


Abstract
The scientific literature on climate change adaptation has become too large to assess manually. Beyond standard scientometrics, questions about if and how the field is progressing thus remain largely unanswered. Here we provide a novel, inquisitive, computer-assisted evidence mapping methodology that combines expert interviews (n = 26) and structural topic modelling to evaluate open-ended research questions on progress in the field. We apply this to 62 191 adaptation-relevant scientific publications (1988–2020), selected through supervised machine learning from a comprehensive climate change query. Comparing the literature to key benchmarks of mature adaptation research, our findings align with trends in the adaptation literature observed by most experts: the field is maturing, growing rapidly, and diversifying, with social science and implementation topics arising next to the still-dominant natural sciences and impacts-focused research. Formally assessing the representativeness of IPCC citations, we find evidence of a delay effect for fast-growing areas of research like adaptation strategies and governance. Similarly, we show significant topic biases by geographic location: especially disaster and development-related topics are often studied in Southern countries by authors from the North, while Northern countries dominate governance topics. Moreover, there is a general paucity of research in some highly vulnerable countries. Experts lastly signal a need for meaningful stakeholder involvement. Expanding on the methods presented here would aid the comprehensive and transparent monitoring of adaptation research. For the evidence synthesis community, our methodology provides an example of how to move beyond the descriptive towards the inquisitive and formally evaluating research questions.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
To achieve the goal of limiting the increase in global average temperature to well below 2 °C, ambitious mitigation action will be required [1]. Even if this goal is met, human livelihoods and ecosystems will still be exposed to substantial climate risks, and many countries in the Global South are especially vulnerable [1]. In this context, adaptation—defined as '[t]he process of adjustment to actual or expected climate and its effects' [2, p 5]—is particularly important. Considering also the Global Stocktake under the Paris Agreement and the upcoming Intergovernmental Panel on Climate Change's (IPCC) sixth Assessment Report (AR6), a comprehensive overview of the scientific literature on adaptation is essential to better enable knowledge sharing and to assess progress in understanding as well as persistent knowledge gaps [3–5].
A number of reviews over the last decade have attempted to document trends in understanding on climate change adaptation and related fields [6, 7]. Systematic reviews, in particular, are increasingly common [7], although the majority of reviews focus on specific regions or issues within adaptation, reviewing a corpus of literature that rarely extends beyond 100 documents (e.g. [8–11], exceptions include [12, 13]). Evidence mapping may typically consider an order of magnitude more articles [14], but even this may not be large enough when considering the sheer volume of literature [15]: Callaghan et al [16] find around 50 000 new papers on climate change in 2018 alone, and adaptation is a quickly growing field herein [17, 18]. The advent of such 'Big Literature' [19] makes it impossible for researchers to keep up with all available information and hinders synthesis efforts, including IPCC reports [16, 19, 20].
Crucially, although Big Literature is a problem for current, largely manual methods, it is also an opportunity for machine learning [14, 21–23]. Text mining methods, for example, use machine learning to uncover patterns in large text-based datasets; in the context of adaptation they have recently been applied to examine policy documents [24, 25] and narratives from researchers and practitioners [25]. Furthermore, some recent evidence maps [15, 26, 27] have made use of machine learning to examine issues such as carbon dioxide removal [28, 29], mitigation in cities [22], climate change governance strategies [30] and the climate change literature as a whole [16].
For adaptation, the closest analogy to a comprehensive map of the literature is the bibliometric analysis by Wang et al [17], together with similar work on related concepts [5, 31–33]. Like most evidence maps [14], these analyses are mainly descriptive; they typically do not examine concrete research questions and their chosen methods often do not allow for formal evaluation of hypotheses. Moreover, work to date relies on relatively coarse-grained heuristics to describe the actual content of adaptation research. As such, it is of limited use for assessing progress in adaptation research. As a consequence, despite the rapidly increasing body of research on adaptation, persistent gaps remain in our knowledge of how the field is maturing [34].
In this article, we develop a new methodology for computer-assisted, inquisitive evidence mapping. We apply this to adaptation-relevant research published over the last 32 years, in order to formally evaluate where progress is (and is not) being made. To this end, we first use expert interviews with researchers and practitioners (n = 26) to identify benchmarks of a mature adaptation research field. We then assess progress towards these benchmarks, capitalising on the opportunities afforded by machine learning to add to the extant literature in two key ways. First, we create a dataset of adaptation-relevant literature; here, taking a machine learning approach allows us to define this in a broad way as any study which focusses on the impacts of climate change on human systems or adjustments to those impacts. This breadth is essential given the diversity of ways in which adaptation research is defined [5, 35, 36], and allows us to place literature which self-defines as adaptation in the wider landscape of impact, adaptation, and vulnerability studies. Second, we analyse this dataset using structural topic modelling (STM) [37], which enables us to assess progress towards the benchmarks in a more formal way than other more descriptive evidence mapping methods (see section 2). We augment STM results with scientometric approaches and insights from the interviews. Overall, this first foray into using machine learning to assess progress in adaptation research can serve as a steppingstone from which to continue analysing this rapidly expanding field.
2. Methods: expert-informed, inquisitive computer-assisted systematic mapping
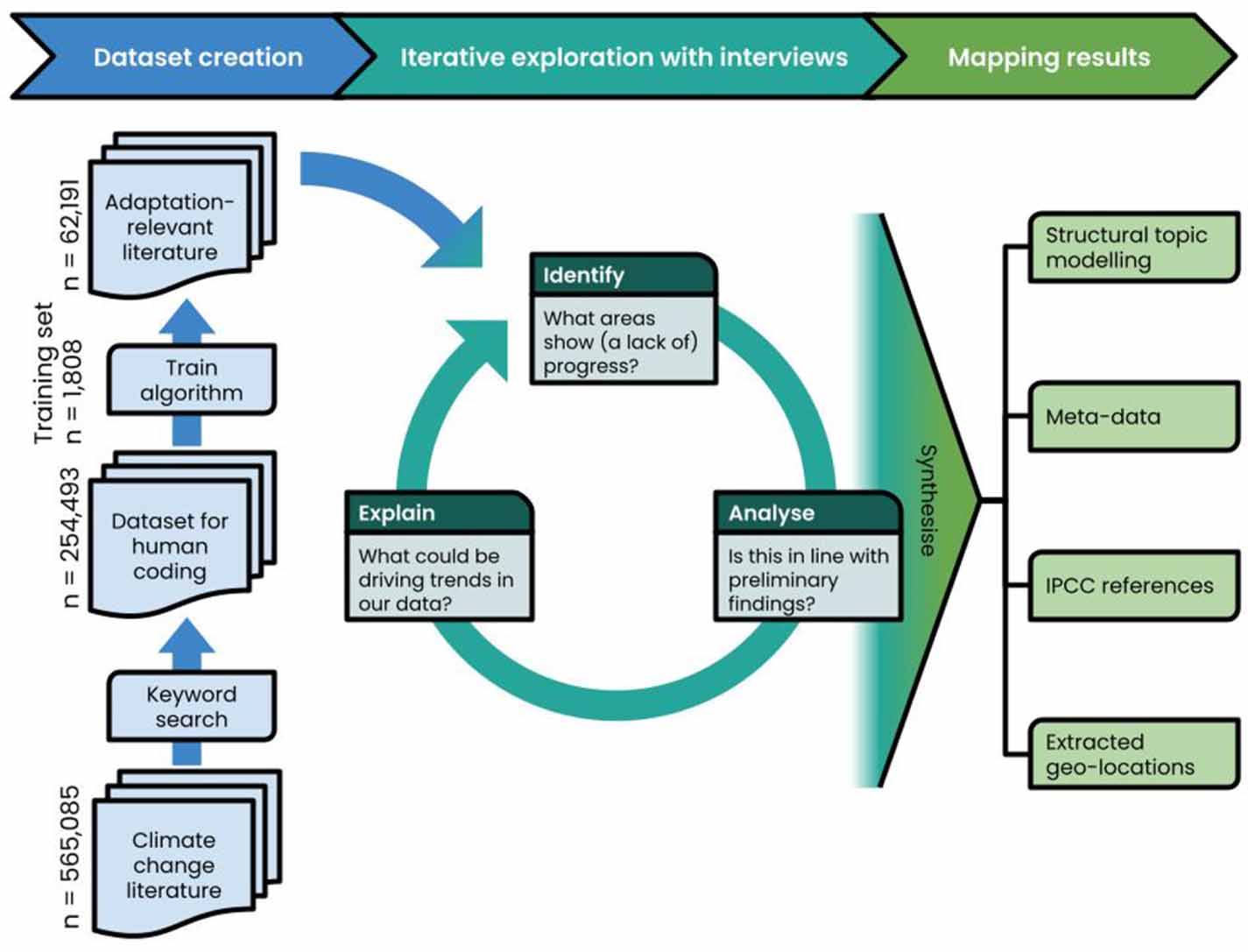
Our approach follows three interactive phases, as outlined in figure 1. Note that the findings used in the interview phase were based on a preliminary, somewhat smaller dataset. We will attempt to describe the machine learning methods for a non-technical audience, but given the limited space, will refer to other sources for more detailed explanations [e.g. 25, 38].
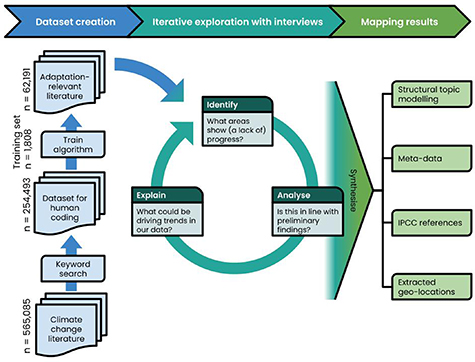
Figure 1. Schematic overview of the research process. The number of included documents is given for each step of the dataset creation phase.
Download figure:
Standard image High-resolution image2.1. Dataset: supervised machine learning to select adaptation-relevant documents
Here we use a methodology rooted in supervised machine learning to identify a corpus of adaptation-relevant publications. Scientometric studies typically develop their datasets from comparatively simple search queries [e.g. 17, 32, 33] to avoid including irrelevant literature. By contrast, systematic reviews and maps conduct extensive high-quality searches [27]. Like such gold-standard queries, our approach incorporates many synonyms for adaptation-relevant terms, except these are 'learned' by an algorithm, allowing for many more documents to be considered. As an added advantage, this allows us to quantify the quality of the dataset. Our dataset is based on the general climate change dataset created by Callaghan et al [16]. This dataset uses abstracts, titles and metadata (no full text) from the Web of Science Core Collections databases. We update their search and expand it (see supplementary materials (available online at stacks.iop.org/ERL/16/054038/mmedia)) to create a dataset with 565 085 documents published between 1985 and 13 August 2020. These documents are imported using a platform called NACSOS: NLP Assisted Classification, Synthesis and Online Screening [39], which also includes machine learning tools. In this dataset, we first conduct a broad keyword search and then use supervised machine learning to select adaptation-relevant literature. Specifically, we use a support vector machine (SVM) [40, using 41], which is an algorithm that aims to mimic human decisions in classification tasks (here: adaptation-relevant or not) based on a so-called training set (here: 1808 hand-coded documents). Inclusion/exclusion criteria for the training set can be found in the supplementary materials.
We then estimate the performance of the SVM using 10k-fold cross-validation, resulting in an overall accuracy of 90% (±3.4%) and an F1 score of 81% (±7.1%). In simpler terms, although this score is comparable to the results of similar work on different documents [30], it also implies that nearly 20% of relevant data is missed and that a similar percentage of papers is a false positive. However, the accuracy did not improve substantially with a larger training set. Note also that this error is not random: the algorithm generally excludes completely irrelevant documents, but struggles where human coders had difficulties consistently identifying relevant articles. We therefore posit that the relatively high error rate is a reflection of assigning binary scores in a field with substantial conceptual 'slipperiness' (see: [34, 42], for similar issues: [43]). Systematic reviews try to ameliorate this through strict selection criteria, but here too a substantial number of documents will not fall unambiguously in either the inclusion or exclusion category (e.g. [9]). A similar error would therefore likely be present—but not quantified—if all selection was done by hand rather than machine. Further limitations of our study include the exclusion of grey literature and studies not indexed in English.
2.2. Expert interviews: scoping expert perceptions of the state of adaptation research
The expert interviews served the dual purpose of both identifying key characteristics of a mature research field (i.e. benchmarking) and 'ground-truthing' the findings of the preliminary analyses, which required a relatively flexible exploratory kind of interview. We therefore conducted semi-structured expert interviews [44, 45].
Initially, experts were approached based on their IPCC affiliation, with most experts being either a Lead Author or a Coordinating Lead author for at least one chapter—mostly chapters in AR5 Working Group II [2, 46] and the Special Report on 1.5 °C [47]. To get perspectives, including non-academic perspectives, further experts were later added through snowball sampling, though experts from Oceania and the Middle East are lacking. In total, 26 experts were interviewed, details of whom can be found in table 1.
Table 1. Details of expert interview participants.
| Number of experts | ||
|---|---|---|
| IPCC affiliation (if any) | Coordinating Lead Author: 10 | Contributing author/other: 4 |
| Lead Author: 9 | ||
| Non-IPCC affiliation | Academic: 17 | Government: 3 |
| NGO and intergovernmental: 6 | ||
| Current location | Europe: 10 | Africa: 3 |
| Latin America and Caribbean: 6 | Asia: 2 | |
| North America: 5 | ||
| Gender | Male: 14 | Female: 12 |
Interviews lasted on average 61 min. Although the content of the interview changed as the analysis developed, each interview was divided into two main sections: First, an open-ended section to let the expert describe the main challenges and developments within the adaptation field in their own words; second a more focussed discussion on specific topics on adaptation, including comments on trends identified through our preliminary analyses. Recurring themes in the interviews were used to iteratively create a list of areas of interest. Once all interviews had concluded, each interview was analysed again in light of the major themes that emerged and the new analyses that had since taken place. The resulting key characteristics of a mature adaptation research were: providing specialist, practice-relevant information; interdisciplinary understanding, including in the IPCC; broad representation; and connection to practice. These form the benchmarks for our evidence map.
2.3. Inquisitive systematic mapping
Systematic maps have been highly descriptive in nature. It is the ambition here to provide a methodological framework that allows to formally assess the research landscape, which we term 'inquisitive, computer-assisted systematic mapping'. For example, Lamb et al [22] point towards differences in research themes across different regions, but it is hard to say whether these differences are statistically meaningful.
To facilitate an inquisitive approach to systematic mapping we root our analysis in STM [37], which is an unsupervised machine learning method that identifies themes in large text corpora. STM is similar to the more standard latent Dirichlet allocation in that both find clusters of words which frequently occur in the same documents, but STM can also incorporate the effect of a set of covariates on the respective topic distributions—e.g. language shifting over time or authors from different countries using different language. Moreover, once the topic model has been created, the effect of the meta-data per topic can be estimated, which allows us to move beyond descriptions of the research field into more formal assessments of progress benchmarks, including indicators for statistical significance.
A range of models with between 50 and 220 topics were created. A higher number of topics means a more granular picture of the literature, but also fragments topics that should stay together. After a first selection, three candidate topic models were discussed by multiple authors, striving to find the lowest number at which a majority of major themes from the interviews still had a clearly defined topic in the model, and setting the final number of topics at 105 by consensus—see also [48]. Labels for the topics were decided on using both the most associated words using various metrics (see supplementary materials) and the most closely associated documents for each topic.
One way to visualise the final topic model is by using a dimensionality reduction algorithm. We use t-distributed stochastic neighbour embedding (t-SNE) [49]. In essence, the topic model assumes that each document is comprised of multiple topics; for each document, it calculates topic scores for every topic. For n documents and k topics, this results in an n× k matrix. t-SNE can reduce this to n× 2, while 'trying' to keep points that are similar in k-dimensional space (similar topics) close in two-dimensional space (similar coordinates). The result can then be plotted, showing clusters of documents which discuss similar topics.
Further, one of the main interests arising from the interviews was the geographic distribution of the literature. We therefore use a pre-trained named entity recognition algorithm [50] to determine where a place name is mentioned in an abstract or title. A dictionary method [51] was used to extract the location of the first author as author affiliations are not given in a sentence and therefore may not always be identified correctly by the pre-trained algorithm.
Callaghan et al [16] already included data on if papers in the dataset were cited in IPCC Assessment Reports. We matched references from IPCC Special Reports as well, using a pre-trained machine learning algorithm called Generation of bibliographic data (GROBID) [52] to identify references and csvmatch [53] to do fuzzy matching.
Lastly, the Web of Science database includes information on the research field, which is based on the journal. These were too specific for our purposes and were therefore converted to more general categories based on the Organisation for Economic Co-operation and Development category scheme [54].
3. Results
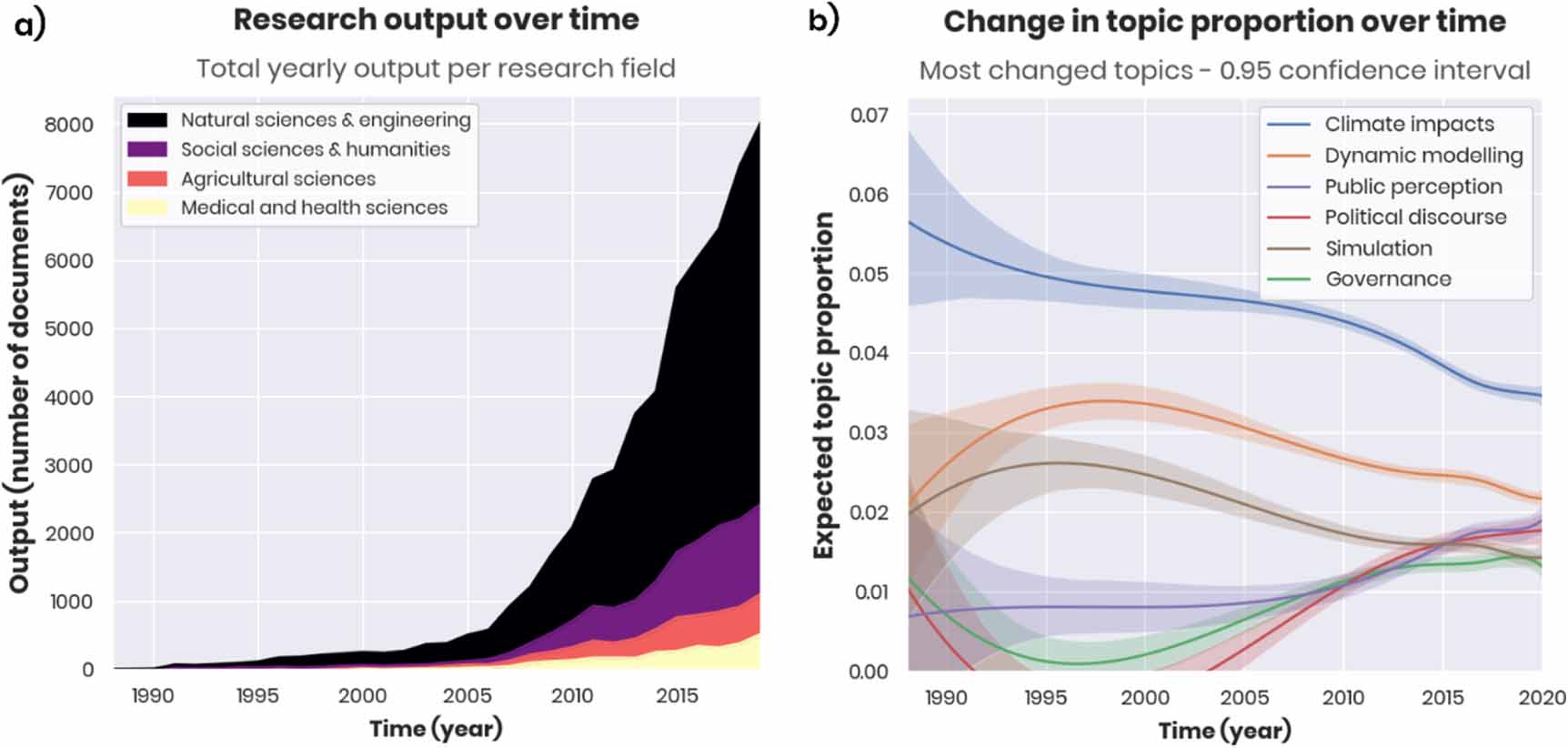
We identify 62 191 adaptation-relevant peer reviewed articles published between 1988 and August 2020 (figure 2(a)). Between 2009 and 2019, the literature output on average grew by 20.6% per year—faster than the broader climate change field [16, 18]. Subsequently, we present an assessment of progress in adaptation research based on this dataset, using quotes and insights from the expert interviews to provide a more qualitative understanding. An overview of our findings is given in table 2.

Figure 2. Changes in papers over time. (a) Shows the output per year (1988–2019), sub-divided by field, based on the Web of Science categories. (b) Shows the topic proportion over time for the three most and three least increased topics since 2000. In layman's terms, a high value means that the texts in the dataset from around that year contain more words related to that topic.
Download figure:
Standard image High-resolution imageTable 2. Summary of results with respect to our selected benchmarks of maturity. The description of these benchmarks includes sub-components, were applicable, and cites work that highlights the importance of these benchmark for mature adaptation research. In the maturity column, we provide a qualitative evaluation by the authors of (progress towards) maturity based on the results below.
| Benchmark | Description | Maturity |
|---|---|---|
| Specialist, applicable information | Information provided by researchers should be able to provide specialist answers to practice-relevant questions [55–57] | Significant progress |
| Interdisciplinary understanding | The interdisciplinary nature of the climate change problem necessitates integration between disciplines [36, 55, 58–60] ... | Mixed |
| ... and the IPCC should represent evidence from different disciplines fairly [61–63] | Mostly mature | |
| Broad representation | There is an imbalance between the Global North and South in terms of quantity [17, 18, 64, 65] ... | Some progress; gaps remain |
| ... and thematic focus [66–68] of the research base which should be addressed. | Gaps remain | |
| Connection to practice | A meaningful connection between research and practitioners, especially local stakeholders, is essential for successful adaptation in practice [57, 69, 70] | Mixed on politics, stakeholders insufficient |
3.1. Vulnerability dominates but the adaptation field is specialising and moving to solutions
A mature adaptation research field should provide an evidence base that can inform decision making through targeted and specialised information [55–57]. Our analysis reveals a rapidly expanding and specialising evidence base with increased attention for implementation-related topics especially (figure 2).
Although these developments point towards a maturing field, at present, natural science journals dominate publishing, accounting for 70.0% of research. A caveat here is that some explicitly interdisciplinary journals are classified [54] as natural sciences, including Climatic Change, the most frequent publication (n = 1961). Still, the topics from STM (table 3) also predominantly point to highly technical subjects (e.g. climate modelling). While social science topics are also represented (e.g. governance, migration), adaptation-relevant research often focusses on what needs to be adapted to as opposed to what responses are needed. Research in the 'problem space', including impacts and vulnerability studies, is thus more common than research in the 'solution space' [71].
Table 3. Results of the structural topic model where the topics are grouped in overarching categories for ease of reference. A more extensive version of this table which includes the most closely associated keywords per topic can be found in the supplementary materials.
| Category | Topic label | ||
|---|---|---|---|
| General climate change | Climate impacts | Global warming | Global challenge |
| Meteorology | Heatwave | In-/decrease (water) | Weather Trend |
| Temperature | Seasonality | Rainfall | |
| Seasonality (ENSO) | Precipitation | ||
| Modelling and Mapping | Simulation | Dynamic Modelling | Downscaling |
| Future Projection | Future and Past | Remote Sensing | |
| Coupled Model | Emission Scenario | ||
| Methods and Methodology | Bias | Uncertainty | Variable |
| Research | Review Study | Key Finding | |
| Ethics | |||
| Physical Environment | Coastal Zone | Sea Level Rise | Sea Level (Deltas) |
| SIDS | Watershed | Stream Flow | |
| River Basin | Glacier and Lake | Ice Surface | |
| Snow/Alpine | Soil | Forestry | |
| Biology | Nature conservation | Ecosystem Services | Species Distribution |
| Land use | |||
| Urban and Infrastructure | Urban | Green Building | Design |
| Sewers and Roads | |||
| Food and Agriculture | Agriculture | Farmer | Food Security |
| Livestock | Fisheries | Crop Yield | |
| Cultivars | Quality of Produce | Crop genetics | |
| Plant Stress | |||
| Water and Water Management | Groundwater | Water Availability | Flood Insurance |
| Drought | Irrigation | Hydrology | |
| Extreme Events | Extreme Event | Wildfire | Disaster |
| Storm Surge | |||
| Adaptation-Related Concepts | Adaptation Strategy | Resilience | Hazard |
| Vulnerability Assessment | Sustainable Development | ||
| Governance and Programmes | Governance | International Policy | Political Discourse |
| Decision Making (Stakeholders) | Roles in Discourse | ||
| Health | Infectious Disease | Public Health | Vector-borne Disease |
| Mortality and Hospital | Affected Groups | ||
| Socioeconomic Factors | Economics | Tourism | Socioeconomics |
| Damage | Social Mobilisation | Education | |
| Public Perception | Environmental Migration | Resource Management | |
| Communities | Tradition/Indigenous | Household | Local Community |
| Countries and Places | Africa | Canada | United States |
| China (Grassland) | India (Rice) | Europe | |
| Australia | |||
| Other/mixed | Mixed (Flash Flood, Asia) | Mixed (Conclusions, Consequences) | Mitigation |
| Energy | |||
Against this continued trend, we see progress towards a more diverse literature: starting around 2008, there is an increasing number of publications from other fields. This aligns with both expert opinion from the interviews and with similar trends documented for the climate change field in general [18, 55]. Multiple experts remarked how climate change research was initially focused on description and attribution from a physical sciences angle, but that climate solutions require a broader perspective. One interviewee stated 'By seeing that very simple adaptation measures can actually fail, you realise what was actually missing—be it a wise communication strategy or be it that you did not think about the psychology, how people use it or [some other perspective].'
Relatedly, research appears to be specialising. The most prominent topic in the topic model overall is on general Climate Change Impacts. However, the relative prevalence of this topic and the other general climate change topics have decreased markedly in the last two decades (figure 2(b)). By contrast, some of the fastest growing topics are Political Discourse, Public Perception, and Urban Issues. This suggests that the literature is increasingly focused on more specialised issues within adaptation (noting that these are relative proportions, so the absolute output will be increasing for many topics, even if their relative share has decreased).
Experts further stated that the previously noted dominance of research in the problem space may be decreasing for three main reasons: solutions are emphasised under the Paris Agreement; the effects of climate change are becoming more apparent, especially in the Global South; and concrete adaptations and adaptation policies are increasingly being implemented [47, chapter 4], meaning they can be evaluated. In line with this, we find increased attention for most topics related to implementation and policy, while the relative share for all modelling topics has been decreasing.
Experts on the policy side, however, indicated that, while there may be an increase in quantity, the quality of research on governance has not progressed as much. One interviewee questioned if in recent years, we have made 'any progress beyond knowing that there are some technical measures, that it is important to involve stakeholders, and that there are various barriers and opportunities? I think personally that we have moved a little, but not as much and not as fast as we had initially thought.'
3.2. Topics are largely distributed along disciplinary boundaries but IPCC reports provide a largely representative synthesis
While specialist knowledge is necessary, cross-disciplinary understanding of the broader adaptation field is also important for mature adaptation research [36, 55, 58]—indeed, disciplinary understandings of adaptation can limit the effectiveness of adaptation in practice as they can lead to oversimplified solutions to multidimensional problems [59, 60]. Our analysis documents evidence of a more integrated assessment for some topics, but most topics in our model remain dominated by one discipline (figure 3).
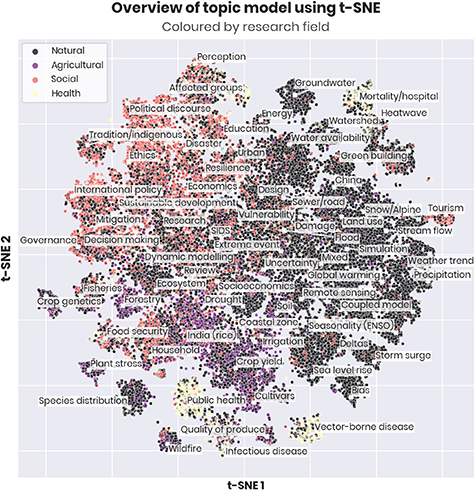
Figure 3. A mapping of the topic model. The 105 dimensions of the topic model are reduced to two so that each document can be plotted as a single dot, where the algorithm attempts to keep documents with a similar topic distribution close together. Dots are then coloured by research field with labelling for locally dominant topics; areas of same-coloured dots around a label therefore imply that most publishing on this topic is from journals in the same field. Due to the dimensionality reduction, the axes have no meaningful unit—see section 2.
Download figure:
Standard image High-resolution imageThe mapping of our topic model corresponds well to the expert interviews and earlier findings [33]. The natural sciences are particularly dominant for topics related to modelling and geography. Articles in social science journals use dissimilar language and focus on topics around economics and politics predominantly. Agricultural topics have strong links to the natural sciences, though topics like food security are highly interdisciplinary. There is an interdisciplinary cluster of articles centred around the health effects of heatwaves, but overall, the health literature is relatively distinct from the rest of adaptation-relevant research, with clusters on vector-borne diseases and public health.
Relatedly, a disconnect between scientists and healthcare practitioners was noted by one expert: 'The challenge is, this [practical experience] is not then put into the research community. (...) All of those health risks [of climate change] are current problems. All of those health risks have policies and programmes to manage them. Until recently, none of those policies and programmes explicitly incorporated climate change.'
Inter/transdisciplinary communication more broadly was also identified as a challenge by multiple experts. One stated that, as a social scientist, they at times felt like they were added to a project 'to explain the results', rather than being integrated in the project cycle. By contrast, experts commented that the representation of social sciences in IPCC reports is increasing, in line with earlier findings [16]. The establishment of a shared vocabulary between disciplines was noted to have taken time to develop but is proving useful, especially for Working Group II. This assertion is especially interesting given both past criticisms [61, 72] and current calls for an integrated assessment of adaptation progress [5, 73].
To test the representativeness of IPCC reports, 4922 IPCC Working Group II (AR 1–5) and Special Report references were matched to documents in the dataset and the effect of this meta-data on the topic proportions examined (figure 4). Generally, this literature has similar topic proportions to the other literature in our dataset. With the exception of the climate impacts topic, under-represented topics are predominantly identical to those identified as fast-growing above; it therefore seems plausible that this may be addressed in the upcoming AR6. Note also that interviewed IPCC authors almost universally agreed that non-scientific publications and non-English publications can be highly relevant, but that these are too often not seen by researchers and rarely included in IPCC reports—nor are they in our dataset. When it comes to representing scientific research however, apart from some delay effects, IPCC reports appear to fairly represent disparate fields of research.
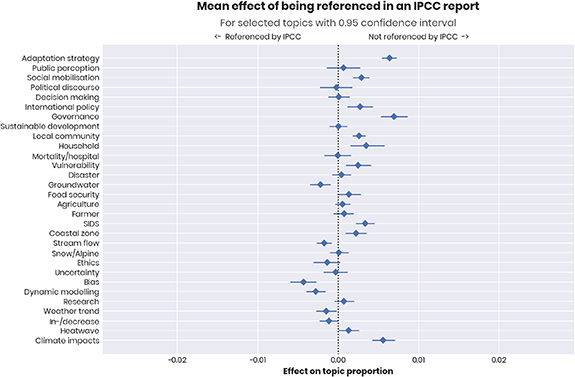
Figure 4. Effect of meta-data on the topic prevalence for selected topics in our topic model, here comparing documents that are cited in IPCC reports to the rest of the dataset. In essence, values further to the left (right) mean that a topic is more (less) likely to occur in documents cited by the IPCC compared to the documents that are not cited. A value in the middle means that the topic is equally represented in both. Axes are identical to figure 6 for easy comparison.
Download figure:
Standard image High-resolution image3.3. Both the amount and the content of research differs by region
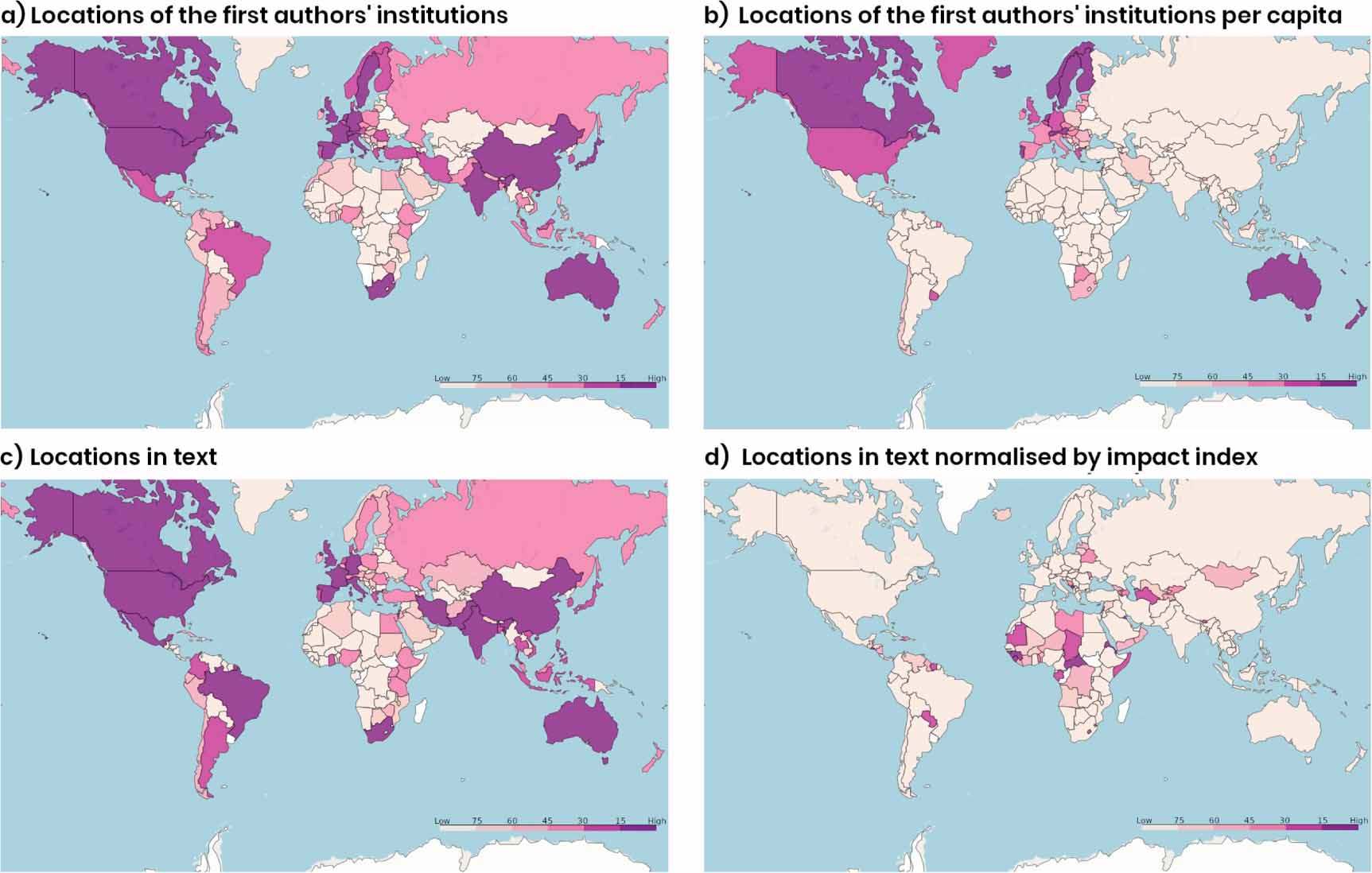
Experts and literature [17, 18, 64, 65] alike pointed to unequal representation between the Global North and South as a persistent problem within the adaptation field. One expert remarked for example that they would expect the Global North to 'dominate the funding and the first author. And the last author'. This is broadly supported by the geographic information extracted from our data, though there are large differences within the North-South division.
The location of the first author could be extracted for 52 977 papers (85.1%—figure 5), of which the largest group was located in the United States (n = 11 749) followed by China (n = 5475). Grouping by United Nations Framework Convention on Climate Change (UNFCCC) Annex I status, 69.4% (n = 25 490) of the documents originate from Annex I countries. It should be noted here though that many researchers have international backgrounds. Authors from an Annex I institution may therefore originate from a Non-Annex I country.
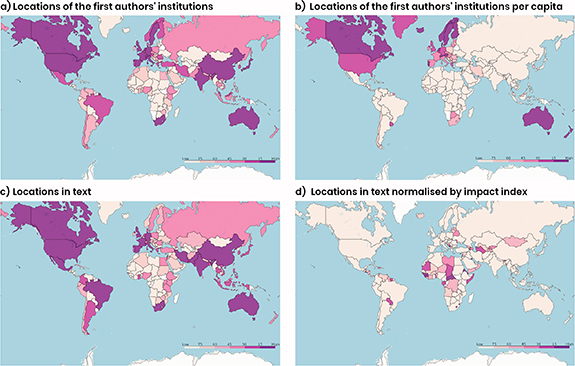
Figure 5. The geographic spread of the number of publications, where the location is based on the country of the first author (a) and (b) and the location identified in the abstract and title (c) and (d); (b) is normalised by the country's population; (d) is normalised by the ND-GAIN index, which ranks countries based on a climate impact score. Colours represent 5 consecutive groups of 15 countries each.
Download figure:
Standard image High-resolution imageBy identifying geographical locations in the title or abstract of our dataset, we estimate where studies are taking place. At least one location was identified in 39 509 papers (63.5%). The imbalance is smaller for these locations: the US is still most prominent (n = 7469), but the gap with China (n = 4938) is smaller. Half (49.5%, n = 19 575) of identified places are in Annex I countries. For 31.2% (n = 6229) of all research taking place in Non-Annex I countries, the primary author is based in an Annex I country.
In interviews, funding imbalances are named most often as driving these inequalities, though there may be increasing awareness from funding agencies around this. Correspondingly, if we consider only the literature since 2015, the trend is towards fewer Annex I authors (64.6%) and more research in Non-Annex I countries (55.6%).
Further, Latin American experts highlighted that international funding applications often require a vulnerability assessment; however, middle income countries cannot always produce this as the initial funding for these vulnerability assessments was focused on Least Developed Countries (LDCs—notably, for National Adaptation Programmes of Action through 5/CP.7 [74] and for National Adaptation Plans through 5/CP.17 [75]). There is some evidence for such a 'middle income gap', especially in parts of Latin America, Eastern Europe, and the Middle East.
Vulnerability does not always translate into more research. Combining place name mentions with indices of vulnerability to climate change [76, data from 2018, 77] highlighted a subset of African and South American countries and Small Island Developing States (SIDS), as well as the Balkans and Central Asia, as understudied—i.e. highly vulnerable, but few papers. However, differences within regions and country groups can be substantial, such as Tonga (n = 4) and the Solomon Islands (n = 144). Overall, there is no consistent relationship between vulnerability and research output.
We can consider North-South inequalities also in terms of the topics of research. Here, a somewhat controversial criticism of the field from one of the experts was that 'theories come from the North, evidence comes from the South'—meaning that studies which define key terms tend to come from Northern countries, which are then applied in case studies in the South [78, 79]. While difficult to operationalise, STM does allow us to calculate the effect of both the location of the author and places mentioned in the text on topic distributions (figure 6). This reveals that many governance-related and conceptual topics are discussed somewhat more by authors based in Annex I countries, but that these topics do not necessarily mention places in Annex I countries. This suggests that a substantial part of this research is conducted by Annex I authors in Non-Annex I countries.
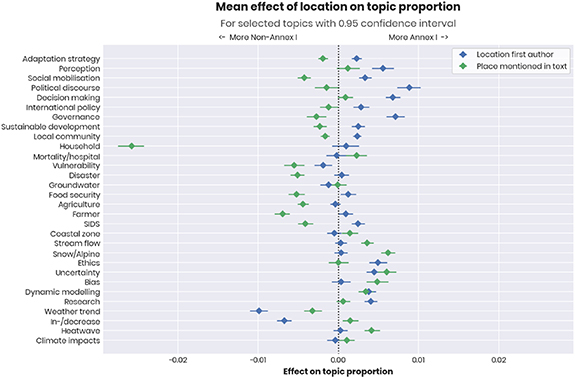
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 6. Effect of meta-data on the topic prevalence for selected topics in our topic model, here comparing the country identified in the abstract and of the country of the first author, where the countries are grouped by UNFCC Annex I status. In essence, values further to the left (right) mean that a topic is more (less) likely to occur in documents on the given topic from Non-Annex I countries, compared to Annex I countries. A value in the middle mean that the topic is equally represented in both.
Download figure:
Standard image High-resolution image{kind=link}
A similar but shifted trend is observed for topics with a strong development link: research here more often takes place in Non-Annex I countries, but authors are not necessarily based there. The Household topic is associated with words like smallholder (farms), but also Ghana and Kenya, which explains why this effect is so pronounced for this topic especially. More generally, the importance of agriculture for the economies of many Southern countries led experts to expect agricultural topics to be overrepresented in Non-Annex I countries, which also corresponds to our data.
By contrast, subjects around modelling and natural sciences tend to be slightly more present in literature from Annex I countries—though the effect is less consistent. The resources and technical knowledge required for this type of research is often higher and more difficult to find in the Global South. One expert, for example, noted that most countries in Central America lack graduate programmes in climatology, as well as the computing power to run state-of-the-art climate models.
3.4. Experts signal the need for connection to practice if not politics
Academic experts had mixed opinions on how their scientific work connected to practice and politics. Some experts found that scientific concepts do at times inform the international negotiations: Loss and Damage was cited as a prime example of this. Vice versa, concepts from the policy side can enter the scientific discourse, especially when they are connected to funding. Together, this points to a feedback loop where researchers are incentivised to use politically salient terminology and decision makers in turn may adopt scientific concepts to substantiate their choices. Although the motivations of authors cannot be gleaned from a topic model, this dynamic likely contributed to the prevalence of many closely related terms such as vulnerability and resilience in our topic model. Underlying this feedback loop is the pressure many experts feel to produce work that is politically relevant. Some experts stated they were uncomfortable with this, as it may have a bearing on the (perceived) impartiality of research. Such reservations fit into a wider and longstanding debate in the literature [e.g. 80], wherein some for example have highlighted the importance of professional ethics for adaptation researchers [81].
Other experts put forward that many adaptation researchers want to make a positive difference, especially for the most vulnerable communities—see also the previously noted prevalence of Annex I researchers in Non-Annex I countries. Although this does not always necessitate a close connection to politics, connections with local communities and meaningful stakeholder involvement are widely seen as important for adaptation research to make such a positive difference in the long term [36, 57, 69]. As one expert focussing on marine and coastal issues noted: 'Building and strengthening local capacity is absolutely critical (...) The best long-term stewards of those coastlines, will be those who live along them and whose lives depend on the oceans and stand the most to lose from projected changes. They are at the frontline. We need to invest in them so they have the skills and knowledge to best prepare them for what is to come.'
Despite this need, as stated before, findings from practice are not widely taken up by the research community. Conversely, practitioner interviewees stated that they were in no position to keep up with the scientific literature; some felt a lack of guidance from the scientific community on basic implementation issues especially; in essence, 'what works where?'
4. Progress in adaptation research
In this paper we present an expert-informed, computer-assisted and inquisitive method for systematic mapping. We demonstrate how machine learning can be used to build a broad corpus of adaptation-related research. We develop existing approaches to computer-assisted systematic mapping [15, 16, 82] by rooting our methodology in STM which allows us to formally assess open-ended research questions emerging from the expert interviews. In our opinion, this is an important step in systematic mapping, which has remained largely descriptive in character [14, 16–18, 22, 83], instead using inquisitive research questions as the foundation for evidence mapping.
We find a wide variety of topics are increasingly being assessed, and research is moving towards implementation of adaptation actions, indicating a maturing research field where researchers are progressively moving into more specialised sub-topics. Moreover, criticisms that the IPCC under-represents especially the social sciences [61, 72] we find are likely a reflection of the quick growth of social science topics and the dominance of natural sciences in adaptation research more broadly, not of a bias within the IPCC.
At the same time, some long-standing issues still need to be resolved. Integration between natural and social sciences continues [72] to be a challenge, and parts of health research appear to be especially separated from mainstream work on adaptation. Research agendas should aim to break down silos, not just between disciplines but also between research and practice [55]. There is also a clear need for work that includes local communities and practitioners and/or that has clear transferable results; projects which take a holistic approach can facilitate knowledge sharing between both different disciplines and groups of stakeholders, even if those project can be more difficult to implement [59, 60]. Arguably, such projects could also help meet recent calls for practice-relevant recommendations from the IPCC [61–63].
There is limited progress towards decreasing the well-established [17, 18, 64, 65] gap in research output between the Global North and South. We find the gap extends to the topics of research, not just to the quantity. The paucity of research in some highly vulnerable countries is also noteworthy. In response, funding structures may have started to shift, but more needs to be done to ensure that funds are distributed justly [84] and that they meet local needs [85], including supporting multi-sector solutions long term [86].
Overall, given both these persistent challenges and the signs of increasing maturity, 'reflexive adaptation' [36] continues to be crucial. Large-scale quantitative approaches can help especially for relatively exploratory analyses; these should augment rather than replace qualitative reflexions [7, 14]. To play an effective role in such critical discussions, the evidence mapping community should move beyond descriptive work and instead further develop methods and approaches that will allow for formal hypothesis testing. We take some tentative steps in that direction here.
It is worth highlighting again that our approach should be seen as a first step. We took a broad view of what could be considered adaptation-relevant, thus providing insights into larger trends. This capitalises on the ability of machine learning methods to handle large datasets, but the trade-off is that we cannot address more detailed questions. Moreover, even this large dataset is not comprehensive (see section 2). Further machine learning work may for example focus on the evidence for adaptation solutions, incorporating also non-academic data sources, and contribute to a comprehensive tracking of adaptation actions around the globe as a foundation for urgently needed progress both in science and policy [3–5, 13, 87]. Ultimately, like any tool, machine learning methods have limitations.
Given the rapid growth of and developments in many research fields though, they are necessary tools. Manual assessment practices, especially global environmental assessments like those by the IPCC or the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services are increasingly challenged by Big Literature; the related science-policy discussion offers few ideas on how to secure credibility, transparency and rigour in the scientific landscape of the 21st century [19, 20]. This paper contributes to a growing body of literature that uses data science tools to help keep abreast of the available science and efficiently summarise the available science [16, 30, 43, 82]. Along with similar efforts to embed machine learning components into evidence synthesis methods [14, 15], we believe that such data science tools can not only prepare global environmental assessments for the age of Big Literature, but also lift them to a higher level of comprehensiveness, timeliness and transparency.
Acknowledgments
We wish to thank the experts interviewed for this work, all of whom were extremely generous with their time. The comments provided by the reviewers were appreciated and greatly improved the work. This work was supported by the UK Natural Environment Research Council (Panorama DTP) and the German Ministry for Education and Research (01LG1910A; 03SFK5J0).
Data availability statement
The data and code that support the findings of this study are available upon reasonable request from the authors.