generalized in various ways, including non-Markovian baths and baths that decohere in other bases than the energy basis. It is also important to find more bounds for the penalty term in terms of controllable parameters. Finally we note that the results of [25] suggest that the bounds obtained here also apply to what is known as thermal operations in the context of resource theories—another interesting question.
Acknowledgments
We are grateful to comments on a draft by Dario Egloff. We acknowledge funding from the EPSRC (UK), the Templeton Foundation, the Leverhulme Trust, the Oxford Martin School, the National Research Foundation (Singapore), the EU collaborative project TherMiQ (Grant agreement No. 618074), the Ministry of Education (Singapore), NSF grant PHY-0803371, an IQIM Fellowship, and a Virginia Gilloon Fellowship, the NRF Grant 2015-003689 (Korea), a BK21 Plus Project (Korea), and the Gordon and Betty Moore Foundation.
Similar results were obtained independently by Salek and Wiesner, using a different set-up and different starting assumptions, in: Fluctuations in Single-Shot  -deterministic Work Extractions [26].
-deterministic Work Extractions [26].
Appendix A.: Properties of  and associated protocol
and associated protocol

As Crooks' theorem, which we use, is for initial thermal states, we designed a thermal state 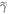 , with the aim of creating a set-up which yields the same worst-case work as for the actual initial state, which is not necessarily thermal. For a given initial state
, with the aim of creating a set-up which yields the same worst-case work as for the actual initial state, which is not necessarily thermal. For a given initial state 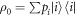 and initial energy eigenvalues Ei, the associated thermal state is defined as
and initial energy eigenvalues Ei, the associated thermal state is defined as 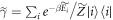 , where
, where 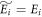 for
for 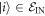 , but for
, but for  ,
, 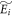 is chosen such that
is chosen such that 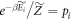 . Physically, this implies replacing the energy levels with small occupation probability pi by much higher energy levels such that their thermal occupation probability is as small as pi. The Hamiltonian associated with
. Physically, this implies replacing the energy levels with small occupation probability pi by much higher energy levels such that their thermal occupation probability is as small as pi. The Hamiltonian associated with 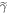 is accordingly
is accordingly 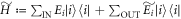 . The normalizing factor is
. The normalizing factor is 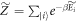 . These definitions imply that
. These definitions imply that
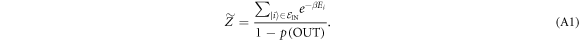
Apart from the given actual protocol, we then also design a ∼-protocol such that it gives the same worst-case work in the case of 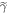 as the initial state. We define the ∼-protocol as beginning with
as the initial state. We define the ∼-protocol as beginning with 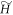 , then lowering the OUT levels back to Ei, i.e., setting
, then lowering the OUT levels back to Ei, i.e., setting 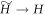 . After that it is the same as the actual protocol. We call the ∼-protocol applied to
. After that it is the same as the actual protocol. We call the ∼-protocol applied to 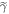 'the ∼-scenario.'
'the ∼-scenario.'
In the ∼-scenario we similarly have 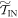 and
and 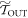 , and
, and 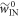 . The following holds:
. The following holds:
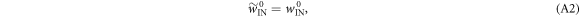
i.e., the worst-case work is the same in the ∼-scenario as in the actual scenario, for the 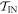 subset of trajectories. This is because the protocol is defined above such that the added initial step in the ∼-scenario only involves shifting the OUT levels (without any thermal hopping). The set of possible work values is the same in
subset of trajectories. This is because the protocol is defined above such that the added initial step in the ∼-scenario only involves shifting the OUT levels (without any thermal hopping). The set of possible work values is the same in 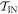 and
and 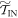 .
.
We now make the following mild restriction on protocols allowed:
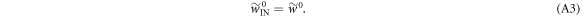
We say this is mild, because the trajectories 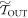 have an extra work gain relative to their sister trajectories in
have an extra work gain relative to their sister trajectories in 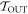 following from their initial lowering. This gain tends to infinity as
following from their initial lowering. This gain tends to infinity as 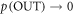 . Thus the ∼-protocol will not have worse possible work values than the actual protocol. The sort of protocols that are ruled out by the mild assumption are those where there is initially a dramatic quench without thermal hopping such that one of the OUT levels is raised very high. As long as it is not raised above the initial value of the level in the ∼-protocol the mild assumption is not violated however—the shifting down and up of the level would have a net work gain. This way the mild assumption does not rule out e.g. 2-level Szilard engine protocols where the second, likely empty, level is lifted very high initially and then lowered quasistatically. This example is studied in a physical system in appendix F below. Moreover, protocols involving thermalization at the start, including quasistatic protocols, or appropriately bounded initial quenches, are not ruled out.
. Thus the ∼-protocol will not have worse possible work values than the actual protocol. The sort of protocols that are ruled out by the mild assumption are those where there is initially a dramatic quench without thermal hopping such that one of the OUT levels is raised very high. As long as it is not raised above the initial value of the level in the ∼-protocol the mild assumption is not violated however—the shifting down and up of the level would have a net work gain. This way the mild assumption does not rule out e.g. 2-level Szilard engine protocols where the second, likely empty, level is lifted very high initially and then lowered quasistatically. This example is studied in a physical system in appendix F below. Moreover, protocols involving thermalization at the start, including quasistatic protocols, or appropriately bounded initial quenches, are not ruled out.
Combining equations (A2) and (A3) gives the desired expression used in the main body:

To help illustrate the notation a simple example of the ∼-protocol and how it relates to the actual protocol is in figure A1.
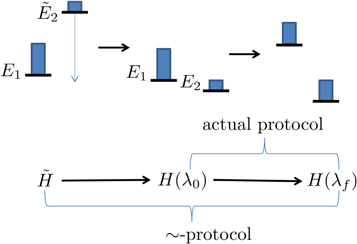
Figure A1. A very simple example of how we prepend an extra step to the actual protocol as part of the theoretical analysis. Here level 2 is designated as OUT. The energy of that level is initially higher than in the actual initial Hamiltonian 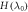 so that its occupation probability is thermal. Then it is lowered down without interacting with a thermal bath. Now the actual protocol begins.
so that its occupation probability is thermal. Then it is lowered down without interacting with a thermal bath. Now the actual protocol begins.
Download figure:
Standard image High-resolution imageAppendix B.: Smooth relative entropy
As noted in the main body, the optimum term reduces to a relative entropy in a special case. If 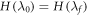 ,
, 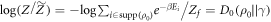 . Moreover if
. Moreover if 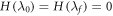 ,
, 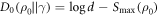 (noting
(noting  ). This recovers the known results from [3, 5, 6] that these are optimal in the respective cases. If p(OUT) defined above is not necessarily zero, this optimal term depends on which levels are chosen to be in
). This recovers the known results from [3, 5, 6] that these are optimal in the respective cases. If p(OUT) defined above is not necessarily zero, this optimal term depends on which levels are chosen to be in 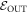 . If one chooses the best cut between IN and OUT, in the sense of minimizing
. If one chooses the best cut between IN and OUT, in the sense of minimizing 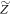 and thus the worst-case work, the optimum one can hope for becomes in those cases
and thus the worst-case work, the optimum one can hope for becomes in those cases 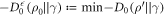 such that
such that 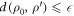 where d is the trace distance (this is called the smooth relative entropy). The interpretation is that the optimal worst-case work one can hope for allowing for an error tolerance of
where d is the trace distance (this is called the smooth relative entropy). The interpretation is that the optimal worst-case work one can hope for allowing for an error tolerance of 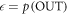 is
is 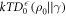 , consistent with [3, 5, 6].
, consistent with [3, 5, 6].
Appendix C.: Relation between worst-case and deterministic work
Certain protocols studied in single-shot statistical mechanics give a pseudo-deterministic work output, i.e. the work distribution is highly concentrated around some value. (It is standard to say that a certain amount of work A is (δ, )-deterministic if one will have ![$W\in [A\pm \delta ]$](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn136.gif) except with probability
except with probability 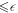 .) For example in [3] one may compress all the randomness onto some bits and extract work from the others with essentially deterministic work output. In [5, 6] and and [26] the expressions given concern the optimal pseudo-deterministic work, optimized over protocols for some given boundary conditions. This is in contrast to this paper and e.g. [7] which make bounds on the optimal worst-case work. We note that from the definitions one sees that bounds on worst-case work are also bounds on deterministic work but not vice versa. This is because demanding that the work cost is bounded from above is a weaker restriction than demanding that it is bounded from both above and below.
.) For example in [3] one may compress all the randomness onto some bits and extract work from the others with essentially deterministic work output. In [5, 6] and and [26] the expressions given concern the optimal pseudo-deterministic work, optimized over protocols for some given boundary conditions. This is in contrast to this paper and e.g. [7] which make bounds on the optimal worst-case work. We note that from the definitions one sees that bounds on worst-case work are also bounds on deterministic work but not vice versa. This is because demanding that the work cost is bounded from above is a weaker restriction than demanding that it is bounded from both above and below.
Appendix D.: Cutting the work-tail, as well as the state-tail
There can actually be (sets of) trajectories which are unlikely even if the initial state of the trajectory is likely, as the hopping probability may be low. For example, if one lifts one level towards a very high value while thermalizing, there is one trajectory corresponding to staying in the rising level throughout, which would be the trajectory that gives the worst-case work. However, if such a trajectory is very unlikely, one would wish to ignore the trajectory when stating the worst-case work. In this section, we show a way to ignore such unlikely trajectories, by not only cutting off part of the initial state as previously, but also cutting off a part of the work distribution. This strategy gives a different penalty term—lower, in general—in the equality for the worst-case work.
D.1. Proof overview
We shall again take the initial density matrix to have the form 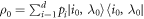 , not necessarily a thermal state. Then a sequence of Hamiltonian changes and thermalizations as described above is applied. This induces some work probability distribution and some worst-case work for the trajectories of interest.
, not necessarily a thermal state. Then a sequence of Hamiltonian changes and thermalizations as described above is applied. This induces some work probability distribution and some worst-case work for the trajectories of interest.
The argument is split in two. First, we define a set of trajectories of interest: some trajectories are unlikely enough to be ignorable. We derive the worst-case work for the set of trajectories of interest. Next, we consider the probability that some trajectory is in the set of interest. Combining these two parts gives our new equality for worst-case work.
D.2. The set of trajectories of interest
We wish to ignore unlikely trajectories. We identify a set of trajectories of interest, defined as excluding trajectories of two types:
1. 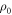 -tail trajectories: These are those which are called
-tail trajectories: These are those which are called 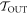 above, i.e., trajectories which start in
above, i.e., trajectories which start in 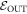 . We now call them
. We now call them  -tail trajectories as using OUT risks generating confusion because of the second type of cut we shall make on the set of trajectories.
-tail trajectories as using OUT risks generating confusion because of the second type of cut we shall make on the set of trajectories.
2. Work-tail trajectories: We also ignore trajectories associated with the worst work values, if those values are sufficiently improbable. This ignoring amounts to cutting off the worst-case tail of the work probability distribution. To simplify the proof, we define this tail in terms of the work probability distribution of the fictional thermal state 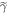 . By 'the work-tail,' we mean the set of trajectories associated with the following work values w: if the initial state is
. By 'the work-tail,' we mean the set of trajectories associated with the following work values w: if the initial state is 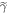 , there is an associated work probability distribution
, there is an associated work probability distribution 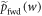 for the given protocol, and an associated worst-case work
for the given protocol, and an associated worst-case work 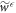 . The work tail trajectories are by definition those with work cost
. The work tail trajectories are by definition those with work cost 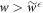 . Since the actual initial state
. Since the actual initial state 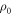 may differ from
may differ from 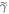 , the probability that some trajectory begins in the work tail does not necessarily equal .
, the probability that some trajectory begins in the work tail does not necessarily equal .
These sets are depicted in figure D1. We shall call the worst-case work in the set of interest 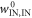 .
.

Figure D1. Depiction of the trajectories of interest. We shall ignore trajectories that have undesirable, very unlikely work values (that are in the work-tail) and trajectories that start in very unlikely energy eigenstates (that start in the ρ-tail).
Download figure:
Standard image High-resolution imageD.3. The worst-case work in that set
We now derive the worst-case work in the set of trajectories of interest: We maximize the work cost w over that set of interest. We shall, for the first part, draw inspiration from an argument, in [15], concerning scenarios governed by Crooks' Theorem. Take the initial state of the forwards process to be 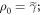 and the initial state of the reverse process as
and the initial state of the reverse process as 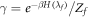 .
.
Maximize Crooks' theorem over the support of 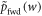 [15]:
[15]:
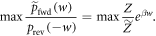
The rhs is monotonic in w, so maximizing the rhs over the support of 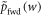 leads to the maximum w-value w0. Taking the logarithm and recalling the
leads to the maximum w-value w0. Taking the logarithm and recalling the 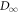 definition yields [15],
definition yields [15],
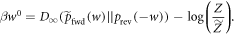
Now, we cut off the work tail by defining a cut-off probability distribution  , if
, if 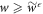 and
and 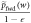 , otherwise, wherein
, otherwise, wherein 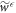 denotes the work guaranteed up to probability if
denotes the work guaranteed up to probability if 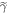 is the initial state. (Dividing by (
is the initial state. (Dividing by (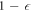 ) normalizes the distribution.) For work values outside the work tail, Crooks' theorem can be reformulated as
) normalizes the distribution.) For work values outside the work tail, Crooks' theorem can be reformulated as
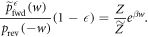
Since the rhs is monotonic,
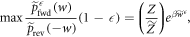
wherein the maximization is over the support of 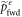 . Taking the logarithm and rearranging yields
. Taking the logarithm and rearranging yields
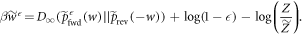
The lhs is the worst-case work in the set of trajectories of interest.
D.4. Probability that a trajectory is in the set of interest
The trajectories of interest are effectively the possible trajectories. To make precise what is meant by 'effective,' we bound the probability that any particular trajectory lies outside that set.
Consider a trajectory followed by a system initialized to 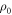 . The probability that the trajectory lies outside the set of interest is bounded by
. The probability that the trajectory lies outside the set of interest is bounded by  , as shown in figure D1.
, as shown in figure D1. 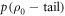 , defined via
, defined via 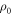 and the choice of effective support, is specified by input parameters.
and the choice of effective support, is specified by input parameters. 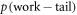 denotes the probability that the trajectory is in the set associated with a worse work cost than
denotes the probability that the trajectory is in the set associated with a worse work cost than 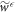 (the work guaranteed up to probability not to be exceeded, if the initial state is
(the work guaranteed up to probability not to be exceeded, if the initial state is 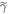 ).
). 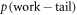 does not necessarily equal for an arbitrary
does not necessarily equal for an arbitrary 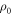 . As
. As 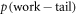 is not an input parameter, we wish to bound it with input parameters.
is not an input parameter, we wish to bound it with input parameters.
Let us drop the subscript 'fwd' and refer simply to p(w). The weight 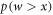 in the actual work tail associated with
in the actual work tail associated with 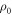 cannot differ arbitrarily from the weight
cannot differ arbitrarily from the weight 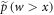 in the work tail associated with
in the work tail associated with 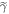 :
:
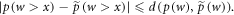
This bound follows from the definition of the variational distance d, which equals the trace distance between diagonal states8 .
The variational distance d is contractive under stochastic matrices, because the trace distance is contractive under completely positive trace-preserving maps. The work distribution is the result of a stochastic matrix's acting on the probability distribution over initial energy eigenstates. Let us now in this paragraph for convenience use Dirac notation for classical probability vectors, representing a probability distribution p(w) as 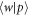 . The work distribution comes from the stochastic matrix
. The work distribution comes from the stochastic matrix  mapping a state
mapping a state 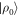 to a work distribution, wherein j labels projectors onto
to a work distribution, wherein j labels projectors onto 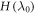 eigenstates,
eigenstates, 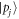 labels the work distribution when starting with an initial state
labels the work distribution when starting with an initial state 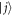 (i.e.,
(i.e., 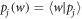 ), and
), and 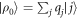 . For example, if there are two possible eigenstates, we can write
. For example, if there are two possible eigenstates, we can write 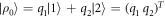 , and the resulting work distribution
, and the resulting work distribution 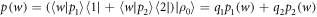 .
.
Thus,
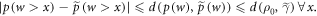
For some 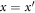 , by definition,
, by definition, 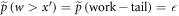 , and
, and 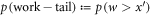 . Thus
. Thus
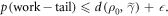
D.5. Main result, also cutting work tail
We conclude that the worst-case work from the trajectories of interest, 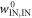 respects
respects
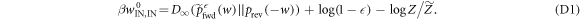
The probability that the trajectory is not in the set of interest is upper-bounded by 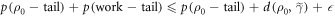 .
.
Appendix E.: Continuous time versus discrete time
We have mainly focused on the discrete-time protocol. Experimental realizations of thermodynamic protocols are often described by a continuous master equation. Here, we show that the discrete protocol leads to a master equation in the continuum model and vice versa. In this section we restrict ourselves to scenarios without energy coherences, i.e., the discrete-classical case.
E.1. From discrete to continuous
We consider a discrete sequence of times, 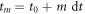 (
(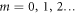 ), and the sequence
), and the sequence 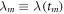 of values of the external parameter. As the waiting time decreases (
of values of the external parameter. As the waiting time decreases (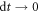 ), the transition probability
), the transition probability 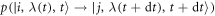 due to thermalization should vanish. To first order, it behaves as
due to thermalization should vanish. To first order, it behaves as
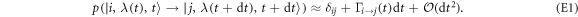
The transition rate 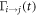 is a possibly complicated function of instantaneous energy levels
is a possibly complicated function of instantaneous energy levels 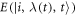 . However, the transition rates inherit the condition
. However, the transition rates inherit the condition
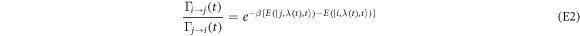
from detailed balance and the condition
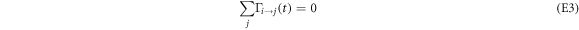
from probability conservation. The occupation probability is
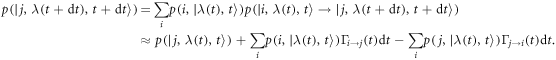
If the occupation probability is a smooth function of time, the master equation
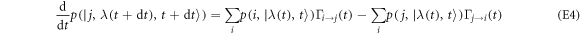
follows. The equivalence is further illustrated in appendix F in the example of an electron box.
E.2. From continuous to discrete
Going in the other direction, we now show explicitly how the discrete-time model can be derived from a physical master equation. Consider a two-level system that has a state 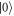 , kept at zero energy, and a state
, kept at zero energy, and a state 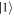 whose energy
whose energy  changes. The Hamiltonian is
changes. The Hamiltonian is 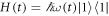 , and the system interacts with a temperature-T heat bath. In [27], a master equation for the density matrix
, and the system interacts with a temperature-T heat bath. In [27], a master equation for the density matrix 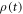 was derived for a such system. In the present case, the master equation is
was derived for a such system. In the present case, the master equation is
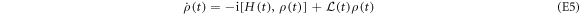
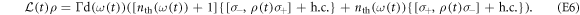
The heat bath, modeled as as set of harmonic oscillators, has a thermal occupation number 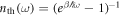 that depends on time because the upper level shifts.
that depends on time because the upper level shifts. 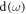 is the dimensionless heat-bath density of states; Γ denotes a rate assumed to be constant;
is the dimensionless heat-bath density of states; Γ denotes a rate assumed to be constant; 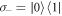 denotes the usual lowering operator; and
denotes the usual lowering operator; and 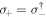 . Equation (E5) has the form of the usual Lindblad master equation, but the Lindblad operator depends on time. The dependence arises only from the level spacing's time dependence. The Hamiltonian part contains the Lamb shift.
. Equation (E5) has the form of the usual Lindblad master equation, but the Lindblad operator depends on time. The dependence arises only from the level spacing's time dependence. The Hamiltonian part contains the Lamb shift.
In the derivation of equation (E5) one assumes, as usual, weak coupling to the heat bath, the Markovian approximation, and the rotating-wave approximation. One also assumes that the adiabatic approximation holds, i.e., the system always remains in its time-local energy eigenstates when the interaction with the heat bath is ignored. This condition is always fullfilled under the assumption of vanishing energy coherences at all times that we made in this section. Indeed, the part of (E5) pertaining to the diagonal elements of 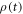 can be derived without the adiabatic assumption [28].
can be derived without the adiabatic assumption [28].
We now consider discrete times 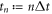 ,
, 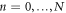 , with
, with 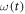 constant during the time intervals
constant during the time intervals 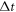 ,
, 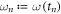 . Restricting ourselves to changes of the Hamiltonian that only involve its spectrum, H(t) and
. Restricting ourselves to changes of the Hamiltonian that only involve its spectrum, H(t) and 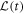 are constant during a given time interval.
are constant during a given time interval.
Consider first the Hamiltonian changes. Heisenberg's equation of motion for the system-and-bath composite implies that 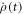 has a finite jump when the Hamiltonian has a finite jump. Therefore,
has a finite jump when the Hamiltonian has a finite jump. Therefore, 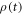 is continuous when the Hamiltonian has a finite jump. Hence for finite Hamiltonian changes during a time
is continuous when the Hamiltonian has a finite jump. Hence for finite Hamiltonian changes during a time 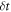 , the system-and-bath composite's density matrix is unchanged in the limit as δt → 0. Hence the system's reduced density matrix is unchanged during the instantaneous shift of energy levels. As for the relaxation process, the initial thermal state is described in terms of occupation probabilities pn for the nth level. The evolution during the relaxation process is given by
, the system-and-bath composite's density matrix is unchanged in the limit as δt → 0. Hence the system's reduced density matrix is unchanged during the instantaneous shift of energy levels. As for the relaxation process, the initial thermal state is described in terms of occupation probabilities pn for the nth level. The evolution during the relaxation process is given by 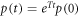 , where T is a matrix that connects the diagonal matrix elements of ρ in the master equation (E5):
, where T is a matrix that connects the diagonal matrix elements of ρ in the master equation (E5): 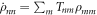 . The transition rates Tnm inherit detailed balance from the rates appearing in the master equation, i.e.,
. The transition rates Tnm inherit detailed balance from the rates appearing in the master equation, i.e., 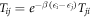 . Detailed balance holds for each power Tk of T,
. Detailed balance holds for each power Tk of T, 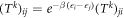 , for all
, for all 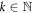 . Therefore, by the power-series expansion of eTt, detailed balance holds also for eTt. We thus have derived, from a physical model of a system that is coupled to a heat bath and whose energy levels are piecewise-constant, the discrete-time model considered in the paper.
. Therefore, by the power-series expansion of eTt, detailed balance holds also for eTt. We thus have derived, from a physical model of a system that is coupled to a heat bath and whose energy levels are piecewise-constant, the discrete-time model considered in the paper.
To illustrate this let us consider a two level system: expressing ![$\rho (t)={p}_{0}(t)| 0\rangle \langle 0| +[1-{p}_{0}(t)]| 1\rangle \langle 1| $](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn223.gif) , we obtain a differential equation for
, we obtain a differential equation for 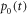 ,
,
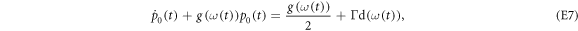
wherein ![$g(\omega (t)):= 2{\rm{\Gamma }}{\rm{d}}(\omega (t))[2{n}_{\mathrm{th}}(\omega (t))+1]$](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn225.gif) . This equation has the general solution
. This equation has the general solution
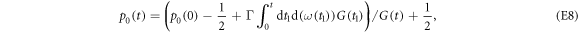
wherein 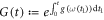 . The integrals in equation (E8) can be calculated analytically:
. The integrals in equation (E8) can be calculated analytically:
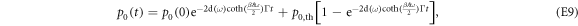
wherein 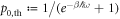 denotes the ground state's thermal occupation. For large times, the memory of the initial state is lost, and the system relaxes towards thermal equilibrium. From equation (E9), we obtain the transition probabilities during relaxation over the time interval between
denotes the ground state's thermal occupation. For large times, the memory of the initial state is lost, and the system relaxes towards thermal equilibrium. From equation (E9), we obtain the transition probabilities during relaxation over the time interval between 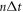 and
and  :
: 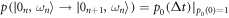 ,
, 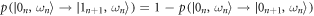 ,
, 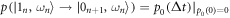 , and
, and 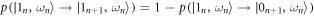 . These transition probabilities obey detailed balance. As they remain unchanged by the inclusion of an instantaneous Hamiltonian change at the end of each time interval,
. These transition probabilities obey detailed balance. As they remain unchanged by the inclusion of an instantaneous Hamiltonian change at the end of each time interval, 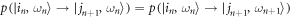 for
for 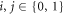 .
.
Appendix F.: Application to solid-state system: electron box
To demonstrate the physical relevance of our results, we take a realistic example, the electron box [16–18, 29, 30], and apply our results to it. We first derive a time-local master equation for the level-occupation probabilities in appendix F.1. As shown in appendix E, the master equation is equivalent to the discrete-time trajectory model discussed in the main text. The work distribution functions are analyzed numerically in appendix F.2 and analytically in appendix F.3. Finally, we upper-bound the penalty term 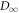 , which reveals the direct physical relevance of our results.
, which reveals the direct physical relevance of our results.
F.1. Theoretical model and its justification
We consider the type of system in [16–18]. Following a semiclassical theory (known as 'the orthodox theory') such as in [31], we derive a master equation and illustrate the work fluctuations. A more complete quantum description is possible [29, 30]. Yet the semiclassical approach is useful for interpreting and identifying work and heat, which are often ambiguous.
The system (figure F1) consists of a large metallic electrode R that serves as a charge reservoir, a small metallic island (or quantum dot) D, and a gate electrode. The island D is coupled only capacitively to the gate electrode but couples to the reservoir R capacitively and via tunneling. The Hamiltonian has four parts: 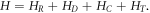 The first two terms,
The first two terms,
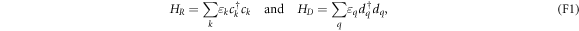
describe the non-interacting parts of the electrode R and the island D. Here, 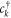 (
(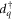 ) creates an electron with momentum
) creates an electron with momentum 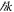 (
(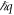 ) and energy
) and energy 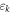 (
(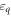 ). The single-particle dispersions
). The single-particle dispersions 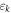 and
and 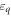 form continua of energy levels. HC is responsible for the electron–electron interaction on the island. We adopt a capacitive model as recounted below. Finally, the tunneling of electrons between R and D is described by
form continua of energy levels. HC is responsible for the electron–electron interaction on the island. We adopt a capacitive model as recounted below. Finally, the tunneling of electrons between R and D is described by
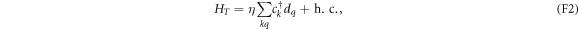
wherein η is the tunneling amplitude. η is assumed not to depend on momenta (or on energy), as in common metals that have wide conduction bands.

Figure F1. A schematic of an electron box.
Download figure:
Standard image High-resolution imageThe effective semiclassical model describes equilibrium: suppose that an electron tunnels between the island D and the reservoir R. The tunneling jolts the system out of equilibrium, but the system equilibrates quickly: Coulomb repulsions redistribute the electrons throughout the circuit. After the redistribution, the junction carries the equilibrium charge QJ, and the gate carries the equilibrium charge Qg. These charges are regarded as being 'on' the island D, due to the island's capacitive couplings to the reservoir R and to the gate. (The island carries also excess electrons, discussed below.) The electrons continue to repel each other, imbuing the system with the equilibrium Coulomb energy
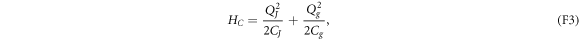
wherein CJ and Cg denote the junction and gate capacitances. One can find that
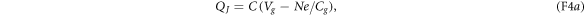
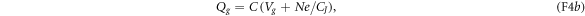
wherein 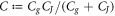 is the system's effective capacitance.
is the system's effective capacitance. 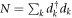 denotes the number of excess electrons, relative to the charge-neutral state, on the island D. When N = 0, the island has zero net charge. HC can thus be rewritten as
denotes the number of excess electrons, relative to the charge-neutral state, on the island D. When N = 0, the island has zero net charge. HC can thus be rewritten as
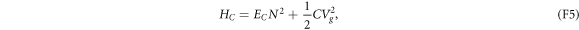
wherein 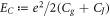 is the single-electron charging energy, one of the largest energy scales of the system.
is the single-electron charging energy, one of the largest energy scales of the system.
We are primarily interested in the macroscopic variable N but not in the microscopic degrees of freedom ck and dq, whose dynamics is typically much faster. One can thus integrate out ck and dq to get the effective Hamiltonian expressed only in terms of N. In the semiclassical approach, this can be achieved by considering the energy that an electron gains by tunneling.
Suppose that an electron tunnels into the island D from the reservoir R. This will change the charge 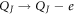 and the excess number of electrons
and the excess number of electrons 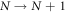 . This new charge configuration, right after the tunneling, is redistributed quickly to a new equilibrium configuration,
. This new charge configuration, right after the tunneling, is redistributed quickly to a new equilibrium configuration,
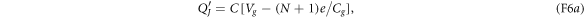
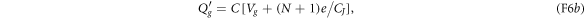
by the gate voltage source. The voltage source has moved the amount
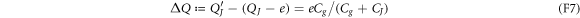
of charge through the transmission line from the junction interface to the gate capacitor by doing the amount
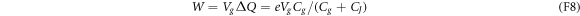
of work on the system. Therefore, the electron's overall energy gain 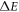 equals the work W minus the change in the electrostatic energy:
equals the work W minus the change in the electrostatic energy:
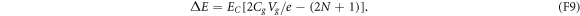
As this energy gain comes from the transition  , the effective Hamiltonian for the macroscopic variable N can be regarded as
, the effective Hamiltonian for the macroscopic variable N can be regarded as
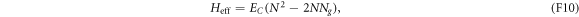
wherein 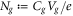 . Recall that the second term comes from the work done on the system by the voltage source.
. Recall that the second term comes from the work done on the system by the voltage source.
The microscopic degrees of freedom removed from the effective macroscopic model cause N to fluctuate randomly. The transition 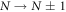 is associated with tunneling of an electron into or from the island. Hence the transition rate follows from Fermi's Golden Rule:
is associated with tunneling of an electron into or from the island. Hence the transition rate follows from Fermi's Golden Rule:
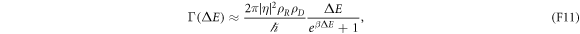
wherein 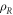 and
and 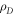 are the densities of states of R and D, respectively, and
are the densities of states of R and D, respectively, and
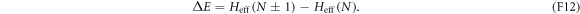
Finally, at sufficiently low temperatures (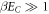 ), higher energy levels play no role. Considering the two lowest levels N = 0 and N = 1 suffices for
), higher energy levels play no role. Considering the two lowest levels N = 0 and N = 1 suffices for ![${N}_{g}\in [0,1]$](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn258.gif) 9
. Let p0 denote the probability that N = 0, and let p1 denote the probability that N = 1. With equations (F10) and (F11), this two-level approximation leads to the master equation
9
. Let p0 denote the probability that N = 0, and let p1 denote the probability that N = 1. With equations (F10) and (F11), this two-level approximation leads to the master equation
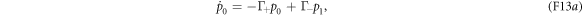
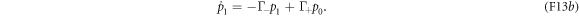
The transition rates are [29, 30]
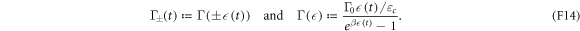
Here, 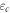 is the bath's high-frequency cutoff (i.e.,
is the bath's high-frequency cutoff (i.e., 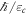 is the correlation time), and
is the correlation time), and 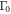 is a constant that characterizes the strength of the coupling to the bath.
is a constant that characterizes the strength of the coupling to the bath. 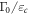 is related to the material properties by
is related to the material properties by 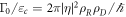 . Note that the transition rates satisfy the detailed-valance relation
. Note that the transition rates satisfy the detailed-valance relation
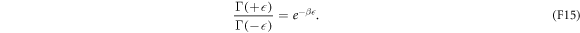
The time-local master equation (F13) is equivalent to the discrete-time trajectory model (see appendix E). Therefore, the electron box is a realistic prototype system to which our results can apply.
F.2. Monte Carlo simulation of the electron box
We performed a Monte Carlo simulation of an erasure protocol in the electron box set-up. Our simulation discretizes the protocol into time steps 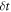 small enough to justify the linear approximation that the population of level i evolves from time step t to
small enough to justify the linear approximation that the population of level i evolves from time step t to 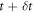 according to
according to 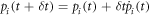 . Using equations (F13), we can write a stochastic matrix acting on the probabilities:
. Using equations (F13), we can write a stochastic matrix acting on the probabilities:
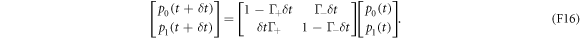
For a two-level system which does not build up quantum coherences, a stochastic thermalizing matrix (which by its definition evolves all states towards the Gibbs state) has only one degree of freedom remaining once the Gibbs state has been chosen: the thermalization speed. All models of two-level thermalizations for a given Gibbs state are equivalent. We pick the conceptually straightforward partial swap: with some probability psw, the system's current state is exchanged with the Gibbs state. With probability 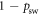 , the state remains unchanged:
, the state remains unchanged: 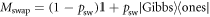 , where
, where  means the vector of 1's. For a Gibbs state associated with an energy-level splitting ,
means the vector of 1's. For a Gibbs state associated with an energy-level splitting ,
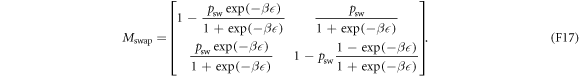
Equating equation (F17) with the matrix in equation (F16), we can find the partial-swap probability in terms of the electron box's physical parameters:
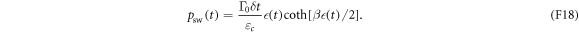
The swap probability 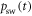 and the energy level splitting
and the energy level splitting 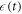 appear as functions of time, as the swap probability changes as the protocol evolves. The probability changes only as a function of an external parameter, the splitting (as opposed to e.g., the current state). Hence Crooks' theorem is still applicable to thermalizations of this type.
appear as functions of time, as the swap probability changes as the protocol evolves. The probability changes only as a function of an external parameter, the splitting (as opposed to e.g., the current state). Hence Crooks' theorem is still applicable to thermalizations of this type.
Figure F2 depicts our Monte Carlo simulation. We randomly generate trajectories by picking a random initial microstate according to the initial-state probability distribution. Then, we evolve the system by small steps, testing at each step if a swap should occur (with probability psw). If a swap occurs, we replace the state with a new microstate randomly chosen according to the Gibbs state associated with the current Hamiltonian. By recording which microstate is occupied when the energy level is raised, we calculate the work cost associated with a particular trajectory. Repeated runs of the simulation allow us to build up a work distribution, to which the results in this paper apply.

Figure F2. Work guaranteed to be extracted from a Szilárd engine up to probability : 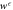 . A Monte Carlo simulation was used to predict the work from the single-electron-box.
. A Monte Carlo simulation was used to predict the work from the single-electron-box. 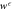 approaches
approaches 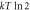 as a function of the protocol's speed. For smaller ,
as a function of the protocol's speed. For smaller , 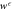 approaches from below; and for higher, from above.
approaches from below; and for higher, from above.
Download figure:
Standard image High-resolution imageF.3. Analytic expression for the work distribution
The work distribution function for an electron box can also be obtained explicitly from the master equation.
Consider an arbitrary work protocol that runs from t = 0 to 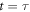 . The gap is tuned as a function
. The gap is tuned as a function 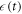 . The trajectory
. The trajectory 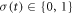 of the system is piece-wise constant, jumping discontinuously from one energy level to another at some random instants tj (
of the system is piece-wise constant, jumping discontinuously from one energy level to another at some random instants tj (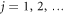 ). Therefore, the trajectory is specified uniquely by the initial condition
). Therefore, the trajectory is specified uniquely by the initial condition 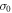 , the number J of jumps, and the corresponding instants tj (
, the number J of jumps, and the corresponding instants tj (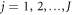 ). The probability distribution function for the trajectory is
). The probability distribution function for the trajectory is
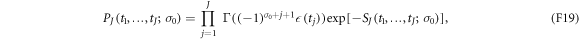
where the effective action associated with a given trajectory has been defined as
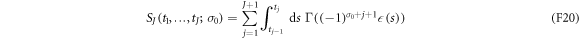
and  and
and  are implied. Checking the normalization is straightforward:
are implied. Checking the normalization is straightforward:
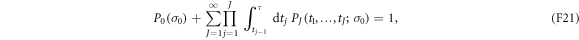
wherein 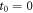 is again implied.
is again implied.
The work is done only while the system is in the state  . Hence the contribution to the work along the trajectory is
. Hence the contribution to the work along the trajectory is
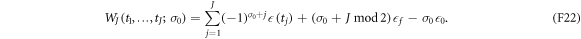
The work distribution function along a trajectory with J jumps is
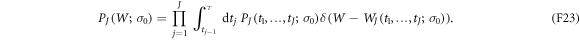
The total work distribution function can be written in a series
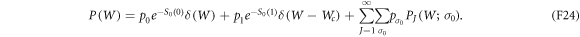
PJ(W) has a factor of 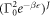 . At low temperatures, PJ is rapidly suppressed as J increases.
. At low temperatures, PJ is rapidly suppressed as J increases.
The expression (F24) for the work distribution is essentially a perturbative expansion in 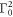 and converges very quickly for small
and converges very quickly for small 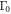 . For large
. For large 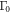 , however, it becomes impractical to use it for actual calculation because of its slow convergence. Therefore, it will be useful to devise a more general method. We examine the characteristic function
, however, it becomes impractical to use it for actual calculation because of its slow convergence. Therefore, it will be useful to devise a more general method. We examine the characteristic function 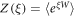 of the work distribution function P(W). We first consider the characteristic function
of the work distribution function P(W). We first consider the characteristic function 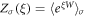 conditioned on all trajectories' starting from a definite initial state
conditioned on all trajectories' starting from a definite initial state 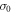 . Regarded as a function of the operation time τ,
. Regarded as a function of the operation time τ, 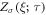 satisfies the master equation [32, 33]
satisfies the master equation [32, 33]
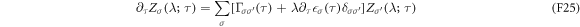
and the initial condition
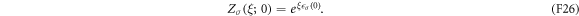
Compared with the original master equation (F13) for the level-occupation probabilities, the new master equation (F25) for the characteristic function contains additional diagonal terms. The full characteristic function is
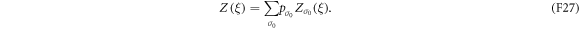
Recall that 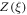 contains the same information as P(W). From
contains the same information as P(W). From 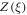 , one can calculate P(W) itself and, as shown in section F.4 below, a bound for
, one can calculate P(W) itself and, as shown in section F.4 below, a bound for 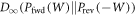 .
.
Let us show that the work distribution in equation (F24) satisfies Crooks' fluctuation theorem,
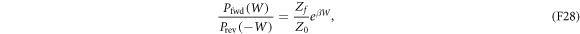
wherein Z0 and Zf are the partition functions for the initial and final Hamiltonians in the forward protocol. Given a forward ramping 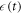 , the reverse ramping
, the reverse ramping 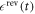 is defined by
is defined by
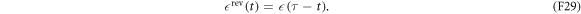
In the forward protocol, consider a trajectory 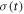 characterized by the initial condition
characterized by the initial condition 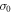 , the number J of energy-level jumps and the jump instants tj (
, the number J of energy-level jumps and the jump instants tj (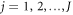 ). One can find a unique trajectory
). One can find a unique trajectory 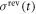 in the reverse protocol, which is defined by the initial condition
in the reverse protocol, which is defined by the initial condition
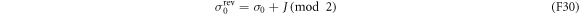
and the flip instants
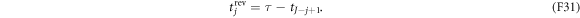
Note that
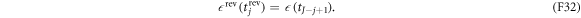
The effective action along the reverse trajectory is the same as that along the forward trajectory (see (F20)):
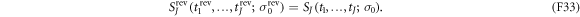
Further, the work contribution along the reverse trajectory is the negative of that along the forward trajectory (see (F22)):
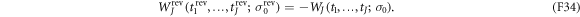
These observations lead to
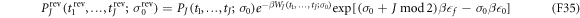
and
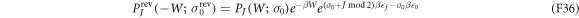
It is then straightforward to prove Crooks' theorem:
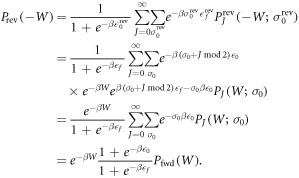
For illustration, examples of the forwards and reverse distributions appear in figure F3.

Figure F3. Work distributions calculated analytically for the forward (a) and reverse (b) processes on an electron box. The two levels initially have the same energy. One level is lifted linearly to 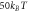 and then returned to 0. The values of the zero-energy tunneling rate
and then returned to 0. The values of the zero-energy tunneling rate 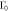 and the operation time τ are set such that
and the operation time τ are set such that 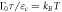 , wherein
, wherein 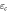 is the relaxation time of the metallic electrode (charge reservoir).
is the relaxation time of the metallic electrode (charge reservoir).
Download figure:
Standard image High-resolution imageF.4. Upper bound on
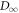
Recall the Markov inequality for a non-negative random variable X:
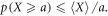
This is derived by noting that there cannot be too much probability of having a value much greater than the average, or else the average would have to be greater. In our case, it reads
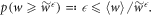
Thus,
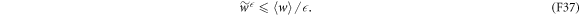
We rearrange the main result, equation (D1):
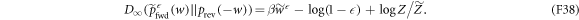
Substituting in equation (F37) yields
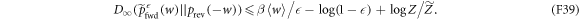
(here 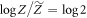 ). One has only to upper-bound
). One has only to upper-bound 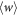 .
. 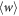 can be upper-bounded most easily with the characteristic function
can be upper-bounded most easily with the characteristic function 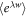 , which bounds
, which bounds 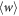 due to convexity. This has been illustrated in figure F4.
due to convexity. This has been illustrated in figure F4.
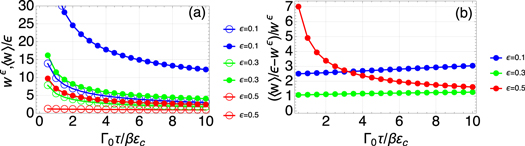
Figure F4.
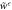 and its upper bounds
and its upper bounds 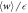 (which in turn bound
(which in turn bound 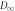 ) for different values of . (a) Individual plots of
) for different values of . (a) Individual plots of 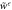 and
and 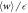 . (b) The relative tightness.
. (b) The relative tightness.
Download figure:
Standard image High-resolution imageWe finally remark that, as shown in [6, 7], in the isothermal limit, the penalty (meaning again the lhs of equation (F38)), goes to zero. The isothermal limit means that the hopping probabilities multiplying together to give a trajectory's probability as in equation (1) take the form of thermal state occupation probabilities 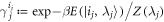 . The probability of a forwards trajectory becomes
. The probability of a forwards trajectory becomes 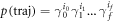 whereas the reverse trajectory has the probability
whereas the reverse trajectory has the probability 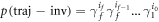 . The probability of a given time sequence of work values from the elementary steps is then a product of individual distributions
. The probability of a given time sequence of work values from the elementary steps is then a product of individual distributions 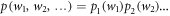 . This allows one to use the McDiarmid inequality for independent random variables as in [7] to show that there is concentration around the average in the limit of breaking up an isothermal time evolution into infinitely many substeps of energy shifts. If we write
. This allows one to use the McDiarmid inequality for independent random variables as in [7] to show that there is concentration around the average in the limit of breaking up an isothermal time evolution into infinitely many substeps of energy shifts. If we write 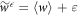 , both and ε tend towards zero in this limit. Combining that with the also known fact that
, both and ε tend towards zero in this limit. Combining that with the also known fact that 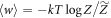 in the isothermal case, we see that the rhs of equation (F38) tends to zero in this limit; thus the lhs also tends to zero. To find, for a given initial state and initial and final Hamiltonians, a protocol such that this penalty tends to zero, one can accordingly begin the protocol with lifting the OUT levels to the corresponding thermal levels, and then perform isothermal quasistatic extraction as described above. The lifting of the OUT levels then undoes their initial lowering in the ∼-protocol, undoing any work cost and returning the state to being a thermal state. This limit also illustrates why the -versions of the worst-case work and associated penalty are physically natural to introduce. Strictly speaking the worst case work w0 could be much larger than the average even in the isothermal case, but the probability of this happening can be arbitrarily small.
in the isothermal case, we see that the rhs of equation (F38) tends to zero in this limit; thus the lhs also tends to zero. To find, for a given initial state and initial and final Hamiltonians, a protocol such that this penalty tends to zero, one can accordingly begin the protocol with lifting the OUT levels to the corresponding thermal levels, and then perform isothermal quasistatic extraction as described above. The lifting of the OUT levels then undoes their initial lowering in the ∼-protocol, undoing any work cost and returning the state to being a thermal state. This limit also illustrates why the -versions of the worst-case work and associated penalty are physically natural to introduce. Strictly speaking the worst case work w0 could be much larger than the average even in the isothermal case, but the probability of this happening can be arbitrarily small.
Footnotes
- 8
See, e.g., section 2 in http://people.csail.mit.edu/costis/6896sp11/lec3s.pdf.
- 9
The model is invariant under
, and studying suffices.
![${N}_{g}\in [0,1]$](https://content.cld.iop.org/journals/1367-2630/19/4/043013/revision2/njpaa62baieqn260.gif)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}