


ABSTRACT
Binary stars are thought to be a controlling factor in globular cluster evolution, since they can heat the environmental stars by converting their binding energy to kinetic energy during dynamical interactions. Through such interaction, the binaries determine the time until core collapse. To test predictions of this model, we have determined binary fractions for 35 clusters. Here we present our methodology with a representative globular cluster NGC 4590. We use Hubble Space Telescope archival Advanced Camera for Surveys data in the F606W and F814W bands and apply point-spread-function-fitting photometry to obtain high quality color–magnitude diagrams. We formulate the star superposition effect as a Poisson probability distribution function, with parameters optimized through Monte Carlo simulations. A model-independent binary fraction of (6.2 ± 0.3)% is obtained by counting stars that extend to the red side of the residual color distribution after accounting for the photometric errors and the star superposition effect. A model-dependent binary fraction is obtained by constructing models with a known binary fraction and an assumed binary mass-ratio distribution function. This leads to a binary fraction range of 6.8%–10.8%, depending on the assumed shape to the binary mass-ratio distribution, with the best fit occurring for a binary distribution that favors low mass ratios (and higher binary fractions). We also represent the method for radial analysis of the binary fraction in the representative case of NGC 6981, which shows a decreasing trend for the binary fraction toward the outside, consistent with theoretical predictions for the dynamical effect on the binary fraction.
1. INTRODUCTION
The standard picture of globular clusters shows that a cluster composed of single stars will undergo core collapse after several relaxation times (Lynden-Bell & Wood 1968; Cohn 1980; Lynden-Bell & Eggleton 1980; Spitzer 1987). Since only about one-fifth of globular clusters show collapsed cores (Djorgovski & King 1986; Harris 1996; 2010 edition), certain heating mechanisms are needed to counteract the gravitational contraction and avoid core collapse. This energy is expected to come primarily from the "burning" of binaries, i.e., the dynamical interactions of binaries with single stars or other binaries will convert the binding energy in the binaries to the single stars or other binaries, so as to heat the environment stars (Heggie 1975; Hut & Bahcall 1983; Goodman & Hut 1989; Hut et al. 1992). Even a small primordial binary fraction is sufficient to prevent core collapse for many relaxation times (Gao et al. 1991; Fregeau et al. 2003), so the binary fraction is an essential parameter that can dramatically affect the evolution of globular clusters.
The binaries remaining in globular clusters are mainly hard binaries, whose binding energy is greater than the average kinetic energy of a single star in that cluster (Hut et al. 1992). Most of the soft ones are destroyed during their first interactions with other stars (Sollima 2008), and would not provide the heating energy. Mass-transfer binaries are among the hardest binaries, and those with degenerate primaries can be bright X-ray sources (Hut et al. 1992; Heinke 2010), such as low mass X-ray binaries (LMXBs). LMXBs are thought to be formed in the dense cores of globular clusters through dynamical exchange processes (Clark 1975; Bailyn 1995; Cohn et al. 2010), as they show a strong correlation between the collisional parameter and their frequency (Pooley et al. 2003). Some cataclysmic variables show this correlation too, which suggests their dynamical origin (Pooley & Hut 2006).
Although theoretical models and simulations are well developed for the evolution of globular clusters with binary burning process, sufficient observations to test these models are lacking. One reason is that it is very difficult to isolate individual stars in the high density region such as the cores of globular clusters from the ground based telescope. The other reason is that photometry errors are very large due to superposition of those unresolved stars. These two difficulties make the observations of binaries fraction challenging.
A direct method to detect binaries in globular clusters is by spectroscopic observation to measure radial velocity variations, which can only be applied to red giant and sub-giant stars. This is because those stars are bright in magnitude and cool in temperature, so there are many strong absorption lines for cross-correlation. This will improve the accuracy of radial velocity measurement to below 1 km s−1. The drawback for this method is that it requires large amounts of observing time over a several years. For some long period binaries (greater than 10 yr), even the current observational accuracy is not enough to discover the small radial velocity change over a reasonable timeframe (5 yr). For binaries composed of two main sequence stars, radial velocity observation present other challenges. Not only are these stars fainter than giants, but they have fewer lines for spectral cross-correlations, thereby demanding high signal-to-noise (S/N) spectra that can place unreasonable demands on even the largest ground-based telescopes. Another issue with ground-based spectroscopic observations is that, even for good seeing conditions, multiple unrelated stars can fall in a single spectral point-spread function (PSF). This restricts such studies to the outer regions of globular clusters, which may not be representative of the dynamically more active inner parts (Gunn & Griffin 1979; Pryor et al. 1988; Yan & Cohen 1996; Cote & Ficher 1996; Cote et al. 1996).
A different direct method for detecting binaries is through observation of eclipsing binaries. This method still needs a substantial observing time investment to monitor many stars in globular clusters and search for the photometric variables through their light curves. While this method is biased by small orbital inclination short period binaries, it is another valuable method for investigating binary systems (Mateo et al. 1990; Yan & Mateo 1994; Yan & Reid 1996; Albrow et al. 2001).
Another method, and the one used here, makes use of the accurate measurement of stars that form the main sequence in a color–magnitude diagram (CMD). For main sequence stars of a single age and metallicity, the width of the main sequence of single stars should be limited only by measurement error. Relative to the single star main sequence, a binary star will be either redder, for a lower mass secondary, or brighter (by 0.75 mag) but at the same color for two stars of equal mass. An ensemble of binaries forms a thickening to the red of the single star main sequence, which we can measure. The method is difficult to execute from the ground because of the precision required at faint magnitudes (S/N = 50–100 at V = 21) and in crowded fields. However, the Hubble Space Telescope (HST) has sufficient sensitivity and spatial resolution to resolve even the core of globular clusters. This greatly improves the photometric accuracy, and makes the measurement of the binary fraction possible as a function of position. This method can detect widely separated binaries, but it is biased against binaries with low-mass secondaries. The benefit of this method is that, it requires relatively less observing time, and one can measure the global binary fraction without other assumptions.
To date, only a few globular clusters have been studied for the binary fraction with HST by analyzing their CMDs. Rubenstein & Bailyn (1997) measured that the binary fraction of NGC 6752 to be 15%–38% in the inner core radius, and probably less than 16% beyond that. Bellazzini et al. (2002) also determined the binary fraction of NGC 288 within its half light radius to be (15 ± 5)% with HST WFPC2 data, depending on the adopted binary mass-ratio function. Its binary fraction outside the half light radius is less than 10%, and most likely closer to 0%. Richer et al. (2004) measured the evolved cluster M4 with proper-motion selected WFPC2 data. They found the binary fraction within 1.5 core radius is about 2%, decreasing to about 1% between 1.5 and 8.0 core radii. Zhao & Bailyn (2005) studied two clusters, M3 and M13, with WFPC2 data, and they found that the binary fraction of M3 within one core radius lies between 6% and 22%, and falls to 1%–3% between 1 and 2 core radii. The binary fraction of M13, however, was not constrained with their method. Davis et al. (2008) measured the binary fraction of the core collapsed cluster NGC 6397 with both Advanced Camera for Surveys (ACS) and WFPC2 data. They well constrained the binary fraction outside the half light radius to be (1.2 ± 0.4)% with 126 orbits of observation with ACS and proper-motion selected clean data, and constrained the binary fraction within the half light radius to be (5 ± 1)% with WFPC2 data.
Sollima et al. (2007) performed the first sample study for the binary fractions in globular clusters. They used aperture photometry to construct the CMDs for 13 low-density, high galactic latitude globular clusters with ACS data. They found a minimum of 6% binary fraction within one core radius for all clusters in their sample, and global fractions ranging from 10% to 50% depending on the clusters and the assumed binary mass-ratio model.
In our survey, we compile a sample of 35 Galactic globular clusters, a larger sample than previous efforts, and one that takes advantage of a wealth of archived HST data. We use the PSF photometry instead of aperture photometry, so that we can analyze high-density clusters in addition to low-density clusters. We try to constrain the binary mass-ratio function depending on the data quality and the number of binaries found, which is the largest uncertainty in determining binary fraction in previous studies. We also analyze the binary fraction radial distribution and variation along the main-sequence. In this paper, the first of two, we present the techniques used in obtaining the binary fraction. We present the sample selection in Section 2, data reduction and photometry method in Section 3, the artificial star tests in Section 4, the high mass-ratio binary fraction estimate in Section 5, the global binary fraction estimate in Section 6, the binary fraction radial analysis in Section 7, and discussions in Section 8.
2. SAMPLE SELECTION
To achieve the primary goal of determining the binary fraction, we need accurate CMDs. CMDs can be made from several different filters, such as a subset of B, V, R, and I, although for the main sequence in the late G to early M spectral region, the most accurate CMDs are composed from a subset of V, R, and I (V and I to be used when possible).
For good photometric errors (0.02 mag rms), about 6,000 stars on the CMD will yield an uncertainty in the binary fraction of 1.5%–2% (after Hut et al. 1992, Table 4). This type of photometric accuracy is achieved with WFPC2 V band images in 1500 s for V = 24.0 (m − M = 14.6 mag for a M1 star), or for V = 24.9 when using the ACS/WFC (m − M = 15.5 mag for a M1 star).
We examined the HST observations taken for every Galactic globular cluster in the list of Harris (1996; 2010 edition) and most have some WFPC2 or ACS observations, but many of these were taken in snapshot mode and are not sufficiently long to meet our criteria. We find about 35 globular clusters that are sufficiently luminous, and with long enough exposures that we can extract useful information on binary fractions. Most of those data sets are from the HST Treasury program for globular clusters with ACS observations in F606W and F814W filters (Sarajedini et al. 2007).
Table 1 shows the basic information for each cluster in this sample, including Galactic longitude (l), Galactic latitude (b), metallicity ([Fe/H]), foreground reddening E(B − V), absolute visual magnitude MV, collapsed core (y/n), core radius (rc), half light radius (rh), log relaxation time at half mass radius (log trh), age (tGyr), and dynamical age (tGyr/trh). The dynamical ages in this sample range from dynamical young clusters (tGyr/trh = 1.5) to dynamical old one (tGyr/trh = 46.4) (see upper right panel in Figure 1). The metallicities in this sample range from metal poor cluster ([Fe/H] = −2.37) to metal rich one ([Fe/H] = −0.32; see Figure 1, lower left panel). Figure 1 lower right panel shows the distribution of those clusters relative to the Galactic disk plane, among which nine clusters are within the ±15° Galactic latitudes, and are potentially affected by non-member stars.

Figure 1. Distributions of properties for each globular clusters in the sample. Upper left: ages distribution. Upper right: dynamical ages distribution. Lower left: [Fe/H] distribution. Lower right: galactic position distribution.
Download figure:
Standard image High-resolution imageTable 1. Basic Properties of the Galactic Globular Clusters in the Samplea
| Object | l | b | [Fe/H] | E(B − V) | MV | Core | rc | rh | log trh | tGyrb | tGyr/trh |
|---|---|---|---|---|---|---|---|---|---|---|---|
| (°) | (°) | Collapse | (') | (') | (Gyr) | ||||||
| NGC 104 | 305.89 | −44.89 | −0.72 | 0.04 | −9.42 | 0.36 | 3.17 | 9.55 | 10.7 | 3.0 | |
| NGC 288 | 152.30 | −89.38 | −1.32 | 0.03 | −6.75 | 1.35 | 2.23 | 9.32 | 11.3 | 5.4 | |
| NGC 362 | 301.53 | −46.25 | −1.26 | 0.05 | −8.43 | y | 0.18 | 0.82 | 8.93 | 8.7 | 10.2 |
| NGC 1851 | 244.51 | −35.03 | −1.18 | 0.02 | −8.33 | 0.09 | 0.51 | 8.82 | 9.2 | 13.9 | |
| NGC 2808 | 282.19 | −11.25 | −1.14 | 0.22 | −9.39 | 0.25 | 0.80 | 9.15 | 9.3 | 6.6 | |
| NGC 4590 | 299.63 | 36.05 | −2.23 | 0.05 | −7.37 | 0.58 | 1.51 | 9.27 | 11.2 | 6.0 | |
| NGC 5053 | 335.70 | 78.95 | −2.27 | 0.01 | −6.76 | 2.08 | 2.61 | 9.87 | 10.8 | 1.5 | |
| M 3 | 42.22 | 78.71 | −1.50 | 0.01 | −8.88 | 0.37 | 2.31 | 9.79 | 11.3 | 1.8 | |
| NGC 5466 | 42.15 | 73.59 | −1.98 | 0.00 | −6.98 | 1.43 | 2.30 | 9.76 | 12.2 | 2.1 | |
| NGC 5897 | 342.95 | 30.29 | −1.90 | 0.09 | −7.23 | 1.40 | 2.06 | 9.57 | 12.3 | 3.3 | |
| NGC 5904 | 3.86 | 46.80 | −1.29 | 0.03 | −8.81 | 0.44 | 1.77 | 9.41 | 10.9 | 4.2 | |
| NGC 5927 | 326.60 | 4.86 | −0.49 | 0.45 | −7.81 | 0.42 | 1.10 | 8.94 | 10.9c | 12.5 | |
| NGC 6093 | 352.67 | 19.46 | −1.75 | 0.18 | −8.23 | 0.15 | 0.61 | 8.80 | 12.4 | 19.7 | |
| NGC 6121 | 350.97 | 15.97 | −1.16 | 0.35 | −7.19 | 1.16 | 4.33 | 8.93 | 11.7 | 13.7 | |
| NGC 6101 | 317.74 | −15.82 | −1.98 | 0.05 | −6.94 | 0.97 | 1.05 | 9.22 | 10.7 | 6.4 | |
| M 13 | 59.01 | 40.91 | −1.53 | 0.02 | −8.55 | 0.62 | 1.69 | 9.30 | 11.9 | 6.0 | |
| NGC 6218 | 15.72 | 26.31 | −1.37 | 0.19 | −7.31 | 0.79 | 1.77 | 8.87 | 12.5 | 16.9 | |
| NGC 6341 | 68.34 | 34.86 | −2.31 | 0.02 | −8.21 | 0.26 | 1.02 | 9.02 | 12.3 | 11.7 | |
| NGC 6352 | 341.42 | −7.17 | −0.64 | 0.22 | −6.47 | 0.83 | 2.05 | 8.92 | 9.9 | 11.9 | |
| NGC 6362 | 325.55 | −17.57 | −0.99 | 0.09 | −6.95 | 1.13 | 2.05 | 9.20 | 11.0 | 6.9 | |
| NGC 6397 | 338.17 | −11.96 | −2.02 | 0.18 | −6.64 | y | 0.05 | 2.90 | 8.60 | 12.1 | 30.4 |
| NGC 6541 | 349.29 | −11.19 | −1.81 | 0.14 | −8.52 | y | 0.18 | 1.06 | 9.03 | 14.0d | 13.1 |
| NGC 6624 | 2.79 | −7.91 | −0.44 | 0.28 | −7.49 | y | 0.06 | 0.82 | 8.71 | 10.6 | 20.7 |
| NGC 6637 | 1.72 | −10.27 | −0.64 | 0.18 | −7.64 | 0.33 | 0.84 | 8.82 | 10.6 | 16.0 | |
| NGC 6652 | 1.53 | −11.38 | −0.81 | 0.09 | −6.66 | 0.10 | 0.48 | 8.39 | 11.4 | 46.4 | |
| NGC 6656 | 9.89 | −7.55 | −1.70 | 0.34 | −8.50 | 1.33 | 3.36 | 9.23 | 12.3 | 7.2 | |
| NGC 6723 | 0.07 | −17.30 | −1.10 | 0.05 | −7.83 | y | 0.83 | 1.53 | 9.24 | 11.6 | 6.7 |
| NGC 6752 | 336.49 | −25.63 | −1.54 | 0.04 | −7.73 | y | 0.17 | 1.91 | 8.87 | 12.2 | 16.5 |
| Terzan 7 | 3.39 | −20.07 | −0.32 | 0.07 | −5.01 | 0.49 | 0.77 | 8.96 | 7.4 | 8.1 | |
| Arp 2 | 8.55 | −20.79 | −1.75 | 0.10 | −5.29 | 1.19 | 1.77 | 9.70 | 11.3 | 2.3 | |
| NGC 6809 | 8.79 | −23.27 | −1.94 | 0.08 | −7.57 | 1.80 | 2.83 | 9.29 | 12.3 | 6.3 | |
| NGC 6981 | 35.16 | −32.68 | −1.42 | 0.05 | −7.04 | 0.46 | 0.93 | 9.23 | 9.5e | 5.6 | |
| NGC 7078 | 65.01 | −27.31 | −2.37 | 0.10 | −9.19 | y | 0.14 | 1.00 | 9.32 | 11.7 | 5.6 |
| NGC 7099 | 27.18 | −46.84 | −2.27 | 0.03 | −7.45 | y | 0.06 | 1.03 | 8.88 | 11.9 | 15.7 |
| Palomar 12 | 30.51 | −47.68 | −0.85 | 0.02 | −4.47 | 0.02 | 1.72 | 9.28 | 6.4 | 3.4 |
Notes. aAll columns except ages tGyr are from Harris (1996; 2010 edition). bAges tGyr are from Salaris & Weiss (2002) except cfrom Fullton et al. (1996), dfrom Alonso-Garcia (2012), and efrom Sollima et al. (2007).
Download table as: ASCIITypeset image
Table 2 shows the HST/ACS observation log for each cluster, including filter type, number of exposures used, exposure time per frame, and data set ID. We only used the long exposure frames here and did not include those short exposure frames because we are only interested in the CMDs below the turn-off point.
Table 2. HST/ACS Observation Log
| Name | Filter | No. of Exposures | Exposure Time | Dataset |
|---|---|---|---|---|
| (s) | ||||
| NGC 104 | F606W | 4 | 50 | J9L960010 |
| F814W | 4 | 50 | J9L960020 | |
| NGC 288 | F606W | 4 | 130 | J9L9AD010 |
| F814W | 4 | 150 | J9L9AD020 | |
| NGC 362 | F606W | 4 | 150 | J9L930010 |
| F814W | 4 | 170 | J9L930020 | |
| NGC 1851 | F606W | 5 | 350 | J9L910010 |
| F814W | 5 | 350 | J9L910020 | |
| NGC 2808 | F606W | 5 | 360 | J9L947010 |
| F814W | 5 | 370 | J9L947020 | |
| NGC 4590 | F606W | 4 | 130 | J9L932010 |
| F814W | 4 | 150 | J9L932020 | |
| NGC 5053 | F606W | 5 | 340 | J9L902010 |
| F814W | 5 | 350 | J9L902020 | |
| M 3 | F606W | 4 | 130 | J9L953010 |
| F814W | 4 | 150 | J9L953020 | |
| NGC 5466 | F606W | 5 | 340 | J9L903010 |
| F814W | 5 | 350 | J9L903020 | |
| NGC 5897 | F606W | 4 | 340 | J9L913010 |
| F814W | 3 | 350 | J9L913020 | |
| NGC 5904 | F606W | 4 | 140 | J9L956010 |
| F814W | 4 | 140 | J9L956020 | |
| NGC 5927 | F606W | 5 | 350 | J9L914010 |
| F814W | 5 | 360 | J9L914020 | |
| NGC 6093 | F606W | 5 | 340 | J9L916010 |
| F814W | 5 | 340 | J9L916020 | |
| NGC 6101 | F606W | 5 | 370 | J9L917010 |
| F814W | 5 | 380 | J9L917020 | |
| NGC 6121 | F606W | 4 | 25 | J9L964010 |
| F814W | 4 | 30 | J9L964020 | |
| M 13 | F606W | 4 | 140 | J9L957010 |
| F814W | 4 | 140 | J9L957020 | |
| NGC 6218 | F606W | 4 | 90 | J9L944010 |
| F814W | 4 | 90 | J9L944020 | |
| NGC 6341 | F606W | 4 | 140 | J9L958010 |
| F814W | 4 | 150 | J9L958020 | |
| NGC 6352 | F606W | 4 | 140 | J9L959010 |
| F814W | 4 | 150 | J9L959020 | |
| NGC 6362 | F606W | 4 | 130 | J9L934010 |
| F814W | 4 | 150 | J9L934020 | |
| NGC 6397 | F606W | 4 | 15 | J9L965010 |
| F814W | 4 | 15 | J9L965020 | |
| NGC 6541 | F606W | 4 | 140 | J9L936010 |
| F814W | 4 | 150 | J9L936020 | |
| NGC 6624 | F606W | 5 | 350 | J9L922010 |
| F814W | 5 | 350 | J9L922020 | |
| NGC 6637 | F606W | 5 | 340 | J9L937010 |
| F814W | 5 | 340 | J9L937020 | |
| NGC 6652 | F606W | 5 | 340 | J9L938010 |
| F814W | 5 | 340 | J9L938020 | |
| NGC 6656 | F606W | 4 | 55 | J9L948010 |
| F814W | 4 | 65 | J9L948020 | |
| NGC 6723 | F606W | 4 | 140 | J9L941010 |
| F814W | 4 | 150 | J9L941020 | |
| NGC 6752 | F606W | 4 | 35 | J9L966010 |
| F814W | 4 | 40 | J9L966020 | |
| NGC 6809 | F606W | 4 | 70 | J9L963010 |
| F814W | 4 | 80 | J9L963020 | |
| NGC 6981 | F606W | 4 | 130 | J9L942010 |
| F814W | 4 | 150 | J9L942020 | |
| NGC 7078 | F606W | 4 | 130 | J9L954010 |
| F814W | 4 | 150 | J9L954020 | |
| NGC 7099 | F606W | 4 | 140 | J9L955010 |
| F814W | 4 | 140 | J9L955020 | |
| Arp2 | F606W | 5 | 345 | J9L925010 |
| F814W | 5 | 345 | J9L925020 | |
| Parlomar 12 | F606W | 5 | 340 | J9L928010 |
| F814W | 5 | 340 | J9L928020 | |
| Terzan 7 | F606W | 5 | 345 | J9L924010 |
| F814W | 5 | 345 | J9L924020 |
3. DATA REDUCTION AND PHOTOMETRY
We retrieved the HST/ACS archival data on F606W and F814W bands for each globular cluster, employing the most recent calibration frames on the fly. A drizzled imaged was produced (Multidrizzle was applied to all FLT images), with care taken to achieve accurate alignment of the images. Standard practices were applied for bad pixel masking and exposure calibrations.
The extraction of stellar magnitudes from the many point sources in these crowded fields depends on the algorithm used. In these fields, especially the crowded central parts of clusters, a star often lies on the wings of another star and these wings are not azimuthally symmetric, which complicates the subtraction. We used two versions of Dolphot (Dolphin 2000), an automated CCD photometry package for general use and for HST data (ACS, WFPC2, and WFC3). The later version uses a more refined library for the PSF of point sources and we found significant improvement in the quality of PSF photometry for Dolphot V1.2 relative to V1.0. This can be found in Figure 2, where the CMD for NGC 4590 near the turn-off point is well defined and the main sequence is narrower by using Dolphot V1.2 (right panel) compared to Dolphot V1.0 (left panel). The more accurate photometry leads to reduced uncertainties in the binary fraction determinations and allows us to probe to smaller binary mass ratios. From the output photometry files, the error weighted average magnitudes for both the F814W and the F606W filters were used, with the zero point set to the VEGA system. More details about the data reduction process can be found in Ji (2011). We note that in the work of Milone et al. (2012), a different extraction routine was developed for their program which appears to lead to slightly smaller errors.

Figure 2. Comparisons of the quality of the CMDs for NGC 4590 between different version of Dolphot, V1.0 (left), V1.2 (right). The latter version shows significant improvement on the accuracy of the stars near the turn-off point, and shows a narrower spread on the main-sequence.
Download figure:
Standard image High-resolution imageNot all parts of the resulting CMD are equally useful and only a limited range is used. We chose stars 1 mag below the turn-off point, since close to the turn-off point, binary sequences turn to merge with the main sequence and lose all of the binary information. At increasingly fainter magnitudes, the photometric uncertainty becomes large enough that those stars are not useful in constraining binary fraction models. Typically, this occurs about 4 mag below the turn-off point. An example of these effects is shown in the CMD of NGC 4590 (Figure 3). The red dashed lines indicate the portion of CMD we used during the analysis (other lines are discussed below).

Figure 3. An example of the observed CMD (left) and the straightened CMD (right) for NGC 4590. The solid green line is the defined MSRL. The solid red line is the equal-mass binary population. The binary fraction is estimated within the range of the dashed red lines.
Download figure:
Standard image High-resolution image4. MAIN SEQUENCE DEFINITION AND ARTIFICIAL STAR TESTS
Without knowing the photometric errors, completeness, and the rate of superposition of stars, we cannot have accurate measurement of binary fractions from the CMD. The artificial star tests, however, can help us understand the photometric errors and accuracy, as well as completeness (or star recovery percentage) at different region of clusters and at different magnitudes. It can also simulate the rate of superposition of stars if performed properly.
4.1. Defining the Main-sequence Ridge Line
To perform artificial star tests and later CMD analysis, we need to define the main-sequence ridge line (MSRL) of the observed CMD first. We constructed the MSRL from the data instead of fitting theoretical isochrones to the CMD, as the latter method is not sufficiently accurate to define the ridge line. To define the MSRL from the CMD, we used a moving box method. In each step, we defined a box with a height of 0.1 mag in the F606W axis, and a width of the entire range in the color (F606W–F814W) axis. Then we searched the peak value of the color histograms in that box with a color bin-size of 0.0015 mag. The color value at the peak and the middle point of the box in the F606W axis direction are the defined MSRL for stars in that box. The process was repeated in increments along the main sequence and the resulting line was then smoothed with the moving average method with a period of 50. In Figure 3, the green line is the defined MSRL.
4.2. Performing the Artificial Star Tests
With the defined MSRL, we performed artificial star tests in Dolphot. The F606W magnitudes of those fake stars were randomly generated while the F814W magnitudes were derived from the MSRL, so that all those fake stars are on the MSRL. The (X, Y) coordinates of those fake stars were randomly chosen from the area of the drizzled reference frame, but were not at the empty non-data CCD area. Each fake star in this list was added to each FLT frame one at a time, and was recovered using the same photometry process by Dolphot. The final photometric output file was screened using the same criteria as used to obtain the CMD, as described above; we added 100,000 fake stars for each image. Figure 4 shows two examples of the artificial star tests, NGC 5053 (low stellar density cluster) and NGC 1851 (high stellar density cluster). The green line is the input fake stars, which are all on the MSRL. The scattered black dots are the recovered fake stars (69,995 stars for NGC 5053 and 52,205 stars for NGC 1851).
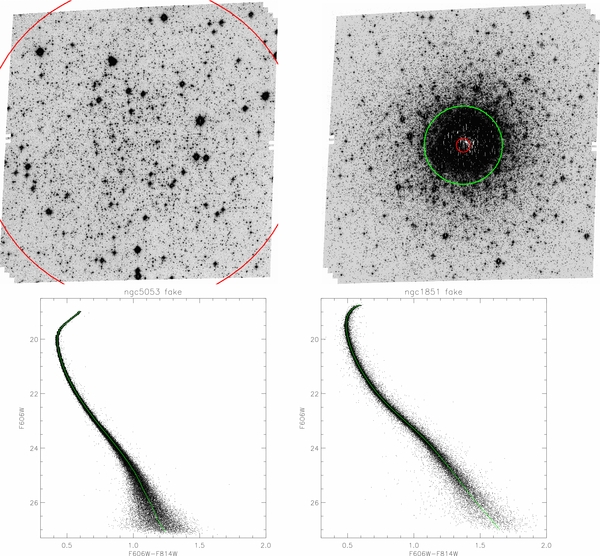
Figure 4. Two examples of the artificial star tests. Left column: low stellar density cluster NGC 5053. Right column: high stellar density cluster NGC 1851. Upper panel: the observed ACS images for these two clusters. The red circle represents core region while the green one is for the half light region. Lower panel: the input fake stars (green lines) and the recovered fake stars (black dots) on CMDs.
Download figure:
Standard image High-resolution image4.3. Photometric Accuracy, Uncertainty, and Completeness
From the input and recovered fake star lists, we studied the photometric accuracy and uncertainty. We compared the photometry for two clusters, NGC 5053 (low stellar density cluster) and NGC 1851 (high stellar density cluster), as their HST/ACS observations are very similar in exposure times: NGC 5053 (F606W: 340 s × 5, F814W: 350 s × 5) and NGC 1851 (F606W: 350 s × 5, F814W: 350 s × 5).
In Figure 5, we plot the magnitude differences for input and recovered stars for F606W filter (first row) and F814W filter (second row). These plots indicate photometric discrepancies, and all of them showing differences within ±0.2 mag. At fainter magnitudes, the magnitudes of the recovered stars tend to be fainter than the input ones. Rows 3 and 4 in Figure 5 show the photometric uncertainties for F606W and F814W filters, respectively, while row 5 in Figure 5 shows the uncertainties in color (F606W–F814W). From those plots we can see that most stars in NGC 1851 have similar photometric accuracy and uncertainties as in NGC 5053, except that in NGC 1851 there are more stars with large errors, even for bright stars.

Figure 5. Examples of the results for the artificial star tests: NGC 5053 (left column) and NGC 1851 (right column). Rows 1 and 2: differences of the input and recovered magnitudes for filter F606W and F814W. Rows 3 and 4: magnitude uncertainties for filter F606W and F814W. Row 5: color uncertainties. Row 6: completeness curve.
Download figure:
Standard image High-resolution imageRow 6 in Figure 5 shows the completeness curve (recovery percentage), which is the ratio of the total number of recovered stars (N(out)) to the total number of input stars (N(In)) in a particular magnitude interval. The completeness curve for NGC 5053 is quite flat down to the 26.5 mag, indicating an even star recovery percentage over a broad magnitude range. However, for NGC 1851, the star recovery percentage is not evenly distributed, with a relatively higher recovery percentage for brighter stars than for fainter ones. This can be seen from the fake CMDs in Figure 4, where there are fewer faint stars in NGC 1851 than in NGC 5053, even though they have similar exposure times. This indicates that faint stars are difficult to recover in dense stellar region due to high and non-uniform background caused by the multitude of stars.
5. THE HIGH MASS-RATIO BINARY FRACTION
A binary with a mass ratio close to unity is easiest to identify because they binaries have the largest distances from the MSRL. This is evident in an examination of the straightened CMD (i.e., the CMD minus the color of the MSRL), where the binaries are distributed to the right side of the main sequence below the turn-off point (Figure 6). The maximum distance is from equal-mass binaries, and this distance varies with the shape of the MSRL (the green line in Figure 6). The minimum separation from the main sequence is for binaries where the secondary is of low mass (mass ratios approaching zero; see the blue solid line in Figure 6). When the photometric errors increase, the main-sequence stars eventually spread to the equal-mass binary region, diluting the binary signature (see Figure 6, right panel for example). This emphasizes the photometric accuracy needed to distinguish binaries from single main-sequence stars (such as stars in the region B of Figure 6).

Figure 6. Demonstration of the regions when measuring the minimum binary fraction. The straightened color–magnitude diagrams are for NGC 5053 (left) and NGC 2808 (right). Left panel: the solid green line is the center of the main sequence. The solid red line is the equal-mass binary population. The solid blue curves are the binary population where the mass ratio equals 0.5 (right curve), and its symmetric one on the left. The dashed red lines are the ±3σ photometric spread of color in comparison. The dashed blue lines are the upper and lower limits of usable stars for both F606W magnitude and residual color. The main-sequence star (or single star) region S is defined between the solid blue lines. The binary region B is where the residual color is greater than the 0.5 mass-ratio binary line and less than 0.2. The residual region R is where the residual colors are beyond the blue side of the left solid blue line but greater than −0.2. Right panel: same as the left but for NGC 2808 with more broadened main sequence due to multiple populations in the main sequence (see Piotto et al. 2007). The 3σ photometric limit lines (dashed red lines) intersect with the equal-mass binary line, indicating that most binary signals are buried.
Download figure:
Standard image High-resolution image5.1. The Model for the Superposition of Stars
The most important source of contamination in identifying binaries arises from the superposition of two unrelated stars that occurs by chance when the star cluster is projected from three dimensions to two dimensions. Two or more stars along the line of sight and within the minimum angular resolution will be measured as one star, and are indistinguishable on the CMD from real binaries. It is very difficult to screen for blended stars, but statistically we can determine their distribution through Monte Carlo simulations. The blending fraction is proportional to the radial stellar number density of a cluster, decreasing from the core to outside region. The general way to measure the blending fraction is through artificial star tests, in which fake stars from MSRL are added to real images and are recovered with the same photometric processes as real stars. Any fake stars overlapping with real stars will represent a blended source, and the recovered magnitudes will be their sum. As long as the added fake stars follow the radial light distribution of a globular cluster, it represents the similar blending fraction as that cluster. The drawback for this method is that it is computationally time-consuming. Consequently, we performed the Monte Carlo simulations for an appropriate set of conditions and then modeled the results analytically, using Poisson statistics (see the Appendix).
In each simulation, we added fake stars to the real star map, where the fake stars have the same luminosity function and light distribution as the real ones, so it should have a similar blending fraction as the observed cluster. To generate the fake star list, we chose fake stars with their V magnitudes sampled by the observed luminosity function, and their I magnitudes calculated from the MSRL (i.e., all the fake stars are on the MSRL and have the same luminosity function as the real stars). The number of total fake stars added is equal to that of the total observed stars to produce a similar condition. Each fake star was assigned a radius r from the center of the cluster, which was sampled by the radial light distribution of real stars, so that the radial light distribution of fake stars is similar to the real ones. Then the azimuth angle is randomly assigned to the fake star to calculate the coordinates (x, y). To that position (x, y), any real star with distance less than 1 resolution element (the minimum resolution size Dolphot used) will be considered as a blended star, and the total magnitude is added. To find those blended stars, we used our k-dimensional tree algorithm by comparing lists of the observed stars and fake stars. To those blended sources we added photometric errors from the observed stars (see Figure 5). We repeated this simulation 30 times to obtain an average number or an average residual color distribution of blended stars.
5.2. The Model for the Field Star Population
Field stars, both faint foreground stars and bright background stars, can also contaminate the binary population on CMDs and thus affect the accuracy of the measurement of the binary fraction, especially for low Galactic latitude clusters. They affect the number of binaries in the binary region on the CMD, as well as the number of single stars on the main-sequence. High galactic latitude clusters do not have many contaminating field stars. For example, NGC 4590 (b = 36 05) only has 24 field stars (simulated from the model of Robin et al. 2003) in the ACS field of view, or 0.06% of the total observed stars in that field. Low Galactic latitude clusters, however, have many contaminating field stars, such as NGC 6624 (b = −791), which has 51,325 field stars in the ACS field of view, about half of the total observed stars in that field. The best way to select cluster members is by proper motion, which, however, requires at least two epochs of HST observations separated by years. An alternative way is to construct the field star model from the theoretical model of the Galaxy to statistically account for those field stars. We used the Stellar population Synthesis model of the Galaxy (Robin et al. 2003) to simulate field stars at the cluster position, with the size of ACS CCD chips, 202'' by 202''. The V and I Johnson–Cousin magnitudes of the generated field stars are corrected for the reddening first and are converted into ACS F606W and F814W magnitudes by the transformations of Sirianni et al. (2005), then are randomly added to the original images along with Poisson noise. Then we adopt the same photometry method with Dolphot to recover those field stars. The recovered field stars will have similar photometry errors as the cluster stars, as well as the completeness and blending effect.
05) only has 24 field stars (simulated from the model of Robin et al. 2003) in the ACS field of view, or 0.06% of the total observed stars in that field. Low Galactic latitude clusters, however, have many contaminating field stars, such as NGC 6624 (b = −791), which has 51,325 field stars in the ACS field of view, about half of the total observed stars in that field. The best way to select cluster members is by proper motion, which, however, requires at least two epochs of HST observations separated by years. An alternative way is to construct the field star model from the theoretical model of the Galaxy to statistically account for those field stars. We used the Stellar population Synthesis model of the Galaxy (Robin et al. 2003) to simulate field stars at the cluster position, with the size of ACS CCD chips, 202'' by 202''. The V and I Johnson–Cousin magnitudes of the generated field stars are corrected for the reddening first and are converted into ACS F606W and F814W magnitudes by the transformations of Sirianni et al. (2005), then are randomly added to the original images along with Poisson noise. Then we adopt the same photometry method with Dolphot to recover those field stars. The recovered field stars will have similar photometry errors as the cluster stars, as well as the completeness and blending effect.
5.3. The Estimate of the High Mass-ratio Binary Fraction
To estimate the high mass-ratio binary fraction, we divided the MSRL-subtracted CMD into different regions to count stars (see Figure 6, left panel). In Figure 6, the green line is the equal-mass binary population. The red line on the right side of the main sequence is the binary population with a binary mass ratio of 0.5. The binary mass ratio of 0.5 is chosen because in most cases, this binary population is beyond the 3σ photometric errors of the main-sequence stars. The dashed blue lines are the upper and lower limits of usable stars for both the F606W magnitude and the residual color. The main-sequence star (or single star) region S is defined between the red lines. The binary region B is where the residual color is greater than the 0.5 binary mass-ratio curve and less than 0.2 (i.e., on the right side of the red lines but on the left side of dash blue line). The residual region R is where the residual colors are beyond the blue side of the symmetric line for the 0.5 binary mass-ratio curve but greater than −0.2.
We count stars separately in those regions for three types of star populations, observed stars, simulated blended stars, and simulated field stars. The simulated blended stars and field stars are generated with methods mentioned in Sections 5.1 and 5.2. Region S contains mainly single stars (main-sequence stars), with some contaminating field stars. Region R contains main-sequence stars with large photometric errors, and with some contaminating field stars. Region B contains mainly binaries with mass ratios greater than 0.5, with some blended stars and field stars. It also has some main-sequence stars with large photometric errors, and can be estimated with the number in region R. So the high mass-ratio binary fraction fb(high q) can be calculated by the expression:

where , , and are the star numbers in region B for the observed stars, blended stars, and field stars, respectively. and are the star numbers in region R for observed stars and field stars, respectively. represents any residual main-sequence stars with large photometric errors. This number should be also subtracted from region B assuming a symmetric distribution. The quantities and are the total star numbers in the dashed blue line box for observed stars and field stars, which is the whole restricted region we use during the analysis. The 1σ error estimate for the binary fractions is estimated using Poisson errors and error propagation.








6. THE GLOBAL BINARY FRACTIONS
The high mass-ratio (>0.5) binary fraction discussion in Section 5 only accounts for those binaries with large deviations from the main sequence. Binaries with small mass ratios, however, are ignored, as they are too close to the main-sequence and are hidden by the photometric errors. In this section, we show that, to within certain limits, one can statistically recover even small mass-ratio binaries hidden in the main sequence as long as the photometric errors are and the rate of superposition of stars are understood.
6.1. The Star Counting Method
To avoid contamination from photometric errors, we followed three procedures. First, we only select stars 3–4 mag below the turn-off point to exclude faint stars with larger photometric errors. Second, we add two Gaussian models to represent the photometric errors during fitting, one for the main component with similar small errors, and the other for stars with larger errors. Tests show this to be a suitable strategy. Third, we introduce the parameter qcut in the binary model, which represents the minimum binary mass ratio that can be extracted from the data.
To estimate this, we first fit the residual color distribution with two Gaussian models, which represent the photometric errors of the main-sequence stars. The fit is only applied from 0.02 on the red side to all the blue side, since the blue side is not affected by both blending stars and real binaries, the broadening is only due to photometric errors. The fit is quite good (with χ2 close to 1). The positive residual of the fitting on the red side is due to binaries, with contamination from blending stars and field stars.
After subtracting the photometric errors, field stars, and blended stars, the residual color distribution on the red site is only from the contribution of physical binaries. We summed all the residuals on the red side and divided it by the total number of stars without the field stars, which gives the binary fraction including low mass-ratio binaries.
6.2. The χ2 Fitting Method
There is another way to account for low mass-ratio binaries, and one can even constrain the binary mass-ratio distribution function. Here, we constructed the binary population by fitting to an additional binary mass-ratio distribution function.
We assume the binary mass-ratio distribution function has the following power-law form: f(q)∝qx, where q ≡ Ms/Mp, and with a minimum value of qmin, and a maximum value of 1 (equal mass binaries). The minimum mass for the secondary star is set to 0.2 M☉ (the observed lowest mass from luminosity function of F606W band), thus this will set a minimum value of qmin not to be 0. First we assume here three different cases for the power of x, x = 0, a flat mass-ratio distribution; x = −1, which leads to a peak at low mass ratios; x = 1, which leads to a peak at high mass ratios. Whenever there are enough stars, we can fit for x rather than assign a value.
To construct the physical binary population, we first assume a binary fraction of fb, or a total of N*fb stars to be in the binary systems, where N is the total number of the observed stars. We then extract V magnitudes with the number N*fb from the observed V magnitude luminosity function to be the V magnitudes of the primary stars. The V magnitudes of the secondary stars are calculated using a mass ratio q extracted from an assumed mass-ratio distribution and an assumed mass–luminosity relationship: L∝M3.5. Their I magnitudes are derived from the MSRL, and the combined binary magnitudes are calculated. Each binary system has added to the photometric errors at their V and I magnitudes to simulate the photometric spreads. Finally, we can obtain the residual color distribution for the constructed binary population by subtracting the color of the MSRL. We repeat this process 30 times for each binary fraction fb, and construct the average profile for the physical binary population as the way we applied it to blended stars.
Now, we have models for single stars (two Gaussian models), field stars (see Section 5.2), the superposition of stars (see Section 5.1), and binary model with the known fraction fb (see Section 6.2). The total sum of all these models will produce the final model that is compared to the observed residual color distribution profile with a χ2 test. For a given cluster, the models for single stars, field stars, and the blending stars are fixed as they depend only on the observed luminosity function, the Galactic positions, and the observed light distribution. The only model that changes during the fitting process is the binary model, as it varies with the binary fraction fb, and the power law index x from the binary mass-ratio distribution function.
We developed the bisection method to search the best-fit fb (i.e., fits with the minimum χ2 value) at each assumed x. In this method, we first chose a wide initial range of binary fraction values (initial range is from 0 to 1). The χ2 values (model comparing to observed counts) were calculated for three binary fraction values, left most, right most, and the middle. Then the χ2 values at the left and right were compared to the middle one, and the left most or right most binary fraction value will be replaced by the middle one if its χ2 value is greater than the middle one. So the search range for the binary fraction now is reduced by half, and we calculated the χ2 value at the middle for the new range, and repeated the process again until the difference of χ2 values or the binary fraction range approached limiting value. The final middle value of the binary fraction range is the best-fit binary fraction with the minimum χ2 value. For clusters with enough bins, we also fit the power of x.
A fitting example is shown in Table 3, for NGC 4590. The first three rows in the table show the fitting results with the power x, and the minimum binary mass ratio qmin fixed, only with the binary fraction as a free parameter in the fit. The error range in the table is estimated by changing the parameter so that the χ2 value changes by 1.0 (or 1σ confidence level). The best-fit value favors the model with the power x = −1, which also gives a higher value of binary fraction (10.8 ± 0.4)%. With the power x, and qmin free to fit, the fit improves significantly (χ2/dof = 88.4/82), with a binary fraction of (10.8 ± 0.3)%. Figure 7 shows the residual color distribution fitted by using only the Gaussian model (upper) and with the best-fit model (lower) for NGC 4590. The symmetric spread of the main-sequence is due to photometric errors, which can be fitted by the Gaussian model fairly well, as there are no large systematic residuals on the blue side. The asymmetric spread of the main-sequence is due to binary populations and blending of stars, which is shown as positive residuals on the red side on the upper panel. In the lower panel, models for binaries and blending of stars are included, and this best-fit model fits well to the observed data. Figure 8 shows the model components for the fitting (upper) and the enlarged view (lower) for NGC 4590. For this cluster, we estimate about 50 field stars in the field of view of HST, so they are a negligible contaminant. In Table 4, we show the binary fractions estimated with the three methods discussed above, the high mass-ratio method (the second column), the star counting method (the third column), and the χ2 fitting method (the fourth column), and we expect the binary fraction obtained with the global methods (the star counting method and the χ2 fitting method) to be higher than the high mass-ratio method, as we approach lower mass-ratio values.

Figure 7. The residual color distribution fitted by a Gaussian (upper) and by the best-fit model (lower). The symmetric spread of the main-sequence is due to photometric errors, which can be fitted by Gaussian model fairly well, as there is no large systematical residuals on the blue side. The asymmetric spread of the main-sequence is due to binary populations and blending of stars, which is shown as positive residuals on the red side on the upper panel. In the lower panel, models for binaries and the blending of stars are included, and this best-fit model fits well to the observed data.
Download figure:
Standard image High-resolution image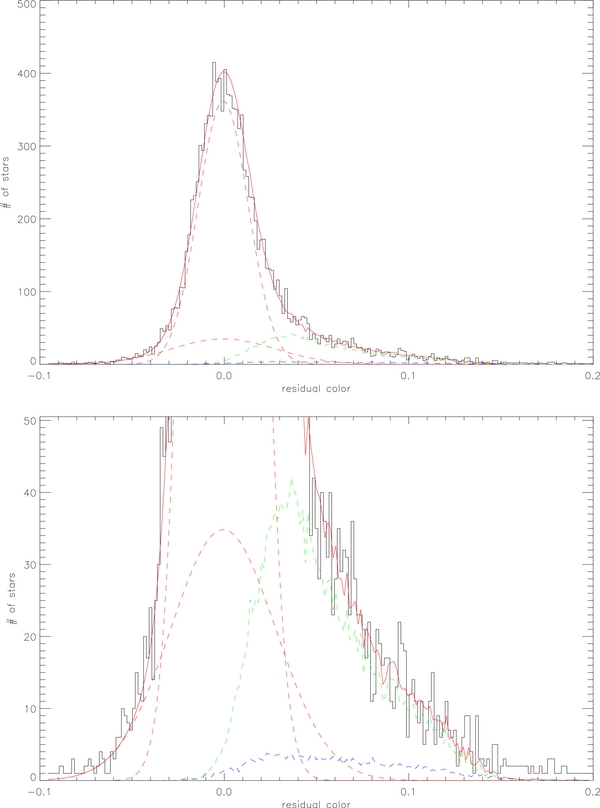
Figure 8. Model components for the fitting (upper) and the enlarged view (lower). Solid red line: overall model; dashed red line: Gaussian model for photometric errors; dashed green line: binary model; dashed blue line: model for blending due to overlapping stars; black histogram: observed residual color distribution. For this cluster, the field star number is about 50 in the field of view of HST, so they are negligible.
Download figure:
Standard image High-resolution imageTable 3. Comparing of the Fitting Results among Different Binary Mass-ratio Models for NGC 4590 Using the χ2 Fitting Method
| Method | Power x | qmin | fb | χ2/dof |
|---|---|---|---|---|
| (%) | ||||
| fixed x, qmin | 0 | 0.24 | 9.4 ± 0.7 | 175.9/84 |
| fixed x, qmin | 1 | 0.24 | 6.8 ± 0.2 | 236.3/84 |
| fixed x, qmin | −1 | 0.24 | 10.8 ± 0.4 | 126.7/84 |
| fit all | −2.3 ± 1.5 | 0.325 ± 0.007 | 10.3 ± 0.4 | 88.4/82 |
Download table as: ASCIITypeset image
Table 4. Binary Fractions within the Half Mass Radius Region with Different Analyzing Methods for NGC 4590
| Source | fb | fb | fb |
|---|---|---|---|
| (q > 0.5)% | (count)% | (fit)% | |
| NGC 4590 | 6.24 ± 0.30 | 7.33 ± 1.39 | 8.62 ± 1.21 |
Download table as: ASCIITypeset image
7. THE BINARY FRACTION RADIAL ANALYSIS
One prominent predicted effect of globular cluster dynamical evolution is mass segregation, which implies that massive stars tend to sink to the center of the core while light stars are redistributed to the outside of the cluster. Since a binary system contains two stars, it is more massive than a single star, so they tend to sink toward the cluster core by mass segregation. By performing radial analysis of binary fractions, we can test for this dynamical effect.
7.1. The Analysis Method
In this analysis, we divide the whole ACS field of view into three annular bins, with their centers at the cluster center obtained from Harris (1996; 2010 edition). The bin sizes were chosen (iteratively) so that each bin contains roughly one-third of the total stars recovered from the whole field, which leads to similar error bars for the binary fraction in each region.
7.2. The Radial CMD Qualities and the Example of the Results
For high density clusters, the CMD quality for the central bin is the worst among the three, which shows larger photometric spread and a lower faint star recovery rate than the other two. This is understandable, as the higher star not only increases the background level, making fainter stars more difficult to detect, but also increases the blending probability, making the PSF determination poorer. For low density clusters, we do not observe large variations in the CMD qualities.
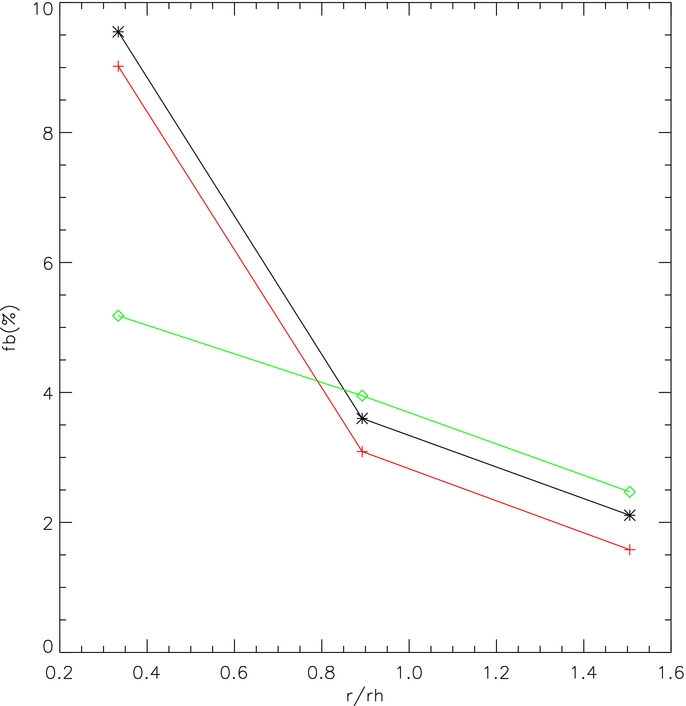
In Table 5 and Figure 9, we show the results of the radial analysis on the binary fraction for NGC 6981 as an example. In Table 5, we list the sizes of the annular bins, binary fractions obtained by the high mass-ratio method, the counting method, and the χ2 fitting method, and the dof/χ2 for the fitting method. In Figure 9, we plot the binary fractions obtained from different methods and from different annular bins against their positions relative to the cluster center, in units of the half mass radius. We clearly see a decreasing trend of the binary fraction toward the outside of this cluster, an effect discussed for the sample of 35 globular clusters in Paper II.

Figure 9. Binary fraction radial distribution for NGC 6981.
Download figure:
Standard image High-resolution imageTable 5. Example of Binary Fraction Radial Analysis for NGC 6981
| Source | Bin Range | fb | fb | fb | χ2/dof |
|---|---|---|---|---|---|
| (rh) | (q > 0.5)% | (count)% | (fit)% | ||
| NGC 6981 | 0.00–0.67 | 9.55 ± 0.58 | 8.62 ± 2.18 | 5.18 ± 0.77 | 54.4/75 |
| 0.67–1.12 | 3.60 ± 0.40 | 3.55 ± 2.20 | 3.95 ± 3.95 | 41.2/66 | |
| 1.12–1.89 | 2.11 ± 0.32 | 1.14 ± 2.22 | 2.47 ± 1.48 | 53.7/58 |
Download table as: ASCIITypeset image
8. ADDITIONAL FACTORS AFFECTING THE BINARY FRACTION AND FINAL COMMENTS
In this section, we will discuss the additional factors that can affect the measurement accuracy of binary fractions in globular clusters using their CMDs.
8.1. The Photometric Errors
The key aspect to estimating the binary fraction using the CMD method is the highly accurate photometry for the CMDs. As the photometric errors become larger, the spread of the main-sequence becomes larger, which will smear out the signals from binaries with small mass ratio. In order to decrease the photometric errors, we need to increase the exposure time. This is true for low density clusters, in which stars are quite isolated, and the PSF can be determined quite well. For most low density clusters in our sample, the photometric errors are approaching their theoretical limit. High density clusters, however, have very crowded central regions, where the high and varied background make the PSF determination uncertain. Most of the errors are not from low S/N ratios but from uncertainties in the PSFs and the backgrounds. Increasing the observing time for those crowded clusters would not help lower the photometric errors. Instead, developing more sophisticated PSF photometry algorithm for crowded region is needed, which is still not fully mature.
8.2. The Metallicity Dispersion
Theoretical modeling shows that the dispersion of the metallicity of a globular cluster can also cause a spread in color on the main sequence. Figure 10 shows that a metallicity (Z) difference of 0.002 (from red to blue line at certain V magnitude), equivalent to δ[Fe/H] = 0.30, can cause a spread of about 0.054 mag in color, and 0.284 in the V magnitude. So given the uncertainty in [Fe/H] of 0.03, the spread in color will be 0.005, and shift in V magnitude will be 0.028. The observed intrinsic color spread is smaller compared to the typical width in color of the main-sequence with the HST observations (about 0.012 for NGC 5053 in our sample), and the shift in V magnitude will not affect the color distribution. Thus the intrinsic metallicity dispersion can be negligible. For multi-population systems (such as NGC 2808), however, this will not be the case (Piotto et al. 2007; Pasquini et al. 2011).

Figure 10. Isochrone Models at different metallicity.
Download figure:
Standard image High-resolution image8.3. The Differential Reddening
Observations on globular clusters located near the Galactic center can be affected by the existence of large and differential extinction of the foreground dust. Alonso-Garcia et al. (2011) discuss a technique to correct this effect. From our sample, most clusters are well above the Galactic plane and with the reddening E(B − V) less than 0.1, which are not important to spread the color of the main sequence comparing to their photometric errors. For clusters near the Galactic plane, however, the reddening can be very large. Along with the heavily contaminated field stars, the determination of binary fractions in those clusters are quite uncertain.
8.4. Comparison with Another Survey
At the same time as this work was being carried out, another group was working toward a similar goal and recently published their comprehensive work (Milone et al. 2012). Although both efforts follow established approaches that use the CMD, there are some differences, which we identify and compare the values derived from the two independent approaches. One important difference is the software used to obtain photometry in crowded fields, which makes extensive use of the PSF libraries. We used Dolphot (V1.2) while Milone et al. (2012) used the proprietary algorithms described by Anderson et al. (2008), developed specifically for crowded field photometry. We used the stellar field model of Robin et al. (2003) while Milone et al. (2012) used the model of Girardi et al. (2005).
Both we and Milone et al. (2012) performed extensive artificial star tests, although with slight differences in how completeness was defined and how finely the globular cluster stellar density was subdivided. Most other procedures were essentially identical, including spline ridge-line fitting to define the main sequence or the magnitude range of the main sequenced used for analysis. The two clusters described here have small reddening, so we did not need the sophisticated corrections applied by (Milone et al. 2012), nor were there multiple epochs of data to be considered.
The two clusters that we discuss here were also analyzed by Milone et al. (2012) and we find general agreement, although the results are expressed slightly differently. For NGC 4590, our binary fractions for q > 0.5 and within the half mass radius was (6.2 ± 0.3)% while (Milone et al. 2012) obtain a somewhat lower value of (5.3 ± 0.7)%. For the total binary fraction, (Milone et al. 2012) doubles the f(q > 0.5) value, which assumes a flat distribution in q, obtaining (10.6 ± 1.4)%. We fit a flat functional form to the CMD distribution and obtain a binary fraction of (9.4 ± 0.7)%. Since these are the same data sets, the differences, which are comparable to the uncertainties, most likely reflect systematic differences between the approaches.
The other comparison that can be made is the radial distribution of NGC 6981, which we find drops by about a factor of four to five from a bin within rh to one that extends to 1.9 rh (from (9.6 ± 0.6)% to (2.1 ± 0.3)%). This decrease is similar to Milones mean result for their sample (Milone et al. 2012) but for this particular object, they find a smaller decline, from about 5% to 3%, with error bars of about 1% for each value. The reason for this difference is not obvious to us. In a companion paper, we will compare our sample to theirs, which will provide the statistical power to identify significant differences and systematic effects.
9. FINAL COMMENTS AND SUMMARY
Binary stars are thought to be a controlling factor in globular cluster evolution. To systematically study them, we conducted this survey of 35 Galactic globular clusters, taking advantage of the wealth of the HST data. In this paper, the first of two, we present the techniques used in obtaining their binary fractions. We used the PSF-fitting photometry with Dolphot (V1.2) to obtain high quality CMDs. We applied three different methods to estimate the binary fractions. The high mass-ratio method, a model-independent method, counts the number of binaries extending above a binary mass ratio of 0.5 on the CMD. The star counting method also takes into account the low mass-ratio binaries after modeling the main-sequence population, star superposition, and the field stars. The χ2 fitting method not only estimates the binary fraction, but also models the binary mass-ratio distribution. We showed a representative globular cluster NGC 4590, with a constrained binary fraction in the range of 6.2%–10.8% by the three methods. To test the effect of globular cluster dynamical evolution, we introduced the binary fraction radial analysis with NGC 6981 as an example, which shows a decreasing trend of binary fraction toward the outside of this cluster. We also discussed the factors that could affect the accuracy of measuring the binary fraction with our methods.
In Paper II, we will show the results of this survey, including accurate CMDs, the binary fractions within the core and the half mass radius obtained with three methods, the radial binary fraction analysis, and the potential binary candidate list for further observation. We will compare our observational results to the theoretical predictions of the globular cluster dynamical evolution.
The authors would like to thank A.E. Dolphin for answering our many questions that arose when using the photometry package Dolphot V 1.2. We appreciate the many thoughtful suggestions from the referee, as well as from Mario Mateo, Jon Miller, Eric Bell, Sally Oey, and Patrick Seitzer. We gratefully acknowledge financial support through an HST grant from NASA.
APPENDIX
The superposition of stars is a contamination that has the same effect as real binaries on CMD. It is very difficult to screen for them, but statistically, we can estimate the number of blended stars. In this appendix, we will discuss the probability for different types of blended stars (i.e., unresolved doubles, triples, etc.) in globular clusters, which can provide a good estimate on the blending frequency for globular clusters at different stellar density.
- 1.Poisson Distribution. The probability that one star is blended with others depends on the projected two-dimensional star number density as well as the angular resolution. It is a Poisson process and the probability can be described by the Poisson probability distribution function:where x is the companion number for the blends, i.e., x = 1 is for unresolved double stars (star with one companion), and x = 2 is for unresolved triple stars (star with two companions), etc. μ is the area ratio of the minimum resolved area to the mean occupied area per star in the reference frame.
- 2.Monte Carlo Blending Test. To test the hypothesis that the blending probability can be described by a Poisson distribution function, we performed the following Monte Carlo simulations. We randomly distributed Ntotal stars in a fixed square area with each size of 100 pixels to form the reference frame. Second, we randomly added one test star to this reference frame. Then we counted how many reference stars are within the minimum resolution radius rmin of the added test star, where rmin = 1 to simulate the ACS image. If the count is more than 0, then the added test star will be considered as a blend. After counting, the test star was removed, and a new test star was randomly added to follow the above process. We added 5000 test stars in all for each simulation, and the final blending fraction is the total number of the blending stars divided by the total number (5000) of added test stars. Blends with different companion number were counted separately. We repeated this simulation 30 times (i.e., 30 different random distributions of the reference stars) for each star number density (i.e., each Ntotal) to get the mean blending fraction and the standard deviation. The simulation setup is shown in Figure 11.


Figure 11. Monte Carlo simulation rules for determining the frequency of blending of stars. Left: the black dots are randomly input reference stars (Ntotal = 200), while the color dots are randomly added test stars with a minimum resolved area within the circles. Right: an enlarged plot for the test stars. Red: added test star without a companion (not a blend); green: added test star with one companion; blue: added test star with two companions.
Download figure:
Standard image High-resolution imageResults were compared to the Poisson probability distribution function (see Figure 12), where μ is defined as

So for the fixed area with size L and the minimum resolution radius rmin, μ only depends on the input star number Ntotal.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 12. Monte Carlo simulation results for the blending effect. Each data point is the mean of 30 Monte Carlo simulations with the standard deviation as the error bars. The underlying lines are the predicted Poisson distribution. Black solid line: blending fraction for blends with one companion; red dotted line: blending fraction for blends with two companions; green dashed line: blending fraction for blends with three companions. The blue vertical dot-dashed line is where the maximum star number density cluster is in our cluster sample. The error bars for the data points with large Ntotal are much smaller than the symbol size.
Download figure:
Standard image High-resolution image{kind=link}
Here we calculated the blending probability for three different blending stars, x = 1 (unresolved double stars), x = 2 (unresolved triple stars), and x = 3 (unresolved quadruple stars), and compared to the Monte Carlo simulations (Figure 12). In Figure 12, we can see that the Poisson distribution curves match those Monte Carlo data points fairly well. This indicates that as long as we know the projected star number density and the minimum resolution, we can estimate the blending fraction using the Poisson distribution function.
For example, in our globular cluster sample, the maximum star number density is from NGC 7078, where we obtain 156,080 stars down to the 26th magnitude in the HST/ACS CCD with the size of 4096 by 4096 pixels, which is equivalent to around 90 stars in the 100 by 100 pixel area of our Monte Carlo simulation setup (see the blue vertical dot-dashed line in Figure 12). Even for this densest cluster, the blending fraction with one companion is less than 3%, and the blending fraction with two companions is much smaller, less than 0.04%. The typical star number recovered in our cluster sample is around 30,000 stars, which is equivalent to around 17 stars in the 100 by 100 pixel area. The blending fraction is less than 0.7% for blends with one companion, which is only a small fraction in the total binary fraction budget. The blending fraction with a higher number of companions is two orders of magnitude smaller.
Note that here we used the average star number density to calculate the blending fraction for the whole field, which is not appropriate, as in globular clusters the star number density varies quickly along the radius. But as long as we only consider a small range of radius, the density gradient will be small, and one can use this method to estimate the blending fraction in that area. The blending model in the fitting process, however, takes into account the stellar number density gradient, as it follows the observed stellar radial distribution.