
Abstract
Over the last decades, the total variation (TV) has evolved to be one of the most broadly-used regularisation functionals for inverse problems, in particular for imaging applications. When first introduced as a regulariser, higher-order generalisations of TV were soon proposed and studied with increasing interest, which led to a variety of different approaches being available today. We review several of these approaches, discussing aspects ranging from functional-analytic foundations to regularisation theory for linear inverse problems in Banach space, and provide a unified framework concerning well-posedness and convergence for vanishing noise level for respective Tikhonov regularisation. This includes general higher orders of TV, additive and infimal-convolution multi-order total variation, total generalised variation, and beyond. Further, numerical optimisation algorithms are developed and discussed that are suitable for solving the Tikhonov minimisation problem for all presented models. Focus is laid in particular on covering the whole pipeline starting at the discretisation of the problem and ending at concrete, implementable iterative procedures. A major part of this review is finally concerned with presenting examples and applications where higher-order TV approaches turned out to be beneficial. These applications range from classical inverse problems in imaging such as denoising, deconvolution, compressed sensing, optical-flow estimation and decompression, to image reconstruction in medical imaging and beyond, including magnetic resonance imaging, computed tomography, magnetic-resonance positron emission tomography, and electron tomography.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
In this paper we give a review of higher-order regularisation functionals of total-variation type, encompassing their development from their origins to generalisations and most recent approaches. Research in this field has in particular been triggered by the success of the total variation (TV) as a regularisation functional for inverse problems on the one hand, but on the other hand by the insight that tailored regularisation approaches are indispensable for solving ill-posed inverse problems in theory and in practice. The last decades comprised active development of the latter topic which resulted in a variety of different strategies for TV-based regularisation functionals that model data with some inherent smoothness, possibly of higher order or multiple orders. For these functionals, this paper especially aims at providing a unified presentation of the underlying regularisation aspects, giving an overview of numerical algorithms suitable to solve associated regularised inverse problems as well as showing the breadth of respective applications.
Let us put classical and higher-order total-variation regularisation into an inverse problems context. From the inverse problems point of view, the central theme of regularisation is the stabilisation of the inversion of an ill-posed operator equation, which is commonly phrased as finding a u ∈ X such that

for given K : X → Y and f ∈ Y, where X and Y are usually Banach spaces. Various approaches for regularisation exist, e.g., iterative regularisation, Tikhonov regularisation, regularisation based on spectral theory in Hilbert spaces, or regularisation by discretisation. Being a regularisation and providing a stable inversion is mathematically well-formalised [84], and usually comprises regularisation parameters. Essentially, stable inversion means that each regularised inverse mapping from data to solution space is continuous in some topology, and being a regularisation requires in addition that, in case the measured data approximates the noiseless situation, a suitable choice of the regularisation parameters allows to approximate a solution that is meaningful and matches the noiseless data. These properties are typically referred to as stability and convergence for vanishing noise, respectively. For general non-linear inverse problems, they usually depend on an interplay between the selected regularisation strategy and the forward operator K, where often, derivative-based assumptions on the local behaviour around the sought solution are made [84, 113]. In contrast, for linear forward operators, unified statements are commonly available such that regularisation properties solely depend on the regularisation strategy. We therefore consider linear inverse problems throughout the paper, i.e., the solution of Ku = f where K : X → Y is always assumed to be linear and continuous.
Variational regularisation, which is the stabilised solution of such an inverse problems via energy minimisation methods, then encompasses—and is often identified with—Tikhonov regularisation (but comprises, for instance, also Morozov regularisation [136] or Ivanov regularisation [114]). Driven by its success in practical applications, it has become a major direction of research in inverse problems. Part of its success may be explained by the fact that variational regularisation allows to incorporate a modelling of expected solutions via regularisation functionals. In a Tikhonov framework, this means that the solution of the operator equation Ku = f is obtained via solving

where Sf
: Y → [0, ∞] is an energy that measures the discrepancy between Ku and the measured data f, and ![${\mathcal{R}}_{\alpha }:X\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn1.gif) is the regularisation functional that depends on regularisation parameters α. From the analytical perspective, two main features of
is the regularisation functional that depends on regularisation parameters α. From the analytical perspective, two main features of  are important: first, it needs to possess properties that allow to guarantee that the corresponding solution map enjoys the stability and convergence properties as mentioned above (typically, lower semi-continuity and coercivity in some topology). Second, it needs to provide a good model of reasonable/expected solutions of Ku = f in the sense that
are important: first, it needs to possess properties that allow to guarantee that the corresponding solution map enjoys the stability and convergence properties as mentioned above (typically, lower semi-continuity and coercivity in some topology). Second, it needs to provide a good model of reasonable/expected solutions of Ku = f in the sense that  is small for such reasonable solutions and
is small for such reasonable solutions and  is large for unreasonable solutions that suffer, for instance, from artefacts or noise.
is large for unreasonable solutions that suffer, for instance, from artefacts or noise.
While the first requirement is purely qualitative and known to be true for a wide range of norms and seminorms, the second requirement involves the modelling of expected solutions as well as suitable quantification, having in particular in mind that the outcome should be simple enough to be amenable to numerical solution algorithms. Suitable models are for instance provided by various classical smoothness measures such as Hilbert scales of smooth functions, i.e., by Hs -norms where s ⩾ 0, but also reflexive Banach-space norms such as Lp -norms, associated Sobolev-space seminorms in Hk,p for 1 < p < ∞, and Besov-space seminorms based on wavelet-coefficient expansions [39, 69, 170]. The reflexivity of the underlying spaces then helps to turn an ill-posed equation into a well-posed one, since the direct method in the calculus of variations can be employed with weak convergence.
However, there are reasons to consider Banach spaces that lack reflexivity, with L1-spaces and spaces of Radon measures being prominent examples. Indeed, L1-type norms as penalties in variational energies have seen a tremendous rise in popularity in the past two decades, most notably in the theory of compressed sensing [77]. This is due to their property of favouring sparsity in solutions, which allows to model more specific a priori assumptions on the expected solutions than generic smoothness, for instance. While sparsity in L1-type spaces over discrete domains, such as spaces of wavelet coefficients, is directly amenable to analysis, sparsity for continuous domains requires to consider spaces of Radon measures and corresponding Radon-norm-type energies which are natural generalisations of L1-type norms. Being the dual of a separable normed space then mitigates the non-reflexivity of these spaces. As a consequence, they play a major role in continuous models for sparsity-promoting variational regularisation strategies.
A particular example is the total variation functional [59, 162], see section 2 below for a precise definition, which can be interpreted as the Radon norm realised as a dual norm on the distributional derivative of u. As such, TV(u) is finite if and only if the distributional derivative of u can be represented by a finite Radon measure. The TV functional then penalises variations of u via a norm on its derivative while still being finite in the case of jump discontinuities, i.e., when u is piecewise smooth. In particular, its minimisation realises sparsity of the derivative which is often considered a suitable model for piecewise constant functions. In addition, it is convex and lower semi-continuous with respect to Lp -convergence for any p ∈ [1, ∞], and coercive up to constants in suitable Lp -norm topologies. These features make TV a reasonable model for piecewise constant solutions and allow to obtain well-posedness of TV regularisation for a broad class of inverse problems. They can be considered as some of the main reasons for the overwhelming popularity of TV in inverse problems, imaging sciences and beyond.
Naturally, the simplicity and desirable properties of TV come with a cost. As previously mentioned, interpreting TV as a functional that generalises the L1-norm of the image gradient, compressed sensing theory suggests that this enforces sparsity of the gradient and hence piecewise constancy, i.e., one might expect that a TV-regularised function is non-constant only on low-dimensional subsets of its domain. While this might in fact be a feature if the sought solution is piecewise constant, it is not appropriate for general piecewise smooth data. Indeed, for non-piecewise-constant data, TV has the defect of producing artificial plateau-like structures in the reconstructions which became known as the staircasing effect of TV. This effect is nowadays well-understood analytically in the case of denoising [54, 139, 158], and recent results also provide an analytical confirmation of this fact in the context of inverse problems with finite-dimensional measurement data [26, 29]. The appearance of staircasing artefacts is in particular problematic since jump discontinuities are features which are, on the one hand, very prominent in visual perception and typically associated with relevant structures, and, on the other hand, important for automatic post-processing or interpretation of the data. As a result, it became an important research question in the past two decades how to improve upon this defect of TV regularisation while maintaining its desirable features, especially the sparsity-enforcing properties.
One first possible answer to this question is to consider the second-order total variation which is the Radon norm of the distributional second derivative. Indeed, if first-order total variation enforces sparse gradients, i.e., a distributional derivative that is supported on lower-dimensional subsets and hence, corresponding to a piecewise constant function, one might expect an analogous behaviour for the second derivative, resulting in piecewise affine functions. The smooth linear ramps that are characteristic for the latter are then typically not conceived as staircasing artefacts such that one might hope for a reduction of these artefacts by employing second-order total variation. These considerations motivate, generally, higher-order total variation as sparsity-enforcing regulariser for smooth regions in an image. However, as also described in section 3 below, pure higher-order total variation regularisation comes with some drawbacks, mainly the inability to recover jump discontinuities. To account for this, several extensions and alternatives have been proposed in the literature which still have the common theme of using higher-order derivatives and sparsity-enforcing functionals to model smooth regions in images.
This review is concerned with these developments with a focus on approaches that are related to the incorporation of higher-order derivatives and maintenance of the sparsity concepts realised by the Radon norm and the underlying spaces of Radon measures. These developments indeed resulted in a variety of different variational regularisation strategies, for which some are very successful in achieving the goal of providing an amenable model for piecewise smooth solutions. It is also a central message of this review that the success of higher-order TV model in terms of modelling and regularisation effect depends very much on the structure and the functional-analytic setting in which the higher-order derivatives are included. Following this insight, we will discuss different higher-order regularisation functionals such as higher-order total variation, the infimal-convolution of higher-order TV as well as the total generalised variation (TGV), which carries out a cascadic decomposition to different orders of differentiation. Starting form the analytical framework of the total-variation functional and functions of bounded variation, we will introduce and analyse several higher-order approaches in a continuous setting, discuss their regularisation properties in a Tikhonov regularisation framework, introduce appropriate discretisations as well as numerical solution strategies for the resulting energy minimisation problems, and present various applications in image processing, computer vision, biomedical imaging and beyond.
Nevertheless, due to the broad range of the topic as well as the many works published in its environment, it is impossible to give a complete overview. The various references to the literature given throughout the paper therefore only represent a selection. Let us also point out that we selected the presented material in particular on a basis that, on the one hand, enables a treatment that is as unified as possible. On the other hand, a clear focus is put on approaches for which the whole pipeline ranging from mathematical modelling, embedding into a functional-analytic context, proof of regularisation properties, numerical discretisation, optimisation algorithms and efficient implementation can be covered. In addition, extensions and further developments will shortly be pointed out when appropriate. Especially, many of the applications in image processing, computer vision, medical imaging and image reconstruction refer to these extensions. The applications were further chosen to represent a wide spectrum of inverse problems, their variational modelling and higher-order TV-type regularisation, and, not negligible, successful realisation of the presented theory. We finally aimed at providing a maximal amount of useful information regarding theory and practical realisation in this context.
2. Total-variation (TV) regularisation
Before discussing higher-order total variation and how it may be used to regularise ill-posed inverse problems, let us begin with an overview of first-order total variation. Throughout the review, we mainly adapt a continuous viewpoint which means that the objects of interest are usually functions on some fixed domain Ω, i.e., an non-empty, open and connected subset Ω ⊂ Rd
in the d-dimensional Euclidean space. This requires in particular a common functional-analytic context for which we assume that the reader is familiar with and refer to the books [1, 85, 204] for further information. In the following, we will make, for instance, use of the Lebesgue spaces Lp
(Ω, H) for H-valued functions where H is a finite-dimensional real Hilbert space as well as their measure-theoretic and functional-analytic properties. Also, concepts of weak differentiability and properties of the associated Sobolev spaces Hk,p
(Ω, H) will be utilised without further introduction. This moreover applies to the classical spaces such as  ,
,  and
and  , i.e., the spaces of uniformly continuous functions on
, i.e., the spaces of uniformly continuous functions on  , of compactly supported continuous functions on Ω and its closure with respect to the supremum norm. As usual, the respective spaces of k-times continuously differentiable functions are denoted by
, of compactly supported continuous functions on Ω and its closure with respect to the supremum norm. As usual, the respective spaces of k-times continuously differentiable functions are denoted by  ,
,  and
and  where k could also be infinity, leading to spaces of test functions.
where k could also be infinity, leading to spaces of test functions.
We further employ, throughout this section, basic concepts from convex analysis and optimisation. At this point, we would like to recall that for a convex function ![$F:X\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn12.gif) defined on a Banach space X, the subgradient ∂F(x) at a point u ∈ X is the collection of all w ∈ X* that satisfy the subgradient inequality
defined on a Banach space X, the subgradient ∂F(x) at a point u ∈ X is the collection of all w ∈ X* that satisfy the subgradient inequality

For F proper, the Fenchel dual or Fenchel conjugate of F is the function ![${F}^{{\ast}}:{X}^{{\ast}}\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn13.gif) defined by
defined by

The Fenchel inequality then states that  for all u ∈ X and w ∈ X* with equality if and only if w ∈ ∂F(u). For more details regarding these notions and convex analysis in general, we refer to research monographs covering this subject, for instance [83, 198].
for all u ∈ X and w ∈ X* with equality if and only if w ∈ ∂F(u). For more details regarding these notions and convex analysis in general, we refer to research monographs covering this subject, for instance [83, 198].
2.1. Functions of bounded variation
Generally, when solving a specific ill-posed inverse problem with, for instance, Tikhonov regularisation, one usually has many choices regarding the regularisation functional. Now, while functionals associated with Hilbertian norms or seminorms possess several advantages such as smoothness and allow, in addition, for regularisation strategies that can be computed by solving a linear equation, they are often not able to provide a good model for piecewise smooth functions. This can, for instance, be illustrated as follows.
Example 2.1. Classical Sobolev spaces cannot contain non-trivial piecewise constant functions. Let Ω ⊂ Rd
be a domain and Ω' ⊂ Ω be non-empty, open with ∂Ω' a null set. Then, the characteristic function u = χΩ', i.e., u(x) = 1 if x ∈ Ω' and 0 otherwise, is not contained in H1,p
(Ω) for any p ∈ [1, ∞]. To see this, suppose that v ∈ Lp
(Ω, Rd
) is the weak derivative of u. Let  be a test function. Clearly,
be a test function. Clearly,

Hence, v = 0 on Ω'. Likewise, one sees that also v = 0 on  . In total, v = 0 almost everywhere and as v is the weak derivative of u, u must be constant which is a contradiction.
. In total, v = 0 almost everywhere and as v is the weak derivative of u, u must be constant which is a contradiction.
The defect which is responsible for the failure of characteristic functions being (classical) Sobolev functions can, however, be remedied by allowing weak derivatives to be Radon measures. These are in particular able to concentrate on Lebesgue null-sets; a property that is necessary as the previous example just showed. In the following, we introduce some basic notions and results about vector-valued Radon measures, in particular, with an eye of embedding them into a functional-analytic framework. Moreover, we would like to have these notions readily available when dealing with higher-order derivatives and the associated higher-order total variation.
Throughout this section, let Ω ⊂ Rd
be a domain and H a non-trivial finite-dimensional real Hilbert space with ⋅ and  denoting the associated scalar product and norm, respectively. As usual, the case H = R corresponds to the scalar case and H = Rd
to the vector-field case, but, as we will see later, H could also be a space of higher-order tensors. The following definitions and statements regarding basic measure theory and can, for instance, be found in [7].
denoting the associated scalar product and norm, respectively. As usual, the case H = R corresponds to the scalar case and H = Rd
to the vector-field case, but, as we will see later, H could also be a space of higher-order tensors. The following definitions and statements regarding basic measure theory and can, for instance, be found in [7].
Definition 2.2. A vector-valued Radon measure or H
-valued Radon measure on Ω is a function  on the Borel σ-algebra
on the Borel σ-algebra  associated with the standard topology on Ω satisfying the following properties:
associated with the standard topology on Ω satisfying the following properties:
- (a)It holds that μ(Ø) = 0,
- (b)For each pairwise disjoint countable collection A1, A2, .... in
 it holds that in H.
it holds that in H.


A positive Radon measure is a function ![$\mu :\mathcal{B}\left({\Omega}\right)\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn22.gif) satisfying (a), (b) (with H replaced by [0, ∞]) as well as μ(K) < ∞ for each compact K ⊂⊂ Ω. It is called finite, if μ(Ω) < ∞.
satisfying (a), (b) (with H replaced by [0, ∞]) as well as μ(K) < ∞ for each compact K ⊂⊂ Ω. It is called finite, if μ(Ω) < ∞.
Naturally, vector-valued Radon measures can be associated to an integral. For μ an H-valued Radon measure and step functions  ,
,  with c1, ..., cN
∈ R, v1, ..., vN
∈ H and
with c1, ..., cN
∈ R, v1, ..., vN
∈ H and  , the following integrals make sense:
, the following integrals make sense:

For uniformly continuous functions  and
and  , the integrals are given as
, the integrals are given as

where {un } and {vn } are sequences of step functions converging uniformly to u and v, respectively. Of course, the above integrals are well-defined, meaning that there are approximating sequences as stated and the above limits exist independently of the specific choice of the approximating sequences. The following definition is the basis for introducing a norm for H-valued Radon measures.
Definition 2.3. For a vector-valued Radon measure μ on Ω the positive Radon measure  given by
given by

is called the total-variation measure of μ.
The total-variation measure is always positive and finite, i.e.,  for all
for all  . By construction, μ is absolutely continuous with respect to
. By construction, μ is absolutely continuous with respect to  , i.e., μ(A) = 0 whenever
, i.e., μ(A) = 0 whenever  for a
for a  . By Radon–Nikodým's theorem, we thus have that each H-valued Radon measure μ can be written as
. By Radon–Nikodým's theorem, we thus have that each H-valued Radon measure μ can be written as  with
with  such that
such that  and
and  almost everywhere with respect to
almost everywhere with respect to  . In this light, integration can also be phrased as
. In this light, integration can also be phrased as

for  ,
,  uniformly continuous. The following theorem, which is a direct consequence of [163, theorem 6.19], provides a useful characterisation of the space of vector valued measures as the dual of a separable space.
uniformly continuous. The following theorem, which is a direct consequence of [163, theorem 6.19], provides a useful characterisation of the space of vector valued measures as the dual of a separable space.
Proposition 2.4. The space  of all vector-valued Radon measures equipped with the norm
of all vector-valued Radon measures equipped with the norm  for
for  is a Banach space.
is a Banach space.
It can be identified with the dual space  as follows. For each
as follows. For each  there exists a unique
there exists a unique  such that
such that

In particular, one has a notion of weak*-convergence of Radon measures. For a sequence {μn
} and an element μ* in  we have that
we have that  in
in  if
if

As the predual space  is separable, the Banach–Alaoglu theorem yields in particular the sequential relative weak*-compactness of bounded sets. That means for instance that a bounded sequence always admits a weakly*-convergent subsequence, a property that may compensate for the lack of reflexivity of
is separable, the Banach–Alaoglu theorem yields in particular the sequential relative weak*-compactness of bounded sets. That means for instance that a bounded sequence always admits a weakly*-convergent subsequence, a property that may compensate for the lack of reflexivity of  .
.
The interpretation as a dual space as well as the density of test functions in  also allows to conclude that in order for a linear functional T defining a Radon measure, it suffices to test against
also allows to conclude that in order for a linear functional T defining a Radon measure, it suffices to test against  and to establish
and to establish  for all
for all  and C > 0 independent of φ. This is useful for derivatives, i.e., the derivative of a
and C > 0 independent of φ. This is useful for derivatives, i.e., the derivative of a  defines a Radon measure in
defines a Radon measure in  if
if

In this case, we denote by  the unique Hd
-valued Radon measure for which
the unique Hd
-valued Radon measure for which  φ ⋅ d∇u = −
φ ⋅ d∇u = − u div φ dx for all
u div φ dx for all  . Here, Hd
is equipped with the scalar product
. Here, Hd
is equipped with the scalar product  for x, y ∈ Hd
. In the case where (1) fails, there exists a sequence {φn
} in
for x, y ∈ Hd
. In the case where (1) fails, there exists a sequence {φn
} in  with
with  and
and  as n → ∞. Thus, allowing the supremum to take the value ∞, this yields following definition.
as n → ∞. Thus, allowing the supremum to take the value ∞, this yields following definition.
Definition 2.5. The total variation of a  is the value
is the value

Clearly, in case TV(u) < ∞, we have  with
with  . Trivially, for scalar functions, i.e., H = R, one recovers the well-known definition [7, 162]. Also, one immediately sees that TV is invariant to translations and rotations, or, more generally, to Euclidean-distance preserving transformations. This is the reason that this definition is also referred to as the isotropic total variation.
. Trivially, for scalar functions, i.e., H = R, one recovers the well-known definition [7, 162]. Also, one immediately sees that TV is invariant to translations and rotations, or, more generally, to Euclidean-distance preserving transformations. This is the reason that this definition is also referred to as the isotropic total variation.
Example 2.6. Piecewise constant functions may have a Radon measure as derivative. Let Ω' ⊂ Ω be a subdomain such that ∂Ω' ∩ Ω can be parameterised by finitely many Lipschitz mappings. Then, the outer normal ν exists almost everywhere in ∂Ω' ∩ Ω with respect to the Hausdorff  measure and one can employ the divergence theorem. This yields, for u = χΩ' and
measure and one can employ the divergence theorem. This yields, for u = χΩ' and  with ||φ||∞ ⩽ 1 that
with ||φ||∞ ⩽ 1 that

so  is a Radon measure. One sees, for instance via approximation, that
is a Radon measure. One sees, for instance via approximation, that  .
.
The class of sets Ω' ⊂ Ω for which χΩ' possesses a Radon measure as weak derivative is actually much greater than the class of bounded Lipschitz domains. These are the sets of finite perimeter, denoted by  . One the other hand, for u ∈ H1,1(Ω), we have
. One the other hand, for u ∈ H1,1(Ω), we have  and the weak derivative as Radon measure is just
and the weak derivative as Radon measure is just  , i.e., the Sobolev derivative interpreted as a weight on the Lebesgue measure. Collecting all functions whose weak derivative is a Radon measure, we arrive at the following space.
, i.e., the Sobolev derivative interpreted as a weight on the Lebesgue measure. Collecting all functions whose weak derivative is a Radon measure, we arrive at the following space.

is the space of H-valued functions of bounded variation. In case H = R, we denote by BV(Ω) = BV(Ω, R) and just refer to functions of bounded variation.
Proposition 2.8. The space BV(Ω, H) with the associated norm is a Banach space. The total variation functional TV is a continuous seminorm on BV(Ω, H) which vanishes exactly at the constant functions, i.e., ker(TV) = H 1, with H 1 being the set of constant, H-valued functions.
The total variation functional is just designed to possess many convenient properties [7].
- The functional TV is proper, convex and lower semi-continuous on each Lp (Ω, H), i.e., for 1 ⩽ p ⩽ ∞.
- For 1 ⩽ p < ∞, each u ∈ BV(Ω, H) ∩ Lp
(Ω, H) can smoothly be approximated as follows: for ɛ > 0, there exists such that
- If Ω is a bounded Lipschitz domain, then there exists a constant C > 0 such that for each u ∈ BV(Ω, H) with
u dx = 0, the Poincaré–Wirtinger estimate
holds.




From the regularisation-theoretic point of view, the fact that TV is proper, convex and lower semi-continuous on Lebesgue spaces is relevant, a property that fails for the Sobolev-seminorm ||∇ ⋅ ||1. The Poincaré–Wirtinger estimate can be interpreted as a coercivity property on a subspace with codimension 1. Also note that this estimate is the same as for H1,1(Ω, H)-functions and the respective constants C coincide. Consequently, the embedding properties of the latter space transfer immediately.
Proposition 2.10. Let Ω is a bounded Lipschitz domain. Then,
- The embedding BV(Ω, H) ↪ Ld/(d−1)(Ω, H) (with d/(d − 1) = ∞ for d = 1) exists and is continuous.
- The embedding BV(Ω, H) ↪ Lp (Ω, H) is compact for each 1 ⩽ p < d/(d − 1).
- Each bounded sequence {un
} in BV(Ω, H) possesses a subsequence which converges to a u ∈ BV(Ω, H) weak* in BV(Ω, H), which we define as in L1(Ω, H), in as k → ∞.




Consequently, the total variation is suitable for regularising ill-posed inverse problems in certain Lp -spaces.
2.2. Tikhonov regularisation
Let us now turn to solving ill-posed inverse problems with Tikhonov regularisation and BV-based penalty, i.e., solving

for some data f in a Banach space Y. As mentioned in the introduction, since the focus of this review is on regularisation terms rather than tackling inverse problems in the most possible generality, we restrict ourselves here to linear and continuous forward operators K : Ld/(d−1)(Ω) → Y. Nevertheless we note that, building on the results developed here for the linear setting, an extension to non-linear operators typically boils down to ensuring additional requirements on the non-linear forward model rather than the regularisation term, see for instance [84, 106, 182].
Measuring the discrepancy in terms of the norm in Y, the problem is then to solve

for some exponent q ⩾ 1. Usually, Y is some Hilbert space and q = 2, resulting in a quadratic discrepancy, which is often used in case of Gaussian noise. For impulsive noise (or salt-and-pepper noise), the space Y = L1(Ω'), with Ω' a domain, turns out to be useful. In case of Poisson noise, however, it is not advisable to take the norm but rather the Kullback–Leibler divergence between Ku and f, i.e. KL(Ku, f), where KL is given, for f ∈ L1(Ω') with f ⩾ 0 almost everywhere, according to the non-negative integral

provided that v ⩾ 0 a.e., and ∞ else. In particular, in this context, we agree to set the integrand to v where f = 0 and to ∞ where v = 0 and f > 0.
In the following, we assume to have given a discrepancy functional Sf : Y → [0, ∞] that is proper, convex, lower semi-continuous and coercive. This is not the most general case but will be sufficient for us in order to ensure existence of minimisers of the Tikhonov functional.
Theorem 2.11. Let Ω be a bounded Lipschitz domain, Y be a Banach space, K : Ld/(d−1)(Ω) → Y linear and continuous (weak*-to-weak-continuous in case d = 1), Sf : Y → [0, ∞] a proper, convex, lower semi-continuous and coercive discrepancy functional associated with some data f and α > 0. Then, there exist solutions of

If Sf is strictly convex and K is injective, the solution is unique whenever the minimum is finite.
We provide the proof for the sake of completeness and as a prototype for the generalisation to higher-order functionals.
Proof. Assume that the objective functional in (3) is proper, otherwise, there is nothing to show. For a minimising sequence {un
}, the Poincaré–Wirtinger inequality gives boundedness of  in Ld/(d−1)(Ω) while the coercivity of Sf
yields the boundedness of {Kun
}. By continuity,
in Ld/(d−1)(Ω) while the coercivity of Sf
yields the boundedness of {Kun
}. By continuity,  must be bounded, so if K
1 ≠ 0, then {
must be bounded, so if K
1 ≠ 0, then { un
dx} is bounded as otherwise, {Kun
} would be unbounded. In the case that K
1 = 0, we can without loss of generality assume that
un
dx} is bounded as otherwise, {Kun
} would be unbounded. In the case that K
1 = 0, we can without loss of generality assume that  un
dx = 0 for all n as shifting along constants does not change the functional value. In each case, {
un
dx = 0 for all n as shifting along constants does not change the functional value. In each case, { un
dx} is bounded, so {un
} must be bounded in Ld/(d−1)(Ω). Hence, by compact embedding (proposition 2.10) we have
un
dx} is bounded, so {un
} must be bounded in Ld/(d−1)(Ω). Hence, by compact embedding (proposition 2.10) we have  in L1(Ω) as k → ∞ for a subsequence
in L1(Ω) as k → ∞ for a subsequence  and u* ∈ BV(Ω). Reflexivity and continuity of K (weak* sequential compactness and weak*-to-weak continuity in case d = 1) give
and u* ∈ BV(Ω). Reflexivity and continuity of K (weak* sequential compactness and weak*-to-weak continuity in case d = 1) give  in Y for another subsequence (not relabelled). By lower semi-continuity, u* has to be a solution to (3).
in Y for another subsequence (not relabelled). By lower semi-continuity, u* has to be a solution to (3).
Finally, if Sf is strictly convex and K is injective, then Sf ◦ K is already strictly convex, so minimisers have to be unique. □
- The discrepancy functional for some f ∈ Y is obviously proper, convex, lower semi-continuous and coercive.
- It follows from lemma A.1 in the appendix that the discrepancy Sf (v) = KL(v, f) defined on Y = L1(Ω') for f ∈ L1(Ω') with f ⩾ 0 almost everywhere is proper, convex and coercive in L1(Ω'). Lower semi-continuity in turn follows as special case of lemma A.2.

Remark 2.13. Note that if the inversion of K : Lp (Ω) → Y is well-posed for some p ∈ [1, ∞], then solutions of (3) still exist (even for α = 0). Clearly, the TV penalty is not necessary for obtaining a regularising effect for these problems. In this case, minimising the Tikhonov function with TV penalty may the interpreted as denoising. The most prominent example might be the Rudin–Osher–Fatemi problem [162] which reads as

for f ∈ L2(Ω). Here, as the identity is 'inverted', the effect of total-variation regularisation can be studied in detail. Minimisation problems of this type with other regularisation functionals are thus a good benchmark test for the properties of this functional.
The stability of solutions in case of varying f depends, of course, on the dependence of Sf
on f. The appropriate notion here is the convergence of the discrepancy functional, i.e., for a sequence {fn
} and limit f, we say that  converges to Sf
if
converges to Sf
if

Moreover, we say that  is equi-coercive if there is a coercive function S0 : Y → [0, ∞] such that
is equi-coercive if there is a coercive function S0 : Y → [0, ∞] such that  in Y for each n.
in Y for each n.
Theorem 2.14. In the situation of theorem 2.11, assume that  converges to Sf
in the sense of (4) and
converges to Sf
in the sense of (4) and  is equi-coercive. Then, for each sequence of minimisers {un
} of (3) with discrepancy
is equi-coercive. Then, for each sequence of minimisers {un
} of (3) with discrepancy  ,
,
- Either as n → ∞ and (3) with discrepancy f does not admit a finite solution.
- Or as n → ∞ and there is, possibly up to constant shifts, a weak accumulation point u ∈ Ld/(d−1)(Ω) (weak* accumulation point for d = 1) that minimises (3) with discrepancy Sf
.


For each subsequence  weakly converging to some u in Ld/(d−1)(Ω) (
weakly converging to some u in Ld/(d−1)(Ω) ( in case d = 1), it holds that
in case d = 1), it holds that  as k → ∞ and u solves (3) with discrepancy Sf
. If solutions to the latter are unique, we have un
⇀ u in Ld/(d−1)(Ω) (
as k → ∞ and u solves (3) with discrepancy Sf
. If solutions to the latter are unique, we have un
⇀ u in Ld/(d−1)(Ω) ( in case d = 1).
in case d = 1).
Proof. Let, in the following  un
dx = 0 for all n if K
1 = 0 and denote by F = Sf
◦ K + αTV as well as
un
dx = 0 for all n if K
1 = 0 and denote by F = Sf
◦ K + αTV as well as  . First of all, suppose that {Fn
(un
)} is bounded. As
. First of all, suppose that {Fn
(un
)} is bounded. As  is equi-coercive, we can conclude as in the proof of theorem 2.11 that {un
} is bounded. Therefore, a weak accumulation point (weak* in case d = 1) exists.
is equi-coercive, we can conclude as in the proof of theorem 2.11 that {un
} is bounded. Therefore, a weak accumulation point (weak* in case d = 1) exists.
Suppose that  as k → ∞. Then,
as k → ∞. Then,

as well as, for each u' ∈ Ld/(d−1)(Ω)

Thus, u is a minimiser for F and plugging in u' = u we see that  . In order to obtain
. In order to obtain  , suppose that
, suppose that  , such that
, such that

which is a contradiction. Thus,  . Finally, if u is the unique minimiser for (3) with discrepancy Sf
, then un
⇀ u as n → ∞ for the whole sequence (
. Finally, if u is the unique minimiser for (3) with discrepancy Sf
, then un
⇀ u as n → ∞ for the whole sequence ( in case d = 1) as any subsequence has to contain another subsequence that converges weakly (weakly*) to u.
in case d = 1) as any subsequence has to contain another subsequence that converges weakly (weakly*) to u.
In order to conclude the proof, suppose that lim infn→∞
Fn
(un
) < ∞. In that case, the above arguments yield an accumulation point as stated as well as a minimiser u ∈ BV(Ω) of F with F(u) ⩽ liminfn→∞
Fn
(un
). In particular, F is proper. By convergence of  to Sf
and minimality, we have
to Sf
and minimality, we have

so the whole sequence of functional values converges.
Finally, in case Fn (un ) → ∞ as n → ∞, F cannot be proper: otherwise, we obtain analogously to the above that ∞ > F(u) ⩾ lim supn→∞ Fn (u) ⩾ liminfn→∞ Fn (un ) for some u ∈ BV(Ω) which is a contradiction. □
Remark 2.15. The convergence of discrepancies as in (4) is related to gamma-convergence. Indeed, the difference is that, for the latter, on the right-hand side of the lim sup inequality, an arbitrary sequence converging to v is allowed (instead of the constant sequence). In this context, as can be seen in the proof of the stability result above, one could still weaken the lim sup-assumption in (4) by allowing not only the constant recovery sequence but any sequence for which the regularisation functional converges. However, in order to maintain an assumption on the discrepancy term that is independent of the choice of regularisation, we chose the slightly stronger condition.
- A typical discrepancy is some power of the norm-distance in Y, i.e., for some q ⩾ 1. It is easy to show that whenever fn
→ f in Y, converges to Sf
in the above sense. Also, the equi-coercivity of is immediate.
- For the Kullback–Leibler divergence, let Y = L1(Ω') for some Ω' and assume that {fn
}, f in L1(Ω') are such that fn
⩽ Cf a.e. in Ω' for some C > 0 and KL(f, fn
) → 0 as n → ∞. Then, it follows from lemma A.2 in the appendix that converges to Sf
= KL(⋅, f), and also that ||fn
− f||1 → 0. The latter in particular implies boundedness of {fn
} in L1(Ω') which, together with the coercivity estimate of lemma A.1 shows that is equi-coercive.





In addition to well-posedness of the Tikhonov-functional minimisation, one is of course interested in regularisation results, i.e., the convergence of solutions to a minimum-TV-solution provided that the data converges and α → 0 in some sense. For this purpose, let u† ∈ BV(Ω) be a minimum-TV-solution of Ku† = f† for some data f† in Y, i.e., TV(u†) ⩽ TV(u) for each Ku = f†, suppose that for each δ > 0 one has given a fδ
∈ Y such that  , and denote by uα,δ
a solution of (3) for parameter α > 0 and data fδ
.
, and denote by uα,δ
a solution of (3) for parameter α > 0 and data fδ
.
Theorem 2.17. In the situation of theorem 2.11, let the discrepancy functionals  be equi-coercive and converge to
be equi-coercive and converge to  in the sense of (4) for some data f† ∈ Y with
in the sense of (4) for some data f† ∈ Y with  if and only if v = f†. Choose for each δ > 0 the parameter α > 0 such that
if and only if v = f†. Choose for each δ > 0 the parameter α > 0 such that

Then, again up to constant shifts, {uα,δ } has at least one weak accumulation point in Ld/(d−1)(Ω) (weak* in case d = 1). Each such accumulation point is a minimum-TV-solution of Ku = f† and limδ→0TV(uα,δ ) = TV(u†).
Proof. Again we assume that  uα,δ
dx = 0 for all (α, δ) if K
1 = 0. Using the optimality of uα,δ
for (3) compared to u† gives
uα,δ
dx = 0 for all (α, δ) if K
1 = 0. Using the optimality of uα,δ
for (3) compared to u† gives

Since α → 0 as δ → 0, we have that  as δ → 0. Moreover, as also δ/α → 0, it follows that lim supδ→0TV(uα,δ
) ⩽ TV(u†). This allows to conclude that {uα,δ
} is bounded in BV(Ω) and, by embedding, admits a weak accumulation point in Ld/(d−1)(Ω) (weak* in case d = 1).
as δ → 0. Moreover, as also δ/α → 0, it follows that lim supδ→0TV(uα,δ
) ⩽ TV(u†). This allows to conclude that {uα,δ
} is bounded in BV(Ω) and, by embedding, admits a weak accumulation point in Ld/(d−1)(Ω) (weak* in case d = 1).
Next, let u* be such an accumulation point associated with {δn
}, δn
→ 0 as well as the corresponding parameters {αn
}. Then,  , so Ku* = f†. Moreover,
, so Ku* = f†. Moreover,  , hence u* is a minimum-TV-solution. In particular, TV(u*) = TV(u†), so
, hence u* is a minimum-TV-solution. In particular, TV(u*) = TV(u†), so  .
.
Finally, each sequence of {δn
}, δn
→ 0 contains another subsequence  for which
for which  as n → ∞, so TV(uα,δ
) → TV(u†) as δ → 0. □
as n → ∞, so TV(uα,δ
) → TV(u†) as δ → 0. □
Finally, if a respective source condition is satisfied, we can, under some circumstances, give rates for some Bregman distance with respect to TV associated with respect to a particular subgradient element [48]. Recall that the Bregman distance  of x, y ∈ X for a convex functional
of x, y ∈ X for a convex functional ![$F:X\to \enspace \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn122.gif) and subgradient element x* ∈ ∂F(x) is given by
and subgradient element x* ∈ ∂F(x) is given by

The convergence rate results are then a consequence of the following proposition.
Proposition 2.18. In the situation of theorem 2.17, let K*w† ∈ ∂TV(u†) for some w† ∈ Y*. Then,

Proof. Using the minimality of uα,δ
yields  . Rearranging, adding ⟨K*w†, u† − uα,δ
⟩ on both sides as well as using Fenchel's inequality twice yields
. Rearranging, adding ⟨K*w†, u† − uα,δ
⟩ on both sides as well as using Fenchel's inequality twice yields

Subtracting  and dividing by α gives the result. □
and dividing by α gives the result. □
For well-known discrepancy terms, one easily gets parameter choice rules that lead to rates for  .
.
- For with q > 1, where 1/q + 1/q* = 1, hence (5) reads asIn the non-trivial case of w† ≠ 0, the right-hand side becomes minimal for giving the well-known rate of for the Bregman distance.
- For the Kullback–Leibler discrepancy, i.e., on L1(Ω'), a direct, pointwise computation shows that the dual functional obeys if almost everywhere, setting −t log(0) = ∞ for t > 0 and −0 log(0) = 0, and else. As w† ∈ L∞(Ω'), we may choose α > 0 such that . Then, the equivalenceholds. Assuming, the weak convergence fδ
⇀ f in L1(Ω') (see lemma A.2) implies independent from δ. Hence, choosing yields the rate for the Bregman distance as δ → 0.















2.3. Further first-order approaches
Besides these functional-analytic properties, functions of bounded variation admit interesting structural and fine properties. Let us briefly discuss the structure of the gradient ∇u for a u ∈ BV(Ω). By Lebesgue's decomposition theorem, ∇u can be split into an absolutely continuous part ∇a
u with respect to the Lebesgue measure and a singular part ∇s
u. We tacitly identify ∇a
u with the Radon–Nikodým derivative, i.e., ∇a
u ∈ L1(Ω, Rd
) via the measure  .
.
The singular part ∇s u therefore has to capture the jump discontinuities of u. Indeed, introducing the jump set, it can further be decomposed. Recall that a u ∈ L1(Ω) is almost everywhere approximately continuous, i.e., for almost every x ∈ Ω there exists a z ∈ R such that

The collection of all points Su for which u is not approximately continuous is called the discontinuity set of u.
Definition 2.20. Let  and x ∈ Ω.
and x ∈ Ω.
- (a)The function u is called approximately differentiable in x if there exists a v ∈ Rd such thatThe vector ∇≈ u(x) = v is called the approximate gradient of u at x.
- (b)The point x is an approximate jump point of u if there exist u+(x) > u−(x) and a ν ∈ Rd , such thatwhere and are balls cut by the hyperplane perpendicular to ν and containing x, i.e.,The set Ju of all approximate jump points is called the jump set of u.






Theorem 2.21. ([7]). Let u ∈ BV(Ω). Then,
- (a)u is almost everywhere approximately differentiable with ∇a u = ∇≈ u in L1(Ω, Rd ).
- (b)The jump set satisfies and we have .
- (c)The restriction ∇u ⌞ (Ω\Su ) is absolutely continuous with respect to.



In particular, the involved sets and functions are Borel sets and functions, respectively.
Denoting by

where ∇j u and ∇c u is the jump and Cantor part of ∇u, respectively, the gradient of a u ∈ BV(Ω) can be decomposed into

with ∇c
u being singular with respect to  and absolutely continuous with respect to
and absolutely continuous with respect to  .
.
This construction allows in particular to define penalties beyond the total variation seminorm (see, for instance [7, section 5.5]). Letting g : Rd → [0, ∞] a proper, convex and lower semi-continuous function and g∞ be given according to

with ∞ allowed, then the functional

where  is the sign of ∇c
u, i.e.,
is the sign of ∇c
u, i.e.,  , is proper, convex and lower semi-continuous on BV(Ω). With the Fenchel-dual functional, i.e.,
, is proper, convex and lower semi-continuous on BV(Ω). With the Fenchel-dual functional, i.e.,  , it can also be expressed in (pre-)dual form as
, it can also be expressed in (pre-)dual form as

Obviously, the usual TV-case corresponds to g being the Euclidean norm on Rd
. Also, g∞(x) = ∞ for some  does not allow jumps in the direction of x, so one usually assumes that g∞(x) < ∞ for each
does not allow jumps in the direction of x, so one usually assumes that g∞(x) < ∞ for each  in order to obtain a genuine penalty in BV(Ω). In addition, if there are c0 > 0 and R > 0 such that
in order to obtain a genuine penalty in BV(Ω). In addition, if there are c0 > 0 and R > 0 such that  for each
for each  , then there is a constant C > 0 such that
, then there is a constant C > 0 such that

for all u ∈ BV(Ω), i.e.,  is as coercive as TV. Consequently, the well-posedness and convergence statements in theorems 2.11, 2.14 and 2.17 as well as in proposition 2.18 can be adapted to
is as coercive as TV. Consequently, the well-posedness and convergence statements in theorems 2.11, 2.14 and 2.17 as well as in proposition 2.18 can be adapted to  in a straightforward manner with the proofs following the same line of argumentation.
in a straightforward manner with the proofs following the same line of argumentation.
Example 2.22. There are several possibilities for replacing the non-differentiable norm function  in the TV-functional by a smooth approximation in 0.
in the TV-functional by a smooth approximation in 0.
Choosing a ɛ > 0, consider

both being continuously differentiable in Rd
and approximating  for ɛ → 0.
for ɛ → 0.
The associated penalties  and
and  are often referred to as Huber-TV and smooth TV, respectively.
are often referred to as Huber-TV and smooth TV, respectively.
Example 2.23. Taking g as a non-Euclidean norm on Rd yields functionals of anisotropic total-variation type. The common choice is g = |⋅|1 which is also often referred to as anisotropic TV.
Remark 2.24. It is worth noting that g as above can also be made spatially dependent, which has applications for instance in the context of regularisation for inverse problems involving multiple modalities or multiple spectra. Under some assumptions, functionals  as in (7) with spatially dependent g are again lower semi-continuous on BV [6] and well-posedness results for TV apply [105].
as in (7) with spatially dependent g are again lower semi-continuous on BV [6] and well-posedness results for TV apply [105].
2.4. Colour and multichannel images
Colour and multichannel images are usually represented by functions mapping into a vector-space. Total-variation functionals and regularisation approaches can easily be extended to such vector-valued functions; definition 2.5 already contains an isotropic variant for functions with values in a finite-dimensional space H, where we used the Hilbert-space norm  as pointwise norm on Hd
for the test functions
as pointwise norm on Hd
for the test functions  .
.
However, in contrast to the scalar case, this is not the only choice yielding TV-functionals that are invariant under distance-preserving transformations. The essential property for a norm |⋅|◦ on Hd needed for the latter is

where  . We call such norms unitarily left invariant. Denoting by |⋅|* the dual norm, the associated total variation for a
. We call such norms unitarily left invariant. Denoting by |⋅|* the dual norm, the associated total variation for a  is given by
is given by

and invariant to distance-preserving transformations. If the norm |⋅|◦ is moreover unitarily right invariant, i.e.,

where  , then it can be written as a unitarily invariant matrix norm and hence |x|◦ only depends on the singular values of the mapping associated with x in a permutation- and sign-invariant manner. More precisely, there exists a norm |⋅|Σ on Rd
with |Pσ|Σ = |σ|Σ for all σ ∈ Rd
and P ∈ Rd×d
with
, then it can be written as a unitarily invariant matrix norm and hence |x|◦ only depends on the singular values of the mapping associated with x in a permutation- and sign-invariant manner. More precisely, there exists a norm |⋅|Σ on Rd
with |Pσ|Σ = |σ|Σ for all σ ∈ Rd
and P ∈ Rd×d
with  being a permutation matrix, such that |x|◦ = |σ|Σ for all x ∈ Hd
, where σ are the singular values of the mapping Hd
→ Rd
given by
being a permutation matrix, such that |x|◦ = |σ|Σ for all x ∈ Hd
, where σ are the singular values of the mapping Hd
→ Rd
given by  . Conversely, any such norm on Rd
induces a unitarily invariant matrix norm. A common choice are the norms generated by the p-vector norm, the Schatten-
p
-norms. For p = 1, p = 2 and p = ∞, they correspond to the nuclear norm, the Frobenius norm and the usual spectral norm, respectively, all of which have been proposed in the existing literature to use in conjunction with TV, see, e.g., [79, 164]. Among those possibilities, the nuclear norm appears particularly attractive as it provides a relaxation of the rank functional [156]. Hence, solutions with low-rank gradients and more pronounced edges can be expected from nuclear-norm-TV regularisation.
. Conversely, any such norm on Rd
induces a unitarily invariant matrix norm. A common choice are the norms generated by the p-vector norm, the Schatten-
p
-norms. For p = 1, p = 2 and p = ∞, they correspond to the nuclear norm, the Frobenius norm and the usual spectral norm, respectively, all of which have been proposed in the existing literature to use in conjunction with TV, see, e.g., [79, 164]. Among those possibilities, the nuclear norm appears particularly attractive as it provides a relaxation of the rank functional [156]. Hence, solutions with low-rank gradients and more pronounced edges can be expected from nuclear-norm-TV regularisation.
Also here, the well-posedness and convergence results in theorems 2.11, 2.14 and 2.17 as well as in proposition 2.18 are transferable to the vector-valued case, as can be seen from equivalence of norms.
Moreover, functionals of the type (7) are possible with g : Hd
→ [0, ∞] proper, convex and lower semi-continuous such that g∞ exists. However, u takes values in H which calls for some adaptations which we briefly describe in the following. First, concerning definition 2.20(a), we are able to generalise in a straightforward way by considering v ∈ Hd
, the norm in H and the scalar product in Hd
such that the approximate gradient of u at x is ∇≈
u(x) ∈ Hd
. For jump points according to (b), we are no longer able to require u+(x) > u−(x) such that we have to replace this by u+(x) ≠ u−(x) and arrive at a meaningful definition replacing the absolute value by the norm in H. However, u+, u− and ν are then only unique up to a sign. Nevertheless, (u+ − u−) ⊗ ν according to  is still unique. The analogue of theorem 2.21 and (6) holds with these notions, with the following adaptation:
is still unique. The analogue of theorem 2.21 and (6) holds with these notions, with the following adaptation:

with the Cantor part being of rank one, i.e.,  where
where  is rank one
is rank one  -almost everywhere [7, theorem 3.94]. The functional
-almost everywhere [7, theorem 3.94]. The functional  according to
according to

then realises a regulariser with the same regularisation properties as its counterpart for scalar functions.
3. Higher-order TV regularisation
First-order regularisation for imaging problems might not always lead to results of sufficient quality. Recall that taking the total variation as regularisation functional has the advantage that the solution space BV(Ω) naturally allows for discontinuities along hypersurfaces ('jumps') which correspond, for imaging applications, to object boundaries. Indeed, TV has a good performance in edge preservation which can also be observed numerically.
However, for noisy data, the solutions suffer from non-flat regions appearing flat in conjunction with the introduction of undesired edges. This effect is called the staircasing effect, see figure 1, in particular panel (c). Thinking of TV as a one-norm type penalty for the gradient, this is, on the one hand, due to the 'linear growth' of the Euclidean norm  at infinity (which implies BV(Ω) as solution space). On the other hand,
at infinity (which implies BV(Ω) as solution space). On the other hand,  is non-differentiable in 0 which can be seen to be responsible for the flat regions in the solutions.
is non-differentiable in 0 which can be seen to be responsible for the flat regions in the solutions.
As we have seen in subsection 2.3, the latter can be remedied by considering convex functions of the measure ∇u instead of TV which are smooth in the origin and have linear growth at ∞, also see example 2.22. Then,  can be taken as a first-order regulariser under the same conditions as for TV regularisation leading to solutions which are still in BV(Ω) and may, in particular, admit jumps. Additionally, less flat regions tend to appear in solutions for noisy data as we no longer have a singularity at 0. However, this feature comes with two drawbacks: first, compared to TV, noise removal seems not to be so strong in numerical solutions. Second, in addition to the regularisation parameter for the inverse problem, one has to choose the parameter ɛ appropriately. A too small choice might again lead to staircasing to appear while choosing ɛ too big may lead to edges being lost, see figure 1(d). The question remains whether we can improve on this.
can be taken as a first-order regulariser under the same conditions as for TV regularisation leading to solutions which are still in BV(Ω) and may, in particular, admit jumps. Additionally, less flat regions tend to appear in solutions for noisy data as we no longer have a singularity at 0. However, this feature comes with two drawbacks: first, compared to TV, noise removal seems not to be so strong in numerical solutions. Second, in addition to the regularisation parameter for the inverse problem, one has to choose the parameter ɛ appropriately. A too small choice might again lead to staircasing to appear while choosing ɛ too big may lead to edges being lost, see figure 1(d). The question remains whether we can improve on this.
Here, we like to discuss and study the use of higher-order derivatives for regularisation in imaging. This can be motivated by modelling images as piecewise smooth functions, i.e., assuming that an image is several times differentiable (in some sense) while still allowing for object boundaries where the function may jump. With this model in mind, higher-order variational approaches arise quite naturally and we refer for instance to [17, 73, 104] for spaces and regularisation approaches related to second-order variational approaches.
3.1. Symmetric tensor calculus
For smooth functions, higher-order derivatives can be represented as tensor fields, i.e., the derivative represents a tensor in each point. As the order of partial differentiation might be interchanged, these tensors turn out to be symmetric. Symmetric tensors are therefore a suitable tool for representing these objects independent from indices. There are several ways to introduce and motivate tensors and vector spaces of tensors. For our purposes, the following definition will be sufficient. Note that there and throughout this chapter, l ⩾ 0 will always be a tensor order.

Figure 1. First-order denoising example. (a) Ground truth, (b) noisy image with additive Gaussian noise (PSNR: 13.9 dB), (c) TV-regularised solution (PSNR: 29.3 dB), (d) regularisation with smooth TV-like penalty  (PSNR: 29.7 dB). All parameters were manually tuned via grid search to yield highest PSNR.
(PSNR: 29.7 dB). All parameters were manually tuned via grid search to yield highest PSNR.
Download figure:
Standard image High-resolution image
as the vector space of l -tensors and symmetric l -tensors, respectively.
Here,  is called symmetric, if ξ(a1, ..., al
) = ξ(aπ(1), ..., aπ(l)) for all a1, ..., al
∈ Rd
and π ∈ Sl
, where Sl
denotes the permutation group of {1, ..., l}.
is called symmetric, if ξ(a1, ..., al
) = ξ(aπ(1), ..., aπ(l)) for all a1, ..., al
∈ Rd
and π ∈ Sl
, where Sl
denotes the permutation group of {1, ..., l}.
For  , k ⩾ 0 and
, k ⩾ 0 and  the tensor product is defined as the element
the tensor product is defined as the element  obeying
obeying

for all a1, ..., ak+l ∈ Rd .
Note that the space of l-tensors is actually the space of (0, l)-covariant tensors, however, we will not need to distinguish between co- and contravariant tensors. We have

while for low orders, the symmetric tensor spaces coincide with well-known spaces Sym0(Rd ) ≡ R, Sym1(Rd ) ≡ Rd and Sym2(Rd ) ≡ Sd×d , the space of symmetric d × d matrices.
In the following, we give a brief overview of the tensor operations that are the most relevant to define regularisation functionals on higher-order derivatives.
Remark 3.2. The space  can be associated with a unit basis. Indexed by p ∈ {1, ..., d}l
, its elements are given by
can be associated with a unit basis. Indexed by p ∈ {1, ..., d}l
, its elements are given by  while the respective coefficient for a
while the respective coefficient for a  is given by
is given by  . Each
. Each  thus has the representation
thus has the representation

The identity of vector spaces  is evident from that.
is evident from that.
The space Syml
(Rd
) is obviously a (generally proper) subspace of  . A (non-symmetric) tensor
. A (non-symmetric) tensor  can be symmetrised by averaging over all permuted arguments, i.e.,
can be symmetrised by averaging over all permuted arguments, i.e.,

The symmetrisation operator  obviously defines a projection. A basis for Syml
(Rd
) is given by
obviously defines a projection. A basis for Syml
(Rd
) is given by  for p ranging over all tuples in {1, ..., d}l
with non-decreasing entries. The coefficients ξp
can still be obtained by
for p ranging over all tuples in {1, ..., d}l
with non-decreasing entries. The coefficients ξp
can still be obtained by  .
.
We would like to equip the spaces with a Hilbert space structure.
Definition 3.3. For  , the scalar product and Frobenius norm are defined as
, the scalar product and Frobenius norm are defined as

Example 3.4. For ξ ∈ Syml (Rd ), the norm corresponds to the absolute value for l = 0, the Euclidean norm in Rd for l = 1 and in case l = 2, we can identify ξ ∈ Sym2(Rd ) with

With the Frobenius norm, tensor spaces become Hilbert spaces of finite dimension and the symmetrisation becomes an orthogonal projection, see, e.g., [99].
- (a)With the above scalar-product and norm, the spaces, Syml
(Rd
) are finite-dimensional Hilbert spaces with and .
- (b)The symmetrisation | | | is the orthogonal projection in onto Syml
(Rd
).




Tensor-valued mappings  on the domain Ω ⊂ Rd
are called tensor fields. The tensor-field spaces
on the domain Ω ⊂ Rd
are called tensor fields. The tensor-field spaces  ,
,  and
and  as well as the Lebesgue spaces
as well as the Lebesgue spaces  are then given in the usual manner. Also, measures can be tensor-valued, giving
are then given in the usual manner. Also, measures can be tensor-valued, giving  , the space of l-tensor-valued Radon measures. Duality according to proposition 2.4 holds, i.e.,
, the space of l-tensor-valued Radon measures. Duality according to proposition 2.4 holds, i.e.,  . Note that for all spaces, the Frobenius norm is used as pointwise norm in the respective definitions of the tensor-field norm. Furthermore, all the above applies analogously to symmetric tensor fields, i.e., mappings between Ω → Syml
(Rd
).
. Note that for all spaces, the Frobenius norm is used as pointwise norm in the respective definitions of the tensor-field norm. Furthermore, all the above applies analogously to symmetric tensor fields, i.e., mappings between Ω → Syml
(Rd
).
Turning to differentiation, the kth Fréchet derivative of a sufficiently smooth l-tensor field, where from now on k ⩾ 1 will always denote an order of differentiation, is naturally a (k + l)-tensor field which we denote by  according to
according to

The fact that gradient tensor-fields are not symmetric in general gives rise to consider the k
th symmetrised derivative given by  . This definition is consistent as
. This definition is consistent as  for k1, k2 ⩾ 0. Divergence operators are then, up to the sign, formal adjoints of these differentiation operators. They are given as follows. Introducing the trace of a tensor
for k1, k2 ⩾ 0. Divergence operators are then, up to the sign, formal adjoints of these differentiation operators. They are given as follows. Introducing the trace of a tensor  according to
according to

gives an l-tensor. It can be interpreted as the tensor contraction of the first and the last component of the tensor. As for the vector-field case, the divergence is now the trace of the derivative. For k-times differentiable  , the kth divergence is thus given by
, the kth divergence is thus given by

Again, this is consistent with repeated application, i.e.,  . Note that there might be other choices of the divergence, such as contracting the derivative with any other than the last components of the tensor. This affects, however, only non-symmetric tensor fields. For symmetric tensor fields, the result is independent from the choice of the contraction components and always a symmetric tensor field.
. Note that there might be other choices of the divergence, such as contracting the derivative with any other than the last components of the tensor. This affects, however, only non-symmetric tensor fields. For symmetric tensor fields, the result is independent from the choice of the contraction components and always a symmetric tensor field.
Example 3.6. The symmetrised gradient of scalar functions Ω → Sym0(Rd ) coincides with the usual gradient while the divergence for mappings Ω → Sym1(Rd ) coincides with the usual divergence.
The cases  and
and  for u0 : Ω → Sym0(Rd
) and u1 : Ω → Sym1(Rd
) can be handled with the identification of Sym2(Rd
) and symmetric matrices Sd×d
:
for u0 : Ω → Sym0(Rd
) and u1 : Ω → Sym1(Rd
) can be handled with the identification of Sym2(Rd
) and symmetric matrices Sd×d
:

Analogously, for the divergence of a v : Ω → Sym2(Rd ), we have that

In particular, for k ⩾ 1, there are the usual spaces of continuously differentiable tensor fields which are denoted by  and equipped with the usual norm
and equipped with the usual norm  . Likewise, we consider k-times continuously differentiable tensor fields with compact support
. Likewise, we consider k-times continuously differentiable tensor fields with compact support  where k = ∞ leads to the space of test tensor fields. Also, for finite k, the space
where k = ∞ leads to the space of test tensor fields. Also, for finite k, the space  is given as the closure of
is given as the closure of  in
in  . Of course, the analogous constructions apply to symmetric tensor fields, leading to the spaces
. Of course, the analogous constructions apply to symmetric tensor fields, leading to the spaces  ,
,  and
and  as well as the space of test symmetric tensor fields
as well as the space of test symmetric tensor fields  .
.
As Ω is assumed to be a connected set, we are able to describe the kernels of ∇k
and  for (symmetric) tensor fields in terms of finite-dimensional spaces of polynomials.
for (symmetric) tensor fields in terms of finite-dimensional spaces of polynomials.
Proposition 3.7. Let  such that ∇k
⊗ u = 0. Then, u is a
such that ∇k
⊗ u = 0. Then, u is a  -valued polynomial of maximal order k − 1, i.e., there are
-valued polynomial of maximal order k − 1, i.e., there are  , m = 0, ..., k − 1 such that
, m = 0, ..., k − 1 such that

If  for
for  , then u is a Syml
(Rd
)-valued polynomial of maximal order k + l − 1, i.e., the above representation holds for ξm
∈ Syml+m
(Rd
), m = 0, ..., k + l − 1 with the sum ranging from 0 to k + l − 1.
, then u is a Syml
(Rd
)-valued polynomial of maximal order k + l − 1, i.e., the above representation holds for ξm
∈ Syml+m
(Rd
), m = 0, ..., k + l − 1 with the sum ranging from 0 to k + l − 1.
Proof. At first we note that any  - and Syml
(Rd
)-valued polynomial of maximal order k − 1 and k + l − 1, respectively, admits a representation as claimed. In case ∇k
⊗ u = 0 for
- and Syml
(Rd
)-valued polynomial of maximal order k − 1 and k + l − 1, respectively, admits a representation as claimed. In case ∇k
⊗ u = 0 for  it follows directly from a basis representation of u(x) that u is a
it follows directly from a basis representation of u(x) that u is a  -valued polynomial of maximal order k − 1.
-valued polynomial of maximal order k − 1.
Now in case  for
for  , we get that ∇k+l
⊗ u = 0, see lemma A.3. This implies that u is a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1 as claimed. □
, we get that ∇k+l
⊗ u = 0, see lemma A.3. This implies that u is a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1 as claimed. □
Next, we would like to introduce and discuss weak forms of differentiation for (symmetric) tensor fields. Starting point for this is a version of the well-known Gauss–Green theorem for smooth (symmetric) tensor fields [28].
Proposition 3.8. Let Ω ⊂ Rd
be a bounded Lipschitz domain,  ,
,  . Then, a Gauss–Green theorem holds in the following form:
. Then, a Gauss–Green theorem holds in the following form:

with ν being the outward unit normal on ∂Ω.
If  ,
,  , the identity reads as
, the identity reads as

If one of the tensor fields u or v have compact support in Ω the boundary term does not appear and the identities are valid for arbitrary domains Ω.
As usual, being able to express integrals of the form  (∇ ⊗ u) ⋅ v dx and
(∇ ⊗ u) ⋅ v dx and  for test tensor fields without the derivative of u allows to introduce a weak notion of ∇ ⊗ u and
for test tensor fields without the derivative of u allows to introduce a weak notion of ∇ ⊗ u and  , respectively, as well as associated Sobolev spaces.
, respectively, as well as associated Sobolev spaces.
Definition 3.9. For  ,
,  is the weak derivative of u, denoted w = ∇ ⊗ u, if for all
is the weak derivative of u, denoted w = ∇ ⊗ u, if for all  , it holds that
, it holds that

Likewise, for  , w ∈ L1
loc(Ω, Syml+1(Rd
)) is the weak symmetrised derivative of u, denoted
, w ∈ L1
loc(Ω, Syml+1(Rd
)) is the weak symmetrised derivative of u, denoted  , if the above identity holds for all
, if the above identity holds for all  .
.
Like the scalar versions, ∇ and  are well-defined and constitute closed operators between the respective Lebesgue spaces with dense domain.
are well-defined and constitute closed operators between the respective Lebesgue spaces with dense domain.
Definition 3.10. The Sobolev space of tensor fields of order l of differentiation order k and exponent p ∈ [1, ∞] is defined as

while  is the closure of the subspace
is the closure of the subspace  with respect to the ||⋅||k,p
-norm.
with respect to the ||⋅||k,p
-norm.
Replacing  by Syml
(Rd
) and letting
by Syml
(Rd
) and letting

defines the Sobolev space of symmetric tensor fields, denoted by Hk,p
(Ω, Syml
(Rd
)). The space  is again the closure
is again the closure  with respect to the corresponding norm.
with respect to the corresponding norm.
By closedness of the differential operators, the Sobolev spaces are Banach spaces. Also, since weak derivatives are symmetric, we have that  in the sense of Banach space isometry, as well as coincidence with the usual Sobolev spaces. For l ⩾ 1, the space
in the sense of Banach space isometry, as well as coincidence with the usual Sobolev spaces. For l ⩾ 1, the space  corresponds to the space where all components of u are in Hk,p
(Ω). However, generally, for l ⩾ 1, the norm of Hk,p
(Ω, Syml
(Rd
)) is weaker than the norm in
corresponds to the space where all components of u are in Hk,p
(Ω). However, generally, for l ⩾ 1, the norm of Hk,p
(Ω, Syml
(Rd
)) is weaker than the norm in  , such that only
, such that only  in the sense of continuous embedding and the latter is a strictly larger space.
in the sense of continuous embedding and the latter is a strictly larger space.
Nevertheless, equality holds if some kind of Korn's inequality can be established which is, for instance, the case for the spaces  for 1 < p < ∞ [120, section 5.6] as well as and the spaces
for 1 < p < ∞ [120, section 5.6] as well as and the spaces  for l ⩾ 1 (which follows from [28, proposition 3.6] via smooth approximation).
for l ⩾ 1 (which follows from [28, proposition 3.6] via smooth approximation).
Finally, let us briefly discuss (symmetric) tensor-valued distributions and the distributional forms of ∇k
and  .
.
Definition 3.11. A  -valued distribution on Ω is a linear mapping
-valued distribution on Ω is a linear mapping  that satisfies the following continuity estimate: for each K ⊂⊂ Ω, there is an m ∈ N and a C > 0 such that
that satisfies the following continuity estimate: for each K ⊂⊂ Ω, there is an m ∈ N and a C > 0 such that

The distribution u is regular if there is a  such that
such that

A Syml
(Rd
)-valued distribution on Ω and its regularity is analogously defined by replacing  by Syml
(Rd
) in the above definition.
by Syml
(Rd
) in the above definition.
Then, the distributional (symmetrised) derivatives are given by (∇k
⊗ u)(φ) = (−1)k
u(divk
φ),  and
and  ,
,  which makes them a
which makes them a  - and Symk+l
(Rd
)-valued distribution, respectively. We then have the following generalisation of theorem 3.7 which will be useful for analysing functionals that depend on (symmetrised) distributional derivatives.
- and Symk+l
(Rd
)-valued distribution, respectively. We then have the following generalisation of theorem 3.7 which will be useful for analysing functionals that depend on (symmetrised) distributional derivatives.
Proposition 3.12. If ∇k
⊗ u = 0 for a  -valued distribution, then u is regular and a
-valued distribution, then u is regular and a  -valued polynomial of maximal degree k − 1.
-valued polynomial of maximal degree k − 1.
If  for a Syml
(Rd
)-valued distribution, then u is regular and a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1.
for a Syml
(Rd
)-valued distribution, then u is regular and a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1.
Proof. This can be deduced from proposition 3.7 via mollification arguments similar as in [28, proposition 3.3]. □
3.2. Functions of higher-order bounded variation
In the following, we discuss functions whose derivative is a Radon measure for a fixed order of differentiation. As higher-order derivatives of scalar functions are always symmetric, it suffices to consider only the symmetrised higher-order derivative  in this case as well as symmetric tensor fields. However, as we are also interested in intermediate differentiation orders, we moreover discuss spaces of symmetric tensors for which the symmetrised derivative of some order is a Radon measure.
in this case as well as symmetric tensor fields. However, as we are also interested in intermediate differentiation orders, we moreover discuss spaces of symmetric tensors for which the symmetrised derivative of some order is a Radon measure.
In the following, recall that k ⩾ 1 denotes a differentiation order and l ⩾ 0 denotes a tensor order.
Definition 3.13. Let Ω ⊂ Rd be a domain.
- (a)In the case l = 0, for, the total variation of order
k is defined asFor general l ⩾ 0 and, the total deformation of order
k is
- (b)The normed space according tois called the space of symmetric tensor fields of bounded deformation of order k. The scalar case, i.e., l = 0, is referred to as the space of functions of bounded variation of order k. The latter spaces are denoted by BVk (Ω).





We note that the Hilbert-space norm on the tensor space for the definition of TVk leads to a corresponding pointwise norm on the derivatives. While this choice is rather natural, and does not require to distinguish primal and dual norms, also other choices are possible for which we refer to [128] in the second-order case.
Let us analyse some of the basic properties of these spaces.
Proposition 3.14. Let Ω ⊂ Rd be a domain, p ∈ [1, ∞]. Then:
- (a)TDk is proper, convex and a lower semi-continuous seminorm on Lp (Ω, Syml (Rd )).
- (b)TDk (u) = 0 if and only if. In particular, TDk
(u) = 0 implies that u is a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1.

Proof. With p* being the dual exponent to p, each test tensor field obeys  for
for  . The functional TDk
is thus a pointwise supremum over a set of continuous linear functionals and, consequently, convex and lower semi-continuous. By definition, it is obviously proper and positively homogeneous since if divk
φ is a test vector field, then also −divk
φ is.
. The functional TDk
is thus a pointwise supremum over a set of continuous linear functionals and, consequently, convex and lower semi-continuous. By definition, it is obviously proper and positively homogeneous since if divk
φ is a test vector field, then also −divk
φ is.
By definition of TDk
we see that TDk
(u) = 0 if and only if  u ⋅ divk
φ dx = 0 for each
u ⋅ divk
φ dx = 0 for each  . But this is equivalent to
. But this is equivalent to  in the distributional sense such that in particular, the polynomial representation follows from proposition 3.12. □
in the distributional sense such that in particular, the polynomial representation follows from proposition 3.12. □
In order to show more properties, for instance, that BDk
(Ω, Syml
(Rd
)) is a Banach space, let us adopt a more abstract viewpoint. We say that a function ![$\left\vert \cdot \right\vert :X\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn279.gif) for X a Banach space is a lower semi-continuous seminorm on
X if
for X a Banach space is a lower semi-continuous seminorm on
X if  is positive homogeneous, satisfies the triangle inequality and is lower semi-continuous. The kernel of
is positive homogeneous, satisfies the triangle inequality and is lower semi-continuous. The kernel of  , denoted
, denoted  , is the set
, is the set  which is a closed linear subspace of X.
which is a closed linear subspace of X.
Lemma 3.15. Let  be a lower semi-continuous seminorm on the Banach space X with norm ||⋅||X
. Then,
be a lower semi-continuous seminorm on the Banach space X with norm ||⋅||X
. Then,

is a Banach space. The seminorm  is continuous in Y.
is continuous in Y.
Proof. It is immediate that Y is a normed space. Let {xn
} be a Cauchy sequence in Y which is obviously a Cauchy sequence in X. Hence, a limit x ∈ X exists for which the lower semi-continuity yields  , the latter since
, the latter since  is a real Cauchy sequence. In particular, x ∈ Y.
is a real Cauchy sequence. In particular, x ∈ Y.
To obtain convergence with respect to  , choose, for ɛ > 0, an n such that for all m ⩾ n,
, choose, for ɛ > 0, an n such that for all m ⩾ n,  . Letting m → ∞ gives, as xn
− xm
→ xn
− x in X,
. Letting m → ∞ gives, as xn
− xm
→ xn
− x in X,

This implies xn → x in Y which is what we intended to show.
Finally, the continuity of  follows from the standard estimate
follows from the standard estimate  for x1, x2 ∈ Y. □
for x1, x2 ∈ Y. □
It is then obvious from proposition 3.14 and lemma 3.15 that BDk (Ω, Syml (Rd )) is a Banach space. In order to examine the structure of these spaces, it is crucial to understand the case k = 1, i.e., BD(Ω, Syml (Rd )) = BD1(Ω, Syml (Rd )), where the symmetrised derivative is only a measure. For l ⩾ 1, these spaces are strictly greater that BV(Ω, Syml (Ω)) as a consequence of the failure of Korn's inequality. Important properties of these spaces are summarised as follows.
Theorem 3.16. ([32, theorem 2.6]).If u is a Syml
(Rd
)-valued distribution on Ω a bounded Lipschitz domain with  , then u ∈ BD(Ω, Syml
(Rd
)).
, then u ∈ BD(Ω, Syml
(Rd
)).
Theorem 3.17. ([28, theorems 4.16 and 4.17]). For Ω a bounded Lipschitz domain and, 1 ⩽ p ⩽ d/(d − 1), the space BD(Ω, Syml (Rd )) is continuously embedded in Lp (Ω, Syml (Rd )). Moreover, for p < d/(d − 1), the embedding is compact.
Theorem 3.18. (Sobolev–Korn inequality [28, corollary 4.20]). For Ω a bounded Lipschitz domain and  a linear and continuous projection onto the kernel of
a linear and continuous projection onto the kernel of  , there exists a constant C > 0 such that for each u ∈ BD(Ω, Syml
(Rd
)) it follows that
, there exists a constant C > 0 such that for each u ∈ BD(Ω, Syml
(Rd
)) it follows that

Note that the projection Rl
as stated always exists as  is finite-dimensional (see proposition 3.12).
is finite-dimensional (see proposition 3.12).
Now, for general k and u ∈ BDk
(Ω, Syml
(Rd
)) fixed,  is a Syml+k−1(Rd
)-valued distribution with the property
is a Syml+k−1(Rd
)-valued distribution with the property

for  . In other words,
. In other words,  , thus theorem 3.16 implies that
, thus theorem 3.16 implies that  and, in particular, we have u ∈ BDk−1(Ω, Syml
(Rd
)). Hence, the spaces are nested:
and, in particular, we have u ∈ BDk−1(Ω, Syml
(Rd
)). Hence, the spaces are nested:

Let us look at the norms: by the Sobolev–Korn inequality (9), for some linear projection  , we see
, we see

which implies

Now,  is well-defined on BDk
(Ω, Syml
(Rd
)), linear, has finite-dimensional image and is hence continuous. We may therefore estimate
is well-defined on BDk
(Ω, Syml
(Rd
)), linear, has finite-dimensional image and is hence continuous. We may therefore estimate

Proceeding inductively, we arrive at the estimate

for some C > 0 independent of u. Therefore, we obtain the following theorem.
Theorem 3.19. If Ω ⊂ Rd is a bounded Lipschitz domain, then the norm equivalence

holds on BDk (Ω, Syml (Rd )). The embeddings

are continuous.
Proof. The nontrivial estimate to establish norm equivalence has just been shown in (10). The continuity of the embedding follows from the fact that the norm on the right-hand side in (11) is increasing with respect to k. □
In the scalar case, we can furthermore establish Sobolev embeddings.
Theorem 3.20. Let Ω be a bounded Lipschitz domain and 0 ⩽ m < k.
For
k − m ⩽ d
: the space BVk
(Ω) is continuously embedded in Hm,p
(Ω) for  , where we set
, where we set  for k − m = d.
for k − m = d.
If  , then the embedding is compact.
, then the embedding is compact.
For
k − m > d
: the space BVk
(Ω) is compactly embedded in  for each
for each ![$\alpha \in \left.\right]0,1 \left[\right. $](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn306.gif) .
.
Proof. In the scalar case,  for β ∈ Nd
a multiindex and u ∈ BVk
(Ω) constitutes an equivalent norm on BVk
(Ω), as a consequence of theorem 3.19. By the Poincaré inequality in BV(Ω),
for β ∈ Nd
a multiindex and u ∈ BVk
(Ω) constitutes an equivalent norm on BVk
(Ω), as a consequence of theorem 3.19. By the Poincaré inequality in BV(Ω),

for each  . This establishes the continuous embedding BVk
(Ω) → Wk−1,d/(d−1)(Ω). Application of the well-known embedding theorems for Sobolev spaces (see [1, theorems 5.4 and 6.2]) then give the results for the cases k − m < d and k − m > d as well as for the case k − m = d and p < ∞.
. This establishes the continuous embedding BVk
(Ω) → Wk−1,d/(d−1)(Ω). Application of the well-known embedding theorems for Sobolev spaces (see [1, theorems 5.4 and 6.2]) then give the results for the cases k − m < d and k − m > d as well as for the case k − m = d and p < ∞.
For the case k − m = d and p = ∞ we note that again by Sobolev embeddings [1, theorem 5.4] we get for a constant C > 0 and all u ∈ Hk,1(Ω) that

Approximating u ∈ BVk (Ω) with a sequence {un } in C∞(Ω) ∩ BVk (Ω) strictly converging to u in BVk (Ω) as in Lemma A.4, the result follows from applying this estimate to each un and using lower semi-continuity of the L∞-norm with respect to convergence in L1. □
We would like to employ TDk
as a regulariser and first characterise its kernel. For that purpose, we note that TDk
(u) = 0 for some u ∈ BDk
(Ω, Syml
(Rd
)) implies that  in the distributional sense, hence proposition 3.12 implies that u is a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1. This yields the following result.
in the distributional sense, hence proposition 3.12 implies that u is a Syml
(Rd
)-valued polynomial of maximal degree k + l − 1. This yields the following result.
Proposition 3.21. The space ker(TDk ) is a subspace of polynomials of degree less than k + l. If l = 0, then ker(TVk ) = Pk−1 = {u : Ω → R|u polynomial of degree ⩽ k − 1}.
Next, we like to discuss coercivity of the higher-order total variation functionals.
Proposition 3.22. Let k ⩾ 1, l ⩾ 0 and Ω be a bounded Lipschitz domain. Then, TDk is coercive in the following sense: for each linear and continuous projection R : Ld/(d−1)(Ω, Syml (Rd )) → ker(TDk ), there is a C > 0 such that

Proof. At first note that by the embeddings BDk (Ω, Syml (Rd )) ↪ BD(Ω, Syml (Rd )) ↪ Ld/(d−1)(Ω, Syml (Rd )) the left-hand side of the claimed inequality is well defined and finite.
We use a contradiction argument in conjunction with compactness. Suppose for R as stated above there is a sequence {un
} such that  and TDk
(un
) → 0 as n → ∞. This implies
and TDk
(un
) → 0 as n → ∞. This implies  being bounded, TDk
(un
− Run
) → 0 and by theorems 3.19 and 3.17 {un
− Run
} has to be precompact in L1(Ω, Syml
(Rd
)), i.e., without loss of generality, we may assume that un
− Run
→ u in L1(Ω, Syml
(Rd
)). By lower semi-continuity,
being bounded, TDk
(un
− Run
) → 0 and by theorems 3.19 and 3.17 {un
− Run
} has to be precompact in L1(Ω, Syml
(Rd
)), i.e., without loss of generality, we may assume that un
− Run
→ u in L1(Ω, Syml
(Rd
)). By lower semi-continuity,

hence u ∈ ker(TDk
) = rg(R). On the other hand, R(un
− Run
) = 0 for each n as R is a projection, thus, Ru = 0 and, consequently, u = 0. In total, we have limn→∞(un
− Run
) = 0 in BDk
(Ω), and again by continuous embedding, also in Ld/(d−1)(Ω) which is a contradiction to  for all n. Consequently, coercivity has to hold. □
for all n. Consequently, coercivity has to hold. □
Corollary 3.23. In the scalar case, for p ∈ [1, ∞] with  if k < d, we also have
if k < d, we also have

Proof. This follows with the embedding theorem 3.20:

□
Remark 3.24. The above coercivity estimate also implies that the Fenchel conjugate of TVk
is the indicator functional of closed convex set in  with non-empty interior. Indeed, for
with non-empty interior. Indeed, for  such that
such that  it follows for any u ∈ Lp
(Ω) that
it follows for any u ∈ Lp
(Ω) that

which means that  . On the other hand, if
. On the other hand, if  , then ⟨ξ, u⟩ > 0 for some u ∈ ker(TVk
). Thus, ⟨ξ, u⟩ > TVk
(u) so
, then ⟨ξ, u⟩ > 0 for some u ∈ ker(TVk
). Thus, ⟨ξ, u⟩ > TVk
(u) so  .
.
It is interesting to note that a coercivity estimate similar to the one of corollary 3.23 also holds between two higher-order TV functionals of different order.
Lemma 3.25. Let Ω be a bounded Lipschitz domain, 1 ⩽ k1 < k2 be two orders of differentiation,  with p ⩽ d/(d − k2) if k2 < d and
with p ⩽ d/(d − k2) if k2 < d and  be a continuous, linear projection. Then there exists a constant C > 0 such that
be a continuous, linear projection. Then there exists a constant C > 0 such that

holds for each  .
.
Proof. Assume the opposite, i.e., the existence of {un
} such that  and
and  as n → ∞. Then, by compact embedding
as n → ∞. Then, by compact embedding  , we have
, we have  as n → ∞ for some
as n → ∞ for some  for a subsequence (not relabelled). On the other hand, the Poincaré estimate gives
for a subsequence (not relabelled). On the other hand, the Poincaré estimate gives  , so un
− Run
→ 0 as n → ∞ in L1(Ω). By closedness of
, so un
− Run
→ 0 as n → ∞ in L1(Ω). By closedness of  this yields v = 0. By convergence in
this yields v = 0. By convergence in  , this gives the contradiction
, this gives the contradiction  as n → ∞. □
as n → ∞. □
3.3. Tikhonov regularisation
The coercivity which has just been established can be regarded as the most important step towards existence for variational problems with TVk -regularisation. Here, we first prove an existence result for linear inverse problems in a general abstract version.
Theorem 3.26. Let X be a reflexive Banach space, Y be a Banach space, K : X → Y be linear and continuous, Sf
: Y → [0, ∞] a proper, convex, lower semi-continuous and coercive discrepancy functional associated with some data f, ![$\left\vert \cdot \right\vert :X\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn332.gif) a lower semi-continuous seminorm and α > 0. Assume that there exists a linear and continuous projection
a lower semi-continuous seminorm and α > 0. Assume that there exists a linear and continuous projection  and a C > 0 such that
and a C > 0 such that

and either
- (a) is finite-dimensional or, more generally,
- (b) admits a complement Z in and ||u||X
⩽ C||Ku||Y
for some C > 0 and all u ∈ Z.



Then, the Tikhonov minimisation problem

is well-posed, i.e., there exists a solution and the solution mapping is stable in sense that, if  converges to Sf
as in (4) and
converges to Sf
as in (4) and  is equi-coercive, then for each sequence of minimisers {un
} of (13) with discrepancy
is equi-coercive, then for each sequence of minimisers {un
} of (13) with discrepancy  ,
,
- Either as n → ∞ and (13) with discrepancy Sf
does not admit a finite solution,
- Or as n → ∞ and there is, possibly up to shifts by functions in , a weak accumulation point u ∈ X that minimises (13) with discrepancy Sf
.



Further, in case (13) with discrepancy Sf
admits a finite solution, for each subsequence  weakly converging to some u ∈ X, it holds that
weakly converging to some u ∈ X, it holds that  as k → ∞. Also, if Sf
is strictly convex and K is injective, finite solutions u of (13) are unique and un
⇀ u in X.
as k → ∞. Also, if Sf
is strictly convex and K is injective, finite solutions u of (13) are unique and un
⇀ u in X.
The same result is true if, for instance, instead of being reflexive, X is the dual of a separable space, and we replace weak convergence by weak* convergence in the (lower semi-) continuity assumptions on K,  , Sf
and in (4).
, Sf
and in (4).
Proof. At first note that  being finite-dimensional implies condition (b) above, hence we can assume that (b) holds. We start with existence. Assume that the objective functional in (13) is proper as otherwise, there is nothing to show. For a minimising sequence {un
}, by the coercivity assumption, {un
− Run
} is bounded in X. Now, (b) implies the existence of a linear and continuous projection
being finite-dimensional implies condition (b) above, hence we can assume that (b) holds. We start with existence. Assume that the objective functional in (13) is proper as otherwise, there is nothing to show. For a minimising sequence {un
}, by the coercivity assumption, {un
− Run
} is bounded in X. Now, (b) implies the existence of a linear and continuous projection  such that id − PZ
projects
such that id − PZ
projects  onto
onto  . With vn
= PZ
Run
, we see that also {un
− Run
+ vn
} is a minimising sequence and it suffices to show boundedness of {vn
} to obtain a convergent subsequence. But the latter holds true since by assumption
. With vn
= PZ
Run
, we see that also {un
− Run
+ vn
} is a minimising sequence and it suffices to show boundedness of {vn
} to obtain a convergent subsequence. But the latter holds true since by assumption  , such that
, such that  , with the right-hand side being bounded as a consequence of the coercivity of Sf
and the boundedness of {un
− Run
}. Hence, as X is reflexive, a subsequence of {un
− Run
+ vn
} converges weakly to a limit u ∈ X. By continuity of K and lower semi-continuity of both Sf
and
, with the right-hand side being bounded as a consequence of the coercivity of Sf
and the boundedness of {un
− Run
}. Hence, as X is reflexive, a subsequence of {un
− Run
+ vn
} converges weakly to a limit u ∈ X. By continuity of K and lower semi-continuity of both Sf
and  it follows that u is a solution to (13). In case Sf
is strictly convex and K is injective, Sf
◦ K is already strictly convex, so finite minimisers of (13) have to be unique.
it follows that u is a solution to (13). In case Sf
is strictly convex and K is injective, Sf
◦ K is already strictly convex, so finite minimisers of (13) have to be unique.
Now let {un
} be a sequence of minimisers of (13) with discrepancy  . We denote by
. We denote by  as well as
as well as  and first suppose that {Fn
(un
)} is bounded. We can then add
and first suppose that {Fn
(un
)} is bounded. We can then add  to un
, with vn
= PZ
Run
, and from equi-coercivity of
to un
, with vn
= PZ
Run
, and from equi-coercivity of  obtain boundedness of {un
− Run
+ vn
} as before.
obtain boundedness of {un
− Run
+ vn
} as before.
This shows that by shifting the minimisers within  always leads to a bounded sequence, i.e., we may assume without loss of generality that {un
} is bounded such that a weak accumulation point exists. Suppose that
always leads to a bounded sequence, i.e., we may assume without loss of generality that {un
} is bounded such that a weak accumulation point exists. Suppose that  as k → ∞. Then, estimating as in the proof of theorem 2.14, we can obtain that u is a minimiser for F and that
as k → ∞. Then, estimating as in the proof of theorem 2.14, we can obtain that u is a minimiser for F and that  as well as
as well as  . Also, if u is the unique minimiser for (13) with discrepancy Sf
, un
⇀ u as n → ∞ follows since any subsequence has to contain another subsequence that converges weakly to u.
. Also, if u is the unique minimiser for (13) with discrepancy Sf
, un
⇀ u as n → ∞ follows since any subsequence has to contain another subsequence that converges weakly to u.
The result for the two remaining cases lim infn→∞ Fn (un ) < ∞ and Fn (un ) → ∞, respectively, finally follows analogously to theorem 2.14. □
Given that ker(TVk
) is finite dimensional, the above result immediately implies well-posedness for  with X = Lp
(Ω), as stated in the following corollary. The crucial ingredient here is the estimate ||u − Ru||p
⩽ CTVk
(u), which restricts the exponent of the underlying Lp
-space to p ⩽ d/(d − k) if k < d. This shows that, the higher the order of differentiation used in the regularisation, the weaker are the requirements on the underlying spaces and, consequently, on the continuity of the operator K.
with X = Lp
(Ω), as stated in the following corollary. The crucial ingredient here is the estimate ||u − Ru||p
⩽ CTVk
(u), which restricts the exponent of the underlying Lp
-space to p ⩽ d/(d − k) if k < d. This shows that, the higher the order of differentiation used in the regularisation, the weaker are the requirements on the underlying spaces and, consequently, on the continuity of the operator K.
Corollary 3.27. With X = Lp (Ω), Ω being a bounded Lipschitz domain, and Sf and K as in theorem 3.26,

is well-posed in the sense of theorem 3.26 whenever ![$p\in \left.\right]1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn363.gif) with p ⩽ d/(d − k) if k < d.
with p ⩽ d/(d − k) if k < d.
As can be easily seen from the respective proofs, also the convergence result of theorem 2.17 and the result on convergence rates as in proposition 2.18 transfer to TVk regularisation.
Theorem 3.28. With the assumptions of corollary 3.27, let u† ∈ BV(Ω) be a minimum-TVk
-solution of Ku† = f† for some data f† in Y and for each δ > 0 let fδ
be such that  and denote by uα,δ
a finite solution of (14) for parameter α > 0 and data fδ
. Let the discrepancy functionals
and denote by uα,δ
a finite solution of (14) for parameter α > 0 and data fδ
. Let the discrepancy functionals  be equi-coercive and converge to
be equi-coercive and converge to  in the sense of (4) and
in the sense of (4) and  if and only if v = f†. Choose for each δ > 0 the parameter α > 0 such that
if and only if v = f†. Choose for each δ > 0 the parameter α > 0 such that

Then, up to shifts by functions in ker(K) ∩ Pk−1, {uα,δ } has at least one Lp -weak accumulation point. Each Lp -weak accumulation point is a minimum-TVk -solution of Ku = f† and limδ→0TVk (uα,δ ) = TVk (u†).
Proposition 3.29. In the situation of theorem 3.28, let K*w† ∈ ∂TVk (u†) for some w† ∈ Y*. Then,

The last result in particular guarantees convergence rates for the settings of example 2.19. Note also that the above results remain true in case p = 1 or in case p = d/(d − k) = ∞ and K is weak*-to-weak continuous.
Let us finally note some first-order optimality conditions. For this purpose, recall that for X a Banach space, the normal cone
 of a set K ⊂ X at u ∈ K is given by the collection of all w ∈ X* for which
of a set K ⊂ X at u ∈ K is given by the collection of all w ∈ X* for which  for all v ∈ K. If we set
for all v ∈ K. If we set  for u ∉ K, we have that
for u ∉ K, we have that  where
where  is the indicator function of K, i.e.,
is the indicator function of K, i.e.,  if u ∈ K and ∞ otherwise.
if u ∈ K and ∞ otherwise.
Proposition 3.30. In the situation of corollary 3.27, if  and Y is a Hilbert space, u* ∈ Lp
(Ω) is a solution of
and Y is a Hilbert space, u* ∈ Lp
(Ω) is a solution of

if and only if

where  is the normal cone associated with the set
is the normal cone associated with the set  where
where

Proof. As  is Gâteaux differentiable, it is continuous with unique subgradient, so, by subdifferential calculus, optimality of u* is equivalent to K*(f − Ku*) ∈ α∂TVk
(u*) which can also be expressed as
is Gâteaux differentiable, it is continuous with unique subgradient, so, by subdifferential calculus, optimality of u* is equivalent to K*(f − Ku*) ∈ α∂TVk
(u*) which can also be expressed as

Now since  , it follows that
, it follows that  , so
, so  . □
. □
Remark 3.31. In the situation of proposition 3.30, it is also possible to give an a-priori estimate for the solutions of (16) in case K is injective on Pk−1. Indeed, with R : Lp
(Ω) → Pk−1 the continuous projection operator on the kernel of TVk
and C > 0 the coercivity constant, i.e., ||u − Ru||p
⩽ CTVk
(u) for all u ∈ Lp
(Ω), by optimality, a solution u* satisfies  and consequently,
and consequently,  . Likewise, comparing with u* − Ru*, optimality also gives
. Likewise, comparing with u* − Ru*, optimality also gives  , which is equivalent to
, which is equivalent to  . Using
. Using  , the latter leads to
, the latter leads to  , where the right-hand side can further be estimated, using
, where the right-hand side can further be estimated, using  with
with  to give
to give

Now, as K is injective on Pk−1 = rg(R), there is a c > 0 such that c||Ru||p ⩽ ||KRu||Y for all u ∈ Lp (Ω). Consequently, employing the triangle inequality and estimating yields

which is an a priori bound that only requires the knowledge of the Poincaré–Wirtinger-type constant C, the constant c in the inverse estimate for K on Pk+1, as well as an estimate on ||K||. Beyond being of theoretical interest, such a bound can for instance be used in numerical algorithms, see section 6, example 6.24.
If the Kullback–Leibler divergence is used instead of the quadratic Hilbert space discrepancy, i.e., Sf
(v) = KL(v, f), Y = L1(Ω'), and data f ⩾ 0 a.e., then one has to choose a u0 ∈ BVk
(Ω) such that KL(Ku0, f) < ∞. Set Cf
= KL(Ku0, f) + αTVk
(u0). Then, an optimal solution u* will satisfy  . Further, we have ||v||1 ⩽ 2KL(v, f) + 2||f||1 for v ∈ L1(Ω') with v ⩾ 0 a.e., see lemma A.1, such that, if c > 0 is a constant with c||Ru||p
⩽ ||KRu||1 for all u ∈ Lp
(Ω), we get
. Further, we have ||v||1 ⩽ 2KL(v, f) + 2||f||1 for v ∈ L1(Ω') with v ⩾ 0 a.e., see lemma A.1, such that, if c > 0 is a constant with c||Ru||p
⩽ ||KRu||1 for all u ∈ Lp
(Ω), we get

and finally arrive at

This constitutes an a priori estimate similar to (17) for the Kullback–Leibler discrepancy, however, with the difference that also a suitable constant Cf has to determined.
Remark 3.32. In order to show the effect of TV2 regularisation in contrast to TV regularisation, we performed a numerical denoising experiment for f shown in figure 2(a), i.e., solved  where
where  or
or  . One clearly sees that TV2 regularisation (figure 2(c)) reduces the staircasing effect of TV regularisation (figure 2(b)) and piecewise linear structures are well recovered. However, TV2 regularisation also blurs the object boundaries which appear less sharp in contrast to TV regularisation.
. One clearly sees that TV2 regularisation (figure 2(c)) reduces the staircasing effect of TV regularisation (figure 2(b)) and piecewise linear structures are well recovered. However, TV2 regularisation also blurs the object boundaries which appear less sharp in contrast to TV regularisation.
This is due to the fact that TVk
regularisation for k ⩾ 2 is not able to produce solutions with jump discontinuities. Indeed, TVk
regularisation implies that a solution u has be to contained in BVk
(Ω) which embeds into the Sobolev space Hk−1,1(Ω) ↪ H1,1(Ω). As we have seen, for instance, in example 2.1, this means that characteristic functions cannot be solutions. More generally, for u ∈ H1,1(Ω) ⊂ BV(Ω), the derivative ∇u interpreted as a measure is absolutely continuous with respect to the Lebesgue measure such that the singular part satisfies ∇s
u = 0. Theorem 2.21 then implies that the jump set Ju
is a  -negligible set, i.e., u cannot jump on (d − 1)-dimensional hypersurfaces.
-negligible set, i.e., u cannot jump on (d − 1)-dimensional hypersurfaces.

Figure 2. Second-order total-variation denoising example. (a) Noisy image (PSNR: 13.9 dB), (b) regularisation with TV (PSNR: 29.3 dB), (c) regularisation with TV2 (PSNR: 27.8 dB), (d) regularisation with  (PSNR: 26.3 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
(PSNR: 26.3 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
Download figure:
Standard image High-resolution imageRemark 3.33. Instead of taking higher-order TV which bases on the full gradient, one could also try to regularise with other differential operators, for instance with the (weak) Laplacian:

However, the kernel of this seminorm is the space of p-integrable harmonic functions on Ω, the Bergman spaces, which are infinite-dimensional. Therefore, in view of theorem 3.26, to use  for the regularisation of ill-posed linear inverse problems, the forward operator K must be continuously invertible on a complement of
for the regularisation of ill-posed linear inverse problems, the forward operator K must be continuously invertible on a complement of  , i.e., well-posed. This limits the applicability of this regulariser. Nevertheless, denoising problems can, for instance, still be solved, see figure 2(d), leading to 'speckle' artefacts in the solutions. Another possibility would be to add more regularising functionals, which is discussed in the next section.
, i.e., well-posed. This limits the applicability of this regulariser. Nevertheless, denoising problems can, for instance, still be solved, see figure 2(d), leading to 'speckle' artefacts in the solutions. Another possibility would be to add more regularising functionals, which is discussed in the next section.
Higher order TV for multichannel images. In analogy to TV, also higher order TV can be extended to colour and multichannel images represented by functions mapping into a vector space, say Rm
. This is achieved by testing with  -valued tensor fields, where
-valued tensor fields, where

and requires to choose a norm for this space. While, also in view of the Frobenius norm used in Symk (Rd ), the most natural choice seems to pick the norm that is induced by the inner product

as with TV, this is not the only possible choice and different norms imply different types of coupling of the multiple channels. Generally, we can take |⋅|◦ to be any norm on  , set |⋅|∗ to be the corresponding dual norm and extend TVk
to functions
, set |⋅|∗ to be the corresponding dual norm and extend TVk
to functions  as
as

where ||φ||∞,∗ is the pointwise supremum of the scalar function x ↦ |φ(x)|∗. By equivalence of norms in finite dimensions, the functional-analytic properties of TVk
and the results on regularisation for inverse problems transfer one-to-one to its multichannel extension. Further, TVk
is invariant under rotations whenever the tensor norm |⋅|∗ is unitarily invariant in the sense that for any orthonormal matrix O ∈ Rd×d
and  it holds that
it holds that

where we define (ξi O)(a1, ..., ak ) = ξi (Oa1, ..., Oak ) for i = 1, ..., m.
Fractional-order TV. Recently, ideas from fractional calculus started to be transferred to construct new classes of higher-order TV, namely fractional-order total variation. The latter bases on fractional partial differentiation with respect to the coordinate axes. The partial fractional derivative of a non-integral order α > 0 of a function u compactly supported on the interval ![$ \left.\right]a,b\left[\right.\to \mathbf{R}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn401.gif) can, for instance, be defined as
can, for instance, be defined as

where k ∈ N is such that k − 1 < α < k and, denoting by Γ the gamma-function, i.e.,  ,
,

as well as

This fractional-order derivative corresponds to a central version of the Riemann–Liouville definition [140, 199]. However, one has to mention that there are also other possibilities to define fractional-order derivatives [146]. On a rectangular domain ![${\Omega}=\left.\right]{a}_{1},{b}_{1}\left[\right.{\times}\cdots {\times} \left.\right]{a}_{d},{b}_{d}\left[\right.\subset {\mathbf{R}}^{d}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn403.gif) and for test vector fields
and for test vector fields  , the fractional divergence of order α can then be defined as
, the fractional divergence of order α can then be defined as ![${\mathrm{d}\mathrm{i}\mathrm{v}}^{\alpha }\varphi ={\sum }_{i=1}^{d}\frac{{\partial }_{\left[{a}_{i},{b}_{i}\right]}^{\alpha }{\varphi }_{i}}{\partial {x}_{i}^{\alpha }}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn405.gif) which is still a bounded function. Consequently, the fractional total variation of order α for u ∈ L1(Ω) is given as
which is still a bounded function. Consequently, the fractional total variation of order α for u ∈ L1(Ω) is given as

It is easy to see that this defines a proper, convex and lower semi-continuous functional on each Lp (Ω) which makes the functional suitable as a regulariser for denoising [194, 199], typically for 1 < α < 2. The use of TVα for the regularisation of linear inverse problems, however, seems to be unexplored so far, and not many properties of the solutions appear to be known.
4. Combined approaches
We have seen that employing higher-order total variation for regularisation yields well-posedness results for general linear inverse problems that are comparable to first-order TV regularisation, where the use of higher-order differentiation even weakens the continuity requirements on the forward operator. On the other hand, TVk regularisation, for k > 1, does not allow to recover jump discontinuities, as we have shown analytically and observed numerically (see remark 3.32). An interesting question in this context is how combinations of TV functionals with different orders behave with respect to these properties. Addressing this question, we consider, in the following, the combination of higher-order TV functionals via addition and infimal convolution. While these two approaches yield regularisation methods with rather different analytical properties, each of them has advantages and disadvantages with respect to continuity requirements on the forward operator and the possibility to recover non-smooth structures such as jumps. Also, a combination of two or more functionals introduces additional parameters. To account for that, we consider multi-parameter convergence results for each of the two approaches, which yield, in particular, an interpretation of the involved parameters and can be helpful for parameter choice in practice.
4.1. Additive multi-order regularisation
In this section, we consider the additive combination of total variation functionals with different orders. That is, we are interested in the following Tikhonov approach:

with αi > 0 for i = 1, 2 and 1 ⩽ k1 < k2. With k1 = 1, k2 = 2, such an approach has for instance been considered in [142] for the regularisation of linear inverse problems.
The following proposition summarises, in the general setting of seminorms, basic properties of the function spaces arising from the additive combination of two different regularisers. Its proof is straightforward.
Proposition 4.1. Let |⋅|1 and |⋅|2 be two lower semi-continuous seminorms on the Banach space X. Then,
- (a)The functional is a seminorm on X.
- (b)We have
- (c)The seminorm is lower semi-continuous andconstitutes a Banach space.
- (d)With Yi the Banach spaces arising from the norms ||⋅||X + |⋅|i , i = 1, 2 (see lemma 3.15),





Setting  for i = 1, 2 shows in particular that the function space associated with the additive combination of the
for i = 1, 2 shows in particular that the function space associated with the additive combination of the  is embedded in
is embedded in  , i.e., the BV space corresponding to the highest order. Hence non-trivial combinations of different
, i.e., the BV space corresponding to the highest order. Hence non-trivial combinations of different  again do not allow to recover jumps and, as the following proposition shows, in fact even yield the same space as the single TV term with the highest order.
again do not allow to recover jumps and, as the following proposition shows, in fact even yield the same space as the single TV term with the highest order.
Theorem 4.2. Let 1 ⩽ k1 < k2, α1 > 0, α2 > 0 and Ω be a bounded Lipschitz domain. For X = L1(Ω) and the seminorm  , let Y be the associated Banach space according to lemma 3.15. Then,
, let Y be the associated Banach space according to lemma 3.15. Then,

in the sense of Banach space equivalence, and for p ∈ [1, ∞], p ⩽ d/(d − k2) if k2 < d,  a continuous, linear projection, there is a C > 0 independent of u such that
a continuous, linear projection, there is a C > 0 independent of u such that

for all u ∈ Lp (Ω).
Proof. For the claimed norm equivalence, one estimate is immediate, while the other one follows from theorem 3.19. Denoting by  a continuous, linear projection, the estimate on ||u − Ru||p
follows from corollary 3.23 and norm equivalence in finite-dimensional spaces as
a continuous, linear projection, the estimate on ||u − Ru||p
follows from corollary 3.23 and norm equivalence in finite-dimensional spaces as

with C > 0 a generic constant. □
Tikhonov regularisation. For employing  as regularisation in a Tikhonov setting, the coercivity estimate in theorem 4.2 is crucial since it allows to transfer the well-posedness result of theorem 3.26. Observe in particular that
as regularisation in a Tikhonov setting, the coercivity estimate in theorem 4.2 is crucial since it allows to transfer the well-posedness result of theorem 3.26. Observe in particular that  is finite-dimensional, such that assumption (a) in theorem 3.26 is satisfied.
is finite-dimensional, such that assumption (a) in theorem 3.26 is satisfied.
Proposition 4.3. With X = Lp
(Ω), ![$p\in \left.\right] 1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn417.gif) , Ω a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex, lower semi-continuous and coercive, 1 ⩽ k1 < k2, α1 > 0, α2 > 0 the Tikhonov minimisation problem
, Ω a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex, lower semi-continuous and coercive, 1 ⩽ k1 < k2, α1 > 0, α2 > 0 the Tikhonov minimisation problem

is well-posed in the sense of theorem 3.26 whenever p ⩽ d/(d − k2) if k2 < d.
It is interesting to note that the necessary coercivity estimate on  uses a projection to the smaller kernel of
uses a projection to the smaller kernel of  and an Lp
norm with a larger exponent corresponding to
and an Lp
norm with a larger exponent corresponding to  . Hence, in view of the assumptions in theorem 3.26, the additive combination of
. Hence, in view of the assumptions in theorem 3.26, the additive combination of  and
and  inherits the best properties of the two summands, i.e., the ones that are the least restrictive for applications in an inverse problems context.
inherits the best properties of the two summands, i.e., the ones that are the least restrictive for applications in an inverse problems context.
Regarding the convergence result of theorem 3.28 and the rates of proposition 3.29, a direct extension to regularisation with  can be obtained by regarding the weights α1, α2 to be fixed and introducing an additional factor α > 0 for both terms, which then acts as the regularisation parameter. A more tailored approach, however, would be to regard both α1, α2 as regularisation parameters and study the limiting behaviour of the method as α1, α2 converge to zero in some sense. This is covered by the following theorem.
can be obtained by regarding the weights α1, α2 to be fixed and introducing an additional factor α > 0 for both terms, which then acts as the regularisation parameter. A more tailored approach, however, would be to regard both α1, α2 as regularisation parameters and study the limiting behaviour of the method as α1, α2 converge to zero in some sense. This is covered by the following theorem.
Theorem 4.4. In the situation of proposition 4.3, let for each δ > 0 the data fδ
be given such that  , let
, let  be equi-coercive and converge to
be equi-coercive and converge to  for some data f† ∈ Y in the sense of (4) with
for some data f† ∈ Y in the sense of (4) with  if and only if v = f†.
if and only if v = f†.
Choose the positive parameters α = (α1, α2) in dependence of δ such that

and  as δ → 0. Set
as δ → 0. Set

and assume p ⩽ d/(d − k) in case of k < d, and that there exists u0 ∈ BVk
(Ω) such that Ku0 = f†. Then, up to shifts in  , any sequence {uα,δ
}, with each uα,δ
being a solution to (20) for parameters (α1, α2) and data fδ
, has at least one Lp
-weak accumulation point. Each Lp
-weak accumulation point is a minimum-
, any sequence {uα,δ
}, with each uα,δ
being a solution to (20) for parameters (α1, α2) and data fδ
, has at least one Lp
-weak accumulation point. Each Lp
-weak accumulation point is a minimum- -solution of Ku = f† and
-solution of Ku = f† and  .
.
Proof. First note that, as consequence of theorem 3.26 and the fact that u0 ∈ BVk
(Ω) with Ku0 = f†, there exists a minimum- -solution to Ku = f†, that we denote by u†, such that TVk
(u†) < ∞. Using optimality of uα,δ
compared to u† gives
-solution to Ku = f†, that we denote by u†, such that TVk
(u†) < ∞. Using optimality of uα,δ
compared to u† gives

Since max{α1, α2} → 0 as δ → 0, we have that  as δ → 0. Moreover, as also δ/max{α1, α2} → 0, it follows that
as δ → 0. Moreover, as also δ/max{α1, α2} → 0, it follows that

The choice of k allows to conclude that {TVk
(uα,δ
)} is bounded, which, in case k = k1, means that  is bounded. Now we show that also in the other case when k = k2,
is bounded. Now we show that also in the other case when k = k2,  is bounded. To this aim, denote by
is bounded. To this aim, denote by  and
and  linear, continuous projections, where Z is a complement of
linear, continuous projections, where Z is a complement of  in
in  , i.e., id − PZ
projects
, i.e., id − PZ
projects  to
to  . Then, by optimality and invariance of K and
. Then, by optimality and invariance of K and  on
on  we estimate
we estimate

which, together with lemma 3.25, norm equivalence on finite-dimensional spaces and injectivity of K on the finite-dimensional space Z, yields

Now, the last expression is bounded due to boundedness of  and equi-coercivity of
and equi-coercivity of  . Hence,
. Hence,  is always bounded and, again using the equi-coercivity of
is always bounded and, again using the equi-coercivity of  and the techniques in the proof of theorem 3.26, one sees that with possible shifts in
and the techniques in the proof of theorem 3.26, one sees that with possible shifts in  , one can achieve that {uα,δ
} is bounded in BVk
(Ω). Therefore, by continuous embedding and reflexivity, it admits a weak accumulation point in Lp
(Ω).
, one can achieve that {uα,δ
} is bounded in BVk
(Ω). Therefore, by continuous embedding and reflexivity, it admits a weak accumulation point in Lp
(Ω).
Next, let u* be a Lp
-weak accumulation point associated with {δn
}, δn
→ 0 as well as the corresponding parameters {αn
} = {(α1,n
, α2,n
)}. Then,  by convergence of
by convergence of  to
to  , so Ku* = f†. Moreover,
, so Ku* = f†. Moreover,

hence, u* is a minimum- -solution. In particular,
-solution. In particular,

so

Finally, each sequence of {δn
}, δn
→ 0 contains another subsequence (not relabelled) for which  as n → ∞, so we have
as n → ∞, so we have  as δ → 0. □
as δ → 0. □
- Theorem 4.4 shows that, with the additive combination higher-order TV functionals, the maximum of the parameters plays the role of the regularisation parameter. The regularity assumption on u0 such that Ku0 = f† on the other hand depends on whether some parameters converge to zero faster than the maximum or not, i.e., it depends on the ratio of the parameters. Assuming for instance that α2/max{α1, α2} → 0 leads to the weaker -regularity requirement for u0.In view of a practical parameter choice strategy, this motivates a parametrisation via (α1, α2) = α(λ1, λ2), where α > 0 is interpreted as the regularisation parameter and chosen in dependence of the noise level, and (λ1, λ2) with max{λ1, λ2} = 1 is interpreted as model parameter, which is chosen (or learned) once for a particular class of image data and then fixed independent of the concrete forward model or noise level.
- Although (20) incorporates multiple orders, a solution is always contained in . Since k2 ⩾ 2, this space is always contained in H1,1(Ω), so jump discontinuities cannot appear. One can observe that for numerical solutions, this is reflected in blurry reconstructions of edges while higher-order smoothness is usually captured quite well, see figure 2(c).
- Naturally, it is also possible to consider the weighted sum of more than two TV-type functionals for regularisation, i.e.,with orders k1, ..., km ⩾ 1 and weights α1, ..., αm > 0. Solutions then exist, for appropriate p, in the space BVk (Ω) for k = max{k1, ..., km }.



Optimality conditions. As for TVk
, one can also consider optimality conditions for variational problems with  as regularisation. Again, in the case that Y is a Hilbert space, q = 2 and
as regularisation. Again, in the case that Y is a Hilbert space, q = 2 and  , one can argue according to proposition 3.30 and obtain that u* is optimal for (20) if and only if
, one can argue according to proposition 3.30 and obtain that u* is optimal for (20) if and only if

or, equivalently,

A difficulty with a further specification of these statements, however, is that it is not immediate that either the subdifferential is additive in this situation or that the dual of the sum of the  equals the infimal convolution of the duals (see definition 4.6 in the next subsection for a definition of the infimal convolution). A possible remedy is to consider the original minimisation problem in the space
equals the infimal convolution of the duals (see definition 4.6 in the next subsection for a definition of the infimal convolution). A possible remedy is to consider the original minimisation problem in the space  instead, such that
instead, such that  becomes continuous. This, however, yields subgradients in the dual of
becomes continuous. This, however, yields subgradients in the dual of  instead of Lp*(Ω) making the optimality conditions again difficult to interpret.
instead of Lp*(Ω) making the optimality conditions again difficult to interpret.
A priori estimates. In order to obtain a bound on a solution u* for a quadratic Hilbert-norm discrepancy, i.e.,  , Y Hilbert space, on can proceed analogously to remark 3.31, provided that K is injective on the space
, Y Hilbert space, on can proceed analogously to remark 3.31, provided that K is injective on the space  . We then also arrive at (17), with α replaced by α1, C being the coercivity constant for
. We then also arrive at (17), with α replaced by α1, C being the coercivity constant for  and c the inverse bound for K on
and c the inverse bound for K on  . Of course, in case K is still injective on the larger space
. Of course, in case K is still injective on the larger space  , the analogous bound can be obtained with α2 instead of α1 and respective constants C, c. In case of the Kullback–Leibler discrepancy, i.e., Sf
(v) = KL(v, f), the analogous statements apply to the estimate (18).
, the analogous bound can be obtained with α2 instead of α1 and respective constants C, c. In case of the Kullback–Leibler discrepancy, i.e., Sf
(v) = KL(v, f), the analogous statements apply to the estimate (18).
Denoising performance. Figure 3 shows the effect of α1TV + α2TV2 regularisation compared to pure TV-regularisation. While staircase artefacts are slightly reduced, the overall image is more blurry than the one obtained with TV, see figures 3(b) and (c). This is expected as additive regularisation inherits the analytical properties of the stronger regularisation term, hence α1TV + α2TV2 is not able to recover jumps. The result is not much different when  is used instead of TV2, see figure 3(d). Nevertheless, although not discussed in this paper, the issue of limited applicability of
is used instead of TV2, see figure 3(d). Nevertheless, although not discussed in this paper, the issue of limited applicability of  for regularisation of general inverse problems, as mentioned in remark 3.33, is overcome in an additive combination with TV since the properties of TV are sufficient to guarantee well-posedness results.
for regularisation of general inverse problems, as mentioned in remark 3.33, is overcome in an additive combination with TV since the properties of TV are sufficient to guarantee well-posedness results.

Figure 3. Additive multi-order denoising example. (a) Noisy image (PSNR: 13.9 dB), (b) regularisation with TV (PSNR: 29.3 dB), (c) regularisation with α1TV + α2TV2 (PSNR: 29.5 dB), (d) regularisation with  (PSNR: 29.4 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
(PSNR: 29.4 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
Download figure:
Standard image High-resolution image4.2. Multi-order infimal convolution
In order to overcome the smoothing effect of total variation of order two and higher, and additive combinations thereof, another idea would be to model an image u as the sum of a first-order part and a second order part, i.e.,

This has originally been proposed in [59], and different variants have subsequently been analysed in [16] and considered in [174, 175] in a discrete setting.
Obviously, such a decomposition exists for each u ∈ BV(Ω) but is, of course, not unique. The parts u1 and u2 are now regularised with first and second-order total variation associated with some weights α1 > 0, α2 > 0. The associated Tikhonov minimisation problem reads as

As we are only interested in u, we rewrite this problem as

This regularisation functional is called infimal convolution of α1TV and α2TV2.
![${F}_{1},{F}_{2}:X\to \left.\right] - \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn471.gif)

is the infimal convolution of F1 and F2.
An infimal convolution is called exact, if for each u ∈ X there is a pair u1, u2 ∈ X with

The infimal convolution may or may not be exact and may or may not be lower semi-continuous, even if both F1, F2 are lower semi-continuous. The next proposition, which should be compared to proposition 4.1 above, provides basic properties and the function spaces associated with infimal convolutions.
Proposition 4.7. Let |⋅|1 and |⋅|2 be two lower semi-continuous seminorms on the Banach space X. Then,
- (a)The functional is a seminorm on X.
- (b)We havewith equality if |⋅|1△|⋅|2 is exact.
- (c)If |⋅|1△|⋅|2 is lower semi-continuous, thenconstitutes a Banach space.
- (d)With Yi the Banach spaces arising from the norms ||⋅||X + |⋅|i , i = 1, 2 (see lemma 3.15),
- (e)It holds that and if |⋅|1△|⋅|2 is exact, then






Proof. The seminorm axioms can easily be verified for  . If u = u1 + u2 for ui
∈ ker(|⋅|i
), i = 1, 2, then
. If u = u1 + u2 for ui
∈ ker(|⋅|i
), i = 1, 2, then

The converse inclusion follows directly from the exactness.
The third statement is a direct consequence of lemma 3.15 while the forth immediately follows from  for i = 1, 2.
for i = 1, 2.
For the fifth statement, the assertion on the Fenchel dual follows by direct computation. Regarding equality of the subdifferentials, let w ∈ X* and u ∈ X such that  . Then, the Fenchel identity yields
. Then, the Fenchel identity yields

for the minimising u1, u2 ∈ X with u1 + u2 = u. As by the Fenchel inequality

the equation (24) can only be true when there is equality in (25). But this means, in turn, that  and
and  . Hence,
. Hence,  . The other inclusion holds trivially. □
. The other inclusion holds trivially. □
The statement (e) will be relevant for obtaining optimality conditions and we note that, as can be seen from the proof, it holds true for arbitrary convex functionals, not necessarily seminorms.
The previous proposition shows in particular that lower semi-continuity and exactness of the infimal convolution are important for obtaining an appropriate function space setting. Regarding the infimal convolution of TV functionals, this holds true on Lp -spaces as follows.
Proposition 4.8. Let Ω be a bounded Lipschitz domain, 1 ⩽ k1 < k2 and p ∈ [1, ∞] with p ⩽ d/(d − k1) if k1 < d. Then, for α = (α1, α2), α1 > 0, α2 > 0, the infimal convolution

is exact and lower semi-continuous in Lp (Ω).
Proof. By continuous embedding, we may assume without loss of generality that p < ∞. Take a sequence {un
} converging to some u in Lp
(Ω) for which  . For each n, we can select
. For each n, we can select  such that
such that  ,
,

and  is in the complement of
is in the complement of  in the sense that
in the sense that  for
for  a linear and continuous projection. The latter condition can always be satisfied since both
a linear and continuous projection. The latter condition can always be satisfied since both  and
and  are invariant on
are invariant on  . Now, by coercivity of
. Now, by coercivity of  as in corollary 3.23, we get that
as in corollary 3.23, we get that  is bounded in
is bounded in  . Hence, by the embedding of
. Hence, by the embedding of  in either L∞(Ω) or
in either L∞(Ω) or  in case of k1 < d as in theorem 3.20, the choice of p and convergence of {un
} in Lp
(Ω), we can extract (non-relabelled) subsequences of
in case of k1 < d as in theorem 3.20, the choice of p and convergence of {un
} in Lp
(Ω), we can extract (non-relabelled) subsequences of  and
and  converging weakly to some u1 and u2 in Lp
(Ω), respectively, such that u = u1 + u2. Thus, lower semi-continuity of both
converging weakly to some u1 and u2 in Lp
(Ω), respectively, such that u = u1 + u2. Thus, lower semi-continuity of both  and
and  implies
implies

such that lower semi-continuity holds. Finally, exactness for u ∈ Lp
(Ω) with  follows from choosing {un
} as the sequence that is constant u. □
follows from choosing {un
} as the sequence that is constant u. □
Given this, the special case  and X = L1(Ω) of proposition 4.7 shows that both
and X = L1(Ω) of proposition 4.7 shows that both  and
and  are embedded in the Banach space Y. Hence, in contrast to the sum of different TV terms, their infimal convolution allows to recover jumps whenever k1 = 1, independent of k2. In fact, as the following proposition shows, the space Y is even equivalent to the BV space corresponding to the lowest order, in particular to BV(Ω) for k1 = 1. Again, the result should be compared to theorem 4.2 above.
are embedded in the Banach space Y. Hence, in contrast to the sum of different TV terms, their infimal convolution allows to recover jumps whenever k1 = 1, independent of k2. In fact, as the following proposition shows, the space Y is even equivalent to the BV space corresponding to the lowest order, in particular to BV(Ω) for k1 = 1. Again, the result should be compared to theorem 4.2 above.
Theorem 4.9. Let 1 ⩽ k1 < k2, α1 > 0, α2 > 0, Ω be a bounded Lipschitz domain, and Y be the Banach space associated with X = L1(Ω) and total-variation infimal convolution according to (26). Then,

in the sense of Banach space equivalence, and for p ∈ [1, ∞], p ⩽ d/(d − k1) if k1 < d, and for  a linear, continuous projection there exists a C > 0 such that
a linear, continuous projection there exists a C > 0 such that

for all u ∈ Lp (Ω).
Proof. We first show the claimed norm equivalence. For this purpose, note that one estimate corresponds to the fourth statement in proposition 4.7.
For the converse estimate, let  and
and  be a projection. Then,
be a projection. Then,

for C independent of  . Indeed, if for {un
} and {wn
} we have
. Indeed, if for {un
} and {wn
} we have  and
and  as well as
as well as  , meaning un
→ 0 in L1(Ω) and
, meaning un
→ 0 in L1(Ω) and  in
in  . The latter implies that
. The latter implies that  is bounded in a finite-dimensional space, hence there is a convergent subsequence (not relabelled) with limit
is bounded in a finite-dimensional space, hence there is a convergent subsequence (not relabelled) with limit  . Then,
. Then,  in
in  and the closedness of
and the closedness of  yields v = 0 which is a contradiction to
yields v = 0 which is a contradiction to  for all n.
for all n.
Using this, together with the estimate

from lemma 3.25, it holds for  and
and  that
that

Taking the infimum over all  , adding ||u||1 on both sides as well as observing that
, adding ||u||1 on both sides as well as observing that  yields
yields

and, consequently, the desired norm estimate. Likewise, the estimate  follows in analogy to proposition 3.22 and corollary 3.23, which immediately gives the claimed estimate for arbitrary α1 > 0, α2 > 0. □
follows in analogy to proposition 3.22 and corollary 3.23, which immediately gives the claimed estimate for arbitrary α1 > 0, α2 > 0. □
Tikhonov regularisation. Again, the second estimate in theorem 4.9 is crucial as it allows to apply the well-posedness result of theorem 3.26.
Proposition 4.10. With X = Lp
(Ω), ![$p\in \left.\right] 1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn523.gif) , Ω being a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex lower semi-continuous and coercive, 1 ⩽ k1 < k2, α1 > 0, α2 > 0, the Tikhonov minimisation problem
, Ω being a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex lower semi-continuous and coercive, 1 ⩽ k1 < k2, α1 > 0, α2 > 0, the Tikhonov minimisation problem

is well-posed in the sense of theorem 3.26 whenever p ⩽ d/(d − k1) if k1 < d.
Compared to the sum of different TV terms, we see that now the necessary coercivity estimate incorporates a projection to the larger kernel of  and an Lp
norm with a smaller exponent corresponding to
and an Lp
norm with a smaller exponent corresponding to  . Hence, in view of the assumptions of theorem 3.26, the infimal convolution of
. Hence, in view of the assumptions of theorem 3.26, the infimal convolution of  and
and  inherits the worst properties of the two summands, i.e., the ones that are more restrictive for applications in an inverse problems context. Nevertheless, such a slightly more restrictive assumption on the continuity of the forward operator is compensated by the fact that the infimal convolution with k1 = 1 allows to reconstruct jumps. In addition, each solution u* of a Tikhonov functional admits an optimal decomposition
inherits the worst properties of the two summands, i.e., the ones that are more restrictive for applications in an inverse problems context. Nevertheless, such a slightly more restrictive assumption on the continuity of the forward operator is compensated by the fact that the infimal convolution with k1 = 1 allows to reconstruct jumps. In addition, each solution u* of a Tikhonov functional admits an optimal decomposition  with
with  , i = 1, 2, which follows from the exactness of the infimal convolution.
, i = 1, 2, which follows from the exactness of the infimal convolution.
Regarding the convergence result of theorem 3.28 and the rates of proposition 3.29, again a direct extension to regularisation with  can be obtained by regarding the weights α1, α2 to be fixed and introducing an additional factor α > 0 for both terms, which then acts as the regularisation parameter. Considering the limiting behaviour for both weights converging to zero, a counterpart of theorem 4.4 can be obtained as follows. There, we allow also for infinite weights αi
, i.e., for αi
= ∞, we set
can be obtained by regarding the weights α1, α2 to be fixed and introducing an additional factor α > 0 for both terms, which then acts as the regularisation parameter. Considering the limiting behaviour for both weights converging to zero, a counterpart of theorem 4.4 can be obtained as follows. There, we allow also for infinite weights αi
, i.e., for αi
= ∞, we set  if
if  and
and  else. We first need a lower semi-continuity result.
else. We first need a lower semi-continuity result.
Lemma 4.11. Let Ω be a bounded Lipschitz domain,  with 1 ⩽ p ⩽ d/(d − k1) if k1 < d, {(α1,n
, α2,n
)} be a sequence of positive parameters converging to some
with 1 ⩽ p ⩽ d/(d − k1) if k1 < d, {(α1,n
, α2,n
)} be a sequence of positive parameters converging to some ![$\left({\alpha }_{1}^{{\dagger}},{\alpha }_{2}^{{\dagger}}\right)\in { \left.\right]0,\infty \left.\right]}^{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn535.gif) and {un
} be a sequence in Lp
(Ω) weakly converging to u* ∈ Lp
(Ω). Then,
and {un
} be a sequence in Lp
(Ω) weakly converging to u* ∈ Lp
(Ω). Then,

Proof. By moving to a subsequence, we can assume that  converges to the limes inferior on the right-hand side of the claimed assertion and that the latter is finite. Choose
converges to the limes inferior on the right-hand side of the claimed assertion and that the latter is finite. Choose  ,
,  sequences such that for each n, we have
sequences such that for each n, we have  ,
,  and
and  being in a complement of
being in a complement of  in the sense that
in the sense that  for a linear, continuous projection
for a linear, continuous projection  . Setting
. Setting  , we obtain
, we obtain

In particular, for a constant C > 0 it holds that

which implies that  is bounded in
is bounded in  . By the embedding of theorem 3.20 and since {un
} is convergent, both
. By the embedding of theorem 3.20 and since {un
} is convergent, both  and
and  admit subsequences (not relabelled) weakly converging to some
admit subsequences (not relabelled) weakly converging to some  and
and  in Lp
(Ω), respectively. Now, in case
in Lp
(Ω), respectively. Now, in case  , we can conclude
, we can conclude

Otherwise, we get by boundedness of  that
that  and by lower semi-continuity that
and by lower semi-continuity that  . Together, this implies
. Together, this implies

This implies the desired statement. □
Theorem 4.12. In the situation of proposition 4.10 and for ![$p\in \left.\right] 1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn556.gif) with p ⩽ d/(d − k1) in case of k1 < d, let for each δ > 0 the data fδ
be given such that
with p ⩽ d/(d − k1) in case of k1 < d, let for each δ > 0 the data fδ
be given such that  , let
, let  be equi-coercive and converge to
be equi-coercive and converge to  for some data f† in Y in the sense of (4) and
for some data f† in Y in the sense of (4) and  if and only if v = f†.
if and only if v = f†.
Choose the parameters α = (α1, α2) in dependence of δ such that

and assume that ![$\left({\tilde {\alpha }}_{1},{\tilde {\alpha }}_{2}\right)=\left({\alpha }_{1},{\alpha }_{2}\right)/\mathrm{min}\left\{{\alpha }_{1},{\alpha }_{2}\right\}\to \left({\alpha }_{1}^{{\dagger}},{\alpha }_{2}^{{\dagger}}\right)\in {\left.\right]0,\infty \left.\right]}^{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn561.gif) as δ → 0. Set
as δ → 0. Set

and assume that there exists u0 ∈ BVk (Ω) such that Ku0 = f†.
Then, up to shifts in  , any sequence {uα,δ
}, with each uα,δ
being a solution to (30) for parameters (α1, α2) and data fδ
, has at least one Lp
-weak accumulation point. Each Lp
-weak accumulation point is a minimum-
, any sequence {uα,δ
}, with each uα,δ
being a solution to (30) for parameters (α1, α2) and data fδ
, has at least one Lp
-weak accumulation point. Each Lp
-weak accumulation point is a minimum- -solution of Ku = f† and
-solution of Ku = f† and  .
.
Proof. First note that, with  a linear, continuous projection, for any u ∈ Lp
(Ω), we have
a linear, continuous projection, for any u ∈ Lp
(Ω), we have

and by the choice of k as well as u0 ∈ BVk
(Ω), that  . Hence, as a consequence of theorem 3.26, there exists a minimum-
. Hence, as a consequence of theorem 3.26, there exists a minimum- -solution u† ∈ BVk
(Ω) to Ku = f†. Using optimality of uα,δ
compared to u† gives
-solution u† ∈ BVk
(Ω) to Ku = f†. Using optimality of uα,δ
compared to u† gives

Now since  and min{α1, α2} → 0 as δ → 0, we have that
and min{α1, α2} → 0 as δ → 0, we have that  as δ → 0. Moreover, as also δ/min{α1, α2} → 0, it follows that
as δ → 0. Moreover, as also δ/min{α1, α2} → 0, it follows that

for ɛ > 0 independent of uα,δ and letting ɛ → 0, we obtain

In particular, using (27), we can conclude that {uα,δ
− Ruα,δ
} is bounded in Lp
(Ω). By introducing appropriate shifts in  as done in theorem 3.26 and using the equi-coercivity of
as done in theorem 3.26 and using the equi-coercivity of  , one can then achieve that {uα,δ
} is bounded in Lp
(Ω) such that by reflexivity, it admits a Lp
-weak accumulation point.
, one can then achieve that {uα,δ
} is bounded in Lp
(Ω) such that by reflexivity, it admits a Lp
-weak accumulation point.
Next, let u* be a Lp
-weak accumulation point associated with {δn
}, δn
→ 0 as well as the corresponding parameters {αn
} = {(α1,n
, α2,n
)}. Then,  by convergence of
by convergence of  to
to  , so Ku* = f†. Moreover, employing lemma 4.11, we get
, so Ku* = f†. Moreover, employing lemma 4.11, we get

hence, u* is a minimum- -solution. The remaining assertions follow as in the proof of theorem 4.4 by replacing the sum with the infimal convolution. □
-solution. The remaining assertions follow as in the proof of theorem 4.4 by replacing the sum with the infimal convolution. □
- Compared to the convergence result for the sum of higher-order TV functionals as in theorem 4.4, we see that now the minimum of the parameters plays the role of the regularisation parameter, but again the ratio of the parameters defines the required regularity assumption on u0 such that Ku0 = f†. For a parameter choice in practice, this again motivates the choice (α1, α2) = α(λ1, λ2) as in remark 4.5, with α > 0 being interpreted as regularisation parameter and (λ1, λ2) with min{λ1, λ2} = 1 being interpreted as model parameter.
- It is also possible to construct infimal convolutions of more than two TV-type functionals and, of course, other functionals than TVk .
- Introducing orders k1, ..., km
⩾ 1 and weights α1, ..., αm
> 0, one can considerSolutions then exist, for appropriate p, in the space BVk (Ω) for k = min{k1, ..., km }.
- The latter is in contrast to the multi-order TV regularisation (20) where the solution space is determined by the highest effective order of differentiation. Letting ki = 1 for some i, the solution space is then BV(Ω) which allows for discontinuities; a desirable property for image restoration.

Optimality conditions. Again, in the situation that Y is a Hilbert space, q = 2 and  , we obtain some first-order optimality conditions. Noting that the dual of the infimal convolution of two functions is the sum of the respective duals, and arguing according to proposition 3.30, an u* is optimal for (30) if and only if
, we obtain some first-order optimality conditions. Noting that the dual of the infimal convolution of two functions is the sum of the respective duals, and arguing according to proposition 3.30, an u* is optimal for (30) if and only if

By proposition 4.7, the subgradients are additive, so in terms of the normal cones introduced in proposition 3.30, the optimality condition reads as

A priori estimates. Also here, in the above Hilbert space situation, i.e.,  and Y Hilbert space, an a-priori bound of solutions u* can be derived thanks to the coercivity estimate (27). One indeed has
and Y Hilbert space, an a-priori bound of solutions u* can be derived thanks to the coercivity estimate (27). One indeed has  with R and C coming from (27). Hence, assuming that K is injective on
with R and C coming from (27). Hence, assuming that K is injective on  , which leads to c||Ru||p
⩽ ||KRu||Y
for all u and some c > 0, one proceeds analogously to remark 3.31 to obtain the bound (17) with α replaced by min{α1, α2}. By analogy, for Sf
(v) = KL(v, f) being the Kullback–Leibler discrepancy, an a priori estimate of the type (18) follows.
, which leads to c||Ru||p
⩽ ||KRu||Y
for all u and some c > 0, one proceeds analogously to remark 3.31 to obtain the bound (17) with α replaced by min{α1, α2}. By analogy, for Sf
(v) = KL(v, f) being the Kullback–Leibler discrepancy, an a priori estimate of the type (18) follows.
Moreover, it is possible to control w* up to  whenever
whenever  . Let, in the following, Cf
⩾ 0 be an a priori estimate for the optimal functional value, for instance,
. Let, in the following, Cf
⩾ 0 be an a priori estimate for the optimal functional value, for instance,  in case of
in case of  , and
, and  for a
for a  with KL(Ku0, f) < ∞ in case of Sf
(v) = KL(v, f). Further, denoting by
with KL(Ku0, f) < ∞ in case of Sf
(v) = KL(v, f). Further, denoting by  a constant such that
a constant such that  for all
for all  (which exists by virtue of the norm equivalence in theorem 4.9), we see that
(which exists by virtue of the norm equivalence in theorem 4.9), we see that  , hence
, hence

Consequently, we obtain the bound

which gives an a priori estimate when plugging in the already-obtained bound on  . Moreover, this estimate implies a bound on
. Moreover, this estimate implies a bound on  by the Poincaré–Wirtinger inequality. However, the norm of w* can not fully be controlled since adding an element in
by the Poincaré–Wirtinger inequality. However, the norm of w* can not fully be controlled since adding an element in  to w* would still realise the infimum in the infimal convolution. Thus, an estimate of the type (33) is the best one could except in the considered setting.
to w* would still realise the infimum in the infimal convolution. Thus, an estimate of the type (33) is the best one could except in the considered setting.
Denoising performance. Figure 4 shows that it is indeed beneficial for denoising to regularise with α1TV△α2TV2 compared to pure TV-regularisation: higher-order features as well as edges are recognised by this image model. Nevertheless, staircase artefacts are still present, see figure 4(c). Essentially, this does not change when the second-order component of the infimal convolution is replaced, for instance by  as in remark 3.33, see figure 4(d). (For the latter penalty functional, basically the same problems as the ones mentioned in remark 3.33 appear.)
as in remark 3.33, see figure 4(d). (For the latter penalty functional, basically the same problems as the ones mentioned in remark 3.33 appear.)

Figure 4. Infimal-convolution denoising example. (a) Noisy image (PSNR: 13.9 dB), (b) regularisation with TV (PSNR: 29.3 dB), (c) regularisation with α1TV△α2TV2 (PSNR: 28.9 dB), (d) regularisation with  (PSNR: 28.6 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
(PSNR: 28.6 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
Download figure:
Standard image High-resolution image5. Total generalised variation (TGV)
5.1. Basic concepts
As a motivation for TGV, consider the formal predual ball associated with the infimal convolution  for α = (α0, α1), α0, α1 > 0. Then
for α = (α0, α1), α0, α1 > 0. Then

and

Neglecting the closure for a moment, this leads to the predual ball according to

Each  possesses a representation as an ∞-bounded first and second-order divergence of some φ1 and φ2. However, as the kernel of the divergence is non-trivial (and even infinite-dimensional for d ⩾ 2), we can only conclude that φ1 = div φ2 + η for some η with div η = 0. Enforcing η = 0 thus gives the set
possesses a representation as an ∞-bounded first and second-order divergence of some φ1 and φ2. However, as the kernel of the divergence is non-trivial (and even infinite-dimensional for d ⩾ 2), we can only conclude that φ1 = div φ2 + η for some η with div η = 0. Enforcing η = 0 thus gives the set

which leads, interpreted as a predual ball, to a seminorm which also incorporates first- and second-order derivatives but is different from infimal convolution: the total generalised variation [37].
There is also a primal version of this motivation via the (TV–TV2)-infimal convolution which reads as follows: writing

we see that the infimal convolution allows to subtract a vector field w = ∇v from the derivative of u at the cost of penalising its derivative  , where the equality is due to symmetry of the weak Hessian ∇2
v. While, by the embedding BD(Ω, Rd
) ↪ Ld/(d−1)(Ω, Rd
), necessarily w ∈ BD(Ω, Rd
), it is not arbitrary among such functions but still restricted to be the gradient of v ∈ BV2(Ω). Omitting this additional constraint (in the predual version above, this corresponds to enforcing η = 0), we arrive at
, where the equality is due to symmetry of the weak Hessian ∇2
v. While, by the embedding BD(Ω, Rd
) ↪ Ld/(d−1)(Ω, Rd
), necessarily w ∈ BD(Ω, Rd
), it is not arbitrary among such functions but still restricted to be the gradient of v ∈ BV2(Ω). Omitting this additional constraint (in the predual version above, this corresponds to enforcing η = 0), we arrive at

which is, as will be shown in this section, is an equivalent formulation of the TGV functional.
Definition 5.1. Let Ω ⊂ Rd
be a domain, k ⩾ 1 and α0, ..., αk−1 > 0. Then, the total generalised variation of order k with weight α for  is defined as the value of the functional
is defined as the value of the functional

which takes the value ∞ in case the respective set is unbounded from above.
For symmetric tensors  of order l ⩾ 0, the total generalised variation is given by
of order l ⩾ 0, the total generalised variation is given by

The space

is called the space of symmetric tensor fields of bounded generalised variation of order k with weight α. The special case l = 0 is denoted by  .
.
Remark 5.2. For k = 1 and α > 0, the definition coincides, up to a factor, with the total deformation of symmetric tensor fields of order l, i.e.,  , in particular
, in particular  . Hence, we can identify the spaces
. Hence, we can identify the spaces  . In particular,
. In particular,  .
.
In the following, we will derive some basic properties of the total generalised variation.
Proposition 5.3. The following basic properties hold:
- (a) is a lower semi-continuous seminorm on Lp
(Ω, Syml
(Rd
)) for each p ∈ [1, ∞].
- (b)The kernel satisfies for the kth order total deformation for symmetric tensor fields of order l. In particular, is a finite-dimensional subspace of polynomials of order less than k + l. For l = 0, we have .
- (c) is a Banach space independent of α.





Proof. Observe that  is the seminorm associated with the predual ball
is the seminorm associated with the predual ball

By definition, each element of  can be associated with an element of the dual space of Lp
(Ω, Syml
(Rd
)), so
can be associated with an element of the dual space of Lp
(Ω, Syml
(Rd
)), so  is convex and lower semi-continuous as pointwise supremum over a set of linear and continuous functionals. The positive homogeneity finally follows from
is convex and lower semi-continuous as pointwise supremum over a set of linear and continuous functionals. The positive homogeneity finally follows from  for each
for each  .
.
The statement about the kernel of  is a consequence of
is a consequence of  if and only if ⟨u, divk
φ⟩ = 0 for each
if and only if ⟨u, divk
φ⟩ = 0 for each  (compare with proposition 3.21).
(compare with proposition 3.21).
Finally,  is a Banach space by lemma 3.15. The equivalence for parameter sets α0, ..., αk−1 > 0 and
is a Banach space by lemma 3.15. The equivalence for parameter sets α0, ..., αk−1 > 0 and  can be seen as follows. Choosing C > 0 large enough, we can achieve that
can be seen as follows. Choosing C > 0 large enough, we can achieve that

This implies

Interchanging roles we get  , so the spaces
, so the spaces  and
and  have equivalent norms. □
have equivalent norms. □
Remark 5.4. As  are all equivalent for different α, we will drop, in the following, the subscript α.
are all equivalent for different α, we will drop, in the following, the subscript α.
Proposition 5.5. The scalar total generalised variation, i.e.,  possesses the following invariance and scaling properties:
possesses the following invariance and scaling properties:
- (a) is translation invariant, i.e. for x0 ∈ and u ∈ BGVk
(Ω) we have that
 given by (x) = u(x + x0) is in BGVk
(Ω − x0) and ,
given by (x) = u(x + x0) is in BGVk
(Ω − x0) and , - (b) is rotationally invariant, i.e. for each orthonormal matrix O ∈ and u ∈ BGVk
(Ω) we have, defining (x) = u(Ox), that ∈ BGVk
(OTΩ) with ,
- (c)For r > 0 and u ∈ BGVk (Ω), we have, defining(x) = u(rx), that ∈ BGVk
(r−1Ω) with







Proof. See [37]. □
The derivative versus the symmetrised derivative. In both ways to motivate the second-order TGV functional as presented at the beginning of this section, we see that symmetric tensor fields and a symmetrised derivative appear naturally in the penalisation of higher-order derivatives. Indeed, in the motivation via the predual ball  of the infimal convolution, symmetric tensor fields (resulting in a symmetrised derivative in the primal version) appear as the most economic way to write the predual ball, since for
of the infimal convolution, symmetric tensor fields (resulting in a symmetrised derivative in the primal version) appear as the most economic way to write the predual ball, since for  , div2
φ = div2(| | |φ). In the primal version, the symmetrised derivative results from writing
, div2
φ = div2(| | |φ). In the primal version, the symmetrised derivative results from writing  and then relaxing ∇v to be an arbitrary vector field w. Nevertheless, also non-symmetric tensor fields and the equality ∇2
v = ∇(∇v) could have been used in these motivations. For the TGV functional, this would have resulted in a primal version of second-order TGV according to
and then relaxing ∇v to be an arbitrary vector field w. Nevertheless, also non-symmetric tensor fields and the equality ∇2
v = ∇(∇v) could have been used in these motivations. For the TGV functional, this would have resulted in a primal version of second-order TGV according to

which is genuinely different from the definition in (35). The following example provides some insight on the differences between using the derivative and the symmetrised derivative of vector fields of bounded variation in a Radon-norm penalty.
Example 5.6. On  define, for given
define, for given  (the unit sphere in R2),
(the unit sphere in R2),

where n⊥ = (n2, −n1). Then, w ∈ BV(Ω, R2) and, with ![$L=\left\{\lambda {n}^{\perp }\enspace \vert \enspace \lambda \in \left.\right] -\frac{1}{2},\frac{1}{2}\left[\right.\right\}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn634.gif) ,
,

A direct computation shows that

thus, the symmetrised derivative depends on the angle of the vector field relative to the jump set, while the derivative does not. In particular, whenever ν2 = 0 such that the vector field can be written as the gradient of a function in BV2(Ω), the two notions coincide. See figure 5 for a visualisation of w for different values of ν.

Figure 5. Visualisation of the function w of example 5.6 and values of  and
and  for different choices of ν. The blue lines show the level lines of a function v such that w = ∇v.
for different choices of ν. The blue lines show the level lines of a function v such that w = ∇v.
Download figure:
Standard image High-resolution image5.2. Functional analytic and regularisation properties
We would like to characterise  in terms of a minimisation problem. This characterisation will base on Fenchel–Rockafellar duality. Here, the following theorem by [8] is employed. Recall that the domain of a function
in terms of a minimisation problem. This characterisation will base on Fenchel–Rockafellar duality. Here, the following theorem by [8] is employed. Recall that the domain of a function ![$F:X\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn638.gif) is defined as dom(F) = {x ∈ X|F(x) < ∞}.
is defined as dom(F) = {x ∈ X|F(x) < ∞}.
Theorem 5.7. Let X, Y be Banach spaces and Λ : X → Y linear and continuous. Let ![$F:X\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn639.gif) and
and ![$G:Y\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn640.gif) be proper, convex and lower semi-continuous. Assume that
be proper, convex and lower semi-continuous. Assume that

Then,

In particular, the maximum on the right-hand side is attained.
As a preparation for employing this duality result, we note:
Lemma 5.8. Let l ⩾ 0, i ⩾ 1 and  ,
,  be distributions of order i − 1 and i, respectively. Then,
be distributions of order i − 1 and i, respectively. Then,

with the right-hand side being finite if and only if  in the distributional sense.
in the distributional sense.
Proof. Note that in the distributional sense,  for all
for all  . Since
. Since  is dense in
is dense in  , the distribution
, the distribution  can be extended to an element in
can be extended to an element in  if and only if the supremum in (41) is finite. In case of finiteness, it coincides with the Radon norm by definition. □
if and only if the supremum in (41) is finite. In case of finiteness, it coincides with the Radon norm by definition. □
This enables us to derive the problem which is dual to the maximisation problem in (37). We will refer to the resulting problem as the minimum representation of  .
.
Theorem 5.9. For k ⩾ 1, l ⩾ 0, Ω a bounded Lipschitz domain and  according to (37), we have for each u ∈ L1(Ω, Syml
(Rd
)):
according to (37), we have for each u ∈ L1(Ω, Syml
(Rd
)):

with the minimum being finite if and only if u ∈ BD(Ω, Syml ( R d )) and attained for some w0, ..., wk where wi ∈ BD(Ω, Syml+i ( R d )) for i = 0, ..., k and w0 = u as well as wk = 0 in case of u ∈ BD(Ω, Syml ( R d )).
Proof. First, take  such that
such that  . We will employ Fenchel–Rockafellar duality. For this purpose, introduce the Banach spaces
. We will employ Fenchel–Rockafellar duality. For this purpose, introduce the Banach spaces

the linear operator

and the proper, convex and lower semi-continuous functionals

With these choices, the identity

follows from the definition in (37).
In order to show the representation of  as in (42), we would like to obtain
as in (42), we would like to obtain

This follows as soon as (39) is verified. For the purpose of showing (39), let ψ ∈ Y and define backwards recursively:  ,
,  for i = k − 1, ..., 1. Hence, φ ∈ X and −Λφ = ψ. Moreover, choosing λ > 0 large enough, one can achieve that
for i = k − 1, ..., 1. Hence, φ ∈ X and −Λφ = ψ. Moreover, choosing λ > 0 large enough, one can achieve that  for all i = 1, ..., k, so λ−1
φ ∈ dom(F) and since 0 ∈ dom(G), we get the representation ψ = λ(0 − Λλ−1
φ). Thus, the identity (43) holds and the minimum is attained in Y*. Now, Y* can be written as
for all i = 1, ..., k, so λ−1
φ ∈ dom(F) and since 0 ∈ dom(G), we get the representation ψ = λ(0 − Λλ−1
φ). Thus, the identity (43) holds and the minimum is attained in Y*. Now, Y* can be written as

with elements w = (w1, ..., wk−1),  , for 1 ⩽ i ⩽ k − 1. Therefore, with w0 = u and wk
= 0 we get, as G* = 0, that
, for 1 ⩽ i ⩽ k − 1. Therefore, with w0 = u and wk
= 0 we get, as G* = 0, that

From lemma 5.8 we obtain that each supremum is finite and coincides with  if and only if
if and only if  for i = 1, ..., k. Then, as wk
= 0, according to theorem 3.16, this already yields wk−1 ∈ BD(Ω, Symk+l−1(Rd
)), in particular
for i = 1, ..., k. Then, as wk
= 0, according to theorem 3.16, this already yields wk−1 ∈ BD(Ω, Symk+l−1(Rd
)), in particular  . Proceeding inductively, we see that wi
∈ BD(Ω, Symk+i
(Rd
)) for each i = 0, ..., k. Hence, it suffices to take the minimum in (43) over all BD-tensor fields which gives (42).
. Proceeding inductively, we see that wi
∈ BD(Ω, Symk+i
(Rd
)) for each i = 0, ..., k. Hence, it suffices to take the minimum in (43) over all BD-tensor fields which gives (42).
In addition, the minimum in (42) is finite if u ∈ BD(Ω, Syml
(Rd
)). Conversely, if TD(u) = ∞, also  for all w1 ∈ BD(Ω, Syml+1(Rd
)). Hence, the minimum in (42) has to be ∞. □
for all w1 ∈ BD(Ω, Syml+1(Rd
)). Hence, the minimum in (42) has to be ∞. □
Remark 5.10. In the scalar case, i.e., l = 0 it holds that

Remark 5.11. The minimum representation also allows to define  recursively:
recursively:

where α' = (α0, ..., αk−1) if α = (α0, ..., αk ).
Remark 5.12. For the scalar  , the minimum representation reads as
, the minimum representation reads as

This can be interpreted as follows. For u ∈ BV(Ω), ∇u is a measure which can be decomposed into a regular and singular component with respect to the Lebesgue measure. The singular part is always penalised with the Radon norm where from the regular part, an optimal bounded deformation vector field w is extracted. This vector field is penalised by TD which, like TV, implies certain regularity but also allows for jumps. Thus,  essentially contains the second-order derivative information of u.
essentially contains the second-order derivative information of u.
Provided that w is optimal, the total generalised variation of second order then penalises the first-order remainder ∇u − w which essentially contains the jumps of u as well as the second-order information  .
.
The next step is to examine the spaces BGVk
(Ω, Syml
(Rd
)). Our aim is to prove that these space coincide with BD(Ω, Syml
(Rd
)) for fixed l ⩾ 0 and all k ⩾ 1. We will proceed inductively with respect to k and hence vary k, l but leave Ω fixed and assume that Ω is a bounded Lipschitz domain. For what follows, we choose a family of projection operators onto the kernel of  (see proposition 5.3).
(see proposition 5.3).
Definition 5.13. For each k ⩾ 1 and l ⩾ 0, denote by  a linear and continuous projection.
a linear and continuous projection.
As  (on Ω and for symmetric tensor fields of order l) is finite-dimensional, such a Rk,l
always exists but is not necessarily unique. A coercivity estimate in Ld/(d−1)(Ω, Syml
(Rd
)) for
(on Ω and for symmetric tensor fields of order l) is finite-dimensional, such a Rk,l
always exists but is not necessarily unique. A coercivity estimate in Ld/(d−1)(Ω, Syml
(Rd
)) for  will next be formulated and proven in terms of these projections. As we will see, the induction step in the proof requires an intermediate estimate as follows.
will next be formulated and proven in terms of these projections. As we will see, the induction step in the proof requires an intermediate estimate as follows.
Lemma 5.14. For each k ⩾ 1 and l ⩾ 0 there exists a constant C > 0, only depending on Ω, k and l such that for each u ∈ BD(Ω, Syml (Rd )) and w ∈ Ld/(d−1)(Ω, Syml+1(Rd )),

Proof. If this is not true for some k and l, then there exist {un } in BD(Ω, Syml (Rd )) and {wn } in Ld/(d−1)(Ω, Syml+1(Rd )) such that

This implies that {Rk,l+1
wn
} is bounded in terms of  in the finite-dimensional space
in the finite-dimensional space  , see proposition 5.3. Consequently, there exists a subsequence, again denoted by {wn
}, such that Rk,l+1
wn
→ w as n → ∞ with respect to ||⋅||1. Hence,
, see proposition 5.3. Consequently, there exists a subsequence, again denoted by {wn
}, such that Rk,l+1
wn
→ w as n → ∞ with respect to ||⋅||1. Hence,  as n → ∞. Further, we have that un
→ 0 as n → ∞ and thus, by closedness of the weak symmetrised gradient,
as n → ∞. Further, we have that un
→ 0 as n → ∞ and thus, by closedness of the weak symmetrised gradient,  as n → ∞ in
as n → ∞ in  , which contradicts
, which contradicts  for all n. □
for all n. □
Proposition 5.15. For each k ⩾ 1 and l ⩾ 0, there exists a constant C > 0 such that


for all u ∈ BD(Ω, Syml (Rd )).
Proof. We prove the result by induction with respect to k. In the case k = 1 and l ⩾ 0 arbitrary, the first inequality is immediate while the second is equivalent to the Sobolev–Korn inequality in BD(Ω, Syml (Rd )), see theorem 3.18.
Now assume that both inequalities hold for a fixed k and each l ⩾ 0 and perform an induction step with respect to k, i.e., we fix l ∈ N, α = (α0, ..., αk ) with αi > 0 for i = 0, ..., k. We assume that assertion (46) holds for α' = (α0, ..., αk−1) and any l' ∈ N.
We will first show the uniform estimate for  for which it suffices to consider u ∈ BD(Ω, Syml
(Rd
)), as otherwise, according to theorem 5.9,
for which it suffices to consider u ∈ BD(Ω, Syml
(Rd
)), as otherwise, according to theorem 5.9,  . Then, with the projection Rk,l+1, the help of lemma 5.14, the continuous embeddings
. Then, with the projection Rk,l+1, the help of lemma 5.14, the continuous embeddings

and the induction hypothesis, we can estimate for arbitrary w ∈ BD(Ω, Syml+1(Rd )),

for C > 0 suitable generic constants. Taking the minimum over all such w ∈ BD(Ω, Syml+1(Rd )) then yields

by virtue of the recursive minimum representation (45).
The coercivity estimate can be shown analogously to proposition 3.22 and corollary 3.23. First, assume that the inequality does not hold true for α = (1, ..., 1). Then, there is a sequence {un } in Ld/(d−1)(Ω, Syml (Rd )) such that

By  , we have
, we have  for each n. Thus, since we already know the first estimate in (46) to hold,
for each n. Thus, since we already know the first estimate in (46) to hold,

implying, by continuous embedding, that {un − Rk+1,l un } is bounded in BD(Ω, Syml (Rd )). By compact embedding (see theorem 3.17), we may therefore conclude that un − Rk+1,l un → u in L1(Ω, Syml (Rd )) for some subsequence (not relabelled). Moreover, as Rk+1,l (un − Rk+1,l un ) = 0 for all n, the limit has to satisfy Rk+1,l u = 0. On the other hand, by lower semi-continuity (see proposition 5.3),

hence  . Consequently, limn→∞
un
− Rk+1,l
un
= u = Rk+1,l
u = 0. From (48) it follows that also
. Consequently, limn→∞
un
− Rk+1,l
un
= u = Rk+1,l
u = 0. From (48) it follows that also  in
in  , so un
− Rk+1,l
un
→ 0 in BD(Ω, Syml
(Rd
)) and by continuous embedding also in Ld/(d−1)(Ω, Syml
(Rd
)). However, this contradicts ||un
− Rk+1,l
un
||d/(d−1) = 1 for all n, and thus, the claimed coercivity for the particular choice α = (1, ..., 1) holds. The result for general α then follows from monotonicity of
, so un
− Rk+1,l
un
→ 0 in BD(Ω, Syml
(Rd
)) and by continuous embedding also in Ld/(d−1)(Ω, Syml
(Rd
)). However, this contradicts ||un
− Rk+1,l
un
||d/(d−1) = 1 for all n, and thus, the claimed coercivity for the particular choice α = (1, ..., 1) holds. The result for general α then follows from monotonicity of  with respect to each component of α. □
with respect to each component of α. □
Corollary 5.16. For k ⩾ 1 and l ⩾ 0 there exist C, c > 0 such that for all u ∈ BD(Ω, Syml (Rd )) we have

In particular, BGVk (Ω, Syml (Rd )) = BD(Ω, Syml (Rd )) in the sense of Banach space isomorphy.
Proof. The estimate on the right is a consequence of (46) while the estimate on the left follows by the minimum representation (42) which gives  . □
. □
Tikhonov regularisation. Once again, the second estimate in proposition 5.15 is crucial to transfer the well-posedness result of theorem 3.26 as follows.
Proposition 5.17. With X = Lp
(Ω), ![$p\in \left.\right]1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn686.gif) , Ω being a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex, lower semi-continuous and coercive, k ⩾ 1, α = (α0, ..., αk−1) with αi
> 0 for i = 0, ..., k − 1, the Tikhonov minimisation problem
, Ω being a bounded Lipschitz domain, Y a Banach space, K : X → Y linear and continuous, Sf
: Y → [0, ∞] proper, convex, lower semi-continuous and coercive, k ⩾ 1, α = (α0, ..., αk−1) with αi
> 0 for i = 0, ..., k − 1, the Tikhonov minimisation problem

is well-posed in the sense of theorem 3.26 whenever p ⩽ d/(d − 1) if d > 1.
Regarding the assumptions of theorem 3.26 on the kernel of the seminorm and the constraint on the exponent p in the underlying Lp -space, we see that, as one would expect, TGVk resembles the situation of the infimal convolution of TV-type functionals rather than their sum, in particular the constraint p ⩽ d/(d − 1) is the same as with first-order TV regularisation.
This is also true for the following convergence result, which should be compared to the results of theorems 4.4 and 4.12 for the sum and the infimal convolution of higher-order TV functionals, respectively. Here, similar as with the infimal convolution, we extend  to weights in
to weights in ![$ \left.\right]0,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn688.gif) by using the minimum representation and defining
by using the minimum representation and defining  for αi
= ∞.
for αi
= ∞.
Theorem 5.18. In the situation of proposition 5.17 and ![$p\in \left.\right]1,\infty \left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn690.gif) with p ⩽ d/(d − 1) if d > 1, let for each δ > 0 the data fδ
be such that
with p ⩽ d/(d − 1) if d > 1, let for each δ > 0 the data fδ
be such that  , and let the discrepancy functionals
, and let the discrepancy functionals  be equi-coercive and converge to
be equi-coercive and converge to  for some data f† in Y in the sense of (4) and
for some data f† in Y in the sense of (4) and  if and only if v = f†.
if and only if v = f†.
Choose the parameters α = (α0, ..., αk−1) in dependence of δ such that

and assume that ![$\left({\tilde {\alpha }}_{0},\dots ,{\tilde {\alpha }}_{k-1}\right)=\left({\alpha }_{0},\dots ,{\alpha }_{k-1}\right)/\mathrm{min}\left\{{\alpha }_{0},\dots ,{\alpha }_{k-1}\right\}\to \left({\alpha }_{0}^{{\dagger}},\dots ,{\alpha }_{k-1}^{{\dagger}}\right)\in \left.\right]0,\infty \left.\right]^{k}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn695.gif) as δ → 0. Set
as δ → 0. Set

and assume that there exists u0 ∈ BVm (Ω) such that Ku0 = f†.
Then, up to shifts in ker(K) ∩
P
k−1, any sequence {uα,δ
}, with each uα,δ
being a solution to (50) with parameters (α0, ..., αk−1) and data fδ
, has at least one Lp
-weak accumulation point. Each Lp
-weak accumulation point is a minimum- -solution of Ku = f† and
-solution of Ku = f† and  .
.
Proof. The proof is analogous to the one of [32, theorem 4.8], which considers the case  for
for  . Alternatively, one can proceed along the lines of the proof of theorem 4.12 with the infimal convolution replaced by TGV to obtain the result. □
. Alternatively, one can proceed along the lines of the proof of theorem 4.12 with the infimal convolution replaced by TGV to obtain the result. □
Remark 5.19. (parameter choice). Similar to the infimal convolution of TV functionals, also for TGV, the minimum of the involved parameters determines the overall regularisation, while the ratio between the minimum and the different parameters reflect the regularity assumption on the ground-truth data. In practice, this suggests a parameter choice as (α0, ..., αk−1) = α(λ0, ..., λk−1), where again α > 0 is chosen in dependence of the noise level and (λ0, ..., λk−1) with min{λ0, ..., λk−1} = 1 is fixed once for a given class of image data and then left constant independent of the concrete forward model or the noise level.
A priori estimates. In case of Hilbert-space data and quadratic norm discrepancy, i.e.,  for Y Hilbert space, one can, in the situation of proposition 5.17 once again find an a-priori bound thanks to the coercivity estimate (47). Let C > 0 be a constant such that
for Y Hilbert space, one can, in the situation of proposition 5.17 once again find an a-priori bound thanks to the coercivity estimate (47). Let C > 0 be a constant such that  for a linear and continuous projection operator R onto Pk−1 for all u ∈ BV(Ω). Further, assume that K is injective on Pk−1 and c > 0 is chosen such that c||Ru||p
⩽ ||KRu||Y
for all u ∈ Lp
(Ω). Then, for a solution u* of the minimisation problem
for a linear and continuous projection operator R onto Pk−1 for all u ∈ BV(Ω). Further, assume that K is injective on Pk−1 and c > 0 is chosen such that c||Ru||p
⩽ ||KRu||Y
for all u ∈ Lp
(Ω). Then, for a solution u* of the minimisation problem

the norm  obeys the a priori estimate (17) with α replaced by min{α0, ..., αk−1}. Also here, if the discrepancy is replaced by the Kullback–Leibler discrepancy Sf
(v) = KL(v, f), then
obeys the a priori estimate (17) with α replaced by min{α0, ..., αk−1}. Also here, if the discrepancy is replaced by the Kullback–Leibler discrepancy Sf
(v) = KL(v, f), then  can be estimated analogously in terms of (18). Let, again, Cf
⩾ 0 be an a priori estimate for the optimal functional value, analogous to the Cf
that leads to (33). Moreover, analogous to the multi-order infimal-convolution case in subsection 4.2, it is possible to estimate each tuple
can be estimated analogously in terms of (18). Let, again, Cf
⩾ 0 be an a priori estimate for the optimal functional value, analogous to the Cf
that leads to (33). Moreover, analogous to the multi-order infimal-convolution case in subsection 4.2, it is possible to estimate each tuple  that realises the minimum in the primal representation (42) of
that realises the minimum in the primal representation (42) of  . Now, in order to estimate, for instance,
. Now, in order to estimate, for instance,  , set
, set  and note that we already have the bound
and note that we already have the bound  where (17) or (18) provides an a-priori estimate of the right-hand side. Choosing a C1 > 0 such that
where (17) or (18) provides an a-priori estimate of the right-hand side. Choosing a C1 > 0 such that  for all w0 ∈ BD(Ω, Sym0(Rd
)) = BV(Ω), we obtain
for all w0 ∈ BD(Ω, Sym0(Rd
)) = BV(Ω), we obtain  and, consequently,
and, consequently,

We thus obtain the bound

which is similar to (33), but involves a norm and not a seminorm due to the structure of  . Using this line of argumentation, one can now inductively obtain bounds on w2, ..., wk−1 according to
. Using this line of argumentation, one can now inductively obtain bounds on w2, ..., wk−1 according to

for i = 1, ..., k − 1, where each Ci
> 0 is a constant such that  for all wi−1 ∈ BD(Ω, Symi−1(Rd
)), whose existence is guaranteed by proposition 5.15. This provides an a-priori estimate for u* and
for all wi−1 ∈ BD(Ω, Symi−1(Rd
)), whose existence is guaranteed by proposition 5.15. This provides an a-priori estimate for u* and  .
.
Denoising performance. In figure 6, one can see how second-order TGV regularisation (figure 6(d)) performs in comparison to first-order TV (figure 6(b)) and α1TV△α2TV2 (figure 6(c)) as regulariser for image denoising. It is apparent that TGV covers higher-order features more accurately than the associated infimal-convolution regulariser with the staircase effect being absent, while at the same time, jump discontinuities are preserved as for first-order TV. This is in particular reflected in the underlying function space for TGV being BV(Ω), see corollary 5.16. In conclusion, the total generalised variation can be seen as an adequate model for piecewise smooth images and will, in the following, be the preferred regulariser for this class of functions.

Figure 6. Total generalised variation denoising example. (a) Noisy image (PSNR: 13.9 dB), (b) regularisation with TV (PSNR: 29.3 dB), (c) regularisation with α1TV△α2TV2 (PSNR: 28.9 dB), (d) regularisation with  (PSNR: 30.4 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
(PSNR: 30.4 dB). All parameters were manually tuned via grid search to give highest PSNR with respect to the ground truth (figure 1(a)).
Download figure:
Standard image High-resolution image5.3. Extensions
TGV for multichannel images. Again, in analogy to TV and higher-order TV, TGV can also be extended to colour and multichannel images represented by functions mapping into the vector space Rm
by testing with  -valued tensor fields. This requires to define pointwise norms on
-valued tensor fields. This requires to define pointwise norms on  for l = 1, ..., k where, apart from the standard Frobenius norm, one can take any norm
for l = 1, ..., k where, apart from the standard Frobenius norm, one can take any norm  on
on  , noting that different norms imply different types of coupling of the multiple channels. With each
, noting that different norms imply different types of coupling of the multiple channels. With each  denoting the dual norm of
denoting the dual norm of  ,
,  can be extended to functions
can be extended to functions  as
as

where  is the pointwise supremum of the scalar function
is the pointwise supremum of the scalar function  on Ω for
on Ω for  . As before, by equivalence of norms in finite dimensions, the functional-analytic and regularisation properties of TGV transfer to its multichannel extension, see e.g. [27, 33]. Rotationally invariance holds whenever all tensor norms
. As before, by equivalence of norms in finite dimensions, the functional-analytic and regularisation properties of TGV transfer to its multichannel extension, see e.g. [27, 33]. Rotationally invariance holds whenever all tensor norms  are unitarily invariant. For k = 2, particular instances that are unitarily invariant can be constructed by choosing
are unitarily invariant. For k = 2, particular instances that are unitarily invariant can be constructed by choosing  as a unitarily invariant matrix norm and
as a unitarily invariant matrix norm and  as either the Frobenius tensor norm or
as either the Frobenius tensor norm or  , i.e., a decoupled norm. This allows, for instance, to penalise the nuclear norm of first-order derivatives and the Frobenius tensor norm of the second order component, as it was done, e.g., in [123].
, i.e., a decoupled norm. This allows, for instance, to penalise the nuclear norm of first-order derivatives and the Frobenius tensor norm of the second order component, as it was done, e.g., in [123].
Infimal-convolution TGV. Beyond the realisation of different couplings of multiple colour channels, the extension to arbitrary pointwise tensor norms in the definition of TGV can also be beneficial in the context of scalar-valued functions. In [109], the infimal convolution of different TGV functionals with different, anisotropic norms was considered in the context of dynamic data as well as anisotropic regularisation for still images. With  for i = 1, ..., n denoting TGV functionals according to (53) for m = 1 of order ki
and each βi
denoting a tuple of pointwise norms, the functional
for i = 1, ..., n denoting TGV functionals according to (53) for m = 1 of order ki
and each βi
denoting a tuple of pointwise norms, the functional  can be defined for
can be defined for  as
as

As shown in [109], this functional is equivalent to  for k = max{ki
} and α any parameter vector, and, in case
for k = max{ki
} and α any parameter vector, and, in case  , the minimum is attained for ui
∈ Ld/(d−1)(Ω) for i = 1, ..., n − 1. Hence, the coercivity estimate on
, the minimum is attained for ui
∈ Ld/(d−1)(Ω) for i = 1, ..., n − 1. Hence, the coercivity estimate on  transfers to
transfers to  and again, all results in the context of Tikhonov regularisation apply.
and again, all results in the context of Tikhonov regularisation apply.
For applications in the context of dynamic data, the norms for the different  can be chosen to realise different weightings of spatial and temporal derivatives. This allows, in a convex setting, for an adaptive regularisation of video data via a motion-dependent separation into different components, see, for instance, figure 7.
can be chosen to realise different weightings of spatial and temporal derivatives. This allows, in a convex setting, for an adaptive regularisation of video data via a motion-dependent separation into different components, see, for instance, figure 7.

Figure 7. Frame of an image sequence showing a juggler (left), and three frames of a decomposition into components capturing slow (top right images) and fast (bottom right images) motion that was achieved with ICTGV regularisation. Reprinted from [35] by permission from Springer Nature Customer Service Centre GmbH: Springer © 2015.
Download figure:
Standard image High-resolution imageSimilarly, for still image regularisation, one can choose  to employ isotropic norms and correspond to the usual total generalised variation, and each
to employ isotropic norms and correspond to the usual total generalised variation, and each  for i = 2, ..., n to employ different anisotropic norms that favour one particular direction. This yields again an adaptive regularisation of image data via a decomposition into an isotropic and several anisotropic parts and can be employed, for instance, to recover certain line structures for denoising [109] or applications in CT imaging [125].
for i = 2, ..., n to employ different anisotropic norms that favour one particular direction. This yields again an adaptive regularisation of image data via a decomposition into an isotropic and several anisotropic parts and can be employed, for instance, to recover certain line structures for denoising [109] or applications in CT imaging [125].
Oscillation TGV and its infimal convolution. The total generalised variation model can also be extended to account for functions with piecewise oscillatory behaviour, which is, for instance, useful to model texture in images [90]. The basic idea to include oscillations is to fix a direction ω ∈ Rd
, ω ≠ 0 and to modify the definition of second-order TGV such that its kernel corresponds to oscillatory functions in the  -direction with frequency
-direction with frequency  :
:

where, as before, α = (α0, α1), α0, α1 > 0. Indeed, the kernel of  is spanned by the functions x ↦ sin(x ⋅ ω) and x ↦ cos(x ⋅ ω). Further, the functional is proper, convex and lower semi-continuous in each Lp
(Ω), and admits the minimum representation
is spanned by the functions x ↦ sin(x ⋅ ω) and x ↦ cos(x ⋅ ω). Further, the functional is proper, convex and lower semi-continuous in each Lp
(Ω), and admits the minimum representation

With  a linear and continuous projection, a coercivity estimate holds as follows:
a linear and continuous projection, a coercivity estimate holds as follows:

for all u ∈ BV(Ω), see [90]. The functional can therefore be used as a regulariser in all cases where TV is applicable.
In order to obtain a texture-aware image model, one can now take the infimal convolution of  with parameter vector
with parameter vector ![${\alpha }_{0}\in { \left.\right]0,\infty \left[\right. }^{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn745.gif) and
and  for parameter vectors
for parameter vectors ![${\alpha }_{1},\dots ,{\alpha }_{n}\in {\left.\right]0,\infty \left[\right. }^{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn747.gif) and directions ω1, ..., ωn
∈ Rd
with ωi
≠ 0 for i = 1, ..., n, i.e.,
and directions ω1, ..., ωn
∈ Rd
with ωi
≠ 0 for i = 1, ..., n, i.e.,

which again yields a proper, convex and lower semi-continuous regulariser on each Lp
(Ω) which is coercive in the sense that  for a linear and continuous projection
for a linear and continuous projection  , see again [90]. It is therefore again applicable as a regulariser for inverse problems whenever TV is applicable. See figure 8 for an example of ICTGVosci-based denoising and its benefits for capturing and reconstructing textured regions.
, see again [90]. It is therefore again applicable as a regulariser for inverse problems whenever TV is applicable. See figure 8 for an example of ICTGVosci-based denoising and its benefits for capturing and reconstructing textured regions.

Figure 8. Example of ICTGVosci denoising. In the top row, the whole image is depicted, while a closeup of the respective marked region is shown in the bottom row. (a) A noisy image (PSNR: 26.0 dB). (b) Results of TGV2-denoising (PSNR: 34.8 dB). (c) Results of ICTGVosci denoising (PSNR: 36.6 dB). Parameters were manually optimised via grid search towards best peak signal-to-noise ratio (PSNR) with respect to the ground truth (not shown). Figure taken from [90]. Copyright © 2018 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Download figure:
Standard image High-resolution image
TGV for manifold-valued data. In different applications in inverse problems and imaging, the data of interest takes values not in a vector space but rather a non-linear space such as a manifold. Examples are sphere-valued data in synthetic aperture radar (SAR) imaging or data with values in the space of positive matrices, equipped with the Fisher–Rao metric, which is used diffusion tensor imaging. Motivated by such applications, TV regularisation has been extended to cope with manifold-valued data, using different approaches and numerical algorithms [68, 98, 129, 192]. A rather simple extension of TV for discrete and finite, univariate signals  living in a complete Riemannian manifold
living in a complete Riemannian manifold  with metric
with metric  is given as
is given as

For this setting, and an extension to bivariate signals, the work [192] provides simple numerical algorithms which yield, in case  is a Hadamard space, globally optimal solutions of variational TV denoising for manifold-valued data. While this allows in particular to extend edge-preserving regularisation to non-linear geometric data, it can again be observed that TV regularisation has a tendency towards piecewise constant solutions with artificial jump discontinuities. To overcome this, different works have proposed extensions of this approach to higher-order TV [10], the (TV–TV2)-infimal convolution [14, 15] and second-order TGV [15, 36]. Here we briefly sketch the main underlying ideas, presented in [36], for an extension of TGV to manifold-valued data. For simplicity, we consider only the case of univariate signals
is a Hadamard space, globally optimal solutions of variational TV denoising for manifold-valued data. While this allows in particular to extend edge-preserving regularisation to non-linear geometric data, it can again be observed that TV regularisation has a tendency towards piecewise constant solutions with artificial jump discontinuities. To overcome this, different works have proposed extensions of this approach to higher-order TV [10], the (TV–TV2)-infimal convolution [14, 15] and second-order TGV [15, 36]. Here we briefly sketch the main underlying ideas, presented in [36], for an extension of TGV to manifold-valued data. For simplicity, we consider only the case of univariate signals  and assume that length-minimising geodesics are unique (see [36] for the general case and details on the involved differential-geometric concepts).
and assume that length-minimising geodesics are unique (see [36] for the general case and details on the involved differential-geometric concepts).
From the continuous perspective, a natural approach to extend TGV for manifold-valued data, at least in a smooth setting, would be to use tangent spaces for first-order derivatives and, for the second-order term, invoke a connection on the manifold for the differentiation of vector fields. In contrast to that, the motivation for the definition of TGV as in [36] was to exploit a discrete setting in order to avoid high-level differential-geometric concepts but rather to come up with a definition of TGV that can be written only in terms of the distance function on the manifold. To this aim, we identify tangential vectors  , with
, with  denoting the tangent space at a point
denoting the tangent space at a point  , with point tuples [a, b] via the exponential map b = expa
(v). A discrete gradient operator then maps a signal
, with point tuples [a, b] via the exponential map b = expa
(v). A discrete gradient operator then maps a signal  to a sequence of point-tuples
to a sequence of point-tuples ![${\left(\left[{u}_{i},{u}_{i+1}\right]\right)}_{i}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn759.gif) , where we regard (∇u)i
= [ui
, ui+1], which generalises first-order differences in vector spaces, since in this case,
, where we regard (∇u)i
= [ui
, ui+1], which generalises first-order differences in vector spaces, since in this case,  . Vector fields whose base points are
. Vector fields whose base points are  can then be identified with a sequence
can then be identified with a sequence ![${\left(\left[{u}_{i},{y}_{i}\right]\right)}_{i}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn762.gif) with each
with each  and, assuming
and, assuming  to be an appropriate distance-type function for such tuples, an extension of second-order TGV can be given as
to be an appropriate distance-type function for such tuples, an extension of second-order TGV can be given as

The difficulty here is in particular how to define D for two point tuples with different base points, as those represent vectors in different tangent spaces. To overcome this, a variant for D as proposed in [36] uses the Schild's ladder [119] construction as a discrete approximation of the parallel transport of vector fields between different tangent spaces. In order to describe this construction, denote by [u,v]t
for  and t ∈ R the point reached at time t after travelling on the geodesic from u to v, i.e., [u,v]t
= expu
(t logu
(v)), where log is the inverse exponential map. Then, the parallel transport of [u, v] (which represents
and t ∈ R the point reached at time t after travelling on the geodesic from u to v, i.e., [u,v]t
= expu
(t logu
(v)), where log is the inverse exponential map. Then, the parallel transport of [u, v] (which represents  ) to the base point
) to the base point  is approximated by [x, y'] where
is approximated by [x, y'] where ![${y}^{\prime }={\left[u,{\left[x,v\right]}_{\frac{1}{2}}\right]}_{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn768.gif) (which represents
(which represents  ). Using this, a distance on point tuples, denoted by DS
, can be given as
). Using this, a distance on point tuples, denoted by DS
, can be given as

Exploiting the fact that ![${D}_{S}\left(\left[u,v\right],\left[u,w\right]\right)={d}_{\mathcal{M}}\left(v,w\right)$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn770.gif) for tuples having the same base point, a concrete realisation of discrete second order TGV for manifold-valued data is then given as
for tuples having the same base point, a concrete realisation of discrete second order TGV for manifold-valued data is then given as

The S-TGV denoising problem for  some given data with
some given data with  then reads as
then reads as

and a numerical solution (which can only be guaranteed to deliver stationary points due to non-convexity) can be obtained, for instance, using the cyclic proximal point algorithm [9, 36]. Figure 9 shows the results for this setting using both TV and second-order TGV regularisation for the denoising of  valued image data, which is composed of different blocks of smooth data with sharp interfaces. It can be seen that both TV and TGV are able to recover the sharp interfaces, but TV suffers from piecewise-constancy artefacts which are not present with TGV.
valued image data, which is composed of different blocks of smooth data with sharp interfaces. It can be seen that both TV and TGV are able to recover the sharp interfaces, but TV suffers from piecewise-constancy artefacts which are not present with TGV.

Figure 9. Example of variational denoising for manifold-valued data. The images show noisy  -valued data (left) which is denoised with TV-regulariser (middle) and TGV-regulariser (right). The sphere
-valued data (left) which is denoised with TV-regulariser (middle) and TGV-regulariser (right). The sphere  is colour-coded with hue and value representing the longitude and latitude, respectively. All parameters were optimised via grid search towards the best result with respect to a suitable distance measure for manifold-valued data, see [36] for details.
is colour-coded with hue and value representing the longitude and latitude, respectively. All parameters were optimised via grid search towards the best result with respect to a suitable distance measure for manifold-valued data, see [36] for details.
Download figure:
Standard image High-resolution imageImage-driven TGV. In case of denoising problems, i.e., f ∈ Lp (Ω), second-order TGV can be modified to incorporate directional information obtained from f, resulting in image-driven TGV (ITGV) [152]. The latter is defined by introducing a diffusion tensor field into the functional:

where  is assumed to be continuous and positive semi-definite in each point. Denoting by fσ
= f*Gσ
a smoothed version of the data f obtained by convolution with a Gaussian kernel Gσ
of variance σ > 0 and suitable extension outside of Ω, the diffusion tensor field D may be chosen according to
is assumed to be continuous and positive semi-definite in each point. Denoting by fσ
= f*Gσ
a smoothed version of the data f obtained by convolution with a Gaussian kernel Gσ
of variance σ > 0 and suitable extension outside of Ω, the diffusion tensor field D may be chosen according to

with parameters γ > 0 and β > 0. If the smallest eigenvalue of D is uniformly bounded away from 0 in  , then ITGV admits the same functional-analytic and regularisation properties as second-order TGV. We refer to [152] for an application and numerical results regarding this regularisation approach in stereo estimation.
, then ITGV admits the same functional-analytic and regularisation properties as second-order TGV. We refer to [152] for an application and numerical results regarding this regularisation approach in stereo estimation.
Non-local TGV. The concept of non-local total variation (NLTV) [94] can also be transferred to the total generalised variation. Recall that instead of taking the derivative, non-local total variation penalises the differences of the function values of u for each pair of points by virtue of a weight function:

where the weight function a : Ω × Ω → [0, ∞] is measurable and a.e. bounded from below by a positive constant. We note that, alternatively, the weight function a may also be chosen as a(x, y) = |x − y|−(θ+d) with θ ∈ ]0, 1[ such that low-order Sobolev–Slobodeckij seminorms can be realised [76]. In the context of non-local total variation, a allows to incorporate a priori information for the image to reconstruct. For instance, if one already knows disjoint segments Ω1, ..., Ωn where the solution is piecewise constant, one can set

where c1 ≫ c0 > 0. This way, the difference between two function values of u in Ωi is forced to 0, meaning u is constant in Ωi .
Non-local total generalised variation now gives the possibility to enforce piecewise linearity of u in the segments by incorporating the vector field w corresponding to the slope of the linear part in a non-local cascade. This results in

with two weight functions a0, a1 : Ω × Ω → [0, ∞], again measurable and bounded a.e. away from zero [154]. In analogy to NLTV, a priori information on, for instance, disjoint segments where the sought solution is piecewise linear, allows to choose weight functions such that the associated NLTGV2 regulariser properly reflects this information. See figure 10 for a denoising example where non-local TGV turns out to be beneficial, in particular in the regions near the jump discontinuities of sought solution.

Figure 10. Example for non-local total generalised variation denoising. (a) An noisy piecewise linear image. (b) Results of  -denoising together with a surface plot of its graph. (c) Results of non-local TGV-denoising together with a surface plot of its graph. Images taken from [154]. Reprinted by permission from Springer Nature.
-denoising together with a surface plot of its graph. (c) Results of non-local TGV-denoising together with a surface plot of its graph. Images taken from [154]. Reprinted by permission from Springer Nature.
Download figure:
Standard image High-resolution image6. Numerical algorithms
Tikhonov regularisation with higher-order total variation, its combination via addition or infimal convolution, as well as total generalised variation poses a non-smooth optimisation problem in an appropriate Lebesgue function space. In practice, these minimisation problems are discretised and solved by optimisation algorithms that exploit the structure of the discrete problem. While there are many possibilities for a discretisation of the considered regularisation functionals as well as for numerical optimisation, most of the algorithms that can be found in the literature base on finite-difference discretisation and first-order proximal optimisation methods. In the following, we provide an overview of the building blocks necessary to solve the considered Tikhonov functional minimisation problems numerically. We will exemplarily discuss the derivation of respective algorithms on the basis of the popular primal-dual algorithm with extragradient [60] and, as alternative, briefly address implicit and preconditioned optimisation methods.
6.1. Discretisation of higher-order TV functionals
We discretise the discussed functionals in 2D, higher dimensions follow by analogy. Moreover, for the sake of simplicity, we assume a rectangular domain, i.e., ![${\Omega}=\left.\right]0,{N}_{1}\left[\right.{\times}\left.\right]0,{N}_{2}\left[\right.\subset {\mathbf{R}}^{2}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn779.gif) for some positive N1, N2 ∈ N. A generalisation to non-rectangular domains will be straightforward.
for some positive N1, N2 ∈ N. A generalisation to non-rectangular domains will be straightforward.
Following essentially the presentation in [37] we first replace Ω by the discretised grid

One consistent way of discretising higher-order derivatives is to define partial derivatives as follows: a discrete partial derivative takes the difference between two neighbouring elements in the grid with respect to a specified axis. This difference is associated with the midpoint between the two grid elements, resulting in staggered grids. For a finite sequence of directions p ∈ ⋃k⩾0{1,2}k , this results, on the one hand, in the recursively defined grids

Note that  does not depend on the order of the pi
and one could use multiindices in N2 instead. Likewise, the discrete partial derivatives recursively given by
does not depend on the order of the pi
and one could use multiindices in N2 instead. Likewise, the discrete partial derivatives recursively given by

yield well-defined functions  for u : Ωh
→ R which do not depend on the order of the entries in p. The discrete gradient
for u : Ωh
→ R which do not depend on the order of the entries in p. The discrete gradient  of order k ⩾ 1 for u : Ωh
→ R is then the tuple that collects all the partial derivatives of order k:
of order k ⩾ 1 for u : Ωh
→ R is then the tuple that collects all the partial derivatives of order k:

Note that due to this construction, the partial derivatives  are generally defined on different grids. However, in order to define the Frobenius norm of
are generally defined on different grids. However, in order to define the Frobenius norm of  , and, consequently, an ℓ1-type norm, a common grid is needed. There are several possibilities for this task (such as interpolation) which has been studied mainly for the first-order total variation. Here, we discuss a strategy that results in a simple definition of a discrete higher-order total variation. It bases on collecting, for (i, j) ∈ Z2, all the nearby points in the different
, and, consequently, an ℓ1-type norm, a common grid is needed. There are several possibilities for this task (such as interpolation) which has been studied mainly for the first-order total variation. Here, we discuss a strategy that results in a simple definition of a discrete higher-order total variation. It bases on collecting, for (i, j) ∈ Z2, all the nearby points in the different  . This can, for instance, be done by moving half-steps forward and backward in the directions indicated by p ∈ {1,2}k
:
. This can, for instance, be done by moving half-steps forward and backward in the directions indicated by p ∈ {1,2}k
:

where e1, e2 are the unit vectors in R2. The Frobenius norm in a point (i, j) ∈ Z2 is then given by

where  is extended by zero outside of
is extended by zero outside of  . Note that here, although
. Note that here, although  does not depend on the order of discrete differentiation, the point (ip
, jp
) does. Thus, a different Frobenius norm for the kth discrete derivative would be constituted by symmetrisation, which means symmetrising
does not depend on the order of discrete differentiation, the point (ip
, jp
) does. Thus, a different Frobenius norm for the kth discrete derivative would be constituted by symmetrisation, which means symmetrising  and taking the Frobenius norm afterwards. In this context, is makes sense to average over the grid points as follows. Denoting by α(p) ∈ N2 the multiindex associated with p ∈ {1,2}k
, i.e., α(p)i
= #{m|pm
= i}, we define
and taking the Frobenius norm afterwards. In this context, is makes sense to average over the grid points as follows. Denoting by α(p) ∈ N2 the multiindex associated with p ∈ {1,2}k
, i.e., α(p)i
= #{m|pm
= i}, we define

for (i, j) ∈ Z2 and α ∈ N2, where  . Then, the grid associated with an α ∈ N2 reads as
. Then, the grid associated with an α ∈ N2 reads as

while the α-component of the symmetrised gradient is given by

where (i, j) ∈ Z2 is chosen such that  and
and  is zero for points outside of
is zero for points outside of  . This results in the symmetrised derivative as follows:
. This results in the symmetrised derivative as follows:

The Frobenius norm of  in a point (i, j) ∈ Z2 can finally be obtained by
in a point (i, j) ∈ Z2 can finally be obtained by

Remark 6.1. For α ∈ N2 with  even, we have (iα
, jα
) = (i, j) for each (i, j) ∈ Z. Indeed, for
even, we have (iα
, jα
) = (i, j) for each (i, j) ∈ Z. Indeed, for  and the reversed tuple
and the reversed tuple  it holds
it holds  . Further, either
. Further, either  leading to (ip
, jp
) = (i, j) or
leading to (ip
, jp
) = (i, j) or  leading to
leading to  . Consequently, (iα
, jα
) = (i, j) according to the definition. In other words, the symmetrisation of the discrete gradient is a natural way of aligning the different grids
. Consequently, (iα
, jα
) = (i, j) according to the definition. In other words, the symmetrisation of the discrete gradient is a natural way of aligning the different grids  to a common grid in this case.
to a common grid in this case.
For  odd, the grid points still do not align. However, we can say that for (i, j), the point (iα
, jα
) lies on the line connecting
odd, the grid points still do not align. However, we can say that for (i, j), the point (iα
, jα
) lies on the line connecting  and
and  . Indeed, for
. Indeed, for  with α(p) = α we can consider
with α(p) = α we can consider  . If
. If  , then (ip
, jp
) is either
, then (ip
, jp
) is either  or
or  . In the case
. In the case  , the point
, the point  is either
is either  or
or  . As (iα
, jα
) is a convex combination of such points, it lies on the line connecting
. As (iα
, jα
) is a convex combination of such points, it lies on the line connecting  and
and  . Hence, the symmetrisation of the gradient leads to more localised grid points.
. Hence, the symmetrisation of the gradient leads to more localised grid points.
We now have everything at hand to define two versions of a discrete total variation of arbitrary order.
Definition 6.2. Let k ∈ N, k ⩾ 1 a differentiation order. Then, for u : Ωh → R, the discrete total variation is defined as

with  according to (57), and discrete total variation for the symmetrised gradient is defined as
according to (57), and discrete total variation for the symmetrised gradient is defined as

with  according to (59).
according to (59).
In order to define a discrete version of the total generalised variation, we still need to discuss the discretisation of the total deformation for discrete symmetric tensor fields. For this purpose, we say that the components of a discrete symmetric tensor field of order l ∈ N, live on the grids  , resulting in
, resulting in

realising a discrete symmetric tensor field of order l. Its Frobenius norm is given in the points (i, j) ∈ Z2 according to

which is compatible with (59) if one plugs in  for some u : Ωh
→ R. The partial derivative of order k described by p ∈ {1,2}k
applied to uα
is then also given by (55), but acts on the grid
for some u : Ωh
→ R. The partial derivative of order k described by p ∈ {1,2}k
applied to uα
is then also given by (55), but acts on the grid  and results in a discrete function on the grid
and results in a discrete function on the grid  which is given in analogy to (54) by replacing Ωh
with
which is given in analogy to (54) by replacing Ωh
with  . The symmetrised derivative
. The symmetrised derivative  , whose components are indexed by β ∈ N2,
, whose components are indexed by β ∈ N2,  , is then defined in a point
, is then defined in a point  where (i, j) ∈ Z2 by
where (i, j) ∈ Z2 by

where

This is sufficient to define a discrete total deformation.
Definition 6.3. Let k, l ∈ N, k ⩾ 1 and l ⩾ 0. Then, for  , the discrete total deformation of order k is defined as
, the discrete total deformation of order k is defined as

with  according to (61) and
according to (61) and  according to (60).
according to (60).
For the sake of completeness, the respective definitions for non-symmetric tensor fields of order l read as

and the pth component, p ∈ {1,2}k+l , of the discrete gradient of order k is given as

For numerical algorithms, it is necessary to write the discrete total variation and total deformation as the one-norm of a (symmetric) tensor with respect to the respective discrete differentiation operator. We therefore introduce the underlying spaces.
Definition 6.4. Let l ∈ N, and q ∈ [1, ∞]. The ℓq -space of discrete l-tensors on Ωh is given by

with  according to (54), and norm
according to (54), and norm

with pointwise norm according to (62). The space  is equipped with the scalar product
is equipped with the scalar product

Analogously, the ℓq -space of discrete symmetric l-tensors on Ωh is defined as

with an analogous norm using (60) as pointwise norm. The scalar product on ℓ2(Ωh , Syml (R2)) is given by

For k ∈ N, equation (61) then defines a linear operator mapping

and (63) induces a linear operator mapping

The norm of these operators can easily be estimated:
Lemma 6.5. We have  and
and  independent of l.
independent of l.
Proof. As  on the respective discrete tensor fields, it is sufficient to prove the statement for k = 1 and l arbitrary. For this purpose, observe that for
on the respective discrete tensor fields, it is sufficient to prove the statement for k = 1 and l arbitrary. For this purpose, observe that for  , p ∈ {1,2}l
, we have
, p ∈ {1,2}l
, we have

and an analogous estimate for  . Consequently,
. Consequently,  for such u. If
for such u. If  , then
, then

so the claim follows.
For the symmetrised gradient, it is possible to pursue the same strategy since  on the respective discrete symmetric tensor fields. Indeed, with the Cauchy–Schwarz inequality and Vandermonde's identity (which reduces to the standard recurrence relation for binomial coefficients in most cases), one obtains
on the respective discrete symmetric tensor fields. Indeed, with the Cauchy–Schwarz inequality and Vandermonde's identity (which reduces to the standard recurrence relation for binomial coefficients in most cases), one obtains

It is then easy to see that  . □
. □
Remark 6.6. For p ∈ {1,2}l
and p0 ∈ {1, 2}, consider the discrete partial derivative  and its negative adjoint
and its negative adjoint  , i.e.,
, i.e.,  for
for  ,
,  . For
. For  , this results in
, this results in

for  , where u is extended by 0 outside of
, where u is extended by 0 outside of  . (In contrast,
. (In contrast,  is only defined for
is only defined for  .)
.)
Consequently, the negative adjoint of the discrete gradient induces a divergence for discrete tensor fields  such that
such that  and
and

for p ∈ {1,2}l . For the discrete divergence that arises as the negative adjoint of the symmetrised gradient on ℓ2(Ωh , Syml (Rd )), one has to take the symmetrisation into account: for u ∈ ℓ2(Ωh , Syml+1(R2)), we have

Here, the operators  act on functions on the grid
act on functions on the grid  and yield functions on the grid
and yield functions on the grid  . Note that in the grid point (iα
, jα
), these partial derivatives have to be evaluated in the grid points
. Note that in the grid point (iα
, jα
), these partial derivatives have to be evaluated in the grid points  and
and  , respectively. This way, the discrete divergence operator is consistently defined.
, respectively. This way, the discrete divergence operator is consistently defined.
Remark 6.7. While the above approach provides a way of discretising higher-order regularisation approaches with finite differences up to an arbitrary order of differentiation, fundamental questions of numerical analysis such as consistency and stability of such discretisations, and consequently, of the existence of error bounds that converge to zero as the discretisations level becomes finer, were not addressed. In view of the non-smooth minimisation problems associated with regularisation approaches in imaging, a first approach to answer such questions is typically to consider convergence of minimisers of the discrete energies to minimisers of the continuous counterpart, e.g., by ensuring gamma-convergence. While for first-order TV regularisation convergence of minimisers is known [57], an extension of such results to higher-order approaches still seems to be open. With respect to error bounds, the situation is similar and we refer to [191] for results on finite-difference discretisations of first-order TV in certain Lipschitz spaces.
6.2. A general saddle-point framework
Having appropriately discretised versions of higher-order regularisation functionals available, we now deal with the numerical solution of corresponding Tikhonov approaches for inverse problems. To this aim, we first consider a general framework and then derive concrete realisations for different regularisation approaches.
Let Ωh
be the discretised grid of subsection 6.1 and define Uh
= ℓ2(Ωh
). We assume a discrete linear forward operator Kh
: Uh
→ Yh
, with  a finite-dimensional Hilbert space, and a proper, convex, lower semi-continuous and coercive discrepancy term
a finite-dimensional Hilbert space, and a proper, convex, lower semi-continuous and coercive discrepancy term ![${S}_{{f}_{h}}:{Y}_{h}\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn859.gif) with corresponding discrete data fh
to be given. Further, we define
with corresponding discrete data fh
to be given. Further, we define ![${\mathcal{R}}_{\alpha }:{U}_{h}\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn860.gif) to be a regularisation functional given in a general form as
to be a regularisation functional given in a general form as  , with Dh
: Uh
× Wh
→ Vh
,
, with Dh
: Uh
× Wh
→ Vh
,  a discrete differential operator and Wh
, Vh
finite-dimensional Hilbert spaces. The expression ||⋅||1,α
here denotes an appropriate ℓ1-type norm weighted using the parameters α and will be specified later for concrete examples. Its dual norm is denoted by
a discrete differential operator and Wh
, Vh
finite-dimensional Hilbert spaces. The expression ||⋅||1,α
here denotes an appropriate ℓ1-type norm weighted using the parameters α and will be specified later for concrete examples. Its dual norm is denoted by  . We consider the general minimisation problem
. We consider the general minimisation problem

for which we will numerically solve the equivalent reformulation

Remark 6.8. Note that here, the auxiliary variable w and the space Wh
are used to include balancing-type regularisation approaches such as the infimal convolution of two functionals. Setting, for example, Wh
= Uh
,  ,
,  and ||(v1, v2)||1,α
= α1||v1||1 + α2||v2||1 for positive α = (α1, α2) yields
and ||(v1, v2)||1,α
= α1||v1||1 + α2||v2||1 for positive α = (α1, α2) yields

Total-variation regularisation can, on the other hand, be obtained by choosing Wh
= {0},  , Dh
(u, 0) = ∇h
u and ||v||1,α
= α||v||1 for α > 0.
, Dh
(u, 0) = ∇h
u and ||v||1,α
= α||v||1 for α > 0.
Remark 6.9. The dual norm  will become relevant in the context of primal-dual algorithms via its Fenchel dual. Indeed, we have the identity
will become relevant in the context of primal-dual algorithms via its Fenchel dual. Indeed, we have the identity  for ||⋅||X
the norm of a general Banach space X and
for ||⋅||X
the norm of a general Banach space X and  its dual norm on X*. This is a consequence of
its dual norm on X*. This is a consequence of  for all u ∈ X and w ∈ X*, so
for all u ∈ X and w ∈ X*, so  for
for  . For
. For  one can find a u ∈ X, ||u||X
⩽ 1 such that, for a c > 0, ⟨w, u⟩ ⩾ 1 + c ⩾ ||u||X
+ c. For each t > 0, we get ⟨w, tu⟩ − ||tu||X
⩾ tc, hence
one can find a u ∈ X, ||u||X
⩽ 1 such that, for a c > 0, ⟨w, u⟩ ⩾ 1 + c ⩾ ||u||X
+ c. For each t > 0, we get ⟨w, tu⟩ − ||tu||X
⩾ tc, hence  .
.
Remark 6.10. While the setting of (64) allows to include rather general forward operators Kh
and discrepancy terms  , it will still not capture all applications of higher-order regularisation that we consider later in subsections 7 and 8. It rather comprises a balance between general applicability and uniform presentation, and we will comment on possible extensions later on such that the interested reader should be able to adapt the setting presented here to the concrete problem setting at hand.
, it will still not capture all applications of higher-order regularisation that we consider later in subsections 7 and 8. It rather comprises a balance between general applicability and uniform presentation, and we will comment on possible extensions later on such that the interested reader should be able to adapt the setting presented here to the concrete problem setting at hand.
From a more general perspective, the reformulation (65) of (64) constitutes a non-smooth, convex optimisation problem of the form

with  Hilbert spaces,
Hilbert spaces, ![$\mathcal{F}:\mathcal{Y}\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn877.gif) ,
, ![$\mathcal{G}:\mathcal{X}\to \left[0,\infty \right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn878.gif) proper, convex and lower semi-continuous functionals and
proper, convex and lower semi-continuous functionals and  linear and continuous. For this class of problems, duality-based first-order optimisation algorithms of ascent/descent-type have become very popular in the past years as they are rather generally applicable and yield algorithms for the solution of (66) that provably converge to a global optimum, while allowing a simple implementation and practical stepsize choices, such as constant stepsizes. The algorithm of [56], for instance, constitutes a relatively early step in this direction, as it solves the TV-denoising problem with constant stepsizes in terms of a dual problem.
linear and continuous. For this class of problems, duality-based first-order optimisation algorithms of ascent/descent-type have become very popular in the past years as they are rather generally applicable and yield algorithms for the solution of (66) that provably converge to a global optimum, while allowing a simple implementation and practical stepsize choices, such as constant stepsizes. The algorithm of [56], for instance, constitutes a relatively early step in this direction, as it solves the TV-denoising problem with constant stepsizes in terms of a dual problem.
For problems of the type (66), it is often beneficial to consider a primal-dual saddle-point reformulation instead of the dual problem alone, in particular in view of general applicability. This is given as

with  denoting the inner product in
denoting the inner product in  . By interchanging minimum and maximum and minimising with respect to x, one further arrives at the dual problem which reads as
. By interchanging minimum and maximum and minimising with respect to x, one further arrives at the dual problem which reads as

Under certain conditions, the minimum in (66) and maximum in (68) admit the same value and primal/dual solution pairs for (66) an (68) correspond to solutions of the saddle-point problem (67), see below.
Now, indeed, many different algorithmic approaches for solving (67) are nowadays available (see for instance [41, 42, 60, 61, 124]) and which one of them delivers the best performance typically depends on the concrete problem instance. Here, as exemplary algorithmic framework, we consider the popular primal-dual algorithm of [60] (see also [144, 203]), which has the advantage of being simple and yet rather generally applicable.
Conceptually, the algorithm of [60] solves the saddle-point problem (67) via implicit gradient descent and ascent steps with respect to the primal and dual variables, respectively. With  , carrying out these implicit steps simultaneously in both variables would correspond to computing the iterates {(xn
, yn
)} via
, carrying out these implicit steps simultaneously in both variables would correspond to computing the iterates {(xn
, yn
)} via

where ∂x
and ∂y
denotes the subgradient with respect to the first and second variable, respectively, and σ, τ are positive constants. To obtain computationally feasible iterations, the implicit step for yn+1 in the primal-dual algorithm uses an extrapolation  of the previous iterate instead of xn+1, such that the descent and ascent steps decouple and can be re-written as
of the previous iterate instead of xn+1, such that the descent and ascent steps decouple and can be re-written as

The mappings  and
and  used here are so-called proximal mappings of
used here are so-called proximal mappings of  and
and  , respectively, which, as noted in proposition 6.11 below, are well-defined and single valued whenever
, respectively, which, as noted in proposition 6.11 below, are well-defined and single valued whenever  are proper, convex and lower semi-continuous. The resulting algorithm can then be interpreted as proximal-point algorithm (see [102, 161]) and weak convergence in the sense that (xn
, yn
) ⇀ (x*, y*) for (x*, y*) being a solution to the saddle-point problem (67) can be ensured for positive stepsize choices σ, τ such that
are proper, convex and lower semi-continuous. The resulting algorithm can then be interpreted as proximal-point algorithm (see [102, 161]) and weak convergence in the sense that (xn
, yn
) ⇀ (x*, y*) for (x*, y*) being a solution to the saddle-point problem (67) can be ensured for positive stepsize choices σ, τ such that  , see for instance [61, 143], or [60] for the finite-dimensional case. In contrast, explicit methods for non-smooth optimisation problems such as subgradient descent, for instance, usually require stepsizes that converge to zero [138] and could stagnate numerically.
, see for instance [61, 143], or [60] for the finite-dimensional case. In contrast, explicit methods for non-smooth optimisation problems such as subgradient descent, for instance, usually require stepsizes that converge to zero [138] and could stagnate numerically.
Overall, the efficiency of the iteration steps in (70) crucially depends on the ability to evaluate  and
and  and to compute the proximal mappings efficiently. Regarding the latter, this is possible for a large class of functionals, in particular for many functionals that are defined pointwise, which is one of the reasons for the high popularity of these kind of algorithms. We now consider proximal mappings in more detail and provide concrete examples later on.
and to compute the proximal mappings efficiently. Regarding the latter, this is possible for a large class of functionals, in particular for many functionals that are defined pointwise, which is one of the reasons for the high popularity of these kind of algorithms. We now consider proximal mappings in more detail and provide concrete examples later on.
Proposition 6.11. Let H be a Hilbert space, ![$F:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn892.gif) proper, convex and lower semi-continuous, and σ > 0.
proper, convex and lower semi-continuous, and σ > 0.
- (a)Then, the mappingis well-defined.
- (b)For u ∈ H, u* = proxσF (u) solves the inclusion relationi.e., proxσF = (id + σ∂F)−1.
- (c)The mapping proxσF is Lipschitz-continuous with constant not exceeding 1.


Proof. See, for instance, [178, proposition IV.1.5, corollary IV.1.3], or [13, proposition 12.15, example 23.3, corollary 23.10]. □
In general, the computation of proximal mappings can be as difficult as solving the original optimisation problem itself. However, if, for instance, the corresponding functional can be 'well separated' into simple building blocks, then proximal mappings can be reduced to some basic ones which are simple and easy to compute.
Lemma 6.12. Let H = H1 ⊥⋯⊥ Hn with closed subspaces H1, ..., Hn , the mappings P1, ..., Pn their orthogonal projectors,

with each ![${F}_{i}:{H}_{i}\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn893.gif) proper, convex and lower semi-continuous. Then,
proper, convex and lower semi-continuous. Then,

Proof. This is immediate since the corresponding minimisation problem decouples. □
Furthermore, Moreau's identity (see [160], for instance) provides a relation between the proximal mapping of a function F and the proximal mapping of its dual F* according to

This immediately implies that for general σ > 0, the computation of (id + σ∂F)−1 is essentially as difficult as the computation of  , in particular the latter can be obtained from the former as follows.
, in particular the latter can be obtained from the former as follows.
Lemma 6.13. Let H be a Hilbert space and ![$F:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn895.gif) be proper, convex and lower semi-continuous. Then, for σ > 0,
be proper, convex and lower semi-continuous. Then, for σ > 0,

In some situations, the computation of the proximal mappings of the sum of two functions decouples into the composition of two mappings.
Lemma 6.14. Let H be a Hilbert space, ![$F:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn896.gif) be proper, convex and lower semi-continuous and σ > 0.
be proper, convex and lower semi-continuous and σ > 0.
- (a)If with proper, convex and lower semi-continuous, u0 ∈ H and α > 0, then
- (b)If H = equipped with the Euclidean norm and with dom(Fm
) ∩ [am
, bm
] ≠ for each m = 1, ..., M, thenfor m = 1, ..., M, whereis the projection to [am , bm ] in.

![$G:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn898.gif)


![$F\left(u\right)={\sum }_{m=1}^{M}{\mathcal{I}}_{\left[{a}_{m},{b}_{m}\right]}\left({u}_{m}\right)+{F}_{m}\left({u}_{m}\right)$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn899.gif)




Proof. Regarding (a), we note that by first-order optimality conditions (additivity of the subdifferential follows from [83, proposition I.5.6]), we have the following equivalences:

which proves the explicit form of proxσF
. The intermediate equality follows from  , which can again be seen from the optimality conditions.
, which can again be seen from the optimality conditions.
In order to show (b), first note that, using lemma 6.12, it suffices to show the assertion for ![$F\left(u\right)={\mathcal{I}}_{\left[a,b\right]}\left(u\right)+f\left(u\right)$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn901.gif) with u ∈ R, a ⩽ b and
with u ∈ R, a ⩽ b and ![$f:\mathbf{R}\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn902.gif) proper, convex and lower semi-continuous such that dom(f) ∩ [a, b] ≠ Ø. Also, the identity
proper, convex and lower semi-continuous such that dom(f) ∩ [a, b] ≠ Ø. Also, the identity ![${\mathrm{p}\mathrm{r}\mathrm{o}\mathrm{x}}_{\sigma {\mathcal{I}}_{\left[a,b\right]}}={\mathrm{p}\mathrm{r}\mathrm{o}\mathrm{j}}_{\left[a,b\right]}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn903.gif) as well as the explicit form of the projection is immediate. Now, denote by u* = proj[a,b]◦proxσf
(u) and write it as u* = νuF
+ (1 − ν)uf
with uF
= proxσF
(u) and uf
= proxσf
(u) and ν ∈ [0, 1]. To see that this is possible, note that in case of uf
∈ [a, b], u* = uf
, in case uf
< a we have that uf
< a = u* ⩽ uF
and similarly in case of uf
> b. But, with
as well as the explicit form of the projection is immediate. Now, denote by u* = proj[a,b]◦proxσf
(u) and write it as u* = νuF
+ (1 − ν)uf
with uF
= proxσF
(u) and uf
= proxσf
(u) and ν ∈ [0, 1]. To see that this is possible, note that in case of uf
∈ [a, b], u* = uf
, in case uf
< a we have that uf
< a = u* ⩽ uF
and similarly in case of uf
> b. But, with  , convexity and minimality of uf
implies that
, convexity and minimality of uf
implies that

Since both u* and uF are in [a, b], the result follows from uniqueness of minimisers. □
In the following we provide some examples of explicit proximal mappings for some particular choices of F that are relevant for applications. For additional examples and further, general results on proximal mappings, we refer to [13, 66].
Lemma 6.15. Let H be a Hilbert space, σ > 0 and ![$F:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn905.gif) . Then, the following identities hold.
. Then, the following identities hold.
- (a)For with f ∈ H, α > 0,
- (b)For for some non-empty, convex and closed set C ⊂ H,with projC denoting the orthogonal projection onto C.
- (c)For F(u) = G(u − u0) with and u0 ∈ H,
- (d)For product of the Hilbert spaces , with each denoting the norm on , , and where ,
- (e)In the situation of (d) and,andwith as in (d).




![$G:H\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn908.gif)






![$\alpha \in {\left.\right]0,\infty \left[\right.}^{ M}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn914.gif)







Proof. The assertion on proxσF
in (a) follows from first-order optimality conditions as in lemma 6.14, the assertion on  is a consequence of lemma 6.13. Assertion (b) is immediate from the definition of the orthogonal projection in Hilbert spaces and (c) follows from a simple change of variables for the minimisation problem in the definition of the proximal mapping. Regarding (d), using lemma 6.12 and noting that
is a consequence of lemma 6.13. Assertion (b) is immediate from the definition of the orthogonal projection in Hilbert spaces and (c) follows from a simple change of variables for the minimisation problem in the definition of the proximal mapping. Regarding (d), using lemma 6.12 and noting that  if and only if
if and only if  for m = 1, ..., M, it suffices to show that for each
for m = 1, ..., M, it suffices to show that for each  and m = 1, ..., M,
and m = 1, ..., M,

To this aim, observe that by definition of the projection in Hilbert spaces,

From this, it is easy to see that the minimum in the last line is achieved for t = 1 in case  and
and  otherwise, from which the explicit form of the projection follows. Considering assertion (e), we have by remark 6.9 that
otherwise, from which the explicit form of the projection follows. Considering assertion (e), we have by remark 6.9 that

so the statements follow by lemma 6.13 and assertion (d). □
Now considering the minimisation problem (65), our approach is to rewrite it as a saddle-point problem such that, when applying the iteration (70), the involved proximal mappings decouple into simple and explicit mappings. To achieve this while allowing for general forward operators Kh , we dualise both the regularisation and the data-fidelity term and arrive at the following a saddle-point reformulation of (65):

recalling that the dual norm of ||⋅||1,α
is denoted by  and that
and that  , see remark 6.9. The following lemma provides some instances of ||⋅||1,α
that arise in the context of higher-order TV regularisers and its generalisations. In particular, for these instances, the corresponding dual norm
, see remark 6.9. The following lemma provides some instances of ||⋅||1,α
that arise in the context of higher-order TV regularisers and its generalisations. In particular, for these instances, the corresponding dual norm  and the proximal mappings
and the proximal mappings  will be provided. Concrete examples will be discussed in example 6.19 below.
will be provided. Concrete examples will be discussed in example 6.19 below.
Lemma 6.16. With M ∈ N, ![$\alpha \in {\left.\right]0,\infty \left[\right.}^{ M}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn929.gif) , l1, ..., lM
∈ N, and
, l1, ..., lM
∈ N, and  for m = 1, ..., M, let
for m = 1, ..., M, let

for v = (v1, ..., vM
) ∈ Vh
, where Vh
is equipped with the induced inner product  and norm, and the one-norm on each
and norm, and the one-norm on each  is given in definition 6.4. Then, the dual norm
is given in definition 6.4. Then, the dual norm  satisfies
satisfies

with the ∞-norm again according to definition 6.4. Further, we have, for m = 1, ..., M, that

where the right-hand side has to be interpreted in the pointwise sense, i.e., for  and (i, j) ∈ Ωh
, it holds that
and (i, j) ∈ Ωh
, it holds that  .
.
Proof. By definition, we have for u, v ∈ Vh with ||u||1,α ⩽ 1 that

hence,  . With (m, i, j) a maximising argument of the right-hand side above, equality follows, in case of v ≠ 0, from choosing u according to
. With (m, i, j) a maximising argument of the right-hand side above, equality follows, in case of v ≠ 0, from choosing u according to  and 0 everywhere else. The case v = 0 is trivial. Also, since Ωh
= {1, ..., N1} × {1, ..., N2} is finite, one can interpret each
and 0 everywhere else. The case v = 0 is trivial. Also, since Ωh
= {1, ..., N1} × {1, ..., N2} is finite, one can interpret each  as
as  , such that lemma 6.15(e) applied to
, such that lemma 6.15(e) applied to  immediately yields the stated pointwise identity for the proximal mapping/projection. □
immediately yields the stated pointwise identity for the proximal mapping/projection. □
Under mild assumptions on  , equivalence of the primal problem (65) and the saddle-point problem (73) indeed holds and existence of a solution to both (as well as a corresponding dual problem) can be ensured.
, equivalence of the primal problem (65) and the saddle-point problem (73) indeed holds and existence of a solution to both (as well as a corresponding dual problem) can be ensured.
Proposition 6.17. Under the assumptions stated for problem (65), there exists a solution. Further, if  is such that
is such that  , then there exists a solution to the dual problem
, then there exists a solution to the dual problem

and to the saddle-point problem (73). Further, strong duality holds and the problems are equivalent in the sense that ((u, w), (v, λ)) is a solution to (73) if and only if (u, w) solves (65) and (v, λ) solves (74).
Proof. At first note that existence for (65) can be shown as in theorem 3.26.
By virtue of theorem 5.7, choosing X = Uh
× Wh
, Y = Vh
× Yh
, ![$F:X\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn944.gif) as F = 0,
as F = 0, ![$G:Y\to \left.\right]- \infty ,\infty \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn945.gif) as
as  , and Λ : X → Y as
, and Λ : X → Y as  , we only need to verify (39) to obtain existence of dual solutions and strong duality. But since dom(F) = X and
, we only need to verify (39) to obtain existence of dual solutions and strong duality. But since dom(F) = X and  , the latter condition is equivalent to
, the latter condition is equivalent to  . Also, since
. Also, since  and
and  , see remark 6.9, the maximisation problem in (40) corresponds to (74). Finally, the equivalence of the saddle-point problem (73) to (65) and (74) then follows from [83, proposition III.3.1]. □
, see remark 6.9, the maximisation problem in (40) corresponds to (74). Finally, the equivalence of the saddle-point problem (73) to (65) and (74) then follows from [83, proposition III.3.1]. □
Remark 6.18. In some applications, it is beneficial to add an additional penalty term on u in form of Φ : Uh
→ [0, ∞] proper, convex and lower semi-continuous to the energy of (65), whereas in other situations when  has a suitable structure, a dualisation of the data term is not necessary, see the discussion below. Regarding the former, the differences when extending proposition 6.17 is that existence for the primal problem needs to be shown differently and that the domain of Φ needs to be taken into account for obtaining strong duality. Existence can, for instance, be proved when assuming that either Φ is the indicator function of a polyhedral set (see [35, proposition 1]), or that ker(Kh
) ∩ ker(Dh
) = {0}. Duality is further obtained when
has a suitable structure, a dualisation of the data term is not necessary, see the discussion below. Regarding the former, the differences when extending proposition 6.17 is that existence for the primal problem needs to be shown differently and that the domain of Φ needs to be taken into account for obtaining strong duality. Existence can, for instance, be proved when assuming that either Φ is the indicator function of a polyhedral set (see [35, proposition 1]), or that ker(Kh
) ∩ ker(Dh
) = {0}. Duality is further obtained when  . Regarding the latter, a version of proposition 6.17 without the dualisation of the data term
. Regarding the latter, a version of proposition 6.17 without the dualisation of the data term  holds even without the assumption on the domain of
holds even without the assumption on the domain of  , however, with a different associated dual problem and saddle-point problem.
, however, with a different associated dual problem and saddle-point problem.
In particular, not dualising the data term has impact on the primal-dual optimisation algorithms. In view of the iteration (70), the evaluation of the proximal mapping for  then becomes necessary, so this dualisation strategy is only practical if the latter proximal mapping can easily be computed. Furthermore, in case of a sufficiently smooth data term, dualisation of
then becomes necessary, so this dualisation strategy is only practical if the latter proximal mapping can easily be computed. Furthermore, in case of a sufficiently smooth data term, dualisation of  can also be avoided by using explicit descent steps for
can also be avoided by using explicit descent steps for  instead of proximal mappings, where the Lipschitz constant of the derivative of
instead of proximal mappings, where the Lipschitz constant of the derivative of  usually enters in the stepsize bound. See [61] for an extension of the primal-dual algorithm in that direction.
usually enters in the stepsize bound. See [61] for an extension of the primal-dual algorithm in that direction.
In view of proposition 6.17, we now address the numerical solution of the saddle-point problem (73). Applying the iteration (70), this results in algorithm 1, which is given in a general form. A concrete implementation still requires an explicit form of the proximal mapping  , a concrete choice of Vh
, Wh
and Dh
as well as an estimate on ||(Dh
, Kh
)|| for the stepsize choice and a suitable stopping criterion. These building blocks will now be provided for different choices of
, a concrete choice of Vh
, Wh
and Dh
as well as an estimate on ||(Dh
, Kh
)|| for the stepsize choice and a suitable stopping criterion. These building blocks will now be provided for different choices of  and
and  in a way that they can be combined to an arrive at a concrete, application-specific algorithm. After that, two examples will be discussed.
in a way that they can be combined to an arrive at a concrete, application-specific algorithm. After that, two examples will be discussed.
Algorithm 1. Primal-dual scheme for the numerical solution of (73).
| 1: function Tikhonov(Kh , fh , α) |
2: 
|
3: Choose σ, τ > 0 such that 
|
| 4: repeat |
| 5: Dual updates |
6: 
|
7: 
|
| 8: Primal updates |
9: 
|
10: 
|
| 11: Extrapolation and update |
12: 
|
| 13: (u, w) ← (u+, w+) |
| 14: until stopping criterion fulfiled |
| 15: return u |
| 16: end function |
Proximal mapping of
 . Depending on the application of interest, and in particular on the assumption on the underlying measurement noise, different choices of
. Depending on the application of interest, and in particular on the assumption on the underlying measurement noise, different choices of  are reasonable. The one which is probably most relevant in practice is
are reasonable. The one which is probably most relevant in practice is

which, from a statistical perspective, is the right choice under the assumption of Gaussian noise. In this case, as discussed in lemma 6.15, the proximal mapping of the dual is given as

A second, practically relevant choice is the Kullback–Leibler divergence as in (2). For discrete data  satisfying
satisfying  for each i, and a corresponding discrete signal
for each i, and a corresponding discrete signal  , this corresponds to
, this corresponds to

where we again use the convention  for
for  and
and  whenever λi
⩾ 0. A direct computation (see for instance [122]) shows that in this case
whenever λi
⩾ 0. A direct computation (see for instance [122]) shows that in this case

Another choice that is relevant in the presence of strong data outliers (e.g., due to transmission errors) is

in which case

can be obtained from lemmas 6.13 and 6.15.
As already mentioned in remark 6.18, in case the discrepancies term is not dualised, a corresponding version of the algorithm of [60] requires the proximal mappings of  which can either be computed directly or obtained from
which can either be computed directly or obtained from  using Moreau's identity as in lemma 6.13. Further, there are many other choices of
using Moreau's identity as in lemma 6.13. Further, there are many other choices of  for which the
for which the  is simple and explicit, such as, for instance, equality constraints on a subdomain in the case of image inpainting or box constraints in case of dequantisation or image decompression.
is simple and explicit, such as, for instance, equality constraints on a subdomain in the case of image inpainting or box constraints in case of dequantisation or image decompression.
Choice of
 and proximal mapping. As we show now, the general form
and proximal mapping. As we show now, the general form  covers all higher-order regularisation approaches discussed in the previous sections.
covers all higher-order regularisation approaches discussed in the previous sections.
- Higher-order total variation. The choice, with k ⩾ 1 the order of differentiation, can be realised withwhich yields, according to lemma 6.16, for (i, j) ∈ Ωh thatHere, we used that whenever Wh = {0}, one can ignore the second argument of Dh : Uh × Wh → Vh and regard it as operator Dh : Uh → Vh .
- Infimal convolution of higher-order TV functionals. The infimal convolutioncan be realised viawhere is given as in (77).
- Second-order total generalised variation. Let α0, α1 > 0. The choicecan be realised viawhere is given again as in (77) with α2 replaced by α0.
- Total generalised variation of order k . The total generalised variation functional of arbitrary order k ∈ N, k ⩾ 1, and weights, i.e.,can be realised viaIn this case,where is given as in (76).













![$\alpha =\left({\alpha }_{0},\dots ,{\alpha }_{k-1}\right)\in {\left.\right]0,\infty \left[\right.}^{k}$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn989.gif)




Stepsize choice and stopping rule. Algorithm 1 requires to choose stepsizes σ, τ > 0 such that  where
where  . This, in turn, requires to estimate
. This, in turn, requires to estimate  which we discuss on the following. The operator Kh
is application-dependent and we assume an upper bound for its norm to be given. Regarding the differential operator
which we discuss on the following. The operator Kh
is application-dependent and we assume an upper bound for its norm to be given. Regarding the differential operator  , an estimate on the norm of its building blocks
, an estimate on the norm of its building blocks  ,
,  is provided in lemma 6.5. As the following proposition shows, an upper bound on
is provided in lemma 6.5. As the following proposition shows, an upper bound on  as well as on the norm of more general block-operators, can then be obtained by computing a simple singular value decomposition of a usually low-dimensional matrix.
as well as on the norm of more general block-operators, can then be obtained by computing a simple singular value decomposition of a usually low-dimensional matrix.
Lemma 6.20. Assume that  with
with  ,
,  is given as
is given as

and that  for each m = 1, ..., M, n = 1, ..., N. Then,
for each m = 1, ..., M, n = 1, ..., N. Then,

where σmax denotes the largest singular value of a matrix.


from which the claimed assertion follows since the matrix norm induced by the two-norm corresponds to the largest singular value. □
This result can be applied in the setting (73), i.e.,  , leading to
, leading to

Alternatively, one could use the result when  or
or  have block structures and a norm estimate is known for each block in addition to an estimate on ||Kh
||. Two concrete examples will be provided at the end of this section below.
have block structures and a norm estimate is known for each block in addition to an estimate on ||Kh
||. Two concrete examples will be provided at the end of this section below.
Remark 6.21. In practice, provided that Lm,n
is a good upper bound for  , the norm estimate of lemma 6.20 is rather tight such that, depending on
, the norm estimate of lemma 6.20 is rather tight such that, depending on  , the admissible stepsizes can be sufficiently large. Furthermore, the constraint
, the admissible stepsizes can be sufficiently large. Furthermore, the constraint  still allows to choose an arbitrary positive ratio θ = σ/τ and, in our experience, often a choice θ ≪ 1 or θ ≫ 1 can accelerate convergence significantly. Finally, we also note that in case no estimate on
still allows to choose an arbitrary positive ratio θ = σ/τ and, in our experience, often a choice θ ≪ 1 or θ ≫ 1 can accelerate convergence significantly. Finally, we also note that in case no estimate on  can be obtained, or in case an explicit estimate only allows for prohibitively small stepsizes, also an adaptive stepsize choice without prior knowledge of
can be obtained, or in case an explicit estimate only allows for prohibitively small stepsizes, also an adaptive stepsize choice without prior knowledge of  is possible, see for instance [34].
is possible, see for instance [34].
Remark 6.22. It is worth mentioning that, in case of a uniformly convex functional in the saddle-point formulation (73) (which is not the case in the setting considered here), a further acceleration can be achieved by adaptive stepsize choices, see for instance [60].
Remark 6.23. Regarding a suitable stopping criterion, we note that often, the primal-dual gap, i.e., the gap between the energy of the primal and dual problem (66) and (68) evaluated at the current iterates, provides a good measure for optimality. Indeed, with

 and
and  if and only if (x, y) is optimal such that, in principle, the condition
if and only if (x, y) is optimal such that, in principle, the condition  with (xn
, yn
) the iterates of (70) can be used as stopping criterion. In case this condition is met, xn
as well as yn
are both optimal up to an ɛ-tolerance in terms of the objective functionals for the primal and dual problem, respectively.
with (xn
, yn
) the iterates of (70) can be used as stopping criterion. In case this condition is met, xn
as well as yn
are both optimal up to an ɛ-tolerance in terms of the objective functionals for the primal and dual problem, respectively.
In the present situation of (73), however, the primal and dual problem (65) and (74) yield

While for the iterates (un
, wn
, vn
, λn
), we always have  as well as
as well as  , algorithm 1 does not guarantee that
, algorithm 1 does not guarantee that  and
and  as well as
as well as  , such that the primal-dual gap is always infinite in practice and the stopping criterion is never met. With some adaptations, however, it is sometimes still possible to obtain a primal-dual gap that converges to zero and hence, to deduce a stopping criterion with optimality guarantees. There are several possibilities for achieving this. Let us, for simplicity, assume that both
, such that the primal-dual gap is always infinite in practice and the stopping criterion is never met. With some adaptations, however, it is sometimes still possible to obtain a primal-dual gap that converges to zero and hence, to deduce a stopping criterion with optimality guarantees. There are several possibilities for achieving this. Let us, for simplicity, assume that both  and
and  are finite everywhere and hence, continuous. This is, for example, the case for
are finite everywhere and hence, continuous. This is, for example, the case for  . Next, assume that a priori norm estimates are available for all solution pairs (u*, w*), say
. Next, assume that a priori norm estimates are available for all solution pairs (u*, w*), say  and
and  for norms
for norms  ,
,  on Uh
, Wh
that do not necessarily correspond to the Hilbert space norms. Such estimates may, for instance, be obtained from the observation that
on Uh
, Wh
that do not necessarily correspond to the Hilbert space norms. Such estimates may, for instance, be obtained from the observation that  and suitable coercivity estimates, as discussed in sections 3–5. Then, the primal problem can, for instance, be replaced by
and suitable coercivity estimates, as discussed in sections 3–5. Then, the primal problem can, for instance, be replaced by

where (t)+ = max{0, t} for t ∈ R, which has, by construction, the same minimisers as the original problem (65), but a dual problem that reads as

where  and
and  denote the respective dual norms. By duality and since the minimum of the primal problem did not change, the modified dual problem also has the same solutions as the original dual problem. Now, as the iterates (vn
, λn
) satisfy
denote the respective dual norms. By duality and since the minimum of the primal problem did not change, the modified dual problem also has the same solutions as the original dual problem. Now, as the iterates (vn
, λn
) satisfy  and
and  , the dual objective is finite for the iterates and converges to the maximum as n → ∞. Analogously, plugging in the sequence (un
, wn
) into the modified primal problem yields convergence to the minimum, hence, the respective primal-dual gap converges to zero for the primal-dual iterates (un
, wn
, vn
, λn
). In summary, the functional
, the dual objective is finite for the iterates and converges to the maximum as n → ∞. Analogously, plugging in the sequence (un
, wn
) into the modified primal problem yields convergence to the minimum, hence, the respective primal-dual gap converges to zero for the primal-dual iterates (un
, wn
, vn
, λn
). In summary, the functional

yields the stopping criterion  which will be met for some n and gives ɛ-optimality of (un
, wn
) for the original primal problem (65).
which will be met for some n and gives ɛ-optimality of (un
, wn
) for the original primal problem (65).
The examples below show how this primal-dual gap reads for specific applications. For other strategies of modifying the primal-dual gap to a functional that is positive and finite, converges to zero and possibly provides an upper bound on optimality of the iterates in terms of the objective functional, see, for instance [31, 34, 41].
Concrete examples.
Example 6.24. As first example, we consider the minimisation problem

i.e., second order-TV regularisation for a linear inverse problem with Gaussian measurement noise. In this setting, we choose Wh
= {0}, Vh
= ℓ2(Ωh
, Sym2(R2)),  and ||v||1,α
= α||v||1. Assuming that ||Kh
|| ⩽ 1 (after possible scaling of Kh
), lemma 6.20 together with the estimate
and ||v||1,α
= α||v||1. Assuming that ||Kh
|| ⩽ 1 (after possible scaling of Kh
), lemma 6.20 together with the estimate  from lemma 6.5 yields
from lemma 6.5 yields

The resulting concrete realisation of algorithm 1 can be found in algorithm 2. Here,  is given explicitly in (76),
is given explicitly in (76),  is the adjoint of
is the adjoint of  and the modified primal-dual gap
and the modified primal-dual gap  evaluated on the iterates (u, v, λ) of the algorithm reduces to
evaluated on the iterates (u, v, λ) of the algorithm reduces to

where Cu
> 0 is an a priori bound on  for solutions u* according to (17), for instance.
for solutions u* according to (17), for instance.
Algorithm 2. Implementation for solving the L2–TV2 problem (78).
| 1: function L2–TV2-Tikhonov(Kh , fh , α) | ⊳ Requirement: ||Kh || ⩽ 1 |
2: 
| |
3: Choose σ, τ > 0 such that 
| |
| 4: repeat | |
| 5: Dual updates | |
6: 
| |
7: 
| |
| 8: Primal updates | |
9: 
| |
| 10: Extrapolation and update | |
11: 
| |
| 12: u ← u+ | |
| 13: until stopping criterion fulfiled | |
| 14: return u | |
| 15: end function |
Example 6.25. As second example, we consider  regularisation for an inverse problem with Poisson noise and discrete non-negative data
regularisation for an inverse problem with Poisson noise and discrete non-negative data  , which corresponds to solving
, which corresponds to solving

with KL being the discrete Kullback–Leibler divergence as in (75).
In this setting, we choose Wh
= ℓ2(Ωh
, Sym1(R2)), Vh
= ℓ2(Ωh
, Sym1(R2)) × ℓ2(Ω, Sym2(R2)),  and ||(v1, v2)||1,α
= α1||v1||1 + α0||v2||1. Setting
and ||(v1, v2)||1,α
= α1||v1||1 + α0||v2||1. Setting

and again assuming ||Kh
|| ⩽ 1, lemma 6.20 together with the estimates  and
and  from lemma 6.5 yields
from lemma 6.5 yields

The resulting, concrete implementation of algorithm 1 can be found in algorithm 3. Here, again  is given explicitly in (76), and, abusing notation, divh
is both the negative adjoint of ∇h
and
is given explicitly in (76), and, abusing notation, divh
is both the negative adjoint of ∇h
and  , depending on the input. The modified primal-dual gap
, depending on the input. The modified primal-dual gap  evaluated on the iterates (u, w, v1, v2, λ) of the algorithm reduces to
evaluated on the iterates (u, w, v1, v2, λ) of the algorithm reduces to

where  whenever λi
⩽ 1 for each i where
whenever λi
⩽ 1 for each i where  for
for  , 0 log(0) = 0, and KL*(λ, fh
) = ∞ else. Further, Cu
is an a priori bound on the two-norm of
, 0 log(0) = 0, and KL*(λ, fh
) = ∞ else. Further, Cu
is an a priori bound on the two-norm of  analogous to (18) while Cw
is an a priori bound on the one-norm of
analogous to (18) while Cw
is an a priori bound on the one-norm of  according to (51).
according to (51).
Algorithm 3. Implementation for solving the KL– problem (79).
problem (79).
1: function KL– -Tikhonov(Kh
, fh
, α) -Tikhonov(Kh
, fh
, α) | ⊳ Requirement: ||Kh || ⩽ 1 |
2: 
| |
3: Choose σ, τ > 0 such that 
| |
| 4: repeat | |
| 5: Dual updates | |
6: 
| |
7: 
| |
8: 
| |
9: 
| |
| 10: Primal updates | |
11: 
| |
| 12: w+ ← w + τ(v1 + divh v2) | |
| 13: Extrapolation and update | |
14: 
| |
| 15: (u, w) ← (u+, w+) | |
| 16: until stopping criterion fulfiled | |
| 17: return u | |
| 18: end function |
We refer to, e.g., [27] for more examples of primal-dual-based algorithms for TGV regularisation.
6.3. Implicit and preconditioned optimisation methods
Let us shortly discuss other proximal algorithms for the solution of (65). One popular method is the alternating direction method of multipliers (ADMM) [89, 95] which bases on augmented Lagrangian formulations for (65), for instance,

which results in the augmented Lagrangian

where τ > 0. For (80), the ADMM algorithm amounts to

Here, the first subproblem amounts to solving a least-squares problem and the associated normal equation is usually stably solvable since  and
and  involve discrete differential operators and hence, the normal equation essentially corresponds to the solution of a discrete elliptic equation that is perturbed by
involve discrete differential operators and hence, the normal equation essentially corresponds to the solution of a discrete elliptic equation that is perturbed by  . For this reason, ADMM is usually considered an implicit method. The second step turns out to be the application of the proximal mappings for
. For this reason, ADMM is usually considered an implicit method. The second step turns out to be the application of the proximal mappings for  and ||⋅||1,α
while the last update steps have an explicit form, see algorithm 4. By virtue of Moreau's identity (72) (also see lemma 6.13), the operators
and ||⋅||1,α
while the last update steps have an explicit form, see algorithm 4. By virtue of Moreau's identity (72) (also see lemma 6.13), the operators  and
and  can easily be computed knowing
can easily be computed knowing  and
and  . We have, for instance,
. We have, for instance,

where the projection operator usually has an explicit representation, see lemma 6.16 and example 6.19. Further, for the discrepancies discussed in subsection 6.2, it holds that

Algorithm 4. ADMM scheme for the numerical solution of (80).
| 1: function Tikhonov-ADMM(Kh , fh , α) |
2: 
|
| 3: Choose τ > 0 |
| 4: repeat |
| 5: Linear subproblem |
| 6: (u, w) ← solution of |

|
| 7: Proximal subproblem |
8: 
|
9: 
|
| 10: Lagrange multiplier |
11: 
|
12: 
|
| 13: until stopping criterion fulfiled |
| 14: return u |
| 15: end function |
While ADMM has the advantage of converging for arbitrary stepsizes τ > 0 (see, e.g. [25]), the main drawback is often considered the linear update step which amounts to solving a linear equation (or, alternatively, a least-squares problem) which can be computationally expensive. The latter can be avoided, for instance, with preconditioning techniques [43, 74]. Denoting again by  , the linear solution step amounts to solving
, the linear solution step amounts to solving  . Introducing the additional variables (u', w') ∈ Uh
× Wh
as well as the constraint
. Introducing the additional variables (u', w') ∈ Uh
× Wh
as well as the constraint  for
for  , we can consider the problem
, we can consider the problem

which is equivalent to (80). The associated ADMM procedure, however, simplifies. In particular, the linear subproblem only involves ρ id whose solution is trivial. Also, the Lagrange multipliers of the additional constraint are always zero within the iteration and the evaluation of the square root  can be avoided. This leads to the linear subproblem of algorithm 4 being replaced by the linear update step
can be avoided. This leads to the linear subproblem of algorithm 4 being replaced by the linear update step

Also, the procedure then requires, in each iteration, only one evaluation of Kh
,  ,
,  and their respective adjoints as well as the evaluation of proximal mappings, such that the computational effort is comparable to algorithm 1. As a special variant of the general ADMM algorithm, the above preconditioned version converges for τ > 0 if
and their respective adjoints as well as the evaluation of proximal mappings, such that the computational effort is comparable to algorithm 1. As a special variant of the general ADMM algorithm, the above preconditioned version converges for τ > 0 if  is satisfied. Thus, an estimate for
is satisfied. Thus, an estimate for  is required which can, e.g., be obtained by lemma 6.20 (also confer the concrete examples in subsection 6.2). While this is the most common preconditioning strategy for ADMM, there are many other possibilities for transforming the original linear subproblem into a simpler one such that, e.g., the preconditioned problem amounts to the application of one or more steps of a symmetric Gauss–Seidel iteration or a symmetric successive over-relaxation (SSOR) procedure [43].
is required which can, e.g., be obtained by lemma 6.20 (also confer the concrete examples in subsection 6.2). While this is the most common preconditioning strategy for ADMM, there are many other possibilities for transforming the original linear subproblem into a simpler one such that, e.g., the preconditioned problem amounts to the application of one or more steps of a symmetric Gauss–Seidel iteration or a symmetric successive over-relaxation (SSOR) procedure [43].
Another class of methods for solving (65) is given by the Douglas–Rachford iteration [80, 130], which is an iterative procedure for solving monotone inclusion problems of the type

in Hilbert space, where A, B are maximally monotone operators. It proceeds as follows:

where σ > 0 is a stepsize parameter. As only the resolvent operators (id + σA)−1 and (id + σB)−1 are involved, the Douglas–Rachford iteration is also considered an implicit scheme. In the context of optimisation problems, the operators A and B are commonly chosen based on first-order optimality conditions, which are subgradient inclusions [45, 89]. Here, we choose the saddle-point formulation (73) and the associated optimality conditions:

For instance, choosing A and B as the first and second operator in the above splitting, respectively, leads to the iteration outlined in algorithm 5: Indeed, in terms of x = (u, w), y = (v, λ) and  , the resolvent for the linear operator A corresponds to solving the linear system
, the resolvent for the linear operator A corresponds to solving the linear system

which is reflected by the linear subproblem and dual update in algorithm 5. The resolvent for B further corresponds to the application of proximal mappings, also see proposition 6.11, where the involved proximal operators are the same as for the primal-dual iteration in algorithm 1. The iteration can be shown to converge for each σ > 0, see, e.g., [45].
Algorithm 5. Douglas–Rachford scheme for the numerical solution of (73).
| 1: function Tikhonov-DR(Kh , fh , α) |
2: 
|
| 3: Choose σ > 0 |
| 4: repeat |
| 5: Linear subproblem |
6: 
|
| 7: Dual update |
8: 
|
9: 
|
| 10: Proximal update |
11: 
|
12: 
|
| 13: until stopping criterion fulfiled |
| 14: return u |
| 15: end function |
As for ADMM, the linear subproblem in algorithm 5 can be avoided by preconditioning. Basically, for the above Douglas–Rachford iteration, the same types of preconditioners can be applied as for ADMM, ranging from the Richardson-type preconditioner that was discussed in detail before to symmetric Gauss–Seidel and SSOR-type preconditioners [40]. In particular, the potential of the latter for TGV-regularised imaging problems was shown in [41].
While all three discussed classes of algorithms, i.e., the primal-dual method, ADMM, and the Douglas–Rachford iteration can in principle be used to solve the discrete Tikhonov minimisation problem we are interested in, experience shows that the primal-dual method is usually easy to implement as it only involves forward evaluations of the involved linear operators and simple proximal operators, and thus suitable for prototyping. It needs, however, norm estimates for the forward operator and a possible rescaling. ADMM is, in turn, a very popular algorithm whose advantage lies, for instance, in its unconditional convergence (the parameter τ > 0 can be chosen arbitrarily). Also, in comparison to the primal-dual method, ADMM is observed to admit, in relevant cases, a more stable convergence behaviour, meaning less oscillations and faster objective functional reduction in the first iteration steps. However, ADMM requires the solution of a linear subproblem in each iteration step which might be expensive or call for preconditioning. The same applies to the Douglas–Rachford iteration which is also unconditionally convergent, comparably stable and usually involves the solution of a linear subproblem in each step. In contrast to ADMM it bases, however, on the same saddle-point formulation as the primal-dual methods such that translating a prototype primal-dual implementation into a more efficient Douglas–Rachford implementation with possible preconditioning is more immediate.
7. Applications in image processing and computer vision
7.1. Image denoising and deblurring
Image denoising is a simple yet heavily addressed problem in image processing (see for instance [127] for a review) as it is practically relevant by itself and, in addition, allows to investigate the effect of different smoothing and regularisation approaches independent of particular measurements setups or forward models. The standard formulation of variational denoising assumes Gaussian noise and, consequently, employs an L2-type data fidelity. Allowing for more general noise models, the denoising problem reads as

where we assume Sf
: Lp
(Ω) → [0, ∞], with p ∈ [1, ∞], to be proper, convex, lower semi-continuous and coercive, and  to be an appropriate regularisation functional. This setting covers, for instance, Gaussian noise (with
to be an appropriate regularisation functional. This setting covers, for instance, Gaussian noise (with  ), impulse noise (with Sf
(u) = ||u − f||1) and Poisson noise (with Sf
(u) = KL(u, f)). With first- or higher-order TV regularisation, additive or infimal-convolution-based combinations thereof, or TGV regularisation, the denoising problem is well-posed for any of the above choices of Sf
. For
), impulse noise (with Sf
(u) = ||u − f||1) and Poisson noise (with Sf
(u) = KL(u, f)). With first- or higher-order TV regularisation, additive or infimal-convolution-based combinations thereof, or TGV regularisation, the denoising problem is well-posed for any of the above choices of Sf
. For  and q > 1, also regularisation with
and q > 1, also regularisation with  is well-posed and figure 11 summarises, once again, the result of these different approaches for q = 2 and Gaussian noise on a piecewise affine test image. It further emphasises again the appropriateness of
is well-posed and figure 11 summarises, once again, the result of these different approaches for q = 2 and Gaussian noise on a piecewise affine test image. It further emphasises again the appropriateness of  as a regulariser for piecewise smooth images.
as a regulariser for piecewise smooth images.

Figure 11. Comparison of different first- and second-order image models for variational image denoising with L2-discrepancy. Left column: the original image (top) and noisy input image (bottom). Columns 2–4: results for variational denoising with different regularisation terms. The parameters were manually optimised for best PSNR (see figures 1–4 and 6 for the PSNR values).
Download figure:
Standard image High-resolution imageIn order to visualise the difference between different orders of TGV regularisation, figure 12 considers a piecewise smooth image corrupted by Gaussian noise and compares TGV regularisation with orders k ∈ {2, 3}. It can be seen there that third-order TGV yields a better approximation of smooth structures, resulting in an improved PSNR, while the second-order TGV regularised image has small defects resulting from a piecewise linear approximation of the data.

Figure 12. Comparison of second- and third-order TGV for denoising for a piecewise smooth noisy image (PSNR: 26.0 dB). The red lines in the original image indicate the areas used in the line and surface plots. A close look on these plots reveals piecewise-linearity defects of  , while the
, while the  reconstruction yields a better approximation of smooth structures and an improved PSNR (
reconstruction yields a better approximation of smooth structures and an improved PSNR ( : 40.7 dB,
: 40.7 dB,  : 42.3 dB). Note that in the line plots, the value 0.05 was subtracted from the TGV-denoising results in order to prevent the respective plots from significantly overlapping with the plots of the original data.
: 42.3 dB). Note that in the line plots, the value 0.05 was subtracted from the TGV-denoising results in order to prevent the respective plots from significantly overlapping with the plots of the original data.
Download figure:
Standard image High-resolution imageAnother problem class is image deblurring which can be considered as a standard test problem for the ill-posed inversion of linear operators in imaging. Pick a blurring kernel k ∈ L∞(Ω0) with bounded domains Ω0, Ω' ⊂ Rd such that Ω' − Ω0 ⊂ Ω. Then, K : L1(Ω) → L2(Ω') given by

is well-defined, linear and continuous. Consequently, by theorems 2.11, 2.14 and proposition 5.17,

for 1 < p ⩽ d/(d − 1) and  admits a solution that stably depends on the data f ∈ L2(Ω'), which we assume to be a noise-contaminated image blurred by the convolution operator K. A numerical solution can again be obtained with the framework described in section 6 and a comparison of the two choices of
admits a solution that stably depends on the data f ∈ L2(Ω'), which we assume to be a noise-contaminated image blurred by the convolution operator K. A numerical solution can again be obtained with the framework described in section 6 and a comparison of the two choices of  for a test image can be found in figure 13. We can observe that both TV and
for a test image can be found in figure 13. We can observe that both TV and  are able to remove noise and blur from the image, however, the TV reconstruction suffers from staircasing artefacts which are not present with
are able to remove noise and blur from the image, however, the TV reconstruction suffers from staircasing artefacts which are not present with  .
.

Figure 13. Deconvolution example. The original image uorig [92] has been blurred and contaminated by noise resulting in f. The images uTV and  are the regularised solutions recovered from f. Reproduced from [92]. CC BY 2.0.
are the regularised solutions recovered from f. Reproduced from [92]. CC BY 2.0.
Download figure:
Standard image High-resolution image7.2. Compressed sensing
The next problem we would like to discuss is compressive sampling with total variation and total generalised variation [27]. More precisely, we aim at reconstructing a single-channel image from 'single-pixel camera' data [78], an inverse problem with finite-dimensional data space. Here, an image is not observed directly but only the accumulated grey values over finitely many random pixel patterns are sequentially measured by one sensor, the 'single pixel'. This can be modelled as follows. For a bounded Lipschitz image domain Ω ⊂ R2, let the measurable sets E1, ..., EM ⊂ Ω be the collection of random patterns where each Em is associated with the mth measurement. The image u is then determined by solving the inverse problem

and f ∈ RM is the measurement vector, i.e., each fm is the output of the sensor for the pattern Em . As the set of u solving this inverse problem is an affine space with finite codimension, the compressive imaging approach assumes that the image u is sparse in a certain representation which is usually translated into the discrete total variation TV(u) being small. A way to reconstruct u from f is then to solve

In this context, also higher-order regularisers may be used as sparsity constraint. For instance, in [27], total generalised variation of order 2 has numerically been tested:

Figure 14 shows example reconstructions for real data according to discretised versions of (81) and (82). As supported by the theory of compressed sensing [52, 53], the image can essentially be recovered from a few single-pixel measurements. Here, TGV-minimisation helps to reconstruct smooth regions of the image such that in comparison to TV-minimisation, more features can still be recognised, in particular, when reconstructing from very few samples. Once again, staircasing artefacts are clearly visible for the TV-based reconstructions, a fact that recently was made rigorous in [26, 29].

Figure 14. Example for TV/TGV2 compressive imaging reconstruction for real single-pixel camera data [157]. Top: TV-based reconstruction of a 64 × 64 image from 18.75%, 9.375%, 6.25% and 4.6875% of the data (from left to right). Bottom: TGV2-based reconstruction obtained from the same data. Figure taken from [27]. Reprinted by permission from Springer Nature.
Download figure:
Standard image High-resolution image7.3. Optical flow and stereo estimation
Another important fundamental problem in image processing and computer vision is the determination of the optical flow [110] of an image sequence. Here, we consider this task for two consecutive frames f0 and f1 in a sequence of images. This is often modelled by minimising a possibly joint discrepancy  for u : [0, 1] × Ω → R subject to the optical flow constraint
for u : [0, 1] × Ω → R subject to the optical flow constraint  , see, for instance, [24]. Here, v : [0, 1] × Ω → Rd
is the optical flow field that shall be determined. In order to deal with ill-posedness, ambiguities as well as occlusion, the vector field v needs to be regularised by a penalty term. This leads to the PDE-constrained problem
, see, for instance, [24]. Here, v : [0, 1] × Ω → Rd
is the optical flow field that shall be determined. In order to deal with ill-posedness, ambiguities as well as occlusion, the vector field v needs to be regularised by a penalty term. This leads to the PDE-constrained problem

where  is a suitable convex regulariser for vector field sequences. Usually,
is a suitable convex regulariser for vector field sequences. Usually,  is chosen such that the initial condition u(0) is fixed to f0, for instance,
is chosen such that the initial condition u(0) is fixed to f0, for instance,  , see [24, 64, 103, 118].
, see [24, 64, 103, 118].
In many approaches, this problem is reformulated to a correspondence problem. This means, on the one hand, replacing the optical flow constraint by the displacement introduced by a vector field v0 : Ω → R2, i.e., u(0) = u0 and u(1) = u0 ◦ (id + v0). The image u0 : Ω → R is either prespecified or subject to optimisation. For instance, choosing again  leads to the classical correspondence problem
leads to the classical correspondence problem

see, for instance, [110], which uses the square of the H1-seminorm as a regulariser. On the other hand, other approaches have been considered for the discrepancy (and regularisation), see [47, 196]. In this context, a popular concept is the census transform [195] that describes the local relative behaviour of an image and is invariant to brightness changes. For an image f : Ω → R, measurable patch Ω' ⊂ R2 and threshold ɛ > 0, it is defined as

Here, one usually sets u0 = f0 and u1 = f1 such that the discrepancy only depends on the vector field v0, such as, for instance,

leading to the optical-flow problem

see, for instance, [137, 188]. A closely related problem is stereo estimation which can also be modelled as a correspondence problem. In this context, f0 and f1 constitute a stereo image pair, for instance, f0 being the left image and f1 being the right image. The stereo information is then usually reflected by the disparity which describes the displacement of the right image with respect to the left image. This corresponds to setting the vertical component of the displacement field v0 to zero, for instance,  . Census-transform based discrepancies are also used for this task [152], leading to the stereo-estimation model
. Census-transform based discrepancies are also used for this task [152], leading to the stereo-estimation model

with a suitable convex regulariser  for scalar disparity images.
for scalar disparity images.
Both optical flow and stereo estimation are non-convex due to the non-convex data terms and require dedicated solution techniques. One possible approach is to smooth the discrepancy functional such that it becomes (twice) continuously differentiable, and approximate it, for each x ∈ Ω, by either first or second-order Taylor expansion. For the latter case, if one also projects the pointwise Hessian to the positive semi-definite cone, one arrives at the convex problem

where v0 is the base vector field for the Taylor expansion and  denotes the orthogonal projection to the cone of positive semi-definite matrices
denotes the orthogonal projection to the cone of positive semi-definite matrices  . Besides classical regularisers such as the H1-seminorm, the total variation has been chosen [193], i.e.,
. Besides classical regularisers such as the H1-seminorm, the total variation has been chosen [193], i.e.,  , which allows the identification of jumps in the displacement field associated with object boundaries. The displacement field is, however, piecewise smooth such that
, which allows the identification of jumps in the displacement field associated with object boundaries. The displacement field is, however, piecewise smooth such that  turns out to be advantageous. Further improvements can be achieved by non-local total generalised variation NLTGV2, see [154], leading to sharper and more accurate motion boundaries, see figure 15. For stereo estimation, a similar approach using first-order Taylor expansion and image-driven total generalised variation
turns out to be advantageous. Further improvements can be achieved by non-local total generalised variation NLTGV2, see [154], leading to sharper and more accurate motion boundaries, see figure 15. For stereo estimation, a similar approach using first-order Taylor expansion and image-driven total generalised variation  also yields very accurate disparity images [152].
also yields very accurate disparity images [152].

Figure 15. Example for higher-order approaches for optical flow determination. (a) An optical flow field obtained on a sample dataset from the Middlebury benchmark [11] using a  regulariser. (b) An enlarged detail of (a). (c) The optical flow field obtained by a NLTGV2 regulariser. (d) An enlarged detail of (c). Images taken from [154]. Reprinted by permission from Springer Nature.
regulariser. (b) An enlarged detail of (a). (c) The optical flow field obtained by a NLTGV2 regulariser. (d) An enlarged detail of (c). Images taken from [154]. Reprinted by permission from Springer Nature.
Download figure:
Standard image High-resolution imageA different concept for solving the non-convex optical flow/stereo estimation problem is functional lifting [4, 55]. For the stereo estimation problem, this means to recover the characteristic function of the subgraph of the disparity image, i.e.,  . Assume that the discrepancy for the disparity w0 can be written in integral form, i.e.,
. Assume that the discrepancy for the disparity w0 can be written in integral form, i.e.,  with a suitable g : Ω × R → R that is possibly non-convex with respect to the second argument. If w0 is of bounded variation, then
with a suitable g : Ω × R → R that is possibly non-convex with respect to the second argument. If w0 is of bounded variation, then  is also of bounded variation and the weak derivative with respect to x and t, respectively, are Radon measures. Denoting by vx
and vt
the respective components of a vector, i.e., v = (vx
, vt
) ∈ R2 × R, these derivatives satisfy the identity
is also of bounded variation and the weak derivative with respect to x and t, respectively, are Radon measures. Denoting by vx
and vt
the respective components of a vector, i.e., v = (vx
, vt
) ∈ R2 × R, these derivatives satisfy the identity  as well as
as well as  . The discrepancy term can then be written in the form
. The discrepancy term can then be written in the form

which is convex with respect to  . In many cases, regularisation functionals can also be written in terms of
. In many cases, regularisation functionals can also be written in terms of  , for instance, by the coarea formula,
, for instance, by the coarea formula,

which is again convex with respect to  . As the set of all
. As the set of all  is still non-convex, this constraint is usually relaxed to a convex set, for instance, to the conditions
is still non-convex, this constraint is usually relaxed to a convex set, for instance, to the conditions

where the limits have to be understood in a suitable sense. Then, the stereo problem (83) with total-variation regularisation can be relaxed to the convex problem

Then, optimal solutions u* for the above problem yield minimisers of the original problem when thresholded, i.e., for ![$s\in \left.\right]0,1\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn1135.gif) , the function
, the function  is the characteristic function of the subgraph of a w0 that is optimal for (83) for the assumed discrepancy and total-variation regularisation [145].
is the characteristic function of the subgraph of a w0 that is optimal for (83) for the assumed discrepancy and total-variation regularisation [145].
Unfortunately, a straightforward adaptation of this strategy to higher-order total-variation-type regularisation functionals is not possible. For TGV2, one can nevertheless benefit from the convexification approach. Considering the  -regularised problem
-regularised problem

one sees that the problem is convex in w and minimisation with respect to w0 can still be convexified by functional lifting. For fixed w, the latter leads to

which is again convex and whose solutions can again be thresholded to yield a  that is optimal with respect to w0 for a fixed w. Alternating minimisation then provides a robust solution strategy for (85) based on convex optimisation [155], see figure 16 for an example. In this context, algorithms realising functional lifting strategies for TV and TGV regularisation have recently further been refined, for instance, in order to lower the computational complexity associated with the additional space dimension introduced by the lifting, see, e.g. [135, 181].
that is optimal with respect to w0 for a fixed w. Alternating minimisation then provides a robust solution strategy for (85) based on convex optimisation [155], see figure 16 for an example. In this context, algorithms realising functional lifting strategies for TV and TGV regularisation have recently further been refined, for instance, in order to lower the computational complexity associated with the additional space dimension introduced by the lifting, see, e.g. [135, 181].

Figure 16. Total-generalised-variation-regularised stereo estimation based on functional lifting and convex optimisation for an image pair of the KITTI dataset [91]. (a) The reference image. (b) The disparity image obtained with TGV2-regularisation [155]. Reprinted from [153] by permission from Springer Nature Customer Service Centre GmbH: Springer © 2013.
Download figure:
Standard image High-resolution image7.4. Image and video decompression
Pixelwise representations of image or image sequence data require, on the one hand, a large amount of digital storage but contain, on the other hand, enough redundancy to enable compression. Indeed, most digitally stored images and image sequences, e.g., on cameras, mobile phones or the world-wide web are compressed. Commonly-used lossy compression standards such as JPEG, JPEG2000 for images and MPEG for image sequences, however, suffer from visual artefacts in decompressed data, especially for high compression rates.
Those artefacts result from errors in the compressed data due to quantisation, which is not accounted for in the decompression procedure. These errors, however, can be well described using the data that is available in the compressed file and in particular, precise bounds on the difference of the available data and the unknown, ground truth data can be obtained. This observation motivates a generic approach for an improved decompression of such compressed image or video data, which consists of minimising a regularisation functional subject to these error bounds, see for instance [5, 31, 200] for TV-based works in this context. Following this generic approach, we present here a TGV-based reconstruction method (see [33, 34]) that allows for a variational reconstruction of still images from compressed data that is directly applicable to the major image compression standards such as JPEG, JPEG2000 or the image compression layer of the DjVu document compression format [108]. A further extension of this model to the decompression of MPEG encoded video data will be addressed afterwards.
The underlying principle of a broad class of image and video compression standards, and in particular of JPEG and JPEG 2000 compression, is as follows: first, a linear transformation is used to transform the image data to a different representation where information that is more and less important for visual image quality is well separated. Then, a weighted quantisation of this data (according to its expected importance for visual image quality) is carried out and the quantised data (together with information that allows to obtain the quantisation accuracy) is stored. Thus, defining K to be the linear transformation used in the compression process and D to be a set of admissible, transformed image data that can be obtained using the information available in the compressed file, decompression amounts to finding an image u such that Ku ∈ D. Using the TGV functional to regularise this compression procedure and considering colour images u : Ω → R3, we arrive at the following minimisation problem:

where K : L2(Ω, R3) → ℓ2 is an analysis operator related to a Riesz basis of L2(Ω, R3), and a Frobenius-norm-type coupling of the colour channels is used in TGV, see subsection 5.3. The coefficient dataset D ⊂ ℓ2 reflects interval restrictions on the coefficients, i.e., is defined as D = {v ∈ ℓ2|vn
∈ Jn
for all n ∈ N} for {Jn
} a family of closed intervals. In case D is bounded, well-posedness of this approach can be obtained via a direct extension of proposition 5.17 to R3-valued functions, which in particular requires a multi-channel version of the Poincaré inequality for TGV as in proposition 5.15. The latter can straightforwardly be obtained by equivalence of norms in finite dimensions, see for instance [27, 33]. Beyond that, existence of a solution to (86) can be guaranteed also in case of a non-coercive discrepancy when arbitrarily many of the intervals Jn
are unbounded, provided that only finitely many of them are half-bounded, i.e., are the form ![${J}_{n}= \left.\right]- \infty ,{c}_{n} \left.\right]$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn1139.gif) or
or  for cn
∈ R, see [33]. In compression, half-bounded intervals would correspond to knowing only the sign but not the precision of the respective coefficient, a situation which does not occur in JPEG, JPEG2000 and DjVu. Thus, in all relevant applications, all intervals are either bounded or all of R, and hence, solutions exist. Further, under the assumption that all but finitely many intervals have a width that is uniformly bounded from below, again an assumption which holds true in all anticipated applications, optimality conditions for (86) can be obtained.
for cn
∈ R, see [33]. In compression, half-bounded intervals would correspond to knowing only the sign but not the precision of the respective coefficient, a situation which does not occur in JPEG, JPEG2000 and DjVu. Thus, in all relevant applications, all intervals are either bounded or all of R, and hence, solutions exist. Further, under the assumption that all but finitely many intervals have a width that is uniformly bounded from below, again an assumption which holds true in all anticipated applications, optimality conditions for (86) can be obtained.
In the application to JPEG decompression, colour images are processed in the YCbCr colour space and the basis transformation operator K corresponds to a colour subsampling followed by a block- and channel-wise discrete cosine transformation, which together can be expressed as Riesz-basis transform. The interval sequence {Jn } can be obtained using a quantisation matrix that is available in the encoded file and each interval Jn is bounded.
In the application to JPEG2000 decompression, again the YCbCr colour space is used and K realises a colour-component-wise biorthogonal wavelet transform using Le Gall 5/3 or CDF 9/7 wavelets as defined in [65, tables 6.1 and 6.2]. Obtaining bounds on the precision of the wavelet coefficients is more involved than with JPEG (see [33, section 4.3]), but can be done by studying the bit truncation scheme of JPEG2000 in detail. As opposed to JPEG, however, the intervals Jn might either be bounded or unbounded.
A third application of the model (86) is a variational decompression of the image layers of a DjVu compressed document. DjVu [100] is a storage format for digital documents. It encodes document pages via a separation into fore- and background layers as well as a binary switching mask, where the former are encoded using a lossy, transform-based compression and the latter using a dictionary-based compression. While the binary switching mask typically encodes fine details such as written text, the fore- and background layer encode image data, which again suffers from compression artefacts that can be reduced via variational decompression. Here, the extraction of the relevant coefficient data together with error bounds has to account for the particular features of the DjVu compression standard (we refer to [108] and its supplementary material for a detailed description and software that extracts the relevant data from DjVu compressed files), but the overall model for the image layers is again similar to the one of JPEG and JPEG2000 decompression. In particular, encoding of the fore- and background layer can be modelled with the operator K, in this case corresponding to a colour-component-wise wavelet transformation using the Dubuc–Deslauriers–Lemire (DDL) (4, 4) wavelets [75], and the data intervals Jn , which are again either bounded or all of R.
In all of the above applications, a numerical solution of the corresponding particular instance of the minimisation problem (86) can be obtained using the primal-dual framework [34] as described in section 6 (see [34] for details). We refer to figure 17 for exemplary results using second-order TGV regularisation. Regarding the implementation, relevant differences arise depending on whether the projection onto the dataset UD can be carried out explicitly or not, the latter requiring a dualisation of this constraint and an additional dual variable. Only in the application to JPEG decompression, this projection is explicit due to orthonormality of the cosine transform and the particular structure of the colour subsampling operator. This has the particular advantage that, at any iteration of the algorithm, the solution is feasible and one can, for instance, apply early stopping techniques to obtain already quite improved decompressed images in a computationally cheap way.

Figure 17. Example of variational image decompression. Standard (left column) and TGV-based (right column) decompression for a JPEG image (top row) compressed to 0.15 bits-per-pixel (bpp), a JPEG2000 image (middle row) compressed to 0.3 bpp, and a DjVu-compressed document page (bottom row) with close-ups. Results from [34] (rows 1 and 2) and [108] (bottom row). Reproduced with permission from [90]. Copyright © 2018 Society for Industrial and Applied Mathematics.
Download figure:
Standard image High-resolution imageVariational MPEG decompression. The MPEG video compression standard builds on JPEG compression for storing frame-wise image data, but incorporates additional motion prediction and correction steps which can significantly reduce storage size of video data. In MPEG-2 compression, which is a tractable blueprint for the MPEG compression family, video data is processed as subsequent groups of pictures (typically 12–15 frames) which can be handled separately. In each group of pictures, different frame types (I, P and B frames) are defined, and, depending to the frame type, image data is stored by using motion prediction and correction followed by a JPEG-type compression of the corrected data. Similar to JPEG compression, colour images are processed in the YCbCr colour space and additional subsampling of colour components is allowed.
While these are the main features of a typical MPEG video encoder, as usual for most compression standards, the MPEG standard defines the decompression procedure rather than compression. Hence, since compression might differ for different encoders, we build a variational model for MPEG decompression that works with a decoding operator (see [35] for more details on MPEG and the model): using the information (in particular motion correction vectors and quantisation tables) that is stored in the MPEG compressed files, we can define a linear operator K that maps encoded, motion corrected cosine-transform coefficient data to (colour subsampled) video data. Furthermore, bounds on the coefficient data can be obtained. Using a second operator S to model colour subsampling and choosing a right-inverse Ŝ, MPEG decompression amounts to finding a video u such that

where v ∈ D with D being the admissible set of cosine coefficient data, and s ∈ ker(S) compensates for the colour upsampling of Ŝ. Incorporating the infimal-convolution of second-order spatio-temporal TGV functionals as regularisation for video data (see subsection 5.3 and [35, 109]), decompression then amounts to solve

Again, the minimisation problem can be solved using duality-based convex optimisation methods as described in section 6 and we refer to figure 18 for a comparison of standard MPEG-2 decompression and the result obtained with this model.

Figure 18. Example of variational MPEG decompression. Standard (top row) and ICTGV-based (bottom row) decompression of the Juggler image sequence from [11]. On the left, the second frame (P-frame) is shown in detail while on the right, all 8 frames are depicted. Reprinted from [35] by permission from Springer Nature Customer Service Centre GmbH: Springer © 2015.
Download figure:
Standard image High-resolution image8. Applications in medical imaging and image reconstruction
8.1. Denoising of dual-energy computed-tomography (CT) data
Since its development in the 1970s, computed x-ray tomography (CT) became a standard tool in medical imaging. As CT bases on x-rays, the health risks associated with ionising radiation is certainly a drawback of this imaging technique. Further, the acquired images do in general not allow to differentiate objects with the same density. For the former point, a low radiation dose is an important goal, being, of course in conflict with the demand of a high signal-to-noise ratio (SNR). Regarding the differentiation of objects with the same density [88, 115], a recently developed approach bases on an additional dataset from a second x-ray source (typically placed in a 90° offset) which possess a different spectrum (or energy) compared to the standard x-ray emitter in CT, the dual-energy CT device, see figure 19(a).
Objects of different material having the same response for one x-ray source may admit a different response for the second source, making a differentiation possible. A relevant application of this principle is, for instance, the quantification of contrast agent concentration. Adjusting a dual-energy CT device such that normal tissue is insensitive for both x-ray sources and sensitive for an administered contrast agent allows to infer its concentration from the difference of the two acquired images, see figure 19(b). This may be useful, for instance, for recognising perfusion deficits and thus aid the diagnosis of, e.g., pulmonary embolism in the lung [131]. However, due to low doses for the dual-energy CT scan as well as a limited sensitivity with respect to the contrast agent, the difference image can be noisy and denoising is required in order to obtain a meaningful interpretation, see figure 19(c).

Figure 19. Example of L1–TGV2 denoising for dual energy computed tomography. (a) A schematic of a dual-energy CT device. (b) A pair of (reconstructed) dual-energy CT images. (c) A noisy difference image with marked perfusion deficit region. (d) Difference image of the TGV-denoised dataset (3D denoising, only one slice is shown).
Download figure:
Standard image High-resolution imageIn the following, a variational denoising approach is derived that takes the structure of the problem into account. First, let A0 and B0 be the noisy CT-reconstructions associated with the respective x-ray source. Then, as the difference image contains the relevant information, we would like to impose regularity on the difference image A − B as well as a 'base' image B instead of penalising each image separately. As we may assume that the contrast agent concentration as well as the density is piecewise smooth, is admits a low total generalised variation, and hence, we choose this functional as a penalty, for instance of second order. Furthermore, as the results should be usable for a quantification, we have to account for that and therefore choose an L1-fidelity term as this is known to possess desirable contrast-preservation properties in conjunction with TV and TGV [38, 62]. In total, this leads to the variational problem

where A0, B0 ∈ L1(Ω) is given and α = (α0, α1) as well as α' = (α0', α1') are positive regularisation parameters. Having the application in mind, the domain Ω is typically a bounded three-dimensional domain with Lipschitz boundary. Then, existence of minimisers can be obtained using the tools from section 5, see proposition 5.17, which nevertheless requires some straightforward adaptations. Due to the lack of strict convexity, however, the solutions might be non-unique. Further, numerical algorithms can be developed along the lines of section 6, for instance, a primal-dual algorithm as outlined in subsection 6.2. In case of non-uniqueness, the minimisation procedure 'chooses' one solution in the sense that it converges to one element of the solution set, such that variational model and optimisation algorithm cannot clearly be separated and other results might be possible using different optimisation algorithms.
Figure 19(d) shows denoising results for the primal-dual algorithm, where a clear improvement of image quality for the difference image in comparison to figure 19(c) can be observed. In particular, the total generalised variation model is suitable to recover the smooth distribution of the contrast agent within the lung, including the perfusion deficit region, as well as the discontinuities induced by bones, vessels, etc. Further, one can see that the dedicated modelling of the problem as a denoising problem for a difference image based on two datasets turns out to be beneficial. A denoising procedure that only depends on the noisy difference image would not allow for such an improvement of image quality.
8.2. Parallel reconstruction in magnetic resonance imaging
Magnetic resonance imaging (MRI) is a tomographic imaging technique that is heavily used in medical imaging and beyond. It builds on an interplay of magnetic fields and radio-frequency pulses, which allows for localised excitation and, via induction of current in receiver coils, for a subsequent measurement of the proton density inside the object of interest [46]. In the standard setting, MRI delivers qualitative images visualising the density of hydrogen protons, e.g., inside the human body. Its usefulness is in particular due to an excellent soft tissue contrast (as opposed to computed tomography) and a high spatial resolution of MR images. The trade-off, in particular for the latter, is the long measurement time, which comes with obvious drawbacks such as patient discomfort, limitations on patient throughput and imaging artefacts resulting from temporally inconsistent data due to patient motion.
Subsampled data acquisition and parallel imaging [97, 149, 179] (combined with appropriate reconstruction methods) are nowadays standard techniques to accelerate MRI measurements. As the data in an MR experiment is acquired sequentially, a reduced number of measurements directly implies a reduced measurement time, however, in order to maintain the same image resolution, the resulting lack of data needs to be compensated for by other means. Parallel imaging achieves this to some extent by using not a single but multiple measurement coils and combining the corresponding measured signals for image reconstruction. On top of that, advanced mathematical reconstruction methods such as compressed sensing techniques [21, 132] or, more general, variational reconstruction have been shown to allow for a further, significant reduction of measurement time with a negligible loss of image quality.
In this context, transform-based regularisation techniques [132, 133] and derivative-based techniques [21, 121] are among the most popular approaches. More recently, also learning-based methods building on the structure of variational approaches have become very popular [101, 150]. Here, we focus on variational regularisation approaches with first- and higher-order derivatives. To this aim, we first deal with the forward model of parallel, static MR imaging.
In a standard setting, the MR measurement process can be modelled as measuring Fourier coefficients of the unknown image. In order to include measurements from multiple coils, spatially varying sensitivity profiles of these coils also need to be included in the forward model via a pointwise multiplication in image space. Subsampled data acquisition then corresponds to measuring the Fourier coefficients only on a certain measurement domain in Fourier space, which is defined by a subsampling pattern. Let  be functions modelling some fixed coil sensitivity profiles for k receiver coils, let σ be a positive, finite Radon measure on Rd
that defines the sampling pattern, and let Ω ⊂ Rd
be a bounded Lipschitz domain that represents the image domain. Then, following the lines of [30], we define, for p ∈ [1, ∞], the MR measurement operator
be functions modelling some fixed coil sensitivity profiles for k receiver coils, let σ be a positive, finite Radon measure on Rd
that defines the sampling pattern, and let Ω ⊂ Rd
be a bounded Lipschitz domain that represents the image domain. Then, following the lines of [30], we define, for p ∈ [1, ∞], the MR measurement operator  as
as

where we extend u by zero to Rd . Note that for each u ∈ Lp (Ω, C), Ku as a function on Rd is bounded and continuous which follows from

Thus, since σ is finite, K indeed linearly and continuously maps into  .
.
While here, we assume the coil sensitivities to be known (such that the forward model is linear), obtaining them prior to image reconstruction is non-trivial and we refer to [21, 166, 185, 190] for some existing methods. In the experiments discussed below, we followed the approach of [21] and employed, for each individual coil, a variational reconstruction with a quadratic regularisation on the derivative (H1-regularisation) followed by the convolution with a smoothing kernel. For each coil, the sensitivity profile was then obtained by division with the sum-of-squares image (which is, despite its name, the pointwise square root of the sum of the squared modulus of the individual coil images).
A regularised reconstruction from MR measurement data  can be obtained by solving
can be obtained by solving

where we test with both  and
and  , in which case we can choose 1 < p ⩽ d/(d − 1). Note that well-posedness for (88) follows from theorems 2.11, 2.14 in the case of TV and from proposition 5.17 in the case of
, in which case we can choose 1 < p ⩽ d/(d − 1). Note that well-posedness for (88) follows from theorems 2.11, 2.14 in the case of TV and from proposition 5.17 in the case of  (where straightforward adaptions are necessary to include complex-valued functions). Numerically, the optimisation problem can be solved using the algorithmic framework described in section 6, where again, some modifications are necessary to deal with complex-valued images.
(where straightforward adaptions are necessary to include complex-valued functions). Numerically, the optimisation problem can be solved using the algorithmic framework described in section 6, where again, some modifications are necessary to deal with complex-valued images.
Figure 20 compares the results between these two choices of regularisation functionals and a conventional reconstruction based on direct Fourier inversion using non-uniform fast Fourier transform (NUFFT) [87] for different subsampling factors and a dataset for which a fully sampled ground truth is available. Undersampled 2D radial spin-echo measurements of the human brain were performed with a clinical 3T scanner using a receive-only 12 channel head coil. Sequence parameters were: TR
= 2500 ms, TE
= 50 ms, matrix size 256 × 256, slice thickness 2 mm, in-plane resolution 0.78 mm × 0.78 mm. The sampling direction of every second spoke was reversed to reduce artefacts from off-resonances [22], and numerical experiments were performed using 96, 48 and 24 projections. As  projections (402 for N = 256 in our case) have to be acquired to obtain a fully sampled dataset in line with the Nyquist criterion [18], this corresponds to undersampling factors of approximately 4, 8 and 16. The raw data was exported from the scanner, and image reconstruction was performed offline.
projections (402 for N = 256 in our case) have to be acquired to obtain a fully sampled dataset in line with the Nyquist criterion [18], this corresponds to undersampling factors of approximately 4, 8 and 16. The raw data was exported from the scanner, and image reconstruction was performed offline.

Figure 20. Parallel undersampling MRI of the human brain (256 × 256 pixels) from 96, 48 and 24 radial projections (top, middle, bottom row). Left column: conventional NUFFT reconstruction. Middle column: reconstruction with TV regularisation. Right column: reconstruction with TGV2 regularisation. All reconstructed images are shown with a closeup of the lower right brain region.
Download figure:
Standard image High-resolution imageIt can be seen that in particular at higher subsampling factors, variational, derivative-based reconstruction reduces artefacts stemming from limited Fourier measurements. Both TV and TGV perform well, while a closer look reveals that staircasing artefacts present with TV can be avoided using second-order TGV regularisation.
8.3. Diffusion tensor imaging
Magnetic resonance imaging offers, apart from obtaining morphological images as outlined in subsection 8.2, many other possibilities to acquire information about the imaged objects. Among these possibilities, diffusion tensor imaging (DTI) is one of the more recent developments. It aims at measuring the diffusion directions of water protons in each spatial point. The physical background is given by the Bloch–Torrey equation which describes the spatio-temporal evolution of magnetisation vector taking diffusion processes into account [183]. Based on this, diffusion-weighted imaging can be performed which uses dedicated MR sequences depending on a direction vector q ∈ R3 in order to obtain displacement information associated with that direction.
This leads to the following model. Assume that ρ0 : R3 → R is the proton density to recover and ρt : R3 × R3 → R is the function such that for each x, x' ∈ R3, the value ρt (x, x') represents the probability of a proton moving from x to x' during the time t > 0. By applying a diffusion-sensitive sequence (such as, e.g., a pulsed-gradient spin echo [180]) associated with the vector q ∈ R3, one is able to measure in k-space as follows:

where k ∈ R3, see [51, 67]. Note that in practice, also the coil sensitivity profile would influence the measurement as outlined in subsection 8.2, however, for the sake of simplicity, we neglect this aspect in the following. Now, sampling q across R3 would then, in principle, allow to recover the six-dimensional function u : (x, x') ↦ ρ0(x)ρt
(x, x') by inverse Fourier transform, since  for each k, q ∈ R3. The 6D-space spanned by the coordinates k and q is called kq
-space. Assuming that for a fixed q ∈ R3, the k-space is fully sampled then allows to recover fq
: R3 → C by inverse Fourier transform, where
for each k, q ∈ R3. The 6D-space spanned by the coordinates k and q is called kq
-space. Assuming that for a fixed q ∈ R3, the k-space is fully sampled then allows to recover fq
: R3 → C by inverse Fourier transform, where

Obtaining and analysing fq for a coverage of the q-space is called q -space imaging which also is the basis of orientation-based analysis such as q -ball imaging [184]. However, as these techniques require too much measurement time in practice, one usually makes assumptions about the structure of ρt in order to avoid the measurement of fq for too many q.
Along this line, the probably simplest model is to assume that for each x, ρt (x, ⋅) follows a Gaussian distribution centred around x with symmetric positive definite covariance matrix 2tD(x) ∈ S3×3, i.e.,

For fixed x ∈ R3, this can be interpreted as the fundamental solution of the diffusion equation

shifted by x and evaluated at time t. The model for ρt thus indeed reflects linear diffusion through a homogeneous medium. This makes sense as diffusion during the measurement process is usually orders of magnitudes smaller than the spatial scale one is interested in, but the homogeneity assumption might also be violated in case when microstructures are present. Nevertheless, with this assumption, in the above case of full k-space sampling, one gets

Clearly, for q = 0, we have f0 = ρ0, and assuming ρ0 > 0 almost everywhere leads to the following pointwise equation that is linear in D:

Hence, one can recover by D by measuring f0 and  for q1, ..., qm
∈ R3 suitably chosen, i.e., such that in particular, D is uniquely determinable from D ⋅ (qi
⊗ qi
) for i = 1, ..., m. In particular, one requires that the symmetric tensors q1 ⊗ q1, ..., qm
⊗ qm
span the space Sym2(R3), meaning that m must be at least 6. Note that according to (89), fq
must be real and non-negative, such that in practice, it suffices to reconstruct the absolute value of fq
, for instance, by computing the sum-of-squares image.
for q1, ..., qm
∈ R3 suitably chosen, i.e., such that in particular, D is uniquely determinable from D ⋅ (qi
⊗ qi
) for i = 1, ..., m. In particular, one requires that the symmetric tensors q1 ⊗ q1, ..., qm
⊗ qm
span the space Sym2(R3), meaning that m must be at least 6. Note that according to (89), fq
must be real and non-negative, such that in practice, it suffices to reconstruct the absolute value of fq
, for instance, by computing the sum-of-squares image.
The inverse problem for D can then be described as follows. Restricting the considerations to a bounded domain Ω ⊂ R3 and letting p ∈ [1, ∞] such that g1, ..., gm
∈ Lp
(Ω) where  , we aim at solving
, we aim at solving

for D ∈ Lp (Ω, Sym2(R3)). It is easy to see that this problem is well-posed, but regularisation is still necessary in practice as the measurements and the reconstruction are usually very noisy. To do so, one can, in the case p = 2, minimise a Tikhonov functional with quadratic discrepancy term and positive semi-definiteness constraints:

Here, {D ⩾ 0} denotes the set of symmetric tensor fields that are positive semi-definite almost everywhere in Ω. Further, the regulariser  is preferably tailored to the structure of symmetric tensor fields. Since the D to recover can be assumed to admit discontinuities, for instance, at tissue borders, the total deformation TD for Sym2(R3)-valued functions as described in subsection 3.2, constitutes a meaningful regulariser. In this context, higher-order regularisation via
is preferably tailored to the structure of symmetric tensor fields. Since the D to recover can be assumed to admit discontinuities, for instance, at tissue borders, the total deformation TD for Sym2(R3)-valued functions as described in subsection 3.2, constitutes a meaningful regulariser. In this context, higher-order regularisation via  for Sym2(R3)-valued functions according to definition 5.1 can be beneficial as, e.g., principal diffusion directions might smoothly vary within the same tissue type [186, 187]. In both cases, problem (91) is well-posed, admits a unique solution which can, once discretised, be found numerically by the algorithms outlined in section 6.
for Sym2(R3)-valued functions according to definition 5.1 can be beneficial as, e.g., principal diffusion directions might smoothly vary within the same tissue type [186, 187]. In both cases, problem (91) is well-posed, admits a unique solution which can, once discretised, be found numerically by the algorithms outlined in section 6.
Once the diffusion tensor field D is obtained, one can use it to visualise some of its properties. For instance, in the context of medical imaging, the eigenvectors and eigenvalues of D play a role in interpreting DTI data. Based on the fractional anisotropy [12], which is defined as

where  are the eigenvalues of D as a function in Ω, one is able to identify isotropic regions (FAD
≈ 0) as well as regions where diffusion only takes place in one direction (FAD
≈ 1). The latter case indicates the presence of fibres whose orientation then corresponds to a principal eigenvalue of D. Figure 21 shows an example of DTI reconstruction from noisy data using TD and TGV2 regularisation for symmetric tensor fields, using principal-direction/fractional-anisotropy-based visualisation. It turns out that also here, higher-order regularisation is beneficial for image reconstruction [187]. In particular, the faithful recovery of piecewise smooth fibre orientation fields may improve advanced visualisation techniques such as DTI-based tractography.
are the eigenvalues of D as a function in Ω, one is able to identify isotropic regions (FAD
≈ 0) as well as regions where diffusion only takes place in one direction (FAD
≈ 1). The latter case indicates the presence of fibres whose orientation then corresponds to a principal eigenvalue of D. Figure 21 shows an example of DTI reconstruction from noisy data using TD and TGV2 regularisation for symmetric tensor fields, using principal-direction/fractional-anisotropy-based visualisation. It turns out that also here, higher-order regularisation is beneficial for image reconstruction [187]. In particular, the faithful recovery of piecewise smooth fibre orientation fields may improve advanced visualisation techniques such as DTI-based tractography.

Figure 21. Example of TD- and TGV2-regularised diffusion tensor imaging reconstruction. (a) Ground truth, (d) direct reconstruction from noisy data, (b) direct inversion of (90) followed by TD-denoising, (c) Tikhonov regularisation according to (91) with TD-regulariser, (e) direct inversion of (90) followed by TGV2-denoising, (f) Tikhonov regularisation according to (91) with TGV2-regulariser. All images visualise one slice of the respective 3D tensor fields.
Download figure:
Standard image High-resolution image8.4. Quantitative susceptibility mapping
Magnetic resonance imaging also has capabilities for the quantification of certain material properties. One of these properties is the magnetic susceptibility which quantifies the ability of a material to magnetise in a magnetic field such as the static field that is used in MRI. Recovering the susceptibility distribution of an object is called quantitative susceptibility mapping (QSM) [72, 177].
Assuming that the static field is aligned with the z-axis of a three-dimensional coordinate system, this susceptibility can be related to the z-component of the static field inhomogeneity δB0 : R3 → R that is caused by the material, which in turn induces a shift in resonance frequency and, consequently, a phase shift in the complex image data. For instance, if  denotes the phase of an MR image acquired with a gradient echo (GRE) sequence with echo time t > 0, the relation between δB0 and φ0 can be stated as:
denotes the phase of an MR image acquired with a gradient echo (GRE) sequence with echo time t > 0, the relation between δB0 and φ0 can be stated as:

where  is the time-independent phase offset induced by a single measurement coil and γ is the gyromagnetic ratio. Using multiple coils, the phase offset φ0 can be recovered [159] such that we may assume, in the following, that φ0 = 0. Pursuing a Lorentzian sphere approach and assuming that in the near field, the magnetic dipoles moments that cause the magnetisation are randomly distributed, one is able to relate δB0 with the magnetic susceptibility χ associated with the static field orientation approximately as follows [172]:
is the time-independent phase offset induced by a single measurement coil and γ is the gyromagnetic ratio. Using multiple coils, the phase offset φ0 can be recovered [159] such that we may assume, in the following, that φ0 = 0. Pursuing a Lorentzian sphere approach and assuming that in the near field, the magnetic dipoles moments that cause the magnetisation are randomly distributed, one is able to relate δB0 with the magnetic susceptibility χ associated with the static field orientation approximately as follows [172]:

where B0 is the static field strength and d : R3\{0} → R is the dipole kernel according to

Assuming further that the susceptibility is isotropic, i.e., does not depend on the orientation of the static field, it may be recovered from the phase data φt . However, the phase image φt is only well-defined where the magnitude of the MR image is non-zero (or above a certain threshold). Denoting by Ω ⊂ R3 a Lipschitz domain that describes where φt is available, recovering χ then amounts to solving

for χ : R3 → R. This problem poses several challenges. First, the values on the left-hand side are only available up to integer multiples of 2π, such that phase unwrapping becomes necessary. There is a plethora of methods available for doing this for discrete data [159], however, in regions of fast phase change, these methods might not correctly resolve the ambiguities introduced by phase wrapping. Consequently, the unwrapped phase image  might be inaccurate.
might be inaccurate.
With unwrapped phase data being available, the next challenge is to obtain χ on the whole space from a noisy version of χ * d on Ω, which is an underdetermined problem. The usual approach for this challenge is to split χ into its contributions on Ω and R3\Ω and only aim at reconstructing χ on Ω. Now, as the dipole kernel d is harmonic on R3\{0}, the function  is harmonic in Ω. Thus, one can write
is harmonic in Ω. Thus, one can write

and solve this equation instead. For QSM, one often estimates ψ first and subtracts this estimate from the data. This step is called background field removal in this context and there are many different approaches for that [173]. Depending on the accuracy of the background field estimate, this step may introduce further errors into the data. Nevertheless, the procedure results in a foreground field estimate  for which only the deconvolution problem
for which only the deconvolution problem

has to be solved. As this problem is ill-posed, it needs to be regularised. A Tikhonov regularisation approach can then be phrased as follows:

for 1 < p < ∞, dt
= 2πγtd and  a regularisation functional on Lp
(Ω). As the convolution with dt
results in a singular integral, the operation χ ↦ χ * dt
is only continuous Lp
(Ω) → Lp
(Ω) by the Calderón–Zygmund inequality [50], i.e., does not increase regularity. In this context, first-order regularisers (H1 and TV) have been used [20], but also TGV2 has been employed [63]. Note that in these approaches, one usually considers p = 2 which might cause problems regarding well-posedness for TV and TGV2 as in 3D, coercivity only holds in L3/2(Ω). This problem can for instance be avoided by setting dt
to zero in a small ball around zero; a strategy that also seems consistent with the modelling of the forward problem [172]. A numerical solution for χ then finally gives a susceptibility map of the region of interest Ω. However, since the overall procedure involves three sequential steps, each possibly introducing an error that propagates, an integrative variational model that essentially only depends on the original wrapped phase data φt
is desirable.
a regularisation functional on Lp
(Ω). As the convolution with dt
results in a singular integral, the operation χ ↦ χ * dt
is only continuous Lp
(Ω) → Lp
(Ω) by the Calderón–Zygmund inequality [50], i.e., does not increase regularity. In this context, first-order regularisers (H1 and TV) have been used [20], but also TGV2 has been employed [63]. Note that in these approaches, one usually considers p = 2 which might cause problems regarding well-posedness for TV and TGV2 as in 3D, coercivity only holds in L3/2(Ω). This problem can for instance be avoided by setting dt
to zero in a small ball around zero; a strategy that also seems consistent with the modelling of the forward problem [172]. A numerical solution for χ then finally gives a susceptibility map of the region of interest Ω. However, since the overall procedure involves three sequential steps, each possibly introducing an error that propagates, an integrative variational model that essentially only depends on the original wrapped phase data φt
is desirable.
Such a model can indeed be derived. First, observe that in case of sufficient regularity, the Laplacian of the unwrapped phase can easily and directly be obtained from φt :

such that  is known up to an additive harmonic contribution. Indeed, this is the concept behind Laplacian phase unwrapping [168]. Further, introducing the wave-type operator
is known up to an additive harmonic contribution. Indeed, this is the concept behind Laplacian phase unwrapping [168]. Further, introducing the wave-type operator

and noticing that d = □Γ, where Γ : R3\{0} → R is the fundamental solution of the Laplace equation, i.e.,  , it follows from (92) that
, it follows from (92) that

In particular, the harmonic contribution from the background field vanishes and the data obtained in (93) can directly be used on the right-hand side. Thus, only a wave-type partial differential equation has to be solved in which there is no longer the need for background field correction. The equation is, however, missing boundary conditions such that one cannot expect to recover χ in all circumstances. Under a priori assumptions on χ, the lack of boundary conditions can be mitigated by the introduction of a regularisation functional. Indeed, assuming that χ is piecewise constant and of bounded variation, the minimisation of TV subject to (94) recovers χ up to an additive constant [44].
Since the data φt
might be noisy, the variational model should also account for errors on the right-hand side of (94) and introduce a suitable discrepancy term. Assuming Gaussian noise for φt
, the right-hand side  is perturbed by noise in H−2(Ω) which suggests a H−2-discrepancy term for (94). The latter can be realised by requiring
is perturbed by noise in H−2(Ω) which suggests a H−2-discrepancy term for (94). The latter can be realised by requiring  for a ψ ∈ L2(Ω) and measuring the L2-norm of ψ. In total, this leads to
for a ψ ∈ L2(Ω) and measuring the L2-norm of ψ. In total, this leads to

where 1 ⩽ p < ∞, the constraint has to be understood in the distributional sense, and  is a regularisation functional on Lp
(Ω) realising a priori assumptions on χ that compensate for the lack of boundary conditions. In [126], the choice
is a regularisation functional on Lp
(Ω) realising a priori assumptions on χ that compensate for the lack of boundary conditions. In [126], the choice  was proposed and studied. Choosing
was proposed and studied. Choosing  , the functional in (95) is coercive up to finite dimensions and the linear PDE-constraint is closed, so one can easily see that an optimal solution always exists and yields finite values once there is a pair (χ, ψ) ∈ L2(Ω) × BV(Ω) that satisfies the constraints.
, the functional in (95) is coercive up to finite dimensions and the linear PDE-constraint is closed, so one can easily see that an optimal solution always exists and yields finite values once there is a pair (χ, ψ) ∈ L2(Ω) × BV(Ω) that satisfies the constraints.
A numerical algorithm for the discrete solution of (95) with TGV2-regularisation can easily be derived by employing the tools of section 6 and, e.g., finite-difference discretisations of the operator □. In [126], a primal-dual algorithm has been implemented and tested for synthetic as well as real-life data. It turns out that the integrative approach (95) is very robust to noise and can in particular be employed for fast 3D MRI-acquisition schemes that may yield low signal-to noise ratio such as 3D echo-planar imaging (EPI) [147]. It has been tested on raw phase data, see figure 22, where the benefits of higher-order regularisation also become apparent. Due to the short scan time that is possible by this approach as well as its robustness, it might additionally contribute to advance QSM further towards clinical applications.

Figure 22. Example for integrative TGV-regularised susceptibility reconstruction from wrapped phase data. (a) Magnitude image (for brain mask extraction). (b) Input phase image φt (single gradient echo, echo time: 27 ms, field strength: 3 T). (c) Result of the integrative approach (95) (scale from −0.15 to 0.25 ppm). All images visualise one slice of the respective 3D image.
Download figure:
Standard image High-resolution image8.5. Dynamic MRI reconstruction
As mentioned in subsection 8.2, data acquisition in MR imaging is relatively slow. This can be compensated by subsampling and variational reconstruction techniques such that in controlled environments, as for instance with brain or knee imaging, a good reconstruction quality can be obtained. The situation is more difficult when imaging parts of the body that are affected, for instance, by breathing motion, or when one aims to image certain dynamics such as with dynamic contrast enhanced MRI or heart imaging. Regarding unwanted motion, there exists a large amount of literature on motion correction techniques (see [197] for a review) which can be separated into prospective and retrospective motion correction and which often rely on additional measurements to estimate and correct for unwanted motion. In contrast to that, dynamic MRI aims to capture certain dynamic processes such as heartbeats, the flow of blood or contrast agent. Here, the approach is often to acquire highly subsampled data, possibly combined with gating techniques, such that motion consistency can be assumed for each single frame of a time series of measurements. The severe lack of data for each frame can then only be mitigated by exploiting temporal correspondences between different measurement times. One way to achieve this is via Tikhonov regularisation of the dynamic inverse problem, which, for instance, amounts to

where p ∈ [1, ∞], T > 0, Ω ⊂ Rd
is the image domain, and for almost every ![$t\in \left.\right]0,T\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn01.gif) , σt
is a positive, finite Radon measure on Rd
that represents the possibly time-dependent Fourier sampling pattern at time t, such that
, σt
is a positive, finite Radon measure on Rd
that represents the possibly time-dependent Fourier sampling pattern at time t, such that  according to (87) models the MR forward operator, and
according to (87) models the MR forward operator, and  represents the associated measurement data. Further, ut
denotes the evaluation of u at time t which is almost everywhere a function in Lp
(Ω). As usual,
represents the associated measurement data. Further, ut
denotes the evaluation of u at time t which is almost everywhere a function in Lp
(Ω). As usual,  corresponds to the regularisation functional that can be used to enforce additional regularity constraints. Note that in order to obtain a well-defined formulation for the time-dependent integral, the σt
have to vary in a measurable way with t such that the associated Kt
and the data ft
are also measurable in a suitable sense. We refer to [30] for details on the necessary notion and spaces, and an analysis of the above problem in the context of optimal-transport-based regularisation.
corresponds to the regularisation functional that can be used to enforce additional regularity constraints. Note that in order to obtain a well-defined formulation for the time-dependent integral, the σt
have to vary in a measurable way with t such that the associated Kt
and the data ft
are also measurable in a suitable sense. We refer to [30] for details on the necessary notion and spaces, and an analysis of the above problem in the context of optimal-transport-based regularisation.
In the context of clinical MR applications, temporal Fourier transforms [117], temporal derivatives [2] or combinations thereof [86] have, for instance, been proposed for temporal regularisation. More recently, methods that build on motion-dependent additive decomposition of the dynamic image data into different components have been successful. The work [141] achieves this in a discrete setting via low-rank and sparse decomposition which, for the low-rank component, penalises the singular values of the matrix containing the vectorised frames in each column. In contrast to that, by employing the ICTGV functional presented in subsection 5.3, the work [167] achieves an additive decomposition and adaptive regularisation of the dynamic data via penalising differently weighted spatio-temporal derivatives. There, problem (96) is solved for the choice

where the  are second-order spatio-temporal TGV functionals that employ different weightings of the components of the spatio-temporal derivatives in such a way that for
are second-order spatio-temporal TGV functionals that employ different weightings of the components of the spatio-temporal derivatives in such a way that for  , changes in time are penalised stronger than changes in space while
, changes in time are penalised stronger than changes in space while  acts the other way around. The numerical solution of (96) can again be obtained within the algorithmic framework presented in section 6 and we refer to [171] for a GPU-accelerated open source implementation and demo scripts.
acts the other way around. The numerical solution of (96) can again be obtained within the algorithmic framework presented in section 6 and we refer to [171] for a GPU-accelerated open source implementation and demo scripts.
Figure 23 shows the result of ICTGV-regularised reconstruction of a multi-coil cardiac cine dataset (subsampled with factor ≈ 11) and compares to the straightforward sum-of-squares (SOS) reconstruction. Since the SOS reconstruction does not account for temporal correspondences, it is not able to obtain a useful result for a high subsampling factor while the ICTGV-based reconstruction resolves fine details as well as motion dynamics rather well. Figure 24 shows a comparison to the low-rank and sparse (L + S) method of [141] for a second cine dataset with a different view. Here, the parameters for the L + S method where optimised for each experiment separately using the (in practice unknown) ground truth while for ICTGV, the parameters were trained a priori on a different dataset and fixed afterwards. It can be seen in figure 24 that both methods perform rather well up the high subsampling factors, where the ICTGV-based is able to recover fine details (highlighted by arrows) that are lost with L + S reconstruction.

Figure 23. Comparison of straightforward sum-of-squares (left) and ICTGV-regularised (right) reconstruction for a dynamic MR dataset with subsampling factor ≈ 11. Each image shows one frame of the reconstructed image sequence along with the temporal evolution of one horizontal and vertical cross section indicated by the red and blue line, respectively.
Download figure:
Standard image High-resolution image
Figure 24. Comparison of L + S- and ICTGV-regularised dynamic MR reconstruction. The first column shows, from top to bottom, a frame of the ground truth image sequence along with the temporal evolution of a vertical and horizontal cross section (indicated by red dotted lines) as well as a close up. Columns 2 and 3 depict the reconstruction results for L + S regularisation, while columns 4 and 5 depict the corresponding results for ICTGV regularisation (subsampling factors r = 12 and r = 16). The red arrows indicate details that are lost by L + S regularisation but maintained with ICTGV regularisation. Reproduced from [167] John Wiley & Sons. © 2016 International Society for Magnetic Resonance in Medicine.
Download figure:
Standard image High-resolution image8.6. Joint MR-PET reconstruction
We have seen in subsections 8.2 and 8.5 that image reconstruction from parallel, subsampled MRI data is non-trivial and can greatly be improved with variational regularisation. Beyond MRI and CT, a further medical imaging modality of high clinical relevance is positron emission tomography (PET). As opposed to standard MR imaging, PET imaging is quantitative and builds on reconstructing the spatial distribution of a radioactive tracer that is injected into the patient prior to the measurement. The forward model in PET imaging is the x-ray transform (often combined with resolution modelling) and, since measurements correspond to photon counts, the noise in PET imaging is typically assumed to be Poisson distributed. Reconstructing images from PET measurement data is a non-trivial inverse problem, where difficulties arise, for instance, from high Poisson noise due to limited data acquisition time, dosage restrictions for the radioactive tracer, as well as from limited measurement resolution due to finite detector size and photon acollinearity. As a result, variational reconstruction methods and in particular TV regularisation are employed also in PET imaging to improve reconstruction (see, for instance, [116, 165]).
In a clinical workflow, often both MR and PET images are acquired, which provides two complementary sources of information for diagnoses. This can also be exploited for reconstruction and in particular, for MR-prior-based PET reconstruction methods, which incorporate structural information from the MR image for PET reconstruction, are now well established in theory [105] and in practice [81, 169, 189]. While those methods regard an a priori reconstructed MR image as fixed, anatomical prior for PET, also joint, synergistic reconstruction is possible and recently became more popular due to the availability of joint MR-PET scanners [82, 122]. An advantage of the latter is that neither of the two images is fixed a priori and, in principle, a mutual benefit for both modalities due to joint reconstruction is possible. To this aim, the regularisation term needs to incorporate an appropriate coupling of the two modalities, and here we discuss the coupled TGV-based approach of [122] that allows to achieve this.
At first, we consider the forward model for PET imaging, which consists of a convolution followed by an attenuated the x-ray transform and additive corrections. With Ω ⊂ Rd
the image domain such that Ω ⊂ BR
(0) for some R > 0, the x-ray transform can be defined as linear operator  , where p ∈ [1, ∞],
, where p ∈ [1, ∞],  , Σ is a non-empty and open subset of the tangent bundle to
, Σ is a non-empty and open subset of the tangent bundle to  , via
, via

Note that here, u is extended by zero outside Ω and the measure μ on Σ is induced by the functional

see [134, section 3.4] for details. We further denote by k ∈ L1(Br
(0)) a convolution kernel with width r > 0 that models physical limitations in PET imaging, for instance, due to finite detector size and photon acollinearity, see [151]. The PET forward model is then defined as 

where u * k denotes the convolution of u and k (using again zero extension),  with a > 0 a.e. includes a correction for attenuation and detector sensitivities and
with a > 0 a.e. includes a correction for attenuation and detector sensitivities and  with c ⩾ 0 a.e. accounts for additive errors due to random and scattered events. Assuming the noise in PET to be Poisson distributed, we use the Kullback–Leibler divergence as defined in (2) for data fidelity.
with c ⩾ 0 a.e. accounts for additive errors due to random and scattered events. Assuming the noise in PET to be Poisson distributed, we use the Kullback–Leibler divergence as defined in (2) for data fidelity.
For the MR forward model, we use again the parallel MR operator KMR according to (87) in subsection 8.2 that includes coil sensitivity profiles and a measurement trajectory defined via a finite, positive Radon measure σ on Rd .
For regularisation, we use an extension of second-order TGV to multi-channel data as discussed in subsection 5.3, which, as in parallel MR reconstruction, is adapted to complex-valued data. That is, we define  for
for  similar to (53), where we use the spectral norm as pointwise dual norm on
similar to (53), where we use the spectral norm as pointwise dual norm on  and the Frobenius norm on
and the Frobenius norm on  . In the primal version of TGV analogous to (35), this results in particular in a pointwise nuclear-norm penalisation of the first-order derivative information ∇u − w and is motivated by the goal of enforcing pointwise rank one of ∇u − w in a discretised setting and hence an alignment of level sets.
. In the primal version of TGV analogous to (35), this results in particular in a pointwise nuclear-norm penalisation of the first-order derivative information ∇u − w and is motivated by the goal of enforcing pointwise rank one of ∇u − w in a discretised setting and hence an alignment of level sets.
With these building blocks, a variational model for coupled MR-PET reconstruction can be written as

where  and
and  , f2 ⩾ 0 almost everywhere is the given measurement data for MR and PET, respectively, and λ1, λ2 > 0 are the weights for the different data terms. Well-posedness for this model follows again by a straightforward adaptation of proposition 5.17 to the multi-channel setting. Regarding the regularisation parameters λ1, λ2, this is a particular case of coupled multi-discrepancy regularisation and we refer to [107] for results on convergence and parameter choice for vanishing noise. A numerical solution can again be obtained with the techniques described in section 6, where the discrete forward operator Kh
is vectorised as Kh
= diag(KMR,h
, KPET,h
) with discretised operators KMR,h
and KPET,h
, and the discrepancy
, f2 ⩾ 0 almost everywhere is the given measurement data for MR and PET, respectively, and λ1, λ2 > 0 are the weights for the different data terms. Well-posedness for this model follows again by a straightforward adaptation of proposition 5.17 to the multi-channel setting. Regarding the regularisation parameters λ1, λ2, this is a particular case of coupled multi-discrepancy regularisation and we refer to [107] for results on convergence and parameter choice for vanishing noise. A numerical solution can again be obtained with the techniques described in section 6, where the discrete forward operator Kh
is vectorised as Kh
= diag(KMR,h
, KPET,h
) with discretised operators KMR,h
and KPET,h
, and the discrepancy  is the component-wise sum of the two discrepancies above in a discrete version.
is the component-wise sum of the two discrepancies above in a discrete version.
Numerical results for 3D in-vivo data using this method, together with a comparison to a standard method, can be found in figure 25 (see also [122] for a more detailed evaluation). As can be seen there, the coupling of the two modalities yield improved reconstruction results in particular for the PET channels, making sharp features and details more visible.

Figure 25. Slices of fused, reconstructed 3D in vivo MR and PET images from an MPRAGE contrast with two-fold subsampling and a 10 min fluorodeoxyglucose (FDG) PET head scan, respectively (left to right: transversal view, coronal view, sagittal view). Top row: standard methods (CG sense [148] for MR, expectation maximisation [176] for PET). Bottom row: nuclear-norm-TGV-based variational reconstruction.
Download figure:
Standard image High-resolution image8.7. Radon inversion for multi-channel electron microscopy
Similar to joint MR-PET reconstruction, coupled higher-order regularisation can also be used in multi-channel electron microscopy imaging for improving reconstruction quality. As a particular technique in electron microscopy, scanning transmission electron microscopy (STEM) allows for a three-dimensional imaging of nanomaterials down to atomic resolution and is heavily used in material sciences and nanotechnology, e.g. for quality control and troubleshooting in the production of microchips. Beyond providing pure density images, spectroscopy methods in STEM imaging also allow to image the 3D elemental and chemical make-up of a sample.
Standard techniques for density and spectroscopy imaging in STEM are high-angle annular dark-field (HAADF) imaging and energy-dispersive x-ray spectroscopy (EDXS), respectively. For both imaging methods, measurement data can be acquired simultaneously while raster-scanning the material sample with a focussed electron beam. HAADF imaging records the number of electrons scattered to a specific annular range while EDXS allows to record characteristic x-rays for specific elements which are emitted when electrons change their shell position. For each position of the electron beam, both HAADF and EDXS measurements correspond to measuring (approximately) the density of a weighted sum of all elements and single element, respectively, integrated along the line of the electron beam that intersects the sample. Scanning over the entire sample orthogonal to an imaging plane, the acquired signals hence correspond to a slice-wise Radon transform of an overall density image (HAADF) and different elemental maps (EDXS).
Due to physical restrictions in the imaging system, the number of available projections (i.e., measurement angles) as well as the signal-to-noise ratio, in particular for EDXS, is limited and volumetric images obtained with standard image reconstruction methods, such as the simultaneous iterative reconstruction technique (SIRT) [93], suffer from artefacts and noise. As a result, regularised reconstruction is increasingly used also for electron tomography, with total-variation-based methods being a popular example [96]. While TV regularisation works well for piecewise-constant density distributions with sharp interfaces, the presence of gradual changes between different sample regions, e.g., due to diffusion at interfaces, motivates the usage of higher-order regularisation approaches for electron tomography [111], also in a single-channel setting [3]. In a multi-channel setting as discussed here, an additional coupling of different measurement channels is very beneficial in particular for the reconstruction of elemental maps and has been carried out with first-order TV regularisation in [201, 202] and second-order TGV regularisation in [111]. In the following, we discuss the TGV-based approach of [111] in more detail and provide experimental results.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
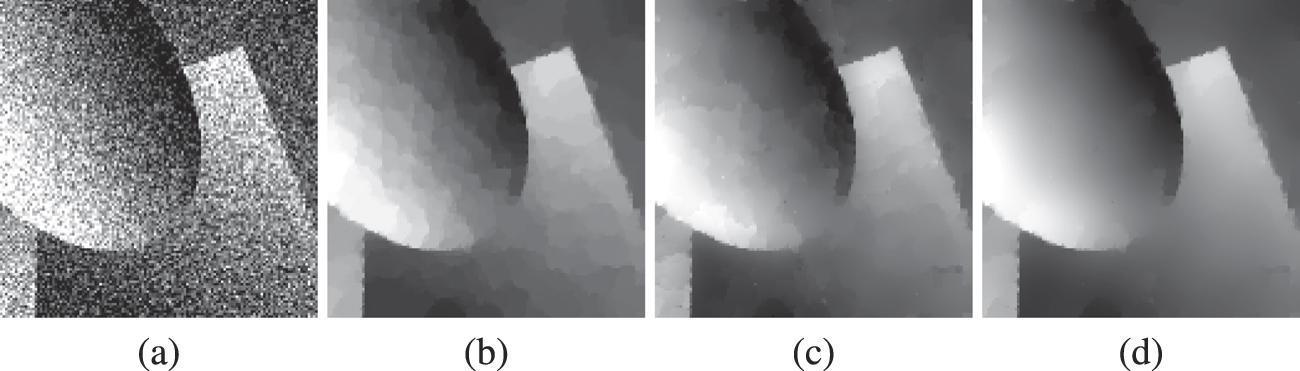{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 26. Example of multi-channel electron tomography. The images show density maps (top row) and elemental maps (bottom row) of one slice of a 3D multi-channel electron tomography reconstruction using different reconstruction strategies [111]. Left column: SIRT [93] method. Middle column: uncoupled TGV-based regularisation. Right column: coupled TGV-based regularisation. Reproduced from [111]. CC BY 3.0.
Download figure:
Standard image High-resolution image{kind=link}
With Σ = Σ1 × Σ2, ![${{\Sigma}}_{1}\subset {\mathcal{S}}^{1}{\times}\left.\right]-R,R\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn021.gif) non-empty, open,
non-empty, open, ![${{\Sigma}}_{2}\subset \left.\right]-R,R\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn022.gif) non-empty, open, for some R > 0 and
non-empty, open, for some R > 0 and  , we define, for
, we define, for ![${\Omega}={B}_{R}\left(0\right){\times}\left.\right]-R,R\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn024.gif) where BR
(0) ⊂ R2 and p ∈ [1, ∞], the forward operator for electron tomography as
where BR
(0) ⊂ R2 and p ∈ [1, ∞], the forward operator for electron tomography as  via
via

which corresponds to a slice-wise 2D Radon transform. By continuity of the Radon transform from L1(BR
(0)) to ![${L}^{1}\left({\mathcal{S}}^{1}{\times}\left.\right]-R,R\left[\right.\right)$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn026.gif) (see [134, section 3.4]) there is a C > 0 such that, for every u ∈ Lp
(BR
(0)) and almost every
(see [134, section 3.4]) there is a C > 0 such that, for every u ∈ Lp
(BR
(0)) and almost every ![$z\in \left.\right]-R,R\left[\right.$](https://content.cld.iop.org/journals/0266-5611/36/12/123001/revision3/ipab8f80ieqn027.gif) ,
,

Integrating over Σ2, it follows that KTEM is bounded from Lp
(Ω) to  . Now assume f1, ..., fn
to be given, multi-channel measurement data and the forward model for the ith measurement channel to be described with
. Now assume f1, ..., fn
to be given, multi-channel measurement data and the forward model for the ith measurement channel to be described with  for i = 1, ..., n. In the example considered below, f = (fHAADF, fYb, fAl, fSi), with fHAADF the HAADF data, and (fYb, fAl, fSi) the EDXS data for ytterbium, aluminium and silicon, respectively. With
for i = 1, ..., n. In the example considered below, f = (fHAADF, fYb, fAl, fSi), with fHAADF the HAADF data, and (fYb, fAl, fSi) the EDXS data for ytterbium, aluminium and silicon, respectively. With  the multi-channel extension of second-order TGV as discussed in subsection 5.3, using a Frobenius-norm coupling of the different channels, we consider
the multi-channel extension of second-order TGV as discussed in subsection 5.3, using a Frobenius-norm coupling of the different channels, we consider

for the reconstruction of multi-channel image data, for which well-posedness again results from a multi-channel extension of proposition 5.17. A numerical solution can be obtained using the framework as described in section 6 where again the discrete forward operator Kh
and the discrepancy term  are vectorised accordingly, similar as in subsection 8.6.
are vectorised accordingly, similar as in subsection 8.6.
Experimental results for this setting and a comparison to other methods can be found in figure 26, where in particular, separate TGV regularisation of each channel is compared to the Frobenius-norm-based coupling as mentioned above. It can be seen in figure 26 that using TGV regularisation significantly improves upon the standard SIRT method. Also, a coupling of the different channels is very beneficial in particular for the elemental maps, making material inclusions visible that can hardly be seen with an uncoupled reconstruction. We refer to [111] for a more detailed evaluation (and comparison to TV-based regularisation).
9. Conclusions
The higher-order total variation strategies and application examples discussed in this review show once again that while regularisation makes it possible to solve ill-posed inverse problems in the first place, the actual choice of the regularisation strategy has a tremendous impact on the qualitative properties of the regularised solutions and can be decisive on whether the inverse problem is considered being solved in practice. In the considered context of Tikhonov regularisation, convex regularisation functionals offer a great flexibility in terms of functional-analytic properties and a priori assumptions on the solutions. With the total variation being an established regulariser sharing desirable properties such as the ability to recover discontinuities, higher-order total variation regularisers offer additional possibilities, mainly the efficient modelling of piecewise smooth regions in which the derivative of some order may jump. We have seen in this paper that a regularisation theory for these functionals can be established and the overall theory is now sufficiently advanced such that the favourable properties of both first- and higher-order TV can be obtained with suitable functionals, for instance by infimal convolution. The underlying concepts are in particular suitable for various generalisations. The total generalised variation, for instance, bases on TV-type penalties for a multiple-order differentiation cascade and thus enables to realise the a priori assumption of piecewise smoothness with jump discontinuities. Further, due to higher-order derivatives being intrinsically connected to symmetric tensor fields, a generalisation to dedicated regularisation approaches for the latter is immediate. All these approaches and generalisations are indeed beneficial for applications and the solution of concrete inverse problems. This is in particular the case for inverse problems in medical imaging.
Of course, there are still several directions of future research, open questions and topics that have not been covered by this review. For instance, one of the major differences between first-order TV and higher-order approaches is the availability of a co-area formula that can be used to describe the total variation of scalar function in terms of its sublevel-sets. Generalisations to vector-valued functions or higher-order derivatives do either not exist or are not practical from the view of regularisation theory for inverse problems. As the co-area formula allows, for instance, to obtain geometrical properties for TV-regularisation [58, 112], it would be interesting to bridge the gap to higher-order TV approaches such that similar statements can be made. Some recent progress in this direction might be the connection between the solutions of certain linear inverse problems and the extremal points of the sublevel sets of the regulariser [26, 29], since the extremal points of the TV-balls are essentially characteristic functions. However, for higher-order TV and the generalisations discussed in this paper, a characterisation of its extremal points is not known to date. Further, in the context of TV-regularisation, only natural orders of differentiation have been considered in detail so far, with regularisation theory for fractional-order TV just emerging [70, 194, 199]. Indeed, there are many open questions for fractional-order TV regularisation ranging from the properties of the fractional derivative operators and their underlying spaces to optimal selection of the fractional differentiation parameter as well as the construction of efficient numerical algorithms. Finally, with all the possibilities of combining distributional differentiation and Radon-norm-penalisation, which are the essential building blocks of the regularisers discussed in this paper, the question arises whether their structure, parameters and differential operators can also be learned by data-driven optimisation. Some results in this direction can already be found in the literature [49, 71], and we expect that more will follow in the future.
Acknowledgments
The authors gratefully acknowledge support of the Austrian Science Fund (FWF) within the project P 29192. The Institute of Mathematics and Scientific Computing at the University of Graz is a member of NAWI Graz (www.nawigraz.at) and BioTechMed Graz (www.biotechmedgraz.at).
Appendix A.: Additional proofs
Lemma A.1. With Ω' ⊂ Rd measurable, in accordance with equation (2), let the functional KL on L1(Ω')2 be given as

where we set the integrand to v where f = 0 and to ∞ where v = 0 and f > 0. Then, KL is well-defined, non-negative, convex and lower semi-continuous. In case f ⩾ 0 a.e., it holds that KL(v, f) = 0 if and only if v = f. Further, for all v, f ∈ L1(Ω'),

and in particular,

for all f, v ∈ L1(Ω').
Proof. At first note that, in case f, v ⩾ 0, KL is given by integrating g : [0, ∞[2 → [0, ∞] with  for
for  , where we use the conventions
, where we use the conventions  for v ⩾ 0 and
for v ⩾ 0 and  for f > 0. It is easy to see that g is non-negative, convex and lower semi-continuous, hence KL is well-defined, non-negative, convex, lower semi-continuous and, in case f ⩾ 0 a.e., KL(v, f) = 0 if and only if v = f. Also, a simple computation (see [23]) shows that for all
for f > 0. It is easy to see that g is non-negative, convex and lower semi-continuous, hence KL is well-defined, non-negative, convex, lower semi-continuous and, in case f ⩾ 0 a.e., KL(v, f) = 0 if and only if v = f. Also, a simple computation (see [23]) shows that for all  ,
,

from which the estimate (A.1) follows with the Cauchy–Schwarz inequality applied to the square root of the above estimate. Now, for the first estimate in (A.2), we take f, v ∈ L1(Ω') and note that in case ||v||1 ⩽ ||f||1, the estimate holds trivially. In the other case, v ≠ 0 and we observe that (A.1) implies

from which the claimed estimate follows from rearranging, dividing by ||v||1 and noting that ||f||1/||v||1 ⩽ 1. The second estimate in (A.2) follows analogously. □
Lemma A.2. For {fn } and f in L1(Ω'), let KL(f, fn ) → 0. Then, ||f − fn ||1 → 0 and for each sequence {vn } in L1(Ω') with vn ⇀ v as n → ∞ for v ∈ L1(Ω'), it holds that

If, in addition, fn ⩽ Cf a.e. in Ω' for all n and some C > 0, then for all v ∈ L1(Ω'), we have

Proof. Assume that KL(f, fn
) → 0. It follows from the second estimate in (A.2) that {KL(f, fn
)} bounded implies {||fn
||1} bounded which, using (A.1), yields that fn
→ f in L1(Ω'). The lim inf estimate then follows from lower semi-continuity as in lemma A.1. Now assume that additionally, fn
⩽ Cf a.e. in Ω' for all n and some C > 0. By L1-convergence we can take a subsequence  such that
such that  pointwise a.e., and
pointwise a.e., and  . As
. As  as k → ∞, we have
as k → ∞, we have  . Also, since f log(v/f) ∈ L1(Ω') and
. Also, since f log(v/f) ∈ L1(Ω') and  , where we set
, where we set  where f = 0, is bounded a.e. uniformly with respect to k, we have
where f = 0, is bounded a.e. uniformly with respect to k, we have  by virtue of Lebesgue's theorem. Together, we get
by virtue of Lebesgue's theorem. Together, we get

which is what we wanted to show. □
Lemma A.3. Let k ⩾ 1, l ⩾ 0 and u : Ω → Syml
(Rd
) be (k + l)-times continuously differentiable such that  in Ω. Then, ∇k+l
⊗ u = 0 in Ω.
in Ω. Then, ∇k+l
⊗ u = 0 in Ω.
Proof. The statement is a slight generalisation of [28, proposition 3.1] and its proof is analogous. We present it for the sake of completeness. Choose a1, ..., a2l+k
∈ Rd
. We show that (∇k+l
⊗ u)(x)(a1, ..., a2l+k
) = 0 for each x ∈ Ω. For this purpose, let L ⊂ {1, ..., 2l + k} with  and denote, dropping the dependence on x, by
and denote, dropping the dependence on x, by

for some bijective π : {1, ..., l} → L, giving a (k + l)-times differentiable uL : Ω → R. Observe that by symmetry, uL does not depend on the choice of π but indeed only on L. Likewise, denote by

for some bijective σ : {1, ..., k + l} → ∁L. By symmetry of the derivative,  only depends on L. We also introduce an analogous notation for the symmetrised derivative
only depends on L. We also introduce an analogous notation for the symmetrised derivative  :
:

and, for some π : {1, ..., l} → L bijective,

Now, as for π : {1, ..., l} → L bijective, the definitions as well as symmetry yield

we see that each  can be written as a linear combination of
can be written as a linear combination of  . Up to the factor
. Up to the factor  , the linear mapping that takes the formal vector
, the linear mapping that takes the formal vector  indexed by all M ⊂ {1, ..., 2l + k},
indexed by all M ⊂ {1, ..., 2l + k},  to the formal vector
to the formal vector  indexed by all L ⊂ {1, ..., 2l + k},
indexed by all L ⊂ {1, ..., 2l + k},  is corresponding to the multiplication with the adjacency matrix of the Kneser graph K2l+k,l
, see, for instance, [19] for a definition. The latter is regular, which can, for instance, be seen by looking at its eigenvalues which are known to be
is corresponding to the multiplication with the adjacency matrix of the Kneser graph K2l+k,l
, see, for instance, [19] for a definition. The latter is regular, which can, for instance, be seen by looking at its eigenvalues which are known to be

see again [19]. Thus, we can find real numbers  indexed by all L ⊂ {1, ..., 2k + l},
indexed by all L ⊂ {1, ..., 2k + l},  and independent from u, and a1, ..., a2l+k
such that for M = {k + l + 1, ..., 2l + k}, the identity
and independent from u, and a1, ..., a2l+k
such that for M = {k + l + 1, ..., 2l + k}, the identity

holds. If  , then the right-hand side is 0 while the left-hand side corresponds to ∇k+l
u(a1, ..., a2l+k
). This completes the proof. □
, then the right-hand side is 0 while the left-hand side corresponds to ∇k+l
u(a1, ..., a2l+k
). This completes the proof. □
Lemma A.4. Let k ⩾ 1 and Ω ⊂ Rd be a bounded Lipschitz domain. For each u ∈ BVk (Ω) and δ > 0, there exists a uδ ∈ BVk (Ω) ∩ C∞(Ω) such that for δ → 0,

i.e., {uδ } converges strictly in BVk (Ω) to u as δ → 0.
Proof. The proof builds on the result [32, lemma 5.4] and techniques from [7, 85]. Choose a sequence of open sets {Ωn
} such that Ω = ⋃n∈N
Ωn
,  for all n ∈ N and any point of Ω belongs to at most four sets Ωn
(cf [7, theorem 3.9] for a construction of such sets). Further, let {φn
} be a partition of unity relative to {Ωn
}, i.e.,
for all n ∈ N and any point of Ω belongs to at most four sets Ωn
(cf [7, theorem 3.9] for a construction of such sets). Further, let {φn
} be a partition of unity relative to {Ωn
}, i.e.,  with φn
⩾ 0 for all n ∈ N and
with φn
⩾ 0 for all n ∈ N and  pointwise in Ω. Finally, let
pointwise in Ω. Finally, let  be a standard mollifier, i.e., ρ is radially symmetric, non-negative and satisfies
be a standard mollifier, i.e., ρ is radially symmetric, non-negative and satisfies  . Denote by ρɛ
the function given by ρɛ
(x) = ɛ−d
ρ(x/ɛ) for ɛ > 0.
. Denote by ρɛ
the function given by ρɛ
(x) = ɛ−d
ρ(x/ɛ) for ɛ > 0.
As ρ is a mollifier and φn
has compact support in Ωn
, we can find, for any n ∈ N, an ɛn
> 0 such that  for any v ∈ BD(Ω, Syml
(Ω)), l ∈ N. Further, as shown in [32, lemma 5.4], for any v ∈ BD(Ω, Syml
(Ω)) fixed, for any δ > 0 we can pick a sequence
for any v ∈ BD(Ω, Syml
(Ω)), l ∈ N. Further, as shown in [32, lemma 5.4], for any v ∈ BD(Ω, Syml
(Ω)) fixed, for any δ > 0 we can pick a sequence  with each
with each  being small enough such that with
being small enough such that with  , we have
, we have

In particular, for u ∈ BVk
(Ω) fixed and vl
= ∇l
u ∈ BDk−l
(Ω, Syml
(Rd
)) for l = 0, ..., k − 1, we can pick a sequence  with each component small enough such that
with each component small enough such that

since  . Further we note that, as additional consequence of the Sobolev–Korn inequality of theorem 3.18, vl
∈ Hk−1−l,1(Ω, Syml
(Rd
)) and hence by the product rule
. Further we note that, as additional consequence of the Sobolev–Korn inequality of theorem 3.18, vl
∈ Hk−1−l,1(Ω, Syml
(Rd
)) and hence by the product rule  , we get
, we get

In addition,

Since each | | |(vl−1 ⊗ ∇φn
) ∈ Hk−l,1(Ω, Syml
(Rd
)), by adaptation of standard mollification results [85, theorem 5.2.2] we can further reduce any  to be small enough such that for each m = 1, ..., k,
to be small enough such that for each m = 1, ..., k,

and consequently,

Now, setting  , we estimate for m = 1, ..., k, using the second estimate in (A.3) and that
, we estimate for m = 1, ..., k, using the second estimate in (A.3) and that  as well as
as well as  ,
,

This shows in particular that uδ
∈ BVk
(Ω) and by construction,  . Taking the limit δ → 0 and using the lower semi-continuity of TVm
, we finally obtain
. Taking the limit δ → 0 and using the lower semi-continuity of TVm
, we finally obtain

for m = 1, ..., k which, together with the first estimate in (A.3), implies the assertion. □